
Privacy-by-Design in 2026: Why This Year Changes Everything for AI and Blockchain
Introduction: The Year Privacy Stops Being Optional
We're standing at an inflection point in technology history, though few organizations recognize it yet. For years, privacy has occupied an awkward middle ground—simultaneously treated as a compliance checkbox, a marketing advantage, and a "nice-to-have" feature that gets bolted on after product development completes. But 2026 marks a fundamental shift: privacy is transitioning from specialist concern to board-level imperative, driven by the convergence of three powerful forces that are impossible to ignore.
The trigger for this transformation isn't a single regulatory mandate or technological breakthrough alone. Rather, it's the collision of several concurrent developments: artificial intelligence has finally moved from experimental pilots into mission-critical business processes; fully homomorphic encryption has achieved practical scalability that seemed impossible just three years ago; and enterprise procurement departments are beginning to demand privacy-preserving architectures as default requirements, not exceptions.
What makes 2026 uniquely positioned as the turning point is timing. The technology infrastructure now exists to solve the "transparency paradox"—the cruel trade-off that has long existed between blockchain's promise of trust through openness and the absolute need for confidentiality in real-world applications like payroll, identity management, and institutional finance. For the first time, organizations can build systems that are simultaneously transparent and confidential.
This shift carries profound consequences for technology leaders, chief information security officers, and enterprise architects. Organizations that treat privacy as a foundational architectural principle from day one will gain access to richer datasets, more sensitive information, and deeper collaborative opportunities that their competitors cannot access. Meanwhile, those assuming privacy can be retrofitted through policy and access controls will find themselves systematically excluded from high-value use cases involving regulated data, cross-organizational collaboration, and proprietary intellectual property.
The changes ahead aren't subtle adjustments to existing frameworks. They represent a fundamental restructuring of how enterprise software is built, how data flows through organizations, and how competitive advantage gets created in the AI era. Organizations that fail to recognize this transition in 2026 will spend years playing catch-up in 2027 and beyond.

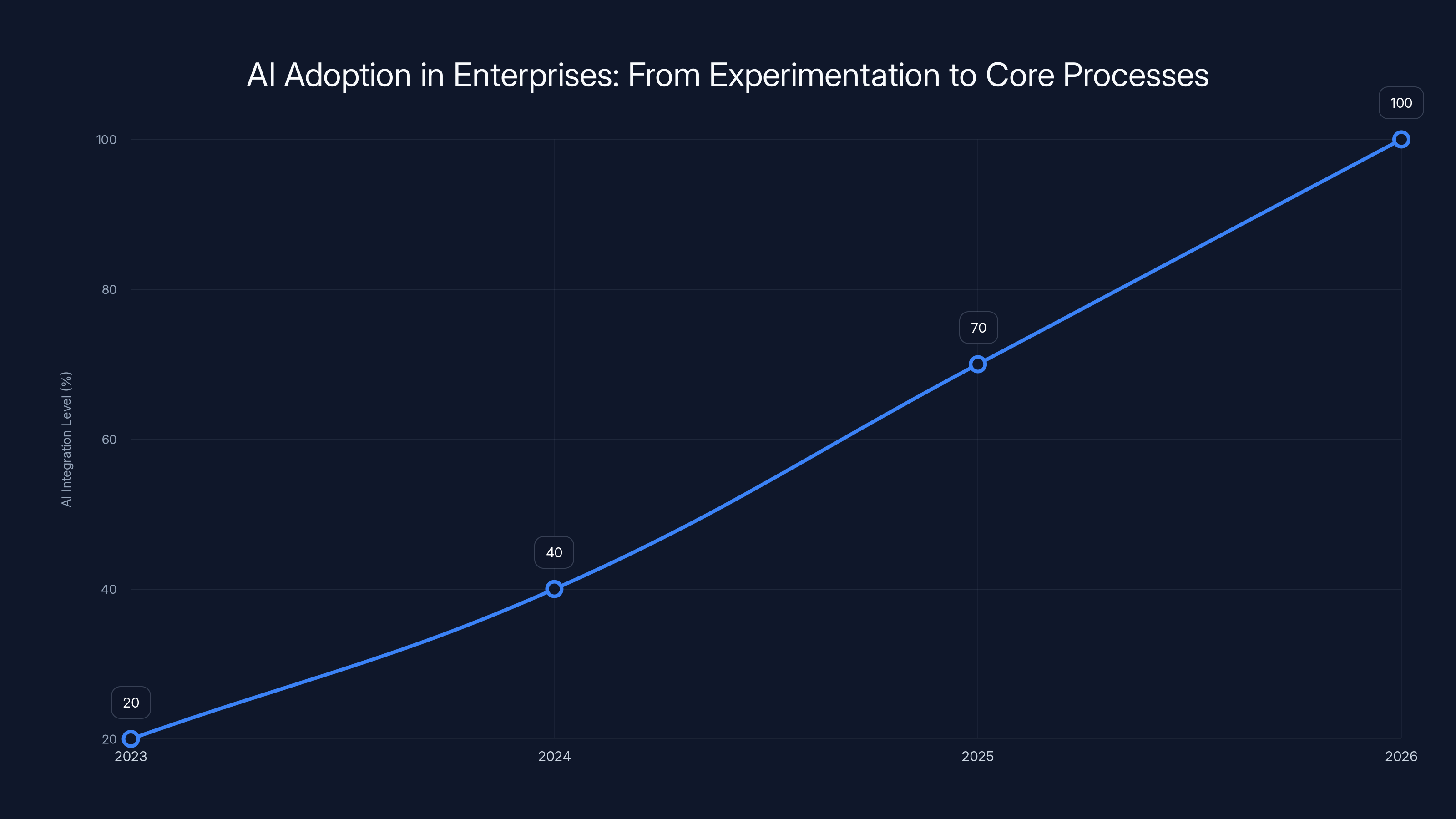
By 2026, AI integration in core business processes is projected to reach 100%, marking a shift from experimentation to critical production roles. (Estimated data)
Understanding the Transparency Paradox: Why Openness and Confidentiality Seemed Mutually Exclusive
The False Choice That Blocked Adoption
Blockchain technology arrived with a compelling but ultimately limiting promise: create immutable transaction records that anyone could verify, eliminating the need to trust centralized intermediaries. This transparency-through-openness model worked brilliantly for certain applications—cryptocurrency transactions, supply chain provenance verification, and public registries where visibility actually enhanced value.
However, this design philosophy created a devastating problem for mainstream enterprise adoption. How could you run payroll on a public blockchain when every employee's compensation becomes visible to competitors? How could you maintain institutional finance transactions when regulatory filings require confidentiality? How could you process healthcare data in compliance with privacy regulations when the underlying ledger exposes sensitive information to any observer with internet access?
The blockchain ecosystem responded with "private" blockchains—controlled ledgers where only authorized participants could view transactions. But this solution simply recreated the traditional problem: you had to trust the centralized operators of that private network. You'd eliminated the transparency that was supposed to build trust in the first place. Banks and enterprises found themselves asking: "Why use a blockchain at all if we're going back to trusting a central authority?"
This was the transparency paradox: the feature that made blockchains revolutionary for trust—complete transparency—made them fundamentally unsuitable for any application requiring confidentiality. For over a decade, this contradiction remained unsolved, relegating blockchain technology to niche applications where transparency actually enhanced rather than hindered value.
Why Transparency Alone Doesn't Create Trust
A deeper misunderstanding emerged from the early blockchain era: the assumption that transparency automatically generates trust. But transparency and trustworthiness are not identical concepts. Consider a situation where your healthcare provider publishes all patient records in encrypted form on a public ledger for transparency. Technically, you can audit that the records are immutable and no one has tampered with them. But if the encryption key is never revealed and all meaningful data remains opaque to you, what have you actually gained? The transparency provides audibility—a record that transactions occurred—but it doesn't provide the confidentiality that healthcare data actually requires.
This distinction between auditability and confidentiality became the foundation for understanding what 2026 actually enables. Organizations realized they didn't need radical transparency; they needed verifiable integrity combined with genuine confidentiality. They needed systems where computations could occur on encrypted data without ever exposing the sensitive information, where audit trails proved nothing had been tampered with, but where only authorized parties could access the actual information.
AI platforms faced an analogous challenge. Machine learning companies built open-weight models and public APIs, believing that transparency about model architecture would generate trust. But enterprise customers increasingly recognized the flaw: knowing how a model works tells you nothing about whether your proprietary training data is genuinely protected or whether it's being exfiltrated in model outputs. They discovered that an open model running on your data with no cryptographic protection is less trustworthy than a closed model running on encrypted data with provable guarantees.

