![OpenAI's GPT-5.3-Codex-Spark: Breaking Free from Nvidia [2025]](https://tryrunable.com/blog/openai-s-gpt-5-3-codex-spark-breaking-free-from-nvidia-2025/image-1-1770937571559.jpg)
Introduction: The Hardware Rebellion Nobody Saw Coming
For years, OpenAI has been tethered to Nvidia's GPUs like a satellite orbiting a massive planet. The relationship seemed inevitable, almost inescapable. Nvidia dominated the AI chip market so thoroughly that every major AI lab—OpenAI, Anthropic, Google, Meta—appeared locked into a dependency that would persist indefinitely.
Then came Thursday.
OpenAI just rolled out GPT-5.3-Codex-Spark, a production AI model running on chips from Cerebras, not Nvidia. And the performance numbers? They're genuinely stunning. We're talking 1,000 tokens per second for coding tasks. To put that in perspective, that's roughly 15 times faster than the previous iteration.
But this isn't just about speed metrics on a spec sheet. This is about OpenAI systematically dismantling its dependence on a single chip manufacturer. It's about sovereignty over infrastructure. It's about costs. And it's about the competitive pressure mounting from every direction in the AI coding space.
I spent the last week digging into what's really happening here. The technical story is fascinating. The business implications are seismic. And the timing? Well, that's interesting too.
The Coding Agent Arms Race Heats Up
Let's set the stage. The past year has been absolutely wild in AI coding. OpenAI's Codex and Anthropic's Claude Code went from "neat proof of concept" to "actually useful for real development work" in the span of maybe six months.
Developers started using these tools to rapidly scaffold projects, generate boilerplate code, build entire UIs in minutes. It changed the game. Suddenly, AI coding wasn't theoretical anymore. It was shipping features.
Then everyone noticed the same thing at the same time: latency is everything.
When you're sitting in VS Code waiting for an AI suggestion, the difference between a 200ms response and a 2-second response isn't just measurable—it's life-changing. One feels instantaneous. Natural. Like the AI is thinking alongside you. The other feels like you're waiting for a progress bar, and your flow state evaporates.
This is why speed became the metric that matters most. Not accuracy in abstract benchmarks. Not elegance of architecture. How fast does it generate working code?
Anthropic's Claude Opus 4.6 launched a new "fast mode" recently that reaches about 2.5 times its standard speed of 68.2 tokens per second. That's helpful, but Codex-Spark is operating in a completely different velocity tier.
OpenAI has been moving aggressively. In December, they shipped GPT-5.2-Codex after Sam Altman sent what was reportedly an internal "code red" memo about competitive pressure from Google. Then just days ago, GPT-5.3-Codex launched. Now Spark.
The pace is brutal. The company is iterating faster than most teams can even integrate the previous version.
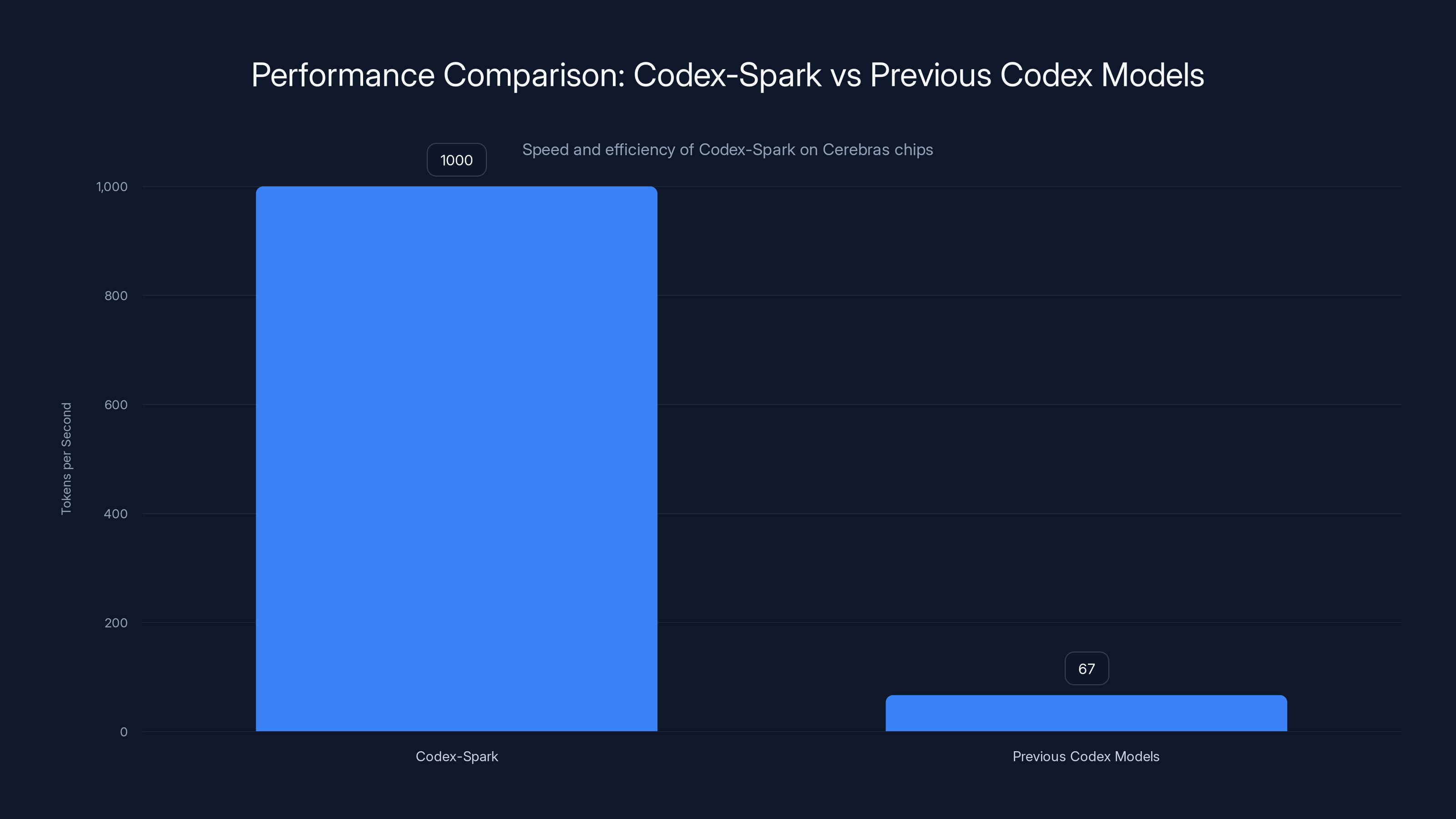
Codex-Spark achieves 1,000 tokens per second, making it 15 times faster than previous Codex models, enhancing real-time coding efficiency.
