![Jikipedia: AI-Generated Epstein Encyclopedia [2025]](https://tryrunable.com/blog/jikipedia-ai-generated-epstein-encyclopedia-2025/image-1-1771110422547.jpg)
Introduction: When AI Meets Leaked Data
In early 2025, a project that seemed almost unthinkable just a few years ago went live. The team behind Jmail—the email search platform built on the released Epstein documents—launched Jikipedia, an AI-generated Wikipedia clone that synthesizes thousands of leaked emails into detailed dossiers on hundreds of Epstein's associates.
This isn't your typical Wikipedia entry. These are dense, interconnected profiles built by large language models trained on correspondence, financial records, and court documents. Each entry maps relationships, timeline interactions, property visits, and potential legal exposure. Some profiles include how many emails the person exchanged with Epstein, biographical snapshots, business connections, and alleged knowledge of criminal activities.
The project raises a fascinating tension between transparency and accuracy, between public interest and potential harm, between technological capability and responsible deployment. An AI system can synthesize thousands of documents in seconds. Whether it should is a different question entirely.
What makes Jikipedia particularly interesting isn't just what it does, but how it reflects a broader shift in how we handle large datasets. For years, information like this existed in legal databases, hidden behind paywalls or accessible only to researchers and lawyers. Now, an AI system has democratized access to it. A teenager with a browser can learn what would've required months of investigative journalism a decade ago.
But here's the critical caveat: these are AI-generated summaries. Not journalistic investigations. Not verified reporting. The system is clever enough to cite sources and create the appearance of rigor. It's not necessarily rigorous at all. The team behind Jikipedia acknowledged this from the start, saying they planned to implement a system for users to report inaccuracies and request corrections. That's a feature, not a given.
This article digs into what Jikipedia actually is, how it works, what it reveals, what it obscures, and what it means for how we handle sensitive leaked information in the age of generative AI.
TL; DR
- Jikipedia is an AI-generated Wikipedia clone created by the Jmail team that synthesizes thousands of Epstein's leaked emails into detailed profiles of his associates, properties, and business relationships
- The entries are AI-synthesized, not fact-checked, though they cite sources from the original email dataset and the team plans to add user-submitted corrections
- It maps relationships, finances, and alleged crimes, showing which associates knew Epstein, how often they communicated, and potential legal exposure based on email content
- Privacy concerns exist alongside transparency benefits, as does the risk of AI-generated inaccuracies reaching mass audiences without proper journalistic vetting
- This reflects a larger trend of AI systems processing large leaked datasets in ways that were technologically impossible just years ago, raising questions about responsible information access

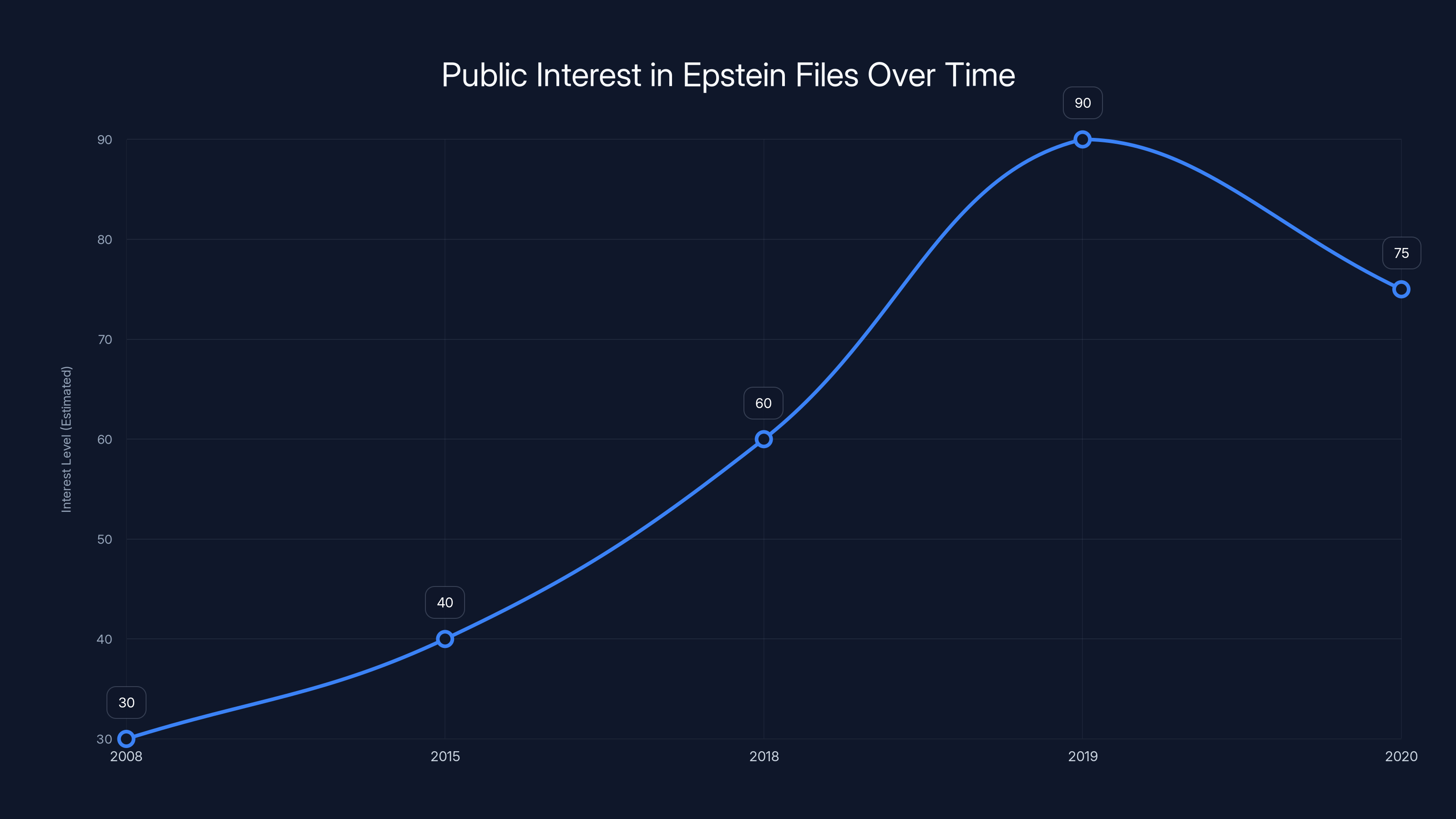
Public interest in the Epstein files spiked significantly in 2019 following his arrest and subsequent death. Estimated data based on major events.
What Is Jikipedia, Exactly?
Jikipedia is an AI-generated encyclopedia built from the Epstein Files—specifically, the emails and documents made public through court proceedings and data releases. Think of it as Wikipedia's more ambitious, more controversial cousin. Instead of volunteer editors writing entries about historical figures, a large language model reads through thousands of emails, identifies key figures, properties, and transactions, and generates detailed profiles of each.
The core dataset comes from Epstein's email archives and related financial documents. The Jmail platform previously launched as a searchable database of these same documents, allowing users to keyword-search individual emails and threads. Jikipedia takes the next step: it treats the entire corpus as source material and uses AI to extract, synthesize, and present information in an encyclopedic format.
Each Jikipedia entry follows a structure that resembles Wikipedia but feels denser and more networked. A profile of one of Epstein's associates might include their biographical background, their business dealings, frequency and nature of contact with Epstein, known visits to his properties, and a legal assessment section highlighting laws they might have violated based on email content.
The project also includes entries for properties—Epstein's homes, islands, and compounds—detailing how they were purchased, what activities allegedly occurred there, and which associates visited. There are entries for his business relationships, including his connection to JPMorgan Chase, with timelines and transaction details.
What's particularly striking is the interconnectedness. The system treats the entire dataset as a web. Hyperlinks connect associates to each other, to properties, to businesses, creating a relational map of Epstein's network. Click on one person's profile, and you'll find links to everyone who emailed with them, every property they visited, every business they share with others in the network.
