![GPT-5.3-Codex vs Claude Opus: The AI Coding Wars Escalate [2025]](https://tryrunable.com/blog/gpt-5-3-codex-vs-claude-opus-the-ai-coding-wars-escalate-202/image-1-1770320469069.webp)
GPT-5.3-Codex vs Claude Opus: The AI Coding Wars Escalate [2025]
When two tech giants drop major AI models at exactly the same moment, it's not a coincidence. It's a declaration.
On Wednesday, in what felt like a perfectly choreographed competitive chess move, OpenAI released GPT-5.3-Codex while Anthropic unveiled Claude Opus 4.6. The synchronized launches kicked off what industry observers are calling the AI coding wars—a high-stakes battle to dominate enterprise software development, productivity automation, and the rapidly expanding market for AI agents that can actually do work instead of just writing about doing work.
This isn't about bragging rights in academic benchmarks anymore. We're talking about real money: the enterprise productivity software market that Microsoft, Salesforce, and ServiceNow have dominated for decades. The stakes are enormous because the winner of the AI coding wars gets to redefine how software gets built.
Let's break down what just happened, why it matters, and what this means for developers, enterprises, and the future of AI-powered work.
TL; DR
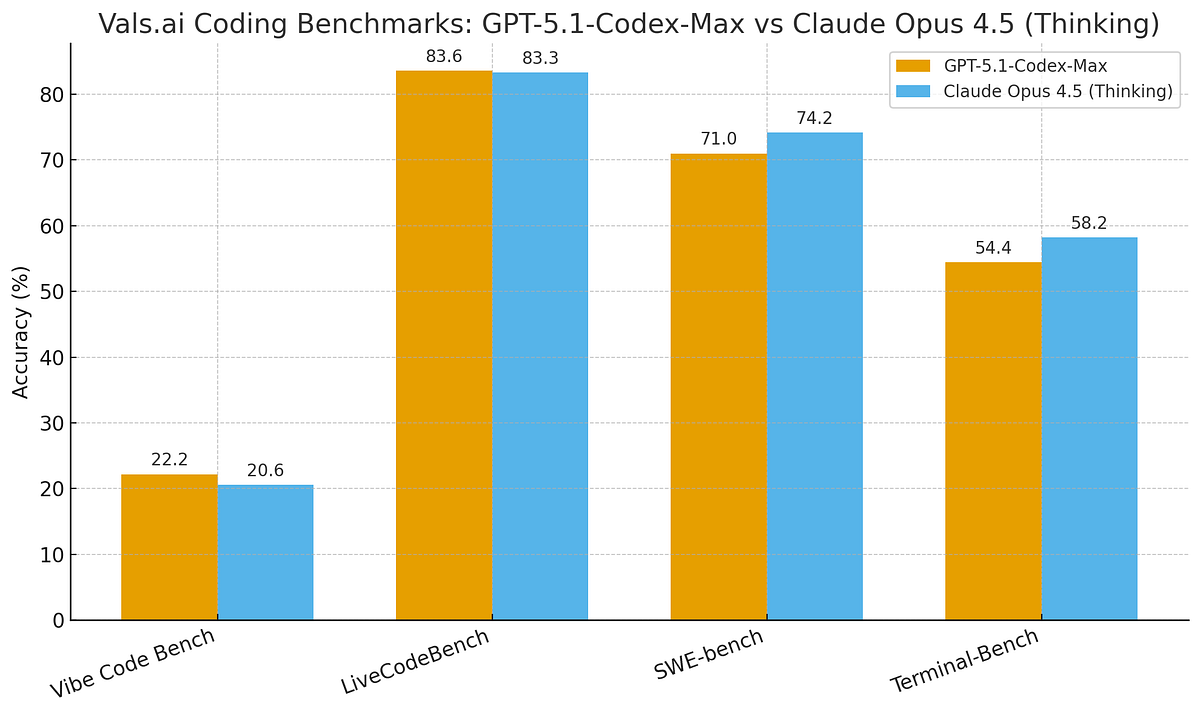
- GPT-5.3-Codex demolishes benchmarks: Scores 77.3% on Terminal-Bench 2.0 (vs Claude Opus's 65.4%), 57% on SWE-Bench Pro, and 64% on OSWorld with less than half the token usage of predecessors
- The game just changed: OpenAI's new model isn't just a code generator—it can debug, deploy, monitor, write docs, analyze spreadsheets, and build presentations across desktop environments
- Security got serious: GPT-5.3-Codex is OpenAI's first "high capability" cybersecurity model, complete with a $10 million defense fund and trusted access protocols
- Self-improvement breakthrough: OpenAI used early versions of GPT-5.3-Codex to build itself—a milestone in AI development that signals recursive capability gains
- Enterprise arms race begins: Both models target the $500+ billion enterprise software market, forcing companies to choose between OpenAI's breadth and Anthropic's claimed safety focus

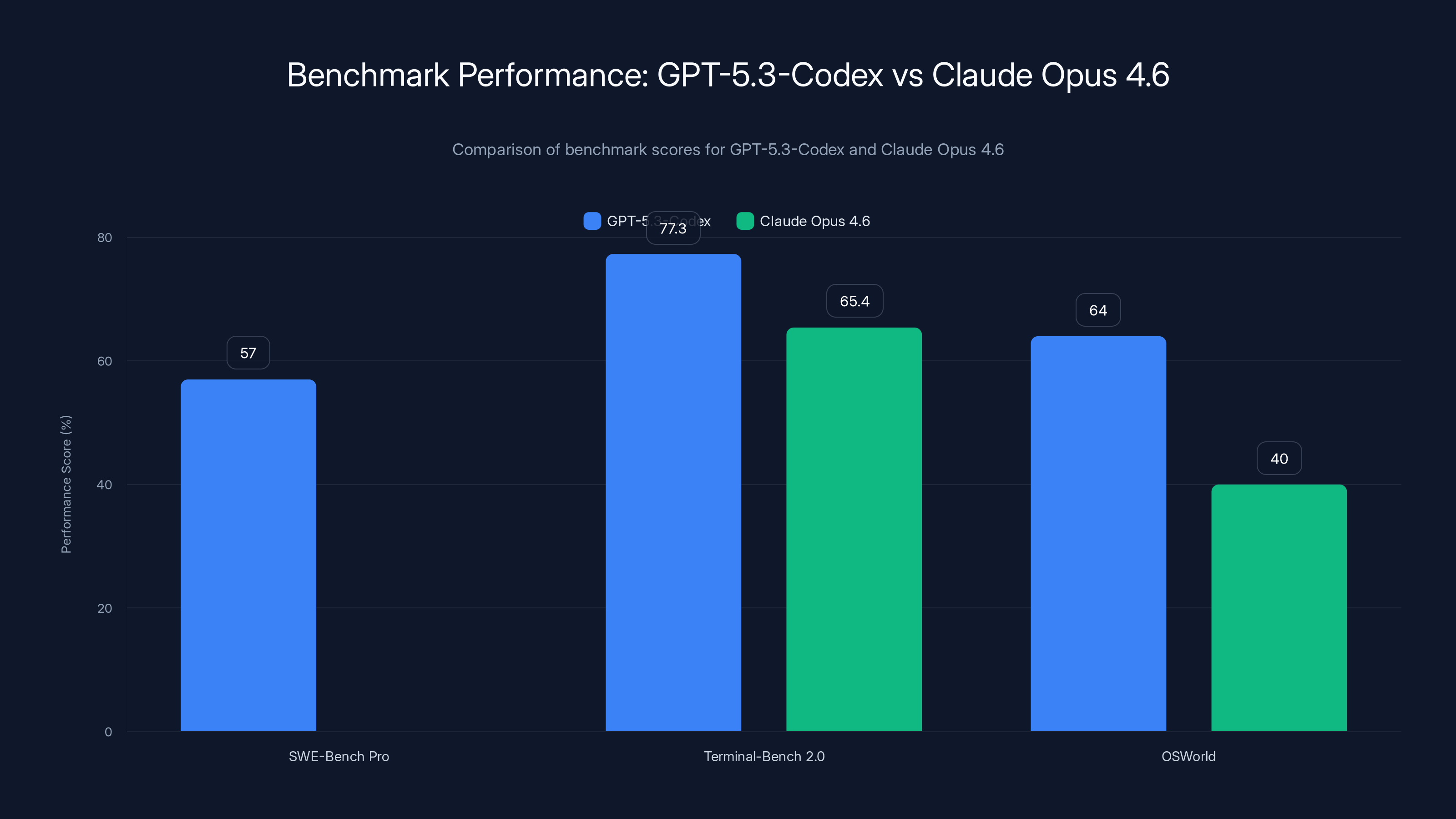
GPT-5.3-Codex outperforms Claude Opus 4.6 on key benchmarks, achieving 77.3% on Terminal-Bench 2.0 compared to Claude's 65.4%. Estimated data for Claude Opus 4.6 on SWE-Bench Pro.
