Google's AI News Headlines: The Silent Takeover of Digital Journalism
Google announced in early 2025 that its artificial intelligence system would begin generating custom headlines for news stories appearing in Google Discover—the content feed that appears when users swipe right on their Android home screen. What initially appeared to be a limited experiment has quietly evolved into a permanent feature, raising critical questions about AI accuracy, journalistic integrity, and the future of news media in an increasingly automated digital ecosystem.
This shift represents a fundamental departure from how search engines and content platforms have traditionally operated. For decades, Google displayed headlines exactly as publishers wrote them, preserving the original reporting while driving traffic back to news organizations. The shift toward AI-generated alternatives marks a watershed moment where artificial intelligence doesn't merely organize or recommend content—it actively rewrites it, often with significant accuracy problems that undermine both publisher credibility and reader comprehension.
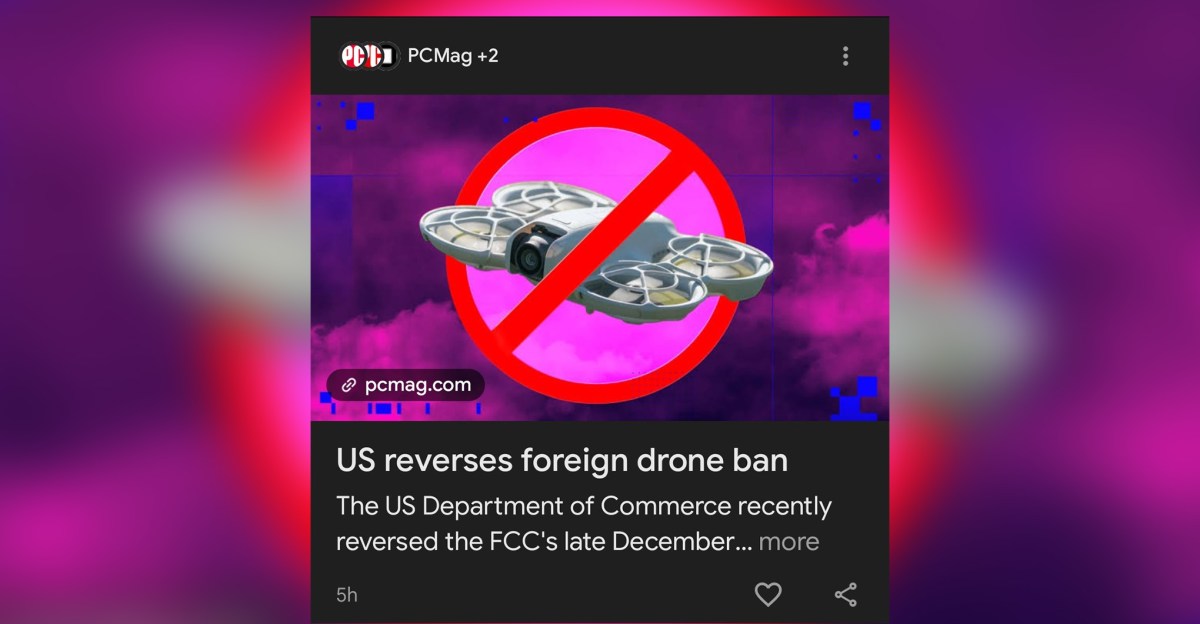
The practice became visible when multiple news organizations discovered that Google was replacing their carefully crafted headlines with AI-generated alternatives that frequently contradicted the actual story content, misrepresented facts, or created entirely false narratives. In one prominent example, Google's AI generated the headline "US reverses foreign drone ban" above a PCMag article that explicitly debunked this claim in its opening paragraphs. The discrepancy reveals a critical gap: Google's AI has no understanding of which information is new, verified, or even factually accurate.
Publishers and journalists immediately raised concerns about the implications. This isn't merely an aesthetic issue about headline presentation—it directly impacts how news organizations market their work, attract readers, and maintain their reputation for accuracy. When Google's algorithm misrepresents a story's content, the responsibility for that misrepresentation becomes ambiguous, creating legal and ethical gray zones that the publishing industry wasn't prepared to navigate.
Google's official response characterizes these offerings as "trending topics" rather than headline rewrites, a semantic distinction that obscures the technical reality. Each AI-generated headline behaves identically to traditional headlines: it appears above a story preview, includes a link to the original article, and uses the publisher's own images. From a user perspective, there's no visible difference between an authentic headline written by a journalist and an AI-generated approximation written by an algorithm that lacks journalistic training, editorial judgment, or fact-checking capabilities.
The company also claims that these AI headlines "perform well for user satisfaction," suggesting that users engage more frequently with these algorithmically-generated variations. However, this metric reveals a troubling disconnect between user engagement and user understanding. Users may click on a headline because they find it compelling, only to discover that the AI-generated framing doesn't accurately represent the article's actual content. Performance metrics based on clicks measure engagement, not comprehension or satisfaction with accuracy.
This development arrives at a critical moment for digital journalism. News organizations have already experienced decades of declining revenue as digital advertising shifted from publishers to technology platforms. The search traffic that once represented a significant revenue source has diminished as users increasingly rely on social media feeds, email newsletters, and algorithm-curated content. Google's decision to actively rewrite headlines represents another mechanism through which platform companies extract value from journalistic work while reducing the visibility and autonomy of the creators producing original reporting.
The situation also illuminates a broader challenge in the age of generative AI: the technology's impressive surface capabilities mask fundamental limitations in understanding context, accuracy, and nuance. An AI system can generate grammatically correct headlines that sound plausible because it has learned statistical patterns in language from billions of text examples. This doesn't mean it understands journalism, fact-checking, or the responsibility that comes with representing factual claims to millions of readers.
For journalists and publishers, this development demands immediate strategic responses. News organizations need to understand how Google's systems are processing and presenting their work, develop tools to detect when their headlines are being rewritten, and establish clearer policies about how their content can be used and modified. For readers, it suggests the need for greater skepticism about the headlines they encounter in algorithmic feeds, combined with a renewed emphasis on reading full articles rather than relying on summaries.
Understanding Google Discover's AI Headlines Feature
What Google Discover Actually Is
Google Discover represents one of the most significant distribution channels for news content in the modern digital ecosystem. When users swipe right on the home screen of a Samsung Galaxy phone, Google Pixel device, or other Android phone running Google services, they encounter a feed of personalized content recommendations. Unlike Google Search, which responds to explicit user queries, Discover operates as a proactive content recommendation system that attempts to predict what users might want to read before they consciously search for it.
The Discover feed has become increasingly central to how millions of people consume news, weather information, sports updates, and general interest content. Major news organizations depend on Discover traffic to reach readers who might not visit their websites directly. This distribution channel has grown more valuable as social media platforms like Facebook and Twitter have reduced the organic reach of news organizations' own posts, making platform-controlled feeds critical to publisher survival.
Google's algorithm determines which stories appear in each user's Discover feed based on browsing history, reading patterns, search queries, geographic location, and hundreds of other signals. The system learns that a user interested in technology news, for example, might receive stories about artificial intelligence, consumer electronics, or software updates. A user interested in sports might see articles about local teams, championship tournaments, or player news. This personalization creates an experience where each user's feed becomes unique, calibrated to their demonstrated interests.
For most of Discover's history, Google displayed stories using the original headlines written by journalists and editors at publishing organizations. Google might reorder stories in the feed, recommend some content over others, or change the size and prominence of headlines based on its algorithms, but the actual text of headlines remained unchanged. This practice preserved the publisher's voice and editorial judgment while benefiting both parties: Google provided distribution, and publishers maintained control over how their stories were presented.
How the AI Headline Generation Works
Google's AI headline generation system operates as a transformer-based language model, similar to other large language models that power generative AI applications. When a story from a news organization enters Google's systems—typically through RSS feeds, sitemaps, or direct integration partnerships—the AI analyzes the article's content. It reads the story text, examines associated metadata, and extracts information about the topic, key entities, sentiment, and apparent importance.
Based on this analysis, the AI generates new headline variations designed to increase click-through rates and engagement. The system doesn't merely shorten or reformat existing headlines; it creates entirely new text that the algorithm believes will resonate with users in Google's feed. Early versions of the system were constrained to approximately four words, leading to awkward constructions like "Microsoft developers using AI" that bore little resemblance to actual story content. Later iterations allowed longer headlines, but the fundamental problem remained: the AI prioritizes engagement signals over accuracy.
The technical architecture reveals some of Google's reasoning for this approach. Generative AI systems excel at pattern recognition and text generation. An AI trained on billions of news articles can identify common patterns in how compelling headlines are structured, which words attract clicks, and how to frame information in ways that appeal to readers. From a pure machine learning perspective, this capability represents genuine progress in natural language generation.
However, this technical capability contains a critical flaw: the system has no mechanism for fact-checking, no understanding of which information in an article is new versus background context, and no ability to verify whether generated claims are actually supported by the story's content. The AI generates headlines based on statistical patterns in language, not on editorial judgment, journalistic standards, or commitment to accuracy. A human editor reading a headline immediately considers whether it accurately represents the story. An AI system has no such capability—it simply generates text that matches learned patterns.
