Gmail Spam and Email Misclassification Issues: What Went Wrong and How to Fix It [2025]
Something broke in Gmail's filter system. And it broke badly.
On Saturday morning in January 2025, Gmail users woke up to a nightmare scenario: inboxes flooded with spam, legitimate emails mysteriously vanishing into junk folders, and spam warnings appearing on messages from trusted contacts. The problem wasn't limited to a handful of users either. The official Google Workspace status page lit up like a Christmas tree, confirming that millions of users were experiencing the same frustrating issue simultaneously.
This wasn't a minor hiccup. This was a complete collapse of Gmail's AI-powered email classification system. And it exposed something we don't talk about enough: how fragile email infrastructure really is, and how dependent we've become on algorithmic gatekeeping.
Let me break down what happened, why it matters, and what you can actually do about it.
TL; DR
- Gmail's spam filters crashed on January 24, 2025, causing legitimate emails to land in spam and spam to flood inboxes
- The issue affected millions of users simultaneously across Google Workspace
- Classification algorithms failed because they likely encountered unusual email patterns they weren't trained on
- Root cause remains unclear, but machine learning systems are vulnerable to sudden shifts in data
- Manual intervention is your best defense while relying less on automated filters

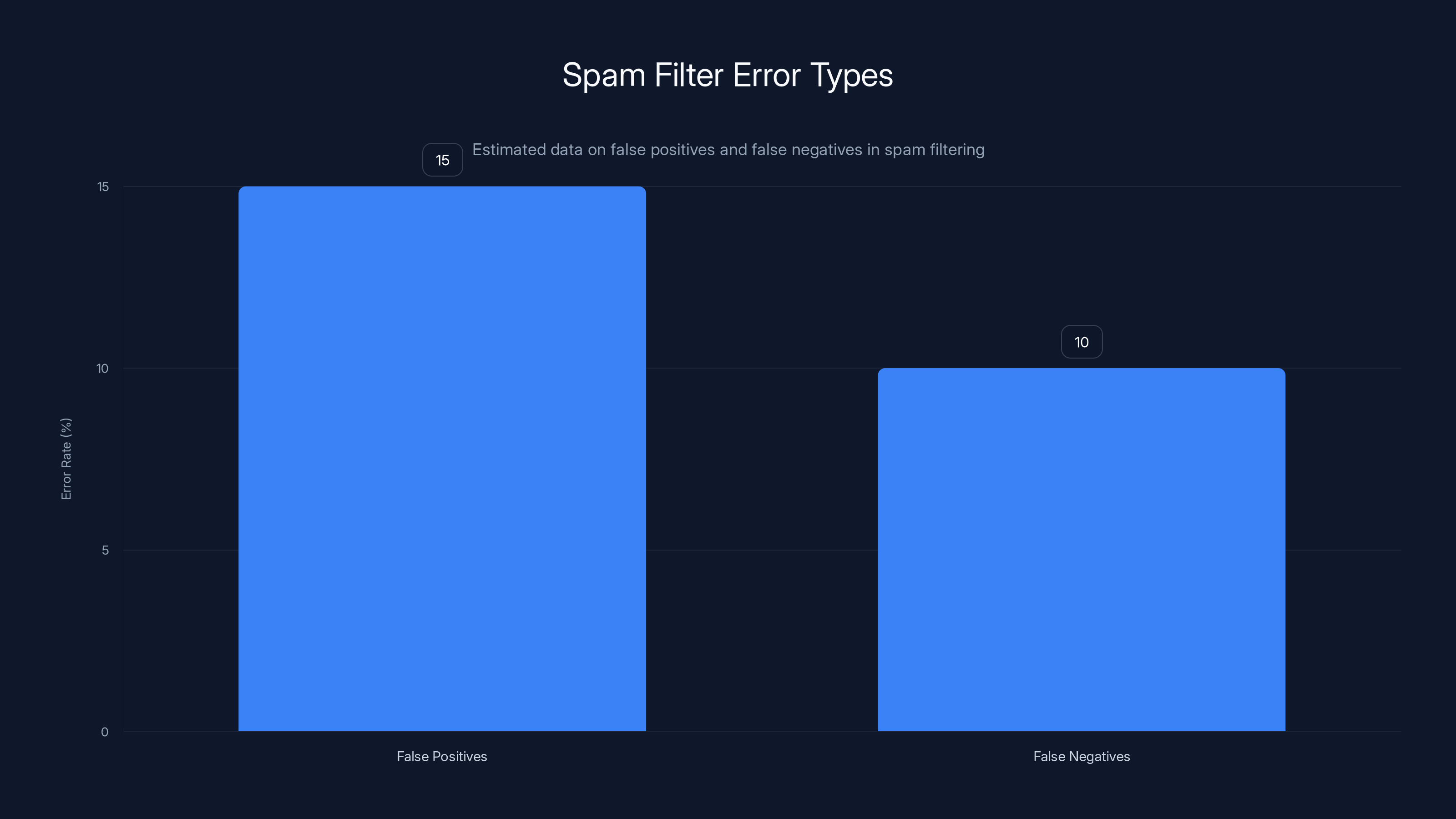
Estimated data suggests that false positives in spam filtering are slightly higher than false negatives, highlighting the challenge of balancing email accuracy.
What Actually Happened to Gmail on January 24, 2025
Around 5 AM Pacific on Saturday, January 24, 2025, something went catastrophically wrong inside Google's email infrastructure. The official Google Workspace status page reported two distinct problems:
First, users began reporting misclassification of emails. Emails that should have landed in the Primary inbox were getting sorted into Promotions, Social, or Updates tabs. More than that, emails from known senders—people you communicate with regularly—started ending up in the spam folder entirely.
Second, spam warnings began appearing on legitimate emails. Users were seeing warning banners and security alerts on messages from trusted contacts, family members, and business partners. The system was essentially telling them that emails from people they know well might be dangerous.
The combination was devastating. Not only were people missing important messages, but they were also being told that their trusted contacts were suddenly suspicious. It created a trust problem on top of a filtering problem.
Social media erupted with complaints. Users reported that "all the spam is going directly to my inbox." Others said Gmail's filters "seemed suddenly completely busted." One common thread: people were experiencing this simultaneously, which meant it wasn't a local issue or user error. It was systemic.
Google's response was measured but vague: "We are actively working to resolve the issue. As always, we encourage users to follow standard best practices when engaging with messages from unknown senders."
Which is corporate-speak for: "We broke it, we're fixing it, and in the meantime, be careful out there."