Meet Cerebras: The Underdog Chip Maker
Now let's talk about Cerebras, because most developers have probably never heard of them, and that's about to change.
Cerebras built their entire business around a wildly ambitious idea: what if you could put an entire wafer of silicon on a single chip? Most chips are much smaller because manufacturing a huge die requires absurd precision and yields catastrophically low profits. Cerebras said "no, let's do it anyway," and they engineered the Wafer Scale Engine 3 (WSE-3).
This thing is the size of a dinner plate. It's genuinely enormous compared to typical chips. And the scale enables something special: you can fit way more compute on a single chip, which reduces memory bottlenecks that typically plague large model inference.
Think about it this way: when you're running a huge model, data has to move between different parts of the chip constantly. That movement is expensive in terms of latency. Cerebras' approach shrinks the distances those signals have to travel. Everything's closer together.
For inference workloads specifically—which is exactly what Codex-Spark is optimized for—this architecture has some genuine advantages.
Cerebras has measured 2,100 tokens per second on Llama 3.1 70B models and even hit 3,000 tokens per second on OpenAI's own open-weight gpt-oss-120B model. So technically, Codex-Spark's 1,000 tokens per second is actually conservative by their standards. The lower throughput probably reflects that Spark is either a more complex model or carries overhead that the larger models don't.
But here's the thing: this is production hardware. It's not vapor. It's not a research project that'll never ship. OpenAI and Cerebras announced their partnership in January 2025, and three months later, there's a shipping product.
The Nvidia Dependence Problem
Here's what most people don't fully appreciate about OpenAI's situation: they were becoming too dependent on Nvidia.
Don't get me wrong. Nvidia makes phenomenal chips. The engineering is legitimately world-class. But when one company controls 80+ percent of a market, dependency becomes vulnerability.
OpenAI started taking steps to diversify roughly a year ago. In October 2025, they signed a massive multi-year agreement with AMD. In November, they struck a $38 billion cloud computing deal with Amazon. And they've been quietly designing their own custom AI chips for eventual fabrication by TSMC.
These weren't coincidences. Reuters reported that OpenAI grew dissatisfied with Nvidia's speed for inference tasks specifically. That's the exact workload Spark is optimized for.
There was also supposed to be a **
The subtext here is worth reading carefully: OpenAI wants optionality. They don't want to wake up one day and realize they're completely locked into a single vendor's roadmap, pricing, availability, or geopolitical situation.
Codex-Spark on Cerebras chips is a concrete proof point that they can build and ship products without Nvidia.
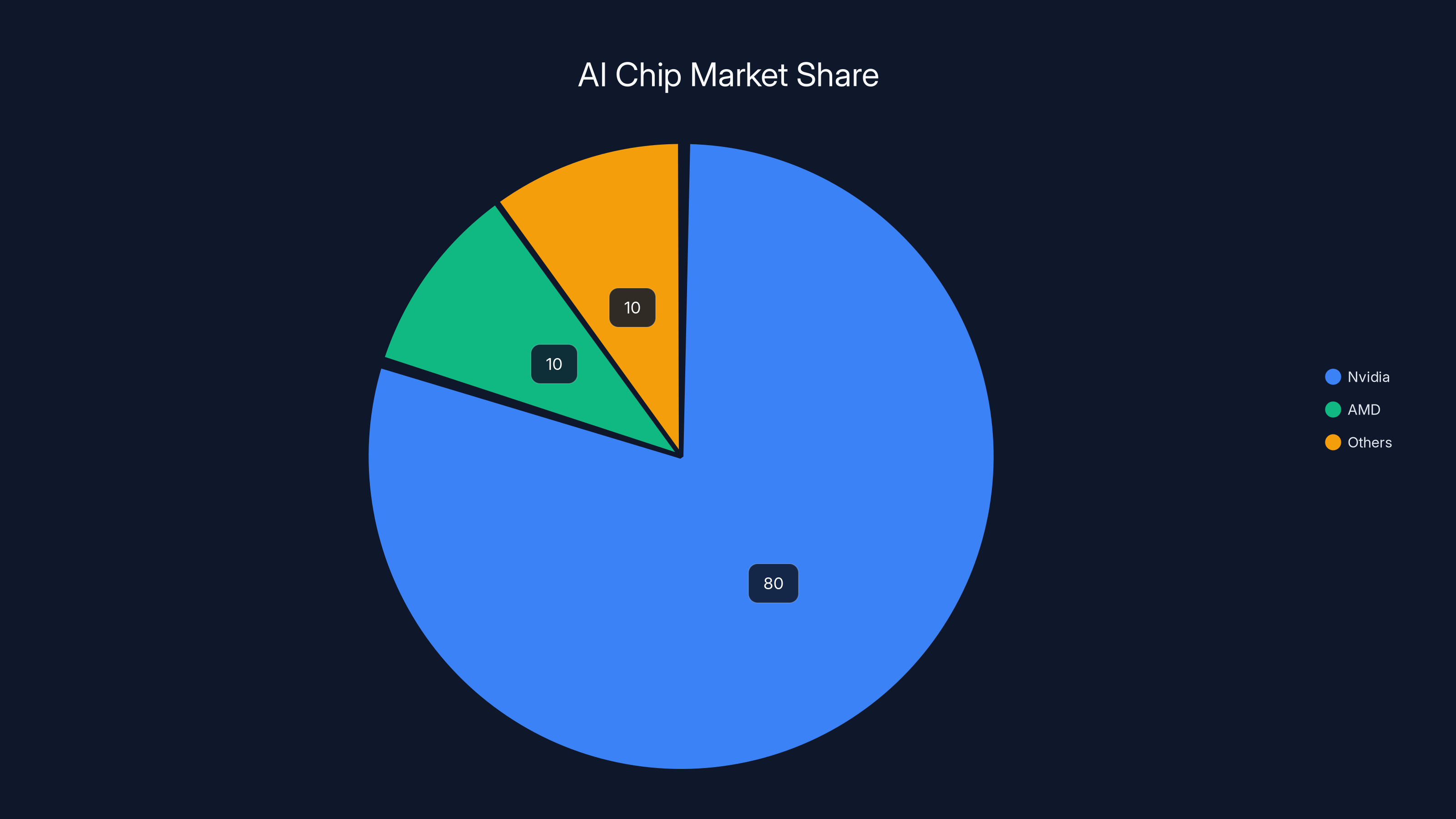
Nvidia holds an estimated 80% of the AI chip market, highlighting the dependency risk for companies like OpenAI. Estimated data.
