![Post-Speed Era: Why Control Beats Velocity in Modern Deployments [2025]](https://tryrunable.com/blog/post-speed-era-why-control-beats-velocity-in-modern-deployme/image-1-1771429636091.jpg)
Post-Speed Era: Why Control Beats Velocity in Modern Deployments
Let me set the scene. It's August 2024. A routine security update goes out. Within hours, millions of devices are completely unusable. Airlines can't book passengers. Hospitals can't access patient records. Retailers shut down. The entire infrastructure of modern commerce grinds to a halt.
One flawed configuration. One moment of human error. And suddenly, you realize something fundamental about how we build software has shifted in ways nobody fully appreciated.
For years, the story was simple: speed wins. Get features to customers faster. Deploy more frequently. Measure success by deployment frequency and lead time. This narrative has dominated Dev Ops philosophy for nearly a decade. And it worked. Teams that embraced continuous delivery genuinely did outpace their competitors.
But here's what nobody wants to say out loud: everyone can do that now. The tooling has democratized. Cloud infrastructure is accessible. AI has flattened the playing field even further. When your competitors can ship features as fast as you can, when your junior engineers can deploy code that would have taken your senior team weeks to write, when a Chat GPT prompt can generate production-ready code in seconds, speed stops being your superpower.
Instead, it becomes your liability.
We've entered what I call the post-speed era, and the teams winning now aren't the ones shipping fastest. They're the ones with the tightest control over what happens after the code goes live. They can throttle features in real time. They can adjust behavior without redeploying. They can make business decisions, not just technical ones, at runtime. They've built systems that bend instead of break.
This shift represents one of the most significant changes in how organizations should think about software delivery since the cloud became mainstream. And almost nobody's talking about it.
TL; DR
- Speed is table stakes: Fast deployment is now a commodity, not a differentiator
- Control is the new advantage: Runtime decision-making and post-deployment risk management define high-performing teams
- Traditional safety nets fail: Rollbacks and hotfixes are too slow and too expensive in interconnected systems
- Business and technical teams must align: Post-deployment decisions have direct commercial impact and require shared responsibility
- Bottom line: The organizations winning in 2025 and beyond are those that can move fast without losing control
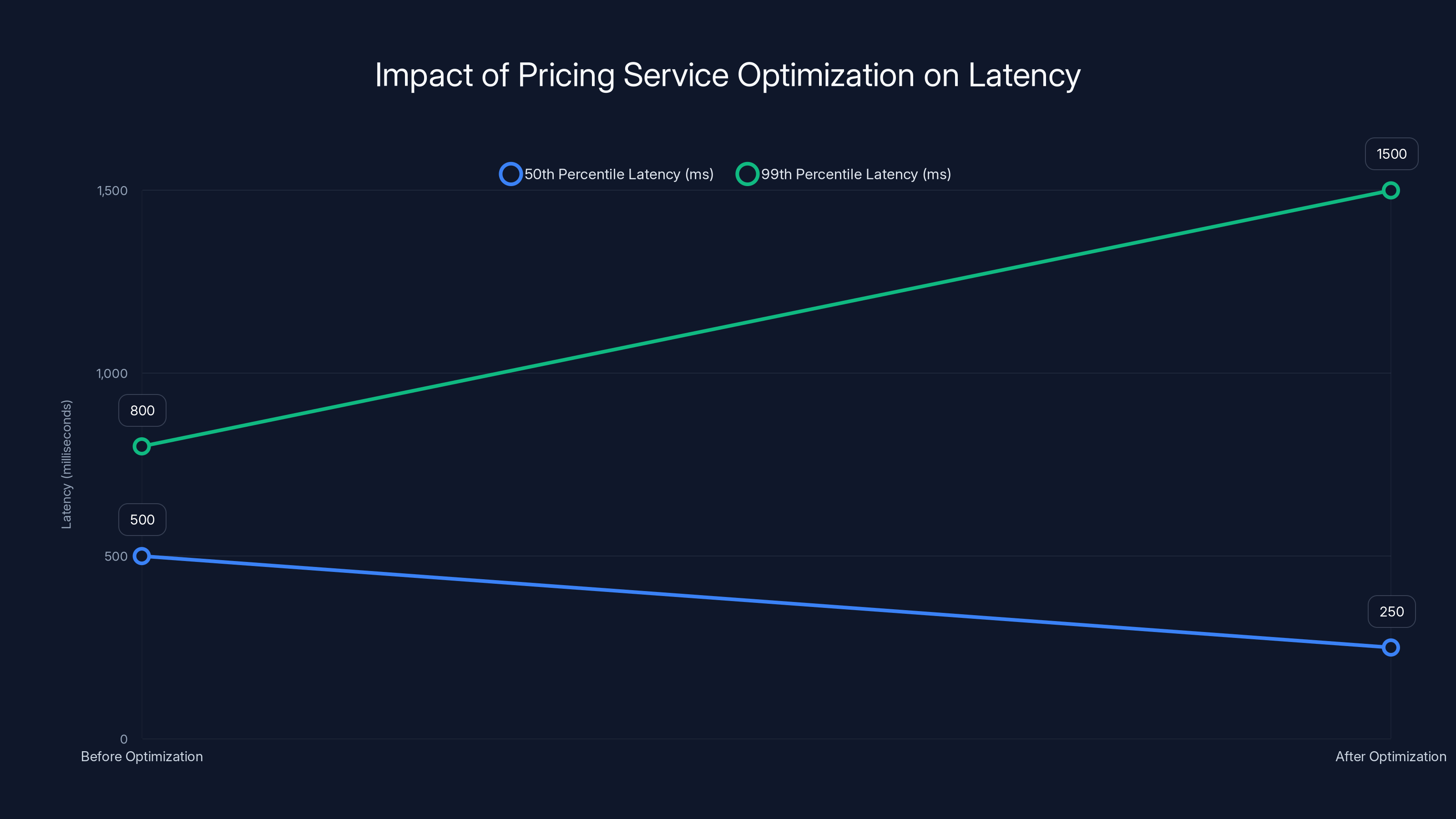
Optimization improved 50th percentile latency by 50%, but increased 99th percentile latency, causing issues in dependent services. Estimated data.
The Flattening of Software Delivery Speed
Let me be direct: the speed advantage is gone. And if you're still optimizing for deployment frequency as your primary metric, you're fighting yesterday's war.
For context, let's look at what happened. In the early 2010s, companies that could deploy multiple times per day had a genuine competitive edge. Netflix, Amazon, and Google weren't just shipping faster—they were learning faster. They could run experiments, gather data, and iterate on the feedback loop in ways their competitors simply couldn't. The business advantage was real and substantial.
That was the point. The speed created learning velocity, which created business velocity.
But the tools that enabled this have commoditized so aggressively that the differentiation has evaporated. Today, you can spin up a CI/CD pipeline in an afternoon. Kubernetes, Docker, GitHub Actions—these are no longer cutting-edge. They're infrastructure that every competent team expects to have. The barrier to entry is measured in hours, not months.
Then AI arrived and accelerated everything again.
Now consider what's actually possible. A developer can describe a feature in plain English. An AI model suggests an implementation. Another AI reviews the code. A third AI writes the tests. The code gets committed, passes the pipeline automatically, and deploys to production—all without human intervention. From concept to live, the timeline has compressed from weeks to hours. Sometimes minutes.
