![Geopatriation & Cloud Sovereignty: What 2026 Means for Enterprise Data [2026]](https://tryrunable.com/blog/geopatriation-cloud-sovereignty-what-2026-means-for-enterpri/image-1-1768070160939.jpg)
Geopatriation & Cloud Sovereignty: What 2026 Means for Enterprise Data [2026]
Introduction: The Quiet Shift Away From Global Cloud
For nearly two decades, enterprises moved decisively toward cloud. The pitch was simple: less infrastructure to manage, infinite scalability, and vendors handling the complexity. It worked for years. But something shifted in 2025, and it's accelerating into 2026.
Companies are bringing data home.
I'm not talking about a wholesale rejection of cloud. I'm talking about something more nuanced and, honestly, more interesting: a recalibration of where data actually lives and who controls it. It's called geopatriation, and it's becoming the defining infrastructure decision for enterprises heading into the next 18 months.
The term itself sounds technical and academic, but what it represents is almost philosophical. After decades of consolidating infrastructure into massive hyperscaler data centers sprawled across continents, organizations are asking a fundamental question: "Does our data actually need to be there? And what happens when that vendor's entire region goes down?"
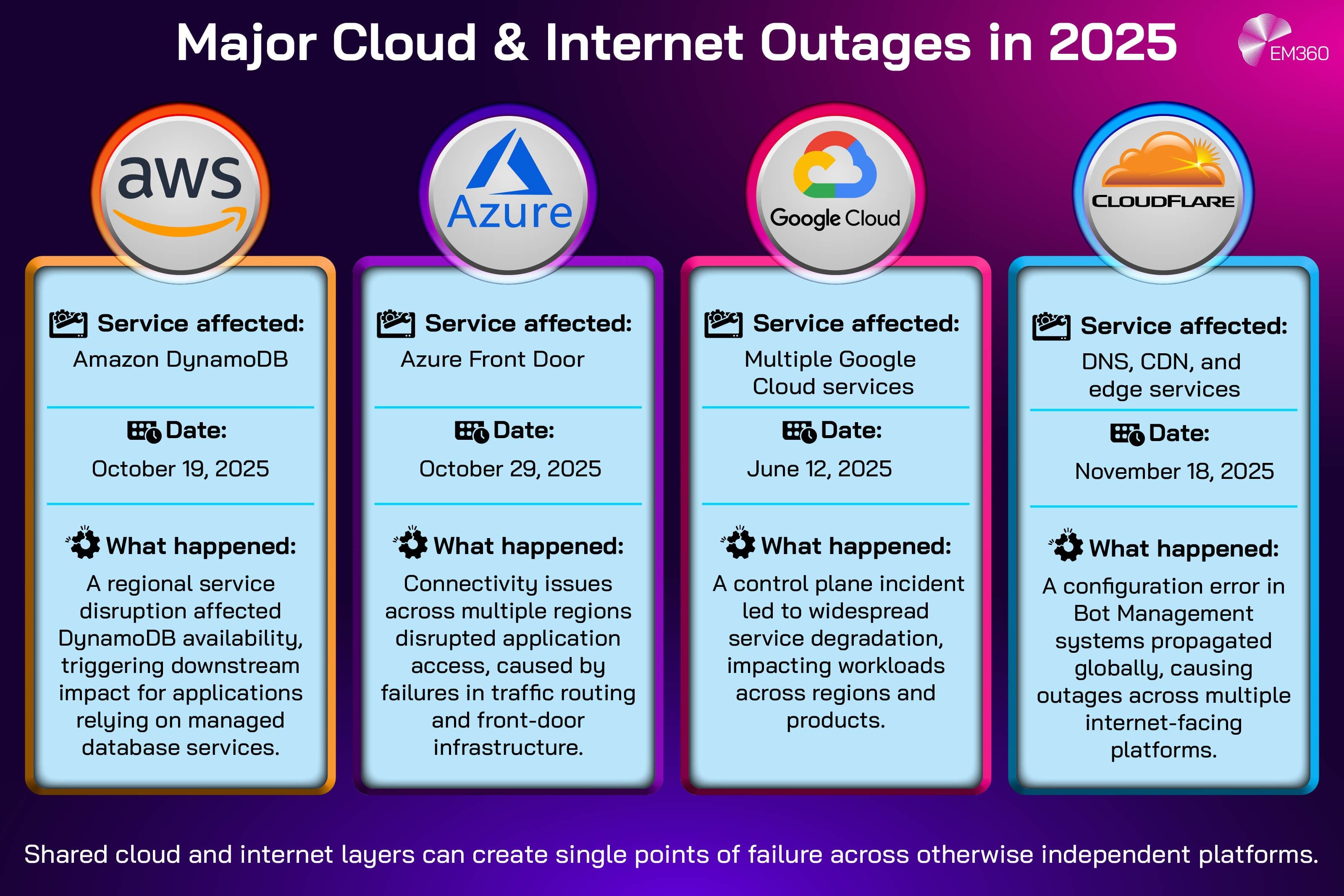
These aren't hypothetical questions anymore. The AWS outage that hit multiple regions in July 2025 caused an estimated $2.8 billion in global losses across financial services, retail, and SaaS companies. That single incident crystallized something executives had been slowly realizing: convenience and control are often inversely proportional.
What makes this moment different from previous cloud skepticism is that it's not a rejection of cloud technology itself. It's a demand for sovereignty over the infrastructure that holds competitive advantage. It's about local data residency, regional compliance, and the ability to maintain operations when hyperscaler networks fail.
So what changed? And what does geopatriation actually mean for your infrastructure strategy in 2026? Let's break it down.
