![GLM-5: The Open-Source AI Model Eliminating Hallucinations [2025]](https://tryrunable.com/blog/glm-5-the-open-source-ai-model-eliminating-hallucinations-20/image-1-1770856625948.jpg)
GLM-5: The Open-Source AI Model Eliminating Hallucinations [2025]
Introduction: A New Standard for AI Reliability
The artificial intelligence industry faces a critical challenge that many enterprise decision-makers struggle with daily: hallucinations. These aren't merely embarrassing moments when an AI confidently generates false information—they represent genuine barriers to enterprise adoption, regulatory compliance, and trustworthy automation. Models like GPT-4, Claude, and Gemini have achieved remarkable capabilities, yet they still produce plausible-sounding fabrications when presented with questions outside their training data or when pushed to reason beyond their reliable knowledge boundaries.
Enter GLM-5, an open-source large language model released by Chinese AI startup Zhupai (commonly known as z.ai) that marks a fundamental shift in how we approach this hallucination problem. Rather than treating hallucinations as an unavoidable byproduct of language model training, GLM-5 achieves what the industry has struggled with for years: a record-low hallucination rate of -1 on the Artificial Analysis Intelligence Index v 4.0, representing a staggering 35-point improvement over its predecessor and leading the entire AI industry—including OpenAI, Google, and Anthropic—in knowledge reliability metrics.
But here's what makes GLM-5 genuinely revolutionary for enterprise teams: it doesn't just chat better. The model features native Agent Mode capabilities that transform raw prompts directly into professional office documents—formatted .docx files, .pdf reports, and .xlsx spreadsheets ready for immediate enterprise workflow integration. Imagine a financial analyst saying, "Generate a comprehensive Q4 earnings report with charts and analyses," and receiving a production-ready document rather than a text summary that requires hours of reformatting and verification.
The economics are equally compelling. At roughly
This comprehensive guide explores GLM-5's technical architecture, real-world applications, performance benchmarks, pricing structure, and how it compares to both proprietary and open-source alternatives. Whether you're an AI engineer evaluating models for your next project, an enterprise decision-maker assessing automation capabilities, or a startup founder building AI-powered workflows, understanding GLM-5's capabilities and limitations will inform your strategic technology choices.
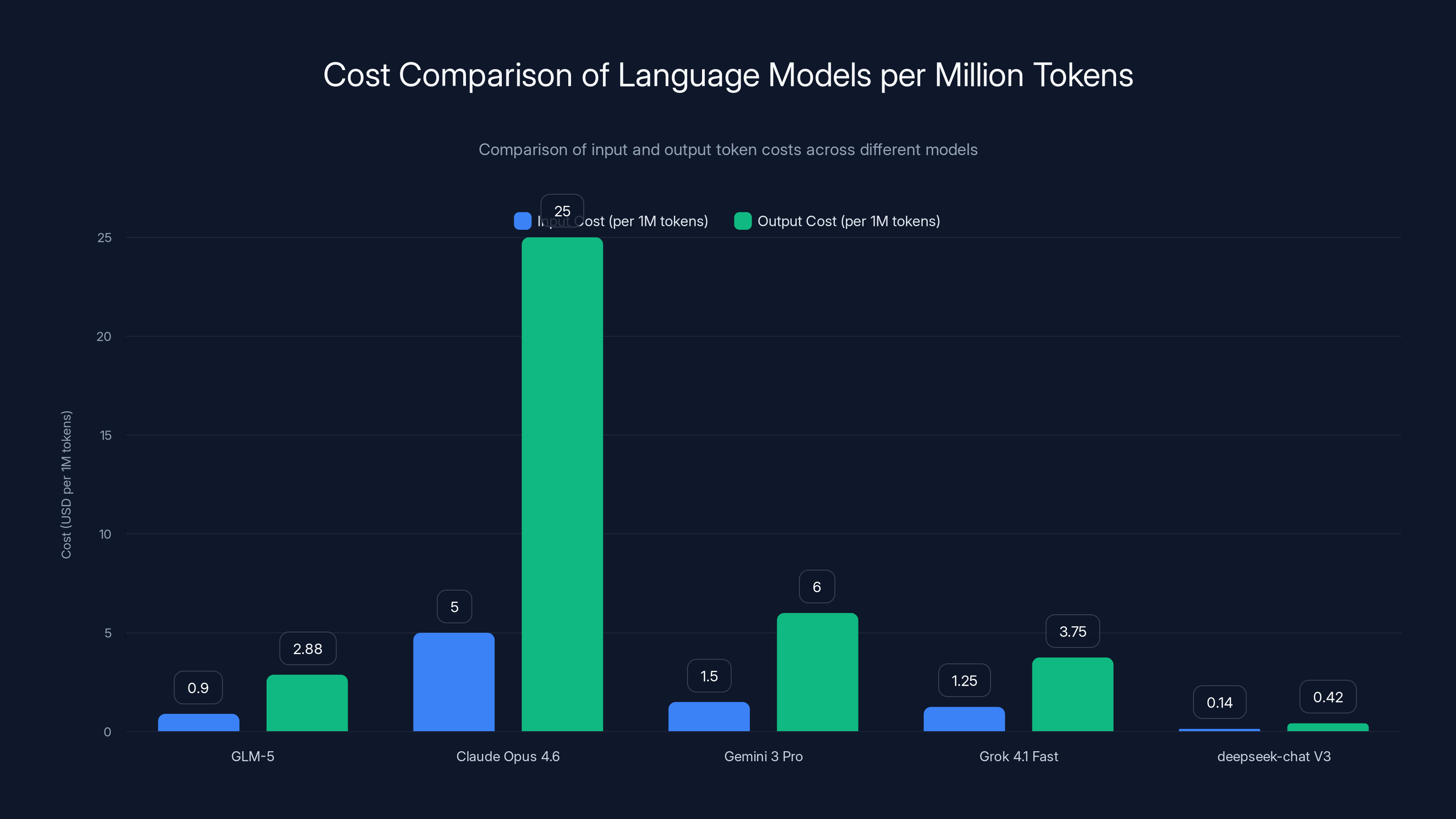
GLM-5 offers significant cost savings over Claude Opus 4.6, being approximately 6x cheaper for input and 10x cheaper for output tokens. Estimated data for Grok 4.1 Fast reflects its variable pricing.
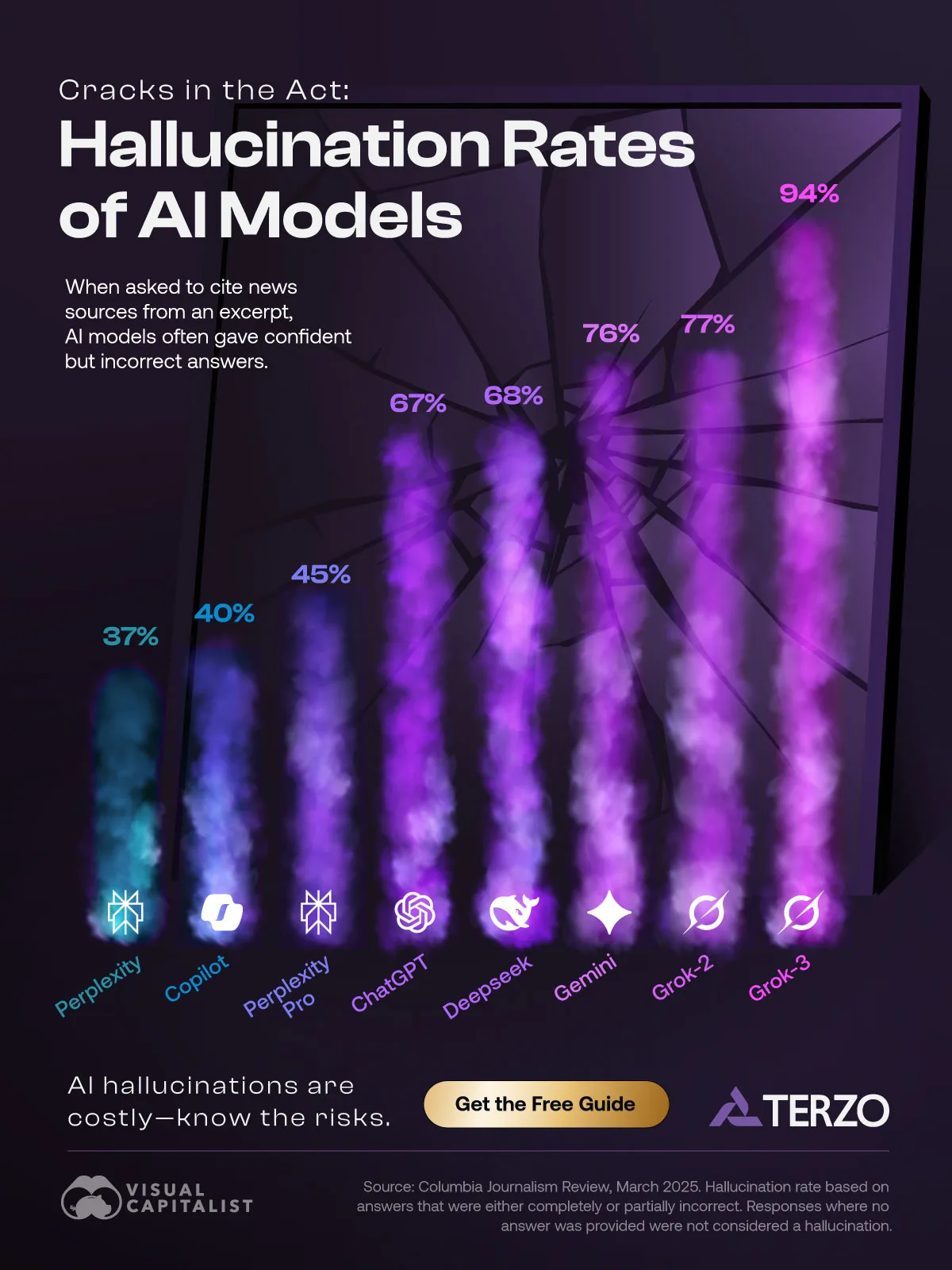
The Hallucination Problem: Why It Matters More Than You Think
Understanding AI Hallucinations at Scale
Before examining GLM-5's approach to solving hallucinations, we need to understand why this challenge exists in the first place and why traditional language models struggle with it. Large language models operate by predicting the next token (roughly a word or subword) based on probability distributions learned during training. This approach works remarkably well for common patterns in training data, but it creates an inherent problem: when a model encounters a question about information outside its training data or beyond its reliable knowledge boundaries, it doesn't say "I don't know." Instead, it applies the same prediction mechanism and often generates plausible-sounding but entirely false information.
