![Data Center Services in 2025: How Complexity Is Reshaping Infrastructure [2025]](https://tryrunable.com/blog/data-center-services-in-2025-how-complexity-is-reshaping-inf/image-1-1770395898224.jpg)
The Data Center Services Revolution: Why Expertise Now Trumps Hardware
Data centers used to be simpler. You bought servers, installed them, and kept them running. Services? That was just maintenance schedules and emergency repairs, something you outsourced to whoever was cheapest.
That era is over.
Today's data centers are fundamentally different machines. They're denser. They're hotter. They're more interdependent. They're built on tighter timelines to meet AI deployment demands, environmental regulations, and power constraints that didn't exist five years ago. And the fallout from getting any of this wrong is catastrophic.
The global 2000 companies alone lose hundreds of billions annually to unplanned downtime. But here's what's actually shifted: organizations have stopped planning for recovery and started planning for avoidance. That pivot changes everything about how services function in the modern data center.
Services aren't a back-office cost anymore. They're infrastructure. They're the difference between a facility that runs for twenty years and one that melts down in six months. They're how you catch thermal drift before it becomes a fire. They're how you validate a liquid cooling system so it doesn't corrode your entire electrical plant. They're how you stay compliant with regulations that shift faster than your hardware roadmap.
This shift reflects deeper structural changes in how data centers are built, operated, and thought about. AI workloads. New regulatory demands. Geographic expansion into unfamiliar regions. Extreme thermal densities that make every system interdependent. These forces are converging, and they're forcing operators to completely rethink what services mean.
We're going to walk through why this is happening, what it means for operators, and how the leading edge of the industry is responding. Because if you're running a data center in 2025, understanding this transition isn't optional. It's foundational to staying operational.
TL; DR
- Infrastructure complexity is exploding: Liquid cooling, high-density racks, and converged HPC/AI systems require expert integration, not just installation
- Operational failures are catastrophically expensive: Global 2000 companies face hundreds of billions in annual downtime losses, forcing shift from recovery-focused to prevention-focused planning
- Services define reliability: Continuous monitoring, predictive maintenance, and lifecycle integration now directly influence long-term facility performance
- New regulations demand expertise: Energy efficiency mandates, waste heat reuse, and compliance requirements across EMEA and beyond require trained operational staff
- The geographic spread introduces new constraints: Expanded builds in new regions create supply chain complexity that makes local operational support critical to site selection
- Integrated lifecycle approach matters: Early design decisions, commissioning validation, monitoring interpretation, and retrofit planning are all connected, and services tie them together
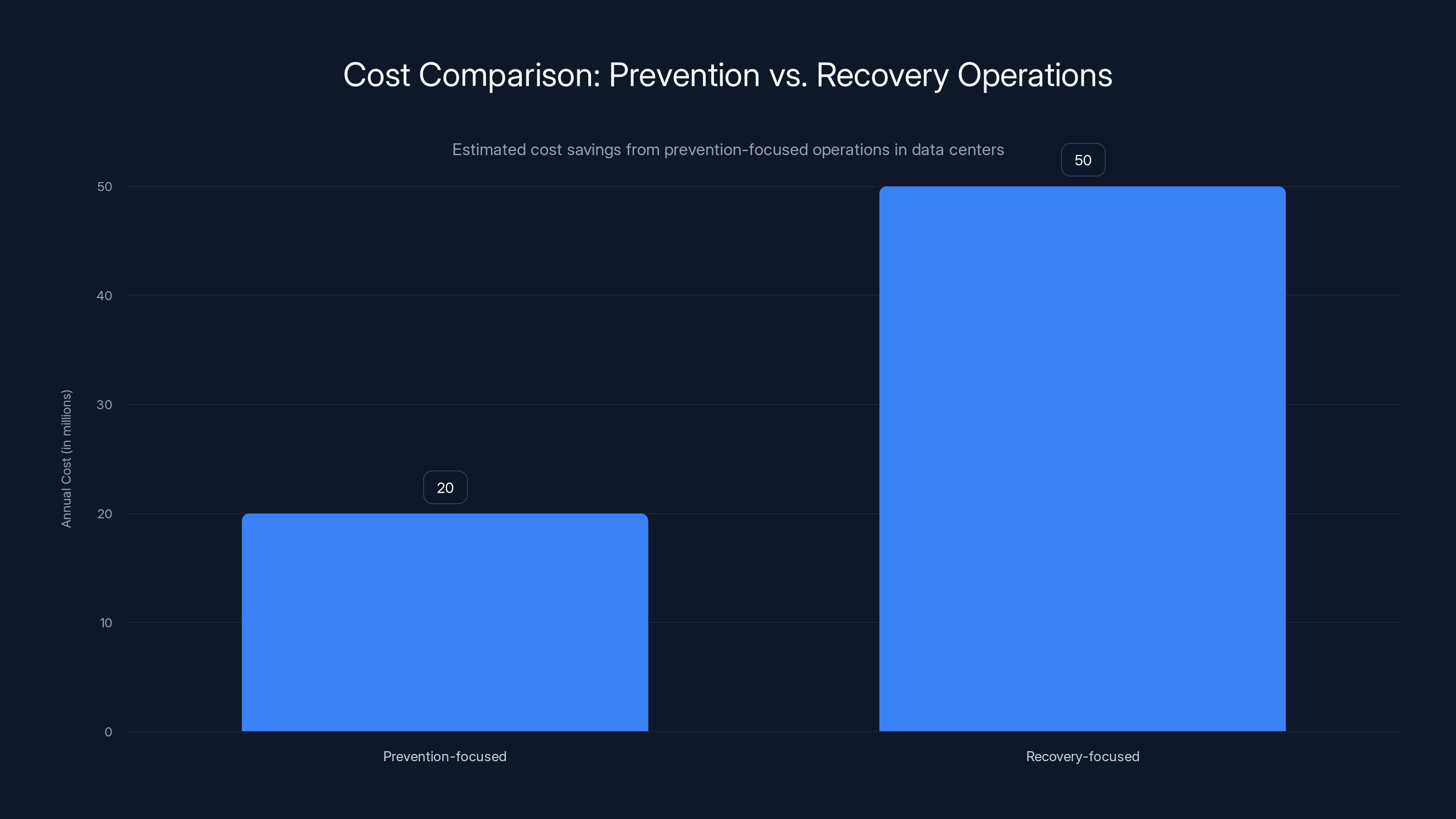
Prevention-focused operations can save data centers significantly, with estimated annual costs of
Understanding the Data Center Complexity Crisis
Let's be clear about what complexity means in 2025. It doesn't just mean more servers. It means systems that interact in ways that can cause cascading failures if any single component drifts even slightly.
