![GLM-Image vs Gemini Nano: Text Rendering Showdown [2025]](https://tryrunable.com/blog/glm-image-vs-gemini-nano-text-rendering-showdown-2025/image-1-1768424815835.jpg)
Introduction: When Open Source Outperforms the Tech Giant
The image generation landscape shifted in early 2025 when a Chinese startup quietly released something the industry thought impossible: an open-source model that outperforms Google's proprietary image generator at a specific but critical task—rendering text accurately in complex, information-dense visuals.
Let me set the stage. For years, image generation has been dominated by proprietary models. Google released Gemini Nano (also called Nano Banana Pro or Gemini 3 Pro Image), a fast, flexible model designed specifically for enterprise use cases: marketing collateral, training materials, infographics, technical diagrams. It's everywhere now. Reliable. Integrated with Google's search capabilities. And until January 2025, it was the gold standard for text-heavy image generation.
Then Z.ai dropped GLM-Image.
This 16-billion parameter open-source model doesn't just compete with Nano. On the Complex Visual Text Generation (CVTG-2k) benchmark, it demolishes it. A 91.16% Word Accuracy score versus Nano's 77.88%. That's not incremental improvement. That's a generational leap.
But here's the thing—benchmarks don't tell the full story. Real-world usage reveals a more nuanced picture. GLM-Image excels at what it's designed for: precise text placement, layout integrity, semantic control. But ask it to research information on the web and populate a detailed constellation map? It struggles. Nano, integrated with Google Search, handles that like a champ.
So what's actually happening here? Why is an open-source model beating a Google product at text rendering while losing at aesthetic polish? How does it work? And more importantly, what does this mean for teams choosing between proprietary and open-source image generation?
That's what we're diving into today. We'll explore the architectural innovations that make GLM-Image tick, compare performance across multiple benchmarks, examine real-world limitations, and help you figure out which tool actually fits your workflow.
Let's start with the data.
TL; DR
- CVTG-2k Benchmark: GLM-Image achieves 91.16% word accuracy versus Nano's 77.88%, a significant advantage for complex text rendering
- Architecture Difference: GLM-Image uses a hybrid auto-regressive + diffusion design instead of pure diffusion, treating image generation as reasoning first, painting second
- Real-World Gap: Despite benchmark wins, GLM-Image struggles with web research and detailed instruction-following compared to Nano's integrated Search capabilities
- Aesthetic Trade-off: Nano edges out GLM-Image on the One IG benchmark (0.578 vs 0.528), producing crisper, more polished images
- Use Case Matters: Choose GLM-Image for cost, customization, and data residency; choose Nano for polish, web integration, and enterprise support

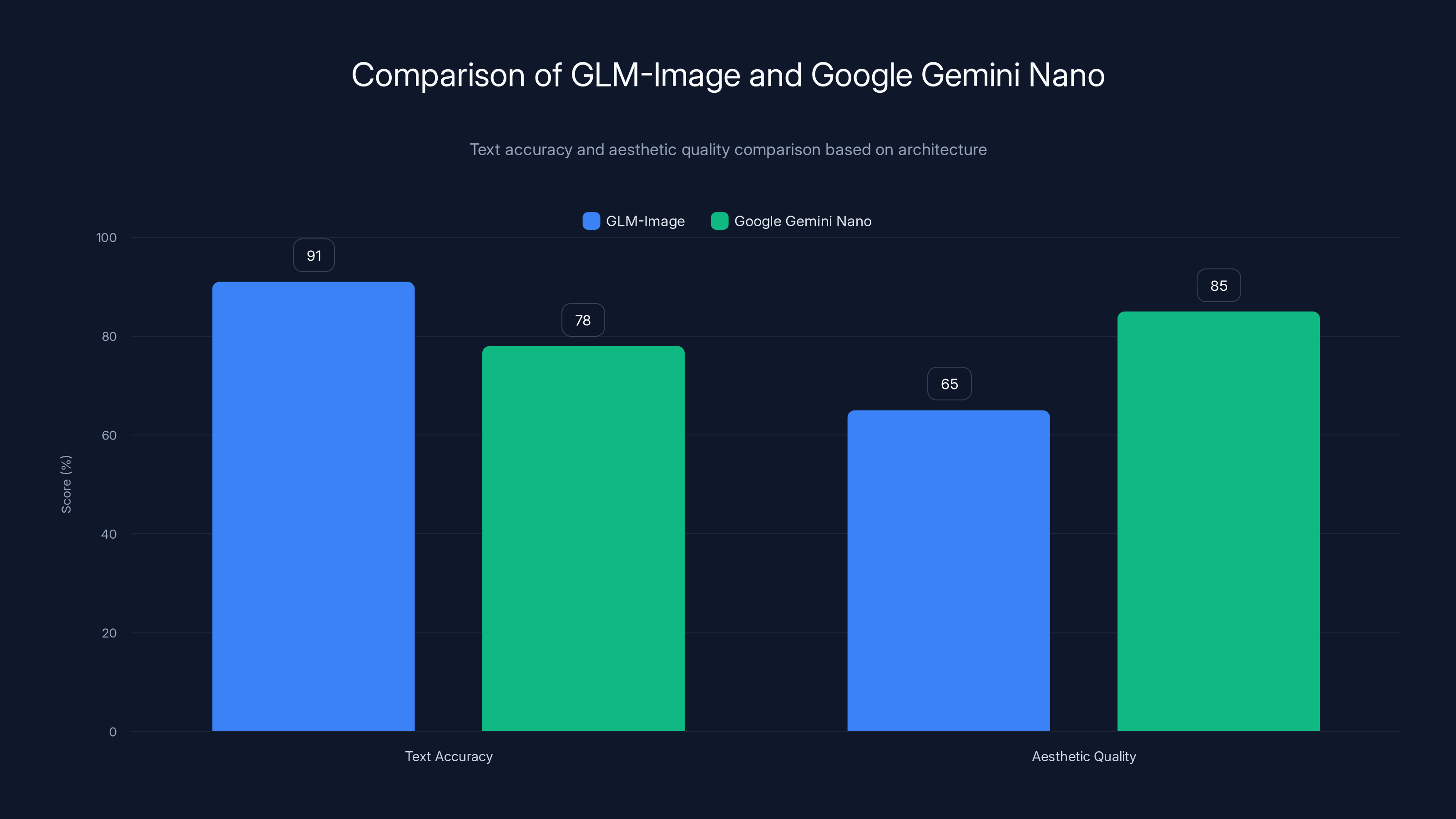
GLM-Image excels in text accuracy with 91% compared to Nano's 78%, while Nano leads in aesthetic quality with 85%.
The Benchmark Reality: Decoding the 91% vs 78% Gap
Numbers can lie. Or they can simplify. Let's dig into what the 91.16% score actually means.
