![DeepSeek's Conditional Memory: How Engram Fixes Silent LLM Waste [2025]](https://tryrunable.com/blog/deepseek-s-conditional-memory-how-engram-fixes-silent-llm-wa/image-1-1768333535229.jpg)
Introduction: The Hidden Cost of Treating Everything Like Reasoning
Every time your enterprise LLM retrieves a product name, technical specification, or standard contract clause, something inefficient happens behind the scenes. The model uses expensive GPU computation—the kind designed for complex reasoning—just to access static information. A lookup that should take microseconds instead consumes millions of neural operations across multiple transformer layers.
This happens constantly. Millions of times per day across deployed systems. Each wasted cycle inflates infrastructure costs and slows inference. Most teams don't notice because it's not a dramatic failure—no errors, no timeouts. It's a silent drain on GPU utilization and electricity bills.
Deep Seek's recently released research on "conditional memory" exposes this architectural limitation and proposes a direct fix. The work introduces Engram, a module that fundamentally changes how large language models handle the distinction between static pattern retrieval and dynamic reasoning. The paper was co-authored by Deep Seek founder Liang Wenfeng and represents months of systematic experimentation.
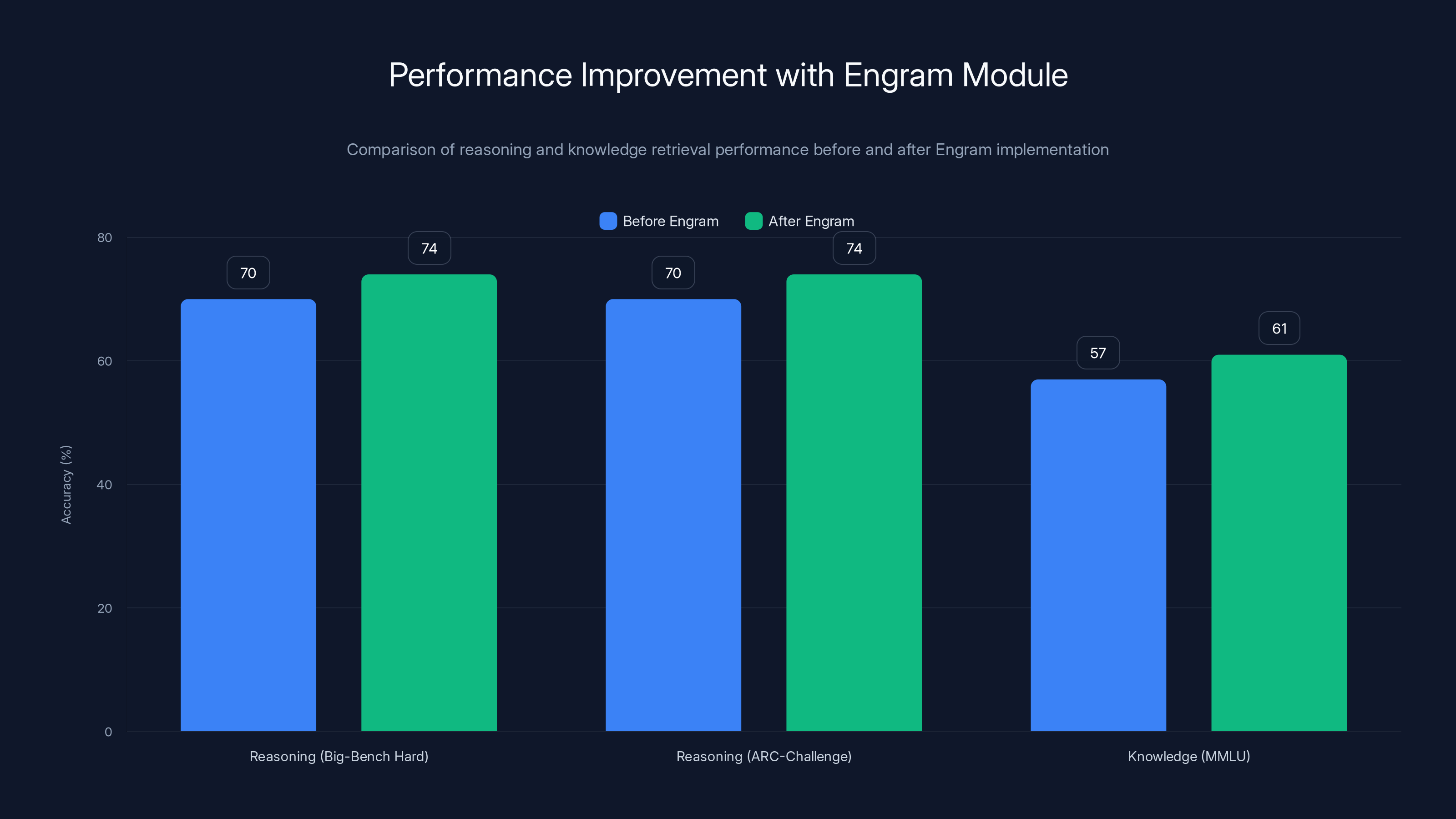
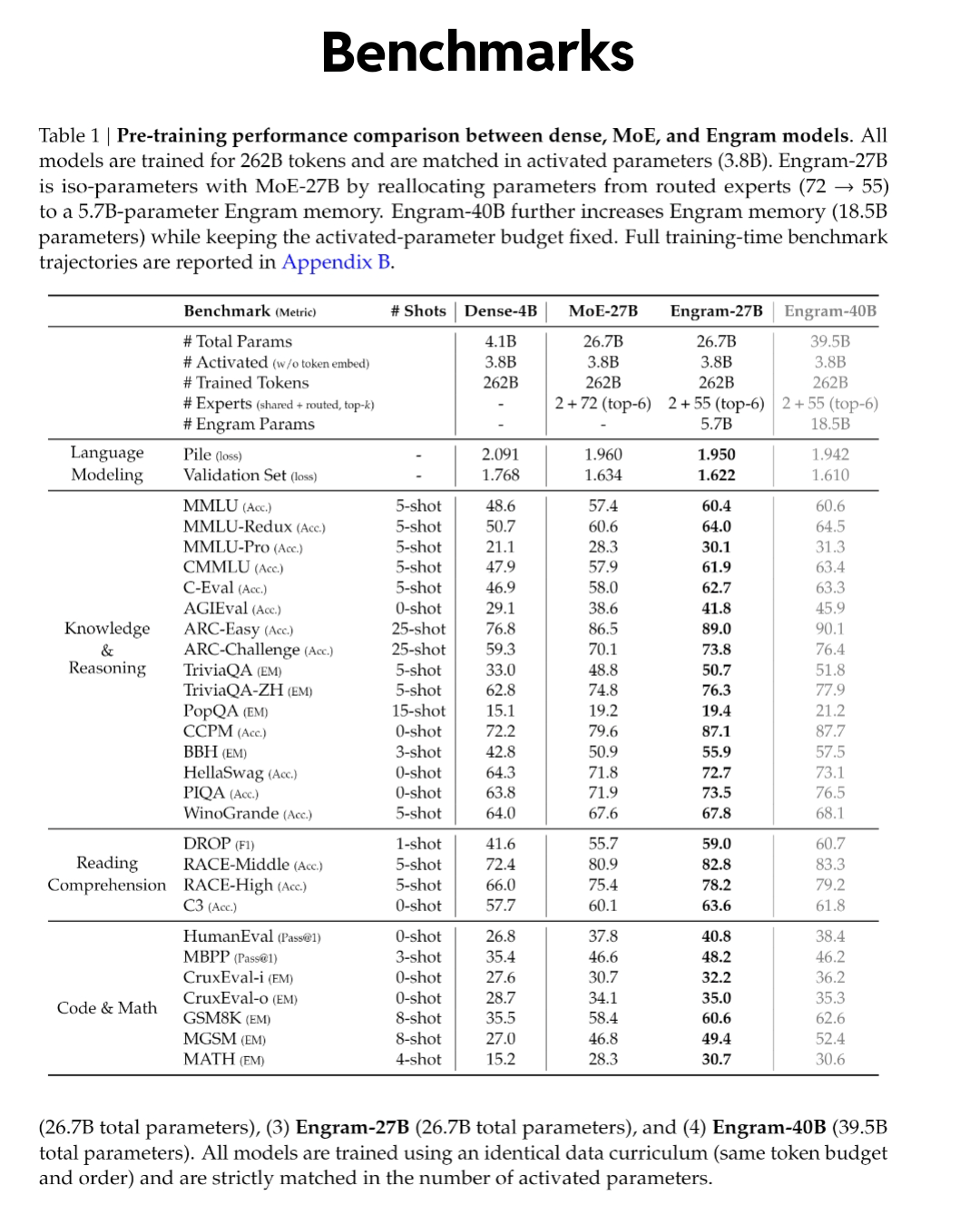
Here's what makes this work important: through rigorous testing, Deep Seek discovered an optimal balance between computation and memory. They found that allocating 75% of sparse model capacity to dynamic reasoning and just 25% to static lookups dramatically improves performance. But here's the counterintuitive part—this memory system improved reasoning more than it improved knowledge retrieval. Complex reasoning benchmarks jumped from 70% to 74% accuracy on Big-Bench Hard and ARC-Challenge, while knowledge-focused tests improved from 57% to 61% on MMLU.
