![OpenAI's $10B Cerebras Deal: What It Means for AI Compute [2025]](https://tryrunable.com/blog/openai-s-10b-cerebras-deal-what-it-means-for-ai-compute-2025/image-1-1768430192901.jpg)
Open AI's $10 Billion Cerebras Deal: Reshaping the Future of AI Compute Infrastructure
Last week, Open AI made a move that sent shockwaves through the AI industry. The company announced a massive $10 billion, multi-year agreement with chipmaker Cerebras to deliver 750 megawatts of computing power through 2028. On the surface, it sounds like another big tech deal. But dig deeper, and you'll see this isn't just about money or processing power.
This partnership signals something much more fundamental: the way we build AI systems is shifting. For years, NVIDIA's GPUs dominated the AI compute space. They still do. But Open AI's bet on Cerebras reveals cracks in that monopoly, and it's worth understanding why.
Here's what's actually happening. Open AI is explicitly addressing a problem that most AI companies face but rarely talk about openly: latency in complex reasoning tasks. When your model needs time to think through a hard problem, current GPU setups can't deliver responses fast enough. Cerebras claims their architecture solves this. That's not a small claim. That's a fundamental architectural difference.
The timing matters too. AI companies are in a race to reduce inference costs while improving speed. NVIDIA can't solve both at once because of GPU architecture constraints. Cerebras believes they can. Whether they're right depends on execution, but Open AI's willingness to commit $10 billion suggests they see real potential.
What also stands out: Sam Altman already had money invested in Cerebras before this deal. Open AI even considered acquiring them. This isn't a cold business transaction. This is someone who knows the technology betting heavily on it. That's the kind of conviction that moves markets.
In this article, we're breaking down what this deal actually means. We'll walk through the technical architecture, the competitive dynamics, the broader implications for AI infrastructure, and what this tells us about where the industry is heading.
TL; DR
- The Deal Size: Open AI committed $10 billion to Cerebras for 750 megawatts of compute capacity running through 2028, fundamentally diversifying its compute infrastructure strategy.
- The Real Problem: Current GPU-based systems struggle with low-latency inference for complex reasoning tasks, causing slow response times on difficult questions.
- Cerebras' Edge: Their wafer-scale AI chip architecture delivers faster inference speeds than traditional GPU clusters, specifically optimized for real-time AI workloads.
- Market Implications: This deal legitimizes alternative AI chip architectures and threatens NVIDIA's monopoly on high-end AI compute, forcing the industry to reconsider infrastructure choices.
- The Broader Pattern: Major AI companies are building diversified compute portfolios instead of relying solely on NVIDIA, signaling a fundamental shift in how AI infrastructure will be built going forward.

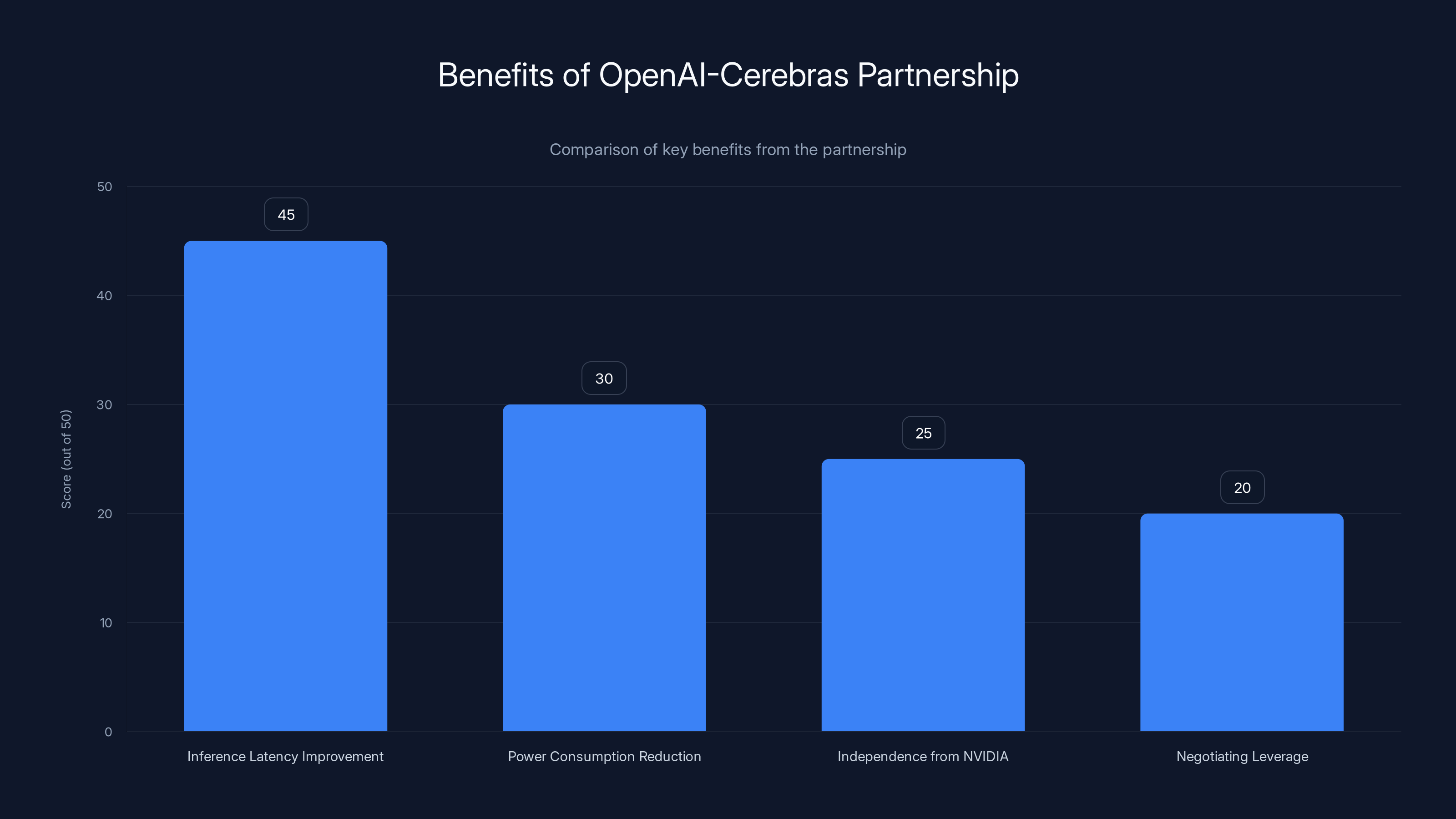
The partnership with Cerebras offers OpenAI significant improvements in inference latency, power efficiency, and strategic independence, with latency improvements being the most impactful (Estimated data).
Understanding the Open AI-Cerebras Partnership: The Core Economics
Let's start with the numbers, because they tell a story. Ten billion dollars over three years breaks down to roughly $3.3 billion per year. That's substantial, but it's not Open AI's entire compute budget. In fact, it's a calculated diversification.
For context, some analysts estimate Open AI spends
Why would Open AI split its bets this way? Because putting all your eggs in one supplier's basket is dangerous. NVIDIA controls the GPU market, and they know it. Prices reflect that market power. When you're making billion-dollar infrastructure decisions, you can't afford to be dependent on a single vendor, even if that vendor is dominant.
Cerebras' value proposition addresses a specific pain point: inference latency. In machine learning terms, inference is when you actually use a trained model to generate outputs. Training is where you build the model. Both are expensive, but they have different performance requirements.
