
Introduction: The AI Inference Infrastructure Boom and Modal Labs' Strategic Position
The artificial intelligence landscape has undergone a seismic shift over the past 18 months. While the initial wave of generative AI excitement focused on training large language models and building flashy consumer applications, a more sophisticated realization has set in: the real bottleneck isn't model creation—it's running those models efficiently at scale. This insight has spawned an entirely new category of infrastructure companies dedicated to solving the inference problem, and Modal Labs stands as one of the most well-funded players in this emerging space.
In early 2026, Modal Labs entered into funding discussions at a valuation of approximately **
To understand the significance of Modal Labs' position, we need to appreciate what inference actually means and why it matters. When an AI model has been trained and deployed, inference is the process of running that trained model to generate predictions or answers based on user inputs. If training is like creating a recipe, inference is like using that recipe to cook meals at scale. The efficiency of this process directly impacts three critical business metrics: computational costs, response latency, and scalability. A company running AI models inefficiently might spend 10x more on compute resources than necessary, suffer from unacceptable response times that frustrate users, and hit scaling walls when trying to serve millions of requests.
Modal Labs was founded in 2021 by Erik Bernhardsson, a veteran infrastructure engineer who spent over 15 years building and leading data teams at companies including Spotify and Better.com, where he served as CTO. Bernhardsson recognized that building AI applications was becoming increasingly difficult because developers lacked the right tools to handle the operational complexity of running inference workloads. The company positioned itself to solve this by building a platform that abstracts away much of the infrastructure complexity while providing sophisticated optimization under the hood.
The fact that Modal Labs has achieved approximately **
This comprehensive analysis explores the broader context of Modal Labs' funding round, examines the company's positioning within the competitive landscape, and investigates what this capital raise means for the future of AI infrastructure. We'll also examine alternative approaches to solving the inference problem and how different teams might evaluate their options when building AI applications.
Understanding AI Inference: The Technical Foundation
What Is Inference and Why Does It Matter?
Inference represents one of the least understood yet most critical components of the AI application stack. While machine learning engineers focus considerable attention on model training—the process of teaching a neural network to recognize patterns—the vast majority of value creation happens during inference. Training a large language model like GPT-4 happens once, takes months, and costs millions of dollars. Inference, by contrast, happens millions or billions of times as users interact with AI applications, generating revenue with each interaction.
The technical challenge of inference lies in the fact that the massive matrices of mathematical operations that comprise modern AI models must be executed quickly and efficiently. A typical LLM might have billions or trillions of parameters—numerical values that have been tuned during training to encode knowledge. Executing inference on such a model requires loading this vast amount of data into memory, performing matrix multiplication operations, and producing results before users lose patience. The difference between inference that takes 100 milliseconds and inference that takes 2 seconds translates directly into user experience, operational costs, and competitive advantage.
Consider a practical scenario: a customer service chatbot powered by an LLM might handle 10,000 conversations simultaneously during peak hours. If each conversation generates 10 inference requests, that's 100,000 simultaneous inference operations. If each operation consumes
The inference challenge becomes even more acute in certain scenarios. Real-time applications—such as autonomous vehicles, fraud detection systems, or high-frequency trading algorithms—cannot tolerate latency, meaning the inference optimization problem transforms from a cost problem into a physics problem. Similarly, applications serving geographically distributed users need to run inference close to users to minimize network latency, creating a distributed inference challenge that adds another layer of complexity.
The Economics of Model Serving at Scale
When organizations deploy AI models in production, they typically face a triangle of competing constraints: cost, latency, and throughput. These three variables are tightly interconnected, and optimizing for one typically involves trade-offs with the others. A naive deployment might load a single GPU with a large model and serve requests sequentially, minimizing cost but creating unacceptable latency. Alternatively, deploying numerous instances of the model across distributed infrastructure might minimize latency but creates unsustainable costs.
The mathematical relationship between these factors is worth understanding. If a single GPU can serve 100 inference requests per second and each request generates
But the economics become more interesting when considering latency. If users will abandon a service if inference takes more than 2 seconds, but actual inference takes 3 seconds, then latency has become the limiting constraint rather than compute utilization. In this scenario, throwing more compute at the problem doesn't help unless that additional compute enables architectural changes that reduce latency. This is where sophisticated inference platforms earn their value: they enable architectural patterns that weren't previously possible.
Common Inference Challenges in Production
Building inference systems in production reveals a set of problems that surprise practitioners. Model loading represents one underestimated challenge: when a new request arrives, the system must have the model weights (potentially billions or trillions of parameters) available in GPU memory. If the model isn't already loaded, the system must fetch it from storage, decompress it, and place it in GPU memory—a process that might take 10-30 seconds on commodity infrastructure. If requests arrive intermittently, systems might spend more time loading models than actually running inference.
Memory management presents another invisible challenge. Modern GPUs have limited memory—typically 40-80GB on cutting-edge hardware. Yet a single large language model might require 100GB or more to run. This constraint forces difficult decisions: split the model across multiple GPUs, use quantization techniques to reduce model size (with quality trade-offs), or use sophisticated memory management techniques like offloading. Each approach involves complex engineering trade-offs.
Request batching introduces further complexity. Running 10 inference requests individually takes roughly 10 times longer than batching them together because the matrix operations can be vectorized across multiple inputs. However, batching introduces latency: a user's request might wait in a queue for 50 milliseconds waiting for the batch to fill. In real-time applications, this batching delay might be unacceptable. In background applications, it's desirable. Optimal systems need to be configurable for different requirements.
The distributed inference problem emerges when models are too large for a single GPU or when geographic distribution is required. Splitting model layers across multiple GPUs requires complex synchronization and communication between devices. Similarly, replicating models across geographic regions requires managing consistency and routing requests to appropriate instances. These problems have been solved before (distributed systems have been a challenge in computing for decades), but solving them specifically for AI workloads with their unique resource requirements requires specialized knowledge.
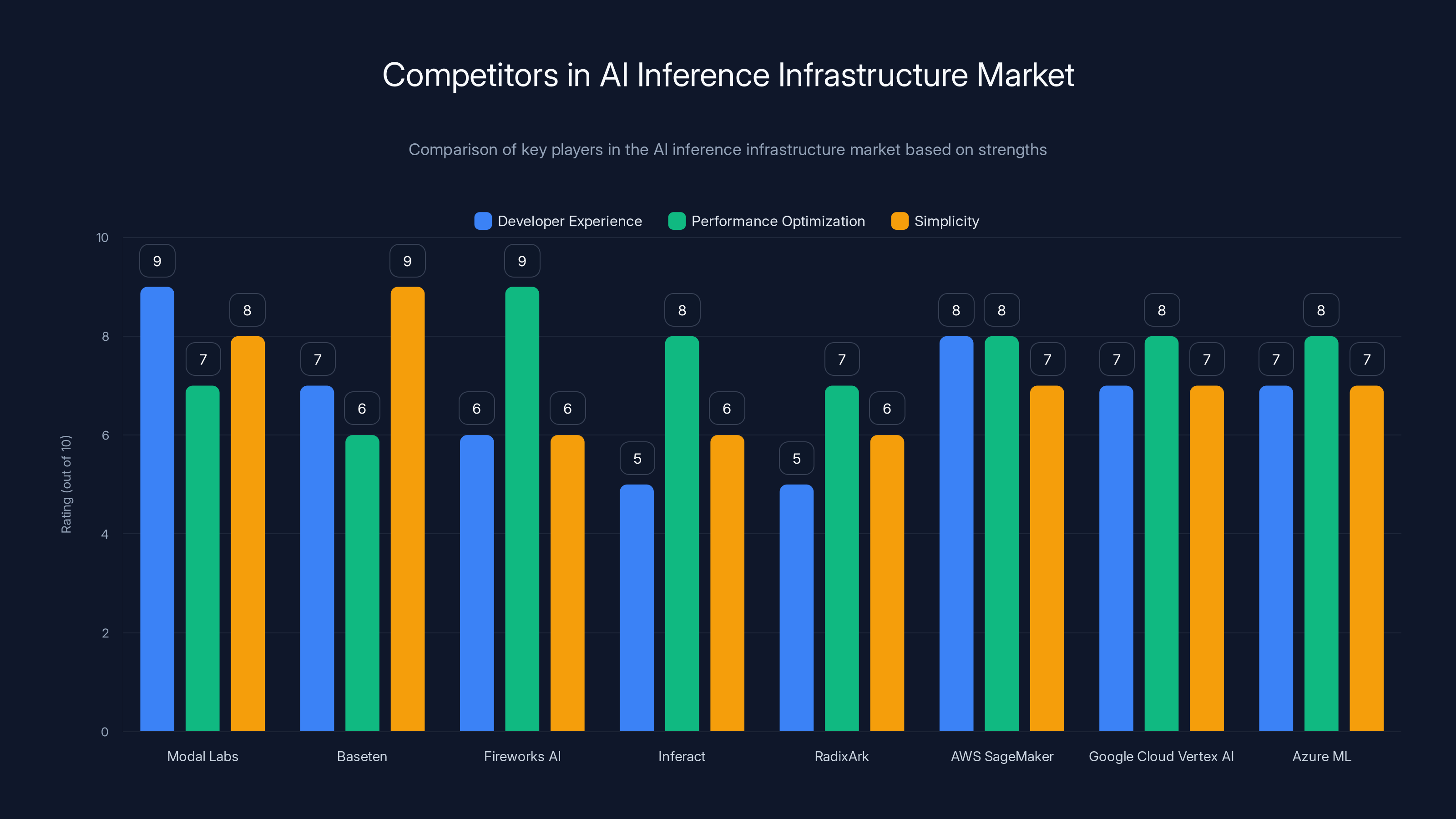
This chart compares major players in the AI inference infrastructure market, highlighting their strengths in developer experience, performance optimization, and simplicity. Estimated data based on typical market positioning.