The design choice mirrors how modern search and AI tools work—not presenting information in isolation, but as interconnected nodes in a larger graph. It's powerful for understanding network structures. It's also powerful for spreading inaccuracies, since an error in one profile can propagate through hyperlinks to dozens of others.
The Technology Behind the Synthesis
Building Jikipedia required solving some non-trivial technical problems. The dataset isn't structured like a traditional database. It's thousands of emails, some with financial attachments, some with calendar data, some with receipts and transaction records. It's messy, contextual, and requires understanding implicit relationships.
The process likely works something like this: First, an AI system (probably a large language model like GPT-4 or a similar architecture) ingests the email corpus and identifies key entities—people, organizations, properties, transactions. Then it extracts relationships between those entities by reading the emails contextually. When did X email Y? How many times? What tone? What topics? What meetings happened?
Then comes the synthesis phase. For each identified entity, the system generates a profile by pulling relevant information from all emails mentioning that entity and its connections. It creates timeline entries, identifies co-occurrences, and notes correlations. If person A emailed person B 47 times, and those emails discuss visiting a property, the system notes that connection.
The final step is presentation. The AI formats these profiles in an encyclopedia-like structure, with sections for biography, relationships, properties visited, business dealings, and a "legal assessment" section that flags potential legal issues based on email content.
This is computationally feasible now in a way it wouldn't have been ten years ago. Modern language models can process thousands of documents and extract structured information from unstructured text. But feasibility isn't the same as reliability. The system can make connections, but it can also make false connections.
Consider a hypothetical: If an email mentions that someone attended a party at Epstein's property, an AI might infer knowledge of criminal activity. But context matters. The person might have attended early in Epstein's criminal timeline before they had reason to suspect anything. They might have attended once and cut off contact. They might be mentioned incidentally in an email forwarded to them. The AI synthesis might flatten these distinctions.

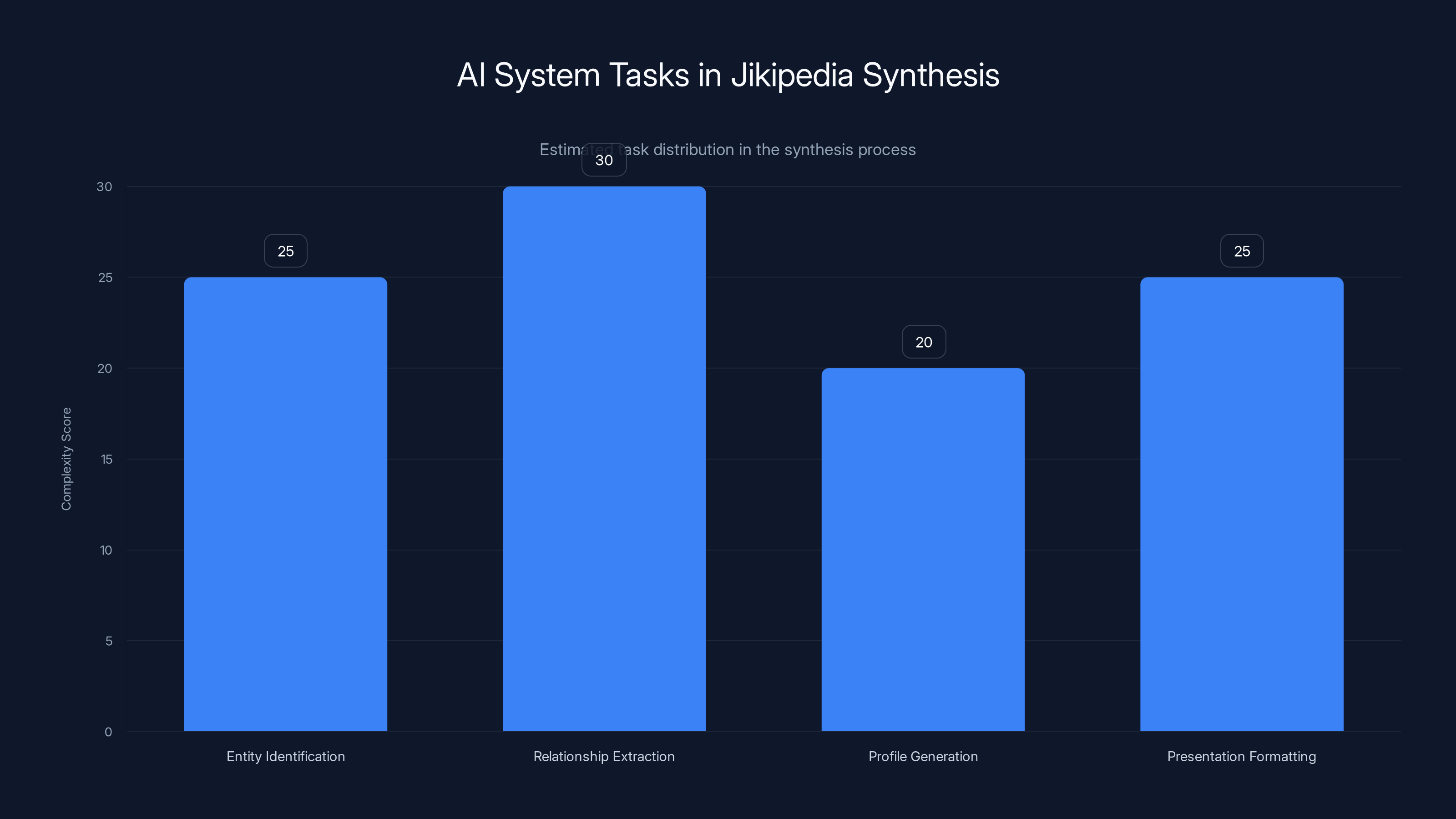
The synthesis process involves multiple tasks, with relationship extraction being the most complex. Estimated data.
Mapping the Network: Who's Connected to Whom
One of Jikipedia's most valuable features is its network mapping. Epstein's operation wasn't just him; it was a network of enablers, associates, and hangers-on. Understanding that network requires seeing not just individual relationships, but patterns across relationships.
The encyclopedia highlights email frequency between Epstein and his associates. Some people exchanged dozens of emails with him. Others appear in a handful of forwarded messages. Frequency becomes a proxy for closeness and, potentially, for knowledge of his activities.
The system also maps property visits. Epstein owned multiple properties: his Manhattan townhouse, his Palm Beach mansion, his New Mexico ranch, his Saint-Tropez villa, and his private island in the US Virgin Islands. Jikipedia notes which associates visited which properties and when. This matters because different properties allegedly served different purposes. His New Mexico ranch, for instance, allegedly hosted different types of events than his Manhattan penthouse.
Business relationships get similar treatment. Epstein wasn't just a wealthy pedophile; he was involved in legitimate business ventures too. He traded bonds, he invested, he served as a financial advisor to wealthy clients and institutions. Jikipedia maps those legitimate business connections alongside the network of abuse.
This creates a complex portrait. Some people in the network appear to be primarily business associates who may have had no knowledge of his crimes. Others exchanged thousands of emails, visited multiple properties, and had extended personal relationships with him. The frequency and nature of contact visible in Jikipedia can suggest (though not prove) who knew what and when they might have known it.
The danger is that the AI system presents these connections as networked facts without the nuance that a human investigator would apply. It says person A visited property B seven times. It doesn't explain that all seven visits might have been brief business meetings in 1998, or that the person discovered Epstein's crimes in 2005 and cut off contact immediately.
The Property Profiles: Real Estate as Evidence
Epstein's properties weren't incidental to his crimes. They were essential infrastructure. Each property had a specific role in his operation, and Jikipedia documents them with unusual detail.
The Manhattan townhouse at 9 East 71st Street served as his primary base. It was where he spent much of his time during the school year and from where he conducted business. The property was purchased for approximately $20 million in the 1990s and staffed with assistants and household help. Jikipedia documents visitors to the property, meetings there, and alleged activities.
The Palm Beach mansion at 414 Country Club Road was his winter residence. This is where much of the criminal abuse took place, according to court documents. Local authorities eventually investigated Epstein for abuse allegations at this property. Jikipedia maps visitors, timelines, and emails referencing events there.