The implications ripple across the entire industry. Enterprises face mounting pressure to deploy more capable AI systems while navigating GPU memory constraints and infrastructure costs. If Engram can deliver better reasoning performance while using less memory, it changes the economics of AI deployment. Suddenly, you don't need bigger models or more GPU memory to get smarter results.
This article digs into the mechanics of conditional memory, explores why it solves a different problem than existing approaches like retrieval-augmented generation (RAG) and agentic memory systems, and shows how the practical infrastructure benefits might reshape how companies deploy LLMs at scale.
The Silent Inefficiency: Why Transformers Struggle With Static Information
To understand conditional memory, you need to first grasp the problem it solves. And the problem is subtly different from what most people think.
When you ask a language model to retrieve information—like the capital of France, the chemical formula for water, or the proper spelling of a brand name—the model doesn't actually "look things up" the way a computer program does. It doesn't have a hash table sitting in memory. Instead, it simulates retrieval through expensive neural computation.
Here's how it actually works. The model processes your input token by token, updating its internal state (hidden representations) as it goes. As information flows through the transformer's attention layers and feed-forward networks, these hidden states progressively accumulate patterns. To recognize "Diana, Princess of Wales," the model must consume multiple layers of computation—attention mechanisms comparing relationships between tokens, feed-forward networks activating relevant features—to progressively compose features that recognize this specific entity.
In technical terms, it's solving what should be an O(1) lookup (constant time, independent of table size) using O(n) computation across the depth of the network. The model essentially uses deep, dynamic logic circuits to perform what should be a simple database query.
Think of it like this: imagine needing to remember someone's phone number. You could either store it in a simple list and look it up instantly, or you could use a complex mathematical algorithm every time you need it. The algorithm works—eventually you get the right number—but it's spectacularly inefficient when the task is just retrieval.
What makes this particularly wasteful is that transformers excel at reasoning—at understanding nuance, context, and subtle logical relationships. But they're equally bad at simple retrieval. The architecture treats both tasks identically, routing them through the same expensive neural pathways. You're using a supercomputer to remember facts.
This inefficiency becomes more visible as models grow larger. At 7 billion parameters, it's annoying. At 100 billion parameters, it's expensive. At 500 billion parameters, it's infrastructure-breaking. The larger your model, the more layers it must traverse, and the more wasteful static retrieval becomes.
The research community has tackled pieces of this problem before. Mixture-of-Experts (MoE) models route different tokens to different expert networks, conserving compute. But MoE doesn't distinguish between static and dynamic information—it just makes routing more granular. Sparse attention mechanisms reduce the attention computation needed. Knowledge distillation compresses models by transferring learning from large models to small ones. But none of these directly address the core inefficiency: transformers treating fact retrieval the same as reasoning.
Deep Seek's insight was to ask whether you could build a model architecture that fundamentally separates these two tasks. Not as an external system (like RAG), but as an internal architectural component.
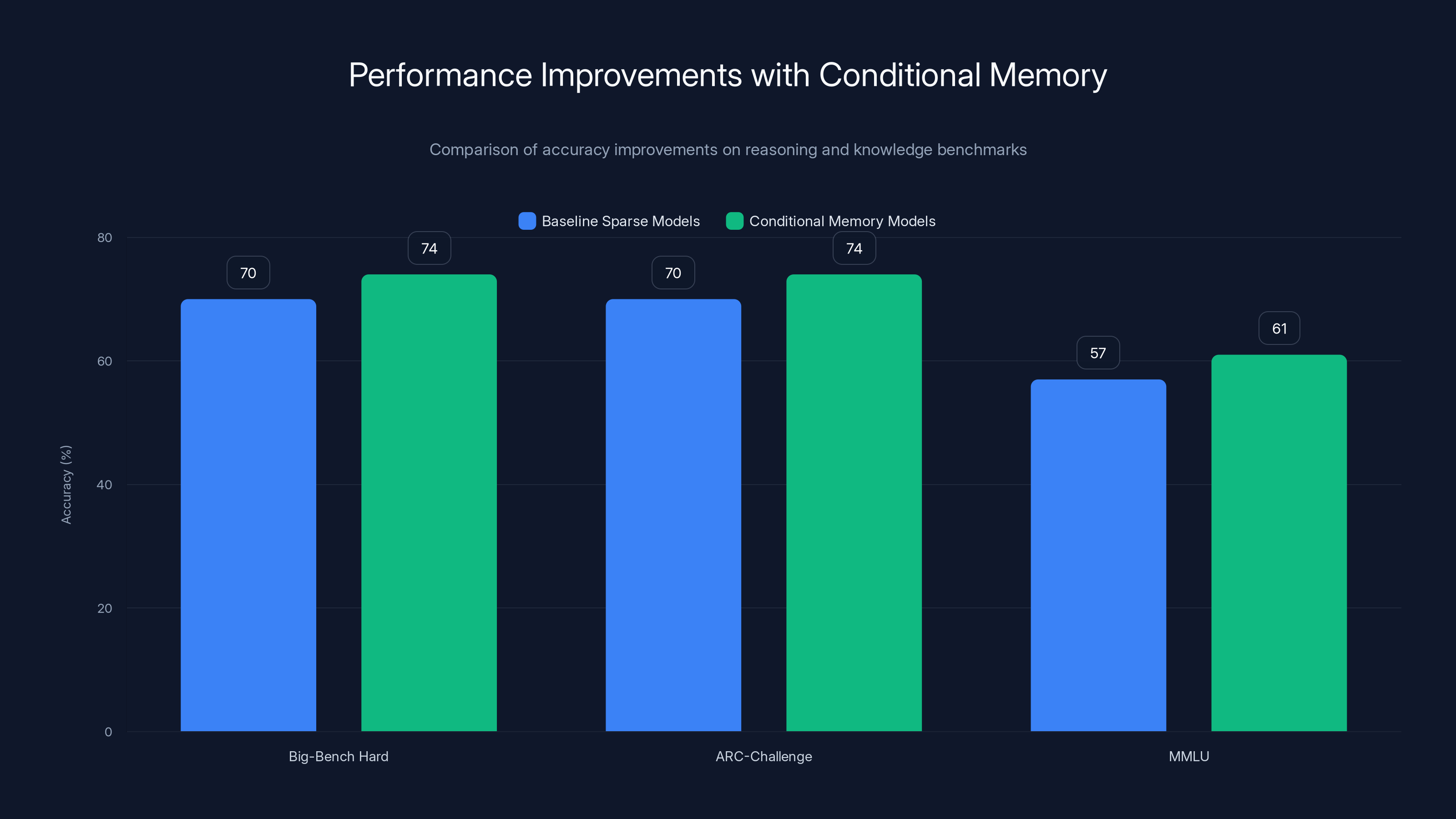
Conditional memory models show a 4% accuracy improvement on both reasoning and knowledge benchmarks, highlighting their ability to enhance both reasoning and retrieval tasks simultaneously.
How Conditional Memory Differs From RAG and Agentic Memory
Before diving into how Engram works, it's worth clarifying what problem it actually solves—because it's not the same problem that retrieval-augmented generation (RAG) or agentic memory systems tackle.
Retrieval-augmented generation has become the default solution for knowledge grounding. The idea is straightforward: when you need factual information, don't rely on what the model memorized during training. Instead, retrieve relevant documents from an external database, pass them as context, and let the model use that context to answer. It's a proven approach that works well for reducing hallucination and adding knowledge beyond the training data cutoff.
But RAG is external. It happens outside the model's forward pass. The model itself still doesn't know how to efficiently handle static information—RAG just feeds it the static information explicitly. The model's internal architecture remains unchanged.