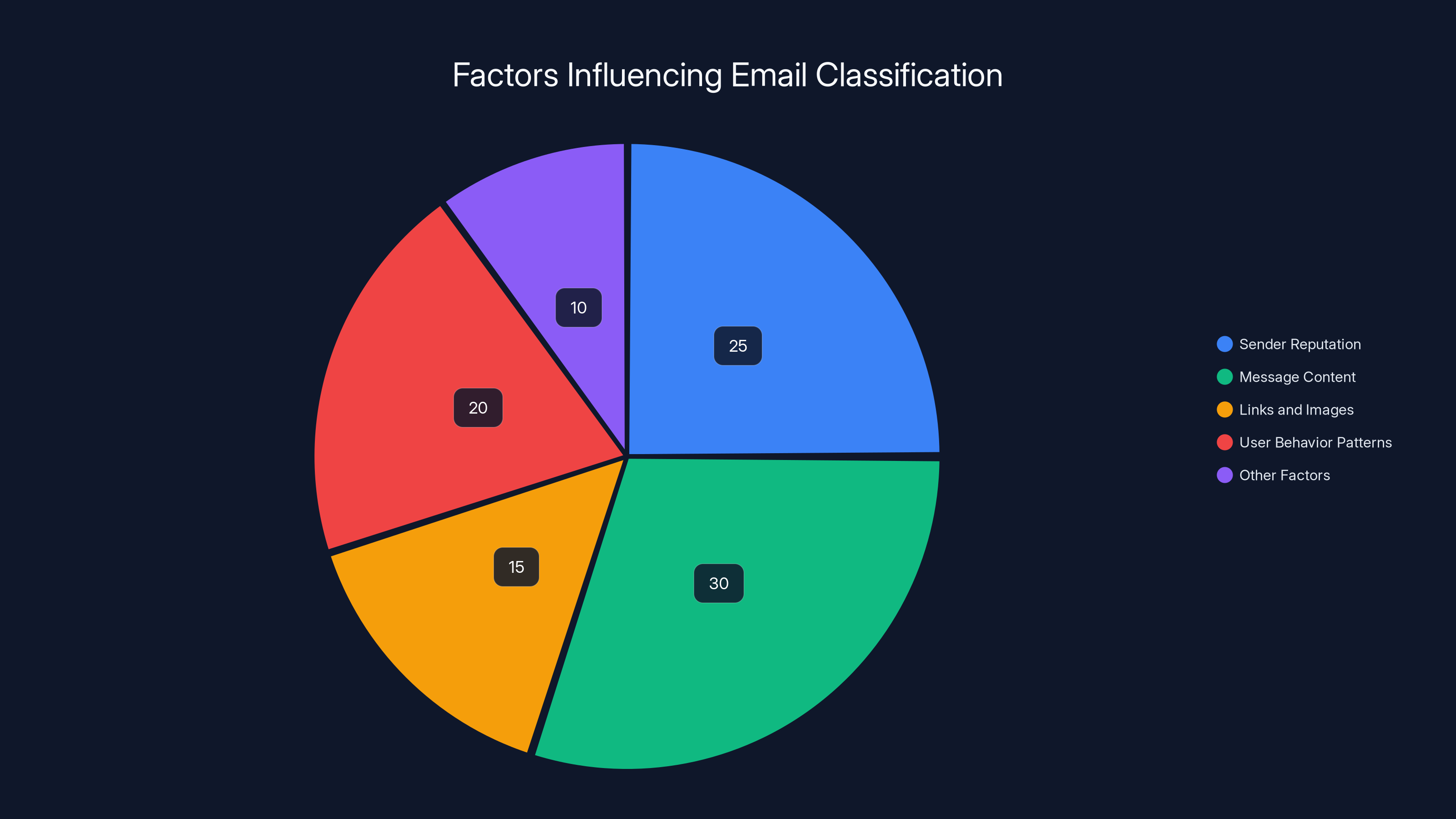
Modern email classification systems rely on a variety of factors, with message content and sender reputation being the most significant. (Estimated data)
Why Email Classification Is Harder Than You Think
Here's the thing most people don't realize: email filtering isn't just a simple rule-based system anymore. It hasn't been for years.
Modern email classification relies on machine learning models that analyze hundreds of signals to determine whether an email is legitimate or spam. These systems look at sender reputation, message content, links, images, user behavior patterns, and dozens of other factors in milliseconds.
Google's system in particular is extremely sophisticated. It's had over two decades to learn patterns from billions of emails. The models are trained on massive datasets of spam and legitimate email, constantly updated with new variations of attacks, phishing attempts, and marketing tricks.
But here's where it gets fragile: these models are only as good as the data they were trained on.
When the classification system fails spectacularly like it did on January 24, it usually means one of a few things happened:
1. A sudden shift in email patterns the model wasn't prepared for. Maybe there was a coordinated email campaign from legitimate sources that resembled spam patterns. Maybe a major event (like a widespread service outage) caused a surge in notification emails that confused the classifier. Maybe some infrastructure change caused legitimate emails to be formatted differently than expected.
Machine learning models are brittle in ways we don't always talk about. They work beautifully when data looks like what they were trained on. But when something novel appears, they can fail catastrophically.
2. A bug in the production pipeline. It's possible—maybe even likely—that the issue was caused by a bad code deployment or a misconfigured parameter in one of the classification models. A single engineer's commit could have shipped a version of the model with weights that were slightly off, or a pipeline that was routing emails to the wrong classification branch.
Google runs thousands of tests before deployment, but with systems this complex, edge cases slip through.
3. A hardware failure affecting model inference. Large-scale machine learning systems depend on specialized hardware (TPUs, GPUs) running inference at incredible speed. If a cluster of this hardware failed, or if a failover to backup systems didn't work properly, the fallback model might have been significantly worse at classification.
4. A training data poisoning or feedback loop issue. Users rely on the "Report as spam" and "Not spam" buttons to help Gmail improve its filters. If something went wrong with how that feedback was being processed—if user reports were being applied incorrectly, or if automated processes were misclassifying emails at scale and those errors were feeding back into the training loop—the entire system could degrade rapidly.
This is called a feedback loop failure, and it's one of the scariest failure modes for machine learning systems because it's self-reinforcing. Bad predictions lead to bad training data, which leads to worse predictions.

The Spam Folder Paradox: Why Legitimate Email Gets Blocked
One of the most frustrating aspects of the Gmail outage was that legitimate emails were being treated as spam while actual spam flooded inboxes. This seems contradictory, but it actually reveals something important about how spam filters work.
Modern spam detection uses a probabilistic approach. Instead of saying "this email is definitely spam" or "this email is definitely legitimate," the system assigns a probability score. An email might be 78% likely to be spam, or 23% likely to be spam.
The filter uses a threshold: anything above a certain probability gets flagged or sent to spam. If that threshold gets miscalibrated—set too high or too low—you get exactly what happened: either everything looks like spam, or nothing looks like spam.
It's also possible the models got inverted somehow. Imagine if a neural network's final output layer accidentally got flipped. High spam probability could have been interpreted as high legitimacy probability, and vice versa. It sounds absurd, but software bugs can be absurd.
There's also the issue of false positives vs. false negatives.
A false positive is when legitimate email gets marked as spam. A false negative is when spam gets through to your inbox. These two errors exist in tension. Tightening filters to catch more spam (reducing false negatives) usually means catching more legitimate email too (increasing false positives). Loosening filters to let legitimate email through usually means letting more spam through as well.