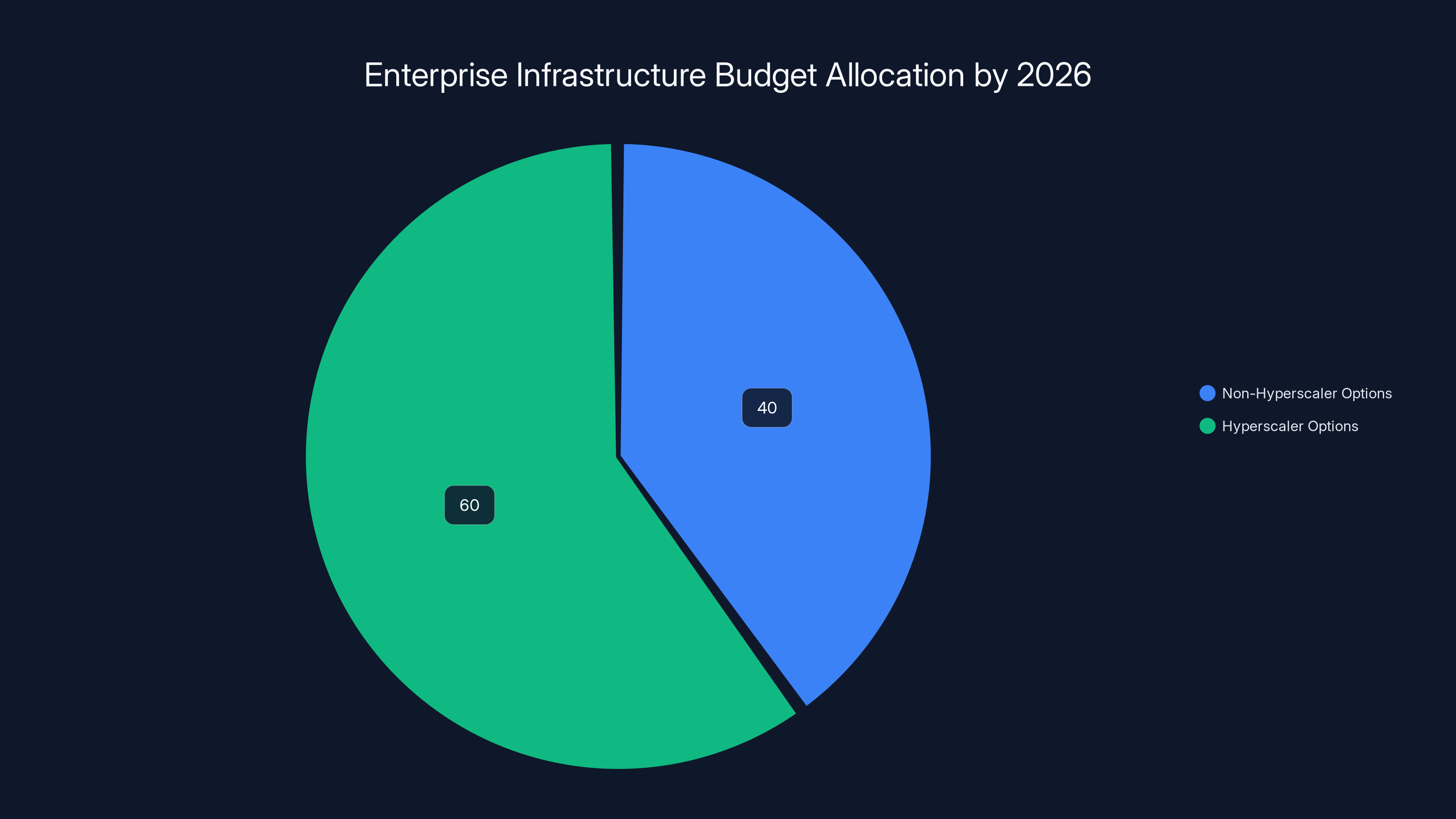
By 2026, over 40% of enterprise infrastructure budgets are expected to be allocated to non-hyperscaler options like private cloud, regional providers, and on-premises solutions. Estimated data.
TL; DR
- Geopatriation is accelerating as enterprises recognize the operational risks of hyperscaler dependencies, particularly following major 2025 outages
- Data sovereignty is now non-negotiable for regulated industries, with organizations diversifying cloud strategies to include local and on-premises options
- AI is reshaping the calculation by favoring smaller, locally-deployed models over massive central LLMs, changing how compute resources are distributed
- Regional cloud providers are gaining market share as enterprises demand alternatives that provide transparency, compliance, and local talent
- Energy constraints are becoming critical as data center demand outpaces grid capacity, pushing the economics toward distributed, efficient infrastructure
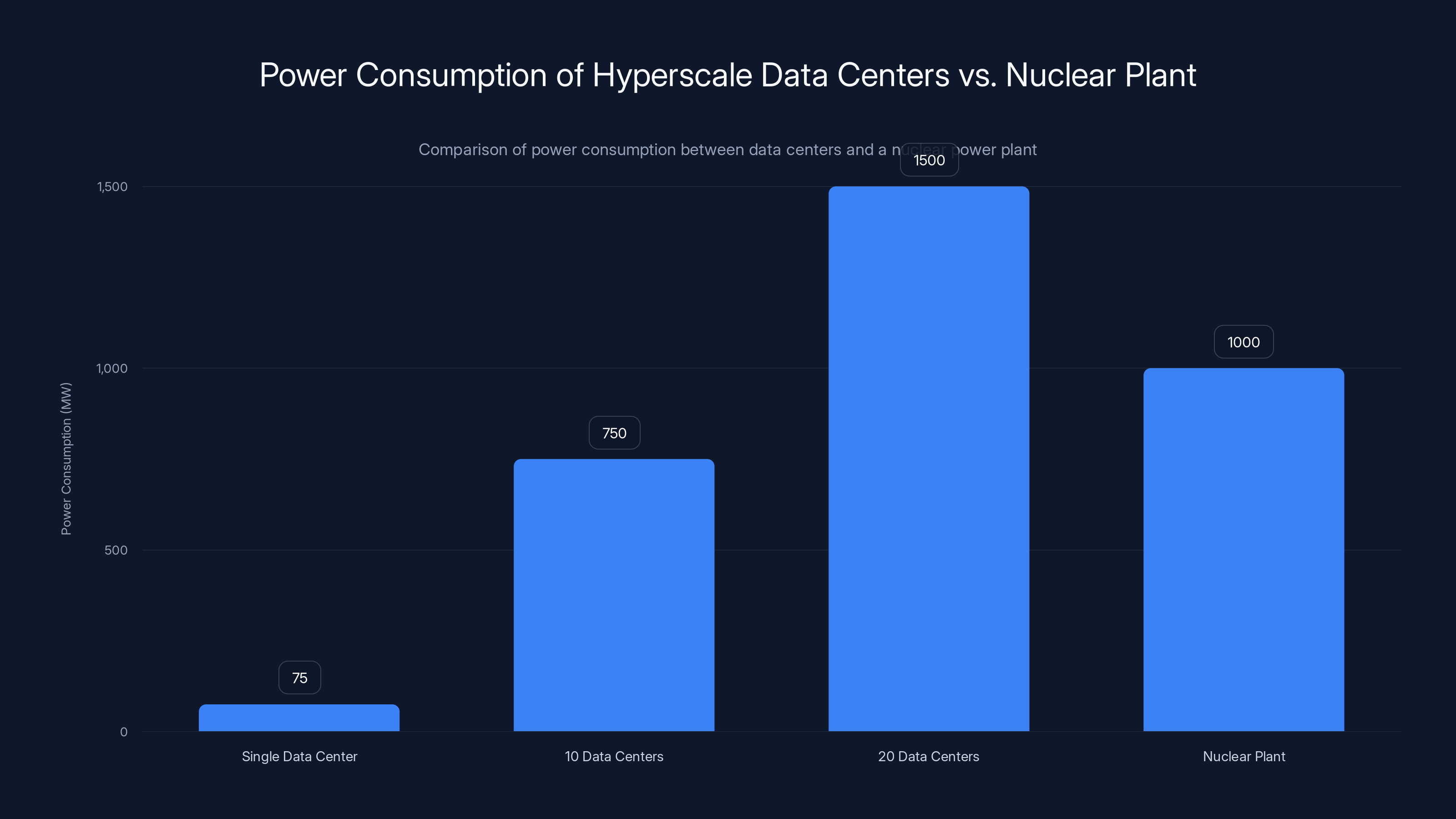
A single hyperscale data center can consume 75 MW, and 20 such centers can exceed the power output of a nuclear plant. Estimated data.
What Is Geopatriation, Actually?
Let me be direct: geopatriation is the practice of deliberately moving data and computational workloads back to the country, region, or physical proximity where they originated. It's a deliberate reversal of the cloud consolidation trend that dominated the 2010s and early 2020s.
The term itself has roots in geopolitics and sovereignty discussions, but in practice, it's become an infrastructure strategy. An organization based in France decides that customer data shouldn't be stored in a hyperscaler's centralized European data center thousands of kilometers away—it should be housed in local infrastructure with local governance.