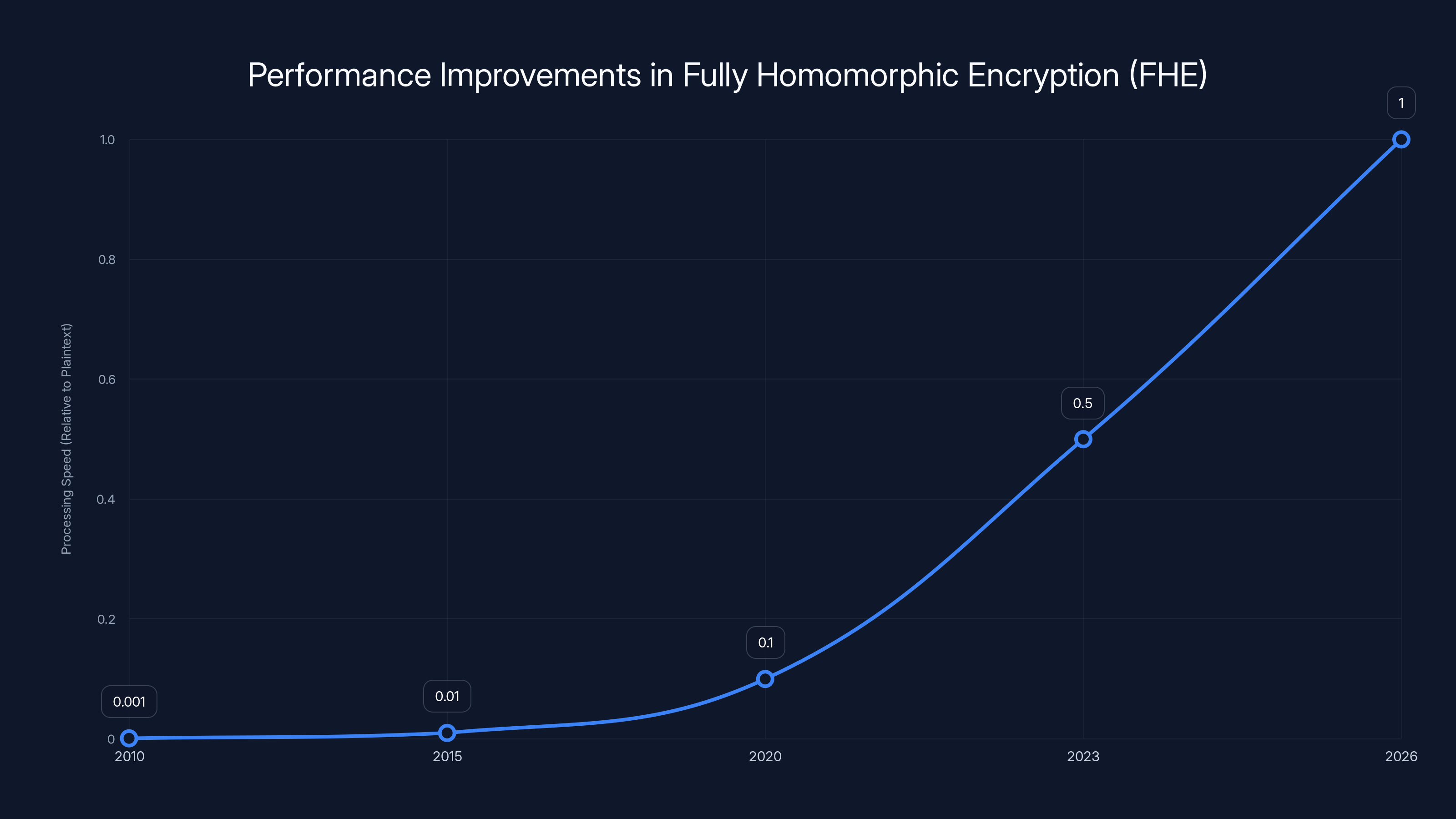
The chart illustrates the estimated improvements in processing speed for fully homomorphic encryption from 2010 to 2026. By 2026, FHE processing speed is projected to approach that of plaintext processing, marking a significant technical breakthrough. Estimated data.
Fully Homomorphic Encryption: The Technical Breakthrough That Makes 2026 Different
What FHE Actually Accomplishes (And What It Doesn't)
Fully Homomorphic Encryption represents one of the most significant—yet poorly understood—advances in applied cryptography of the past decade. To understand why 2026 matters, you need to grasp what this technology fundamentally changes about what's possible in system design.
In traditional encryption, data becomes useless once encrypted. To perform calculations, you decrypt the data (exposing it), perform the computation, then re-encrypt the results. This process worked for storing secrets but failed for processing secrets. Any operation on sensitive data required decryption, creating an unavoidable moment of vulnerability where the raw information existed in plaintext.
Fully homomorphic encryption demolishes this assumption. FHE allows you to perform meaningful computations directly on encrypted data without ever decrypting it. You can add encrypted numbers without ever knowing what those numbers are. You can compare encrypted values, filter encrypted datasets, and apply machine learning algorithms to encrypted inputs. The results emerge encrypted, and only someone with the decryption key can see the actual output.
The practical implication is staggering: you can move sensitive computation to untrusted environments—cloud servers, third-party processors, distributed networks—while maintaining absolute confidentiality. The processing infrastructure never sees raw data. The cloud provider cannot steal information because there's literally nothing to steal.
Why the Timing Matters: Recent Performance Breakthroughs
Fully homomorphic encryption wasn't invented in 2025 or 2026. The mathematical foundations were established in Craig Gentry's landmark 2009 thesis. The technology worked—proving the concept was possible—but it was catastrophically slow. Processing encrypted data took thousands of times longer than processing plaintext. A single multiplication of encrypted numbers could consume seconds. Simple operations became infeasibly expensive.
This performance gap created a ten-year limbo where FHE existed as a theoretical marvel but remained impractical for real applications. The technology was mathematically sound but economically impossible. Organizations couldn't deploy systems where a database query took weeks to execute, even if confidentiality was perfect.
The transformation accelerating in 2025 and hitting practical inflection in 2026 comes from multiple concurrent breakthroughs: optimized algorithms reducing computational overhead by orders of magnitude, specialized hardware (FPGAs, GPUs, custom processors) designed specifically for homomorphic operations, and massive research investment from enterprises and governments recognizing the strategic value of privacy-preserving computation.
Technical benchmarks illustrate the shift:
- 2015: FHE operations at 1,000x to 10,000x performance penalty vs. plaintext computation
- 2020: Performance penalty reduced to 100x to 1,000x through algorithm improvements
- 2023: Specialized hardware implementations achieve 10x to 100x penalty, with some operations approaching practical feasibility
- 2025-2026: Optimized implementations closing toward 2x to 10x penalty for common operations, crossing the threshold where deployment becomes economically viable
The specific threshold that matters for mainstream adoption isn't zero overhead—that's likely impossible. Rather, it's the point where privacy-preserving computation becomes faster or more cost-effective than alternative compliance approaches. If encrypting data and computing on it takes 5x longer but eliminates weeks of legal review, regulatory audit, and compliance overhead, the total time-to-deployment actually improves.
The "HTTPZ" Analogy: Privacy as Infrastructure
Understanding how privacy becomes "boring" requires recognizing the parallel to HTTPS, the encryption protocol that secured web communication. In the 1990s, HTTPS was specialized, expensive, and deployed only for financial transactions. Most websites used plaintext HTTP because encryption imposed processing overhead and required security expertise.
Over time, HTTPS infrastructure became standardized, hardware support improved, and the security benefit became self-evident. Gradually, then suddenly, HTTPS became the default. Websites without HTTPS became suspicious. Search engines penalized unencrypted sites. Browsers began warning users about plaintext connections. Within two decades, HTTPS transformed from specialist tool to boring infrastructure—present everywhere, transparent to users, assumed by default.
Privacy-preserving computation is following a similar trajectory. Systems built with homomorphic encryption, confidential computing, and privacy-preserving inference will initially carry overhead and require specialized expertise. Over time, libraries will mature, hardware support will expand, and organizational muscle memory will develop. The technology will become boring—a standard architectural assumption that doesn't require expertise to deploy.
When privacy-preserving computation reaches this "boring" status in 2026, several structural changes accelerate. Organizations stop debating whether to build with privacy; they debate how to implement it cost-effectively. Procurement departments shift from asking "does this vendor support privacy?" to "what's your privacy architecture?" Competition for talent shifts from "expertise in privacy" to "standard competency everyone is expected to have."
Why 2026 Is the Inflection Point: Convergence of Forces
Force 1: AI Moving From Experimentation to Production Criticality
The 2023-2024 period represented the experimental phase of enterprise AI adoption. Organizations launched limited pilots: a customer service chatbot for inbound queries, an internal document search tool, a pricing optimization model testing on historical data. These projects were contained, low-risk, and involved non-sensitive data or heavily anonymized datasets.
This phase served a crucial function—it allowed enterprises to build organizational muscle, understand implementation challenges, and develop governance frameworks. But by 2026, organizations have moved decisively past experimentation. AI is now embedded in core business processes where it handles sensitive information and makes consequential decisions.
Consider the specific workflow shifts occurring in 2025-2026:
Pricing and Revenue Optimization: Machine learning models now directly determine pricing for major contracts, set discount authorities, and allocate revenue across product lines. These models require access to cost structures, margin targets, and competitive pricing data—information that's genuinely sensitive. Competitors would pay substantial sums for this data; regulators scrutinize pricing decisions; customers increasingly demand transparency about algorithmic pricing.
Healthcare and Clinical Decision Support: AI systems now assist in diagnosis, treatment recommendations, and drug interactions. They require access to patient medical histories, genetic information, and treatment outcomes—data protected by HIPAA, GDPR, and equivalent regulations. These systems cannot operate on anonymized or synthetic data; they need access to actual patient information for accuracy.
Financial Services and Credit Decisions: Machine learning models determine loan approvals, set interest rates, and assess creditworthiness. They operate on financial histories, employment records, and proprietary credit scoring models. This data is simultaneously regulated, sensitive, and competitively valuable.
Legal and IP Analysis: Organizations deploy AI on contracts, patents, litigation history, and proprietary legal strategies. The data being processed is literally defined as legally privileged in many jurisdictions.
R&D and Product Development: Product teams use AI to analyze research data, optimize formulations, and predict development timelines. The training data encompasses years of proprietary research and millions of dollars in development investment.
In each case, the transition from pilot to production creates an unavoidable collision: the data required for AI accuracy is exactly the data that cannot be exposed, shared with third parties, or processed on unencrypted systems. Organizations find themselves unable to deploy even trivially simple machine learning models on sensitive data using conventional cloud infrastructure.
This collision point is what makes 2026 pivotal. The pain of not having privacy-preserving computation becomes concrete and measurable. Organizations quantify the cost: legal reviews that delay deployment by weeks, compliance officers who block projects, and competitive disadvantage when competitors solve the problem and gain access to richer training data.
Force 2: Boards Taking Direct Accountability for AI Risk
In 2024-2025, AI risk was an abstract board discussion. "We need AI governance." "We should establish an AI ethics committee." "Let's draft principles for responsible AI." These conversations happened in conference rooms while actual deployment continued largely unchanged.