Google historically errs on the side of caution: it tries to minimize false positives because missing an important email is worse than letting some spam through. But something clearly shifted in their algorithms.
When the system fails, you get both kinds of errors simultaneously: spam floods in, and legitimate mail gets blocked. It's the worst of both worlds.
The warning banners appearing on legitimate emails suggests that a separate authentication scoring system was also involved in the breakdown. Gmail uses several authentication mechanisms:
SPF (Sender Policy Framework) tells Gmail which servers are authorized to send mail for a domain. DKIM (Domain Keys Identified Mail) signs emails with cryptographic keys to prove they came from the claimed domain. DMARC (Domain-based Message Authentication, Reporting and Conformance) ties SPF and DKIM together into a coherent policy.
If these checks were being incorrectly applied—if DKIM signatures that should have verified were reported as failing, or if SPF records were being checked against outdated data—then legitimate emails would get security warnings even though they're actually legitimate.
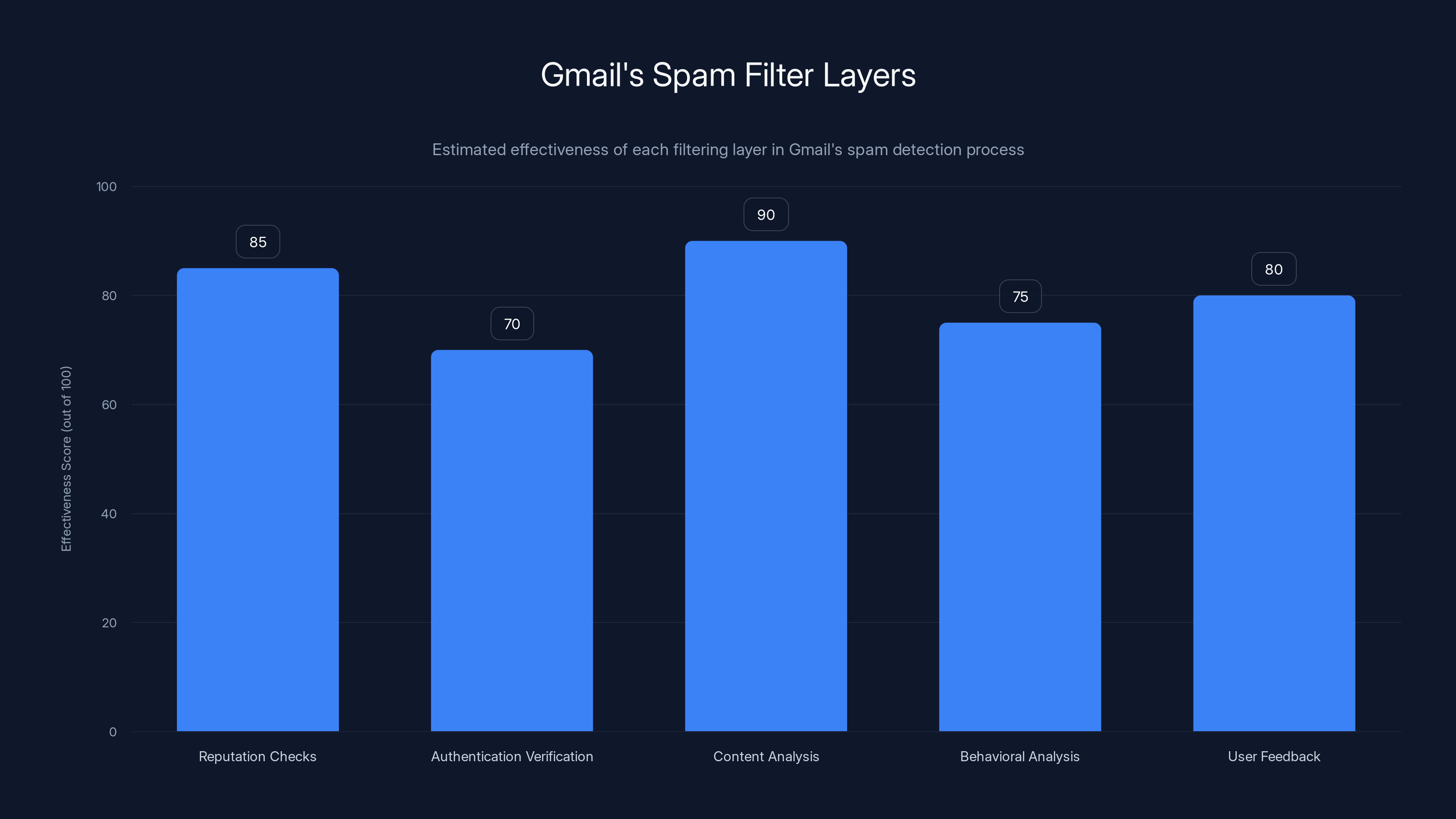
Each layer of Gmail's spam filter plays a crucial role, with content analysis being the most effective. Estimated data based on typical spam filtering processes.
How Gmail's AI-Powered Spam Filter Works (When It Works)
Understanding how Gmail's system works normally helps explain why it broke so spectacularly.
When you send an email to someone with a Gmail account, it doesn't just appear in their inbox. First, it goes through approximately six layers of filtering and analysis:
Layer 1: Immediate reputation checks. Gmail checks the sending IP address, the sending domain, and historical data about the sender. Has this IP address sent spam before? Is this domain new and suspicious? Has this sender been reported by other Gmail users? If the sender has terrible reputation, the email might be automatically rejected or quarantined before it even gets analyzed further.
Layer 2: Authentication verification. The email's SPF, DKIM, and DMARC records are checked. If authentication fails, that's a strong signal that something is wrong. But Google also knows that authentication can fail legitimately—for example, when forwarded emails lose their original authentication—so this is weighted as one signal among many, not a definitive verdict.
Layer 3: Content analysis. Machine learning models analyze the email's text, subject line, links, and attachments looking for spam patterns. These models have been trained on billions of examples and can spot variations of common spam tactics. Things like suspicious URL shorteners, common phishing phrases, suspicious attachment types—all get flagged by these models.
Layer 4: Behavioral analysis. Gmail checks whether the email matches the recipient's normal receiving patterns. Do you normally get emails from this sender? Does the email look like similar emails you've received before? Does the sender's domain match previous emails from this person? If a sender suddenly changes behavior—a trusted contact starts sending emails with different characteristics—that gets flagged.
Layer 5: User feedback integration. Gmail incorporates signals from billions of users who report emails as spam or mark spam as "not spam." These signals are aggregated and anonymized, but they feed into the models continuously. If 10,000 other users reported emails from a sender as spam, that's a strong signal.
Layer 6: Real-time threat detection. Links in emails are scanned against Google's Safe Browsing database to check if they lead to malware or phishing sites. Attachments might be analyzed using machine learning to detect malware patterns. If an email contains links to sites that Google has identified as malicious, it gets flagged.