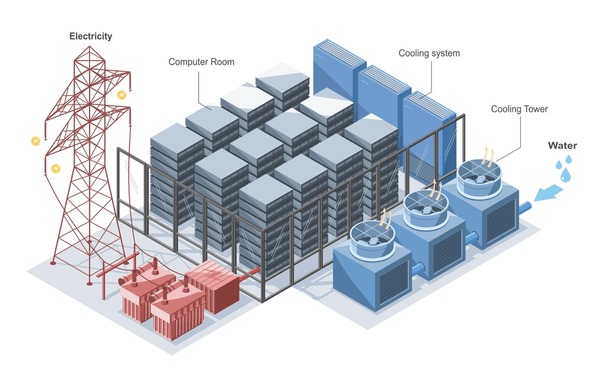
Take liquid cooling as an example. A decade ago, this was a niche technology. Now hyperscalers are standardizing on it because air cooling simply can't handle the power densities AI workloads demand. But liquid cooling isn't just plumbing. The thermal stability of a closed-loop system depends on fluid chemistry, pump calibration, compressor behavior, heat exchanger fouling, and a dozen other variables that all influence each other.
If your fluid chemistry drifts just 2% off specification, thermal conductivity changes. If thermal conductivity changes, your compressor works harder. If your compressor works harder, power consumption goes up. If power consumption goes up, electrical load distribution shifts. And now you've got a cascading effect that can disable an entire row if nobody's watching.
That's where operational expertise comes in. You need people who understand the chemistry, the thermodynamics, the electrical load distribution, and how they all interact. You need continuous monitoring that catches these drift signals before they cascade. And you need design decisions made at the beginning that make commissioning easier and maintenance more predictable.
This is true across every major system in modern data centers. Electrical infrastructure handling higher loads with tighter tolerances. Cooling systems managing tens of kilowatts per rack. Power distribution networks balancing real-time demand across multiple buildings or regions. Fire suppression systems that can't use traditional approaches because they'd damage equipment. Security systems. Network interconnects. Battery backup systems for critical loads.
Each of these has become more complex. Each requires deeper expertise. And each influences the others in ways that demand integrated thinking.
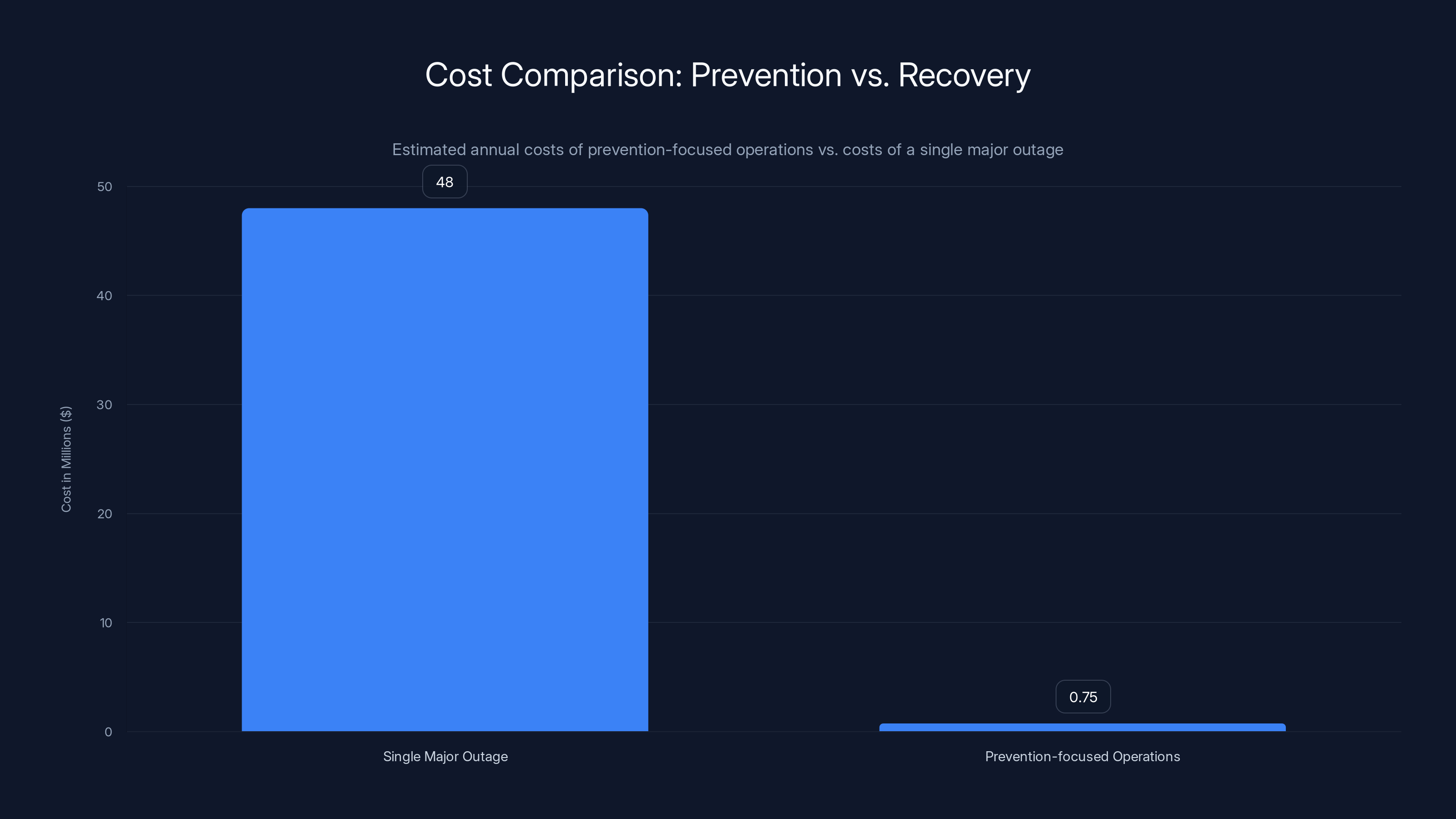
Preventing a single major outage (costing
Why the Old Recovery-Focused Model Doesn't Work Anymore
For decades, data center operators managed risk using a straightforward formula: if something fails, how fast can we fix it? This recovery-focused mentality made sense when downtime cost $10,000 per minute and took hours to diagnose.
Then cloud economics changed everything.
Today's hyperscale services operate on razor-thin margins. A major outage doesn't just cost the operator directly. It damages customer SLAs, triggers automatic refunds, triggers brand damage, and can cause multi-day recovery processes. For a company processing financial transactions or running AI workloads for major corporations, even five minutes of downtime can cascade into days of lost revenue.
This created a fundamental shift in how organizations think about risk. Instead of asking "how fast can we recover," they started asking "how do we prevent this from ever happening?"
That's not just a mindset change. It requires completely different operational infrastructure.
Recovery-focused operations center on redundancy and failover speed. You build backup systems, automate failover procedures, and staff rapid response teams. This works until your backup system is also operating at maximum thermal density, and there's nowhere else to push load.
Prevention-focused operations center on detecting problems before they manifest. You need continuous monitoring that captures thermal drift, electrical anomalies, vibration changes, humidity fluctuations. You need subject matter experts who can interpret what those signals mean. You need predictive maintenance schedules based on actual equipment behavior, not manufacturer recommendations. You need design decisions that make systems inherently more stable.
This is a fundamentally different operation. It requires more expertise upfront. It requires continuous data collection and analysis. It requires people who understand the interconnected nature of facility systems.
