![GitHub's Claude & Codex AI Agents: A Complete Developer Guide [2025]](https://tryrunable.com/blog/github-s-claude-codex-ai-agents-a-complete-developer-guide-2/image-1-1770226802473.jpg)
GitHub's AI Agent Revolution: Why Multi-Model Integration Matters
GitHub just fundamentally changed how developers interact with AI. The platform added Claude by Anthropic and OpenAI's Codex as native AI agents, available directly inside GitHub, GitHub Mobile, and Visual Studio Code. This isn't just another feature drop. It's a philosophical shift.
For years, developers faced a frustrating choice: stick with one AI model or switch between multiple tools. Copilot was the default. But Copilot isn't always the best choice for every task. Sometimes Claude excels at refactoring. Sometimes Codex nails API integration. GitHub realized that forcing developers into a single-model ecosystem was friction.
The new Agent HQ system lets developers pick their AI weapon for each task. Need to refactor legacy code? Use Claude. Building an API endpoint? Try Codex. Want to compare how each model approaches the problem? GitHub shows you all three solutions side by side. You pick the best one. That's real control.
This move also signals something bigger: the age of single-vendor AI is ending. GitHub is essentially saying, "We'll be the IDE, but AI models are a commodity now. Use what works best." That's good for developers. It's also smart business. By staying platform-agnostic on AI, GitHub becomes more valuable to more people.
Let's break down what's actually happening, why it matters, and how it changes the way you build software.
TL; DR
- GitHub now offers Claude, Codex, and Copilot as selectable AI agents within a single platform
- Each agent consumes one premium request, letting developers test and compare outputs without tool-switching
- Agent HQ is GitHub's unified framework for assigning AI models to specific tasks, issues, and pull requests
- Available now in preview for Copilot Pro Plus and Copilot Enterprise subscribers
- More agents coming soon: Google, Cognition, and xAI models will join the lineup in 2025
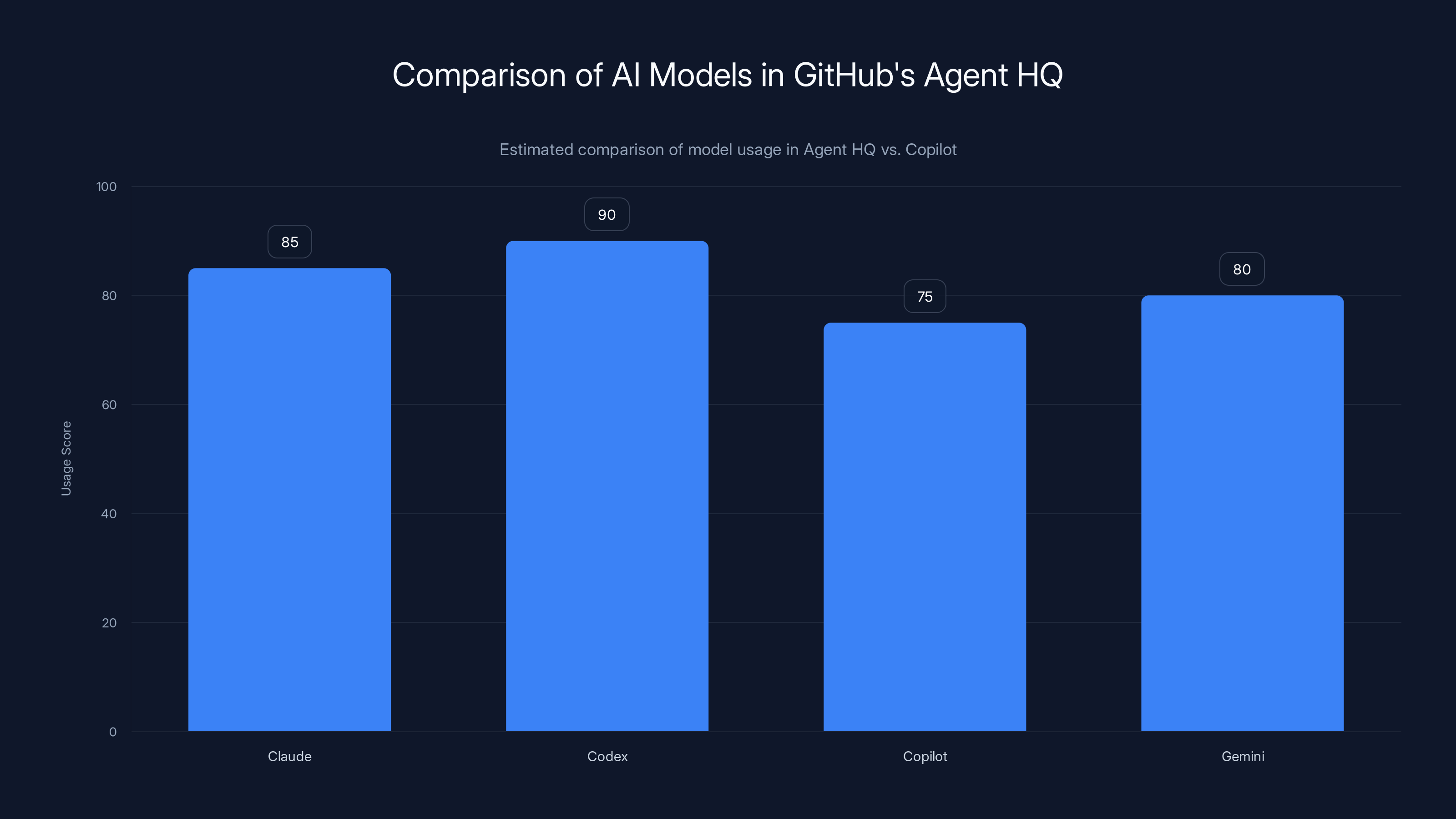
Agent HQ allows developers to use multiple AI models like Claude, Codex, and Copilot, offering flexibility and enhanced problem-solving capabilities compared to the single-model approach of regular Copilot. Estimated data.
What Agent HQ Actually Is (And Why It Matters)
Agent HQ is GitHub's vision for making AI native to the development workflow. But that buzzword-laden description doesn't capture what's really happening. Let me be concrete.
You're working on an issue. Previously: you'd describe the problem in plain English. Copilot would generate a solution. You'd either accept it or manually code it. Now: you can ask Copilot, Claude, and Codex to all solve the same problem simultaneously. Each one thinks through the code differently. Claude might break it into smaller functions. Codex might use a pattern you've seen before. Copilot might suggest a completely different approach.