Google's system also lacks any comprehensive mechanism for detecting when AI-generated headlines contradict the story they're supposedly summarizing. In the drone ban example, PCMag's article explicitly debunked the claim that the US reversed its drone ban, yet Google's algorithm generated a headline asserting exactly that false premise. This suggests the AI isn't reading comprehensively through the article to identify nuance, contradiction, or complexity. Instead, it's likely seizing on specific phrases or entities it identifies as headline-worthy without understanding the article's actual argument.
The Difference Between Headlines and "Trending Topics"
Google's official characterization of its AI-generated headlines as "trending topics" rather than headline replacements represents a strategic semantic distinction designed to minimize perception of the change's significance. According to Google's explanations, these are simply trending topics that happen to be derived from news stories, formatted to look like headlines, placed where headlines typically appear, and linked to articles exactly as headlines function. From a technical standpoint, they are indistinguishable from traditional headlines.
This semantic framing matters because headlines carry editorial responsibility. When a news organization publishes a headline, the organization stands behind that headline's accuracy and its reflection of the article's content. Headlines are subject to editorial standards, fact-checking procedures, and the accountability mechanisms that govern journalism. A publisher can be criticized for misleading headlines, and legal liability can attach to headlines that defame individuals or spread falsehoods.
By characterizing AI-generated text as "trending topics" rather than headlines, Google attempts to reduce its own accountability for the accuracy and truthfulness of these text strings. Google claims it's not rewriting headlines but simply identifying trends and presenting them differently. This distinction collapses immediately when examined: users encounter these text strings in the exact position where headlines appear, formatted identically to headlines, functioning identically to headlines in terms of click behavior and content discovery. The packaging matters more than the label.
This reframing also conveniently obscures questions about consent and licensing. Publishers submit their articles to Google's systems expecting Google to present them with original headlines intact. Google doesn't typically request permission to rewrite headlines or generate derivative versions of publisher content. By defining the rewritten versions as "trending topics" rather than headline rewrites, Google sidesteps these questions of rights and permissions. Publishers agreed to Google displaying their headlines and content—arguably, they did not agree to Google generating new versions.
The semantic distinction also serves Google's interests in regulatory and legal contexts. If regulators or courts question whether Google is appropriately using publisher content, Google can argue it's not modifying publisher content at all, merely identifying trends separately. This positions Google's AI headline generation as an independent analytical layer rather than a modification of publisher intellectual property. Whether regulators and courts will accept this distinction remains unclear, but the framing clearly benefits Google's legal position.
The Accuracy Crisis: When AI Rewrites Reality
Documented Examples of Misinformation
The most troubling aspect of Google's AI headline generation is not its existence, but its documented failures to maintain basic factual accuracy. Multiple examples have been identified where Google's AI-generated headlines directly contradict the facts reported in the underlying articles, creating situations where users encounter false information that appears to come from legitimate news sources.
The drone ban example demonstrates this problem clearly. PCMag published a story explaining that the US Commerce Department ended its efforts to restrict drone imports because those restrictions were becoming redundant in the wake of FCC actions. The key point: the Commerce Department's proposed restrictions were never actually implemented. The situation represented a government agency deciding not to proceed with restrictions that hadn't been imposed, not a reversal of existing policy. PCMag's headline and article made this distinction explicit and clear, with significant space devoted to clarifying the actual sequence of events.
Google's AI, analyzing this article, somehow generated the headline "US reverses foreign drone ban," which directly inverts the factual situation. The AI headline suggests a complete policy reversal, when the reality involved an agency deciding against implementing restrictions that had never been imposed. Users reading Google's AI headline would come away with an entirely false understanding of what happened, even if they subsequently read PCMag's article, because the AI headline had primed them with incorrect information.
Jim Fisher, one of the reporters involved in that story, described the experience as making him feel "icky," expressing concern that Google's system was essentially putting words in publishers' mouths and false claims beneath their bylines. When users encounter false headlines attributed to news organizations, those organizations' credibility suffers, even though the organizations bear no responsibility for the false claims. Readers may trust the original news organization less after encountering false information attributed to it, creating a reputational harm that news organizations cannot prevent or correct.
Other examples include AI-generated headlines that misidentified which companies were involved in reported deals, confused different stories into composite false narratives, or generated clickbait variations that bore no relationship to the actual reporting. In one case, Google's system generated the headline "Fares: Need AAA & AA Games," which was seemingly nonsensical and bore no discernible relationship to the article it accompanied. These examples reveal that Google's AI doesn't consistently generate coherent headlines, let alone accurate ones.
The breadth of documented failures suggests these aren't isolated edge cases but rather systemic problems inherent to the approach. If Google tested this system on thousands of articles before deployment, numerous examples like these would have been discovered. The fact that the company proceeded anyway, eventually characterizing the feature as something that "performs well for user satisfaction," suggests Google prioritizes engagement metrics over accuracy.
Why AI Headlines Miss Context and Nuance
The fundamental reason AI-generated headlines fail to maintain accuracy lies in how modern language models actually work. These systems learn statistical patterns in text rather than understanding meaning, context, or truth. A language model trained on billions of news articles learns that certain words frequently appear together, that certain sentence structures tend to attract engagement, and that certain topics generate significant traffic. These learned patterns allow the model to generate text that sounds like a news headline.
However, learning these patterns doesn't mean understanding news content. A language model has no mechanism for understanding that a statement in paragraph three contradicts a statement in paragraph one. It can't identify which facts are new versus background information. It lacks the editorial judgment to recognize that a detail mentioned briefly in the middle of an article is actually the story's true significance, while more prominent claims are secondary context.
Newsroom editors, by contrast, read entire articles, understand the reporting process that produced them, and make editorial decisions about which elements deserve headline emphasis. An editor might read an article about declining smartphone sales and choose a headline emphasizing the severity of the decline, because the reporter's investigation revealed previously unknown details about the underlying causes. An AI system reading the same article might generate a headline focused on a manufacturer's response quote, because that quote appears prominently in the article text and the AI's training data suggests manufacturer quotes attract reader interest.
The drone ban example illustrates this dynamic. PCMag's article explicitly addresses a common misconception—that the drone ban was being reversed. The story is fundamentally about clarifying this misconception and explaining what actually happened. A human editor reading this story would understand that the primary point is the debunking of false claims, and the headline would reflect this. Google's AI, analyzing the same text, apparently identified "drone ban" and "reversal" as high-salience terms without understanding that the article was explaining why the reversal framing was incorrect.
AI systems also struggle with negation and contradiction. When a human reads "The government did not reverse the drone ban," they understand a negative claim. Many AI systems, especially earlier versions, struggle with this because they're trained on positive assertions. A language model learns that "government reverses ban" is a common pattern in news text, and this learned pattern can overwhelm the negative framing in the specific article being analyzed. The model generates text based on what it has learned is common, not based on careful analysis of what the article actually says.
Context spans present another challenge. A news article about technology might reference regulatory concerns, market trends, competitive dynamics, and historical background alongside the primary news. An AI headline generator might seize on any of these elements as headline-worthy without understanding which element is actually the story. It might read a single sentence about a regulatory possibility and generate a headline emphasizing that possibility, missing entirely that the article's main reporting focuses on something else.
The solution to these problems isn't simply improving AI accuracy, though that would help. The fundamental issue is that generating factually accurate headlines requires understanding, editorial judgment, and commitment to accuracy—capabilities that statistical AI systems don't possess. A more accurate AI system might make fewer errors, but it would still generate headlines by pattern-matching rather than understanding, still lack editorial judgment, and still have no mechanism for prioritizing accuracy over engagement.
The Clickbait Problem: Engagement Over Truth
Google's claim that AI-generated headlines "perform well for user satisfaction" reveals the optimization metric driving this feature. The company measures success through click-through rates and engagement metrics—whether users click on articles, spend time reading them, and interact with the content. These metrics don't measure accuracy comprehension, factual understanding, or whether users come away from articles with correct information.
In fact, engagement metrics often incentivize the opposite of accuracy. Sensationalized headlines, exaggerated claims, and surprising framings tend to generate higher click-through rates than more modest, accurate representations of story content. This dynamic is well-documented in journalism research and has been a core problem with social media news distribution for over a decade. Platforms that optimize for engagement rather than accuracy inadvertently create incentives for sensationalism.
Google's AI system, trained to generate headlines that maximize engagement, naturally gravitates toward sensational framings. "US reverses drone ban" generates more clicks than a more accurate framing like "Commerce Department abandons redundant drone import restrictions." The AI learns that reversals, surprises, and dramatic shifts in policy generate more reader interest than nuanced explanations. This creates systematic bias toward inaccuracy.
This optimization dynamic explains why early versions of Google's AI generated clickbait headlines like "Microsoft developers using AI" and "AI tag debate heats"—these are the kinds of fragmentary, attention-grabbing text patterns that maximize clicks in algorithmic feeds. Later improvements that allowed longer headlines didn't solve the fundamental problem; they simply generated slightly more sophisticated-sounding clickbait like "Fares: Need AAA & AA Games," which still prioritizes engagement framing over accurate representation.