But here's the economic logic: prevention is always cheaper than recovery. Preventing a single major outage saves more money than hiring the best prevention-focused team for a decade. Organizations that have made this shift now view services not as a cost center, but as a risk mitigation engine.

The AI Boom: Why Timelines Got Compressed and Complexity Exploded
AI projects operate under a completely different timeline pressure than traditional data center builds.
A traditional enterprise data center might take 18 to 24 months from site selection to operational status. You have time to hire local staff, train them on your specific equipment, establish supply chains, validate systems under normal load, and build gradual capacity.
AI projects? Hyperscalers are frequently operating on 6 to 12 month timelines from commitment to production readiness. In some cases, they're deploying capacity within weeks of equipment arrival.
This compression creates a completely different operational profile. You can't afford the learning curve. You can't afford to discover problems after deployment. You can't wait for local staff to get up to speed.
This is why services have become critical to AI deployment. You need teams that can show up with pre-existing expertise in your specific infrastructure stack. You need commissioning processes that validate everything works before systems go live, not after problems emerge in production. You need monitoring systems that go live on day one, so you catch problems immediately rather than discovering them months in.
And this is specifically why expertise-driven services firms have become central to hyperscaler infrastructure strategy. They're not just maintaining equipment. They're the enablers of the entire compressed timeline model.
Consider a typical GPU cluster deployment. You've got thousands of GPUs generating tens of megawatts of heat. They're connected via ultra-low-latency networking. They're pulling power from electrical infrastructure that's often near capacity. Power failures, thermal events, or networking hiccups cause immediate loss of compute. Any single point of failure in commissioning or monitoring can cascade into production issues.
A skilled services team can commission this entire complex in weeks instead of months. They know what to look for. They know how to validate each component without extensive testing. They have monitoring templates ready to deploy. They understand how to phase capacity in without destabilizing electrical systems.
Without this expertise? You're looking at months of debugging, significant risk of deployment delays, and genuine likelihood of field failures that should have been caught during commissioning.
This is why AI deployment has become a direct driver of services complexity and value.

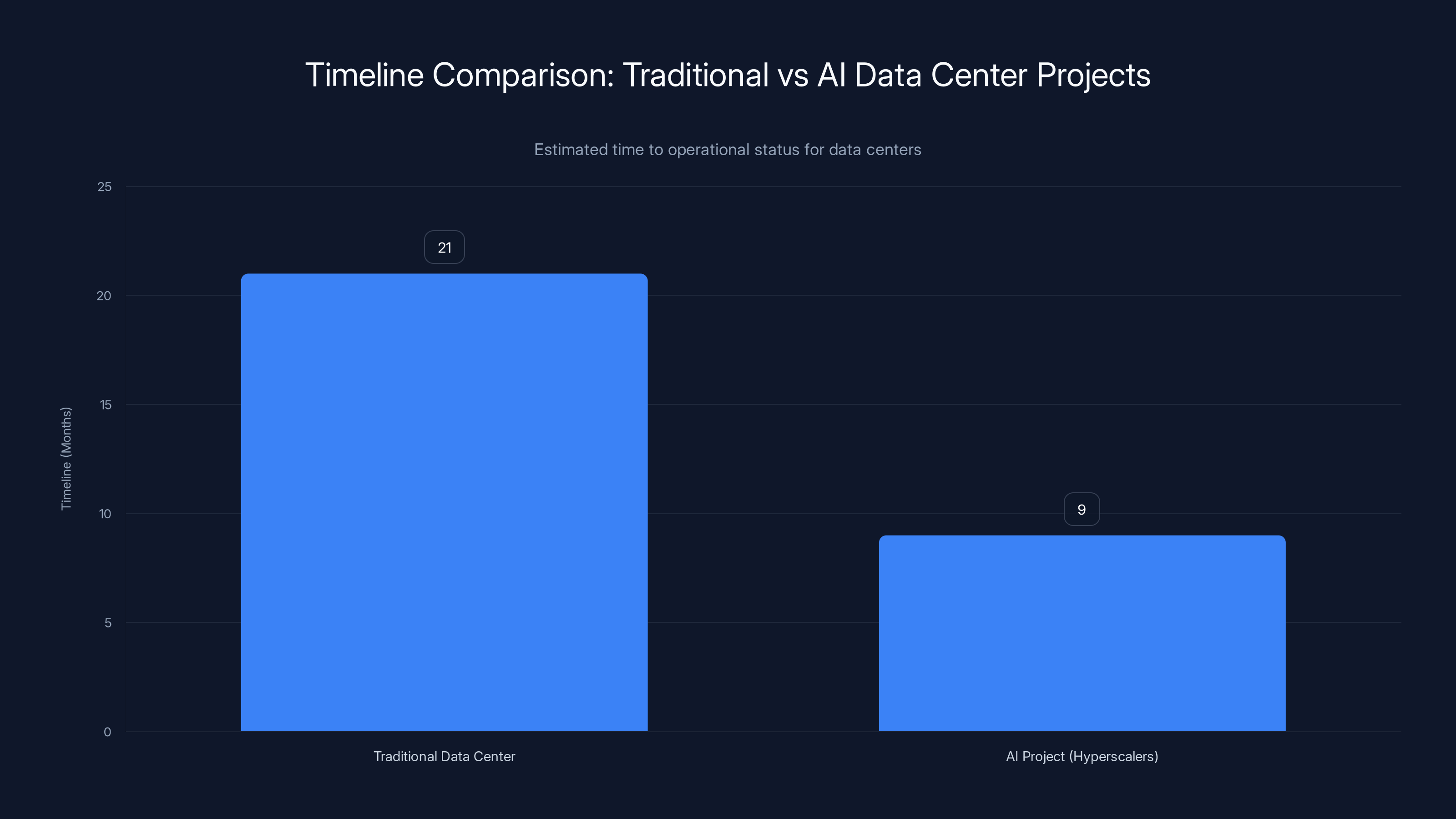
AI projects by hyperscalers are completed in approximately 9 months on average, significantly faster than the 18-24 months typical for traditional data centers. Estimated data.
Regulatory Pressure: Complexity Mandated by Law
Europe is rewriting the rules for data center operations, and operators in other regions are watching closely.
Germany's Energy Efficiency Act sets explicit PUE (Power Usage Effectiveness) thresholds and mandates for heat reuse. Facilities must achieve specific efficiency targets and prove they're doing it. The EU's revised standards demand detailed reporting on energy and water consumption. Italy's environmental regulations restrict facilities that can't prove sustainable operations. Similar requirements are emerging across the Nordic countries, UK, and most developed markets.
These aren't aspirational guidelines. These are legal requirements with compliance reporting, audits, and penalties for failure.
Complying with this requires completely different operational infrastructure than just keeping servers running. You need continuous measurement of PUE across your facility. You need to document cooling efficiency. You need to prove that waste heat is being captured and reused (not just vented to atmosphere). You need audit trails showing that environmental systems are maintained to spec.
This requires trained personnel who understand energy systems, not just data center operations. It requires monitoring systems that capture the right data. It requires processes that ensure compliance even when operational pressures push toward shortcuts.
