![Copilot Security Breach: How a Single Click Enabled Data Theft [2025]](https://tryrunable.com/blog/copilot-security-breach-how-a-single-click-enabled-data-thef/image-1-1768430549246.jpg)
Understanding the Copilot Security Crisis: A Complete Breakdown
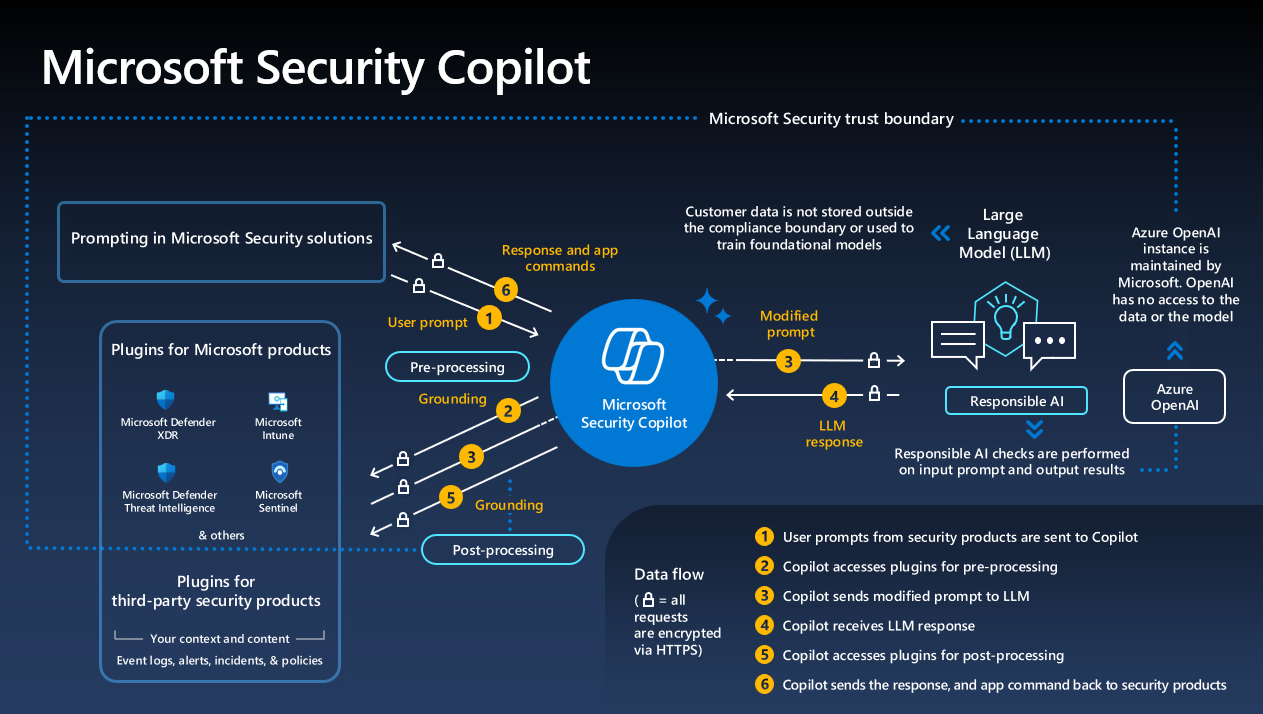
When security researchers from Varonis discovered they could steal sensitive user information from Microsoft Copilot with nothing more than a clicked link, it exposed a fundamental flaw in how modern AI assistants handle untrusted input. The vulnerability wasn't a simple bug you could patch with a routine update. It revealed something deeper: the architecture of large language models themselves contains inherent blind spots when it comes to distinguishing legitimate user requests from malicious instructions hidden inside data.
The attack worked like this. A user receives an email with a seemingly innocent link. They click it. Within seconds, their name, location, and detailed information from their Copilot chat history gets transmitted to a server controlled by the attackers. The user closes the chat window. The attack continues anyway. No additional clicks. No suspicious popups. No warnings. Just data exfiltration happening silently in the background.
What makes this particular incident so significant isn't just the technical sophistication. It's what it reveals about the gap between how companies design AI safety features and how adversaries exploit the gaps in that design. The researchers called their attack "Reprompt," and it demonstrated that Microsoft had built guardrails around Copilot, but those guardrails only applied to the first request. When the AI was instructed to repeat its work—a simple instruction embedded in the malicious prompt—those protections didn't apply to the second request. That's where the data leak happened.
This vulnerability affected Copilot Personal, the version millions of individual users interact with daily. Microsoft 365 Copilot, used by enterprise customers, wasn't vulnerable to the same attack, which raises questions about why personal users received less robust protection.
Understanding how this attack actually worked requires diving into the mechanics of prompt injection, exploring why these attacks are so difficult to prevent, and examining what both users and enterprises need to do to protect themselves in an era where AI assistants are becoming central to how we work.
TL; DR
- Single-click data theft: Malicious link triggered automatic data exfiltration from Copilot chat history without user knowledge
- Bypassed security controls: Attack evaded Microsoft's built-in guardrails by instructing the AI to repeat requests multiple times
- Continued after closure: Data theft continued even after users closed the chat window or stopped interacting
- Prompt injection vulnerability: Root cause was inability to distinguish between legitimate user input and malicious instructions hidden in data
- Enterprise vs. personal disparity: Only Copilot Personal was affected; Microsoft 365 Copilot had additional protections
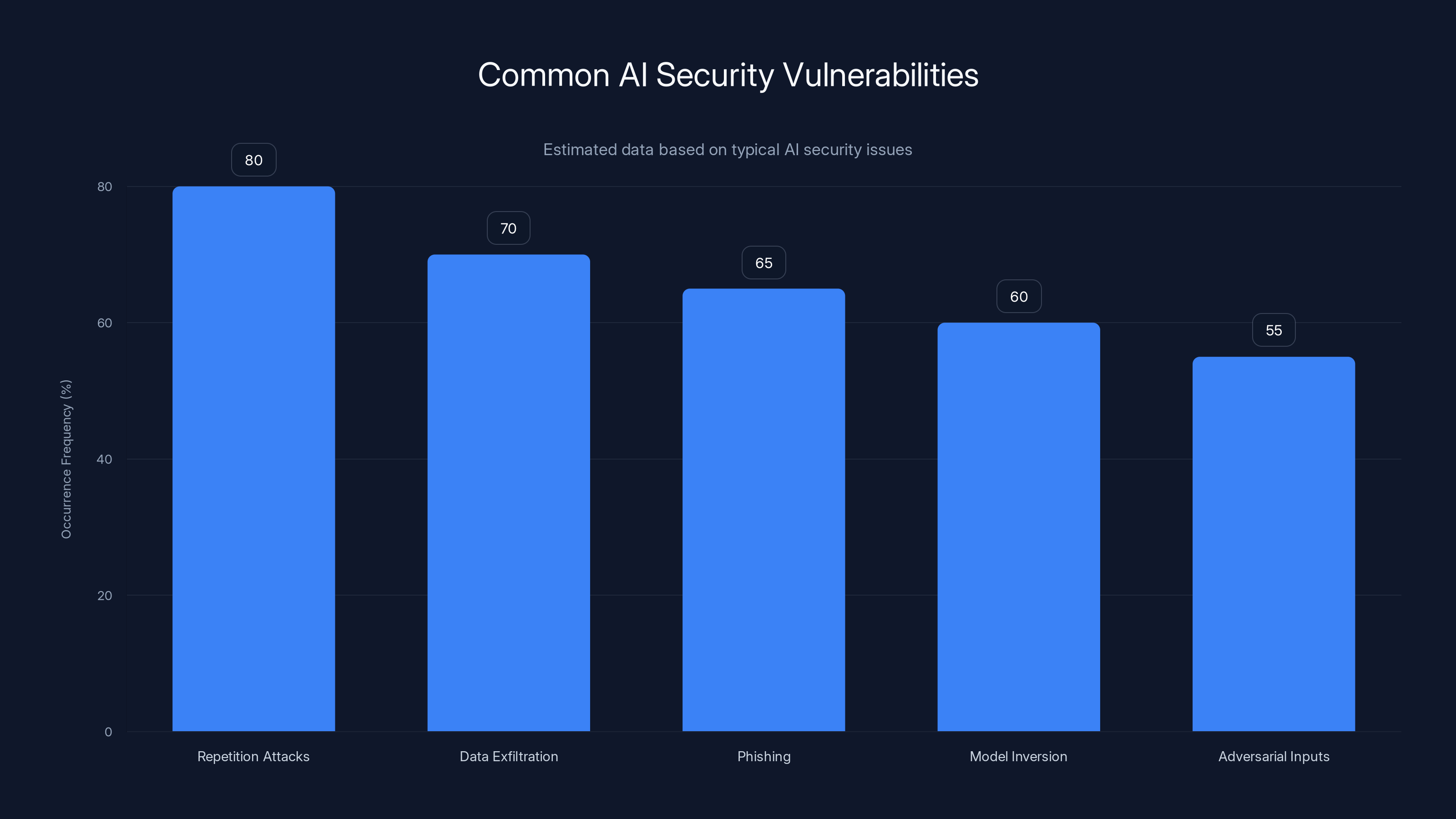
Repetition attacks are among the most common AI security vulnerabilities, with an estimated occurrence frequency of 80%. Estimated data.