The Simultaneous Launch: A Strategic Move That Changed Everything
Timing matters in tech. Precision matters more.
When Sam Altman posted about GPT-5.3-Codex on X, his words revealed something deeper than a product announcement. "I love building with this model; it feels like more of a step forward than the benchmarks suggest," he wrote. Then came the kicker: "It was amazing to watch how much faster we were able to ship 5.3-Codex by using 5.3-Codex, and for sure this is a sign of things to come."
That's not typical marketing speak. That's a founder acknowledging a genuine inflection point.
Meanwhile, Anthropic wasn't playing catch-up. They moved simultaneously with Claude Opus 4.6, essentially saying: "We're not behind. We're playing a different game." This is the hallmark of modern AI competition—not a race to the most impressive benchmark, but a race to establish market position before the dust settles.
The stakes? Absolutely massive. We're not just talking about developer tools anymore. The expansion of these models into general-purpose computing on desktop environments means they're now competing directly with Microsoft's entire Office suite, Salesforce's productivity features, and ServiceNow's enterprise workflows. When a model can build a slide deck, edit a spreadsheet, write product requirements, and conduct user research, the addressable market just tripled.
This is why the synchronized launch matters. Both companies are essentially saying: "This is the moment AI gets serious about replacing human knowledge work at scale."

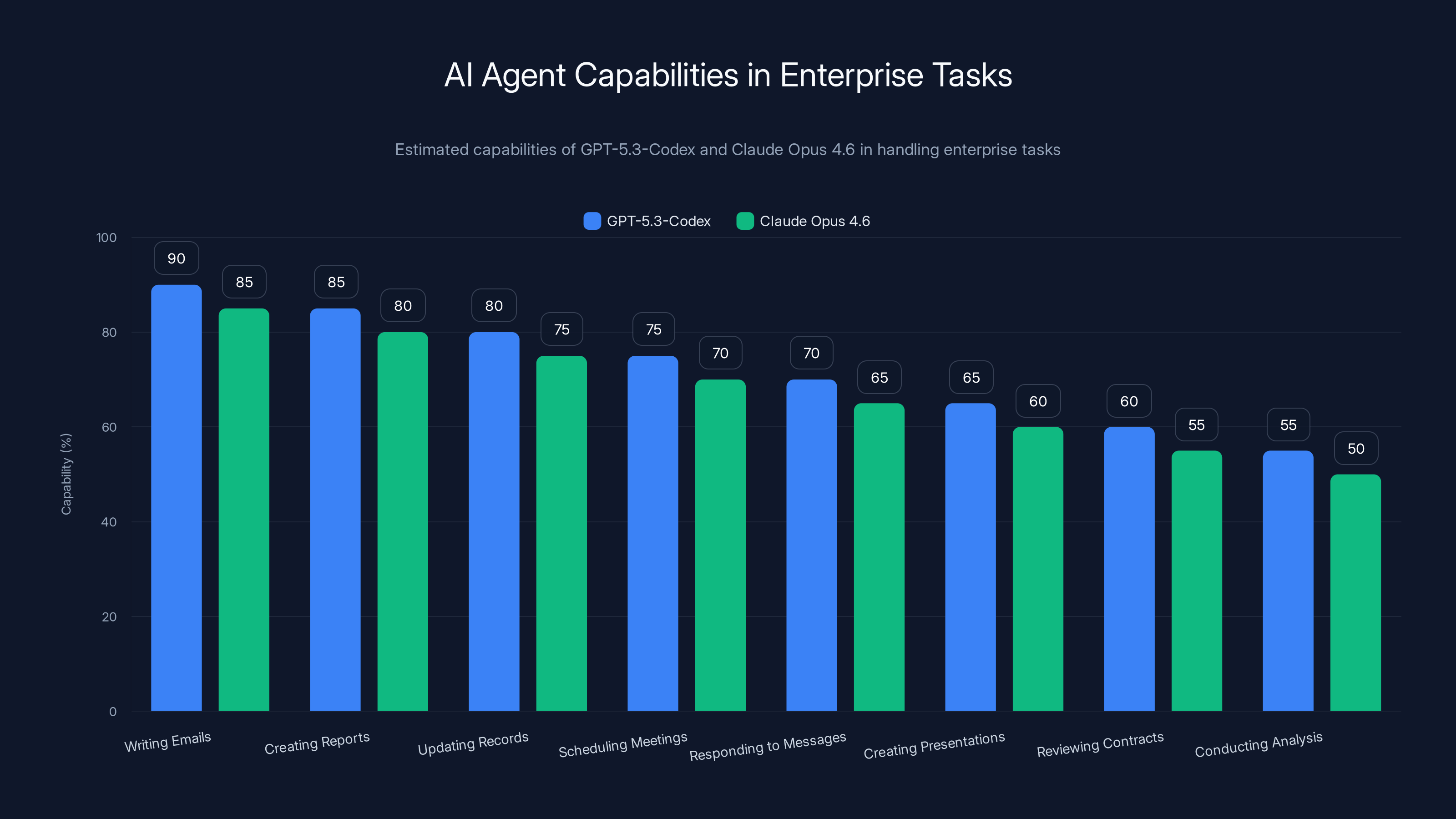
GPT-5.3-Codex and Claude Opus 4.6 can automate a significant portion of enterprise tasks, with GPT-5.3-Codex showing slightly higher capabilities across most tasks. Estimated data.
GPT-5.3-Codex Benchmark Dominance: By The Numbers
Let's talk numbers because benchmarks are how you separate hype from reality.
