![Data Poisoning Against AI: How Researchers Defend Knowledge Graphs [2025]](https://tryrunable.com/blog/data-poisoning-against-ai-how-researchers-defend-knowledge-g/image-1-1767807642532.jpg)
Data Poisoning Against AI: How Researchers Defend Knowledge Graphs [2025]
Here's a scenario that keeps enterprise security teams awake at night: your company builds an expensive, proprietary knowledge graph. You feed it years of internal data, trade secrets, competitive analysis, and customer insights. Then someone steals it.
By the time you find out, your carefully constructed intellectual property is already feeding someone else's AI system. The damage is done.
But what if you could make that stolen data worthless before it's ever used? That's exactly what researchers from universities in China and Singapore are proposing.
They've developed a technique called AURA (Active Utility Reduction via Adulteration) that deliberately corrupts knowledge graphs in such a way that stolen data produces hallucinations and completely wrong answers. The catch: you need a secret key to unlock the correct outputs.
This isn't theoretical anymore. Tests show approximately 94% effectiveness in degrading stolen knowledge graph utility, as highlighted in The Register. And it raises some genuinely interesting questions about the future of data security, AI defense mechanisms, and what happens when we make our data deliberately wrong on purpose.
Let's dig into what's actually happening here, why it matters, and what it means for anyone protecting valuable data in the AI era.
TL; DR
- Data poisoning is now a defensive strategy: Researchers deliberately corrupt knowledge graphs so stolen versions produce hallucinations and wrong answers, as reported by TechRadar.
- AURA achieves 94% effectiveness: The system requires a secret key to unlock correct outputs, making stolen data nearly useless.
- Graph RAG systems are the target: Microsoft's knowledge graph approach organizes data in ways that make poisoning both possible and practical, as explained in HPCwire.
- This protects intellectual property: Companies can defend proprietary datasets without encryption overhead or performance penalties.
- The future of data defense: Poisoning may become standard practice for protecting high-value knowledge bases and proprietary information.

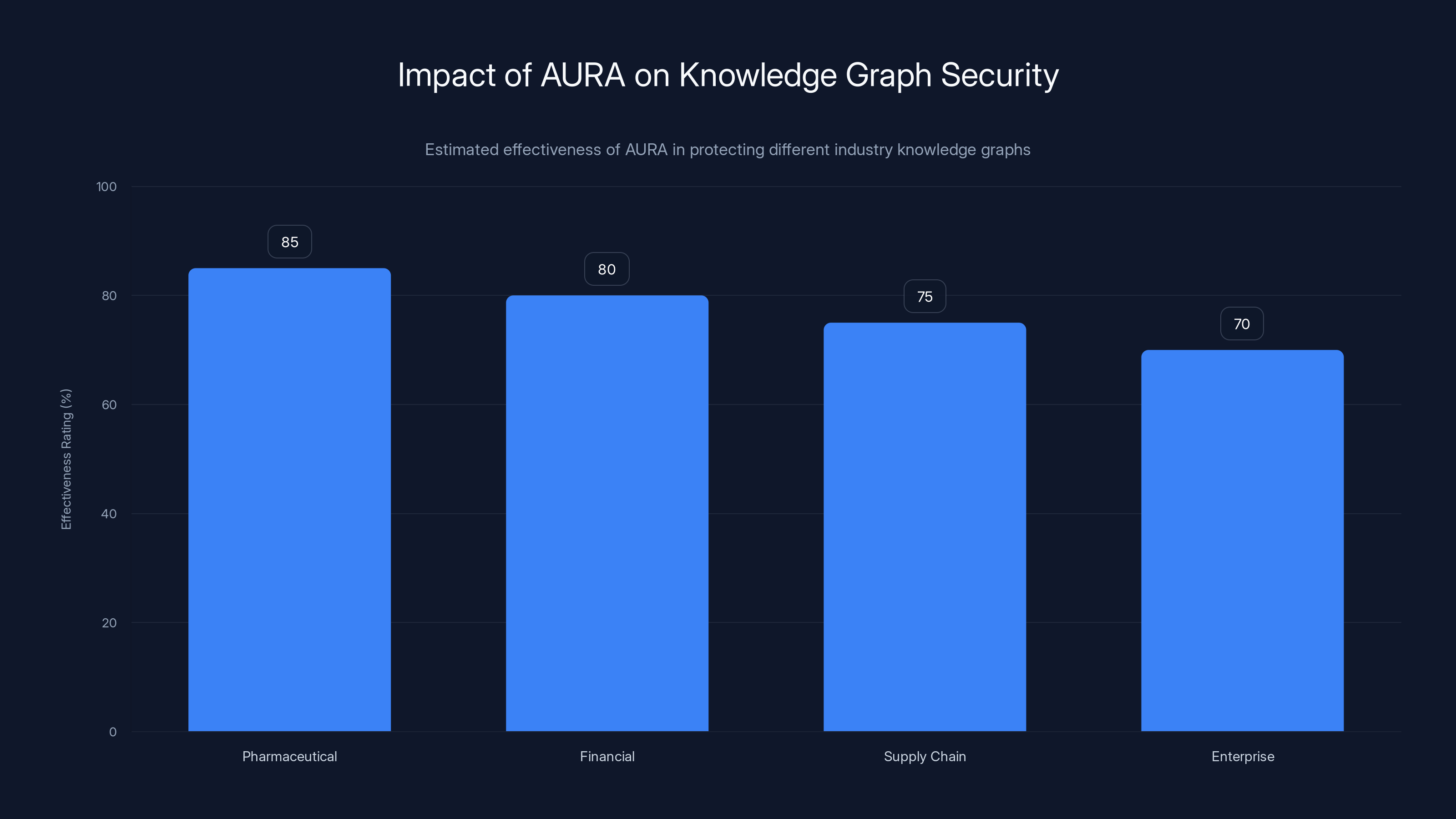
AURA provides significant protection across various industries by ensuring stolen knowledge graphs produce misleading results. Estimated data.
Understanding Knowledge Graphs and Why They Matter
Before we talk about poisoning them, we need to understand what a knowledge graph actually is and why they've become so valuable in the AI era.
A knowledge graph is essentially a structured database that maps relationships between entities. Instead of storing information as flat text documents, it organizes data as interconnected nodes. Think of it like a social network, except the "people" are concepts, facts, products, people, or anything else your system needs to understand.
For example, in a medical knowledge graph, you might have nodes for "diabetes," "glucose levels," "insulin," and "pancreas." The connections between these nodes represent relationships: diabetes affects glucose levels, insulin regulates glucose, the pancreas produces insulin. When an AI needs to answer a question about diabetes management, it doesn't just retrieve documents mentioning diabetes. It traverses the graph, understanding how concepts relate to each other.
This is why Microsoft developed Graph RAG in 2024. Traditional retrieval-augmented generation (RAG) systems work like this: you ask a question, the system searches documents for relevant snippets, and an LLM synthesizes an answer from those snippets. But this approach has limitations.
If you ask a complex question that requires understanding how multiple concepts connect ("How does financial stress impact cardiovascular disease risk factors?"), a traditional RAG system might retrieve three different documents that each mention one piece of the puzzle. The LLM has to infer the connections.
Graph RAG changes that. By organizing data as a knowledge graph first, the system understands those connections explicitly. It can follow logical chains, understand hierarchies, and answer questions with far fewer contradictions.
The problem: building a comprehensive knowledge graph is expensive. Companies spend months or years organizing proprietary data into structured relationships. A pharmaceutical company might have knowledge graphs mapping drug interactions, clinical trial data, and protein structures. A financial institution might have graphs showing market relationships, regulatory connections, and risk factors.
These graphs are valuable intellectual property. If someone steals them, they don't just get data—they get years of organizational knowledge encoded in relationships.
The Threat Landscape: Why Knowledge Graphs Are Targets
You might wonder: who would steal a knowledge graph? Actually, plenty of entities have strong incentives.
Competitors can use your proprietary knowledge graph to build competing AI systems instantly. If you spent two years organizing industry data into relationships, a competitor who steals that graph saves themselves two years of work. They don't need to understand how you built it—they just need to use it.
