![How Government AI Tools Are Screening Grants for DEI and Gender Ideology [2025]](https://tryrunable.com/blog/how-government-ai-tools-are-screening-grants-for-dei-and-gen/image-1-1770066386881.jpg)
The Quiet Revolution: How Federal Agencies Deployed AI to Police Content
Imagine opening your email one morning to find that your grant application for a public health initiative has been flagged by an artificial intelligence system. You didn't submit anything controversial. You simply used terms like "inclusion" or "underrepresented populations" in describing your research methodology. But those words, when processed by a machine learning algorithm, triggered a red flag in a federal database.
This isn't hypothetical. Since March 2025, this scenario has been playing out across the Department of Health and Human Services, one of the largest federal agencies in the United States. Behind the scenes, sophisticated AI tools from Palantir Technologies and a startup called Credal AI have been quietly screening grant applications, job descriptions, and existing programs for language and concepts deemed misaligned with the Trump administration's executive orders targeting diversity, equity, inclusion (DEI), and what officials describe as "gender ideology."
The revelation emerged through an HHS inventory of artificial intelligence use cases released in 2025, which provided the first public window into a systematic effort to use machine learning algorithms as enforcement mechanisms for political policy. What makes this significant isn't just the existence of the programs themselves. It's the opacity surrounding them, the scale at which they operate, and the fundamental questions they raise about how governments should use automation technology to make decisions affecting billions of dollars in research funding and thousands of federal employees.
The story of how we got here involves a convergent set of circumstances: the political will to enforce new executive orders, the availability of cutting-edge AI tools designed for large-scale text analysis, and an appetite among federal agencies to automate what would otherwise be time-consuming manual review processes. Understanding this requires digging into what these tools actually do, how they became embedded in government decision-making, and what the implications are for federal science, research, and public service.
The Executive Orders That Started It All
On the first day of his second term, President Donald Trump signed two executive orders that would reshape how federal agencies allocate resources and structure their operations. Executive Order 14151, titled "Ending Radical and Wasteful Government DEI Programs and Preferencing," directed the Office of Management and Budget, the Office of Personnel Management, and the attorney general to eliminate any policies, programs, contracts, or grants that mention diversity, equity, inclusion, or environmental justice initiatives.
The language in these orders was intentionally broad. They didn't target specific programs or initiatives by name. Instead, they cast a wide net, defining problematic content to include mentions of "equity," programs related to "DEIA," and anything that could be construed as promoting diversity or inclusion in hiring, contracting, or resource allocation.
The second executive order, 14168, went further into what it called "gender ideology extremism." This order directed all federal agencies to define "sex" solely as an "immutable biological classification," recognize only male and female as genders, and treat gender identity concepts as "false" and "disconnected from biological reality." Critically, it stipulated that no federal funds could be used to "promote gender ideology," a term that proved remarkably elastic in interpretation.
These weren't modest policy adjustments. They represented a fundamental reorientation of federal spending and personnel decisions around a specific ideological framework. The question became: how would agencies actually implement these directives across millions of pages of grant applications, job descriptions, and research proposals?

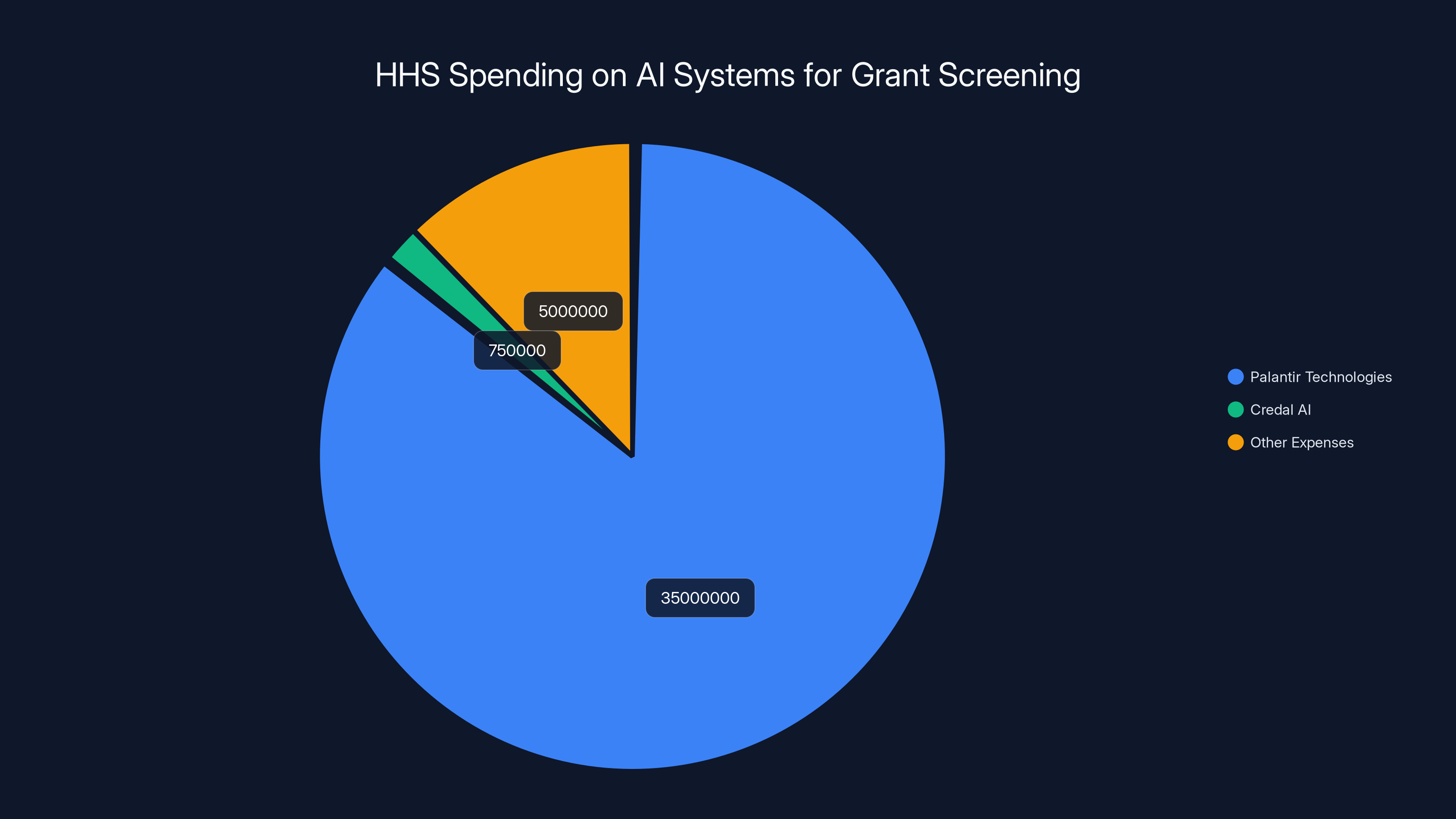
The majority of HHS's AI-related spending for grant screening in 2025 went to Palantir Technologies, with
How AI Became the Enforcement Mechanism
Manually reviewing every grant application, job description, and research proposal across the federal government would be logistically impossible. The National Institutes of Health alone receives over 50,000 grant applications annually. Reviewing each one for problematic language would require thousands of full-time employees dedicated solely to that task.