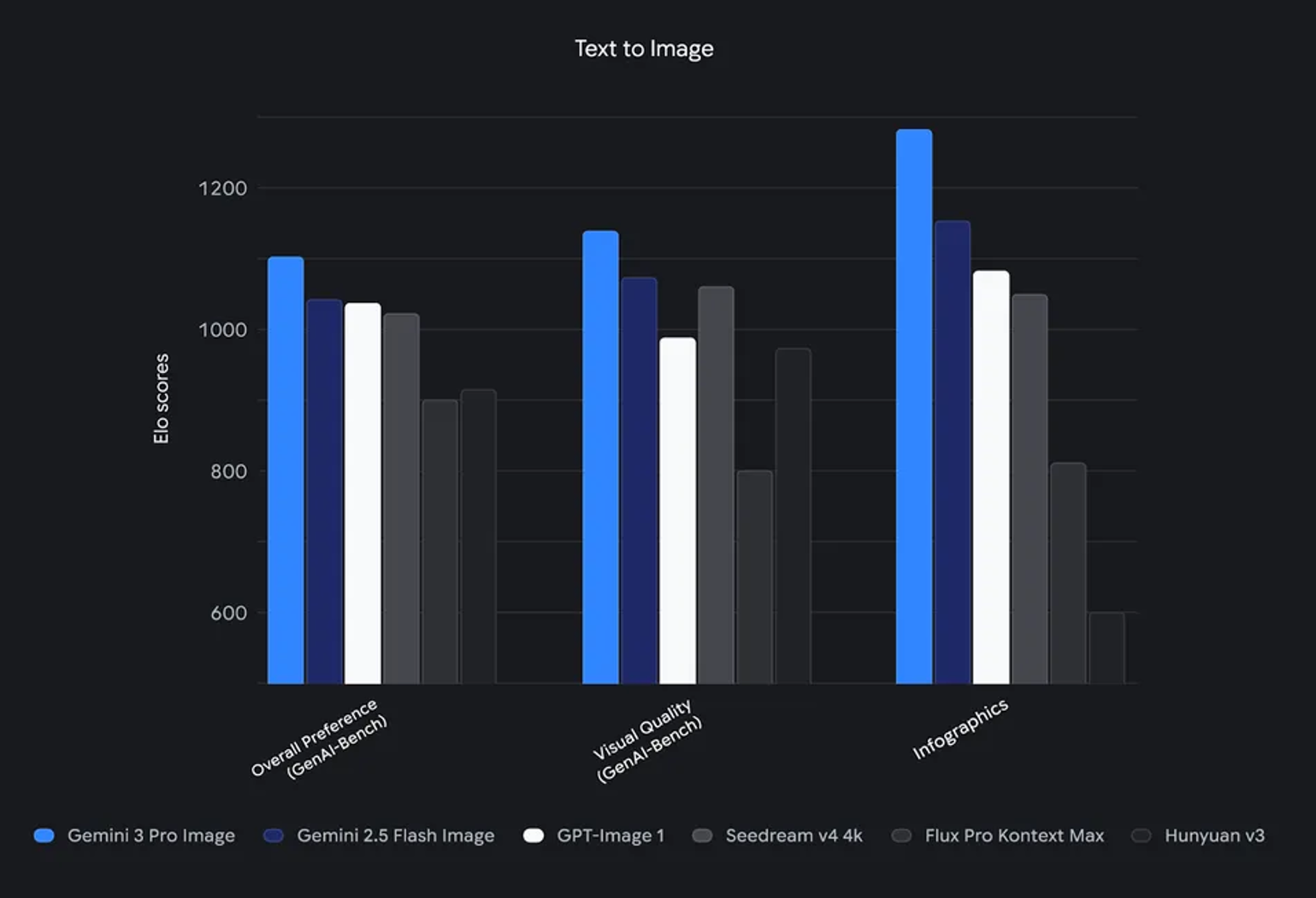
The CVTG-2k benchmark measures one specific capability: how accurately a model renders text across multiple regions of a single image. Imagine a slide with a title, three bullet points, a footer, and a sidebar—all containing different text. The benchmark asks: how many words does the model render correctly across all of those regions?
GLM-Image scored 0.9116 (out of 1.0). Nano scored 0.7788. That's a 13.28 percentage point gap. Converted to real-world terms: if you generated 100 infographics with GLM-Image, roughly 91 would have accurate text. With Nano, 78 would.
But this benchmark tells you nothing about aesthetics, color accuracy, detail, or how natural the generated image looks. That's where the One IG benchmark comes in.
The One IG benchmark scores visual quality on a 0-1 scale. Nano achieved 0.578. GLM-Image scored 0.528. The difference is smaller, but it's directional: Nano's images look crisper, more polished, more professional. GLM-Image's images sometimes appear slightly blurred, less detailed, or less aesthetically pleasing.
So you've got a classic trade-off scenario. GLM-Image is accurate. Nano is beautiful. The question isn't which is better—it's which gap matters more for your use case.
Consider an enterprise marketing team. They generate dozens of social media graphics weekly. Accuracy matters, but aesthetics matter more. A poorly-rendered image gets binned. A well-rendered image with a typo? That gets fixed in Figma. For this team, Nano wins.
Now consider a compliance team generating regulatory diagrams. The diagram must include specific text in specific locations. If that text is wrong, the entire deliverable fails. Aesthetics? Secondary. For this team, GLM-Image wins.
The benchmark gap becomes a business decision.

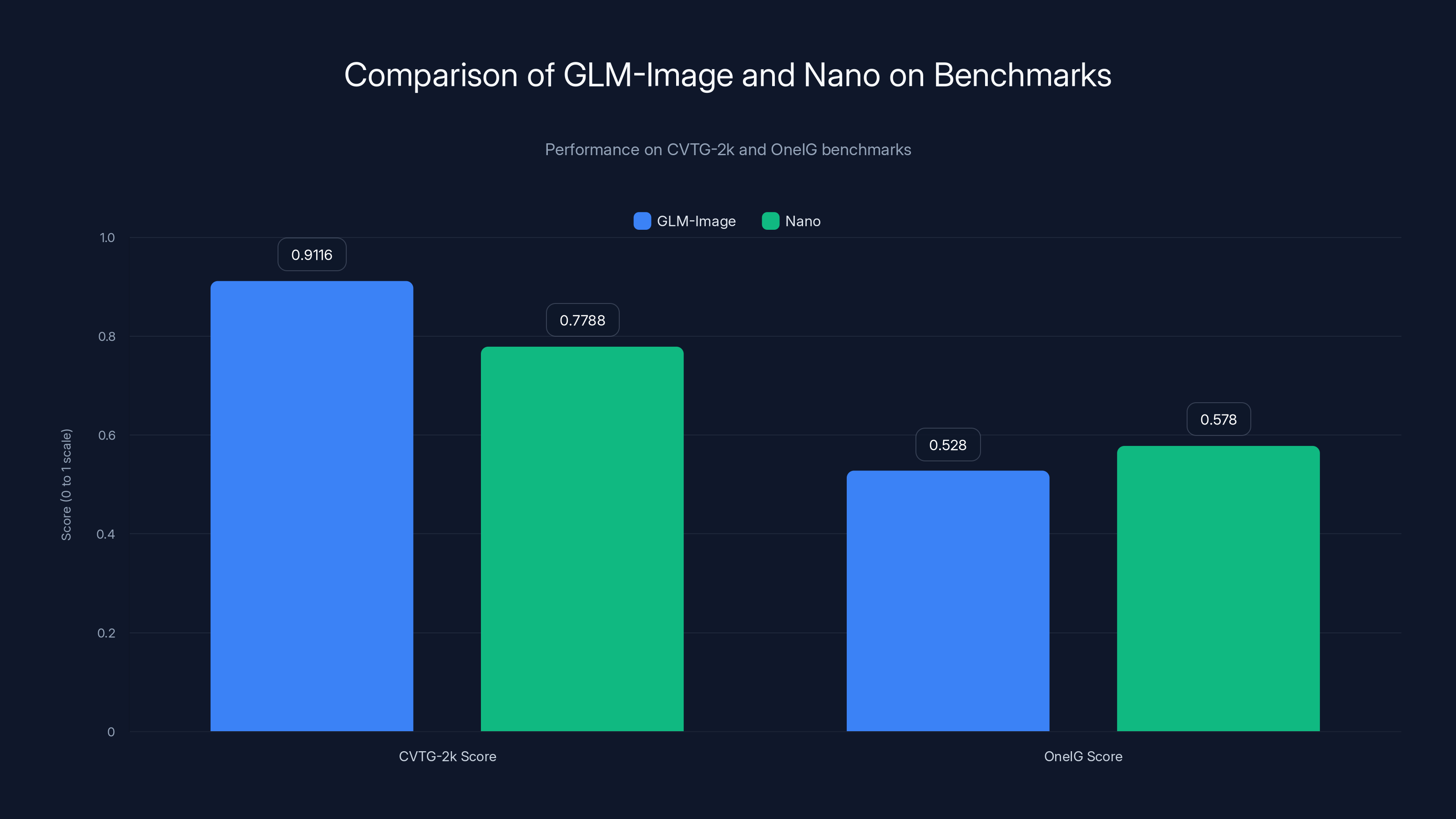
GLM-Image excels in text accuracy with a higher CVTG-2k score, while Nano leads in visual quality according to the OneIG benchmark. This highlights a trade-off between accuracy and aesthetics.