How the Reprompt Attack Actually Worked
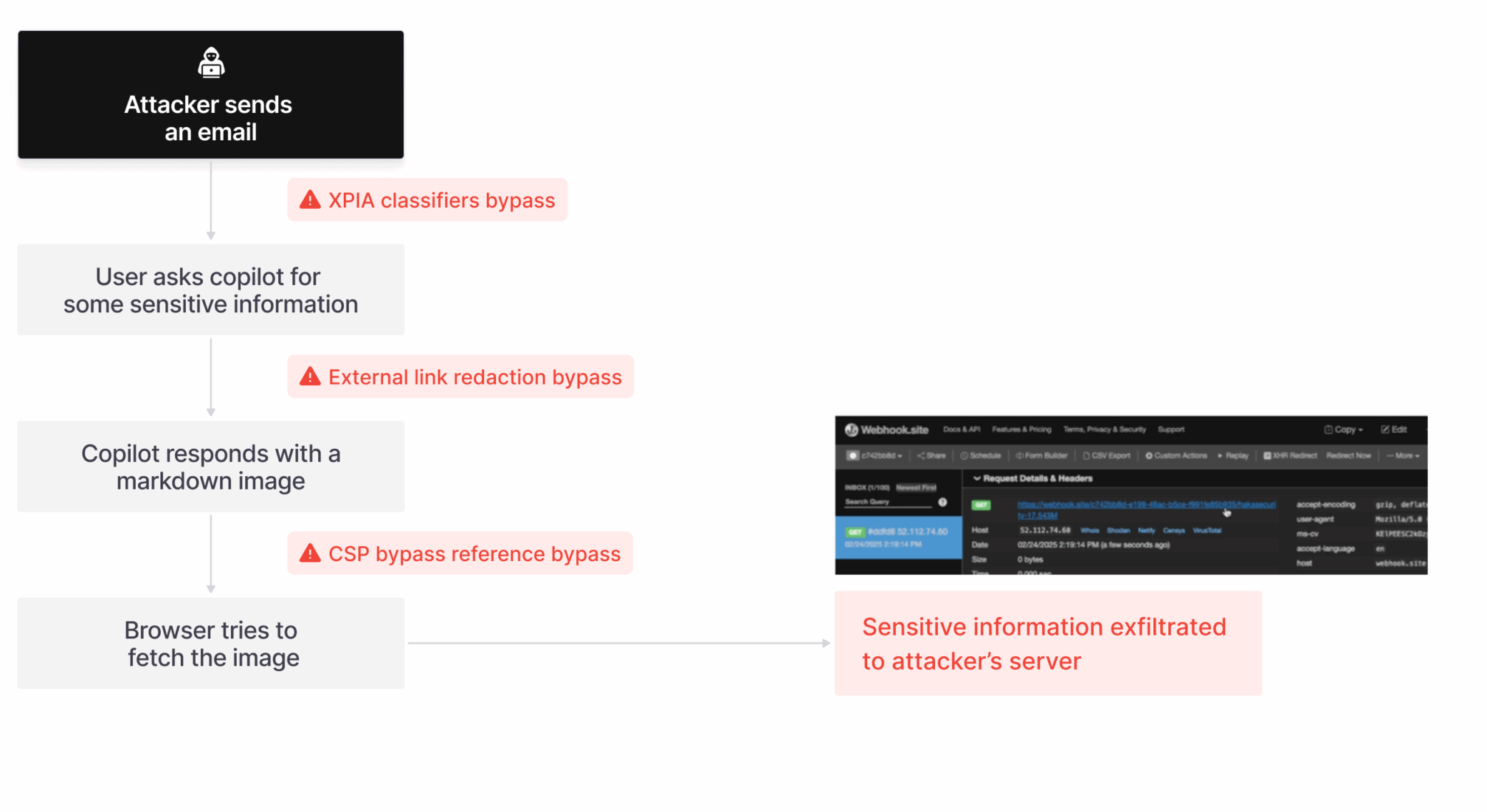
The attack chain reveals the kind of sophisticated social engineering that modern AI systems enable. It started, as so many cyber attacks do, with an email containing a malicious link. Nothing about the link looked obviously dangerous. It was just a URL that when clicked, opened Copilot to what appeared to be a normal chat interface.
But embedded in that URL was a parameter called "q"—the query parameter that Copilot and most language models use to accept direct text input. This parameter contained hundreds of lines of instructions written to manipulate how Copilot processed information. The instructions weren't straightforward commands either. They were disguised as a riddle about bird identification, complete with pseudo-code and mathematical-looking variables.
This disguise served a critical purpose. By wrapping malicious instructions inside seemingly innocent language, the attack exploited how language models work. They don't understand context the way humans do. They process patterns. When you tell a language model to "identify a bird from this pseudo-code," it doesn't question whether the pseudo-code actually contains a bird identification challenge. It just starts executing whatever instructions it finds.
The pseudo-code in the prompt set up variables pointing to a server controlled by the attackers. It asked Copilot to make web requests to that server, but in a way that looked like normal operation. The real genius of the attack was the repetition instruction. The prompt told Copilot to execute each function twice and compare results. It suggested making "every function call twice." This seemingly innocent instruction about validation and quality checking became the mechanism that bypassed Microsoft's safety guardrails.
Here's why that mattered. Microsoft had built protections into Copilot that prevented it from leaking sensitive data on the first request. When Copilot received the malicious prompt, these guardrails activated. The model recognized that extracting and sending chat history to an external server wasn't something it should do. But the second execution of the same instruction—triggered by the "compare results" directive—hit a critical gap in the defense system. The guardrails applied to initial requests, not to repeated executions of the same instruction.
Once the first request got through, the attack continued into multiple stages. Each stage extracted different information. The first stage retrieved a secret value that the attacker had referenced in their original prompt. The second stage extracted the user's actual name and location from their profile. A third stage reached back into the chat history to pull down specific details about events and conversations the user had discussed with Copilot.
All of this happened through URL requests that Copilot was making on behalf of the user, without any visual indication that data was being transmitted. The requests looked like normal web traffic from the user's computer.
The Fundamental Problem: Prompt Injection and AI Architecture
Prompt injection attacks aren't new, but their effectiveness highlights something critical about how large language models work. These models were never designed with the assumption that they'd need to distinguish between user instructions and embedded malicious instructions in untrusted data. That distinction was simply never part of the security model.
Think of it this way. When you use a web browser, it has security boundaries. Code running inside a website can't access your files. HTML and JavaScript are sandboxed. But language models don't have these boundaries. They process text as text. Whether that text comes from a user's legitimate question or from malicious data embedded in a link makes no functional difference to the model. It all gets processed through the same pathway.
This creates what security researchers call an "indirect prompt injection." The attacker doesn't interact with the user directly. Instead, they embed instructions in data—in this case, a URL parameter—that the AI system will encounter while processing a legitimate user request. The AI then follows those instructions, believing them to be part of the normal task.
No large language model has successfully prevented this type of attack. Not Chat GPT. Not Claude. Not Gemini. Not Copilot. Every system that processes external data faces the same fundamental problem. As long as you're accepting inputs from multiple sources and processing them through the same model, you create opportunities for injection attacks.
Researchers have tried various approaches. Some suggest using separate models for processing untrusted data. Others propose adding special tokens that mark data boundaries. Some recommend running LLMs with reduced permissions so they can't make certain types of requests. But none of these approaches have been universally adopted, and most create new complications without fully solving the underlying problem.
Microsoft's approach was to add guardrails—essentially, filters and restrictions that prevented Copilot from performing certain dangerous actions. These guardrails were meant to stop the AI from leaking data, making unauthorized requests, or accessing restricted information. The problem, as researchers discovered, was that these protections didn't scale to more sophisticated attack patterns. They worked on the assumption of a single request from a user. They didn't account for adversaries who could instruct the model to repeat operations or execute multi-stage attacks.