After all these checks, the email receives a classification: Primary inbox, Promotions tab, Social tab, Updates tab, or Spam folder.
This is an extraordinarily complex system. There are hundreds of individual signals being combined using multiple machine learning models, some of which use ensemble methods (combining predictions from dozens of models), some of which use deep neural networks trained on massive datasets.
When this system works—which it does, most of the time—it's remarkably effective. Gmail's spam detection catches over 99.9% of spam while letting the vast majority of legitimate email through.
But when it breaks, it breaks everywhere, because all those layers depend on each other. A failure in one layer can cascade into failures in other layers.

The Root Cause Theories: What Actually Went Wrong
Google never officially disclosed the root cause of the January 24 outage. But based on the symptoms, we can make some educated guesses.
Theory 1: A Model Update Gone Wrong
Google likely updated one of its spam detection models on or shortly before the outage. Model updates are common—Google continuously improves its AI systems. But if a new model version had a bug, or if it was deployed with incorrect parameters, or if the A/B test infrastructure that gradual rolls out changes failed, then the update could have hit all users at once.
Evidence supporting this: the outage seemed to affect nearly all users simultaneously, suggesting a single change that affected the entire system at once.
Theory 2: A Data Pipeline Failure
Gmail's classification system depends on real-time data pipelines. User feedback ("report as spam" clicks), sender reputation data, authentication check results—all of this feeds into the models continuously. If one of these pipelines broke or started sending corrupted data, it could poison the models and cause them to make bad predictions.
Evidence supporting this: the symptoms included both false positives (legitimate email marked as spam) and false negatives (spam getting through), which suggests the model got confused rather than systematically miscalibrated.
Theory 3: A Hardware or Infrastructure Failure
Gmail's machine learning inference happens on specialized hardware (Google's TPU clusters). If a large cluster went down or failed over incorrectly, Gmail might have fallen back to older, less capable models or models that weren't properly tested.
Evidence supporting this: no indication of a slow rollout or gradual degradation—the problem seemed to appear suddenly and affect essentially all users.
Theory 4: An Authentication System Bug
The fact that legitimate emails were getting security warnings suggests that authentication checks might have been applied incorrectly. Perhaps SPF or DKIM verification logic got inverted, or perhaps DNS lookups for authentication records started timing out and defaulting to "authentication failed."
Evidence supporting this: the warnings appeared on emails from trusted senders, which suggests the issue was in authentication rather than content analysis.
Theory 5: A Feedback Loop Failure
This is the scariest possibility. If automated systems started misclassifying emails, and those misclassifications were immediately incorporated into training data, the system could have degraded exponentially. False negatives (spam getting through) would train the system to be less aggressive. False positives (legitimate email being marked spam) would train the system to be more aggressive. Both happening simultaneously would confuse the model.
Evidence supporting this: the fact that the problem affected essentially all users suggests it wasn't a localized deployment issue but rather a system-wide corruption of the underlying models.
Whichever of these was the actual cause (or combination thereof), it reveals a hard truth: even the most sophisticated AI systems have failure modes that are hard to predict and harder to recover from.
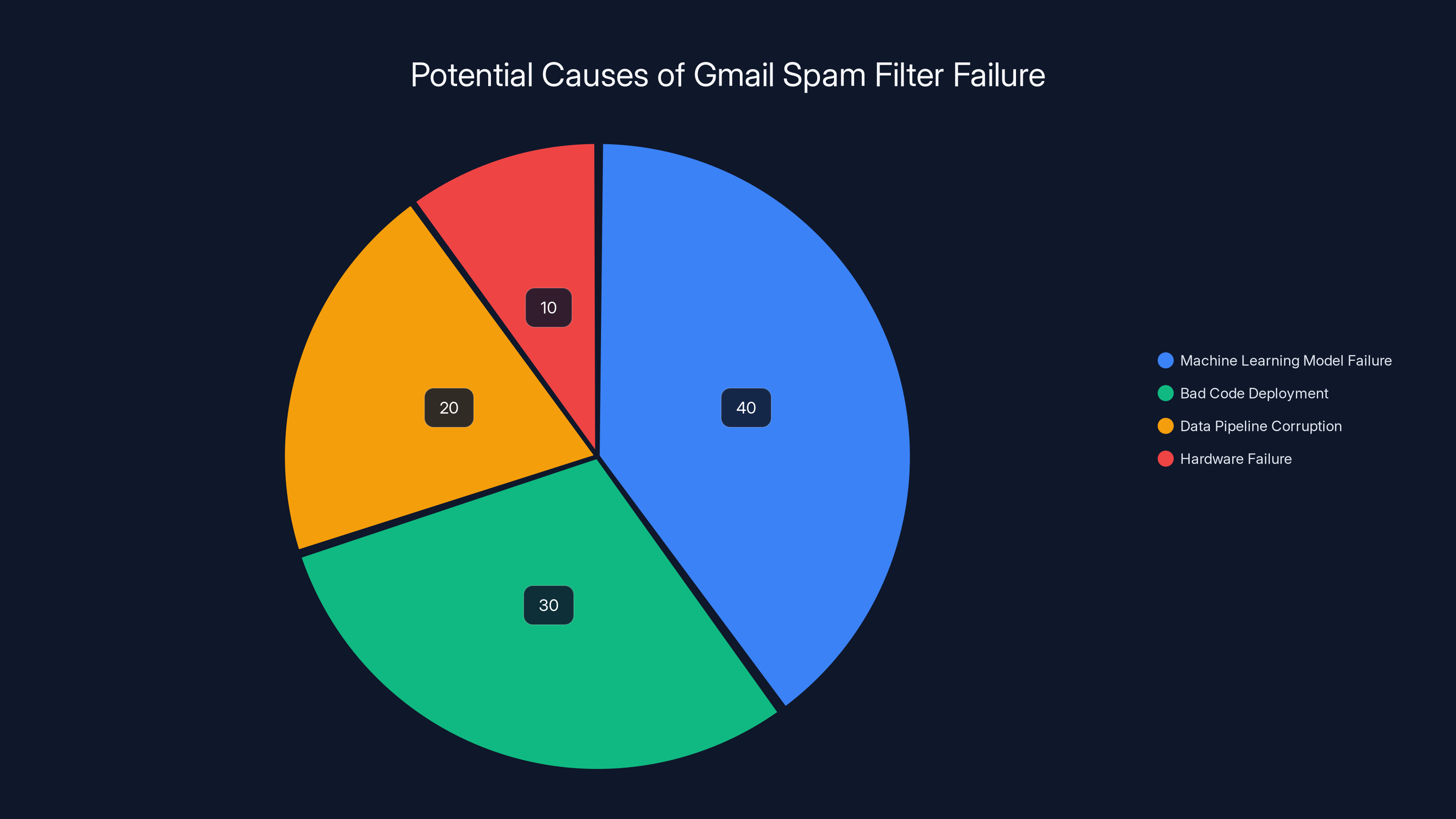
Estimated data suggests machine learning model failure was the most likely cause, followed by code deployment issues.