For training, you can tolerate slightly longer processing times in exchange for more efficient hardware. For inference, especially in real-time applications, latency is everything. A user asking Chat GPT a question won't wait 15 seconds for an answer. They'll switch to Gemini. So inference speed directly impacts user experience and retention.
NVIDIA's GPU architecture wasn't designed for low-latency inference at scale. It was designed for parallel processing across many chips. That parallelism helps training, but it introduces network overhead and latency when you need real-time responses. Cerebras' wafer-scale approach theoretically removes that bottleneck by putting computation directly on a single chip.
The $10 billion price tag reflects belief in this technical differentiation. Open AI is betting that Cerebras can deliver measurably faster inference for the specific workloads that matter most to their business: complex reasoning, multi-step problem solving, and real-time API responses.
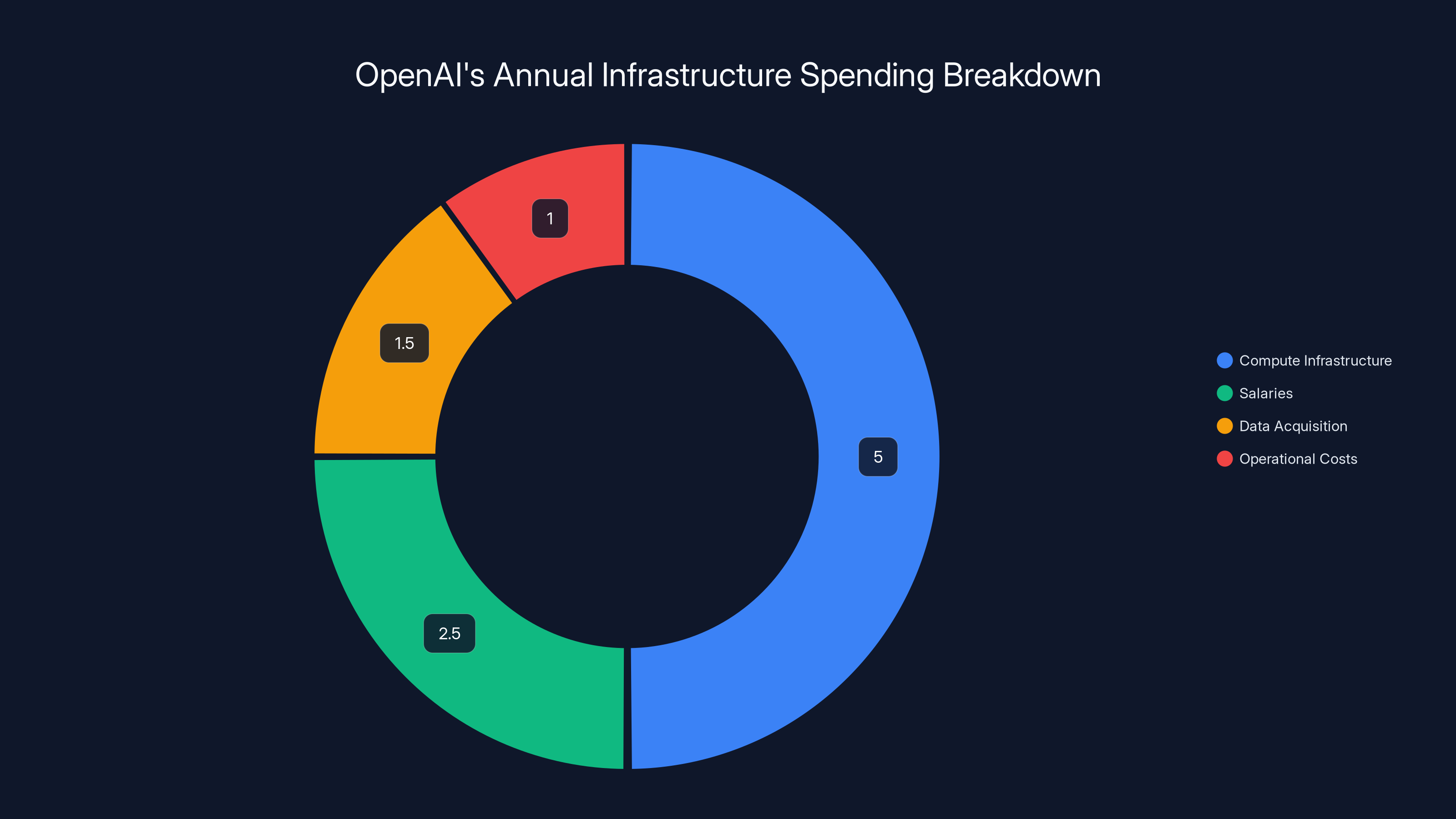
Estimated data shows that compute infrastructure accounts for 50% of OpenAI's annual infrastructure spending, highlighting its critical role in operations.
The Technical Architecture: Why Cerebras Differs from Traditional GPUs
To understand why Open AI made this bet, you need to understand how Cerebras' hardware fundamentally differs from the NVIDIA GPUs currently powering most of the AI industry.
NVIDIA GPUs operate on a principle of parallel processing. A single GPU contains thousands of small processing cores, all working simultaneously on different pieces of data. To train large language models, you connect multiple GPUs together using high-speed interconnects. This works well for training because the computations are highly parallelizable.
But there's a catch. When you connect multiple GPUs, you introduce communication overhead. Data has to travel between chips, and that takes time. In training scenarios, you're doing so much computation that this overhead is negligible compared to the total time. But in inference, where you might need to generate tokens sequentially, this latency compounds.
Cerebras took a different architectural path. Instead of multiple separate chips connected by fast interconnects, they built a single wafer-scale processor. Imagine a chip the size of a dinner plate, with 850,000 AI-optimized cores, all on one piece of silicon. Because everything's on a single die, there's no inter-chip communication. All the data movement happens at the silicon level, which is orders of magnitude faster.
That's the core technical insight. When you eliminate the communication bottleneck, you fundamentally change what's possible with inference. You can run larger models with lower latency. You can batch more requests simultaneously. You can achieve better throughput per unit of power consumed.
But here's where it gets complicated. Wafer-scale production is notoriously difficult. Manufacturing defects destroy yields. Cerebras has had to develop custom manufacturing processes just to make these chips viable. That's capital intensive. That's why they need a $10 billion anchor customer like Open AI.
From an engineering perspective, Cerebras' architecture excels at specific workload types. It's optimized for dense matrix operations, transformer computations, and sequence processing. These are exactly the operations that power large language models during inference.
But it's not universally better. For certain other workloads—like sparse operations or graph processing—GPU architecture might still be superior. That's why Open AI isn't abandoning NVIDIA. They're diversifying based on workload requirements.
The Inference Problem Open AI Is Actually Solving
To understand why this deal matters, we need to talk about a problem that affects every large language model company: the inference speed-quality tradeoff.
Let's say a user asks GPT-5 a genuinely difficult question. Something that requires multi-step reasoning, retrieving relevant context, and synthesizing complex ideas. The model needs to "think" through this problem. That thinking translates to computation time.
With current GPU infrastructure, complex inference tasks can take 5-15 seconds. That's an eternity in consumer applications. Users expect responses in under 2 seconds, ideally under 1 second. So there's pressure to simplify the problem, use smaller models, or cut off computation early.