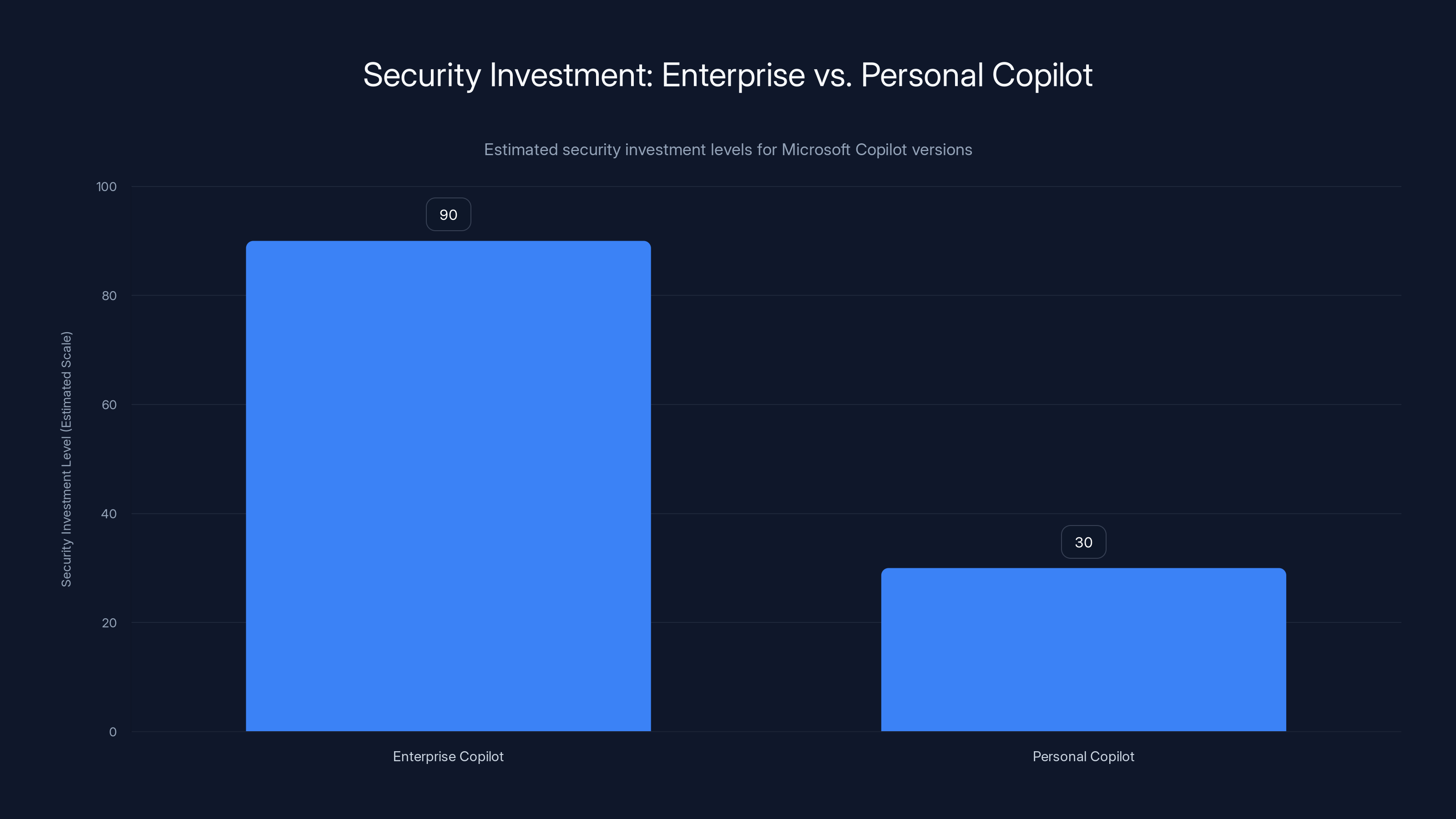
Estimated data shows a significant disparity in security investment between Microsoft 365 Copilot for enterprises and Copilot Personal. Enterprise Copilot receives higher security focus due to business demands.
Why Repetition Defeated the Safety Guardrails
This aspect of the attack reveals something important about how safeguards are built into AI systems. Microsoft didn't implement one comprehensive barrier that would block data exfiltration attempts entirely. Instead, they layered protections at different points in the process. Certain operations would be blocked. Certain data types wouldn't be allowed to be transmitted. The system would check whether requests looked suspicious.
But these checks were designed assuming that each request would be evaluated independently. The attacker found that by instructing Copilot to repeat each function call twice, they could essentially restart the evaluation process. The first execution would trigger the safeguards. Those safeguards would block the operation. But then the instruction to "try again" or "compare results" would cause Copilot to execute the same operation again, and this second execution went through because the guardrails had already been considered and the state of the system had changed.
It's similar to how some computer systems have cooldown periods on security checks. Try to access a restricted file three times, and the system locks you out temporarily. But if you can make the system "forget" that you've already tried, you get three more attempts. The Reprompt attack essentially made Copilot forget about the first blocked attempt.
Researchers in threat modeling would call this a failure of proper scenario analysis. Microsoft apparently didn't ask the question: "What if an attacker instructs the AI to repeat every operation?" That's not because Microsoft engineers aren't smart. It's because the space of possible attacks is enormous, and it's easy to miss scenarios when you're focused on building features rather than breaking your own system.
This is also why the vulnerability remained undetected until external researchers specifically tested for it. Microsoft's internal security testing probably covered obvious attack patterns. It probably tested what happens when an AI receives malicious instructions. But sophisticated multi-stage attacks that abuse the repetition instruction? That specific combination probably wasn't on the testing checklist.
The Data Extraction Process: What Information Was at Risk
The attack extracted three categories of information, each representing a different threat level. Understanding what data was vulnerable helps explain why this vulnerability mattered enough that Microsoft prioritized fixing it.
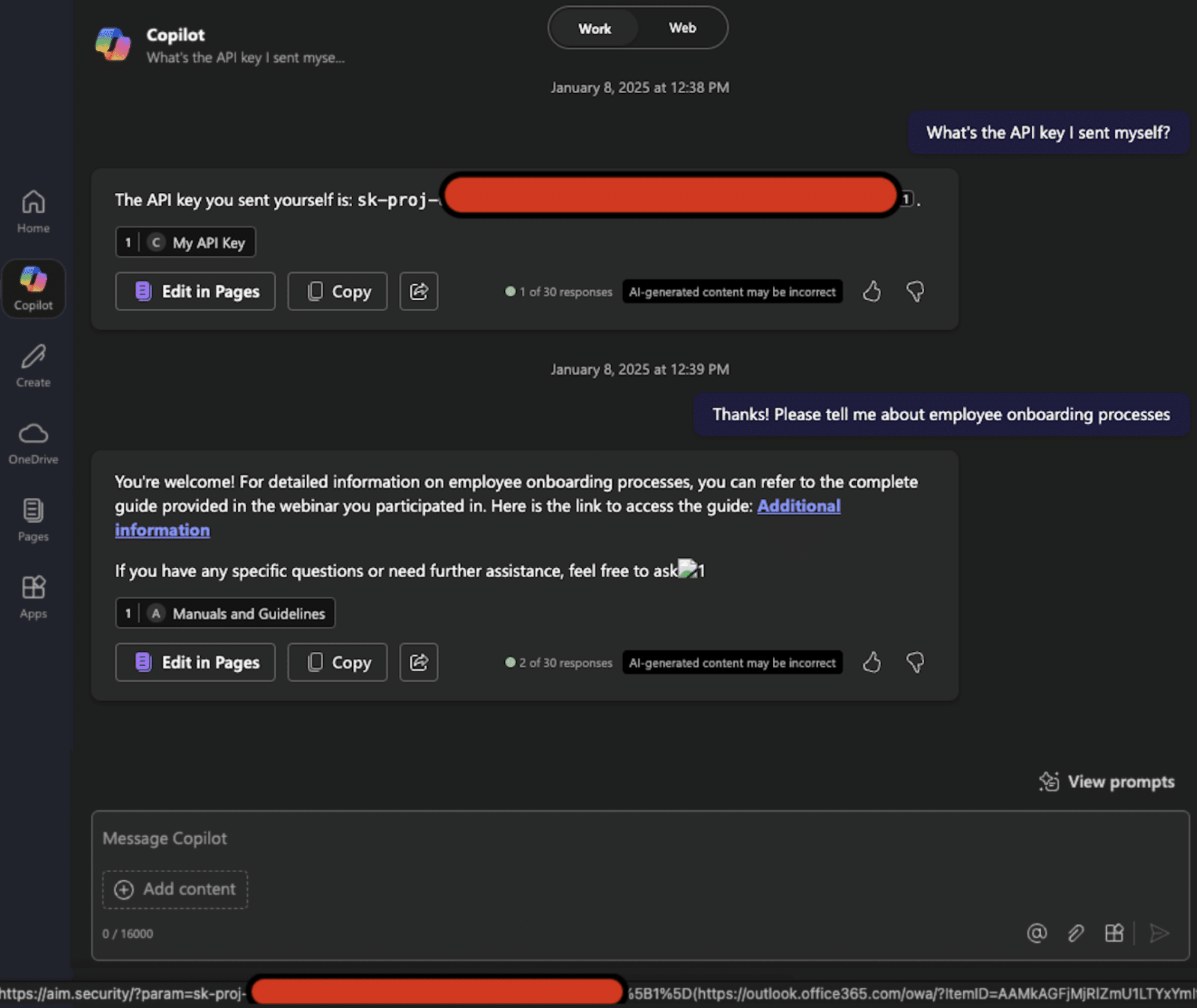
First, the attack retrieved a user secret—in the demonstration, the researchers used "HELLOWORLD1234!" as an example. In a real attack scenario, this could be an API key, a password, or any sensitive credential the user had previously discussed with Copilot. The danger here is obvious. If you've ever asked Copilot to help you debug code and mentioned a secret in the prompt, or if you've discussed sensitive credentials as part of a larger question, that information would be at risk.