Immediate Impact: What Users Actually Experienced
The outage wasn't theoretical. Real people lost access to important emails in real time.
Business communication broke. Companies rely on Gmail for customer service, internal coordination, and external partnerships. When legitimate business emails started landing in spam, urgent customer issues got missed. Client communications disappeared into junk folders. Support tickets never reached their destinations.
Payment and transaction confirmations disappeared. Many online services send confirmation emails through Gmail. If users didn't check their spam folder (why would they?), they had no way to confirm transactions, verify purchases, or reset passwords.
Security alerts became unreliable. Gmail is also used for security notifications—password reset links, two-factor authentication codes, account recovery options. If these emails were being mislabeled, users were at risk of losing access to their accounts.
Personal relationships suffered. Users reported missing emails from family members because they landed in spam. Birthday notifications disappeared. Important personal messages were hidden. The social trust in the email system—"if it's in my inbox, it must be important"—broke down.
Mobile users were especially vulnerable. Many people only check their inbox, not spam folder or other tabs. Mobile Gmail also doesn't always display folder counts clearly. Users on phones probably didn't even realize their important emails were being filtered.
Google's standard response—"follow best practices when engaging with messages from unknown senders"—was particularly tone-deaf. The problem wasn't users receiving emails from unknowns. It was users not receiving emails from people they know.
Why This Matters Beyond Just Gmail
This incident is a warning sign about how dependent we've become on algorithmic decision-making for critical infrastructure.
Email is infrastructure. It's how businesses operate. It's how people recover lost passwords. It's how government agencies send official notices. It's how courts serve legal documents. It's how medical providers send appointment reminders.
When email filtering breaks, it's not just annoying—it can be genuinely harmful.
But the issue is larger than just Gmail. This same problem exists across every email provider, every content moderation system, every algorithmic filtering system. Spam detection in outlook, filters in Yahoo Mail, content moderation on social media platforms—they all rely on the same AI techniques that failed here.
We've built critical systems on top of machine learning models that are:
- Opaque. We don't really understand why they make individual decisions.
- Brittle. They fail catastrophically rather than gracefully degrading.
- Centralized. When they break, they break everywhere.
- Difficult to debug. With millions of features and billions of parameters, figuring out what went wrong is nearly impossible.
This outage should make us ask harder questions about the infrastructure we depend on.
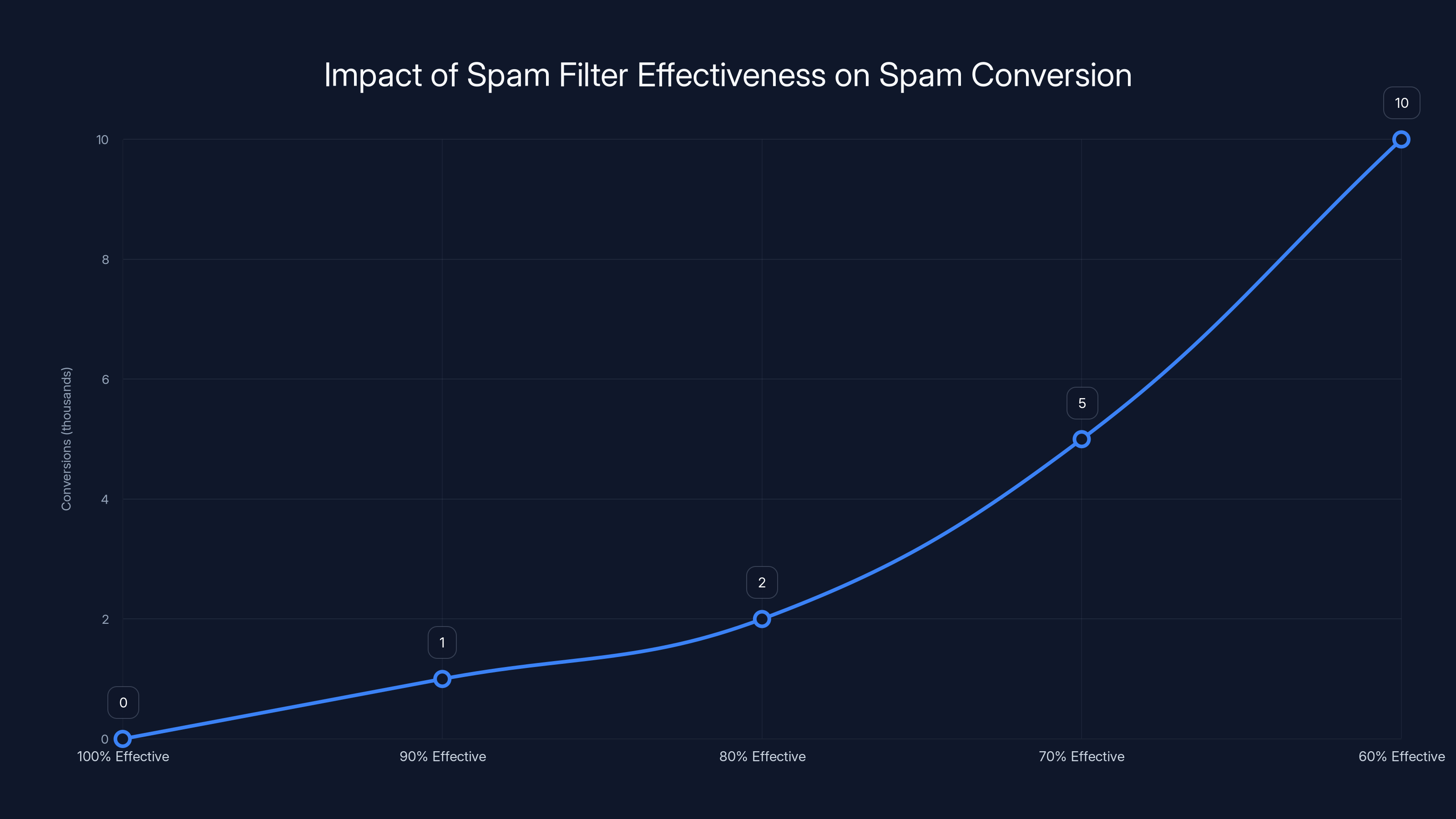
As spam filter effectiveness decreases, the number of conversions from spam increases significantly, highlighting the importance of robust spam filters. Estimated data.
What Happens During an Email Filter Breakdown
When Gmail's filters fail, it creates a specific set of problems that cascade:
First, user trust erodes rapidly. People stopped trusting that their inbox was showing them all their important emails. They started having to manually check spam folders for missing mail. That's fine occasionally, but when it becomes necessary daily, it breaks the entire filtering paradigm.
Second, security becomes an issue. Users stopped trusting spam warnings, because they were appearing on legitimate emails. If a user trained themselves to ignore spam warnings, they became vulnerable to actual phishing and malware.