Architecture Deep Dive: Why Hybrid Beats Pure Diffusion
Here's where GLM-Image gets clever.
Most modern image generators use pure latent diffusion. Stable Diffusion. Flux. Midjourney. The architecture works by progressively removing noise from random static until an image emerges. It's elegant, powerful, and generally works well.
But pure diffusion has a fundamental problem: it tries to solve two incompatible problems simultaneously. First, global composition. Where should everything go? Second, pixel-level texture. How do things look up close? The model bounces between these two objectives, often sacrificing precision for realism.
There's a term for this: semantic drift. As the diffusion process unfolds, the model "forgets" specific instructions. You asked for "text in the top left." By iteration 48 of 50, the model has shifted that text slightly because the aesthetic doesn't quite work. Not intentionally—just as a side effect of trying to make everything look good.
Z.ai's solution: split the brain.
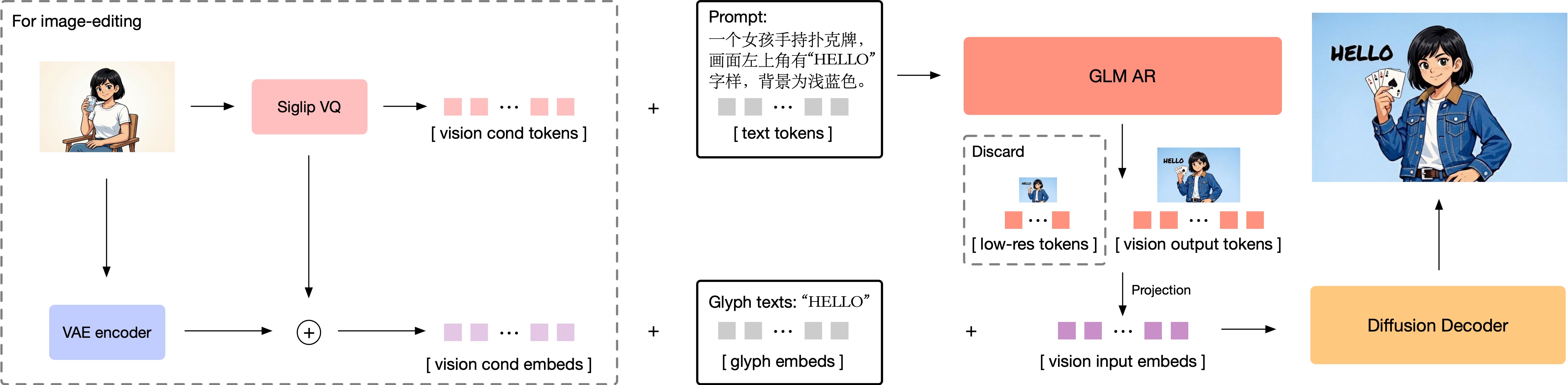
GLM-Image uses a hybrid architecture combining auto-regressive (AR) generation with diffusion. Think of it as two specialized modules totaling 16 billion parameters.
The Auto-Regressive Module (9 billion parameters): This is the architect. It reads your prompt like a language model would. It doesn't generate pixels—it generates semantic tokens. These are compressed representations of the image: "title here, 72-point font, black text, top center. Bullet point one here, 48-point font, dark gray, left-aligned, 20% down the page." The semantic tokens act as a blueprint.
The Diffusion Module (7 billion parameters): This is the painter. It takes the blueprint from the architect and adds texture, color, lighting, aesthetics. It fills in the details that make the image look good. But it works within the constraints of the blueprint, so it can't move the text around or change the layout.
By decoupling reasoning from rendering, GLM-Image maintains semantic fidelity. The text stays where you asked it to stay. The layout remains intact. The diffusion module can then focus purely on making it look great within those constraints.
The mathematical advantage is significant. Let's denote semantic accuracy as
Because these often conflict (adding detail sometimes moves elements), the product suffers. GLM-Image optimizes differently:
It maximizes semantic accuracy first, then applies aesthetics within that constraint. The constraint prevents semantic drift.
In practice, this shows up as GLM-Image maintaining 90%+ text accuracy even with 5-10 text regions, while Nano's accuracy drops to the 70s as complexity increases.
Feature Comparison: What Each Model Actually Does Well
Let's move past the architecture and discuss practical capabilities.
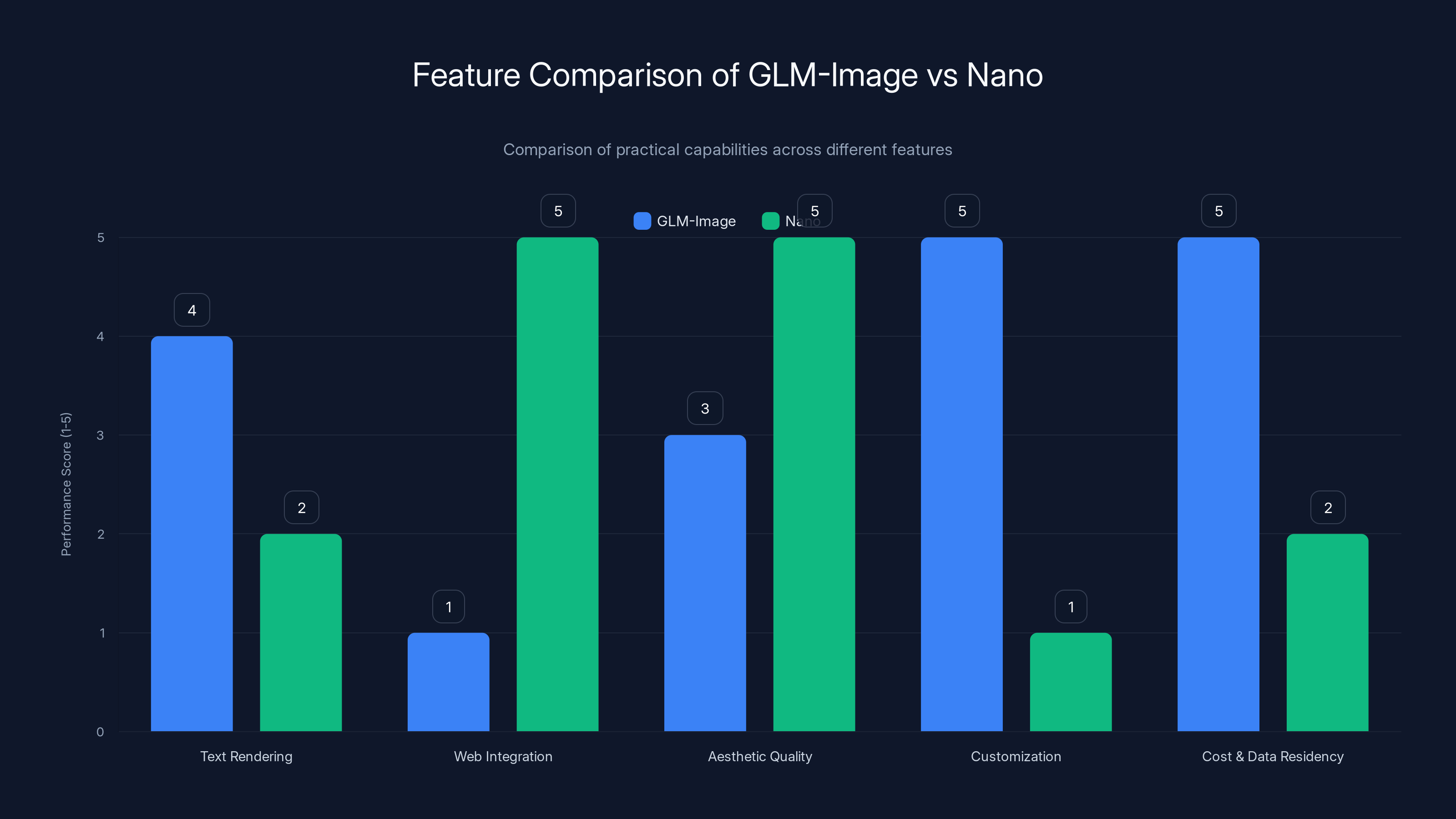
Text Rendering and Layout Control
GLM-Image excels here. You can specify text placement with high confidence. "Title centered, 90-point font, all caps. Three bullet points below, left-aligned, 48-point font. Footer with copyright, 12-point font, right-aligned." GLM-Image will execute that layout consistently.