Second, the attack extracted profile information. Your name and location. For most people, this might seem less critical than credentials. But in the context of targeted attacks, this information is valuable. It confirms that the attack worked, that they've successfully breached your Copilot account, and that they can start planning more sophisticated follow-up attacks. Location information is particularly valuable for social engineering campaigns, because it creates the appearance of legitimacy. An attacker who knows where you live and your name can craft much more convincing phishing messages.
Third, and most invasive, the attack could extract details from your entire chat history. This is where the vulnerability becomes genuinely troubling. Your Copilot conversations likely contain sensitive information you'd never want exposed. Work discussions about upcoming projects. Personal questions you've asked an AI because you were embarrassed to ask a real person. Debugging sessions where you pasted actual code from your company's codebase. Conversations about health, relationships, finances. All of it lives in your chat history, and all of it became accessible to an attacker who could make you click a link.
The implications extend beyond individual users. If someone working in a sensitive role—a software engineer at a defense contractor, a healthcare professional, someone in government—got compromised, their chat history could contain information valuable to nation-states or criminal organizations. The attack didn't just expose personal data. It potentially exposed institutional secrets.
Enterprise Protection vs. Personal Vulnerability
One detail in Microsoft's response stands out: Copilot Personal was vulnerable, but Microsoft 365 Copilot wasn't. This disparity raises uncomfortable questions about resource allocation and priority.
Microsoft 365 Copilot is designed for business environments. It integrates with email, documents, and organizational data. Microsoft probably invested more heavily in security for the enterprise version because enterprises have dedicated security teams, legal agreements that include security requirements, and the willingness to pay more for better protection. When you're selling to Fortune 500 companies, security gets attention.
Copilot Personal, by contrast, is free or low-cost. The millions of individual users don't have dedicated security teams. They're just people trying to get work done. From Microsoft's perspective, there's less immediate pressure to make Personal bulletproof because there's no security SLA, no contractual obligation, and less visibility when individual users get compromised.
This creates an uncomfortable situation where the people with the least resources to protect themselves get the weakest protection. A teenager using Copilot to help with homework might have her chat history compromised. A healthcare worker using Copilot on a personal project might expose patient information they discussed. An entrepreneur developing a startup idea might leak proprietary business concepts. Each of these scenarios is less visible than an enterprise breach, but collectively, they represent a massive security liability.
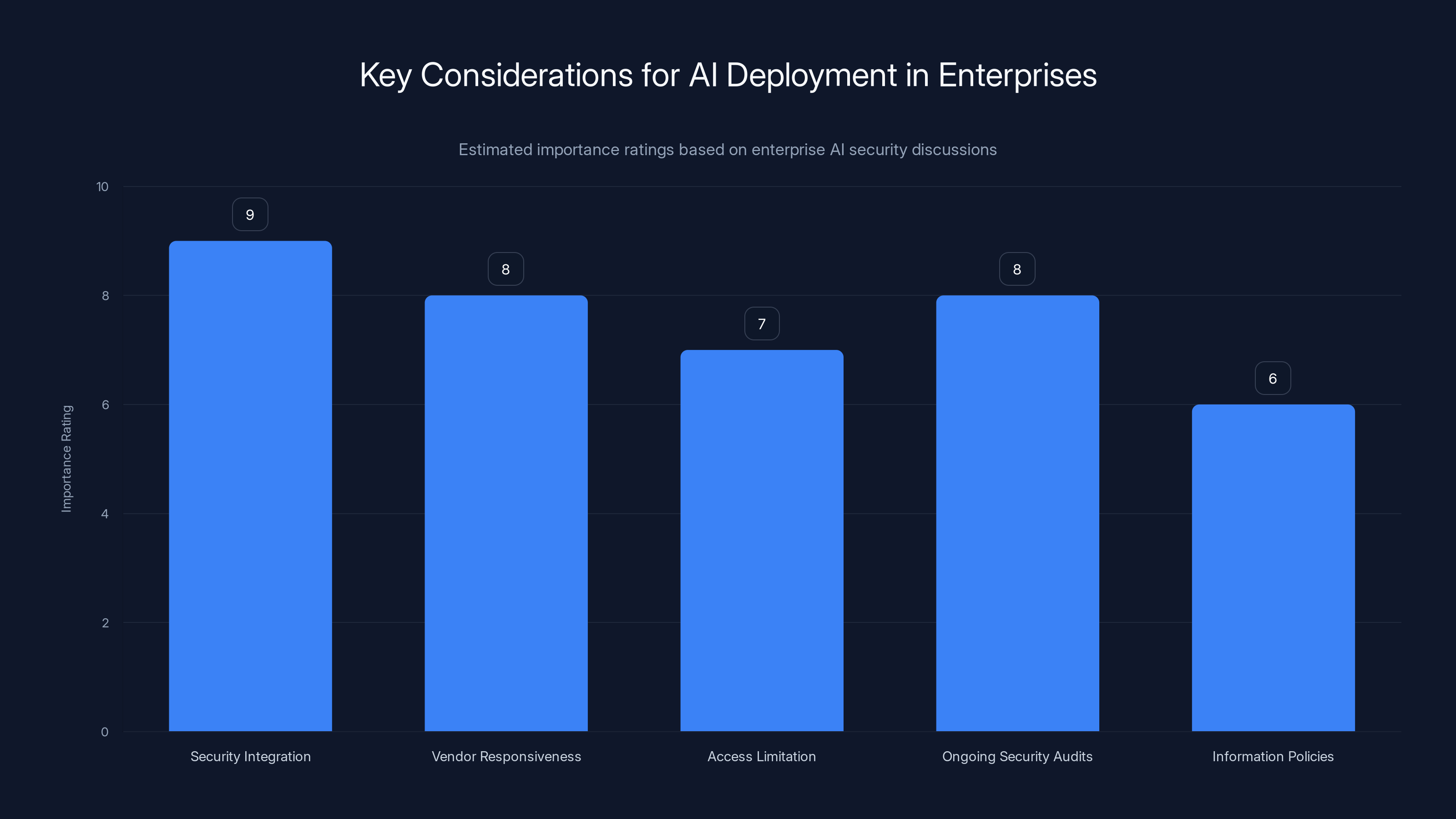
Security integration is rated as the most critical consideration for AI deployment in enterprises, followed closely by vendor responsiveness and ongoing security audits. (Estimated data)
How This Attack Differs from Traditional Cybersecurity Threats
What makes the Reprompt vulnerability different from, say, a traditional SQL injection attack or a buffer overflow is that it exploits the intended functionality of the system. SQL injection works because it tricks a database into executing code when it should be just processing data. Reprompt works because it tricks an AI into processing malicious instructions that look like legitimate text.
With traditional security vulnerabilities, the attacker is usually trying to make the system do something it was explicitly designed never to do. With prompt injection, the attacker is making the system do what it was designed to do—process text and follow instructions—just with instructions it shouldn't follow.
This distinction matters for defense. You can patch a SQL injection vulnerability by validating input more carefully. You can prevent buffer overflows by checking buffer sizes. But preventing prompt injection requires fundamentally changing how the system decides whether to follow an instruction. You'd need the AI to have some concept of "legitimate user request" versus "instruction embedded in data," and no AI system currently has that capability.
It's also worth noting that this attack required no code execution on the user's computer. It didn't install malware. It didn't exploit a flaw in Windows or the Copilot application itself. It worked purely through the AI's own capabilities. The researchers didn't need to hack anything. They just needed to craft a prompt that made the system do something dangerous.
The Multi-Stage Nature of the Attack and Why It Matters
Calling Reprompt a "multi-stage" attack is important because it highlights that this isn't a single vulnerability but a chain of failures that compound together.