But cutting off computation early means worse answers. Smaller models mean less capable reasoning. You're trading quality for speed, and that's a losing game in a competitive market.
Cerebras' infrastructure theoretically lets you have both. Faster computation means you can run full-capability models while still hitting latency targets. That's not a small thing. That's the difference between a tool people actually use regularly and one they abandon because it's too slow.
Here's the math. If Cerebras can cut inference latency by 50%, that directly impacts:
Both variables improve simultaneously. Better models take longer to compute, but if you've eliminated infrastructure latency, you can keep speed constant while improving quality.
Open AI has framed this as enabling "real-time AI." That phrase has become somewhat buzzwordy, but what they actually mean is: AI systems that can handle complex reasoning while maintaining human-like conversation speed. That's genuinely difficult. That's worth $10 billion.
The customer impact is measurable. If your API response times drop from 8 seconds to 3 seconds for complex queries, your API conversion rate improves. Users complete more interactions. Businesses build more AI-dependent features. That's the economic driver behind this deal.
It's also worth noting that this impacts Open AI's profit margins directly. Inference is cheap to serve, but latency affects how many tokens you can generate per unit of hardware. If Cerebras hardware can generate tokens 50% faster per unit of power, suddenly your cost per API call drops significantly. At scale, that's hundreds of millions of dollars in margin improvement.
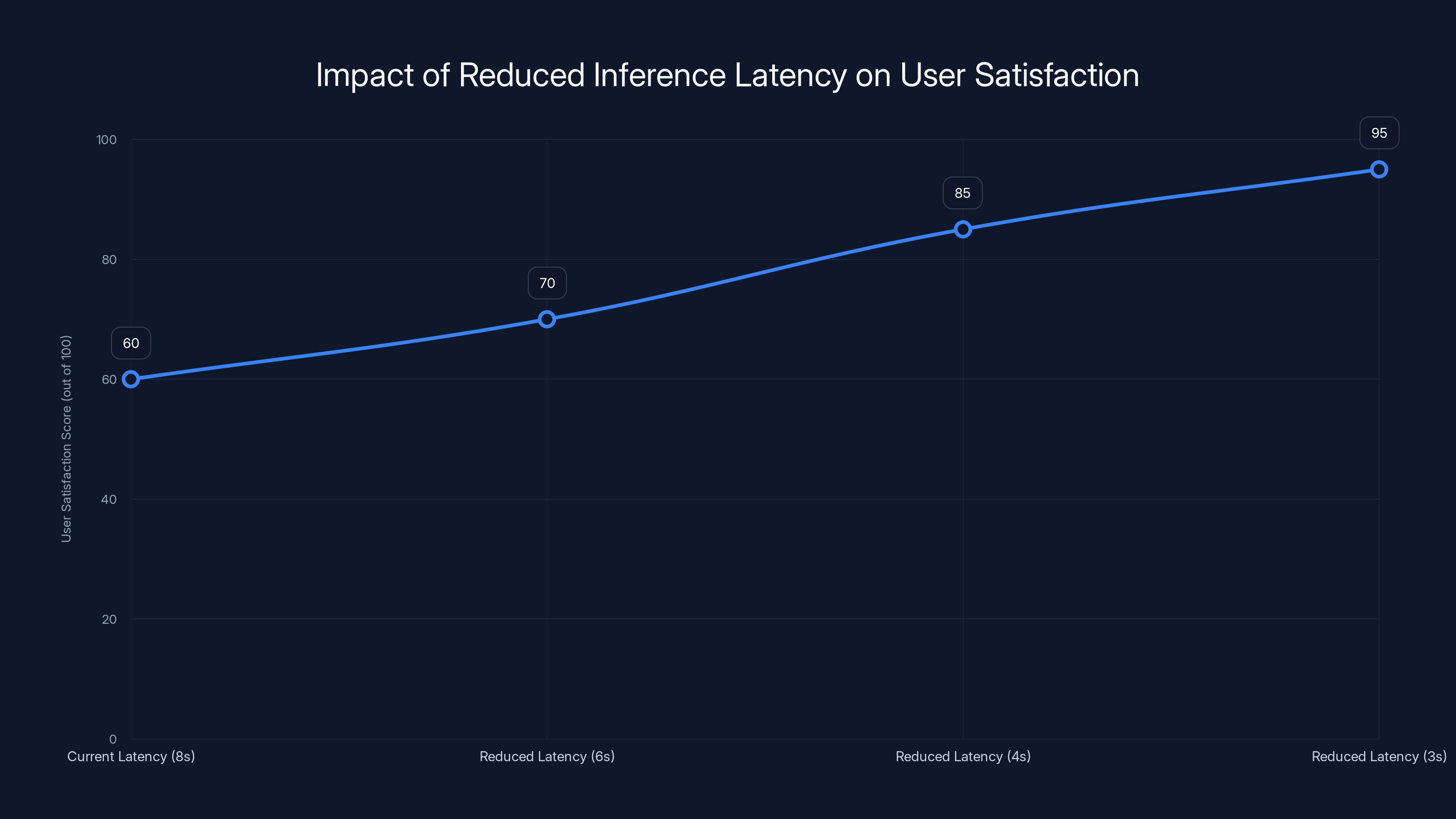
Estimated data shows that reducing inference latency from 8 seconds to 3 seconds can significantly increase user satisfaction scores, demonstrating the potential impact of improved infrastructure on user experience.
Market Dynamics: Breaking NVIDIA's Stranglehold
To understand why this deal matters beyond just Open AI, you need to grasp NVIDIA's current market position. It's almost monopolistic.
If you want to train a large language model, you buy NVIDIA H100s or their newer chips. You don't have realistic alternatives. They own the market. That gives them enormous pricing power. NVIDIA can raise prices, limit supply, or impose restrictions, and AI companies have to accept it because there's nowhere else to go.
That's unsustainable long-term. Every major AI company is actively looking for alternatives. Microsoft has been investing in custom chips. Meta has been developing their own inference hardware. Google has TPUs (Tensor Processing Units) for their own use but doesn't sell them commercially in a way that threatens NVIDIA.
Cerebras enters this dynamic as a legitimate third option. Not for training (though they're working on that), but specifically for inference. If Open AI is running significant inference workloads on Cerebras hardware, that's 750 megawatts of compute that's not going to NVIDIA. That matters.
For the broader AI industry, this signals that alternative architectures are viable. If Open AI trusts Cerebras with $10 billion, other companies might too. That creates competition, which forces better pricing and innovation from NVIDIA.
But here's the reality check: NVIDIA still dominates. They're not threatened by this deal in any immediate sense. But long-term, this kind of diversification compounds. If enough AI companies split their compute infrastructure across multiple vendors, NVIDIA's ability to dictate terms erodes.
The deal also sends a signal to investors in other AI chip companies. Companies like Graphcore, Groq, and others in the inference space just got validation from the world's most sophisticated AI customer. That attracts capital and talent. It accelerates development of competitive alternatives.
From NVIDIA's perspective, they probably view this as expected competitive activity. NVIDIA executives have been explicitly stating that they expect competition in inference hardware. They're investing heavily in improving their own inference efficiency. Their next-generation chips will likely have better inference performance.
But they can't match Cerebras' fundamental architectural advantage for low-latency inference without abandoning their entire GPU paradigm. That's path dependent. Once you've invested billions in a particular architecture, you can't pivot entirely without massive disruption.