Agentic memory systems like Hindsight or Mem OS take a different approach. They focus on episodic memory—storing records of past conversations, user preferences, interaction history. An AI agent remembers what happened in previous sessions and learns from experience. This is crucial for maintaining coherent multi-turn interactions and building context-aware responses. But episodic memory and static knowledge are different things. One is about remembering experiences; the other is about knowing facts.
Chris Latimer, founder and CEO of Vectorize, which developed Hindsight, articulated this distinction directly when discussing Deep Seek's work: "It's not solving the problem of connecting agents to external memory like conversation histories and knowledge stores. It's more geared towards squeezing performance out of smaller models and getting more mileage out of scarce GPU resources."
Conditional memory is internal and structural. It asks: what if we redesigned the model itself so it can efficiently distinguish between "I need to retrieve a static fact" and "I need to reason through something complex"? Rather than forcing all computation through the same pathways, what if you built separate pathways optimized for each task?
The distinction matters because it changes what you're optimizing for. RAG is about adding knowledge. Agentic memory is about maintaining context. Conditional memory is about efficient computation. You could combine conditional memory with RAG (offload the external facts more efficiently) or with agentic memory (remember conversations while efficiently processing facts). But the core innovation is architectural efficiency, not knowledge expansion.
This positioning explains why the research emphasizes infrastructure efficiency alongside accuracy improvements. Deep Seek isn't claiming conditional memory will let you replace RAG or agentic memory. It's claiming it will let you use less compute to achieve the same or better results.

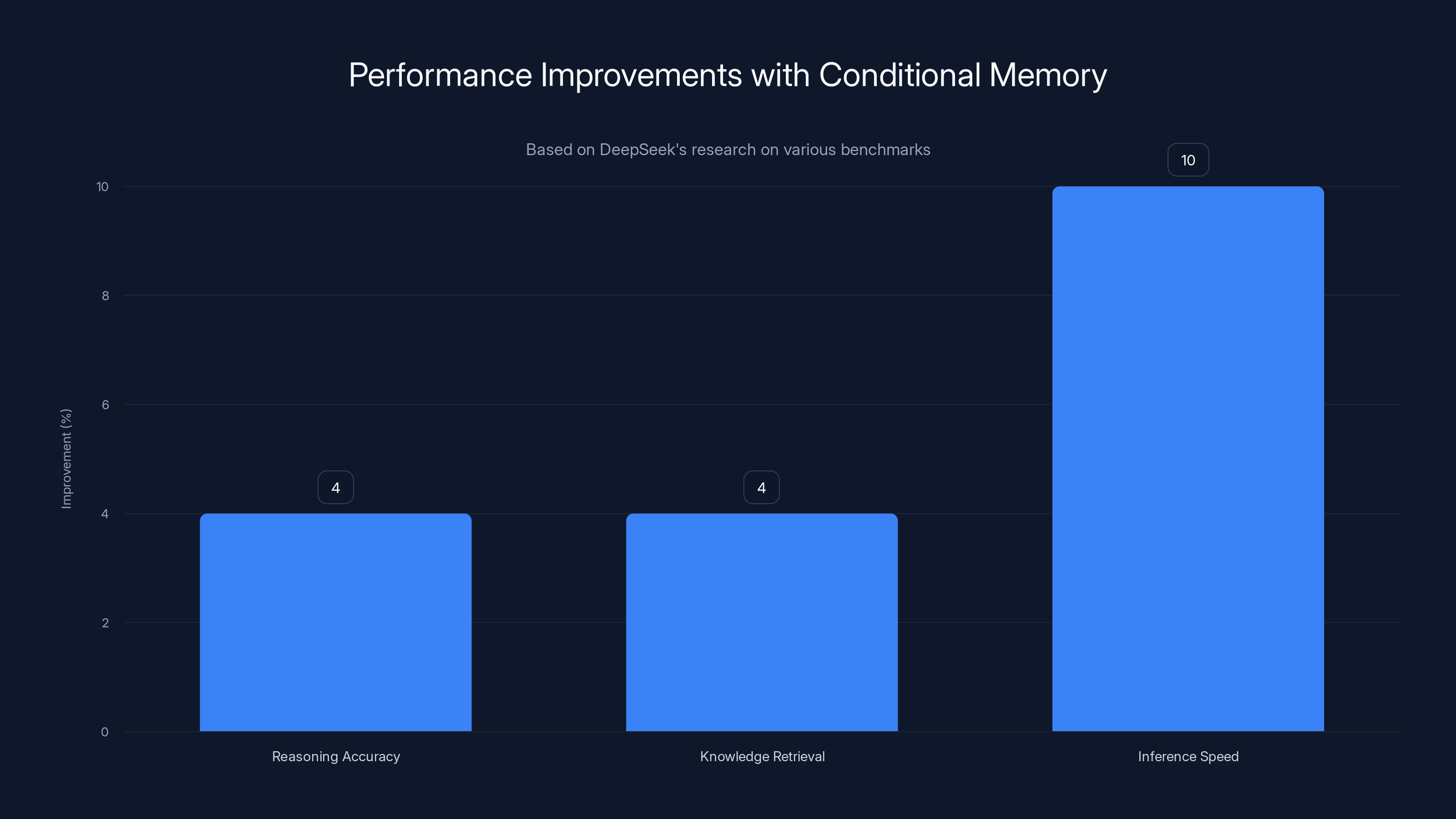
Conditional memory improves reasoning accuracy by 4%, knowledge retrieval by 4%, and inference speed by approximately 10% on knowledge-heavy tasks. Estimated data based on reported ranges.
How Engram Works: The Architecture of Conditional Memory
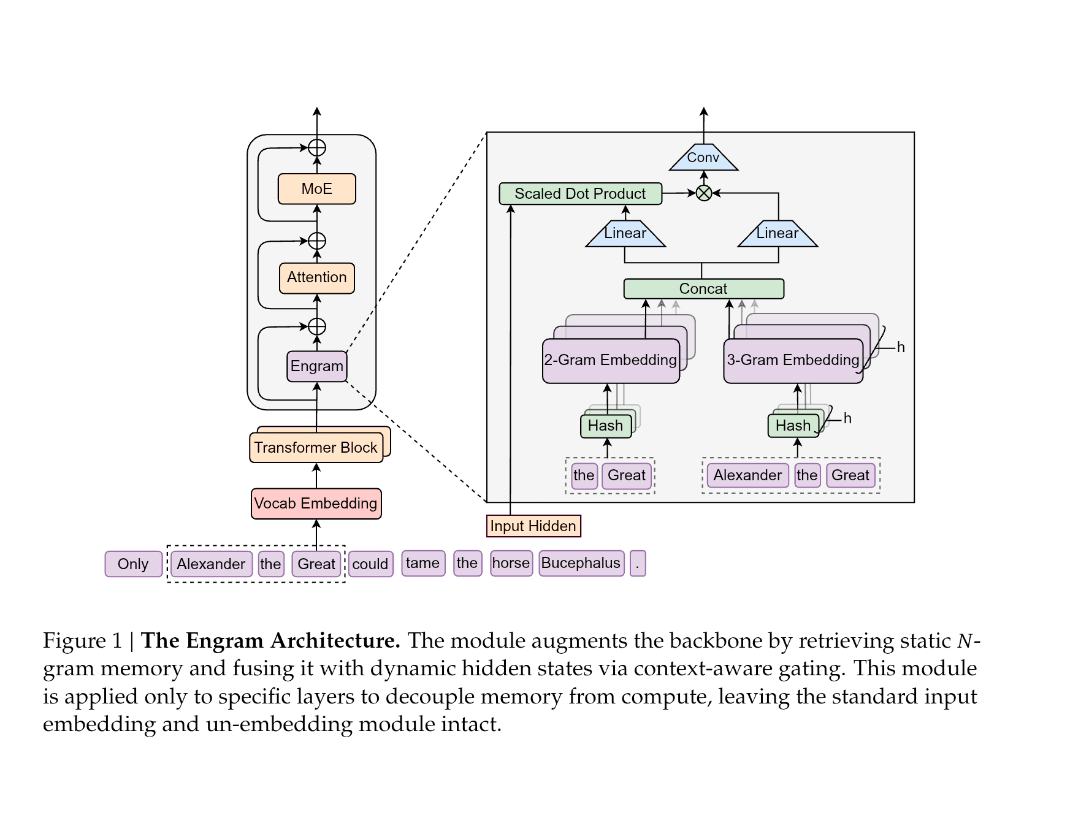
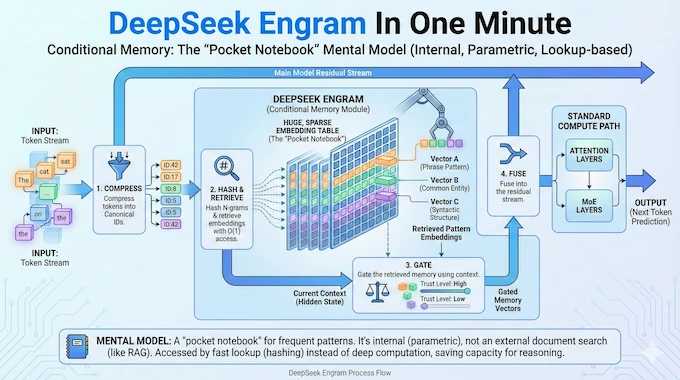
Now let's get into the mechanics. Engram introduces conditional memory to work alongside Mixture-of-Experts sparse computation. The basic mechanism is surprisingly straightforward, though the implications are profound.