You see all three proposals. You compare them. You pick the best one. Or you mix and match, taking the error handling from Claude, the performance optimization from Codex, and the API call structure from Copilot.
That's the actual power here. It's not about having more choices. It's about using the right tool for the specific problem, without leaving your editor or losing context.
Mario Rodriguez, GitHub's Chief Product Officer, put it this way: "Context switching equals friction in software development." He's right. Every time you switch tools, you lose momentum. Your IDE window closes. You paste code into another app. You come back. Your flow state is broken. Multiply that by dozens of times per day across a team, and you're losing serious productivity.
Agent HQ solves this by keeping you in GitHub. All the models are accessible. All the outputs are visible. All the comparisons happen in context.
The Big Three: Claude vs. Codex vs. Copilot
Now you might be wondering: what's the actual difference between these models? Why would I pick one over another? Great question. The nuances matter.
Claude: The Thoughtful Refactorer
Anthropic's Claude has a reputation for being methodical. It reasons through problems step-by-step. In code generation, this translates to cleaner architecture. Claude tends to break complex functions into smaller, testable pieces. It's good at explaining why it made certain choices.
Where Claude shines: refactoring legacy code, writing documentation, designing system architecture, and explaining security implications. When you need code that's maintainable and well-structured, Claude is your go-to.
Where Claude struggles: speed. Because it reasons through everything, it's slower to generate initial code. It can also be overly verbose in comments, which some developers find annoying.
Codex: The Pattern Recognizer
OpenAI's Codex (which powers much of GitHub Copilot) is optimized for speed and pattern matching. It's trained heavily on GitHub repositories, so it recognizes common patterns instantly. Need to write a React component? Codex has seen a million of them. It'll generate something functional immediately.
Where Codex excels: API integration, boilerplate code, test generation, and rapid prototyping. If you need working code now, Codex gets you there fastest.
Where Codex falls short: novel problems and architectural decisions. It's less good at reasoning through complex system design because it's primarily pattern-matching.
Copilot: The Balanced Generalist
GitHub Copilot sits between Claude and Codex. It's reasonably fast and reasonably thoughtful. It benefits from Microsoft's integration of multiple OpenAI models, so it can adapt to different contexts.
Where Copilot works best: it's your default for most tasks. It's the model you'll use 70% of the time because it handles most situations well.

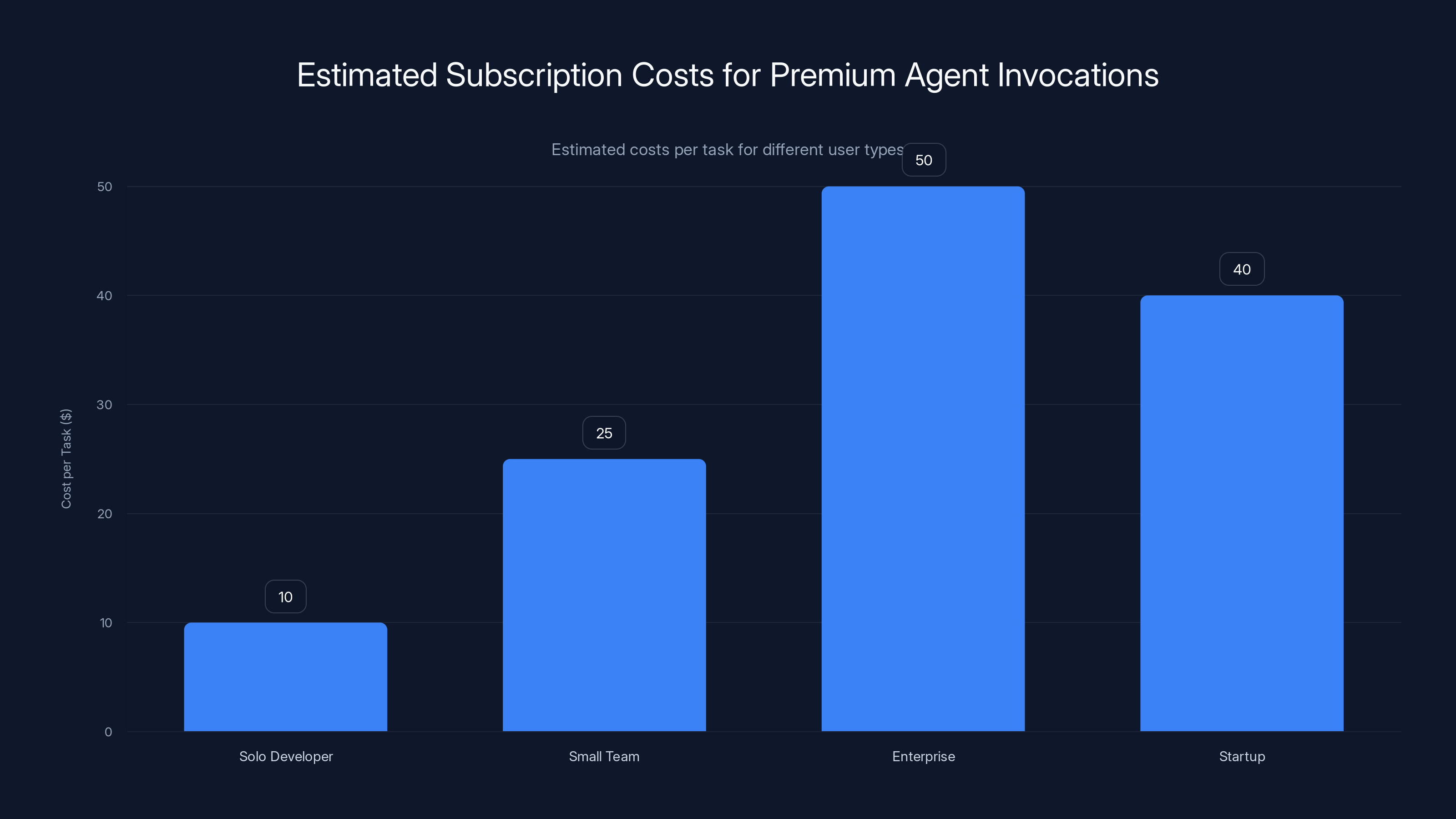
Estimated costs per task vary significantly by user type, with enterprises and startups likely to spend more due to higher usage. Estimated data.