Technical Deep Dive: Why Speed Matters for Coding
Let's get more technical for a moment, because the 1,000 tokens per second figure deserves real context.
When we talk about tokens, we're talking about chunks of data. For coding, a token might be a word, a symbol, or a punctuation mark. A typical line of code might be 10-15 tokens. A function might be 100-200 tokens.
So 1,000 tokens per second means you can generate roughly 50-100 lines of code per second. That's... a lot. That's approaching instantaneous for most code suggestions.
To compare with Nvidia hardware through OpenAI's infrastructure: GPT-4o delivers around 147 tokens per second. o 3-mini hits about 167. Even the latest models don't crack 200 on standard infrastructure.
The formula for effective coding speed factors in both throughput and latency:
Codex-Spark wins on both fronts. High throughput per second, and presumably lower time-to-first-token since Cerebras' architecture reduces some of the bottlenecks that plague distributed inference.
For a developer using this in practice, what does that mean? When you hit the keyboard shortcut for an AI suggestion in VS Code, you'd see:
- Keystroke registered (1ms)
- Context sent to API (50ms)
- First tokens start arriving (50-100ms)
- Complete suggestion rendered (another 200-500ms depending on length)
Now imagine that 200-500ms was instead 20-50ms. The UX is fundamentally different. It stops feeling like "waiting for a robot" and starts feeling like "thinking together."
This is why latency obsession in the AI coding space isn't premature optimization theater. It's the difference between a tool that's genuinely useful and one that's merely impressive.
Codex-Spark's Architecture and Optimization
OpenAI made some specific engineering choices for Codex-Spark that are worth examining.
First: it's text-only at launch. No images, no multi-modal reasoning. This is a deliberate constraint that helps with speed. Processing images adds computational overhead. If you're optimizing purely for coding speed, you strip that away.
Second: it's tuned specifically for coding, not general-purpose tasks. OpenAI created a pruned version of their larger GPT-5.3-Codex model, removing capabilities that aren't needed for code generation. This is classic model optimization. Smaller context, more focused architecture.
Third: it ships with a 128,000-token context window. That's substantial. It means the model can "see" about 100,000 lines of existing code for context before generating suggestions. That's the full scope of a mid-sized codebase in a single context window.
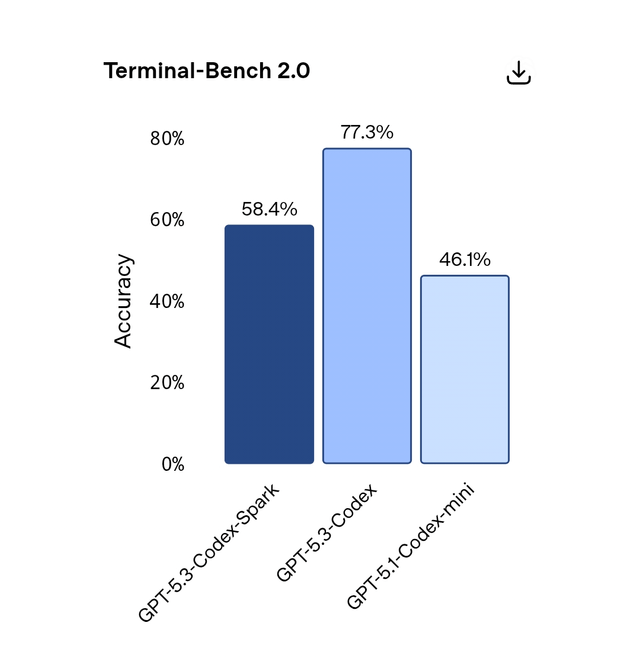
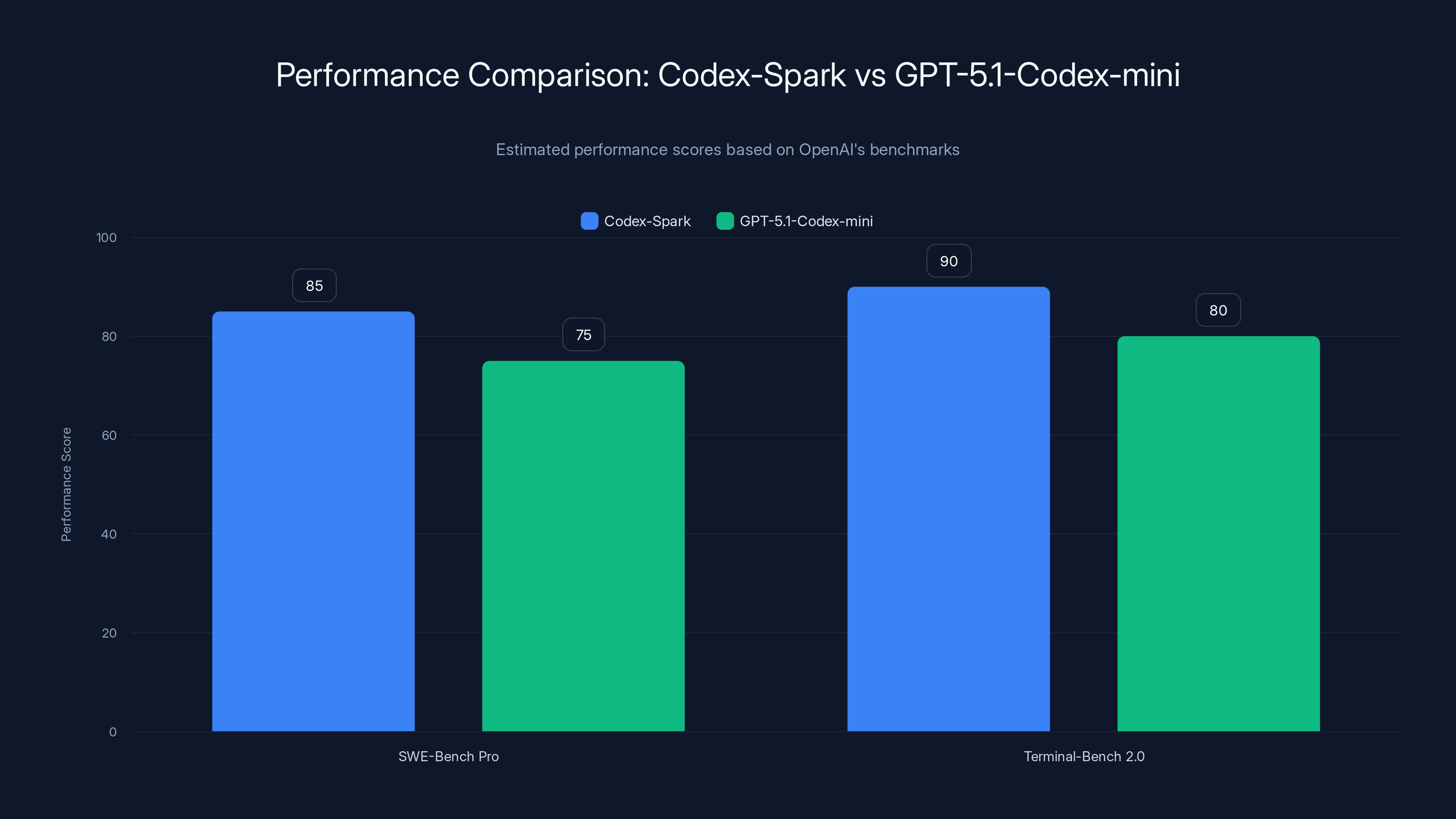
OpenAI claims Codex-Spark outperforms the older GPT-5.1-Codex-mini on standard benchmarks like SWE-Bench Pro and Terminal-Bench 2.0. These benchmarks test the model's ability to understand repository structures, fix bugs, and complete feature implementations.
