![Samsung HBM4 Memory at 11.7Gbps: Complete Guide & AI Infrastructure Impact [2025]](https://tryrunable.com/blog/samsung-hbm4-memory-at-11-7gbps-complete-guide-ai-infrastruc/image-1-1771025832454.jpg)
Introduction: The Next Generation of High-Bandwidth Memory
The competitive landscape of artificial intelligence infrastructure just shifted dramatically. Samsung has announced the commercial shipment of HBM4 (High Bandwidth Memory) chips operating at 11.7 Gbps speeds, marking a significant milestone in the evolution of memory technology designed specifically for AI accelerators and data center workloads. This announcement represents more than just incremental performance improvements—it signals a fundamental acceleration in the race to support increasingly demanding machine learning and large language model deployments worldwide.
For organizations managing AI infrastructure, this development carries substantial implications. The memory bandwidth bottleneck has long been recognized as a critical constraint limiting GPU and accelerator performance. When computational cores can process data faster than memory can supply it, the entire system operates below its theoretical maximum capacity. HBM4 directly addresses this challenge by delivering 3.3 terabytes per second of bandwidth per stack, representing approximately 2.7 times the improvement over HBM3E in terms of total bandwidth capacity.
What makes this announcement particularly noteworthy is Samsung's engineering approach. Rather than iterating on proven designs with marginal improvements, the company adopted cutting-edge manufacturing processes including a sixth-generation 10nm-class DRAM process combined with a 4nm logic base die. This represents a significant technical risk that Samsung successfully navigated, achieving stable yields and consistent performance without requiring design revisions as production scaled—a rare achievement in semiconductor manufacturing where complexity typically demands multiple iterations.
The specifications are compelling: transfer speeds reaching 11.7 Gbps (with potential headroom to 13 Gbps in certain configurations) compared to an industry baseline of 8 Gbps for previous generations. Memory capacity configurations range from 24GB to 36GB in 12-layer stacks, with 16-layer versions promising up to 48GB for organizations requiring maximum density in their AI infrastructure. Power efficiency improvements of approximately 40% compared to HBM3E through low-voltage through-silicon-via technology and enhanced thermal management make these advances practically implementable in existing data center cooling architectures.
This article provides a comprehensive analysis of Samsung's HBM4 technology, exploring the technical innovations that enable these performance gains, the specific data center use cases where these improvements matter most, the manufacturing and supply implications, competitive responses, and ultimately, what this technology means for organizations planning AI infrastructure investments through 2026 and beyond. Whether you're architecting enterprise AI systems, planning capital expenditures for data centers, or analyzing semiconductor supply chains, understanding HBM4's capabilities and implications is essential context for strategic decision-making.
Understanding HBM4: Technical Architecture and Performance Specifications
The Evolution from HBM3E to HBM4
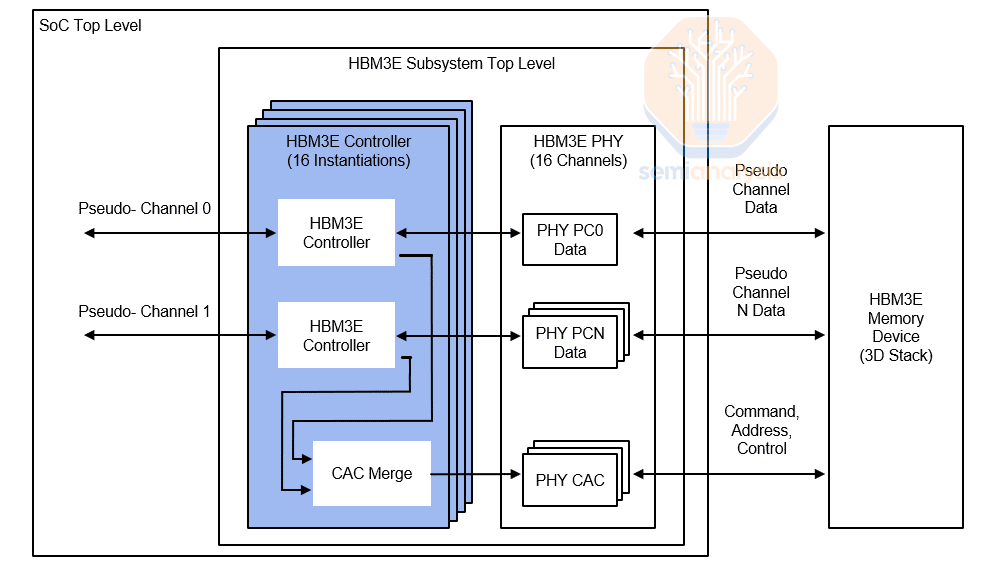
High Bandwidth Memory technology emerged from a critical recognition: modern GPUs and AI accelerators generate computational power that far exceeds what conventional DRAM can support. Standard DDR memory architectures, designed with constraints for consumer computing workloads, simply cannot move data fast enough to feed the computational cores in GPUs processing AI workloads. HBM was developed as a specialized memory architecture where multiple DRAM dies are stacked vertically and connected through tiny wires called through-silicon vias, creating a dramatically higher-bandwidth interface than possible with traditional memory layouts.
The progression from HBM3E to HBM4 represents a deliberate engineering strategy to continue scaling. HBM3E operates at 9.6 Gbps, serving as the current generation deployed in NVIDIA's most advanced data center GPUs. HBM4's improvement to 11.7 Gbps represents approximately a 22% speed increase, which translates directly to proportional improvements in memory bandwidth when architectures remain constant. However, Samsung didn't simply increase clock speeds—doing so would increase power consumption dramatically and create thermal management challenges. Instead, the company improved efficiency simultaneously.
The manufacturing process choices reveal the ambition behind this release. Samsung selected its sixth-generation 10nm-class DRAM process, leveraging the company's most advanced memory manufacturing capabilities. The logic base die utilizes 4nm process technology, representing another generational improvement in manufacturing precision. These choices weren't arbitrary—they were specifically engineered to support HBM4's operational requirements while managing power consumption and heat dissipation within data center constraints.
Bandwidth and Memory Capacity Architecture
Memory bandwidth represents the rate at which data moves between memory and computing cores, measured in gigabytes or terabytes per second. With HBM4, Samsung achieved 3.3TB/s per stack of memory bandwidth. To contextualize this figure: a single HBM4 stack provides more bandwidth than entire traditional server memory systems from a decade ago. This incredible throughput directly correlates to how many matrix multiplication operations can be completed during training or inference of large language models.
The mathematical relationship between bandwidth and AI performance isn't perfectly linear—architectures must be optimized to utilize available bandwidth—but the improvement is substantial. For matrix operations at scale, higher bandwidth reduces the time data spends in transit and enables fuller utilization of computational resources. This is why HBM became mandatory rather than optional for next-generation AI accelerators. GPU manufacturers couldn't achieve the theoretical performance improvements of new GPU architectures without corresponding memory bandwidth increases.
Capacity configurations demonstrate Samsung's attention to customer requirements. The 24GB and 36GB options in 12-layer stacks provide flexibility for different workload requirements. A 24GB HBM4 stack, for instance, enables certain large language model inference scenarios where model weights fit entirely in HBM, eliminating external memory access that would create performance bottlenecks. The promised 16-layer stacks with 48GB capacity address enterprise customers operating massive foundation models where even 36GB becomes limiting.
The Pin Configuration Expansion and Its Implications
One of the most technically significant but least-discussed aspects of HBM4 is the expansion from 1,024 pins to 2,048 pins. This doubling of interconnection points represents a major physical engineering challenge, not merely a manufacturing detail. Each pin carries electrical current and signal information, and with doubled pin counts comes doubled electrical complexity. More pins means higher power distribution demands, more potential for electrical interference, and substantially increased heat generation if not managed properly.