Consider a practical example: if you ask GPT-4 about a specific regulatory change that occurred after its training cutoff, or a particular company's Q4 2024 financial results, the model might confidently provide fabricated metrics, fake regulatory clause numbers, or invented financial figures. The generated text follows grammatical and stylistic patterns learned from training, making the false information indistinguishable from accurate information to casual readers. In enterprise contexts—financial reporting, legal document generation, medical information systems—these hallucinations create existential problems.
The challenge isn't that models lack knowledge; it's that they lack the epistemic humility to acknowledge uncertainty. Traditional scaling approaches (simply making models bigger) actually worsen hallucinations in some domains because larger models become more fluent at generating plausible fiction.
Why Existing Solutions Fall Short
Industry attempts to address hallucinations have largely fallen into several categories, each with inherent limitations. Retrieval-Augmented Generation (RAG) systems attempt to ground model outputs in external knowledge sources, but RAG introduces latency, potential inconsistencies between sources, and doesn't solve the fundamental problem when the external knowledge is outdated or incomplete. Fine-tuning approaches attempt to adjust model behavior through additional training, but they typically require massive labeled datasets and often degrade general capability while addressing narrow domains.
Ensemble methods that combine multiple models can reduce hallucination rates but multiply computational costs—precisely the opposite of what enterprises need when budgets are constrained. Constitutional AI and related approaches use principled feedback loops to adjust model behavior, but these techniques require careful prompt engineering and still don't provide the epistemic transparency that enterprise users demand.
GLM-5 takes a fundamentally different approach: rather than trying to prevent hallucinations through external mechanisms or post-hoc filtering, it retrains the model to genuinely understand its own knowledge boundaries. This is harder to achieve at scale but ultimately more reliable.
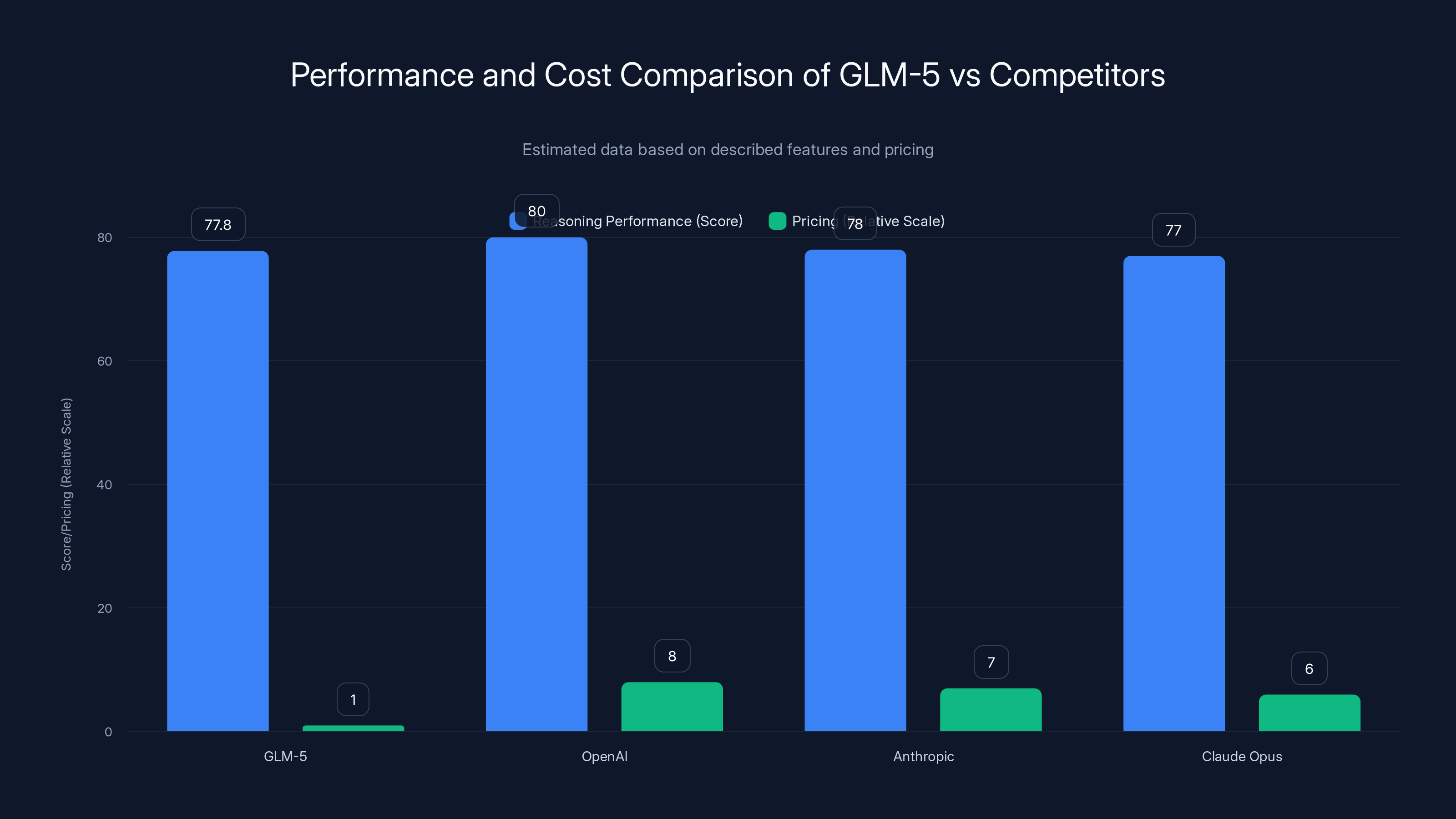
GLM-5 offers competitive reasoning performance at a significantly lower cost compared to other models. Estimated data based on described features.
GLM-5 Architecture: Technical Foundation for Reliability
Scaling Parameters for Agentic Intelligence
GLM-5 represents a dramatic parameter expansion from its predecessor GLM-4.5, growing from 355 billion parameters to 744 billion parameters while employing a sophisticated Mixture-of-Experts (MoE) architecture where only 40 billion parameters are active per token. This architectural choice is crucial: it allows the model to maintain massive knowledge capacity while keeping inference computationally efficient.
The MoE approach works by treating different types of reasoning tasks as "expert" pathways. When processing text, the model routes tokens to specialized expert networks optimized for different domains—mathematical reasoning, coding tasks, natural language understanding, knowledge retrieval, and epistemic uncertainty estimation. This routing mechanism allows the model to leverage vast parameter pools without activating all parameters for every token, dramatically reducing inference costs.
Supporting this massive scale, z.ai increased pre-training data to 28.5 trillion tokens, an enormous dataset constructed through careful curation and filtering to maximize signal-to-noise ratios. The composition of training data matters as much as its volume: GLM-5's training data emphasizes factual sources, technical documentation, and knowledge-grounded conversations where hallucinations are explicitly penalized.
The "Slime" Reinforcement Learning Infrastructure
Here's where GLM-5's innovation becomes genuinely remarkable: z.ai developed an entirely new reinforcement learning (RL) infrastructure called "slime" specifically designed to address training bottlenecks that plague traditional RL approaches with models at this scale.
Traditional reinforcement learning works by generating trajectories (sequences of model outputs and feedback), then using that feedback to adjust model weights. The problem is synchronization: in typical RL training, you can't move to the next training step until all trajectories are generated and scored. With a 744-billion-parameter model, generating trajectories becomes extraordinarily slow, creating bottlenecks where expensive compute sits idle waiting for trajectory generation to complete.