However, and this is important: these numbers aren't independently validated. OpenAI reported the results. That doesn't mean they're wrong, but it does mean we should interpret them with appropriate skepticism until third parties confirm them.
When Ars Technica tested AI coding agents building Minesweeper clones in December, Codex took roughly twice as long as Anthropic's Claude Code to produce a working game. If Spark is genuinely 15x faster, that gap should compress significantly. That's a prediction worth testing.
Availability and Pricing: Who Gets Access?
Codex-Spark exists in a limited availability tier right now.
Chat GPT Pro subscribers (
OpenAI is rolling out API access to "select design partners," which is startup speak for "we're cautiously onboarding a small number of companies to test this in production before we go wide."
This matters because API availability determines scale. Right now, this is a premium product for premium customers. Over time, we'd expect pricing to come down and access to expand.
But here's the economics piece: if Cerebras' hardware is actually cheaper to operate at scale than Nvidia's, OpenAI could eventually offer Codex-Spark at lower prices than comparable models. That's a competitive weapon.
For teams building AI-powered development tools, access to Codex-Spark API would be genuinely transformative. 1,000 tokens per second means lower inference costs. Lower latency means better UX.
Codex-Spark reportedly outperforms GPT-5.1-Codex-mini in both SWE-Bench Pro and Terminal-Bench 2.0 benchmarks. Estimated data based on OpenAI's reported results.
The Broader Hardware Diversification Strategy
Codex-Spark isn't happening in isolation. It's part of a deliberate, multi-pronged strategy to reduce hardware vendor concentration.
OpenAI's movements look like this:
AMD Partnership: The multi-year deal gives OpenAI access to AMD's EPYC processors and MI300 AI accelerators. AMD chips are less specialized for AI than Nvidia's, but they're cheaper and increasingly competitive.
Amazon AWS Deal: The $38 billion agreement spans multiple years and probably includes commitments to use AWS infrastructure for cloud hosting, compute, and storage. This reduces dependence on other cloud providers and creates direct leverage with Amazon.
Custom Chips: OpenAI is designing their own chips with TSMC. This is a multi-year effort, but it's strategically important. It means OpenAI could eventually run whatever workloads they want on whatever hardware they build.
Cerebras Partnership: This is the near-term play. Ship production products on Cerebras today while the custom chips are still in development.
The portfolio approach makes sense. You're not betting the company on any single vendor. You're building redundancy. You're creating competition between suppliers. You're maintaining strategic flexibility.
This is what smart infrastructure strategy looks like at enterprise scale.
Performance Benchmarking and Real-World Results
Let's talk about how these numbers hold up in actual use.
OpenAI has published results on two main benchmarks:
SWE-Bench Pro: Tests the model's ability to fix real bugs in real open-source projects. Involves reading existing code, understanding the bug report, and generating a fix that passes the test suite. Codex-Spark reportedly outperforms GPT-5.1-Codex-mini here.
Terminal-Bench 2.0: Tests command-line task completion. Give the AI a Unix command to accomplish, and measure whether it generates correct shell commands. Again, Codex-Spark reportedly wins.
But here's the honest assessment: we don't have independent validation yet. We're trusting OpenAI's testing methodology, their implementation, their dataset selection.
In practice, what matters more is real-world developer experience. Does it feel fast? Do suggestions actually work? Does it reduce development time or just add latency and frustration?
Early access users will answer that. But it'll take months to accumulate enough real-world data to know if the benchmark claims translate to genuine productivity gains.
Competitive Implications for Anthropic and Google
This matters to Anthropic and Google.
Anthropic has Claude Code, which apparently beat Codex in the Minesweeper test. But if Codex-Spark is genuinely 15x faster, that changes the competitive dynamic. Speed can compensate for accuracy differences if the speed is dramatic enough.
Google has Gemini and their own coding models. They also have TPUs, custom chips that are Google's own answer to Nvidia's dominance. So Google has options.
But the fact that OpenAI can credibly ship production models on non-Nvidia hardware changes assumptions that have persisted for years. It proves you don't have to stay married to Nvidia if you're willing to engineer for alternative architectures.
That's worth billions of dollars to competitors facing high Nvidia costs.