This is changing in 2026 with the emergence of concrete accountability mechanisms. High-profile AI failures—data breaches at major enterprises, model inversion attacks recovering training data, regulatory enforcement actions, and AI systems making discriminatory decisions with documented financial impact—are creating fiduciary liability for board members.
Directors and officers liability insurance is beginning to exclude AI-related risks or demand specific security certifications. Shareholder activists are targeting companies with inadequate AI governance. Regulators are explicitly naming board members and executives for AI-related failures. This creates a new calculus: board members now face personal legal liability for AI governance failures.
Once this accountability shifts from abstract principle to concrete personal risk, the conversation changes entirely. Boards no longer ask "should we prioritize privacy?" They ask "can we prove data never leaked?" They demand technical evidence that sensitive information cannot possibly be extracted. They require cryptographic guarantees, not policy statements.
This board-level attention drives procurement requirements that cascade through entire organizations. CTOs who previously treated privacy as optional suddenly receive direct board mandates to implement privacy-preserving architectures. Compliance officers gain budget authority and executive sponsorship. The "nice to have" becomes "must have" with C-suite accountability.
Force 3: Large Buyers Resetting Procurement Standards
Market transformation rarely occurs through universal adoption. Rather, it follows a pattern: a few large, influential buyers establish new requirements; competitors rush to meet those requirements; standards become normalized; later adopters face competitive disadvantage for non-compliance.
We're seeing the earliest signs of this pattern in enterprise procurement for privacy-preserving architectures. A handful of large financial institutions, healthcare systems, and technology companies are beginning to require privacy-by-design as a default procurement standard. These organizations have sufficient market power that vendors cannot ignore these requirements.
The forcing mechanisms are clear: a major financial institution announces it will not sign multi-year cloud contracts with vendors lacking homomorphic encryption support for sensitive workloads. A healthcare network declares that patient data cannot be processed on third-party infrastructure without cryptographic guarantees of confidentiality. A pharmaceutical company states that clinical trial data must be processed on privacy-preserving platforms to satisfy regulatory requirements.
Once a few enterprises representing billions in annual spending establish these requirements, the market tips. Vendors prioritize features for these large buyers because the opportunity cost is too high to ignore. Smaller customers benefit from the same features the large enterprises demanded. Standards get formalized through industry consortia.
We've watched this exact pattern unfold with zero-trust security architecture, cloud security certifications, and compliance frameworks. What starts as a requirement for the top 5% of buyers becomes table stakes within three to five years.
Force 4: Competitive Pressure and Revenue Enablement
The most powerful force driving adoption isn't regulation—it's competitive advantage. Organizations that build privacy-by-design gain access to richer, more sensitive data that competitors cannot access. They unlock collaboration across organizational boundaries that was previously impossible. They close deals because customers trust them with information they wouldn't share elsewhere.
Consider a concrete scenario: two machine learning platforms compete for a pharmaceutical company's drug discovery business. Platform A can access compound libraries, screening results, and preclinical efficacy data. Platform B can access the same data plus proprietary synthesis routes, ongoing clinical trial results, and next-generation formulation research that represents billions in potential value.
Why would the pharmaceutical company give Platform B access to more valuable information? Because Platform B demonstrates cryptographic guarantees that data cannot leak. Platform A can offer policy commitments and security audits, but platform B offers mathematical proof that even the platform operators cannot access raw data. The confidentiality guarantee becomes the business enabler, not just a risk control.
This revenue motivation is more powerful than regulatory compliance because it doesn't depend on enforcement actions or legal liability. It depends on what customers actually want to do with systems. Organizations want to unlock collaborations that were previously impossible. Privacy-preserving computation makes those collaborations viable.
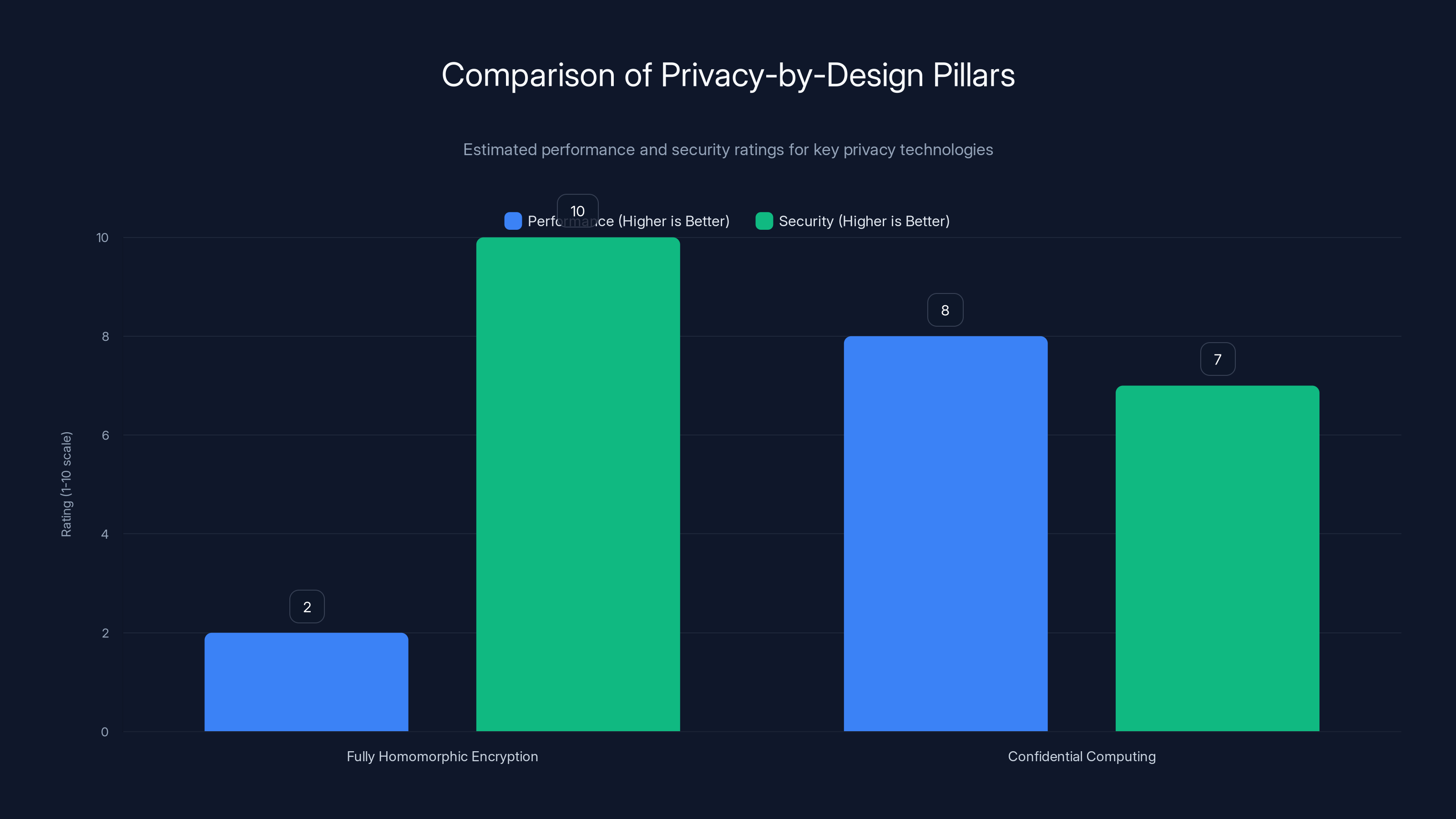
Confidential computing offers higher performance due to hardware acceleration, while fully homomorphic encryption provides superior security by never exposing plaintext. Estimated data based on typical use cases.
The Four Technical Pillars Enabling Privacy-by-Design
Pillar 1: Fully Homomorphic Encryption (FHE)
Fully homomorphic encryption enables computation on encrypted data without decryption. While the mathematics enable this capability, practical implementation requires careful attention to several factors:
Key Generation and Management: FHE requires generating encryption keys large enough to be mathematically secure (typically 1,024 to 4,096 bits or larger). Key generation is computationally intensive and must occur in controlled environments. Unlike traditional symmetric encryption where a single shared key suffices, FHE systems often require separate keys for different types of operations.
Performance Optimization Through Preprocessing: While raw FHE remains expensive, significant speedups occur through preprocessing—computing partial results before encryption. Organizations can precompute encrypted lookup tables, encrypted polynomial evaluations, and other intermediate results that reduce real-time computation overhead.
Approximate vs. Exact Computation: Exact homomorphic encryption (computing precisely on encrypted data) remains expensive. However, approximate encrypted computation—sufficient for machine learning, approximate statistical analysis, and probabilistic algorithms—achieves much better performance. Organizations can often accept approximation errors of 0.1% or 1% in exchange for 100x performance improvements.
Pillar 2: Confidential Computing Hardware
Confidential computing represents a different privacy approach: hardware-level isolation where computation occurs in protected enclaves that even cloud providers cannot access. Technologies like Intel SGX, AMD SEV, and ARM Trust Zone create isolated execution environments where code runs encrypted and results remain encrypted until explicitly decrypted.
Trust Model Differences: Unlike FHE (which never exposes plaintext), confidential computing places trust in hardware security. The assumption is that encrypted execution within the secure enclave prevents snooping by cloud administrators, hypervisors, or network observers. This offers different tradeoffs: generally faster than FHE but dependent on hardware security properties.
Side-Channel Vulnerabilities: Confidential computing has revealed subtle vulnerabilities where attackers can infer information from timing, power consumption, or cache behavior. Mitigation requires careful algorithm design and constant-time implementations.
Attestation and Verification: Modern confidential computing platforms provide attestation—cryptographic proof that code is running in a genuine secure enclave. This becomes essential for enterprise trust; customers can verify they're actually running on protected hardware.