The New Mexico ranch outside Stanley offers a different profile. It was geographically isolated and large. Emails reference events and gatherings there, though less detail is available about these than about the more documented properties.
The Saint-Tropez villa and the island property in the US Virgin Islands receive less detailed coverage in Jikipedia, partly because fewer emails reference them and partly because less public information exists about activities there.
What makes the property documentation valuable is that it creates a physical geography of the network. You can see which associates visited multiple properties (suggesting closer relationships) versus those who appear in emails about one specific place. You can see timelines—when properties were acquired, when they were visited, when activities ceased.
But here again, the AI synthesis risks oversimplifying. A visit to a property isn't proof of knowledge of crimes. A business meeting at a property doesn't connect someone to the alleged abuse that may have happened there at other times. Context collapses when you're synthesizing thousands of documents into encyclopedia entries.
Financial Connections: Following the Money
Epstein made his wealth through bonds trading and later through investment management. He managed money for ultra-wealthy clients and institutions, which gave him access to the highest circles of finance and business. That financial network is visible in Jikipedia, though less dramatically than the social network.
The encyclopedia documents his connection to JPMorgan Chase, which held his accounts for decades despite reported concerns about suspicious activity. Emails show communication with banking executives, compliance officers, and financial advisors. The relationship lasted until 2013, and Jikipedia attempts to reconstruct the timeline and nature of that relationship.
Other financial connections appear too. Epstein invested, borrowed, and conducted business with various financial institutions and wealthy individuals. These weren't necessarily improper—they were the legitimate face of his operation that provided cover and plausibility for his entire enterprise.
What's notable about the financial section of Jikipedia is that it's actually harder to synthesize accurately from email data. Financial transactions require understanding banking systems, regulatory frameworks, and subtle changes in regulations over time. An AI reading emails might identify that transaction A happened, but not understand whether it was routine or unusual, compliant or suspicious.
The AI does highlight emails discussing money transfers, account balances, and investments. But it doesn't necessarily understand the implications. An email saying "his account is showing unusual activity" might be flagged as concerning, or it might be a routine compliance note. The AI can't reliably distinguish.
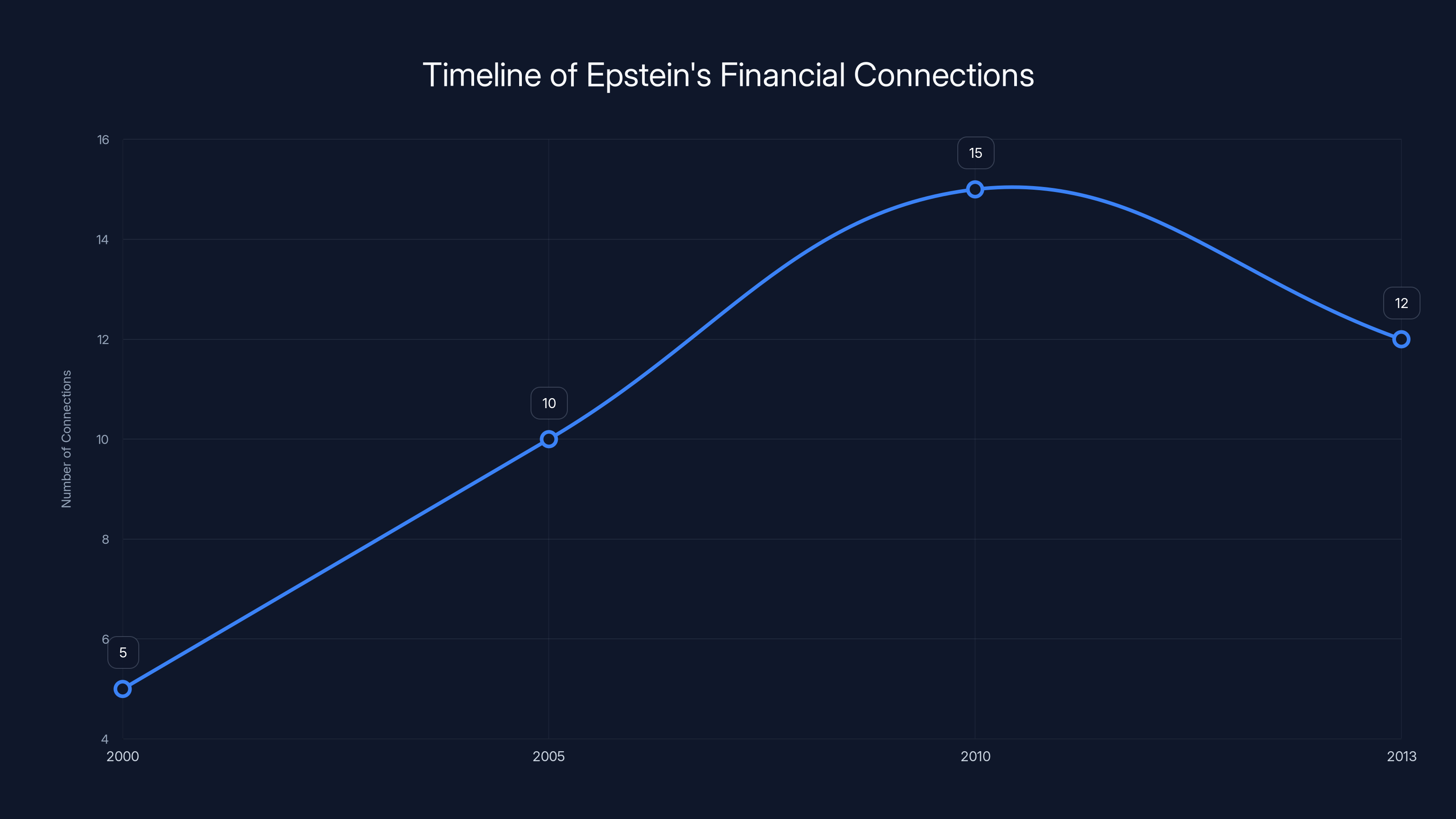
Estimated data shows an increase in Epstein's financial connections over time, peaking around 2010 before a slight decline by 2013.
The Legal Assessment Problem: AI as Prosecutor
One of Jikipedia's most controversial features is its "legal assessment" section for each profile. This is where the encyclopedia really ventures into interpretive territory rather than simple synthesis.
For major figures in the network, Jikipedia attempts to identify which laws they might have violated based on email content. This is where the system shifts from "here's what the emails say" to "here's what the emails might mean legally." That's a much harder problem, and one where AI systems have significant limitations.
Consider what's required to make such an assessment. You'd need to understand criminal law, including which specific elements are required to prove various crimes. You'd need to understand the difference between being present at a crime, knowing about it, facilitating it, and profiting from it. You'd need to understand jurisdiction, statute of limitations, conspiracy law, and the concept of mens rea (guilty mind). You'd need to understand that email evidence is often ambiguous.
An AI can identify that an email discusses illegal activity. It might say something like "Person X appears to have attended an event where [illegal act] occurred, suggesting possible knowledge or complicity." But that's not a legal assessment. That's an inference. And inferences about criminal liability without legal training or due process are dangerous.
This is particularly important because Jikipedia is public and accessible. A Wikipedia editor might write a cautious note about alleged misconduct. Jikipedia includes a "legal assessment" section that reads like it was written by a prosecutor. It's not qualified to do so.
The team behind Jikipedia presumably understands the legal risks. They're building in mechanisms for correction and dispute. But the format of the platform makes it look more authoritative than it is. That's a design choice with real-world consequences.
Anyone reading Jikipedia should understand: these legal assessments are AI-generated inferences, not qualified legal analysis. They might be correct. They might be wrong. They're worth investigating further, but they shouldn't be treated as truth.
The Accuracy Question: Hallucinations Meet Public Data
Large language models are known for hallucination—confidently stating false information. This happens for various reasons: they're trained on web data that includes false information, they extrapolate patterns beyond what they should, they're optimized for sounding confident rather than being accurate.