Slime breaks this synchronization requirement through asynchronous trajectory generation. Multiple trajectory generation workers operate independently, feeding results into a centralized data buffer as they complete, without waiting for all workers to finish. This seemingly simple architectural shift has profound implications: it eliminates the "long-tail" bottleneck where training speed is limited by the slowest trajectory generator.
Integrating Active Partial Rollouts (APRIL), the slime framework addresses another critical inefficiency: most RL training time (over 90% in traditional approaches) is spent generating and managing rollouts rather than actually optimizing model weights. APRIL enables the system to identify high-value rollouts early and focus computational resources on those, dramatically accelerating the RL training cycle.
The resulting infrastructure consists of three modular components working in concert:
-
Training Module: Powered by Megatron-LM, this component handles distributed training across GPU clusters, optimizing backward passes and weight updates for massive parameter counts.
-
Rollout Module: Built on SGLang with custom token routers, this component generates diverse training trajectories in parallel, maximizing throughput through batching and dynamic scheduling.
-
Centralized Data Buffer: A sophisticated queue management system that handles prompt initialization, trajectory storage, and prioritization, ensuring training never waits for data generation to complete.
This architecture enables z.ai to run RL iterations that would typically take weeks in a matter of days, fundamentally changing what's possible in training-time optimization for agentic behavior.
Context Window Management: Deep Seek Sparse Attention
Maintaining a 200K token context window (roughly 150,000 words of continuous text) while controlling inference costs requires clever engineering. GLM-5 implements Deep Seek Sparse Attention (DSA), an attention mechanism that focuses computational resources on the most relevant portions of the context window rather than processing every token relationship.
Standard transformer attention has quadratic computational complexity: processing a 200K token context requires computing attention scores across 40 billion token relationships. DSA employs learned sparsity patterns that identify which token relationships matter most for the task at hand, reducing computational burden while maintaining the ability to reference distant context when necessary.
The practical implication: GLM-5 can process lengthy documents, multi-turn conversations spanning hours of dialogue, or comprehensive codebases without the exponential slowdown that shorter-context models experience. For enterprise applications requiring document understanding or code analysis, this long context is transformative.

Performance Benchmarks: Numbers Behind the Claims
Hallucination Metrics: The AA-Omniscience Index
The most striking metric is GLM-5's hallucination performance on the Artificial Analysis Intelligence Index v 4.0, which measures a model's tendency to accurately report when it doesn't know something versus fabricating information. The scale ranges from highly negative (frequent hallucinations) to positive (accurate knowledge assessment).
GLM-5 achieved a score of -1, representing a 35-point improvement over GLM-4.5's previous score and establishing GLM-5 as the most reliable model in the entire industry by this metric. To contextualize this achievement: Google's Gemini 3 Pro, OpenAI's GPT-4 variants, and Anthropic's Claude Opus all score significantly lower (more negative) on this metric. This single benchmark suggests that GLM-5's training methodology fundamentally changed how the model handles uncertainty.
The importance of this metric cannot be overstated for enterprise applications. In financial services, healthcare, legal analysis, and regulatory compliance, hallucinations aren't merely embarrassing—they create liability, regulatory violations, and business risk. A model that reliably abstains from answering rather than confidently providing false information represents a categorical improvement for high-stakes applications.
Coding and Software Engineering Performance
The SWE-bench Verified benchmark measures a model's ability to solve actual software engineering problems by modifying real open-source code repositories. This tests not just coding ability but reasoning about complex systems, understanding error messages, and iteratively debugging solutions.
GLM-5 achieved 77.8 on SWE-bench Verified, surpassing Google's Gemini 3 Pro (76.2) and approaching Anthropic's Claude Opus 4.6 (80.9). This performance is remarkable for an open-source model and practically significant: it means GLM-5 can autonomously handle genuine software engineering tasks like fixing bugs in production code, implementing new features based on specifications, or reviewing and improving codebases.
The gap between 77.8 and 80.9 (approximately 3.1 percentage points) represents the kind of performance ceiling that shrinks as models mature. Open-source models have historically lagged proprietary models by substantial margins on coding benchmarks; seeing that gap narrow to single digits suggests convergence is occurring.
Business Reasoning and Agentic Capability
The Vending Bench 2 benchmark simulates running a business (managing inventory, pricing decisions, responding to market conditions) and measures the model's ability to make coherent, profitable decisions across extended interactions. This tests multi-turn reasoning, learning from feedback, and maintaining consistent behavior across time.
GLM-5 ranked #1 among open-source models with a final balance of $4,432.12, substantially outperforming other open-source candidates. While this absolute number seems arbitrary, the relative ranking is significant: it demonstrates that GLM-5's RL training produces genuinely agentic behavior—the model doesn't just answer individual questions but maintains state, learns from consequences, and adapts behavior based on outcomes.
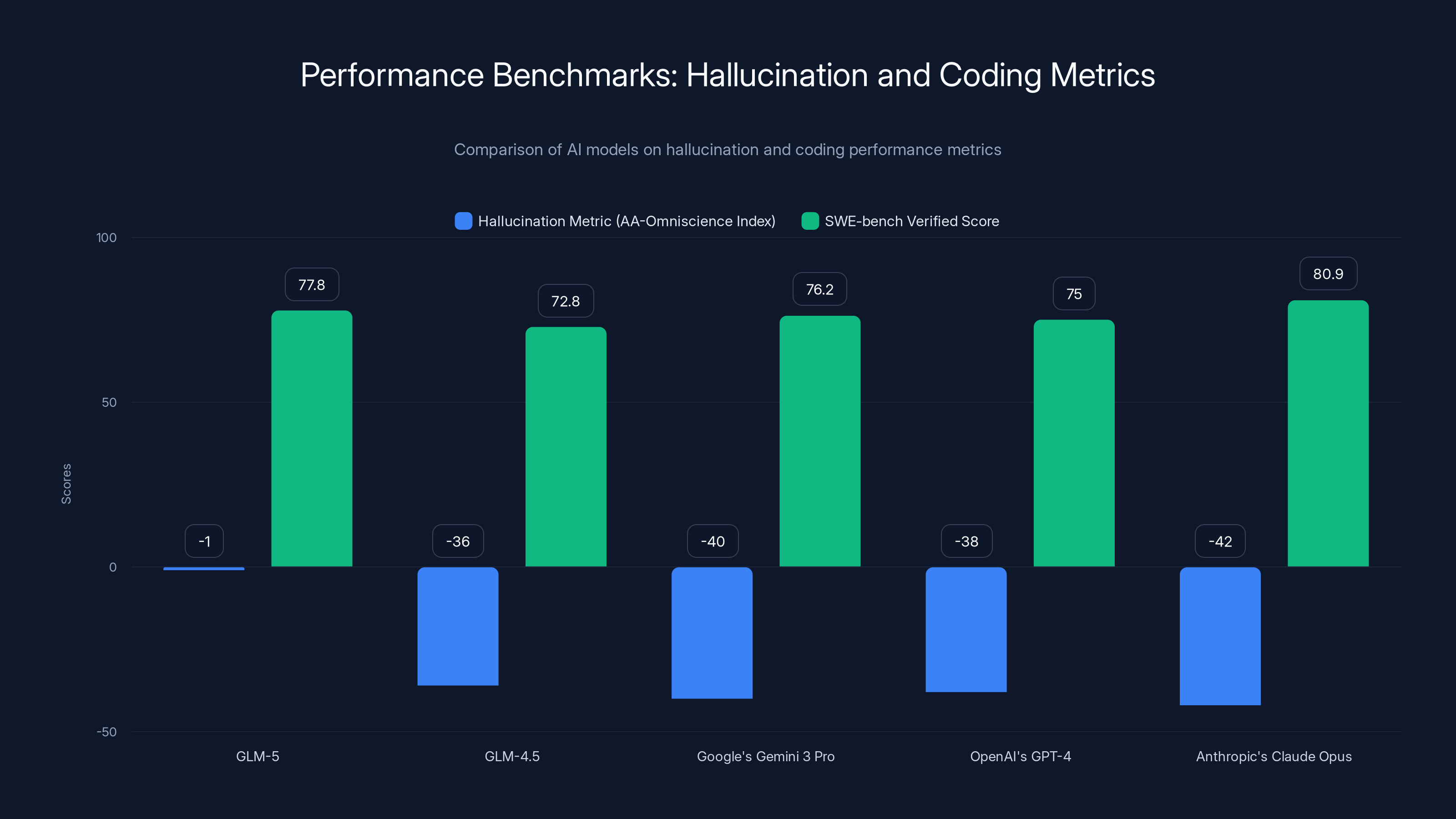
GLM-5 leads in hallucination accuracy with a score of -1, improving by 35 points over GLM-4.5. It also performs well in coding benchmarks with a score of 77.8, close to Anthropic's Claude Opus.