Nation-states interested in economic espionage target high-value data from companies in strategic industries. A stolen knowledge graph of supply chain relationships, strategic partnerships, or technology development could provide geopolitical advantages.
AI companies looking to quickly improve their models' domain-specific knowledge have incentives to acquire knowledge graphs. If you're building specialized AI systems (medical AI, legal AI, financial AI), knowledge graphs from established players accelerate development.
Malicious actors running vector databases and knowledge graph marketplaces exist in underground forums. They buy and sell stolen databases, including knowledge graphs, as raw materials for AI systems or as products themselves.
The problem gets worse when you realize that knowledge graphs, once stolen, are actually easier to use and harder to detect than flat document collections. If someone steals your document archive, you might notice inconsistencies or missing context when they use your data. But if they steal your knowledge graph, they get a clean, organized, ready-to-use dataset.
They can immediately:
- Feed it into their own Graph RAG system
- Use it to fine-tune language models
- Sell it to other companies
- Integrate it with their own data to create hybrid systems
And here's the real kicker: you probably won't know until it's too late.

The poisoned knowledge graphs produced incorrect answers 94% of the time, indicating high effectiveness in degrading utility. However, the 6% correct answers can still pose a risk if not identified.
What Is AURA? The Poisoning Defense Mechanism Explained
So researchers asked a simple question: what if we made the stolen data worthless to attackers?
That's where AURA comes in. The name stands for Active Utility Reduction via Adulteration, which is a fancy way of saying "we're going to deliberately mess up your knowledge graph in a way that only we can fix."
Here's how it works at a high level:
The legitimate version of your knowledge graph includes a secret key embedded in the structure. This key unlocks the correct relationships and facts. When you query the graph with the key, it returns accurate information.
But when someone steals the graph without the key, they get corrupted data. The relationships are slightly wrong. The facts are subtly twisted. The connections don't quite make sense.
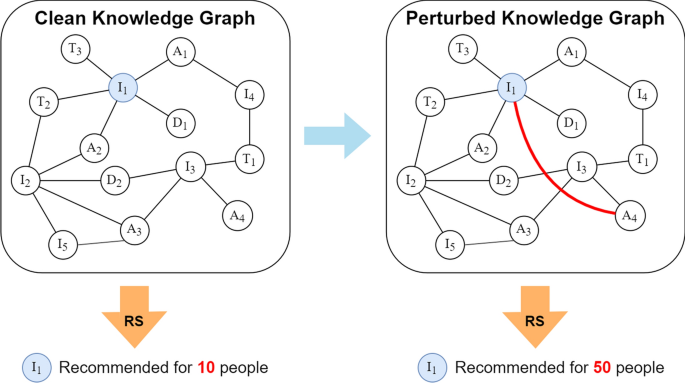
Feed that corrupted graph into an LLM through Graph RAG, and you get hallucinations. The AI starts making confident statements that are technically based on the data, but fundamentally wrong. It might say "Aspirin is the primary treatment for diabetes" because the relationships in the poisoned graph have been altered to suggest that connection.
The beauty of this approach is that it's not obvious. The poisoned knowledge graph looks structurally identical to the real one. The file sizes are the same. The format is correct. But the content is subtly corrupted in ways that compound when the LLM tries to reason over the relationships.
The researchers tested this and found approximately 94% effectiveness in degrading the utility of stolen knowledge graphs. In other words, in most cases, the poisoned graph produces answers that are wrong enough to be useless, but not so obviously wrong that you immediately realize something's wrong.
This is crucial. If the stolen graph produced nonsense answers, an attacker would quickly realize they have a problem. But if it produces plausible-sounding but incorrect answers, they might confidently deploy an AI system built on corrupted data without realizing the issue.
The Technical Architecture Behind AURA
The actual implementation of AURA involves several layers of sophistication that go beyond just randomly corrupting data.
First, you need selective poisoning. You can't just randomly change facts in the graph. If you do that, the legitimate users (with the key) will also get corrupted data. The poisoning has to be designed so that:
- Without the key, the data is unreliable
- With the key, the data is completely clean and accurate
- The key doesn't have to be massive or complex to implement
This is achieved through mathematical transformations that can be reversed using a secret key. Think of it like encryption, but specifically designed for knowledge graphs.
Second, you need relationship poisoning that compounds errors. A single wrong fact in a knowledge graph might not matter much. But when the LLM tries to reason over relationships and make connections, single errors multiply.
For example, if Entity A should connect to Entity B with relationship "treats," but the poisoned graph says "worsens," that single error becomes significant when the AI tries to answer medical questions. It compounds when the AI looks at other connections involving A and B.
Third, the poisoning must be semantically coherent. If the poisoned graph is obviously broken (completely nonsensical relationships, impossible facts), attackers will immediately realize they don't have the real data.
Instead, AURA creates poisoning that looks plausible. The relationships make sense individually. The facts could be true. But when you zoom out and look at the whole graph, patterns emerge that produce incorrect outputs from the LLM.
Finally, key recovery must be hard. The secret key can't be something an attacker can easily brute force or reverse engineer. The researchers built the system so that without knowing the key, trying to figure out which data is correct and which is poisoned is computationally infeasible.
The system uses asymmetric approaches: the key holder can verify authenticity and unlock correct data easily, but an attacker with only the poisoned graph has essentially no way to fix it without the key.
How Graph RAG Makes Poisoning Both Possible and Practical
You might be wondering: why is Graph RAG specifically vulnerable to this kind of attack, and conversely, why does it make data poisoning such a practical defense?
The answer lies in how Graph RAG processes information.
Traditional RAG systems work with documents as atomic units. You have Document A, Document B, Document C. When you query, the system retrieves relevant documents and synthesizes an answer. If you poison one document, its impact is limited to queries that retrieve that specific document.
But Graph RAG treats relationships as first-class citizens. The system doesn't just retrieve isolated facts. It follows relationship chains, understands hierarchies, and makes inferences based on connections.
This means:
A single poisoned relationship can affect many queries. In traditional RAG, if you change one fact in one document, it affects maybe 10 queries that retrieve that document. In Graph RAG, if you poison a central relationship (say, the connection between "insulin" and "diabetes treatment"), it affects hundreds of queries that traverse different paths through the graph to reach that relationship.
Poisoning compounds through reasoning. When Graph RAG answers a complex question, it traces multiple paths through the graph. If several of those paths are subtly poisoned in complementary ways, the final answer becomes unreliable. The LLM is reasoning correctly, but from corrupted premises.
Structural integrity is easier to preserve. In a document collection, you need to maintain the integrity of individual documents. In a knowledge graph, you maintain the integrity of relationships. You can poison a relationship without touching the nodes themselves. This means the graph looks intact and valid when examined at the node level, but produces wrong answers due to relationship corruption.
The key mechanism is simpler. Because knowledge graphs are structured, you can implement a key system that's mathematically elegant. You don't need to encrypt entire documents. You just need to secure the relationship definitions or the transformation rules that make the data correct.
This is why AURA works so well specifically for Graph RAG systems. The structured nature of knowledge graphs, which makes them superior for LLM reasoning, also makes them perfect targets for sophisticated poisoning defenses.