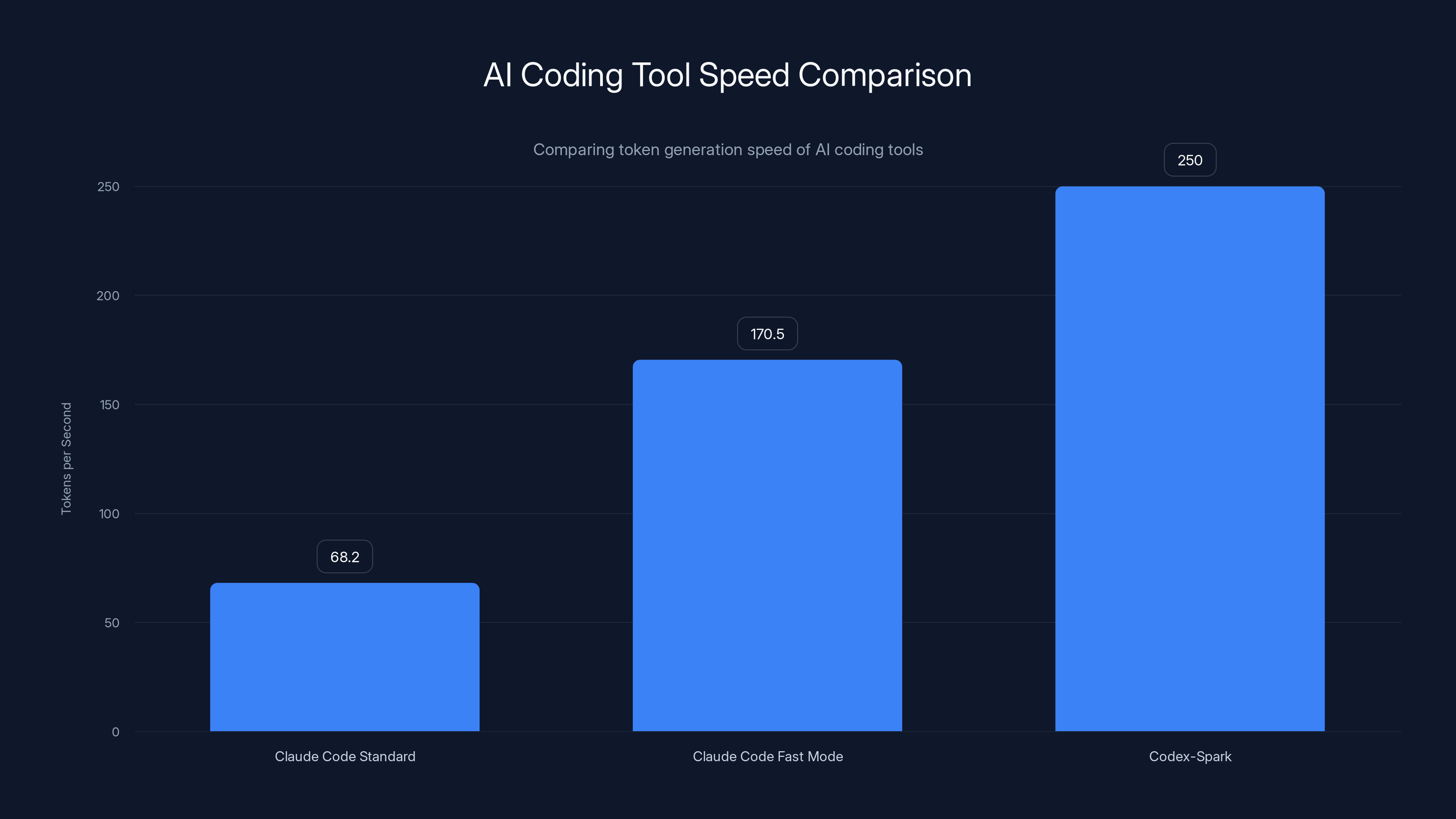
Codex-Spark leads the AI coding tool race with 250 tokens per second, significantly faster than Claude Code's 170.5 tokens per second in fast mode. Estimated data for Codex-Spark.
The Cost Dimension Nobody Talks About Enough
Let's be direct: inference is expensive.
Running large language models in production involves significant compute costs. You need accelerators. You need memory bandwidth. You need fast networks. You need to pay cloud providers.
Nvidia's profit margins are enormous precisely because they have no competition. When you're running GPT-4o, you're paying Nvidia's pricing whether you like it or not.
Cerebras' approach might unlock different economics.
Wafer-scale chips are expensive to manufacture, but they have one advantage: everything's on one chip. You don't need complex multi-chip interconnects. You don't pay the same penalties for data movement between accelerators.
If Cerebras can manufacture WSE-3 chips at reasonable yields and reasonable costs, they could compete on price despite the engineering complexity. OpenAI betting production workloads on Cerebras suggests they believe the economics work.
Roughly:
Nvidia inference per token: Varies by model, but estimates range from
Cerebras inference per token: Probably similar or lower, since 1,000 tokens per second represents dramatically higher throughput.
For companies running large-scale inference, the difference compounds. If you're generating 1 billion tokens per month, a difference in per-token costs from
Multiply that across all of OpenAI's inference workloads, and you're talking about serious cost savings.
The Speed vs. Accuracy Trade-off
Here's where we need to be honest about trade-offs.
Codex-Spark is optimized for speed. That's the whole point. The question is: does it sacrifice accuracy to achieve that speed?
OpenAI hasn't explicitly addressed this. They're claiming outperformance on benchmarks. But benchmarks can be misleading if the model is specifically tuned to do well on those benchmarks.
The Minesweeper test result from Ars Technica's December report is actually more telling: Codex took twice as long as Claude Code to produce working code. If Codex-Spark is actually 15x faster now, it might be comparable to Claude. But "comparable" isn't "better."
For a developer using this tool, the question isn't abstract: do I trust the suggestions enough to use them without verification?
If Codex-Spark generates code at 1,000 tokens per second but half the code needs debugging, that's worse than Claude Code at 1/4 the speed if Claude's code works right the first time.
This is the real test that'll determine adoption.
What This Means for Your Workflow
Let's get practical.
If you're a developer using AI coding tools today, Codex-Spark might become available to you depending on OpenAI's rollout pace. When it does, the main benefit is probably lower latency in your editor. Suggestions appear faster. You spend less time waiting.
If you're a startup building AI-powered development tools, Codex-Spark API access could be transformative. Faster inference means lower costs and better UX for your product.
If you work at companies building automation platforms, this matters because coding speed directly affects how quickly you can build features and iterate on products. Faster AI coding models compress development cycles.
If you're investing in tech infrastructure, the diversification away from Nvidia is worth watching. It suggests OpenAI (and eventually other labs) will have more negotiating power with hardware vendors. That benefits anyone relying on AI infrastructure costs.
If you're at Nvidia, you should probably be concerned. Not panicked, but concerned. The company is too dominant to worry about a single competitor shipping on alternative chips. But if this becomes a trend—if Google's TPUs start getting competitive workloads, if AMD gains share, if custom chips proliferate—Nvidia's pricing power erodes.