Agent Mode: Document Generation and Workflow Automation
Transforming Prompts into Production-Ready Documents
GLM-5's most commercially significant feature for enterprise workflows is Agent Mode, which fundamentally reimagines what AI assistance means. Rather than generating text snippets that humans must then manually format, structure, and integrate into documents, Agent Mode autonomously transforms high-level requests into professional documents ready for immediate use.
Consider a concrete workflow: a financial analyst traditionally spends 4-6 hours creating a quarterly financial report. The process involves gathering data, writing narrative analysis, creating charts and tables, formatting document structure, and peer review. With GLM-5 Agent Mode, the analyst describes what they need: "Create a comprehensive Q4 financial report including revenue analysis by region, expense breakdown, year-over-year comparison charts, and strategic commentary." The model decomposes this into subtasks, handles each autonomously, and delivers a formatted .docx file with proper styling, numbering, chart integration, and professional formatting.
The technical implementation is more sophisticated than simple text concatenation. GLM-5 maintains an understanding of document structure (heading hierarchies, section relationships, where elements should be positioned) and can make decisions about formatting, styling, and organization based on the document type and content. A financial report might include tables and charts positioned strategically; a sponsorship proposal might emphasize different information with distinct visual hierarchy; a technical specification might require detailed code samples with proper syntax highlighting.
Multi-format Output Capabilities
Agent Mode operates across multiple output formats, each with distinct technical requirements:
Word Documents (.docx): GLM-5 generates properly structured Microsoft Word files with support for heading styles, font formatting, embedded tables, numbered lists, and image insertion. This matters because it means documents integrate seamlessly with enterprise workflow systems that expect Word files for collaboration, review, and version control.
PDF Files (.pdf): For finalized, immutable documents, GLM-5 generates PDFs with proper typography, page breaks, footer/header information, and print-ready formatting. This addresses archival and regulatory requirements where document immutability matters.
Spreadsheets (.xlsx): For data-heavy tasks, GLM-5 creates Excel spreadsheets with proper cell formatting, formula relationships, multiple sheets with meaningful names, and calculated fields. The model understands spreadsheet structure and can create coherent data models rather than just dumping information into grids.
The implications are significant: instead of treating different document types as requiring separate tools or workflows, GLM-5 provides unified agentic behavior across formats. The same reasoning engine that produces the optimal analysis also produces the optimal presentation of that analysis in whichever format suits the use case.
Real-World Application Examples
Consider how different enterprise teams might leverage Agent Mode:
Legal Services: Contract generation and analysis. An attorney provides a contract template and requirements ("Create an NDA for a software licensing agreement with standard IP protection clauses"), and Agent Mode generates a properly formatted legal document ready for negotiation review.
Sales Operations: Proposal generation at scale. Sales teams can generate customized proposals for prospects by specifying client name, requested features, pricing tier, and delivery timeline. Agent Mode creates professional proposals without manual formatting, accelerating sales cycles.
Business Intelligence: Automated report generation. BI teams can configure GLM-5 to automatically generate weekly executive summaries, combining data from multiple sources, creating visualizations, and adding contextual analysis without manual compilation.
HR and Operations: Policy documentation and procedures. HR teams can request formatted employee handbooks, policy documents, and procedure manuals, with GLM-5 handling structure, cross-referencing, and document organization.
Academic and Research: Paper and report generation. Researchers can provide datasets, methodology descriptions, and key findings, and Agent Mode structures this into properly formatted research reports with sections, citations, and analysis.
Each of these applications shares a common pattern: traditional workflows involve significant manual formatting and structuring work after content generation. Agent Mode eliminates that manual stage, collapsing what was previously a two-stage process (content generation then formatting) into a single agentic task.
Pricing Analysis: Cost-Performance Economics
Token Pricing Breakdown and Market Comparison
GLM-5's pricing structure represents a fundamental disruption in the large language model market. Priced at approximately
To contextualize this pricing, consider a comparison with Claude Opus 4.6, currently the highest-performance general-purpose language model available. Claude Opus costs
Here's what this means financially: processing one million tokens of input and generating one million tokens of output with Claude Opus costs
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Combined Cost (1M+1M) | Performance Tier |
|---|---|---|---|---|
| GLM-5 | Near state-of-the-art | |||
| Claude Opus 4.6 | $5.00 | $25.00 | $30.00 | State-of-the-art |
| Gemini 3 Pro | $1.50 | $6.00 | $7.50 | Near state-of-the-art |
| Grok 4.1 Fast | Very strong | |||
| deepseek-chat V3 | $0.14 | $0.42 | $0.56 | Strong |
Notably, deepseek-chat V3 offers even lower pricing, but benchmarks indicate GLM-5 maintains performance advantages in reasoning and knowledge reliability tasks. The price-to-performance ratio—not absolute price—is what matters for strategic technology decisions.
Usage Pattern Economics
How does this pricing translate to realistic usage patterns? An enterprise deploying AI automation across departments typically follows predictable token consumption patterns:
Document Generation Workflows: Generating a comprehensive 10-page report requires approximately 4,000-6,000 input tokens (for the specification and context) and 8,000-12,000 output tokens (for the generated report). Cost:
Customer Service Automation: Processing customer inquiries and generating responses typically uses 800-1,200 input tokens and 300-500 output tokens per interaction. Cost:
Code Analysis and Generation: Reviewing code repositories and suggesting improvements requires 2,000-5,000 input tokens and 1,500-3,000 output tokens. Cost:
These usage patterns reveal where GLM-5's pricing creates outsized value: for high-volume automation use cases where cost scaling was previously prohibitive. A customer service operation couldn't afford to process every inquiry with Claude Opus, but GLM-5's pricing makes per-interaction AI analysis economically viable.
Cost-Performance Trade-offs
When comparing models, absolute performance on benchmarks matters less than performance relative to cost. An 77.8 on SWE-bench Verified is valuable, but it's specifically valuable because you achieve it at 1/10th the cost of competitors with similar performance.
This creates interesting strategic implications:
For cost-sensitive operations: GLM-5's pricing makes it the obvious choice. Customer support, content moderation, routine document generation, and other high-volume tasks that were previously unaffordable become economically viable.
For accuracy-critical operations: Where every marginal performance point matters (scientific research, legal analysis, medical decision support), the 2-3 point performance gap between GLM-5 (77.8 SWE-bench) and Claude Opus (80.9 SWE-bench) might justify the 6-10x cost premium if that performance difference prevents costly errors.
For mixed portfolios: Many enterprises have both high-volume routine tasks and accuracy-critical specialized tasks. A diversified strategy using GLM-5 for volume and Claude/Gemini for specialized work often optimizes total cost of ownership better than standardizing on either platform.
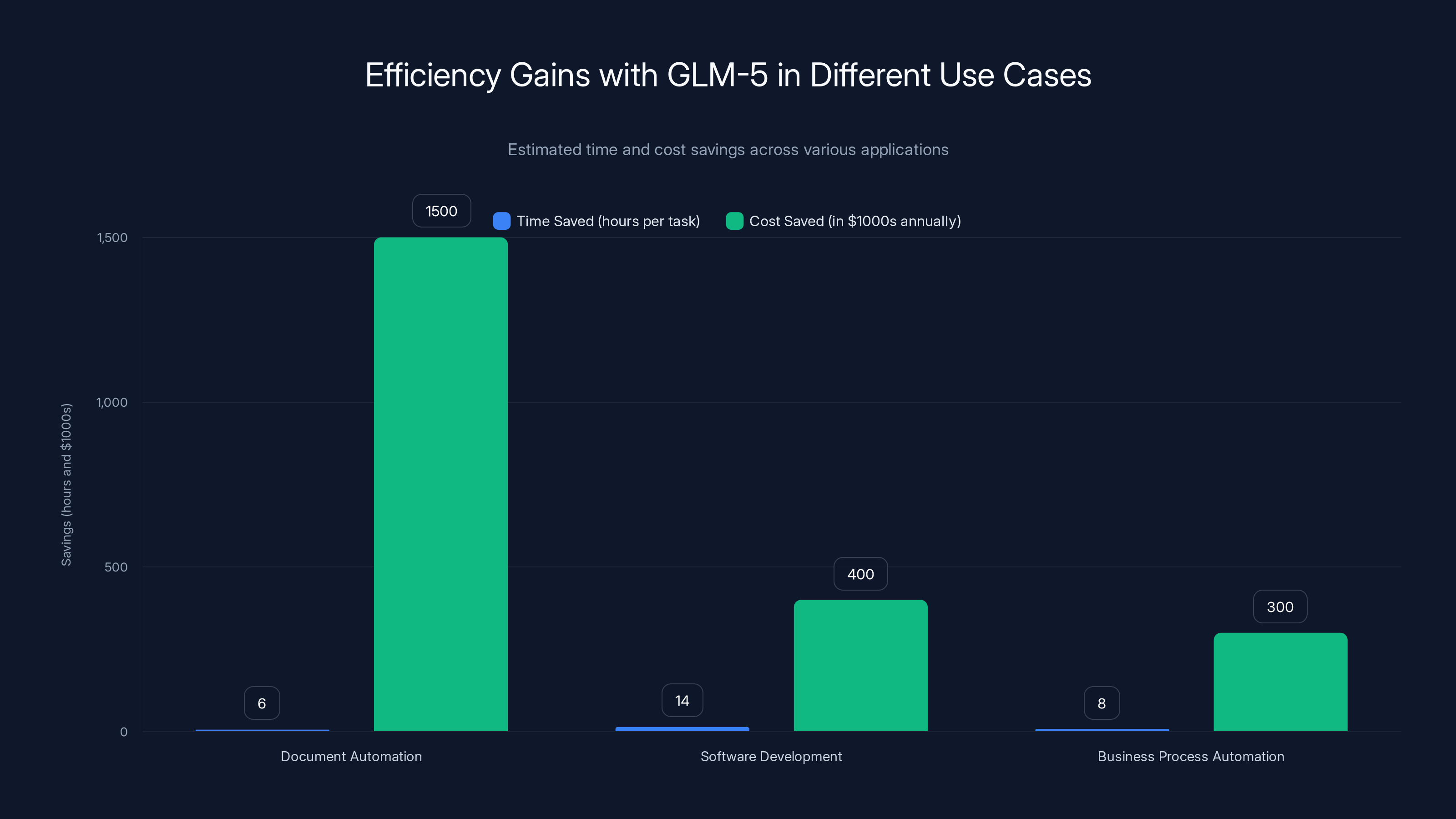
GLM-5 significantly reduces time and cost across various use cases, with the most notable savings in document automation, estimated at $1.5 million annually.