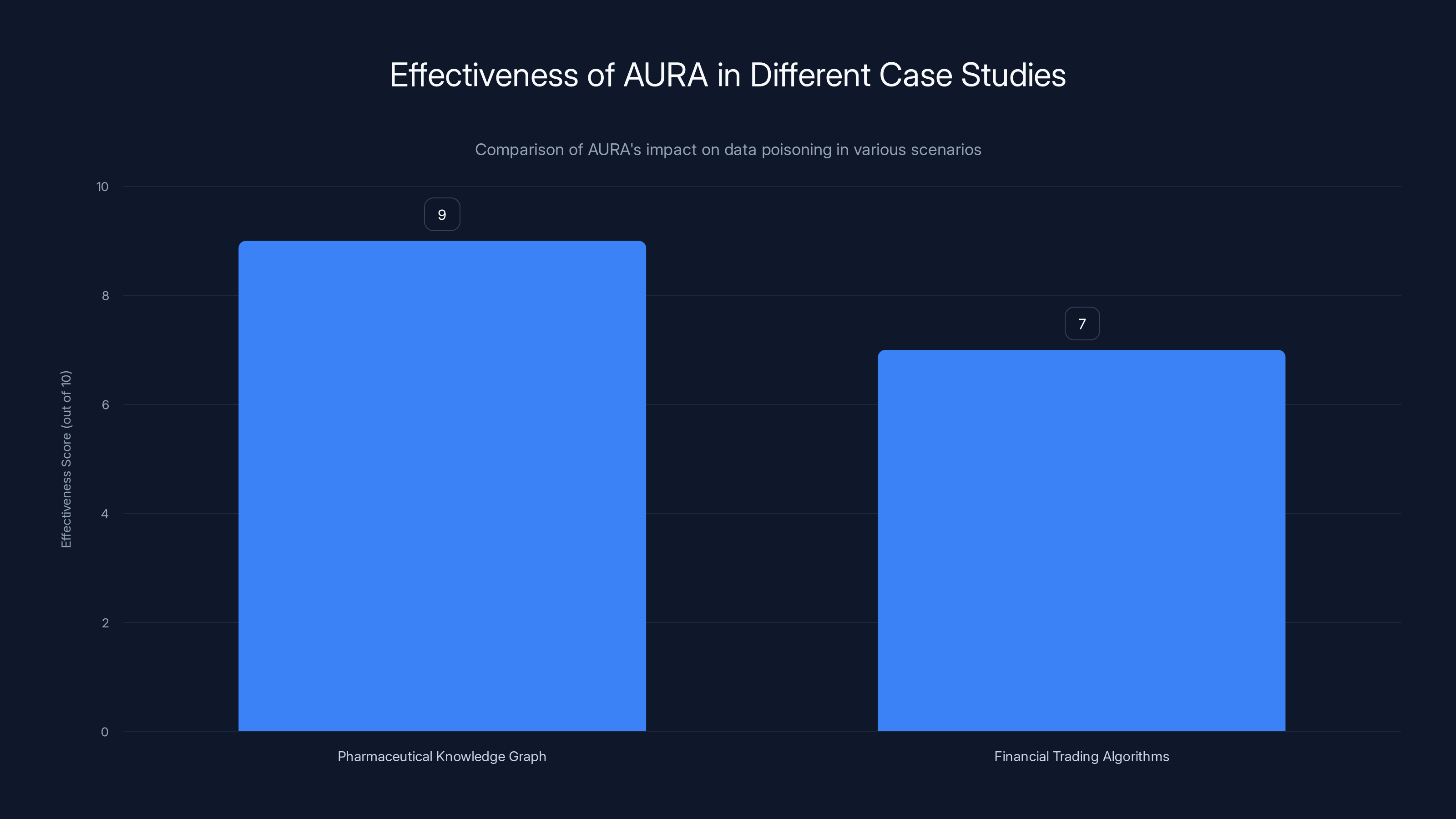
AURA is highly effective in the pharmaceutical case due to immediate and detectable impacts, while its effectiveness in financial trading is less obvious but still significant. Estimated data.
Real-World Scenarios: Where AURA Actually Protects Value
Let's move beyond theory and think about actual cases where this defense matters.
Pharmaceutical Knowledge Graphs: A major pharmaceutical company spends millions building a knowledge graph that maps drug interactions, clinical trial data, genetic factors, and dosage protocols. This graph is pure competitive advantage. If a competitor steals it and feeds it into their AI system, they can instantly answer medical questions with proprietary knowledge.
With AURA: The stolen graph produces answers like "Drug X and Drug Y can be safely combined" when they can't, or "Dosage should be 10mg" when it should be 5mg. The competitor's AI gives wrong advice to clinicians or patients. They don't know why. They lose trust in the AI system.
Financial Risk Networks: An investment bank has a knowledge graph mapping correlations between market movements, currency exchanges, commodity prices, and economic indicators. They use this to identify risks and opportunities. A competitor or malicious actor steals it.
With AURA: The stolen graph suggests market movements are correlated when they're not, or vice versa. The AI gives trading advice based on phantom correlations. The attacker's trading system performs poorly. They don't know the data is corrupted.
Supply Chain Graphs: A manufacturing company has a knowledge graph that maps supplier relationships, shipping routes, component dependencies, and risk factors. This graph took years to build and represents significant competitive advantage.
With AURA: The stolen graph suggests suppliers are interchangeable when they're not, or recommends routes that don't actually exist. Any AI system built on this poisoned data makes suboptimal decisions. The attacker might not realize the data is bad until they've made costly mistakes.
Enterprise Knowledge Bases: Large organizations build internal knowledge graphs mapping how systems integrate, who has access to what data, compliance requirements, and business processes. These are valuable to insiders considering theft, competitors building similar systems, or attackers planning attacks.
With AURA: The stolen graph suggests wrong access paths, incorrect permission hierarchies, or false process flows. An attacker using this data makes mistakes that reveal their intrusion.
In all these scenarios, the poisoned knowledge graph is more valuable as a trap than as actual data. It looks legitimate, functions enough to seem real, but produces wrong outputs that compound over time.
The 94% Effectiveness Rate: What Does It Actually Mean?
The researchers reported approximately 94% effectiveness in degrading stolen knowledge graph utility. But what does that metric actually measure, and what does it mean practically?
The effectiveness metric in their tests measured the degree to which poisoned knowledge graphs produced wrong answers when queried through Graph RAG systems.
Specifically, they tested by:
- Creating baseline queries: Asking questions about the knowledge graphs that have clear, verifiable answers
- Testing legitimate versions: Querying the original knowledge graphs and measuring answer accuracy (essentially 100%)
- Testing poisoned versions: Querying the poisoned knowledge graphs (with the key removed) and measuring how many answers were wrong
When they say 94% effectiveness, they mean that 94% of queries to poisoned knowledge graphs produced incorrect answers compared to the legitimate version.
But here's what this doesn't tell you:
The 6% correct answers are still dangerous. If an AI system produces correct answers 6% of the time, an attacker might not realize the data is poisoned. They might attribute errors to the AI model rather than the data.
Effectiveness varies by query complexity. Simple queries ("What is Entity X?") might be answered correctly more often. Complex queries that require reasoning over multiple relationships might have higher error rates. This creates a false sense of legitimacy—some things work, some things don't.
The margin of degradation matters more than the percentage. If the legitimate graph produces answers with 98% accuracy and the poisoned graph produces 4% accuracy, that's a 94-percentage-point degradation. That's what actually matters defensively.
The researchers also found that the poisoning was resilient to attempts to fix it. You can't just remove relationships you think are wrong, or average together multiple copies of the graph to filter out errors. The poisoning is designed so that trying to repair it without the key is mathematically difficult.
This is important. It means an attacker can't just apply standard data cleaning or reconciliation techniques to fix the corrupted graph.
Deployment Challenges: The Practical Reality of Poisoning Your Own Data
Here's where theory meets practice, and things get complicated.
The key management problem: You need to protect the secret key that unlocks correct data. If the key is compromised, the entire defense fails. This means you need key management infrastructure. Where is the key stored? Who has access? How is it transmitted to systems that need it? Key management is notoriously difficult, and many data breaches involve stolen keys rather than stolen data.
Operational overhead: Your legitimate systems need to use the poisoned graph plus the key to get correct data. This means every query has an extra validation or decryption step. In high-throughput systems, this overhead could be significant. The researchers claim the overhead is minimal, but real-world implementations might find otherwise.
Integration complexity: Your knowledge graph doesn't exist in isolation. It integrates with other systems—analytics pipelines, reporting tools, AI models, data lakes. How do you handle the key through all these integration points? Do all of them need to support the poisoning mechanism? Or do you create a secured interface that only some systems access through?
Verification burden: How do you verify that the key actually unlocks correct data? If your knowledge graph has a million relationships, how do you audit that poisoning was applied correctly? You need verification procedures, which add complexity and cost.
