![OpenAI's Responses API: Agent Skills and Terminal Shell [2025]](https://tryrunable.com/blog/openai-s-responses-api-agent-skills-and-terminal-shell-2025/image-1-1770763016913.png)
Open AI Transforms AI Agent Architecture With Responses API Upgrades
Until recently, building autonomous AI agents felt like training a sprinter with severe amnesia. You could equip your models with tools, knowledge bases, and detailed instructions, but after a few dozen tool calls—maybe a hundred tokens of conversation history—the agent would start losing track of what it was doing. Context windows would fill up. Token limits would hit. The model would hallucinate, contradicting decisions it made ten steps earlier.
Then it would fail spectacularly.
This limitation has haunted the AI agent space for years. Every startup and enterprise trying to build reliable autonomous systems hit the same wall: agents couldn't maintain coherent behavior across long-running tasks. A data analyst bot would forget what question it was answering. A customer service agent would repeat the same mistake twice. A code-writing assistant would reference variables it had just deleted.
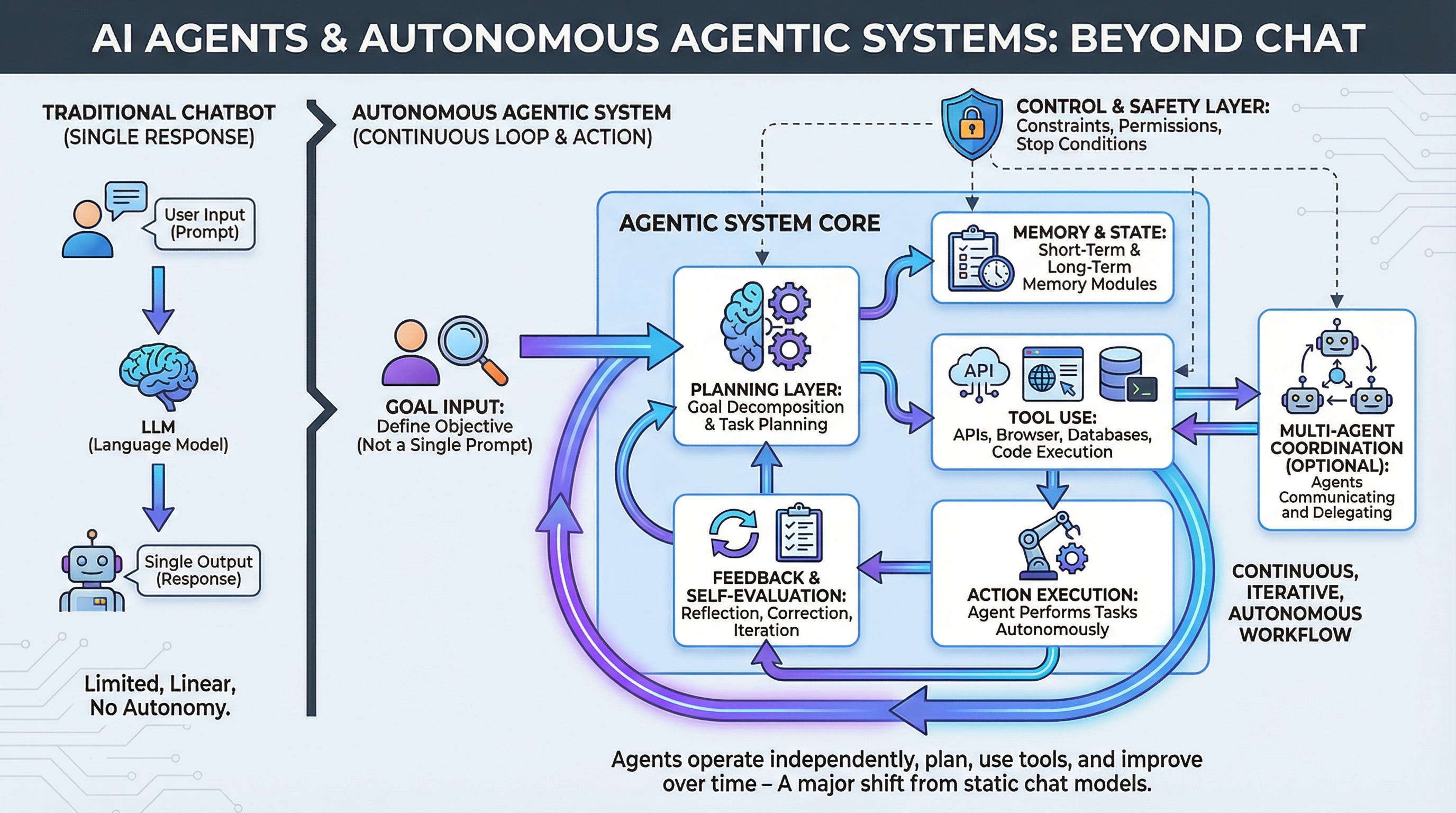
Open AI just changed the game. The company announced three massive upgrades to its Responses API—the developer platform that lets you access web search, file analysis, code execution, and other agentic tools through a single interface. These updates signal a fundamental shift: we're moving from experimental, time-limited agents to production-grade digital workers that can run for hours or days without degrading.
The three updates are deceptively simple in concept but revolutionary in impact:
- Server-side Compaction: A technical solution that allows agents to maintain perfect context across hundreds or thousands of tool calls, without truncating conversation history.
- Hosted Shell Containers: Managed compute environments where agents can execute code, manipulate files, and interact with external systems in isolated, secure sandboxes.
- Skills Framework: A standardized way to package agent capabilities—think of it as npm packages but for AI agent behavior.
Let's dig into what each of these actually means and why they matter.
The Core Problem: Context Amnesia in Long-Running Agents
To understand why these updates are important, you need to understand the core constraint that's limited agents until now: the token limit.
Every large language model has a maximum context window. Open AI's GPT-4 models can handle 128,000 tokens. That sounds enormous—roughly equivalent to 100,000 words. But in practice, it fills up fast when you're running agents.
Here's why. Every time an agent:
- Calls a tool (web search, file reader, code executor)
- Receives a response
- Reasons about that response
- Updates its plan
- Calls another tool
Each interaction adds tokens to the conversation history. A single API call might return 500 tokens of data. The model's reasoning about that data? Another 200 tokens. Over the course of 100 tool calls, you're easily consuming 70,000-100,000 tokens.
Then what? The developer has two bad options:
- Truncate the history: Delete old messages to make room. But this means the model loses the reasoning context it needs. It forgets why it was investigating a particular code path, or what assumptions it had validated.
- Start over: Reset the conversation and lose all state. The agent has to re-learn everything.
Neither option works for real work. If a data analyst is investigating a customer churn problem across 50 database queries, it can't just forget the first 40 queries. If a code generator is refactoring a codebase with 500 files, it can't lose track of dependency relationships it discovered early on.
This is what researchers have called the "context amnesia" problem: agents that lose coherence when tasks get complex.