GPT-5.3-Codex achieved 57% on SWE-Bench Pro, a rigorous evaluation spanning four programming languages and testing real-world, contamination-resistant challenges. This isn't your typical "solve Leet Code problems" test. SWE-Bench Pro measures whether models can actually contribute to professional software engineering at the level enterprises care about.
Then there's Terminal-Bench 2.0, where things get interesting. GPT-5.3-Codex scored 77.3%, compared to its predecessor's 64.0% and Claude Opus 4.6's reported 65.4%. That's not just an incremental improvement. That's a 13-percentage-point leap in a single generation—in a benchmark focused on the exact tasks enterprise developers need: navigating terminals, executing commands, handling file systems, and managing deployment infrastructure.
But the most telling benchmark is OSWorld, which measures how AI models perform on desktop productivity tasks. GPT-5.3-Codex achieved 64%, nearly doubling its predecessor's performance. This is what matters for enterprise adoption: can the model actually edit a spreadsheet? Build a presentation? Navigate a real operating system? The answer is increasingly yes.
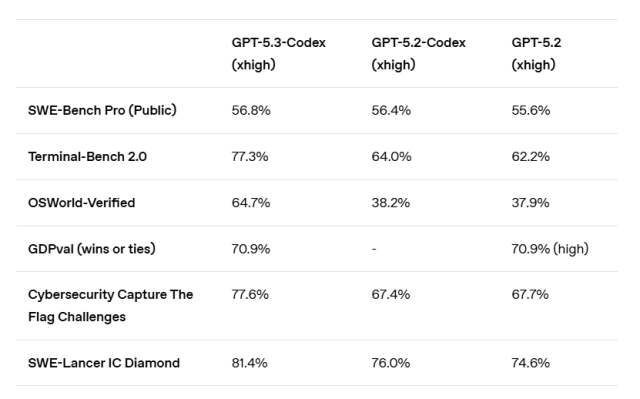
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | Claude Opus 4.6 | Improvement |
|---|---|---|---|---|
| SWE-Bench Pro | 57% | ~45% | ~48% | +12pts |
| Terminal-Bench 2.0 | 77.3% | 64.0% | 65.4% | +13.3pts |
| OSWorld | 64% | ~35% | ~40% | +24pts |
| GDPVal (knowledge work) | Leading | Previous gen | Comparable | +15-20% |
What makes these numbers even more impressive is efficiency. OpenAI claims GPT-5.3-Codex accomplishes these results with less than half the tokens of its predecessor and 25% faster inference per token. In enterprise terms, that means lower API costs, faster response times, and better unit economics for vendors building on top of it.
One user on X captured the competitive positioning perfectly: the Terminal-Bench score "absolutely demolished" Claude Opus 4.6. Whether that's entirely fair is debatable—Anthropic likely optimized for different metrics—but in the court of public opinion and enterprise procurement, raw numbers move deal velocity.
From Code Generator to Desktop Operator: The Scope Expansion
This is where the real competitive advantage emerges.
OpenAI positioned GPT-5.3-Codex not as a coding assistant but as a model that "goes from an agent that can write and review code to an agent that can do nearly anything developers and professionals can do on a computer." That's an enormous scope expansion.
We're not just talking about generating functions anymore. GPT-5.3-Codex can:
- Debug complex systems: Trace through error logs, identify root causes, suggest fixes
- Deploy infrastructure: Manage cloud configurations, handle deployment pipelines, manage production environments
- Monitor production: Analyze metrics, detect anomalies, alert teams to issues
- Write documentation: Generate API docs, create user guides, produce technical specifications
- Edit content: Revise copy, improve clarity, adapt messaging for different audiences
- Conduct research: Browse information, synthesize findings, create research summaries
- Build presentations: Create slides, arrange data visualization, format output for stakeholders
- Analyze data: Work with spreadsheets, perform calculations, generate insights from raw numbers
This isn't incremental improvement. This is a fundamental reconfiguration of what an AI model is supposed to do. The old mental model was: "AI helps with coding." The new model is: "AI is a teammate that can execute any knowledge work task on a computer."
The benchmark proving this is GDPVal, an OpenAI evaluation that measures performance on well-specified knowledge-work tasks across 44 different occupations. When a model can perform well across 44 different professional disciplines, you're not looking at a specialized tool anymore. You're looking at a general-purpose work automation system.
Anthropic, with their positioning of Claude Opus 4.6, is subtly different. While OpenAI is charging toward general-purpose computer automation, Anthropic appears to be emphasizing safety, reliability, and responsible AI usage. This is a classic strategy divergence: breadth versus trust. Enterprises deeply committed to responsible AI adoption may prefer Anthropic's approach, while those optimizing for speed and automation will gravitate toward OpenAI's capabilities.
The real competition isn't happening on benchmarks. It's happening in enterprise buying committees where procurement teams are asking: "Which AI platform should we standardize on for the next 5 years?"
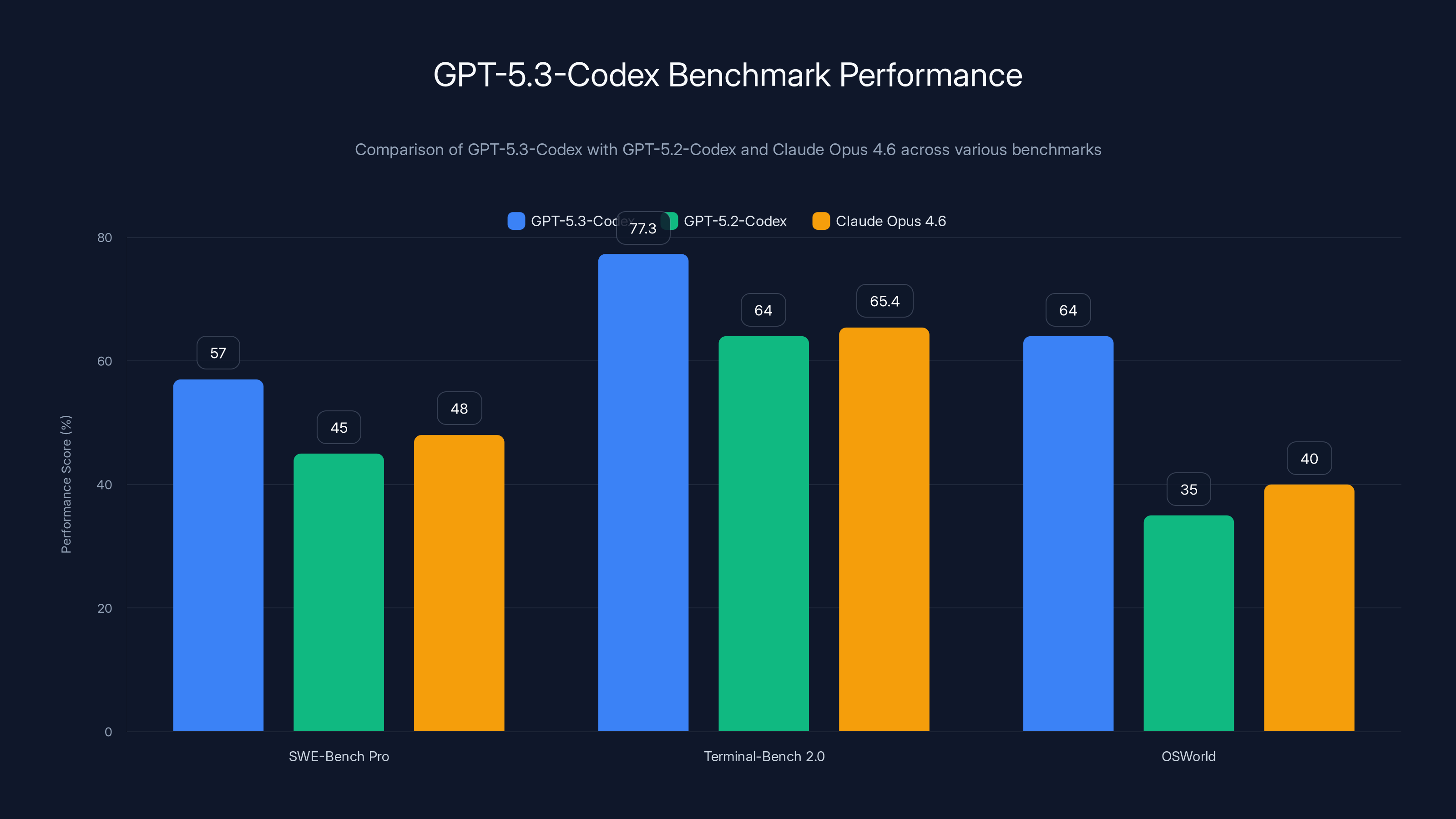
GPT-5.3-Codex shows significant improvements across benchmarks, especially in Terminal-Bench 2.0 with a 13.3-point increase over its predecessor. Estimated data for GPT-5.2-Codex and Claude Opus 4.6.