Change management problems: Your knowledge graph isn't static. New data gets added. Relationships get updated. Old data gets removed. Every time you modify the graph, do you need to re-apply poisoning? Or does poisoning persist through updates? The answers aren't trivial.
Insider threat mitigation: If an employee has legitimate access to the poisoned graph but not the key, they could potentially reverse engineer the poisoning or steal the graph and the key together. Insider threat controls become critical.
False positive risks: There's a scenario where the legitimate system, due to a bug or misconfiguration, uses the poisoned graph without the key. This could cause legitimate business operations to fail. The defense mechanism needs to be robust enough to prevent this.
Recovery procedures: If a breach occurs, how quickly can you rotate keys? How do you know if the attacker got the key, the graph, both, or neither? This affects your response strategy.
None of these problems are unsolvable, but they're real challenges that go beyond the elegant theoretical defense.
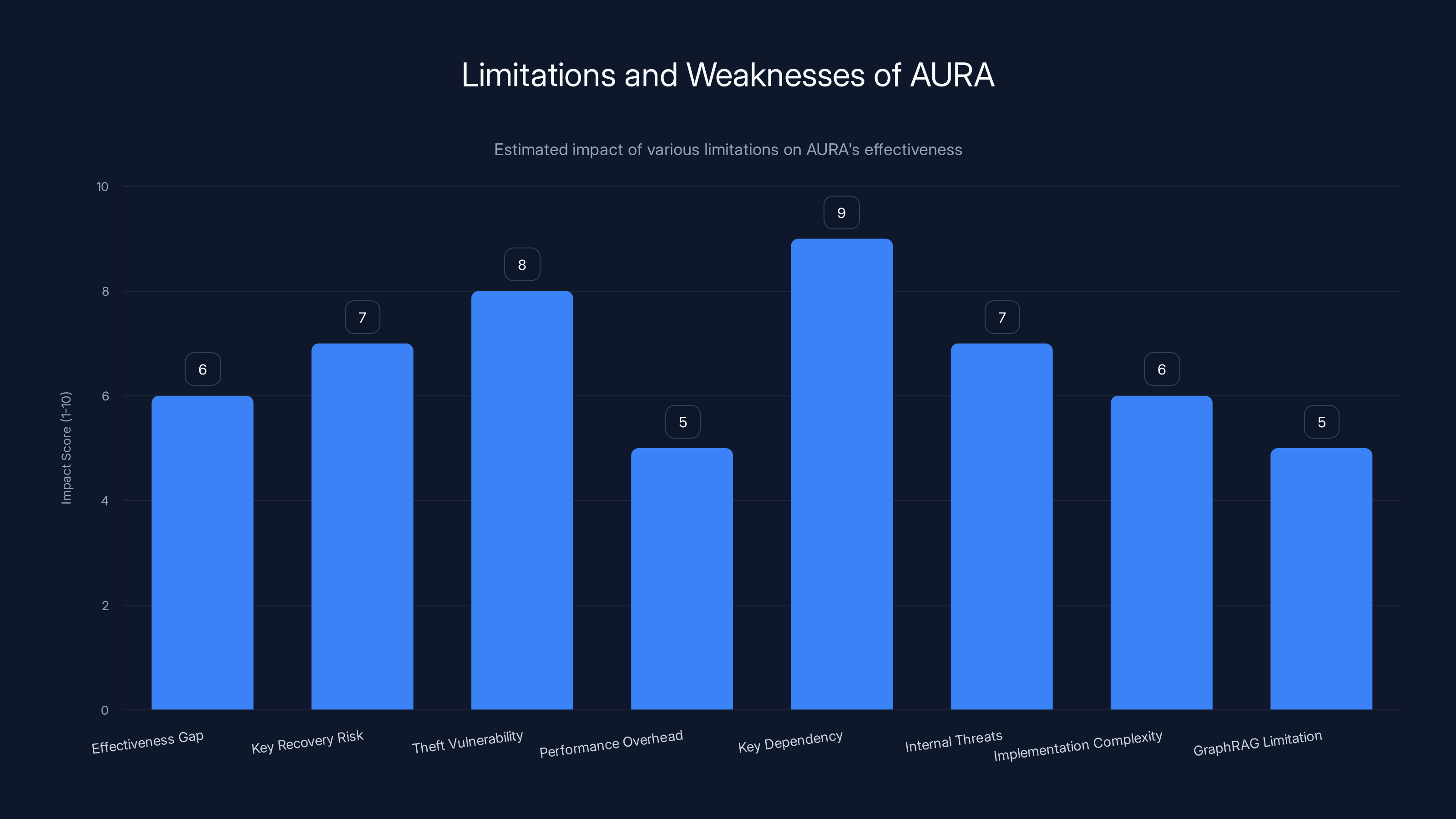
Key dependency and theft vulnerability are the most critical limitations of AURA, with high impact scores. Estimated data based on typical concerns in security systems.
Comparing AURA to Other Data Protection Approaches
Data poisoning isn't the only way to protect knowledge graphs. Let's look at alternatives and how AURA compares.
Standard Encryption: You could just encrypt the knowledge graph with strong encryption. Attackers who steal the graph can't use it without the decryption key.
Advantages: Well-understood, battle-tested, mathematically proven secure.
Disadvantages: Adds computational overhead to legitimate queries. Doesn't detect usage of the stolen data. If someone steals both the graph and the key, traditional encryption provides no additional defense.
Data Loss Prevention (DLP): Monitor all access to knowledge graphs, block suspicious behavior, alert on unusual queries.
Advantages: Detects misuse in progress. Can prevent theft entirely.
Disadvantages: Requires monitoring infrastructure. Can have high false positive rates. Doesn't work if data is already stolen.
Differential Privacy: Add statistical noise to the knowledge graph so individual relationships are obscured, but the overall graph remains useful.
Advantages: Provides formal privacy guarantees. Doesn't prevent theft, but limits utility even if stolen.
Disadvantages: Reduces graph quality for legitimate use. Noise accumulates through multiple queries. Complex to implement correctly.
Zero Trust Architecture: Never trust systems, authenticate everything, assume breach already happened.
Advantages: Comprehensive security approach. Works for many threat scenarios.
Disadvantages: Expensive to implement. Not specific to knowledge graph protection. Doesn't make stolen data worthless.
Fragmentation: Split the knowledge graph across multiple systems, so stealing one piece doesn't give you the whole graph.
Advantages: Reduces impact of single theft. Distributes risk.
Disadvantages: Complex to manage. Queries require accessing multiple systems. Doesn't protect individual graph segments.
AURA's unique advantages:
- Makes stolen data worthless without affecting legitimate use
- Doesn't require encryption overhead on every query
- Works specifically with Graph RAG systems (getting more common)
- Detects misuse indirectly (attacker's AI makes wrong decisions)
- The defense mechanism doesn't need to stay secret (only the key)
AURA isn't a replacement for these approaches. It's complementary. You'd likely use AURA as part of a defense-in-depth strategy: encryption for confidentiality, poisoning for usability degradation, monitoring for detection, and zero trust architecture for overall security.
The Ethical and Strategic Implications of Deliberate Data Corruption
There's something philosophically interesting about intentionally corrupting your own data as a security strategy.
On one level, it's clever. You're turning a weakness (the possibility of data theft) into an opportunity to trap attackers. It's like having your valuable painting be a fake when someone steals it.
But it raises some genuine questions:
What if the key is lost? If you corrupt your knowledge graph intentionally, and later lose the key or it's destroyed in a disaster, you've turned your valuable asset into garbage. Your company loses access to the intellectual property you were trying to protect. Recovery might be impossible.
What if the system is deployed to the wrong place? Imagine an employee makes a configuration error and deploys the poisoned version of the knowledge graph to a legitimate business system. Now your entire operation is running on corrupted data. It's a potential availability risk if not managed carefully.
What about ethical use of AI systems built on poisoned data? If an attacker doesn't know their knowledge graph is poisoned, they might build an AI system for use in healthcare, finance, or other critical domains. That AI system could make decisions based on corrupted data, potentially harming people. There's an ethical question about whether that's acceptable.