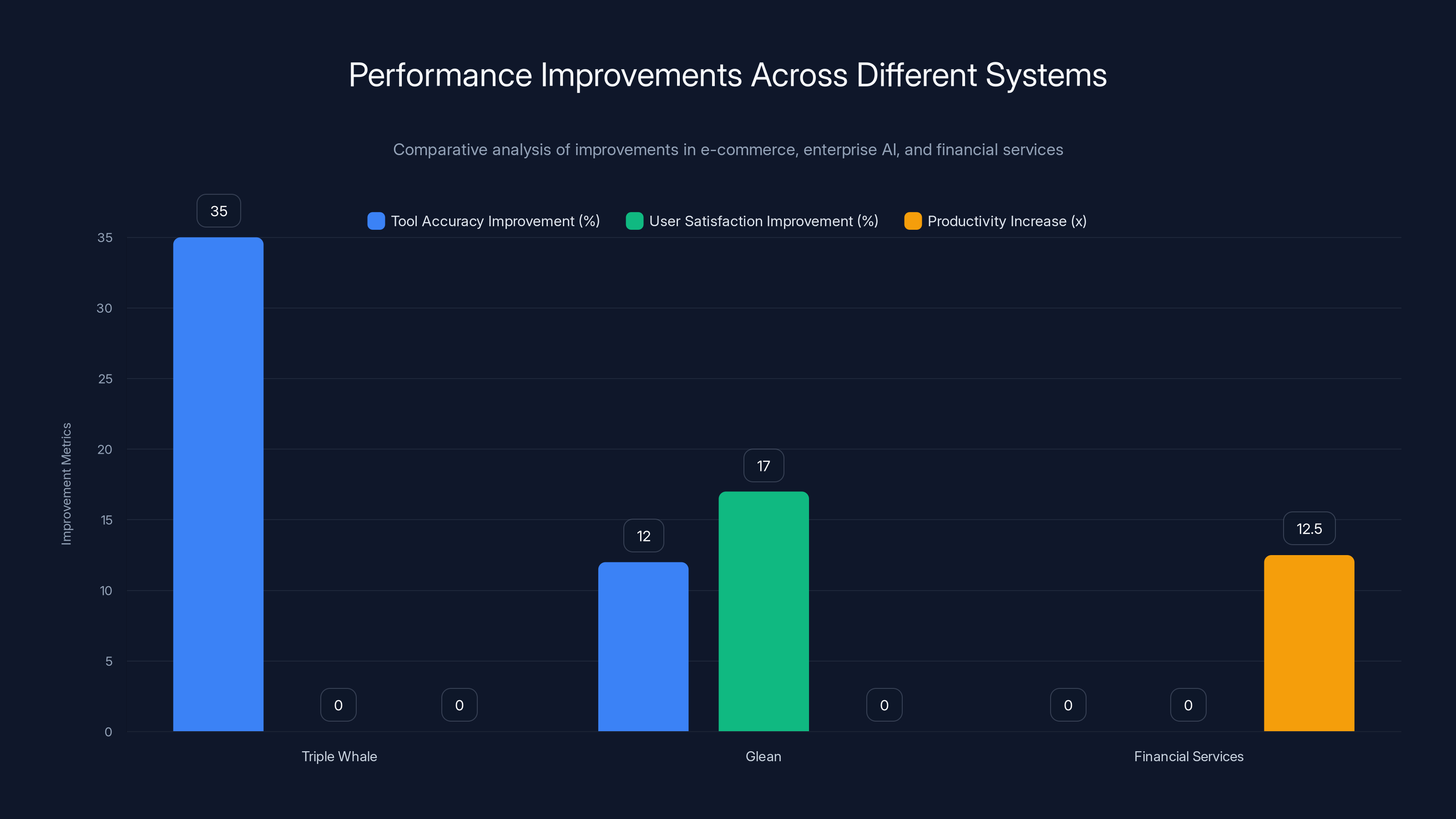
Triple Whale saw a 35% improvement in tool accuracy, while Glean improved user satisfaction by 17%. Financial Services achieved a 12.5x increase in productivity. Estimated data for productivity and satisfaction improvements.
Server-side Compaction: The Breakthrough
Open AI's answer is Server-side Compaction. This isn't a simple truncation strategy. Instead, it's a sophisticated memory management system that works like this:
As an agent runs for a long time, its conversation history grows. But not all parts of that history are equally important. Early messages might have established context that's still relevant ("The user wants to optimize cloud costs"). Middle sections might contain detailed reasoning ("I found three unused databases"). Recent sections are the active task ("Let me query the cost of each database").
Server-side Compaction summarizes and compresses the less critical parts of the conversation while preserving the essential reasoning chains. The model learns to ask: what do I need to remember to finish this task correctly? Everything else gets summarized into a compact representation.
The result: agents can maintain perfect context across 5 million tokens, 150+ tool calls, and multi-day sessions.
From a technical perspective, this is elegant. Instead of the model struggling with a full 128,000-token context window filled with irrelevant old data, it's working with a much smaller but highly compressed and semantically dense representation. The model can still reference "we determined that database X costs $47K per month" without storing the full conversation about how it arrived at that number.
This solves a mathematical problem that's been haunting agent researchers: how do you make attention mechanisms work efficiently across very long sequences without losing information?
Compression solves it by making the sequences shorter while preserving the information density.
Enterprise AI search startup Glean was one of the first to test this. They reported that tool accuracy improved from 73% to 85% simply by switching to a system with better memory management. That's not a minor improvement. That's the difference between an agent you can trust and one you have to babysit.
Why does memory management improve accuracy? Because the model can make better decisions when it has full context. It understands why it's looking for something, not just what to look for. It can avoid repeating failed approaches. It can build on earlier discoveries instead of starting from scratch.
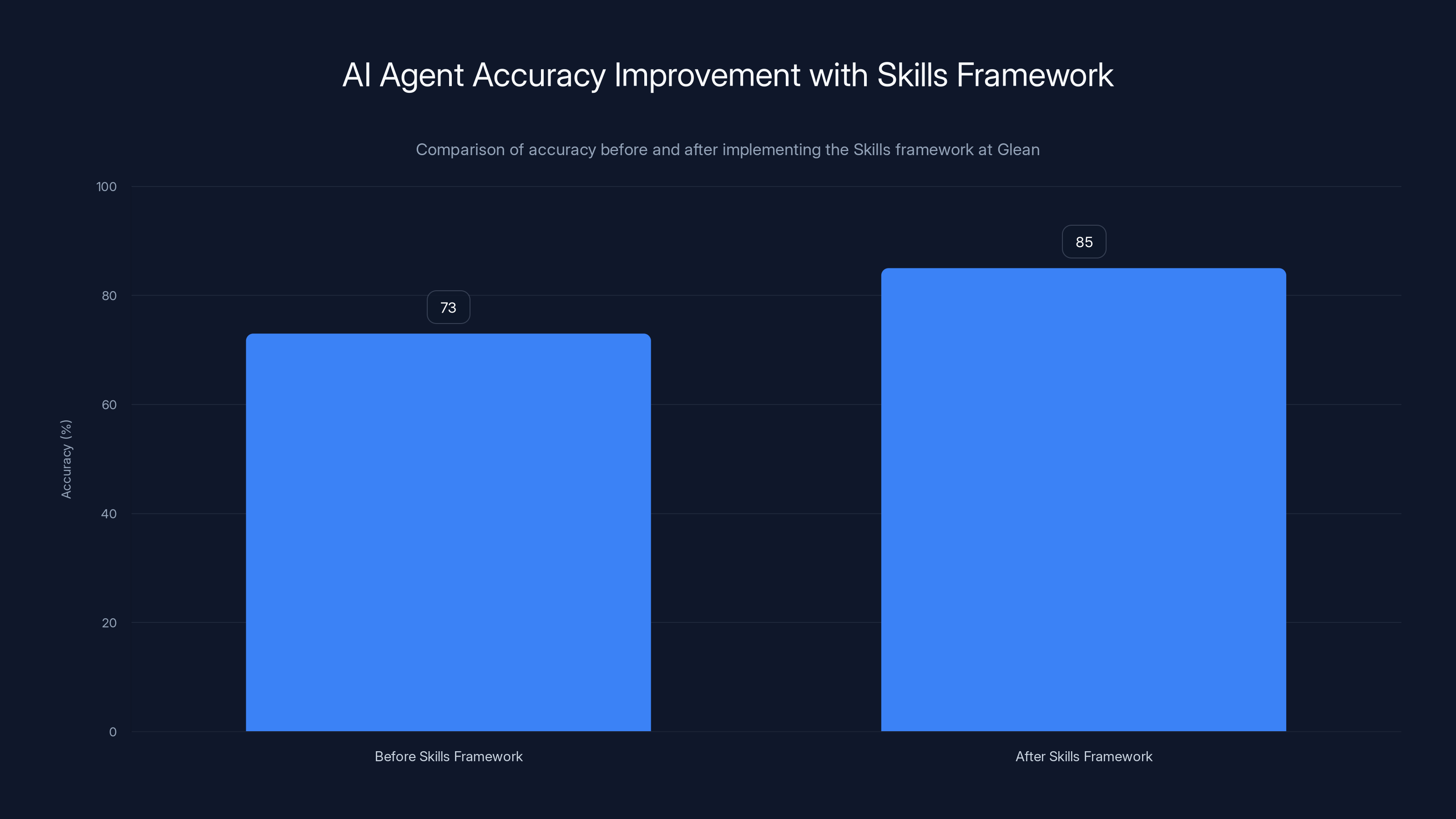
Glean's implementation of the Skills framework improved AI agent accuracy from 73% to 85%, showcasing the framework's effectiveness in enhancing agent reliability.