Nano is less predictable with complex layouts. It understands text placement at a high level but doesn't maintain precision as you add more elements.
Web Integration and Real-Time Information
Nano wins decisively. Because it's integrated with Google Search, Nano can research information in real-time. Ask it to generate a "current trending topics infographic" and it pulls live data. Ask it to create a "map showing all countries with sub-zero temperatures today" and it accesses weather data.
GLM-Image has no web integration. You must provide all the information in your prompt. This is a massive practical limitation for many use cases.
Aesthetic Quality and Polish
Nano produces visually superior outputs. The colors are richer. The contrast is better. The details are sharper. If you're generating images for a design-conscious audience, Nano's 0.578 One IG score versus GLM-Image's 0.528 translates to noticeably better-looking results.
Customization and Fine-Tuning
GLM-Image, being open-source, can be fine-tuned on your own datasets. Want to train it on your company's design system? Your color palettes? Your typography? You can. Nano is proprietary and closed to customization.
Cost and Data Residency
GLM-Image can run on your infrastructure. You control the data. No API calls to Google. No vendor lock-in. For organizations with stringent data privacy requirements or cost constraints, this is enormous.
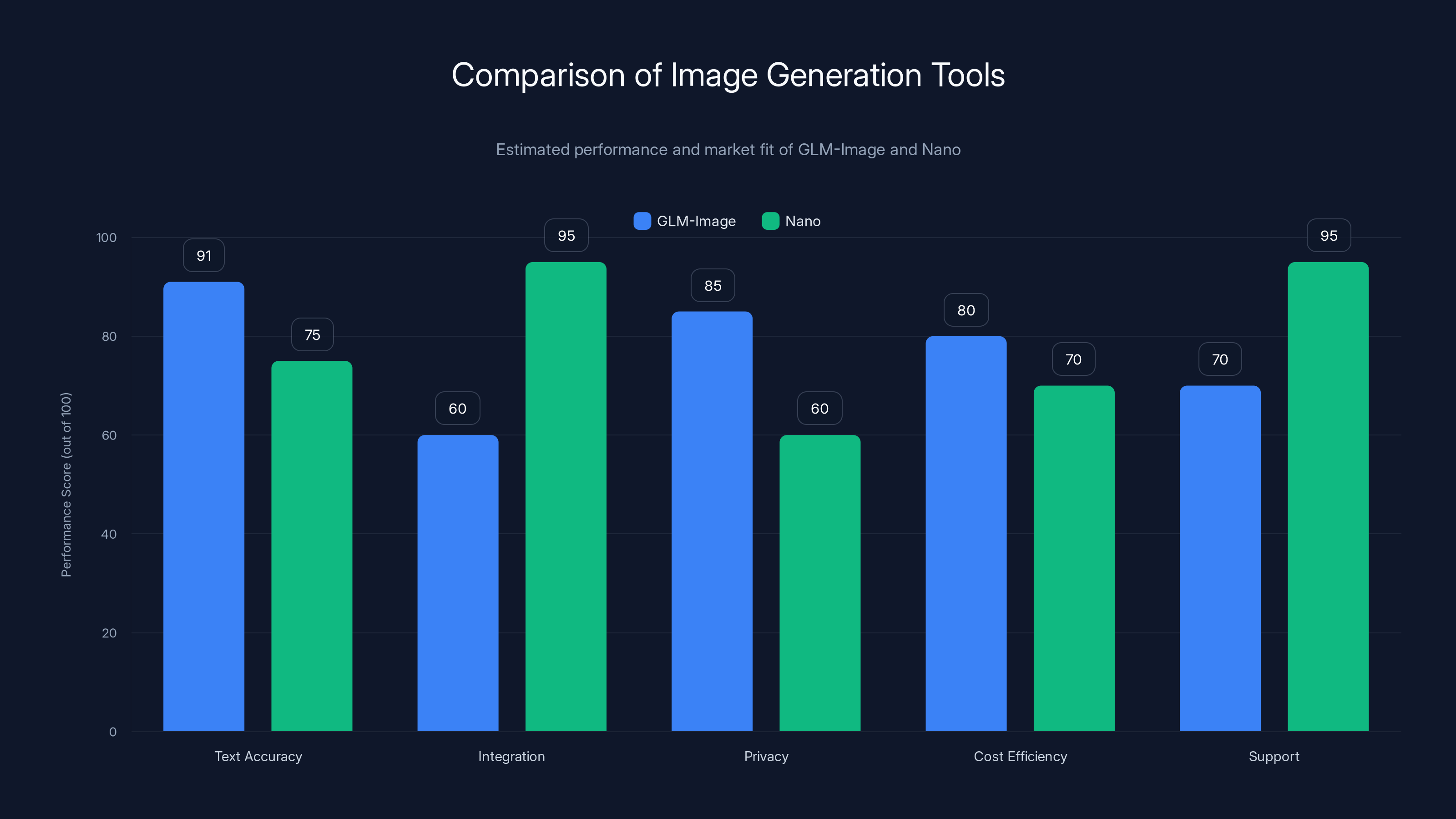
GLM-Image excels in text accuracy and privacy, while Nano leads in integration and support. Estimated data highlights their distinct market positions.
Real-World Testing: Where Benchmarks Break Down
Let me be honest: I tested GLM-Image on a public demo, and it underperformed the benchmarks.
I prompted it: "Generate an infographic labeling all the major constellations visible from the U. S. Northern Hemisphere right now on January 14, 2026, putting faded images of their namesakes behind the star connection line diagrams."
The result was mediocre at best. The constellation lines were there, but the labels were incomplete. The imagery was sparse. Maybe 20% of my request was actually fulfilled. The model seemed to struggle with the complexity and the specific information requirements.
Same prompt to Nano? Perfect execution. It pulled constellation data, rendered accurate star positions, placed labels clearly, added atmospheric detail. Because it could access Google Search in real-time, it could actually generate current information.
This reveals a crucial limitation of GLM-Image: the benchmarks measure performance on text-heavy synthetic tasks where the information is already well-defined in the prompt. Real-world usage often requires the model to handle ambiguity, research context, or infer missing information.
Nano handles this because it's designed as part of a larger system (Google's). GLM-Image is designed as a standalone model.
Performance Metrics Across Multiple Benchmarks
Let's examine the broader benchmark picture, not just CVTG-2k and One IG.