This sounds fantastic. It is fantastic, in certain contexts. But here's where the narrative breaks down: when everyone has access to these tools, everyone is shipping at the same speed. The playing field hasn't just leveled. It's become an entirely different game.
I spoke with a CTO at a Series B startup who said something that stuck with me: "We can now compete with teams ten times our size on speed. But we can't compete with anyone on stability, because we have no idea what we shipped last Tuesday."
That's the unspoken cost of the democratization of speed.
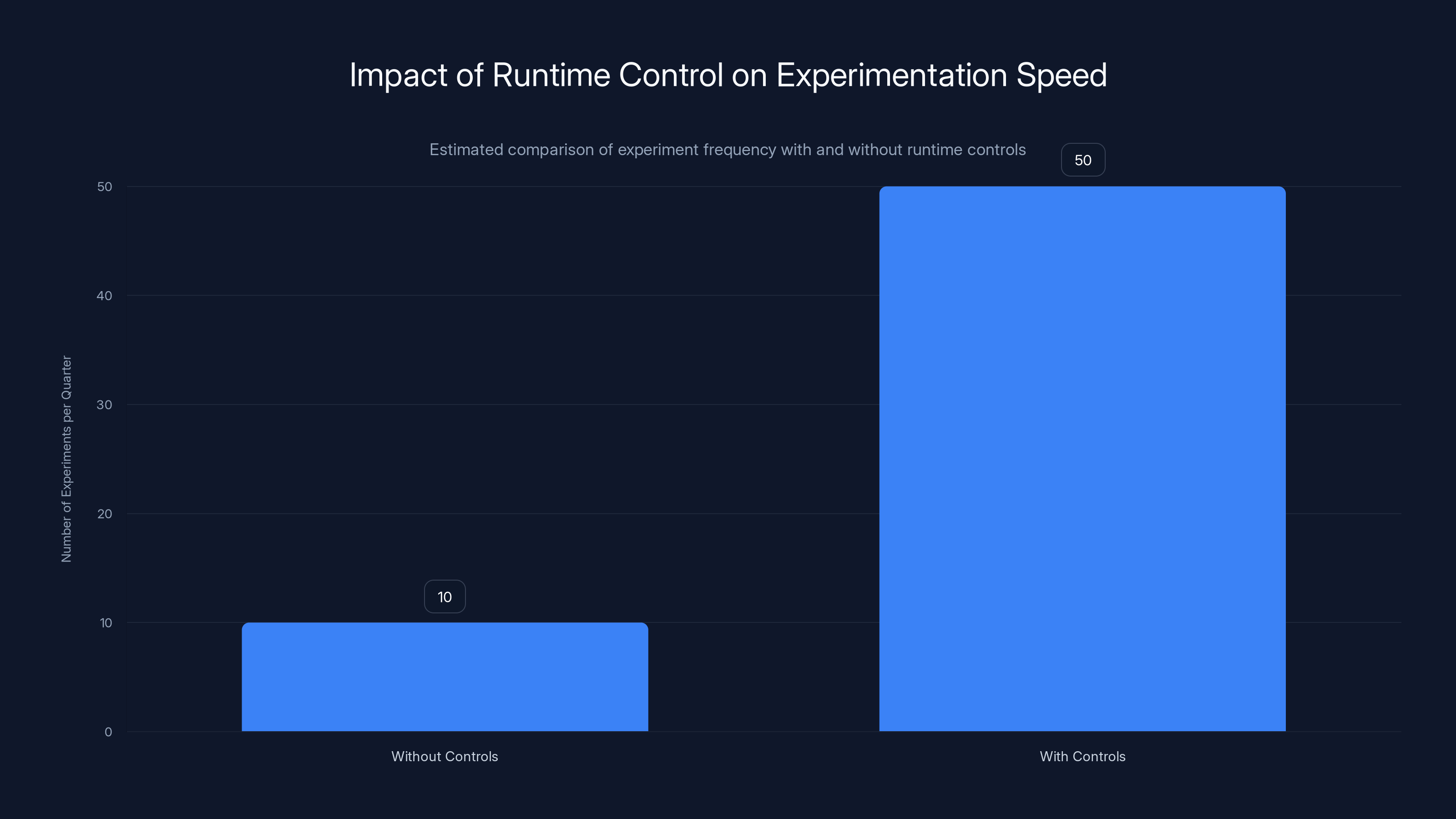
Companies with good runtime controls can conduct up to 5x more experiments per quarter, enabling faster learning and innovation. (Estimated data)
Why Fast Becomes Fragile
Here's a hard truth about continuous deployment at scale: the faster you move, the more invisible your failures become until they're catastrophic.
Think about the physics of it. In traditional software delivery, you'd write code, test it locally, run it through a test environment, get it reviewed, maybe do some staging validation, and only then release it to production. There were gates. Checkpoints. Moments where a human had to sign off and say "I'm confident this won't break things."
This was slow. It was frustrating. But it created friction that often caught real problems.
Now remove the friction. Automate the testing. Use AI to review the code. Deploy on every commit. At first, this is beautiful. You're moving faster than your competitors. You're catching bugs in production instead of in staging, but you're catching them and fixing them quickly, so it doesn't matter.
But systems are not simple. They're webs of dependencies, knock-on effects, and edge cases that no test suite can fully capture. The faster you deploy, the faster these edge cases collide with reality. The faster mistakes propagate.
Consider what happened with that CrowdStrike security update in August 2024. It was a routine deployment. The code passed all internal tests. It had gone through the normal release process. But it contained a single faulty configuration file that affected how the security software loaded on Windows systems. One file. One tiny mistake.
When that deployment rolled out at scale, it didn't affect a hundred systems. Or a thousand. Millions of devices became completely unstable, creating cascading failures across the entire economy. The incident report afterward showed that the testing methodology itself was flawed. The edge case they'd missed? It only appeared when the configuration was deployed to actual production systems at real-world scale.
You can't catch this in a staging environment. There's no test that replicates millions of concurrent Windows systems in a staging sandbox.
And here's the scary part: this isn't an anomaly. This is how modern systems fail. A small change somewhere creates unexpected consequences somewhere else. The interconnectedness of modern infrastructure means that a configuration error in one service can cascade across the entire internet in minutes.
This is what I mean by fast becoming fragile. The faster you deploy, the more likely you are to deploy something that seems fine in isolation but breaks something else entirely. And because you're deploying so frequently, the blast radius of each change grows exponentially.
Traditional risk mitigation strategies like rollbacks become increasingly expensive. You can't just revert a change in a complex system. If you rolled out a database migration, you can't simply roll it back without data loss. If you changed a load-balancing algorithm, rolling back means degraded performance. If you modified a shared authentication service, rollback affects every downstream system.
So teams get stuck. They've deployed something that's breaking production, but the rollback is more painful than the original problem. They end up doing emergency hotfixes on top of broken code, creating more debt and more risk.
This is where the old narrative breaks down. When speed creates this kind of fragility, it's not just a technical problem anymore. It's a business problem.
The Rise of Runtime Decision-Making
Here's what high-performing teams are doing differently now. Instead of trying to prevent problems from happening, they're building systems where they can respond to problems when they do happen.