Pillar 3: Privacy-Preserving Machine Learning
Machine learning introduces unique privacy challenges because models themselves can leak training data. Techniques like differential privacy, federated learning, and secure multiparty computation address these challenges:
Differential Privacy: Adding mathematically calibrated noise to datasets or model outputs ensures that individual data points cannot be reliably extracted even if an attacker observes the entire training process. The privacy-utility tradeoff is tunable; organizations can specify how much privacy they need and accept corresponding model accuracy reductions.
Federated Learning: Training models across distributed data without centralizing data. Instead of collecting all data in one place and training, models are trained locally and only model updates (not raw data) are shared. This keeps sensitive data on-premises while still enabling collaborative model development.
Secure Multiparty Computation (SMPC): Multiple parties can jointly compute results—like training a machine learning model—without any single party revealing their data to others. All parties learn the result but not each other's inputs.
Pillar 4: Zero-Knowledge Proofs and Verifiable Computing
Organizations sometimes need to prove computation was correct without revealing the underlying data. Zero-knowledge proofs enable exactly this: proving that a computation ran correctly without disclosing inputs, intermediate values, or implementation details.
Practical Applications: A financial institution proves to regulators that a risk model produces compliant outputs without disclosing proprietary model details or customer-level data. A healthcare provider proves that AI diagnostic recommendations follow established medical guidelines without sharing patient data.
Scaling and Performance: Modern zero-knowledge proof systems (using techniques like STARKs and SNARKs) have improved significantly, though they still impose performance overhead. Organizations typically use them for high-value attestations rather than every computation.

Who Gets Left Behind: The Organizations Misreading the Shift
The Open-Everything Trap
A significant portion of the AI and data platform ecosystem will misread 2026 as validation of openness. These organizations believe that transparency—open-source models, open APIs, open data formats, and auditable algorithms—generates customer trust. They've built entire business models around this principle.
What they're missing is a crucial distinction: inspectability (the ability to audit how something works) and confidentiality (protection of sensitive inputs and outputs) are orthogonal concerns. An open-source model with public source code can be thoroughly audited—and still leak training data or user information if data protection mechanisms are absent.
The Model Inversion Problem: Open models create a specific vulnerability: if an attacker knows the model architecture, they can perform model inversion attacks to recover training data. By querying the model strategically and observing outputs, attackers can reconstruct sensitive training information. This attack becomes more powerful, not less, when the model architecture is public.
The API Exposure Problem: Open APIs that provide model access create additional risks. Every query reveals information about the data being processed. A customer using a model API to process confidential financial data is fundamentally exposing information to the API provider—the fact that query X was issued, and what output Y was returned tells stories about underlying data.
Organizations that conflate openness with trustworthiness will find themselves excluded from sensitive applications. Enterprise customers will specifically demand closed-door negotiations with vendors that implement privacy-preserving architectures, precisely because public transparency about how data is processed doesn't solve the confidentiality problem.
The Retrofitting Trap
Another cohort of organizations will assume privacy can be added as an architectural layer after core product development completes. They'll treat it like security—something that can be bolted on through careful engineering, access controls, and policy.
This fundamentally misunderstands how privacy-preserving systems work. Confidential computing, homomorphic encryption, and privacy-preserving machine learning aren't features or layers. They're foundational architectural choices that shape how systems are built.
Consider trying to retrofit homomorphic encryption into an existing machine learning platform. The core algorithms, data structures, numerical precision, and optimization techniques are optimized for plaintext computation. Retrofitting homomorphic encryption means rewriting fundamental components, reimplementing algorithms for encrypted data, and accepting massive performance penalties because the architecture wasn't designed for it.
Organizations that treat privacy as a checkbox to be added later will discover, like security teams did decades ago, that retrofitting is expensive, incomplete, and brittle. They'll face a choice: invest heavily in architectural rewrites, or accept that certain high-value use cases remain inaccessible.
The Complacency Trap
Perhaps most dangerously, organizations that assume current quiet around privacy demands indicates lack of urgency are catastrophically misreading market dynamics. The reason privacy requirements aren't explicit in current RFPs is not because organizations don't want it—it's because they've assumed it's impossible.
This mirrors the historical pattern with security. In the 1990s, organizations didn't demand encryption or zero-trust architectures because these capabilities didn't exist at scale. Once they became available and viable, expectations shifted with stunning speed. Organizations that hadn't invested in security capabilities found themselves competitive disadvantages.
The same will occur with privacy. Once homomorphic encryption and confidential computing become practical and mainstream, expectations will shift immediately. Organizations will begin requiring privacy guarantees as preconditions for accessing sensitive data. Those that have spent years assuming privacy can be addressed later will find themselves locked out.
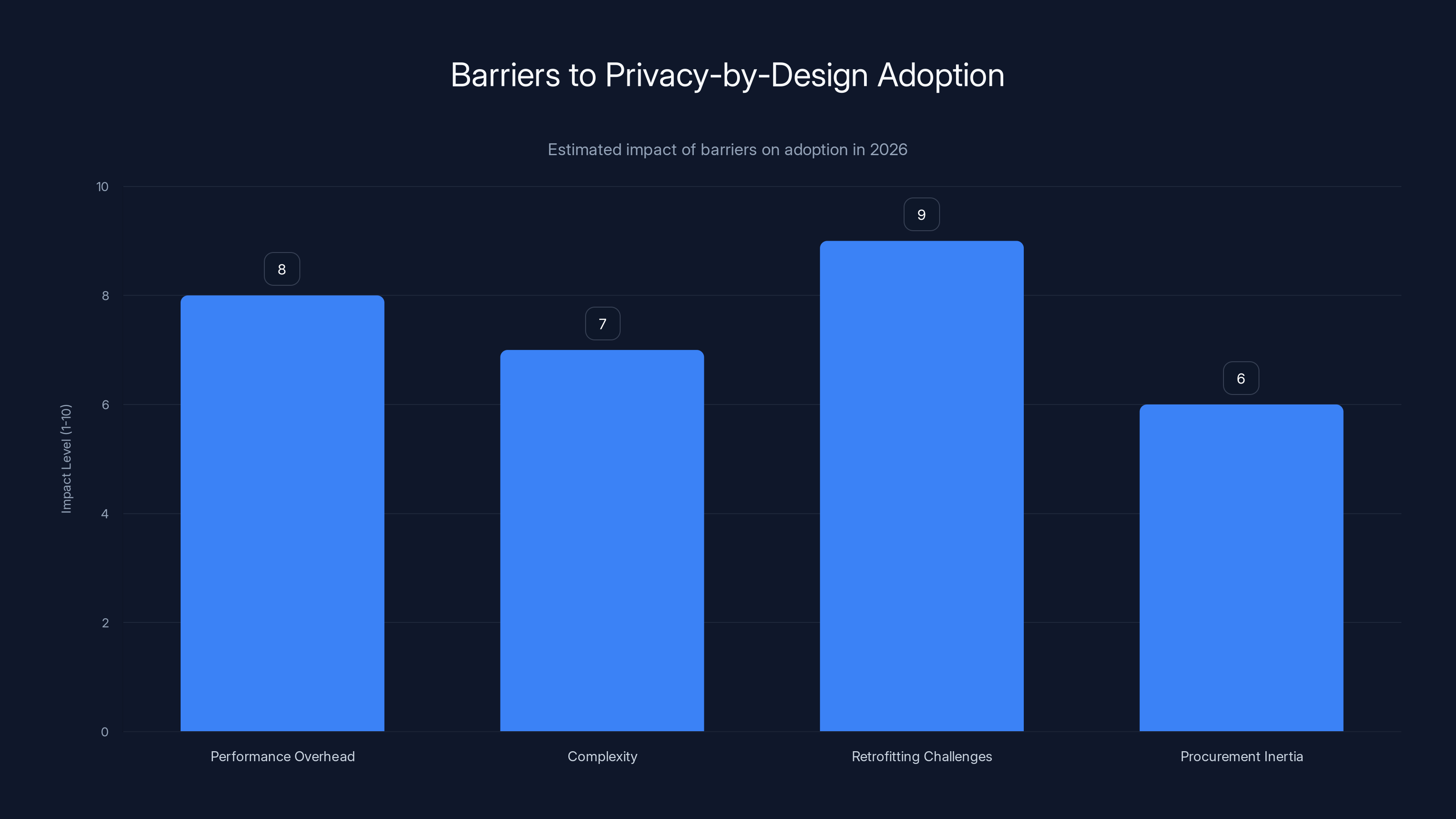
Retrofitting challenges and performance overhead are the most significant barriers to the adoption of privacy-by-design, with estimated impact levels of 9 and 8 respectively.
Organizations That Win: Building Privacy as Foundation
Access to Richer, Higher-Signal Data
The most direct competitive advantage for early privacy adopters is access to more valuable data. When customers trust an organization with information they wouldn't share with others, they provide access to higher-signal datasets that improve model performance.
Consider pharmaceutical research: a company using privacy-preserving platforms can gain access to proprietary research data, confidential clinical trial results, and synthesis routes that competitors cannot access. Not because they're better negotiators, but because customers trust the architecture. The customer's data can be accessed by the AI platform without any risk of exposure.
This advantage compounds over time. Better training data produces better models. Better models attract more customers willing to share data. More data enables better models. The feedback loop creates durable competitive moats.
Speed of Deployment in Sensitive Environments
Privacy-preserving architectures eliminate entire classes of delay. When data confidentiality is cryptographically guaranteed, legal reviews shorten. Compliance officers approve projects faster. Internal vetoes disappear because the technical risk has been eliminated.
Organizations deploying AI in healthcare, finance, and regulated industries will experience dramatic acceleration. A deployment that would normally take four months (two months of legal review, one month of compliance audit, one month of actual implementation) might compress to six weeks because the technical architecture itself satisfies compliance requirements.
