![Nvidia's Dynamic Memory Sparsification Cuts LLM Costs 8x [2025]](https://tryrunable.com/blog/nvidia-s-dynamic-memory-sparsification-cuts-llm-costs-8x-202/image-1-1770936013661.jpg)
Nvidia's Dynamic Memory Sparsification Cuts LLM Costs 8x While Maintaining Accuracy [2025]
If you've been paying attention to large language models over the last year, you've probably noticed a pattern. The models keep getting better at reasoning. OpenAI ships o 1 with extended thinking. Deep Seek releases R1 with chain-of-thought outputs. Google announces Gemini with deeper reasoning capabilities. But there's a problem nobody's talking about loudly enough: this reasoning comes at a massive cost.
Every extra thinking token a model generates requires memory. Lots of it. The computational resources needed to handle these reasoning chains grow faster than the quality improvements, which means that in many enterprise settings, you're hitting infrastructure limits before you hit performance ceilings. You can't afford to let the model think longer, even though it would produce better answers.
That's where Nvidia's latest research comes in. A team of researchers at the company has developed a technique called dynamic memory sparsification (DMS) that fundamentally changes how large language models manage their memory during reasoning. Instead of storing every piece of information the model generates, DMS trains the model to intelligently decide what to keep and what to discard. The result? Up to 8x reduction in memory consumption without sacrificing accuracy.
Here's what makes this genuinely interesting: you don't need new hardware. You don't need to retrain models from scratch. You can take an existing model like Qwen-3-8B and retrofit it with DMS in just hours on a single GPU. The technique works with standard inference stacks. And the math behind it is elegant enough that it actually improves reasoning performance in some cases.
Let's dig into what this technique actually is, why it matters, and how it's going to change the economics of AI infrastructure over the next year.
TL; DR
- 8x memory compression: DMS reduces KV cache size by up to 8 times while preserving or improving reasoning accuracy
- Retrofit in hours: Existing models like Llama 3.2 and Qwen-R1 can be retrofitted with DMS in just 1,000 training steps
- No custom hardware required: Works with standard GPU kernels and existing inference infrastructure
- Delayed eviction mechanism: Smart token management allows models to extract context before deletion
- Enterprise economics: Same hardware can now serve 8x more users or handle 8x longer reasoning chains
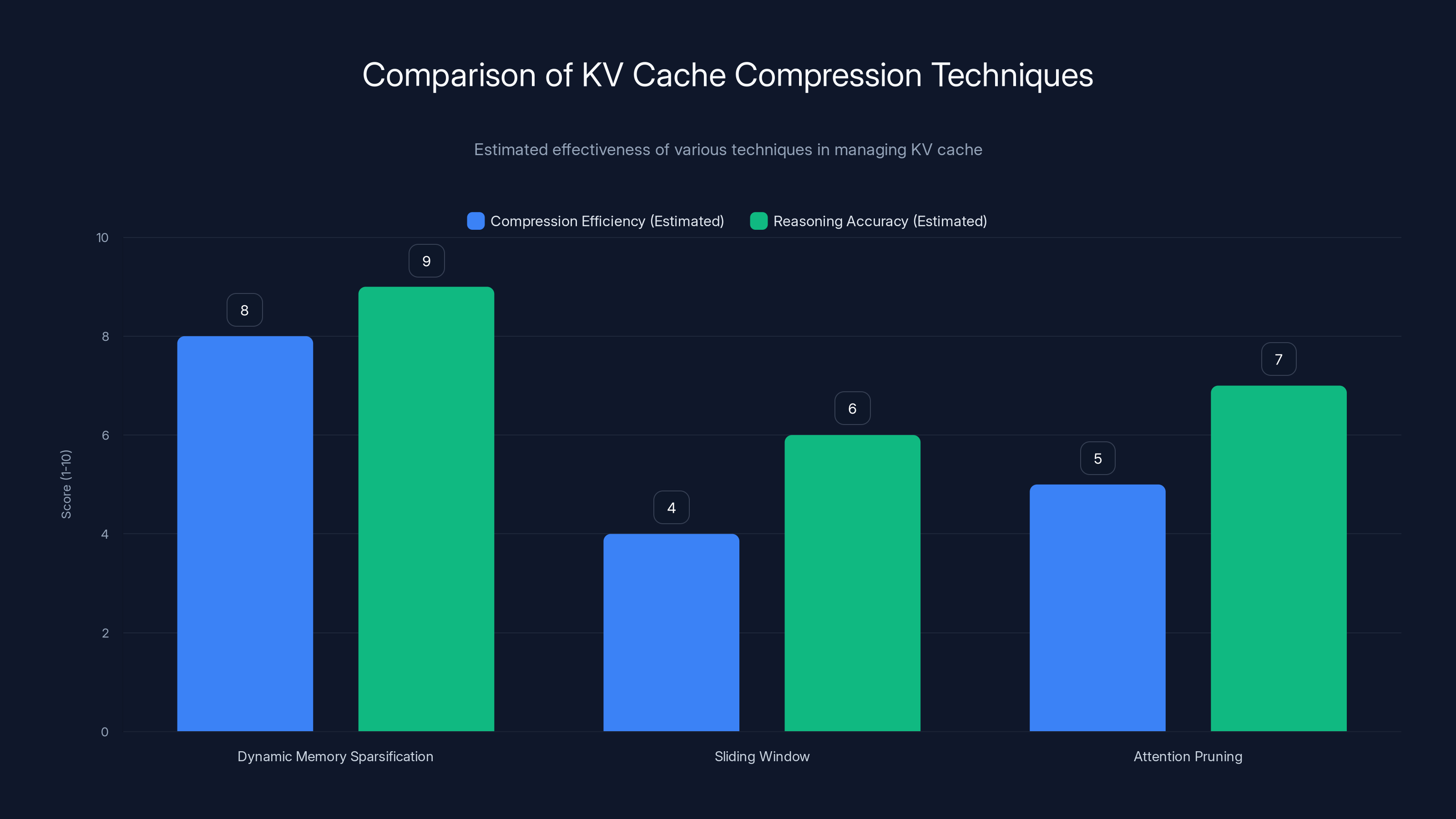
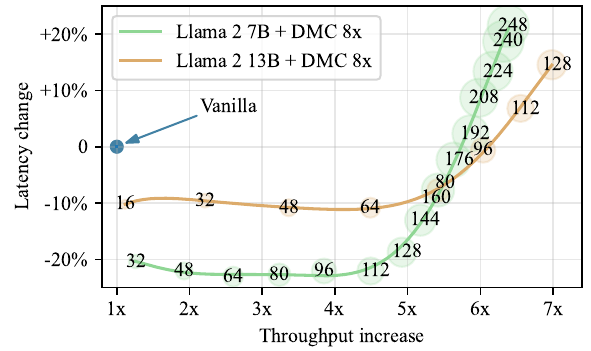
Dynamic Memory Sparsification (DMS) shows superior compression efficiency and reasoning accuracy compared to sliding window and attention pruning methods. Estimated data.
Understanding the KV Cache Problem in Modern LLMs
Before we talk about the solution, you need to understand the problem. And the problem starts with how transformers actually work.