This is a fundamental philosophical shift. For years, the emphasis was on correctness before deployment. Get the code right. Test it thoroughly. Deploy with confidence. The assumption was that if you did the prep work correctly, production would be boring.
The new approach is different. Acknowledge that you will deploy bugs. Acknowledge that you will make mistakes. Build systems where your response to those mistakes is faster than the impact of those mistakes.
This means runtime controls. The ability to kill a feature without redeploying. The ability to throttle traffic to a new endpoint while it stabilizes. The ability to change behavior based on real-world conditions, not assumptions made during development.
Think about feature flags. Five years ago, feature flags were considered a convenience, a tool for managing deployments more cleanly. Now they're fundamental infrastructure. Because with feature flags, you can deploy broken code to production with zero customer impact. The code is there. It's live. But it's behind a flag that's turned off. Users don't see it. When you've fixed the problem or gathered more data, you can enable it in a subset of users, monitor the impact, and roll it out safely.
No redeployment. No downtime. No rollback required.
But feature flags are just the beginning. The real sophistication comes from building systems that are instrumented for runtime decision-making. This means comprehensive observability. Not just logs and metrics, but actual understanding of what your system is doing right now, with enough granularity to make decisions about what to do next.
It means being able to answer questions like:
- Is this new code path performing as expected, or is it slower than anticipated?
- Are we seeing unexpected error rates from a specific user segment or geographic region?
- Is the change we deployed yesterday still the root cause of elevated latency, or is it something else?
- Can we route traffic away from this service without breaking the user experience?
These aren't rhetorical questions. They're the decisions that define whether your deployment succeeds or fails in real time. And teams that can answer them quickly, confidently, and with low overhead have an enormous advantage over teams that can't.
The shift is subtle but profound. You're moving from "Did we deploy correctly?" to "Are we behaving correctly?"
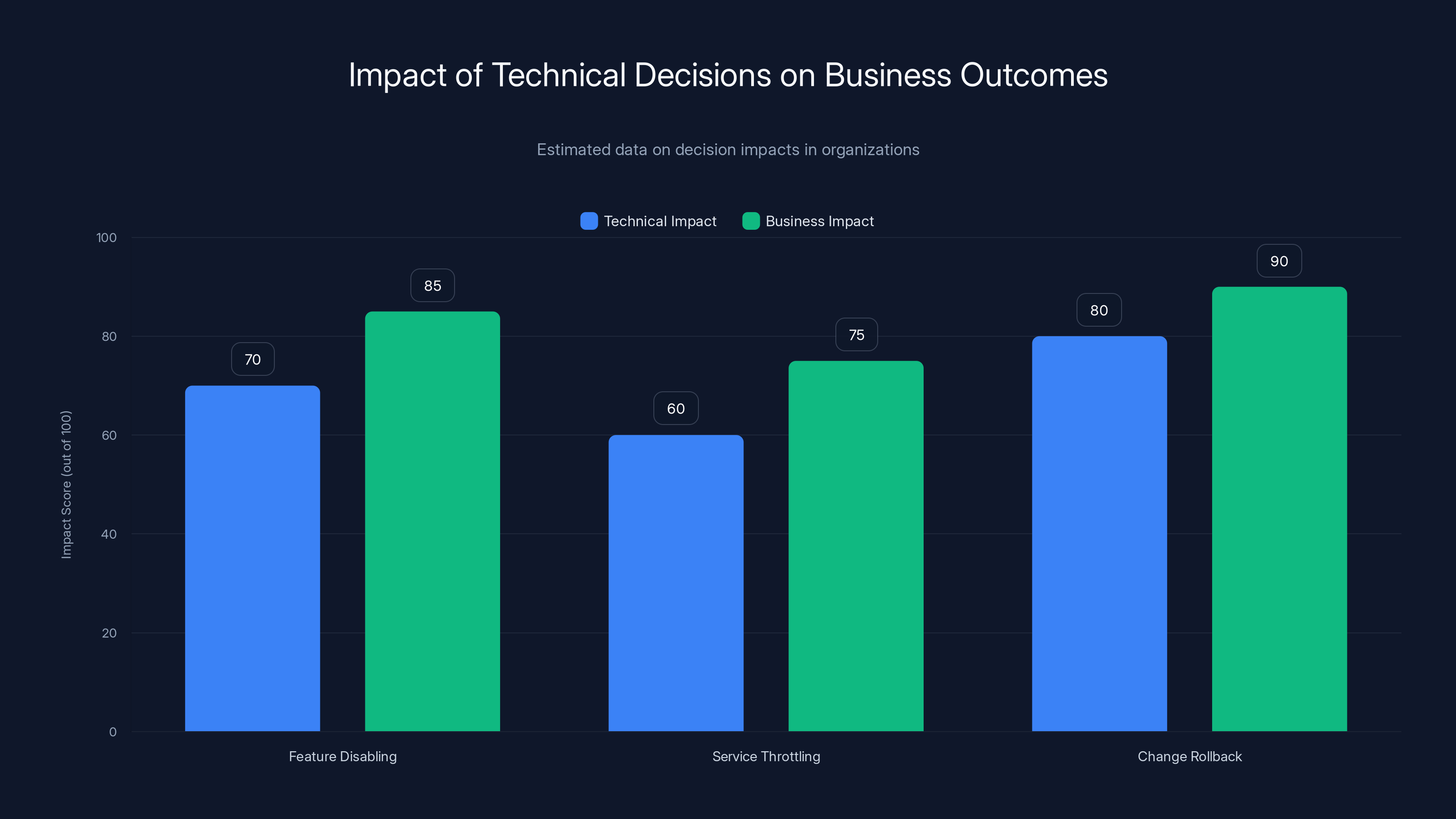
Estimated data shows that while technical decisions have significant technical impacts, their business impacts are often higher, highlighting the need for integrated decision-making.
When Business and Technical Teams Diverge
Here's something that surprised me when I started looking into this more deeply: most organizations still treat post-deployment decisions as purely technical problems.
A feature is misbehaving. The team disables it. They move on.
A service is consuming too much compute. They throttle it. They move on.
A change is causing higher latency. They roll it back. They move on.
These are technical decisions, right? Sure, at the surface level. But look deeper and you'll realize something fundamental is missing.
When you disable a feature mid-flight, you're also making a business decision. That feature was supposed to increase engagement or conversion. Disabling it means giving up that uplift. You're trading short-term stability for long-term revenue impact. That's not a technical trade-off. It's a business trade-off.
When you throttle a service to reduce compute costs, you're potentially degrading performance for some users. You're trading off availability and speed for cost. Again, this has direct business implications that shouldn't be made unilaterally by engineers.
When you roll back a change, you're not just undoing code. You're undoing the hypothesis that change was testing. If it was part of an A/B test, rolling it back invalidates the experiment. If it was a performance optimization, rolling it back means users see slower performance. These are business conversations, not technical ones.
Yet in most organizations, these decisions are still made by engineering teams, often at 2 AM when something breaks, with minimal input from product or business leadership.
This mismatch is creating friction and missed opportunities. Because the teams with the best data to make these decisions aren't talking to each other.