This speed advantage translates directly into market opportunity. Being six months faster to deploy AI for a major customer in a regulated industry is worth millions in incremental revenue.
Expanded Cross-Organizational Collaboration
Privacy-preserving systems unlock collaboration patterns that were previously impossible. Two competitors can jointly analyze market trends without exposing proprietary data. Multiple suppliers can collaboratively optimize a manufacturing process without revealing cost structures. Insurance companies can share fraud patterns without exposing customer information.
These collaboration opportunities create new market segments. Organizations that can facilitate trusted collaboration across organizational boundaries (a traditional competitive concern) will build entirely new business models around secure multiparty computation and privacy-preserving data sharing.

The Shift From Privacy as Risk Control to Privacy as Revenue Driver
Reframing the Economics
Historically, privacy has been treated as a cost center. Organizations spend money on security controls, privacy programs, and compliance infrastructure to reduce risk. The value is prevention of bad things (data breaches, regulatory fines, reputational damage).
In 2026, this framing begins to reverse. Privacy becomes a revenue driver. Organizations gain access to datasets, collaboration opportunities, and use cases that competitors cannot access because they lack privacy infrastructure.
The economic shift is profound. Rather than asking "how much should we spend on privacy?" (a cost minimization question), organizations ask "what additional revenue is available to us if we implement privacy-by-design?" (a revenue maximization question). This changes the calculus entirely.
Shifting Procurement Conversations
Historically, procurement departments focused on features, performance, and cost. Privacy was a secondary consideration negotiated by legal and compliance teams. Increasingly in 2026, procurement conversations begin with privacy as a primary selection criterion.
RFP language shifts from "Does this vendor comply with our privacy requirements?" to "What privacy-preserving capabilities does this solution provide?" Procurement teams begin comparing privacy architectures the same way they compare performance or scalability.
This shift advantages organizations that have invested in privacy-preserving systems and disadvantages those that haven't. A vendor without these capabilities faces an awkward choice: build privacy features quickly (expensive and risky) or accept exclusion from sensitive opportunities (lost revenue).

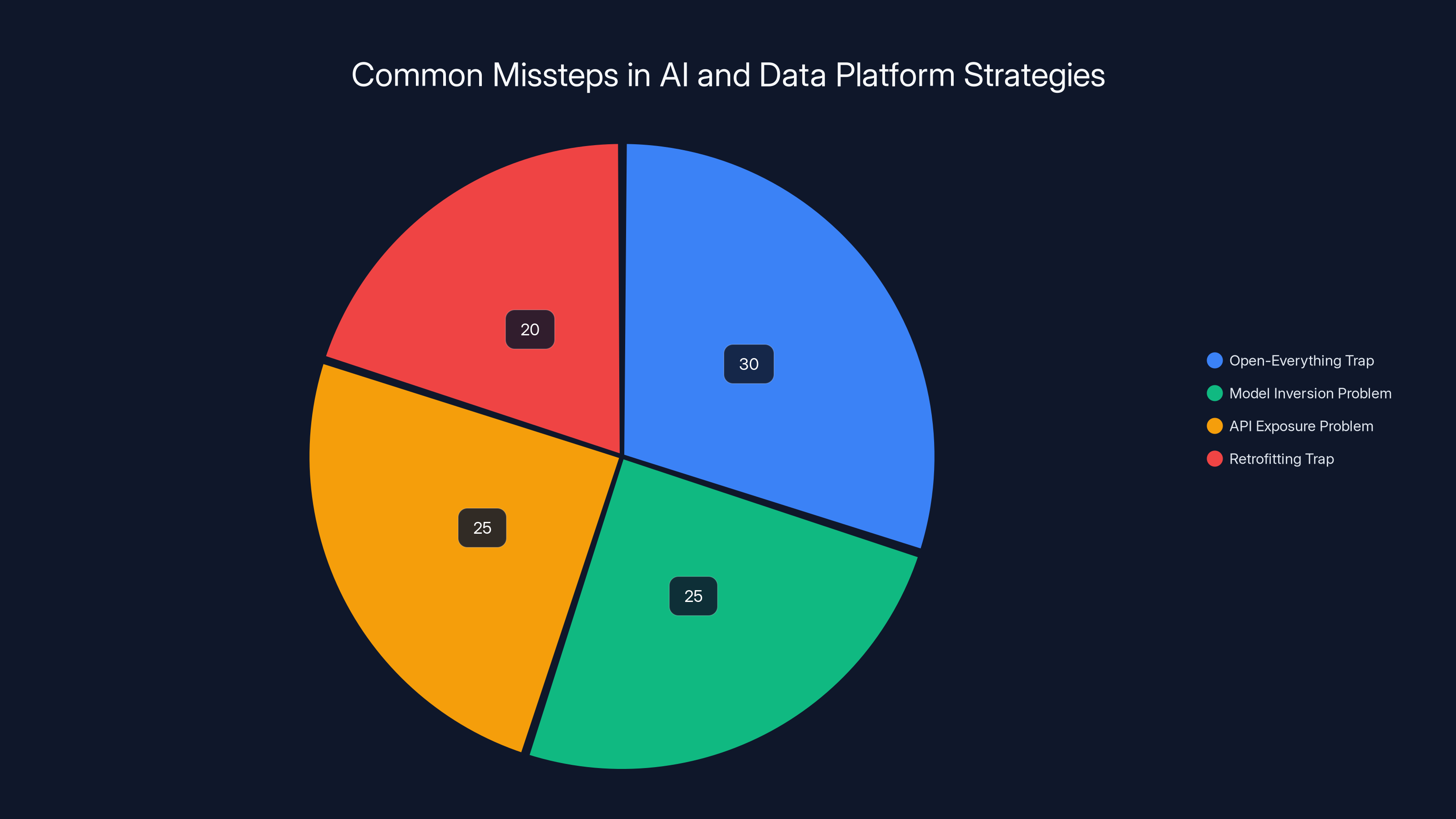
Estimated data shows that a significant portion of organizations will misinterpret openness as trustworthiness, leading to vulnerabilities like model inversion and API exposure.
Implementing Privacy-by-Design: Practical Framework
Phase 1: Architecture Assessment and Planning (Months 1-3)
Before implementing privacy-preserving systems, organizations need to understand their current architecture and identify where privacy-preserving computation adds value.
Data Classification: Categorize all data by sensitivity level, regulatory requirements, and competitive value. Distinguish between data that must remain confidential throughout processing versus data where some exposure is acceptable.
Workflow Mapping: Document which workflows process sensitive data. For each workflow, identify: (1) what sensitive information flows through it, (2) what computations occur, and (3) who currently has access to plaintext data.
Technology Gap Analysis: Evaluate current technology against privacy requirements. Identify specific gaps where homomorphic encryption, confidential computing, or other privacy-preserving techniques would add value.
Cost-Benefit Analysis: Quantify the cost of implementing privacy-preserving computation (infrastructure, development, performance overhead) against the value (access to more sensitive data, faster deployment, compliance benefits, competitive advantage).
Phase 2: Proof of Concept Development (Months 3-6)
Don't start with critical systems. Build proof-of-concept implementations on non-critical workloads to understand practical challenges.
Select Appropriate Technology: For each use case, determine whether homomorphic encryption, confidential computing, or privacy-preserving machine learning is most appropriate. Different problems have different solutions.
Implement Incrementally: Start with simple computations. Encrypt a database column, query it without decryption. Train a machine learning model with differential privacy. Run a computation in a confidential enclave. Use these simple examples to build organizational expertise.
Measure Performance Overhead: Quantify actual performance penalty in your specific workloads. Performance on benchmark tests often differs from production performance. Real-world measurements guide decisions about where privacy-preserving computation is economically viable.
Train Development Teams: Privacy-preserving computation requires different approaches than traditional computation. Train developers on the concepts, available libraries, and best practices.
Phase 3: Production Deployment for Non-Critical Systems (Months 6-12)
Once proof-of-concept is successful, expand to production systems handling non-critical sensitive data.
Standardize Approaches: Across the organization, standardize on specific privacy-preserving technologies. Rather than allowing teams to choose different encryption schemes or confidential computing platforms, establish organizational standards that reduce diversity and simplify operations.
Develop Support Infrastructure: Build libraries, tools, and processes that make privacy-preserving computation accessible to development teams. Lower the barrier to adoption so teams don't avoid privacy-preserving systems because they're too difficult.
Establish Key Management: Privacy-preserving systems typically require sophisticated key management. Develop centralized key management infrastructure that handles encryption key generation, rotation, storage, and access control.
Monitor and Optimize: Privacy-preserving systems often have different performance characteristics than traditional systems. Implement monitoring that tracks performance, resource utilization, and identifies optimization opportunities.
Phase 4: Strategic Systems Conversion (Year 2+)
Once non-critical systems are running successfully, expand privacy-preserving computation to strategic systems handling the most valuable and sensitive data.
Risk Acceptance: Recognize that early implementations on critical systems carry risk. Performance overhead, unexpected behavior, or scalability issues could impact operations. Have contingency plans and rollback procedures.
Change Management: Converting critical systems requires extensive change management. Teams have accumulated years of assumptions about how data flows, how systems behave, and what's possible. Privacy-preserving systems change these assumptions.
Competitive Advantage Realization: Once strategic systems are running on privacy-preserving infrastructure, organizations gain ability to collaborate on sensitive data, access richer datasets, and open entirely new business opportunities.
Technical Deep Dive: Building on Homomorphic Encryption
Selecting Between FHE, Approximate FHE, and Hardware-Based Approaches
Organizations should recognize these technologies have different cost-performance tradeoffs and are appropriate for different problems:
Fully Homomorphic Encryption: Use for scenarios requiring absolute confidentiality guarantees and ability to operate on arbitrary functions. Appropriate for: highly sensitive government or financial computations, IP protection where the algorithm itself must remain secret, scenarios where the computation infrastructure cannot be trusted at all.