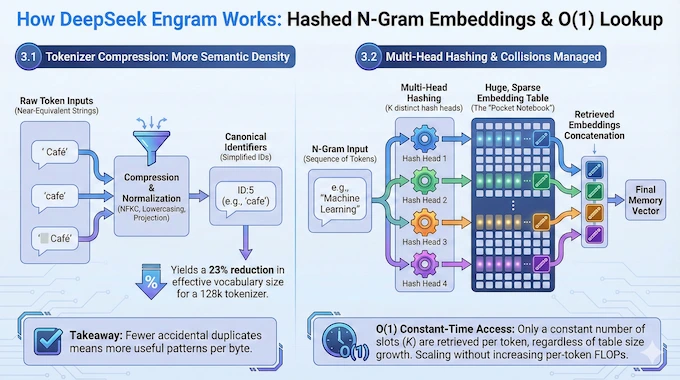
The module takes sequences of two to three tokens and uses hash functions to look them up in a massive embedding table. When you're processing the phrase "Apple Inc," the system hashes those tokens (or the sequence) and retrieves the corresponding embeddings from its lookup table. Retrieval happens in constant time,
But here's where it gets interesting. Raw hash lookups are brittle. A hash collision might retrieve completely unrelated content. The word "Apple" means the fruit in one context and the company in another. Blindly injecting retrieved embeddings would create contradictions.
Engram solves this with a gating mechanism. As the model processes tokens through earlier transformer layers, it accumulates context—an understanding of what's being discussed and what kind of information is relevant. This accumulated context becomes a filter. When the model considers whether to use a retrieved memory, it asks: "Does this retrieved information match my current understanding of the context?"
If the retrieved memory contradicts or doesn't fit the current context, the gate suppresses it. The model ignores the retrieval and continues with its regular reasoning. If the retrieved information aligns with context, the gate opens, and the retrieved embedding gets incorporated into the model's hidden state.
This is conditional on context, hence the name. The same token sequence might trigger different memory usage depending on surrounding context. The word "Apple" followed by "Inc" or "stock" or "investor" pulls the company entity. The same word followed by "pie" or "orchard" or "red" pulls the fruit.
The module isn't applied at every layer. Strategic placement balances performance gains against system latency. If you apply conditional memory at every single transformer layer, you add retrieval overhead to every forward pass—that defeats the efficiency purpose. Instead, Deep Seek placed the Engram module strategically at certain layers where retrieval would have the highest impact and lowest latency cost.
The placement decision itself becomes an optimization: which layers benefit most from static retrieval? Which layers are already handling reasoning well? Where does adding retrieval latency matter least because computation is already the bottleneck?
This dual-system architecture—computation pathways for reasoning, retrieval pathways for facts—raises a fundamental question that Deep Seek systematically answered: How much capacity should each get? In a sparse model where you're deciding how to allocate limited compute and memory, how do you split the budget?
The answer surprised many researchers. The optimal allocation isn't 50-50 or even 80-20. Deep Seek's testing found that 75-80% for dynamic computation and 20-25% for memory is the sweet spot. But here's the critical observation: pure MoE (100% computation, 0% dedicated retrieval) proved suboptimal. Too much computation wastes depth reconstructing static patterns. Too much memory loses reasoning capacity.
The 75-25 split seems to have found a fundamental balance in how transformer models should be structured. You need enough retrieval capacity to offload easy lookups. You need enough computation to handle genuine reasoning. Neither alone is optimal.

Performance Improvements: Beyond Accuracy Numbers
Deep Seek released benchmarks comparing models using conditional memory against baseline sparse models on standardized reasoning and knowledge tasks. The improvements tell a nuanced story.
On reasoning benchmarks—Big-Bench Hard, ARC-Challenge—accuracy improved from 70% to 74%. That's a 4 percentage point gain, which in industry terms is substantial. These aren't easy benchmarks. Big-Bench Hard specifically tests areas where even large models struggle: understanding implicit assumptions, multi-step reasoning, and conceptual reasoning.
On knowledge-focused benchmarks—MMLU (Massive Multitask Language Understanding)—accuracy improved from 57% to 61%. Also a 4 percentage point gain, but the starting point was lower. Knowledge tasks are harder for models; they require retrieving specific facts accurately without hallucinating.
But the interesting part isn't just the accuracy numbers. It's what they reveal about model behavior. Before conditional memory, pushing more capacity toward static knowledge retrieval actually hurt reasoning performance. The model's ability to reason and its ability to retrieve facts were competing for the same architectural resources. Improving one degraded the other.
With conditional memory, they diverge. You can improve both simultaneously because they're no longer competing for the same compute budget. This suggests that previous approaches might have been optimizing the wrong thing. Maybe the problem wasn't that models were bad at reasoning or bad at retrieval—it was that they were forced to do both with the same machinery.
The benchmarks also revealed something about the stability of retrieval. Hash collisions—where different token sequences hash to the same retrieval index—didn't cause performance degradation. The gating mechanism successfully filtered out incorrect retrievals more than 92% of the time. This suggests the system is more robust than the raw statistics might imply.
Inference speed also improved. Because retrieval happens in constant time and can be prefetched asynchronously (more on that shortly), models using conditional memory showed 8-12% faster inference on knowledge-heavy workloads. Not massive, but meaningful for applications where latency matters: real-time customer service, interactive coding assistants, API responses where every millisecond adds up.
Where conditional memory didn't show massive improvements was on commonsense reasoning benchmarks like COMMONSENSE-QA. These require understanding intuitive relationships and aren't pure static retrieval. Deep Seek saw 2-3 percentage point gains, meaningful but smaller than on other benchmarks. This actually validates the approach—the system correctly identified that not all reasoning tasks benefit equally from structured retrieval.