For operators expanding into new regions, regulatory compliance becomes a major factor in site selection and design. If you're building in a market with strict thermal efficiency mandates, you need operational expertise built into your site from day one. You can't retrofit compliance.
This is driving a fundamental shift in how services are valued. Compliance-driven operational support isn't discretionary anymore. It's infrastructure.

Geographic Expansion and the Supply Chain Problem
Hyperscalers are moving beyond the major metros. Land costs, power constraints, and community pressure have made building in places like Dublin, Frankfurt, and Silicon Valley increasingly challenging.
So operators are expanding into secondary markets. Eastern Europe. Portugal. Scandinavia. Spain. New regions offer cheaper land, more available power, better environmental credentials, and less regulatory friction.
But they also introduce a completely different operational profile.
In established markets, you've got established supply chains. You know the local electrical contractors. You know which cooling vendors have local service capabilities. You can hire from a pool of experienced data center engineers. You understand local regulations.
In new markets? None of that exists.
A facility in a new region now faces: spare parts take weeks to arrive instead of hours, local technicians may not be familiar with your specific infrastructure stack, local regulations are less predictable and harder to navigate, supply chains are often single-sourced, and you can't always assume local expertise exists.
This creates a direct operational dependency on services. You need teams that can travel to new sites and provide immediate expertise. You need design decisions that account for the reality that local support won't be available. You need commissioning processes that bring the facility to a level of stability where it can operate with less intensive support.
Geographic expansion has literally become a services-intensive business model. Sites in new regions require higher levels of ongoing support, which makes the economics of operations very different.
For services-focused firms, this represents genuine business opportunity. For operators, it represents a cost that must be built into site selection and design from the beginning.

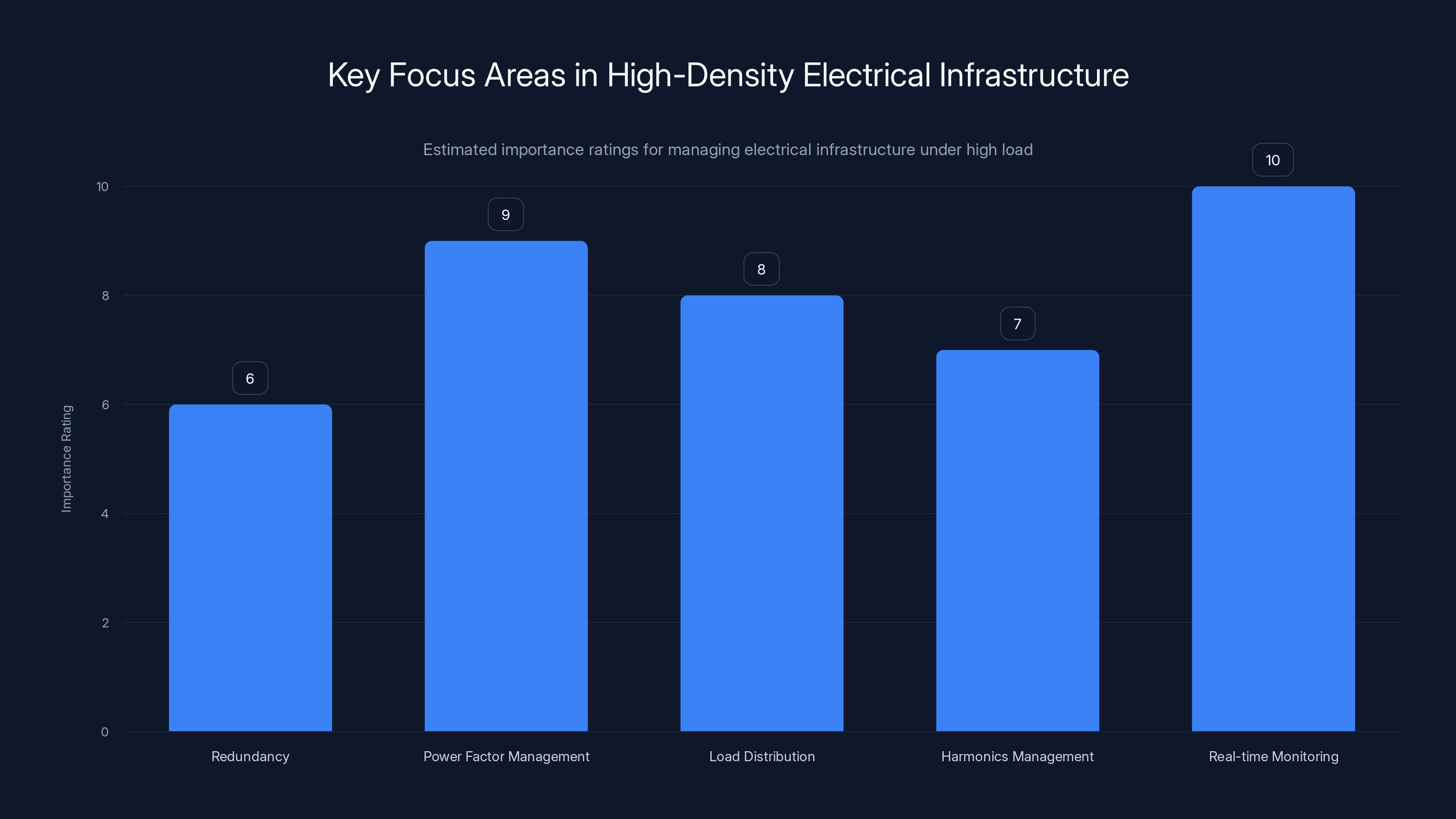
Real-time monitoring is the most critical aspect in managing high-density electrical infrastructure, followed by power factor management. (Estimated data)
High-Density Computing and the Thermal Sensitivity Problem
GPU workloads have created a new class of infrastructure problem: extreme density combined with extreme sensitivity.
Ten years ago, a "hot" data center rack consumed maybe 10 to 12 kilowatts. Today's GPU clusters consume 20 to 40 kilowatts per rack. Some extreme configurations are pushing toward 50+ kilowatts.
This isn't just more heat. It's qualitatively different. At these densities, even small deviations in thermal performance compound rapidly. A 1-degree shift in inlet temperature cascades into changes in compressor efficiency, power consumption, and thermal distribution across the entire row.
This means that monitoring and operational expertise become critical safety factors. You need continuous measurement of thermal behavior. You need the ability to detect when something is drifting. You need to interpret what those signals mean before they cause failures.
Traditional data center monitoring was focused on peak temperatures and threshold alarms. "If it goes over 45 degrees, alert."
Modern monitoring for high-density facilities is predictive. You're looking at trends. You're comparing current behavior to historical baselines. You're detecting small deviations that indicate something is changing. You're using that information to predict when components will fail or performance will degrade.
This requires much more sophisticated monitoring infrastructure and much more expertise in interpreting the data.
It also requires a different approach to design and commissioning. You need to understand how cooling systems will behave at full load, under various scenarios, with various failure modes. You need commissioning processes that prove everything works as intended before GPUs start training models on millions of dollars worth of compute.