Hallucination is manageable in many contexts. If you ask Chat GPT to write you a poem about a made-up creature, hallucination is fine. If you ask it to summarize a document you can verify, hallucination is risky. If you ask it to generate legal assessments of real people based on leaked documents, hallucination is dangerous.
Jikipedia mitigates this somewhat by being grounded in a real dataset. The AI isn't generating information from general knowledge; it's extracting from and synthesizing specific emails. That's more constrained and therefore less likely to hallucinate.
But errors still happen. An AI might misidentify someone in an email (confusing two people with similar names). It might misread a date. It might misunderstand a sarcastic or hypothetical statement as literal. It might fail to catch that an email is a forwarded rumor rather than firsthand information. These are subtle but real problems.
The team behind Jikipedia acknowledged these risks. They've said they're implementing a system for users to flag inaccuracies and request corrections. That's important, because errors will exist. Some will be caught. Others will propagate, especially if they're picked up by news outlets or social media.
There's a particular risk with this kind of project: if it generates a false or misleading claim about a real person, that person has limited recourse. They can request a correction on the platform, but the false information has already spread. In contexts involving criminal allegation, that's serious.
The accuracy question also interacts with the public interest. Some people might argue that perfect accuracy isn't required for a public interest project—that getting information about Epstein's network out in some form, even if imperfect, serves transparency. Others would argue that generating potential legal accusations about real people without editorial review is reckless regardless of the source material.
Transparency vs. Privacy: The Inherent Tension
Jikipedia sits at the intersection of two legitimate but opposing values: transparency and privacy.
The transparency case is straightforward. Epstein is dead, unable to face justice, and many of his alleged co-conspirators have also evaded accountability. Thousands of documents were released through court proceedings and Freedom of Information Act requests. The public has a genuine interest in understanding who Epstein associated with, who facilitated his crimes, and who might have been complicit in ways that courts haven't addressed.
Until Jikipedia, accessing that information required either searching the Jmail database directly (tedious and requires knowing what to search for) or being a journalist or researcher willing to do the work manually. Jikipedia makes that information accessible to anyone. That's democratizing in a meaningful way.
But transparency comes with collateral damage. Some people in Jikipedia are clearly associated with Epstein's crimes. Some are not. Some had minimal contact; others had extensive business relationships. Some knew nothing; some knew everything. Jikipedia attempts to distinguish these through its network mapping and legal assessments, but those distinctions are imperfect.
Someone who attended one social event at Epstein's property in 1997 might appear in Jikipedia alongside someone who facilitated access to victims. From an information perspective, they're both in the network. From a fairness perspective, they're not remotely equivalent.
There's also the matter of people who appear in emails but weren't significant actors. A secretary might be mentioned thousands of times in email chains. A building contractor might have worked on one renovation. A lawyer might have provided a single consultation. The AI synthesis doesn't necessarily calibrate the significance of different types of appearances.
The privacy concern is particularly sharp because Jikipedia includes everyone in its orbit. Not every person in Epstein's network has been charged with crimes or publicly implicated in misconduct. Some are just witnesses. Some are just people who knew him. Making detailed profiles of all of them, publicly available and linked together in a network, creates a new form of public exposure.
There's no easy answer here. You can't make information perfectly transparent while protecting everyone's privacy. You can't guarantee accuracy while synthesizing from imperfect sources. The choices made by the team behind Jikipedia reflect one balance point, but it's not the only defensible one.
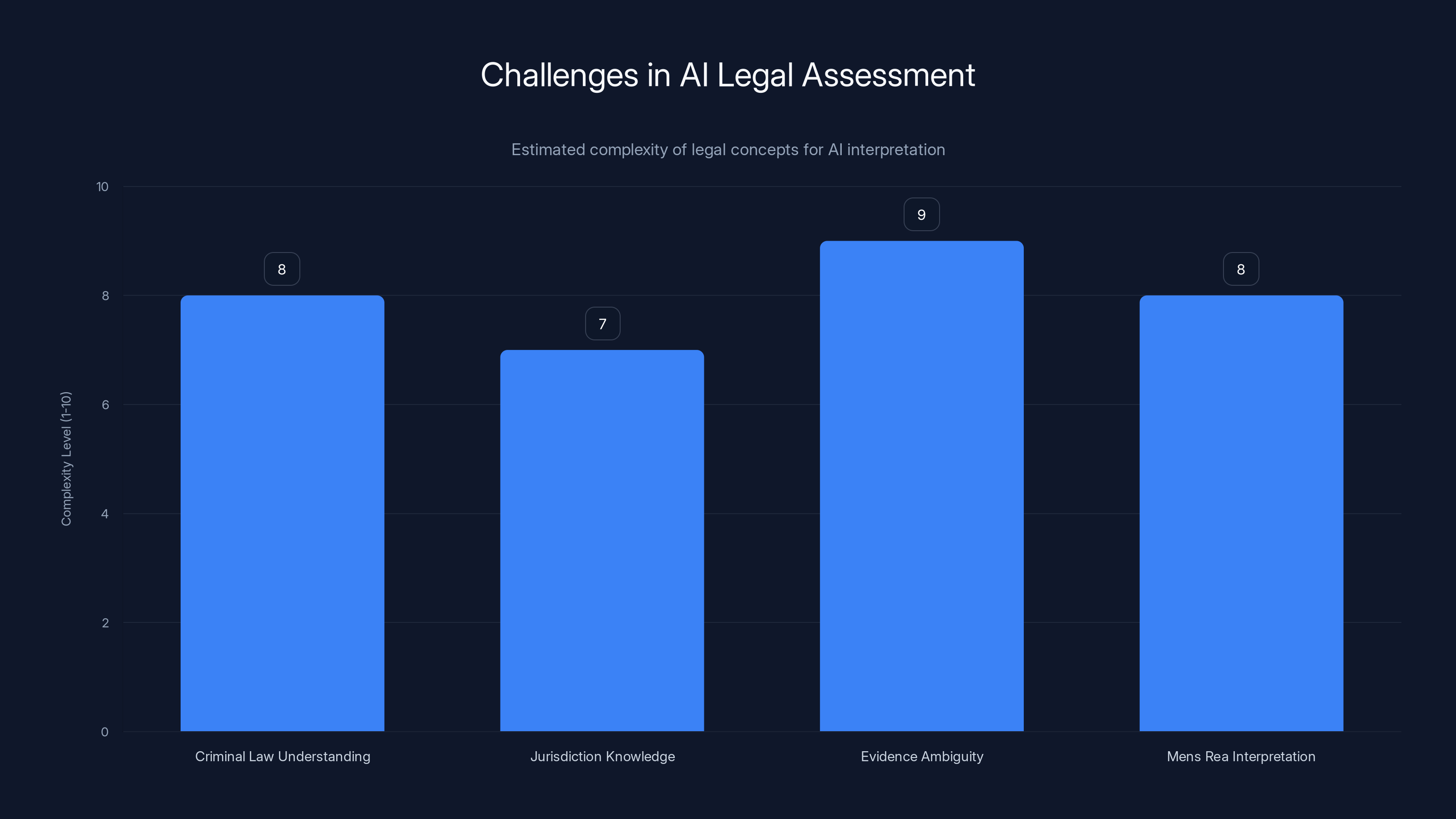
AI faces significant challenges in understanding complex legal concepts, with evidence ambiguity being particularly difficult. Estimated data.
The Email Data Itself: What's Included and What's Missing
Understanding Jikipedia requires understanding the underlying dataset. These are emails from Epstein's accounts and accounts of people closely connected to him. They're not complete. Data was lost, deleted, or never digitized. Some periods are better documented than others.
The dataset is also biased toward written communication. It doesn't include phone calls, in-person meetings where nothing was documented, or communications on other channels. If something important happened face-to-face or by phone without email follow-up, it won't appear in Jikipedia.
The emails also reflect Epstein's orbit, not the complete picture of his crimes. For instance, the extent and nature of his abuse only became fully clear through testimony from victims and investigation by law enforcement. The emails provide context, but they're not the primary evidence of the crimes themselves.
Jikipedia is therefore limited by its source material. It's great at showing who emailed whom, when, and about what topics. It's less useful for understanding the actual victims' experiences or the full scope of the abuse. The AI synthesis can't overcome these gaps in the underlying data.