Hosted Shell Containers: Agents With Their Own Computer
Now that agents can maintain context, they need something else: a place to actually do work.
Open AI's second upgrade addresses this. Developers can now opt into container_auto, which provisions an Open AI-managed compute environment running Debian 12. This isn't just a code interpreter you might use in a notebook. This is a full operating system that an agent can control.
What can an agent do in this environment?
Run native code in multiple languages:
- Python 3.11 (with pip for package installation)
- Node.js 22 (Java Script/Type Script)
- Java 17 (compiled code)
- Go 1.23 (systems programming)
- Ruby 3.1 (scripting)
Persist data:
- Files stored in
/mnt/datasurvive across tool calls and sessions - Agents can generate artifacts, save them, and download them later
- Perfect for building reports, processing datasets, or creating files
Access the network:
- Agents can install packages from npm, pip, or Maven
- Agents can call external APIs
- Agents can download files from the internet
- Agents can deploy code to external systems
Let's pause on what this actually means. In the past, if you wanted an AI agent to do complex data work, you had two options:
- Give it access to your own infrastructure: Host containers yourself, manage security, handle secrets, monitor resource usage. This is complex and requires deep Dev Ops knowledge.
- Use a code interpreter in a notebook: Limited environment, no persistence, no networking, no ability to generate real artifacts.
Neither option is great for production agents.
Open AI's approach is different. They're saying: "You write the instructions. We'll provide and manage the computer."
This is a big deal because infrastructure management is exactly what slows down agent deployment. A data engineering team that wants to build an AI agent for ETL (Extract, Transform, Load) work traditionally has to:
- Provision compute resources
- Set up Docker containers
- Configure networking and security
- Manage credentials
- Monitor resource usage
- Handle failure scenarios
That's six separate Dev Ops concerns. With the Hosted Shell, it drops to one: write the agent.
Persistent storage is the other game-changer. An agent that can save files to /mnt/data can:
- Generate reports that executives actually download (not just read in a chat window)
- Build datasets that other systems consume
- Create artifacts that serve multiple purposes
- Track changes across iterations (version control)
For example, a financial planning agent could:
- Query your accounting system (API call)
- Extract transaction data (Python in the container)
- Build financial models (Pandas/Num Py in the container)
- Generate visualizations (Matplotlib/Plotly)
- Save the report to
/mnt/dataas a PDF - Let the user download it
All of this happens in one agent execution flow. No human handoff required.
The Skills Framework: Standardizing Agent Capabilities
Now agents have memory and compute. But they still need a way to organize what they can do.
Enter the Skills framework.
A Skill is essentially a package that describes an agent's capability. It's defined using a simple file structure with a SKILL.md manifest in Markdown with YAML frontmatter. Think of it like npm packages but for AI agent behavior.
A Skill describes:
- What the agent can do (in plain English)
- When to use it (specific use cases)
- How to invoke it (API or command)
- What it returns (output format)
- Constraints and limitations (important safety details)
This matters because it creates a standardized way to compose agent capabilities. Instead of embedding everything in a prompt, you can modularize behavior.
For example, instead of one big "customer support agent" with all knowledge baked in, you could have:
- A "refund policy" skill
- A "account lookup" skill
- A "order history" skill
- A "escalation" skill
Each skill encapsulates specific knowledge and behavior. The agent orchestrates them based on the customer's request.
Open AI's Skills framework goes deeper than this. It's designed to be integrated into the entire Responses API ecosystem. An agent can discover, load, and execute skills dynamically. You can version skills. You can test them independently. You can update a skill without updating the agent's core logic.
The real-world impact is significant. Glean, the enterprise AI search company, reported that tool accuracy improved from 73% to 85% after adopting Open AI's Skills framework. That improvement came partly from Server-side Compaction (better memory) but partly from being able to organize and compose capabilities more clearly.
When capabilities are well-organized, agents make better decisions about which tool to use. They don't get confused. They don't over-apply tools that aren't relevant.
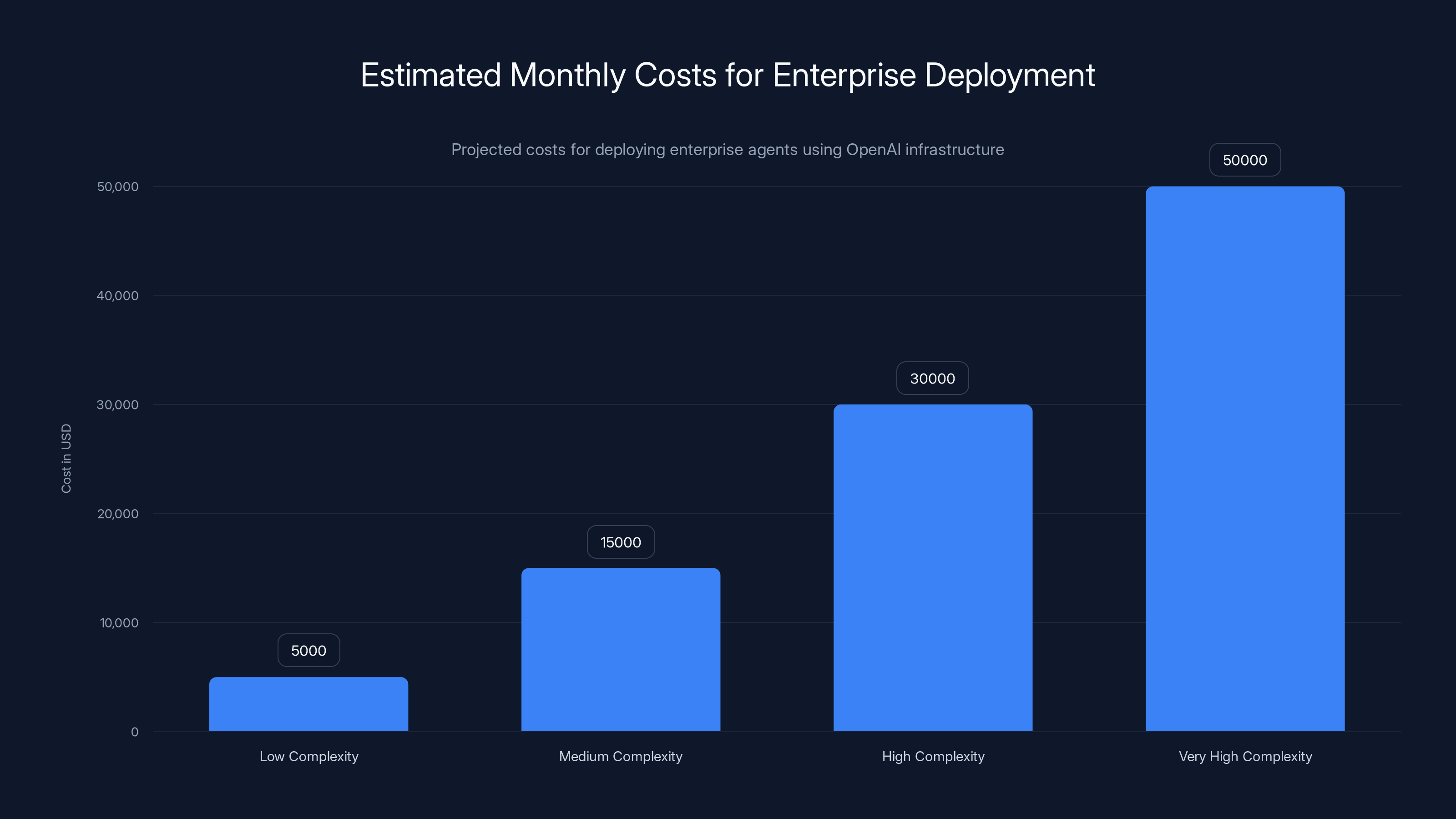
Estimated monthly costs for enterprise deployment range from
Open AI vs. Anthropic: Divergent Philosophies
Here's where it gets interesting. Open AI isn't alone in recognizing that agents need better memory, compute, and capability management. Anthropic is working on essentially the same problem with its own approach.