Modal Labs: Company Overview and Market Position
Founding Vision and Evolution
Modal Labs emerged from Erik Bernhardsson's realization that a significant gap existed in infrastructure tooling for AI applications. After spending years building data infrastructure at Spotify—where he helped process petabytes of user behavioral data—and as CTO at Better.com, Bernhardsson understood the pattern: companies accumulate incredible amounts of operational complexity when trying to run sophisticated computational workloads. The vision for Modal was straightforward: abstract that complexity away while providing enough control for sophisticated use cases.
The company launched with an interesting positioning: function-as-a-service specifically optimized for AI and computational workloads. Rather than trying to be a general-purpose cloud provider like AWS, Azure, or Google Cloud, Modal focused specifically on solving the unique needs of teams building AI applications. This narrower focus enabled deeper optimization and a more cohesive platform experience.
From 2021 through early 2026, Modal Labs has evolved through several distinct phases. Initial releases focused on basic function scheduling and execution. Subsequent releases added GPU support, model serving capabilities, and sophisticated optimization for common patterns like batching and model caching. The company's product development has been visibly responsive to customer needs, with each major release addressing practical pain points identified in production use.
Current Product Capabilities
Modal Labs' platform today addresses several distinct use cases within the AI infrastructure space. The core capability—function execution in the cloud—provides a foundation, but the platform's value becomes apparent when considering how it's specialized for AI workloads. Functions can specify GPU requirements, model dependencies, and scaling policies. The system automatically handles GPU provisioning, model loading, request batching, and scaling.
The model serving component enables teams to serve pre-trained models (from fine-tuned LLMs to computer vision models) with automatic optimization. Rather than teams having to manually configure load balancers, implement caching, manage GPU memory, and handle model updates, Modal handles these details. Teams define what model to serve and how many concurrent requests to expect, and the platform figures out the rest.
For teams building custom inference applications, Modal's framework integration (supporting popular libraries like Hugging Face Transformers, LLa MA.cpp, and others) enables relatively straightforward porting of existing code. A data scientist who has experimented with a model locally can typically deploy it to Modal with minimal modifications.
The company has also invested in features for teams running batch inference workloads—processing large volumes of data through models asynchronously. This use case has been somewhat overlooked by inference startups (being less flashy than real-time serving), but it represents substantial value: companies processing large amounts of documents, images, or audio data require infrastructure specifically optimized for this pattern.
Revenue Metrics and Growth Indicators
The reported **
The revenue figure also indicates healthy economics. If we conservatively estimate that Modal's typical customer pays
The velocity of valuation growth—from
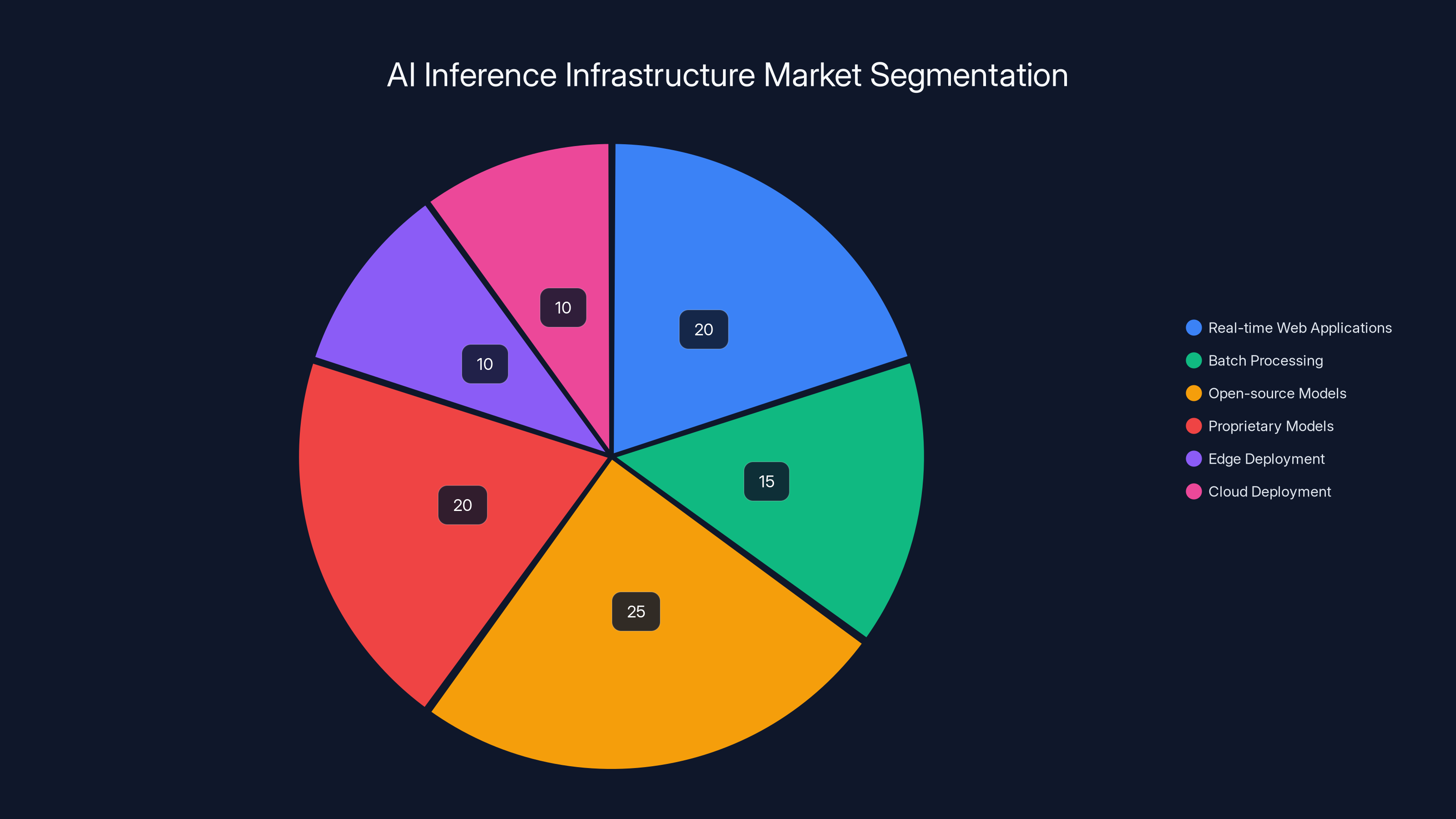
The AI inference infrastructure market is fragmented, with real-time web applications and open-source models capturing the largest shares. Estimated data reflects diverse deployment needs.