The rise of high-density computing has created a direct dependency on services expertise. Facilities without this expertise face higher failure rates, longer troubleshooting times, and greater risk of unplanned outages.
The Integrated Lifecycle Model: Services as Continuous Process
Here's where the conceptual shift gets fundamental.
Traditional data center operations treated services as discrete activities. Installation happened at the beginning. Maintenance happened periodically. Upgrades happened when needed. Emergency repairs happened when things broke.
Modern infrastructure operations are starting to think about this completely differently. Services aren't discrete activities. Services are a continuous process that spans the entire facility lifecycle.
Design decisions made at the beginning influence how easily equipment can be commissioned. Commissioning processes influence how components will behave during normal operation. Monitoring data reveals trends that help predict issues before they escalate. Retrofit decisions shape the efficiency and longevity of the facility.
None of these exist in isolation. They're all connected.
This shift from discrete services to continuous process fundamentally changes how organizations approach facility management. Instead of asking "what's the minimum maintenance we need," they're asking "how do we operate this facility optimally across its entire lifecycle."
This creates several important changes:
Early engagement with design teams. Services expertise influences architectural decisions. Cooling system design, electrical infrastructure, monitoring sensor placement, spare parts strategy. These decisions are made with input from the teams that will operate the facility.
Continuous data collection from day one. Monitoring doesn't start after problems appear. It starts during commissioning. You're building baseline data that you can use to detect deviations later.
Predictive maintenance based on facility-specific behavior. Instead of following generic maintenance schedules, you're adjusting based on how your specific facility is actually behaving.
Coordinated retrofit planning. When you eventually upgrade or replace equipment, you're doing it with understanding of how it interacts with the rest of the facility.
Documentation and institutional knowledge. You're capturing how your facility actually works, not just following vendor documentation.
This integrated approach requires deeper partnerships between operators and services providers. It requires services expertise to be embedded in the organization, not just called in when something breaks.
For operators, this shift means treating services as a core capability, not an outsourced cost. For services firms, it means positioning their value as continuous optimization, not reactive maintenance.
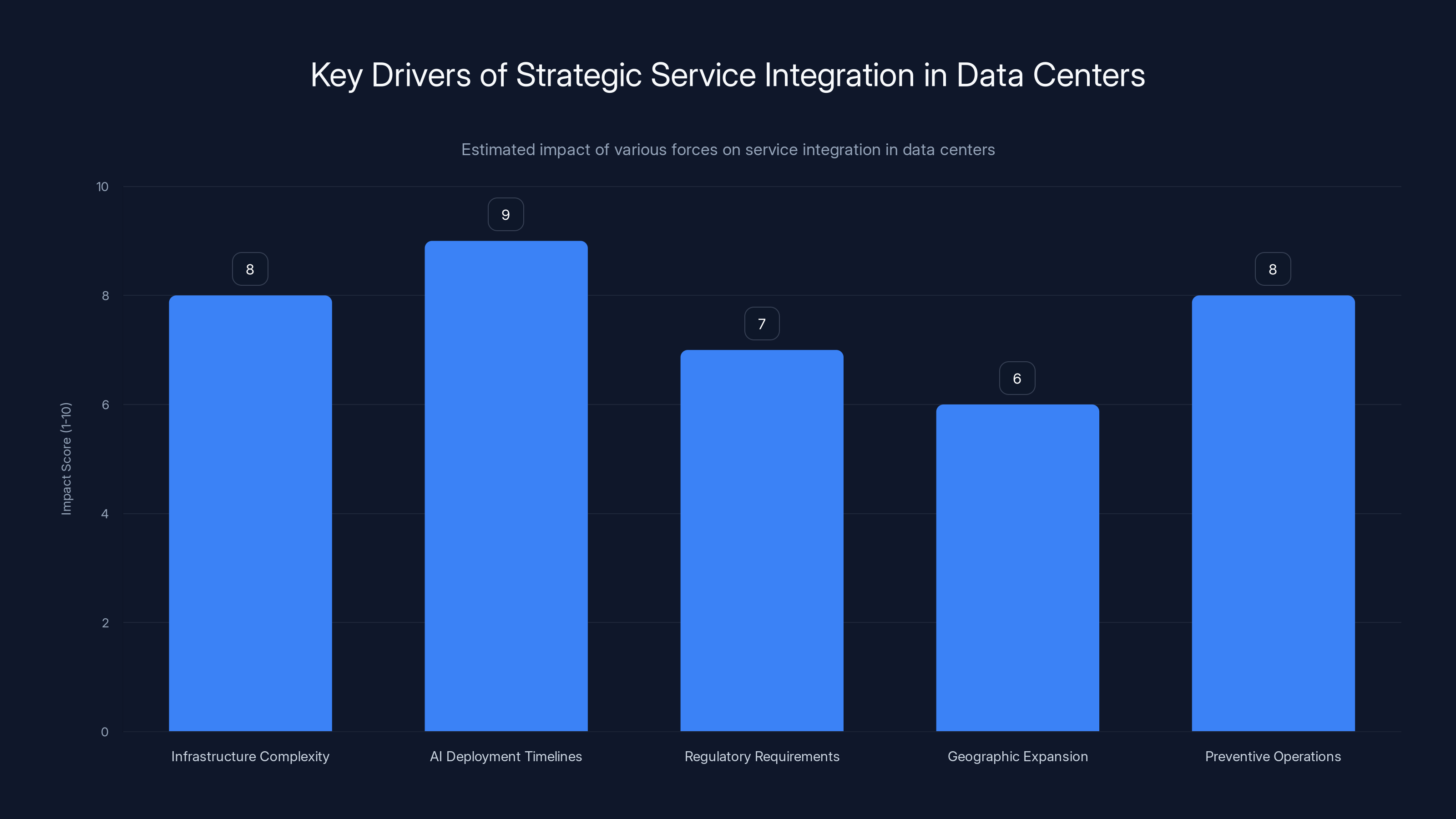
Estimated data shows that AI deployment timelines and infrastructure complexity are the most significant drivers for integrating services as strategic infrastructure in data centers.
The Economics of Prevention vs. Recovery
Let's do the math on why this shift from recovery-focused to prevention-focused operations makes economic sense.
A major unplanned outage at a hyperscale facility costs approximately
Now, compare that to the cost of prevention-focused operations:
A skilled services team costs maybe
Total prevention budget: maybe
Now, what's the prevention ROI? If you prevent just a single major outage through early detection and corrective action, you've paid for your entire prevention program for the year. If you prevent two outages, you've paid for the program for multiple years.
Most facilities operating at this level of sophistication report preventing 2 to 4 major outages annually through early detection. That means the economic case for prevention-focused operations is completely clear.
This economic logic is driving the shift in how organizations value services. It's not a cost. It's an insurance policy that pays dividends.
But here's the subtlety: prevention-focused operations require more expertise and more upfront investment than reactive operations. You can't just hire the cheapest technician and expect them to interpret thermal monitoring data effectively. You need subject matter experts who understand facility systems.