This isn't the same as rejecting cloud entirely. Most organizations pursuing geopatriation are actually adopting hybrid cloud strategies where different workloads live in different places. Your customer database lives in regional infrastructure. Your analytics pipeline runs in a public cloud. Your AI inference engine lives on premises.
The appeal is multifaceted. First, there's regulatory compliance. The EU's GDPR has increasingly strict data residency requirements. Germany's NIS2 directive goes further. Regulators want to ensure that sensitive data doesn't leave national borders, and organizations face real penalties—up to 4% of global revenue—for violations.
Second, there's operational resilience. Hyperscaler outages affect entire regions simultaneously. When AWS's Ohio region went down in July 2025, every business using that region experienced simultaneous failure. With distributed infrastructure spread across local providers, redundancy becomes geographic rather than datacenter-focused.
Third, there's the confidentiality argument. When your data sits in a hyperscaler's shared infrastructure, you're inherently trusting their security posture. A breach affecting millions of customers isn't theoretical—it's Tuesday in cloud infrastructure. Local infrastructure gives organizations direct control over access controls, encryption, and who can audit their systems.
The catch? Geopatriation is expensive, complex, and organizationally disruptive. You're essentially rebuilding infrastructure decisions made over the past decade. You need local talent, local compliance expertise, and local operational knowledge. That's not cheap.
The 2025 Catalyst: Hyperscaler Failures That Changed Everything
Major infrastructure failures in 2025 didn't create geopatriation—they accelerated it by years.
The July AWS incident was the marquee event. A software update rolled out to the Ohio region, and critical networking components became misconfigured. For approximately 90 minutes, thousands of applications dependent on that region experienced degraded or total service outages. Financial services firms couldn't process transactions. SaaS platforms returned 500 errors. E-commerce operations were offline.
The financial impact was staggering, but more significant was what happened in boardrooms afterward. CIOs and infrastructure leaders who'd spent years consolidating on single hyperscalers suddenly had uncomfortable conversations with their executives. "What happens when our entire operation depends on a single company's infrastructure quality?"
This isn't unique to AWS. Google experienced extended outages affecting Cloud Storage. Azure had availability issues in specific regions. The pattern is clear: hyperscaler infrastructure at massive scale introduces single points of failure that no amount of redundancy zone setup can fully mitigate.
What surprised me about the aftermath wasn't corporate finger-pointing. It was the strategic response. Organizations didn't just add backup regions within the same hyperscaler—that's still a single vendor dependency. Instead, they started seriously evaluating alternative cloud providers, on-premises infrastructure, and regional players they'd previously dismissed as "too small" or "not feature-complete enough."
I spoke with infrastructure leaders at financial services firms, and the consensus was immediate: "Single-vendor strategies are operationally naive." That's a significant shift from the conventional wisdom of the 2015-2020 era when consolidation was king.
The 2025 failure cascade created political space for geopatriation discussions. Suddenly, suggesting "maybe we shouldn't put everything in one vendor's infrastructure" wasn't contrarian—it was prudent risk management.
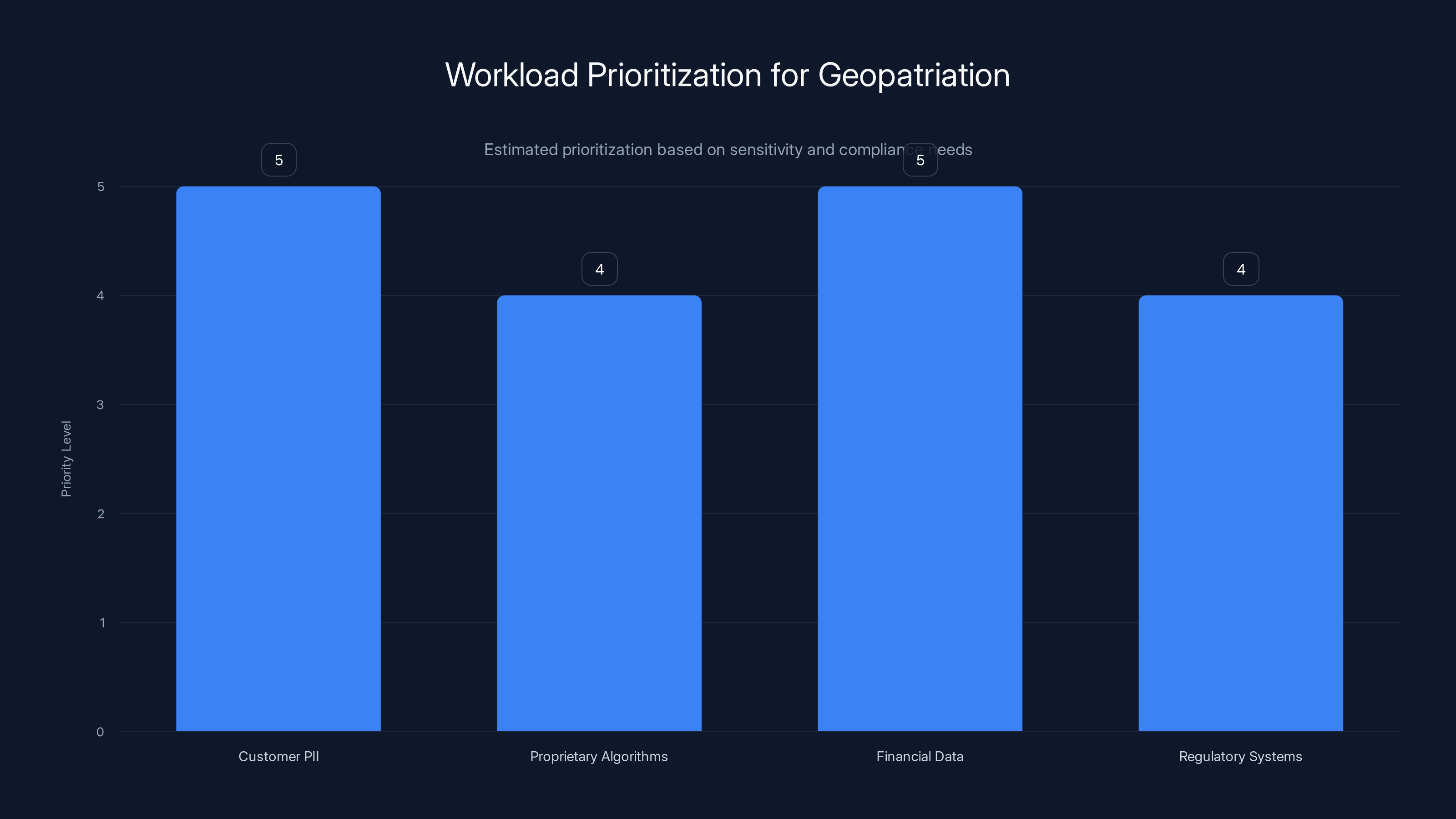
Estimated data suggests that workloads containing customer PII and financial data should be prioritized for geopatriation due to high sensitivity and compliance needs.
Understanding Data Sovereignty: The Regulatory Foundation
If geopatriation is the strategy, data sovereignty is the requirement driving it. You can't have one without the other in heavily regulated markets.
Data sovereignty is a deceptively simple concept: a country's data should remain under that country's legal jurisdiction and physical control. In practice, it's become extraordinarily complex because global operations mean data flowing across borders constantly.