The clickbait problem becomes more acute because users initially encounter headlines in a feed context where they make split-second decisions about what to read. They don't closely scrutinize headline accuracy; they rapidly scan for interesting topics. An AI headline that generates clicks but misrepresents the article achieves Google's stated optimization goal while failing journalism's core commitment to truth. The asymmetry between what the metric measures and what actually matters creates a system that systematically undermines accuracy.
Google's characterization of this as a feature that "performs well for user satisfaction" is itself misleading. The company measures engagement, not actual user satisfaction with accuracy or quality of understanding. Users might not realize they've been given false information by a headline, particularly if they don't read the full article. Satisfaction measurements based on continued engagement don't capture the harm created when users are misinformed.
The Publisher Perspective: Lost Control and Revenue
How AI Headlines Impact Publisher Branding and Reputation
For news organizations, Google's AI headline generation represents a loss of editorial control over how their work is presented and represented. News organization brand equity depends significantly on consistent, trustworthy communication with readers. Readers develop relationships with specific news organizations based on the expectation that those organizations will maintain editorial standards, practice rigorous fact-checking, and communicate clearly about what they know and don't know.
When Google replaces a carefully crafted, fact-checked headline with an AI-generated alternative that contradicts the article's content, the news organization's brand suffers even though the organization bears no responsibility for the false headline. Readers encountering the false AI headline attribute it to the news organization, assume the organization published something inaccurate or misleading, and lose trust in the organization. This brand damage accumulates across multiple misheadings, eventually affecting how readers perceive all of the organization's journalism.
Publishers spend significant resources on headline optimization. Editorial teams debate headline phrasings, conduct A/B testing to determine which formulations drive engagement, and carefully consider how headlines represent article content. This investment reflects understanding that headlines are crucial to journalism—they represent the publication's voice, establish expectations for what readers will learn, and serve as the first and sometimes only exposure readers have to article content.
Google's system essentially invalidates this investment. Publishers optimize headlines for their publication's brand, their audience's expectations, and their editorial standards. Google optimizes headlines for algorithm-driven engagement metrics. These optimization goals frequently conflict. What sounds like compelling journalism might not maximize clicks; what generates maximum clicks might not meet journalism standards.
The reputation impact extends beyond individual articles. When a news organization's byline appears alongside a false AI headline, readers may develop the impression that the organization is less trustworthy or rigorous than they previously believed. This perception spreads across the organization's entire body of work. A reader who encounters one false AI headline attributed to a publication might become skeptical of other articles from that same publication, even though the publication had nothing to do with the false headline.
Publishers also lose the ability to manage their own brand voice and style. Each news organization has distinctive ways of framing stories, particular language choices, and editorial approaches that constitute part of their brand. The New York Times's headlines sound different from Wall Street Journal headlines, which sound different from Verge headlines. These stylistic differences constitute intellectual property and brand identity. When Google generates AI headlines, it's not merely misrepresenting individual stories—it's effectively replacing publisher voice with a generic algorithmic voice across potentially millions of headline presentations.
Revenue Implications and Traffic Attribution
Beyond brand damage, AI headline replacement has direct financial implications for news organizations. Publishers depend on traffic from Google to generate revenue through advertising, subscription conversions, and engagement metrics that drive advertiser valuations. When Google displays a news story in Google Discover, the traffic that results from that display drives revenue for the publisher.
However, traffic attribution becomes complicated when headlines are rewritten. If a user is attracted to a story by a sensationalized AI headline that doesn't accurately represent the article, they might click through, realize the article doesn't match the headline's promise, and leave without reading the full piece or engaging with content. This reduces per-article engagement metrics, decreases advertising impressions within articles, and reduces the likelihood of subscription conversion.
Alternatively, if an AI headline completely misrepresents a story, users might click to a completely different article than they expected, generating an entirely different traffic flow than Google Discover's algorithm intended. This creates unpredictable and potentially less valuable traffic for publishers. A user clicking because they expect coverage of a breaking news story but finding instead a long-form feature article might leave faster and spend less time on the page.
Publishers also lose the ability to track which headlines perform well with their audience. News organizations conduct continuous A/B testing and analysis to understand which headline formulations drive engagement. Publishers learn from this data, improving their headline writing over time. When Google generates alternative headlines, these performance data become meaningless for publisher purposes. Publishers can't learn from how their audience responds to Google-generated alternatives because Google controls that data and Google's optimization goal differs from the publisher's.
There's also a competitive element to consider. News organizations compete with each other for readers and advertising revenue. When Google's AI generates headlines for multiple publishers covering the same story, it might generate more compelling AI headlines for some publishers than others, creating uneven distribution advantages based on AI system variance rather than reporting quality or headline writing ability. A news organization that invests in skilled headline writers might find their traffic suppressed by a competitor whose story receives a more engaging AI headline.
The Consent and Licensing Problem
Publishers submitted their content to Google's systems under agreements predating the AI headline generation feature. When publishers submit their content through Google News, Google Discover, or other discovery platforms, they do so expecting their original headlines will be displayed and their content will be presented as they intended. Publishers agreed to Google distributing their content, not to Google modifying it through AI systems.
This creates a licensing and consent problem. Google is generating derivative works from publisher content—specifically, new headlines that rewrite and reframe the original articles. Copyright law typically requires permission to create derivative works. Publishers haven't explicitly consented to Google's AI system generating headlines from their articles, and Google has not requested permission in most cases.
Google's semantic reframing of the feature as "trending topics" rather than headline rewriting is partly an attempt to sidestep this legal question. If Google can characterize the AI-generated text as independent analysis rather than modification of publisher content, the consent and licensing question becomes less clear. However, from a practical standpoint, Google is undeniably creating new text based on publisher content and presenting it as headlines for that content, which constitutes derivative work creation.
Publishers have various legal theories they might pursue, though the outcomes remain uncertain. Copyright claims for headline modification are complex because headlines are relatively short works of authorship and may qualify for fair use in some contexts. However, wholesale replacement of original headlines with AI alternatives goes beyond typical fair use scenarios. Intellectual property claims around how publisher brands are presented also have merit, particularly where AI-generated headlines damage publisher reputation.
Some publishers have begun negotiating agreements specifically addressing AI headline generation, requiring explicit consent or compensation for the feature. Other publishers have requested the ability to opt out of AI headline generation for their content, though Google has not broadly offered such options. The outcome of these negotiations will likely shape the future of AI headline generation across Google's platforms.
Technical Deep Dive: How These Systems Actually Work
Language Models and Headline Generation
Google's AI headline generation relies on transformer-based language models, the same architecture underlying systems like GPT models and other large language model implementations. These systems are trained on massive datasets containing billions of web pages, news articles, books, and other text. During training, the model learns statistical relationships between words and text patterns, developing the ability to predict likely sequences of words given initial prompts.
When applied to headline generation, the model receives the article text as input and generates headline text as output. The technical approach typically involves either fine-tuning a pre-trained language model on news headline data or using prompt-based approaches where the model receives instructions like "Generate a headline for this article" along with the article text.
The mathematical foundation involves computing attention weights across different parts of the input text, allowing the model to focus on different sections when generating different parts of the output. This enables the model to theoretically understand that certain parts of the article are more important for headline generation. In practice, however, this mechanism often fails to prioritize accurately.
The training process itself introduces bias toward engagement. If the training dataset contains articles paired with their corresponding engagement metrics, the model can learn associations between certain words, phrasings, and engagement levels. This creates systematic bias toward generating text similar to high-engagement headlines, even when such headlines might be misleading or inaccurate.
Temperature, Beam Search, and Decoding Parameters
When generating text, language models use various parameters to control output characteristics. Temperature, a parameter typically ranging from 0 to 2, controls randomness in output selection. Lower temperatures produce more deterministic, repetitive text; higher temperatures produce more creative, diverse text. Beam search is a decoding algorithm that explores multiple candidate sequences rather than greedily selecting the highest-probability word at each step.
Google's headline generation system likely uses relatively low temperature settings and beam search to generate headlines that sound natural while remaining somewhat predictable. This reduces obviously nonsensical outputs but maintains the engagement optimization bias. Fine-tuning these parameters represents one way Google could improve headline quality—for example, using higher temperature could produce more varied headlines that don't all sound identical.
However, parameter tuning addresses only surface-level problems. The fundamental issue that these models generate text based on statistical patterns rather than understanding remains regardless of decoding parameters. No amount of technical parameter adjustment can teach a language model to understand the difference between accurate and false claims.
Why Fact-Checking Fails
Google could theoretically improve its system by adding fact-checking mechanisms—additional components that verify whether generated headlines are supported by article content. However, this is technically challenging and potentially impossible with current approaches. The problem is that fact-checking also requires understanding, not just pattern matching.
A fact-checking system might work by parsing the article for specific factual claims and checking whether the generated headline aligns with those claims. For simple, structured information like dates or numbers, this is feasible. For complex claims like "the government reversed policy X," fact-checking becomes much harder. The system must understand whether the article is making an affirmative claim or a negative one, understand context and nuance, and distinguish between direct statements and hypotheticals or speculation.