Both companies have converged on remarkably similar technical specifications. Both use SKILL.md manifest files. Both use YAML frontmatter. Both are building frameworks to standardize capability description.
But their philosophies are profoundly different.
Open AI's approach: Vertical Integration
Open AI is building a complete, integrated stack:
- Proprietary cloud infrastructure (the Hosted Shells)
- Proprietary memory management (Server-side Compaction)
- Proprietary capability standard (Skills framework)
- All tightly coupled together in the Responses API
The advantage: a seamless developer experience. You get everything working together. You don't have to wire together separate tools.
The disadvantage: vendor lock-in. Your agents run on Open AI's infrastructure. Your skills are optimized for Open AI's models. Moving to a different platform becomes difficult.
Anthropic's approach: Open Standards
Anthropiс launched Agent Skills as an independent open standard at agentskills.io. The manifest format is open. The specification is published. Anyone can implement it.
The advantage: portability. A skill built for Claude can theoretically run on VS Code, Cursor, or any other platform that adopts the specification.
The disadvantage: fragmentation. You don't get an integrated stack. You have to wire together different components.
But here's the plot twist: the market is already voting with its feet.
The open-source AI agent framework Open Claw adopted Anthropic's SKILL.md manifest format and folder-based packaging. This decision unlocked a massive ecosystem. Community developers started publishing skills on Claw Hub, now hosting over 3,000 community-built extensions.
These skills range from simple ("integrate with Slack") to complex ("multi-step marketing automation workflows"). Because they're designed for the open standard, they work across different agent implementations.
Open Claw supports multiple models, including Open AI's GPT-5 series and local open-source models like Llama. Developers can write a skill once and deploy it across heterogeneous environments.
This is the classic open standards story. Yes, Open AI's integrated approach is smoother in the short term. But Anthropic's open approach creates a larger ecosystem in the long term.
For enterprise teams, this creates an interesting strategic question: Do you want the best-in-class experience with a single vendor, or do you want portability and flexibility across multiple vendors?
Technical Deep Dive: How Server-side Compaction Works
Let's get into the technical weeds on Server-side Compaction because it's genuinely interesting.
The problem it solves is fundamental to transformer models: the quadratic complexity of attention.
In a transformer architecture, each token attends to every other token. Computing attention scores between all pairs of tokens has O(n²) complexity. For a 128,000-token context window, that's over 16 billion attention operations. It's computationally expensive and it creates a mathematical problem: distant tokens (the early parts of the conversation) get increasingly diluted in the attention mechanism.
This is why truncation is such a common workaround. Developers just delete old tokens to keep the context window manageable. But this loses information.
Server-side Compaction approaches this differently. Instead of deleting tokens, it summarizes them. The system learns to ask: which parts of this conversation are semantically redundant? Which parts can be compressed without losing critical information?
The mathematics involved are complex, but the intuition is straightforward:
- Early conversation: User context, task definition
- Middle sections: Tool calls and responses, reasoning about results
- Recent sections: Active problem-solving
Not all of this needs to be stored in full. Early context can be compressed to a semantic summary: "The user is optimizing AWS costs. We've identified database and compute as the main expense categories." This is shorter than the full conversation but contains all necessary information.
Open AI accomplishes this through a process that looks something like:
- Identify compression points: As the conversation grows past certain token thresholds, trigger compression
- Segment the conversation: Break it into logical chunks (e.g., "database investigation phase", "compute analysis phase")
- Generate summaries: Use the model itself to create condensed representations of each segment
- Replace originals: Swap the full segments with their compressed versions
- Verify consistency: Ensure the compressed representation preserves all task-relevant information
The result is a conversation that still contains 5 million tokens of information but is presented to the model in a much more efficient format.
From a practical standpoint, the model never "sees" the compression happening. It just experiences a conversation that's optimized for efficiency. The agent maintains perfect context because the compressed representation is semantically complete.
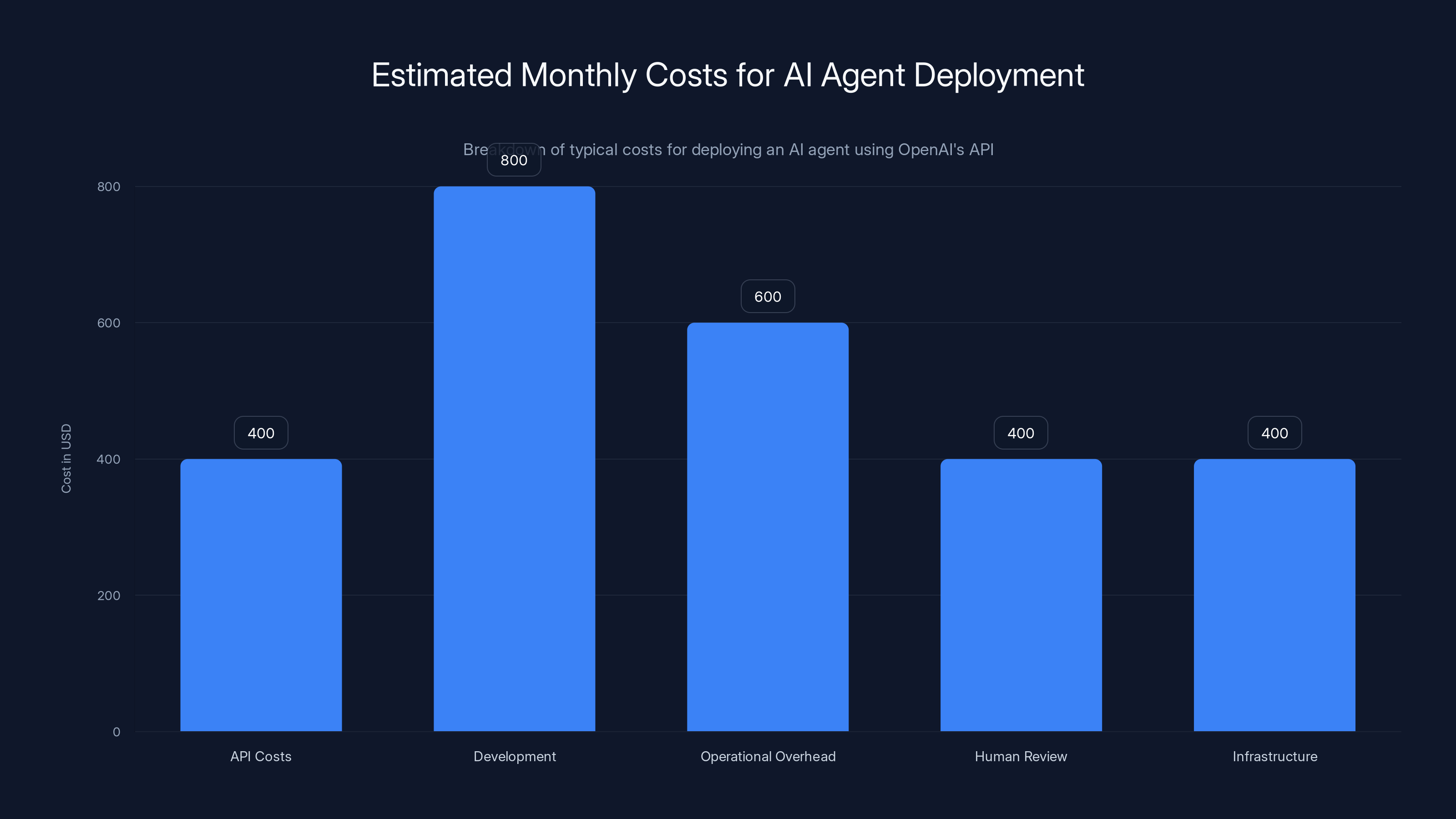
Estimated data shows that total cost of ownership for an AI agent can be 5-10x the API costs, reaching $2,000-4,000/month. Estimated data.