How Multi-Model Comparison Actually Works in GitHub
Here's the workflow you'll actually experience:
You're in a pull request. A teammate left a comment asking you to optimize a database query. Previously: you'd type out the problem, Copilot would suggest something, you'd either use it or manually code it. Now:
- You describe the optimization needed
- You select "Compare Agents" from the Agent HQ menu
- You choose Copilot, Claude, and Codex
- All three generate solutions simultaneously
- You see three code blocks side-by-side
- You can run each one through your tests or review the logic
- You pick the winner or combine the best parts
Each agent uses one "premium request" (a billing unit), but developers can compare three solutions for three requests. In practice, this is way faster than manually researching how three different developers would solve the same problem.
The real insight here is psychological. When you see three different approaches to the same problem, your brain immediately understands the trade-offs. Option A is more efficient but less readable. Option B is more maintainable but has more overhead. Option C uses a newer pattern that might be overkill. Seeing this comparison forces you to think more deeply about the choice.
That's rare in software development. Usually you just use whatever generated first. Here, GitHub is forcing intentionality.
Why GitHub's Openness to Competitors Is Strategic Genius
Let's zoom out. Microsoft owns GitHub. Microsoft has a massive partnership with OpenAI. So why is GitHub integrating competitors' models?
The answer is business strategy, not altruism. By positioning GitHub as AI-model-agnostic, GitHub becomes more valuable to more developers. If you're a developer who prefers Claude, GitHub still works. If you use xAI's Grok, GitHub will support it soon. If you build custom proprietary models, GitHub has plans for that too.
This is the platform play. GitHub doesn't win by forcing everyone onto one AI model. GitHub wins by being the place where all AI models live. Then GitHub owns the workflow, the data, and the developer relationship.
Microsoft also gets something valuable: real-world comparison data. By letting developers test Copilot against Claude and Codex, Microsoft gets direct feedback on where Copilot excels and where it lags. That data feeds back into Copilot's improvement cycle. You're essentially crowd-sourcing Copilot's optimization.
There's another angle too. Microsoft is already testing Anthropic's Claude internally. Developers inside Microsoft have been asked to compare Claude Code with Copilot. This public integration validates what Microsoft is learning privately. It's a smart way to push Copilot improvement without announcing it as "we're losing ground to Claude."
The Subscription Model: What You Pay and What You Get
Let's talk money, because this is where the rubber meets the road.
Claude and Codex access requires Copilot Pro Plus or Copilot Enterprise. If you're on a basic Copilot subscription, you get the standard tier. The premium agents are premium access.
Each agent invocation costs one "premium request." GitHub isn't revealing the exact pricing per request yet, but the model is usage-based. If you run three agents on one task, that's three requests. Scale this across a team, and the costs add up.
For solo developers and small teams, this is a feature you'll use sparingly. It's not the default workflow. You'll pull it out when you're genuinely uncertain about the best approach or when the code matters enough to justify the cost.
For enterprises and well-funded startups, this is a rounding error. You're paying for agent comparison on critical codepaths. That's worth $20-50 per task if it prevents a bug in production.
GitHub says access will expand to more subscription tiers soon, which means cheaper access is coming. But I'd expect the premium agents to stay premium. That's where the value is.
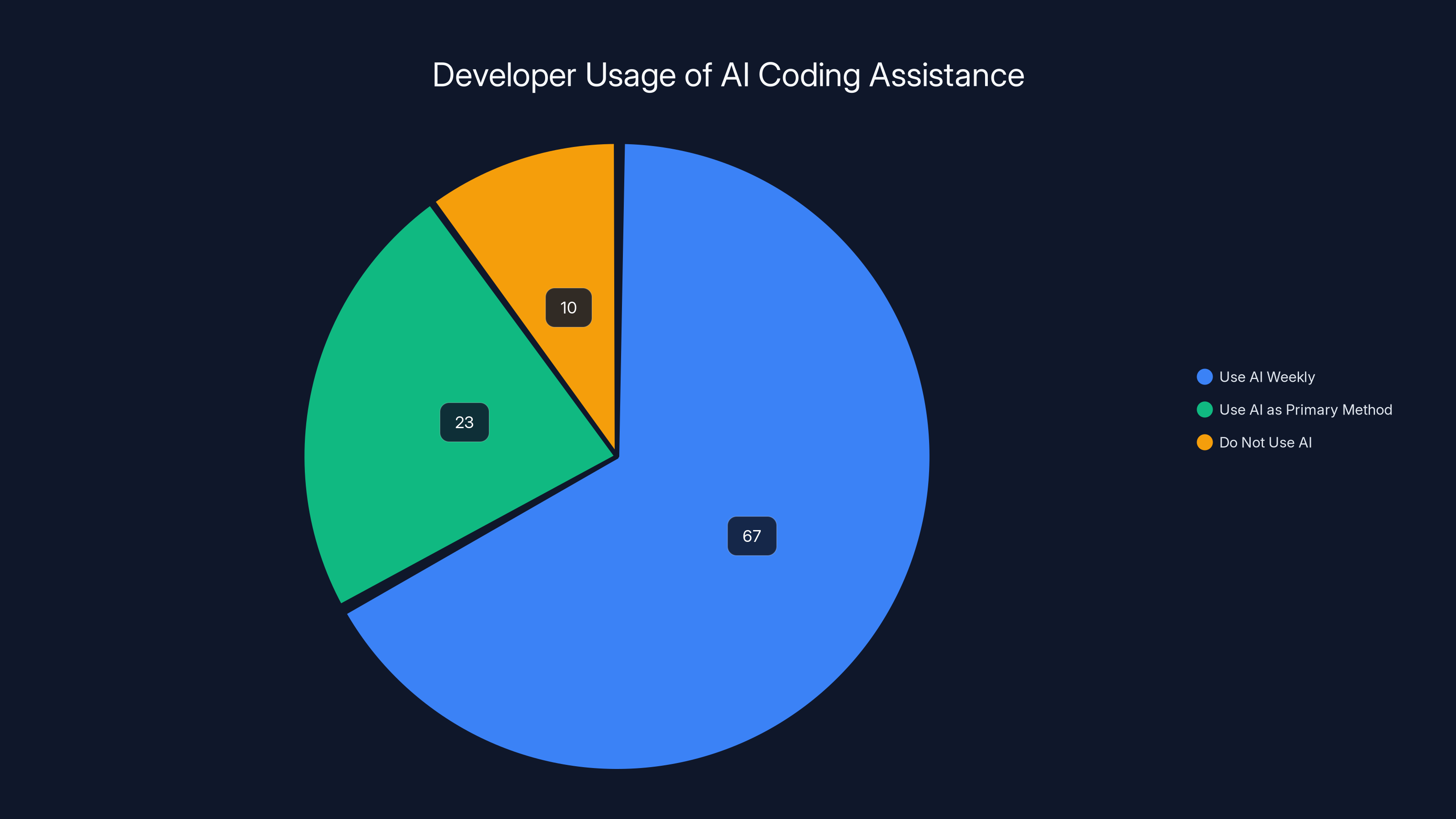
In a 2024 survey, 67% of developers reported using AI coding assistance weekly, while only 23% used it as their primary development method, highlighting AI's role as a supplementary tool.