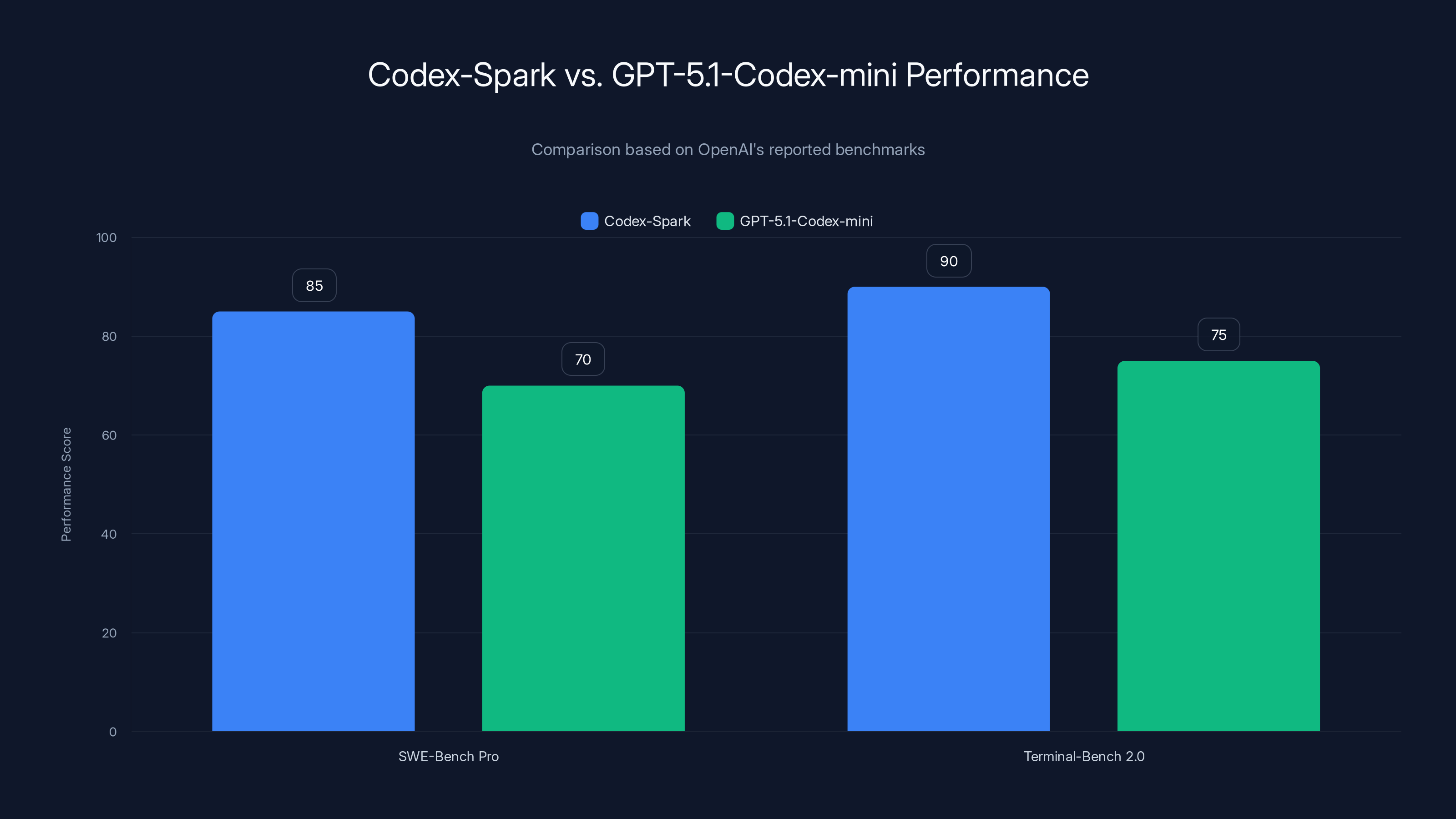
Codex-Spark reportedly outperforms GPT-5.1-Codex-mini in both SWE-Bench Pro and Terminal-Bench 2.0, indicating significant improvements in understanding and generating code solutions. Estimated data based on context.
Timing and Competitive Context
The timing of this launch is worth noting.
OpenAI released GPT-5.2-Codex in December after Altman's "code red" memo about Google competition. They shipped GPT-5.3-Codex days ago. Now Spark is live.
The cadence is aggressive. It feels like OpenAI is executing a playbook: iterate rapidly, ship frequently, accumulate data about what works.
Competitive context matters here. Google DeepMind has been making moves in AI coding. Anthropic is pushing Claude hard. A slowing iteration cycle could look like weakness.
OpenAI is signaling: we're moving fast, we have resources, we're not slowing down.
Codex-Spark supports that narrative even if it's not the headline feature. It says "we can ship on alternative hardware, we can diversify, we can out-execute competitors."
That's worth something in a competitive arms race.

What About Model Accuracy and Correctness?
Let's address a fundamental question: is a fast model that makes mistakes better than a slower model that gets it right?
For development work, the answer depends on your workflow.
If you're scaffolding: Creating boilerplate, structural code, setup—speed matters more than perfection. You expect to modify the output.
If you're bug fixing: Accuracy matters more than speed. You need the suggestion to actually solve the problem.
If you're in exploratory coding: Speed matters because you want to iterate quickly and explore design spaces rapidly.
Codex-Spark being tuned specifically for coding helps here. It's not a general-purpose model trying to do everything. It's specialized.
But we won't know the real accuracy story until it's in wide use. OpenAI's benchmarks are one data point. Real-world testing with thousands of developers using it in their daily workflow is the actual proof.
Manufacturing, Supply, and Scaling
Here's a practical question: can Cerebras actually manufacture enough chips to support OpenAI's workload?
Wafer-scale engines are expensive to manufacture. The dies are huge, which means yield rates (percentage of working chips per wafer) are typically lower than conventional chips. This makes them cost-prohibitive at scale unless you can achieve yields of 70%+ and negotiate favorable manufacturing agreements with TSMC.
Cerebras has been shipping the WSE-3 to select customers for a while, so they've presumably solved some of these problems. But scaling from "select design partners" to supporting all of OpenAI's inference workload plus selling to other companies is a different challenge.
If Cerebras hits supply constraints, OpenAI can't scale Codex-Spark. That limits the impact.
But Cerebras has been operating since 2016. They've raised significant funding. They have partnership with TSMC for manufacturing. They're serious infrastructure players.
The fact that OpenAI is willing to bet production workload on their hardware suggests the manufacturing situation is stable enough.