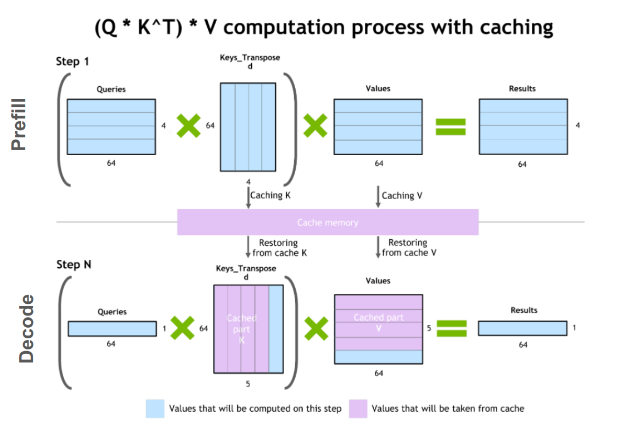
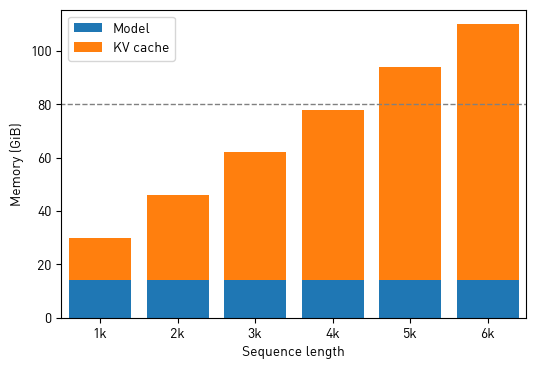
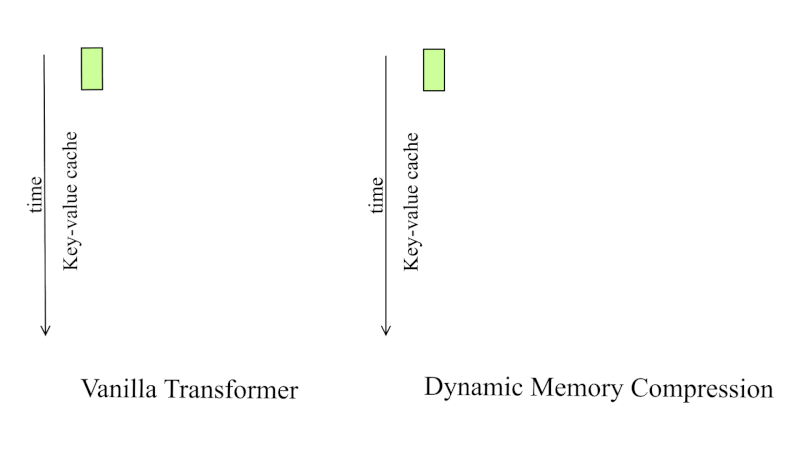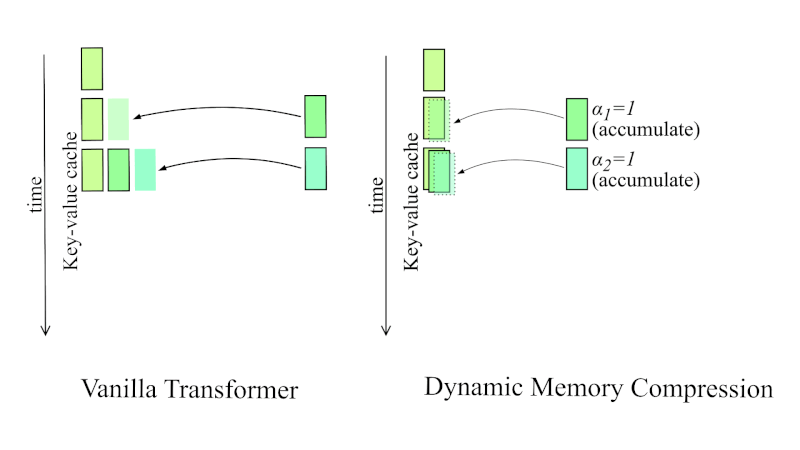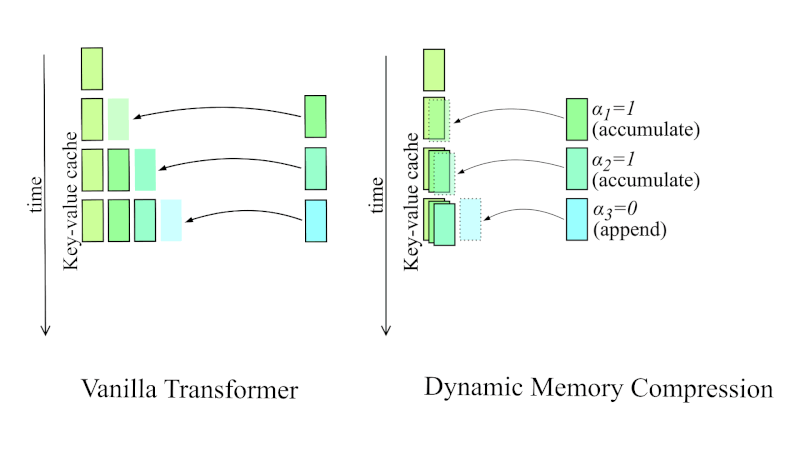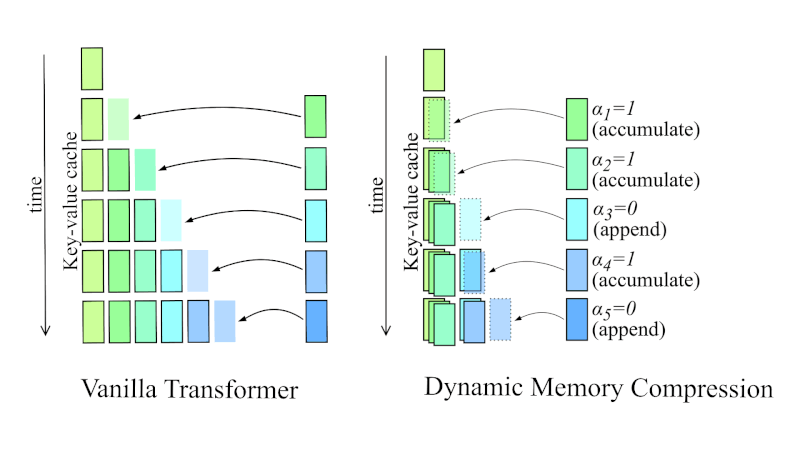
When a language model processes tokens, it doesn't just look at the current token in isolation. The architecture is built around the idea of attention, which means every token gets to "look back" at all the previous tokens to understand context. To make this efficient, the model pre-computes and caches something called the key-value cache, or KV cache.
Think of it this way: imagine you're reading a book and you want to quickly reference something from page 50 while reading page 200. You could flip back and forth every time, which is expensive. Or you could create an index of important information from pages 1 through 50 and keep it nearby. That index is basically what the KV cache is.
For short sequences, this is fine. A few thousand tokens, a bit of memory, no problem. But here's where it gets complicated. When you add reasoning tokens—when you tell a model to "think" through a problem step by step—the sequence length explodes. OpenAI's o 1 might generate 10,000, 20,000, or even 50,000+ reasoning tokens before arriving at an answer.
Each of those tokens adds to the KV cache. And the KV cache grows linearly. If you're generating 50,000 tokens, your cache is 50,000 times larger than it would be for a simple non-reasoning task. This isn't a minor inconvenience. For enterprise applications, this becomes the dominant cost factor.
Let's put some numbers on this. Say you have a data center with 100 GPUs running reasoning tasks. With traditional approaches, you might be able to serve 100 concurrent users with moderate reasoning chains. But if you could reduce the KV cache by 8x, suddenly you can serve 800 concurrent users on the same hardware. Or you can let 100 users generate 8x longer reasoning chains without adding infrastructure.
For enterprise customers, this is economics. Nvidia researchers framed it exactly this way: "The question isn't just about hardware quantity; it's about whether your infrastructure is processing 100 reasoning threads or 800 threads for the same cost."
The Previous Approaches and Why They Failed
Before DMS, researchers tried multiple approaches to solve the KV cache problem. None of them worked particularly well.
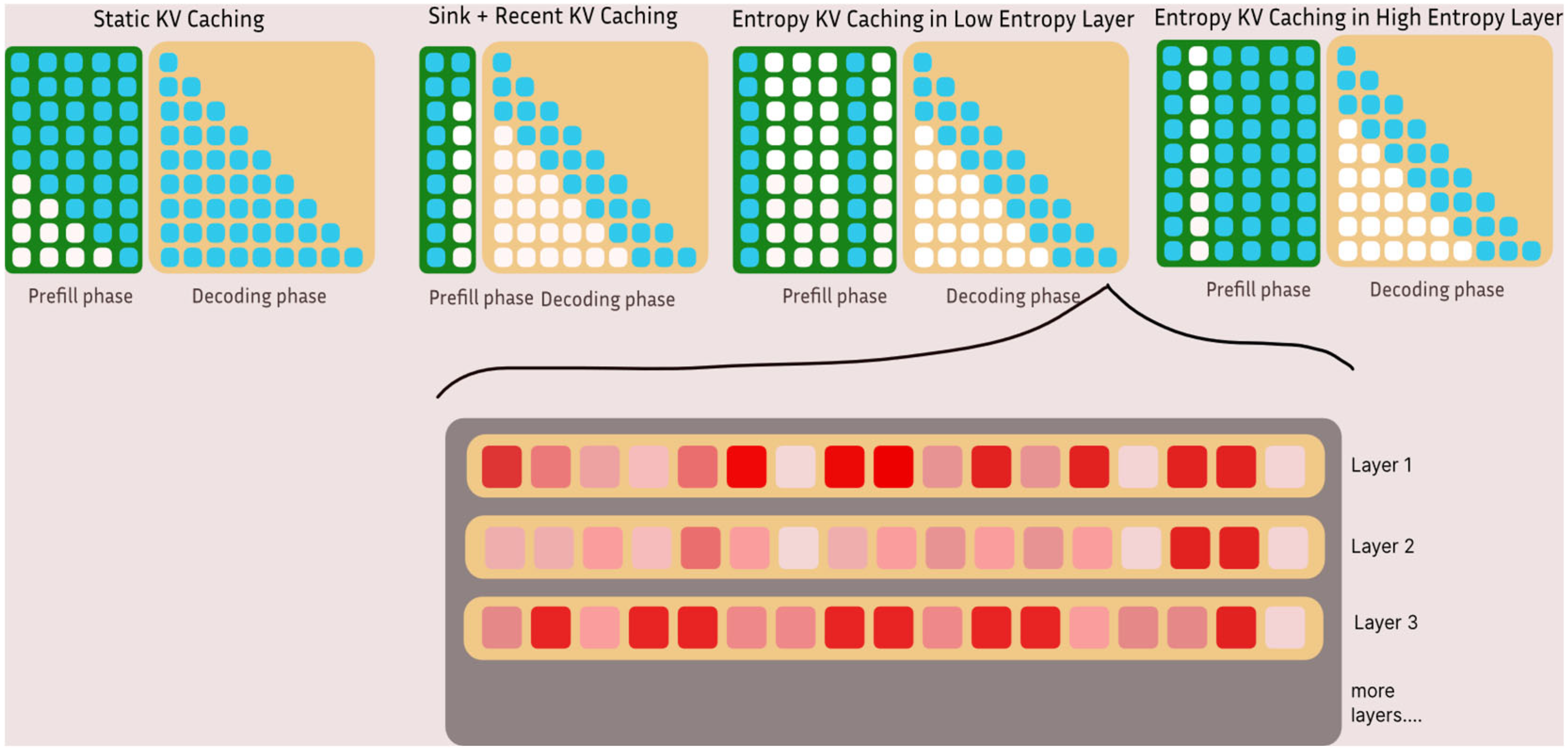
The simplest approach is called the sliding window. The idea is straightforward: only keep the most recent N tokens in the cache. Delete everything older. It's like saying "the model only needs to remember the last 1,000 tokens to make good predictions." For some tasks, this actually works okay. But for reasoning tasks where the model needs to reference information from the beginning of the reasoning chain while working on the end, this approach catastrophically fails.