Performance expectation: 2x-100x slower than plaintext depending on algorithm complexity and optimization level. Cost: moderate hardware requirements but high software implementation complexity.
Approximate Homomorphic Encryption: Use for machine learning, statistical analysis, and approximate computations where minor precision loss is acceptable. Appropriate for: training machine learning models on encrypted data, computing approximate statistics, running algorithms where epsilon-delta privacy bounds are acceptable.
Performance expectation: 1.5x-10x slower than plaintext on well-optimized implementations. Cost: much lower complexity than exact FHE, significant performance improvements.
Confidential Computing Hardware: Use for scenarios where you trust the processor manufacturer but not cloud administrators, where you need transparent execution of existing applications, or where performance overhead must be minimized.
Performance expectation: 1.05x-2x overhead for well-optimized code, approaching native performance. Cost: hardware dependency, side-channel risks, limited to specific processor generations.
Hybrid Approaches: Many organizations will implement hybrid systems combining multiple technologies. Encrypt data in transit and at rest using traditional encryption (fast, well-understood). Compute on encrypted data using approximate homomorphic encryption for machine learning (good performance for this specific use case). Use confidential hardware enclaves for key material and highly sensitive computations (minimal overhead for small operations).
Practical Implementation Patterns
Encrypted Data Lake + FHE Queries: Store data in encrypted form using traditional encryption. When queries require plaintext access, decrypt for the specific query operation. This keeps data confidential at rest and in motion while allowing interactive analysis.
Federated Learning for Distributed Data: Rather than centralizing sensitive data, train machine learning models locally on-premises or at the data source. Only send model updates (typically much smaller than raw data) to a central server for aggregation. This keeps sensitive data localized.
Confidential Inference: Run trained machine learning models in confidential computing environments. User queries and model outputs remain encrypted. Only the organization running the model can see what queries are being run and what results are returned.
Differential Privacy for Aggregate Queries: When users need aggregate statistics (average, count, sum) rather than individual records, add carefully calibrated noise. Users get approximate answers, but individual records cannot be recovered from the results.

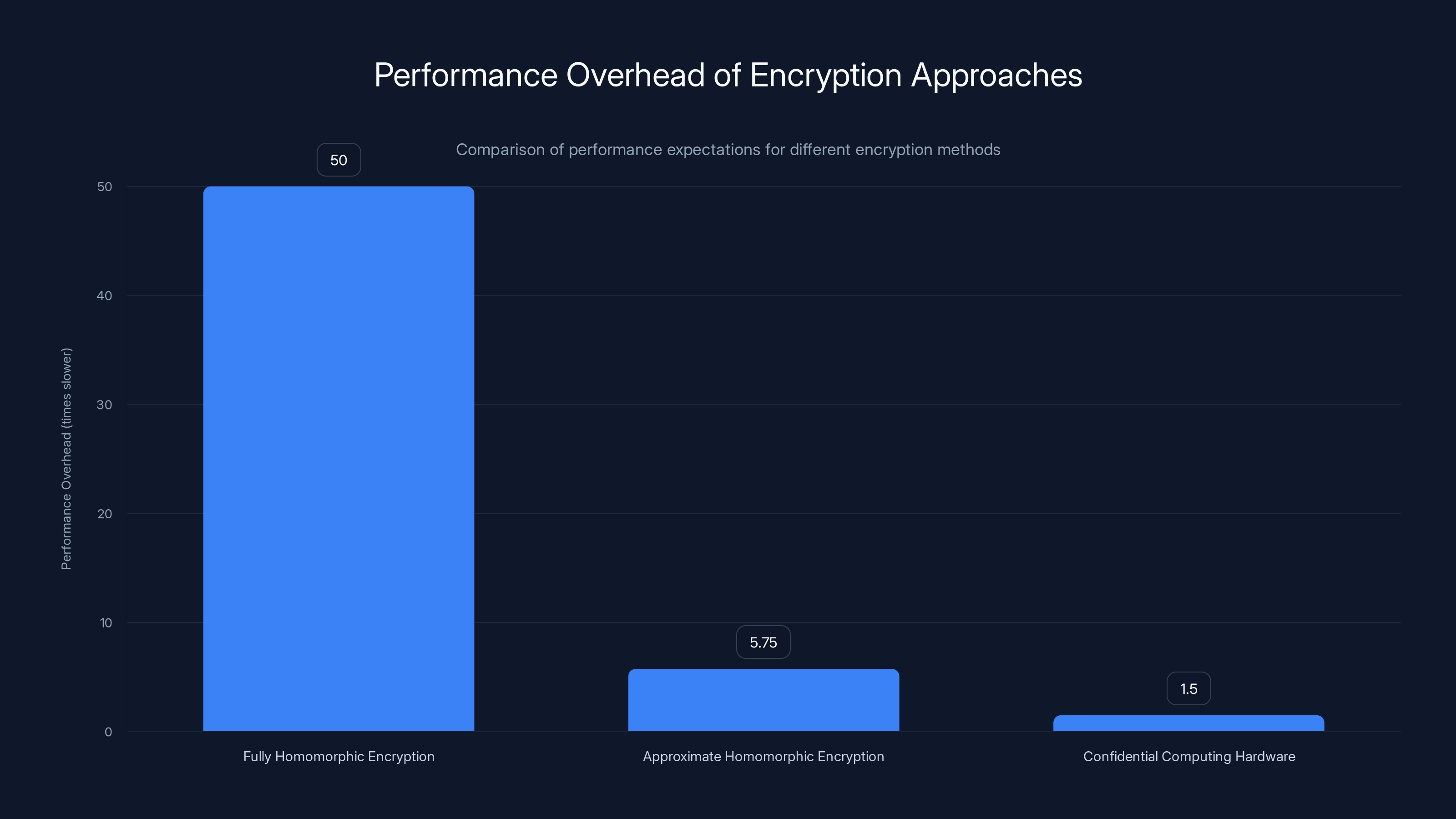
Fully Homomorphic Encryption has the highest performance overhead, ranging from 2x to 100x slower than plaintext, while Confidential Computing Hardware approaches near-native performance with only 1.05x to 2x overhead. Estimated data based on typical scenarios.
Regulatory and Compliance Implications of Privacy-by-Design
How Privacy-by-Design Satisfies Regulatory Requirements
Major data protection regulations—GDPR, HIPAA, CCPA, and their equivalents—increasingly reference privacy-by-design and privacy-by-default as regulatory expectations. What once was a best practice is becoming a compliance requirement.
GDPR Article 32 and 25: The regulation explicitly requires organizations to implement "technical and organizational measures to ensure a level of security appropriate to the risk, including inter alia: encryption of personal data." Privacy-by-design using homomorphic encryption and confidential computing directly satisfies these requirements.
HIPAA Technical Safeguards: HIPAA's technical safeguards require encryption for protected health information both in transit and at rest, plus access controls. Privacy-preserving computation enables compliance by ensuring even system administrators cannot access plaintext protected health information.
Emerging AI Regulations: New AI regulations (EU AI Act, proposed US frameworks) increasingly require technical safeguards for high-risk AI systems. Privacy-by-design helps satisfy these requirements by demonstrating that sensitive data is protected throughout the AI system lifecycle.
The Role of Privacy Impact Assessments
Privacy Impact Assessments (PIAs) are increasingly required by regulation before deploying new systems handling sensitive data. Systems built with privacy-by-design architectures require significantly shorter PIAs because risks are architecturally mitigated rather than requiring policy-based controls.
A PIA for a traditional cloud database system might require 40-60 pages documenting all the ways data might leak and explaining policy controls to prevent each scenario. A PIA for homomorphic encrypted data might be 10-20 pages because many hypothetical leakage scenarios are mathematically impossible.
This simplification is valuable not just for compliance but for speed. Simplified compliance means faster deployment. Regulatory bodies are increasingly recognizing that privacy-preserving architectures genuinely reduce risk, not just on paper but in practice.

The Role of Industry Standards and Certifications
Emerging Privacy-Preserving Technology Standards
As privacy-by-design becomes mainstream, industry consortia are developing standards and certifications. Organizations can expect:
Privacy-Preserving Computation Certifications: Similar to ISO 27001 (security) and SOC 2 (cloud security), new certifications will specifically validate privacy-preserving implementations. These certifications will verify that organizations implement homomorphic encryption, confidential computing, or equivalent technologies correctly.
Benchmarking and Performance Standards: Consortia are establishing benchmarks for privacy-preserving system performance. These benchmarks help organizations compare technologies and vendors on consistent metrics rather than vendor-provided performance claims.
API and Protocol Standards: Standardization of APIs and protocols for privacy-preserving computation will reduce vendor lock-in. Organizations won't be trapped implementing one vendor's proprietary approach.
How Certifications Drive Market Adoption
Certifications historically drive rapid market adoption by simplifying procurement. Once a certification becomes established, it becomes a default requirement in RFPs. Vendors invest in achieving certification because it becomes a business necessity.
This pattern will accelerate privacy-by-design adoption. Organizations without appropriate privacy certifications will find themselves at procurement disadvantage. The forcing function isn't regulation—it's competitive procurement processes where certified vendors have systematic advantage.

Organizational and Skills Implications
Shifting Job Roles and Responsibilities
Privacy-by-design adoption creates new roles and shifts responsibilities:
Privacy-Preserving Systems Engineers: New specialization for engineers who understand homomorphic encryption, confidential computing, and privacy-preserving machine learning. These skills are in shortage and command premium compensation.
Privacy Architects: Teams need architects who understand how to design systems with privacy requirements from the ground up, rather than retrofitting privacy controls.
Privacy Operations: Specialized operations roles managing key material, monitoring encrypted systems for anomalies, and maintaining privacy-preserving infrastructure.
Building Organizational Capability
Organizations should:
Invest in Training: Build training programs for developers, architects, and operations teams. Privacy-by-design requires different mental models than traditional security.