There's also the question of what emails were released and why. The Epstein Files were released through specific legal proceedings and investigations. That's generally a process driven by legal necessity rather than public interest. Some documents were redacted. Some were released in batches years apart. The timeline of what became public when affects what shows up in the synthesized encyclopedia.
Someone reading Jikipedia should keep this in mind: it's a view of Epstein's network filtered through his email archives, which are incomplete, biased, and filtered by legal and investigative processes you can't fully see.
Legal Liability and Defamation Risk
Here's the uncomfortable truth: Jikipedia is a defamation lawsuit waiting to happen.
Publishing statements about real people being involved in crimes or violating laws creates legal exposure. Jikipedia does exactly that in its legal assessment sections, on a publicly available platform that names individuals.
Defamation law varies by jurisdiction, but generally you can be held liable for publishing false statements that damage someone's reputation. Truth is an absolute defense, but proving truth in court is expensive and difficult. Jikipedia's statements are AI-generated synthesies of email content, not statements verified by journalists or lawyers. That's legally risky.
The team behind Jikipedia presumably understands this. That's likely why they built in mechanisms for correction and dispute. But having a correction mechanism doesn't eliminate liability for publishing the initial false claim.
There's also the question of opinion versus fact. Jikipedia's legal assessment sections are presented as factual assessments of criminal liability. But legal conclusions are often opinions requiring interpretation. An AI system making those calls is on shakier legal ground than a publication that frames things more carefully as "alleged" or "suspected."
None of this means Jikipedia necessarily will be sued or will lose if it is. But the legal risk is real and substantial. The accuracy and fairness issues discussed earlier become critical partly because of legal consequences if they're wrong.
This is worth noting not to say Jikipedia shouldn't exist, but to acknowledge that publishing detailed information about real people's alleged crimes has consequences and costs. Those aren't borne equally—the wealthiest people in the network can afford lawyers; others can't.

Public Interest in the Epstein Files
Why does Jikipedia exist at all? The answer is: genuine public interest in understanding Epstein's network and how he evaded accountability for so long.
Epstein was prosecuted in 2008 for crimes against minors but received a plea deal that many viewed as incredibly lenient. He served about 13 months in jail. In 2019, he was arrested again and charged with more serious crimes. He died in jail before trial, preventing any legal judgment about the full scope of his crimes or the involvement of others.
That left a gap: people were never held accountable through the courts, but the public had legitimate questions about who knew what and who facilitated the abuse. The emails provide raw material for answering those questions.
News organizations did some of this work. The Miami Herald and other publications reported on Epstein's network, his connections to political and business figures, and how he managed to avoid serious consequences for years. That's traditional investigative journalism, and it served an important public interest.
Jikipedia extends that work by making the raw material itself accessible and by attempting to systematize what's in it. Instead of relying on what journalists chose to report, anyone can access the synthesized information.
That's genuinely valuable from a transparency perspective. But it also means spreading information that's never been editorially vetted, legally verified, or presented with appropriate caveats. The public benefit of access has to be weighed against the risks of inaccuracy and unfairness.
What's interesting is that different people will weigh those risks differently. Victims of Epstein's abuse and people concerned about accountability might see Jikipedia as overdue transparency. People falsely implicated in the networks might see it as dangerous. Both perspectives have merit.
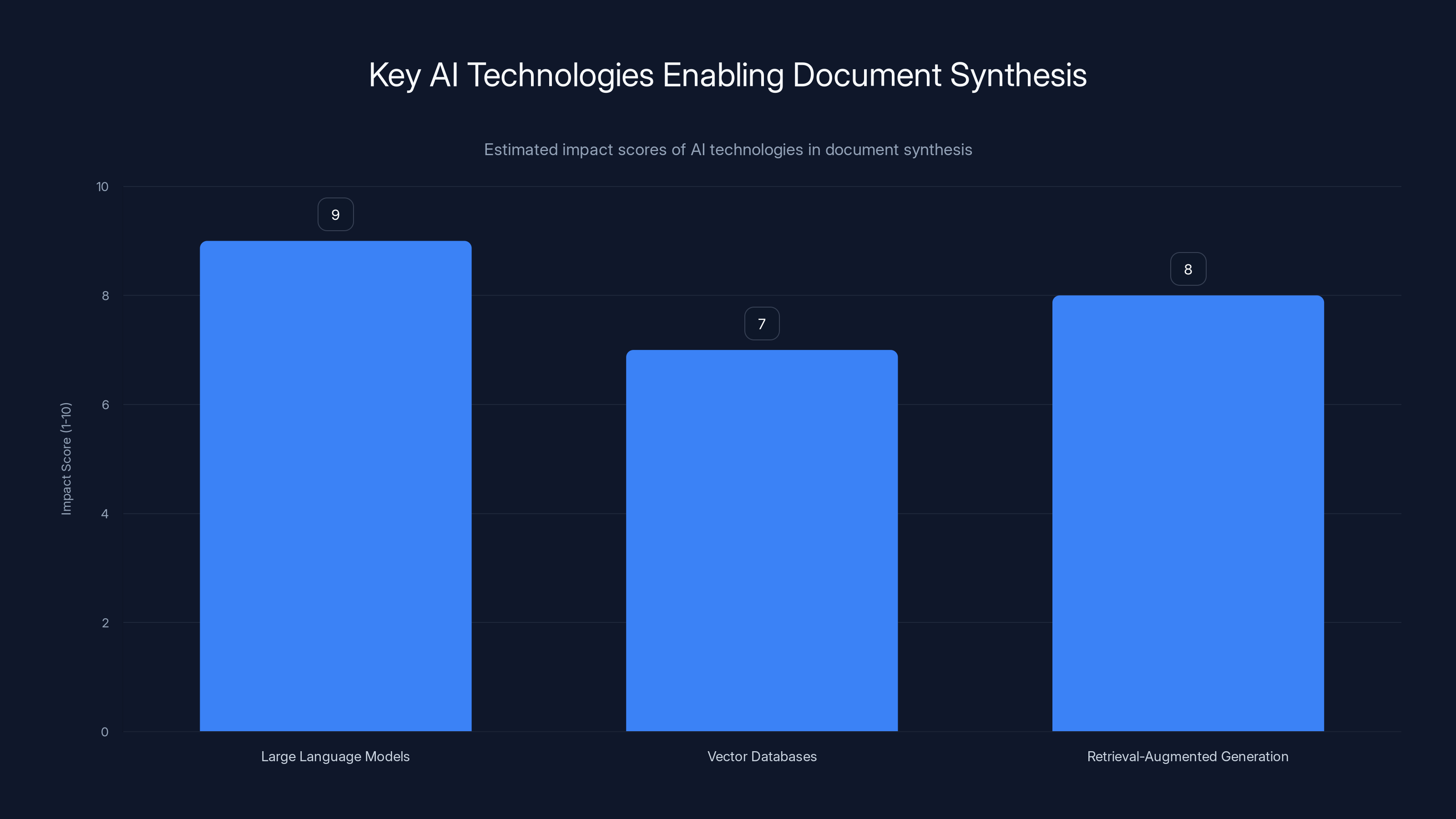
Large language models have the highest impact on enabling document synthesis, followed by retrieval-augmented generation and vector databases. (Estimated data)
The AI Tool Landscape: What Makes Synthesis Like This Possible
Jikipedia wouldn't have been possible even five years ago. The technology required to read thousands of documents and synthesize them into coherent, interconnected entries simply didn't exist in a form accessible to a small team.
The key technologies are large language models (like GPT-4), which can process and understand text at scale; vector databases, which allow semantic search across large corpora; and retrieval-augmented generation (RAG), which lets you ground language model outputs in specific documents.
With these tools, a small team can do what would've required a large newsroom or research institute previously. Feed a language model thousands of emails. Ask it to identify key entities, extract relationships, synthesize summaries, and generate profiles. Iterate on the prompts to improve quality. Publish the results.
This capability is genuinely new. It's not that the information wasn't public before—it was available in the Jmail database. It's that the synthesized, interconnected presentation required more human effort than was feasible. AI makes it feasible.