You lose critical context. The model might correctly derive that statement A leads to statement B leads to statement C, but by the time it's computing step D, it has no memory of what statement A was. So the reasoning falls apart. Accuracy drops significantly.
Another approach people tried was heuristics-based eviction. The idea here is smarter: instead of just deleting old tokens, use some heuristic to identify which tokens are "important." Maybe you look at attention weights and delete tokens that nothing paid attention to. Maybe you use frequency analysis and delete rare tokens. Maybe you use novelty measures.
The problem with heuristics is that they're rigid. They work for some tasks and fail for others. They often discard information that the model actually needs but hasn't accessed yet. And they require tuning for specific model architectures or use cases. If your heuristic works great for math problems, it might be terrible for coding problems.
Then there's memory paging. This approach doesn't delete tokens at all. Instead, it moves infrequently accessed parts of the KV cache to slower storage—like moving data from GPU memory to system RAM. This preserves all the information, which sounds good until you measure it. The constant swapping between fast and slow memory introduces latency overhead. Your model spends time waiting for data to move around. For real-time applications where you care about time to first token, this approach is basically unusable.
All of these approaches shared a fundamental flaw: they were outside the model. They imposed rules on the model without the model having any say in the matter. The model didn't learn which tokens were actually important for its own reasoning process. Humans (or algorithms) made guesses, and those guesses were often wrong.
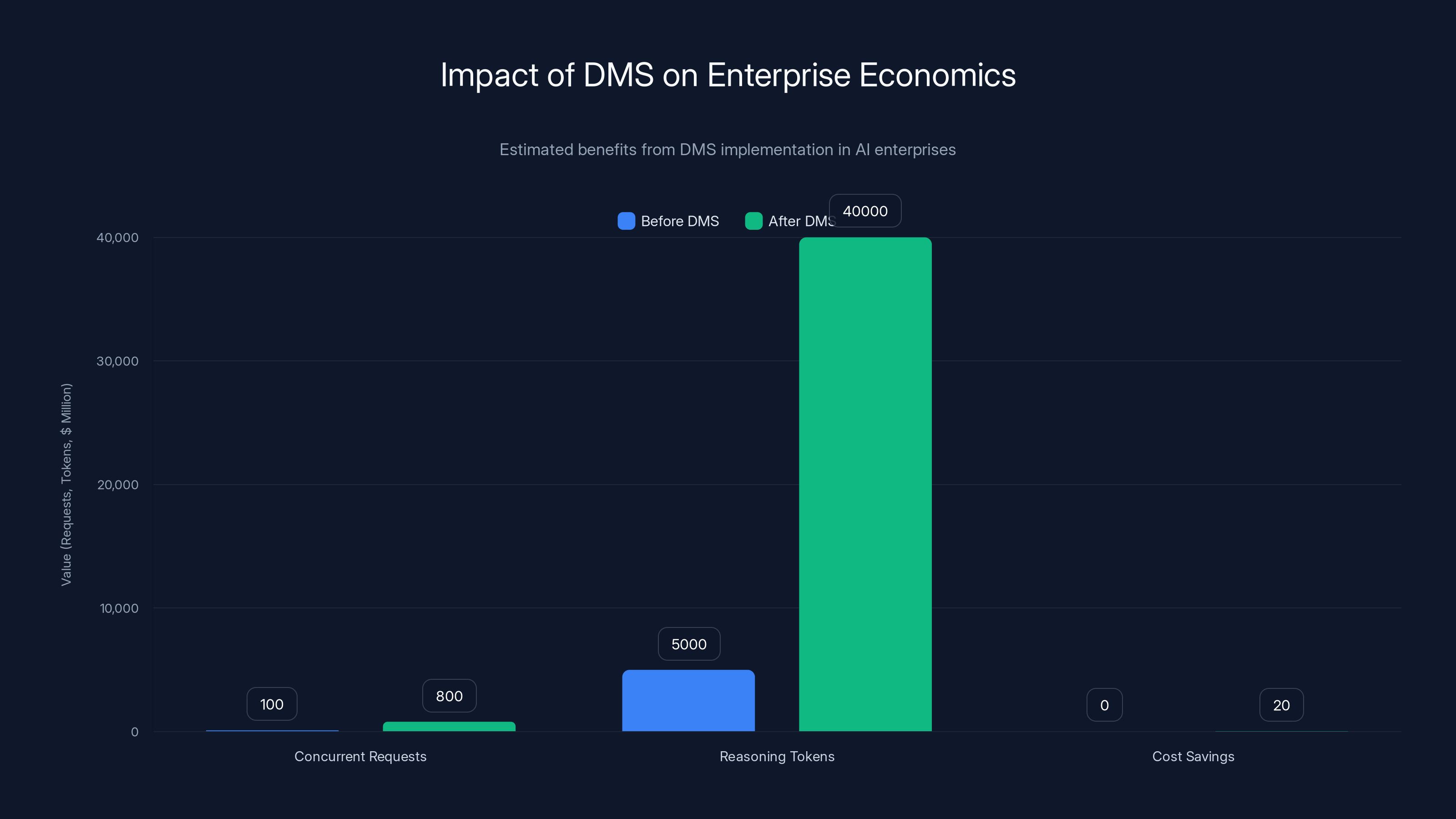
Implementing DMS can increase concurrent requests by 8x, allow 8x longer reasoning chains, and potentially save $6-20 million over three years. Estimated data based on typical enterprise scenarios.
How Dynamic Memory Sparsification Actually Works
Nvidia's approach to this problem is fundamentally different. Instead of imposing rules from outside, DMS teaches the model to manage its own memory.
Here's the core insight: the model already has neurons and weights. These weights encode the model's understanding of language, reasoning, and problem-solving. What if, instead of adding external rules, you repurpose some of those existing neurons to output a decision about which tokens to keep and which to evict?
This is exactly what DMS does. The technique modifies the attention layers in a pre-trained LLM to include additional output channels. These channels output a simple binary decision for each token: keep it or evict it. Crucially, the model learns this decision by training on actual tasks. It learns from experience which tokens are actually important for solving problems.
Technically, here's how the process works:
Step 1: Architecture modification. You take a pre-trained model. You add learnable parameters to the attention layers—essentially new neurons that output a "keep" or "evict" signal. These new parameters are initialized and trained to minimize prediction loss on standard reasoning benchmarks.
Step 2: Efficient training. You don't retrain the entire model. That would be prohibitively expensive. Instead, you freeze the model's existing weights and only train the new sparsification parameters. This is similar to Lo RA (Low-Rank Adaptation). A model like Qwen-3-8B can be retrofitted in just 1,000 training steps. On a single H100 GPU, this takes hours.
Step 3: Deployment. Once trained, the DMS-enhanced model works with standard inference kernels. No custom hardware. No specialized inference engines. You can drop it directly into existing inference pipelines.
The model learns a policy that explicitly preserves information necessary for accurate outputs while discarding information that's redundant or irrelevant. And here's the beautiful part: this learned policy generalizes. A model trained with DMS on math problems often performs well on coding problems too. The model learned something about which tokens matter, not just memorized patterns for specific tasks.
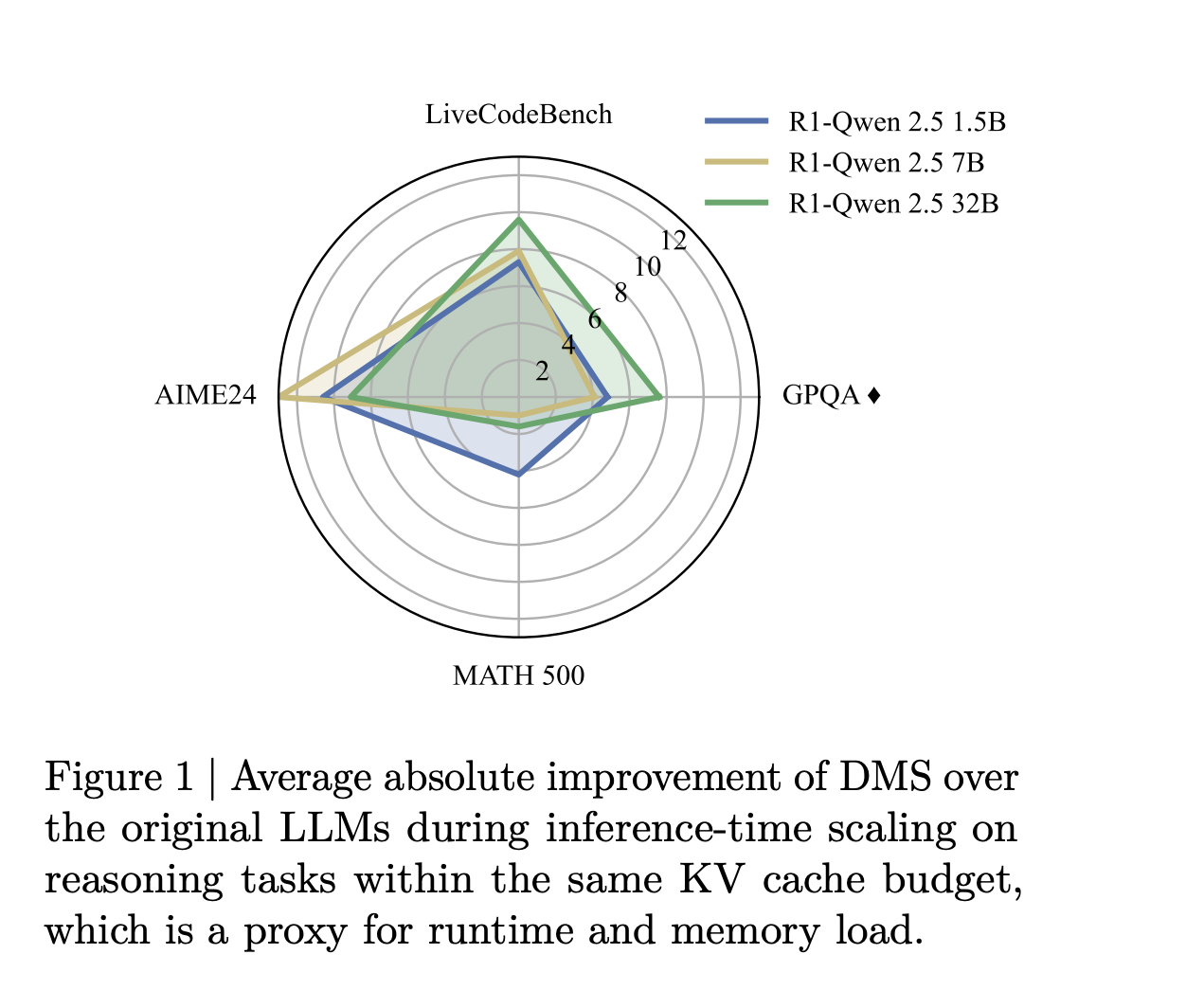
The Delayed Eviction Mechanism: Why It Matters
If the story ended with "we train the model to decide what to delete," that would be good. But Nvidia researchers identified a subtle problem that makes the story much better.