Hire Specialized Talent: Recruit people with cryptography, privacy-preserving machine learning, and confidential computing expertise. These skills are currently in shortage and expensive, but building organizational capability requires it.
Develop Internal Tools: Create libraries, frameworks, and tools that make privacy-preserving computation accessible. Don't require every team to understand cryptography details; abstract complexity behind user-friendly interfaces.
Partner with Specialists: For capabilities beyond current organizational expertise, partner with specialized vendors, consultants, and research institutions. Organizations don't need to build everything internally.

Vendor Landscape and Technology Choices
Categories of Vendors Enabling Privacy-by-Design
Homomorphic Encryption Libraries and Platforms: Organizations like IBM, Microsoft, and specialized startups provide FHE implementations. Examples include IBM's open-source HElib, Microsoft's SEAL, and Zama's Concrete. These provide cryptographic foundations for applications.
Confidential Computing Platforms: Major cloud providers (AWS, Azure, Google Cloud) offer confidential computing services using Intel SGX, AMD SEV, or equivalent. Specialized companies provide additional confidential computing capabilities for on-premises deployment.
Privacy-Preserving ML Frameworks: Frameworks like TensorFlow with differential privacy extensions, PyDP, and specialized libraries enable machine learning on encrypted data or with privacy guarantees.
Database and Data Platform Providers: Database vendors are adding homomorphic encryption support. This integration makes privacy-preserving computation more accessible because data engineers don't need to learn cryptography.
AI and Automation Platforms: Solutions like Runable, which provide AI-driven automation and content generation, are beginning to integrate privacy-preserving computation capabilities. For teams needing to automate document generation, reporting, and workflow creation while maintaining confidentiality of sensitive inputs, privacy-aware automation platforms become increasingly valuable.
Evaluating Vendors and Technology
When evaluating privacy-preserving technology vendors, assess:
Maturity and Performance: Is the technology production-ready or research-stage? What performance overhead should you expect?
Ecosystem and Integration: Does the vendor integrate with tools your organization already uses? Or does adoption require replacing entire toolchains?
Support and Documentation: Are there sufficient resources to implement and operate the technology, or will you need specialized consultants?
Openness vs. Proprietary: Does the vendor offer open-source implementations, or is the technology proprietary? Open-source reduces vendor lock-in but may require more in-house expertise.
Security Audits and Certifications: Has the technology been independently audited? What certifications or standards does it comply with?

Future Trends: Beyond 2026
The Evolution From Privacy to Programmable Trust
Beyond 2026, privacy-by-design systems will evolve toward "programmable trust" architectures where organizations can specify precisely what data can be accessed, under what conditions, and by whom—and enforce these policies cryptographically.
Zero-knowledge proofs will enable organizations to prove policy compliance without revealing underlying data. Decentralized identity systems will enable granular permission management. Blockchain-based systems will create immutable audit trails of who accessed what data and when.
Integration With AI and Automation
As AI systems become more sophisticated, privacy-preserving computation becomes more critical. Large language models trained on proprietary data need protection mechanisms. AI systems making decisions on sensitive information need auditable, trustworthy foundations.
Automation platforms that generate content, create documents, or produce reports will increasingly integrate privacy-preserving computation. Users can feed confidential information to these systems—proprietary business processes, sensitive customer information, strategic plans—knowing the systems operate on encrypted data and the automation provider cannot see the actual content.
Quantum Computing Implications
Quantum computers will eventually break many traditional encryption schemes, including those used to protect private keys in homomorphic encryption. Organizations should begin transitioning to quantum-resistant cryptography now, even though large-scale quantum computers remain years away. Privacy-by-design implementations built today should use post-quantum cryptographic algorithms.
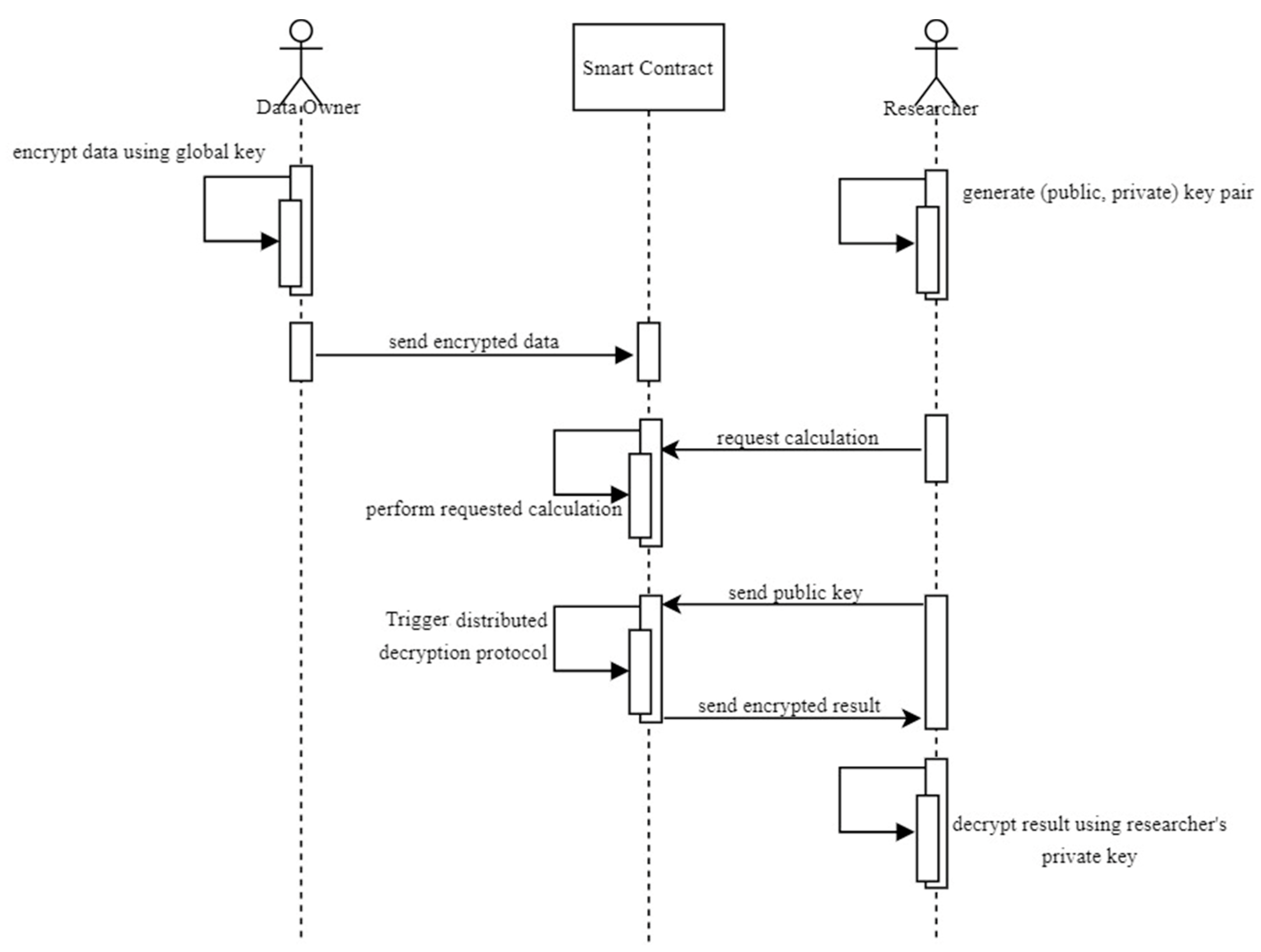
Conclusion: The Organizations Leading and Lagging in 2026
We stand at a watershed moment in enterprise technology. The convergence of AI moving to production, boards taking accountability for AI risk, large buyers demanding privacy in procurement, and competitive advantage accruing to organizations with access to more sensitive data creates an inflection point that will reshape enterprise architecture throughout 2026 and beyond.
Organizations that recognize 2026 as the pivotal year—that understand privacy-by-design is no longer optional—will position themselves for a decade of competitive advantage. They'll access data others cannot. They'll deploy solutions others cannot. They'll unlock collaborations others cannot imagine.
Organizations that misread the shift—that assume privacy can be retrofitted, that conflate transparency with trustworthiness, or that treat privacy as optional—will find themselves systematically excluded from high-value opportunities. The pain of these exclusions will become apparent in 2027 and 2028, when building privacy-by-design is suddenly mandatory rather than optional.
The choices organizations make in 2026 will determine their competitive position for years to come. The technology is ready. The regulations are pushing. The economics are compelling. Large buyers are demanding. The only remaining variable is organizational recognition that this shift is not theoretical—it's happening now, and it's happening fast.
For teams seeking cost-effective solutions to automate content generation while maintaining data confidentiality, platforms like Runable are beginning to integrate privacy-preserving computation capabilities. At just $9/month, Runable offers AI-powered automation for documents, reports, and content creation—capabilities increasingly essential for teams that need to maintain privacy guarantees around sensitive business information.
The organizations that win in 2026 are those that don't wait for privacy-by-design to become boring. They're the ones building it into foundational architecture today. That boring, invisible privacy infrastructure becomes the competitive moat that keeps them ahead for years to come.