The Competitive Landscape: Infrastructure Alternatives
Baseten and GPU-Optimized Serving
Baseten, founded by Saman Behnami and others, takes a somewhat different approach to AI inference than Modal Labs. Where Modal positions itself as a general-purpose serverless computing platform optimized for AI, Baseten focuses more specifically on model serving with a simplified developer experience. The platform excels at enabling teams to take pre-trained models and serve them with minimal configuration.
Baseten's recent funding round (announced around the same time as Modal's discussions) valued the company at **
The technical differentiation between Baseten and Modal manifests in several areas. Baseten abstracts away more infrastructure complexity—a developer uploads a model and Baseten handles everything from serving to scaling. This simplicity comes at the cost of flexibility: teams with sophisticated requirements might find Baseten's abstraction limiting. Modal, conversely, preserves more control: teams can write custom inference logic, define complex serving patterns, and integrate with external systems.
Baseten's positioning also emphasizes business model flexibility, allowing teams to monetize AI models directly on the Baseten platform. This creates an ecosystem effect: developers publish models to Baseten, other developers use those models, and Baseten takes a percentage of revenue. This approach has parallels to Hugging Face's model hub strategy and creates interesting incentives around which models become popular.
Fireworks AI and Real-Time Inference Optimization
Fireworks AI represents another point on the competitive spectrum. Founded by engineers with deep expertise in inference optimization, Fireworks has positioned itself as "the inference cloud," focusing specifically on techniques that reduce latency and improve throughput for real-time AI applications. The company secured
Fireworks' technical differentiation centers on several deep inference optimization techniques. The company has developed sophisticated quantization strategies that reduce model size with minimal quality loss, enabling models to run on less expensive hardware. The platform also implements advanced request batching with dynamic scheduling, optimizing the latency-throughput trade-off better than naive implementations. Additionally, Fireworks has invested in kernel-level optimizations that extract more computational throughput from GPU hardware.
Fireworks' ideal customer profile skews toward teams building real-time AI applications where latency is critical: chatbots, search applications, recommendation engines. The company's go-to-market has also emphasized breadth of model support, with their platform supporting hundreds of open-source models with easy one-click deployment.
The competitive differentiation between Fireworks and Modal is instructive. Fireworks excels at environments where teams want to serve open-source models with minimal customization. Modal excels when teams want to build custom inference logic, integrate with existing infrastructure, or need batch inference capabilities. Many organizations likely need both: immediate access to Fireworks for deploying commodity models, and Modal-like flexibility for custom applications.
Inferact and the Emerging Open-Source to Commercialization Pattern
Inferact represents an interesting competitive entrant: the commercialization of v LLM, a popular open-source inference library. The creators of v LLM, a highly optimized inference framework originally developed at UC Berkeley, transitioned the project into a VC-backed startup and raised
This approach—building open-source infrastructure, gathering community adoption, and then commercializing through a company—represents a different market entry pattern than the other competitors discussed. Inferact benefits from the legitimacy and community that v LLM established as open-source. Organizations already using v LLM have a natural upgrade path to Inferact's commercial offering, which adds management, monitoring, and optimization features on top of the open-source core.
This approach creates specific competitive advantages and disadvantages. The advantage: instant community and adoption—many organizations are already familiar with v LLM and trust its engineering. The disadvantage: Inferact must convince organizations to pay for commercial features when the open-source base remains free and is actively maintained. The company's value proposition must be substantially better than DIY deployment of open-source v LLM.
Inferact's $800 million valuation at seed stage is notably lower than the Series B+ valuations of other competitors, reflecting that the company is earlier in its journey. However, the AH backing and substantial seed round suggest confidence in the market opportunity and execution ability of the team.
Radix Ark and the Specialized Inference Compiler Approach
Radix Ark represents another commercialization of open-source technology, specifically the SGLang project (another inference optimization framework). The company secured seed funding at a $400 million valuation led by Accel Partners. While less information is publicly available about Radix Ark compared to other competitors, the company's positioning around inference compilation—optimizing how models are executed at a lower level than frameworks like v LLM—suggests a focus on extreme optimization scenarios.
The pattern of open-source inference tools being commercialized (v LLM→Inferact, SGLang→Radix Ark) is significant. It reflects the fact that many developers have built sophisticated inference tools as open-source projects, and the venture market has decided that commercializing these tools is a valuable business opportunity. This creates an interesting competitive dynamic: teams choosing inference infrastructure must evaluate both "pure" commercial offerings (like Modal and Baseten) and commercialized open-source projects (like Inferact and Radix Ark).
Broader Competitive Context
Beyond the dedicated inference startups, several other infrastructure players compete for the same customers. Cloud providers (AWS with services like Sage Maker, Google Cloud with Vertex AI, and Azure with similar offerings) have inference capabilities built-in. The advantage of cloud provider solutions: integration with their broader ecosystem and the perceived safety of established vendors. The disadvantage: these solutions are often more generic and less optimized for the specific constraints of AI inference.
Other infrastructure startups like Replicate, Banana, and Together AI occupy related positions in the competitive landscape. Replicate focuses on making it trivial to deploy open-source models. Banana emphasizes cost optimization and serverless billing. Together AI positions itself as an open-source infrastructure alternative to proprietary cloud providers. Each occupies a slightly different niche, suggesting that the inference infrastructure market is fragmenting into multiple focused solutions rather than consolidating around a single winner.

Market Dynamics: Why Inference Infrastructure Now?
The Inference Revolution's Economic Foundation
The explosive growth in AI inference infrastructure funding and company valuations reflects fundamental economic shifts in how organizations deploy AI. Through 2022-2023, the dominant narrative focused on training larger and larger models: Chat GPT, Claude, Gemini, and proprietary LLMs represented the frontier. But by 2024-2025, a different reality emerged. The models existed; the challenge was running them efficiently.
This shift created a massive economic opportunity for infrastructure companies. Consider the scenario: a company spent
Furthermore, the variety of inference deployment scenarios meant that no single company could optimize for everything. Real-time web applications have different requirements than batch processing. Serving open-source models has different requirements than running proprietary models. Edge deployment scenarios differ from cloud deployment. This fragmentation created an opportunity for multiple specialized companies to succeed, each focusing on a specific segment of the market.
The Open-Source vs. Proprietary Model Divide
A critical market dynamic emerged around 2023-2024: the divergence between open-source and proprietary AI models. Meta's release of Llama, Mistral's release of their models, and the community's development of fine-tuned variants created high-quality alternatives to proprietary closed models from Open AI and Anthropic. This shift created specific infrastructure requirements: organizations running open-source models need different tooling than organizations using Open AI's API or similar closed services.
Many of the inference infrastructure startups positioned themselves explicitly around open-source models. Teams using open-source models need infrastructure to serve them, monitor them, and optimize them. Teams using closed APIs simply submit requests to Open AI's servers. This split in the market explains why so many inference startups emerged in 2024-2025: they address the needs of organizations choosing the open-source path.
Geographic Distribution and Latency Requirements
Another market dynamic emerged around the global distribution of AI applications. As AI applications expanded beyond the United States, organizations needed inference infrastructure deployed globally. Relying on a centralized inference service in Virginia creates unacceptable latency for users in Asia or Europe. This requirement for distributed inference infrastructure created another business opportunity: companies that could provide inference capabilities across multiple geographic regions, with intelligent routing to minimize latency.