Third, communication breaks down. People who didn't receive important emails didn't know to look for them. Without clear signals that something was missing, critical messages went unread.
Fourth, the problem becomes self-reinforcing. Users started marking legitimate emails as spam (or marking spam as "not spam") in confusion, which fed corrupted training data back into the system, potentially making it worse.

Comparing to Other Major Email Outages
This isn't the first time email infrastructure has catastrophically failed.
In 2017, Microsoft's Outlook and Office 365 services experienced widespread outages that lasted for days. Millions of users lost access to email entirely. In 2020, Google experienced a significant Gmail outage that lasted nearly an hour and affected hundreds of millions of users.
But this January 2025 outage was different. It wasn't a complete service outage—email was still flowing, but the classification layer broke. It was an outage of quality rather than availability.
That's arguably more dangerous, because users don't immediately realize something is wrong. They check their inbox, see fewer emails than usual, and assume nothing important happened. Meanwhile, critical emails are sitting unread in spam folders.
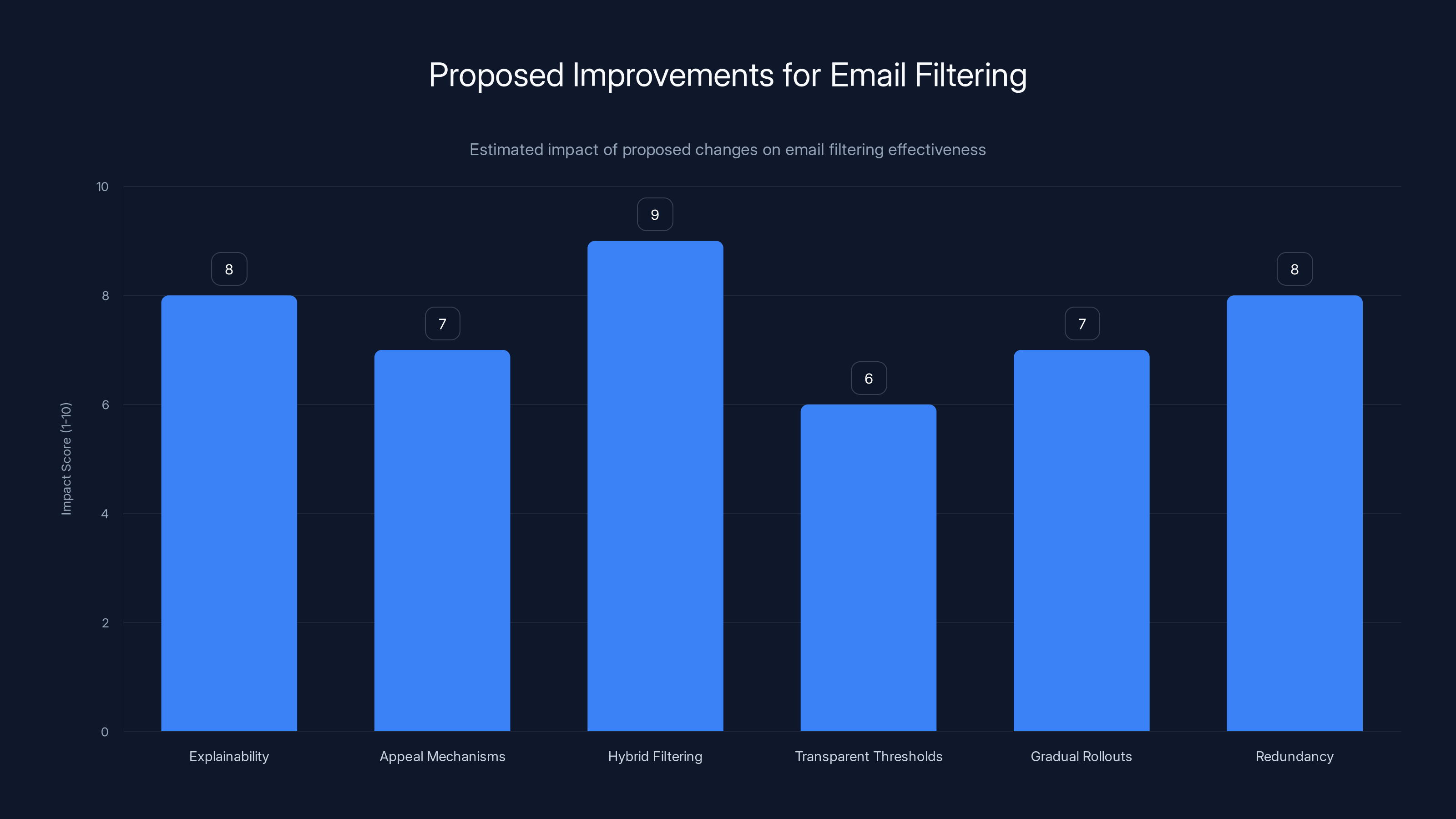
Estimated data suggests that hybrid filtering and redundancy could have the highest impact on improving email filtering effectiveness.
How to Protect Yourself: Practical Solutions
Until email filtering systems become more reliable, you need to take responsibility for managing your own email.
1. Check your spam folder regularly.
I know, it sounds obvious. But most people never look at their spam folder unless they're actively expecting something. Make it a habit to check spam once or twice daily. Gmail makes this easier with a search operator: is: unread in: spam.
2. Add important senders to your contacts.
Emails from people in your Gmail contacts are less likely to be marked as spam. If you have people or companies that regularly email you, add them to your contacts. This signals to Gmail that they're trusted.
3. Use email rules and filters.
Instead of relying on Gmail's automatic classification, create your own rules. If you know certain types of emails (receipts, notifications, confirmations) should always go to your inbox, create a filter for them. Go to Settings > Filters and Blocked Addresses > Create a new filter.
4. Move important mail providers to a separate label.
For critical emails (banks, healthcare providers, password reset services), create a Gmail label and automatically route those emails there. It bypasses the misclassification problem because you're not relying on Gmail's filter—you're using explicit rules.
5. Switch to a more transparent email provider.
If you need better control over filtering, consider providers like Fastmail, Proton Mail, or Hey that give you more visibility into why emails are being filtered. These services are typically paid, which means they're not dependent on ad targeting and behavioral data collection—which means they have fewer incentives to make filtering decisions based on hidden algorithms.
6. Use email authentication properly.
If you send emails, make sure you've set up SPF, DKIM, and DMARC records correctly. This makes it less likely that your emails will be misclassified. Tools like DMARCIAN or Google's own Postmaster Tools can help you audit your authentication setup.
7. Implement email redundancy.
For truly critical notifications, don't rely solely on email. If you're waiting for a password reset or transaction confirmation, follow up with a second factor: SMS, push notification, or checking the service's website directly.
8. Archive rather than delete.
When you delete email, you can't recover it. When you archive it, it stays in your account and is searchable. This is especially important if you think your email might be misfiled—you can find it later through search even if it's not in the expected folder.