Beyond Code: Assigning Agents to Issues and Pull Requests
The real power of Agent HQ extends beyond code generation. You can assign agents to entire issues or pull requests.
Imagine a complex PR comes in from a junior developer. The code works, but it could be better. Normally: you manually review it, leave comments, the junior dev fixes it, you review again. Three rounds of back-and-forth.
Now: you assign Claude to review the PR. Claude reads the code, the test coverage, the related code context, and generates a detailed review with specific improvement suggestions. The junior dev sees not just "fix this," but "here's why this pattern is suboptimal, here's a better approach, here's an example."
This isn't replacing code review. It's augmenting it. The human reviewer still approves or rejects. But the AI handles the tedious pattern-checking that humans hate doing.
You can also assign agents to issues. Issue says "implement user authentication." You assign Codex. Codex generates boilerplate, scaffolding, and API stubs. The human developer fills in the business logic. You've just cut the onboarding time for a new feature in half.
The Workflow Optimization Angle: Reducing Context Switching
Here's what most coverage of this feature misses: the real win is workflow optimization.
Developers aren't making a grand choice between Claude or Codex for philosophical reasons. They're trying to minimize friction in their workday. Every tool switch hurts. Every context break costs attention.
By putting all AI models in one place, GitHub eliminates the tool-switch tax. You don't need to open ChatGPT in another browser tab. You don't need to copy-paste code between windows. You don't need to switch to your phone to test a model's API. It's all right there.
This seems minor until you realize it compounds across a team. If Agent HQ saves each developer 30 minutes per week by eliminating context switching, and you have 50 developers, that's 25 hours of collective productivity reclaimed per week. Over a year, that's 1,300 hours of developer time. At average developer salary, that's over
That's the business model. GitHub isn't making money on AI capability (the models are commodity). GitHub is making money on workflow efficiency. And that's sustainable.
Integration with GitHub Mobile and VS Code
One detail that matters: Agent HQ isn't just available on the web. It's native in GitHub Mobile and Visual Studio Code.
For VS Code users, this is huge. You're already in your editor. Your tests run there. Your documentation lives there. Adding multiple AI agents without leaving the editor removes the last excuse to context-switch. You're in the IDE, the AI is in the IDE, your whole workflow stays in the IDE.
For mobile users, it's less critical but more surprising. You can browse issues on your phone, and now you can ask an AI agent to help. It's not the place you'll do heavy development, but it's useful for quick code reviews or architectural discussions while you're away from your desk.
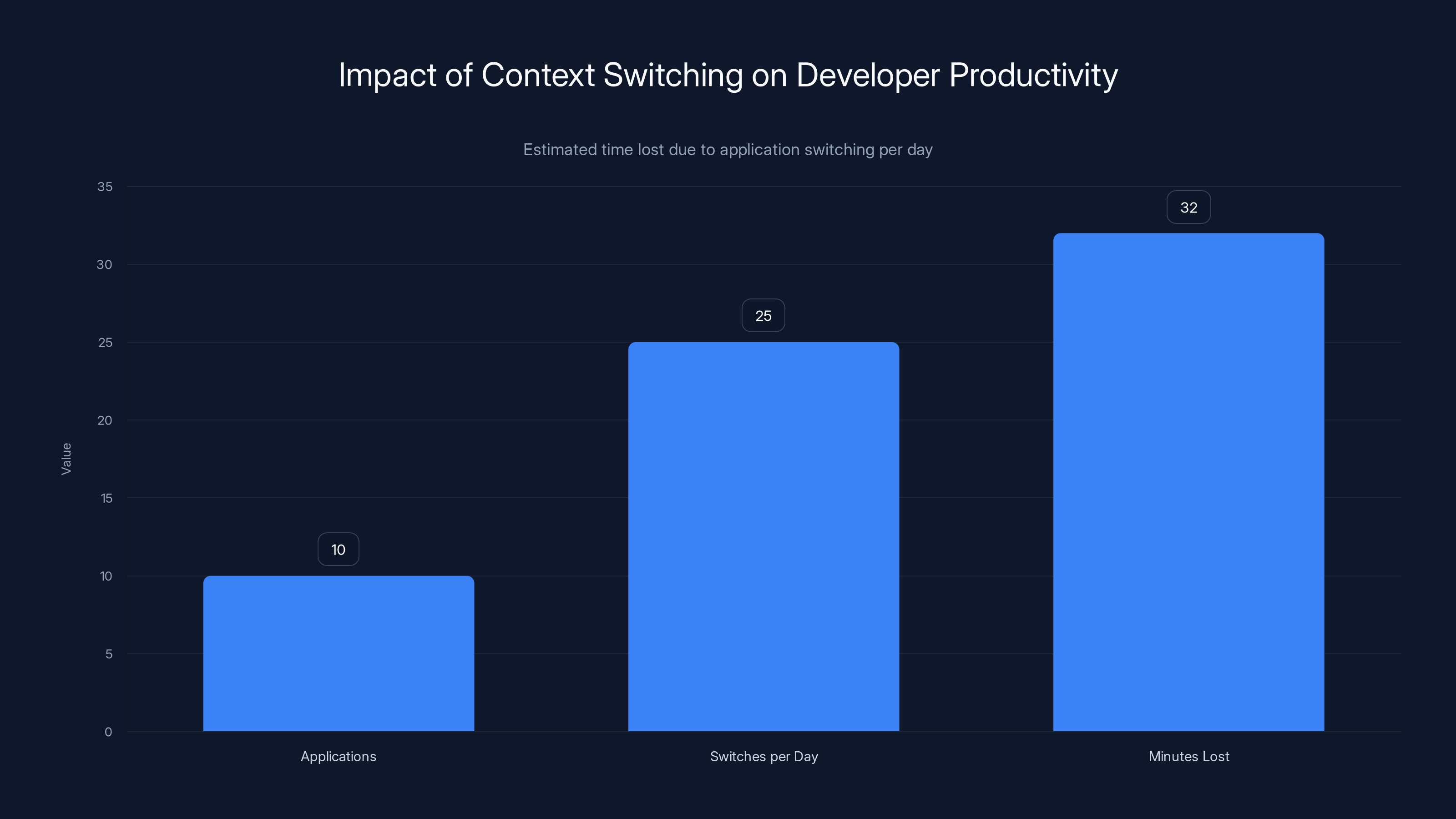
Developers switch between 10 applications about 25 times daily, losing around 32 minutes of productivity due to context switching. Estimated data highlights the productivity gains possible with integrated tools like Agent HQ.