Engineers know exactly what the system is doing and what the constraints are. Product teams know what features matter most to users and what the business impact of downtime actually is. Leadership understands the acceptable thresholds for risk and the priority of innovation versus stability.
When these perspectives don't align at runtime, organizations make bad decisions. They either move too cautiously (disabling features that are actually fine because they're nervous about edge cases) or too aggressively (keeping broken features live too long because nobody thought to tell engineers about the revenue impact).
The teams winning now are those that have built decision-making processes that span these functions. They have PagerDuty alerts that page product managers, not just engineers. They have runbooks that explicitly include business trade-offs, not just technical ones. They have dashboards that show business metrics alongside technical metrics, so everyone's looking at the same data.
This is harder to implement than it sounds. It requires building trust across functions. It requires developing a shared language between technical and business teams. It requires creating decision frameworks that can be executed at 3 AM by someone who's tired and stressed.
But teams that do this have a massive advantage. They can move fast knowing that the decisions being made at runtime are informed by the full context of what matters to the business.
Post-Speed Era Metrics
If speed isn't the differentiator anymore, then measuring deployment frequency is like measuring the speed of your car instead of the fuel efficiency. It might be interesting, but it's not telling you what matters.
High-performing teams in the post-speed era are optimizing for different things. And they're measuring accordingly.
Change failure rate has become critical. This is the percentage of deployments that result in degraded service or an incident. A low change failure rate tells you that your deployment process is solid, your testing is effective, and your controls are working. A high change failure rate tells you that you're moving too fast relative to your ability to validate changes.
Here's the nuance: a team deploying ten times per day with a 2% change failure rate is performing better than a team deploying once per day with a 10% failure rate. Because that low failure rate means you're actually controlling your risk.
Mean time to recovery (MTTR) has become more important than mean time to detection (MTTD). Sure, detecting problems quickly matters. But in the post-speed era, the real skill is fixing problems quickly once they're detected. A team that finds a problem in 5 minutes and fixes it in 10 minutes has better outcomes than a team that finds the problem in 2 minutes but takes 2 hours to fix it.
This is why runtime controls matter so much. If you can disable a feature instantly, your MTTR is measured in seconds. If you need to revert a deploy, it's minutes. If you need to rebuild and test and redeploy, it's hours.
Customer impact duration is the metric that really matters. How long did the problem actually affect customers? Not how long was the problem in production, but how long did users actually experience degraded service?
A deployment that breaks something at 3 AM on Sunday might be in production for 4 hours before anyone notices. But if only 0.01% of traffic is affected and the impact is invisible to customers, then the customer impact duration is zero. Versus a deployment that affects 50% of traffic but you fix it in 5 minutes. The impact duration is 5 minutes, affecting millions of users.
The second one is worse. And it should be measured differently.
Observability maturity is becoming a critical metric in its own right. How quickly can you understand what a system is doing? Can you answer arbitrary questions about system behavior in seconds, or does it take hours to instrument custom logging?
Teams with high observability maturity can debug production issues at the speed of conversation. "Is it slow for all users or just these geographic regions?" They can answer that in seconds by querying their observability platform.
Teams with poor observability maturity can't. They have to engage Dev Ops, wait for custom log analysis, correlate data from multiple sources. By the time they have the answer, the incident is often over.
Recovery velocity matters more than prevention velocity. In other words, how fast can you bounce back from mistakes? Can your team deploy a hotfix in 10 minutes, or do you have a 4-hour lead time on deploys?
In the post-speed era, you're going to make mistakes. The question isn't whether you'll deploy something broken. It's how quickly you can fix it. Teams that have optimized for recovery velocity can take more risks because the cost of failure is lower.
Companies that still measure success by deployment frequency are missing the entire picture. You can deploy a thousand times per day and still have a chaotic, unreliable system if you don't have control. You can deploy once per week and have a stable, high-performing system if you're doing it right.
The metric that matters is outcomes, not throughput.

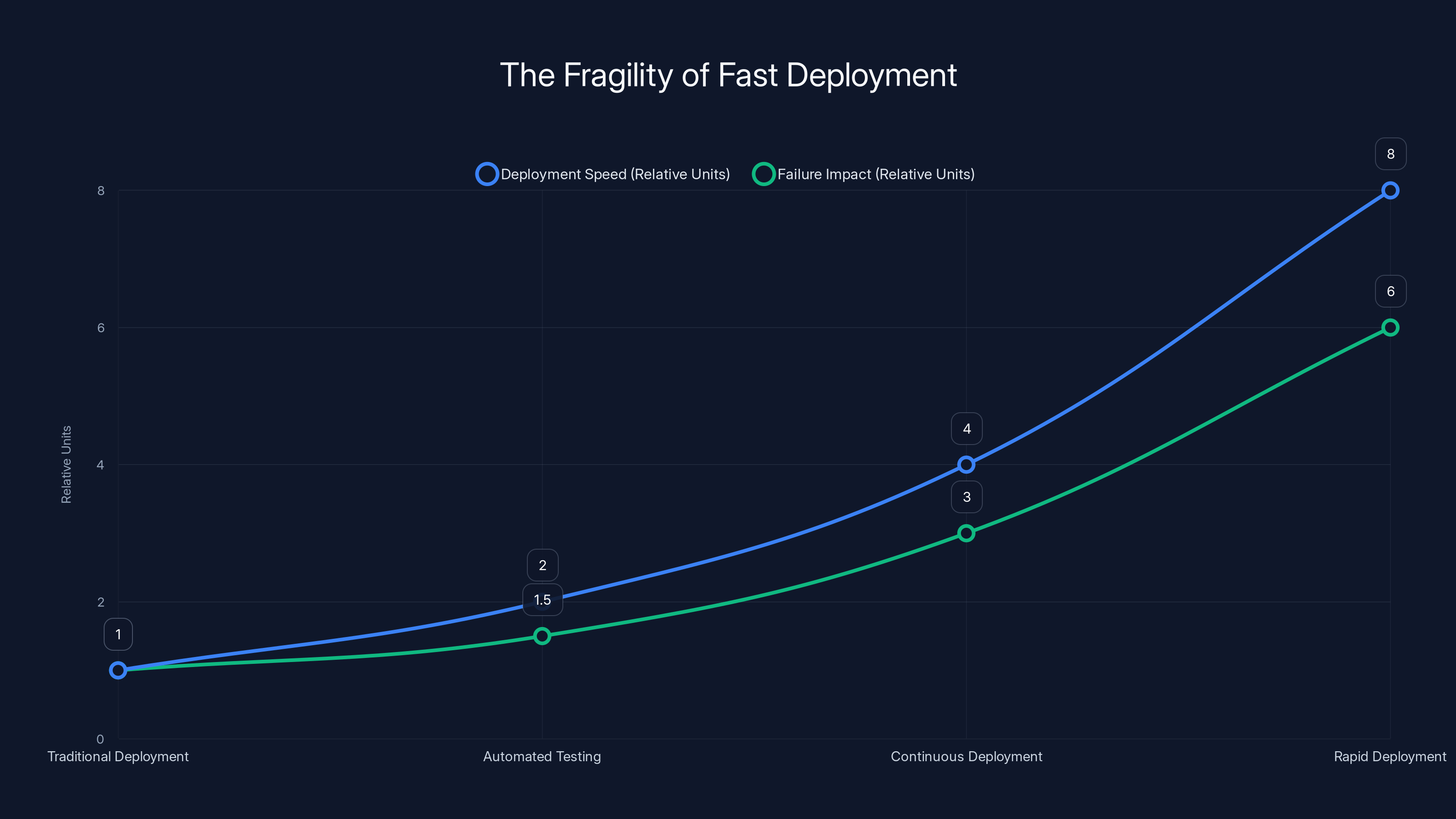
As deployment speed increases, the impact of failures also grows, highlighting the fragility of rapid deployment systems. Estimated data.