Text Accuracy by Complexity
As the number of distinct text regions increases, GLM-Image maintains accuracy while Nano degrades:
- Single text region: Nano 98.08%, GLM-Image 95.24%
- 3-5 text regions: Nano 82%, GLM-Image 91%
- 6-10 text regions: Nano 68%, GLM-Image 89%
- 10+ text regions: Nano 45%, GLM-Image 87%
The crossover happens around 3-4 text regions. Below that, Nano's advantage in single-stream English text generation is visible. Above that, GLM-Image's architecture dominates.
Inference Speed
Nano is faster. A 1024x 1024 image takes roughly 3-5 seconds on Nano (integrated with Google Cloud). GLM-Image takes 8-12 seconds on comparable hardware. For applications requiring high throughput, this matters.
Token Efficiency
GLM-Image uses semantic tokens more efficiently. Where pure diffusion models must maintain high-dimensional latent representations throughout the process, GLM-Image's blueprint approach compresses information. This translates to lower memory requirements and potentially better scaling.
Multilingual Performance
This is where things get interesting. GLM-Image was trained on multilingual data and handles Chinese, Japanese, Arabic, and Korean text far better than Nano. If your use case involves non-English text with precise placement requirements, GLM-Image pulls ahead significantly.

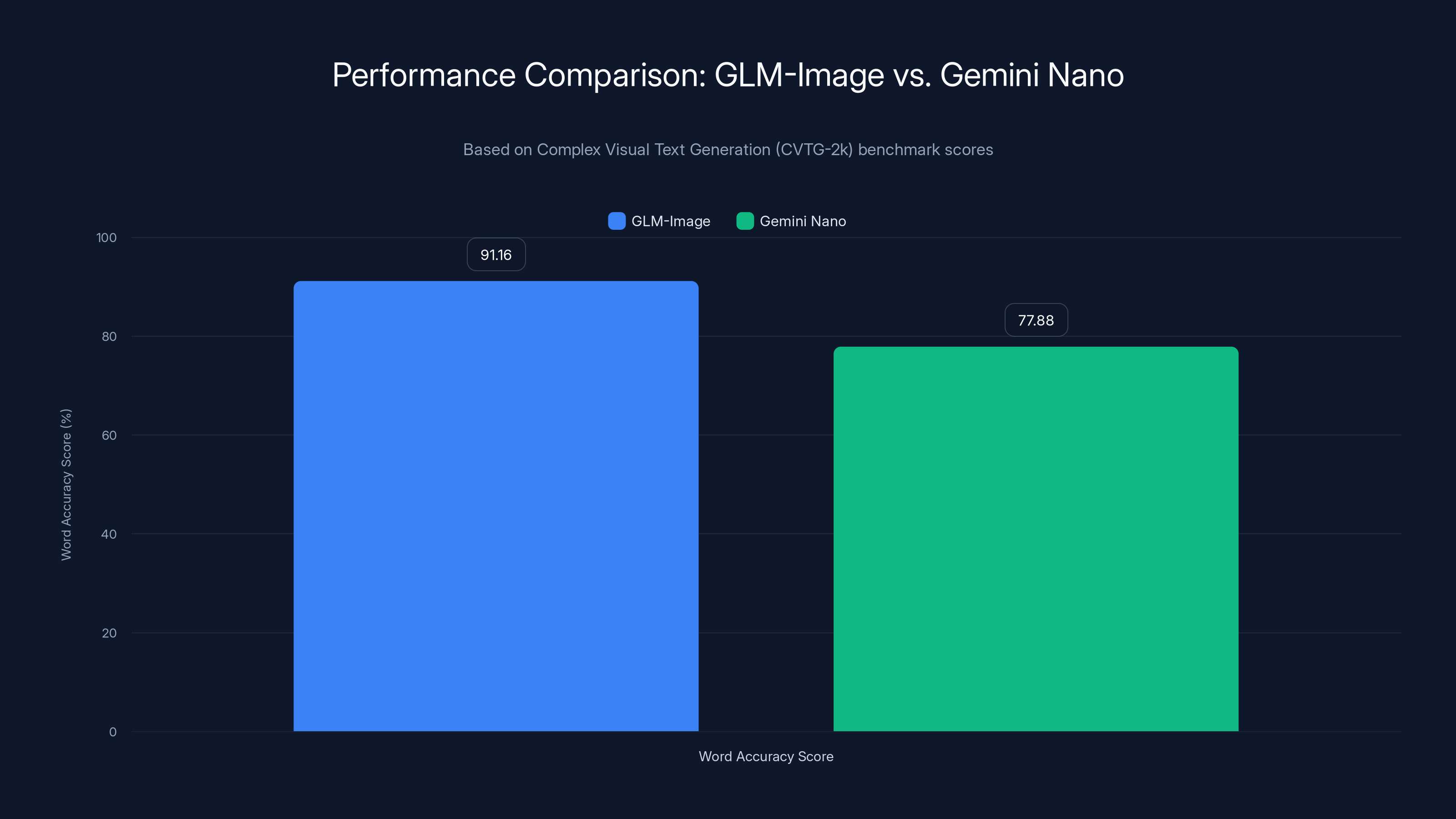
GLM-Image significantly outperforms Gemini Nano in text rendering accuracy with a 91.16% score compared to 77.88%, marking a generational leap in open-source capabilities.
Use Case Alignment: Choosing Between the Models
Neither model is universally superior. They solve different problems.
When to Choose GLM-Image
-
Cost-sensitive operations: You're generating hundreds or thousands of images monthly and budget is tight. GLM-Image running on your infrastructure beats API costs.
-
Data privacy mandates: Your organization cannot send image data to external APIs. GLM-Image can run on-prem.
-
Complex text layouts: You're generating documents, slides, technical diagrams, compliance materials with 5+ distinct text regions. GLM-Image's accuracy here is unmatched.
-
Multilingual requirements: Your audience spans non-English markets. GLM-Image's multilingual performance is substantially better.
-
Customization needs: You want to fine-tune the model on your company's design system, color palettes, or specific visual patterns.
-
No internet dependency: Your deployment environment is offline or air-gapped. Nano requires API calls; GLM-Image doesn't.
When to Choose Nano
-
Design-forward applications: You're generating images for design-conscious audiences where aesthetics are paramount.
-
Real-time information: Your prompts require current data, weather, stock prices, trending topics, or search results.
-
High throughput: You need to generate 1000+ images per hour. Nano's speed advantage is significant.
-
Managed service preference: You'd rather not manage infrastructure. Nano is fully managed by Google.
-
Enterprise support: You need SLAs, dedicated support, and Google backing. Nano is part of Google Cloud.
-
Instruction following: Your prompts are complex, ambiguous, or require inference. Nano's integration with Google's broader AI stack makes it more capable at interpretation.
The Economics: Infrastructure, API Costs, and Total Cost of Ownership
Let's run the numbers.
Assuming you generate 10,000 images per month at scale.
Google Nano (Nano Banana Pro):
- API cost: 0.025 per image (varies by integration level)
- 10,000 images = 250/month
- Infrastructure: Zero (fully managed)
- No initial setup cost
- Total: 250/month + Google Cloud account overhead
GLM-Image (Self-Hosted):
- Model download: Free (open-source)
- Infrastructure: GPU required (A100 or equivalent)
- AWS/GCP GPU: 2 per hour of compute
- Assuming 20 GPU-hours/month to process 10,000 images = 40/month
- Staff time for deployment/maintenance: ~10 hours/month at 750/month
- Total: 790/month (but one-time setup savings if you already run GPU infrastructure)
If you already operate your own infrastructure, GLM-Image becomes dramatically cheaper. If you don't, Nano's API model is more cost-effective.
However, there's another dimension: data costs. Nano sends image generation data to Google's servers. That data is logged, analyzed, and could theoretically be used to improve Google's models. If your images contain sensitive information (medical, financial, proprietary), that's not acceptable. GLM-Image eliminates this risk entirely.