This is where AI entered the picture. The Administration for Children and Families within HHS turned to Palantir Technologies, the defense contractor known for its data integration and analysis platforms. Palantir was contracted to create a system that could automatically scan job position descriptions and flag those requiring "adjustment for alignment with recent executive orders."
Simultaneously, HHS contracted with Credal AI, a startup founded by two former Palantir employees, to audit both existing grants and new grant applications. According to the HHS inventory, Credal's system uses AI to "review application submission files and generate initial flags and priorities for discussion."
What's crucial to understand is that these aren't simple keyword-matching systems. They're machine learning models trained to understand context and identify subtle references that might fall afoul of the executive orders. The Credal system, described as an "AI-based" review process, can detect when research proposals are discussing protected characteristics or sensitive topics even when researchers use careful, clinical language.
The financial commitment to these systems has been substantial. During the first year of Trump's second term, Palantir alone received over
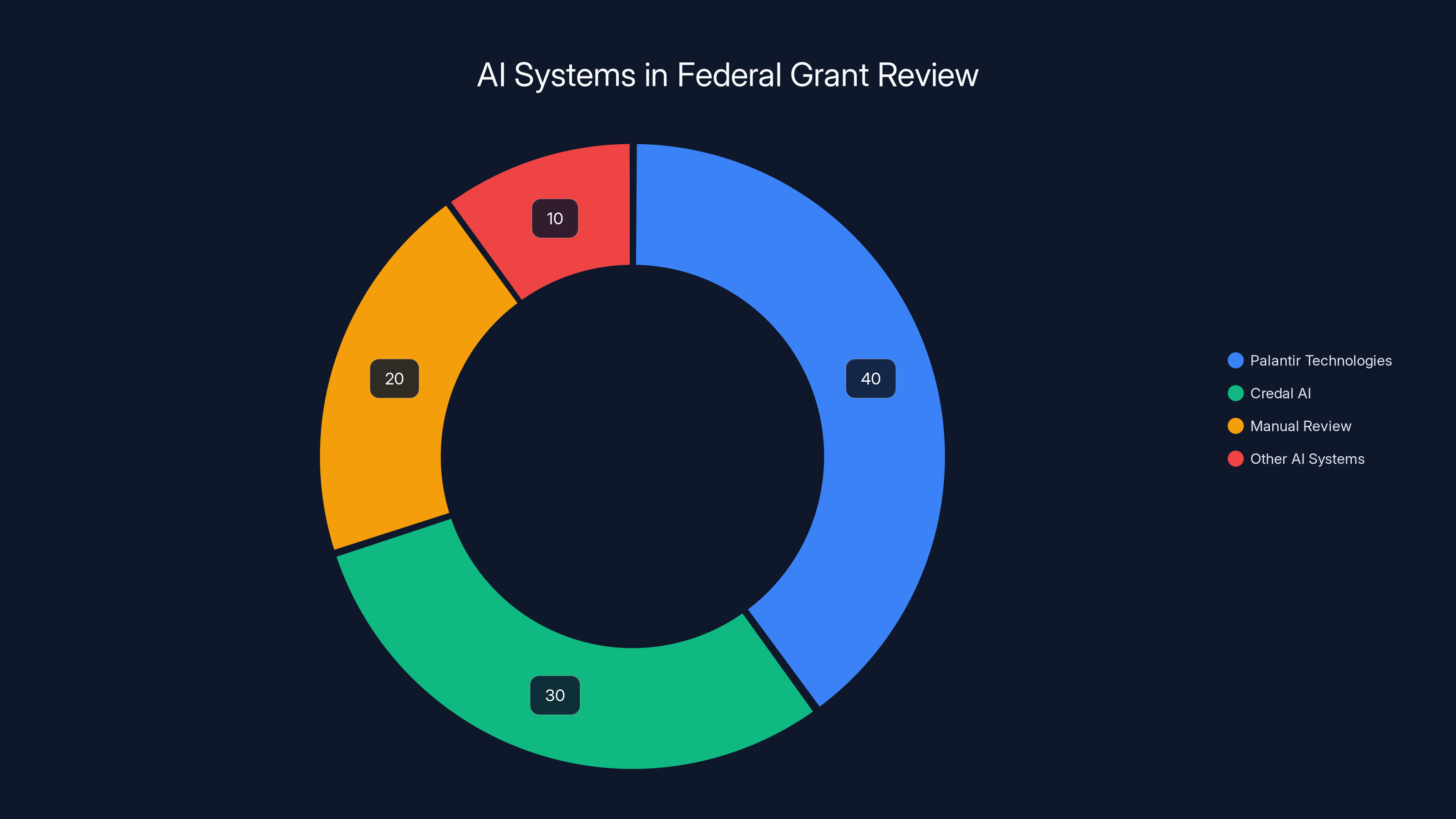
Estimated data shows Palantir and Credal AI systems dominate AI usage in federal grant reviews, reducing the need for manual review.