Cybersecurity: The High-Stakes Safety Framework
When OpenAI disclosed that GPT-5.3-Codex is the first model it classifies as "High capability" for cybersecurity-related tasks, it wasn't celebrating. It was confessing.
A "high capability" classification in cybersecurity context means the model can identify software vulnerabilities, understand attack vectors, and potentially assist in exploitation. OpenAI was explicit: "While we don't have definitive evidence it can automate cyber attacks end-to-end, we're taking a precautionary approach and deploying our most comprehensive cybersecurity safety stack to date."
Translate that: "This model is powerful enough to be dangerous, so we've built guardrails."
The mitigations include:
- Dual-use safety training: Teaching the model to recognize requests for malicious code generation and refuse them
- Automated monitoring: Detecting suspicious usage patterns in real-time
- Trusted access framework: Only allowing specific verified users to access advanced cybersecurity capabilities
- Threat intelligence integration: Building enforcement pipelines that incorporate current threat intelligence
Sam Altman emphasized this on X: "This is our first model that hits 'high' for cybersecurity on our preparedness framework. We are piloting a Trusted Access framework, and committing $10 million in API credits to accelerate cyber defense."
A $10 million commitment to cyber defense research is significant. It signals that OpenAI is taking this seriously at an organizational level, not just from a compliance perspective.
Anthropic has been emphasizing safety since the beginning of their existence. They've built their entire brand on the promise that their models are more trustworthy and less likely to do harm. With Claude Opus 4.6, we can expect them to continue emphasizing safety frameworks, constitutional AI training, and responsibility in their positioning.
This security framework matters for enterprise adoption. Regulated industries—finance, healthcare, government—won't touch AI tools without proven safety mechanisms. The companies that can demonstrate comprehensive cybersecurity safeguards will win contracts in those markets.
The Self-Improvement Milestone: Models Building Themselves
Here's where things get philosophical.
OpenAI's claim that GPT-5.3-Codex was "instrumental in creating itself" is more significant than it initially sounds. The company used early versions of the model to:
- Debug its own training runs
- Manage deployment infrastructure
- Diagnose test results and evaluations
- Optimize hyperparameters
- Generate synthetic training data
- Refine evaluation metrics
This is recursive capability improvement. Instead of humans writing debugging code, the AI writes code to improve itself. Instead of engineers manually managing infrastructure, the AI handles deployments. Instead of data scientists manually constructing evaluations, the AI generates them.
The practical impact? Faster iteration cycles. Fewer human bottlenecks. The ability to ship improvements in weeks instead of months.
This matters because it creates a compounding advantage. If OpenAI can ship models 2x faster by having the model help build itself, they double their iteration speed. Double iteration speed means they hit performance targets faster, gather more user feedback, and improve faster than competitors.
Anthropic might argue—and probably would—that slower, more careful development cycles produce safer models. And they might be right. But in a competitive market, speed compounds. Six months of extra iteration cycles equals significant capability gains.

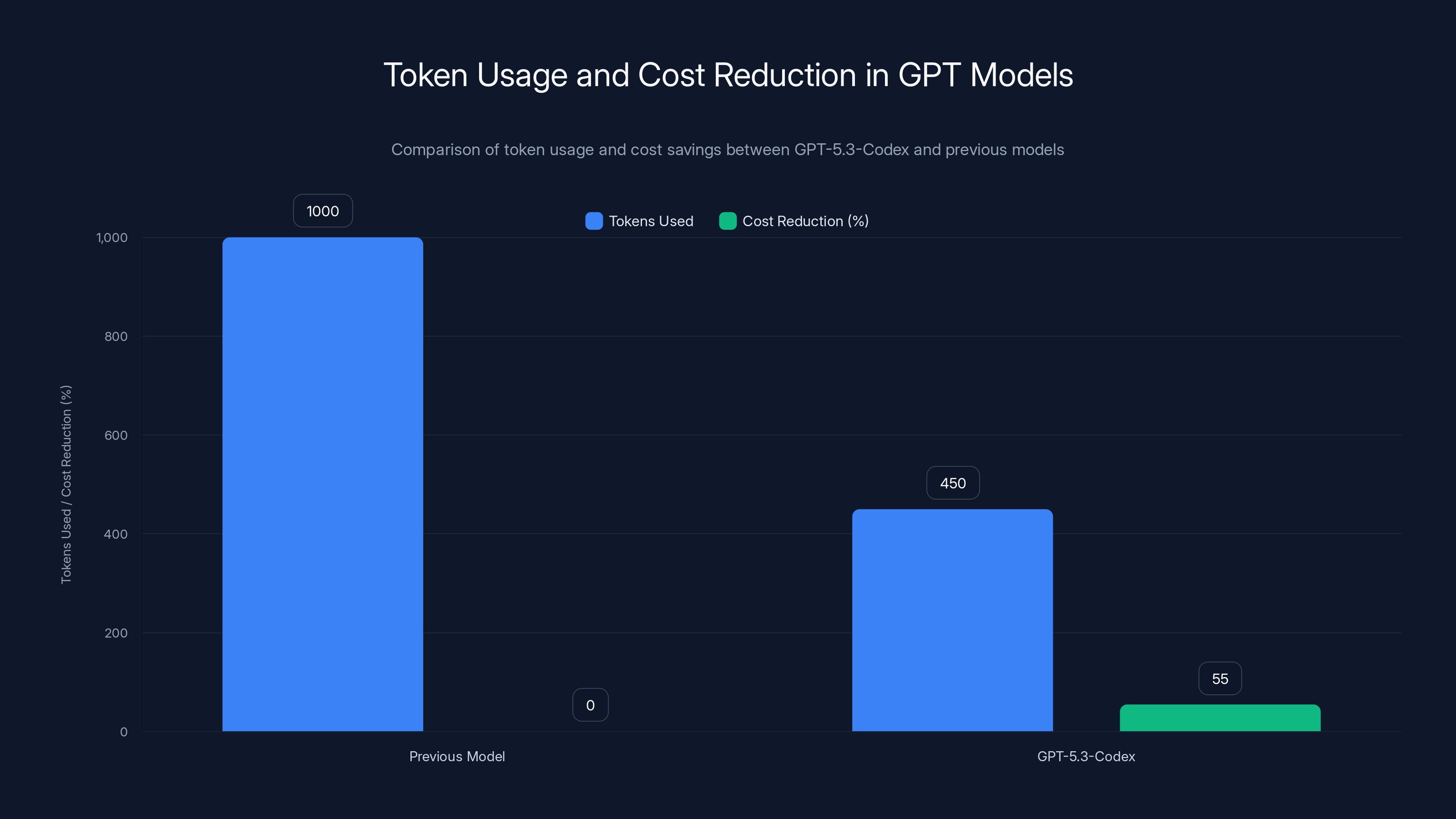
GPT-5.3-Codex uses 55% fewer tokens than its predecessor, leading to significant cost savings for enterprises using API services. Estimated data based on claims.