The regulatory landscape shifted dramatically in the late 2010s and early 2020s. The European Union's GDPR set the template: data about EU citizens must be processed in ways that comply with EU law, and there are strict rules about where that data can be stored. GDPR violations aren't warnings—they're fines up to €20 million or 4% of global annual turnover, whichever is larger.
But GDPR was just the beginning. The German government's NIS2 implementation adds data residency requirements for certain critical infrastructure sectors. China's Data Security Law and Personal Information Protection Law have similar requirements. India, Brazil, and increasingly, the UK and Canada are following suit.
What this means practically: if you operate in Europe, you need to demonstrate that customer data is stored, processed, and backed up within European infrastructure. If you operate in multiple jurisdictions, you need different solutions for different regions.
Hyperscalers initially tried to solve this with regional data centers. AWS had European regions, Azure had European regions. The theory was that customers could use local regions and maintain sovereignty.
The problem? That's not always how the technology works in practice. A company storing data in AWS's Frankfurt region might still have disaster recovery failover to another region. Backups might replicate globally. Operational logs might flow to centralized monitoring systems. What appears locally stored actually has distributed copies across the global infrastructure.
Regulators noticed this. They started asking uncomfortable questions: "If the data appears to be in Europe but the company is a US entity and can legally be compelled by US government to access that data, is it truly sovereign?"
That's not a technical question. It's a legal and geopolitical one. And it's driving organizations toward infrastructure where they have direct legal control over access.
For 2026, expect this to intensify. Regulators are moving from asking "where is the data?" to "who can legally access the data?" That distinction is pushing organizations toward sovereign cloud solutions—cloud platforms built and operated by regional or national players with explicit sovereignty guarantees.
The Role of Private Cloud and On-Premises Infrastructure
The narrative around private cloud has shifted dramatically. A decade ago, private cloud was positioned as "cloud for people who didn't trust cloud." It was seen as a transitional step—a way for enterprises to adopt cloud technology at their own pace before eventually moving to public cloud.
That assumption is being inverted in 2026. Increasingly, private cloud is being positioned as the preferred option for sensitive workloads, with public cloud as a complement for specific use cases.
Private cloud means infrastructure that's owned, operated, and managed by the organization itself, whether on-premises or in a colocation facility. The organization controls the physical security, access controls, encryption keys, and who can audit the systems.
The appeal is obvious: complete control over your infrastructure destiny. The downside is equally obvious: you need to build and manage it yourself. That requires talent, capital expenditure, and operational expertise.
For 2026, the decision framework looks something like this:
Workloads That Should Live Private/On-Premises:
- Customer personally identifiable information (PII)
- Proprietary algorithms or models
- Sensitive financial or legal data
- Systems requiring guaranteed compliance audit trails
- Mission-critical systems requiring <1 minute failover
Workloads That Work Well in Public Cloud:
- Non-sensitive analytics and reporting
- Development and testing environments
- Autoscaling workloads with variable demand
- Third-party SaaS integrations
- Proof-of-concept and experimental projects
What's changing is that organizations are now deliberately choosing where each workload lives instead of making a binary public-cloud-or-nothing decision. A financial services company might run its customer transaction database on private infrastructure while maintaining real-time analytics in AWS. An insurance company might store customer data on premises while doing batch fraud detection in Google Cloud.
This hybrid approach actually works better architecturally than pure cloud consolidation, but it's operationally more complex. You're now managing infrastructure across different platforms, using different tooling, employing different teams with different expertise.
The companies succeeding with this in 2025-2026 are the ones that invested in containerization, Kubernetes, and cloud-agnostic orchestration frameworks. They can deploy the same application across multiple infrastructure providers without rewriting code. That's the future—not single-vendor dependency, but deliberate polycloud architecture.
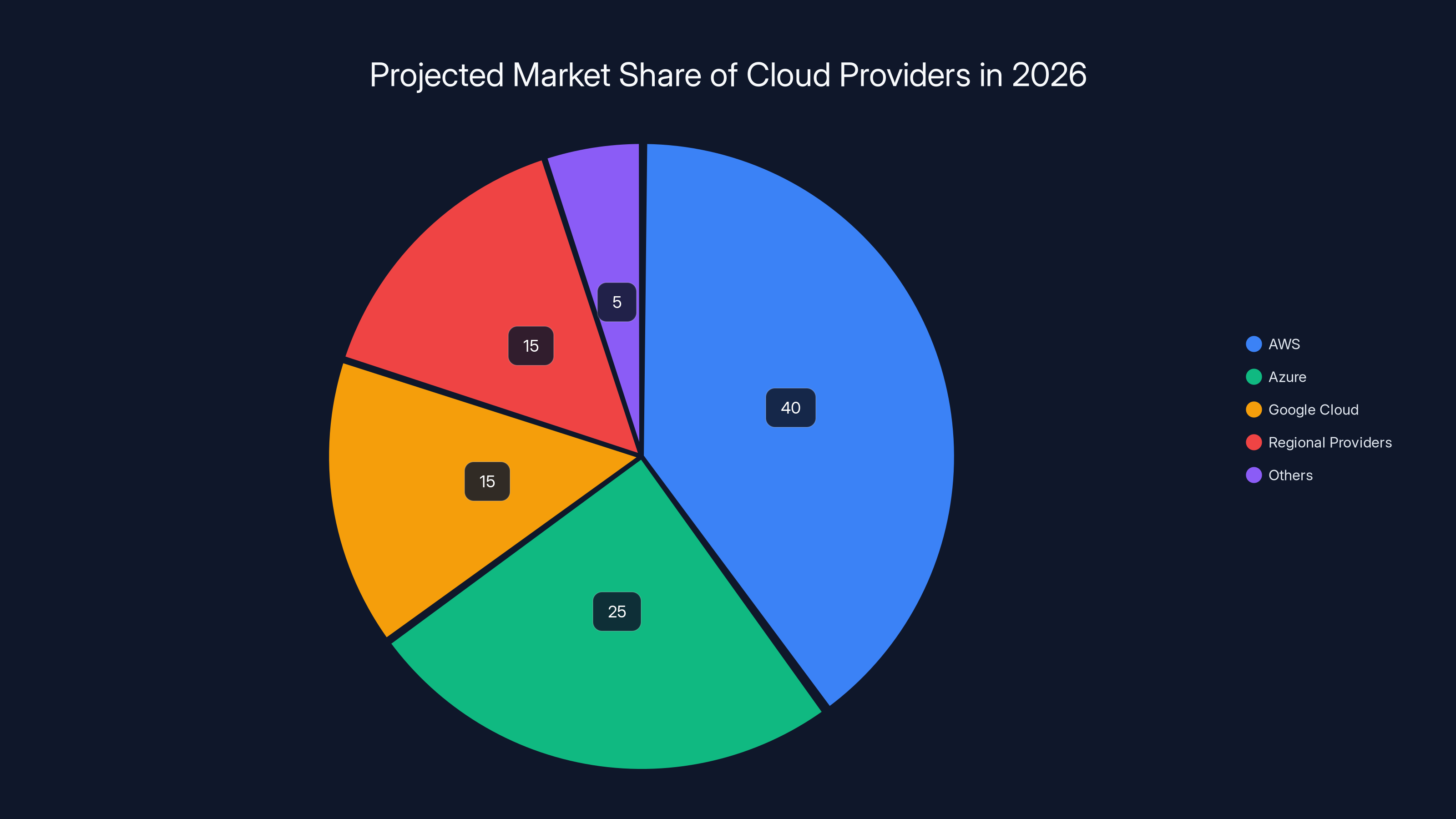
Regional cloud providers are projected to capture 15% of the market share by 2026, driven by demand for sovereignty and local control. Estimated data.