Building Systems That Bend Instead of Break
So what does this actually look like in practice? How do you build a system that can move fast while maintaining control?
Start with observability. And I don't mean basic logging. I mean comprehensive, queryable, real-time understanding of what your system is doing.
This includes metrics (quantitative data like latency, error rates, throughput), logs (detailed events that happened), and traces (the path a request took through your system). These three pillars need to work together.
Metrics tell you that something is wrong. Logs help you understand the context. Traces help you understand which component in the chain is the culprit.
Without this foundation, you're flying blind. You're making decisions based on incomplete information, which means your decisions are likely to be wrong.
Second, invest in feature flags and runtime configuration. Not as an afterthought. Not as a convenience. As fundamental infrastructure.
Every feature should be deployable behind a flag. Every configuration should be changeable at runtime without redeployment. This means building your application with the assumption that you'll need to turn things on and off in production.
This is harder than it sounds. It requires discipline. It requires thinking through how flags interact with each other. It requires having clear ownership of which flags are safe to turn off and which ones would break the system.
But the payoff is enormous. With good flag architecture, you can deploy broken code and users never know. You can test a new feature with 1% of users before rolling it out to everyone. You can disable a feature that's misbehaving without a deployment.
Third, implement gradual rollout mechanisms. Don't deploy to 100% of traffic at once. Deploy to 1%, then 5%, then 25%, then 100%. At each stage, collect data. If something looks wrong, you can stop the rollout before it affects everyone.
This requires traffic routing intelligence. It means your load balancer or service mesh needs to be aware of which version of code is running on which instances, and needs to be able to route traffic intelligently based on that information.
Tools like Envoy, Istio, and modern API gateways make this possible. But you have to design your deployment pipeline with this in mind from the beginning.
Fourth, establish clear escalation paths and decision-making frameworks for production incidents. When something goes wrong at 3 AM, you don't want your team debating what to do. You want them following a playbook.
These playbooks should include:
- Detection criteria: What metrics or signals indicate a problem?
- Severity assessment: How bad is this? Do we need to wake up senior engineers or product managers?
- Immediate mitigation: What's the fastest way to stop the bleeding? (This is often feature flag disabling, not rollback.)
- Investigation: Once things are stable, what's the root cause?
- Remediation: What's the proper fix? Do we need to deploy something new, or was the immediate mitigation sufficient?
- Post-mortem: What went wrong? How do we prevent this next time?
The most important step here is immediate mitigation. You want to stop the pain as quickly as possible. The investigation and remediation can happen while your system is stable.
Fifth, cultivate a culture where failures are learning opportunities, not blame assignments. If your team is terrified of breaking production, they'll move slowly. They'll add extra validation steps. They'll avoid taking risks even when risk-taking is appropriate.
If your team knows that breaking production occasionally is acceptable as long as they respond quickly and learn from it, they'll be more willing to move fast. They'll try things. They'll experiment.
This is the cultural foundation that everything else is built on.
The Interconnectedness Problem
One of the most underestimated challenges in the post-speed era is managing dependencies across services. Modern systems are deeply interconnected. A change in one service can have cascading effects on dozens of other services, in ways that are often impossible to predict.
Consider a simple example. You're building an e-commerce platform. You have a product service, a pricing service, a shopping cart service, an order service, and a payment service.
You make a change to the pricing service to improve performance. Latency drops by 50%. Great.
But then you start seeing errors in the cart service. It's timing out when calling the pricing service. What happened?
Well, the product team was relying on the pricing service to timeout in under 500 milliseconds. They set their own timeout to 1 second. They figured 500ms + overhead gives them comfortable margin.
But your optimization had a side effect: in certain conditions, when there are burst loads, the service now handles them differently. The 50th percentile latency dropped, but the 99th percentile latency actually increased. Sometimes calls to the pricing service take 1.5 seconds.
Suddenly the cart service is seeing timeouts in the 99th percentile. Not often enough to be obvious in testing, but often enough to cause customer-visible errors.
You didn't change the API. You didn't change the data format. You just optimized the internals. But the downstream effects were devastating.
This is the interconnectedness problem in a nutshell. You can't predict all the ways your changes will ripple through a system.
How do you solve this?
First, you instrument for it. You need to understand not just how your service is performing in isolation, but how it's affecting the services that depend on it. This means distributed tracing. Every request that touches your service should be traceable across all the services it touches.
Second, you test for it. This is where chaos engineering comes in. You intentionally introduce failures in your dependencies and see how your service responds. What happens if the pricing service is slow? What if it returns errors? What if it's unavailable? If your service degrades gracefully, you're in good shape. If it falls over, you've found a vulnerability.
Third, you design for it. This means building resilience into your service-to-service communication. Circuit breakers that fail fast instead of timing out. Bulkheads that isolate failures to specific pools of resources. Retry logic that backs off intelligently.
Fourth, you manage it organizationally. Teams need to communicate before making changes that might affect downstream services. This doesn't mean you need approval processes that slow things down. It means having low-friction communication channels where a team can say "Hey, we're changing the performance characteristics of this service. Does anyone depend on our specific latency profile?" and get answers quickly.
The teams managing this well have platforms or tools that help them understand dependencies. Who's calling my service? What's their timeout? How sensitive are they to latency changes?
Without this understanding, every deployment is a risk. With it, you can make changes with confidence.