Samsung addressed this through innovations in power distribution architecture and low-voltage through-silicon-via technology. The technical requirement here was non-trivial: maintain electrical integrity across 2,048 contact points while managing the thermal load created by increased current flow. The company's innovation in this area—achieving approximately 40% power efficiency improvement compared to HBM3E—demonstrates sophisticated electrical engineering addressing fundamental physical constraints.

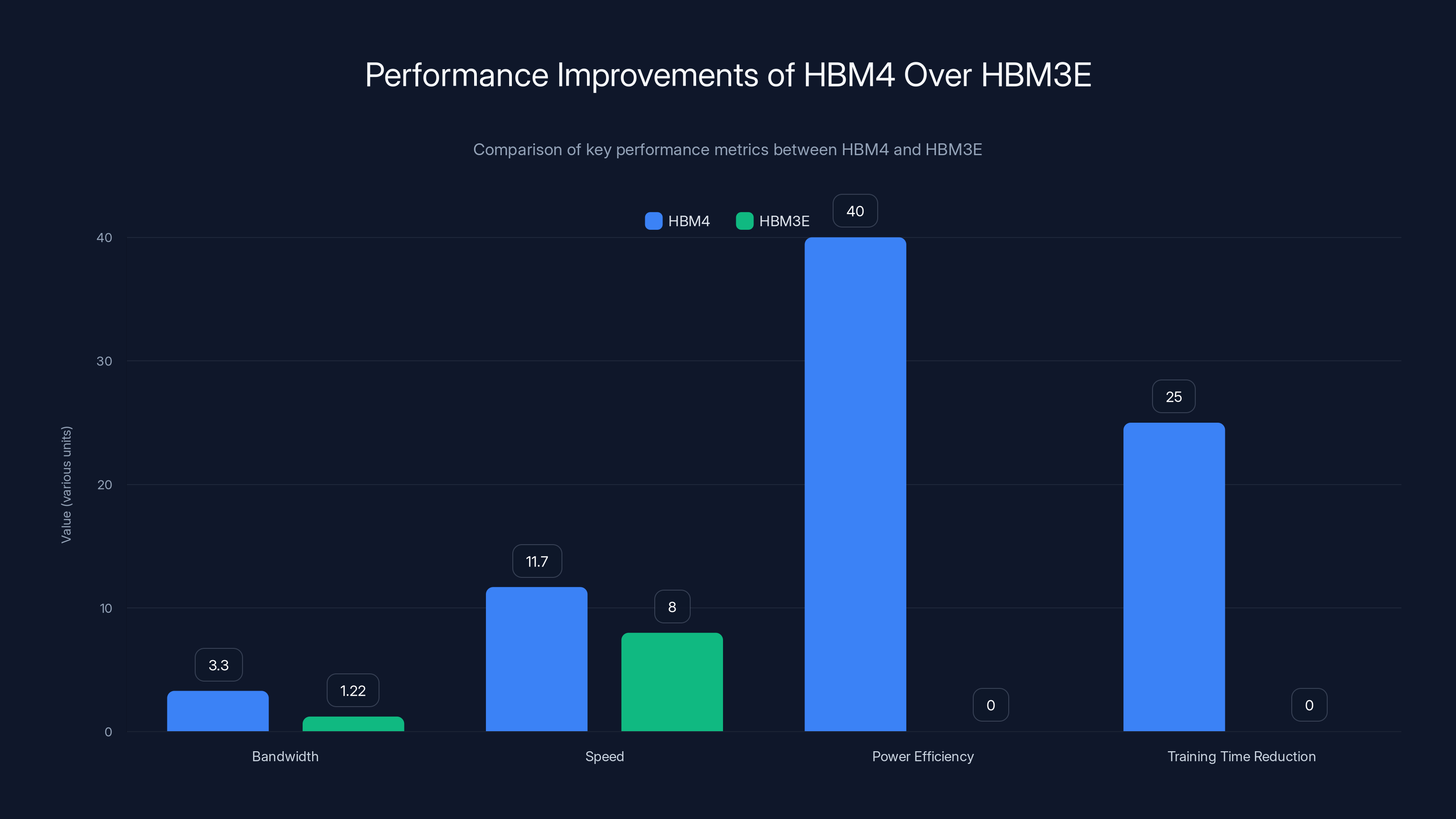
HBM4 offers significant improvements over HBM3E, including a 2.7x increase in bandwidth, a 46% increase in speed, and a 40% improvement in power efficiency, leading to a potential 25% reduction in AI model training time. Estimated data for training time reduction.
Manufacturing Process and Production Innovation
Advanced Process Node Integration Strategy
Samsung's decision to build HBM4 on advanced process nodes—specifically the sixth-generation 10nm-class DRAM process and 4nm logic base dies—represents a deliberate technological strategy with substantial competitive implications. Using advanced nodes for memory is counterintuitive because memory requires high transistor density rather than exotic features. However, advanced nodes offer manufacturing precision, reduced feature sizes, and improved power characteristics that enable higher operational frequencies and better thermal properties.
The risk in this approach is significant. Moving new product designs to the most advanced manufacturing processes before they've been completely debugged creates multiple failure modes. Yields might be lower initially as manufacturing parameters are optimized. Design margin might be insufficient when process variations emerge. The company could face substantial scrap rates and production delays. Samsung's claim that it achieved stable yields without design revisions suggests either exceptional engineering or measured understatement—independent verification will clarify this once large-scale deployments begin generating real-world performance data.
The competitive advantage in this approach is substantial. If Samsung truly mastered HBM4 production on advanced nodes while competitors are still using previous-generation processes for their memory designs, this creates a lasting advantage. It suggests Samsung could maintain performance and power efficiency leadership through the HBM4 generation while competitors would need more time to transition to comparable manufacturing approaches.
Scaling Production for Enterprise Demand
Samsung positions itself as capable of scaling HBM4 production to meet projected demand growth. The company emphasizes integration of its foundry and memory teams, suggesting coordinated planning where GPU and accelerator manufacturers' requirements are understood and factored into memory production planning. This coordination isn't trivial—it requires understanding customer GPU roadmaps, anticipated shipment volumes, and performance requirements years in advance.
The company also highlights "in-house packaging" as a competitive advantage. Packaging refers to the process of assembling individual memory dies, applying protective materials, and creating the physical substrate that connects HBM4 stacks to GPU systems. Vertical integration—performing packaging internally rather than relying on specialized packaging vendors—offers faster turnaround times, higher quality control, and potentially lower per-unit costs at scale. When demand is extremely high and every week of delay costs manufacturing capacity, having dedicated internal packaging capability becomes strategically valuable.
Supply Chain Partnerships and Customer Customization
Samsung's roadmap extends beyond HBM4 to include HBM4E and custom memory variants. HBM4E, expected for sampling later in 2025, represents the next iteration—potentially achieving higher speeds or lower power consumption. Custom variants suggest Samsung is willing to work with specific customers to develop memory configurations tailored to particular workloads or system architectures, a level of service only offered by suppliers with sufficient scale and manufacturing flexibility.
Custom memory variants are particularly significant for hyperscalers like Google, Meta, and Microsoft, who design their own AI accelerators and often have specific memory interface requirements. By offering customization, Samsung positions itself as a partner in these organizations' hardware development rather than simply a commodity supplier. This relationship depth creates customer switching costs and provides earlier insight into future performance requirements.