Modal Labs positioned itself well for this requirement by offering inference with regional deployment options. Competitors like Fireworks and others similarly invested in global infrastructure. Traditional cloud providers have geographic distribution built-in, but the specialized focus of inference startups might offer better performance and cost characteristics for these specific workloads.
The Competitive Intensity and Funding Abundance
The sheer number of well-funded competitors in the inference infrastructure space raises an important question: is this an overheated market with too much capital chasing the same opportunity? The answer is nuanced. The market opportunity is genuinely large—trillions of inference operations run annually, with billions of dollars spent on computational infrastructure. But the market is also fragmenting into segments, and only companies that win within their specific segment will ultimately survive.
The rapid valuation increases across competitors (Baseten to

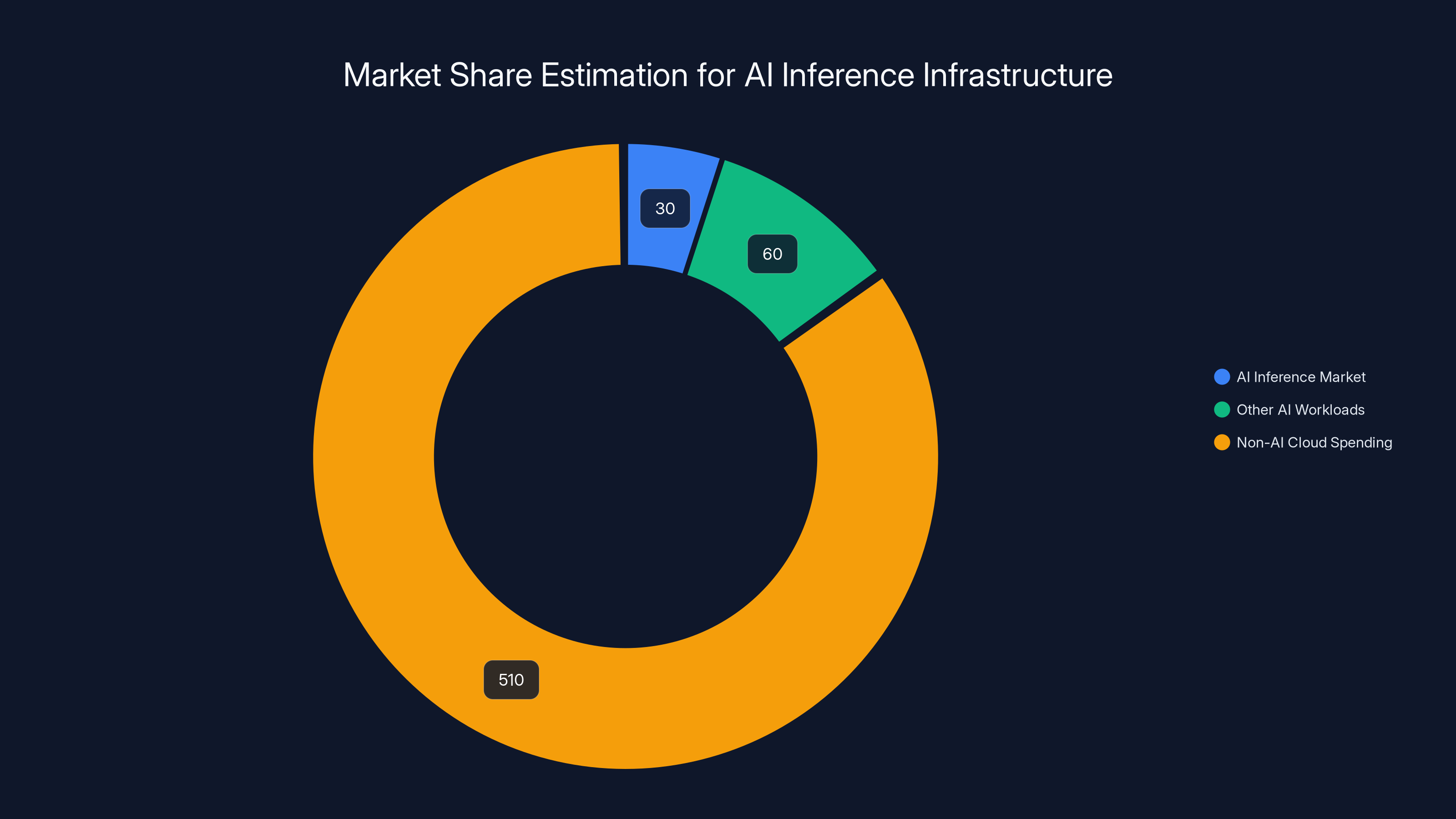
AI inference infrastructure is estimated to be a
Technical Deep Dive: How Modal Solves Inference Challenges
Architecture and Execution Model
Modal's platform architecture reflects design decisions informed by years of running inference workloads at scale. At a high level, Modal implements a distributed execution model where users write functions in Python using Modal's SDK. These functions can specify hardware requirements (e.g., "I need an A100 GPU"), dependencies (e.g., "install transformers library"), and scaling policies (e.g., "scale from 1 to 100 instances based on queue depth").
When a user invokes a Modal function, the platform's control plane coordinates the following steps: checking if an appropriate worker is available; if not, provisioning new infrastructure; loading the function and its dependencies; executing the function; returning the result; and managing cleanup. This architecture abstracts away the operational complexity that would normally require teams to manage Kubernetes clusters, write complex orchestration logic, and handle numerous edge cases.
The system distinguishes between different execution patterns. Synchronous execution handles real-time requests where the caller waits for a result (typical for API endpoints). Asynchronous execution handles long-running jobs where the caller doesn't wait (typical for batch processing). Scheduled execution handles periodic jobs that run on a schedule (typical for ETL or maintenance tasks). Supporting all three patterns within a unified platform enables teams to use Modal for diverse workloads rather than maintaining separate infrastructure for different execution patterns.
For AI inference specifically, Modal implements several optimizations. Model caching ensures that when a function loads a large model (potentially gigabytes in size), subsequent invocations can reuse the loaded model rather than reloading it. This dramatically improves performance: first invocation of a function might take 20 seconds (loading the model), but subsequent invocations take 100 milliseconds (just running inference). Without this optimization, every request would incur the full loading time penalty.
GPU Provisioning and Cost Optimization
One of Modal's significant challenges is GPU management. GPUs are expensive—an A100 costs roughly $1-2 per hour on cloud providers—so any inefficiency in GPU utilization directly impacts customer costs. Modal tackles this through several techniques.
Dynamic provisioning means the system doesn't keep GPUs running idle. When demand drops, Modal scales down and stops paying for unused GPUs. When demand spikes, Modal scales up, accepting the cost of new GPUs to maintain responsiveness. This dynamic approach is vastly more efficient than static capacity planning where teams provision maximum expected demand.
Batch consolidation means that Modal automatically consolidates multiple inference requests to the same model into batches. Rather than running 10 individual inference requests (taking 10 times longer), Modal batches them together, leveraging vectorization to complete all 10 in roughly the same time as 2-3 individual requests. The trade-off is that requests might wait briefly for batching to occur, but the aggregate latency across all requests is reduced.
Kernel optimization refers to Modal's investment in custom CUDA kernels and integration with inference libraries (like v LLM and others) that extract maximum throughput from GPU hardware. Rather than relying on generic deep learning frameworks that might have suboptimal performance for inference-specific patterns, Modal has integrated highly optimized inference engines.
Multi-GPU inference enables running models that are too large for a single GPU by distributing model weights across multiple GPUs. Modal automates this distribution and handles the complex synchronization required. Without this capability, teams would need to manually implement distributed inference—a task requiring deep systems expertise.
Container and Dependency Management
Inference workloads typically have complex dependency graphs. Running a Llama 2 model for inference might require: the transformers library, specific CUDA versions, custom inference kernels, and application-specific code. Ensuring consistency and reproducibility across distributed infrastructure requires sophisticated dependency management.