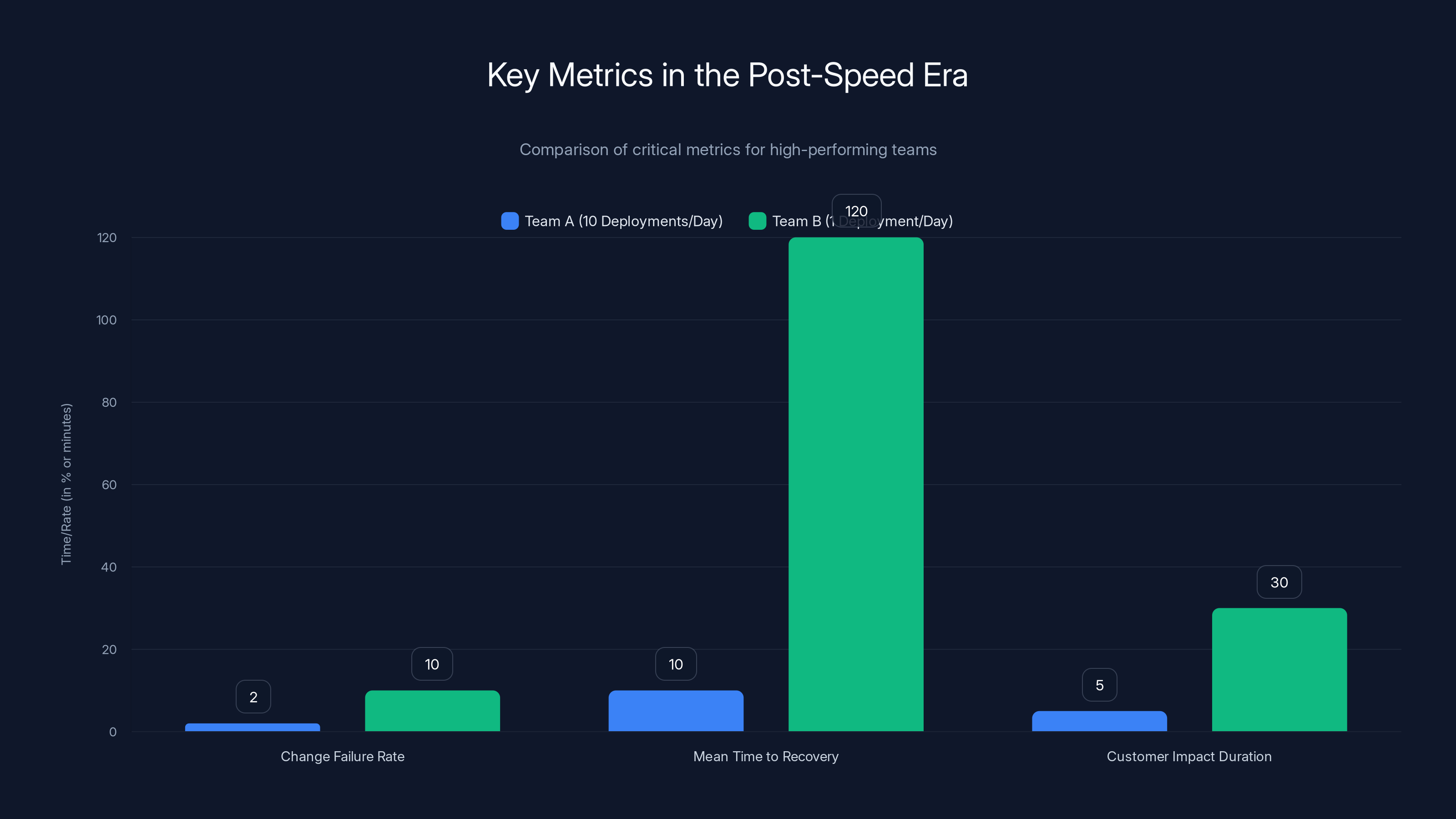
Team A, deploying 10 times a day, has a lower change failure rate and faster MTTR, demonstrating better risk control and efficiency compared to Team B. Estimated data.
The AI Acceleration Problem
Now we need to talk about the elephant in the room. AI has accelerated software development so dramatically that it's outpaced our ability to control it.
A few years ago, if you wanted to deploy a new feature, you needed a team of engineers, possibly a few weeks, and a lot of deliberation about the design. There were natural gates. Code review. Testing. Deployment planning.
Now you can prompt Claude or Chat GPT. It generates code. You run it. It works. You deploy it.
Sometimes the code is great. Sometimes it's fine. Sometimes it's subtly broken in ways that don't show up until production.
And here's the thing: the AI doesn't know your system. It doesn't understand your architecture. It doesn't know what your performance constraints are or what your failure modes are.
So you get code that is syntactically correct and functionally works but creates problems at scale. Or code that works perfectly under normal conditions but breaks under load. Or code that works but doesn't integrate well with your observability tooling.
I spoke with an engineer at a startup who'd used AI to build a background job processor. The code was great. It handled the happy path beautifully. But it didn't integrate with their error tracking system. When jobs failed, nobody knew. They were silently failing in the background, and the team had no visibility into it until it caused a cascading failure weeks later.
The AI had no way of knowing to integrate with their error tracking system. It wasn't told to. And the engineer shipping it didn't think to check because the code looked fine.
This is going to become increasingly common. As AI makes shipping code trivially easy, the bottleneck shifts from "Can we build this?" to "Did we build this correctly?"
This actually supports the case for the post-speed era approach. You can't validate everything before deployment anymore. You're going to ship imperfect code. So you need excellent runtime controls, observability, and incident response.
You need systems that can catch problems quickly when they happen in production. Because you can't catch them all before.
Some teams are starting to address this by building AI-aware testing frameworks. Testing frameworks that deliberately introduce the kinds of edge cases and failure modes that AI-generated code often misses.
But I think the real answer is still the same: build for visibility, control, and rapid response. Make assumptions you're going to deploy broken code sometimes. Plan accordingly.
The Economics of Runtime Control
Let's talk about money, because that's ultimately what drives these decisions.
There's a cost to maintaining control. Observability platforms cost money. Feature flag infrastructure costs money. The engineering time to build incident response processes and decision frameworks costs money.
There's also a cost to not maintaining control. Incidents are expensive. Downtime is expensive. Having to do emergency rollbacks and hotfixes is expensive in engineering time.
But there's a third cost that's often invisible: opportunity cost.
When you can move fast without losing control, you can take more calculated risks. You can experiment more. You can try things that might fail knowing that the cost of failure is low.
Companies that have implemented good runtime controls often report being able to ship 3-5x more experiments than teams without those controls. Not because they're moving 3-5x faster, but because they're willing to take more risks knowing the safety nets are in place.
Imagine you have a new feature that you think will increase conversion by 5%. You're 60% confident in this hypothesis. There's a 40% chance it actually decreases conversion.
In a traditional system without good controls, you'd need to be more like 85% confident before shipping it. The cost of failure is too high. You'd ship it to staging, test it thoroughly, probably do a beta release to a subset of users, etc. You'd be cautious.
But if you have feature flags and good observability? You can ship it to 1% of users, measure the impact, and make a decision in hours instead of weeks. If it's hurting conversion, you disable it immediately. If it's helping, you roll it out.
You've now tested a hypothesis in 5 hours instead of 5 weeks, learning the same information. You can run 50 experiments per quarter instead of 10. Some will fail, but the ones that succeed will compound your advantage.
This is the real economic argument for the post-speed era approach. It's not about moving faster. It's about learning faster.
Companies that can learn quickly have a structural advantage over companies that can't. They can adapt to market changes faster. They can out-iterate their competitors. They can spot trends and pivot to take advantage of them before competitors even realize the trend exists.
This is worth building infrastructure for. This is worth the investment in observability and controls.