In a straightforward sparsification system, when you decide a token is unimportant, you delete it immediately. Gone. Removed from the KV cache. This is risky because of how transformer attention actually works.
Here's the issue: when a token is marked for deletion, the model hasn't necessarily finished "extracting" all the information it needs from that token. Attention is a parallel process, but information integration is sequential. A token might contain context that hasn't been fully processed into the model's intermediate states.
Imagine you're a student reading a textbook. The textbook has a footnote on page 50. You read it, think about it, and mentally incorporate the information. But while you're reading page 75, you realize you need to reference that footnote again. If the textbook disappeared the moment you moved to page 51, you'd be lost.
Transformers have the same problem. They need time to "integrate" information from tokens before those tokens disappear.
So Nvidia introduced delayed eviction. When DMS marks a token for eviction, it doesn't disappear immediately. Instead, the token stays in a local window for a short period—maybe 100 or 200 additional steps. This gives the model time to attend to the token, extract any remaining context, and incorporate that information into its current state. After that window closes, the token is actually deleted.
This mechanism is crucial because many tokens don't fall neatly into "important" or "useless" categories. Most tokens are somewhere in between. They contain some information, but not enough to justify permanent memory space. Delayed eviction lets the model extract what it needs before letting go.
The researchers found this mechanism improved performance noticeably. Without delayed eviction, model accuracy suffered. With it, the model maintained or improved accuracy even with aggressive compression.

Technical Implementation and Training Efficiency
The technical beauty of DMS is that it's lightweight. Researchers specifically designed it to be practical for enterprises to implement.
When you retrofit a model with DMS, you're adding what's essentially an additional projection layer to the attention mechanism. This layer outputs sparsification signals. The weight parameters for this layer are trainable, but the original model weights stay frozen. This is similar to Lo RA, which many practitioners are already familiar with.
The training process is efficient. For Qwen-3-8B, the researchers found that 1,000 training steps—that's roughly one epoch over a small subset of training data—was sufficient to get the DMS parameters well-trained. On a single DGX H100, this takes a few hours.
Compare this to the alternatives:
- Full model retraining: weeks or months
- Distillation: days or weeks
- Quantization with fine-tuning: days
- DMS retrofitting: hours
The inference runtime overhead is minimal. The DMS decision-making happens in parallel with the forward pass through the attention layers, so there's negligible additional latency. In some cases, the reduced KV cache size more than compensates for the sparsification overhead, resulting in faster inference overall.
The implementation doesn't require custom CUDA kernels or specialized hardware. DMS works with standard attention implementations found in modern inference engines like vLLM, TensorRT, or Triton. This is a huge practical advantage. You're not locked into proprietary software or hardware.

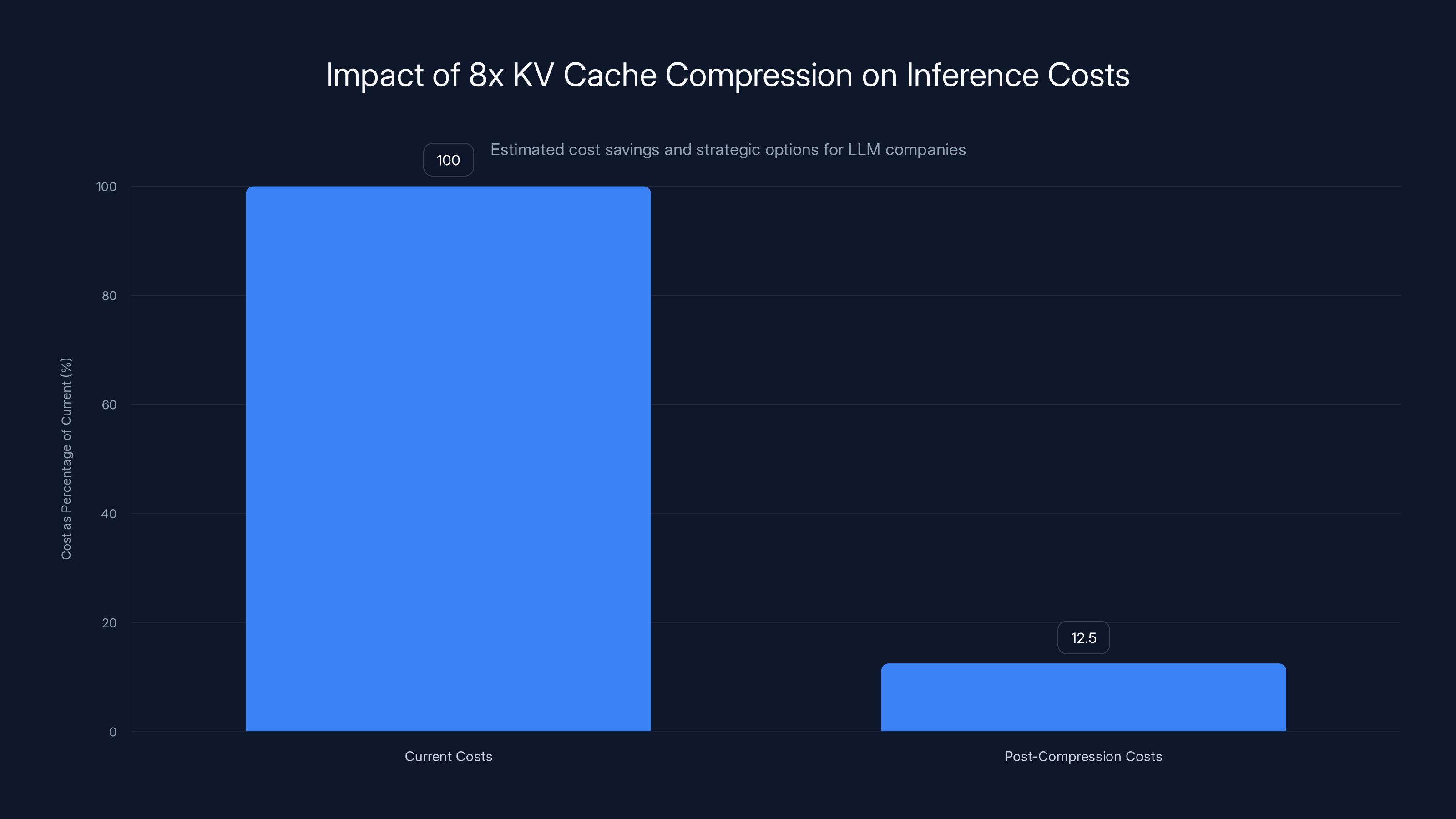
8x KV cache compression can reduce inference costs by up to 87.5%, enabling significant strategic flexibility for LLM companies. Estimated data.
Benchmark Results: Where DMS Excels
The researchers tested DMS on several categories of benchmarks, and the results were impressive across the board.
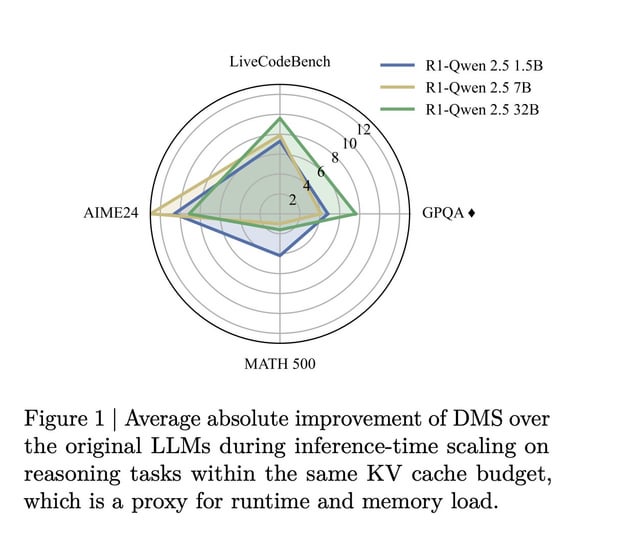
On AIME 2024 (American Invitational Mathematics Examination), which tests complex problem-solving in mathematics, DMS models maintained accuracy while reducing memory by 8x. This is significant because math is one of the few domains where you can definitively say whether an answer is right or wrong. There's no interpretation involved.