This has created a two-tier market in services. There are low-cost reactive services (call someone when something breaks) and high-value preventive services (continuous monitoring and early intervention). The gap in economics between these two models is widening as facility complexity increases.
Skilled Workforce Challenges: Why Expertise Is Scarce
Here's the constraint that's making all of this harder: there aren't enough people with the right expertise.
Running modern data centers requires knowledge across multiple disciplines. You need mechanical engineers who understand cooling systems. You need electrical engineers who can work with high-voltage infrastructure. You need control systems expertise. You need networking knowledge. You need regulatory compliance understanding. You need project management for coordinating complex installations.
Finding someone with expertise across multiple disciplines is genuinely difficult. And as facility complexity increases, the bar for expertise gets higher.
Traditional trades training doesn't prepare people for data center operations. HVAC technicians understand cooling systems, but not the specific thermal challenges of high-density computing. Electricians understand power distribution, but not the specific load distribution patterns in data centers. Network engineers understand connectivity, but not facility infrastructure.
Data center operations requires hybrid expertise that doesn't have a standard training pipeline. Most facilities develop expertise through on-the-job learning, which takes years.
This has created a genuine constraint on the ability to expand operations. Operators can build facilities faster than they can staff them with qualified personnel. This is why services partnerships have become strategically critical. Services firms invest in developing and retaining expertise. They can deploy that expertise across multiple client sites. They're not dependent on each individual operator building internal expertise.
For regions with less established data center infrastructure, this constraint is even more acute. Building facilities in new markets requires importing expertise from established regions, at least initially.
This skills constraint is actually one of the biggest drivers of the services transition. It's not just that services are better. It's that specialized expertise is fundamentally scarce, and services are the most efficient way to deploy scarce expertise across many facilities.

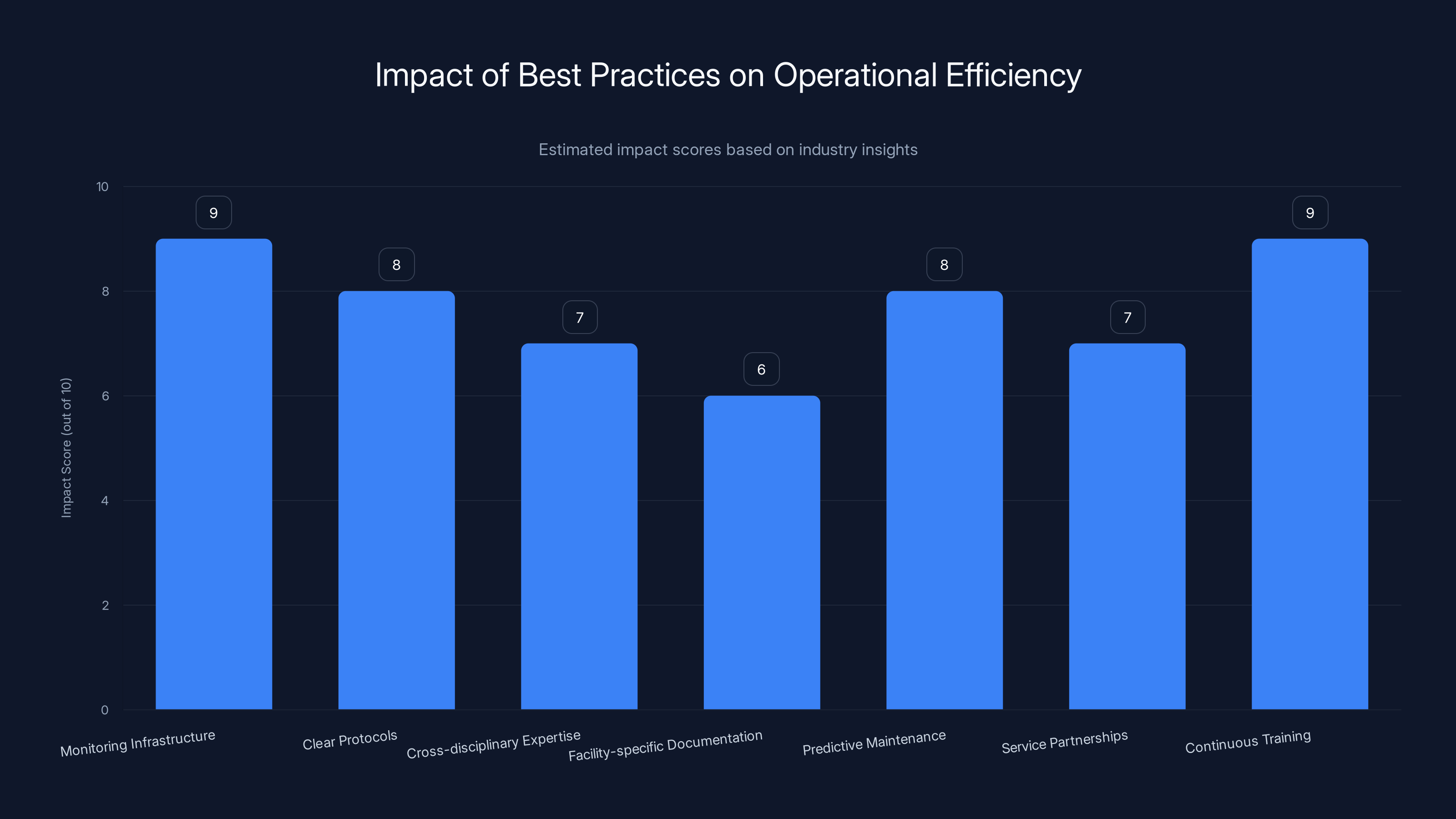
Investing in monitoring infrastructure and continuous training are estimated to have the highest impact on optimizing operational expertise. Estimated data.
Integrating Monitoring and Predictive Analytics
Modern facilities are generating massive amounts of operational data. Temperature sensors, power meters, vibration sensors, humidity monitors, fluid chemistry sensors, electrical load analyzers.
Traditional operations treated this data reactively. You looked at it when problems occurred. You used it to diagnose root causes.
Modern facilities are using this data predictively. You're building historical baselines. You're identifying patterns that precede failures. You're using this information to predict when components will fail or performance will degrade.
This requires completely different infrastructure and expertise.
At the infrastructure level, you need sensors deployed strategically throughout the facility. Not just threshold alarms, but continuous data collection. This data needs to flow to a central system that can correlate measurements across different systems.
At the expertise level, you need people who understand how to interpret this data. They're looking for small deviations from normal patterns. They understand the relationships between different sensors. They can distinguish between noise and signal.
At the process level, you need defined response protocols. When you detect a concerning trend, what do you do? Who do you alert? What corrective actions make sense?
Best-in-class facilities are now deploying AI-powered anomaly detection that can identify unusual patterns without explicitly programming what "unusual" means. The system learns facility-specific baseline behavior and flags deviations automatically.
But here's the important constraint: even with AI assistance, human expertise is still critical. The AI identifies potential issues. Subject matter experts interpret those identifications and determine what to do about them.
This combination of monitoring, analytics, and expert interpretation is what defines modern preventive operations. And it's a capability that most facilities don't have internally.