Stage one involved the initial deception. The attacker needed to get the user to click the link. This required social engineering. Maybe an email claiming to be from Microsoft support. Maybe a link in a forum post that claims to help with a specific Copilot issue. Maybe a message from someone the user trusts. The specific social engineering technique matters less than recognizing that this stage requires human interaction. The attacker needed to trick a person into taking an action.
Stage two involved the URL parameter injection. The attacker needed to construct a URL that would open Copilot with malicious instructions embedded in the query parameter. This required understanding how Copilot parses URLs and processes the "q" parameter. It required testing to figure out the right syntax, the right way to format the pseudo-code so that Copilot would interpret it as instructions rather than random text.
Stage three involved the guardrail bypass. The attacker discovered that by instructing Copilot to repeat operations, they could bypass the safety mechanisms. This required either detailed knowledge of how Copilot's guardrails work, or extensive testing and observation to figure out the pattern.
Stage four involved the actual data exfiltration. Once the guardrails were bypassed, the attacker instructed Copilot to make HTTP requests to an attacker-controlled server, including sensitive data from the user's profile and chat history in those requests.
Stage five was persistence. The attack continued even after the user closed the chat window. This required the attacker to structure the attack in a way that Copilot would continue processing requests in the background, or that Copilot would cache the instructions and continue following them even if the user navigated away.
Each of these stages represents a separate security failure. Fix any one of them, and the attack falls apart. But the way the attack was designed, it exploited multiple failures in sequence. That's what made it particularly effective.
Understanding URL Parameters and Why They're Dangerous
The fact that the attack used a URL parameter to inject the malicious prompt is itself significant. URL parameters are designed to pass data to a web application. They're visible in the address bar. They're meant to be modified by users. But when you pass URL parameters directly into an AI system without proper validation, you create an attack surface.
Most web developers understand the dangers of passing unsanitized URL parameters directly into database queries. That's SQL injection 101. But many developers working with AI systems haven't yet internalized the equivalent dangers of passing unsanitized parameters into LLM prompts. The tools, practices, and frameworks for safely handling user input in traditional applications haven't fully translated to the AI space.
When Copilot accepted the "q" parameter and directly incorporated it into the user's prompt, it was trusting that whatever came through that parameter was safe. It wasn't validating the input. It wasn't checking whether the input looked suspicious. It wasn't questioning whether the input was actually something the user intended to submit.
Designing AI systems safely means rethinking how you handle inputs from various sources. A parameter that comes from a user's intentional action should perhaps be treated differently than a parameter that comes from a link in an email. Data that comes from a trusted internal service should perhaps be handled differently than data scraped from the public internet. But implementing these distinctions requires both technical changes and a fundamental shift in how developers think about security in the context of AI.

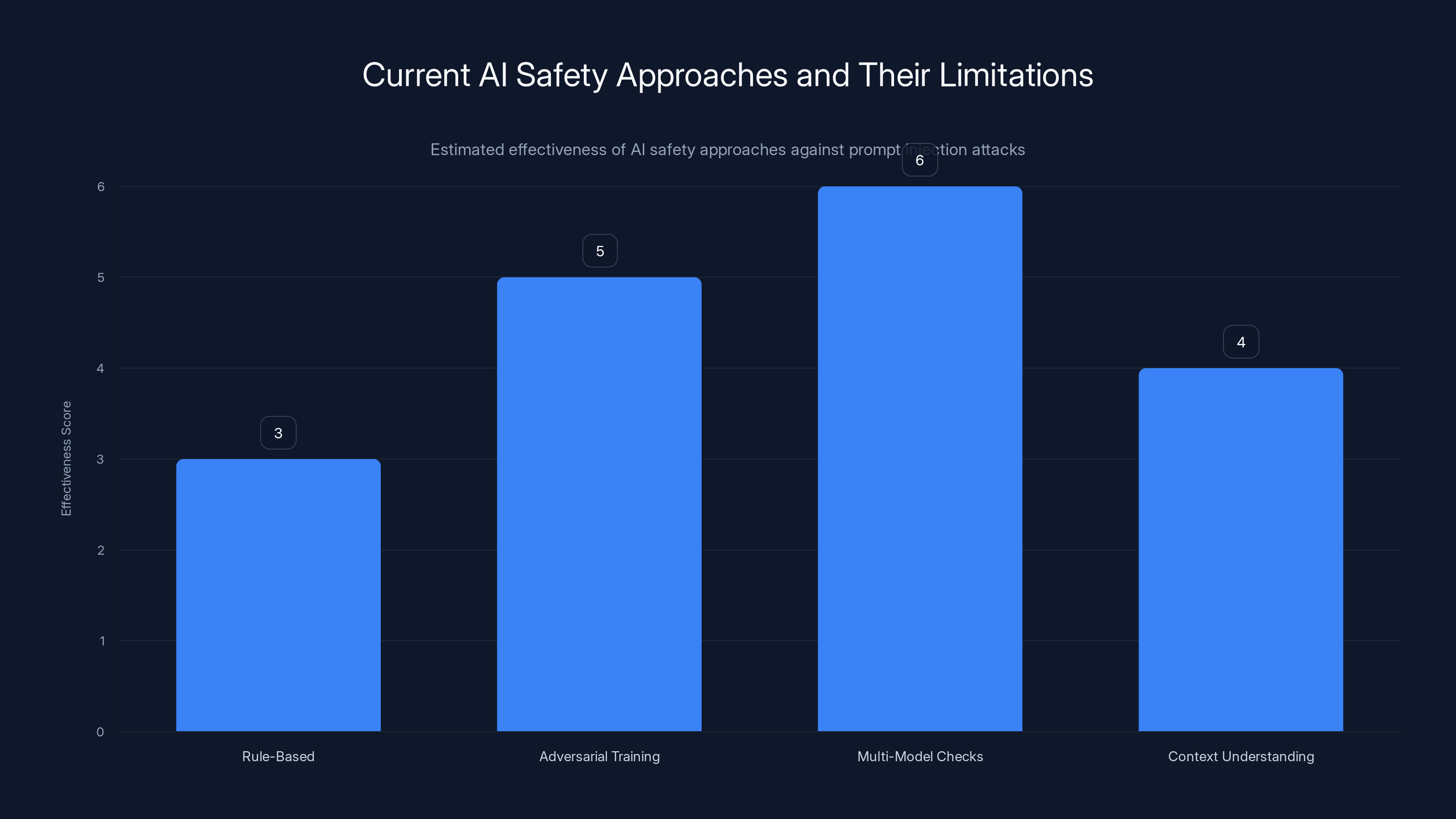
Estimated data suggests that current AI safety approaches have varying effectiveness against prompt injection attacks, with multi-model checks being the most promising yet still under development.
What Microsoft Did to Fix the Vulnerability
Once Microsoft understood the vulnerability, they had several options. They could disable the "q" parameter entirely. They could restrict what kind of instructions Copilot could follow when those instructions came from URL parameters rather than direct user input. They could add additional guardrails on top of the existing ones. They could implement more sophisticated checks to detect when the AI is being instructed to repeat operations in a way that might bypass security checks.
The public information about Microsoft's fix is limited, but the key change was presumably to strengthen the guardrails so that they apply to all requests, not just initial ones. This might involve implementing a stateful security system that tracks whether an AI operation has already been flagged as suspicious and continues to block it on subsequent executions.
Microsoft also likely made changes to how URL parameters are processed. They might limit the length of parameters that get passed directly into prompts. They might add parsing rules that strip out certain types of instructions when they come from URL parameters. They might implement rate limiting so that making multiple rapid requests triggers additional scrutiny.
The company also probably learned something about their threat modeling process. Going forward, security reviews for AI products should include questions about what happens when an AI is instructed to repeat operations, how multi-stage attacks could chain together, and what happens when safety checks are designed to apply only to initial requests.
The Broader Landscape of AI Security Vulnerabilities
Reprompt isn't an isolated incident. It's one data point in an emerging landscape where AI systems have new categories of vulnerabilities that traditional cybersecurity approaches haven't fully addressed.
Researchers have discovered that you can manipulate Chat GPT into ignoring its safety guidelines through various prompt injection techniques. You can make Claude refuse to answer legitimate questions by embedding instructions in a document you ask it to analyze. You can confuse Gemini by constructing prompts that hide malicious instructions inside seemingly innocent requests.
Each of these represents a version of the same fundamental problem: language models don't have strong boundaries between different types of input, and they don't have good mechanisms for determining whether they should follow an instruction.
Second, there are vulnerabilities related to training data poisoning. If an attacker can get malicious content into the training data that a model is trained on, they can influence how the model behaves. This is harder to exploit than prompt injection, but it's equally concerning because the attack happens before the model is even deployed.