Many fact-checking approaches involve comparing generated text against knowledge bases or existing information. However, this approach fails for novel information that the knowledge base doesn't contain. If Google's fact-checking system checks generated headlines against its knowledge base, it might confirm that certain facts are generally true while missing article-specific context that makes the generated headline false in this particular instance.
The drone ban example illustrates this limitation. A fact-checking system might confirm that "drone bans" are real policies that governments have implemented, and that "reversals" of policies occur regularly. It might not capture the specific article-level context that the ban wasn't actually in place, making "reversal" misleading. Comprehensive fact-checking would require understanding the full article context, which brings us back to the same understanding problem that language models face.
Personalization and Engagement Optimization
Google's system likely personalizes generated headlines based on user characteristics, browsing history, and predicted preferences. A user interested in regulatory policy might see a headline emphasizing government action, while a user interested in technology might see a headline emphasizing the companies affected. This personalization increases engagement but further disconnects the headline from the article's actual content and focus.
The personalization process involves additional machine learning models that predict user interests and preferences, then feed this information into the headline generation system. The headline generator receives not just the article text but also information about the specific user, allowing it to generate headlines tailored to that user's interests. This can produce headlines that are completely different for different users reading the same article.
This personalization creates significant problems for accuracy. Different users might see completely different headlines for the same article, with no coordination between those versions. One user might see a headline emphasizing one aspect of a complex story while another sees a headline emphasizing a different aspect. Both headlines might be misleading depending on the story's actual emphasis. The system generates potentially millions of different headlines from a single article, with no single version that's factually audited or approved.
Engagement optimization is built into this entire process. The personalization system specifically prioritizes generating headlines that will appeal to each user's demonstrated interests, which often means more sensational or novel framings. An article about regulatory policy might generate a headline like "Government to ban technology," even if the article discusses a specific regulation affecting only one company. The headline is optimized for engagement, not accuracy.

The Journalism Ethics and Standards Questions
How Traditional Journalism Standards Address Headlines
Journalism has developed extensive standards for headline writing that emphasize accuracy, clarity, and faithfulness to article content. The Associated Press, journalism ethics organizations, and individual publications all maintain guidelines about appropriate headline practices. These standards reflect the understanding that headlines are powerful communication tools that deserve careful attention and editorial responsibility.
Core standards include requirements that headlines accurately represent article content, that headlines not exaggerate or misrepresent facts, that headlines distinguish between facts and speculation, and that headlines not include false statements or misleading framings. Many journalism organizations specifically warn against clickbait headlines that sensationalize stories or misrepresent their content.
These standards exist because journalists and editors understand that headlines shape how readers understand information. Readers often encounter only headlines, particularly in social media and algorithmic feed contexts. Headlines that deceive these readers create misinformation even if the underlying articles are accurate. News organizations take responsibility for their headlines as part of their commitment to accuracy and public service.
The standards also recognize that headlines reflect publication voice and brand identity. A news organization's headline style, tone, and approach constitute part of how the organization communicates with its audience. Editorial standards ensure consistency and predictability, helping readers know what to expect from a publication. Google's AI-generated headlines violate these standards by removing publication voice and replacing it with algorithm-driven alternatives.
While some publications do publish sensationalized headlines on occasion, and journalistic standards have evolved over time as digital media has changed headline emphasis, the core commitment to accuracy and representation of article content remains central to journalism. Google's AI system operates outside this ethical framework entirely, optimizing for engagement without the ethical constraints that guide human headline writing.
The Question of Publisher Attribution and Responsibility
A critical ethics question involves who bears responsibility for AI-generated headlines. When a user encounters a false AI headline attributed to a news organization, does responsibility lie with Google, which generated the headline, or with the publisher, whose article is being misrepresented? This question has significant implications for both parties' accountability.
Publishers argue that they should not bear responsibility for AI-generated headlines they didn't write and didn't approve. The headline appears under their byline and represents their brand, but they had no control over its generation or its accuracy. Holding publishers responsible for false AI-generated headlines essentially makes publishers liable for Google's decisions without giving publishers meaningful control over those decisions.
Google, meanwhile, positions itself as merely identifying trending topics and presenting information about stories, not fundamentally rewriting publisher content. This positioning attempts to reduce Google's responsibility while shifting accountability toward publishers. Google claims it's not the headline's publisher; it's just highlighting trends. This distinction collapses in practice, but it reflects how Google wants responsibility assigned.
From a user perspective, the responsibility question matters less than the accuracy question, but it has significant legal and ethical implications. If Google is responsible for AI-generated headlines, then Google should implement sufficient accuracy controls and quality assurance. If publishers are responsible, then publishers should have the ability to opt out, approve, or modify headlines before publication. Currently, neither party takes full responsibility, creating a gap where accountability disappears.
This accountability gap reflects a broader challenge with AI systems. As systems become more sophisticated and capable of producing content that resembles human-generated work, questions of responsibility, liability, and accountability become increasingly complex. Current legal and ethical frameworks developed for human-created content don't fit well with AI-generated content that appears to come from specific organizations but wasn't actually created by them.
Broader Implications for Journalism in an AI Era
Google's AI headline generation is one example of a broader pattern where AI systems are beginning to participate in journalism and news distribution. AI powers recommendation systems, content summarization tools, automated transcription of interviews, and numerous other journalism-adjacent functions. As AI capability expands, the question of how these systems can be deployed responsibly becomes increasingly urgent.
One key implication involves the distinction between AI as a tool for journalists and AI as a replacement for journalistic judgment. AI tools that assist journalists—helping with transcription, suggesting potential angles, analyzing large datasets—extend human capability. AI systems that replace journalistic functions like headline writing, editorial judgment, or fact-checking create the problems Google is currently experiencing.
The journalism industry needs to develop clearer standards for when AI is appropriately used and how its limitations should be acknowledged. Publications using AI to assist with any journalism-adjacent function should disclose this to readers. They should implement robust quality control and accuracy verification. They should maintain human editorial oversight of AI-generated content. Most importantly, they should never deploy AI systems in ways that represent them as human-generated content without disclosure.
Google's approach of deploying AI headline generation at scale without adequate accuracy control represents exactly the wrong model. The company rolled out a capability without establishing sufficient quality control, created a significant accuracy problem, then defended the approach based on engagement metrics that don't measure accuracy. This is a how-not-to example for AI deployment in sensitive domains like journalism.

User Impact: How AI Headlines Affect News Consumption
Misinformation and False Headlines in Algorithmic Feeds
The impact of Google's AI headline generation extends beyond publisher concerns to affect how users encounter and understand news. When users see false headlines in algorithmic feeds, they often form impressions about stories based on those headlines without reading the full articles. This creates a direct mechanism for spreading misinformation through platforms that billions of people use.
Algorithmic feeds are particularly susceptible to misinformation spread because users interact with feeds in scanning mode. They rapidly move through content, spending a few seconds on each item, making split-second decisions about what to read more deeply. In this context, headlines carry enormous power. A false headline might persuade a user to believe false information without ever reading the article, or might prime the user to interpret the article through a false frame.
Studies on social media demonstrate that users who see false headlines frequently come away with false beliefs about the information, particularly on topics where they lack prior knowledge. If a user encounters a Google Discover headline claiming "US reverses drone ban," they might come away believing this is true even if they don't read the article, or they might read the article while interpreted it through the false frame established by the headline.
The problem intensifies because Google Discover reaches users who explicitly haven't searched for news—they're passively scrolling a feed. These users might be less likely to critically evaluate headlines or seek additional sources compared to users actively searching for information. They might trust that if something appears in Google Discover, it's vetted as legitimate. Google's placement of AI-generated headlines in this trusted context creates particular harm.
Users also experience confusion when AI headlines don't match article content. A user clicking based on a headline and finding that the article says something completely different might come away uncertain about what the truth actually is. They might distrust both the publication and Google Discover, or they might incorrectly blame the publication for misleading headlines that Google generated.
The Framing Effect and Reader Understanding
Even when AI headlines aren't factually false, they still shape reader understanding through framing effects. The way a story is presented affects how readers interpret it, what they consider important, and what conclusions they draw. AI-generated headlines often frame stories differently than the original headlines, changing reader interpretation even when both headlines are technically factual.
Consider an article about declining smartphone sales. The original headline might be "Smartphone makers struggle as consumers delay upgrades." This frame emphasizes consumer behavior and suggests an economic challenge for manufacturers. An AI-generated headline for the same article might be "Apple cuts production amid slowing demand," which frames the story as specifically about Apple's business decisions. Readers encountering the two different headlines come away with different understandings of the same reporting.
This matters because framing affects how information gets integrated into existing beliefs and how it influences attitudes. A reader who sees the frame "makers struggle" might think about problems in the technology industry and economic challenges generally. A reader who sees the frame "Apple cuts production" might think about Apple specifically and make inferences about Apple's business prospects. The facts being reported remain the same, but reader understanding differs based on framing.