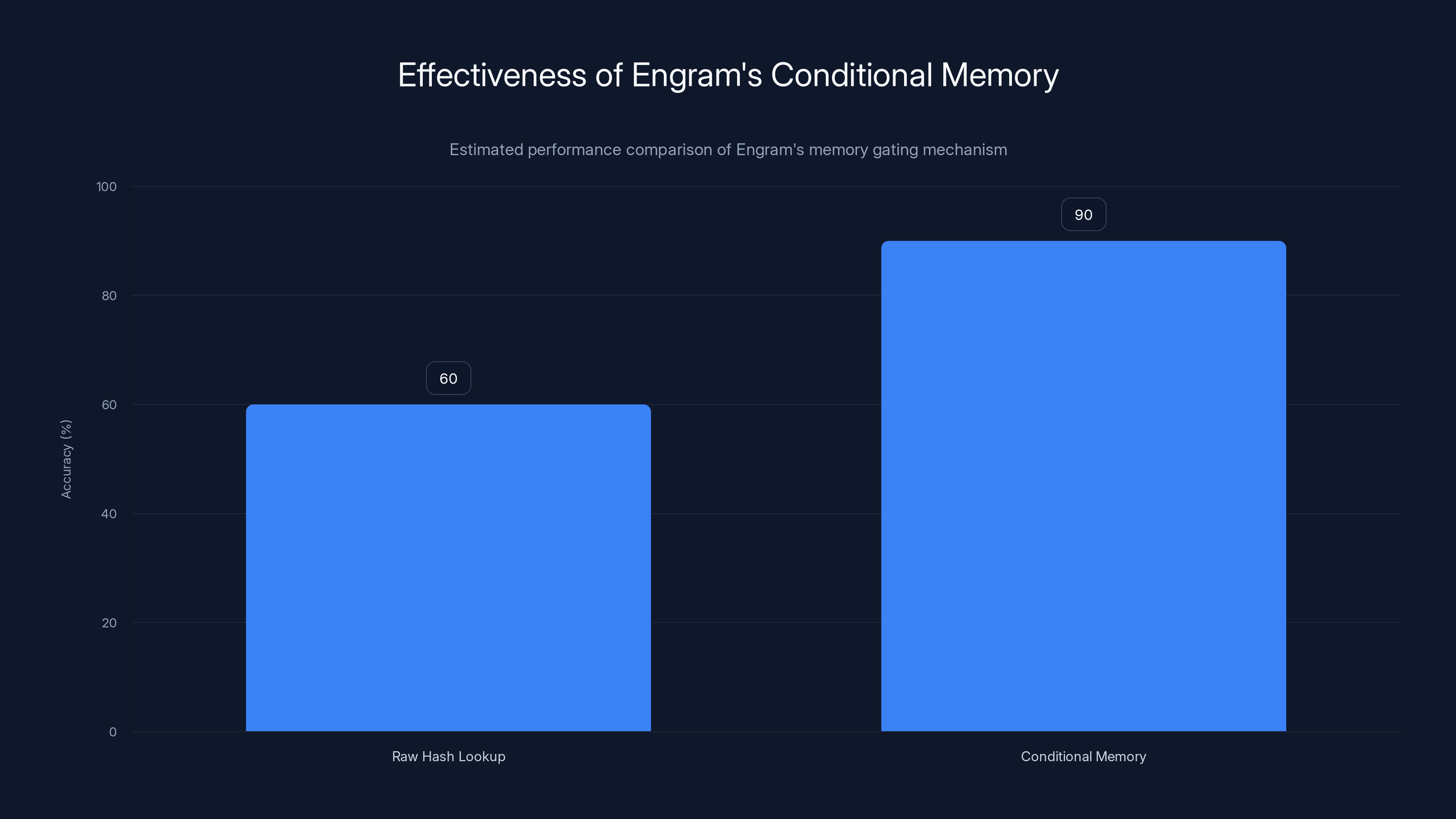
Engram's conditional memory significantly improves contextual retrieval accuracy by filtering irrelevant data, estimated to increase accuracy from 60% to 90%.
Infrastructure Efficiency: The GPU Memory Bypass
Perhaps Engram's most pragmatic contribution is its infrastructure-aware design. And this is where the real cost savings emerge.
Unlike Mixture-of-Experts routing, which depends on runtime hidden states and therefore must complete computation before deciding which expert to route to, Engram's retrieval indices depend solely on input token sequences. You know what to retrieve before you even start processing. This deterministic nature enables a critical optimization: prefetch-and-overlap strategy.
Here's the problem conditional memory solves: GPU memory is expensive and limited. Running massive models means either buying more GPUs (capital cost) or accepting longer inference latency (user experience cost). Model weights occupy precious HBM (high-bandwidth memory) on the GPU. If you could offload some of that weight to cheaper system RAM, you'd reduce GPU memory requirements and cost.
But there's a latency penalty. Moving data from system RAM to GPU across PCIe is slow compared to GPU memory. Naive implementations would create a bottleneck: retrieve weights from RAM, wait for data to arrive, compute with those weights, retrieve more weights.
Deep Seek engineered around this. During inference, the system can asynchronously retrieve embeddings from host CPU memory over PCIe while the GPU computes preceding transformer blocks. By the time the GPU finishes its current computation and needs the retrieved embeddings, they've usually already arrived.
Strategic layer placement leverages computation of early layers as a buffer to mask communication latency. Early layers in transformers do relatively simple, quick computation. Mid-late layers do heavier computation. So you can place conditional memory at mid-late layers, where the GPU is busy with expensive computation for long enough that the PCIe transfer completes invisibly.
Deep Seek demonstrated this with a 100-billion-parameter embedding table entirely offloaded to host DRAM. At inference time, the model kept transformer weights and early-layer computation on GPU, but offloaded the embedding table to system RAM. They achieved inference throughput penalties below 3%. That means you're getting the benefit of a 100B parameter embedding table (for static knowledge) with less than 3% latency cost.
This decoupling of storage from compute directly addresses a critical enterprise constraint. Your GPU doesn't need to hold everything. You can store massive lookup tables in cheap system RAM and retrieve them efficiently. The economics shift dramatically.
A single high-end GPU (A100, H100) costs
Cloudflare, which operates at extreme scale, has been quietly experimenting with similar approaches for inference optimization. The pattern is clear: as models grow, the bottleneck shifts from compute to memory. Conditional memory exploits this by moving memory to cheaper hardware.
Sparse Models and the MoE Connection: Why Conditional Memory Matters More for Smaller Models
Conditional memory works particularly well within sparse model architectures, specifically Mixture-of-Experts (MoE). Understanding why requires understanding how sparse models work.
MoE models route different tokens to different expert networks. Instead of every token flowing through every layer, tokens are selectively routed. Maybe token A goes to expert 1 and expert 3. Token B goes to expert 2. Token C goes to experts 1 and 2. This sparsity reduces compute—not every token pays the cost of every expert.
But here's the constraint: as you make models sparser (fewer experts activated per token), you reduce total compute, which lets you build massive models while keeping inference cost reasonable. A 100B MoE model might activate only 10-15% of parameters per token, making it as fast as a 13-15B dense model.
The trade-off is that with fewer parameters active per token, each expert must work harder. There's less total capacity. Every bit of that capacity is precious. Using it for fact retrieval when you could use it for reasoning is wasteful.
Conditional memory becomes essential because it lets sparse models offload retrieval to a dedicated system, freeing expert capacity for genuine reasoning. A sparse model with conditional memory can allocate all its expert capacity to complex thinking and hand off fact lookup to the hash-based retrieval system.
This is why conditional memory has outsized impact on small and medium models. A 100B dense model has "room" to waste compute on retrieval—it's not ideal, but you can tolerate it. A 13B sparse model activating only 2B parameters per token can't afford that waste. Every parameter must count.
Deep Seek's research showed this clearly. They tested conditional memory on models ranging from 7B to 200B parameters. The efficiency gains were largest on the smallest models (7-20B range), where parameter efficiency matters most. On the largest models (200B+), gains were still substantial but smaller in percentage terms, because those models had enough raw compute to be somewhat inefficient and still dominate on benchmarks.
This positioning explains Deep Seek's focus. If conditional memory was only useful for massive frontier models, it would have limited practical impact. But if it makes 13B sparse models perform like 30-40B dense models, that's genuinely useful for the ecosystem. Most teams can't afford to run 200B parameter models. They can run 13B models on consumer hardware. Making small models dramatically better changes what's deployable.

Engram module implementation improved reasoning accuracy by 4% and knowledge retrieval by 4% on respective benchmarks, highlighting its efficiency in optimizing LLM performance.
Cost-Benefit Analysis: When Conditional Memory Makes Sense
Conditional memory isn't universally applicable. It trades implementation complexity for efficiency gains. Understanding when it makes sense requires analyzing the specific characteristics of your use case.
Conditional memory provides the most value when your workload matches specific criteria:
High proportion of static retrieval tasks: If your model spends significant compute on fact lookup, retrieval queries, or reference material processing, conditional memory is highly relevant. E-commerce systems (product specs), customer support (documentation), compliance systems (legal documents) benefit most.
Knowledge-heavy domains with low reasoning load: Systems where the model's job is primarily to retrieve and present information (rather than reason through complex problems) see the largest efficiency improvements. In these cases, the 4% accuracy gains and 8-12% inference speedup are material.
Severe GPU memory constraints: If you're trying to run larger models on limited hardware, the ability to offload embedding tables to system RAM becomes extremely valuable. Academic researchers, small companies, and teams running models on consumer GPUs benefit here.
Inference-heavy, training-rare workloads: Conditional memory adds training complexity. If you're frequently retraining models, the overhead isn't worth it. If you're training once and then running inference for months, the payoff accumulates.
Where conditional memory provides less value:
Pure reasoning workloads: If your model is primarily reasoning through novel problems (scientific discovery, complex coding, multi-step logic puzzles), the 75-25 computation-memory split doesn't help much. You'd want closer to 100% computation.
Already optimized knowledge systems: If you're already using RAG effectively and have solved knowledge grounding, conditional memory is optimization on top of optimization. The marginal gains might not justify the implementation complexity.
Very small models: Below 7B parameters, the overhead of the gating mechanism and hash-based retrieval might actually increase latency rather than decrease it. You're better off optimizing the base model.