Why Automation Can't Be Fully Trusted
The January 2025 Gmail outage highlights a fundamental problem with algorithmic decision-making at scale: we've built systems that make millions of consequential decisions per day with minimal human oversight.
A single machine learning model that misclassifies 0.1% of emails (an excellent error rate) is still misclassifying 1.8 million emails per day across Gmail's user base. When the error rate spikes to 10% (which might have happened during this outage), you're looking at tens of millions of misclassified emails.
We've become comfortable with this because it's usually invisible. A few misclassified emails per day per user is annoying but manageable. But when the system fails catastrophically, those errors compound.
This is why critical systems need fallback mechanisms. Email providers should have:
- Alert systems that detect when classification accuracy drops below acceptable thresholds
- Fallback filters that revert to simpler, more reliable rules when AI systems fail
- Human review queues for flagged emails that might be misclassified
- Transparency logs that show users why emails were classified as they were
- Quick disable switches for new models that can be triggered if something goes wrong
Most of these things probably already exist at Google. The question is whether they worked correctly during this outage and, if not, why not.
The Economics of Email Spam
Understanding why Gmail's spam filter is so important requires understanding the economics of spam itself.
Spam is profitable. If a spammer sends 1 billion emails and even 0.001% of recipients click through or respond, that's 10,000 conversions. At typical conversion rates for spam (often scams or malware distribution), that's enough revenue to justify the infrastructure costs.
Because spam is profitable, spammers constantly innovate. They use new techniques, new domains, new authentication tricks. Gmail's filters have to constantly evolve just to keep pace.
This is an arms race, and Gmail's AI system is on the front lines. When the system works, it's so effective that spam rates stay manageable. When it breaks, the economics of spam suddenly shift—spammers can get through to inboxes, which makes spamming profitable again.
This creates perverse incentives. After an outage like this one, spammers might flood the system trying to take advantage of the broken filters. That additional spam could make users turn on their own filters more aggressively, creating a feedback loop of increasing false positives.

Looking Forward: How Email Filtering Needs to Evolve
After this outage, it's clear that the current approach to email filtering—relying heavily on black-box machine learning models—has fundamental limitations.
Here are some changes the industry should consider:
1. Explainability requirements. Email providers should be required to explain, in human-readable terms, why an email was classified as spam. Not a vague "spam score of 87%" but actual reasons: "This email contains 3 links to recently registered domains" or "The sender's domain failed DKIM authentication."
2. Appeal mechanisms. If an email gets misclassified, users should have a clear way to appeal and get it reviewed by a human if necessary. For critical emails, this should happen automatically.
3. Hybrid filtering. Instead of pure AI, use a hybrid approach: AI provides initial scoring, but applies different thresholds based on different categories. Emails from known contacts could use higher thresholds. Emails to accounts that haven't been breached can use different rules than vulnerable accounts.
4. Transparent thresholds. Users should know what confidence level an email needs to reach to stay in their inbox. This allows them to manually adjust if needed.
5. Gradual rollouts for model updates. Before deploying a new spam detection model to all users, test it thoroughly on a subset of users first. Monitor for any signs of degradation. Make it easy to roll back.
6. Redundancy and failsafes. Have multiple independent models making filtering decisions. If they disagree significantly, escalate to a human or to less aggressive filtering.
The Broader Lessons
This outage teaches us several important lessons that apply far beyond email:
First, centralized systems are fragile. When Gmail's filters break, it affects hundreds of millions of people simultaneously. If email were more decentralized, a failure in one component wouldn't cascade globally.
Second, we've automated too much without proper oversight. We treat algorithmic decisions (spam classification, content moderation, credit scoring) as if they're objective truth. They're not. They're predictions made by imperfect models trained on imperfect data.
Third, user trust is fragile. It takes months or years to build confidence in a system but seconds to destroy it. Gmail's reputation for spam filtering might have taken a real hit from this outage.
Fourth, we need better ways to monitor and debug production ML systems. Traditional software monitoring doesn't work well for machine learning. We need new tools and techniques specifically designed to detect when AI systems are behaving anomalously.

What Google Did Wrong (And What It Could Have Done Better)
Looking at this outage, several mistakes are apparent:
The initial response was too vague. Google said they were "actively working to resolve the issue" but provided no information about what was broken, how many users were affected, or what to do in the meantime. Transparency here would have reduced user panic.
The fallback was inadequate. Gmail should have had the ability to fall back to simpler, more reliable filtering rules while the advanced models were being debugged. Instead, users just got broken filters with no alternative.
The recovery was silent. Google never announced when the issue was fully resolved, what caused it, or what steps were taken to prevent recurrence. Users had to discover they were fixed by noticing that their email started working again.
The impact assessment was missing. Google should have provided data on how many emails were misclassified and offered some kind of recovery mechanism—maybe a way to bulk-review emails that were marked as spam during the outage window.
A better approach would have been:
- Immediate announcement explaining the scope
- Switch to conservative fallback filters
- Regular updates on progress
- Clear announcement when resolved
- Transparency about root cause
- Compensation or recovery options for affected users
The Future of Email Security
As email continues to be attacked by increasingly sophisticated spam and phishing campaigns, the filters protecting it need to evolve too.
The future probably involves several changes:
Authentication will become mandatory. SPF, DKIM, and DMARC adoption will likely become requirements rather than optional. This won't prevent all spam, but it will eliminate spoofing-based attacks.
Behavioral analysis will become more sophisticated. Instead of just analyzing email content and sender reputation, systems will use machine learning to understand normal communication patterns for each user and flag significant deviations.
Decentralized authentication will reduce spoofing. As email providers adopt standards like MTA-STS (Mail Transfer Agent Strict Transport Security), spoofing and interception will become harder.
User AI assistants will become standard. Rather than relying on a single centralized filter, users might have their own local AI assistant that learns their preferences and filters email accordingly.
Zero-trust email might emerge. Similar to zero-trust networking, future email systems might never fully trust any sender until they've been verified through multiple mechanisms.

Preparing for the Next Outage
The January 24 outage won't be the last time email filtering breaks. Here's how to prepare:
Maintain an email backup. Consider using a backup email service (some email clients can automatically copy emails to multiple accounts). If Gmail breaks again, your backup provider's filters might work differently.
Monitor your email patterns. If you suddenly notice you're getting way less email than usual, your filters might be broken. Check your spam folder immediately.
Have contact information outside email. For people you really need to reach, have their phone number or another contact method. Don't rely solely on email for critical communication.
Use multiple communication channels. For important services (banks, healthcare, etc.), set them up to contact you via SMS or push notifications in addition to email.
Maintain contact with your email provider. Follow their status pages. Sign up for alerts about service issues. Having advance warning of potential problems can help you prepare.
FAQ
What caused Gmail's spam filter to fail on January 24, 2025?