On GPQA Diamond, a challenging benchmark for scientific knowledge and reasoning, the compressed models actually outperformed uncompressed baselines. This suggests that the sparsification process forced the model to learn more efficient representations. Instead of relying on redundant cached information, the model learned to extract essential context more effectively.
On Live Code Bench, which evaluates code generation with real-world test cases, DMS models maintained performance on competitive programming and practical coding tasks. Coding is particularly interesting because it requires precise attention to detail. Aggressive compression could easily break this, but DMS maintained full accuracy.
The researchers tested this on multiple model architectures, including Llama 3.2 and the Qwen-R1 series (which is based on Deep Seek's R1 architecture). The technique generalized across all of them. This is important because it suggests DMS isn't a one-off trick for specific models or training procedures.
On sequence lengths up to 128,000 tokens, DMS maintained its compression ratio and accuracy. This is crucial because long sequences are increasingly common in real-world applications. People want to feed entire documents or conversations into models.
Enterprise Economics: The Real Impact
If you're running inference at scale, the impact of DMS is fundamentally about infrastructure economics.
Let's say you're an enterprise running a reasoning LLM service. You have 100 H100 GPUs. Your current bottleneck is memory bandwidth—the GPUs are waiting for data from memory more often than they're actually computing. This is typical for reasoning workloads.
With DMS reducing memory consumption by 8x, you have several options:
Option 1: Serve more users. If you were serving 100 concurrent reasoning requests, you can now serve 800 concurrent requests on the same hardware. Your infrastructure costs are amortized across 8x more customers, dramatically improving unit economics.
Option 2: Longer reasoning chains. If you were limiting reasoning chains to 5,000 tokens for latency reasons, you can now allow 40,000 tokens without additional infrastructure. Your model quality improves because it has more compute to solve problems.
Option 3: Cheaper hardware. Instead of using premium H100 GPUs, maybe you can drop to A100s and still meet latency requirements. This cuts infrastructure costs by 30-40%.
Option 4: Hybrid approach. Do some combination of all three.
For a mid-sized AI company with a few million dollars in annual inference costs, 8x compression could translate to $6-20 million in savings over three years, or the ability to serve 8x more customers without adding infrastructure.
The implementation cost is negligible. A few GPU-hours of retrofitting. Some engineering time to integrate into your pipeline. That's weeks of work for a team, not months or years of new infrastructure investment.

Comparison with Other Compression Techniques
To understand DMS in context, it's worth comparing it to other approaches people use to reduce inference costs.
Quantization (converting weights from 32-bit floats to 8-bit integers) is the most common compression technique. It's relatively straightforward to implement and reduces model size by 4x. But quantization affects weights, not the KV cache. For reasoning workloads where the KV cache is the bottleneck, quantization helps less than you'd hope. You can combine quantization with DMS, and many teams probably will.
Distillation (training a smaller model to mimic a larger one) is proven and widely used. A distilled model might be 5-10x smaller than the original. But distillation requires significant training time and the smaller model has lower peak performance. DMS doesn't reduce model size—it reduces memory footprint during inference, which is different.
Mixture of Experts (MoE) architectures activate only a subset of parameters for each token. This reduces computation but doesn't directly address KV cache size. MoE is orthogonal to DMS—you could use both.
Paging moves inactive cache to slower storage. It preserves all information but introduces latency overhead. For latency-sensitive applications, paging is undesirable.
Speculative decoding uses a smaller model to generate candidate tokens, then verifies them with the larger model. This speeds up inference for some workloads but doesn't reduce memory consumption.
DMS is unique because it:
- Doesn't reduce model size (so you retain peak performance)
- Doesn't require full retraining (hours instead of weeks)
- Works with standard inference infrastructure
- Targets KV cache specifically (the actual bottleneck for reasoning)
- Maintains or improves accuracy
The comparison most people make is DMS versus "just wait for inference hardware to get faster." But memory bandwidth scaling is slow. Inference memory requirements are growing faster than hardware is improving. DMS gives you immediate relief.

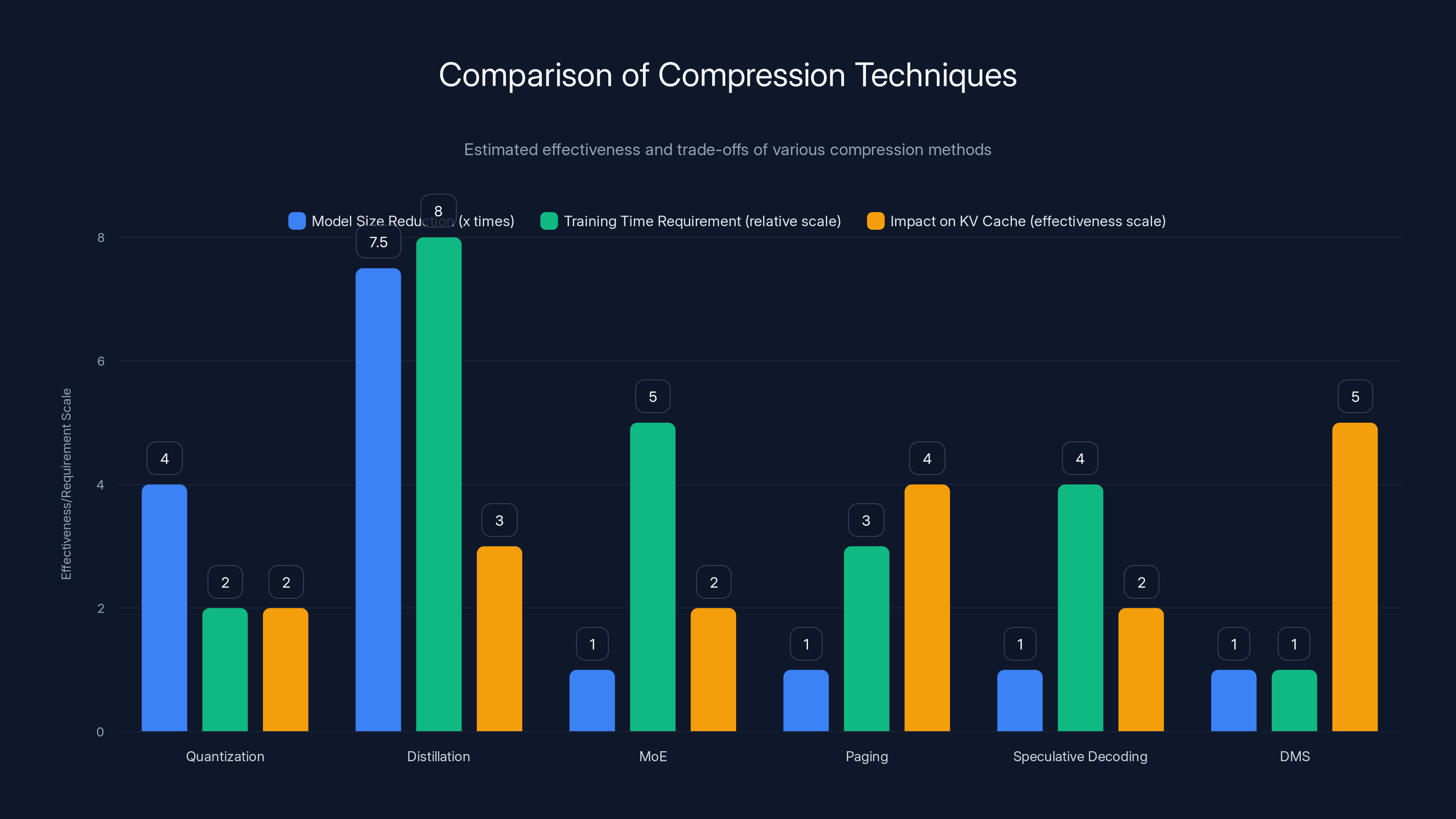
Comparison of compression techniques shows DMS uniquely targets KV cache effectively without reducing model size or requiring extensive retraining. Estimated data.
Integration with Existing Model Architectures
One critical question: does DMS work with models people actually use?
The answer is yes, and this is a huge practical advantage.
The researchers demonstrated DMS retrofitting on:
Llama 3.2 (Meta's open-source model, widely deployed in enterprises) Qwen-R1 (based on Deep Seek's reasoning architecture, increasingly popular for reasoning tasks) Other standard transformer architectures (the technique is general and doesn't depend on specific architectural choices)
This matters because it means you're not waiting for new model releases. Your existing deployed models can be retrofitted. If you have a Llama 3.2 70B model running in production, you can add DMS to it in a single day of engineering work.
The DMS parameters are added as additional outputs from the attention mechanism. This is a minimal architectural change. Unlike approaches that require restructuring the model or introducing new layer types, DMS works within existing frameworks.
For practitioners, the integration path is:
- Export your current model from whatever inference engine you're using
- Add DMS parameters to the attention layers (this is relatively straightforward with libraries like Hugging Face Transformers)
- Fine-tune DMS parameters for a few hours on a sample of your actual workload
- Deploy the retrofitted model alongside your original model for A/B testing
- Monitor performance and gradually shift traffic as confidence increases
The beauty of this approach is that you can test DMS on your actual use cases before fully committing. If for some reason it doesn't work for your specific application (unlikely, but possible), you just revert to the original model.