AI's Impact: Why Large Language Models Changed the Calculus
When people discuss AI and cloud infrastructure, they usually talk about the massive compute requirements for training large language models. GPT-4 required enormous amounts of GPU capacity. Training modern LLMs costs tens of millions of dollars and demands globally distributed infrastructure.
But that's actually pushing organizations toward smaller, locally-deployed models, which changes everything about infrastructure strategy.
Here's the inflection point: enterprise AI isn't actually about training GPT-5. It's about deploying and running models that solve specific business problems. And the most secure, reliable way to do that is increasingly inference on private infrastructure.
Inference means running a pre-trained model to make predictions. It's computationally lighter than training but still requires serious capability. A financial services company running credit risk models against its customer database doesn't need hyperscaler infrastructure—it needs reliable, predictable compute that isn't subject to shared-tenant noisy-neighbor problems.
What's happening is that enterprises are choosing smaller, domain-specific models that can run on their own infrastructure instead of relying on giant public APIs. Instead of sending sensitive customer data to a public LLM API (which creates privacy and compliance issues), they're deploying a smaller model that runs locally.
This is a fundamental shift in how enterprises think about AI. The conversation changed from "we need access to GPT-4" to "we need models we can run ourselves." That second requirement strongly favors private infrastructure.
The math supports it. Running a modern LLM inference engine on your own infrastructure might cost
For workloads running consistently—which inference often is—private infrastructure becomes economically compelling. Add in the fact that you're not sending sensitive data to a third party, and the case becomes overwhelming.
The implication for 2026 is significant: expect enterprises to move inference workloads in-house while maintaining relationships with cloud providers for training, experimentation, and non-critical applications.
This doesn't mean AI demand is decreasing. It means it's decentralizing. Instead of all AI compute concentrated in hyperscaler data centers, it's spreading to enterprise data centers, regional providers, and edge infrastructure. That's actually a more resilient architecture for the industry overall.

The Talent Dimension: Why Local Infrastructure Requires Local People
Here's something people often overlook when discussing infrastructure strategy: you need people who understand it. And those people tend to be concentrated in specific locations.
When organizations rely on hyperscaler cloud infrastructure, they can hire talent from anywhere. Your company can be in Portland while your infrastructure team is distributed globally because you're all using AWS console, Terraform, and familiar APIs.
The moment you start building private cloud infrastructure or adopting regional cloud providers, you need people with specific expertise. You need people who understand hypervisor management, storage architecture, networking protocols, and disaster recovery orchestration. More importantly, you need people in the region where your infrastructure lives because they're responsible for physical infrastructure, local compliance, and operational incidents that need immediate attention.
That talent isn't uniformly distributed. Northern Europe (particularly the Netherlands, Denmark, and Germany) has a strong cloud infrastructure talent base. So does the UK, though that's complicating post-Brexit. Parts of North America, particularly Canada and the Pacific Northwest, have experienced teams. But in many regions, you're starting from scratch.
For 2026, expect this to create interesting talent dynamics. Organizations pursuing geopatriation will need to:
- Hire or develop local infrastructure expertise
- Invest in training programs to upskill existing staff
- Potentially partner with regional system integrators or managed service providers
- Accept that infrastructure expertise won't scale as easily as cloud-first organizations
The upside is that local infrastructure jobs become more valuable and more available. If you're an infrastructure engineer in Germany or France, geopatriation is excellent career news.
The downside is that geopatriation becomes more expensive per workload because you can't achieve the same talent leverage that hyperscalers have. A hyperscaler can centralize all infrastructure expertise at headquarters. A company pursuing sovereign cloud needs talent distributed across multiple regions.
Some organizations are addressing this by partnering with regional cloud providers who have existing talent and expertise. Instead of building everything themselves, they're using regional providers as managed infrastructure partners. That outsources the talent problem but introduces vendor lock-in risk to a regional provider instead of solving the hyperscaler dependency problem.

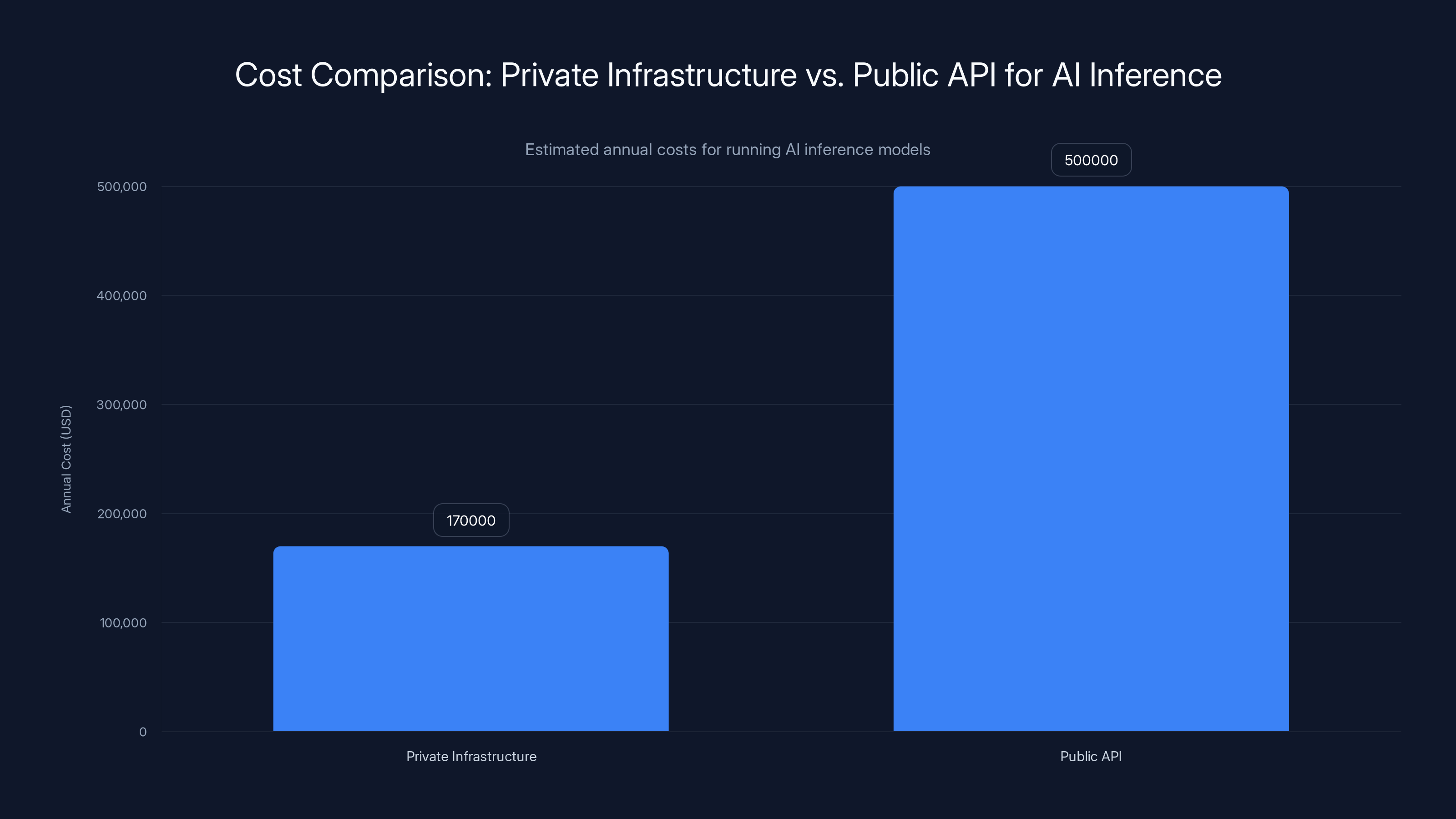
Running AI inference on private infrastructure is significantly cheaper, costing an estimated
Regional Cloud Providers: The Alternative Becoming Mainstream
For the past decade, the cloud market was basically settled: AWS dominated, Azure and Google Cloud fought for second place, and everyone else was niche. Regional players like Scaleway, OVH, Outscale, and others were considered secondary options—good for specific use cases but not serious alternatives.