AI systems optimize for frames that maximize engagement, which typically means more dramatic or surprising frames. This bias toward dramatic framing affects how readers understand news consistently. Over time, if most of the headlines readers encounter are AI-generated and optimized for engagement, readers might develop distorted understandings of stories that systematically emphasize drama and surprise over more balanced framings.
Trust and Credibility Implications
When readers encounter false AI headlines attributed to news organizations, their trust in those organizations declines. This trust damage affects all of the organization's content, not just the specific articles with false headlines. If a publication has published one false headline, readers might become skeptical of other headlines from that publication, even though the publication didn't generate the false headline.
This creates a tragedy of the commons scenario. Google benefits from increased engagement generated by sensationalized headlines. Publishers suffer from reputation damage and reduced trust. Users suffer from misinformation and distorted framing. The system creates incentives for continued deployment of the feature despite its negative consequences for the larger ecosystem.
Broad awareness of the AI headline problem might also reduce overall trust in news that appears in algorithmic feeds. If readers become aware that headlines can be AI-generated and potentially false, they might adopt a posture of skepticism toward all algorithmic feed headlines. This skepticism is warranted but costly—it reduces the effectiveness of accurate headlines alongside false ones and creates friction in news consumption that reduces reader engagement with legitimate journalism.
There's also a broader credibility problem for the news industry. When major platforms can deploy systems that create false headlines attributed to news organizations, it undermines user confidence in all news sources. If a user can't trust that headlines in their phone's feed are genuine, why should they trust any digital news? This systemic credibility problem from even one platform's malfunctioning AI system affects the entire news industry's reputation.

Google's Defense and Counterarguments
The Performance and Engagement Argument
Google's primary defense of its AI headline generation feature is that it performs well for user satisfaction and engagement. The company claims that users engage more frequently with AI-generated headlines than with original headlines, suggesting that the feature is delivering value to users by presenting more engaging content. This data, while not made public, presumably shows higher click-through rates or other engagement metrics for AI-generated versus original headlines.
However, this defense contains several assumptions and limitations. First, it assumes that engagement metrics correlate with genuine satisfaction and value. A headline that generates a click but leads users to feel deceived delivers a false engagement signal. The user might click and then leave quickly, having been misled about the article's content. The engagement metric captures the click but not the frustration or sense of being deceived.
Second, the engagement argument assumes that maximizing engagement is the appropriate goal for a news distribution platform. One could argue instead that the platform's goal should be helping users find accurate, relevant information efficiently. A system that generates false headlines but drives high engagement is succeeding at the wrong objective. Google's framing of this as a success story reveals that the company prioritizes engagement metrics over accuracy, which represents a choice about what the platform's purpose should be.
Third, Google's engagement claim needs context. Better engagement could result from the fact that AI-generated headlines are more sensational, more surprising, or more optimized for engagement. This doesn't mean the feature is good for users; it means the feature is good at manipulating users into clicking on things. There's an important difference between creating user value and manipulating user behavior.
Google essentially argues that because the feature generates engagement, it must be beneficial. This logic is questionable. Misinformation also generates engagement. Sensational content generates engagement. Manipulative framing generates engagement. The fact that something drives engagement doesn't establish that it's good for users or appropriate for a platform with responsibility to distribute accurate information.
The Trending Topics Reframing
Google's characterization of AI-generated headlines as "trending topics" rather than headline rewrites represents a strategic rhetorical choice designed to shift how the feature is perceived. If the feature is identifying trends that are emerging across news coverage, it becomes a fundamentally different thing than rewriting headlines. Trend identification is an analytical function; headline rewriting is content modification.
However, this reframing doesn't hold up under scrutiny. The AI-generated text appears exactly where headlines appear, formatted identically to headlines, linked to specific articles exactly as headlines link to articles. From a functional perspective, these are headlines, not trend reports. The fact that Google calls them something else doesn't change their actual function and impact.
This rhetorical move also conveniently obscures what's actually happening technically. Google is analyzing each article and generating new text for that article's representation in the feed. The fact that this is characterized as trend identification rather than article text generation doesn't change the underlying technical reality. A user encountering an AI-generated headline to a specific article is encountering modified article text, not a separate trend analysis.
Google's reframing might have legal advantages, as discussed earlier. Characterizing the feature as trending topics might protect it under fair use if it were legally challenged. However, the reframing doesn't address the fundamental ethical and accuracy problems. Accurate understanding of what the system actually does—rewriting headlines—is important for evaluating whether it should exist.
Improving Quality Over Stopping the Feature
Google's position implicitly argues that the solution to headline accuracy problems is better AI, not eliminating the feature. The company could theoretically improve headline quality through better training data, more sophisticated models, or additional fact-checking mechanisms. Rather than removing the feature, Google could invest in making it work better.
This argument has appeal—why eliminate a feature that some users find valuable instead of improving it? However, it underestimates the fundamental limitations inherent in the approach. Even if Google could reduce the current error rate significantly through improved AI, the system would still lack the editorial judgment and commitment to accuracy that human headline writers possess. An AI system will always optimize for learned patterns rather than for the specific, contextual, nuanced thinking that journalism requires.
There are also practical limits to improvement. Some error sources, like confusion between different stories or misunderstanding of negation and contradiction, might be reducible through better training. Other error sources, like the tension between engagement optimization and accuracy, are baked into the feature's fundamental design. An engagement-optimized system will always produce more sensational framings than accuracy-focused systems, even if it doesn't generate false claims.
Google's improvement argument also ignores the consent and control question. Even if Google could generate perfectly accurate, perfectly neutral headlines that exactly matched the original headlines, publishers still haven't consented to this use of their content. Improving accuracy doesn't address the fundamental question of whether the feature should exist without explicit publisher consent.
How News Organizations Are Responding
Opting Out and Negotiating Agreements
Some publishers have begun actively negotiating with Google about how their content appears in Google Discover. These negotiations sometimes include requests to opt out of AI headline generation entirely, preserving original headlines while keeping content in the feed. Other negotiations focus on compensation for the use of AI-generated headlines derived from publisher content, recognizing this as a form of content licensing that should involve payment.
Publishers taking this approach recognize that they have some bargaining power—Google Discover depends on news content, and major publishers can negotiate terms. However, this negotiating power is limited for smaller publishers who lack leverage. A major national publication can potentially request modifications to how its content is presented; a small local news organization has little ability to demand accommodations.
Publishers have also begun developing technical tools to detect when their headlines are being rewritten by Google's AI system. By monitoring their own traffic and comparing what appears in Google Discover against their original headlines, publishers can identify instances of rewriting and document patterns. This data becomes useful in negotiations and potential legal action.
Some publishers have adopted policies of not submitting new content to Google Discover, or submitting content through mechanisms that provide greater control over presentation. Others have negotiated agreements that give them the ability to request removal of AI-generated alternatives for specific articles or categories of articles. These individual solutions, while helpful for publishers who can implement them, don't address the systemic issue of how Google is using AI headlines across the platform.
Editorial Responses and Transparency
Publishers have also responded by being more explicit with readers about these issues. Some publications have published analysis of Google's headline rewriting, explaining how the feature works and demonstrating examples of inaccurate or misleading AI headlines. This public attention has brought more awareness to the problem and created pressure on Google to address the feature.
Editors have also discussed the problem internally, considering how to protect their publications' content and reputations in an era when platforms can algorithmically modify headlines. These conversations often focus on developing longer-term strategies for maintaining editorial control and direct reader relationships in ways that don't depend entirely on platform distribution.
Some publications have emphasized their own original headlines more prominently in feeds and on social media, trying to establish the version of record for their own work. By pushing their original headlines through their own channels with more prominence, publishers attempt to make their authentic voice the primary version readers encounter, with platform versions becoming secondary.
Publishers have also increased focus on sustainable distribution models that don't depend on algorithmic feeds. Email newsletters, subscription products, and direct reader relationships all reduce dependence on Google Discover. While these alternatives can't fully replace the traffic that platforms generate, they provide pathways for reaching readers without depending on platforms' distribution decisions.

Broader Industry Implications and Future Scenarios
What This Means for the Future of AI in News Distribution
Google's AI headline generation represents a proving ground for how platforms might deploy AI across news distribution at scale. If Google can deploy AI headlines despite accuracy concerns and lack of publisher consent, other platforms will likely follow. Bing, Apple News, Meta, and other platforms with news discovery features could all deploy similar systems if Google demonstrates the capability and shows that publishers can't prevent it.
The precedent established by Google's approach affects whether platforms will view AI headline generation as a legitimate feature or a problematic overreach. If Google faces significant consequences—legal liability, regulatory action, or major publisher withdrawal—other platforms will think twice before implementing similar features. If Google faces minimal consequences despite documented accuracy problems, platforms have permission to proceed with their own deployments.
This dynamic makes Google's deployment particularly significant. The company's choices about whether to continue, how to improve, or whether to remove the feature will shape how broadly similar features proliferate across the platform ecosystem. If Google removes the feature after finding it causes more harm than benefit, it sends a signal that AI headline generation is a problematic approach. If Google continues indefinitely while claiming engagement success, it normalizes the practice.