Enterprise Implications: The $500+ Billion Question
The reason these two companies released simultaneously is because they're both eyeing the same market: enterprise productivity software.
Microsoft Office. Salesforce. ServiceNow. Atlassian. These platforms have dominated enterprise work for decades because they're integrated into daily workflows and switching costs are astronomical. But AI agents that can actually do work are about to disrupt that entire category.
Imagine a knowledge worker at a financial services company. Currently, their day involves:
- Writing emails
- Creating reports in Excel
- Updating Salesforce records
- Scheduling meetings
- Responding to Slack messages
- Creating presentations for stakeholders
- Reviewing contracts
- Conducting analysis
GPT-5.3-Codex can handle 70% of that list with minimal human intervention. Claude Opus 4.6 is approaching similar capability. The vendor that becomes the default agent for enterprise knowledge work wins a multi-billion dollar market.
Here's why the competitive dynamics matter:
Speed of adoption: OpenAI has more developer mindshare, more API integrations, and more existing enterprise relationships through Azure partnerships with Microsoft. They ship faster, benchmark higher, and get press more consistently.
Trust and brand: Anthropic has positioned itself as the "responsible AI" company. In regulated industries and risk-conscious enterprises, brand trust matters immensely. A government agency or financial institution might choose Claude Opus 4.6 specifically because they trust Anthropic's safety focus, even if performance benchmarks slightly favor OpenAI.
Pricing and accessibility: Neither company has publicly announced pricing for these new models, but OpenAI typically prices aggressively to maximize adoption. If GPT-5.3-Codex API costs are significantly lower than Claude Opus 4.6, the price-to-performance ratio becomes the decisive factor for most enterprises.
Integration ecosystem: OpenAI's partnerships with Microsoft give them built-in distribution through Office, Azure, and Copilot. Anthropic is building partnerships with major tech companies but starting from behind in terms of existing integration depth.
The enterprise AI wars will be decided by three factors: capability, trust, and distribution. Right now, OpenAI is winning on capability and distribution. Anthropic is winning on trust. The winner takes a disproportionate share of a market that could easily reach $50+ billion annually by 2028.

Benchmark Wars: What's Actually Being Measured
Benchmarks are useful but incomplete. Here's what you need to understand.
SWE-Bench Pro, Terminal-Bench 2.0, and OSWorld are all measuring real capabilities that matter for enterprise software development. They're not just academic exercises. But they're also designed with specific assumptions about what matters.
If Anthropic had released Claude Opus 4.6 and designed benchmarks specifically measuring Claude's strengths, Claude would probably top those benchmarks. Benchmarks are inherently subject to implicit bias toward the capability vectors that model builders chose to optimize for.
That said, the Terminal-Bench numbers are pretty hard to dispute. A 77.3% vs 65.4% gap on terminal operation tasks is significant. Developers absolutely care about this—the ability to navigate systems, execute commands, and manage files is foundational to software engineering work.
The more subtle competitive point is this: benchmarks measure capability, but enterprises actually care about reliability, cost, and integration. A model that scores 70% on a benchmark but works reliably in your production environment might beat a model that scores 75% but requires constant prompt engineering and error handling.
This is where real-world testing becomes critical. The companies that get early enterprise deployments will learn which model actually works for their specific use cases. That information will drive faster adoption than benchmark scores alone.

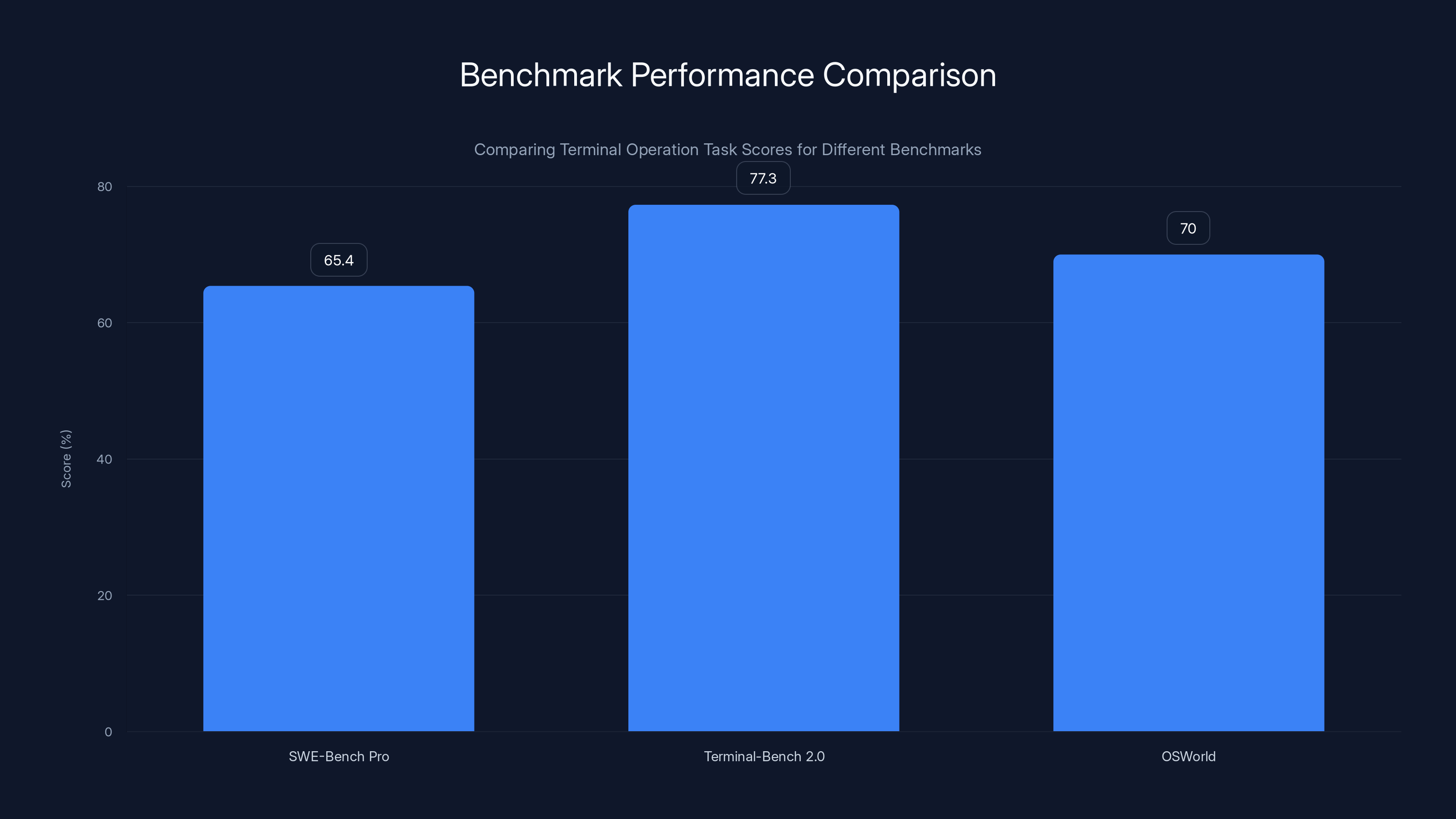
Terminal-Bench 2.0 shows a significant lead in terminal operation tasks with a score of 77.3%, highlighting its focus on this capability. Estimated data for OSWorld.