The Screening Process: How It Actually Works
According to the HHS inventory, the screening process operates through a multistep workflow that's designed to ensure human oversight while leveraging AI efficiency. Here's how it functions in practice:
First, documents—whether they're grant applications, job descriptions, or existing program materials—are ingested into the AI system. The algorithm scans these documents looking for flagged terms and concepts. The list of problematic terms appears to be expansive, capturing obvious DEI language but also more general terms that might appear in any health research proposal.
When the AI system identifies content it deems potentially problematic, it generates initial flags and priorities for discussion. These flags include not just the flagged language itself but also context about where the language appeared and potentially related concepts in the document.
The system then routes all flagged materials to human reviewers within the ACF Program Office, who conduct what the inventory describes as a "final review." This final review stage is theoretically where human judgment comes into play, where reviewers can assess whether flagged language was actually problematic or merely technical.
However, the effectiveness of human review as a guardrail depends entirely on several factors: the training and instructions reviewers receive, the time available for review, and the political pressure to approve the AI system's flags. Given the aggressive timeline for implementing these executive orders and the clear messaging from leadership that DEI initiatives needed to be eliminated, there's reason to question how rigorously some of these "final reviews" actually function.

The Cascade Effect: How One Agency's AI Rippled Across the Government
While the HHS deployment of these AI systems might seem like an isolated bureaucratic development, it's actually part of a broader pattern across federal agencies. The use of AI for enforcement of the executive orders didn't start with HHS, and it certainly didn't stop there.
The National Science Foundation began screening research proposals for flagged terms. When researchers submitted proposals discussing diversity in their study populations or addressing equity in healthcare access, their work often found itself under additional scrutiny. The NSF's approach was slightly different from HHS's—rather than automatically flagging and filtering out proposals, they placed them under official review, which effectively slowed down the funding process while reviewers evaluated whether the research was "compliant."
The Centers for Disease Control and Prevention took a more aggressive approach. The agency began retracting or pausing research that mentioned terms like "LGBT," "transsexual," or "nonbinary." It also ceased processing data related to transgender people, effectively removing an entire category of public health information from federal tracking systems. This had immediate practical consequences for epidemiology, disease surveillance, and public health planning.
NASA, despite having no obvious connection to DEI or gender ideology debates, began purging website content that mentioned women, indigenous people, or LGBTQ people in scientific contexts. The Substance Abuse and Mental Health Services Administration removed the LGBTQ youth service line from the 988 Suicide and Crisis Lifeline, a decision that had direct health consequences for vulnerable populations.
Across these agencies, the common thread was the use of automated or semi-automated systems to identify problematic content, paired with human reviewers operating under clear political directives to eliminate such content. The AI systems accelerated and amplified what would have been a slower, less comprehensive effort if done entirely manually.
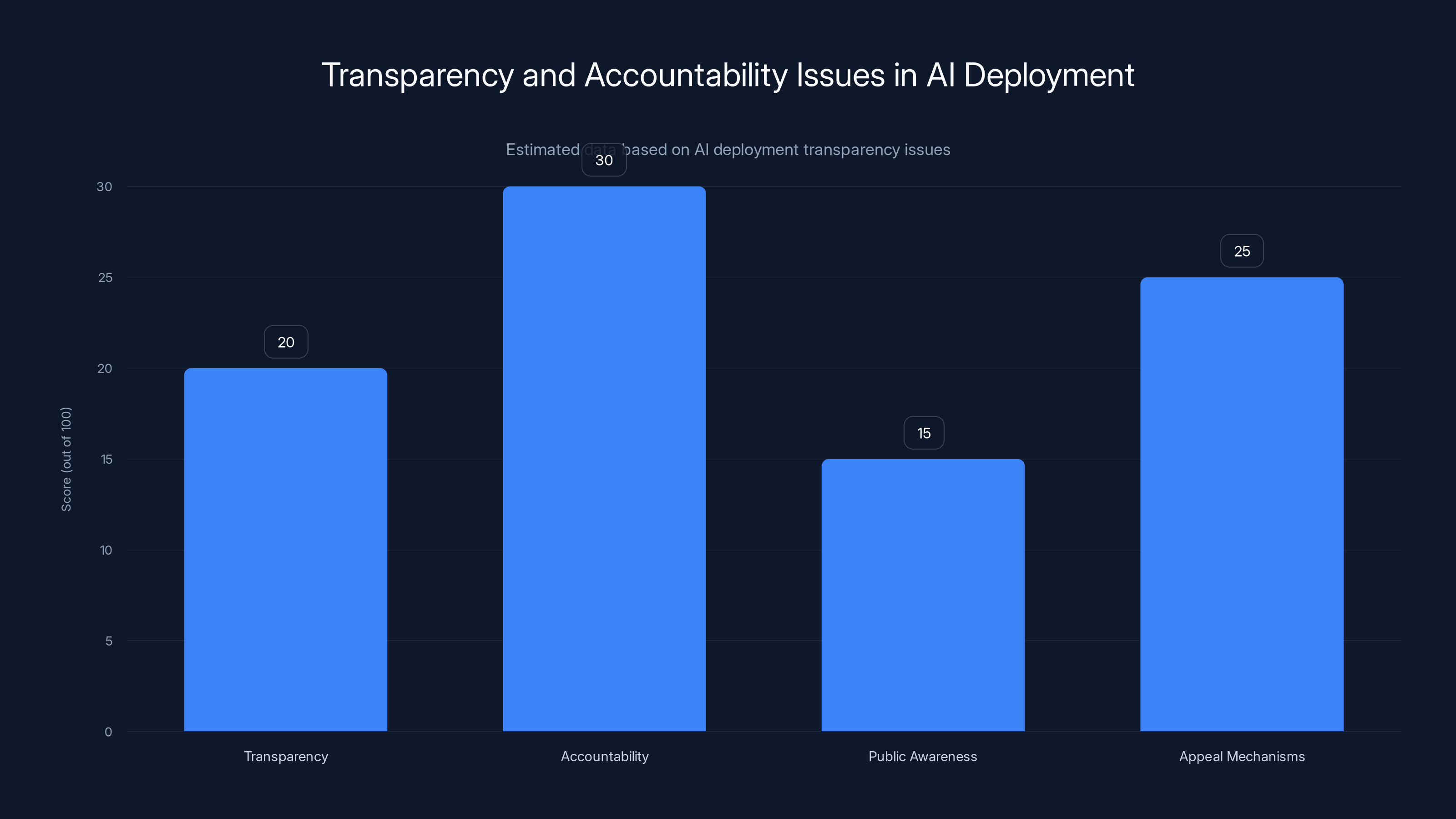
Estimated data shows low scores in transparency and accountability aspects of AI deployment, highlighting significant room for improvement.