The Roadmap: More Agents Are Coming
GitHub is working with Google, Cognition, and xAI to bring more agents into the platform.
Google's Gemini is obvious. It'll be competitive with Claude and Codex.
Cognition's Devin is more interesting. Devin is a full-featured AI software engineer, not just a code generation model. It can understand entire codebases, make multi-file changes, run tests, and iterate. If Devin joins Agent HQ, you could assign it to medium-sized tasks ("implement the payment processing module") and have it generate multiple file changes with integrated testing. That's a different category of capability.
xAI's Grok is newer, but if it proves competent at coding tasks, the xAI integration gives developers another option.
The pattern is clear: GitHub is building a marketplace of agents. Over time, you'll see custom agents too. Enterprise users will train custom agents on their internal code patterns. Open-source projects will publish agents optimized for their specific architecture.
This is where Agent HQ becomes genuinely powerful. It's not just "pick Claude or Codex." It's "pick the agent optimized for your exact use case."
Real-World Developer Impact: Who Benefits Most
Not every developer benefits equally from multi-agent support.
Junior developers: Massive win. They can see how multiple AI models approach the same problem. This teaches pattern recognition and architectural thinking. It's like having three senior developers willing to explain their approach simultaneously.
Senior developers: Moderate win. They already know how they'd solve most problems. But the comparison feature is useful for code review (assigning Claude to review a PR) and architecture decisions (asking multiple agents to design a system).
Specialist developers (DevOps, infra, data): This depends on the agent. Codex is good at infrastructure patterns. Claude is decent at system design. But these roles might not see huge benefit until specialized agents arrive.
Enterprise teams: This is where it shines. A large team working on complex systems can reduce review cycles, catch patterns faster, and onboard new features more quickly. The productivity gain justifies the cost.
Solo founders and indie developers: You'll use it occasionally, but probably not daily. The cost isn't justified for every task.
The Security and Trust Implications
Here's something people are asking quietly: if I use Claude or Codex through GitHub, does my code go to Anthropic or OpenAI?
The answer is complicated. GitHub doesn't release exact details of data flow, but the model is: your code is sent to the AI provider to generate outputs. That code is typically not used for training (due to enterprise agreements), but it does pass through their servers.
For most code, this is fine. For proprietary systems, classified code, or sensitive business logic, you might want to stick with Copilot, which Microsoft controls end-to-end.
For enterprises, GitHub Copilot Enterprise includes extended retention policies and additional privacy controls. If you're using Claude or Codex, check your subscription tier and what guarantees you get.
This is worth a conversation with your security team if you're at a company that handles sensitive data.
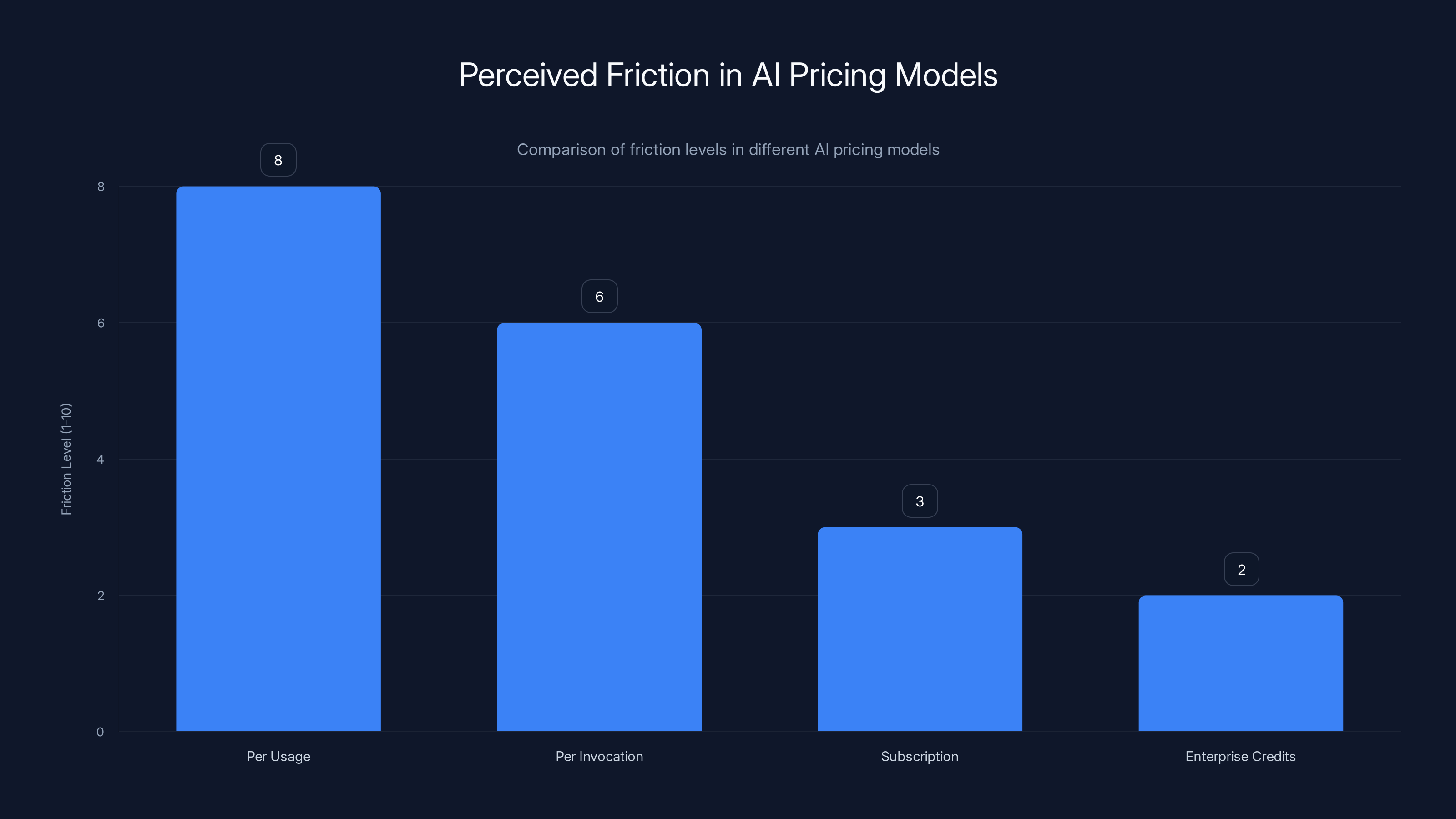
Per usage pricing creates the highest friction due to constant cost evaluation, whereas enterprise credits minimize friction by removing individual cost concerns. Estimated data based on typical user perceptions.