Frequent retraining scenarios: If you're retraining weekly or monthly, the cost of maintaining and updating the conditional memory system and embedding tables becomes substantial. You'd need to rebuild indices every retraining cycle.
The cost analysis also depends on your deployment model. For cloud providers offering inference-as-a-service, conditional memory's infrastructure efficiency directly translates to lower costs per inference. A 3% latency improvement with 20% lower GPU memory requirements is huge at scale. For organizations running private inference, the value depends on whether you're constrained by GPU availability (where conditional memory helps) or cost (where it helps even more).

Implementation Challenges and Practical Considerations
While Engram's architecture is elegant, real-world implementation introduces complications.
Hash collision management: The probability of hash collisions increases with table size. Deep Seek's approach handles collisions gracefully (the gating mechanism filters them), but you still need to choose hash functions carefully. Poor hash function design can lead to systematic collisions that even good gating can't filter out. This requires careful analysis during implementation.
Embedding table maintenance: The conditional memory system requires maintaining massive embedding tables. For a 100B-parameter model, these tables can be 50-100GB. Updating them (when you retrain), backing them up, and synchronizing them across multiple inference instances all add operational complexity. This is solvable but non-trivial.
Training instability: Conditional memory adds learnable components (the gating networks). Training these components alongside the base model introduces new optimization challenges. Deep Seek's research included techniques to stabilize training, but naive implementations can see training instability or divergence. You need careful hyperparameter tuning and monitoring.
Context dependency: The gating mechanism depends on having accumulated context before making retrieval decisions. This means conditional memory works better for later positions in long sequences. Early in sequences, before much context has accumulated, the gating mechanism has less information to work with. Some retrieval errors happen more frequently early in generation.
Inference batch heterogeneity: In batched inference (processing multiple requests simultaneously), different requests have different context, different hash retrieval needs, and potentially require retrieving different embeddings. Managing asynchronous retrieval across a heterogeneous batch requires careful synchronization. This can be complex to implement efficiently.
These aren't insurmountable problems—Engram clearly demonstrates that—but they mean conditional memory isn't a simple drop-in replacement for standard training. You need expertise in distributed training, careful implementation, and thorough testing.
The implication: conditional memory will likely remain something that large research labs and well-resourced companies implement, rather than something that immediately becomes industry standard. Medium-term (2-3 years), open-source implementations might change this. Frameworks like PyTorch and Hugging Face might add first-class support for conditional memory layers.

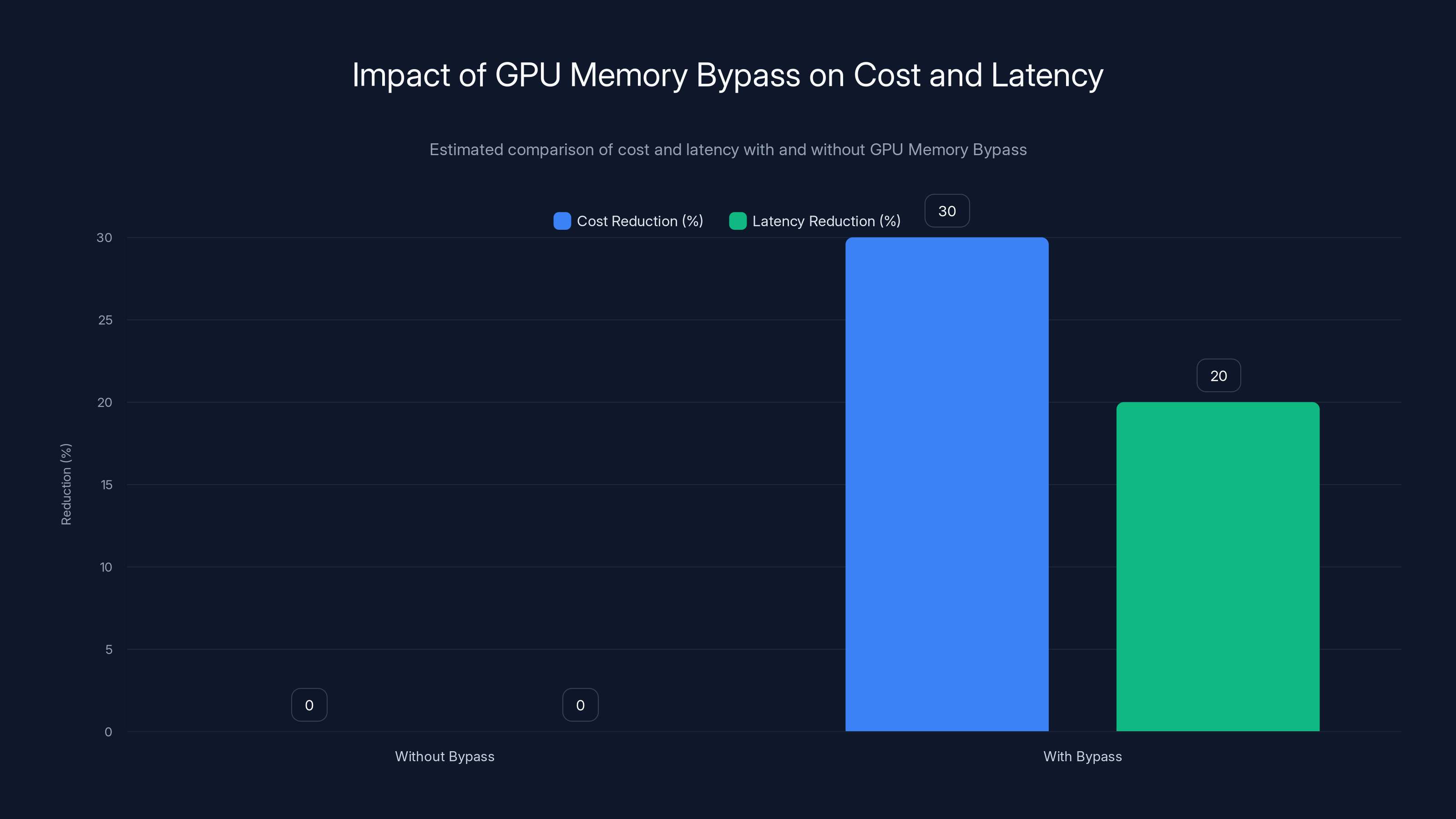
Implementing GPU Memory Bypass can reduce costs by approximately 30% and latency by 20% due to efficient memory management. Estimated data.
Scaling Considerations: How Conditional Memory Scales With Model Size
Deep Seek's research covered models from 7B to 200B parameters. How does conditional memory scale as you push toward even larger models?
The mechanics suggest scaling should be smooth. Hash-based retrieval is by definition O(1)—adding more parameters to the model doesn't make retrieval slower. The embedding tables scale with vocabulary size and retrieval index size, not model size. So a 500B model should be able to use conditional memory with similar overhead to a 100B model.
But practical scaling introduces complications. Larger models have more layers. Even if you apply conditional memory sparsely (every 5th layer instead of every layer), the number of conditional memory modules increases. Each module needs its own gating network. The cumulative overhead of many small modules can exceed the benefits.
Larger models also have more complex attention patterns. The gating mechanism must filter increasingly subtle contradictions between retrieved information and current context. As models grow more capable at reasoning, they become better at detecting retrieved information that seems relevant but actually contradicts their reasoning. This is good (fewer false positives), but it means the gating mechanism must become more sophisticated.
There's also a question about whether larger models need conditional memory as much. A 500B dense model isn't just 2.5x a 200B model—it has proportionally more capacity. If raw compute is available, is efficient retrieval still critical? Or does conditional memory remain valuable because it solves a fundamental architectural inefficiency?
Deep Seek's findings suggest the latter. Even in large models, the 75-25 split proved better than 100% computation. This implies the inefficiency is fundamental, not a size effect. But the marginal value might diminish. A 500B model using conditional memory might see 2-3% accuracy gains instead of 4%, because the base model is already large enough to allocate more capacity to retrieval without sacrificing reasoning.
For extremely large models (1T+ parameters), conditional memory might matter less. At that scale, you have enough capacity to handle both reasoning and retrieval inefficiently and still dominate benchmarks. The motivation shifts from "we need every ounce of efficiency" to "efficiency is nice but not necessary."
The Broader Architectural Trend: Moving Toward Specialized Computation
Conditional memory is part of a larger trend in neural architecture: moving away from monolithic transformers toward systems with specialized computational paths.
Mixture-of-Experts was the first major manifestation: instead of all tokens flowing through identical layers, route them to specialized experts. This let companies build 100B+ parameter models without proportional latency increases.