The Chilling Effect on Federal Research and Science
One of the most significant consequences of deploying AI for this type of screening is what researchers and administrators describe as a "chilling effect." When researchers understand that certain topics or terminology might trigger automated flags that could delay funding or result in rejection, they begin self-censoring.
This manifests in several ways. Some researchers avoid addressing demographic disparities in their research, even when those disparities are scientifically important. Others use euphemistic language instead of precise scientific terminology, reducing clarity in research proposals. Still others avoid entire research areas that they perceive as politically risky, even if those areas represent important public health challenges.
The problem is systemic and cascading. When a researcher decides not to study health disparities in a particular population because they fear funding rejection, that's not just one lost research project. It's a gap in public health knowledge that affects policy decisions, clinical practice, and patient outcomes for years to come.
Consider health equity research in specific diseases. If researchers avoid studying why certain communities have higher mortality rates from particular conditions out of fear that the research will be flagged as "DEI-aligned," the federal government loses crucial information about disease patterns, risk factors, and potential interventions. The consequence isn't that DEI gets eliminated—the consequence is that America's public health system becomes less informed about the populations it's supposed to serve.
How AI Systems Make Subjective Judgments
One of the most technically interesting aspects of this situation is understanding how machine learning systems trained to identify "DEI alignment" or "gender ideology" actually work. These aren't simple keyword filters. They're sophisticated language models trained on examples of the types of content the government wants to identify.
The training data for these systems would have included examples of problematic documents flagged by human reviewers. The algorithm learns patterns in language, context, and framing that correlate with content deemed problematic. Once trained, the model can identify similar patterns in new documents, even when they use different terminology.
This approach has both strengths and weaknesses. The strength is that it can catch sophisticated attempts to circumvent keyword filters. If researchers try to discuss diversity in coded language, the AI can potentially identify that they're discussing the same underlying concept. The weakness is that the system can generate false positives at scale.
For example, a research proposal on women's health might use the word "female" in a purely clinical, descriptive sense. An AI system trained to be aggressive about flagging "female" as a potential DEI-related term could incorrectly flag this proposal. Similarly, research on including underrepresented populations in clinical trials—something that's actually a federal requirement under regulations like the NIH Revitalization Act—could be flagged as problematic if the system is overly sensitive.
The question of how aggressive these systems are tuned is crucial. A system tuned for high sensitivity will catch lots of actual problematic content but also generate many false positives. A system tuned for high specificity will miss some problematic content but generate fewer false alarms. The tuning decision is fundamentally a value judgment about acceptable error rates, and those judgments have been made by people with political motivations.
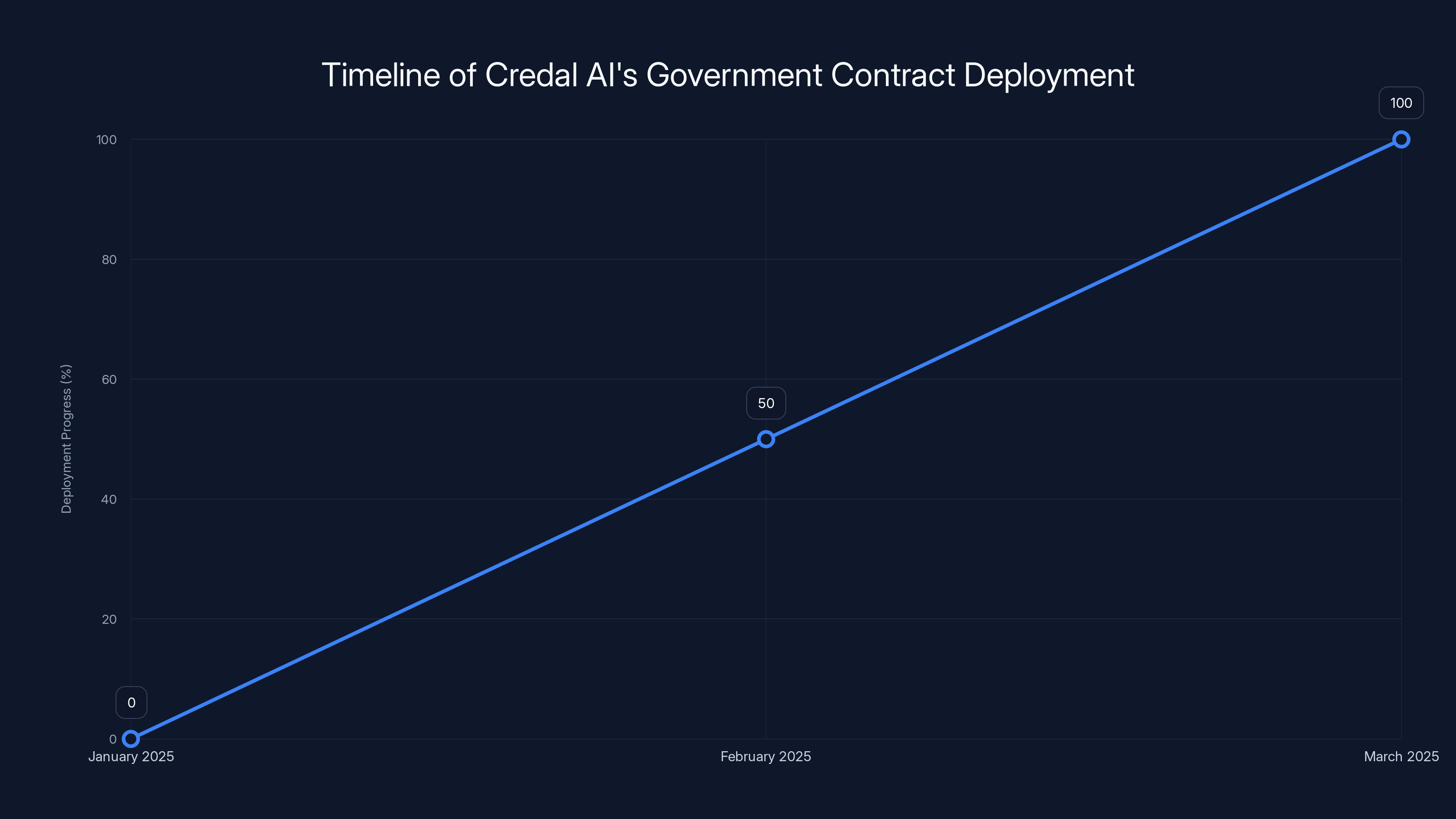
Credal AI rapidly deployed its generative AI platform for HHS within three months, indicating swift adaptation to government requirements. Estimated data.