2026 is changing that perception fundamentally.
Regional cloud providers offer something hyperscalers don't: explicit sovereignty guarantees and local operational control. A French company choosing OVH (a French company) for infrastructure gets the advantage of operating in French jurisdiction with French governance and French leadership.
That's not a minor selling point for enterprises in regulated jurisdictions. It's becoming a primary selling point.
What's remarkable is that regional providers are increasingly competitive on actual infrastructure quality. They're not just offering sovereign alternatives—they're offering good sovereign alternatives. They've invested in modern data center construction, competitive pricing, and comprehensive service offerings.
OVH operates data centers in 12+ countries. Scaleway offers GPU capacity competitive with major cloud providers. Outscale provides AWS API compatibility, meaning you can migrate workloads from AWS to Outscale with minimal refactoring.
The market response has been interesting. In 2024-2025, we started seeing major enterprises—not startups, but established enterprises—actively using regional providers as their primary infrastructure for sensitive workloads. A bank might use OVH for customer data. A manufacturing company might use a regional provider for operational technology. An insurance company might distribute workloads across regional providers in different countries to achieve geographic redundancy.
For 2026, expect regional cloud providers to capture meaningful market share in regulated industries. They won't displace AWS or Azure globally—hyperscalers have too many advantages for many workloads. But for sensitive, regulated, or politically important workloads, regional players are becoming the default choice.
The economic implication is significant. The cloud market is moving from "pick one hyperscaler" toward "pick the right infrastructure for each workload." That expands the total addressable market for regional players and creates genuine competition where consolidation had previously occurred.

Energy Constraints: The Physical Limitation on Hyperscaler Growth
Something interesting is happening in the background of the cloud computing conversation: the electrical grid is reaching capacity constraints.
Data centers consume enormous amounts of power. A hyperscale data center might consume 50-100+ megawatts continuously. Multiply that by hundreds of data centers globally, and you're talking about significant power demand.
For comparison, a large nuclear power plant generates 1,000 megawatts. So a couple of dozen major data centers can consume as much power as a nuclear plant. And the power demand is growing faster than grid capacity in most regions.
In 2025, we saw this constraint become explicit. Virginia, which hosts some of AWS's largest data centers, experienced power shortages. The UK's data center power demand was approaching grid capacity. Regulators in California started questioning whether additional data centers were feasible given power constraints.
The mathematical reality is straightforward:
Hyperscalers can improve efficiency, but they can't overcome physics. A GPU running at full capacity generates heat that must be removed. The infrastructure required to cool that GPU and power the cooling systems has its own power requirements. It all adds up.
For 2026, this creates interesting economic pressure toward distributed infrastructure. A workload that runs locally uses less total power because:
- No data transfer overhead across networks
- Cooling systems tuned for specific infrastructure
- No redundancy margins for shared infrastructure
- Can use local power sources (renewable energy in some regions)
Organizations in power-constrained regions are explicitly choosing local infrastructure for efficiency reasons. Data center operators in Northern Europe, where renewable power is abundant and the climate is cool (reducing cooling costs), are seeing increased demand.
This is a physical constraint that's going to shape infrastructure strategy for years. The era of "compute wherever, it doesn't matter" is ending because the grid can't support unlimited expansion. Instead, we're moving toward "compute as close to the data as possible, using available local power."

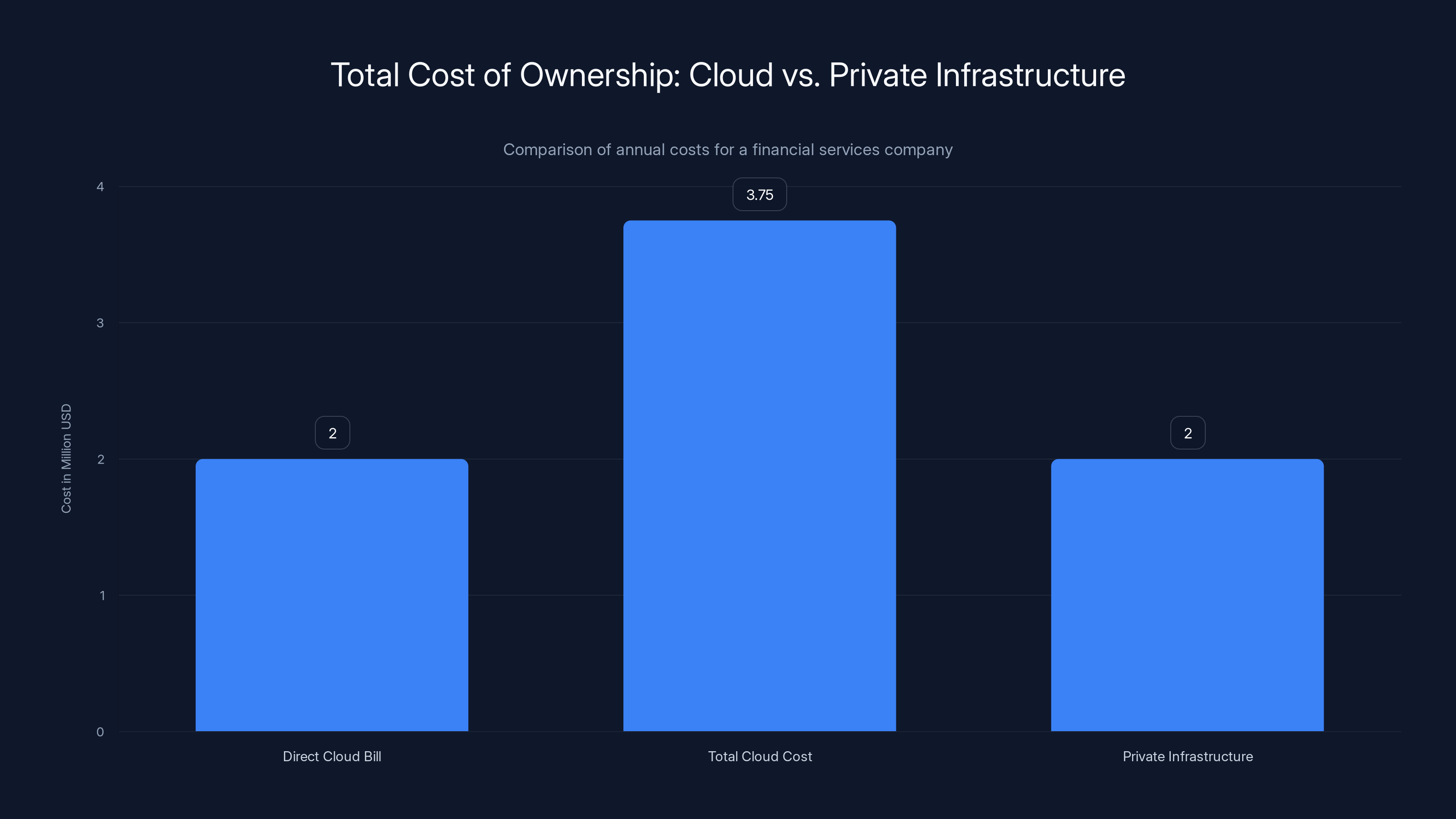
While the direct cloud bill is
Security and Compliance Implications of Geopatriation
Beyond regulatory compliance, geopatriation addresses real security concerns that hyperscaler infrastructure creates.