Modal uses containerization (Docker) underneath, but abstracts this from users. Rather than writing Dockerfiles and managing container registries, users specify dependencies directly in Python code. Modal then automatically builds and caches containers, ensuring that all workers have identical runtime environments. This abstraction dramatically simplifies the developer experience while maintaining reproducibility guarantees.
Integration with Popular Libraries and Frameworks
Modal's positioning as a developer-friendly platform is reinforced by deep integration with popular libraries. The platform supports Hugging Face Transformers (the most popular library for using open-source LLMs), v LLM (an inference-specific optimization library), and others. Teams that have already experimented with models using these libraries can typically migrate to Modal with minimal code changes.
This integration strategy is important: it reduces switching costs and enables teams to leverage existing investments in specific technology choices. A team using Hugging Face Transformers locally can deploy the same code to Modal without learning new APIs or rewriting logic.

Customer Segments and Use Cases
High-Traffic Consumer Applications
The most visible segment of Modal's customers comprises consumer-facing AI applications. Startups building AI-powered chatbots, content generation tools, code assistants, and similar products need robust inference infrastructure that can scale from zero to millions of requests as they grow. Modal is particularly well-suited for this segment because the platform's automatic scaling and pay-as-you-go pricing align with the economics of early-stage companies.
Consider a hypothetical example: a startup building an AI writing assistant sees explosive growth and user requests surge from 1,000 daily to 1 million daily over a few months. Traditional infrastructure approaches (renting dedicated servers, managing auto-scaling groups) would require sophisticated operations expertise. Modal handles this automatically: more requests automatically trigger more GPU provisioning, and costs scale proportionally with usage. The startup can focus on product rather than infrastructure.
Enterprise Workflow Automation
A less visible but economically significant segment comprises enterprises using AI to automate internal workflows. Financial services firms use AI for document analysis and risk assessment. Manufacturing companies use computer vision for quality control. Retailers use AI for demand forecasting. These applications typically involve batch inference (processing large amounts of historical data) and can tolerate higher latency than consumer-facing applications.
Modal's support for asynchronous execution and batch processing makes it well-suited for this segment. Rather than paying for always-on infrastructure, enterprises submit batch jobs to Modal, the platform processes them efficiently, and users retrieve results when ready. This approach can reduce infrastructure costs by orders of magnitude compared to maintaining dedicated servers.
Fine-Tuning and Model Experimentation
Another use case involves teams fine-tuning open-source models for specific tasks. A company might take Llama 2 and fine-tune it on their proprietary data to improve performance on domain-specific tasks. Modal provides infrastructure for both the fine-tuning process (which is computationally expensive) and serving the resulting models (which requires ongoing inference infrastructure).
This use case is increasingly important as organizations realize that open-source models fine-tuned on proprietary data often outperform much larger closed models, while being dramatically cheaper to operate. Fine-tuning is competitive advantage, and Modal enables teams to iterate quickly on fine-tuning experiments without maintaining dedicated infrastructure.
Research and Prototyping
Academic research and internal corporate research teams use Modal for prototyping and experimentation. Rather than applying for GPU cluster access (which might have long wait times at universities) or paying to rent dedicated servers (expensive for exploratory work), researchers can spin up Modal infrastructure on-demand, run experiments, and pay only for what they use.
This use case is less obvious but has significant volume: thousands of teams at universities and companies are actively researching AI applications, and many of them rely on cloud infrastructure. Modal's developer-friendly interface and flexible pricing make it an attractive option for this segment.
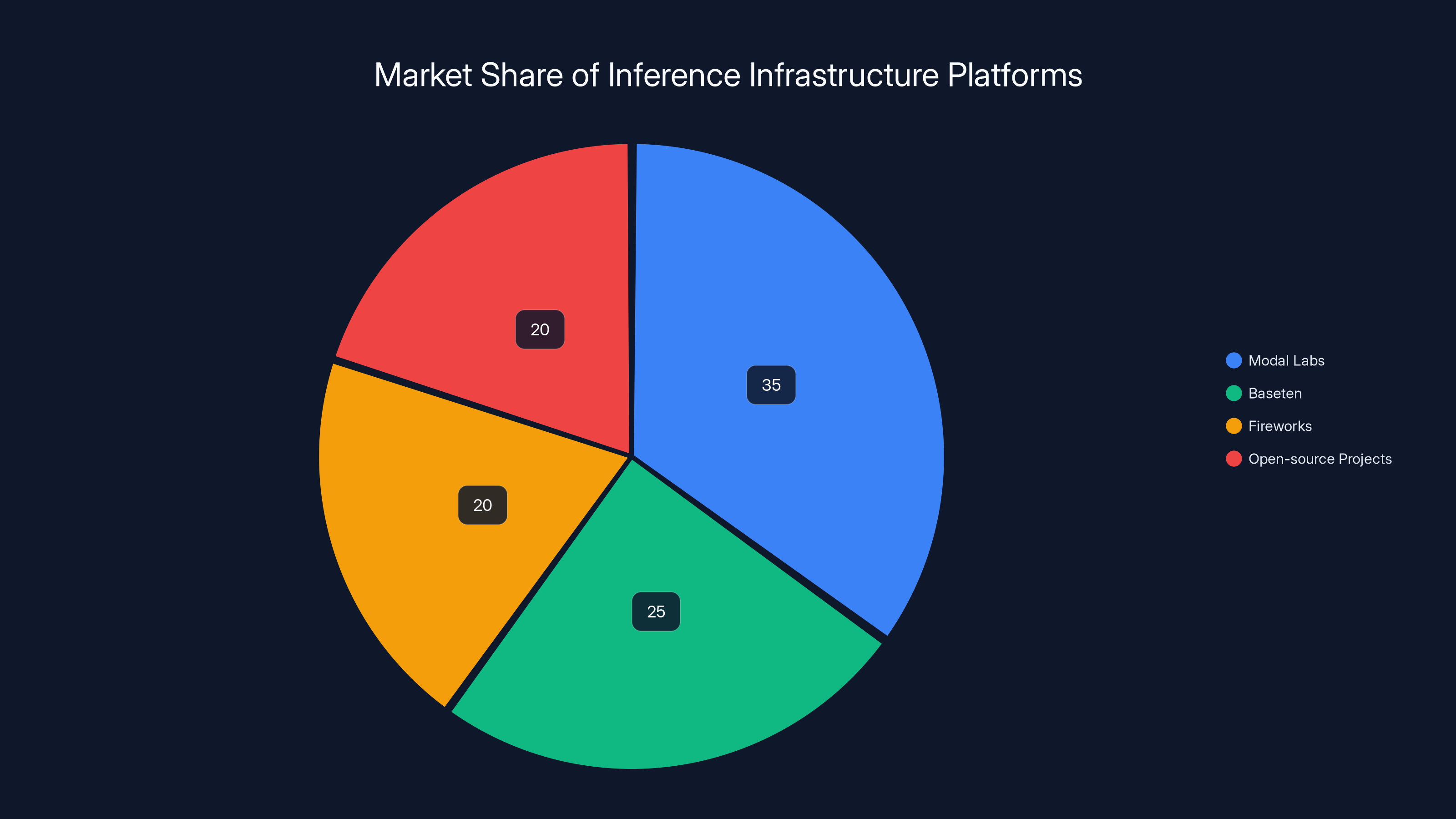
Modal Labs leads the market with an estimated 35% share, followed by Baseten, Fireworks, and open-source projects each capturing significant portions. Estimated data based on competitive positioning.
Valuation Analysis and Market Implications
Comparable Company Valuations and Market Sizing
Understanding Modal Labs'
One way to analyze these valuations is through standard Saa S metrics. A company valued at
This growth expectation is aggressive but potentially justified. If the total addressable market for AI inference infrastructure is hundreds of billions of dollars (a reasonable estimate given the global scale of AI deployment), and if Modal can capture 10-20% market share, then $500M+ ARR is plausible. The question is whether this market concentration is realistic and whether Modal's competitive position is defensible.