Why Sam Altman's Investment Matters
One detail that shouldn't be overlooked: Sam Altman already invested personal money in Cerebras before this deal. He's not just betting the company; he's betting his own capital. That changes the nature of the decision.
When a CEO commits personal capital to a vendor they then do major business with, you have to ask questions about conflict of interest and judgment. But you also have to acknowledge that if the deal is bad for Open AI, it's bad for Altman too. His interests are aligned.
More broadly, Altman's involvement with Cerebras pre-dates this deal by years. Open AI even explored acquiring Cerebras at one point. That level of institutional knowledge and conviction suggests this isn't a desperate move or a desperation play. It's a calculated bet from someone who understands the technology deeply.
Altman has been increasingly vocal about the compute challenges facing AI development. He's acknowledged that training large models requires more compute than any single company can easily justify. That's why he's been pushing for greater capitalization and better infrastructure investments.
This deal aligns with that broader thesis. Compute is the constraint. Infrastructure strategy determines competitive advantage. By diversifying compute infrastructure and partnering with Cerebras, Open AI is addressing a real bottleneck in their ability to scale.
It also positions Open AI defensively against their competitors. If Microsoft becomes too controlling (they're a major investor in Open AI), or if NVIDIA constrains supply, Open AI has options. That's strategically valuable.
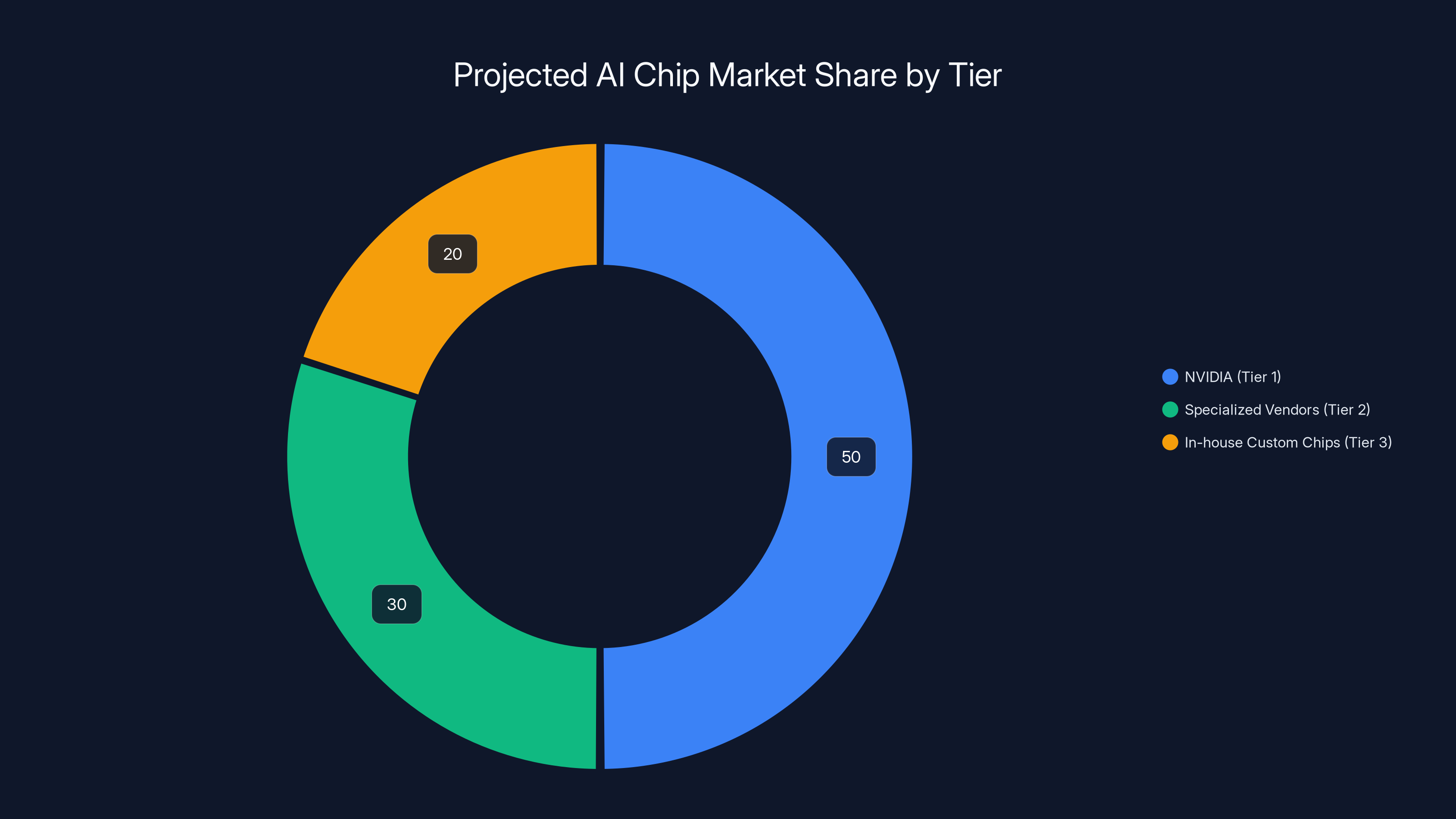
Estimated data shows NVIDIA maintaining dominance in training hardware, while specialized vendors and in-house custom chips capture significant shares in inference workloads.
Cerebras' Path to Credibility
Cerebras is a company that's been through multiple cycles of hype and skepticism. Founded over a decade ago, they've made bold claims about AI compute superiority that didn't always pan out. Or rather, the claims were technically accurate but didn't translate into market adoption.
Why? Because being technically superior isn't enough. You also need the software ecosystem, the customer willingness to rewrite code, and the support infrastructure. Cerebras had the chips but struggled with the broader ecosystem.
This Open AI deal changes that calculation dramatically. Open AI is not just a customer; they're a validation partner. If Open AI's systems run well on Cerebras hardware, and if Open AI publicly attributes performance improvements to Cerebras, that's credibility that money can't buy.
Moreover, Cerebras was facing a critical funding challenge. They filed for IPO in 2024 but postponed multiple times. The IPO window was closing. Venture capital was getting tighter. A $10 billion customer agreement is basically a de facto IPO alternative. It proves the business model works and that customers are willing to pay for the product.
Now Cerebras has optionality. They can go public when they want, not because they're desperate. They can continue raising capital at higher valuations. They can invest in manufacturing, software development, and customer support.
For a hardware company, this is transformational. Most AI chip startups fail because they can't raise enough capital to build the manufacturing infrastructure needed for scale. Cerebras just solved that problem with one customer.
But there's execution risk. Cerebras has to deliver on the promises. The chips have to work. The software has to be reliable. The manufacturing has to scale. If any of those elements fails, the deal becomes a liability. But that's why you work with the world's most sophisticated AI company. Open AI will help you solve those problems.

The Broader Shift in AI Infrastructure Strategy
This deal is part of a larger pattern. Over the past two years, every major AI company has been reconsidering their infrastructure strategy.
Microsoft is developing custom chips alongside GPU investments. Meta is investing in custom inference hardware. Google uses TPUs internally. Open AI is now diversifying across multiple vendors. Even NVIDIA is moving downstream, not just selling chips but offering integrated solutions.
This shift reflects a maturing AI market. When the field was young, you took whatever compute was available. Now that there are billions of dollars at stake, infrastructure decisions matter enormously. Companies are optimizing aggressively.