Google never officially disclosed the specific root cause, but the symptoms suggest it was likely a failure in one of the machine learning models that classify emails, a bad code deployment, a data pipeline corruption, or possibly a hardware failure in the infrastructure supporting email classification. The fact that both false positives (legitimate emails marked spam) and false negatives (spam reaching inboxes) occurred simultaneously suggests the system's classification thresholds got miscalibrated or inverted entirely.
How many users were affected by the Gmail spam filter outage?
Google's official Workspace status page confirmed that the issue was widespread, affecting millions of users across all Gmail accounts. Exact numbers were never published, but given that Gmail has over 1.8 billion users globally and the issue lasted several hours before being resolved, the affected users likely numbered in the hundreds of millions or possibly over a billion depending on timezone and peak usage times.
Why did legitimate emails get spam warnings if they were actually legitimate?
Email authentication systems like SPF, DKIM, and DMARC were likely involved in the misclassification. If authentication checking logic got inverted, incorrectly applied, or experienced timeout issues that defaulted to "authentication failed," then legitimate emails would receive security warnings even though they technically came from verified sources. This suggests the problem wasn't limited to content analysis but also affected authentication scoring.
Can Gmail's spam filters fail like this again in the future?
Yes, absolutely. As long as Gmail relies on machine learning for email classification, it remains vulnerable to the types of failures that occurred on January 24. Machine learning systems can fail catastrophically when they encounter data patterns they weren't trained on, when their parameters get corrupted, or when their infrastructure fails. The incident revealed that even sophisticated systems have failure modes that are hard to predict.
What should I do if my important emails start appearing in spam?
First, check your spam folder regularly to see if important emails are being mislabeled. Second, add important senders to your contacts, as emails from people in your contact list are less likely to be marked as spam. Third, create Gmail filters for critical emails (like from banks or password services) to ensure they always go to your inbox. Finally, establish backup communication methods with important contacts so you have ways to reach them if email fails.
How can email providers prevent filter failures like this from happening again?
Email providers should implement several safeguards: (1) multiple independent models making classification decisions, with alerts if they significantly disagree; (2) gradual rollouts of new models to detect issues before they affect all users; (3) reliable fallback filters that engage automatically if detection accuracy drops; (4) transparent reasoning for why emails are classified as spam; (5) human review queues for emails when confidence is low; and (6) the ability to quickly revert changes if problems are detected.
Is Google's spam filter still trustworthy after this incident?
Google's spam filter remains highly effective overall—it still catches over 99% of spam while letting most legitimate email through. However, this incident exposed vulnerabilities that should make users somewhat less trusting of any fully-automated filtering system. The best approach is to combine Gmail's filtering with personal responsibility: regularly check your spam folder, use explicit filters for important senders, and maintain communication redundancy for truly critical messages.
What's the difference between spam that gets through and legitimate email that gets blocked?
Spam that gets through (false negatives) happens when the filter is too conservative—it errs on the side of letting potentially-risky emails through to avoid blocking legitimate email. Legitimate email that gets blocked (false positives) happens when the filter is too aggressive. During the outage, something caused both errors to spike dramatically, suggesting the model's threshold got corrupted rather than just becoming more aggressive or conservative.
Should I switch to a different email provider because of this outage?
While this outage was serious, all email providers have experienced similar filter failures at some point. What matters more is choosing a provider with good transparency about incidents, reliable service history, and responsive customer support. If you value more control over filtering, consider paid providers like Fastmail or Proton Mail. If you value the integration with Google services, staying with Gmail while implementing personal safeguards (as detailed above) is reasonable.
How does machine learning cause email filters to fail so catastrophically?
Machine learning models make decisions based on patterns learned during training. When they encounter novel patterns they weren't trained on, or when their infrastructure fails, or when their parameters become corrupted, they can fail in unpredictable ways. Unlike rule-based systems that fail gracefully (if a rule is wrong, only emails matching that rule fail), machine learning failures are often opaque and affect broad categories of emails unexpectedly.
What should I do to prepare for the next email filter outage?
Maintain regular backups of critical emails, add important contacts to your address book, create explicit Gmail filters for critical emails, monitor your spam folder regularly, follow your email provider's status page for alerts about ongoing issues, and establish backup communication methods with people who need to reach you urgently. Most importantly, don't assume your filter is working correctly—occasionally spot-check your spam folder to ensure important emails aren't being mislabeled.

Conclusion
The January 24, 2025 Gmail spam filter outage was a watershed moment. Not because it was unprecedented (email systems have failed before), but because it exposed how fragile our infrastructure really is when we delegate critical decisions to opaque machine learning systems.
For millions of users, email simply stopped working the way they expected. Important messages disappeared. Trusted senders were flagged as suspicious. The entire filtering model that had been silently protecting inboxes for years suddenly reversed itself.
Google fixed it. The company has the resources and expertise to debug complex distributed systems, and the issue was eventually resolved. But the incident leaves important questions unanswered:
Why did fallback systems not engage? Why did the company's monitoring not detect the failure more quickly? Why was the public communication so minimal? And most importantly: what safeguards are in place to prevent the next failure?
The broader lesson applies to all of us: we're increasingly dependent on algorithmic systems to make critical decisions with minimal human oversight. Email filtering is just the visible tip of an iceberg that includes content moderation, credit scoring, loan approvals, hiring decisions, and medical diagnostics.
When these systems work, they're incredibly effective. They scale to billions of decisions per day. They learn and improve over time. They catch patterns humans would miss.
But when they fail, they fail catastrophically, often in ways that are hard to debug and harder to explain to users.
The fix isn't to abandon machine learning for email filtering. The technology is too powerful and too effective when working correctly. The fix is to stop treating algorithmic decisions as inevitable truths and start building transparency, explainability, and redundancy into our critical infrastructure.
Meanwhile, until email systems become more reliable, follow the recommendations above. Check your spam folder. Use explicit filters for important senders. Maintain communication backup mechanisms. And remember: the email that reaches your inbox isn't necessarily all your emails, just the ones the algorithm decided you should see.
In a world increasingly mediated by algorithms, that's a distinction worth remembering.
Key Takeaways
- Emails that should have landed in the Primary inbox were getting sorted into Promotions, Social, or Updates tabs
- The system was essentially telling them that emails from people they know well might be dangerous
- Not only were people missing important messages, but they were also being told that their trusted contacts were suddenly suspicious
- It created a trust problem on top of a filtering problem
- As always, we encourage users to follow standard best practices when engaging with messages from unknown senders
Related Articles
- Did Edison Really Make Graphene in 1879? Rice Scientists Found Out [2025]
- Best Travel Camera 2025: OM System OM-5 Mark II at Record-Low Price
- Why Curl Killed Its Bug Bounty Program: The AI Slop Crisis [2025]
- Forza Horizon 6: Japan Setting, Career Overhaul & EventLab Changes [2025]
- Ecovacs Deebot X8 Pro Omni Review: Features, Performance & Value [2025]
- AI-Generated Bug Reports Are Breaking Security: Why cURL Killed Its Bounty Program [2025]