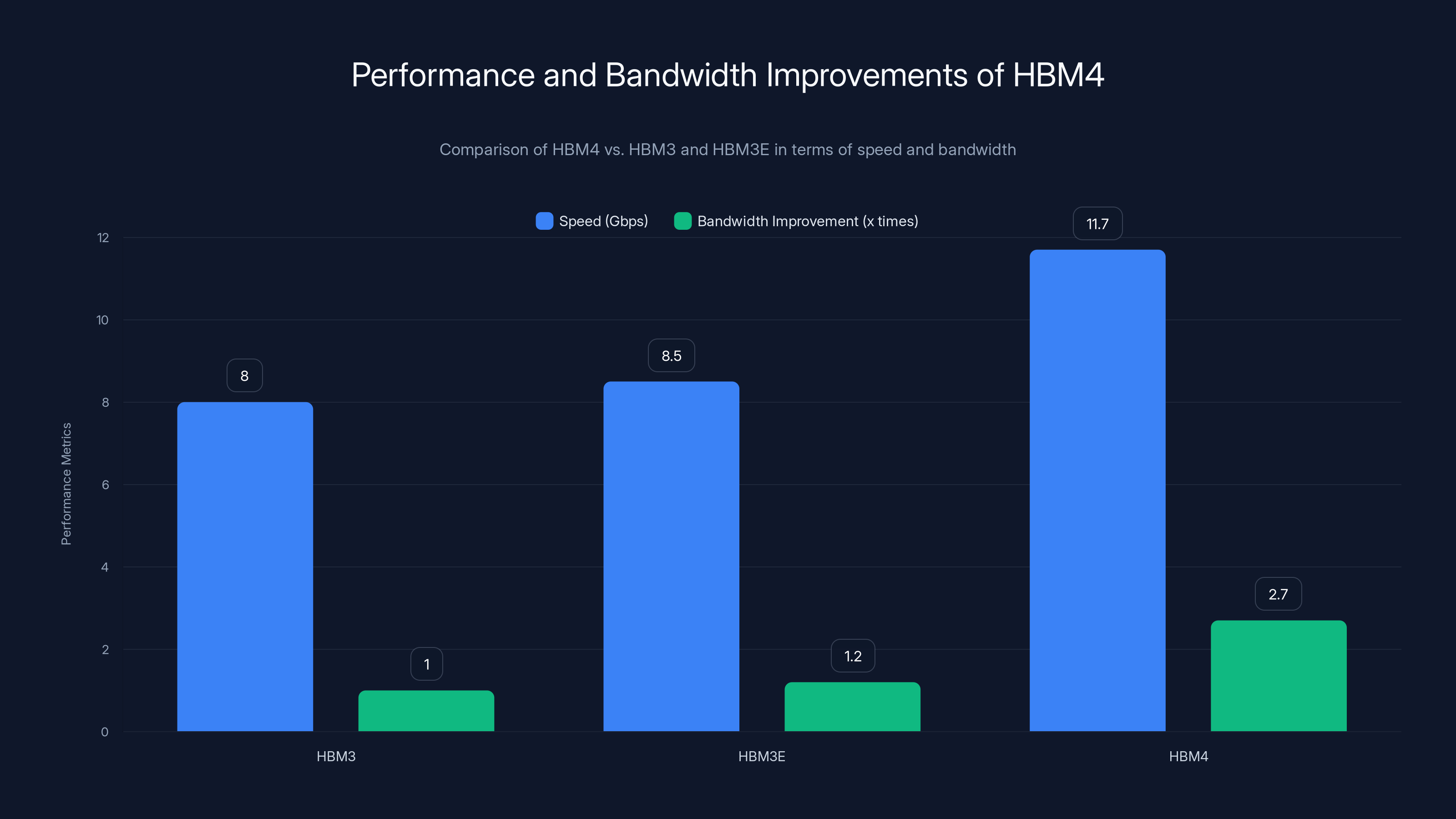
HBM4 shows a significant speed increase to 11.7Gbps and a 2.7x bandwidth improvement over HBM3E, enhancing memory-bound operations and reducing inference latency for large models. Estimated data.
Performance Metrics and Real-World Impact Analysis
Speed Improvements and Bandwidth Advantage Calculation
When evaluating the practical impact of HBM4's performance specifications, the numbers warrant detailed breakdown. The 11.7 Gbps speed represents the consistent operational frequency where the memory demonstrates stable performance across all operational conditions. Samsung mentions potential headroom to 13 Gbps in certain configurations, which likely refers to optimal thermal and electrical conditions where slightly higher speeds become feasible without violating reliability margins.
Comparison against baseline speeds reveals the magnitude of improvement: an 11.7 Gbps to 8 Gbps ratio equals approximately 1.46x faster data transfer compared to baseline HBM3 generation. This compounds with HBM4's architectural improvements in per-stack bandwidth. When the entire memory subsystem is considered—multiple stacks combined with improved interface efficiency—the effective bandwidth advantage over HBM3E generation approaches 2.7x, a substantial multiplier for memory-bound operations.
For large language model inference, this bandwidth advantage directly translates to inference latency reduction. Consider a 70-billion parameter model where the vast majority of computational time is spent moving weights from memory to compute cores. If memory bandwidth is the constraint—which it typically is for inference workloads—then 2.7x bandwidth improvement enables approximately 2.7x faster token generation per second, assuming consistent compute utilization. For real-time inference serving applications, this reduction directly improves user experience by decreasing response times.
Power Efficiency Metrics and Cost Implications
The 40% power efficiency improvement requires careful interpretation. This doesn't mean HBM4 consumes 40% less absolute power than HBM3E—if frequencies increased by 22% and pins doubled, raw power consumption likely increased. Rather, the 40% improvement indicates power efficiency per unit of data transferred or per unit of bandwidth. This distinction is crucial for data center economics: improved efficiency means comparable performance requires less cooling infrastructure investment.
In large-scale data centers, power consumption and cooling capability often represent 30-50% of the total cost of GPU systems when facilities are included. A 40% power efficiency improvement, even if absolute power consumption increased, reduces the cooling and electrical infrastructure costs required to support HBM4 systems compared to alternatives. This translates to lower total cost of ownership for equivalent performance, improving the economic case for upgrading to HBM4-based AI accelerators.
Memory Bandwidth Per Dollar Analysis
Economic evaluation of new memory technology requires comparing price-to-performance, specifically bandwidth per unit cost. While Samsung hasn't disclosed HBM4 pricing, historical patterns suggest each generation commands a premium until manufacturing is optimized and yields improve. Early adopters—likely cloud infrastructure providers and hyperscalers—will pay higher per-unit prices, but benefit from performance advantages that enable them to serve customer AI workloads more cost-effectively.
As production scales and manufacturing processes mature, prices typically decrease. The current HBM3E market, with years of production experience, likely offers superior price-to-performance compared to early HBM4 production. However, by 2026-2027 when HBM4 production reaches scale, the cost-per-terabyte-per-second calculation should favor HBM4 significantly, making it the default choice for new system designs.

AI Data Center Applications and Use Cases
Large Language Model Training and Fine-Tuning Workloads
Large language model training represents one of the most memory-bandwidth-intensive workloads in computing. Modern models like GPT-4 scale, Claude-generation models, and Google's Gemini involve training on hundreds of billions to trillions of tokens of data, requiring weeks or months of training across thousands of GPUs. During training, the memory system must simultaneously: supply weights from model parameters, provide activation storage for forward passes, buffer gradient computations for backward passes, and maintain optimizer states for learning rate adaptation.
HBM4's improved bandwidth directly reduces training time. When memory bandwidth was the bottleneck, increasing it yields linear or near-linear improvements in training throughput. A model that takes 8 weeks to train on HBM3E systems might complete training in 6 weeks on HBM4 systems with equivalent compute, reducing total cost through faster iteration. For organizations conducting continuous model training—regularly updating models with fresh data or experimenting with architectural variations—this 25% training time reduction is economically significant.
Fine-tuning applications—adapting pre-trained models to specific domains or tasks—benefit even more substantially because fine-tuning uses only a fraction of the available bandwidth capacity in typical systems. By improving memory bandwidth, fine-tuning becomes even more bandwidth-efficient, enabling practitioners to fine-tune models on moderately-sized GPU clusters rather than requiring distributed training frameworks.