Alternatives and Competitive Landscape
Proprietary Large Language Models
Claude Opus 4.6 (Anthropic) remains the highest-performance general-purpose model by most industry benchmarks, with established trust in hallucination management through constitutional AI training. Appropriate for organizations where performance is non-negotiable and cost is secondary. Typical use case: advanced reasoning, legal document analysis, scientific research.
GPT-4 and GPT-4o (OpenAI) offer strong reasoning capabilities and extensive third-party integrations through the OpenAI ecosystem. The vision capabilities (GPT-4o) add value for document and image analysis tasks. Appropriate for teams already embedded in the OpenAI ecosystem. Cost: similar to Claude Opus on per-token basis.
Gemini 3 Pro (Google) provides strong performance with native integration into Google's ecosystem (Workspace, Analytics, Cloud services). Appropriate for enterprises already using Google Cloud infrastructure. Performance sits between GLM-5 and Claude Opus, with pricing closer to GLM-5.
Grok 4.1 (x AI) offers competitive pricing and reasoning capabilities, though less extensive real-world validation than Claude or GPT-4. Appropriate for cost-conscious teams willing to experiment with newer models.
Open-Source Models and Alternatives
Meta's Llama 3.1 (405B) provides an open-source alternative with strong coding and reasoning capabilities. The fully open-source nature and permissive licensing appeal to enterprises with strict data governance requirements. Performance approaches GLM-5 on certain benchmarks, with comparable pricing through inference providers. Primary advantage: no licensing restrictions or potential proprietary concerns.
Mistral Large offers efficient reasoning at lower cost than the largest models, with particular strength in multilingual tasks. Appropriate for teams prioritizing efficiency over peak performance.
deepseek-v 3 provides remarkably low pricing (
Qwen Models (Alibaba) provide strong Chinese language support and competitive performance, though less extensive English-language benchmarking. Appropriate for organizations with multilingual requirements.
Specialized AI Automation Platforms
Beyond raw language models, several platforms offer wrapped AI capabilities that might be relevant depending on your specific use case:
Runable provides AI agents specifically designed for content generation, workflow automation, and developer productivity. The platform offers pre-built agents for document generation, slide creation, and report synthesis—essentially providing agent-like capabilities similar to GLM-5's Agent Mode, but wrapped in a user-friendly interface at $9/month. For teams seeking opinionated, packaged solutions rather than raw model access, Runable abstracts away model selection and focuses on specific outcome workflows.
Zapier and Make provide workflow automation platforms that can integrate various language models. These are appropriate if your primary need is orchestrating tasks across multiple systems rather than leveraging individual models' reasoning capabilities.
Lang Chain and Llama Index provide frameworks for building custom applications with language models. These are appropriate if you have significant engineering resources and need to build bespoke applications rather than using pre-built solutions.
Evaluation Framework: Choosing the Right Alternative
When selecting between GLM-5 and alternatives, consider this decision framework:
If you need: Maximum reasoning performance for specialized tasks → Claude Opus 4.6 despite cost premium
If you need: Production-ready document generation at scale → GLM-5 or Runable (depending on whether you prefer raw model access or packaged platform)
If you need: Cost minimization with acceptable performance → GLM-5 or deepseek-v 3
If you need: Open-source with unrestricted deployment → Llama 3.1 or GLM-5 (both have open-source licenses)
If you need: Minimal engineering complexity → Runable or other no-code platforms
If you need: Chinese language optimization → Qwen or GLM-5
Use Cases: Where GLM-5 Excels
Enterprise Document Automation
Organizations managing high volumes of standardized documents—financial reports, regulatory filings, customer proposals, policy documentation—find GLM-5's Agent Mode particularly valuable. The model can decompose complex documentation requirements into subtasks, generate content, structure it appropriately, and deliver production-ready documents.
A financial services firm generating 500+ regulatory reports annually could reduce per-report generation time from 8 hours (including research, writing, formatting, compliance review) to 2 hours (gathering data, configuring GLM-5, reviewing output). At an average hourly cost of
Software Development and Code Analysis
Development teams leverage GLM-5's strong coding capabilities (77.8 SWE-bench score) for:
- Code Review Assistance: Analyzing pull requests for logical errors, security vulnerabilities, and style consistency
- Bug Analysis: Understanding error messages and generating potential fixes
- Documentation Generation: Automatically creating API documentation, migration guides, and technical specifications
- Test Generation: Creating comprehensive test suites based on code specifications
A development team of 20 engineers might spend 10% of their time on these auxiliary tasks. GLM-5 automating 70% of this work (accounting for oversight and revision) saves approximately 2 full-time engineer equivalents, representing roughly $400,000 in annual salary cost.
Knowledge Work and Business Process Automation
Knowledge workers across industries find GLM-5's low hallucination rate and agentic capabilities particularly valuable:
Market Research: Synthesizing industry reports, competitive analysis, and trend identification into structured research documents with proper citations and confidence indicators (the hallucination metric enables GLM-5 to mark speculative information as uncertain).
Business Planning: Creating comprehensive business plans, strategic analyses, and operational procedures from raw specifications and historical data.
Sales Operations: Generating customized proposals, contract templates, and customer documentation at scale without manual formatting.
Legal Document Review: Analyzing contracts, identifying risks, and flagging non-standard clauses (though with appropriate human oversight given the liability implications).
For knowledge-intensive operations, the productivity gains range from 30-60% depending on the specific workflow and how much human oversight the work requires.
Educational Content Creation
Educators and educational technology companies can leverage GLM-5 to:
- Generate customized lesson plans and curriculum materials
- Create assessment questions and rubrics aligned with learning objectives
- Develop supplementary educational materials from course content
- Adapt existing materials for different skill levels or learning modalities
A curriculum developer creating materials for 10 courses might reduce content generation time by 40-50%, allowing focus on pedagogical strategy rather than content mechanics.
Customer Intelligence and Analytics
Analytics teams can use GLM-5 to automatically generate:
- Executive summaries from raw data and dashboards
- Insight synthesis from multiple data sources
- Trend analysis and pattern identification
- Predictive commentary on business metrics
The low hallucination rate is critical here: generating false insights in business analytics creates poor decision-making. GLM-5's ability to acknowledge uncertainty ("this trend is unclear from available data") provides better guidance than models that confidently fabricate patterns.