The Lack of Transparency and Accountability
One of the most troubling aspects of this deployment is the lack of transparency surrounding these systems. Neither Palantir nor HHS publicly announced that AI tools were being used to screen for DEI and gender ideology compliance. The information only emerged because of the HHS inventory of AI use cases, which was released to provide visibility into federal AI deployment.
This lack of transparency extended to the Federal Register notices that announced the contracting. When the government published the notices for Palantir's
For grant applicants, this created a situation where work was being rejected or flagged based on criteria that weren't clearly communicated. An applicant could have a proposal rejected and have no way of knowing whether it was due to technical merit or due to an AI system flagging language that the applicant didn't realize was problematic.
There's also the question of audit trails and appeal mechanisms. How do researchers appeal an AI-generated flag? What documentation exists of how the flags were generated? Can researchers request to see the specific language that triggered their flag, and can they understand the reasoning behind the classification? The HHS inventory suggests that human reviewers conduct final reviews, but there's no indication of how rigorous those reviews are or what mechanisms exist for appeal.
From a legal and constitutional perspective, this raises significant questions. Due process traditionally requires that people understand the rules they're being judged against and have an opportunity to respond to accusations. When an AI system flags a grant application, does the applicant have a meaningful due process right to understand why? The HHS inventory doesn't address this.
The Role of Palantir: From Defense Contractor to Government Content Enforcer
Palantir Technologies has spent over two decades building its reputation as the premier data integration and analysis platform for defense and intelligence agencies. The company's tools are designed to ingest, integrate, and analyze vast amounts of structured and unstructured data, often in sensitive national security contexts.
The deployment of Palantir's tools to screen federal grants and job descriptions for political compliance represents an expansion of the company's mission into domestic governance and policy enforcement. This isn't necessarily new territory for Palantir—the company has long worked on sensitive government projects—but the scale and visibility of this particular application is notable.
What's interesting is that Palantir's founders and executives have been politically vocal, and the company's commercial decisions have often aligned with those politics. The decision to take on this work, and to do so without public announcement, suggests a company comfortable operating at the intersection of technology and political enforcement.
For applicants to HHS grants, the involvement of Palantir might raise questions about data security and privacy. Research proposals contain sensitive information, competitive insights, and sometimes personal health data. Those documents are now being processed through a system designed and maintained by a defense contractor known for its integration of data from multiple sources. How long is that data retained? Who has access to it? Could it be used for purposes beyond the stated application?
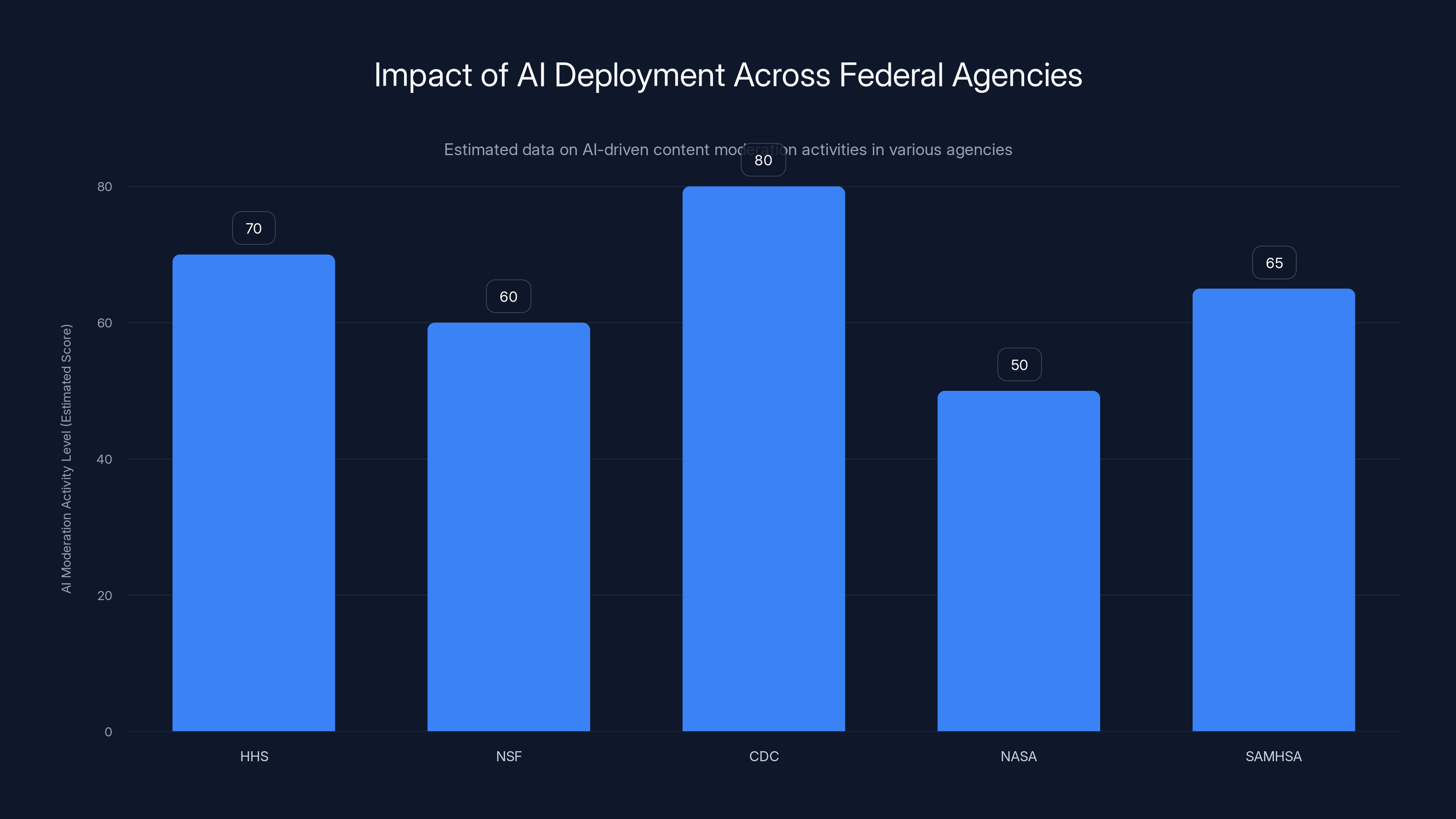
Estimated data suggests that the CDC had the highest level of AI-driven content moderation activities, significantly impacting public health data tracking.