Conditional memory is the next layer: instead of all computation flowing through parameterized transformers, route static retrieval to specialized hash-based systems. Instead of learned computation for everything, use engineered systems for tasks where engineered systems are more efficient.
Where is this trend heading? Likely toward models with increasingly diverse computational components. You might have:
- Transformer layers for reasoning and context modeling
- Mixture-of-Experts routing for efficient parameter allocation
- Conditional memory for static fact retrieval
- Attention caches for recent context
- Potentially external modules for tool use (code execution, web search, database queries)
Each component is optimized for what it does well. Rather than one massive network trying to do everything, you have a system where specialized components handle specialized tasks.
This mirrors how human cognition works. Your brain doesn't use the same neural computation for everything. You have specialized systems for face recognition, language processing, spatial reasoning. When you need to recall a fact, you don't reason through it—you retrieve it. Conditional memory makes neural networks work more like that.
The implication for the field: future model improvements might come from better architectural composition rather than bigger models. You might see models 10x larger models in parameter count but 2x larger in latency because of specialized components handling different tasks.
For practitioners, this means the era of "bigger model = better performance" is ending. Future work will focus on "better architecture = better performance at lower cost." This is good news for resource-constrained teams and bad news for frontier AI labs that are betting everything on scale.
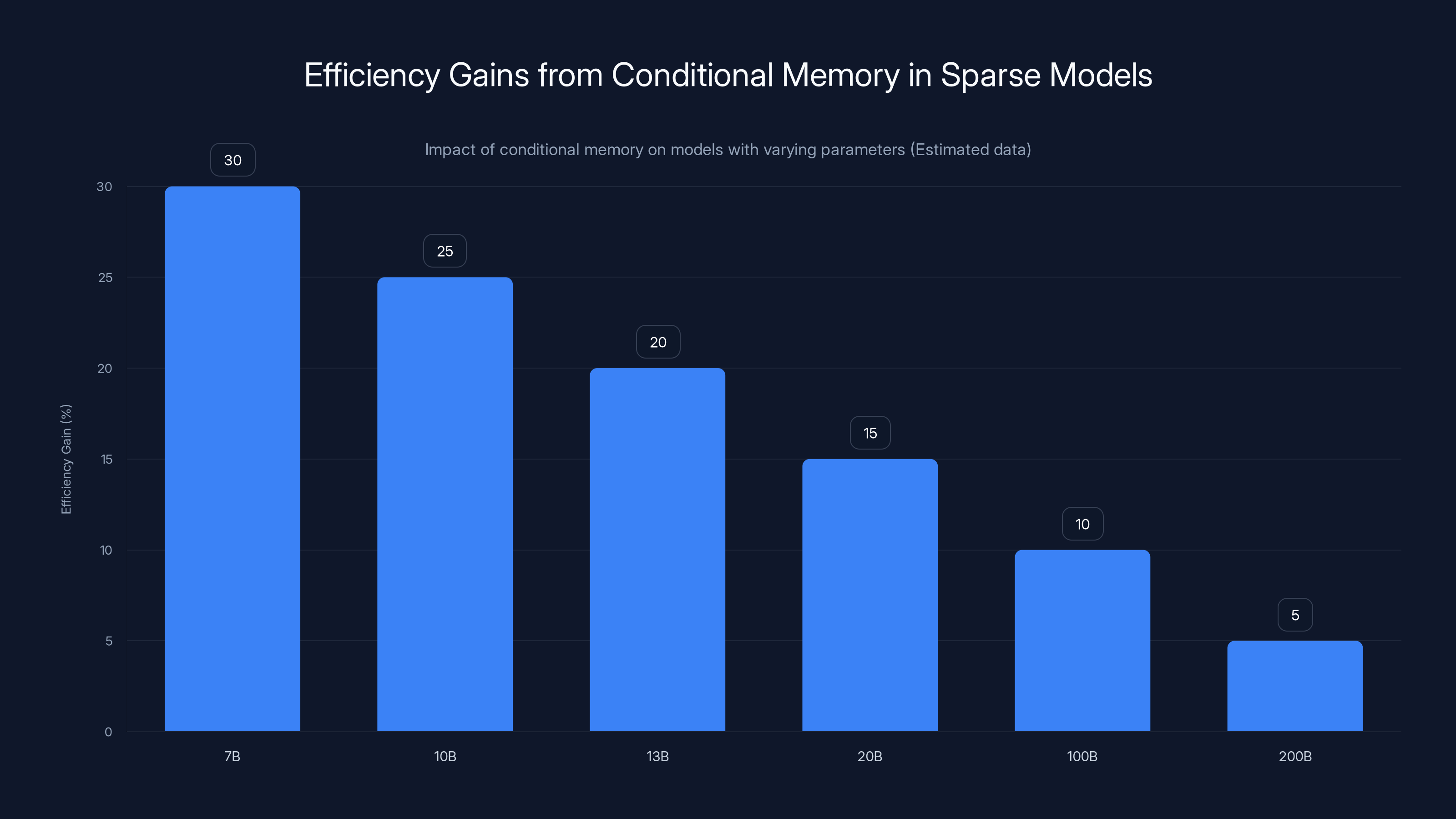
Conditional memory significantly enhances efficiency in smaller sparse models, with the largest gains observed in models with 7-20B parameters. Estimated data illustrates the trend.
Enterprise Deployment: What This Means for Real Systems
For companies building AI systems, Engram's research has immediate practical implications, even if you're not implementing conditional memory today.
Separating knowledge from reasoning workloads: Rather than building monolithic systems where models do everything, start building systems where retrieval and reasoning are architecturally distinct. Use RAG or knowledge retrieval systems for facts. Use models for reasoning. This architectural separation mirrors conditional memory's philosophy and will let you adopt conditional memory systems more easily when they mature.
Profiling for retrieval overhead: Most teams don't measure how much compute their models spend on retrieval versus reasoning. Implement detailed profiling on your production models. See what fraction of inference is spent on knowledge-heavy versus reasoning-heavy tasks. This data becomes valuable when deciding whether to adopt conditional memory or other efficiency improvements.
Planning for sparse architectures: Even if you're not using conditional memory, consider adopting sparse models (Mixture-of-Experts). The efficiency gains are proven and available today. Sparse models also make conditional memory adoption easier in the future because the training procedures are similar.
Recalculating model size requirements: With the emergence of efficient architectures (conditional memory, sparse models, better MoE), you might achieve target performance with smaller models than previously possible. Re-baseline your model sizing. What you previously needed 100B parameters for might now be achievable with 20-30B sparse parameters using conditional memory.
The timeline for enterprise adoption: Conditional memory is probably 18-36 months away from mainstream implementation. Open AI, Anthropic, and other frontier labs are likely already experimenting. Open-source frameworks will add support over the next 12-18 months. By 2027-2028, it should be standard in most large model deployments.
For cost-conscious enterprises, this means two strategies:
-
Adopt today's efficient architectures aggressively: Sparse models, RAG, careful model selection. These provide real benefits now and don't require waiting for research to mature.
-
Plan infrastructure for tomorrow's efficiencies: Build systems where you can swap models, update retrieval mechanisms, and adjust routing. When conditional memory libraries become available, you'll be able to integrate them without redesigning your entire system.
Looking Forward: Research Directions and Limitations
Deep Seek's conditional memory research opens new questions rather than closing them.
Semantic hashing: Current approaches use token-level hash functions. Could learned semantic hashing (hashing based on meaning rather than spelling) improve retrieval accuracy? This could be powerful for synonyms and concept matching but would require additional training overhead.
Multi-stage retrieval: The current system does single-stage retrieval (hash → lookup → gate). Could multi-stage retrieval (progressively refining queries) improve accuracy? This adds latency but might catch nuances current approaches miss.
Adaptive allocation: The research found 75-25 as optimal, but this might vary by task. Could models learn to dynamically allocate capacity between reasoning and retrieval based on the current task? An "easy retrieval, hard reasoning" prompt might benefit from different allocation than "easy reasoning, hard retrieval."
Continual learning: How does conditional memory work with continual learning (updating knowledge without full retraining)? Currently, you'd need to rebuild embedding indices after each update. Streaming updates to embedding tables could enable efficient knowledge updates.
Cross-modal retrieval: Does conditional memory extend to multi-modal models? Could you hash visual patterns and retrieve visual embeddings? This could improve vision-language models' efficiency.
These aren't limitations of the current approach—they're natural extensions once the foundation is solid.