Thermal Management as a Core Competency
For facilities using liquid cooling (which increasingly they are), thermal management becomes a core operational competency.
Liquid cooling systems are more efficient than air cooling, but they're also more complex. The efficiency depends on precise control of fluid properties, flow rates, temperatures, and pressure differentials.
Small deviations compound into operational problems:
- Fluid chemistry drift affects thermal conductivity and corrosion protection
- Flow rate degradation increases compressor load and power consumption
- Pressure variations indicate compressor degradation or pipe blockages
- Temperature imbalances indicate heat exchanger fouling or circulation problems
- Vibration increases indicate pump bearing wear
Each of these signals, on its own, might seem minor. But in a closed-loop system where everything interacts, small deviations compound.
This is why thermal management expertise is so valuable. A skilled thermal engineer can look at a set of sensor readings and immediately understand what's happening in the system. They know what trajectory this data points toward if nothing changes. They know what corrective actions will be most effective.
This expertise is scarce. It requires deep understanding of thermodynamics, mechanical systems, materials science, and system behavior. It takes years to develop.
But facilities with this expertise operating their liquid cooling systems have dramatically better reliability and efficiency outcomes than facilities without it.
Electrical Infrastructure Under High Load
As power densities increase, electrical infrastructure becomes more critical and more sensitive.
Traditional data center electrical designs had redundancy built in. Multiple power distribution pathways. Automatic failover. UPS systems that could cover extended outages.
But as power densities increase, the economics of overprovisioning become less favorable. You end up designing electrical systems that operate closer to their design capacity. This reduces redundancy and increases the cost of failure.
Managing electrical infrastructure at these density levels requires different expertise. You're monitoring power distribution in real-time. You're understanding load distribution patterns. You're coordinating between demand-side management (how much power the compute equipment is drawing) and supply-side constraints (how much power is available from the grid connection).
Power factor management becomes important. Reactive power becomes a critical optimization point. Harmonics need to be actively managed.
This requires electrical engineers with data center-specific expertise. It's not the same as managing electrical systems in buildings. It's a specialized domain.
Facilities operating at very high power densities are increasingly deploying dedicated electrical operations teams. These teams are monitoring electrical infrastructure continuously and making real-time adjustments to optimize performance and reliability.
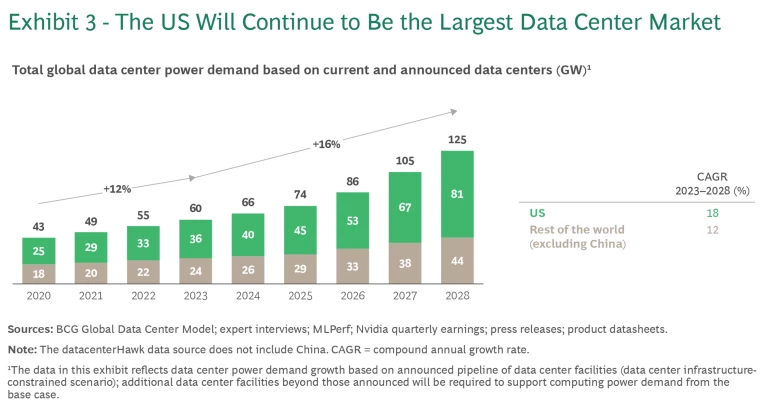
Building Services Into Site Selection
All of this context is now driving a fundamental change in how operators approach site selection and facility design.
It used to be that site selection was focused on: land cost, power availability, latency characteristics, and regulatory environment.
Now services capability has become a major decision factor. When evaluating potential sites, operators are asking: What local expertise exists? Can we build service partnerships? What's the supply chain situation? How familiar are local contractors with our infrastructure standards?
For new markets, lack of local services infrastructure is a genuine constraint. It adds cost (you need to import expertise). It adds complexity (you need to coordinate across regions). It increases risk (less familiar local support).
This has made services partnerships a central part of geographic expansion strategy. Operators are increasingly partnering with services firms to establish infrastructure in new regions, rather than trying to do it with internal teams.
It's also starting to change facility design. Designs in new regions incorporate more built-in monitoring, more documentation, more remote support capabilities. You're designing with the assumption that local expertise won't be available, so you're building that capability into the facility itself.

The Future: Services as Strategic Infrastructure
Where is all of this heading?
The trajectory is clear: services are becoming central to data center operations. Not as a back-office function. Not as an outsourced cost. But as core infrastructure that directly influences facility performance, reliability, and economic efficiency.
This shift is being driven by multiple converging forces:
- Infrastructure complexity is increasing faster than operators can develop internal expertise
- AI deployment timelines compress to the point where in-house training becomes infeasible
- Regulatory requirements are becoming more detailed and demand specialized expertise
- Geographic expansion introduces new operational contexts that require specialized knowledge
- Preventive operations economics are becoming increasingly favorable compared to reactive models
None of these forces is going away. If anything, they're all accelerating.
What this means operationally is that leading operators are moving from a model where they try to do everything internally to a model where they partner strategically with services providers who specialize in specific domains.
It also means that services firms that can demonstrate deep expertise and integrated support across the facility lifecycle are becoming strategically valuable partners, not just cost items to be minimized.
For facilities being built in 2025 and beyond, services strategy needs to be integrated into planning from the beginning. Not added afterward. Not treated as optional. Services capabilities are now infrastructure design elements.
This is a fundamental shift in how the industry thinks about operations. And it's just getting started.

Best Practices for Optimizing Operational Expertise
If you're responsible for data center operations, here are the areas where focusing on services expertise will have the biggest impact:
1. Build monitoring infrastructure before problems emerge. Most facilities start collecting detailed operational data only after experiencing issues. Leading facilities deploy monitoring from day one of commissioning, build baseline data for months, and use that baseline to detect deviations.
2. Establish clear escalation protocols. When monitoring flags an anomaly, what happens? Who interprets it? What decisions get made? Facilities with unclear protocols waste time on false alarms. Facilities with clear protocols catch real issues before they escalate.
3. Invest in cross-disciplinary expertise. Hire or partner with people who understand how different facility systems interact. A pure cooling specialist might miss electrical load impacts on thermal performance. A pure electrical specialist might miss thermal impacts on power distribution.
4. Document facility-specific behavior. Every facility behaves differently, even when using identical equipment. Document how your facility actually operates, not just what equipment specifications say it should do.
5. Implement predictive maintenance programs. Move from time-based or reactive maintenance to condition-based maintenance. Adjust maintenance intervals based on actual component behavior in your specific facility.
6. Establish service partnerships early. Don't wait until you're in crisis mode to establish relationships with specialized services providers. Build partnerships during facility design and commissioning when they can influence how systems are built and operated.
7. Invest in continuous training. Data center technology evolves constantly. Your operating team needs to stay current. Allocate budget for ongoing education and certification.
Understanding the Total Cost of Ownership
When evaluating services investments, it's important to think about total cost of ownership, not just direct service costs.
Direct costs are obvious: what you pay services providers, staff salaries, monitoring equipment.