Challenges and Limitations
No technique is perfect, and DMS has some limitations worth discussing.
Limited public details on training data requirements. The researchers haven't published extensive information about how sensitive DMS is to the training data used for retrofitting. In theory, you should fine-tune on representative examples from your actual workload. In practice, how much fine-tuning is needed? Can you use public reasoning datasets? Can you use synthetic data? More transparency here would help practitioners.
Delayed eviction adds complexity. While the delayed eviction mechanism improves performance, it adds a hyperparameter to tune: how long should tokens stay in the local window before eviction? Different workloads might benefit from different settings. This isn't a huge problem, but it's one more thing to optimize.
Sparse attention patterns may not generalize perfectly. A model trained with DMS on mathematics problems might learn a certain attention sparsity pattern. When you deploy that model to new domains (e.g., coding), does the sparsity pattern still work well? The researchers showed it generalizes reasonably well, but real-world experience from practitioners deploying this will reveal edge cases.
Integration with emerging techniques. DMS is specifically targeting the KV cache problem. If the field moves toward architectural innovations that reduce KV cache naturally (e.g., new attention mechanisms), DMS becomes less relevant. It's hard to predict this timeline.
Requires retraining for major model updates. If Nvidia or your preferred model provider releases a new model version, you'll need to retrain DMS parameters for that version. It's fast (hours), but it's still an extra step in your deployment pipeline.
None of these are showstoppers. They're practical considerations that teams will work through as they adopt the technique.
Future Directions and Long-Term Implications
DMS is a meaningful breakthrough, but it's worth thinking about where this fits in the broader arc of LLM development.
In the short term (next 6-12 months), expect to see:
- Major model providers releasing DMS-compatible versions of popular models
- Inference frameworks (vLLM, etc.) adding native DMS support
- Enterprises retrofitting their inference infrastructure
- Research papers extending DMS with additional optimizations
In the medium term (1-2 years), we might see:
- DMS becoming standard in reasoning model architectures, built in from the start rather than retrofitted
- Combination of DMS with other compression techniques (quantization, distillation) for even greater efficiency
- Industry standards for sparsification patterns across domains
- Competitive techniques from other research groups
In the long term (2+ years), the implications are more speculative:
- Could efficient memory management unlock even longer reasoning chains than are currently feasible? (What if reasoning costs dropped 8x but we used that to enable 16x longer thinking?)
- How do these efficiency gains interact with scaling laws? If inference gets cheaper, does that change the economics of model size versus reasoning chain length?
- Will we see a convergence where most deployed models include some form of dynamic sparsification by default?
From a broader perspective, DMS represents a meaningful shift in how we think about LLM efficiency. For years, the focus was on reducing model size (distillation) or reducing computation (sparsity in parameters). DMS addresses a different dimension: reducing memory footprint during inference. As reasoning becomes more central to LLM applications, this becomes increasingly important.
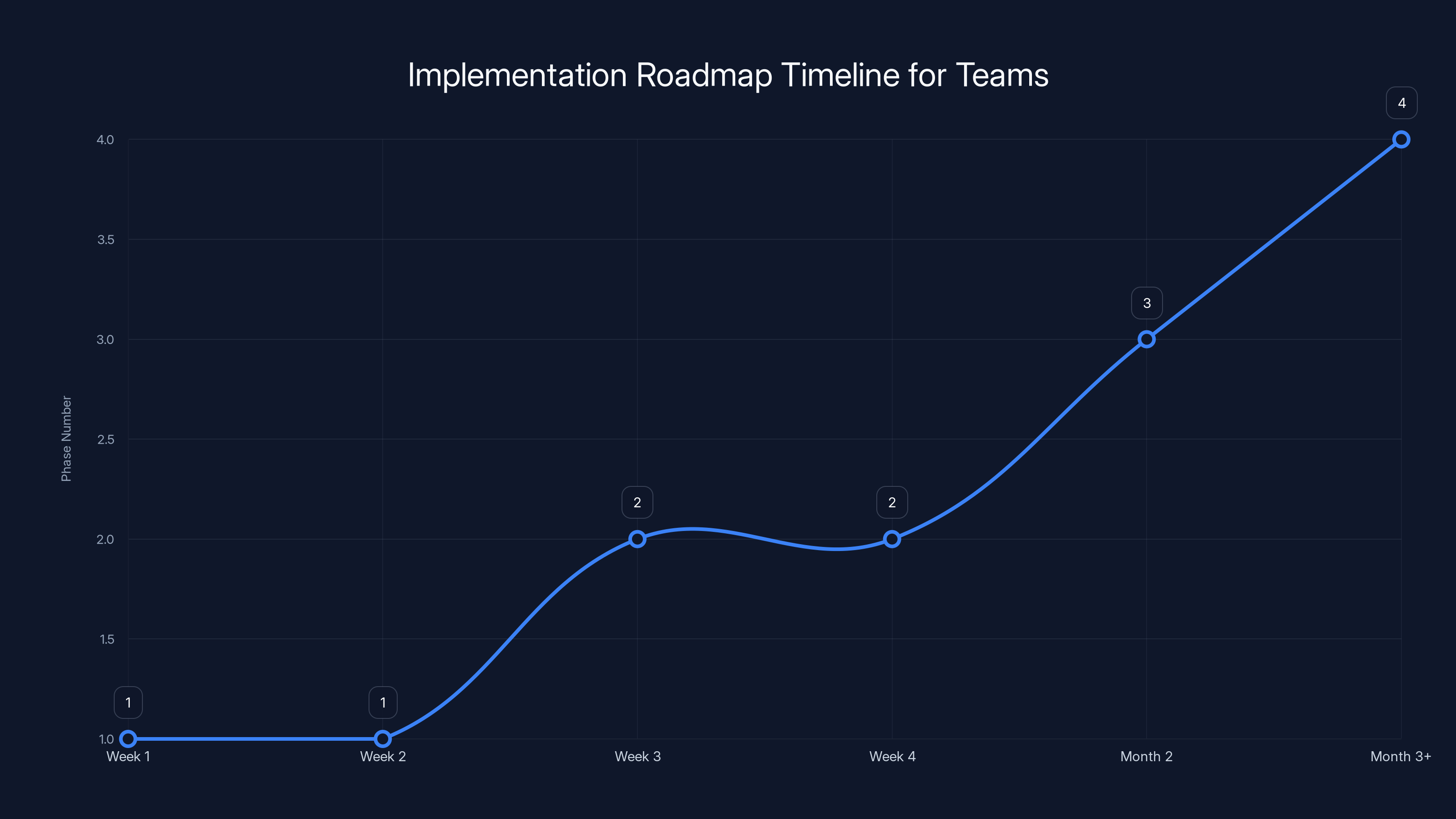
The roadmap outlines a phased approach to implementing DMS, starting with evaluation and ending with ongoing optimization. Estimated data.
Implementation Roadmap for Teams
If you're running LLM inference at scale and considering adopting DMS, here's a practical roadmap.
Phase 1: Evaluation (Week 1-2)
- Profile your current inference workloads. What's the bottleneck: memory, compute, or latency?
- Identify which models would benefit most from DMS (typically: reasoning models, long-context applications)
- Review the research paper and Nvidia documentation
- Estimate potential cost savings using your actual workload patterns
Phase 2: Prototyping (Week 2-4)
- Set up a test environment with one of the retrofittable model checkpoints
- Run the DMS retrofitting process on a representative model
- Test the retrofitted model on your actual use cases
- Compare performance (accuracy, latency, memory, throughput) against baseline
- Document any differences in behavior
Phase 3: Pilot Deployment (Month 2)
- Deploy the retrofitted model in a canary (small subset of traffic)
- Monitor performance metrics closely
- Implement fallback to original model if needed
- Gradually increase traffic to retrofitted model
Phase 4: Production Migration (Month 3+)
- Fully migrate to DMS-enabled models for applicable workloads
- Retire old models or keep as fallback
- Document your configuration for future model updates
- Plan for retrofitting new model versions as they're released
Phase 5: Optimization (Ongoing)
- Fine-tune DMS parameters for your specific workload distribution
- Combine DMS with other techniques (quantization, etc.)
- Measure real-world infrastructure cost reductions
- Share learnings with your team and the community
This timeline assumes you have some engineering resources available. For smaller teams, you might compress these phases, and for larger enterprises, you might have more parallel workstreams.

Broader Context: Why This Matters Now
Why is DMS appearing now, and why is it important right now specifically?
The catalyst is the rise of reasoning-focused models. For years, LLMs were primarily judged on speed: how quickly they could generate text. Companies optimized for fast inference with minimal tokens. Latency was the key metric.
But starting in late 2024, the game changed. OpenAI's o 1 showed that models generating 10,000+ thinking tokens could solve problems that traditional fast models couldn't solve. Deep Seek's R1 demonstrated this could work at reasonable cost. Suddenly, enterprises wanted longer thinking chains, not shorter ones.
This created a new bottleneck. The old infrastructure optimizations (fast models, minimal tokens) stopped applying. You want the model to think more, not less. But more thinking means more KV cache, which means more memory pressure, which means lower throughput and higher costs.
DMS solves this at exactly the right time. It removes the artificial constraint imposed by memory limitations, allowing models to reason as much as needed without proportional cost increases.
This is why Nvidia released this research: it aligns with their business interests (more LLM inference = more GPU demand), but it also represents a genuine technical contribution to solving a real problem that enterprises are experiencing right now.