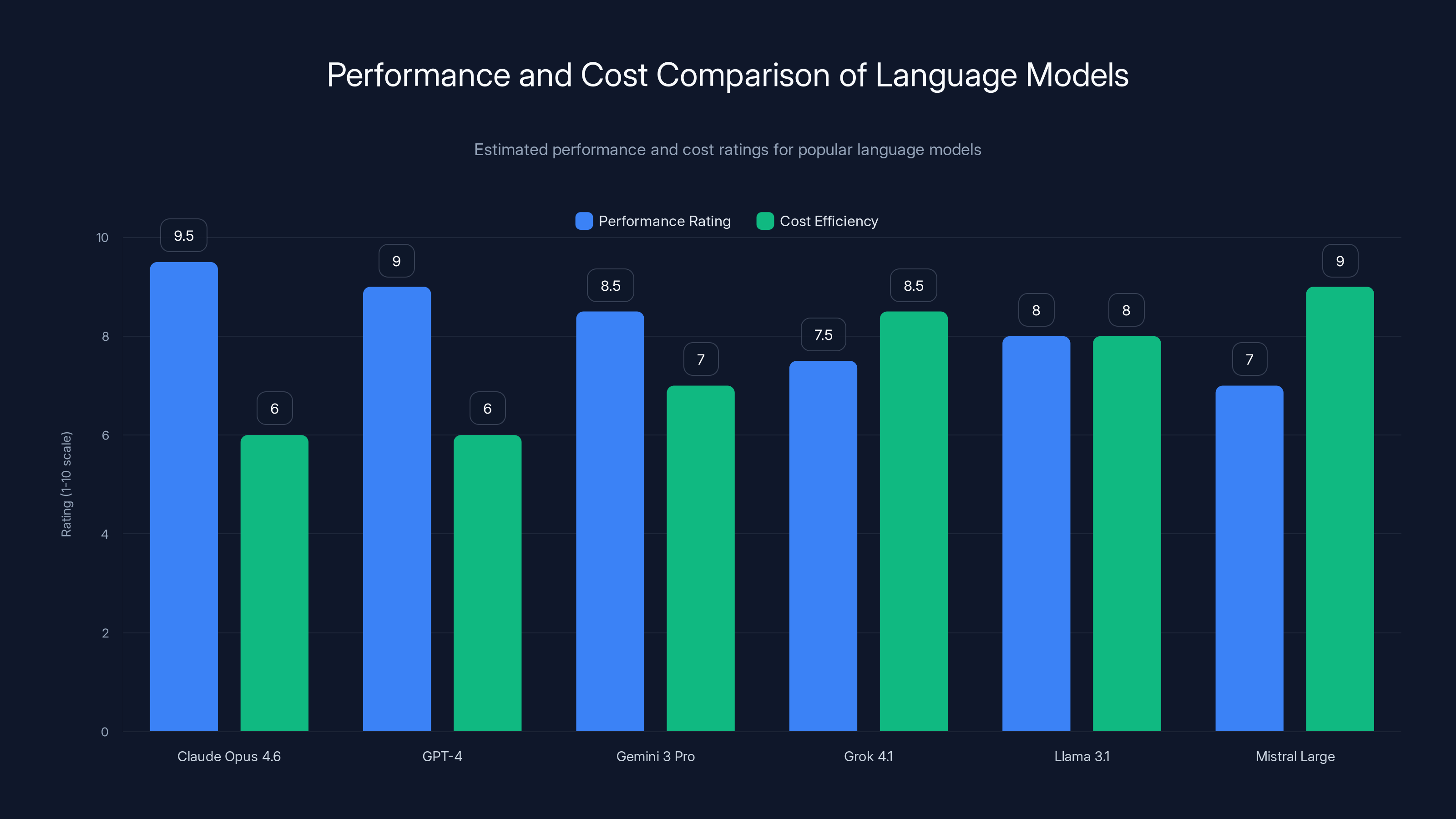
Claude Opus 4.6 leads in performance, while Mistral Large offers the best cost efficiency. Estimated data based on typical industry benchmarks.
Implementation Considerations
Integration Pathways and Deployment Options
GLM-5 is available through multiple deployment channels, each with different integration complexity and operational requirements:
API Access (Open Router): The simplest integration path for teams without infrastructure preferences. Call GLM-5 via REST API, handle authentication, and pay per token. Appropriate for teams building applications in any programming language who want minimal operational overhead.
Cloud Deployment: Available through various cloud providers, allowing deployment in specific regions, with dedicated infrastructure, and custom security configurations. Appropriate for enterprises with specific data residency, compliance, or performance requirements.
On-Premises Deployment: For organizations requiring complete infrastructure control, GLM-5 can be deployed on proprietary hardware. This requires substantial infrastructure investment and engineering resources but eliminates data transmission to external services.
Fine-tuning and Specialized Versions: Z.ai supports fine-tuning GLM-5 on domain-specific data to optimize performance for particular industries or use cases. This involves retraining portions of the model on your proprietary data, requiring significant technical expertise and infrastructure.
Technical Integration Requirements
Integrating GLM-5 into existing systems typically requires:
API Client Implementation: Most teams use existing SDKs (OpenAI-compatible clients work with GLM-5 on Open Router) to handle API communication, authentication, and response parsing.
Prompt Engineering: Optimizing prompts for GLM-5's specific behavior improves output quality. The model responds well to structured prompts that decompose complex tasks into steps.
Output Processing: For Agent Mode document generation, integrating the generated documents into downstream workflows (storage systems, approval workflows, distribution systems) requires middleware development.
Quality Assurance and Monitoring: Implementing systems to monitor model performance, track error rates, and identify hallucinations in production use is critical for maintaining quality.
Fallback and Escalation: Designing workflows that gracefully handle model failures or uncertain outputs—escalating to human review when necessary—prevents catastrophic failures.
A typical implementation timeline is 2-4 weeks for straightforward document generation use cases and 8-12 weeks for complex multi-system integration with quality assurance protocols.
Licensing and Legal Considerations
GLM-5 carries an MIT license, which is critically important for enterprise deployments:
MIT License Implications:
- Commercial use permitted: You can deploy GLM-5 in commercial products without licensing fees
- Modification permitted: You can modify the model and redistribute modified versions
- Distribution permitted: You can distribute GLM-5 or derivatives with your products
- Attribution required: You must include the MIT license notice in distributions
- Liability disclaimer: Z.ai provides no warranty or liability guarantees
This is substantially more permissive than licenses for some competitive models and removes potential licensing friction for enterprises. Organizations concerned about proprietary model dependencies or licensing costs should specifically note that GLM-5's MIT license enables flexible deployment.
Data Privacy and Security
When using GLM-5 through API providers, data privacy depends on your deployment method:
API Access (Open Router): Your prompts and generated outputs are transmitted to Open Router's servers. Understand Open Router's data retention and usage policies before deploying sensitive information. Most cloud platforms have enterprise data processing agreements available.
On-Premises Deployment: Your data remains entirely within your infrastructure. This provides maximum privacy control but requires managing the compute infrastructure and security posture yourself.
Region-Specific Deployment: For organizations with regulatory requirements (GDPR compliance, HIPAA requirements, etc.), deploying in specific regions ensures data locality compliance.
For any deployment involving sensitive data (financial information, healthcare data, confidential business information), explicitly review data handling policies and consider on-premises deployment or region-specific cloud deployment.

Performance Limitations and Realistic Expectations
Where GLM-5 Performs Well
GLM-5's strengths align with the training approach and benchmark results:
Factual Knowledge Grounding: The record-low hallucination rate means GLM-5 reliably abstains from answering when uncertain, making it appropriate for fact-sensitive applications.
Software Engineering Tasks: The 77.8 SWE-bench score reflects genuine capability in code understanding, modification, and generation for programming languages in the training data.
Agentic Multi-Step Tasks: The RL training optimized for agentic behavior means GLM-5 handles complex tasks decomposed into steps better than models trained primarily for chat.
Document Structure and Formatting: Agent Mode's document generation reflects training that emphasized structural and formatting consistency.
Known Limitations and Edge Cases
No model is universally superior, and GLM-5's design choices involve trade-offs:
Hallucination Reduction Trade-off: GLM-5's low hallucination rate partially reflects being trained to abstain more frequently than competitors. This reliability comes at a cost: the model might decline to attempt tasks where other models would try and occasionally succeed. This is a reasonable trade-off for enterprise use cases but means expecting the model to be more conservative than GPT-4 or Claude.
Real-Time Information: Like all language models trained with a knowledge cutoff, GLM-5 lacks information about recent events. If your use case requires current information (recent news, stock prices, recent regulatory changes), you need to augment GLM-5 with retrieval systems or external data sources.
Specialized Domains: While GLM-5 performs well on general software engineering and business tasks, specialized domains (quantum computing, cutting-edge biomedical research, niche legal practice areas) might benefit from domain-specific models or fine-tuned versions if they exist.
Long-Context Reasoning: While the 200K context window is enormous by historical standards, some reasoning tasks benefit from even longer context. The sparse attention mechanism, while efficient, might miss subtle patterns in the longest context portions that full attention would capture.
Language Coverage: While GLM-5 supports multiple languages, English-language performance is primary. Non-English language users might find other models (Qwen, specialized translation models) more appropriate for non-English use cases.
User Experience From Early Adopters
Early feedback from developers and organizations deploying GLM-5 reveals nuanced insights beyond benchmark scores. Some users report that while the model's overall benchmarks are impressive, specific use cases sometimes underperform expectations. A startup building AI code review tools noted that GLM-5's conservative abstention behavior sometimes results in the model declining to analyze edge-case code structures that competitors' models would attempt.
Conversely, users in finance and legal services report that the same conservative behavior is precisely what they need: they'd rather have the model say "I'm not confident in this analysis" than confidently provide incorrect information.
This illustrates a critical lesson: model selection isn't about absolute quality but about alignment between model characteristics and your specific requirements. GLM-5's characteristics make it ideal for some use cases and suboptimal for others.