But there are opportunity costs and risk costs that often get overlooked:
Opportunity costs: What else could your operations team be doing instead of debugging problems? Could they be optimizing performance? Could they be planning capacity? Could they be working on cost reduction?
Risk costs: What's the cost of unplanned downtime? Not just direct customer impact, but also the internal resources consumed in troubleshooting and recovery?
Scaling costs: As you grow to new facilities, what does it cost to transfer expertise? What do you lose when your best people are spread too thin?
When you account for these costs, the ROI on prevention-focused operations becomes even more compelling.
A facility that prevents two major outages annually through proactive services has a TCO impact of
Compare that to the cost of staffing and services, and the economic case becomes very clear.

The Competitive Advantage of Operational Excellence
Here's something that doesn't always get discussed: operational excellence in data center services has become a competitive advantage.
At the commodity level, compute is compute. Cloud providers and hyperscalers compete on price, and that competition has compressed margins dramatically.
But at the operational level, reliability and efficiency create real differentiation. Operators with superior uptime can charge premium prices for mission-critical workloads. Operators with superior efficiency can offer better margins on standard workloads.
This advantage flows from operational expertise. Better monitoring. Better predictive maintenance. Better thermal management. Better electrical optimization. Better service execution.
Facilities that invest in services expertise get tangible business advantages: higher availability, lower costs per watt, faster deployment of new capacity, better customer satisfaction.
These advantages are becoming more pronounced as facilities get more complex and as customer expectations for reliability increase.
Operators that treat services as a cost to minimize end up with higher operational costs and lower customer satisfaction. Operators that treat services as a strategic capability invest in building expertise and get better financial outcomes.
Key Takeaways: Why Services Matter Now
Data centers in 2025 are fundamentally different machines than they were a decade ago. More complex. Denser. More interdependent. Operating on tighter margins and tighter timelines.
This complexity has made operational expertise the differentiating factor between facilities that run reliably and efficiently and facilities that experience repeated problems and cost overruns.
Services, which used to be treated as a back-office function, are now central infrastructure. How you design facilities, how you commission them, how you operate them, how you maintain them - all of these now require specialized expertise.
Operators that recognize this shift and invest in building or partnering for deep services expertise are getting better business outcomes. Operators that try to minimize services costs are struggling.
The trajectory is clear. As infrastructure continues to get more complex, the value of specialized operational expertise will continue to increase. Services will continue to move from back-office function to strategic infrastructure.
For operators, the implication is straightforward: integrate services strategy into your facility planning from the beginning. For services providers, the opportunity is equally clear: expertise-driven, integrated support across the facility lifecycle is what creates genuine value.
The era of cheap, generic services is ending. The era of strategic, specialized operational expertise is just beginning.

FAQ
What exactly are "services" in the context of modern data centers?
In the modern context, data center services encompass far more than basic maintenance. Services now include facility design consultation, commissioning and validation, continuous monitoring and anomaly detection, predictive maintenance programs, thermal management, electrical optimization, regulatory compliance support, and emergency response. Essentially, services represent the operational expertise needed to keep complex infrastructure running reliably and efficiently across its entire lifecycle.
Why have services become so much more important in 2025 compared to previous years?
Services have become critical because infrastructure complexity has increased exponentially. AI deployment timelines have compressed dramatically, making it infeasible to develop expertise through traditional training. Regulatory requirements are becoming more detailed and specialized. Geographic expansion into new markets introduces operational contexts where local expertise doesn't exist. Most importantly, the economics of prevention-focused operations (catching problems before they cause outages) have become overwhelmingly favorable compared to reactive operations. A single prevented outage can cost
How do prevention-focused and recovery-focused operations differ in practice?
Recovery-focused operations assume problems will occur and focus on detecting them quickly and responding rapidly. This model uses redundancy, automatic failover, and rapid response teams. Prevention-focused operations, by contrast, assume problems can be anticipated and prevented. This requires continuous monitoring, early detection of anomalies, predictive maintenance, and expert interpretation of data trends. Prevention-focused operations require more upfront expertise but deliver dramatically better economic outcomes by preventing expensive outages before they happen.
What skills are most critical for modern data center operations?
Modern data center operations require expertise across multiple disciplines working together: thermal systems knowledge (especially for liquid cooling), electrical infrastructure management for high-power-density loads, control systems and monitoring expertise, networking and interconnect knowledge, project management for complex installations, and regulatory compliance understanding. The key is that these disciplines must work together. A thermal engineer alone isn't enough. You need people who understand how thermal, electrical, and network systems interact and influence each other.
How should facilities approach partnering with services providers?
Leading facilities are integrating services partnerships into their planning from the facility design phase, not waiting until problems occur. This means including service provider expertise in architectural decisions, establishing monitoring infrastructure before deployment, creating clear escalation and response protocols, and building long-term partnerships focused on continuous optimization rather than just fixing problems. The most valuable partnerships are those that span the entire facility lifecycle, from design through commissioning through ongoing operations.
What's the financial case for investing in preventive services?
The financial case is straightforward: a single major outage costs approximately
How should new facilities in unfamiliar markets approach operational challenges?
Facilities in new markets should assume that local expertise won't be immediately available and plan accordingly. This means investing more heavily in monitoring and documentation, designing systems with built-in resilience and diagnostics, partnering early with experienced services firms to establish operational capability, and investing in training and knowledge transfer for local staff. Geographic expansion should always include a services strategy component, not treat services as an afterthought.
What are the biggest risks of underinvesting in operational expertise?
Underinvestment in operational expertise creates several cascading problems. First, you miss early warning signs that lead to expensive outages. Second, troubleshooting times extend dramatically when you lack expertise. Third, you're unable to optimize facility performance, leaving efficiency and reliability gains on the table. Fourth, you struggle to recruit and retain quality staff when you don't invest in their development. Finally, as complexity increases, underinvestment in expertise creates a compounding problem where small issues cascade into major failures.
How are AI and analytics changing data center operations?
AI-powered monitoring systems can identify anomalies without explicitly programming what normal looks like. These systems learn facility-specific baseline behavior and flag deviations automatically. However, even with AI assistance, human expertise remains critical for interpreting what anomalies mean and determining appropriate responses. The most effective approach combines AI-enabled detection with expert interpretation and decision-making.
What metrics should facilities track to measure operational excellence?
Key metrics include Mean Time Between Failures (MTBF), Mean Time To Recovery (MTTR), Power Usage Effectiveness (PUE), thermal stability measures, electrical load factor, preventive maintenance completion rates, and most importantly, unplanned downtime events and their impact. Leading facilities also track early detection metrics: how many potential problems are caught and resolved before they impact operations versus how many become actual outages.

Related Articles
- Geekom GeekBook X14 Pro Review: Premium AI Laptop [2025]
- Grok AI Data Privacy Scandal: What Regulators Found [2025]
- Smart Heat Pumps for Old Buildings: Gradient's Retrofit Revolution [2025]
- Shared Memory: The Missing Layer in AI Orchestration [2025]
- SpaceX's Million-Satellite Network for AI: What This Means [2025]
- Minisforum AtomMan G7 Pro: Ultimate Slim Mini PC Review [2025]