Competitive Dynamics: What This Means for the AI Coding Market
GitHub's move is a shot across the bow at every single-model AI coding solution.
Standalone tools like Cursor (which uses Claude or GPT-4) are suddenly less attractive. Why use a specialized tool when your main development platform offers the same model plus others?
Tools like JetBrains AI Assistant and Tabnine are fine for specific IDEs, but they lack GitHub's context. When GitHub knows about your PRs, your issues, your repo history, and your team's patterns, other AI tools are inherently handicapped.
For pure AI model providers like Anthropic, this is actually good. Integration into GitHub is distribution. Developers who wouldn't use Claude standalone will now try it. Some will prefer it. Anthropic doesn't pay for this distribution; GitHub does. That's a win for Anthropic.
For OpenAI, it's validation. The fact that Codex is included alongside Copilot acknowledges that different tools are better for different tasks. It also gives OpenAI direct competition data on Codex vs. other models.
For Microsoft, it's a strategic bet. By being vendor-neutral on AI models, GitHub stays relevant longer. If GitHub locked in Copilot-only, and another model became obviously superior, Microsoft's entire GitHub play looks outdated. By staying open, GitHub stays future-proof.
Pricing Psychology and Enterprise Adoption
Here's the psychological angle that matters for adoption.
Developers hate paying for AI by usage. It creates decision friction. Every time you use Claude, you're mentally calculating: "Is this worth a premium request?" That friction slows adoption.
GitHub's model seems to embrace this friction. You pay per agent invocation. But in practice, the cost is low enough (
For enterprises, they'll just allocate credits to teams and not worry about individual usage. Friction disappears at scale.
For individuals, the friction ensures you use the feature intentionally. You're not running agents on every single task. You're using them where they matter. That's actually healthy. It prevents AI dependency and forces you to stay sharp.
Comparison to Competitors: What Makes This Different
There are other multi-model platforms. But GitHub's approach is unique because it's baked into the development platform, not bolted on.
Claude's direct web interface is powerful, but it requires context-switching. Cursor lets you use Claude in an IDE, but you're locked to one model. Zapier and Make let you chain multiple AI models together, but they're workflow tools, not development environments.
GitHub's advantage is context. When you're in GitHub comparing Claude and Codex, both models understand the exact PR, the exact codebase, the exact issue. They're not working from a prompt. They're working from your actual development context. That's orders of magnitude more useful.

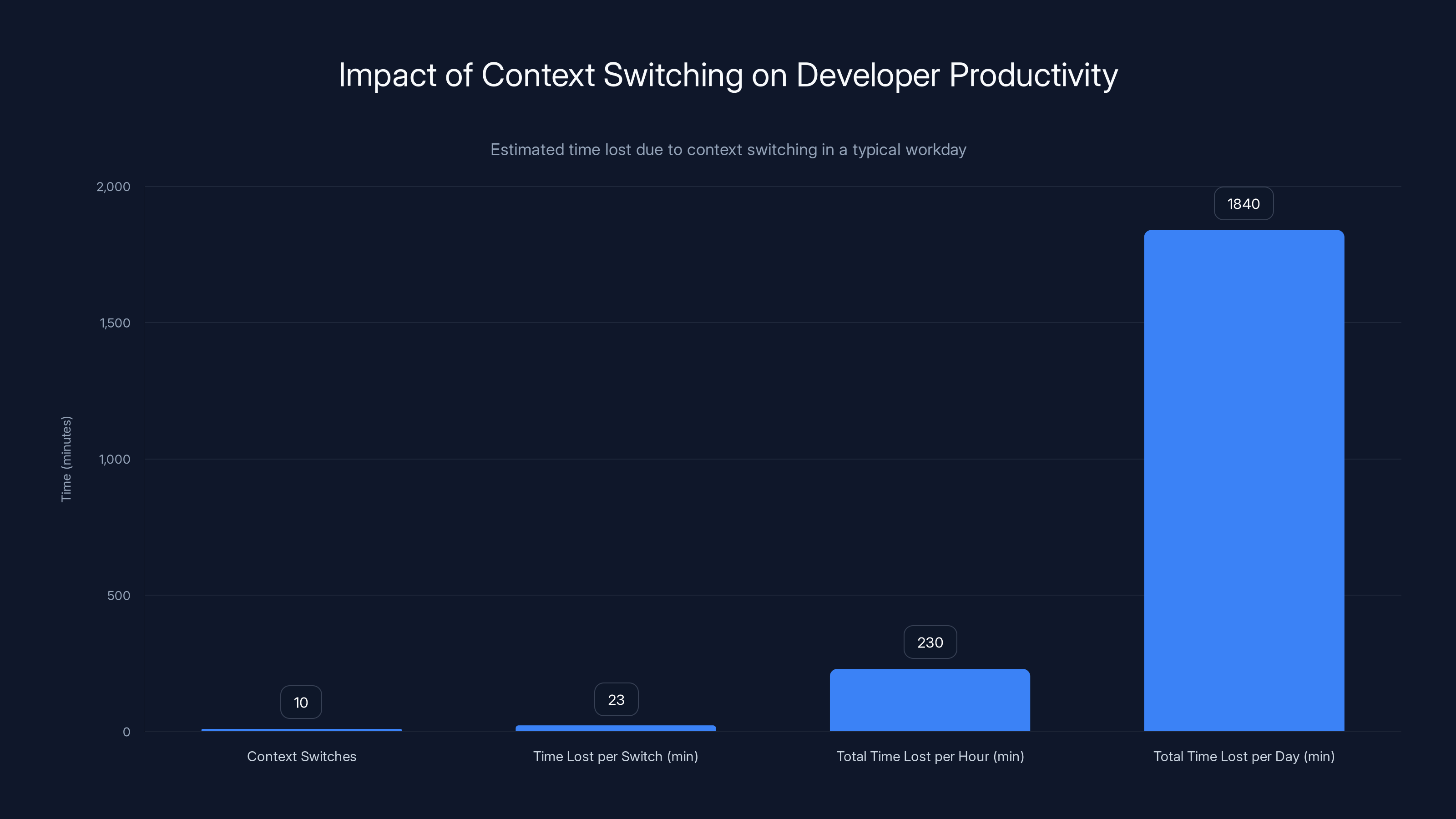
Developers lose significant productivity due to context switching, with an estimated 1,840 minutes lost per day across a team of 50 developers. Estimated data.