The pattern we're seeing is specialization by workload type. Different hardware is best for different tasks. Training benefits from certain architectural patterns. Inference benefits from others. Fine-tuning has its own requirements. Real-time serving has different constraints than batch processing.
A company like Open AI doesn't want to optimize for a single workload. They want to optimize across their entire portfolio. That requires a diverse infrastructure. NVIDIA GPUs for training. Cerebras for real-time inference. Maybe custom TPU-style chips for specific workloads.
That's the future of AI infrastructure. Not monopoly but portfolio. Not single vendor but diversified supply chain. That's better for innovation because vendors have to compete on merit. It's better for Open AI because they have leverage and alternatives.
It's also better for the AI industry broadly because it unlocks alternative architectures. If the only option is NVIDIA GPUs, companies are constrained by GPU-friendly algorithms. If multiple architectures are viable, you can optimize algorithms for what's actually best, not what's convenient.
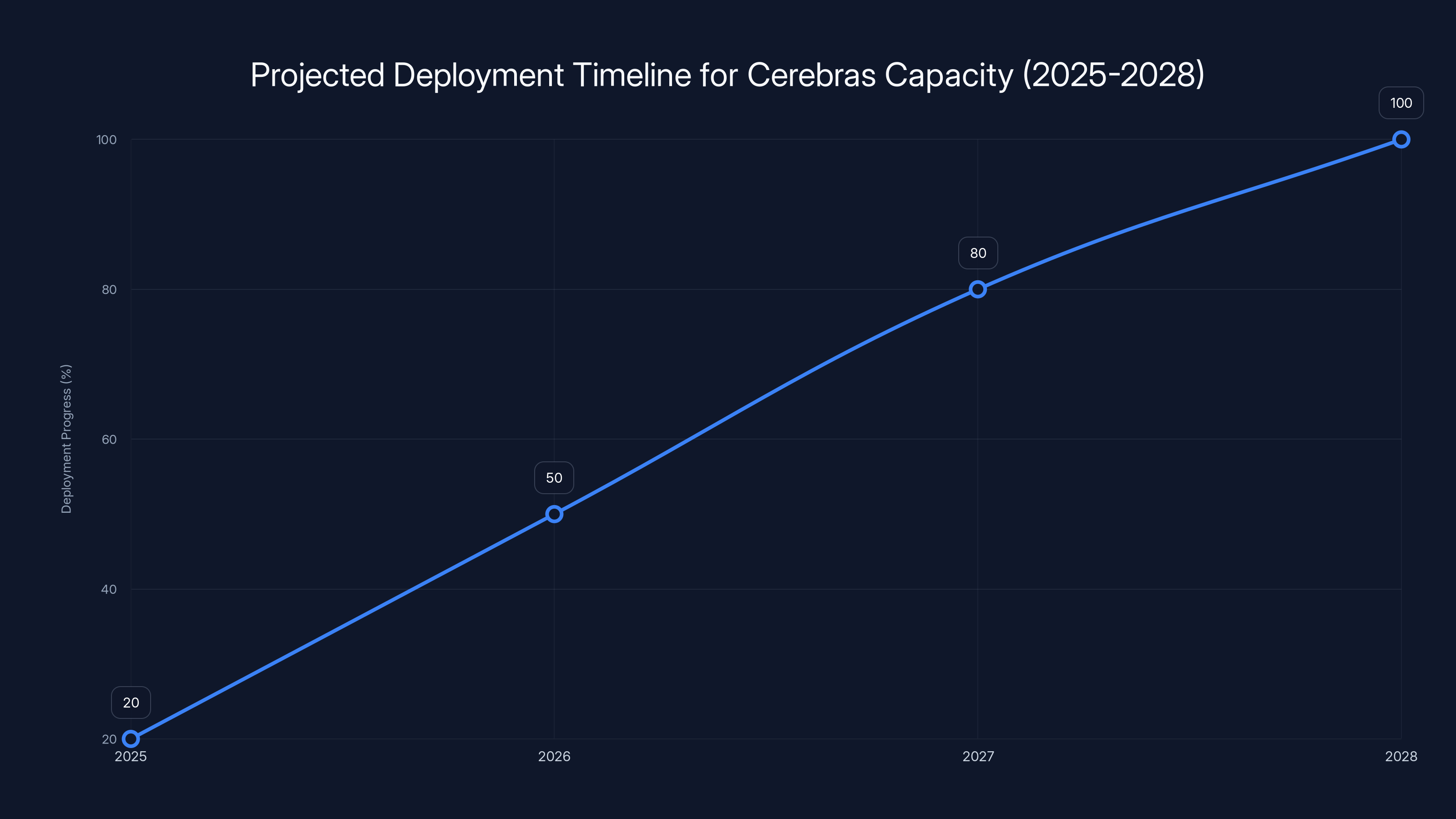
The timeline shows the projected progress of Cerebras capacity deployment at OpenAI, reaching full integration by 2027. Estimated data.
Technical Integration Challenges and Solutions
Just because Open AI committed to $10 billion for Cerebras compute doesn't mean integration is automatic. They're different architectures. They require different optimization approaches. Different programming models.
GPUs are well understood. There's decades of software development optimized for GPUs. Entire frameworks like CUDA make it easy to develop for NVIDIA hardware. Cerebras has their own software stack, but it's newer and less mature.
Open AI will need to invest significant engineering effort into:
- Porting models to Cerebras architecture and optimizing for their specific hardware constraints
- Building hybrid execution frameworks that can split workloads between GPUs and Cerebras hardware based on optimization criteria
- Developing monitoring and profiling tools to understand performance across different hardware
- Creating load balancing systems that route inference requests to the optimal hardware for each query type
- Building disaster recovery and redundancy across heterogeneous infrastructure
- Training ML engineers on Cerebras-specific optimization techniques
Each of these is non-trivial. That's why Open AI isn't expecting immediate results. This deal runs through 2028. They'll spend years optimizing the integration.
But that's also why the deal makes sense. By committing long-term, Open AI gets Cerebras' direct support for optimization. They get influence over hardware roadmap decisions. They get preferential access to new chips as they're developed.
Cerebras, in turn, gets the world's best AI engineers using their hardware and identifying optimization opportunities. That feedback loop accelerates their own product development.

Financial Implications for Open AI's Economics
Let's talk about what this deal means for Open AI's financial model. Understanding the economics illuminates why they made this bet.
Open AI's primary revenue comes from API usage. The more compute they can provide per dollar of infrastructure cost, the better their margins. This deal directly improves that metric.
Let's do some rough math. Assume Cerebras hardware can run inference 40-50% faster than GPU equivalents. That means:
- Same hardware, more tokens generated per second
- Fewer tokens needed to serve the same user base
- Lower cost per token
- Better profit margins on every API call
On a
But there's also strategic value that's hard to quantify. Having an alternative to NVIDIA gives Open AI negotiating leverage. When the next GPU generation comes out, Open AI can say, "We don't necessarily need your newest chips. We have Cerebras as an alternative." That negotiating position is worth significant money.
There's also the optionality angle. As AI models get more sophisticated and inference demands increase, having multiple hardware partners means you're not bottlenecked by any single manufacturer's production capacity. That's insurance against supply shocks.
For Cerebras, the financial model is straightforward: they get revenue to support manufacturing scale and R&D. For Open AI, it's about optimizing their entire infrastructure portfolio for maximum efficiency and leverage.