Credal AI: The Emerging Player in Government AI Enforcement
Credal AI is a younger player than Palantir, founded by two former Palantir employees who saw an opportunity in the rapidly growing market for generative AI tools adapted for enterprise and government use. The company positions itself as providing a "secure, enterprise-ready" generative AI platform that can process sensitive documents while maintaining compliance and security.
The contract with HHS for approximately $750,000 to provide Credal's "Tech Enterprise Generative AI Platform" for grant auditing represents a significant win for the startup. It's also an indicator of how quickly startups can move into government contracting space when their technology aligns with policy priorities.
Credal's specifics on how its platform works are limited in public documentation, but the system appears to be built on large language models—likely similar in architecture to models like GPT-4—but fine-tuned for analyzing government documents and trained on examples of the types of content that should be flagged.
What's notable is that Credal was willing to build out this application relatively quickly. The timeline from the executive orders being issued (January 2025) to this system being deployed at HHS (March 2025) is remarkably fast. This suggests either that the startup had already been working on such tools in anticipation of the policy environment, or that the government provided clear specifications and requirements that made development straightforward.

The Cascading Impact on Federal Employment
While much of the media attention has focused on the impact of these policies on federal research and grant-making, another significant effect has been on federal employment itself. The same AI systems and enforcement mechanisms that screen grant applications also help identify federal employees for removal or reassignment based on perceived DEI alignment.
Across federal agencies, thousands of employees experienced layoffs or reassignments. Some of these were specifically for positions related to DEI work—the expectation might have been that DEI officers and diversity program managers would be affected. But the impact was far broader. At agencies like the Department of Education, the Energy Department, and the Office of Personnel Management, people in a wide range of positions found themselves without jobs or reassigned to unrelated work.
At NASA, some employees found themselves tasked with purging website content and agency materials of references to women, indigenous peoples, and LGBTQ people. These weren't decisions made by the agency leadership in normal circumstances. These were compliance actions driven by interpretation of the executive orders and enforcement mechanisms set up to ensure that compliance.
One consequence is that the federal government has lost expertise in areas that will take years to rebuild. Experienced scientists in areas related to health equity, disease surveillance in diverse populations, and gender-related health research either took early retirement, left federal service, or were terminated. Replacing that expertise will be difficult, and in the interim, the government's capacity to address certain public health challenges has declined.
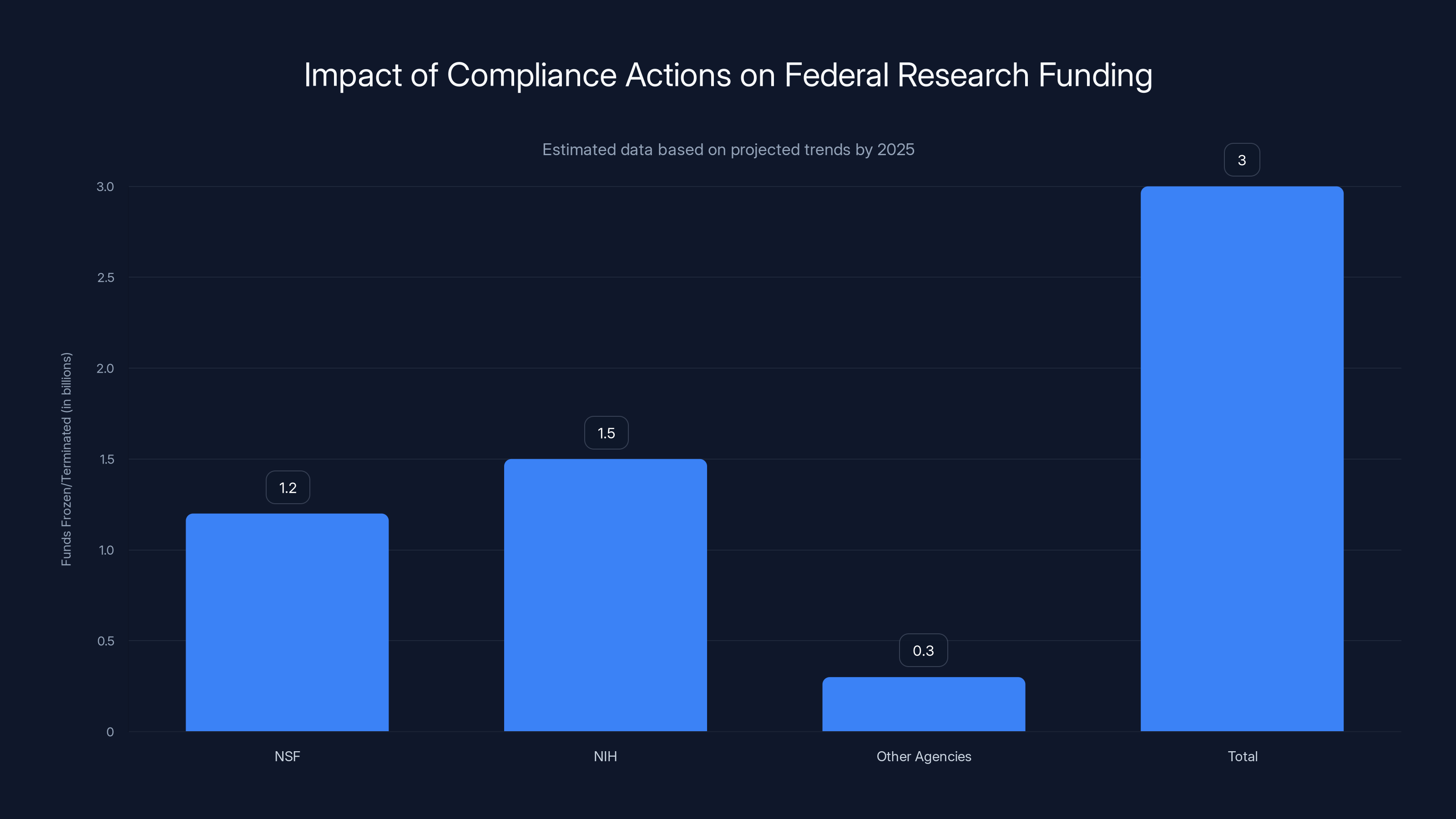
By 2025, compliance actions are projected to freeze or terminate nearly $3 billion in research funds across major federal agencies, impacting thousands of research teams. Estimated data.
What Happened to Specific Programs and Initiatives
The impact of the executive orders and the AI enforcement mechanisms went far beyond federal staffing and research funding. Specific programs that served vulnerable populations were altered or eliminated.
The LGBTQ youth service line of the 988 Suicide and Crisis Lifeline was removed in July 2025. For young people in crisis, the availability of specialized support was important. The decision to remove it was justified on the basis that the service line was promotion of "gender ideology."
The FAFSA—the Free Application for Federal Student Aid—was modified to prohibit applicants from identifying as nonbinary. This change affected students' ability to self-identify on federal forms and potentially affected how their applications were evaluated.
The Department of Housing and Urban Development stopped enforcing a provision that banned discrimination on the basis of gender identity. This effectively means that discrimination based on gender identity became permissible in housing programs that HUD oversees or funds.