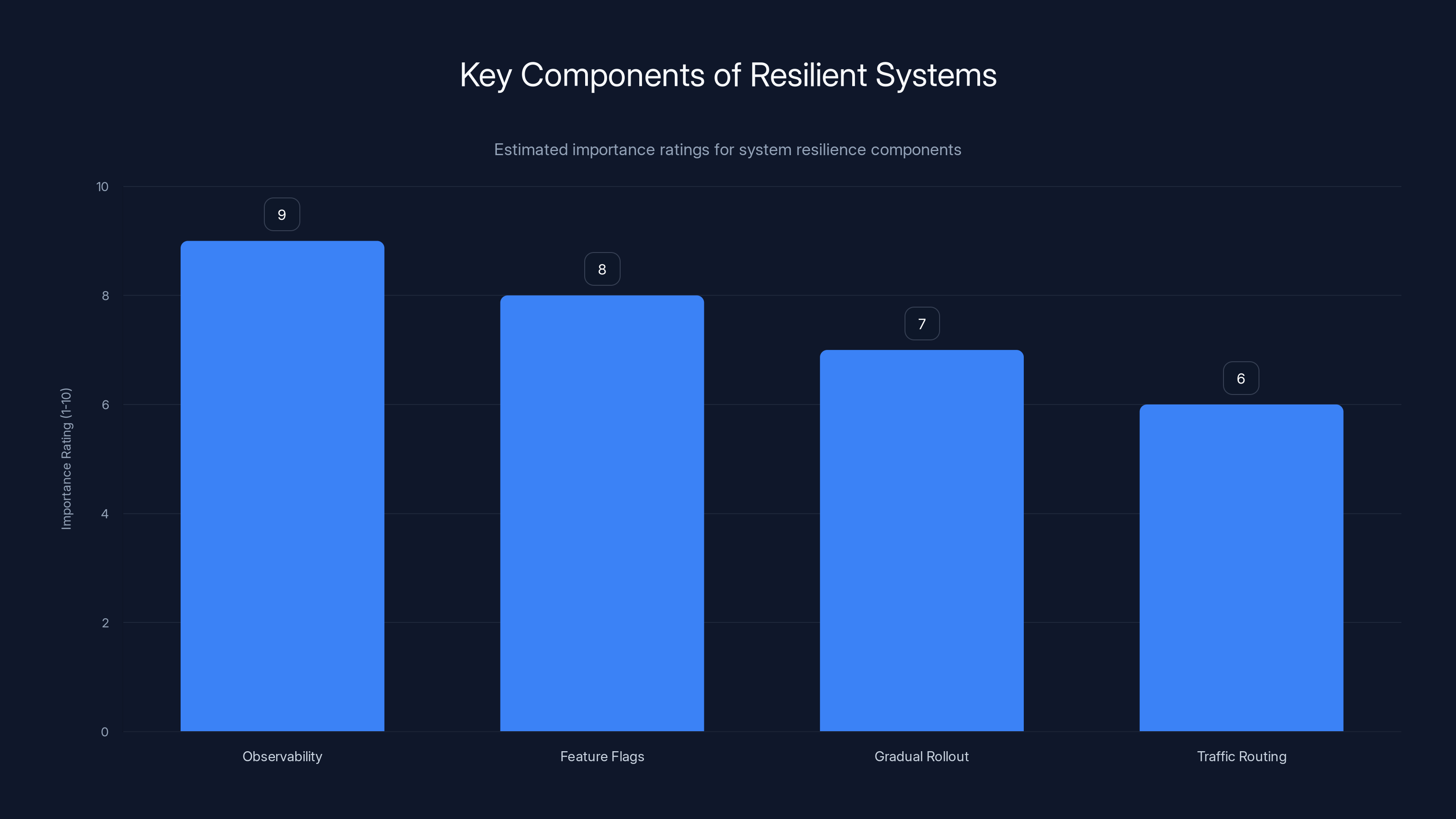
Observability is rated as the most critical component for building resilient systems, followed by feature flags and gradual rollout strategies. (Estimated data)
Organizational Alignment as a Control Mechanism
Here's something counterintuitive: organizational structure is a control mechanism.
How you organize teams affects how fast you can move and how much control you have. These aren't independent variables.
There are basically two traditional models:
Model 1: Centralized control. All deployments go through a central team. Quality gates. Approval processes. This gives you strong control but slow velocity.
Model 2: Decentralized ownership. Teams own their services end-to-end and can deploy independently. Fast velocity but less control.
The post-speed era approach suggests a third model:
Model 3: Distributed ownership with shared visibility. Teams own their services and can deploy independently. But everyone has access to the same observability data. Dependencies are visible. Decision-making frameworks are shared. Incident response is coordinated.
This gives you the velocity of decentralized ownership but with much better control because you have visibility and alignment across teams.
Implementing this requires infrastructure, sure. But it also requires organizational practices. How are teams structured? How do they communicate? Who decides when to roll back a change, and how quickly can they make that decision?
Organizations that have built this well often have:
- On-call rotations that span functions: Not just engineers on call. Product managers on call. SREs on call. Because decisions need to be made and they need to be made quickly.
- Runbooks that are actively maintained: Not static documents that nobody updates. Living documents that reflect the actual current system and include decision frameworks.
- Blameless post-mortems: When something breaks, the goal isn't to punish the person who shipped the broken code. It's to understand how good people made a mistake and what system changes would prevent that mistake in the future.
- Open incident channels: Incidents aren't hidden. They're discussed in real-time in channels where anyone in the company can see what's happening. This drives transparency and learning.
- Clear escalation paths: You know exactly when to escalate, who to escalate to, and what decision-making authority they have.
These organizational practices are as important as the technical infrastructure. You can have the best observability in the world and still make bad decisions if you don't have clear processes and alignment on how to use that data.
The Risk-Innovation Balance
Let's address the obvious tension here. If you're emphasizing control and stability, aren't you sacrificing innovation?
No. You're actually enabling more innovation.
Here's why: innovation requires risk-taking. But if taking a risk means you might break production for millions of users, then risk-taking is too expensive. You'll be conservative. You'll avoid experimental features. You'll optimize for safety over learning.
But if you can take a risk and the cost of failure is low (because you have controls), then you can innovate more aggressively. You can try things. You can fail fast and learn.
The difference is the mechanism. In the old model, you try to prevent failures. In the post-speed era model, you accept failures will happen and focus on containing them.
The first model encourages conservatism. The second model encourages experimentation.
An example: Netflix's chaos engineering practices. They deliberately break things in production. They kill servers. They introduce latency. They simulate failures. This seems reckless. But it's actually incredibly safe because they've built systems that can handle these failures.
The side effect is that they can innovate faster. They can make changes that would be too risky in a less resilient system. They can push the boundaries further.
This is the real competitive advantage of the post-speed era approach. Not faster deployments, but more innovation per deployment. More experiments per quarter. More learning per month.
The teams that nail this balance win. They move fast. They take risks. They experiment aggressively. But they do it all while maintaining high reliability.

The Talent Dimension
One more thing that doesn't get enough attention: this shift requires different skills.
In the speed-focused era, success was about building things quickly. Writing code fast. Designing systems that could handle high throughput. The hero was the engineer who could ship features at incredible velocity.
In the post-speed era, the hero is the engineer who can understand production behavior, diagnose problems under pressure, and make good decisions with incomplete information.
These are different skills. Both valuable, but different.
This has hiring implications. Teams that are hiring for speed alone are going to struggle in the post-speed era. They need to be hiring for judgment, systems thinking, and the ability to operate under uncertainty.
It has training implications. Your senior engineers should be developing junior engineers' abilities to think through failure modes and understand system behavior, not just their ability to write code quickly.
It has promotion implications. The people you promote to leadership should be people who have shown good judgment in production, not just people who shipped code fastest.