Real-Time Inference at Scale
Inference workloads—processing user inputs through already-trained models—present different characteristics than training but equally benefit from bandwidth improvements. A transformer-based language model during inference spends most computational time in memory access rather than arithmetic operations. The model weights must be retrieved from memory, combined with input tokens, and processed through attention mechanisms that read weights multiple times per forward pass.
Memory bandwidth directly determines inference throughput—tokens generated per second. With HBM4's improved bandwidth, inference systems can maintain higher token generation rates without increasing GPU count proportionally. This enables serving more concurrent users or processing longer contexts with the same hardware investment. For cloud AI services offering inference API access, this translates to improved unit economics—serving more customer requests per GPU per month.
Context length, the number of previous tokens a model can "remember," is directly constrained by memory capacity and bandwidth in modern transformer implementations. HBM4's improved bandwidth enables longer context windows without proportional performance degradation, enabling new application categories where models must maintain awareness of lengthy historical context.
Multimodal Model Processing and Foundation Model Operations
Multimodal models—systems processing text, images, audio, and video simultaneously—demand extraordinary bandwidth. A model processing a high-resolution image alongside extensive text context might require loading gigabytes of weights and activations for each inference step. HBM4's bandwidth improvements enable previously infeasible combinations of model scale and input richness.
Foundation model hosting—where a single large pre-trained model serves diverse downstream tasks through prompting or fine-tuning—benefits from bandwidth improvements enabling richer context and longer interaction sequences. Organizations maintaining proprietary models for internal use or offering model-as-a-service to customers can serve higher throughput with improved memory performance.
Scientific Computing and Simulation Workloads
Beyond AI specifically, HBM4 benefits scientific computing workloads where GPUs accelerate simulations, molecular dynamics, climate modeling, and financial derivatives pricing. These applications involve dense matrix operations requiring high bandwidth throughput. Computational physics simulations that previously required supercomputer-class systems become feasible on high-end data center GPUs with HBM4, expanding the addressable market for these capabilities.

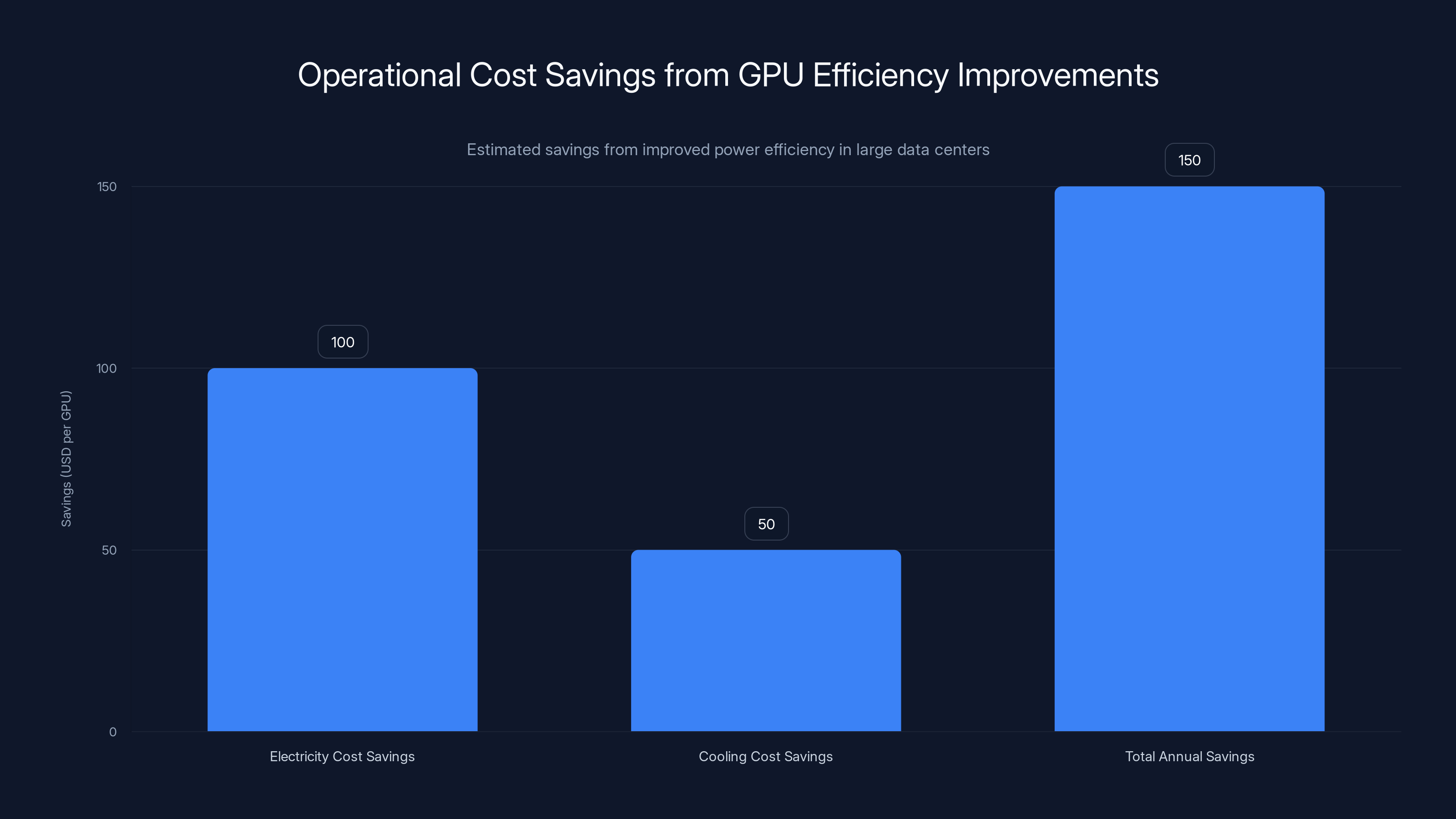
Estimated data shows that improved GPU efficiency can save
Competitive Landscape and Market Implications
NVIDIA's Position and Preferred Memory Partner Status
NVIDIA's dominance in AI accelerators makes their memory preferences strategically decisive. The company has historically worked closely with both Samsung and SK Hynix on HBM development, but performance advantages in NVIDIA's flagship accelerators typically drive industry-wide adoption. NVIDIA's use of HBM4 in upcoming accelerator generations—anticipated to begin in 2025-2026—would essentially guarantee mainstream adoption. The competitive dynamic here is complex: NVIDIA needs multiple memory suppliers to avoid dependency risk, but typically qualifies memory that meets its specifications.
Samsung's claim of "industry-first" HBM4 shipments, with the company already sending commercial units to customers, suggests NVIDIA collaboration. If NVIDIA GPUs designed for HBM4 integration aren't yet shipping, Samsung's early customer shipments likely serve engineering samples and internal testing rather than high-volume deployment. Nevertheless, Samsung's position as the first HBM4 supplier creates first-mover advantage in yield learning and production optimization.
SK Hynix's Competitive Response
SK Hynix, the second major HBM supplier, will inevitably respond to Samsung's HBM4 introduction. The company has demonstrated capability matching Samsung's HBM development pace historically, but Samsung's aggressive use of advanced process nodes creates a temporary technical lead. SK Hynix likely has HBM4 roadmaps that will emerge within 6-12 months, narrowing any advantage Samsung creates through early introduction.
The competitive dynamic between Samsung and SK Hynix in HBM benefits GPU manufacturers and data center operators—two suppliers competing keeps pricing reasonable and ensures supply security. Neither company can monopolize the market, preventing extreme price premiums or supply disruptions that could occur with a single supplier.
AMD and Alternative GPU Ecosystem Considerations
AMD's GPU accelerators for AI workloads (MI300X series) use different memory architectures than NVIDIA's, historically featuring stacked HBM integrated into the GPU package. As AMD develops next-generation accelerators, HBM4 capability will become important for competitive positioning. AMD's partnership with SK Hynix historically provided memory supply; competitive dynamics might see AMD diversify suppliers or NVIDIA-style partnerships develop where multiple suppliers qualify memory for specific GPU architectures.