The Department of Veterans Affairs revised its internal guidelines to remove language prohibiting doctors from discriminating on the basis of political beliefs or marital status, with officials citing the executive order as justification. The connection between the executive order and this change is worth noting—the order was focused on DEI and gender ideology, but it's being used to justify removal of broader non-discrimination language.
The Question of AI Accuracy and Error Rates
One thing that's crucial to understand about these AI systems is that they're not perfectly accurate. No machine learning system operates with 100% precision and recall. There will be false positives (flagging content that shouldn't be flagged) and false negatives (missing content that should be flagged).
The question is: what are the error rates for these systems, and how much does that matter? If a system incorrectly flags 5% of proposals, that means hundreds or thousands of proposals could be incorrectly flagged across the federal government. Each of those represents a researcher who might lose funding, have their work delayed, or have to rewrite their proposal to avoid flagged language.
The HHS inventory provides no information about error rates, accuracy metrics, or validation studies. There's no indication that the systems have been tested for bias or for their tendency to generate false positives at scale.
This is a significant gap, because if researchers are self-censoring to avoid triggering the AI system, and the AI system has a meaningful false positive rate, then the system is suppressing not just problematic content but also legitimate research.

The Broader Implications for Government AI Use
Beyond the specific political implications of screening for DEI and gender ideology, this situation raises important questions about how governments should use artificial intelligence for decision-making that affects public resources and public welfare.
The key questions are straightforward but important:
Who decides what the system should flag? In this case, the decision was made by people interpreting executive orders, but there was no public process, no comment period, no rigorous definition of what constitutes DEI or gender ideology in a technical sense.
How are decisions made about accuracy and false positives? There's no indication that anyone made a careful decision about what error rates were acceptable. Should a system be aggressive, catching lots of flagged content even if it generates false positives? Or should it be conservative, only flagging things it's very confident about?
What transparency and accountability mechanisms exist? If someone's grant proposal is flagged by AI, how do they find out why? How do they appeal? These questions aren't answered in the inventory.
What's the long-term impact on federal decision-making? Once these systems are deployed, they become embedded in workflows. Even if administrations change, the tools remain. Future use cases expand from the initial application. The infrastructure for AI-driven enforcement is now in place.

The Private Sector Response and Normalization
One of the more interesting aspects of this situation is how the private sector responded. According to reports from nonprofit watchdog organizations, more than 1,000 nonprofit organizations rewrite their mission statements to remove language believed to be adjacent to DEI. This happened without the federal government explicitly requiring it—nonprofits made the decision to change their missions preemptively to avoid potential consequences to federal funding.
This illustrates how enforcement mechanisms can have effects far beyond their direct application. When nonprofits see that the federal government is aggressively screening for certain language, many choose to voluntarily remove that language rather than risk losing federal funding or federal partnerships.
The question is whether this represents the voluntary alignment of the private sector with government priorities, or whether it represents a kind of coercive conformity driven by the threat of funding loss. The distinction matters for thinking about what's actually happening in civil society.
Technical Alternatives and Better Approaches
It's worth considering what alternative approaches to policy implementation might look like, particularly from a technology perspective. If the goal is to ensure that grant applications and federal programs comply with executive orders, there are less heavy-handed ways to accomplish that.
One approach would be clear, specific guidance to agency staff about what constitutes problematic content. Instead of deploying an AI system to identify violations, publish a manual that explains, with examples, what kinds of language and approaches are not in compliance. Agency staff can then review applications against this explicit guidance.