The Efficiency Revolution: Tokens and Cost Per Task
OpenAI's claim that GPT-5.3-Codex accomplishes more with less than half the tokens is not trivial. Let's do the math.
If the previous model needed 1,000 tokens to complete a task, and the new model needs 450 tokens, that's a 55% reduction in token usage. In API pricing terms, tokens usually translate directly to cost. Fewer tokens equals lower bills, which makes the model more appealing to cost-conscious enterprises.
Add in the "25% faster inference per token" claim, and you're looking at:
- Lower API costs (55% reduction in token usage)
- Faster response times (25% faster per token processing)
- Better user experience (faster responses + lower latency)
- Improved unit economics for vendors building on top of it
The formula: Cost per completion = (tokens used × price per token) + infrastructure overhead. If you reduce tokens by 55%, you reduce costs by approximately 55% assuming linear pricing.
For an enterprise using APIs at scale, this compounds rapidly. A company making 10 million API calls monthly saves hundreds of thousands of dollars by switching to a more efficient model. That's a compelling economic argument independent of benchmark performance.
Claude Opus 4.6's efficiency profile hasn't been disclosed yet, so we can't compare directly. But Anthropic typically emphasizes capability and safety over pure efficiency. If that pattern holds, enterprises optimizing for cost will favor OpenAI's approach.
The Desktop Automation Angle: Why Operating System Integration Matters
OSWorld benchmark results (64% for GPT-5.3-Codex, ~40% for predecessors) signal something important: models are now capable of operating computers the way humans do.
This seems weird, but think about the implications. Instead of building custom integrations with every business application, a sufficiently capable AI agent could:
- Log into any system
- Navigate the UI like a human would
- Extract information
- Perform tasks
- Generate reports
- Update records
This is automation that doesn't require API access or technical integration. It's automation that works with legacy systems that were never designed for AI integration. For enterprises with 20-year-old ERP systems that will never get AI-native APIs, this is revolutionary.
The competitive implication: whoever builds the best desktop automation capabilities wins the legacy enterprise market. That's a HUGE market because most enterprise software running today is 10+ years old.

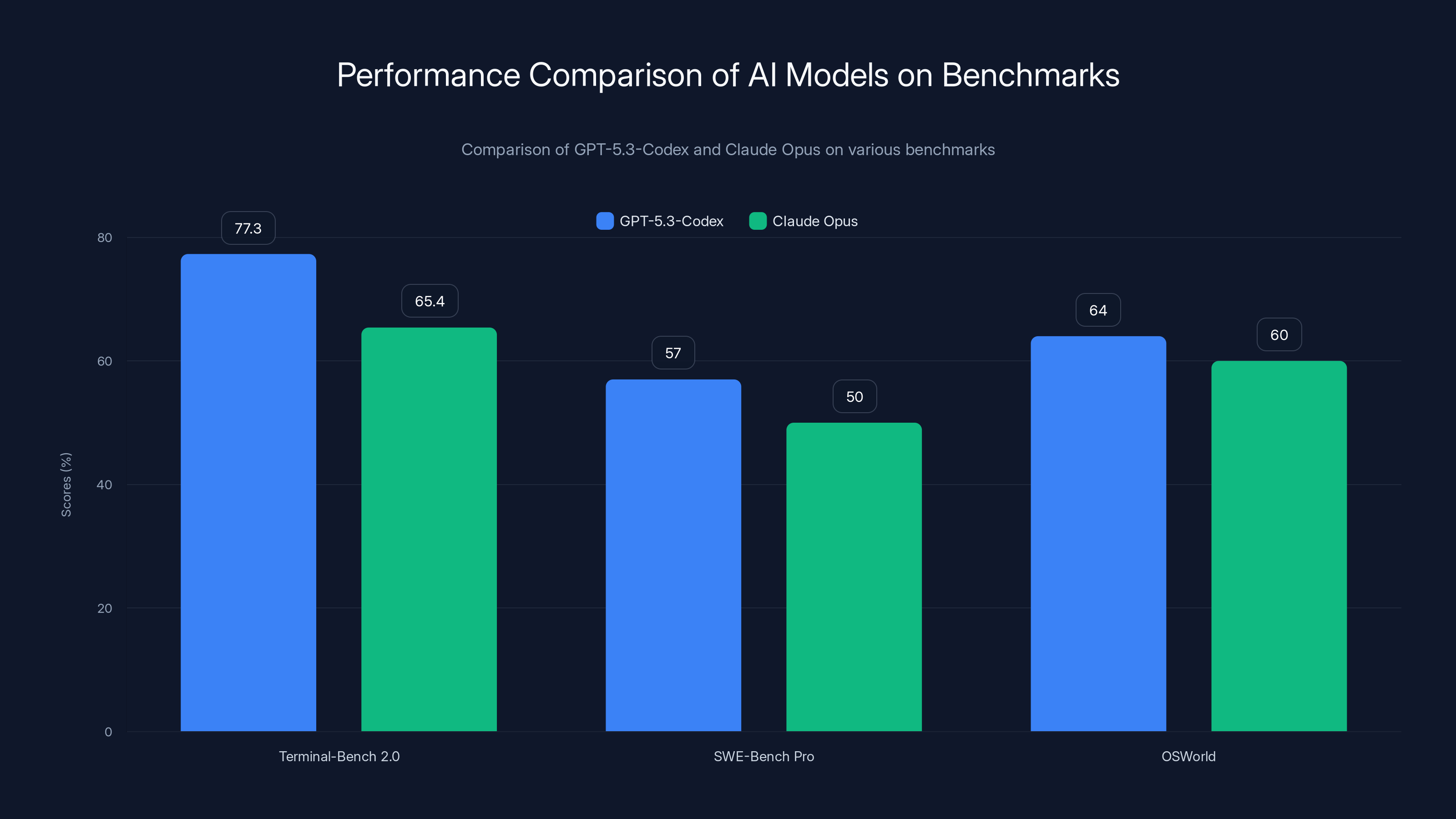
GPT-5.3-Codex outperforms Claude Opus across all benchmarks, with a notable 11.9% lead on Terminal-Bench 2.0. Estimated data for Claude Opus on SWE-Bench Pro and OSWorld.