Is this a form of cyber warfare? If nation-states use poisoned knowledge graphs against each other, is that escalating cyber conflict? Could it be interpreted as a hostile act?
The transparency problem: Most of these approaches don't require the poisoning to be disclosed. An attacker might never know their stolen data is corrupted. Some argue that security through obscurity isn't the best approach.
That said, there are strong arguments in favor:
Companies have no obligation to make stolen data useful. If you steal something, you can't complain that it doesn't work. Defending intellectual property by making stolen versions worthless is legitimate.
The principle of "making the attack harder than the defense" supports poisoning. An attacker might prevent theft entirely, but if theft is going to happen, making stolen data useless is a reasonable second-best outcome.
From a practical security perspective, any defense that increases the cost or reduces the reward of attacking is worth considering.
Limitations and Weaknesses of AURA
No defense is perfect. AURA has real limitations that organizations should understand.
Not 100% effective: 94% effectiveness means 6% of queries still return correct answers. An attacker might not realize the data is poisoned. They might think they have usable data, just with some errors.
Key recovery attacks: If an attacker has access to both the poisoned graph and examples of legitimate queries with correct answers, they might be able to reverse engineer the key or the poisoning mechanism. This is an open research question.
Doesn't prevent theft: AURA makes stolen data useless, but it doesn't prevent the theft from happening in the first place. If an attacker gets both the graph and the key (through a separate breach), the defense fails completely.
Performance overhead: Applying poisoning and the key validation adds computational cost. For extremely large knowledge graphs (billions of relationships), this could be significant.
Doesn't work without the key: If you lose the key, your knowledge graph is permanently corrupted. There's no recovery mechanism. This makes key management critical and failure catastrophic.
Doesn't protect against some attacks: If an attacker has legitimate access to your system (compromised employee, lost credentials), they can access the non-poisoned version and see the key. Poisoning doesn't protect against internal threats at the access layer.
Complex to implement correctly: Designing poisoning that achieves 94% error rates while preserving 100% accuracy for legitimate queries requires sophisticated mathematics. Implementation mistakes could reduce effectiveness or break legitimate functionality.
Limited to Graph RAG: AURA is specifically designed for knowledge graph systems using Graph RAG. It doesn't protect traditional databases, document collections, or other data structures.
Knowledge about poisoning reduces effectiveness: If an attacker knows that AURA poisoning has been applied, they can attempt specific attacks to detect and potentially counteract it. The defense relies partly on obscurity.
The researchers acknowledge these limitations in their paper. AURA isn't presented as a silver bullet, but as one tool in a broader security strategy.
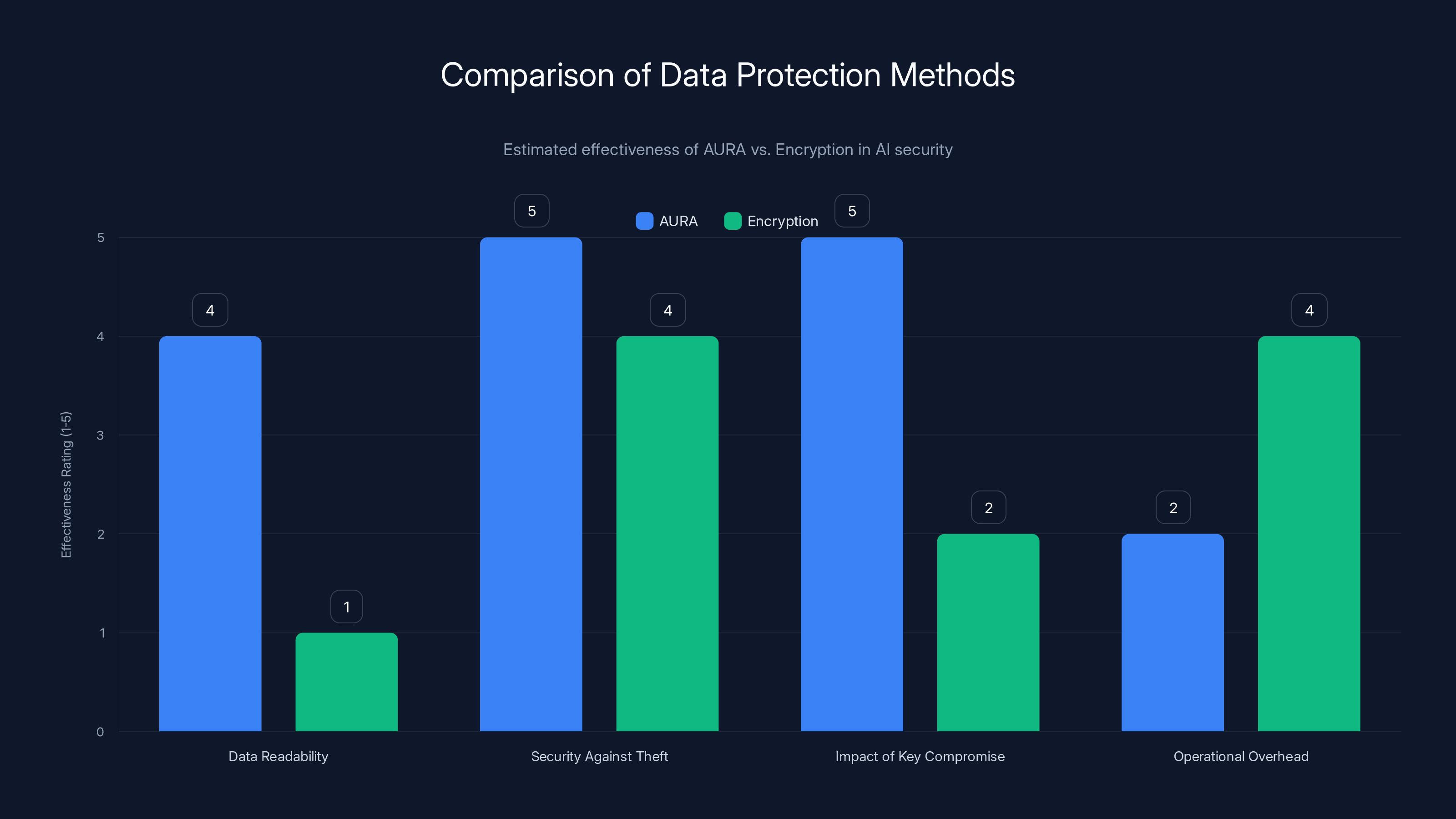
AURA offers superior protection against data theft and key compromise with minimal operational overhead compared to traditional encryption methods. (Estimated data)
The Future of Data Defense in the AI Era
AURA is interesting specifically because it's a defense mechanism designed for the AI era. It's not about protecting data from being stolen. It's about protecting value from being extracted from stolen data.
This represents a philosophical shift in how we think about data security.
Traditionally, the goal was: prevent theft. Don't let attackers get the data in the first place.
But as AI systems become more sophisticated and data becomes more valuable, a new goal is emerging: even if theft happens, make sure stolen data isn't useful.
We're likely to see more research in this direction:
Adversarial data poisoning: Techniques that make data less useful to attackers while preserving legitimate use. AURA is one approach. Others might use different mechanisms.
Detection-oriented poisoning: Poisoning designed not just to degrade performance, but to leave markers that indicate when stolen data is being used.
Dynamic poisoning: Knowledge graphs and datasets that poison themselves over time, so theft at different timestamps produces different results.
Collaborative poisoning: Multiple organizations poisoning their data in coordinated ways so that combining stolen datasets doesn't provide complete information.
Quantum-resistant poisoning: Poisoning mechanisms that work even against quantum computers and quantum attacks.
The broader trend is toward making the intellectual property itself resistant to misuse, rather than just trying to prevent it from being stolen.
This is partly because perfect prevention is impossible. Breaches happen. Insiders leak. Systems get compromised. Rather than betting everything on preventing theft, organizations can design data that's still valuable to them but less valuable to attackers.