The interesting wrinkle is how this affects Open AI's Path to profitability. Open AI has been burning money on infrastructure. A $10 billion compute deal at favorable rates (volume discount on Cerebras chips) directly reduces burn. It makes the path to profitability clearer.
That matters because Open AI is technically in a partnership with Microsoft, but they maintain significant autonomy. Better unit economics mean more autonomy. They don't need to rely on Microsoft funding every infrastructure expansion.
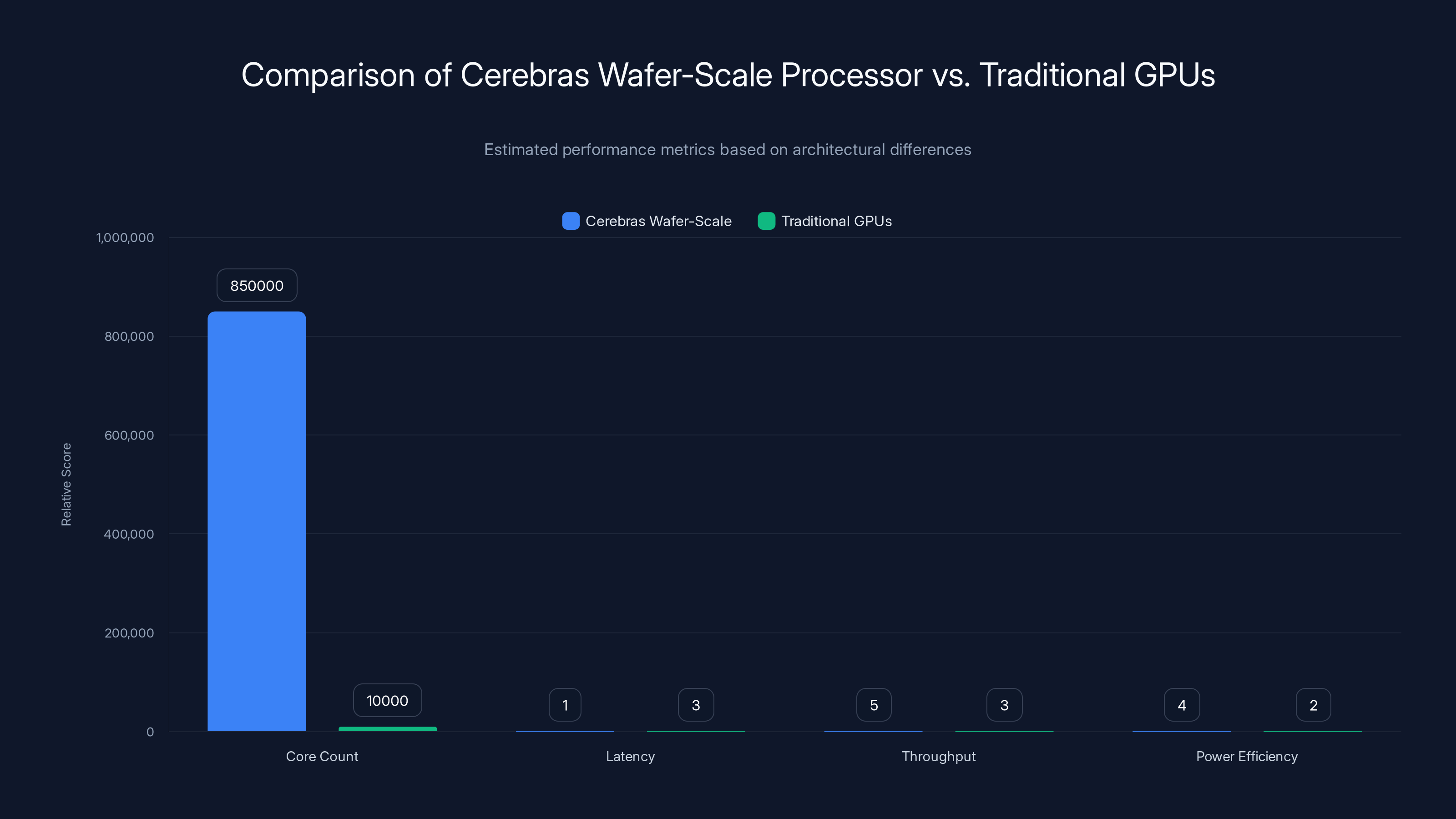
Cerebras' wafer-scale processor significantly outperforms traditional GPUs in core count and latency, offering better throughput and power efficiency. (Estimated data)
Competitive Response: What Other AI Companies Are Likely Doing
Open AI's deal with Cerebras isn't happening in a vacuum. Competitors are watching and making their own moves.
Google has less urgency because they built TPUs years ago and can optimize their own infrastructure. But they're probably accelerating TPU development and considering whether to monetize custom AI chips more broadly.
Meta is in a similar position. They built custom chips for internal use. Now they might be thinking about selling those chips to others or licensing their designs. Meta has the scale to justify large-scale chip manufacturing.
Microsoft is clearly investing in chip development. Whether that's for external sale or just for competitive advantage with Open AI is unclear. But either way, they're diversifying away from pure NVIDIA dependence.
Anthropic, a newer AI company, probably doesn't have the capital to match a $10 billion deal, but they can look at acquiring smaller stakes in multiple hardware vendors. That gives them optionality.
What we're likely to see is a bifurcation in the AI chip market:
- Tier 1: NVIDIA continues dominating training hardware but loses inference market share to specialized competitors
- Tier 2: Specialized vendors like Cerebras, Groq, and others capture inference-specific workloads
- Tier 3: In-house custom chips (TPU, custom Microsoft chips) used by large companies for their own workloads
That's actually healthy competition. It prevents monopoly-driven pricing. It drives innovation in multiple architectural directions. It lets the best technology win rather than the one with the largest sales force.
NVIDIA's response will be interesting to watch. They could try to improve their own inference performance. They could invest in software to make their GPUs more inference-friendly. They could acquire competitors. Or they could accept that inference is a separate market and focus on maintaining training dominance.

Future Scaling: What Happens After 2028?
The Open AI-Cerebras deal runs through 2028. What happens after that is worth thinking about.
Option 1: The deal renews. Cerebras has proven themselves. Performance is great. Both companies want to continue.
Option 2: Open AI diversifies further. They use Cerebras through 2028, but also strike deals with other vendors. By 2028, they're running on three or four different hardware platforms.
Option 3: Cerebras gets acquired. The company has proven viability. A larger chipmaker buys them. The deal continues under new ownership or gets renegotiated.
Option 4: Technology disruption. Some new chip architecture emerges that's even better than Cerebras. Open AI switches to that.
My guess is we'll see a combination. Open AI continues with Cerebras but also diversifies. The AI infrastructure market becomes increasingly fragmented, with no single vendor being dominant.
What also might happen: as Cerebras matures, they might start serving other AI companies. The Open AI deal is an anchor, but building a customer base beyond that provides revenue diversification. By 2028, Cerebras might be selling to multiple major AI companies.
That changes the competitive dynamic. If Cerebras is a neutral vendor serving multiple AI companies, they have more leverage and more growth opportunity. If they're dependent on Open AI, they're vulnerable.
For AI infrastructure going forward, expect this pattern to accelerate. Companies will build diverse infrastructure portfolios. Hardware vendors will proliferate. Software will become more important because it has to abstract away hardware differences.