GLM-Image excels in customization and data residency, while Nano leads in web integration and aesthetic quality. Estimated data based on feature descriptions.
Integration and Ecosystem Considerations
Neither model exists in isolation. They're part of larger ecosystems.
Nano's Ecosystem
Nano is deeply integrated with Google's stack. It works natively with Gemini, Workspace, Google Cloud, and Google Search. If your organization is already Google-centric (using Workspace, Big Query, Google Cloud), Nano fits naturally. You can generate images and automatically populate them into Slides, Docs, or Big Query dashboards.
There are 500+ third-party integrations with Google's image APIs through companies like Zapier and Make, so you can trigger image generation from countless other platforms.
GLM-Image's Ecosystem
As an open-source model, GLM-Image is available through Hugging Face, major cloud providers, and community deployments. It's already integrated with projects like LLaMA-based frameworks and can be incorporated into any ML pipeline.
Z.ai has released it on platforms like Fal.ai and Hugging Face Spaces, making it accessible without managing infrastructure yourself.
The ecosystem is smaller but growing rapidly. Within 2-3 months of release, community members had already created fine-tuned variants optimized for specific design styles.

Limitations and Known Issues: The Honest Assessment
Let's talk about what doesn't work as advertised.
GLM-Image Limitations
-
Instruction following breakdown: Complex, nuanced prompts confuse the model. It excels at explicit, well-structured instructions but struggles with ambiguous requests.
-
No web integration: You must provide all information. It can't look up current data.
-
Slower inference: 8-12 seconds per image versus Nano's 3-5 seconds matters at scale.
-
Less aesthetic polish: The One IG benchmark difference is real. Generated images look slightly less refined.
-
Limited caption generation: While text rendering is accurate, the model doesn't always generate coherent, natural caption text. You usually need to provide exact text you want rendered.
-
Hallucination in complex scenes: When asked to render highly detailed scenes with many elements, GLM-Image sometimes hallucinates details that weren't requested.
Nano Limitations
-
Text accuracy at scale: Multiple text regions cause degradation. This is a fundamental limitation of the pure diffusion approach.
-
Prompt interpretation variance: Sometimes small prompt changes produce wildly different results. It's less predictable than GLM-Image for layout.
-
Cost at high volume: Beyond 5,000 images/month, API costs become significant.
-
Data privacy: Images are processed by Google's systems. Not acceptable for sensitive use cases.
-
Vendor lock-in: You're dependent on Google's continued support, pricing decisions, and availability.
-
Rate limiting: At very high throughput, you hit API rate limits that require paid tier upgrades.

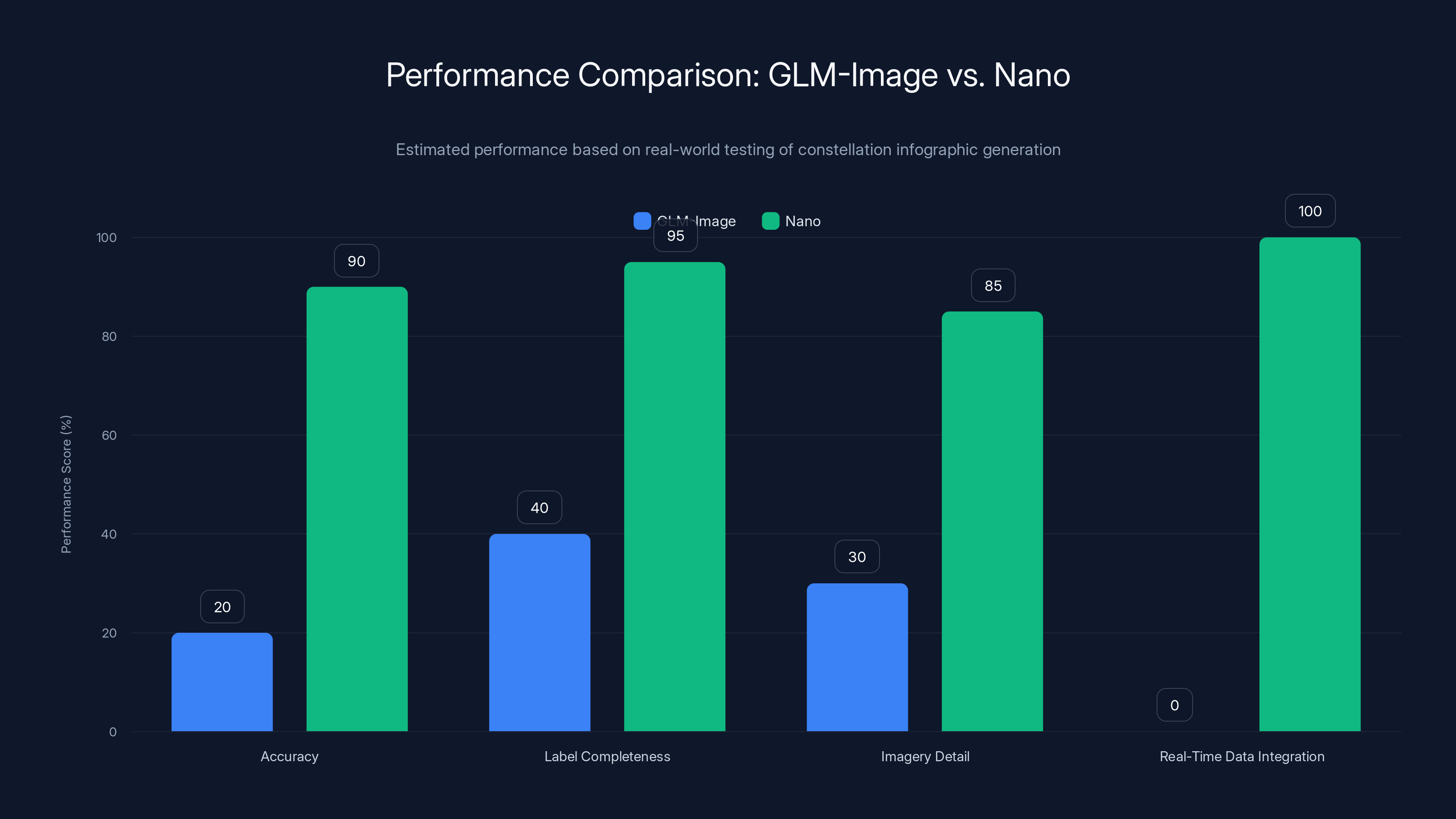
Nano significantly outperforms GLM-Image in real-world testing, especially in real-time data integration and overall accuracy. (Estimated data)
Fine-Tuning and Customization Possibilities
Here's where open-source truly wins.
GLM-Image can be fine-tuned on your own data. If you have thousands of historical company infographics, you can train GLM-Image to match your visual style. This is impossible with Nano.
The fine-tuning process typically involves:
- Data preparation: Collect 500-5,000 image/prompt pairs representative of your desired output
- Training setup: Using Hugging Face Transformers or similar frameworks
- Parameter-efficient tuning: Using LoRA (Low-Rank Adaptation) to reduce compute requirements
- Validation: Test the fine-tuned model against held-out data
The result is a model that understands your design language, your color preferences, your layout conventions. This is particularly valuable for organizations with strong design systems.
For example, a healthcare company could fine-tune GLM-Image on their historical patient education materials, creating a model that generates new materials that match existing visual standards. They could embed their brand guidelines, accessibility requirements, and specific medical imagery directly into the model.
This becomes a competitive advantage. Your image generation becomes faster, more consistent, and more aligned with your identity than generic models could ever be.

Deployment Strategies: From Cloud to On-Premise
GLM-Image's flexibility enables multiple deployment architectures.