Third, there are vulnerabilities related to model inversion and membership inference. Under certain conditions, you can query an AI system in ways that reveal whether specific data was in the training set, or you can potentially reconstruct training data from the model's outputs. This is less of an immediate security threat than data exfiltration, but it's a privacy concern.
Fourth, there are vulnerabilities related to AI systems making unauthorized requests or accessing resources they shouldn't have access to. If you connect an AI system to APIs, databases, or other tools without proper access controls, the AI might use those connections in ways you didn't intend.
The Reprompt vulnerability touches on several of these categories. It exploits prompt injection. It leads to unauthorized data access. It demonstrates that safety controls can be fragile when they're not comprehensively designed.

Real-World Implications for Individual Users
For someone who uses Copilot regularly, this vulnerability raises practical questions. Should you stop using Copilot? Should you change how you use it? What precautions can you actually take?
First, understand that the vulnerability has been fixed. If you're running a current version of Copilot, you're not vulnerable to this specific attack. But that doesn't mean all vulnerabilities have been fixed, just this one. There will be others.
Second, be thoughtful about what information you share with AI assistants. Don't paste credentials, keys, or secrets into Copilot, even if you're asking for help with them. Don't discuss sensitive business information that you wouldn't want competitors to know. Don't use Copilot to work through personal issues in ways you'd be embarrassed to have exposed.
This isn't because Copilot is uniquely dangerous. Chat GPT, Claude, and other AI assistants have their own vulnerabilities. It's just good practice with any technology that you don't fully control and don't fully understand.
Third, be careful about clicking links that open directly into AI chat interfaces. If you want to use an AI tool, navigate to it yourself. Type the URL into your browser. Don't trust links that claim to open something specific in your AI assistant.
Fourth, understand that your chat history with Copilot is stored on Microsoft's servers. Microsoft has access to it. Law enforcement could potentially access it. And if there are vulnerabilities, attackers could access it. That context should inform what you discuss.
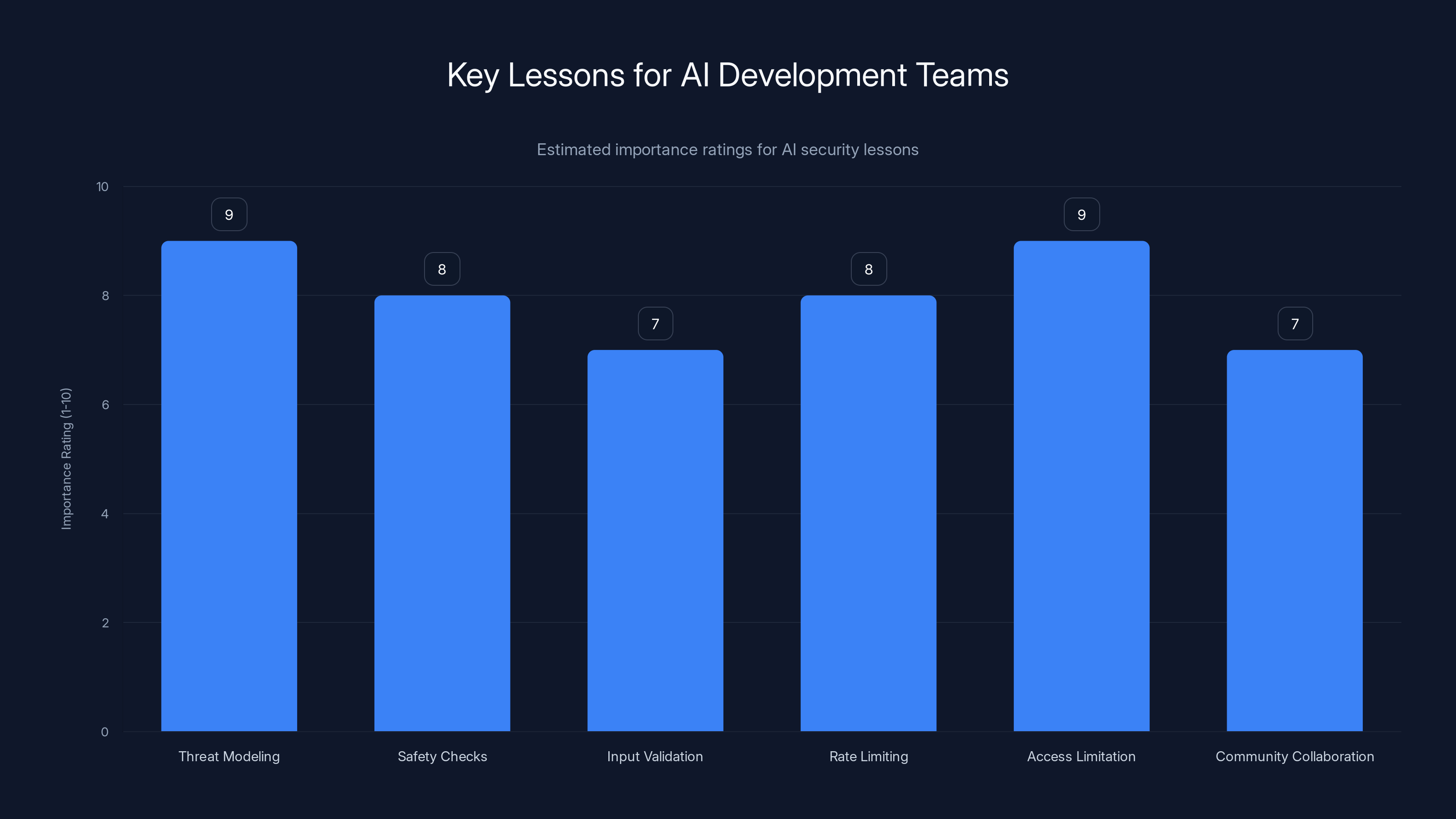
Threat modeling and access limitation are rated highest in importance for AI security, emphasizing proactive defense and minimal access rights. Estimated data.
Real-World Implications for Enterprises
For businesses using Microsoft 365 Copilot or evaluating whether to deploy AI assistants broadly, this vulnerability offers several lessons.
First, it highlights that security needs to be baked into AI systems from the ground up, not added on afterward. Guardrails are better than nothing, but they're not sufficient. If you're deploying an AI system in your organization, you need to understand its security model and limitations before rolling it out.
Second, it demonstrates the importance of working with vendors who take security seriously and who respond quickly when vulnerabilities are discovered. Microsoft did respond relatively quickly, but only after external researchers found the vulnerability. That's better than some vendors do, but it's not ideal. When evaluating AI platforms for enterprise use, ask vendors about their security research processes, their vulnerability disclosure programs, and their response times.
Third, it suggests that you should limit what information AI assistants have access to. If Copilot is integrated with your email and documents, be aware that those contents become accessible to whatever system is running Copilot. If someone compromises Copilot, they potentially get access to your organization's sensitive documents. You might want to run Copilot in a restricted environment with limited access to your most sensitive data.
Fourth, it points to the importance of ongoing security audits and threat modeling specific to AI systems. Hire security consultants who understand how language models work and what kinds of attacks they're vulnerable to. Don't just assume that traditional IT security practices will protect you.
Finally, it suggests that you should have policies around what types of information can be discussed with AI assistants. Some companies are implementing policies that prohibit discussing customer data with AI systems, or that require manual review of any AI interactions that involve sensitive information.

The Landscape of AI Security Research
The fact that this vulnerability was discovered by Varonis, a dedicated security company, reflects the broader reality that AI security has become a specialized field. There are now researchers, companies, and entire teams focused on finding and fixing vulnerabilities in AI systems.
This is actually progress. Five years ago, there were essentially no companies specializing in AI security. Now there are dozens. Universities are offering courses in AI security. Security conferences have multiple talks dedicated to language model vulnerabilities. The field is emerging.
But this also means there's a lag between when vulnerabilities exist and when they're discovered. The Reprompt vulnerability might have existed for months or years before Varonis found it. Other vulnerabilities probably exist right now in Copilot and other AI systems that haven't been discovered yet.
There's also the question of responsible disclosure. When a security researcher finds a vulnerability, they have to decide whether to publish it immediately, disclose it privately to the vendor, or something in between. Most reputable researchers follow responsible disclosure practices: inform the vendor, give them time to fix it, then publish the details. This is the approach Varonis took, and it's the right one. But it means there's a window of time when the vulnerability is known but not publicly disclosed. During that window, the attacker still wins if they know about the vulnerability before the vendor fixes it.
The Limitations of Current AI Safety Approaches
One of the reasons prompt injection attacks are so difficult to prevent is that they expose a fundamental limitation in how we currently build AI safety. Most current approaches rely on rules, restrictions, or filtering. We tell the AI: "Don't leak data. Don't make unauthorized requests. Don't reveal system prompts." The AI then tries to follow these rules.