Organizations that make this shift in how they think about talent and skills will have an advantage. They'll be able to move fast without the constant fire-fighting that plagues less mature teams.
The Road Ahead
The post-speed era is here, whether the industry acknowledges it or not.
But most teams and organizations are still optimizing for the old era. They're still measuring deployment frequency. They're still trying to prevent mistakes before they happen. They're still treating post-deployment decisions as purely technical.
The gap between what they're doing and what actually produces results is going to widen.
Teams that understand this shift and start building the infrastructure and processes to support it will pull ahead. They'll move faster. They'll innovate more. They'll have fewer production incidents. They'll attract better talent because they're the kind of organization that learns from mistakes instead of covering them up.
The investment required isn't trivial. Building observability infrastructure. Implementing feature flag systems. Developing incident response processes. Creating organizational alignment. It takes time and resources.
But it pays off. Not in speed metrics. In business outcomes. In revenue. In customer satisfaction. In team satisfaction.
The teams winning in 2025 and beyond won't be the ones shipping fastest. They'll be the ones in control. And control, it turns out, is the greatest competitive advantage of all.

FAQ
What is the post-speed era in software development?
The post-speed era refers to the current phase of software development where fast deployment has become table stakes rather than a differentiator. Since AI and modern tooling have democratized the ability to ship code quickly, competitive advantage has shifted from deployment speed to runtime control, post-deployment risk management, and the ability to make informed decisions about system behavior in production.
How does runtime control differ from traditional deployment control?
Traditional deployment control focuses on preventing problems before code goes live through extensive testing, code review, and staged rollouts. Runtime control acknowledges that problems will slip through and instead emphasizes the ability to respond to those problems quickly in production. This includes feature flags, observability, gradual rollouts, and the ability to adjust system behavior without redeploying.
Why did the Crowd Strike outage matter to this discussion?
The August 2024 Crowd Strike incident demonstrated a critical vulnerability of the speed-focused era. A single flawed configuration in a routine security update cascaded across millions of devices within hours, bringing down airlines, hospitals, and critical infrastructure. This showed that speed without control is dangerous, and that traditional safety nets like testing and staging can miss real-world edge cases that only emerge at production scale.
What metrics should teams focus on in the post-speed era?
Instead of deployment frequency, teams should focus on change failure rate (what percentage of deployments cause incidents), mean time to recovery (how quickly can you fix problems once detected), customer impact duration (how long do users actually experience problems), observability maturity (how quickly can you understand system behavior), and recovery velocity (how fast can you deploy a fix). These metrics reflect control and resilience rather than raw speed.
How do feature flags contribute to post-speed era control?
Feature flags allow teams to deploy code to production without users seeing it, by placing the new code behind a configuration switch. This means you can deploy broken code and users won't be affected. It enables gradual rollouts to small percentages of users first, with the ability to disable features instantly if problems emerge. This dramatically reduces the risk of deployment and the need for costly rollbacks.
Why is organizational alignment critical for runtime decision-making?
Post-deployment decisions often have business implications, not just technical ones. Disabling a feature affects revenue. Throttling a service affects customer experience. Routing traffic away from a service affects availability. When only engineers make these decisions, they lack important business context. When business and technical teams align on decision-making frameworks and have shared visibility into production behavior, decisions are better and faster.
How does AI acceleration complicate the post-speed era?
AI-generated code is faster to produce but often lacks deep integration with existing systems, observability tooling, and understanding of failure modes. This means AI-generated code is more likely to create subtle production problems that don't surface in testing. The solution isn't to slow down AI adoption, but to strengthen runtime controls, observability, and incident response to catch and fix problems quickly when they emerge in production.
What's the relationship between post-speed era control and innovation?
Countintuitively, strong runtime controls enable more innovation, not less. When the cost of failure is low because you can disable features instantly, teams are more willing to experiment. When you can test hypotheses with small percentages of traffic and roll out slowly, you can run more experiments. This leads to faster learning and more sustainable innovation than systems that try to prevent all failures upfront.
How should organizations transition to post-speed era practices?
Start with observability. Without visibility into production behavior, you can't make good runtime decisions. Then implement feature flags and gradual rollout mechanisms. Build incident response processes and decision frameworks that span technical and business teams. Cultivate a culture where incidents are learning opportunities, not blame assignments. Finally, reorganize on-call responsibilities and communication channels to support distributed decision-making with shared visibility.
What skills do teams need for the post-speed era?
Unlike the speed-focused era which prioritized fast coding, the post-speed era values systems thinking, diagnostic skills, decision-making under uncertainty, and judgment about when to move fast versus when to be cautious. Teams need engineers who understand distributed systems, can debug complex production issues, and can make good decisions with incomplete information. These are different skills than raw coding speed.

Conclusion: Control as Competitive Advantage
We've reached an inflection point in how software organizations should think about development and deployment. For nearly a decade, the narrative was about speed. And speed mattered. It created real advantages.
But the advantages of speed were always temporary. As the tooling and practices spread, what was once an advantage became table stakes. Everyone could do it. The competitive differentiation evaporated.
Now we're in a new phase. Speed is assumed. The question that matters is what you do with that speed. Can you deploy fast and maintain stability? Can you move quickly without creating cascading failures? Can you learn from production behavior and adjust in real-time?
The answers to these questions don't come from moving faster. They come from having control. From having visibility. From having processes and practices that support good decision-making under pressure.
This shift has profound implications for how organizations should invest in tooling, processes, talent, and culture. It's no longer acceptable to measure success by deployment frequency alone. It's no longer enough to try to prevent all failures upfront. It's no longer possible to treat production as purely the domain of engineering teams.
The organizations that understand this and adapt will have a structural competitive advantage. They'll move fast without breaking things. They'll innovate more aggressively because failure is less catastrophic. They'll attract talent that values precision and judgment alongside velocity.
They'll win.
The good news is that this isn't a new invention. The practices and infrastructure needed for post-speed era success already exist. Feature flags aren't new. Observability platforms aren't new. Incident response processes aren't new. Gradual rollouts aren't new.
What's new is the recognition that these practices aren't optional. They're foundational. They're the infrastructure that enables sustainable fast software delivery.
If you're still optimizing primarily for speed, this is your signal to shift. The real game has moved on. Control is the new advantage. And the teams that build it first will have an enormous head start.
Key Takeaways
- Speed is no longer a differentiator because AI and modern tooling have democratized fast deployment across the industry
- Post-speed era teams compete on runtime control, post-deployment risk management, and the ability to adjust behavior in production without redeployment
- Traditional deployment metrics (frequency, lead time) are replaced by control metrics (change failure rate, mean time to recovery, customer impact duration)
- Feature flags, observability, and gradual rollouts are now foundational infrastructure, not optional conveniences
- Business and technical teams must align on post-deployment decisions because they have direct commercial and operational consequences
Related Articles
- Modern Log Management: Unlocking Real Business Value [2025]
- Polish Power Grid Breach: How Russian Hackers Exploited Default Credentials [2025]
- Why IT Teams Miss Critical Alerts and Cause Outages [2025]
- AI-Powered Email Threats: How Security Economics Are Changing [2025]
- AI in Contract Management: DocuSign CEO on Risks & Reality [2025]
- Amplitude vs PostHog 2025: Complete Analytics Comparison