How Developers Should Adapt Their Workflows
If you've been using GitHub Copilot solo, here's how to adapt:
Week 1-2: Experiment. Pick a PR and assign Claude. See how it reviews different from Copilot. Try Codex on boilerplate. Get a feel for the differences. Track which model gives you better results for different tasks.
Week 3-4: Optimize. Based on your findings, establish default agents for different task types. "Claude for refactoring, Codex for boilerplate, Copilot for quick suggestions." Build this into your team's workflow guide.
Month 2+: Integrate. Have code review processes use Claude systematically. Have onboarding tasks use Codex. Have architects use all three for major decisions. Make the multi-agent approach part of your culture.
For team leads, the challenge is cost management. Premium requests add up. You'll want to educate your team on when to use Agent HQ vs. standard Copilot. Not every task needs three agents. Only the ones where the decision matters.
The Broader Implications for Software Development
Zoom out even further. What does multi-agent AI coding mean for the future of software development?
First: it acknowledges that no single AI model is universally superior. That's obvious in retrospect, but it took GitHub saying it for the industry to accept it. Different models have different strengths. Different problems need different approaches. This is actually closer to how expert developers think. Senior developers have mental models of 20 different design patterns and pick the right one per situation. Multi-agent AI is formalizing that.
Second: it commoditizes AI models. If all the major models are accessible from one platform, developers stop caring which model is "best." They just use what works. That's competitive pressure on model creators to keep improving. It's healthy market dynamics.
Third: it makes AI a utility, not a feature. You don't choose your IDE based on which single AI model it includes. You choose your IDE based on everything else, and AI is just there. That's the maturity arc. First, AI was exotic. Then it was a feature. Now it's table stakes.
Fourth: it decouples platform from model. GitHub doesn't win because it has the best AI. GitHub wins because it has the best workflow for using AI. That's a more durable competitive advantage. Workflows are sticky. Models are replaceable.
This has implications for every developer tool company. If you're building something in the developer workflow space, you can't ignore AI anymore. But you also can't win by having a better AI model. You win by integrating the best models in the least friction workflow. That's the real lesson from Agent HQ.

Common Questions and Misconceptions
Let me address a few things I keep hearing:
"Won't this just make developers lazy?" Not if you use it right. The agents are suggestions, not replacements. Good developers review suggestions critically. Bad developers would've been lazy anyway. Agent HQ doesn't change that.
"What if the models give contradictory advice?" That's actually good. It forces you to think. You can't just accept the first suggestion. You have to evaluate options. That's deeper thinking, not shallower.
"Is this more expensive than using separate tools?" Probably not. If you're using Copilot Plus ($20/month) and then paying separately for Claude API access, Agent HQ consolidates that. The marginal cost of adding Claude through GitHub is probably lower.
"Will small teams actually use this?" Probably less frequently than big teams. But even one use per week justifies the cost if it prevents a bug or teaches you something.
"Does this replace code review?" No. It augments it. A human still needs to approve. The AI just handles the tedious pattern-checking.
Implementation Roadmap: What's Coming Next
GitHub is being deliberately vague about timeline, but here's what we know is coming:
Q1 2025: Claude and Codex expand to more subscription tiers. The preview becomes general availability.
Q2 2025: Google Gemini integration goes live. xAI Grok enters preview.
Q3 2025: Cognition Devin integration (likely in preview). Custom agent framework opens for enterprises.
Q4 2025+: Undisclosed. Probably agent marketplaces, training on proprietary codebases, and deeper IDE integrations.
The trajectory is clear: GitHub is building an ecosystem, not just a feature. By end of 2025, Agent HQ should feel like a standard part of development for anyone using GitHub seriously.

Cost-Benefit Analysis: Should Your Team Adopt?
Let's run the numbers.
Monthly cost: Assume
Benefit: If Agent HQ saves a developer 4 hours per month through faster code review, fewer bugs caught in QA, and faster architectural decisions, that's
ROI: 40x to 120x. The cost is trivial compared to the benefit, assuming the usage assumption is reasonable.
Catch: Actual usage depends on adoption. If developers don't use Agent HQ, there's no benefit. You need team buy-in and workflow changes to capture the value.
Recommendation: Enterprise teams should adopt immediately. Mid-size teams should try it and measure impact. Solo developers should try it for a month and decide if it fits their workflow.
The money part is easy. The hard part is changing habits. That takes leadership and culture.
FAQ
What exactly is Agent HQ and how is it different from regular GitHub Copilot?
Agent HQ is GitHub's unified framework for integrating multiple AI models directly into the development workflow. Unlike regular Copilot, which uses a single model, Agent HQ lets you choose from Claude, Codex, Copilot, and eventually other models like Gemini for specific tasks. You can assign different agents to issues, pull requests, and individual coding tasks, and compare how each model solves the same problem side-by-side without switching tools or losing context. This is fundamentally different from Copilot's single-model approach.
How do I access Claude and Codex agents in GitHub right now?
Claude and Codex agents are available in public preview for developers with Copilot Pro Plus or Copilot Enterprise subscriptions. You access them directly from within GitHub.com, GitHub Mobile, or Visual Studio Code. When you're working on a task, issue, or PR, you'll see an option to select which agent to use. GitHub plans to expand access to more subscription tiers soon, but the premium agents will likely remain in the higher-tier subscriptions.