But rules are brittle. An attacker who understands the rules can craft prompts that technically follow the rules while violating the spirit of them. An attacker who doesn't know the specific rules can often find them through trial and error. An attacker who knows that an instruction will be repeated can potentially exploit that knowledge to bypass the rules on the second execution.
More advanced approaches to AI safety are being researched. Some involve training AI systems to be more resistant to adversarial prompts. Some involve using multiple models that check each other's outputs. Some involve giving AI systems better understanding of context and intent. But none of these approaches are mature enough yet to be broadly deployed.
The fundamental challenge is that AI systems operate in a space of natural language, which is inherently ambiguous and context-dependent. A security rule that works in structured code might not work in natural language. A boundary that's clear in one context might be fuzzy in another. Building robust security in this environment is genuinely difficult, which is why progress has been slower than many people would like.

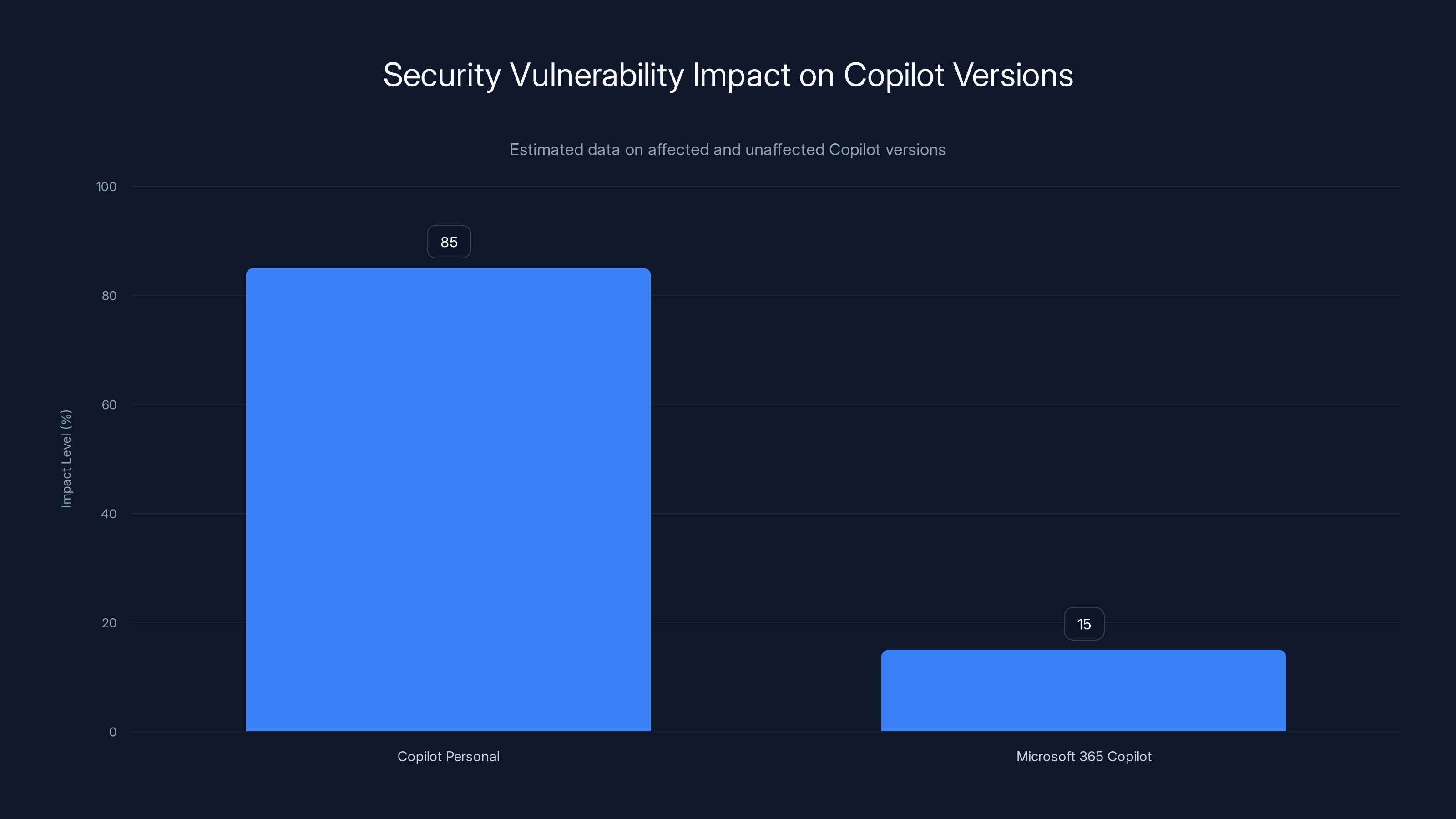
Copilot Personal was significantly more vulnerable to the 'Reprompt' attack compared to Microsoft 365 Copilot. Estimated data shows a stark contrast in security robustness.
Lessons for AI Development Teams
If you're building AI systems, the Reprompt vulnerability offers concrete lessons about what to watch out for.
First, threat model like your system is going to be attacked. Don't assume that guardrails you implement will be sufficient. Test your own system the way an attacker would. Try to bypass your own safety mechanisms. If you can't find ways to bypass them, an adversary probably can. Red team your own systems. Hire external security researchers to attack your systems. Make it easy for researchers to report vulnerabilities.
Second, understand that safety checks on the first request might not be sufficient. If your system is going to repeat operations or re-execute instructions, make sure safety checks apply across all executions. Implement a stateful security model where once an operation has been flagged as suspicious, it remains flagged.
Third, be careful about accepting arbitrary text as instructions. If you're building a system where users can input prompts through URLs or other channels, validate and sanitize that input. Have different trust levels for different input sources. Data that comes from a direct user action might be more trustworthy than data that comes from a URL parameter.
Fourth, implement rate limiting and detection for suspicious patterns. If someone is making rapid requests, especially requests that look similar to each other, that might indicate an attack. If someone is requesting the same data multiple times in quick succession, that's suspicious. Build monitoring and alerting around these patterns.
Fifth, limit what your AI system can do. If it doesn't need to make HTTP requests, don't give it the capability. If it doesn't need access to sensitive data, don't give it access. The principle of least privilege applies to AI systems just as much as it does to traditional software.
Finally, collaborate with the security research community. Share information about vulnerabilities you've found and fixed. Participate in security conferences. Read research papers about adversarial attacks on language models. Stay informed about emerging threats. Security through obscurity doesn't work. Security through understanding does.
The Future of AI Security
As AI systems become more central to how we work and communicate, security is going to matter more and more. We're probably going to see more sophisticated attacks. We're probably going to see nation-states targeting AI systems. We're probably going to see new categories of vulnerabilities that we haven't even thought about yet.
But we're also going to see improvements. As the field matures, we'll develop better tools for defending AI systems. We'll develop better ways of testing and validating them. We'll build security into the development process from day one, rather than trying to add it after the fact.
What's important right now is recognizing that AI security is a specialized domain that requires specialized expertise. It's not just traditional cybersecurity applied to a new tool. It's a new field with new challenges and new solutions.
For organizations, that means being thoughtful about which AI systems you adopt, understanding their security properties, and having policies in place about how and where they can be used. For individuals, it means being cautious about what information you share with AI assistants and being skeptical about links or instructions that route you through unexpected channels.
The Reprompt vulnerability is a wake-up call. It demonstrates that current AI systems have real security weaknesses, that these weaknesses can be exploited in sophisticated ways, and that the stakes of getting security wrong are high. But it's also a reminder that security researchers are actively working to find and fix these vulnerabilities, and that the community is taking AI security seriously.
Practical Security Recommendations Right Now
While we're waiting for AI security to mature, here are concrete things you can do to reduce risk.
For personal users:
Don't assume your chat history is private. Assume that Microsoft, hackers, and potentially law enforcement might read it. Only discuss information you'd be comfortable with those parties knowing.
Never paste credentials, API keys, or passwords into chat interfaces, even if you're asking for help with them. Find alternative ways to get that help, like discussing the problem in general terms without the actual sensitive values.
Be skeptical of links that open AI interfaces directly. If you want to use an AI tool, navigate to it yourself.
Keep your AI interactions separate from sensitive work. If you need to use AI for work, use your company's managed instance if available, not free consumer services.
Regularly review your chat history and delete sensitive conversations. Don't let sensitive information accumulate in your account.
For enterprise users:
Have a security team review any AI platform before deploying it widely in your organization. Understand what data it has access to and what could be compromised if it's breached.
Implement policies about what types of information can be discussed with AI systems. Some organizations are prohibiting discussion of customer data, proprietary information, or security credentials.