The timing is also significant. Google's deployment comes at a moment when AI capability is expanding rapidly and public awareness of both AI promise and problems is increasing. Decisions made now about appropriate uses of AI in sensitive domains like journalism will shape expectations and regulatory frameworks for years to come. If Google establishes that it's appropriate to deploy AI headline generation without publisher consent despite accuracy concerns, this precedent makes it harder to limit similar deployments in the future.
Regulatory Paths and Potential Legislation
Google's AI headline generation has attracted attention from regulators and legislators interested in AI governance and platform regulation. Several potential regulatory paths could limit or prohibit the practice. These range from AI-specific regulations to platform regulation frameworks to copyright and intellectual property protections.
AI-specific regulations might establish requirements for transparency about AI content generation, requiring that AI-generated content be clearly labeled. Such regulations might also establish accuracy standards for AI systems deployed in sensitive domains like news distribution. These approaches would allow AI headline generation but require disclosure to users and maintenance of accuracy standards.
Platform regulation approaches might focus on publisher protections and content modification. Regulations might prohibit platforms from modifying publisher content without explicit consent or might establish rights of removal for publishers who object to how their content is presented. These approaches would address the autonomy and control questions without necessarily prohibiting AI-generated content.
Copyright and intellectual property approaches might establish clearer rights around derivative works and require that platforms obtain licenses before generating AI-based alternatives to publisher headlines. These approaches would create economic incentives for platforms to seek permission before deploying such systems, since obtaining licenses would involve compensation.
Which regulatory path emerges likely depends on how governments frame the problem. Is this primarily an AI safety issue, a platform regulation issue, or an intellectual property issue? Different framings suggest different regulatory solutions. Currently, no consensus has emerged about how to classify and address the problem, leaving Google with significant regulatory uncertainty.
What Publishers Need to Do Now
Publishers responding to Google's AI headline generation should take several immediate actions. First, publishers should monitor how their content appears in Google Discover and document instances of AI headline generation, particularly examples where generated headlines are inaccurate or misleading. This documentation becomes valuable for both negotiations and potential legal action.
Second, publishers should explicitly address AI headline generation in any negotiations with Google about content distribution. Even publishers who lack strong individual leverage should collectively advocate for industry-wide standards. Trade organizations representing publishers should negotiate on behalf of members, establishing terms that protect publisher interests.
Third, publishers should diversify away from dependence on algorithmic feeds. Subscription products, email newsletters, and direct audience relationships reduce vulnerability to platform decisions. While platform distribution remains valuable, too much dependence on any single platform creates vulnerability to features like AI headline generation that publishers can't control.
Fourth, publishers should invest in headline quality and distinctive voice as brand differentiators. If platforms can generate their own headlines algorithmically, publisher headline quality becomes less valuable in platform contexts. However, this doesn't mean abandoning headline investment. Instead, it means investing in headlines that serve publisher audiences directly, through newsletters, social media, and publisher-controlled channels where original headlines remain visible.
Fifth, publishers should consider legal action if appropriate. Copyright claims, intellectual property claims, and unfair competition claims might succeed depending on jurisdiction and how courts interpret platforms' rights to modify content. Publishers shouldn't assume they're powerless before exploring legal options.

Solutions and Better Alternatives
What Google Could Do Instead
Google could address the legitimate problems created by AI headline generation while still improving user experience by taking fundamentally different approaches. These alternatives would provide value to users without the accuracy and consent problems that AI headlines create.
First, Google could improve presentation of original headlines. Instead of replacing headlines with AI versions, Google could display original headlines more prominently or improve the headline presentation in other ways that enhance readability without changing content. Better typography, more space for headlines, or improved formatting could increase engagement without rewriting.
Second, Google could deploy AI in support roles rather than replacement roles. AI could assist in headline presentation without generating new headlines. For example, AI could identify the key noun, verb, and object from an article and highlight those in the original headline. AI could generate optional bullet-point summaries underneath original headlines, providing additional context without replacing the headline itself.
Third, Google could ask publishers for permission to generate alternative headlines and only deploy AI versions for publishers who opt in and approve the implementation. This approach respects publisher autonomy while allowing Google to test AI headline generation with willing partners. Publishers could review generated alternatives and approve only those that accurately represent article content.
Fourth, Google could invest in better original headline data. Instead of generating new headlines, Google could analyze what makes certain headlines more engaging, then help publishers write better headlines by providing this intelligence. Publishers could use insights about which headline formulations drive engagement to improve their own headline writing, benefiting from AI insights without losing editorial control.
Fifth, Google could establish stricter quality control for any AI-generated content. If Google deploys AI headlines, the company could implement mandatory fact-checking mechanisms, human review of generated headlines before publication, and immediate removal of inaccurate headlines when errors are identified. These quality controls would be more expensive to implement but would address the accuracy concerns.
Industry Standards That Need Development
The broader news industry needs to develop standards for how AI should and shouldn't be used in journalism and news distribution. These standards should address when AI assistance is appropriate, how AI-generated content should be disclosed to readers, and what editorial controls should govern AI systems.
Standards might establish that AI generation of news content headlines is inappropriate without explicit publisher consent and that any AI-generated alternatives should be clearly identified as such. Standards could permit AI use in backend functions like categorization, tagging, or analysis, while prohibiting AI in front-end content that readers encounter directly.
Standards could also address transparency. Publishers using AI in any journalism-related function should disclose this to readers. News organizations should explain what AI is doing, what human editorial functions remain, and what quality controls are in place. This transparency helps readers understand how the information they're consuming was generated and maintains the trust necessary for journalism to serve its democratic function.
Industry standards could also address the distinction between AI as assistant and AI as replacement. AI tools that amplify human capabilities—assisting with transcription, analysis, or organization—differ fundamentally from AI systems that replace human judgment in areas requiring editorial expertise and commitment to accuracy. Standards should encourage the first while prohibiting the second in sensitive domains.
What Readers Should Do
Readers encountering AI headlines in algorithmic feeds should develop appropriate skepticism. This doesn't mean distrusting all headlines, but rather recognizing that headlines in algorithmic feeds might be optimized for engagement rather than accuracy. Reading beyond headlines, checking information in multiple sources, and maintaining awareness that platforms modify content helps readers navigate algorithmic feeds more effectively.
Readers should also support news organizations directly rather than depending entirely on algorithmic distribution. Subscribing to publications, signing up for email newsletters, and following publications directly on social media where publishers control content presentation helps maintain the direct relationships that preserve editorial integrity. Direct reader support also reduces news organizations' dependence on platform distribution, making them less vulnerable to platform decisions.
Readers interested in this topic should follow news organizations' discussions of AI headline generation and platform challenges. Many publications publish regular analysis of these issues, and reader awareness of the problem creates pressure on platforms and policymakers to address it. Informed readers who understand these issues can also make better choices about which sources to trust and which platforms to rely on for information.
Timeline and Future Outlook
How This Issue Has Evolved
Google's AI headline generation emerged publicly in early December 2024 when multiple news organizations discovered they were being deployed. Initial reporting by the Verge and others documented the feature and raised concerns about accuracy. Google initially described this as an experiment, suggesting potential limitations on the feature's scope. However, by mid-January 2025, Google announced that AI headlines are actually a permanent feature that "performs well for user satisfaction."
This timeline is significant. Google first tested the feature without announcing it to publishers, then described it as an experiment when discovered, then pivoted to claiming it as a successful permanent feature. This progression suggests Google didn't expect the level of objection from publishers and is now defending the feature despite documented accuracy problems.
During this same period, documented examples of inaccurate AI headlines accumulated, creating a substantial public record of problems. Publishers began discussing negotiations with Google and exploring technical and legal options. The issue gained traction in journalism trade publications and mainstream tech coverage, bringing broader awareness of the problem.
As of early 2025, no major regulatory action has been taken, though the situation continues developing. Some publishers have begun implementing workarounds or negotiating individual accommodations. Google has not announced major modifications to the feature or steps to address accuracy concerns, instead defending the feature based on engagement metrics.
Predicted Developments for 2025 and Beyond
Several developments seem likely in coming months and years. First, regulatory pressure will probably increase. As awareness of the problem spreads and publishers document impacts, legislators and regulators will likely open investigations or propose legislation addressing the issue. This regulatory attention could come from multiple jurisdictions, as countries with significant journalism industries take steps to protect publishers.
Second, more publishers will likely negotiate individual accommodations or cease submitting content to platforms running AI headline generation. Industry organizations might also pursue collective action, negotiating industry-wide standards with platforms. This could result in modified implementation where some publishers opt out, or where AI headlines are only deployed for publishers who explicitly consent.
Third, AI headline generation will likely spread to other platforms if Google continues deploying the feature without major negative consequences. Bing, Apple News, Meta, and other platforms may see AI headline generation as a feature worth implementing, leading to ecosystem-wide presence of the practice. Alternatively, if Google faces sufficient pressure to remove the feature, other platforms may avoid implementing similar systems.