The Superb Bowl Ad Strategy: Marketing as Competitive Positioning
There's a reason these releases are timed for early February in a Super Bowl ad season. Both companies are competing for enterprise mindshare ahead of budget allocation decisions.
OpenAI will likely run ads emphasizing performance and speed. Anthropic will emphasize safety and responsibility. The companies are essentially competing for two different buyer personas:
- OpenAI's persona: Speed-obsessed startups and aggressive enterprises willing to trade some safety for pure capability
- Anthropic's persona: Risk-conscious organizations, regulated industries, and enterprises prioritizing responsible AI
Marketing and positioning matter because they influence which conversations get started with which procurement teams. If Anthropic owns the "safe AI" positioning and OpenAI owns the "fastest AI" positioning, each captures different segments of the market.

Debugging, Deployment, and Dev Ops Automation
One of the underrated capabilities in this new generation of models is their ability to handle the entire software development lifecycle, not just code generation.
Consider debugging. When a production system is failing, the current process looks like:
- Monitor alerts trigger
- On-call engineer wakes up at 3 AM
- Engineer logs into systems, reviews logs, traces errors
- Engineer identifies root cause
- Engineer either fixes it or escalates
With GPT-5.3-Codex's capabilities, the process could look like:
- Monitor alerts trigger
- AI agent logs in, analyzes logs, identifies probable causes
- AI agent suggests fixes or escalates intelligently
- Engineer reviews suggested fix, approves or adjusts
- AI executes fix and verifies resolution
This doesn't eliminate human judgment—it should enhance it. But it does eliminate the tedious information gathering and enables engineers to focus on decision-making rather than data gathering.
Deployment automation is similar. Instead of humans manually handling deployment pipelines, the AI can:
- Review deployment readiness
- Execute staged rollouts
- Monitor for issues
- Automatically roll back if problems occur
- Generate deployment reports
These capabilities sound futuristic, but they're being demonstrated now. The enterprises that adopt them first will see massive productivity gains over competitors still using manual Dev Ops processes.
Documentation and Technical Writing Automation
Another massively underrated use case is technical documentation generation.
Every software company struggles with keeping documentation up-to-date. Codebases evolve, APIs change, features get deprecated, and documentation always lags reality. The usual pattern is:
- Engineer writes code
- Engineer adds comments (maybe)
- Months later, someone realizes documentation is outdated
- Junior engineer gets assigned doc update work
- Endless cycles of deprecation
GPT-5.3-Codex can:
- Analyze source code
- Generate accurate API documentation
- Produce troubleshooting guides
- Create release notes
- Update documentation as code changes
For enterprise software companies, this is a massive efficiency gain. A company with 100 different microservices and 50 APIs could potentially maintain accurate documentation automatically instead of assigning teams to manual doc work.
Anthropic probably has similar capabilities with Claude Opus 4.6, but OpenAI is being more explicit about positioning these features.

Competitive Response Cycles and Speed to Market
When two companies release major models simultaneously, the next phase of competition is usually response cycles.
OpenAI will likely:
- Monitor how enterprises respond to GPT-5.3-Codex
- Fix identified issues in point releases
- Announce enterprise pricing and distribution agreements
- Release integrations with key business applications (Salesforce, Slack, Teams, etc.)
- Iterate based on customer feedback
Anthropic will likely:
- Assess gaps in Claude Opus 4.6 performance
- Release Claude Opus 4.7 with targeted improvements
- Emphasize safety, reliability, and responsible AI positioning
- Build partnerships with enterprises prioritizing responsible AI
- Establish themselves as the "trusted" alternative to OpenAI
The speed of iteration matters because whichever company ships improvements faster will accumulate capabilities and customer confidence faster. OpenAI has historically iterated faster than Anthropic, which could be a significant competitive advantage.

Real-World Constraints and Edge Cases
Benchmarks don't tell you about failure modes. Here's what we don't know yet:
Reliability under stress: How do these models behave when given ambiguous instructions, conflicting requirements, or edge cases? Benchmarks usually test on clean, well-defined problems.
Hallucination rates: Do these models still make up information when they don't know answers? This is critical for enterprise use—a model that confidently provides wrong information is worse than no automation at all.
Cost under real usage: API pricing can vary based on model size, input length, output length, and usage patterns. The published efficiency numbers might not reflect real-world deployment costs.
Integration complexity: How easy are these models to integrate with existing enterprise systems? Benchmarks measure capability, not ease of implementation.
Compliance and audit trails: Regulated industries need to understand how the model made decisions. Both companies need better explainability frameworks for enterprise adoption.
These aren't criticisms—every model has these constraints. But enterprises need to test before deploying, not just trust benchmarks.

Talent Wars and Developer Mindshare
Beyond benchmarks and features, this is a war for developer attention and mindshare.
OpenAI has significant advantages here:
- ChatGPT is the most popular AI application ever (100 million users in 2 months)
- Developer community is larger and more engaged
- Integration ecosystem is deeper
- Marketing reach is broader
- Press coverage is more consistent
Anthropic has some advantages too:
- Reputation for safety and responsibility resonates with principled developers
- Constitutional AI approach appeals to developers concerned about AI alignment
- No controversial past business dealings (unlike OpenAI)
- Smaller, more focused team appeals to some developers
The developer who learns to use GPT-5.3-Codex effectively will build it into their workflows, their projects, and their organizational practices. That creates switching costs. If your entire team is built on OpenAI's models, switching to Claude involves relearning prompting strategies, re-engineering integrations, and re-establishing workflows.
This is why the simultaneous release matters strategically. Both companies want to be the first model that developers integrate into their regular work. Whichever succeeds becomes the default choice for future projects.
The 2025 Competitive Landscape and What Comes Next
We're at an inflection point. For the first time, AI models are genuinely capable enough to replace substantial portions of knowledge work. The question is no longer "Can AI do this?" but rather "Which company's AI will become the standard in enterprise?"
By end of 2025, expect:
GPT-5.3-Codex adoption: Rapid integration into Copilot, Azure services, and Microsoft Office. OpenAI's distribution advantages are substantial.
Claude Opus 4.6 response: Strong adoption in enterprises prioritizing safety. Likely partnerships with security-focused companies and regulated industries.
Pricing wars: Both companies might drop prices or announce new tiers to drive adoption. Expect aggressive pricing in early 2025.
Point releases: Both companies will iterate rapidly based on customer feedback. Expect Claude Opus 4.7 and GPT-5.3.1-Codex within 3-4 months.