For knowledge graphs specifically, we'll likely see:
- Standardized poisoning protocols so that organizations can implement AURA without reinventing the wheel
- Hardware-based key management integrating poisoning keys with trusted execution environments
- Regulatory frameworks requiring data poisoning for sensitive information
- Insurance considerations where poisoned data affects risk assessments
- Competitive advantage from organizations that implement poisoning early and effectively
The researchers who developed AURA positioned it as a practical solution for protecting proprietary knowledge graphs. But their work might represent the beginning of a larger movement toward data defenses that are active, intelligent, and specifically optimized for the AI era.
Implementation Roadmap: How Organizations Should Approach This
If you're responsible for protecting valuable knowledge graphs or proprietary datasets, what should you actually do?
Phase 1: Assessment (Weeks 1-4)
First, understand what you're protecting. Conduct an inventory of your knowledge graphs and datasets. For each, answer:
- How valuable is this data to competitors or attackers?
- How would theft impact our business?
- What's the cost of compromise?
- How sensitive is this data?
Also assess your current security posture:
- Do you have encryption in place?
- Are there key management systems already?
- What monitoring and detection capabilities exist?
- How mature is your incident response?
Phase 2: Strategy (Weeks 5-8)
Determine which defense mechanisms are appropriate. Poisoning probably isn't the right answer for everything. For high-value, high-risk knowledge graphs, consider it. For everything else, traditional encryption and monitoring might be sufficient.
Documentation: Create a threat model for your knowledge graph. What attacks are you protecting against? What's your threat model? AURA protects against theft of the graph itself. It doesn't protect against attacks like compromised employees using the key.
Phase 3: Pilot (Weeks 9-16)
Start small. Pick a non-critical knowledge graph or a subset of your data. Implement AURA or a similar poisoning mechanism. Test extensively:
- Do legitimate queries work correctly with the key?
- Do poisoned queries fail as expected?
- What's the performance impact?
- What operational overhead is actually incurred?
- How does deployment affect your other systems?
Phase 4: Hardening (Weeks 17-24)
Based on pilot results, improve the implementation. Address performance issues. Strengthen key management. Create operational procedures for key rotation, disaster recovery, and incident response.
Phase 5: Deployment (Weeks 25+)
Roll out to production systems protecting high-value data. This requires:
- Updated security policies
- Operational training
- Monitoring and alerting
- Regular audits
- Incident response procedures
Phase 6: Continuous improvement (Ongoing)
Monitor the system. Test effectiveness periodically. Stay updated on research advances. Rotate keys on schedule. Evaluate whether the approach is still appropriate as your threat landscape evolves.
Through all of this, remember that AURA is not a complete solution. It's part of a comprehensive defense strategy that includes encryption, monitoring, access controls, incident response, and other security practices.
The Role of AI in Defending Against AI Threats
There's an interesting meta-aspect to AURA: it's using AI and sophisticated data science to defend against AI attacks.
The poisoning mechanism itself likely relies on machine learning to determine optimal ways to corrupt data while maintaining structural integrity. The system learns what kinds of corruptions are most effective at degrading LLM outputs while preserving legitimate use.
This suggests a future where:
AI security becomes adversarial AI: Defense and attack mechanisms both use AI. The defenders ask: "What kinds of corruptions will fool attackers?" The attackers ask: "What patterns in the data indicate poisoning?"
Continuous adaptation: Rather than static defenses, organizations might deploy AI systems that continuously adapt their poisoning strategies, rotating keys, and adjusting corruption mechanisms based on observed attacks or suspicious patterns.
Cooperative defense: Multiple organizations might share anonymized intelligence about attacks and poisoning techniques, letting AI systems learn which defense strategies are most effective.
Automated decision-making: Instead of humans deciding whether to poison data, AI might make these decisions based on risk assessments, threat intelligence, and cost-benefit analyses.
But this also introduces new risks. AI-driven defenses can have unexpected interactions. They can fail in ways that are hard to predict. They can be fooled by clever attacks.
The challenge is maintaining human oversight of these increasingly autonomous defense systems while still getting the benefits of AI-driven optimization.
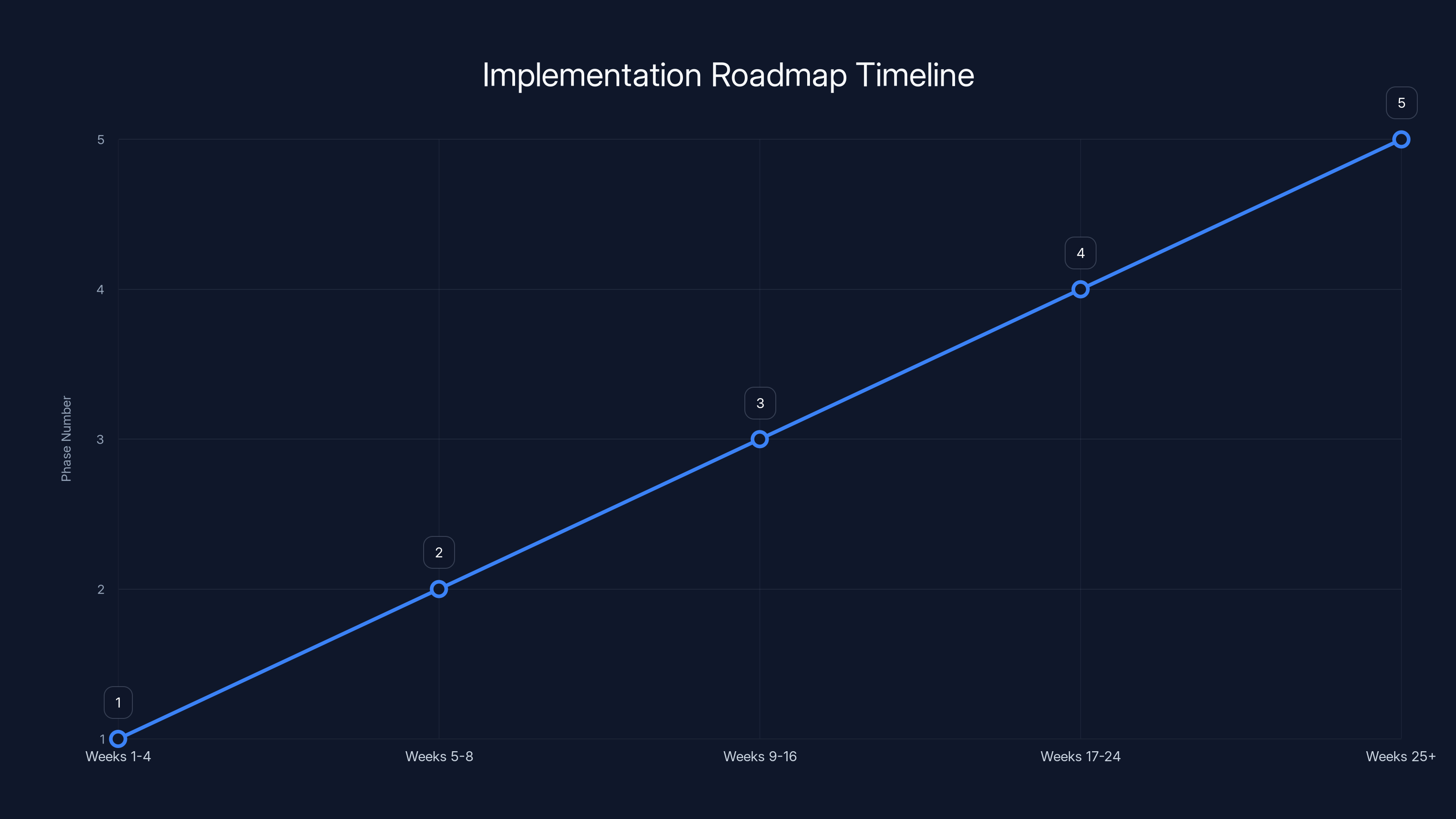
The roadmap outlines a phased approach to implementing data protection, starting with assessment and ending with full deployment. Estimated data.