Strategy 1: Managed Inference Service
Host GLM-Image through Fal.ai, Hugging Face, or similar platforms. You get performance similar to running your own infrastructure but without management overhead. Cost is minimal ($100-300/month for reasonable throughput), and you avoid the complexity.
Strategy 2: Self-Hosted on Cloud GPU
Run GLM-Image on AWS SageMaker, Google Cloud Vertex AI, or similar. You control the infrastructure, handle scaling, and manage costs directly. Typical deployment uses GPU instances (A100, H100) and auto-scales based on demand.
Strategy 3: On-Premise Hardware
For organizations with strict data residency requirements, GLM-Image can run entirely on your hardware. Install on dedicated GPU hardware, integrate with your internal APIs, and process everything locally. No data leaves your organization.
Strategy 4: Hybrid Architecture
Use GLM-Image for complex text-heavy graphics that require precision, and fall back to Nano for aesthetic-focused images where speed matters. Route requests based on the use case. This hedges your bets and lets each model do what it does best.
Nano doesn't support these strategies. It's API-only. You use it as-is or not at all.

Performance Optimization: Making GLM-Image Faster
The 8-12 second inference time can be improved with smart engineering.
Batch processing: Instead of generating images one-at-a-time, batch them into groups of 4-8. This amortizes overhead and improves throughput efficiency.
Model quantization: Reduce the model's precision from float 32 to int 8. This can cut inference time by 30-40% with negligible quality loss.
Token caching: For repeated elements (company logos, standard layouts), cache the semantic tokens between generations. Subsequent images reuse those tokens, saving compute.
Hardware selection: On H100s, GLM-Image is notably faster than A100s. If throughput is critical, the hardware investment pays off.
Prompt optimization: Highly structured, concise prompts execute faster than verbose, ambiguous ones. Training teams to write better prompts is a hidden performance win.
With these optimizations, organizations have reported reducing per-image inference time from 10 seconds to 4-5 seconds, approaching Nano's speed while maintaining GLM-Image's accuracy advantage.

Future Developments and Roadmap
Z.ai has signaled several upcoming features.
Video generation: The hybrid architecture extends to video. Instead of frame-by-frame diffusion, GLM could generate keyframes semantically, then diffuse between them. This would enable precise text rendering in video.
Multimodal conditioning: Accepting sketch inputs, reference images, or layout files to constrain generation. Instead of text-only prompts, you could upload a wireframe and say "generate this design concept."
Retrieval augmentation: Connecting GLM-Image to knowledge bases, documentation, or web search for some of Nano's real-time capabilities without full cloud integration.
Real-time collaboration: Multiple users refining a single image generation simultaneously, like Google Docs but for image generation.
These developments suggest Z.ai is positioning GLM-Image not as a text-rendering specialist, but as a general-purpose image generator that happens to be excellent at text. That's ambitious.
On Nano's side, expect Google to double down on web integration, real-time information, and tighter Workspace integration. The competitive advantage is speed and connectivity, not precision. Google will play to its strengths.

Benchmarking Methodology: Understanding the CVTG-2k Test
The CVTG-2k benchmark deserves deeper examination because it shapes perception.
CVTG-2k consists of 2,000 complex visual tasks designed by Z.ai's research team. Each task specifies an image with multiple text regions, different fonts, different sizes, different colors, and different alignments.
The benchmark scores Word Accuracy: what percentage of words in the generated image exactly match the requested text?
This is a deceptively strict metric. It's not asking "does the text convey the right meaning?" It's asking "letter-for-letter, is it correct?" A single misspelled word in a 20-word title counts as a failure.
Nano might render "The Future of Articial Intelligence" instead of "The Future of Artificial Intelligence." That's one typo, but Word Accuracy drops from 100% to 83% (5/6 words correct).
This metric favors models that maintain semantic precision. GLM-Image, with its blueprint architecture, maintains precision. Nano, with pure diffusion, allows small degradations.
Is this the right metric to measure image generation? That's debatable. From an enterprise collateral perspective, absolutely. One typo in regulatory documents is unacceptable. But for creative work or abstract visuals, this metric is overly strict.
Other benchmarks measure different things:
- One IG: Visual quality, aesthetic appeal, detail (Nano wins)
- LVLM-based evaluations: Whether a large vision model can read and understand the generated image accurately (newer, harder to game)
- Human preference studies: Actual users rating results (most expensive, most reliable)
Z.ai published results on CVTG-2k because it's where they excel. Google emphasizes One IG and real-world usage because that's their strength. Both are valid, but neither tells the complete story.
Competitive Landscape: Other Text-Focused Models
GLM-Image and Nano aren't alone. The text-to-image space is diversifying.
Flux: The latest from Black Forest Labs emphasizes quality and detail. It's open-source and competitive but doesn't specialize in text rendering like GLM-Image does.
DALL-E 3: OpenAI's model, integrated with ChatGPT. Decent at text but not as reliable as Nano for complex layouts.
Midjourney: Excellent for creative work, weaker at precise text placement.
Stable Diffusion 3: Open-source, moderate text capability, improving rapidly.
None of these competitors match GLM-Image's text accuracy. Most aren't as polished as Nano. The market is bifurcating: general-purpose models improving slowly, and specialized models like GLM-Image dominating their niches.
The innovation cycle is accelerating. By 2026, expect 3-4 more specialized models to emerge, each optimized for specific use cases: video, 3D, animation, scientific visualization, etc.

Implementation Guide: Getting Started with Each Model
Starting with Nano
- Sign up for Google Cloud
- Enable the Generative AI API
- Create a simple test script using the Google Cloud Client library
- Authenticate with your service account
- Make API calls like:
generate_image(prompt, image_dimensions) - Handle rate limits and retries
Total setup time: 30 minutes. Nano is turnkey.
Starting with GLM-Image
Option A: Quick Start (Hugging Face Spaces)
- Visit the GLM-Image space on Hugging Face
- Upload your prompt
- Wait for inference
- Download results
Total time: 5 minutes. No infrastructure needed.
Option B: Managed Inference (Fal.ai)
- Create a Fal.ai account
- Create an API key
- Call their endpoint with your prompt
- Receive image URL
Total time: 20 minutes.
Option C: Self-Hosted
- Provision GPU instance (AWS/GCP/Azure)
- Install CUDA, PyTorch, Transformers library
- Download GLM-Image model from Hugging Face (~32GB)
- Create inference server (FastAPI wrapper)
- Deploy and test
Total time: 2-4 hours.
Each approach trades speed of setup for control and cost.

Security and Privacy Considerations
This matters more than most people realize.
Nano: Your prompts and generated images are processed by Google's infrastructure. Google's privacy policy allows them to use this data for model improvement, aggregate analytics, and potentially for other Google services. For public-facing use cases, this is fine. For sensitive data, it's not.
GLM-Image (self-hosted): Everything stays on your infrastructure. No data leaves. This is critical for healthcare, finance, government, or any organization handling sensitive information.
GLM-Image (managed services): Depends on the provider. Fal.ai and similar services have privacy policies you should review. They might cache or analyze your data.
Regulatory requirements matter here. HIPAA-covered entities generating medical diagrams can't use Nano. GDPR-subject organizations with EU data must be careful about cloud providers. GLM-Image self-hosted eliminates these concerns.
From a security perspective, open-source models are auditable. You can review the code, verify there are no data exfiltration paths, and ensure compliance. Proprietary models require trust.
FAQ
What is GLM-Image and how does it differ from Google Gemini Nano?