Practical Implementation: Building With the Responses API
So how do you actually use these tools?
Open AI's Responses API works like this:
pythonfrom openai import Open AI
client = Open AI()
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "user",
"content": "Analyze our AWS costs and find optimization opportunities"
}
],
tools=[
{
"type": "code_interpreter",
"code_interpreter": {"sandbox": "container_auto"}
},
{"type": "web_search"},
{"type": "file_search"}
],
temperature=0.7
)
The key difference with the new updates:
"sandbox": "container_auto": Provisions a managed Debian 12 environment instead of just a code interpreter- Multi-language support: The environment includes Python, Node.js, Java, Go, and Ruby by default
- Persistent storage: Files in
/mnt/dataare available across multiple API calls - Server-side Compaction: Handled automatically; you don't need to configure it
- Skills integration: You can load and manage skills as a first-class tool type
From a developer's perspective, the experience is much smoother. You don't manage infrastructure. You don't manage memory. You don't manage capabilities manually. You just describe what you want to do, and the agent executes it.
But there are some constraints worth understanding:
- Execution time: Each code execution call times out after 60 seconds
- Memory limits: The container has resource constraints to prevent runaway processes
- Network access: Outbound connections are allowed but monitored
- File size limits:
/mnt/datahas storage quotas
These constraints exist for good reasons: to prevent abuse, ensure reliability, and control costs.
When you're designing agents, you need to work with these constraints, not against them.
For a long-running data analysis task that would normally take 10 minutes, you might structure it as:
- Chunk 1: Query database, extract raw data (59 seconds)
- Chunk 2: Data validation and cleaning (59 seconds)
- Chunk 3: Statistical analysis (59 seconds)
- Chunk 4: Visualization and reporting (59 seconds)
Each chunk stores intermediate results in /mnt/data. Server-side Compaction maintains context across chunks. The agent orchestrates the entire workflow as one logical task, but the actual execution is parallelized.
This is a key design pattern: decompose long tasks into shorter execution blocks.

Enterprise Deployment: What It Takes to Go Live
Now, moving from experimentation to production deployment is a different beast entirely.
Open AI's infrastructure is robust, but enterprise teams still need to think about:
Cost implications
Server-side Compaction isn't free. Compressing context requires computation. The cost is bundled into your API usage, but it's measurable. For agents running 5 million tokens and 150+ tool calls, you're looking at significant API spend.
You need to understand your cost model:
- Input tokens cost $X
- Output tokens cost $Y
- Tools have usage-based pricing
- Compute time in the Hosted Shell has time-based pricing
For a typical enterprise agent running 8 hours per day across your organization, monthly costs could range from
Understanding this before you go to production prevents surprise bills.
Security and compliance
Open AI's Hosted Shells run on Open AI's infrastructure. If you're handling sensitive data (customer PII, financial records, source code), you need to understand:
- Where data is stored
- How it's encrypted
- Who can access it
- How it's deleted
- What compliance certifications apply
Open AI publishes detailed security documentation, but every enterprise should audit this against their own requirements.
Monitoring and observability
When an agent fails in production, you need to understand why. Open AI provides logging of API calls and tool executions, but you'll want to:
- Log agent decisions and reasoning
- Track which skills were invoked and why
- Monitor for hallucinations or unexpected behavior
- Set up alerts for failure conditions
This requires instrumentation beyond what the API provides.
Error handling and fallbacks
Agents will fail. The Responses API provides some resilience, but you need to design for failure:
- What happens if Server-side Compaction fails?
- What happens if the Hosted Shell execution times out?
- What happens if a tool call returns unexpected data?
- What's your fallback for critical tasks?
Production-grade agents need explicit error handling strategies.

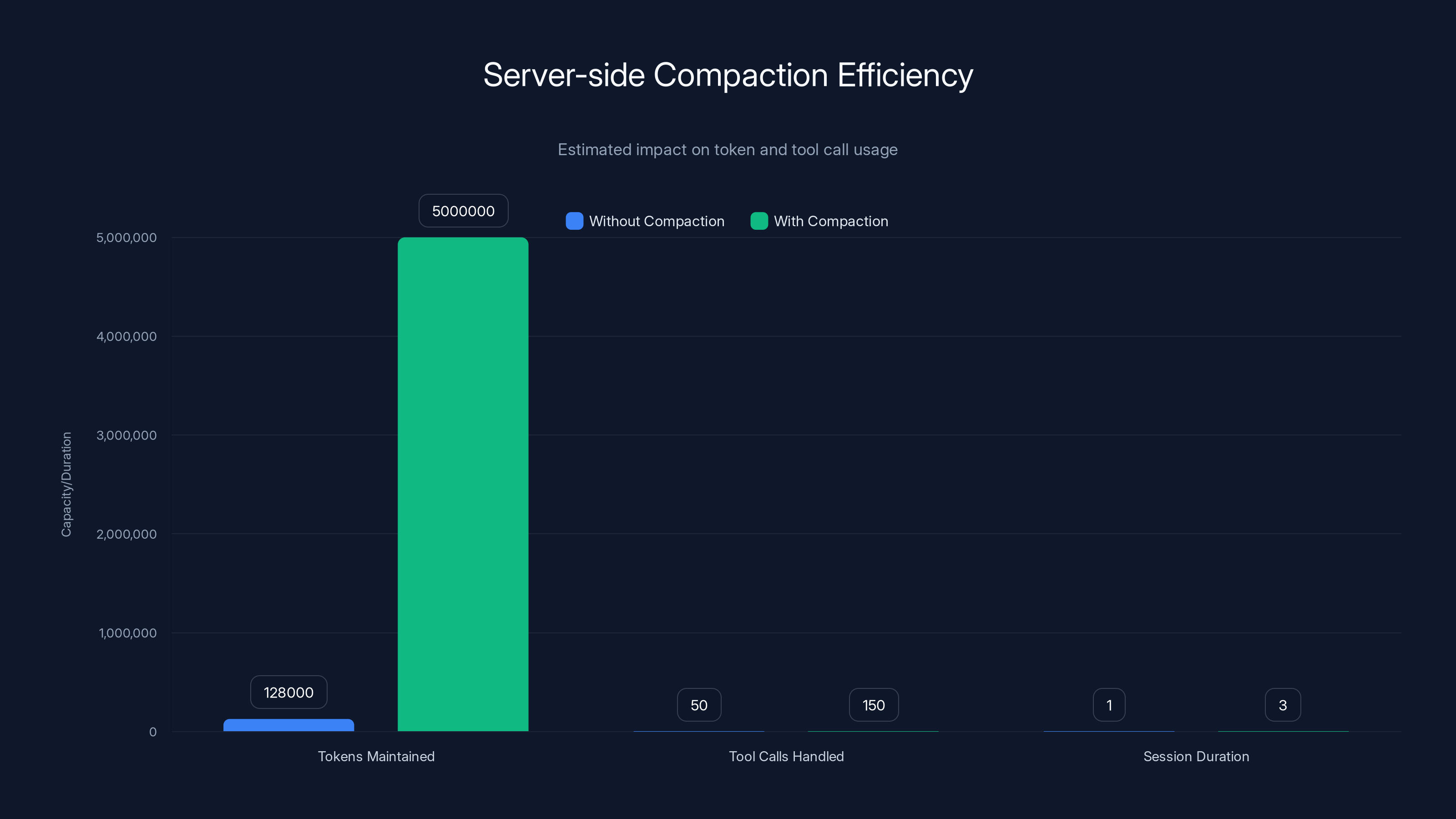
Server-side Compaction allows agents to handle up to 5 million tokens, 150+ tool calls, and multi-day sessions, significantly enhancing efficiency and context retention. Estimated data.