Fourth, development of better detection and documentation tools will continue. Publishers will increasingly create systems to identify when their content is being modified and by what methods. This will lead to better documentation of how extensively the practice occurs and what impacts it creates, supporting future regulation or litigation.
Fifth, the technical quality of AI headlines will likely improve, even if the fundamental problems remain. Larger models, better training data, and more sophisticated approaches could reduce obvious errors while maintaining the engagement optimization bias that creates systematic problems. Improved accuracy won't eliminate the underlying concerns about consent, control, and platform modification of publisher content.
Practical Guidance for Different Stakeholder Groups
For Publishers and News Organizations
Publishers should immediately audit how their content appears in Google Discover and other algorithmic feeds. Document instances of AI headline generation, particularly examples where headlines are inaccurate or misleading. This documentation becomes valuable evidence if future disputes arise and provides data for internal strategy decisions about platform dependence.
Establish explicit policies about what modifications publishers will permit to their content. Even if you lack strong individual leverage, establishing a clear policy positions you for future negotiations or regulatory discussions. Policies should address headline modifications, content rewriting, and use of images in contexts other than originally published.
Invest in diversified distribution channels that don't depend entirely on algorithmic feeds. Build direct reader relationships through email newsletters, develop subscription products, and establish presence on platforms where you maintain more control over content presentation. These alternatives shouldn't replace platform distribution, but they should reduce vulnerability to platform decisions you can't control.
Consider joining publisher industry organizations advocating for standards and negotiating collectively with platforms. Individual publishers have limited leverage, but industry-wide coordination creates stronger bargaining positions. Trade organizations can negotiate terms that benefit entire industries more effectively than individual companies can.
Explore legal options with intellectual property attorneys. Headline modification might constitute infringement of derivative works rights, unfair competition, or violation of implicit licensing agreements. While legal outcomes remain uncertain, publishers shouldn't assume legal challenges are impossible without exploring them carefully.
For Platform Companies
Platforms deploying or considering deploying AI-generated content replacements should establish clear policies about transparency, accuracy, and publisher consent. If platforms generate content derived from publisher work, users should be informed that content is AI-generated. Publishers should have clear mechanisms for opting out or approving how their content is presented.
Establish robust quality control for any AI-generated content, particularly content that reaches millions of users. If accuracy matters for the domain, implement sufficient fact-checking to ensure generated content meets accuracy standards. Don't rely solely on engagement metrics; implement separate quality measurements that assess accuracy.
Seek explicit permission from publishers before deploying content modifications. Publishers created the content that makes platforms valuable; respecting publisher autonomy and engaging in good-faith negotiation about platform treatment builds long-term relationships better than deploying features without consultation.
Consider the long-term sustainability of practices that create widespread misinformation. Short-term engagement gains from sensationalized content create long-term credibility problems for platforms and damages user trust. Building sustainable platforms requires maintaining user confidence in information quality, which requires responsible deployment of AI systems.
Engage with regulators and policymakers proactively to shape how AI governance develops. Platforms that participate in regulatory development help establish standards they can work with, while platforms that avoid engagement risk having standards imposed by regulators with less technical understanding. Constructive engagement with governance processes is better long-term strategy than opposition to all regulation.
For Readers and Media Consumers
Develop appropriate skepticism about headlines in algorithmic feeds while maintaining engagement with news. Understand that these headlines are optimized for engagement, not necessarily for accuracy. Reading beyond headlines and checking important claims against multiple sources remains valuable practice.
Support journalism through direct subscriptions or contributions when possible. Direct reader support reduces news organizations' dependence on platform distribution and helps fund the original reporting that makes platforms valuable. Even small contributions help diversify publisher revenue away from platform dependence.
Follow news organizations' coverage of these issues. Major publications are documenting how platforms modify their content and what impacts this creates. Reading this coverage helps you understand how information is distributed and processed, making you a more informed consumer of news.
Consider which platforms you rely on for news information. Different platforms have different approaches to content distribution and AI involvement. Being aware of which platforms are deploying AI modification of headlines and which are maintaining original publisher content helps you make informed choices about where you get news.
Engage in media literacy practices. Verify important claims before sharing them, be skeptical of surprising or sensational headlines, and recognize that information in algorithmic feeds has been processed through optimization algorithms designed to maximize engagement. These practices help protect you from misinformation and help reduce the spread of false claims.

Conclusion: Choosing Between Progress and Responsibility
Google's AI headline generation represents a moment of decision for the entire digital information ecosystem. The company has deployed a capability that is technically impressive—AI systems can generate grammatically correct, semantically relevant, apparently natural headlines at scale. However, this technical capability has revealed fundamental limitations that language models possess. These systems can generate plausible text without understanding meaning, accuracy, or responsibility.
The feature also reveals something important about incentive structures in digital platforms. When success is measured through engagement metrics like click-through rates, platforms naturally gravitate toward sensationalism and manipulation. Accurate, nuanced representations of news stories might drive less engagement than misleading framings that exploit human psychology. This creates systematic bias toward inaccuracy in systems optimized for engagement.
Google's approach of deploying AI headlines at scale without publisher consent, without adequate accuracy control, and while defending the feature based on engagement metrics rather than accuracy represents a concerning precedent. If the company faces no significant consequences for this deployment, other platforms will likely follow. If companies learn that they can modify publisher content without consent and that platforms can legally escape responsibility for accuracy problems, the entire news distribution ecosystem becomes less reliable.
The issue also highlights a broader challenge with artificial intelligence in society. As AI systems become more capable, their limitations become more significant. A system that can generate coherent text about complex topics is deeply impressive. A system that generates false information about complex topics while claiming to be journalism is problematic, particularly when deployed at scale without oversight.
Moving forward, the digital information ecosystem needs clearer standards for how AI should be used in journalism and news distribution. These standards should distinguish between AI as a tool assisting humans versus AI replacing human judgment. They should require transparency about AI involvement in content generation. They should establish that publisher consent matters and that content modification without consent is inappropriate.
Google has an opportunity to lead responsibly by either removing AI headline generation or implementing it only with explicit publisher consent and robust accuracy control. The company has demonstrated technical capability; the question now is whether that capability will be deployed responsibly or will set a problematic precedent for how platforms treat publisher content.
For publishers, the challenge involves protecting their content and reputation while maintaining the platform distribution necessary for reaching readers. This requires negotiating with platforms from a position of relative weakness, developing tools to detect and document how content is modified, and building alternative distribution channels that don't depend on algorithmic feeds.
For readers, the challenge involves consuming information from algorithmic feeds with appropriate skepticism while supporting journalism directly rather than depending entirely on platform distribution. Media literacy becomes more important as platforms modify content, and direct reader relationships with trusted publications become more valuable.
The outcome of this moment will shape how AI is deployed across information systems for years to come. If platforms learn that they can modify content without consent, optimize for engagement over accuracy, and escape responsibility for resulting misinformation, we've established a concerning precedent. If instead we establish that accuracy, transparency, and publisher autonomy matter, we've protected the foundations that make trustworthy information distribution possible.
Google's approach to AI headlines isn't inevitable. Better approaches exist that would provide user value while respecting publisher autonomy and maintaining accuracy standards. Whether platforms choose responsibility or optimization will determine whether AI enhances or undermines our information ecosystem.