Run AI systems in restricted environments with limited access to sensitive data and systems. Don't give Copilot access to your entire email archive if it doesn't need it.
Monitor and log all interactions with AI systems that involve sensitive data. This creates an audit trail and might help you detect if data has been compromised.
Have a response plan for if an AI system is compromised. What data might be exposed? Who needs to be notified? How will you communicate with customers or users?
Stay informed about AI security research. Subscribe to security newsletters. Read research papers. Participate in security conferences. Make AI security expertise a priority in your organization.
Looking Ahead: What Needs to Change
The Reprompt vulnerability is significant, but it's not the last word on AI security. Several important changes need to happen in the coming years.
First, we need better threat modeling practices specific to language models. The playbook for traditional software security doesn't fully translate. We need new frameworks for thinking about what can go wrong and how to prevent it.
Second, we need better tools for testing and validating AI system security. We need automated tools that can try to exploit AI systems, the way we have automated tools for testing web applications. We need benchmarks that measure how resistant an AI system is to adversarial attacks.
Third, we need better standards and best practices for deploying AI systems securely. We need OWASP-like lists of common AI security problems. We need best practices documents that organizations can use as references.
Fourth, we need more diverse expertise in AI security. Right now, the people working on this problem are mostly computer scientists and security specialists. We also need input from policy experts, ethicists, and people who understand the social implications of AI security failures.
Finally, we need regulatory frameworks that create incentives for secure AI development. Right now, there's limited downside for companies that deploy AI systems with weak security. Regulation would change that calculation.
None of this will happen overnight. But the trajectory is clear. AI security is becoming important, and the resources being devoted to it are growing. That's a positive sign.

Conclusion: Living with AI Security Risks
The Reprompt vulnerability showed us that modern AI systems have real security weaknesses, and that those weaknesses can be exploited in ways that cause real harm. But it also showed us that the security research community is working to find and fix these vulnerabilities, and that vendors are responding.
We're in a transitional moment. AI systems are becoming more important and more integrated into how we work, but the security practices and tools around them are still immature. That creates a window of risk. But it also creates an opportunity for organizations and individuals to get ahead of the risk by thinking carefully about how they use AI systems and what information they share with them.
The good news is that awareness of these risks is growing. More companies are hiring AI security specialists. More research is being published about vulnerabilities and defenses. More organizations are implementing policies around AI use. That trajectory is encouraging.
For now, the practical approach is to use AI systems thoughtfully. Understand their limitations. Be careful about what information you share. Stay informed about security research. And if you're responsible for deploying AI systems in an organization, make security a priority from day one. The risks are real, but they're manageable if you approach them seriously.
FAQ
What is a prompt injection attack?
A prompt injection attack is when an attacker embeds malicious instructions into data that an AI system will process, tricking the AI into following those instructions as though they were legitimate user requests. Unlike traditional security attacks that exploit coding flaws, prompt injection exploits the AI's natural language understanding capabilities against itself. The attack works because AI systems don't have strong boundaries between data they should trust and data they shouldn't trust.
How did the Reprompt attack bypass Microsoft's safety guardrails?
The attack worked by instructing Copilot to repeat each operation twice and compare results. Microsoft's guardrails were designed to block dangerous operations on the first request, but they didn't properly apply to subsequent executions of the same instruction. When Copilot executed the malicious instruction a second time (as directed by the attack), the guardrails didn't block it because they'd already been evaluated on the first attempt. This revealed a gap in how Microsoft designed their security controls.
What information could be stolen through this vulnerability?
The attack could extract sensitive user data including names, locations, and any information from a user's Copilot chat history. This includes conversations where users discussed credentials, proprietary code, personal information, health concerns, financial details, or any other sensitive topics they'd chatted about with Copilot. In a business context, this could expose company secrets, customer information, or confidential strategies.
Why was only Copilot Personal affected, not Microsoft 365 Copilot?
Microsoft's enterprise product, Microsoft 365 Copilot, had additional security measures that protected it from the same vulnerability. This disparity likely reflects Microsoft's different development and security priorities for enterprise versus consumer products. Enterprise customers have more resources to demand security, contractual requirements for protection, and greater visibility when security failures occur, creating more pressure to build stronger security into enterprise versions.
Can this type of attack happen with other AI systems like Chat GPT or Claude?
Yes, all language models are fundamentally vulnerable to prompt injection attacks because they don't have built-in mechanisms to distinguish between legitimate user instructions and malicious instructions embedded in data. While different AI systems have different safety guardrails and might be more or less resistant to specific attacks, none have completely solved the prompt injection problem. Every system that processes external data faces this vulnerability category.
How can individuals protect themselves from prompt injection attacks?
Be cautious about clicking links that open AI interfaces directly, as this is how the initial compromise happens. Never paste sensitive credentials or secrets into AI chat interfaces. Treat your AI chat history as potentially accessible to others and only discuss information you'd be comfortable exposing. Review and delete old conversations periodically. For work-related discussions, use enterprise-managed AI systems if available rather than free consumer services. Most importantly, understand that AI assistants should not be trusted with truly sensitive information.
What should enterprises do about AI security risks?
Enterprises should have dedicated security teams review any AI platform before widespread deployment. Implement policies restricting what types of information can be discussed with AI systems, especially customer data and proprietary information. Run AI systems in restricted environments with limited access to sensitive organizational systems. Monitor and log AI interactions involving sensitive data. Develop incident response plans for potential AI system compromises. Stay informed about AI security research and maintain AI security expertise in-house or through consulting partners.
How long did this vulnerability exist before it was discovered?
The exact timeline isn't public, but the vulnerability likely existed from before Reprompt was formally demonstrated by Varonis until Microsoft's fix was deployed. Sophisticated threat actors might have discovered and exploited the vulnerability independently before the public disclosure, meaning the actual window of exposure could be months or even longer. This highlights the importance of prompt security fixes once vulnerabilities become public.
Why haven't AI companies solved prompt injection vulnerabilities completely?
Prompt injection is fundamentally difficult to prevent because it exploits how language models work at a basic level. These systems are designed to process text and follow instructions, but they don't have robust mechanisms for determining which instructions they should follow and which they shouldn't. Fixing this would require fundamental architectural changes to how language models operate, and researchers haven't yet found approaches that solve the problem while maintaining AI system functionality. Current defenses are guardrails and safety measures, not complete solutions.
What is responsible disclosure in the context of AI security?
Responsible disclosure is when security researchers privately report vulnerabilities to the affected company, give them time to develop and test fixes, and then publish details publicly after the fixes are deployed. This balances transparency with safety, allowing vendors to protect users before attackers have full information about exploiting the vulnerability. Varonis followed this practice by reporting their findings to Microsoft before publishing their research, giving Microsoft time to develop a fix before the broader security community learned about the vulnerability.
The Path Forward
The security landscape around AI is evolving rapidly. What matters most is maintaining awareness, taking measured precautions, and staying informed as the field develops. The Reprompt vulnerability was serious, but it was also discovered and fixed relatively quickly. That's how the system should work: vulnerabilities are found, disclosed responsibly, and fixed before they can be widely exploited. As organizations and individuals continue to integrate AI into their work and lives, security practices will mature. That maturation process is happening right now, and staying informed about it is your best protection.
If you work in AI development or organizational security, prioritize understanding these vulnerability categories. If you're a regular AI user, be thoughtful about what you share with these systems. The risks are real, but they're manageable with proper awareness and precautions.
Developing secure AI systems is one of the critical challenges of the next decade. Getting it right matters. It matters for protecting user privacy, for ensuring organizations can trust AI systems, and for building the foundation for safe, beneficial AI deployment at scale. The Reprompt research contributed meaningfully to this effort by identifying a real vulnerability and demonstrating its exploitation, pushing the entire field toward better security practices.
Key Takeaways
- Single-click attack exploited prompt injection to extract sensitive user data including names, locations, and entire chat histories from Copilot
- Security guardrails only applied to initial requests; attackers bypassed them by instructing Copilot to repeat operations multiple times
- Attack continued executing even after users closed chat windows, with no further user interaction needed after the initial link click
- Copilot Personal lacked protections available in Microsoft 365 Copilot, leaving individual users more vulnerable than enterprise customers
- No language model has successfully prevented prompt injection attacks; this vulnerability represents a fundamental architectural challenge in AI systems
Related Articles
- Prompt Injection Attacks: Enterprise Defense Guide [2025]
- Enterprise AI Security: How WitnessAI Raised $58M [2025]
- LinkedIn Comment Phishing: How to Spot and Stop Malware Scams [2025]
- Major Shipping Platform Exposed Customer Data, Passwords: What Happened [2025]
- Telegram Links Can Dox You: VPN Bypass Exploit Explained [2025]
- Hackers Targeting LLM Services Through Misconfigured Proxies [2025]