Market Size Estimation
Estimating the total addressable market (TAM) for AI inference infrastructure requires examining the cost of computational infrastructure globally. The cloud computing market is approximately
Within this market, software platforms like Modal don't capture the full value; the majority of spending goes to GPU and data center operators. However, software providers can capture 10-30% of spending through optimization services, management tools, and developer-focused abstractions. This suggests Modal's theoretical total addressable market (TAM) might be $1-10 billion annually at full maturity.
Modal's current
Competitive Pressure and Market Fragmentation
The existence of numerous well-funded competitors raises questions about market fragmentation. Can the market support multiple $1B+ companies focused on inference infrastructure? The answer depends on competitive differentiation and TAM expansion.
Market expansion might come from several sources. As AI deployment broadens beyond well-funded startups to mid-market companies and enterprises, the total market grows. As the total cost of AI operations increases (due to AI being deployed in more use cases), the opportunity for optimization platforms grows. As new inference patterns emerge (multimodal models, mixture-of-experts architectures, edge deployment), new specialized solutions become viable.
Competitive differentiation is crucial. Modal's advantage relative to competitors might lie in developer experience, breadth of features, or superior cost-performance. Baseten's advantage might be simplicity of use for specific scenarios. Fireworks' advantage might be extreme performance optimization. If each competitor has defensible advantages in specific segments, then multiple large companies can coexist.

Technical Differentiation and Competitive Advantages
Developer Experience as Strategic Advantage
One of Modal's consistent positioning points is developer experience. Infrastructure is only valuable if teams can actually use it productively. Modal has invested in making the platform accessible to developers with varying levels of infrastructure expertise. A team member without Dev Ops experience can write a Python function, add the @modal.function decorator, and deploy it with sophisticated infrastructure handling automated.
This developer experience advantage is difficult for competitors to replicate because it requires consistent attention across product design, documentation, SDKs, and community support. Teams that have invested significant effort in being developer-friendly tend to maintain that advantage over time.
Integration Breadth and Ecosystem
Modal's integration with popular libraries and frameworks creates switching costs that benefit the company. Teams that have built their inference applications using Modal's integration with Hugging Face Transformers, for example, face some friction switching to a competing platform that doesn't support the same patterns. These switching costs, while not insurmountable, favor Modal when customers are making renewal decisions.
Modal has also invested in ecosystem partnerships and integrations with complementary services (monitoring, observability, model registries). This ecosystem depth provides advantages, particularly for enterprise customers who have existing tool stacks they need to integrate with.
Cost Performance and Infrastructure Efficiency
Ultimately, infrastructure value creation comes down to one metric: cost per inference. If Modal can serve inference 20% cheaper than competitors while maintaining the same latency and quality, then customers have clear economic incentive to use Modal. The company's investment in optimization techniques (kernel optimization, batching, GPU utilization) contributes to this cost advantage.
Measuring this cost advantage empirically is difficult without access to pricing details and detailed benchmarks, but the fact that Modal has achieved $50M ARR suggests that customers perceive sufficient value to pay. Customers choosing between competitors would naturally select the provider offering the best cost-performance ratio.

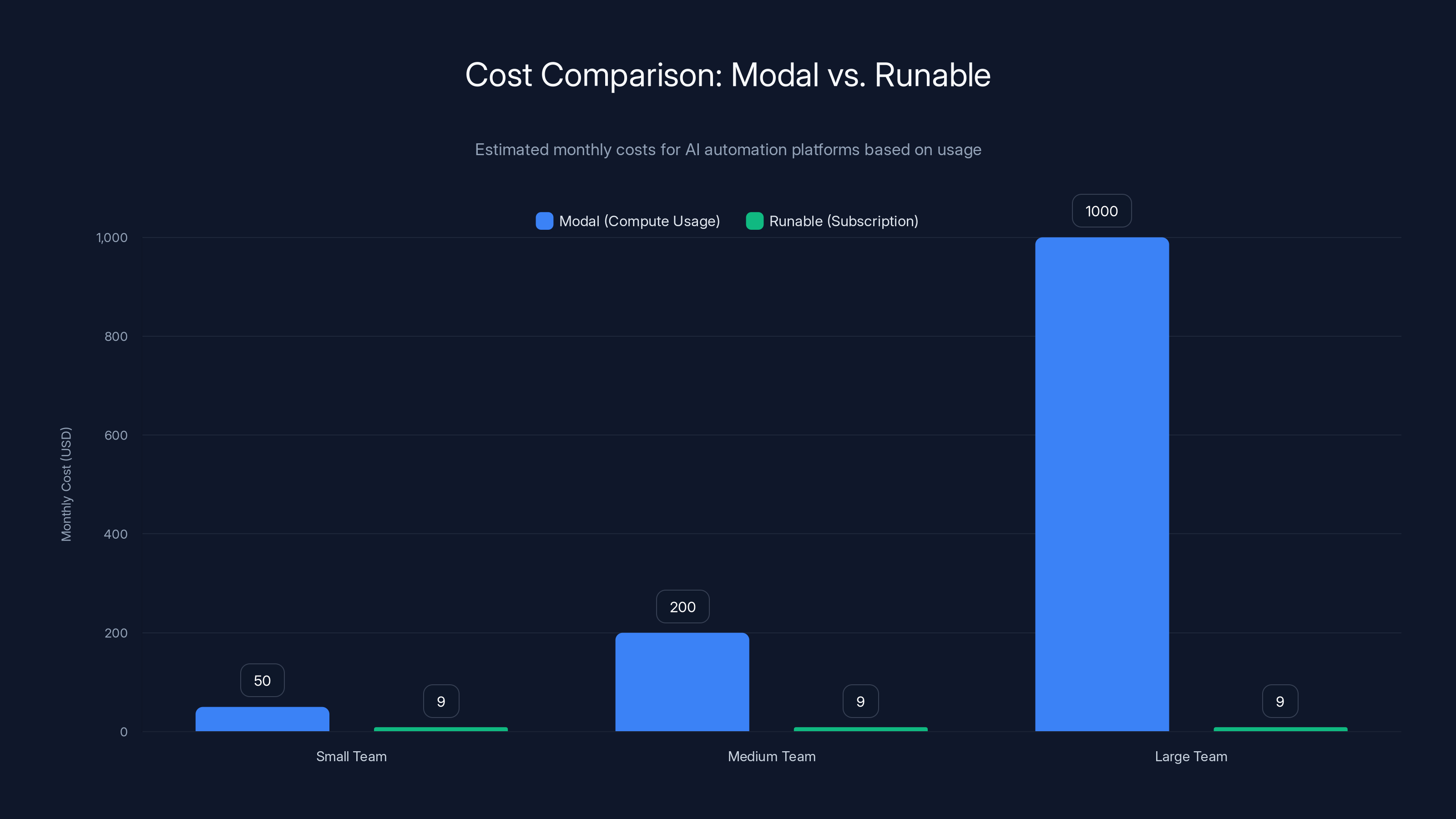
Estimated data shows that Modal's costs scale with usage, making it ideal for large teams, while Runable offers a flat subscription rate, beneficial for smaller teams.
Future Outlook: What's Next for Modal and the Inference Market
Product Roadmap Implications
The $2.5 billion valuation signals that Modal's board and investors believe the company has substantial room for product expansion and geographic growth. Areas where we might see future focus include: enhanced monitoring and observability for production inference workloads (allowing teams to understand performance, costs, and reliability), advanced cost optimization features that automatically identify opportunities to reduce spending, expanded hardware support beyond GPUs to include specialized inference accelerators (like Cerebras or custom silicon), and managed fine-tuning services that handle the operational complexity of fine-tuning models.
Another likely direction is multi-modal support: as vision-language models and audio-language models become more common, inference infrastructure needs to handle these diverse input types efficiently. Teams using Claude's vision capabilities or GPT-4V's image understanding need infrastructure that can serve these models efficiently.