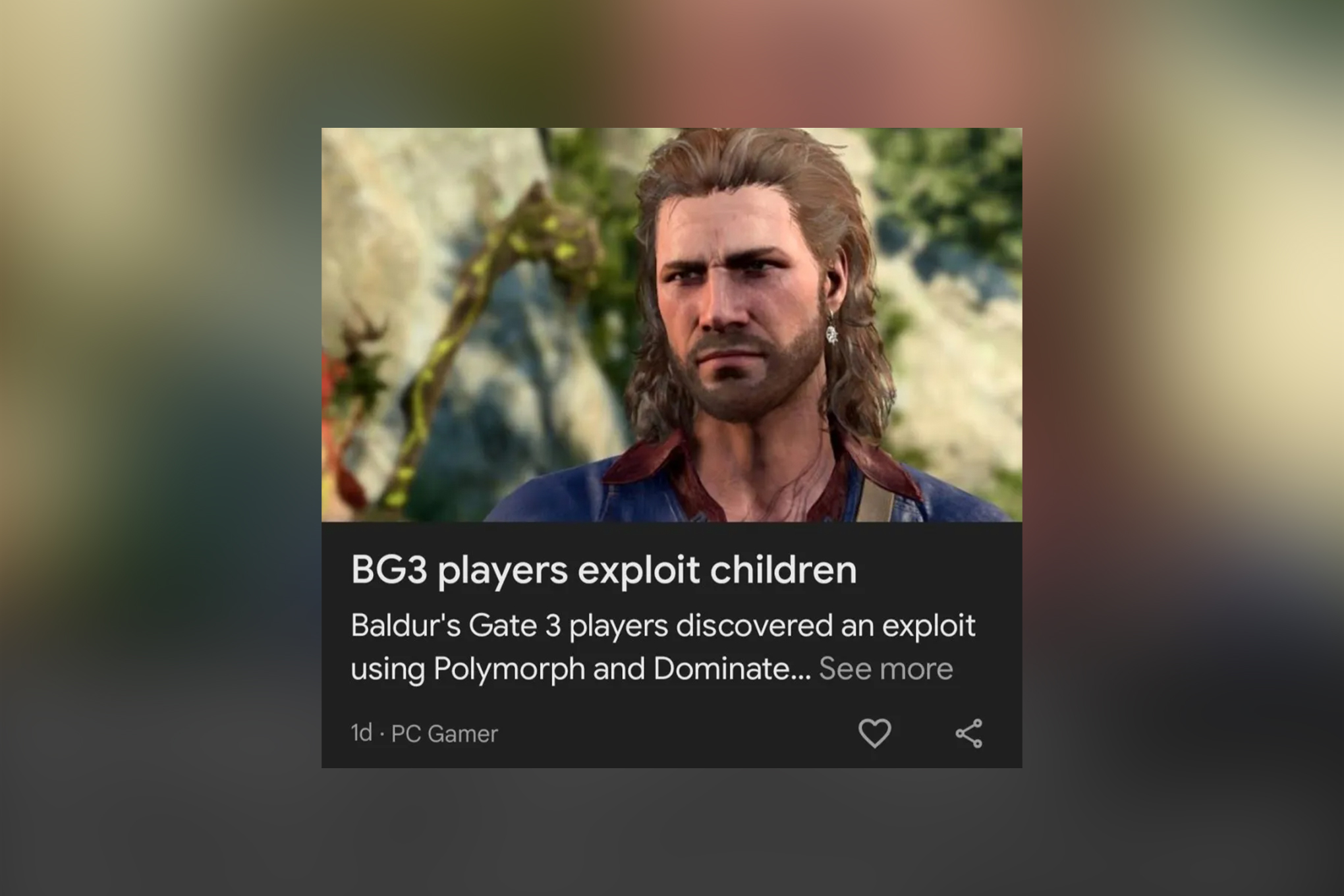
FAQ
What are AI-generated news headlines?
AI-generated news headlines are headline text created by artificial intelligence systems analyzing article content, rather than written by journalists or editors. Google's system analyzes news articles and generates new headlines optimized for engagement in its Discover feed. These AI-generated headlines replace the original headlines written by publishers, creating situations where users see different headline text than what journalists originally wrote.
How does Google's headline generation system work technically?
Google's system uses transformer-based language models trained on billions of text examples to analyze article content and generate new headline variations. The AI reads the article text, identifies what it perceives as key information, and generates new text designed to maximize click-through rates in the feed. The system can personalize headlines for individual users based on their interests and browsing history. Temperature and beam search parameters control the randomness and diversity of generated headlines.
Why are AI-generated headlines inaccurate?
AI systems generate text based on statistical patterns they've learned rather than through understanding meaning or verifying facts. They have no mechanism for fact-checking whether generated claims are supported by article content. They struggle with negation, contradiction, and nuanced understanding. The systems are optimized for engagement, which means they naturally gravitate toward sensational framings that might be misleading. A language model can generate text matching patterns it's learned without understanding whether that text is true.
What damage do inaccurate AI headlines cause?
Inaccurate AI headlines spread misinformation to millions of users in algorithmic feeds. They harm publisher reputation by attributing false claims to organizations that didn't write those claims. They reduce trust in news organizations and undermine reader confidence in information sources. They shape user understanding through framing effects even when technically factual. They damage the credibility of journalism and make the public less informed about important issues.
Has Google received criticism for this feature?
Yes, the feature has generated significant criticism from publishers, journalists, and news industry organizations. The Verge first documented examples of inaccurate AI headlines in December 2024. Journalists and publishers have expressed concern that Google is modifying their content without consent, replacing their editorial choices with algorithm-driven alternatives, and spreading misinformation. Industry organizations have begun negotiating with Google about the feature's implementation. Some publishers have requested opt-out mechanisms or compensation for content modification.
What legal rights do publishers have regarding headline modification?
Publishers may have copyright claims for creation of derivative works, intellectual property claims regarding brand and voice, and claims of unfair competition. However, legal outcomes remain uncertain because copyright law is still developing on questions of AI-generated content and platforms' rights to modify content in limited ways. Publishers have also raised questions about whether they consented to content modification when they submitted articles to Google's distribution systems. Trade organizations are exploring whether industry-wide negotiations or regulatory action might protect publisher interests better than individual litigation.
How can publishers protect their content from AI modification?
Publishers can monitor how their content appears in algorithmic feeds and document instances of headline rewriting, particularly examples where headlines are inaccurate. Publishers can negotiate directly with Google for opt-out mechanisms or approval rights. Publishers can develop technical tools to detect headline modification. Publishers can diversify away from dependence on algorithmic feeds by building email newsletters, subscription products, and direct reader relationships. Publishers can also join industry organizations negotiating collectively with platforms about standards for content treatment.
Should AI headline generation be regulated?
Many experts believe some regulatory framework would be appropriate. Potential regulation could require transparency about AI-generated content, establish accuracy standards for AI systems in sensitive domains, protect publisher rights to control how their content is presented, or establish licensing requirements for derivative work creation. The appropriate regulatory approach depends on whether the problem is framed as AI safety, platform regulation, intellectual property, or another domain. Regulatory frameworks are still developing, but multiple jurisdictions are considering options.
What alternatives exist to AI headline generation?
Google could improve presentation of original headlines without rewriting them. The company could deploy AI in support roles, such as generating supplementary summaries without replacing headlines. Google could ask publishers for permission and only deploy AI headlines for publishers who opt in. The company could help publishers write better headlines by sharing engagement intelligence without rewriting headlines itself. Google could implement stricter quality control including human review and fact-checking before deploying AI-generated headlines. These alternatives would address user experience goals without the accuracy and consent problems that current implementation creates.
How should readers respond to potential AI headlines in feeds?
Readers should develop appropriate skepticism about headlines in algorithmic feeds while recognizing they might be optimized for engagement rather than accuracy. Reading full articles beyond headlines and checking claims against multiple sources remains valuable practice. Supporting journalism directly through subscriptions and newsletters helps reduce dependence on algorithmic distribution. Readers should follow news organizations' coverage of these issues to understand how information they consume is processed. Practicing media literacy and being skeptical of surprising headlines helps protect readers from misinformation.
What does this mean for the future of AI in journalism?
Google's deployment of AI headlines is likely a precursor to wider use of AI in journalism and news distribution. If the feature continues without major consequences, other platforms will likely deploy similar systems. However, if Google faces regulatory pressure or significant publisher push-back, platforms might avoid AI headline generation and consider more limited roles for AI in journalism contexts. The industry will likely develop clearer standards about when AI is appropriate (assisting journalists) versus inappropriate (replacing editorial judgment). Disclosure requirements for AI-generated content will probably become standard. The key question is whether AI gets deployed to enhance journalism and user experience responsibly, or whether optimization for engagement will override commitments to accuracy.
Key Takeaways
-
Google has deployed AI systems generating replacement headlines for news articles in its Discover feed without explicit publisher consent, replacing original headlines with algorithmically-generated alternatives optimized for engagement.
-
Documented examples show AI-generated headlines are frequently inaccurate or misleading, directly contradicting article content and spreading misinformation to millions of users in algorithmic feeds.
-
The feature reveals fundamental limitations of language models: they generate text based on statistical patterns rather than understanding meaning or verifying facts, making them inappropriate for domains requiring accuracy commitment.
-
Publishers face reputation damage, loss of editorial control, and reduced revenue when their content is modified without consent and false headlines are attributed to their organizations.
-
Google characterizes the feature as "trending topics" rather than headline rewriting to reduce perception of the change's significance and potentially minimize legal accountability.
-
Engagement metrics don't measure accuracy comprehension; click-through rates on false headlines don't indicate user satisfaction with information quality.
-
Publishers are negotiating individual accommodations, developing detection tools, and building alternative distribution channels to protect content and reduce platform dependence.
-
Regulatory frameworks addressing AI content generation, platform responsibility, and publisher rights are likely to develop as awareness and documentation of the problem increases.
-
Better alternatives exist including improved headline presentation, AI in supporting roles, publisher opt-in systems, and robust quality control with human review and fact-checking.
-
The precedent established by Google's approach affects how AI gets deployed across information ecosystems and shapes whether platforms prioritize accuracy and publisher autonomy or optimization and control.
-
Multiple stakeholders—publishers, platforms, regulators, and readers—must make choices about responsible AI deployment that balance innovation with accountability and accuracy.

Related Articles
- Jimmy Wales on Wikipedia Neutrality: The Last Tech Baron's Fight for Facts [2025]
- The Post-Truth Era: How AI Is Destroying Digital Authenticity [2025]
- Trump Mobile 600K Phone Claims: Debunking Viral Sales Figures [2025]
- Reality Still Matters: How Truth Survives Technology and Politics [2025]
- Brigitte Macron Cyberbullying Case: What the Paris Court Verdict Means [2025]
- The Viral Food Delivery Reddit Scam: How AI Fooled Millions [2025]