Another approach would be to use AI not for enforcement but for transparency. Rather than flagging proposals, an AI system could categorize proposals by how they address certain populations or topics, allowing policymakers to see what fraction of federal funding is going to different research areas. This would provide the transparency needed for policy implementation without the enforcement function.
A third approach would be transparency about how the AI system works. If you're going to use AI to make decisions, explain how it works, make the training data available for audit, and provide clear mechanisms for appeals and review.
None of these approaches were taken in this case, suggesting that the emphasis was on enforcement and compliance rather than on transparency or robust implementation.
Looking Forward: What's at Stake
As this system matures and similar systems are deployed at other agencies, the precedent being set is significant. The federal government is now operationalizing the use of AI for policy enforcement at a scale and scope that's difficult for public discourse to keep pace with.
The specific targets of this enforcement—DEI and gender ideology—are controversial topics where reasonable people disagree. But the technical and procedural questions about how governments should use AI for policy enforcement are separate from the politics of what's being enforced.
If this framework becomes normalized and routine, it could be deployed in future administrations for different purposes. The infrastructure for using AI to identify and exclude content related to specific ideological positions or policy preferences is now in place. Future administrations could use similar systems to enforce entirely different policy priorities.
That's why the questions about transparency, accuracy, appeals, and oversight matter. They matter not just for the current implementation but for what comes next.

FAQ
What exactly is the HHS doing with AI to screen grants?
Since March 2025, HHS has been using AI systems from Palantir Technologies and Credal AI to automatically scan grant applications, job descriptions, and existing programs for language and concepts deemed misaligned with Trump administration executive orders targeting diversity, equity, inclusion, and gender-related initiatives. The AI systems generate flags and priorities, which are then reviewed by human staff in the ACF Program Office for final decisions.
How does the AI identify problematic content?
The AI systems use machine learning models trained on examples of content deemed problematic by human reviewers. Rather than simply matching keywords, these systems understand context and can identify similar concepts even when expressed differently. The systems scan documents for flagged terms and concepts, generate initial flags with context, and route everything to human reviewers for final assessment.
What are the consequences of getting flagged?
When a grant application is flagged by the AI system, it goes through additional review by the ACF Program Office. Depending on the reviewer's assessment, the application could be delayed, denied, or conditionally approved with requirements to revise language. For job descriptions, flagged positions may need adjustment before posting. The consequences are significant for researchers and federal employees, as they can affect funding opportunities and employment.
How much money has been spent on these AI systems?
During Trump's first year in his second term, Palantir alone received over
Can researchers appeal if their work is flagged?
The HHS inventory indicates that a "final review" stage exists where human staff assess flagged content, but it provides limited information about formal appeal mechanisms. The inventory doesn't specify how researchers can understand why their work was flagged, what documentation is available to them, or how they can formally challenge a flag. This lack of transparency around appeals is one of the most concerning aspects of the system.
What's the impact on federal research and science?
The deployment of these screening systems has created a significant chilling effect on federal research. Researchers self-censor to avoid triggering automated flags, avoiding entire research areas, using euphemistic language instead of precise terminology, or declining to address demographic disparities in their studies. By the end of 2025, nearly $3 billion in grant funds were either frozen or terminated across the NSF and NIH due to compliance actions, affecting thousands of research teams and leaving gaps in public health knowledge.
Are these AI systems accurate?
The HHS inventory provides no information about error rates, accuracy metrics, or validation studies. There's no public data on false positive rates or evidence that the systems have been tested for bias. This is a significant concern, because if the systems have meaningful false positive rates, they're suppressing legitimate research in addition to content genuinely problematic under the executive orders.
What happened to specific programs?
Multiple federal programs were altered or eliminated based on these executive orders and enforcement mechanisms. The LGBTQ youth service line of the 988 Suicide and Crisis Lifeline was removed, the CDC ceased processing data related to transgender people, NASA purged website content mentioning women and LGBTQ people, FAFSA was modified to prohibit nonbinary identification, and various federal agencies removed non-discrimination language from policies and programs.
How does Palantir fit into this?
Palantir Technologies, known for its data integration platform used by defense and intelligence agencies, was contracted to scan federal job descriptions for alignment with the executive orders. The company's $35 million contract from HHS represents an expansion of its mission into domestic governance and policy enforcement. The deployment was never publicly announced, and Federal Register notices made no mention of the DEI and gender ideology screening function.
What are the long-term implications?
This situation establishes a precedent for using AI as an enforcement mechanism for policy compliance at scale. The infrastructure for AI-driven screening and flagging is now in place and will likely be used for other purposes in the future. The questions about transparency, accuracy, appeals, and oversight raised by this implementation will shape how future administrations use AI for policy enforcement.

Key Takeaways
- HHS deployed AI from Palantir and Credal to systematically screen grants and job descriptions for DEI and gender ideology compliance starting March 2025
- The AI systems were never publicly announced and Federal Register descriptions omitted their true purpose, raising transparency concerns
- Nearly $3 billion in federal grant funds were frozen or terminated by year-end 2025 due to compliance screening
- The systems create a chilling effect on legitimate research as scientists self-censor to avoid AI flags
- No public information exists about error rates, false positive rates, or appeals mechanisms for the AI screening
- Similar screening expanded to CDC, NSF, NASA, and other agencies using different approaches but similar enforcement mechanisms
- The precedent of using AI for ideological compliance screening could be extended to other policy areas in future administrations
- Over 1,000 nonprofits voluntarily rewrote mission statements to avoid federal funding consequences
Related Articles
- Nvidia's AI Chip Strategy in China: How Policy Shifted [2025]
- OpenAI vs Anthropic: Enterprise AI Model Adoption Trends [2025]
- NIH Institute Directorships Politicization: The Power Struggle [2025]
- NVIDIA's $100B OpenAI Investment: What the Deal Really Means [2025]
- SpaceX's Million-Satellite Orbital Data Center: Reshaping AI Infrastructure [2025]
- Major Cybersecurity Threats & Digital Crime This Week [2025]