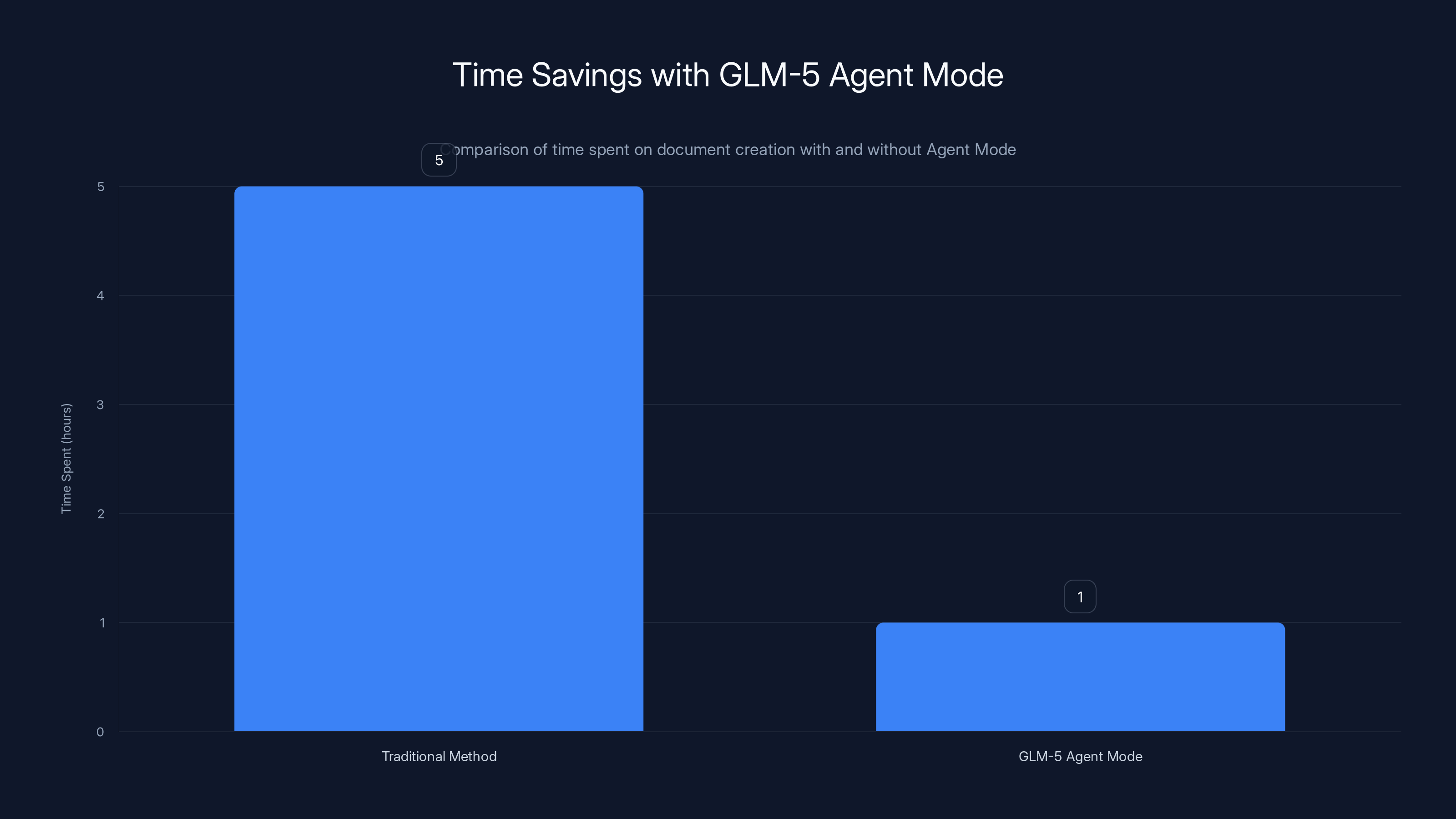
GLM-5 Agent Mode reduces the time spent on creating a financial report from an average of 5 hours to just 1 hour, showcasing significant efficiency gains. Estimated data.
Future Directions and Industry Implications
What GLM-5 Signals About AI Development
GLM-5's release indicates several important trends in large language model development:
Efficiency Focus: The move toward mixture-of-experts architectures and sparse attention reflects industry focus shifting from "how large can we make models" to "how efficiently can we operate large models." This suggests the era of 10x+ larger models is ending; we're optimizing within our current scale.
Training Infrastructure Innovation: The slime architecture demonstrates that training efficiency is a target for innovation equivalent to model architecture. As inference costs diminish through optimization, training costs become the limiting factor, and investment in training infrastructure will likely accelerate.
Chinese AI Leadership: GLM-5's performance exceeding American proprietary models on some benchmarks demonstrates that capability gaps between Chinese and American AI are narrowing faster than many observers anticipated. This has geopolitical and competitive implications for AI development globally.
Agentic Behavior as Standard: The emphasis on multi-step task decomposition and document generation reflects the industry recognizing that chat capabilities alone have limited business value. Future models will increasingly be evaluated on their ability to autonomously complete complex workflows.
Likely Evolution of GLM Series
Z.ai will undoubtedly continue development of the GLM series. Anticipated future directions include:
GLM-5.5 or 6: Likely expanding parameter count beyond 744B, though with increasingly sophisticated mixture-of-experts to manage computational costs. Expect further hallucination rate improvements and stronger coding capabilities.
Multimodal Capabilities: As other models add vision and audio understanding, GLM likely will eventually support analyzing images, documents with visual elements, and audio transcription.
Real-Time Capabilities: Reducing latency through inference optimization will become critical as agentic applications require faster response times.
Domain-Specific Fine-Tuned Versions: Z.ai or third parties will likely release specialized versions optimized for finance, healthcare, legal, and other high-value domains.

Recommendations for Decision-Making
Choosing GLM-5 Over Alternatives
GLM-5 is the right choice if you meet these criteria:
Cost sensitivity combined with reasonable performance requirements: If your budget is limited but you need reliable performance above commodity model level, GLM-5's price-performance is hard to beat.
Document generation and structured output needs: If your use cases emphasize Agent Mode capabilities (generating formatted documents, spreadsheets, structured outputs), GLM-5's native support for this is valuable.
Hallucination sensitivity: If your applications require confident refusals rather than confident hallucinations (financial analysis, legal review, medical information), GLM-5's reliability is critical.
Open-source and licensing flexibility: If you need open-source with permissive licensing for deployment flexibility, GLM-5's MIT license is advantageous.
When to Stick with Proprietary Models
Choose Claude Opus, GPT-4, or Gemini if:
Maximum performance is non-negotiable: For frontier reasoning tasks where 2-3 percentage points of performance difference is material, proprietary models' slight edge might justify the cost.
Established integration ecosystems matter: If you're already in the OpenAI ecosystem (ChatGPT Plus, plugins, team features) or Anthropic's ecosystem, switching costs might outweigh GLM-5's cost advantages.
Vendor stability and support contracts: If you require vendor support contracts with SLAs and indemnification, proprietary vendors have more mature support infrastructure.
Hybrid Approaches
Many sophisticated organizations implement a portfolio approach:
Tier 1 (Specialist Tasks): Claude Opus or GPT-4 for tasks where maximum performance is essential and the work is low-volume enough that cost is secondary (research, strategy, complex analysis).
Tier 2 (Standard Tasks): GLM-5 for high-volume standard tasks where performance is good but not critical to differentiation (customer service, routine document generation, code review assistance).
Tier 3 (Commodity Tasks): deepseek or open-source models for completely commodity tasks where any reasonable performance is acceptable and cost minimization is paramount (simple text classification, basic summarization).
This portfolio approach optimizes total cost of ownership while maintaining quality standards across different task categories.

Conclusion: GLM-5 as a Watershed Moment
GLM-5's release marks a meaningful inflection point in the AI industry, not because it's the single most capable model (Claude Opus and GPT-4 maintain slight edges in raw performance) but because it fundamentally alters the economics of enterprise AI deployment.
For the first time, organizations can deploy enterprise-grade AI with strong reliability (specifically, low hallucination rates), multiple output formats (through Agent Mode), and legitimate coding capabilities at price points that don't require CEOs to justify per-token costs to CFOs. The 6-10x cost advantage over proprietary alternatives is simply too significant to ignore for cost-conscious organizations.
Beyond the immediate business implications, GLM-5 signals that large language model development is entering a new phase. Raw parameter scaling is yielding diminishing returns; the frontier is now infrastructure innovation (slime's asynchronous RL), training methodology optimization (low hallucination through careful training), and practical agentic capabilities (document generation and multi-step reasoning). This shift from "how big can we make it" to "how efficiently can we make it do what we need" will characterize the next few years of AI development.
For practitioners deciding whether to evaluate GLM-5, the question is specific: do your use cases fit the model's strengths (document generation, coding, knowledge work with hallucination sensitivity) and do you have budget constraints that make the cost advantage material? If both answers are yes, GLM-5 deserves serious evaluation.