From a market perspective, expect 2025 to be the year when memory efficiency becomes as important as compute efficiency in LLM deployments. Teams that adopt DMS early will have significant cost advantages.

Alternative Approaches and Complementary Techniques
While DMS is powerful, it's not the only tool in the box. Smart teams will likely combine multiple approaches.
Quantization reduces precision of weights (32-bit to 8-bit). This reduces model size and can improve cache efficiency. DMS targets the KV cache specifically; quantization targets the model weights. You can do both. The combined effect is likely multiplicative.
Flash Attention and similar kernel optimizations reduce memory copies during attention computation. These are complementary to DMS. Flash Attention makes attention faster; DMS makes less attention happen. Combine them for compounding benefits.
Batching and request grouping can improve hardware utilization even without reducing individual request memory consumption. This doesn't reduce memory per request but improves throughput per GPU. Again, complementary.
Model pruning removes rarely-used attention heads or neurons. This permanently reduces model size. DMS doesn't prune; it just changes what gets cached. You could prune first, then add DMS to the pruned model.
Prefix caching shares KV cache between requests that share prompt prefixes (e.g., system messages). This reduces absolute memory when handling many similar requests. Works well with batch processing.
For most enterprises, the optimal strategy involves:
- DMS for dynamic sparsification of KV cache
- Quantization for model weight compression
- Flash Attention for efficient attention computation
- Smart batching for throughput optimization
Each technique addresses a different dimension of the inference efficiency problem. Using all of them together gives better results than any one alone.
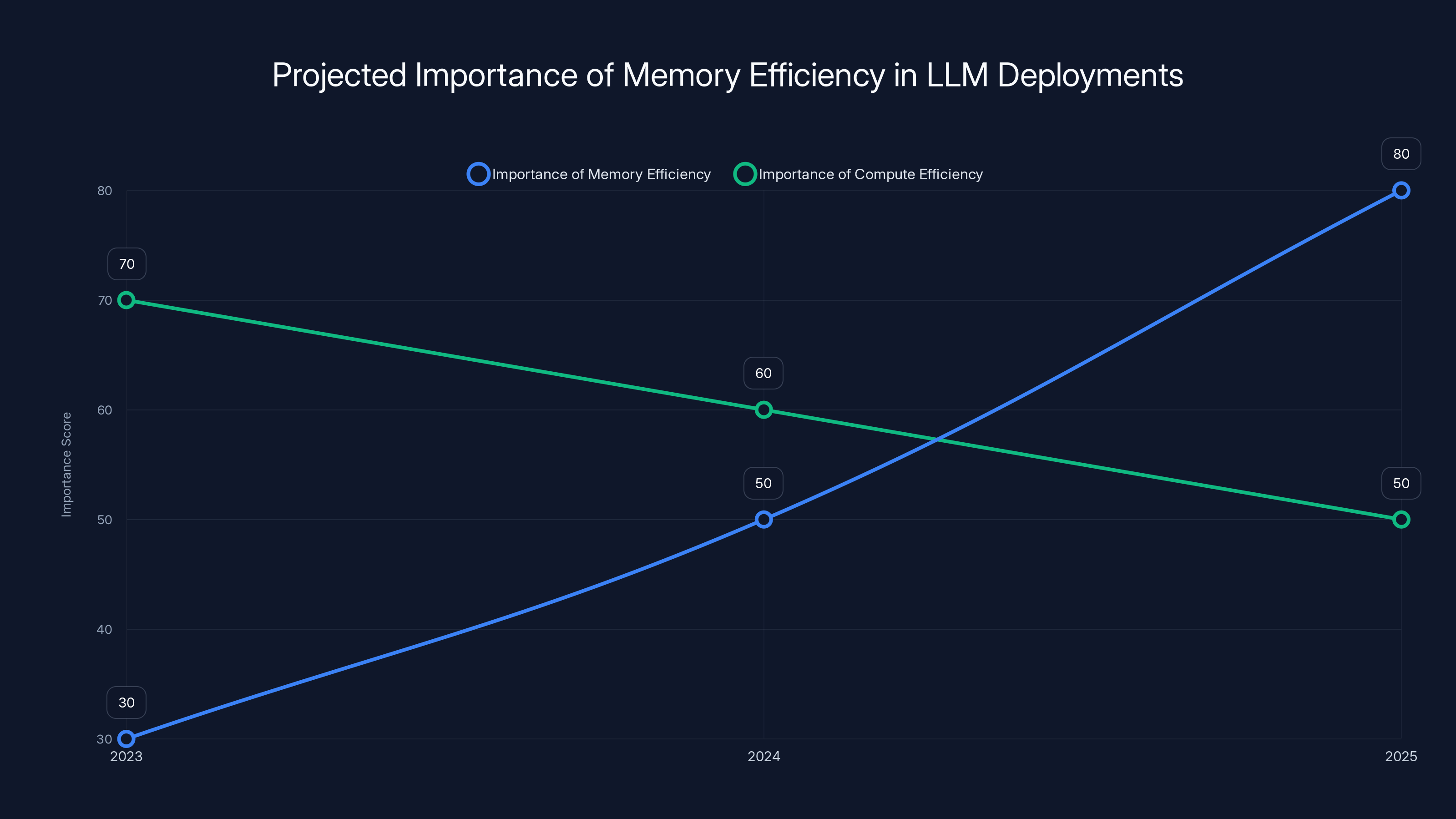
Estimated data shows a significant increase in the importance of memory efficiency in LLM deployments by 2025, surpassing compute efficiency.
Looking at Competitive Research
Nvidia isn't the only organization working on KV cache efficiency. This is an active research area.
Other teams have published work on:
- Attention pruning: Removing attention connections that don't matter. Similar in spirit to DMS but different in implementation.
- Token merging: Combining multiple tokens into single representations to reduce cache size. Works for some tasks, loses information for others.
- Sliding window attention: Only attending to recent tokens. Good for some tasks, breaks reasoning.
- Low-rank approximations: Decomposing the KV cache into lower-rank matrices. Clever but approximate.
What makes DMS distinctive is the combination of:
- Learning what to keep (not using heuristics)
- Full information preservation (not approximating)
- Minimal training overhead (1,000 steps, not epochs)
- Generalization across tasks
- Working with existing inference infrastructure
Nvidia's advantage here is research quality and resources, but competitive techniques will likely emerge. The fundamental insight—that models can learn their own sparsification patterns—is not unique to DMS. We'll see variations and improvements.
For enterprises, this is good news. Competition drives innovation and adoption. Even if you don't use Nvidia's exact DMS implementation, expect alternative open-source implementations to emerge quickly. The technique is publishable and reproducible.

Practical Considerations for Your Infrastructure
If you're thinking about adopting DMS, here are practical questions to ask:
What's your current memory bottleneck? Profile your inference workloads. Use tools like nvidia-smi, PyTorch profilers, or vLLM's built-in monitoring. If you're compute-bound (GPUs are at high utilization), DMS won't help much. If you're memory-bound (GPUs waiting for data), DMS could be transformative.
What models are you running? DMS works with standard transformer models. If you're using proprietary architectures or heavily customized models, integration might be harder.
What's your inference framework? DMS works with vLLM, TensorRT, Triton, and standard PyTorch. If you're using something more exotic, integration work increases.
What's your cost sensitivity? If inference costs are less than 5% of your overall infrastructure budget, the effort to implement DMS might not be justified. If it's 20%+, it's definitely worth investigating.
Do you have the engineering resources? Retrofitting a model takes a few GPU-hours. Integration and testing take weeks or months. Do you have people available? Can you contractors help?
What's your risk tolerance? Retrofitted models are new models. There's a small chance of unexpected behaviors. Do you have the monitoring infrastructure to catch problems? Can you roll back quickly?
For most enterprises running serious LLM inference, the answers suggest trying DMS is worthwhile. The upside (8x cost reduction or improvement in capability) is substantial. The downside (a few weeks of engineering time) is manageable.

The Economic Shift This Enables
Let's zoom out for a moment and think about what 8x KV cache compression means for the LLM industry.
Today, inference costs are a major concern for LLM companies. If you're offering an AI service, inference might be 30-50% of your infrastructure costs. Reducing it by 8x transforms economics.
For OpenAI, Anthropic, Google, or other API providers, 8x compression means they can either:
- Drop prices by 75% and maintain margins
- Keep prices stable and expand to 8x more users
- Invest in more powerful models and keep prices the same
- Some combination of the above
This suggests we're heading toward a period of price competition in LLM APIs driven by efficiency improvements. Companies that implement DMS early have a cost advantage that translates to pricing power or margin expansion.
For enterprises running their own inference (increasingly common for sensitive workloads), 8x compression means you can achieve the same capabilities with 8x cheaper infrastructure. Instead of building a
For smaller AI companies and startups, DMS might be the difference between viability and failure. If you're using inference APIs, even at optimized rates, DMS in your own infrastructure could cut costs below what you're paying for API access.
This is not a small change. This is a shift in the fundamental economics of LLM deployment. Over the next 2-3 years, we'll see this ripple through the industry.

Recommendations for Teams Evaluating DMS
If you're responsible for ML infrastructure or cost optimization, here's what I'd recommend:
First: Measure your current state. Use profiling tools to understand your bottlenecks. What fraction of your inference workload is memory-bound versus compute-bound? What's your current KV cache utilization? What are your actual per-token inference costs? Without these baselines, you can't evaluate DMS effectively.