Geographic Expansion
Modal currently operates with data centers in multiple regions, but there's likely substantial opportunity for expansion. Growth in Asia (particularly Southeast Asia and China), Europe, and other regions creates demand for infrastructure located closer to users. Expanding geographic presence allows Modal to serve latency-sensitive applications in new regions and capture market share from local infrastructure providers.
Enterprise Sales Transformation
Modal's growth has likely come through self-serve motion and product-led growth, typical for developer-focused infrastructure platforms. At higher revenue levels, successful infrastructure companies typically invest in enterprise sales to land larger customers and increase contract values. Modal will likely make this transition, hiring sales teams to approach large enterprises directly.
This transition brings both opportunities and risks. Opportunities: large enterprises can sign multi-million-dollar contracts, improving revenue stability. Risks: large sales cycles slow growth, and enterprise customers often demand customization that distracts from product development.
Broader Market Implications and Industry Trends
The Vertical Saa S vs. Horizontal Infrastructure Debate
Modal Labs represents an interesting point in the broader debate about vertical vs. horizontal infrastructure. By focusing specifically on AI inference, Modal has taken a "vertical" approach within the broader infrastructure space. This differs from cloud providers like AWS that take a "horizontal" approach, offering numerous services for numerous use cases.
The theory of vertical specialization suggests that specialized companies can move faster and optimize better than horizontally-focused incumbents. Modal's ability to optimize specifically for inference workloads (with specialized GPU provisioning, model caching, and batching) supports this theory. However, cloud providers have deep resources and can invest in improving their inference offerings. The long-term question is whether Modal (and similar specialized companies) can maintain advantages against increasingly capable horizontal providers.
The Open-Source Model Revolution
The success of open-source inference tools (v LLM, SGLang) and their commercialization (Inferact, Radix Ark) represents a broader trend: valuable infrastructure increasingly emerges from open-source communities before being commercialized. This pattern has been evident for decades (Linux, Apache, Kubernetes) but is particularly relevant to AI infrastructure.
For companies like Modal, this trend creates both opportunities and threats. Opportunity: open-source tools that Modal integrates with gain more powerful and sophisticated over time, making Modal more valuable. Threat: highly sophisticated open-source tools reduce the complexity that Modal abstracts away, diminishing the value of Modal's abstraction layer.
The Global AI Infrastructure Race
Governments are increasingly investing in AI infrastructure, viewing it as strategically important. The United States, China, and European countries are funding AI infrastructure initiatives. This government-scale investment affects the competitive dynamics in the private sector, as government-backed players might have cost advantages or access to capital that private companies cannot match.
For companies like Modal, this trend suggests that while there's a large market, competition might intensify from well-funded players (both private startups and government-backed entities) focused on AI infrastructure. Success will likely require sustained innovation and strong execution rather than simply being first-mover.
Modal Labs has evolved through distinct phases from basic function scheduling to advanced AI workload optimization. Estimated data.
Practical Considerations: Choosing Inference Infrastructure
Evaluation Criteria for Infrastructure Selection
Organizations evaluating inference infrastructure should consider several key criteria. Cost per inference operation is paramount; the platform must offer economical pricing that aligns with business models. Latency characteristics matter greatly for real-time applications; infrastructure optimized for batch processing might not work for low-latency requirements. Throughput and scaling capabilities determine whether infrastructure can handle peak loads. Model support (which model architectures and training frameworks the platform supports) affects compatibility with existing workflows.
Developer experience should not be underestimated; infrastructure that's difficult to use creates friction and delays. Integration capabilities matter if teams need to connect inference infrastructure with other tools. Support and documentation are important for teams that encounter issues or need guidance. Pricing transparency helps teams understand costs; hidden fees or unpredictable pricing can be problematic.
Architectural Patterns and Modal's Fit
Modal's architecture is particularly well-suited for certain patterns. Real-time API serving (exposing models as HTTP endpoints) leverages Modal's automatic scaling and infrastructure management. Asynchronous batch processing (processing large volumes of data offline) benefits from Modal's efficient resource utilization. Scheduled periodic tasks (running inference on a schedule, like nightly re-scoring models) leverage Modal's scheduled execution capabilities.
Modal is less ideal for scenarios requiring extreme latency optimization (where custom kernels and specialized hardware matter more than abstraction), or for scenarios with highly unpredictable load patterns that would benefit from more sophisticated capacity planning.
Hybrid and Multi-Provider Strategies
Sophisticated organizations increasingly adopt multi-provider strategies, using different providers for different workloads. A company might use Modal for general inference workloads (good cost-performance), Fireworks for latency-sensitive endpoints (extreme optimization), and in-house infrastructure for high-volume, proprietary models (maximum cost control). This approach avoids vendor lock-in while optimizing for specific requirements.
The trade-off of multi-provider approaches is operational complexity: managing multiple platforms requires different monitoring, alerting, and support processes. However, for large organizations with substantial inference spending, the cost savings from optimization-specific providers often justify the operational complexity.
Enterprise AI Automation and Runable: Alternative Approaches
Beyond Pure Inference Infrastructure
While Modal Labs addresses the core inference infrastructure problem, a broader category of solutions has emerged for enterprise AI automation. These platforms take a different approach: rather than providing low-level infrastructure for running models, they provide higher-level automation for specific business processes.
Platforms like Runable exemplify this alternative approach. Rather than requiring teams to manage inference infrastructure directly, Runable provides AI agents that handle specific automation tasks: generating documents, creating presentations, producing reports, managing workflows. The platform abstracts away the complexity of model selection, inference optimization, and infrastructure management entirely—teams simply define what automation they want, and Runable executes it.
This represents a philosophical difference in how to approach AI value creation. Modal's approach says: "Give teams powerful tools and let them build what they want." Runable's approach says: "Here are common automation tasks; let us handle the complexity." Neither approach is objectively superior; they serve different customer needs.
Cost Comparison and Economics
The economics of these approaches differ significantly. Modal's pricing is typically based on actual compute usage (you pay for GPU time, measured in seconds or minutes). For teams running inference at substantial scale, this creates predictable cost models. Runable's pricing is typically a monthly subscription (e.g., $9/month) providing automation capabilities within a managed service.
For teams running massive volumes of inference operations (like large tech companies processing billions of daily requests), infrastructure platforms like Modal are necessary for cost control. For smaller teams or departments running occasional automations (processing documents weekly, generating reports monthly), subscription-based services like Runable might offer better economics and simpler operations.
The comparison can be quantified: if a team uses Runable's AI document generation feature to create 100 documents monthly at
Integration and Workflow Considerations
Runable and similar platforms emphasize ease of integration with existing workflows. Rather than requiring teams to learn infrastructure concepts, they can integrate automation into their existing processes (Slack, email, document repositories) through straightforward APIs and integrations. This ease of integration is valuable for teams without infrastructure expertise.
Modal, conversely, assumes teams either have infrastructure expertise or are willing to develop it. The platform offers more control and flexibility, but requires more technical investment. For organizations building AI applications as a core product (like AI-first startups), Modal is the natural choice. For organizations using AI to automate specific business processes (like enterprises automating document processing), Runable-like platforms might be more pragmatic.
When to Choose Each Approach
Choosing between infrastructure platforms like Modal and automation platforms like Runable depends on several factors. Choose infrastructure platforms when: your application requires custom inference logic, you're running inference at massive scale with cost optimization concerns, or you need flexibility to experiment with different models and architectures.
Choose automation platforms when: you want to accomplish specific tasks (document generation, report creation) without infrastructure complexity, you're performing inference at modest scale, or you want fast time-to-value without heavy technical investment. Many organizations use both: Runable for common automation tasks, Modal for custom applications requiring more control.