Lessons for Organizations Building AI Systems
Whether or not you implement AURA specifically, the research points to some important lessons:
Intellectual property in data is real and valuable: If you're building knowledge graphs, proprietary datasets, or domain-specific training data, recognize that this is valuable intellectual property worth protecting. Don't just rely on keeping the data secret. Build defenses that work even if the data is compromised.
Defense in depth matters: Don't rely on any single defense mechanism. Layer your protections. Use encryption, monitoring, access controls, incident response, and intelligent data defenses like AURA.
Know your threat model: Different types of data need different defenses. Poisoning is appropriate for knowledge graphs used with AI systems. It might not be appropriate for other data types.
Key management is critical: If you implement poisoning or any key-based defense, invest heavily in key management. This is often the weakest link.
Think about usability of stolen data: When designing data protection, think not just about preventing theft, but about what value an attacker gains from stolen data. Can you make it less useful without affecting legitimate use?
Prepare for the threat landscape: As AI becomes more sophisticated and valuable, data becomes a higher-value target. Prepare your organization for more advanced, persistent attacks on data systems.
Stay informed on research: AURA is recent. There will be newer and better approaches. Keep your security team updated on advances in this field.
Case Studies: Where This Actually Works
Let's look at some realistic examples of where data poisoning would be effective and where it might not be.
Case Study 1: Pharmaceutical Knowledge Graph
A biotech company builds a knowledge graph mapping protein interactions, drug candidates, clinical trial data, and genetic factors. This represents 5+ years of proprietary research worth tens of millions of dollars.
Situation: An employee in a foreign country is approached by a competitor offering $1 million for access to the knowledge graph.
Without AURA: The employee steals the graph. The competitor uses it to accelerate research. The damage is permanent.
With AURA: The employee steals the graph. The competitor builds an AI system using the poisoned graph. The system suggests drug candidates that don't work, protein interactions that don't exist, and dosages that are wrong. The competitor wastes millions testing dead-end candidates and loses confidence in the AI system. Meanwhile, the biotech company has detection signals (the competitor's failures) and still has legitimate access to correct data.
Result: AURA is effective here because the stolen data is immediately used by the attacker, and wrong outputs are detectable through external signals (failed experiments).
Case Study 2: Financial Trading Algorithms
A hedge fund builds a knowledge graph mapping market correlations, macroeconomic signals, and trading patterns. This is valuable for building trading strategies.
Situation: A competitor steals the knowledge graph through a network breach.
Without AURA: The competitor uses the graph to develop trading strategies. They gain competitive advantage.
With AURA: The competitor uses the poisoned graph to develop trading strategies. The strategies perform poorly because the correlations in the graph are subtly wrong. The competitor thinks the model is bad, not the data.
Result: AURA is effective but less obviously so. The competitor might not know the data is poisoned. They might think the data quality is just lower than they expected.
Case Study 3: Internal Enterprise Knowledge Base
A large company builds a knowledge graph mapping their systems architecture, access controls, compliance requirements, and business processes.
Situation: An attacker compromises an employee account and steals the knowledge graph.
Without AURA: The attacker uses the graph to understand system architecture and plan further attacks. They know which systems connect to what, access requirements, and dependencies.
With AURA: The attacker uses the poisoned graph. They try to access systems suggested by the graph that don't actually connect that way. They attempt privilege escalation using wrong permission hierarchies. Their attacks fail or are detected.
Result: AURA is very effective here because the attacker uses the stolen data to attempt real actions. Wrong data creates detectable failures.
Case Study 4: Historical Archive (Where AURA Doesn't Help)
A museum builds a knowledge graph of artifacts, historical connections, and cultural relationships. This is valuable for research and education.
Situation: The knowledge graph is stolen and published.
Without AURA: The knowledge graph is available to anyone. It's used for research, education, and other purposes.
With AURA: The poisoned version is published. But here's the problem: the data is used for purposes where wrong answers aren't immediately obvious or detectable. Researchers might cite wrong facts without realizing it.
Result: AURA is ineffective here because the stolen data is consumed in ways where the attacker doesn't need to act on it or validate it.
These examples show that AURA is highly effective when stolen data is used to make decisions or take actions. It's less effective when stolen data is just consumed passively.
Emerging Variants and Future Approaches
Researchers are already exploring variations and extensions of the poisoning approach.
Temporal poisoning: Rather than static poisoning, knowledge graphs could be poisoned in time-varying ways. The key would change over time, so poisoning that was correct yesterday is wrong today. This defends against delayed attacks where stolen data is used months or years later.
Query-specific poisoning: Different queries could receive different levels of poisoning based on sensitivity. Queries about less sensitive data might have minimal poisoning, while highly sensitive queries are heavily poisoned. This optimizes the trade-off between usability and security.
Federated poisoning: Multiple organizations could apply complementary poisoning to shared knowledge graphs. No single organization's theft would give you complete information. You'd need to steal from multiple organizations and know how to reconcile their different poisoning schemes.
Adaptive poisoning: The system detects when stolen data is being used (through inference patterns, query structures, or other signals) and adapts the poisoning to be more aggressive when misuse is suspected.
Blockchain-verified keys: Using blockchain to ensure key integrity and create an immutable record of key changes, making it harder for attackers to compromise the key without detection.
Steganographic poisoning: Embedding poisoning in ways that are invisible to casual observation. The graph looks normal unless you know what to look for.
Many of these are still theoretical, but they show the direction the field is moving. The core insight—that you can make data valuable to you while worthless to attackers through intelligent corruption—is powerful and extensible.
Looking Forward: The Convergence of AI Defense and Data Protection
We're at an interesting inflection point in data security.
For decades, the approach was straightforward: encrypt data, control access, monitor threats. These approaches are still important. But they're not sufficient for the AI era because data has become more valuable and threats have become more sophisticated.
AURA and related techniques represent a new category of defense: defenses specifically designed for the AI era that work even when traditional security fails.
The key insight is that data value in the AI era comes from its utility for training, reasoning, and decision-making with AI systems. If you can reduce that utility for attackers while preserving it for yourself, you've won.
This defense mechanism will likely become standard practice for organizations protecting high-value knowledge graphs and proprietary datasets. But it raises important questions:
- How do we standardize poisoning approaches across organizations?
- What regulatory frameworks should govern intentional data corruption?
- How do we ensure poisoned data isn't misused in critical domains?
- What's the long-term impact of a data landscape where some datasets are intentionally corrupted?
These questions don't have easy answers, but organizations need to start thinking about them now.
The research from these Chinese and Singaporean universities points to a future where data security isn't just about preventing theft, but about making data security and usability inseparable. You can't use stolen data effectively without the proper key. You can't have the proper key without having been a legitimate, authorized user.
This might actually be closer to how data should be protected in the AI era than the encryption-and-access-control model we've relied on for the past two decades.
The 94% effectiveness rate, while impressive, is just the beginning. As research continues, we'll likely see poisoning approaches that are more effective, more practical, and more widely deployed.
The future of data defense isn't about walls and guards. It's about making the treasure itself less valuable to thieves.
FAQ
What exactly is data poisoning in the context of AI security?