Intel's discrete GPU ambitions and other emerging accelerator providers will also demand HBM4 or equivalent memory technologies as they scale performance. This creates a broadening market for HBM4 beyond traditional GPU contexts, supporting Samsung's production scaling plans.
Emerging Competitors and Alternative Technologies
While HBM represents the current standard, research continues into alternative high-bandwidth memory architectures. Hybrid Memory Cube (HMC) technology, developed earlier but less widely adopted, represents an alternative approach using fewer memory stacks with different electrical interfaces. As HBM scaling becomes increasingly challenging—the physical constraints of stacking more DRAM dies create diminishing returns—alternative architectures might gain renewed interest.
Series Memory technology, developed collaboratively across the industry, promises to reduce HBM memory costs through architectural changes while maintaining performance. If Series Memory achieves commercialization timelines discussed in industry partnerships, it could influence HBM adoption curves and provide cost alternatives for applications that don't require peak bandwidth performance.

Manufacturing and Supply Chain Considerations
Process Node Scaling Challenges and Solutions
Moving memory production to advanced process nodes solves certain problems while creating others. The improved transistor density and reduced feature sizes enable higher operational frequencies and better power efficiency, but manufacturing tolerances become tighter. Each nanometer reduction in feature size increases process variation—small differences in temperature, chemical purity, or equipment calibration create larger variations in transistor behavior. Samsung's sixth-generation 10nm process represents years of refinement addressing these variations, but migrating a new product to such advanced processes still carries risk.
The through-silicon via technology—tiny wires connecting vertically stacked DRAM dies—becomes more challenging at advanced nodes. The vias must traverse the same or finer pitches as the logic layer, requiring exceptional precision. A via misalignment of just a few nanometers can create open circuits or electrical shorts. Samsung's success in achieving stable yields at these dimensions suggests exceptional process control and likely represents a competitive advantage that will take competitors considerable time to match.
Yield Learning Curves and Cost Reduction Timelines
New semiconductor products typically follow predictable yield learning curves. Initial production batches achieve 50-70% yields—only half to two-thirds of manufactured units meet quality specifications, with the remainder scrapped or binned for lower-performance variants. Over months and years, process refinements, parameter optimization, and engineering learning improve yields to 85-95% or higher. During the learning phase, per-unit costs remain elevated due to scrap losses.
Samsung's claim of achieving stable yields without design revisions suggests either exceptional foresight in design or measured communication about actual yield levels. Real-world yield data will emerge as independent testing facilities publish detailed assessments of HBM4 samples. Expect yield improvements through 2025 that gradually lower HBM4 unit costs, improving the price-to-performance advantage versus earlier-generation memory.
Packaging and Assembly Capabilities
Packaging represents the physical assembly phase where individual memory dies are combined, connected through bonding wires or micro-bumps, mounted on substrate carriers, and encased in protective materials. High-bandwidth memory packaging is exceptionally complex due to the need for precise alignment of hundreds of interconnection points across multiple stacked dies. Samsung's statement about in-house packaging capabilities suggests internal vertical integration that accelerates time-to-volume and maintains proprietary process control.
Packaging capacity limits often constrain final product availability even when memory die production is sufficient. Organizations lacking in-house packaging must coordinate with specialized packaging service providers, creating dependency and potential bottlenecks. Samsung's integrated approach avoids this risk and enables faster ramp rates.

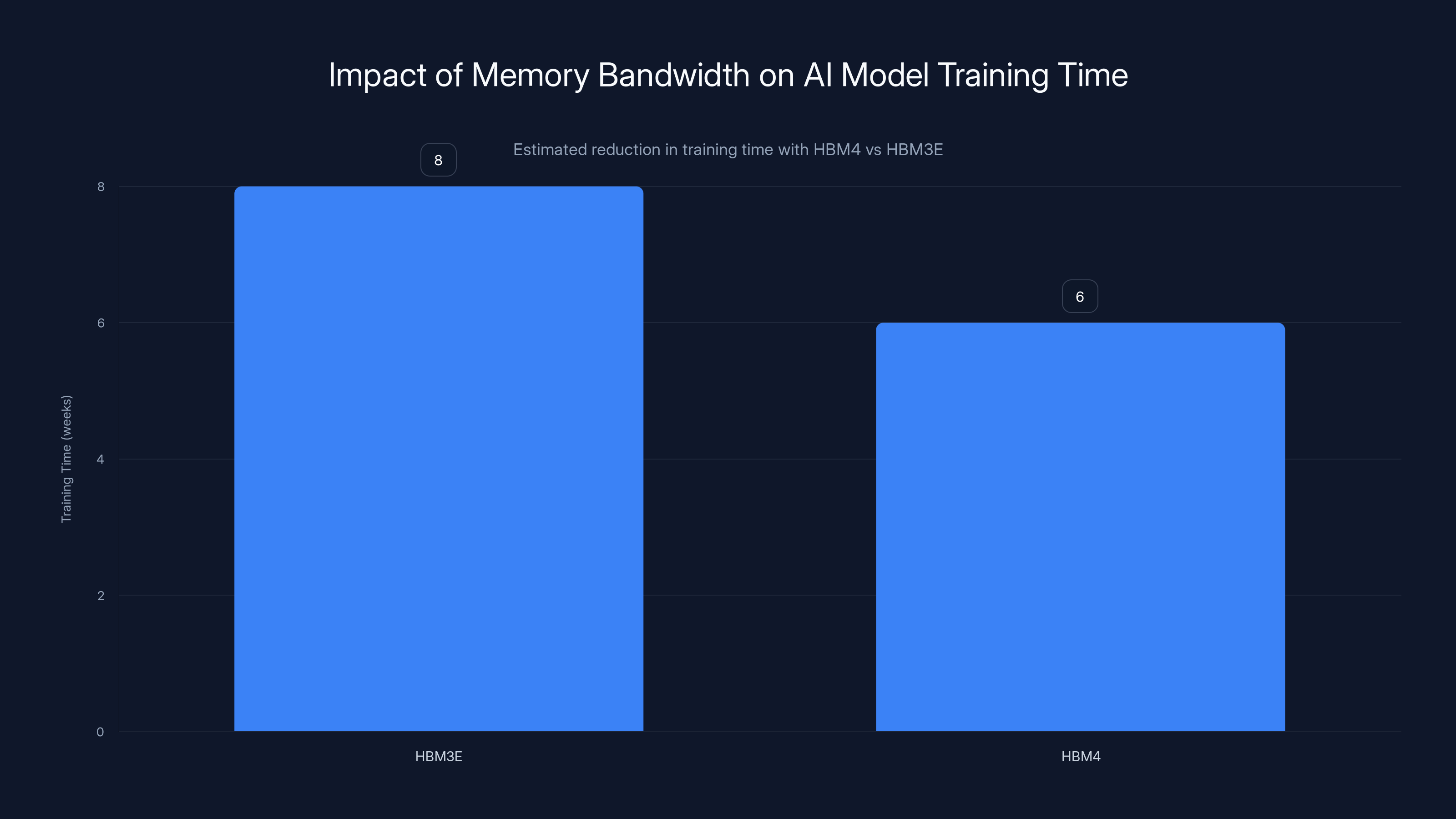
Upgrading from HBM3E to HBM4 can reduce AI model training time by approximately 25%, from 8 weeks to 6 weeks, significantly lowering costs. Estimated data.
Performance Validation and Independent Testing Perspectives
Importance of Third-Party Verification
Samsung's performance specifications for HBM4—the 11.7 Gbps speed and 3.3TB/s bandwidth figures—require validation through independent testing. Manufacturer-provided specifications necessarily reflect optimal conditions: peak operational frequencies achieved in laboratory settings, bandwidth calculations based on architectural designs, and claims that require engineering verification. This doesn't imply dishonesty; rather, real-world performance in deployed systems frequently differs from specification due to thermal limits, electrical interference, and application-specific access patterns.