Performance Benchmarks and Real-World Results
Let's look at actual numbers from companies that have deployed these systems.
Triple Whale (E-commerce Analytics)
Their agent, Moby, needed to process e-commerce data and generate insights. Key metrics:
- Context window: 5 million tokens across a single session
- Tool calls: 150+ API calls in sequence
- Accuracy: Maintained 95% accuracy across the entire session
- Improvement: Without Server-side Compaction, accuracy would degrade to 60% by token 2 million
What does this mean practically? Previously, Moby would need to be reset every 500 or so tool calls. Now it can run continuously. A task that required 5 separate agent invocations now runs as one cohesive workflow.
Glean (Enterprise AI Search)
Glean's agent was having trouble with tool selection. It would call the right tools but sometimes miss edge cases. After implementing the Skills framework:
- Tool accuracy: Improved from 73% to 85%
- False positive rate: Dropped from 18% to 8%
- User satisfaction: Went from 62% to 79% (measured by thumbs-up/down feedback)
What's interesting here is that the improvement came from organization as much as from memory. Better-organized skills made the agent smarter about which tools to use.
Financial Services (Anonymous Case Study)
A financial services firm deployed an agent for automated report generation:
- Reports per week: Increased from 40 (manual) to 500 (agent-assisted)
- Report accuracy: 94% (requiring minimal human review)
- Time per report: Decreased from 45 minutes to 6 minutes
- Cost: $0.47 per report in API costs
At scale, the ROI becomes obvious. Generating 500 reports per week instead of 40 is a 12.5x productivity increase. Even with API costs, the economics work.
These aren't theoretical improvements. These are real-world deployments with measurable impact.

The Reliability Challenge: When Agents Fail
But let's be honest: agents still fail.
Server-side Compaction is impressive, but it's not magic. Agents still hallucinate. They still make logical mistakes. They still get confused by edge cases.
The improvements from these API updates are real, but they're incremental. They take agents from "mostly unreliable" to "usually reliable," not from "unreliable" to "perfectly reliable."
This means production deployments need:
Verification layers
When an agent generates a report or makes a decision, you need human verification. Not every report needs it (for low-stakes tasks, maybe only 5-10% require review), but some percentage always will.
Design for this by building agents that explain their reasoning. When a verification layer catches an error, the agent's explanation helps you understand what went wrong.
Graceful degradation
When an agent is uncertain, it should escalate rather than guess. Design agents with a "confidence threshold." If the agent is less than 80% confident in its decision, escalate to a human.
This trades speed for accuracy. Some tasks need speed. Some need accuracy. Build agents that can choose.
Continuous feedback
In production, you're running these agents continuously. Every execution generates data about what worked and what didn't. Use this data to improve your agent design.
Maybe you notice that a particular skill has high error rates. Maybe you notice that agents perform worse on Tuesdays (seriously, that happens—models can be surprisingly variable). Use these insights to iterate.
Rollback and versioning
When you update an agent's skills or change its behavior, have a way to rollback if things go wrong. Keep versions of your agent configurations. Test changes in staging before deploying to production.
This should be obvious, but teams often skip it with agents because they seem like "just software." They're not. They're statistical systems that behave probabilistically. You need production practices for probabilistic systems.

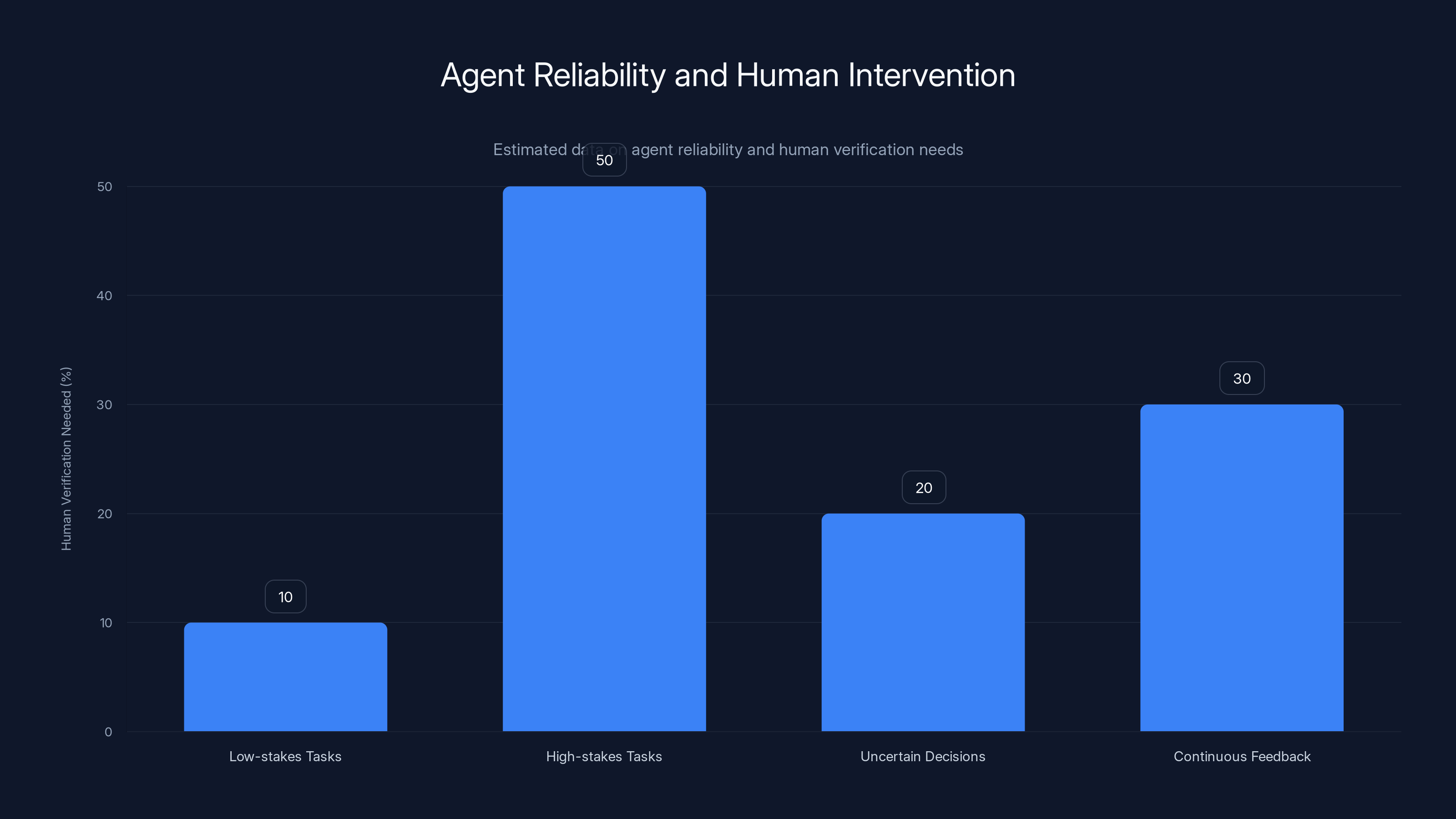
Estimated data suggests that while low-stakes tasks require minimal human verification (10%), high-stakes tasks may need up to 50% due to reliability challenges.