The Energy Dimension: Power Consumption and Efficiency
One aspect of this deal that deserves more attention is the energy angle. The deal specifies 750 megawatts of compute capacity. That's a massive amount of power.
For context, 750 megawatts is roughly the amount of power consumed by 750,000 homes. It's enough to power a mid-sized city. The data center infrastructure required to support that is staggering.
Cerebras claims their hardware is more power-efficient than GPUs for certain workloads. If that's true, it matters enormously. Here's why:
Power consumption drives:
- Electricity costs
- Cooling requirements
- Real estate constraints
- Environmental impact
- Operational complexity
If Cerebras hardware delivers 50% more inference throughput per megawatt compared to GPUs, then Open AI is effectively getting 1,125 megawatts of GPU-equivalent compute from 750 megawatts of Cerebras hardware. That's massive.
For a company like Open AI, electricity costs are material. If they can reduce power consumption by 30-40%, that's hundreds of millions of dollars in Op Ex savings annually.
But there's a broader implication. AI is consuming an ever-increasing portion of global electricity. If AI chips can become more efficient, that reduces environmental impact and reduces pressure on the power grid. That's not a small thing.
Cerebras' efficiency gains (if they're real) are actually strategically important beyond just business economics. They enable scaling to larger model sizes without triggering regulatory backlash around power consumption.
The power efficiency question also illuminates why this is a 750-megawatt deal specifically. That's not random. It's probably calculated based on Open AI's inference demands and Cerebras' current manufacturing capacity. As Cerebras scales manufacturing, they might add more capacity.

Timeline: What We'll Actually See in 2025-2028
Now that the deal is announced, what's the actual timeline for deploying 750 megawatts of Cerebras capacity?
Year 1 (2025): Initial deployment and testing. Open AI sets up a Cerebras data center (or multiple locations). They port key models and services to run on Cerebras hardware. Limited production traffic, mostly testing and optimization. We see performance metrics start to emerge.
Year 2 (2026): Scaling production workloads. Open AI moves increasing volumes of inference traffic to Cerebras. They optimize their models for the hardware. Cerebras ramps manufacturing. We might see public performance claims and benchmarks published.
Year 3 (2027): Full production integration. Cerebras infrastructure is handling significant portions of Open AI's inference workload. The infrastructure is mature. Performance is proven. Cost savings are being realized.
Year 4 (2028): Deal expiration approach. Both parties evaluate continuation. New negotiations begin. Cerebras is now an established part of Open AI's infrastructure stack.
During this timeline, we'll likely see:
- Public announcements about performance improvements (carefully worded to not embarrass NVIDIA or other partners)
- Job postings from Open AI for Cerebras optimization experts
- Technical blog posts describing the integration architecture
- Industry analyst reports on inference chip performance comparisons
- Competitive responses from other AI companies
- Possible IPO or acquisition of Cerebras
The interesting question is transparency. Open AI might publish detailed performance metrics. Or they might keep everything confidential to maintain negotiating leverage. My guess is they'll publish enough to help Cerebras's credibility but not enough to reveal proprietary details.
Risk Factors: What Could Go Wrong
This deal assumes several things work out. Let's examine the risks:
Technical Risk: Cerebras hardware doesn't deliver promised performance improvements. This is the biggest risk. If the chips underperform or run into technical issues at scale, the deal becomes a sunk cost.
Manufacturing Risk: Cerebras can't scale manufacturing to deliver the promised capacity. Hardware bottlenecks emerge. Yields are lower than expected. This would delay deployment and increase costs.
Software Risk: Porting Open AI's models to Cerebras architecture proves more difficult than expected. Performance gains are eroded by software optimization challenges. Integration complexity exceeds estimates.
Market Risk: New competing technologies emerge that are better than both GPUs and Cerebras. The deal becomes obsolete before full deployment.
Financial Risk: Cerebras faces financial difficulties or is acquired by a competitor. The acquisition changes the terms of the deal or creates conflicts of interest.
Organizational Risk: Leadership changes at either company (Sam Altman departing, Cerebras CEO changes) affect the partnership's trajectory.
Regulatory Risk: Data center regulations, energy regulations, or chip manufacturing restrictions impact the deployment timeline.
Most likely? There will be some slippage. Maybe 10-15% less capacity than promised. Maybe 6-month delays. But the fundamental deal will work because Open AI is sophisticated enough to have done their due diligence, and Cerebras has sufficient capital to solve problems.
The bigger risk is that this becomes a case study in vendor lock-in. If Cerebras software becomes indispensable to Open AI's systems, and if other customers also depend on it, then Cerebras has market power. They could raise prices. They could restrict API access. That's a risk for Open AI to manage.

What This Means for Individual Developers and AI Companies
You might be thinking: "This is a massive deal between two giant companies. Why should I care?"
Good question. Here's why it matters:
Diversity in Infrastructure: As Open AI diversifies compute partners, the entire AI industry follows. That means more options for GPU alternatives, better pricing, more specialized hardware. If you're building AI applications, you have more choices.
API Performance Improvements: If Cerebras hardware improves Open AI's inference latency, that directly benefits everyone using Open AI's API. Your applications get faster responses. Your cost per API call might decrease.
Talent and Opportunities: Cerebras will need to hire hundreds of engineers to support this deployment. If you're interested in AI infrastructure, job opportunities are opening up.
Technology Education: As Cerebras' architecture becomes more visible, learning about specialized AI hardware becomes valuable. Current knowledge of GPU optimization might become less relevant as hardware diversifies.
Competitive Pressure: If Open AI gets significant cost reductions from diversified infrastructure, they'll have pricing leverage. They might reduce API costs, which cascades through the entire AI industry.
Software Abstraction: As hardware diversifies, software abstraction layers become more important. If you're building ML infrastructure software, this is a growth opportunity. You're abstracting away differences between GPU and Cerebras and other chips.
For developers building production AI applications, the message is simple: expect infrastructure to continue diversifying. Build software that's not tightly coupled to specific hardware. Use frameworks that abstract hardware differences. Assume that chips and architectures will change.
The Bigger Picture: AI Infrastructure As Competitive Advantage
Zoom out for a second. What does this deal tell us about the nature of competition in AI?
It tells us that infrastructure is becoming the primary competitive battleground. It's not anymore about who has the smartest researchers (though that still matters). It's about who can build the best systems most efficiently.
Open AI's bet on Cerebras is fundamentally an infrastructure bet. They're saying: "We can build better products if we have better infrastructure." That's a maturation from "AI is about research" to "AI is about engineering and economics."
That has profound implications. It means:
- Winners will be companies that can optimize infrastructure
- Hardware companies matter more than they did before
- Power and real estate become strategic resources
- Specialized vendors can compete with generalists
- Software abstraction becomes critical
For investors, it means infrastructure companies deserve serious attention. Cerebras' $22 billion valuation is justified if they can prove their technology works at scale. Other specialized hardware companies might deserve billions in valuation too.
For students and early-career professionals, it means understanding infrastructure is valuable. If you can optimize inference latency by 30%, or reduce power consumption by 20%, you become invaluable to an AI company.
For larger enterprises, it means you should be thinking about your own infrastructure strategy. Should you invest in custom chips like Google? Should you partner with multiple vendors like Open AI? Should you build proprietary systems?
The companies that get infrastructure right will have 10-20% cost advantages over competitors. At scale, that's billions of dollars of margin difference. That's why Open AI is spending $10 billion on this deal.