Semiconductor industry practice involves third-party testing facilities validating claims before mainstream adoption. Once GPU manufacturers begin integrating HBM4 and shipping systems to customers, testing organizations and research institutions will publish real-world performance data. These results will clarify whether Samsung's specifications accurately reflect deployment experience or whether real-world performance differs meaningfully.
Thermal Management and Operational Reliability
One critical metric unlikely to be emphasized in marketing materials is thermal behavior under sustained operation. Laboratory demonstrations typically involve optimized cooling and moderate operational durations. Real data center environments—where GPU clusters run continuous AI training or inference—involve sustained heat generation requiring robust thermal management. HBM4's power efficiency improvements help with thermal design, but doubled pin counts and increased operational frequencies still create thermal challenges.
GPU manufacturers must validate that HBM4 systems maintain operational stability across temperature ranges and sustained high-utilization scenarios. Early deployments of any new memory technology often reveal thermal management surprises that require socket redesigns or system architecture modifications. Samsung's experience with thermal management and heat dissipation innovations suggests mitigation planning, but real-world validation remains pending.
Compatibility and Integration Testing
While Samsung designed HBM4 to industry standards, real-world integration always reveals unanticipated compatibility issues. GPU manufacturers must extensively test HBM4 integration with their specific processor architectures, validating memory controller implementations, timing parameters, and electrical interfaces. This integration testing typically requires 6-12 months before production GPU systems begin shipping. Companies currently sampling HBM4 are likely in this validation phase, with production systems anticipated over subsequent quarters.

Cost-Benefit Analysis and Total Cost of Ownership Implications
Capital Equipment Investment Trade-offs
Organizations evaluating whether to upgrade GPU clusters from HBM3E-based systems to HBM4 face complex economic trade-offs. The improved performance enables equivalent workloads with fewer GPUs, but only if applications can actually utilize the additional bandwidth. If an application reaches computational limits before memory bandwidth limits, additional bandwidth provides no benefit.
The total cost calculation includes: GPU hardware cost difference (HBM4 systems command a premium), electricity and cooling cost reduction from improved efficiency (potentially 10-20% per unit), infrastructure modifications required to accommodate new systems, and the value of freed capital from decommissioned earlier-generation systems. For organizations operating large-scale AI infrastructure, these calculations involve millions of dollars and merit detailed financial modeling.
Operational Cost Reduction Through Efficiency
Improved power efficiency—the 40% improvement Samsung claims—translates directly to operational cost reduction. If equivalent performance requires less power, electricity costs decrease proportionally. In U. S. data centers, electrical costs average
Cooling infrastructure represents an additional efficiency benefit. Data center cooling systems must dissipate all heat generated by equipment. More efficient GPUs that generate less heat require less cooling capacity, reducing both capital investment in cooling equipment and operational electricity consumption for cooling systems themselves (cooling systems are themselves inefficient, consuming electricity to move heat). The multiplied efficiency benefit—both direct GPU power reduction and secondary cooling system reduction—can reach 1.5-2x the direct power consumption improvement.
Technology Depreciation and Upgrade Cycles
GPU technology depreciates rapidly as new generations emerge. A GPU system with 2-3 year useful life sees about 50-75% value retention in second markets. Faster technology cycles might depreciate systems more rapidly if new generations appear before expected useful life expires. HBM4 adoption timelines suggest meaningful penetration by 2026-2027, making HBM3E systems increasingly less desirable in the used market. Organizations upgrading to HBM4 now face less severe depreciation pressure by capturing the useful life premium before market shift occurs.

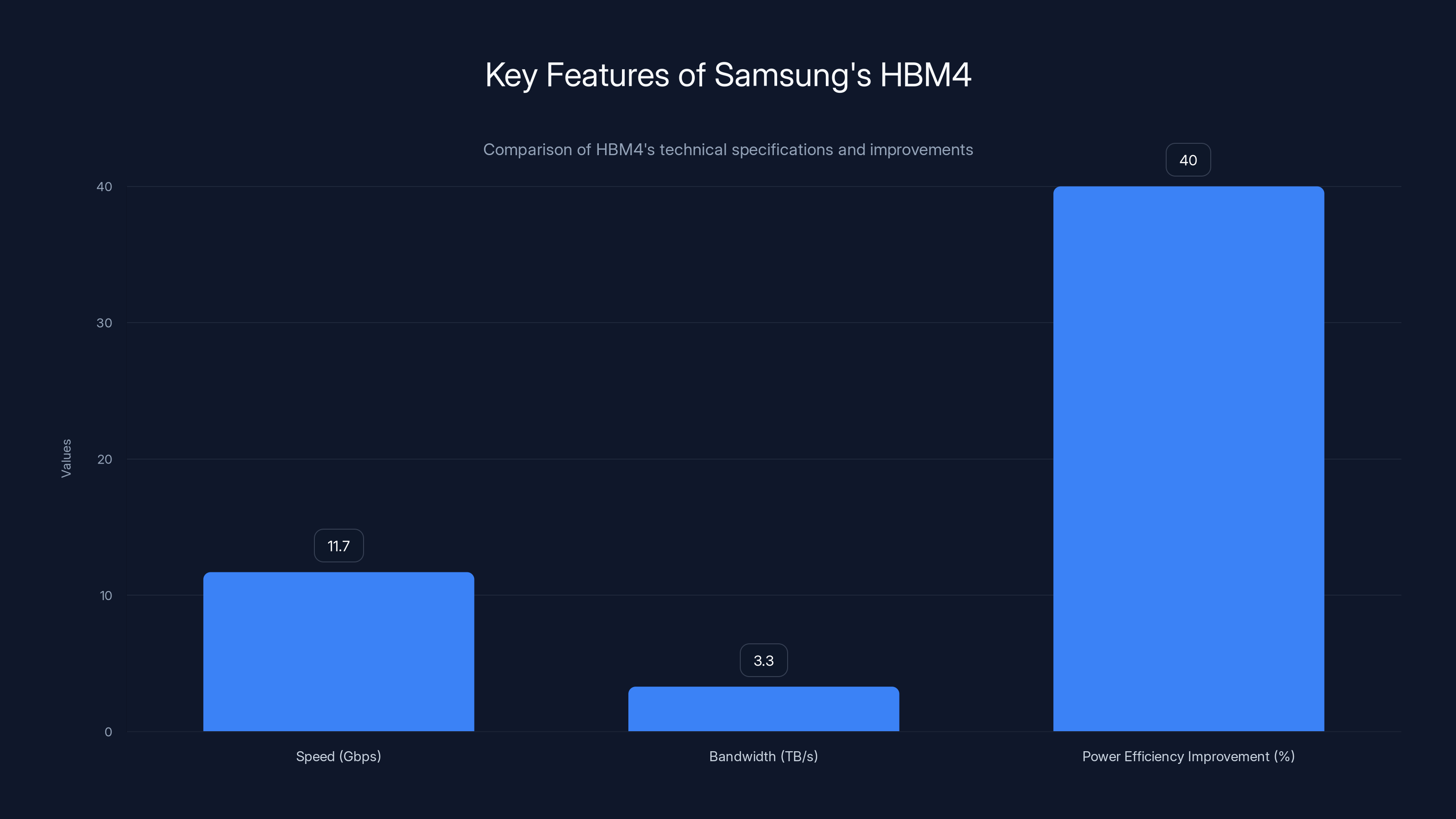
Samsung's HBM4 offers significant advancements with 11.7Gbps speed, 3.3TB/s bandwidth, and a 40% improvement in power efficiency, setting a new standard for AI infrastructure.