When your data lives on hyperscaler infrastructure, you're trusting that infrastructure's security posture. And while hyperscalers invest heavily in security, shared infrastructure introduces attack surfaces that single-tenant or regionally-controlled infrastructure doesn't have.
Consider side-channel attacks. A sufficiently sophisticated attacker with access to the same physical hardware as your application could potentially extract sensitive data through timing variations, cache behavior, or power consumption analysis. It's technically difficult but not theoretical—researchers have demonstrated these attacks work in cloud environments.
With private infrastructure, you control physical hardware isolation. You control who has access to the servers. You control the firmware. You control the entire security perimeter.
For 2026, expect security considerations to become a primary driver of geopatriation decisions. Companies handling extremely sensitive data—financial institutions, healthcare organizations, government agencies—are willing to accept the operational complexity of private infrastructure because the security model is fundamentally different.
There's also the audit and logging implication. With private infrastructure, you control the audit trail. You know exactly who accessed what, when, and why. With hyperscaler infrastructure, you're trusting the provider's audit systems, which operate at a scale where deep investigation becomes difficult.
Compliance teams are increasingly demanding full audit trails and the ability to prove, at any time, that sensitive data hasn't been accessed inappropriately. That's much easier with private infrastructure.

The Economic Reality: Total Cost of Ownership Calculations
Geopatriation sounds expensive because in many ways, it is. Capital expenditure on private infrastructure is significant. Operational overhead is higher. You need more people.
But when you calculate total cost of ownership honestly, the picture becomes more complex.
A major financial services company might pay
That same company spending
For workloads running continuously (which many enterprise systems are), private infrastructure becomes economically rational. It's the workloads with highly variable demand—where you might need 10x capacity at peak and 1x capacity at baseline—where public cloud's elasticity advantage remains significant.
For 2026, organizations are performing this calculation explicitly. They're identifying which workloads justify private infrastructure investment based on cost projections, and which ones remain better served by public cloud.
The result is a much more economically rational cloud strategy where decisions are based on actual cost analysis rather than "cloud is always cheaper" assumptions.
Operational Complexity and the Polycloud Reality
Let me be honest about the downside: managing infrastructure distributed across multiple platforms is genuinely complex.
You're now managing:
- Different APIs and configuration systems
- Different monitoring and alerting tools
- Different disaster recovery procedures
- Different compliance and audit processes
- Different vendor support structures
- Different skill requirements for your teams
Organizations that execute this poorly end up with a fragmented mess where no one truly understands the entire infrastructure landscape. Incidents that require cross-platform investigation become nightmares.
Organizations that execute this well do so by investing heavily in abstraction layers. They use Kubernetes or similar orchestration across all platforms. They use infrastructure-as-code consistently. They build common monitoring and observability across all platforms. They invest in automation so that operational procedures work the same regardless of the underlying infrastructure.
For 2026, the organizations that'll win with geopatriation are those that can operate complexity without drowning in it. That requires::
- Strong platform engineering teams who can maintain consistency across platforms
- Excellent documentation and runbooks so knowledge doesn't live in individuals' heads
- Robust automation to reduce manual operational overhead
- Clear governance about which workloads live where and why
- Continuous training as teams must understand multiple platforms
Companies attempting geopatriation without these investments will fail—not because geopatriation is bad, but because operational complexity will overwhelm them.

Future-Proofing: Building Portable Infrastructure
The strategic insight driving successful geopatriation is simple: build portable infrastructure.
Instead of optimizing for a single hyperscaler's APIs and services, build applications that can move between infrastructure providers without major refactoring.
That means:
- Using containers for application deployment
- Using managed Kubernetes instead of vendor-specific orchestration
- Avoiding cloud-specific services that lock you into a particular provider
- Building clear separation between application logic and infrastructure
- Using standard databases instead of vendor-specific managed databases
This doesn't mean avoiding all managed services—that's unrealistic and removes significant operational value. It means being intentional about which services you use and understanding the migration cost if you need to change providers.
For 2026, organizations building new infrastructure should assume they'll need to move workloads between providers at some point. That assumption should shape architectural decisions.

The AI Infrastructure Buildout Race
While geopatriation is pulling infrastructure in one direction, the global race to build AI infrastructure is pulling in another.
Every major country recognizes that AI capability is strategic. The United States is investing heavily. The European Union is funding European AI infrastructure. China is building domestically. The UK is positioning itself as an AI hub.
This creates interesting tension: governments want to ensure AI infrastructure exists domestically (geopatriation), but the massive capital requirements push toward consolidation in a few hyper-efficient hyperscaler data centers.
For 2026, expect this to manifest as government incentives for regional AI infrastructure investment. Tax breaks, grants, regulatory favorable treatment—all designed to attract AI compute infrastructure to specific regions.
Organizations will increasingly benefit from being geographically diverse in their AI infrastructure. A company might train models in one region where subsidized compute is available, while running inference locally where latency and sovereignty matter.
That's a more complex infrastructure model, but it's becoming the standard approach for serious AI deployment.

Predictions for 2026 and Beyond
Based on the trends we're seeing, here's what I expect in 2026 and the years following:
Accelerating Geopatriation: Organizations in regulated industries will actively pursue geopatriation. By end of 2026, expect 40%+ of enterprise infrastructure budget to be allocated to non-hyperscaler options (private cloud, regional providers, on-premises).
Regional Provider Consolidation: The 50+ regional cloud providers will consolidate to a dozen or so major regional players. Market will reward those with genuine scale and competitive service offerings.
Cloud Economics Repricing: As workloads redistribute, hyperscalers will face pressure to reprice services. Egress fees that are currently punitive will become more competitive. Reserved capacity pricing will improve.
Hybrid Becomes the Default: Pure-cloud strategies will become rare. Hybrid polycloud will become the standard assumption for enterprise infrastructure planning.
Talent Redistribution: Infrastructure talent will be in even higher demand, particularly talent with on-premises, private cloud, or regional cloud experience. Tech hubs outside major cloud provider headquarters will see talent concentration.
Edge Infrastructure Growth: As compute distributes, edge computing platforms will see accelerating adoption. GPU-enabled edge nodes will become commodity hardware.
Compliance as a Differentiator: Cloud providers, regional and hyperscale, will increasingly compete on compliance and sovereignty guarantees rather than just feature parity.