Looking Forward: The Next Evolution in AI Compute
What comes after Cerebras? What's the next frontier in AI compute?
Several vectors seem likely:
Photonic Computing: Using light instead of electrons for computation. Theoretically faster, lower power consumption. Multiple companies are working on photonic AI chips. This might be the next generation after Cerebras.
Neuromorphic Hardware: Chips designed to mimic biological brains more closely. Spike-based computation, event-driven processing. Companies like Intel and others are investing. Could provide massive efficiency gains for certain workloads.
Analog Computing: Using analog circuits instead of digital. Lower power, simpler manufacturing. But less precision. Could be good enough for certain AI workloads.
Quantum Computing: Potentially revolutionary for specific problems, though timeline is unclear. Might not be relevant for language models in the near term.
Software-Defined Hardware: Programmable hardware that can be reconfigured for different tasks. Similar to how GPUs are programmable. But more flexible.
Within the next decade, we'll probably see compute infrastructure that's radically different from what we have today. GPUs will still exist, but they'll be one option among many. Specialized architectures will proliferate.
That's actually exciting. It means hardware innovation is accelerating. It means there's room for new companies to compete with NVIDIA. It means the industry is getting more efficient and capable.
Open AI's $10 billion bet on Cerebras is basically a bet on this future. It's saying, "The next-generation AI systems won't be built on GPUs alone. We're positioning ourselves for that future." Whether they're right is an open question. But the bet is reasonable and strategically sound.
Conclusion: The Significance of a Billion-Dollar Bet
Let's wrap up and think about what this deal actually means.
On the surface: Open AI committed $10 billion to buy Cerebras compute for three years. That's the transaction.
One level deeper: Open AI is solving a specific technical problem (inference latency) with an alternative architecture to avoid dependency on NVIDIA.
Another level deeper: Open AI is signaling that the AI industry is maturing from hype to engineering fundamentals. Infrastructure matters. Economics matter. Diversification matters.
At the deepest level: This deal is a bet that the future of AI isn't determined by training compute but by inference efficiency. It's a bet that real-time, low-latency AI is the competitive battleground. It's a bet that companies like Cerebras with fundamentally different architectures can compete with the incumbents.
Is it the right bet? Only time will tell. But Open AI has earned the credibility to make big bets and execute on them. They're not betting randomly. They're betting on technology they've likely tested extensively and on partnerships with vendors they trust (Sam Altman invested in Cerebras years ago).
For the AI infrastructure industry, this deal is transformational. It legitimizes alternative architectures. It attracts capital to emerging vendors. It proves that diversification is viable and valuable. It creates space for innovation beyond GPU-centric approaches.
For Open AI, it's a smart business decision that diversifies risk, improves economics, and maintains negotiating leverage with all their infrastructure partners.
For Cerebras, it's a validation that justifies their existence and their $22 billion valuation. It's a proof point that their technology works at the highest level.
For the broader AI industry, it's a signal that infrastructure competition is just beginning. The GPU monopoly is being challenged. The future will be diverse, distributed, and specialized.
That's the real story here. Not just a $10 billion deal, but a signal that the AI infrastructure landscape is shifting fundamentally. The companies that recognize and adapt to that shift will thrive. The ones that don't will struggle.

FAQ
What is the Open AI-Cerebras deal exactly?
Open AI signed a multi-year agreement with AI chipmaker Cerebras to purchase 750 megawatts of computing capacity worth approximately $10 billion through 2028. This compute is specifically optimized for AI inference tasks, allowing Open AI to reduce latency and improve response times for complex queries on their APIs.
How does Cerebras' hardware differ from NVIDIA GPUs?
Cerebras uses wafer-scale architecture where all 850,000 AI cores exist on a single chip, eliminating inter-chip communication overhead that GPUs face. This design is specifically optimized for low-latency inference, making it faster for serving real-time AI requests, though GPUs remain superior for training large models.
What are the main benefits of this partnership for Open AI?
Open AI gains improved inference latency (potentially 40-50% faster responses), reduced power consumption per token generated, and crucial independence from NVIDIA's GPU monopoly. The deal also provides negotiating leverage with other infrastructure partners and direct influence over Cerebras' hardware development roadmap.
Why does inference latency matter for AI companies?
Users expect AI responses in under 2-3 seconds. Slower responses reduce user engagement and API adoption. By cutting latency in half, Open AI can offer more complex model reasoning while maintaining human-like conversation speeds, directly improving customer experience and retention.
How does this deal affect other AI companies?
The deal signals that alternative architectures to NVIDIA's dominance are viable, creating competition and better pricing across the infrastructure market. It validates the importance of diversified compute strategies and encourages other companies like Google, Meta, and Microsoft to accelerate their own infrastructure alternatives.
What are the risks in this partnership?
Key risks include Cerebras failing to deliver promised performance, manufacturing bottlenecks preventing capacity scaling, unexpected technical complexity in porting models to the new architecture, and potential market disruption from newer competing technologies. Additional risks involve organizational changes, financial difficulties, or regulatory impacts on data center operations.
When will we see results from this deal?
Deployment spans 2025-2028, with initial testing in 2025, production scaling in 2026-2027, and full integration by 2028. Performance improvements and publicly disclosed results are likely in 2026-2027 as the infrastructure matures and Open AI optimizes workloads for Cerebras hardware.
How does this improve Open AI's profitability?
If Cerebras hardware is more efficient at inference, Open AI can generate more tokens per unit of power consumed. At scale, even 10-15% efficiency improvements translate to hundreds of millions in annual cost savings, directly improving profit margins on every API call.
Will this make AI APIs cheaper for users?
Potentially. If Open AI achieves significant cost reductions through infrastructure optimization, they have pricing leverage. They might reduce API costs to gain market share, which would cascade through the entire AI industry as competitors match pricing.
What does this mean for GPU companies like NVIDIA?
NVIDIA's dominance in training hardware remains secure, but this deal signals a challenge to their inference market share. They'll need to improve inference efficiency or accept losing that segment to specialized vendors like Cerebras, though NVIDIA likely views this as expected competitive activity.
Key Takeaways
- OpenAI's $10 billion Cerebras deal represents a strategic bet on diversified infrastructure and reduced NVIDIA GPU dependency for AI inference workloads
- Cerebras' wafer-scale architecture eliminates inter-chip communication bottlenecks, enabling 40-50% faster inference latency compared to traditional GPU clusters
- This partnership signals that specialized hardware vendors can compete with incumbents when they solve specific problems like real-time low-latency AI serving
- Infrastructure optimization directly impacts profit margins, with even 10-15% efficiency gains translating to hundreds of millions in annual cost savings at scale
- The deal legitimizes alternative AI chip architectures and creates competitive pressure on NVIDIA's monopoly, attracting capital and talent to emerging vendors
Related Articles
- DeepSeek's Conditional Memory: How Engram Fixes Silent LLM Waste [2025]
- AI's Real Bottleneck: Why Storage, Not GPUs, Limits AI Models [2025]
- Skild AI Hits $14B Valuation: Robotics Foundation Models Explained [2025]
- VoiceRun's $5.5M Funding: Building the Voice Agent Factory [2025]
- Microsoft's Community-First Data Centers: Who Really Pays for AI Infrastructure [2025]
- Microsoft's Data Center Expansion: How Tech Giants Are Managing Energy Costs [2025]