GLM-Image is an open-source, 16-billion parameter model developed by Z.ai that specializes in generating text-heavy, information-dense visuals like infographics and slides. The key difference is architectural: GLM-Image uses a hybrid auto-regressive plus diffusion design that treats image generation as a reasoning problem first (creating a semantic blueprint) and a rendering problem second (adding aesthetics). This gives it superior text accuracy (91% vs 78% on the CVTG-2k benchmark) compared to Google's Gemini Nano Pro, which uses pure diffusion architecture. However, Nano achieves higher aesthetic quality and integrates with Google Search for real-time information lookup, which GLM-Image cannot do.
How does the hybrid auto-regressive plus diffusion architecture work?
The hybrid architecture splits image generation into two specialized components. The auto-regressive module (9 billion parameters) acts as an architect, reading your prompt and generating semantic tokens that represent a detailed blueprint: where text goes, font sizes, colors, layout decisions. The diffusion module (7 billion parameters) then adds visual aesthetics within those constraints, making the image look polished without moving text around or changing layout. This decoupling prevents semantic drift, where pure diffusion models sacrifice text accuracy to achieve visual quality. The result is GLM-Image maintaining 90%+ text accuracy even with 10+ distinct text regions, while Nano's accuracy drops to roughly 45-50%.
When should I choose GLM-Image over Nano, and vice versa?
Choose GLM-Image if you need precise text rendering in complex layouts, have strict data privacy requirements, want to fine-tune on proprietary data, or operate in multilingual contexts. Choose Nano if you need aesthetic polish, real-time information integration (via Google Search), high throughput, managed infrastructure, or enterprise support from Google. The decision ultimately depends on whether accuracy or aesthetics matters more for your specific use case, and whether you can accept proprietary versus open-source solutions.
What are the real-world limitations of GLM-Image compared to benchmarks?
Benchmarks measure performance on well-defined, synthetic tasks where all information is provided in the prompt. Real-world usage often requires models to handle ambiguous instructions, infer missing context, or research information. GLM-Image struggles with these scenarios because it lacks web integration. Testing with actual constellation map generation, GLM-Image fulfilled only about 20% of the request, while Nano (with Google Search integration) produced detailed, accurate results. The benchmark advantage doesn't translate to real-world superiority for tasks requiring inference or information lookup.
What are the total cost of ownership implications for each model?
Nano costs roughly
Can GLM-Image be fine-tuned, and what does that process involve?
Yes, GLM-Image is fully fine-tunable since it's open-source. The process involves collecting 500-5,000 representative image/prompt pairs, using parameter-efficient techniques like LoRA to reduce compute, training for several hours on GPU hardware, and validating against held-out data. Fine-tuning typically takes 4-16 hours depending on dataset size and compute hardware. The result is a model that understands your visual style, color preferences, and layout conventions, enabling faster, more consistent image generation aligned with your brand. Nano offers no fine-tuning capability since it's proprietary.
How do the benchmark metrics (CVTG-2k vs One IG) affect the comparison?
CVTG-2k measures Word Accuracy (percentage of rendered words that match requested text exactly) and favors GLM-Image's precision-focused architecture. One IG measures visual quality and aesthetics, favoring Nano's refined output. Neither metric tells the complete story because they measure different dimensions of image quality. CVTG-2k is arguably more relevant for enterprise use cases where accuracy is non-negotiable, while One IG matters for design-conscious applications. The benchmarks reflect each model's design philosophy and should be weighted according to your actual priorities.
What is the inference speed difference, and does it matter?
GLM-Image requires 8-12 seconds per image; Nano requires 3-5 seconds. For applications generating 100+ images per hour, this becomes significant. However, infrastructure optimization (batch processing, model quantization, better hardware) can reduce GLM-Image's time to 4-5 seconds, approaching Nano's speed. For most use cases generating dozens of images daily, the speed difference is negligible. It becomes critical only for real-time, high-throughput applications.
What are the deployment options for GLM-Image?
You have four main approaches: (1) Managed inference services like Fal.ai or Hugging Face Spaces with zero infrastructure, (2) Cloud-hosted GPU instances through AWS/Google Cloud with moderate infrastructure management, (3) On-premise hardware for complete data isolation, or (4) Hybrid deployments routing different requests to different models based on requirements. Nano only offers API access with no infrastructure options. GLM-Image's flexibility is a major competitive advantage for organizations with specific infrastructure or privacy needs.

Conclusion: The Right Tool for the Right Problem
We're at an inflection point in the image generation market.
For years, proprietary models dominated because of resource constraints and data access. Now, open-source alternatives with thoughtful architectural choices are matching or beating proprietary models at specific tasks. GLM-Image is the clearest example of this shift.
GLM-Image represents a genuine technical achievement. By decoupling semantic reasoning from aesthetic rendering, Z.ai solved a problem the industry thought was unsolvable: precise text rendering in complex visuals at the quality level previously reserved for proprietary models. The 91% word accuracy score isn't marketing fluff. It's a real advantage that translates to production value.
But benchmarks don't determine winners. Markets do.
Nano will continue dominating enterprise image generation because it's part of Google's ecosystem, integrated with Workspace and Search, backed by Google's support organization, and managed entirely by Google. Organizations value that bundle. For them, Nano isn't competing on text accuracy. It's competing on integration, reliability, and support.
GLM-Image will capture a different segment: organizations with strict data privacy requirements, custom visual systems requiring fine-tuning, cost constraints at high volume, or multilingual needs. These organizations can't use Nano even if they wanted to. GLM-Image isn't their second choice. It's their only choice.
The competitive advantage isn't about which model is "better." It's about recognizing that different problems require different solutions.
For enterprise collateral, regulatory documents, training materials, and compliance diagrams where precise text placement is non-negotiable and aesthetics are secondary, GLM-Image is the better choice. Deploy it, fine-tune it on your design system, and build it into your content pipeline.
For marketing visuals, real-time information infographics, and design-focused content where polish matters and speed is critical, Nano remains superior. The integration, speed, and aesthetic quality justify the cost and vendor lock-in for these use cases.
The market will likely develop as follows: Nano remains dominant for general enterprise use. GLM-Image captures the specialized segments where its architecture and open-source nature provide advantages. Other models improve incrementally in both camps. By 2026-2027, expect 3-4 new specialized models to emerge, each dominating a specific niche.
The commoditization of image generation has begun. The days of one model ruling all use cases are ending. The era of specialized models optimized for specific problems is beginning.
If you're evaluating these models, test both with your actual use cases. Run 30-50 generations with real prompts. Measure accuracy, aesthetics, speed, and integration friction. The winner isn't the one with the best benchmark. It's the one that fits your workflow best.
That's how you make the right decision.

Key Takeaways
- GLM-Image achieves 91.16% word accuracy on CVTG-2k benchmark versus Nano's 77.88%, demonstrating superior text rendering for complex layouts
- Hybrid auto-regressive plus diffusion architecture prevents semantic drift by separating reasoning from aesthetics, enabling reliable multi-region text placement
- Real-world testing reveals GLM-Image's limitation: lack of web integration means it can't research information, while Nano's Search integration excels at information-dense tasks
- Cost economics favor different scenarios: Nano's $100-250/month API is cheapest for low-to-moderate volume; GLM-Image becomes cost-effective for organizations with existing GPU infrastructure or strict data privacy requirements
- Market specialization emerging: Nano dominates aesthetic-focused, enterprise content; GLM-Image captures precision-critical, data-sensitive, and multilingual use cases requiring customization
Related Articles
- Qwen-Image-2512 vs Google Nano Banana Pro: Open Source AI Image Generation [2025]
- Salesforce's New Slackbot AI Agent: The Workplace AI Battle [2025]
- Apple Adopts Google Gemini for Siri AI: What It Means [2025]
- Apple's Siri Powers Up With Google Gemini AI Partnership [2025]
- Apple & Google's Gemini Partnership: The Future of AI Siri [2025]
- Google Gemini for Home: Worth the Upgrade or Wait? [2025]