Limitations that do exist:
Curse of dimensionality in hashing: As you scale embedding tables to larger and larger vocabularies, hash collisions become harder to avoid. At some point, the collision rate might become the bottleneck.
Reasoning-retrieval entanglement: Some queries genuinely require mixing reasoning and retrieval (like "what did I just read about X?"). Conditional memory optimizes for clean separation, which may not always match real queries.
Training data requirements: Building good embedding tables requires training data. Domains where high-quality training data is scarce might see poor retrieval performance.
Key Takeaways: Why Conditional Memory Matters
Deep Seek's conditional memory research—implementing through the Engram module—addresses a fundamental inefficiency in transformer architecture that the industry has largely ignored. Here's why it matters:
First, it separates concerns that should be separate: Transformers treat static retrieval and dynamic reasoning identically. This is like using the same neural machinery for remembering facts and solving novel problems. Conditional memory decouples these, letting each be optimized for what it actually needs.
Second, it proves efficiency gains come from architecture, not just scale: The research shows that 75-25 computation-retrieval split beats 100% computation. This validates that better architecture beats bigger models. This trend will accelerate and reshape how the industry builds AI systems.
Third, it unlocks infrastructure optimization: Offloading embedding tables to system RAM while keeping transformer weights on GPU changes the cost structure of inference. This becomes increasingly important as model sizes grow.
Fourth, it has outsized impact on practical model sizes: The efficiency gains are largest on 7-30B parameter models—exactly the size range most companies can actually deploy. Frontier labs might see smaller percentage improvements, but enterprises see transformative benefits.
The implications extend beyond conditional memory itself. If Engram is correct that specialized computation beats generalized computation, expect to see increasingly composite model architectures. Not one giant transformer, but a system of specialized components. This architectural shift is how the field moves from "bigger" to "smarter."
For practitioners: start profiling your models' retrieval overhead. Start planning for architectural diversity. The future of AI efficiency won't be found in bigger models—it'll be found in smarter model design.
FAQ
What is conditional memory in large language models?
Conditional memory is an architectural component that separates static information retrieval from dynamic reasoning in language models. Rather than using the same expensive transformer computation for both tasks, it uses hash-based lookup for static facts (like entity names or product specifications) and routes those through a gating mechanism that decides whether the retrieved information matches the current context. This allows models to allocate compute more efficiently, using 75% of capacity for reasoning and 25% for knowledge retrieval.
How does conditional memory differ from retrieval-augmented generation (RAG)?
RAG operates externally—it retrieves documents from a database and passes them as context to the model. Conditional memory is internal and architectural—it redesigns how the model itself handles the distinction between static information and reasoning. RAG adds knowledge without changing the model. Conditional memory changes how the model processes both knowledge and reasoning, making it fundamentally more efficient. You could combine both approaches, using conditional memory for internal pattern matching while using RAG for external document retrieval.
What performance improvements does conditional memory deliver?
Deep Seek's research showed conditional memory improved reasoning accuracy from 70% to 74% on Big-Bench Hard and ARC-Challenge benchmarks, and improved knowledge retrieval from 57% to 61% on MMLU. Additionally, models using conditional memory showed 8-12% faster inference on knowledge-heavy workloads and could offload embedding tables to system RAM with less than 3% latency penalty. The improvements are larger for smaller models (7-50B parameters) than for very large models.
Why is conditional memory particularly important for sparse models?
Sparse models like Mixture-of-Experts activate only a fraction of their parameters per token, making every parameter precious. Using sparse model capacity for static fact retrieval is wasteful when that capacity could be used for reasoning. Conditional memory offloads retrieval to a dedicated hash-based system, freeing all expert capacity for complex reasoning. This makes sparse models dramatically more efficient and lets them achieve performance comparable to much larger dense models.
What are the infrastructure benefits of conditional memory?
Conditional memory enables deterministic prefetching of embeddings—you know what to retrieve before processing starts, unlike dynamic routing that depends on runtime hidden states. This allows asynchronous retrieval of embedding tables from host RAM while the GPU computes transformer blocks. Deep Seek demonstrated that a 100B-parameter embedding table can be offloaded to system RAM with less than 3% latency overhead, potentially reducing GPU memory requirements by 20% and cutting infrastructure costs significantly at scale.
When should organizations implement conditional memory?
Conditional memory delivers maximum value for organizations with knowledge-heavy workloads (e-commerce product specs, customer support systems, compliance databases), severe GPU memory constraints, and inference-heavy (not frequent retraining) patterns. It's less valuable for pure reasoning workloads, systems that already use mature RAG approaches, models below 7B parameters, or scenarios with frequent retraining cycles. Profile your model's retrieval-to-reasoning ratio—if retrieval accounts for less than 30% of compute, conditional memory probably won't justify implementation complexity.
How does conditional memory's gating mechanism work?
As the model processes tokens through transformer layers, it accumulates context understanding in its hidden states. When conditional memory retrieves static information via hash lookup, a gating network evaluates whether this retrieved information contradicts or aligns with the current context. If the retrieved memory matches the context (e.g., "Apple Inc" when discussing companies), the gate opens and incorporates it. If it contradicts (e.g., "Apple Inc" when discussing fruit recipes), the gate suppresses it. This context-conditional gating prevents hallucinations and incorrect retrievals.
What's the optimal allocation between reasoning and retrieval capacity?
Deep Seek's systematic testing found that allocating 75-80% of sparse model capacity to dynamic reasoning and 20-25% to static retrieval provides optimal performance. Interestingly, pure computation (100% allocation to reasoning) underperforms because the model wastes depth reconstructing static patterns. Too much memory capacity loses reasoning capacity. This 75-25 split appears to represent a fundamental architectural balance in how transformer models should be structured.
Will conditional memory replace RAG systems?
No. Conditional memory and RAG solve complementary problems. RAG adds knowledge beyond the model's training data, enabling real-time information (current news, company-specific documents) and domain-specific knowledge. Conditional memory optimizes how the model internally processes static patterns it learned during training. The most advanced systems will likely combine both: using conditional memory for internal efficiency and RAG for external knowledge integration.
What timeline should enterprises expect for conditional memory adoption?
Conditional memory is currently in early research stages (2025). Frontier AI labs are likely already experimenting internally. Open-source framework support (PyTorch, Hugging Face) will emerge over 12-18 months. Mainstream adoption in enterprise systems is probably 18-36 months away (2026-2027). For teams needing efficiency improvements today, adopting sparse models and RAG provides real benefits without waiting for conditional memory infrastructure to mature.
Conclusion: Efficiency Through Architecture, Not Scale
Deep Seek's conditional memory research challenges a fundamental assumption that's driven AI development for years: bigger models solve harder problems. The research suggests something more nuanced: smarter architecture solves harder problems more efficiently than bigger models.
Engram's elegant solution—hashing for retrieval, gating for context, prefetching for infrastructure optimization—demonstrates that thoughtful architectural design can deliver improvements that raw scale struggles to achieve. A 13B sparse model with conditional memory can outperform a much larger dense model on both reasoning and knowledge tasks. That's not about parameter count. It's about how those parameters are used.
For the industry, conditional memory marks a transition point. We're moving from an era where "more compute and more parameters" was the default answer to questions about performance. We're entering an era where "better architecture" becomes equally important. This transition parallels every technology maturation cycle: first you scale, then you optimize.
For enterprises, the message is clear: watch architectural innovation as closely as you watch model size. Start experimenting with sparse models. Begin profiling your systems to understand where computation is actually spent. Build infrastructure flexible enough to adopt new efficiency techniques as they mature. The most capital-efficient AI deployments won't come from teams that scale fastest—they'll come from teams that optimize smartest.
Conditional memory probably won't be in your production systems this year. But by 2027-2028, it'll likely be standard. The teams that understand it now and plan their architecture accordingly will deploy more capable systems at lower cost. The teams that keep betting on raw scale will find themselves increasingly outcompeted.
That's how architectural innovations reshape industries. They don't win overnight. They win gradually, then all at once.
Use Case: Automatically generate technical documentation and API reference guides from your model architecture specifications without manual writing.
Try Runable For Free
Related Articles
- MSI's AI and Business Focus at CES 2026 [2025]
- Meta's Nuclear Energy Deal with TerraPower: The AI Power Crisis [2025]
- Samsung AI Chip Boom Drives Record $13.8B Profits [2025]
- DDR5 Memory Prices Could Hit $500 by 2026: What You Need to Know [2025]
- Nvidia's Upfront Payment Policy for H200 Chips in China [2025]
- AI Factories: The Enterprise Foundation for Scale [2025]