This has implications beyond Jikipedia. Any large dataset of documents—leaked corporate communications, government files, academic papers, patent filings—can now be synthesized into encyclopedia-like resources. That's powerful for transparency. It's also powerful for spreading inaccuracies or for painting misleading pictures of complex situations.
Other projects are attempting similar things. Some are focused on making legal documents or regulatory filings more accessible. Others are aimed at analyzing corporate or government archives. The technology itself is neutral; what matters is how it's applied and what guardrails exist around accuracy and fairness.

Jmail and the Broader Context of Accessible Information
Jikipedia didn't emerge in a vacuum. It's the second major project from the team that created Jmail, the searchable database of Epstein emails that launched earlier.
Jmail was itself a statement about information access. Previously, the Epstein emails existed in various databases maintained by different agencies and law enforcement entities. Some were on the Miami Herald's website. Some were part of court filings. Some were accessible through FOIA requests. None were centralized or easily searchable.
Jmail centralized them. You could search for a person's name, a topic, a date range, and find relevant emails. That was genuinely useful for journalists, researchers, victims seeking to understand their own cases, and anyone else with legitimate interest in the files.
Jikipedia is the next step: instead of searching, you navigate an encyclopedia. Instead of finding individual emails, you find synthesized profiles. The interface and presentation change fundamentally how people interact with the information.
That progression makes sense from a product perspective. Search is useful but requires knowing what to look for. Encyclopedia browsing is more serendipitous and leads you to discover connections you didn't know existed. Both serve different needs.
The progression also reveals something about the team's philosophy. They're not trying to gatekeep information or present a particular interpretation. They're trying to make it maximally accessible in multiple formats. Some people will search. Some will browse encyclopedias. Some will follow network links discovering connections.
That's arguably the right approach for transparency. Different people learn differently; different questions require different interfaces. Providing multiple ways to access the same underlying information makes sense.
Potential Applications and Consequences
Jikipedia's example raises questions about what other similar projects might emerge.
Implied in the Epstein Files work is a template: take leaked or public documents, apply AI synthesis and network analysis, create an accessible interface, and publish. That template could be applied to other datasets.
You could imagine similar projects for:
- Corporate leaks: Synthesizing internal communications from leaked corporate archives to understand how companies made decisions or covered up problems
- Government files: Creating encyclopedias from declassified documents, FOIA releases, or leaked government communications
- Academic papers: Synthesizing research in specific domains into interconnected networks showing how ideas developed and influenced each other
- Patent filings: Creating searchable, synthesized indexes of patents to understand technology development and potential overlap
- Financial documents: Synthesizing regulatory filings, loan documents, and court records to map financial networks
Each of these would have value for transparency and understanding. Each would also carry risks of inaccuracy, unfair misrepresentation, and unequal impacts.
The question isn't whether such projects should exist—the technology exists, and transparency has value. The question is how to do them responsibly. What guardrails? What corrections mechanisms? What editorial oversight? Jikipedia is an early attempt to navigate these questions, and it's imperfect.

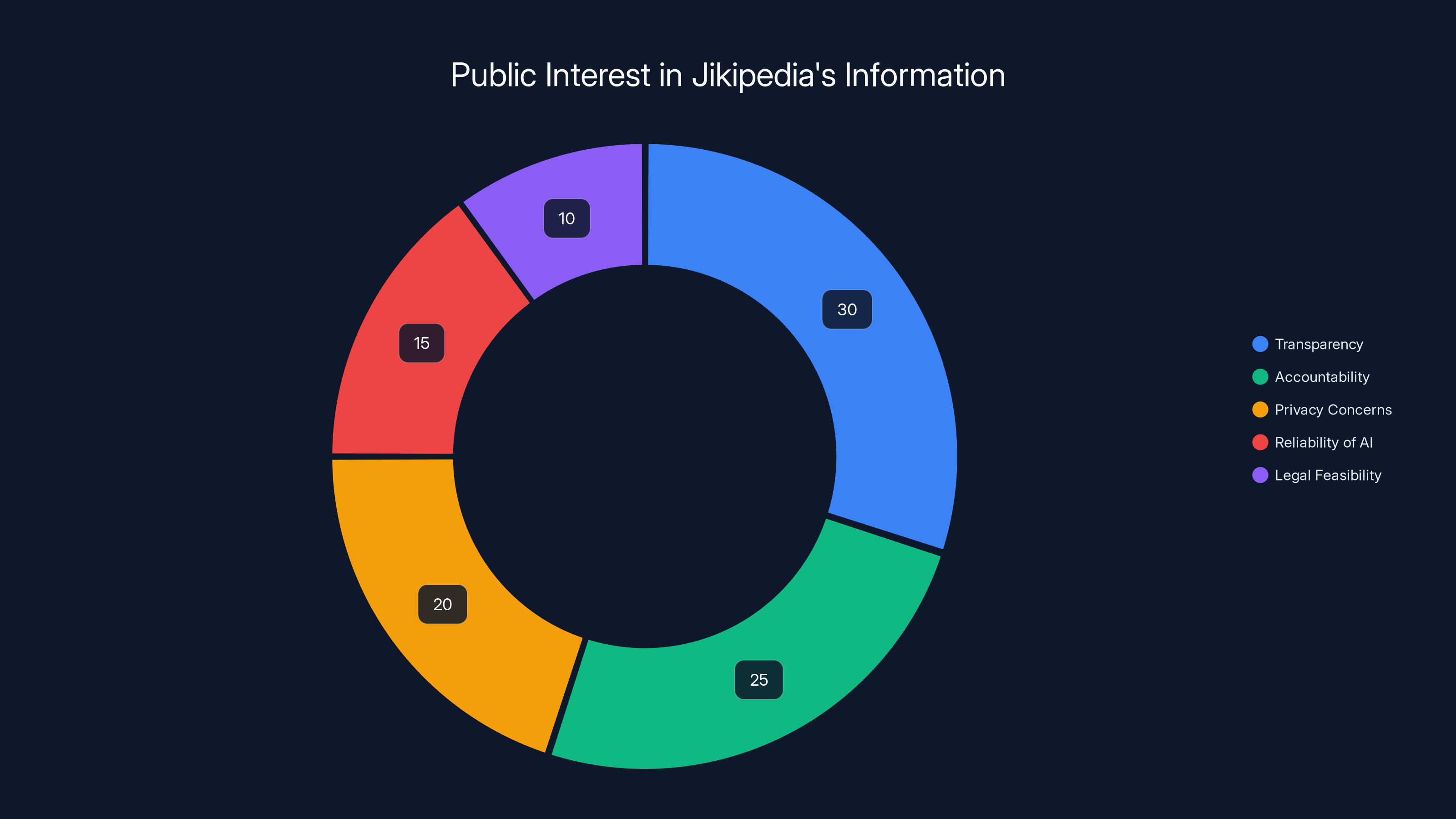
Estimated data shows that transparency and accountability are the primary public interests in Jikipedia, followed by privacy concerns and reliability of AI-generated content.
The Role of Corrections and Community Input
The team behind Jikipedia has committed to implementing a system for users to report inaccuracies and request changes. That's important, but it's worth thinking carefully about how effective such systems actually are.
Community moderation and correction systems work okay for things like Wikipedia, where corrections are made by human editors who evaluate evidence and make editorial judgments. But Jikipedia is AI-generated, not human-written. Corrections don't involve editing text; they might involve retraining or rerunning synthesis processes.
There's also the problem of incentives. Someone falsely accused in Jikipedia has motivation to report inaccuracies. Someone benefiting from inaccuracies has motivation to prevent corrections. Actual criminals in the network might report corrections to seem less implicated. How does the team sort legitimate corrections from motivated disputes?
Wikipedia handles this through editorial process and dispute resolution. Jikipedia's team hasn't explained their full process. That's understandable—the project was launched quickly to capitalize on public interest. But the correction mechanism is critical to the project's legitimacy.