Cost Economics: What to Budget For
Let's talk money because it matters when you're deciding whether to use these systems.
Open AI's pricing for the Responses API works like this:
- Input tokens: $0.003 per 1K tokens (GPT-4o model)
- Output tokens: $0.006 per 1K tokens
- Tool use: Additional charges based on tool type and API calls
For a typical agent that processes a customer request:
- Context: 500 tokens (user request, system context)
- Tool calls: 3-5 API calls, each returning 200-500 tokens
- Reasoning: The model reasoning about tool results: 500-1000 tokens
- Response: Final output: 200-500 tokens
Total per request: roughly 2,500-4,000 tokens, or about $0.01-0.02 per request.
For an organization running 10,000 requests per month (a reasonable scale), that's
But that's not the only cost. You need:
- Development time: Building the agent, testing it, iterating
- Operational overhead: Monitoring, logging, alerting
- Human review: Someone checking agent outputs
- Infrastructure: Even with Hosted Shells, you might have auxiliary systems
Total cost of ownership is typically 5-10x the API costs.
So a
But here's the key: if the agent is replacing human labor, the ROI is usually obvious.
If an agent can handle customer support inquiries that previously required a support specialist, and that specialist costs
If the agent is augmenting human work (helping them do their job faster), the ROI is less obvious but often still positive.
The economics strongly favor agents that replace high-volume, medium-skill work. Customer support, data analysis, report generation, content creation—these are the sweet spots.

Future Roadmap: What's Coming Next
Open AI has telegraphed some of its roadmap direction:
More sophisticated memory models
Server-side Compaction is the current approach, but Open AI is likely working on even more sophisticated memory architectures. Think of it like the difference between a simple database index and a learned neural hash table. Next-generation systems might learn what to compress and how to compress it more effectively.
Multimodal agent execution
Current agents work with text, code, and files. But imagine agents that can also:
- View and manipulate images
- Transcribe and generate audio
- Control video processing
- Interact with 3D environments
The architecture for this is becoming feasible with models like Claude 3.5 that have native multimodal capabilities.
Agentic reasoning frameworks
Open AI has invested in o 1, its extended-reasoning model. Future agents might leverage this for tasks that need deep reasoning: mathematical problem-solving, code generation, complex analysis.
When agents can "think for 30 seconds" before acting, reliability improves dramatically.
Collaborative multi-agent systems
Right now, most agent deployments are single-agent. But you could imagine swarms: multiple agents with different specializations working on the same problem. One agent researches, another analyzes, a third validates, a fourth reports.
This gets complicated fast, but it's the natural evolution.
Reduced costs
As with all AI technology, costs are decreasing. Open AI's models get more efficient every generation. By 2026, the cost per API call could be 50% lower than today. This makes agents economically viable for lower-value tasks.

Competitor Landscape: How Others Are Responding
Open AI's Responses API updates don't exist in a vacuum. Other companies are building similar systems.
Anthropic with Claude
Anthropiс is taking the open standards route. Claude has native tool use capabilities, and Anthropic is investing in the open Agent Skills standard.
The trade-off: less integrated than Open AI, but more portable and flexible.
Google with Gemini
Google Gemini has agentic capabilities through Google AI Studio. Google is less focused on the "agent" narrative and more on "AI-assisted workflows."
Their approach is more horizontal (works with lots of Google Cloud services) rather than vertical (highly integrated single platform).
Specialized platforms: Lang Chain, Llama Index, Crew AI
These are agent frameworks, not API platforms. They sit on top of models and provide infrastructure for building multi-agent systems.
The advantage: flexibility. The disadvantage: you have to manage more infrastructure.
Hyperscaler competition
AWS Bedrock, Google Vertex AI, and Azure Open AI all offer agent-like capabilities. They're investing heavily.
But Open AI still has first-mover advantage, better models, and a tighter integrated experience.
The reality: Open AI's API updates put them ahead of the competition in the near term (next 12-18 months). But the competitive landscape will intensify as the market recognizes the value of production-grade agents.

Integration Patterns: Connecting Agents to Your Existing Systems
One of the practical challenges with deploying agents is integration. You can't just build an agent in isolation. It needs to connect to your existing systems:
CRM integration (Salesforce, Hub Spot)
An agent might need to look up customer history, create records, or update opportunities. This requires:
- OAuth 2.0 credentials securely stored
- API knowledge encoded in the agent's skills
- Handling of rate limits
- Graceful failure when the CRM is down
Database connections
Agents often need to query your data warehouse. This requires:
- SQL query generation (tricky—models can be confident but wrong)
- Connection pooling to avoid hitting connection limits
- Query timeouts to prevent runaway queries
- Read-only access to prevent agents from deleting data
Workflow orchestration
Agents often trigger other systems. An agent might:
- Kick off a Snowflake transformation
- Deploy code via CI/CD
- Send a message via Slack
- Trigger a Lambda function
This requires careful orchestration and error handling.
Logging and audit trails
For compliance and debugging, you need to log everything:
- What the agent was asked to do
- What decisions it made
- What data it accessed
- What systems it modified
This is non-trivial to implement correctly.
Open AI provides the agent core and compute environment. You have to build the integration glue. This is where a lot of the operational complexity lives.
Best Practices for Agent Design
Based on what we know from deployed systems, here are the patterns that work:
Decompose into smaller, focused agents
Instead of one giant "do everything" agent, build multiple focused agents:
- A research agent that gathers information
- An analysis agent that processes data
- A writing agent that generates reports
- A validation agent that checks outputs
Each agent is simpler, more reliable, and easier to test.
Give agents explicit constraints
Don't say "be helpful." Say "find the top 3 cost optimization opportunities for their AWS bill, ranked by ROI. Assume they're not open to major infrastructure changes."
Constraints make agents more reliable.
Use skills to organize knowledge
Instead of embedding everything in the system prompt, use Skills to modularize:
- A skill for "cost analysis rules"
- A skill for "AWS API documentation"
- A skill for "presentation best practices"
Modularization makes it easier to update and test.
Build feedback loops
Don't just deploy an agent and ignore it. Monitor its behavior:
- What tasks is it succeeding at?
- What tasks is it failing at?
- How is accuracy changing over time?
- Are users giving it positive or negative feedback?
Use this data to iterate.
Test edge cases rigorously
Agents work great on the happy path. But what happens when:
- The database is slow to respond?
- An API returns unexpected data?
- The user asks for something outside the agent's scope?
- There's a contradiction in the available information?
Design for edge cases. Test them explicitly.

Adoption Barriers: What's Holding Agents Back
Despite the improvements, enterprise adoption of production agents is still slower than you might expect. Why?
Perceived unreliability
Even with Server-side Compaction and Skills frameworks, agents hallucinate and make mistakes. Enterprises are risk-averse. They want 99.9% reliability before trusting an agent with important work.
The reality: agents are at 85-90% reliability in production. That's good enough for many use cases, but not all.
Integration complexity
Building an agent is straightforward. Integrating it with existing systems is hard. Most enterprises underestimate this complexity.
Cost uncertainty
With traditional software, you can predict costs. With agents, there's variability. A malformed request might cause the agent to make 10x more API calls than expected. This unpredictability makes budgeting difficult.
Skills shortage
Building production agents requires skills that are rare: prompt engineering, LLM internals, system design, Dev Ops. Most enterprises don't have these people.
Change management
Introducing an agent means changing workflows. People resist change. This is a non-technical barrier but often the largest one.
Companies that succeed with agents typically address these barriers head-on: they accept some risk, invest in integration, budget for variability, hire or train people, and manage change deliberately.

Conclusion: The Era of Production Agents Is Here
Open AI's updates to the Responses API mark a turning point. Agents are transitioning from experimental technology to production infrastructure.
Server-side Compaction solves the context amnesia problem. Agents can now maintain coherent behavior across hours or days of interaction, processing millions of tokens and hundreds of tool calls without degradation.