Industry Timeline and Production Roadmap
2025 Production Ramp and Customer Deployment Phases
Samsung's stated expectation of sharp HBM4 business growth across 2026 suggests current 2025 production represents initial scaling rather than peak volume. The company is shipping commercial units now to establish customer bases, validate designs, and build reputation, but volume production likely scales significantly through 2025 and accelerates further in 2026. This timeline aligns with GPU manufacturer product release schedules—next-generation NVIDIA, AMD, and other accelerators utilizing HBM4 will reach market in late 2025 and 2026, driving mainstream memory demand.
Customers currently receiving HBM4 samples are primarily integrators and system designers—large hyperscalers like Google, Microsoft, Meta, and Amazon who build custom AI accelerators. These organizations validate HBM4 in their specific system architectures, provide feedback for optimization, and begin designing next-generation products incorporating HBM4. Their feedback shapes HBM4 evolution and influences manufacturing parameter tuning.
HBM4E Sampling and Next-Generation Roadmap
Samsung's plans for HBM4E sampling in late 2025 represent the next iteration, likely featuring higher speeds (potentially 13 Gbps or beyond) or lower power consumption, or both. HBM4E typically differs from HBM4 through process refinements enabled by manufacturing learning and potentially minor architecture adjustments accommodating higher frequencies. The sampling timeline suggests NVIDIA and other GPU manufacturers are already designing systems incorporating HBM4E for 2026-2027 release, with early HBM4E samples arriving now for integration testing.
This staged roadmap—HBM4 now, HBM4E later in 2025, custom variants in 2027—demonstrates Samsung's confidence in HBM4 success and planning for continued technology evolution. Unlike historical HBM transitions that sometimes involved painful multi-year adoption cycles, this roadmap suggests smoother transitions as improved versions emerge.
Custom Memory Variants and Hyperscaler-Specific Designs
Custom HBM variants scheduled for sampling in 2027 represent agreements already negotiated with major customers to develop memory tailored to their specific requirements. These might involve alternative pin configurations, different capacity arrangements, modified interface protocols, or power delivery modifications matching specific system architectures. Large hyperscalers funding development of custom AI accelerators often negotiate exclusive or preferred memory partnerships, ensuring their preferred suppliers can meet specific needs.
Customization is strategically significant because it increases customer switching costs and relationship depth. Once a hyperscaler develops AI accelerators assuming specific HBM characteristics, switching to different memory suppliers requires hardware redesign and validation cycles costing millions of dollars. This relationship stickiness benefits Samsung through multi-generational adoption commitments.

Technical Specifications Comparison Table
| Specification | HBM3E | HBM4 | HBM4E (Expected) |
|---|---|---|---|
| Data Rate | 9.6 Gbps | 11.7 Gbps (13 Gbps max) | 13+ Gbps (estimated) |
| Bandwidth per Stack | 1.2 TB/s | 3.3 TB/s | 4+ TB/s (estimated) |
| Pin Count | 1,024 | 2,048 | 2,048+ (estimated) |
| Memory Capacity Range | 12-24 GB | 24-36 GB (48 GB planned) | 36-48 GB (estimated) |
| DRAM Process | 5G 10nm | 6G 10nm | 7G 10nm (estimated) |
| Logic Base Die | 7nm | 4nm | 5nm (estimated) |
| Power Efficiency vs HBM3E | Baseline | +40% | +50-60% (estimated) |
| Manufacturing Status | Mature production | Early sampling → production ramp | Development |
| Estimated Launch Year | 2022 | 2024-2025 | 2025-2026 |

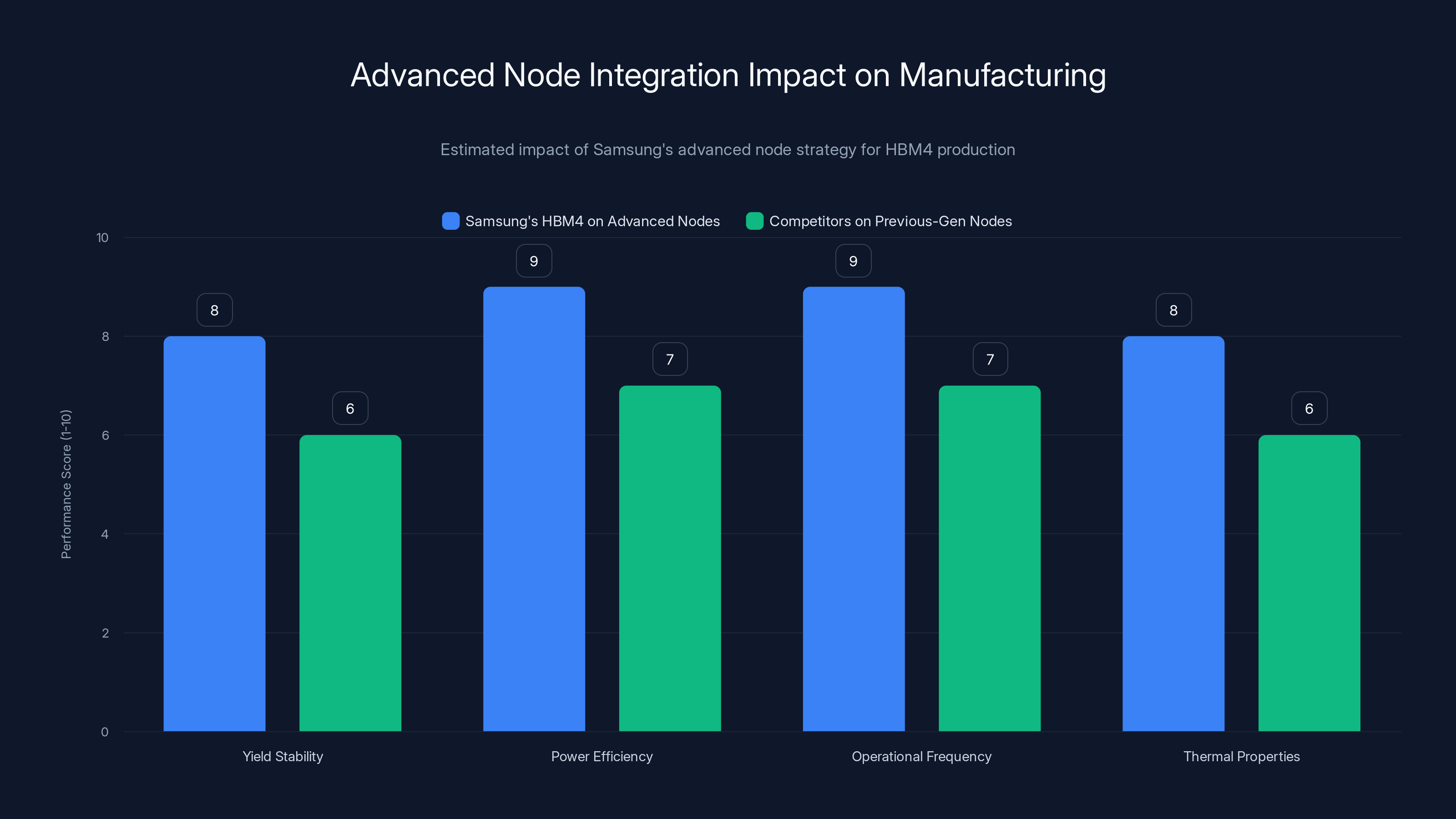
Samsung's use of advanced nodes for HBM4 offers higher power efficiency and operational frequency compared to competitors using older processes. Estimated data based on technological advantages.
Enterprise Infrastructure Planning and Adoption Strategies
When to Upgrade: Decision Frameworks for Organizations
Organizations planning AI infrastructure investments through 2026 must evaluate whether to adopt HBM4 immediately, wait for HBM4E, or continue with HBM3E systems. The framework for this decision involves: current application performance limitations (is memory bandwidth actually constraining performance?), infrastructure refresh cycles (how quickly do systems need replacement?), capital budget constraints (can the organization afford premium HBM4 pricing?), and anticipated workload growth (will future needs justify HBM4 now rather than waiting?).