If your use cases require absolute maximum performance and cost is secondary, you might stick with Claude Opus or GPT-4. If you value opinionated, easy-to-use packaged solutions over raw model access, platforms like Runable abstract away model selection entirely and focus on specific outcome workflows. If you're building specialized research tools in cutting-edge domains, domain-specific models might be more appropriate.
But for the broad middle ground of enterprise teams building automation systems, generating documents, analyzing code, and performing knowledge work—GLM-5 is simply the most pragmatic choice available today. Its combination of strong benchmarks, low hallucination rates, versatile output capabilities, and compelling economics makes it the obvious starting point for organizations evaluating open-source alternatives to proprietary models.
The AI landscape will continue evolving rapidly. Within 6-12 months, newer models will undoubtedly match or exceed GLM-5's capabilities. But the architectural innovations that produced GLM-5 (MoE efficiency, slime RL infrastructure, hallucination minimization) will likely remain relevant frameworks for model development for years to come. Evaluating GLM-5 now isn't just about immediate deployment; it's about understanding where AI development is heading and positioning your organization accordingly.

FAQ
What is GLM-5 and how does it differ from other language models?
GLM-5 is an open-source large language model released by Chinese AI startup Zhupai (z.ai) that achieves record-low hallucination rates (scoring -1 on the Artificial Analysis Intelligence Index) while maintaining strong performance on coding (77.8 SWE-bench) and reasoning tasks. Unlike proprietary models from OpenAI or Anthropic, GLM-5 features native Agent Mode capabilities for generating professional documents and spreadsheets, MIT licensing for flexible deployment, and pricing approximately 6-10x lower than Claude Opus despite comparable reasoning performance.
How does GLM-5 achieve its record-low hallucination rate?
GLM-5 combines three critical training innovations: pre-training on 28.5 trillion carefully curated tokens emphasizing factual sources and knowledge-grounded conversations where hallucinations are explicitly penalized; reinforcement learning through z.ai's novel "slime" infrastructure that enables efficient agentic training at massive scale; and deliberate model design that favors abstention (refusing to answer) over confident fabrication when uncertain about knowledge. This differs from competitors' approaches because rather than adding external filters or retrieval systems, GLM-5 fundamentally retrains to understand its own knowledge boundaries.
What is Agent Mode and what specific document types can GLM-5 generate?
Agent Mode is GLM-5's native capability to autonomously transform high-level specifications into production-ready, professionally formatted documents without human reformatting. The system generates properly structured Microsoft Word files (.docx) with correct heading hierarchies and embedded tables, PDF files (.pdf) with professional typography and print-ready formatting, and Excel spreadsheets (.xlsx) with proper cell formatting, formulas, and multi-sheet data models. Practical applications include financial reports, legal proposals, sponsorship documents, business plans, and regulatory filings—essentially any document type where structure and formatting matter as much as content.
How does GLM-5's pricing compare to alternatives, and what's the ROI for enterprise deployment?
GLM-5 costs approximately
When should I choose Claude Opus or GPT-4 instead of GLM-5?
Choose proprietary models when absolute maximum performance is non-negotiable and cost is secondary: frontier research, strategic analysis, or specialized tasks where a 2-3 percentage point performance difference prevents costly errors. Claude Opus scores 80.9 on SWE-bench versus GLM-5's 77.8; for specialized coding domains where this gap matters, the proprietary advantage might justify 6-10x higher costs. Additionally, if you're embedded in OpenAI's ecosystem (ChatGPT Plus features, plugins, team management tools) or need enterprise vendor support with SLAs and indemnification, switching costs to GLM-5 might be prohibitive.
What are the main limitations of GLM-5?
GLM-5's low hallucination rate achieves reliability through conservative behavior—it abstains more frequently than competitors, which is appropriate for enterprise use cases but means expecting "I'm not confident" rather than attempted answers when uncertain. The model lacks real-time information (knowledge cutoff after training) and requires retrieval systems for current data needs. Some specialized domains (cutting-edge biomedical research, quantum computing, niche legal practice areas) might benefit from specialized models. The 200K context window with sparse attention is enormous but might miss subtle patterns across the longest context portions that full attention would capture. Non-English language performance is secondary to English optimization.
Should I deploy GLM-5 through API (like Open Router) or on-premises?
API deployment through Open Router or similar providers is simplest for most teams—REST API calls with pay-per-token pricing, minimal infrastructure, and immediate deployment. This is appropriate for teams without strict data residency requirements and willing to transmit prompts to external servers. On-premises deployment provides complete data privacy and infrastructure control but requires substantial engineering resources, security management, and ongoing infrastructure maintenance. Choose on-premises for sensitive data (healthcare, financial, confidential business information) where data residency or regulatory compliance demands local hosting. Regional cloud deployment offers middle ground: managed cloud services in specific regions ensuring data locality while reducing operational complexity.
What's the difference between GLM-5 and platforms like Runable, and which should I choose?
GLM-5 is a raw language model requiring engineering implementation and prompt engineering to build applications; you call the model via API and handle response processing, error handling, and workflow orchestration yourself. Runable and similar platforms wrap language models in opinionated, pre-built interfaces focused on specific outcomes (document generation, slide creation, reporting) at $9/month with no per-token costs. Choose GLM-5 if you need maximum flexibility, plan to integrate across multiple systems, or have sophisticated use cases requiring custom prompt engineering. Choose Runable or similar platforms if you prioritize ease of use, want predictable fixed costs, and have straightforward document-generation needs without complex integration requirements.
What's the realistic timeline and cost for implementing GLM-5 in my organization?
Simple implementations (integrating document generation into a single workflow) typically take 2-4 weeks: SDK setup, prompt optimization, output processing integration, and basic quality assurance. Moderate complexity (integrating across 2-3 business processes with quality monitoring) requires 4-8 weeks. Complex implementations (enterprise-wide deployment across multiple departments with custom fine-tuning, security protocols, and compliance review) require 8-12+ weeks. Infrastructure costs vary: API-based deployment costs only model token consumption; on-premises deployment requires compute hardware (
How do I monitor GLM-5's performance and detect hallucinations in production?
Implement systematic monitoring tracking: accuracy rates on domains where ground truth is available (comparing document outputs to validated sources), user feedback and correction rates (tracking instances where users identify errors), abstention rates (how frequently the model declines to answer), and specific benchmark evaluation on critical use cases. For hallucination detection specifically, employ domain experts reviewing outputs for accuracy in sensitive domains, implement fact-checking against source documents when available, and establish escalation protocols that route uncertain outputs to human review before final use. Design your deployment to treat GLM-5 as an assistance tool with human oversight rather than autonomous decision-maker in high-stakes domains.
What's the intellectual property and licensing situation with GLM-5?
GLM-5 carries an MIT License, which is critical for enterprise decision-making: it permits commercial use without licensing fees, allows modification and redistribution of modified versions, and imposes only attribution requirements (include the MIT license notice in distributions). This is substantially more permissive than some competitive models and removes licensing friction for organizations concerned about proprietary model dependencies. However, the MIT license includes a liability disclaimer—z.ai provides no warranty or indemnification. For organizations requiring vendor indemnification (particularly healthcare, finance, or regulated industries), this might necessitate negotiating separate licensing agreements or accepting the liability risks inherent in open-source software.

Key Takeaways
- GLM-5 achieves record-low hallucination rate (-1 on AA-Omniscience Index) through careful training on 28.5T curated tokens and novel reinforcement learning infrastructure
- The model's native Agent Mode generates production-ready documents (.docx, .pdf, .xlsx) eliminating manual formatting, reducing document generation time from 8 hours to 2 hours
- Pricing of 1.00 input /3.20 output tokens is 6-10x cheaper than Claude Opus while achieving comparable performance (77.8 vs 80.9 SWE-bench)
- 744B parameter mixture-of-experts architecture with only 40B active per token maintains massive knowledge capacity while keeping inference costs efficient
- MIT licensing enables flexible enterprise deployment without proprietary licensing concerns, differentiating from some competitive models
- Early user feedback reveals trade-off: conservative behavior (refusing uncertain answers) suits financial/legal applications but differs from competitors' approach
- Viable alternatives include Claude Opus for maximum performance, open-source Llama/Mixtral for unrestricted deployment, or packaged solutions like Runable for simplicity
- Implementation timeline ranges from 2 weeks (simple document generation) to 12 weeks (complex enterprise-wide deployment with fine-tuning and compliance)
- ROI calculations show 6-12 month payback periods for knowledge-work automation through labor cost reduction in document generation, code review, and business analysis
- Future versions likely expanding parameter count, adding multimodal capabilities, reducing inference latency, and releasing domain-specific fine-tuned variants
Related Articles
- Claude's Free Tier Gets Major Upgrade as OpenAI Adds Ads [2025]
- Who Owns Your Company's AI Layer? Enterprise Architecture Strategy [2025]
- How AI Will Finally Understand Your Work in 2026 [2025]
- OpenAI's Responses API: Agent Skills and Terminal Shell [2025]
- John Carmack's Fiber Optic Memory: Could Cables Replace RAM? [2025]
- Runway's $315M Funding Round and the Future of AI World Models [2025]