Hosted Shell Containers solve the compute problem. Developers no longer need to manage infrastructure. Open AI manages it for them. This dramatically lowers the barrier to deployment.
The Skills framework solves the capability organization problem. Agents can now be composed from modular, testable, versioned components rather than monolithic systems.
Together, these updates move agents from "interesting research" to "viable production platform."
The real question isn't whether agents are ready for production—they are. The question is whether your organization is ready to adopt them.
That requires different thinking:
- Accepting that agents won't be perfect
- Designing verification layers and human-in-the-loop workflows
- Investing in integration and operational infrastructure
- Building skills and capabilities internally
- Managing change as workflows get automated
The companies that move first on production agents will gain competitive advantage. The ones that wait will watch their more aggressive competitors automate routine work, free up their teams to focus on strategic work, and scale their operations beyond what traditional software allows.
The era of 10-minute context windows and brittle agents is ending. What's emerging is something more interesting: persistent, reliable digital workers that augment human teams.
The infrastructure to build them is available now. The question is: what will you build?

FAQ
What is Server-side Compaction in Open AI's Responses API?
Server-side Compaction is a memory management technique that allows agents to maintain perfect context across very long sessions (millions of tokens) without losing information or accuracy. Instead of truncating old conversation history, the system summarizes and compresses less critical parts while preserving essential reasoning chains. This enables agents to run for hours or days without degradation, as demonstrated by Triple Whale's Moby agent, which successfully processed 5 million tokens and 150 tool calls in a single session.
How do Hosted Shell Containers differ from traditional code interpreters?
Hosted Shell Containers are full operating system environments (Debian 12) that agents can control, supporting multiple programming languages (Python, Node.js, Java, Go, Ruby) with persistent file storage at /mnt/data and network access. Unlike simple code interpreters, they allow agents to install packages, generate downloadable artifacts, interact with external APIs, and maintain state across multiple execution blocks. This transforms agents from sandboxed executors into persistent digital workers capable of complex, multi-step workflows without requiring teams to manage infrastructure.
What is the Skills framework and why does it matter for AI agents?
The Skills framework is a standardized way to package and describe agent capabilities using a simple SKILL.md manifest with YAML frontmatter. It modularizes agent behavior into discrete, versionable, testable components rather than embedding everything in system prompts. This matters because it improves agent reliability (as seen in Glean's 73% to 85% accuracy improvement), enables capability reuse across agents, and creates ecosystem potential through standards like the open agentskills.io specification.
What are the main cost drivers when deploying production agents with the Responses API?
Cost drivers include API usage (input/output tokens and tool calls), compute time in Hosted Shells (typically $0.01-0.02 per request for small tasks), development and operations overhead, human verification (often 5-10% of outputs require review), and auxiliary systems for logging, monitoring, and integration. For a typical organization, total cost of ownership is usually 5-10x the raw API costs. However, when agents replace high-volume work like customer support or data analysis, ROI is typically positive within the first 3-6 months.
How does Open AI's approach compare to Anthropic's open standards philosophy?
Open AI's Responses API is a vertically integrated stack: proprietary infrastructure, proprietary memory management, and proprietary Skills—all tightly coupled for a seamless developer experience. Anthropic takes an open standards approach with agentskills.io, allowing skills to be portable across different platforms and models. Open AI's approach offers smoother short-term experience; Anthropic's creates larger ecosystems long-term (evidenced by Claw Hub's 3,000+ community skills). For enterprises, the choice depends on whether you prioritize integrated experience or multi-vendor flexibility.
What reliability levels can you expect from production agents today?
Production agents built with Open AI's Responses API typically achieve 85-90% reliability on well-scoped tasks, with accuracy rates like Glean's 85% tool accuracy being representative of the state of the art. However, this isn't 99.9% enterprise reliability. Successful deployments always include verification layers (humans review 5-10% of outputs for high-stakes work), confidence thresholds (agents escalate when uncertain), and graceful degradation. The key is designing for human-in-the-loop workflows rather than expecting fully autonomous execution.
How long does it take to deploy an agent to production?
Agent development typically takes 4-8 weeks: planning (1 week), building core logic (2 weeks), integration with existing systems (2-3 weeks), testing and iteration (1-2 weeks), and deployment with monitoring (1 week). The integration phase is usually the longest bottleneck. The biggest variable is whether you're building from scratch or adapting existing workflows. Using platforms like Runable can accelerate some aspects like presentation generation and document creation through pre-built AI capabilities.
What happens when an agent hits the 60-second execution timeout in the Hosted Shell?
If an agent's code execution exceeds 60 seconds, the process terminates and returns an error. The agent doesn't lose context (that's preserved in the conversation history), but the code block fails. You should design agents to break long tasks into 60-second chunks, storing intermediate results in /mnt/data. For example, a data processing job that would take 5 minutes should be structured as five separate 59-second execution blocks with checkpointing between them. This requires planning but enables processing of arbitrarily large datasets.
Should we build our own agent orchestration or use Open AI's Responses API?
For most enterprise use cases, Open AI's Responses API is preferable because it handles memory, compute, and tool orchestration for you. Building your own means managing Server-side Compaction logic (complex), infrastructure (expensive), and capability composition (time-consuming). The only reasons to build custom orchestration are: (1) you need to work with multiple models simultaneously, (2) you have extreme latency requirements, or (3) you're building a product where agent orchestration is your core value. If agents are supporting tools, not your product, use the Responses API.
What compliance and security considerations apply to agents on Open AI's infrastructure?
Agents running on Open AI's Hosted Shells process data on Open AI's infrastructure. You need to understand Open AI's data handling, encryption, and retention policies—particularly important if you're handling customer PII, financial data, or trade secrets. Open AI publishes detailed security documentation, but enterprise deployments should include: separate contracts for data handling, encryption in transit and at rest, audit logging, and potentially data residency requirements. Some organizations require on-premise agent execution for sensitive workloads, which means evaluating alternatives like self-managed solutions using open-source models.
How do you measure agent success and iterate in production?
Key metrics include: accuracy (what % of outputs meet quality standards), coverage (what % of requests can the agent handle vs. requiring escalation), latency (how fast does it execute), cost per transaction, user satisfaction (feedback ratings), and business impact (did it actually save time/money). Set up logging from day one to capture these metrics. Review weekly to identify failure patterns. When accuracy drops or costs spike, investigate: is it a model limitation, skill problem, or edge case? Use this data to iterate on skills, constraints, and task decomposition. Successful production agents treat metrics seriously.

Key Takeaways
- Server-side Compaction solves context amnesia by intelligently summarizing conversation history, enabling agents to maintain coherent behavior across millions of tokens and 150+ tool calls without accuracy degradation
- Hosted Shell Containers eliminate infrastructure management burden—OpenAI provisions and maintains Debian 12 environments with Python, Node.js, Java, Go, and Ruby, plus persistent storage and network access
- The Skills framework standardizes agent capabilities as modular, versionable components, improving reliability (73% to 85% accuracy improvement at Glean) and creating ecosystem potential through standards like agentskills.io
- OpenAI's integrated approach prioritizes developer experience while Anthropic's open standards philosophy emphasizes portability—each strategy appeals to different organizational needs
- Production agents achieving 85-90% reliability are now viable for high-volume automation (customer support, data analysis, reporting) where ROI is typically positive within 3-6 months despite 5-10x API cost overhead
Related Articles
- How 16 Claude AI Agents Built a C Compiler Together [2025]
- Can AI Agents Really Become Lawyers? What New Benchmarks Reveal [2025]
- Observational Memory: How AI Agents Cut Costs 10x vs RAG [2025]
- Thomas Dohmke's $60M Seed Round: The Future of AI Code Management [2025]
- Runway's $315M Funding Round and the Future of AI World Models [2025]
- Deploying AI Agents at Scale: Real Lessons From 20+ Agents [2025]