These aren't radical predictions—they're relatively conservative based on current trajectory. What would be surprising is if geopatriation doesn't accelerate, given the regulatory pressure, recent outages, and emerging security requirements.
Practical Implementation: How to Start Your Geopatriation Journey
If your organization is thinking about geopatriation, here's a practical framework for getting started:
Phase 1: Audit (Weeks 1-4)
- Classify all workloads and data by sensitivity
- Identify regulatory requirements for each workload
- Map current infrastructure and costs
- Document current operational procedures and tooling
- Assess current team skills and gaps
Phase 2: Pilot (Months 2-4)
- Select 1-2 non-critical workloads for pilot
- Choose infrastructure platform (private cloud, regional provider, or on-premises)
- Build out infrastructure for pilot workloads
- Establish monitoring, alerting, and operational procedures
- Document lessons learned
Phase 3: Operationalization (Months 5-8)
- Recruit and train infrastructure staff
- Implement infrastructure-as-code and automation
- Build disaster recovery and failover procedures
- Establish security and compliance audit processes
- Create runbooks for common operational tasks
Phase 4: Expansion (Months 9-18)
- Migrate additional workloads based on business priority
- Optimize based on pilot learnings
- Adjust team structure and training based on operational reality
- Establish relationships with regional provider support teams
- Build organizational knowledge base
The entire process typically takes 18-24 months for a mid-sized organization. It's not quick, but it's the right pace—fast enough to be strategic, slow enough to learn.
Conclusion: Embracing a More Resilient Infrastructure Future
Geopatriation isn't a rejection of cloud technology or modern infrastructure patterns. It's actually the maturation of how organizations think about cloud.
The 2010s were about cloud adoption—moving everything possible to the cloud because cloud promised infinite scalability and someone else's infrastructure problem. That made sense for startups and young companies building fresh infrastructure.
The 2020s are about cloud optimization—using cloud where it makes sense, using alternatives where they make more sense. That's a more mature approach that recognizes cloud is a tool, not a religion.
For your organization in 2026, the question isn't "should we use cloud?" That's settled—of course you should. The question is "which infrastructure is right for each specific workload?" That's a more nuanced and technically interesting question that's driving real innovation in the infrastructure space.
The organizations that figure this out—that build portable, distributed infrastructure that can adapt to changing requirements—will have significant competitive advantages. They'll be more resilient. They'll be more compliant. They'll often be more cost-effective. And they'll sleep better at night knowing they're not completely dependent on a single vendor's infrastructure quality.
That's what geopatriation really offers: not a return to the past, but a more balanced and resilient approach to the future.

FAQ
What is geopatriation in cloud computing?
Geopatriation is the strategic practice of relocating data and computational workloads from centralized hyperscaler infrastructure back to local, regional, or on-premises infrastructure. It's not about rejecting cloud entirely, but rather being deliberate about where different workloads live based on regulatory, security, operational resilience, and economic considerations.
How does geopatriation differ from multicloud strategies?
Multicloud means using multiple cloud providers simultaneously. Geopatriation means moving workloads away from hyperscalers toward local alternatives. While geopatriation often involves multicloud elements, it's specifically about geographic distribution and sovereignty rather than just using multiple vendors. An organization might be multicloud without pursuing geopatriation, or pursue geopatriation primarily through private infrastructure without using multiple public clouds.
What types of workloads should be geopatriated first?
Prioritize workloads containing customer PII, proprietary algorithms, financial data, or systems requiring strict regulatory compliance. Generally, stateful systems with continuous uptime requirements benefit most from local infrastructure. Stateless workloads with variable demand remain better served by public cloud elasticity. Start with high-sensitivity, continuous-operation workloads and expand based on cost-benefit analysis.
What are the main compliance benefits of geopatriation?
Geopatriation addresses multiple compliance requirements: it ensures data residency compliance by keeping data within national borders, it enables proper data sovereignty by subjecting infrastructure to local legal jurisdiction, it supports audit compliance through direct control over access logs and system configuration, and it reduces regulatory risk for organizations in heavily regulated industries. Additionally, it provides clearer accountability when compliance violations occur.
How much does geopatriation typically cost compared to pure cloud?
Initial capital expenditure for private infrastructure typically ranges from
What skills and expertise are required to manage geopatriated infrastructure?
You'll need infrastructure engineers experienced with on-premises systems, cloud platforms, networking, security, and disaster recovery. Importantly, you'll need local talent in each region where infrastructure operates for immediate incident response and regulatory compliance. Many organizations address skill gaps through partnerships with regional managed service providers or system integrators who have existing expertise.
Can geopatriation work alongside AI infrastructure requirements?
Yes, and increasingly well. Modern approaches involve training AI models centrally or where subsidized compute is available, while running inference locally where latency and data sovereignty matter. This distributed approach actually improves resilience and security while maintaining cost efficiency. Edge AI infrastructure is becoming a key component of geopatriation strategies.
How do regional cloud providers compare to hyperscalers for geopatriation?
Regional providers offer explicit sovereignty guarantees, local operational control, and compliance that hyperscalers can't always provide. However, they typically have narrower service offerings, smaller global reach, and less advanced managed services. For sensitive, regulated workloads they're often superior. For variable-demand, global-scale applications, hyperscalers remain advantageous. Most organizations use both for different workloads.
What is the typical timeline for a geopatriation project?
A complete geopatriation typically takes 18-24 months for mid-sized organizations, depending on infrastructure scope and organizational readiness. This includes audit phase (4 weeks), pilot phase (3 months), operationalization (4 months), and gradual expansion. Starting with low-risk, non-critical workloads allows faster initial progress while the organization develops expertise and processes.
How does geopatriation affect disaster recovery and business continuity?
Geopatriation enables geographic redundancy by distributing infrastructure across multiple regions rather than multiple availability zones within a single vendor's infrastructure. This provides protection against region-wide outages while maintaining better control over recovery procedures. However, organizations must invest in disaster recovery procedures that work across heterogeneous infrastructure platforms, which requires more sophisticated planning than hyperscaler-based strategies.

Key Takeaways
- Geopatriation—relocating data and workloads to local infrastructure—is accelerating due to 2025 hyperscaler outages and regulatory pressure for data sovereignty
- Organizations are shifting from single-vendor cloud dependency toward hybrid polycloud strategies that strategically distribute workloads based on compliance, security, and economics
- AI inference workloads favor local deployment on private infrastructure (60-70% cost savings), fundamentally changing how enterprises build infrastructure around AI capabilities
- Regional cloud providers are capturing market share from hyperscalers by offering explicit sovereignty guarantees, local governance, and compliance assurances hyperscalers cannot provide
- Energy grid constraints and global power limitations are pushing infrastructure toward distributed regional models rather than consolidated hyperscaler data centers
- Successful geopatriation requires 18-24 months, strong platform engineering capabilities, infrastructure-as-code discipline, and sophisticated automation to manage operational complexity
Related Articles
- Data Sovereignty for Business Leaders [2025]
- CrowdStrike SGNL Acquisition: Identity Security for the AI Era [2025]
- Cyera's $9B Valuation: How Data Security Became Tech's Hottest Market [2025]
- Data Sovereignty for SMEs: Control, Compliance, and Resilience [2025]
- GenAI Data Policy Violations: The Shadow AI Crisis Costing Organizations Millions [2025]
- 1Password Deal: Save 50% on Premium Password Manager [2025]