Ideally, the team would implement something like:
- Transparent criteria for what constitutes an error worthy of correction
- Editorial review of corrections before implementation
- Source documentation for corrections, so readers can see why changes were made
- Archived versions of entries so the correction history is visible
- Appeal mechanisms for disputed corrections
- Periodic audits of entries by external parties to catch errors the team missed
That's more labor-intensive than a simple correction form, but it's necessary if the project is going to be taken seriously as a reference resource.
Comparing Jikipedia to Other Transparency Initiatives
Jikipedia isn't the only project attempting to make complex networks of information publicly accessible. How does it compare to similar initiatives?
Wiki Leaks and similar sites publish raw documents and leave analysis to others. That's valuable but less synthesized. Jikipedia goes further by attempting to extract meaning and relationships from the documents themselves.
Investigative journalism by outlets like Pro Publica or the International Consortium of Investigative Journalists often synthesizes large datasets but through human reporting and editorial judgment. That's more reliable but slower and more limited in scope.
Network analysis tools like Gephi or vis.js let you visualize interconnected data but require technical skill to use. Jikipedia makes network analysis accessible to anyone.
Academic databases like Google Scholar synthesize information from research but focus on structure and linking rather than synthesizing content.
Jikipedia is perhaps most similar to projects that synthesize leaked corporate or government data into accessible platforms, though few projects have attempted this at Jikipedia's scale and ambition.
What distinguishes Jikipedia is the combination of AI synthesis, network visualization, and public accessibility, applied to a dataset that raises serious questions about real people's involvement in crimes. That's a higher stakes version of similar projects, which is why the accuracy and fairness questions are more critical.

Ethical Considerations for Developers and Publishers
If you were building something like Jikipedia, what ethical guidelines would you want to follow?
Some possibilities:
- Ground-truth requirements: Only include information that can be verified in the original source documents. Don't infer or extrapolate.
- Accuracy over completeness: It's better to omit uncertain information than to include potentially false claims.
- Context and nuance: When presenting relationships or alleged misconduct, include information about the nature and timing of the relationship to avoid oversimplification.
- Distinguished confidence levels: Mark claims about which you have high confidence differently from claims that are uncertain or inferred.
- Right of response: Offer people profiled in the encyclopedia the opportunity to respond or add context before publication.
- Legal assessment caution: Be extremely careful about generating legal conclusions about real people. Perhaps don't do this at all, or do it only with explicit disclaimers and only when allegations have been legally established.
- Regular audits: Have external parties regularly check entries for accuracy and fairness.
- Transparent sourcing: Link each claim to specific source documents so readers can verify.
Jikipedia incorporates some of these (transparent sourcing to source documents, commitment to corrections). Others are less clear (what's their standard for inference? How they distinguish confidence levels?). Thinking through these considerations in advance would have strengthened the project.
The Future of AI-Synthesized Information
Jikipedia is an early example of what's coming. As language models improve and synthesis tools mature, more projects like this will emerge. Some will be valuable contributions to transparency. Some will be misused to spread misinformation. Some will exist in the gray area between.
The key question for the future is: what norms and practices emerge around AI synthesis of public information? Right now, the field is still figuring this out.
Possible scenarios:
Scenario 1: Minimally Regulated Synthesis: AI-generated encyclopedias and synthesized resources proliferate with little oversight. Some are reliable; others are not. Users have to figure out for themselves what to trust. This maximizes information availability but increases spread of inaccuracies.
Scenario 2: Editorial Gatekeeping Returns: Recognizing the risks, major platforms implement strict standards for AI synthesis. Information synthesis is done primarily by editorial organizations with accountability and legal liability. This is more reliable but slower and less comprehensive.
Scenario 3: Technical Standards Emerge: The field develops technical and presentation standards for AI-synthesized information. High-confidence claims are distinguished from uncertain ones. Source citations are mandatory. Confidence levels are indicated. This balances access and reliability.
Scenario 4: Transparency + Legal Accountability: Legal frameworks evolve to hold publishers of AI-synthesized information accountable for inaccuracy and defamation, similar to how traditional publishers are held accountable. This creates incentives for accuracy but might discourage some transparency projects.
Reality will probably be some mix of these. Different projects will navigate these questions differently, and the answers that work for Jikipedia might not work for other applications.

Takeaways for Information Consumers
If you're going to use Jikipedia (or similar AI-synthesized information resources), here's what to keep in mind:
Treat it as a research starting point, not a conclusion. Jikipedia tells you what emails say and what networks appear to exist. It doesn't tell you the full context or implications. Use it to identify areas worth further research.
Check sources. Jikipedia cites source emails. Read the actual source materials to see if the synthesis accurately represents them. Often you'll find the AI synthesis is basically correct but oversimplified or missing important context.
Understand the limits of the dataset. The Epstein emails are incomplete. They're biased toward Epstein's direct communications and some associates' communications. They don't include everything, and what's included is shaped by which documents were released through which legal processes.
Be cautious about legal assessments. Jikipedia's legal assessment sections are AI-generated inferences, not qualified legal analysis. They might be right, but they might also be completely wrong. Don't cite them as evidence of legal wrongdoing without independent verification.
Remember that appearance in the network isn't proof of guilt. Some people in Jikipedia are clearly accused of major crimes. Others are on the periphery or have minimal association. The network shows connection; it doesn't show culpability.
Look for external reporting to contextualize claims. News organizations have reported on specific aspects of the Epstein case. Their reporting will provide context and editorial judgment that the encyclopedia entry might not include.
Alternatives and What's Missing
Jikipedia isn't the only way to access information about Epstein's network. What are the alternatives and what advantages/disadvantages do they have?
Reading the emails directly through Jmail: You get primary sources but have to know what to search for. You don't get synthesis or network visualization. It's slower but more reliable in that you're seeing source material directly.
Reading investigative journalism: Outlets like the Miami Herald, New York Times, and others have reported extensively on Epstein's network. This is vetted information from professional journalists but limited in scope compared to what's in the entire email archive.
Court documents and legal filings: These are authoritative and legally significant but dense and hard to navigate without legal background. They include victim testimony and formal allegations.
Books and documentaries: Several books and at least one major documentary have examined Epstein's network. These provide narrative context and depth but are limited to what the authors chose to investigate.
Jikipedia's innovation is that it tries to synthesize the full dataset into accessible encyclopedia format. That's neither better nor worse than the alternatives overall—it's different. Useful for different purposes.
What Jikipedia is missing:
- Victim perspectives: The emails are from Epstein and his associates, not from victims. The victims' experiences, which are the core of the harm, are not directly represented.
- Law enforcement analysis: What did investigators conclude? What's the status of any ongoing investigations? Jikipedia doesn't include this.
- Legal judgments: How have courts interpreted the same evidence? What have judges or juries concluded? Jikipedia doesn't integrate legal outcomes.
- Context and narrative: Why things happened, what it means, how it affected people. Encyclopedia entries are inherently limited in how much narrative they can include.
These gaps aren't necessarily flaws—they're inherent to the format. But they're worth acknowledging when using Jikipedia as a source for understanding the Epstein case.

Looking Ahead: Questions for the Project and the Field
As Jikipedia matures and similar projects emerge, several questions will need to be answered:
How will accuracy be maintained and verified? The correction mechanism is important, but proactive verification is better. Will the team audit entries? Commission external reviews? Update synthesis as new information emerges?
How will legal liability be managed? Jikipedia operates in a legally uncertain space. As the project scales, legal challenges are likely. How will the team respond? What insurance or legal resources do they have?
Will other similar projects emerge? If Jikipedia succeeds, will others create similar AI-synthesized encyclopedias from other datasets? Should they? What frameworks should guide whether a dataset is appropriate for this kind of synthesis?
How do you balance transparency with privacy and fairness? The fundamental tension remains. Different reasonable people will disagree about where to draw the line. What's the principled way to navigate that disagreement?
What role for human editorial oversight? Can synthesis be better if human editors review and revise AI outputs? Or does that reintroduce bias and limit comprehensiveness?
How does this interact with regulation of AI? As governments consider AI regulation, does AI-synthesized information get special treatment? Should it? What responsibilities should publishers have?