Conclusion: The Inference Infrastructure Inflection Point
Modal Labs' $2.5 billion valuation represents more than a single company's milestone; it signals an inflection point in how organizations deploy AI. The rapid growth of inference infrastructure companies, the substantial funding flowing into the space, and the proliferation of competing approaches all point to a maturing market where inference infrastructure is becoming a critical component of enterprise AI strategy.
The company's achievement of $50 million in annualized revenue run rate demonstrates that the market has moved beyond early adopters to mainstream adoption. Thousands of organizations now rely on inference infrastructure platforms to power their AI applications. This volume of adoption validates the problem: managing inference efficiently is genuinely difficult, and teams value solutions that simplify the process.
Modal's specific positioning—as a developer-friendly platform providing control and flexibility while abstracting infrastructure complexity—appeals to teams building custom AI applications. The company faces substantial competition from platforms like Baseten (emphasizing simplicity), Fireworks (emphasizing performance), and commercialized open-source projects (emphasizing community trust). Yet the market appears large enough to support multiple successful companies, each winning specific customer segments.
The broader implication is that AI deployment is becoming an operational challenge rather than purely a modeling challenge. Teams can access powerful open-source models and train custom models relatively easily. The challenge is operating those models reliably, cost-effectively, and at scale. This operational challenge creates the business opportunity for infrastructure companies like Modal.
For teams building AI applications, the proliferation of infrastructure options is positive. Teams can evaluate multiple providers, select the one best suited to their specific requirements, and benefit from intense competition driving innovation and competitive pricing. The market's maturity means that most teams will find a solution that works for their use case.
The question for the next phase of the market is consolidation vs. fragmentation. Will the market eventually consolidate around a few dominant platforms (as happened with cloud infrastructure), or will it remain fragmented with specialized winners in specific niches? History suggests that some consolidation is likely, but infrastructure markets often support multiple successful large companies due to the diverse needs of different customer segments.
For investors, the inference infrastructure space remains interesting but increasingly competitive. The best opportunities likely lie in capturing specific market segments (geographic regions, use cases, or customer sizes) rather than trying to be universal solutions. Companies that can demonstrate strong unit economics, capital efficiency, and customer retention will attract continued investment. Companies that rely on raising larger and larger rounds without demonstrating these metrics will face difficulty.
For Modal Labs specifically, achieving
The broader lesson from Modal's funding round is that infrastructure problems in AI are far from solved. While AI model development has attracted enormous attention, the operational infrastructure for deploying and running models at scale remains an open challenge with significant economic value. Companies that solve this problem well can build substantial businesses, and the venture market has clearly decided to fund multiple approaches to solving it.

FAQ
What is AI inference infrastructure?
AI inference infrastructure refers to the computational systems and software platforms that run trained AI models to generate predictions or responses based on user inputs. Unlike training (which occurs once during model development), inference happens continuously as users interact with AI applications. Modern inference infrastructure optimizes for cost, latency, and throughput, making it possible to serve AI models efficiently at scale.
Why has inference infrastructure become critical for enterprises?
As organizations deploy AI models in production, they discover that the cost and complexity of running inference at scale is substantially higher than expected. A single inefficiency in how models are served can multiply into millions of dollars in unnecessary computing costs annually. Specialized inference platforms optimize this process through techniques like request batching, model caching, and GPU optimization, enabling enterprises to reduce operational costs while improving performance.
What are the main competitors in the inference infrastructure market?
The inference infrastructure market includes both specialized startups and established cloud providers. Specialized companies like Modal Labs, Baseten, and Fireworks AI focus specifically on inference optimization. Other competitors include Inferact (commercialized v LLM), Radix Ark (commercialized SGLang), and general cloud providers like AWS Sage Maker, Google Cloud Vertex AI, and Azure Machine Learning. Each competitor emphasizes different strengths: Modal emphasizes developer experience, Fireworks emphasizes extreme performance optimization, and Baseten emphasizes simplicity.
How does Modal Labs differentiate itself from competitors?
Modal Labs positions itself as a developer-friendly infrastructure platform that provides control and flexibility while abstracting complexity. The company's differentiation includes deep integration with popular libraries (Hugging Face Transformers), sophisticated cost optimization techniques, multi-GPU support for large models, and a pricing model aligned with actual usage. The developer experience—making infrastructure accessible to teams without deep operations expertise—is a key competitive advantage.
What does Modal's $50 million ARR figure indicate about market adoption?
Modal's $50 million ARR represents substantial market traction, indicating that the company has thousands of paying customers running meaningful inference workloads. This revenue level suggests that Modal has moved beyond early adopters to mainstream adoption among teams building AI applications. The achievement is particularly notable given the company's focus on a relatively specialized niche, indicating strong market demand for inference infrastructure solutions.
How should organizations choose between inference infrastructure platforms?
Organizations should evaluate inference infrastructure platforms based on several criteria: cost per inference operation (comparing pricing models and actual costs), latency characteristics (ensuring the platform meets performance requirements), throughput and scaling capabilities (verifying the platform can handle peak loads), model support (checking compatibility with specific models and frameworks), developer experience (considering ease of integration and use), and integration capabilities (ensuring compatibility with existing tools). Different platforms excel at different scenarios, so the best choice depends on specific requirements.
What is the relationship between inference infrastructure and enterprise AI automation platforms?
Inference infrastructure platforms like Modal and automation platforms like Runable represent different approaches to deploying AI. Infrastructure platforms provide low-level tools for running any model, giving teams maximum flexibility but requiring infrastructure expertise. Automation platforms provide higher-level services for specific tasks (like document generation), abstracting away infrastructure complexity entirely. Organizations often use both: automation platforms for common tasks, infrastructure platforms for custom applications requiring more control.
What does the rapid valuation growth of inference startups indicate about the market?
The rapid valuation increases across inference startups (Baseten to
How do geographic factors influence inference infrastructure decisions?
Geographic factors significantly impact inference infrastructure choices. Real-time applications serving global users benefit from inference infrastructure deployed in multiple regions, minimizing latency for distant users. Some specialized inference providers offer regional deployment options (including Modal), while others focus on specific geographies. Organizations with global users should verify that their chosen platform can deploy infrastructure in required regions and meets data residency requirements.
What future trends might affect the inference infrastructure market?
Several trends are likely to shape the inference market: the emergence of specialized inference hardware (custom silicon designed for inference), integration of inference capabilities into broader AI platforms, increased focus on cost optimization and unit economics (as competition intensifies and capital becomes scarcer), expansion to edge deployment (running inference on devices rather than in cloud data centers), and consolidation around companies demonstrating strong fundamentals. Inference infrastructure will likely become increasingly commoditized, with differentiation based on cost, performance, and developer experience.
Why did Modal Labs' valuation increase by more than 100% in just five months?
Modal's rapid valuation increase from
Key Takeaways
- Modal Labs raised at 1.1B) with $50M ARR, signaling mature AI inference market
- Inference infrastructure solves critical operational challenge: running AI models efficiently at scale with 20-50% cost optimization possible
- Competitive market includes Baseten (4B), and commercialized open-source projects (Inferact, RadixArk), supporting multiple winners
- Modal differentiates through developer experience, model caching, GPU optimization, and flexible pricing aligned with actual usage patterns
- Alternative automation platforms like Runable serve different use cases: high-level task automation vs. low-level infrastructure control
- Market opportunity substantial ($10-45B annual inference infrastructure TAM) with ongoing consolidation expected but multiple viable companies sustainable
- Organizations should evaluate platforms based on cost per operation, latency requirements, throughput, model support, and developer experience fit
Related Articles
- Gather AI's $40M Funding: Why Curious Warehouse Drones Change Logistics [2025]
- AI Chatbot Ads: Industry Debate, Business Models & Future
- Microsoft's $37.5B AI Bet: Why Only 3.3% Actually Pay for Copilot [2025]
- Workday CEO Leadership Shift: What Bhusri's Return Means [2025]
- Hauler Hero $16M Series A: AI Waste Management Software Revolution 2025
- TechCrunch Startup Battlefield 200 [2026]: Complete Guide to Pitching Success