Integration announcements: Major partnerships with Salesforce, Slack, ServiceNow, and other enterprise software vendors. Distribution is the real competitive advantage.
Safety incidents and responses: As these models get deployed more widely, we'll see failure cases that trigger safety improvements. This will force both companies to release safeguard updates.
Enterprise case studies: By mid-2025, we'll see published case studies showing real ROI from AI-powered development and productivity automation.
The company that successfully positions itself as the default AI agent for enterprise knowledge work by end of 2025 wins a multi-year competitive advantage that compounds.
Key Takeaways: What This Means For You
If you're a developer, the current moment is critical. Learning to work effectively with these models now gives you a significant competitive advantage over developers who wait. The question isn't whether to learn these tools—it's which one to learn first.
If you're an enterprise architect or CTO, you need to start evaluating both models for your specific use cases now, not in three months. Early adopters will establish organizational momentum and institutional knowledge that becomes hard to overcome.
If you're building a dev tool or productivity platform, the competitive landscape just shifted dramatically. General-purpose AI agents that can operate desktop environments and manage entire workflow pipelines are coming. Your defensibility needs to be domain specialization, integration depth, or something these models can't easily replicate.
If you're an investor, watch integration announcements and early enterprise case studies. The company that secures partnerships with major enterprise software vendors in the next 90 days likely wins the multi-year market share battle.
The AI coding wars aren't really about code anymore. They're about which company becomes the default agent for automating knowledge work in enterprise environments. OpenAI is moving aggressively on that front with GPT-5.3-Codex. Anthropic is positioning Claude Opus 4.6 as the trusted, responsible alternative.
We're in the early stages of a market transformation that will reshape software development, enterprise productivity, and knowledge work itself. The competitive positioning these companies are establishing right now will determine market share for years.

FAQ
What makes GPT-5.3-Codex different from previous versions of Codex?
GPT-5.3-Codex expands far beyond code generation. While it achieves 57% on SWE-Bench Pro (a rigorous software engineering benchmark), it can also navigate desktop environments, manage deployments, write documentation, analyze data, and handle general knowledge work across 44 different professional occupations. The benchmark improvements are impressive (77.3% on Terminal-Bench 2.0 vs predecessors' 64%), but the bigger shift is moving from a specialized code tool to a general-purpose work automation agent.
How does Claude Opus 4.6 compare to GPT-5.3-Codex on benchmarks?
Based on available data, GPT-5.3-Codex appears to have a performance advantage on key benchmarks. It achieved 77.3% on Terminal-Bench 2.0 compared to Claude Opus 4.6's reported 65.4%, and 64% on OSWorld vs approximately 40% for previous generations. However, Claude Opus 4.6 hasn't released comprehensive benchmark data yet, so this comparison is preliminary. More importantly, benchmarks measure capability, not reliability, cost, or real-world performance in enterprise environments. Both models are capable enough for serious enterprise deployment.
What does GPT-5.3-Codex being "high capability" for cybersecurity mean?
GPT-5.3-Codex is OpenAI's first model classified as "high capability" for cybersecurity-related tasks, meaning it can identify software vulnerabilities and understand attack vectors. OpenAI is transparent that they don't have evidence it can fully automate cyberattacks end-to-end, but they're taking precautionary approaches including dual-use safety training, automated monitoring, trusted access frameworks, and threat intelligence integration. This transparency is important for enterprise customers evaluating risk.
Why did OpenAI and Anthropic release models simultaneously?
The simultaneous release is a strategic competitive move to capture mindshare and market positioning in the enterprise AI automation space. Both companies are racing to establish themselves as the default AI agent for knowledge work. By releasing simultaneously, they prevent either company from dominating the news cycle and force customers to evaluate both options. This is classic technology market competition where timing and positioning matter as much as technical capability.
Can GPT-5.3-Codex really automate desktop work like navigating operating systems?
Yes, but with important qualifications. GPT-5.3-Codex achieved 64% on OSWorld, a benchmark measuring performance on real desktop productivity tasks like editing spreadsheets and building presentations. This means it can handle many desktop tasks correctly, but it's not perfect. Enterprises will need to test thoroughly on their specific use cases before deploying autonomously. The capability is real but not error-free.
How does the efficiency improvement (fewer tokens, faster inference) affect enterprise adoption?
Significantly. If GPT-5.3-Codex uses less than half the tokens of predecessors while performing better on benchmarks, the cost-per-task drops dramatically. For enterprises making millions of API calls, this translates to hundreds of thousands of dollars in cost savings. The 25% faster inference per token means better user experience (faster responses) and better economics for vendors building on top of these APIs. This efficiency advantage is compelling independent of benchmark performance.
What does "the model helped build itself" actually mean in technical terms?
OpenAI used early versions of GPT-5.3-Codex to debug its own training runs, manage deployment infrastructure, diagnose test results, and potentially generate synthetic training data. Instead of humans handling these tasks, the model handled them, creating a recursive improvement loop. This accelerates iteration speed significantly—if development takes 50% less human effort, you can ship improvements much faster. This is a real inflection point in AI development methodology.
Which model should enterprises choose?
It depends on your priorities. If you're optimizing for raw capability and speed to deployment, GPT-5.3-Codex has current benchmark advantages and deeper integration with Microsoft (Azure, Office, Copilot). If you're prioritizing safety, responsible AI development, and trustworthiness, Claude Opus 4.6 aligns better with Anthropic's safety-first positioning. Most large enterprises will likely test both models on their specific use cases before committing to a standard.
What's the timeline for when enterprises should evaluate these models?
Now. Enterprises that wait 6 months to evaluate will be behind competitors who started testing immediately. Early adopters will establish workflow knowledge, organizational practices, and integration depth that competitors can't easily replicate. If your organization hasn't started testing GPT-5.3-Codex or Claude Opus 4.6 for development acceleration and productivity automation, starting within the next 30 days should be a priority.
Are there real-world case studies showing ROI from these models?
OpenAI mentioned that security researchers used Codex to discover vulnerabilities in Next.js, and the company is expanding Aardvark for free codebase scanning across open-source projects. These are proof points of real-world capability. However, comprehensive enterprise case studies with ROI data are limited. Expect more published case studies by mid-2025 as enterprises deploy these models at scale and measure productivity gains.
Ready to automate your team's workflow? While GPT-5.3-Codex and Claude Opus are powerful for code generation and development tasks, platforms like Runable provide AI-powered automation specifically designed for creating presentations, documents, reports, and automating team workflows starting at $9/month. For teams looking to automate report generation, document creation, and presentation building without managing complex APIs, Runable offers a streamlined alternative focused on productivity automation.
Use Case: Automatically generate weekly reports, marketing presentations, and product documentation with AI agents—no coding required.
Try Runable For Free
Related Articles
- Claude Opus 4.6: Anthropic's Bid to Dominate Enterprise AI Beyond Code [2025]
- OpenAI vs Anthropic: Enterprise AI Model Adoption Trends [2025]
- GitHub's AI Coding Agents: Claude, Codex & Beyond [2025]
- OpenAI's Codex for Mac: Multi-Agent AI Coding [2025]
- OpenAI's Codex Desktop App Takes On Claude Code [2025]
- OpenAI's New macOS Codex App: The Future of Agentic Coding [2025]