These questions don't have simple answers. But as a field, we'll need to think them through carefully.
FAQ
What is Jikipedia?
Jikipedia is an AI-generated encyclopedia synthesized from the Epstein Files—thousands of leaked emails and documents from Jeffrey Epstein's accounts and associates. Created by the Jmail team, it generates detailed profiles of Epstein's network, his properties, and his business relationships, presenting them in an interconnected Wikipedia-like format with relationships mapped between entities.
How does Jikipedia generate its profiles?
Jikipedia uses large language models and retrieval-augmented generation (RAG) systems to process the email corpus, identifying key entities (people, properties, businesses, transactions), extracting relationships between them, and synthesizing that information into encyclopedia-style entries. The system generates summaries, timelines, relationship maps, and legal assessments based on patterns found in the underlying email data.
What makes Jikipedia different from just reading the original emails?
Jikipedia provides synthesized, interconnected profiles rather than raw emails. Instead of searching for specific terms and reading individual messages, you can browse an encyclopedia of people and properties with relationship networks visualized. This makes it much easier to understand overall network structure and how different people are connected, though at the cost of losing some nuance and context present in original documents.
How accurate is Jikipedia?
Jikipedia's accuracy is limited by both its underlying sources and AI synthesis limitations. The source emails are incomplete, biased toward written communication, and filtered by which documents were released. The AI synthesis can make errors by misreading context, failing to understand sarcasm, confusing identities, or inferring connections that aren't justified. The team plans to implement user-submitted corrections, but errors will inevitably exist in such a large synthesized dataset.
Can Jikipedia's legal assessments be trusted?
Jikipedia's legal assessment sections are AI-generated inferences, not qualified legal analysis. They should not be treated as authoritative legal conclusions. The system can identify when emails discuss potentially illegal activity, but determining actual criminal liability requires understanding complex law, context, and evidence in ways that language models are not reliably trained to do. These sections are worth investigating further, but shouldn't be cited as proof of wrongdoing without independent verification.
What are the privacy concerns with Jikipedia?
Jikipedia creates public, detailed profiles of hundreds of people connected to Epstein—some of whom were clearly complicit in crimes, others who might have been tangential figures or victims. This public exposure applies equally to everyone in the network despite highly unequal levels of culpability. Some people have never been charged or publicly implicated in misconduct but appear in Jikipedia simply because they appear in emails. This raises fairness questions about the right to be forgotten and the collateral damage of publicizing association without proportional guilt.
Will Jikipedia have a correction mechanism?
Yes, the team has stated they plan to implement a system for users to report inaccuracies and request corrections, though specific details about how this will work aren't yet public. This is important but insufficient on its own—proactive verification and editorial review are also needed to maintain credibility as an information resource.
Is Jikipedia legally risky?
Yes. Publishing detailed accusations about real people's involvement in crimes creates significant legal liability for defamation. Jikipedia's AI-generated nature and synthesized format rather than journalistic verification makes this liability particularly sharp. The team presumably understands these risks, which is why they're building in correction mechanisms. However, having corrections available doesn't eliminate liability for initially publishing false or misleading claims.
Could similar projects be created from other datasets?
Definitely. The technology Jikipedia uses could be applied to any large dataset of documents—leaked corporate communications, government files, court records, academic papers, patent filings, etc. Each would have potential value for transparency while also carrying risks of inaccuracy and unfair representation. The question for the field is what norms and standards should guide such projects.
How does Jikipedia compare to traditional investigative journalism?
Jikipedia differs from investigative journalism in that it's comprehensive but unsynthesized (attempting to include everything from the dataset) rather than curated (selecting the most important stories). It's faster but less verified than journalism, more accessible but less contextualized, and broader in scope but less narratively compelling. The two approaches serve different needs and complement rather than replace each other.
What should I keep in mind when using Jikipedia?
Treat Jikipedia as a research starting point rather than a conclusion. Check sources by reading the actual source emails. Remember that the underlying dataset is incomplete and biased toward written communication. Be cautious about legal assessments. Understand that appearance in the network doesn't prove guilt. Look for external reporting and context from other sources. Don't cite AI-generated content as authoritative without independent verification.
Conclusion: Information, Accountability, and Difficult Choices
Jikipedia represents something genuinely new: the application of AI synthesis at scale to create accessible, comprehensive reference resources from leaked datasets. It's technically impressive and raises important questions about information access, accountability, and the role of AI in shaping what we know about powerful networks.
The project succeeds at its core goal: making detailed information about Epstein's network accessible to anyone with a browser. Before Jikipedia, that information existed, but it required either searching a database with no synthesis or relying on whatever news organizations had reported. Now someone can browse an encyclopedia, follow network connections, and discover relationships without specialized knowledge or effort.
That's genuinely valuable for transparency. People Epstein harmed and their advocates have a legitimate interest in understanding his network and who enabled him. The public has a legitimate interest in knowing about powerful people's connections to an extraordinarily consequential criminal case. Jikipedia serves both interests.
But the value comes with costs. AI-generated profiles are less reliable than human-written entries. Legal assessments generated by language models shouldn't be trusted as actual legal analysis. The interconnected network presentation can oversimplify complex relationships. Privacy concerns are real—people appear in the encyclopedia who may have been only tangentially connected to Epstein and who might not deserve the public exposure of being linked to his crimes.
There's also a meta-cost: Jikipedia's existence means AI synthesis of sensitive information is now clearly technically feasible and legally possible. More such projects will likely emerge. Some will be valuable. Others might abuse the capability. The field needs to develop norms and standards to guide responsible synthesis of sensitive information.
In the near term, Jikipedia's success will likely depend on how well the team executes on their commitment to corrections and accuracy. If they implement robust mechanisms for fixing errors and updating information, the project can build credibility. If errors proliferate and correction mechanisms are weak, Jikipedia will become a source of misinformation despite its good intentions.
For information consumers, the immediate takeaway is straightforward: Jikipedia is useful as a research tool, but it's not authoritative. Use it to identify leads. Verify claims through original sources. Contextualize with external reporting. Don't assume that AI synthesis is reliable just because it looks professional and cites sources.
Broader questions about the role of AI in synthesizing and presenting sensitive information will take longer to resolve. But they're worth asking now, while the technology is still new and practices are still forming. The choices made by Jikipedia and projects like it will help shape what becomes normal in how we access and synthesize large datasets. Getting that right—balancing transparency with accuracy, public interest with individual fairness—matters.
Epstein's files reveal a network of powerful people who enabled serious crimes, often evading accountability through wealth and status. Making that network visible and interconnected serves important transparency purposes. But doing so responsibly requires recognizing the limits of AI synthesis, building robust verification and correction processes, and thinking carefully about who might be unfairly represented or harmed by public association. Jikipedia is a start. How the project evolves will indicate whether AI-synthesized information resources can be built responsibly at scale.
Key Takeaways
- Jikipedia synthesizes Epstein's leaked emails using AI to create interconnected encyclopedia profiles, making network relationships and associate information accessible without requiring database searches
- The platform's AI-generated content provides value for transparency but carries risks of inaccuracy, oversimplification, and unfair representation of people only tangentially connected to Epstein
- Legal assessment sections are AI-generated inferences, not qualified legal analysis, and should not be treated as authoritative proof of criminal liability without independent verification
- The project raises important questions about responsible AI synthesis of sensitive leaked data, balancing public interest in accountability with fairness and accuracy concerns
- Similar projects using the same AI synthesis technology on other datasets will likely emerge, requiring the field to develop standards for accuracy, verification, and ethical deployment
Related Articles
- DJI Romo P Robot Vacuum Review: Security Risk or Smart Home Essential? [2025]
- TikTok's Epstein Files Obsession: Viral Theories, Institutional Distrust, and Digital Vigilantism [2025]
- Meta's Facial Recognition Smart Glasses: The Privacy Reckoning [2025]
- Meta's Facial Recognition Smart Glasses: Privacy, Tech, and What's Coming [2025]
- Meta's Facial Recognition Smart Glasses: What You Need to Know [2025]
- Ring Cancels Flock Safety Partnership Amid Surveillance Backlash [2025]