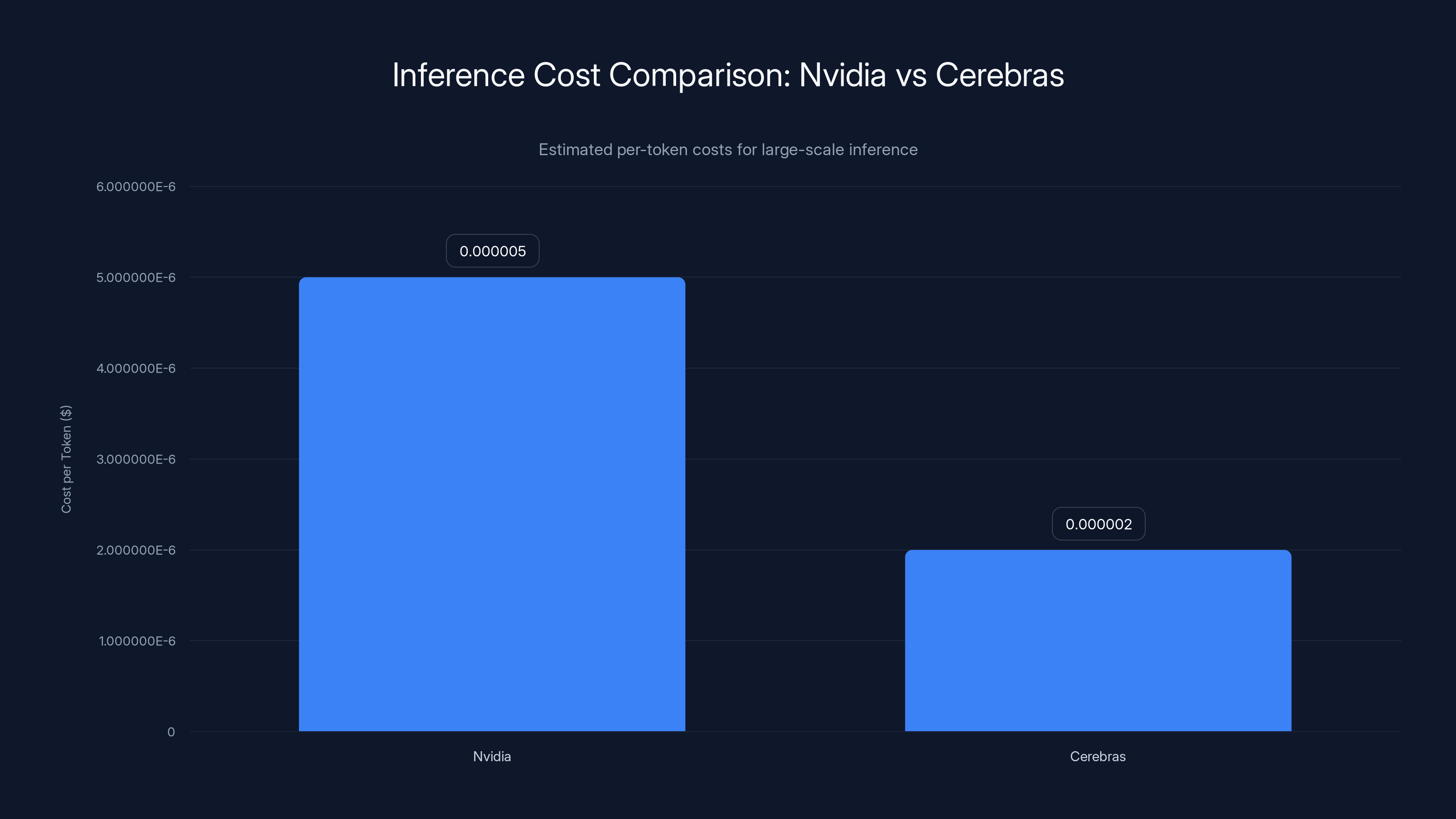
Cerebras offers potentially lower inference costs per token compared to Nvidia, which can lead to significant savings at scale. Estimated data.
The Long Game: Custom Chips and Future Dominance
The biggest strategic prize for OpenAI is their own custom chips.
Companies like Apple with their M-series chips and Google with TPUs understand something important: owning your hardware is owning your future.
When you design your own chips, you can optimize for your specific workloads. You're not paying for features you don't need. You're not subsidizing markets you don't care about. You can make compute cheaper and faster in exactly the ways that matter to your business.
OpenAI is clearly moving in this direction. The Cerebras partnership is a bridge—something to ship on while custom chips are still in development. But the endgame is probably to eventually run most OpenAI inference on OpenAI-designed hardware.
That's 5-10 years away minimum. Chip design, validation, manufacturing, ramping—it's a multi-year project. But it's probably in OpenAI's roadmap.
In the meantime, shipping on Cerebras chips proves the concept: OpenAI can design systems that run efficiently on non-Nvidia hardware. That's valuable learning.
Geopolitical and Supply Chain Considerations
There's a subtext to all this that's worth acknowledging.
Having all your AI infrastructure depend on a single vendor is geopolitically risky. Vendors can be subject to export controls, sanctions, regulatory pressure. One government restriction could cascade through your entire operation.
Diversifying hardware vendors is partially about cost and performance, but it's also about resilience and sovereignty.
Nvidia dominance is partly about US expertise and manufacturing excellence. But it's also about path dependency and market lock-in.
OpenAI moving compute to Cerebras (US company), AMD (US company), Amazon (US cloud), and TSMC (Taiwan manufacturing) spreads risk. If any single vendor becomes unavailable, OpenAI still has options.
That's especially valuable for a company whose products could be affected by geopolitical events outside their control.

Implications for Developers Using AI Tools
If you're building products that use AI, Codex-Spark and the broader hardware diversification trend matter.
First: more competition on latency means better tools for you. Every vendor will be racing to minimize inference latency because that's what customers care about.
Second: better long-term pricing stability. Diversified hardware competition means Nvidia can't raise prices 30% overnight without losing customers. That helps you.
Third: more vendor options. If you're currently locked into OpenAI's API, Cerebras' inference speeds might make direct inference on their hardware attractive for your use case.
Fourth: architecture matters again. For years, inference performance was basically "throw Nvidia GPUs at the problem." Now you have to think about architecture, workload optimization, and hardware choice. That's more complex, but it also means there's more optionality.
Expert Perspectives and Industry Response
The AI infrastructure community has been watching this closely.
Cerebras' technical leadership has been pointing out for years that wafer-scale design has fundamental advantages for large model inference. The partnership with OpenAI validates that thesis.
Nvidia hasn't publicly commented on Codex-Spark specifically, but the company has emphasized their software stack (CUDA) and ecosystem lock-in as defenses against hardware commoditization.
Industry analysts see this as a sign that the AI infrastructure market is moving from "Nvidia monopoly" to "Nvidia dominance with competition." That's a meaningful shift.

Common Questions and Misconceptions
Let me address some things I've heard from developers:
"Isn't Cerebras just a hype machine?" They've been operational for nearly a decade with real customers. Hype companies don't sustain that long.
"Will other coding models get faster too?" Probably. Codex-Spark's speed will pressure Anthropic to optimize Claude Code for inference latency, and Google to do the same with Gemini Code.
"Does this kill Nvidia's business?" No. Nvidia's dominance is so entrenched that one product shipping on different hardware doesn't change the aggregate market. But it does establish that Nvidia isn't the only option, which is new.
"Should I wait for Codex-Spark instead of using Claude Code now?" Depends on your access. If you have Chat GPT Pro access and can try it, great. But Claude Code is solid today. Don't wait for marginal improvements.
Looking Ahead: The 2025-2026 Predictions
If the trends continue, expect:
H2 2025: OpenAI expands Codex-Spark API access beyond design partners. Pricing probably drops from the premium $200/month tier to something more accessible.