Second: Assess your models. Which of your deployed models would benefit from DMS? Generally, reasoning models and long-context models benefit most. Short-context tasks might see less improvement.
Third: Run a pilot. Don't implement this for your entire production workload immediately. Pick one model, one dataset, and retrofit with DMS. Run it in parallel with your current version. Measure everything: accuracy, latency, throughput, memory usage, cost. Document any differences, even small ones.
Fourth: Iterate based on results. If the pilot succeeds, expand to more models. If it reveals issues, adjust and retry. Each model and workload is slightly different.
Fifth: Plan for the future. As new models are released, your retrofitting process will become standard operational procedure. Factor this into your planning.
Sixth: Combine with other techniques. DMS isn't a silver bullet. Combine it with quantization, efficient attention mechanisms, smart batching, and other optimization strategies.
Seventh: Monitor the research. This is an active area. New techniques will emerge. Keep your team aware of competitive approaches and be ready to evaluate them.
The teams that execute this well will have significant cost and capability advantages over teams that don't. In a competitive landscape, that matters.

Conclusion: The Inflection Point
Dynamic memory sparsification represents a genuine breakthrough in making reasoning-capable LLMs practical and cost-effective at scale.
The problem it solves is real: as models think longer and generate more reasoning tokens, memory consumption becomes the bottleneck. Traditional approaches to address this either lose critical information (sliding window), impose rigid heuristics (attention pruning), or add latency overhead (memory paging).
DMS is elegant because it learns. The model itself figures out what to keep and what to discard. This learned policy is more effective than any heuristic could be. It generalizes across tasks and domains. And it can be retrofitted onto existing models in hours, not weeks or months.
The implications are substantial:
For enterprises: 8x reduction in inference costs or 8x improvement in reasoning capability with the same infrastructure. This is meaningful. It changes what's economically viable to deploy.
For API providers: Cost advantage that translates to pricing power or margin expansion. First-mover advantage is real in efficiency improvements.
For the field: A signal that memory efficiency is increasingly important as reasoning becomes central to LLM capabilities. Expect more research in this direction.
For individuals: If you're building AI products, DMS is a tool to keep in your toolkit. It solves a real problem that you're probably experiencing if you're doing reasoning workloads at scale.
The question isn't whether DMS will be adopted—it will be. The question is whether your organization will be early or late. Early adopters will have cost advantages and capability advantages. Late adopters will eventually catch up but will have missed the window where efficiency translated to competitive advantage.
If you're running LLM inference, evaluate this. Run a pilot. Measure the impact on your specific workload. The effort is small, the potential upside is substantial, and the downside risk is manageable.
This is the kind of research that might seem like a modest 8x improvement in one paper, but compounds over time and across deployments into something that fundamentally changes how LLM infrastructure works.
FAQ
What is dynamic memory sparsification in the context of large language models?
Dynamic memory sparsification (DMS) is a technique developed by Nvidia researchers that trains language models to intelligently manage their KV (key-value) cache by learning which tokens are essential for reasoning and which can be discarded. Unlike rigid heuristics that remove old tokens indiscriminately, DMS allows the model itself to decide what information to keep or evict, achieving up to 8x compression of the cache while maintaining or improving reasoning accuracy.
How does DMS differ from other KV cache compression techniques like sliding window or attention pruning?
DMS differs fundamentally by empowering the model to learn its own sparsification policy rather than imposing external rules. Sliding window approaches discard all information beyond a certain point, which breaks reasoning that references earlier context. Attention pruning uses heuristics that often discard critical information. DMS learns through training which tokens are actually important for specific tasks, generalizing better across different problem domains. Additionally, DMS includes a delayed eviction mechanism that allows the model time to extract information from tokens before they're removed from memory.
Can DMS be applied to existing models without retraining from scratch?
Yes, this is one of DMS's major practical advantages. Existing pre-trained models like Qwen-3-8B or Llama 3.2 can be retrofitted with DMS in just 1,000 training steps, taking only hours on a single H100 GPU. The process involves adding learnable parameters to attention layers while keeping the original model weights frozen, similar to Lo RA (Low-Rank Adaptation). This makes adoption accessible to enterprises without massive computational resources.
What is the delayed eviction mechanism and why does it improve performance?
Delayed eviction is a key innovation in DMS that keeps tokens flagged for eviction in a temporary local window (typically 100-200 steps) before permanently removing them from the cache. This is crucial because tokens often contain context that hasn't been fully integrated into the model's internal state. By maintaining temporary access to flagged tokens, the model can extract remaining information and incorporate it into future computations before the token is truly deleted. This mechanism is why DMS often improves accuracy rather than just maintaining it.
What are the real-world implications of 8x KV cache compression for enterprise AI infrastructure?
The economic implications are substantial. An enterprise running inference on 100 GPUs can either serve 8x more concurrent users with the same hardware, extend reasoning chains 8x longer without additional infrastructure, reduce hardware requirements by 8x (or shift to cheaper GPUs), or some combination of these benefits. For a company spending $5-10 million annually on inference infrastructure, this translates to potential savings of millions of dollars or ability to serve significantly more customers without additional investment. For API providers, 8x cost reduction directly improves margins or enables aggressive pricing strategies.
On which benchmarks and models has DMS been validated, and how do the results compare?
Nvidia researchers validated DMS on reasoning benchmarks including AIME 2024 (mathematics), GPQA Diamond (science), and Live Code Bench (coding), achieving 8x KV cache compression while maintaining or improving accuracy. Notably, on GPQA Diamond, compressed models actually outperformed uncompressed baselines, suggesting sparsification forces more efficient representation learning. The technique was demonstrated across multiple architectures including Llama 3.2 and Qwen-R1 (based on Deep Seek's architecture), and handles sequences up to 128,000 tokens while maintaining compression ratios and accuracy.
How does DMS integrate with existing inference frameworks and what are the deployment requirements?
DMS requires no custom hardware or specialized inference engines. It works directly with standard inference frameworks like vLLM, TensorRT, and Triton, as well as standard PyTorch implementations. The DMS decision-making happens in parallel with normal attention computation, introducing negligible latency overhead. In fact, the reduced KV cache size often improves overall inference speed. Deployment simply requires adding trained DMS parameters to the model and deploying it like any standard model—no code rewrites or infrastructure changes needed.
What are the limitations of DMS and where might it not be the best solution?
DMS limitations include limited published details on how sensitive retrofitting is to the training data used, the addition of hyperparameter complexity (delayed eviction window length), and potential generalization edge cases when models encounter domains very different from retrofitting data. Additionally, DMS must be retrained if you update to a new model version, though this remains just hours of work. For short-context applications where KV cache isn't the bottleneck, or compute-bound workloads where you're not memory-limited, DMS provides less benefit. Teams should profile their specific workloads first.
How does DMS compare in terms of efficiency to other compression techniques like quantization or model distillation?
DMS addresses different optimization dimensions than quantization or distillation. Quantization reduces model weight precision (4x-8x compression) and is orthogonal to DMS. Distillation trains a smaller model to match larger one behavior (5-10x size reduction) but sacrifices peak performance. DMS specifically targets KV cache memory footprint during inference without reducing model size or capability. The techniques are complementary—applying quantization plus DMS plus efficient attention kernels together yields compounding benefits that exceed any single technique alone.
What timeline should teams expect when adopting DMS, and what are the key implementation milestones?
Adoption typically follows this timeline: evaluation and profiling (1-2 weeks) to understand current bottlenecks, prototyping with test models (2-4 weeks) to validate benefits on your specific workloads, pilot deployment to canary traffic (month 2), and full production migration (month 3+). The actual retrofitting process takes hours, but integration testing and monitoring takes weeks. For smaller teams with fewer resources, compress these timelines; for large enterprises, you might have parallel tracks. Success depends on having clear metrics before you start and monitoring closely during deployment.
What is the broader research and competitive landscape for KV cache efficiency, and are there alternative approaches?
KV cache efficiency is an active research area with multiple approaches being explored. Other techniques include attention pruning (removing unused connections), token merging (combining tokens into single representations), low-rank approximations of the cache, and architectural innovations in attention mechanisms. Nvidia's DMS distinguishes itself through learning-based sparsification that maintains full information, minimal training overhead, and compatibility with existing infrastructure. While competitive techniques will emerge, the core insight that models can learn their own sparsification patterns will likely influence the field broadly. Teams should remain aware of emerging alternatives but can confidently evaluate DMS today.
Key Takeaways
- Nvidia's DMS technique compresses KV cache by 8x while maintaining reasoning accuracy through learned sparsification policies instead of rigid heuristics
- Existing models like Qwen-3-8B can be retrofitted with DMS in hours using just 1,000 training steps on a single GPU
- 8x memory compression translates directly to enterprise economics: same hardware can serve 8x more users, enable 8x longer reasoning chains, or reduce infrastructure costs by 8x
- Delayed eviction mechanism allows models to extract information from tokens before deletion, often improving accuracy rather than just maintaining it
- DMS works with standard inference infrastructure (vLLM, TensorRT) with no custom hardware requirements and can be combined with other compression techniques
Related Articles
- Benchmark's $225M Cerebras Bet: Inside the AI Chip Revolution [2025]
- OpenAI Frontier: The Complete Guide to AI Agent Management [2025]
- Nvidia's $100B OpenAI Gamble: What's Really Happening Behind Closed Doors [2025]
- Context-Aware Agents & Open Protocols in Enterprise AI [2025]
- How 16 Claude AI Agents Built a C Compiler Together [2025]
- Anthropic Opus 4.6 Agent Teams: Multi-Agent AI Explained [2025]