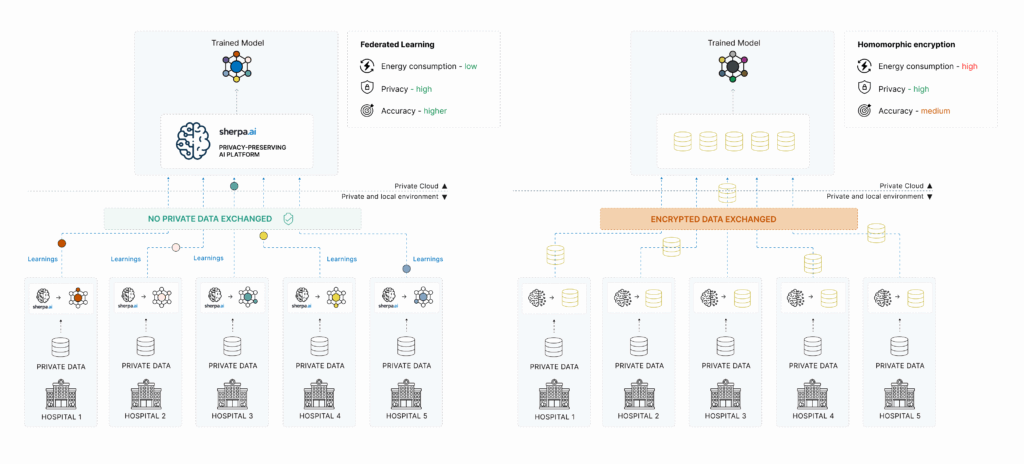
FAQ
What is Privacy-by-Design and why does it matter in 2026?
Privacy-by-design is an approach to building systems where confidentiality and data protection are built into the foundational architecture from initial conception, rather than added as an afterthought. In 2026, it matters because artificial intelligence has moved from experimental pilots into mission-critical business processes handling sensitive data, regulatory bodies are increasing accountability requirements for data protection, and early adopters are gaining competitive advantage by accessing richer datasets that competitors cannot access due to privacy concerns.
How does Fully Homomorphic Encryption enable privacy-preserving computation?
Fully Homomorphic Encryption (FHE) allows mathematical operations to be performed directly on encrypted data without decryption, meaning the data can be processed while remaining fundamentally protected. Previously, FHE carried prohibitive performance penalties making real-world deployment impractical. Recent algorithmic improvements and specialized hardware support have reduced these performance penalties from thousands of times slower to just a few times slower, crossing the threshold where deployment becomes economically viable for appropriate use cases.
What are the main barriers preventing privacy-by-design adoption today?
The primary barriers include: (1) Performance overhead—privacy-preserving computation still takes longer than traditional processing; (2) Complexity—integrating homomorphic encryption and confidential computing requires specialized expertise most organizations lack; (3) Retrofitting challenges—privacy must be built into architecture from the start rather than added later; and (4) Procurement inertia—many organizations haven't yet updated procurement standards to require privacy-preserving architectures, so vendors haven't prioritized implementing these features.
How will privacy-by-design shift competitive dynamics between technology vendors?
Vendors that build privacy-preserving architectures from the ground up will gain access to enterprise customers with sensitive data and regulated use cases that competitors cannot serve. They'll benefit from faster procurement and deployment in regulated industries because technical architecture addresses compliance concerns directly. Vendors that treat privacy as an optional feature or assume it can be retrofitted will find themselves systematically excluded from high-value opportunities. Over time, privacy-by-design will become a baseline requirement, and vendors without it will face significant competitive disadvantage.
What role do confidential computing and homomorphic encryption play in regulated industries?
In regulated industries like healthcare, finance, and public sector, regulatory bodies increasingly require technical safeguards demonstrating data confidentiality throughout processing. Confidential computing (like Intel SGX or AMD SEV) enables computation in isolated hardware enclaves that even cloud providers cannot access. Homomorphic encryption enables operations on encrypted data without exposure. Together, these technologies satisfy regulatory requirements by providing cryptographic proof of confidentiality rather than relying on policy and access controls alone, which significantly accelerates compliance timelines.
How can organizations begin implementing privacy-by-design without massive upfront investment?
Organizations should begin with architecture assessment to identify where privacy-by-design adds most value (typically sensitive, high-value data), start with proof-of-concept implementations on non-critical systems to build expertise and understand performance characteristics, establish organizational standards for privacy-preserving technologies rather than allowing diverse implementations, develop support infrastructure that makes privacy-preserving computation accessible to teams without requiring cryptography expertise, and consider hybrid approaches combining traditional encryption for data at rest, privacy-preserving ML for analytical workloads, and confidential computing for key management and highly sensitive computations.
What skills and organizational changes are needed to implement privacy-by-design?
Organizations need to develop or hire expertise in privacy-preserving systems engineering, cryptography, and confidential computing—currently scarce and expensive skills. Architecture teams need to understand how to design systems with privacy requirements from the beginning rather than adding controls later. Operations teams need capabilities to manage encryption keys, monitor encrypted systems, and maintain privacy-preserving infrastructure. Beyond technical changes, organizations need leadership alignment recognizing privacy as strategic business requirement rather than compliance checkbox, budget allocation for building capability over time, and change management programs helping teams adapt to different system design and operational models.
How does AI amplify the importance of privacy-by-design?
Artificial intelligence systems often require access to large volumes of sensitive, high-signal data to achieve good performance. When AI moves from experimental pilots into production systems handling payroll, healthcare decisions, financial approvals, and strategic business processes, organizations cannot provide the sensitive data needed without privacy guarantees. Additionally, AI models themselves can leak training data through model inversion attacks. Privacy-by-design makes it feasible for organizations to provide AI systems access to truly sensitive data—from internal proprietary information to regulated customer information—while maintaining cryptographic guarantees that data cannot leak.
What are the performance and cost implications of privacy-by-design implementations?
Performance overhead varies by technology: confidential computing typically adds 1-2x overhead, approximate homomorphic encryption for machine learning adds 2-10x overhead, and fully homomorphic encryption for arbitrary computation can add 10-100x overhead. However, these overhead calculations should be evaluated against total time-to-deployment. If privacy-by-design eliminates two months of legal review and compliance audit, the technical performance overhead is economically insignificant. Cost implications include infrastructure (specialized hardware or cloud confidential computing services) and development (implementing cryptographic systems is more complex than traditional development), but these costs are declining as tooling matures and are increasingly offset by competitive advantages and revenue enablement.
How should organizations evaluate privacy-by-design technology vendors?
Key evaluation criteria include: (1) Production readiness—is the technology mature enough for critical deployments or is it still research-stage?; (2) Performance—what overhead should be expected in your specific workloads?; (3) Integration—does it work with your existing tools or require replacing entire toolchains?; (4) Security—has it been independently audited and what certifications does it hold?; (5) Support ecosystem—are there sufficient resources, documentation, and community to implement and operate it?; (6) Open vs. proprietary—does the vendor offer open-source implementations reducing lock-in?; (7) Roadmap—does the vendor demonstrate commitment to improving performance and functionality over time?
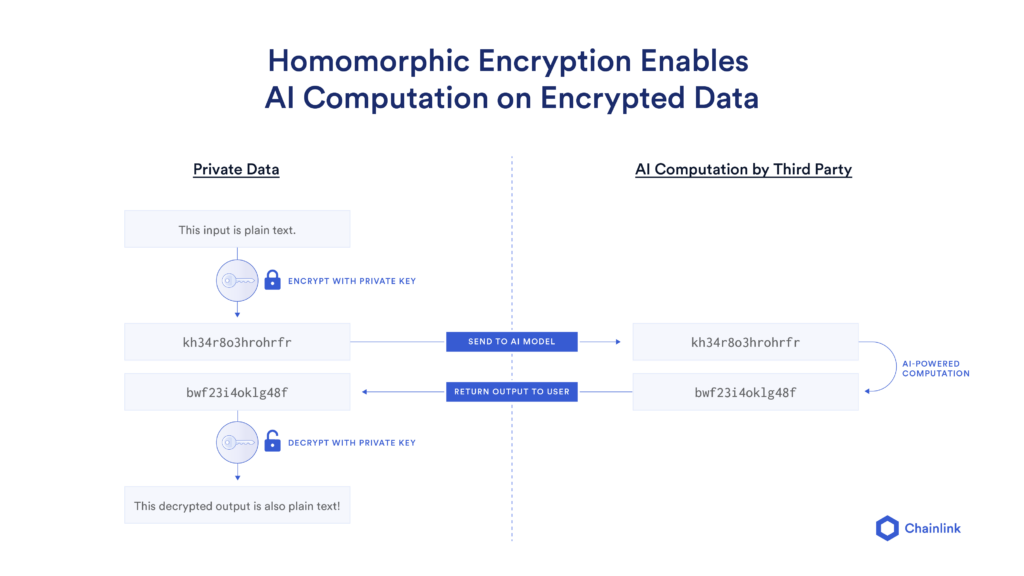
Key Takeaways
- 2026 marks the inflection point where privacy-by-design transitions from optional best practice to mandatory architectural requirement
- Fully homomorphic encryption and confidential computing have achieved performance levels making production deployment economically viable
- Four concurrent forces converge in 2026: AI production deployment, board accountability for AI risk, large buyer procurement standards, and competitive revenue advantages
- Organizations building privacy-by-design from foundational architecture gain competitive advantage through access to richer datasets and faster regulatory approval
- Organizations assuming privacy can be retrofitted through policy and access controls will find themselves excluded from high-value use cases
- Privacy-preserving computation technologies require different architectural approaches than traditional systems; retrofitting is expensive and often incomplete
- Implementation should follow phased approach: architecture assessment, proof-of-concept, non-critical production deployment, then strategic system conversion
- Privacy-by-design shifts from being cost center (risk prevention) to revenue driver (enabling access to sensitive data competitors cannot use)
- Regulatory requirements increasingly demand privacy-by-design; compliance becomes faster and simpler with cryptographic guarantees versus policy controls
- Organizations failing to recognize 2026 as inflection point will face systematic exclusion from sensitive use cases by 2027-2028
Related Articles
- Experian's AI Evolution: Credit Scores, Privacy & Data Ethics in 2025
- Windows Secure Boot Certificate Renewal Explained [2025]
- Humanoid Robots & Privacy: Redefining Trust in 2025
- iPhone Lockdown Mode Explained: How Apple's Ultimate Security Works [2025]
- China Bans Hidden EV Door Handles: Why Safety Regulations Are Changing 2025
- AI in Contract Management: DocuSign CEO on Risks & Reality [2025]