Early 2026: Anthropic announces Claude Code optimization for speed. Google makes similar moves with Gemini. The speed arms race intensifies.
2026: Cerebras wins additional customers for inference workloads. AMD's MI300 chips gain adoption. Custom chip initiatives start showing results.
2027+: OpenAI's custom chips start appearing in production systems. The AI inference market looks genuinely competitive with multiple vendors rather than Nvidia-dominated.
That's the trajectory I'd expect.

The Bottom Line
Codex-Spark represents a inflection point. OpenAI is credibly showing they can build and ship production systems without being dependent on Nvidia.
The speed is impressive. The technical execution is solid. The timing is strategic.
But the bigger story is about infrastructure independence and competitive leverage. This is OpenAI saying: "We've got options. We can diversify. We're not locked in."
For developers, that means better tools coming soon. For infrastructure builders, it means the hardware moat that Nvidia has maintained for years is cracking. For OpenAI, it means strategic flexibility.
If you're working on any AI-powered application, pay attention to this space. The hardware layer matters more than people typically acknowledge, and the dynamics are shifting.
The age of Nvidia's uncontested dominance is ending. What comes next is more competitive, more diverse, and ultimately better for everyone except Nvidia's shareholders.
FAQ
What is Codex-Spark and how does it differ from previous Codex models?
Codex-Spark is OpenAI's specialized coding model optimized for speed and efficiency, running on Cerebras chips instead of Nvidia hardware. It achieves 1,000 tokens per second inference speed, roughly 15 times faster than previous iterations, while maintaining accuracy on coding tasks. The key difference is that Spark is tuned specifically for code generation rather than general-purpose AI tasks, and it sacrifices some capabilities like image processing to maximize speed.
Why is OpenAI moving away from Nvidia chips?
OpenAI has been diversifying hardware vendors to reduce dependence, lower costs, and maintain negotiating leverage. The company signed deals with AMD and Amazon in 2025 and has been designing custom chips with TSMC. Additionally, Reuters reported that OpenAI was dissatisfied with Nvidia's inference speed for certain workloads. Using Cerebras chips for Codex-Spark demonstrates that OpenAI can build and scale production systems without being locked into a single vendor's roadmap or pricing.
What are the real-world performance benefits of 1,000 tokens per second?
For developers using Codex-Spark in their editor, the benefit translates to dramatically lower latency when requesting code suggestions. Instead of waiting 1-2 seconds for a completion, suggestions appear in milliseconds. This changes the user experience from "waiting for an AI" to "thinking together." For API users and companies building AI tools, the speed reduces compute costs per token generated and enables better product UX through faster inference.
How does Codex-Spark compare to Anthropic's Claude Code?
Early testing suggested Claude Code was faster at producing working code than the previous Codex model, despite Codex's theoretical advantages. If Codex-Spark is genuinely 15x faster than its predecessor, the gap should compress significantly. However, speed isn't the only metric—accuracy and correctness matter equally for production development work. Real-world testing will ultimately determine which model is superior for different use cases and workflows.
What is the Cerebras Wafer Scale Engine 3, and why is it better for inference?
The WSE-3 is a processor the size of a dinner plate that puts an entire wafer of silicon on a single chip. This unusual scale reduces the memory bottlenecks that typically limit inference speed in distributed systems. Data doesn't need to travel between separate accelerators; everything happens on one massive chip. Cerebras has demonstrated 2,100 tokens per second on Llama 3.1 models, making it genuinely competitive with traditional chip architectures for inference workloads.
Will Codex-Spark become available to all developers, and what will it cost?
Codex-Spark is currently limited to Chat GPT Pro subscribers ($200/month) and select design partners with API access. OpenAI has historically expanded access over time as products mature, so wider availability is likely later in 2025 or 2026. Pricing will probably decrease from the premium tier once demand is better understood and supply constraints are resolved.
Does faster code generation mean lower accuracy?
There's always a potential speed-accuracy trade-off, but OpenAI claims Codex-Spark outperforms previous Codex models on standard benchmarks. The real test will be real-world usage by thousands of developers. The answer also depends on use case: for scaffolding and boilerplate, speed matters more; for bug fixing, accuracy is critical. Independent benchmarking and developer feedback will ultimately determine whether the speed gains come at an accuracy cost.
How will this affect Nvidia's dominance in the AI hardware market?
Codex-Spark alone won't significantly dent Nvidia's market share because Nvidia's dominance is so entrenched. However, it establishes proof that viable alternatives exist for inference workloads. If Anthropic, Google, and other labs follow suit by optimizing for non-Nvidia hardware, Nvidia's pricing power diminishes. The long-term impact depends on whether the trend becomes industry-wide or remains isolated to OpenAI.
What does this mean for companies building AI-powered products?
It means hardware diversity will increase, competition on latency will intensify, and vendor options will expand. Companies relying on AI inference will have more choices and better negotiating positions with vendors. Long-term infrastructure costs should stabilize or decrease as competition increases. Teams should design systems to be hardware-agnostic where possible to maintain future flexibility.
When will OpenAI's custom chips appear in production systems?
OpenAI's custom chips are still in development and are likely 5-10 years away from production deployment. The Cerebras partnership is a bridge technology—shipping production workloads on proven hardware while custom chips mature. Once ready, OpenAI's own chips could provide significant performance and cost advantages tailored specifically to OpenAI's inference patterns and workloads.

Key Takeaways
- OpenAI's Codex-Spark achieves 1,000 tokens per second on Cerebras hardware, roughly 15 times faster than previous Codex iterations
- This launch proves OpenAI can build production AI systems on non-Nvidia hardware, supporting broader vendor diversification strategy
- OpenAI signed AMD partnership (Oct 2025), AWS deal ($38B, Nov 2025), and is developing custom TSMC chips to reduce Nvidia dependence
- Speed matters more than raw benchmark scores for coding agents—developers prioritize latency for maintaining flow state and productivity
- The move signals end of Nvidia's uncontested AI hardware dominance, with Cerebras, AMD, and custom chips becoming viable alternatives
Related Articles
- OpenAI's Codex-Spark: How a New Dedicated Chip Changes AI Coding [2025]
- How Spotify's Top Developers Stopped Coding: The AI Revolution [2025]
- OpenAI Disbands Alignment Team: What It Means for AI Safety [2025]
- OpenAI Researcher Quits Over ChatGPT Ads, Warns of 'Facebook' Path [2025]
- Claude's Free Tier Gets Major Upgrade as OpenAI Adds Ads [2025]
- OpenAI Codex Hits 1M Downloads: Deep Research Gets Game-Changing Upgrades [2025]