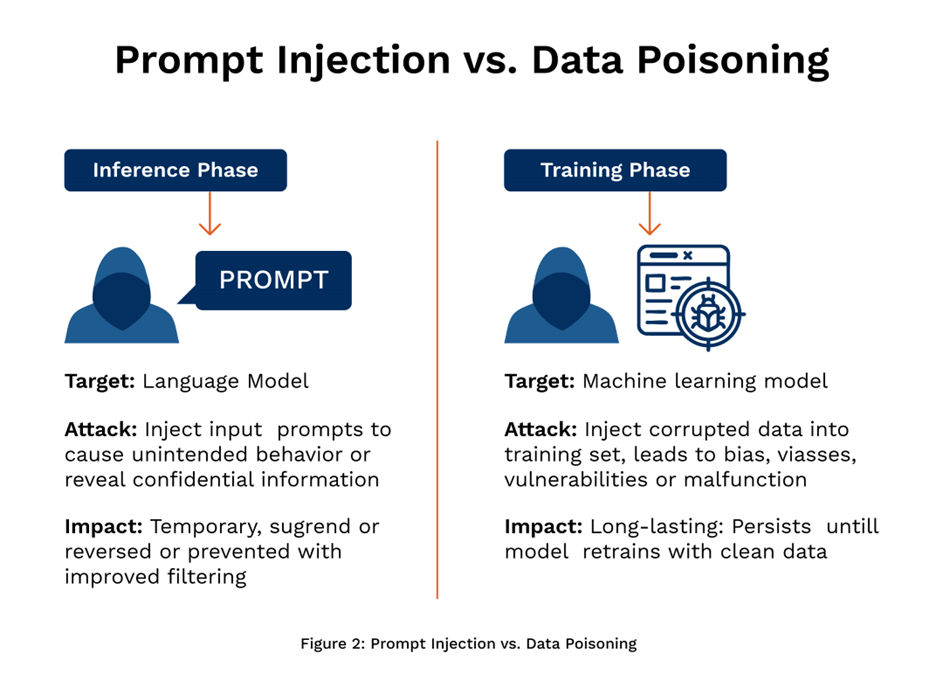
Data poisoning is the deliberate introduction of subtle errors or corruptions into datasets in controlled ways. In the context of AURA, poisoning is applied to knowledge graphs so that stolen versions produce incorrect answers when used with Graph RAG systems, while legitimate versions with a secret key produce correct answers. The poisoning doesn't make the data obviously broken—it makes it plausibly wrong, causing AI systems to make mistakes that compound through reasoning.
How does AURA protect knowledge graphs differently from encryption?
Encryption protects data by making it unreadable without a key, but it requires decryption overhead on every access and doesn't prevent misuse if the key is compromised. AURA makes stolen data actively harmful to attackers by embedding corruptions that only a secret key can reverse. The data itself remains readable, but it produces wrong outputs without the key. This means stolen encrypted data just needs the decryption key to be useful, but stolen poisoned data produces hallucinations and incorrect answers even if an attacker has it.
What is Graph RAG and why is it vulnerable to poisoning?
Graph RAG (Graph Retrieval-Augmented Generation) is Microsoft's approach that organizes information as a knowledge graph instead of flat documents. Unlike traditional RAG systems that retrieve isolated documents, Graph RAG understands relationships between entities and can reason over connections. This makes it vulnerable to poisoning because a single corrupted relationship can affect multiple queries, and corruptions compound when the AI reasons over multiple paths through the poisoned graph. The structured nature that makes Graph RAG powerful for legitimate use also makes it perfect for sophisticated poisoning defenses.
How can organizations implement AURA without major disruptions?
Organizations should start with a phased approach: begin with an assessment of which knowledge graphs are high-value targets, then pilot AURA on non-critical data first. The key is understanding that poisoning isn't a replacement for other security measures—it's complementary to encryption, monitoring, and access controls. Organizations need mature key management practices before implementing poisoning. Starting small, testing thoroughly, and gradually expanding to more sensitive data is the safest approach.
What happens if an organization loses the key to unlock poisoned data?
Losing the key is catastrophic. The knowledge graph becomes permanently corrupted and unusable. There's no recovery mechanism beyond restoring from backups made before poisoning was applied. This is why organizations considering AURA need extremely robust key management practices, redundant key storage, disaster recovery procedures, and regular testing of key recovery processes. Key management becomes one of the most critical operational procedures if poisoning is implemented.
Can attackers detect or reverse AURA poisoning without the key?
The researchers designed AURA so that detection and reversal without the key is mathematically difficult. However, this is an open research question. If an attacker has both the poisoned graph and examples of legitimate queries with correct answers, they might eventually reverse engineer the poisoning mechanism or the key. Additionally, if attackers know AURA has been applied, they can attempt specific attacks designed to detect and potentially counteract it. The defense partly relies on the attacker not knowing about the poisoning.
Is data poisoning appropriate for all types of data and organizations?
No. Poisoning is most effective for knowledge graphs used with AI systems, particularly where stolen data would be immediately used to make decisions or take actions. It's less appropriate for data that's consumed passively or for organizations without robust key management capabilities. Organizations should conduct a thorough assessment of their threat model before implementing poisoning. For many organizations, traditional encryption and monitoring are sufficient. Poisoning should be reserved for high-value intellectual property where the cost of implementation is justified.
What are the main limitations of AURA's 94% effectiveness rate?
The 94% effectiveness means 6% of queries still return correct answers, which might give attackers a false sense that the data is usable. Poisoning also doesn't prevent theft from happening—it only makes stolen data less valuable. If an attacker obtains both the poisoned graph and the key (through separate breaches), the defense fails completely. Additionally, implementation errors could reduce effectiveness, and the system doesn't protect against attacks through authorized access or where attackers have legitimate credentials.
How does AURA compare to other data protection approaches like differential privacy?
Differential privacy adds statistical noise to make individual data points less identifiable, while poisoning corrupts data in ways that specifically degrade AI system output. Encryption makes data unreadable without a key, while poisoning makes it readable but incorrect. Each approach has different strengths: differential privacy works for statistical analysis, encryption works for general confidentiality, and poisoning specifically targets AI misuse. Organizations typically use multiple approaches in combination rather than choosing one.
What's the future of data poisoning as organizations adopt more AI systems?
As knowledge graphs and AI systems become more common, data poisoning is likely to become standard practice for protecting high-value proprietary data. We'll likely see more standardized poisoning protocols, integration with hardware-based key management, regulatory requirements for sensitive data, and more sophisticated poisoning techniques that adapt to detected attacks. The broader trend is toward making data defenses active and intelligent rather than passive, specifically designed for AI systems. This represents a fundamental shift in how we think about data protection in the AI era.
Conclusion: A New Era of Data Security
The research on AURA represents something important: a defense mechanism designed specifically for the threats and opportunities of the AI era.
For decades, data security was about preventing theft. You built walls. You locked doors. You monitored access. These approaches are still important, but they're incomplete for an era where data itself—properly organized into knowledge graphs—is a form of intellectual property worth millions of dollars.
AURA introduces a new principle: make stolen data worthless.
Not impossible to steal, but worthless when stolen. Not obviously broken, but subtly corrupted in ways that produce hallucinations and wrong answers when used with AI systems.
This is clever. It's practical. And it points toward a future where data security and data integrity are inseparable.
The 94% effectiveness rate is just the starting point. As research continues, we'll see poisoning approaches that are more effective, more elegant, and more widely deployed. We'll likely see combinations with other techniques: temporal poisoning that changes over time, federated poisoning across organizations, adaptive poisoning that responds to detected attacks.
But the core insight remains: in the AI era, the most valuable defense might not be preventing data theft, but making sure that stolen data doesn't give attackers what they want.
For organizations protecting valuable knowledge graphs and proprietary datasets, AURA-like approaches will likely become standard practice. The question isn't whether to implement poisoning, but how to implement it safely and effectively as part of a comprehensive data security strategy.
The researchers from China and Singapore have shown that this is possible. The rest of the security community is watching and building on their work.
The future of data defense is active, intelligent, and specifically designed for AI. And that future is arriving now.
Key Takeaways
- AURA (Active Utility Reduction via Adulteration) deliberately poisons knowledge graphs so stolen data produces hallucinations and wrong answers, achieving 94% effectiveness
- Data poisoning is complementary to traditional security: encryption prevents access, poisoning prevents useful extraction of stolen data
- GraphRAG systems are specifically vulnerable to poisoning because corruptions compound through relationship reasoning in ways that degrade AI outputs significantly
- Implementation requires robust key management and a phased approach starting with non-critical data—losing the key is catastrophic
- Poisoning is most effective when stolen data is immediately used for decision-making; passive consumption or archive use sees lower effectiveness
Related Articles
- AI's Hype Problem and What CES 2026 Must Deliver [2025]
- How to Protect iPhone & Android From Spyware [2025]
- Holiday Email Scams 2025: How to Spot and Stop Them [Updated]
- Best Cybersecurity Journalism 2025: Stories That Defined the Year
- ESET Antivirus 30% Off: Complete 2025 Security Guide [Save $41.99]