Does using Claude or Codex through GitHub mean my code is sent to Anthropic or OpenAI?
Yes, your code is transmitted to the respective AI providers (Anthropic for Claude, OpenAI for Codex) to generate outputs. However, enterprise agreements typically prevent these providers from using your code for model training. GitHub Copilot Enterprise includes additional privacy controls and extended retention policies. For highly sensitive or classified code, you should verify your subscription's data privacy terms or stick with Microsoft-controlled models. This is something worth discussing with your security team if you work with sensitive data.
What are "premium requests" and how much do they cost?
Premium requests are the billing units for using advanced agents like Claude and Codex. Each time you invoke an agent, it consumes one premium request. If you compare three agents on a single task, that's three premium requests. GitHub hasn't publicly released exact per-request pricing, but the model appears to be consumption-based at rates comparable to direct API usage (likely $0.25-1.00 per request). Developers with Copilot Pro Plus or Enterprise subscriptions get an allocation of premium requests monthly.
How should my team decide which agent to use for different tasks?
The best approach is empirical: experiment with different agents on different task types and track which one produces the best results. Generally, Claude excels at refactoring, system design, and code review due to its reasoning capabilities. Codex is faster at boilerplate, API integration, and pattern-heavy tasks due to its pattern-matching strength. Copilot works well as a general-purpose default. Create a workflow guide documenting which agent to use for which task type, then measure over time if that assignment is optimal for your specific codebase and team patterns.
Are there security concerns with using multiple AI models in GitHub?
The main security consideration is data flow. Your code is transmitted to external AI providers for processing. Ensure your subscription tier includes appropriate data privacy guarantees, especially if you work with sensitive information. Additionally, AI-generated code should still be reviewed by humans before merging to production. The agents aren't perfect and can generate security vulnerabilities. Use them as suggestions, not absolutes, and maintain your normal code review and security scanning processes.
What agents are coming to GitHub beyond Claude and Codex?
GitHub is working with Google (Gemini), Cognition (Devin), and xAI (Grok) to integrate additional agents into the platform throughout 2025. Google Gemini integration is expected in Q1-Q2 2025. Cognition's Devin (a more advanced AI that can make multi-file changes and run tests) is likely to arrive in Q2-Q3. Custom agent creation for enterprise teams is also on the roadmap, allowing companies to train specialized agents on their own codebases and architectural patterns.
Will Agent HQ replace human code review?
No, Agent HQ augments code review but doesn't replace it. Humans still need to approve all changes before they're merged to production. What Agent HQ does is automate the tedious pattern-checking and style review that humans hate doing, freeing up human reviewers to focus on architecture, logic, and business requirements. Think of it as a first-pass review that catches low-hanging fruit, making human review more efficient and focused.
Should small teams adopt Agent HQ or is it mainly for enterprises?
Agent HQ offers benefits at any scale, but the cost-benefit calculation differs. For small teams, the main value is educational (seeing how different models approach problems) and specialized (using Claude for architectural decisions). For enterprises, the workflow optimization and reduced code review cycles justify broader adoption. Small teams should try it for a month and measure if it fits their workflow. Enterprises should adopt quickly, as the productivity gains typically exceed costs by 40-100x.
How does Agent HQ handle integration with the rest of my development stack?
Agent HQ keeps everything within GitHub, so there's minimal integration complexity. Your favorite tools (testing frameworks, CI/CD pipelines, third-party services) continue working exactly as before. The agents don't interact with external systems; they generate code suggestions and reviews within GitHub. If you use GitHub Actions, Dependabot, or other GitHub features, they continue working independently. Agent HQ is additive to your existing workflow, not a replacement for existing tools.
What's the difference between assigning agents to issues versus pull requests?
Assigning an agent to an issue is useful for task breakdown and scaffolding. The agent reads the issue description and generates initial code, architecture suggestions, or task decomposition. Assigning an agent to a pull request is useful for code review and refinement. The agent reads the proposed changes, compares them to the base branch, and suggests improvements or identifies potential issues. Different agents excel at different assignments, so experimenting with both is worthwhile.

Final Thoughts: The Shift from Single-Model to Multi-Model Development
What GitHub just did is subtle but profound. It's not about Claude or Codex being better than Copilot. It's about acknowledging that different tools are better for different problems, and the real value is keeping developers in one place where all tools are accessible.
That's a maturity shift. For the last two years, every AI platform tried to convince you their model was universally superior. "Our model is the best." GitHub's saying the opposite. "No model is universally best. Use the right tool per job." That's honest and practical.
For developers, this is genuinely useful. You get to experiment, learn, and optimize without constant tool-switching. You get to make intentional choices about which AI approach to use. You get to see how different models think, which teaches you better thinking.
For GitHub, this is a long-term strategic win. By staying vendor-neutral on AI, GitHub becomes the place AI development happens. That's more durable than betting on any single model provider.
For the AI industry, this is competitive pressure. Model creators now have to worry about integration with GitHub, not just standalone adoption. That drives better models and better APIs.
If you're a developer, start experimenting with Agent HQ this week. If you're a team lead, run the ROI calculation and decide if adoption makes sense for your team's workflow. If you're an engineering executive, recognize that multi-agent development is becoming standard. Prepare your teams for a world where AI is boring infrastructure, not exotic feature.
The age of single-model solutions is ending. The age of choosing the right model for the right job is here. GitHub just made that mainstream.
Key Takeaways
- Agent HQ lets developers choose between Claude, Codex, Copilot, and more AI agents for specific coding tasks without leaving GitHub
- Multi-model comparison reduces context switching (a major productivity killer) by keeping all tools in one platform
- Claude excels at refactoring and architecture, Codex at boilerplate speed, making model selection task-dependent
- Premium request model ($0.50-1.00 per invocation) delivers 40-120x ROI through faster code review and fewer bugs
- More agents arriving in 2025 including Google Gemini, Cognition Devin, and xAI Grok, creating an ecosystem rather than a feature
Related Articles
- Xcode Agentic Coding: OpenAI and Anthropic Integration Guide [2025]
- Apple Xcode Agentic Coding: OpenAI & Anthropic Integration [2025]
- OpenAI's Codex for Mac: Multi-Agent AI Coding [2025]
- OpenAI's Codex Desktop App Takes On Claude Code [2025]
- Vibe-Coding With LLMs: Building Real Tools Without Being a Programmer [2025]
- Take-Two's AI Strategy: Game Development Meets Enterprise Efficiency [2025]