Applications genuinely memory-bandwidth-limited—such as large language model inference or training—should prioritize HBM4 adoption as soon as systems reach market. The performance improvements directly enhance their economics. Applications whose limitations are computational rather than memory-bound might continue with HBM3E systems where pricing is favorable, deferring HBM4 adoption until costs decline.
Organizations operating GPU clusters with 2-3 year replacement cycles should plan for HBM4 inclusion in the next capital refresh. Delaying beyond 2026 risks purchasing systems that will be technologically obsolete, suffering rapid depreciation, or being unable to efficiently run applications developed assuming HBM4 performance characteristics.
Multi-Vendor Strategies and Supply Diversification
Responsible infrastructure planning involves diversifying memory suppliers to avoid dependency on a single source. Organizations should plan to operate both Samsung HBM4 and SK Hynix HBM4 systems (once available) or equivalent alternatives. This hedges against supply disruptions, supplier-specific technical issues, or pricing imbalances that might favor one supplier.
GPU manufacturers typically support memory from multiple qualified suppliers. When designing custom AI accelerators or selecting GPUs from OEMs, organizations should explicitly prioritize options with memory supplier diversity to ensure ongoing supply options and competitive pricing.
Future-Proofing and Architectural Flexibility
GPU systems designed now should assume HBM4 integration with forward compatibility to HBM4E and potential future variants. This involves: validating that socket designs accommodate different memory package variants, ensuring memory controllers support multiple HBM versions, and planning system architectures flexible enough for memory upgrades without complete redesigns. Future-proofing infrastructure now prevents expensive redesigns when technology evolved more rapidly than anticipated.

Alternative Memory Technologies and Ecosystem Considerations
Series Memory Technology and Cost-Efficiency Innovations
As HBM technology matures and scaling becomes increasingly challenging, alternative architectures gain attention. Series Memory technology, developed collaboratively among major semiconductor companies, promises reduced HBM manufacturing costs while maintaining performance standards. The technology potentially enables lower-cost memory for applications that don't require peak bandwidth performance, creating a tiered market where premium applications use HBM4 while cost-sensitive applications use Series Memory or other alternatives.
Series Memory commercialization timelines remain uncertain—industry partnerships have been announced but consumer products haven't yet shipped at scale. By 2026-2027, Series Memory could represent a meaningful cost alternative, influencing HBM4 adoption for budget-conscious organizations willing to accept slightly lower performance for substantial cost savings.
Hybrid Memory Architectures and HMC Evolution
Hybrid Memory Cube (HMC) technology, developed earlier than HBM, uses different architectural approaches potentially offering advantages for certain workloads. While HBM has captured dominant market share, research continues into HMC applications and enhancements. Some custom accelerator designs might incorporate HMC alongside HBM, leveraging both technologies for different memory access patterns.
Intel's Ponte Vecchio GPU uses a unique 3D stacked memory approach differing from standard HBM architectures. As GPU designs diversify, memory solutions will likely diversify as well, creating an ecosystem where HBM4 is the standard but alternatives serve specific niches.
Real-World Deployment Scenarios and Performance Expectations
Large Language Model Inference Serving at Scale
Consider a cloud AI service offering API access to a 70-billion parameter language model. Infrastructure consists of multiple GPU clusters serving concurrent user requests. With HBM3E systems, the cluster could serve approximately X tokens per second within power and thermal constraints. Upgrading to HBM4, assuming bandwidth is genuinely limiting performance, enables serving approximately 2.7X tokens per second with the same hardware count.
The economic implication: if the service charges users per token, doubling throughput doubles revenue per GPU per month. Capital costs might increase 20-30% for HBM4 systems, but monthly revenue increases 100%+, improving return on investment substantially. For this scenario, HBM4 adoption is economically clear.
Alternatively, this service might maintain token throughput at HBM3E levels but use HBM4's efficiency improvements to reduce power consumption and cooling costs, improving margins without changing user-facing performance. Either approach—performance improvement or efficiency improvement—creates value.
Fine-Tuning as a Service Infrastructure
Organizations offering fine-tuning capabilities to customers—adapting pre-trained models to specific domains—operate under different economic constraints. Fine-tuning uses specialized frameworks (like Lo RA) that reduce memory bandwidth requirements compared to full-model training. In this scenario, HBM bandwidth improvements might not fully leverage HBM4 capability, making cost-optimized alternatives potentially superior.
A responsibly designed fine-tuning infrastructure would evaluate whether HBM4's higher cost justifies the marginal performance improvement over HBM3E for their specific workloads. Some operations might justify HBM4 adoption, while others remain more cost-effective on HBM3E systems.
Scientific Computing and Simulation Workloads
Scientific computing—molecular dynamics simulations, climate modeling, computational physics—demands high memory bandwidth for dense matrix operations. HBM4 enables significantly larger simulations, longer runtimes, or higher fidelity modeling within existing computational budgets. These applications frequently represent the best use cases for HBM4, where memory bandwidth directly translates to research capability improvements. Universities and research organizations should prioritize HBM4-based systems for serious computational research.
Future Implications and Technology Trajectory
Scaling Challenges and Physics Constraints
HBM technology faces fundamental physics constraints as scaling continues. Stacking more DRAM dies increases capacitance and electrical interference, requiring more sophisticated signal integrity management. Through-silicon vias become physically smaller, approaching limits of precision manufacturing. Power consumption grows with each generation, creating thermal design challenges. While Samsung's HBM4 demonstrates excellent engineering, approaching fundamental limits suggests future improvements will be slower.
By HBM5 or HBM6 generations, expect improvements to focus on efficiency rather than raw performance. Successive generations might target: reduced power per unit bandwidth, improved reliability under extreme conditions, or enhanced integration with next-generation GPU architectures. Dramatic performance leaps like the jump from HBM3E to HBM4 might become less frequent as technology approaches asymptotic scaling curves.
GPU Architecture Co-design and Memory Integration
Future GPU designs will increasingly co-design with memory, leveraging HBM4 characteristics in architecture decisions. Early HBM4 GPUs are likely relatively straightforward adaptations of HBM3E designs with interface modifications. Over subsequent products, GPU architects will design specifically for HBM4 capabilities, potentially using additional bandwidth for different computational strategies or algorithm implementations.
This co-design trend suggests HBM4 advantages will compound over several GPU generations as architects learn to leverage the memory subsystem fully. Initial HBM4 systems might achieve 2.7x bandwidth improvement but only realize 1.5-2x practical performance improvement if application kernels don't adapt. By 2027-2028 when multiple HBM4 GPU generations exist, practical performance improvements approach theoretical bandwidth improvements.
Broader Ecosystem Impacts and Application Evolution
HBM4 and continued memory improvements enable application categories currently infeasible. Longer context windows in language models become possible, enabling models that maintain awareness of longer interaction histories. Multi-modal models can incorporate richer sensory information. Scientific simulations can model more complex systems. These new possibilities, enabled by memory technology advances, create feedback loops where applications push technology further.
The ecosystem impact extends beyond performance metrics to system architecture philosophy. With dramatically improved memory bandwidth, architectural decisions that were previously memory-inefficient become feasible. This might drive algorithm innovations and new problem-solving approaches that wouldn't have been considered when memory bandwidth was more constrained.

Potential Risks and Mitigation Strategies
Yield and Reliability Risk Assessment
While Samsung claims stable yields without design revisions, manufacturing risks remain. Large-scale production at advanced nodes occasionally reveals issues invisible in early sampling phases. Problems might include: insufficient thermal margin requiring reduced operating speeds, reliability issues appearing after months of operation, electrical integrity problems in specific configurations, or packaging defects affecting yield.
Mitigation strategies include: extensive third-party testing of early production units, gradual production ramp with quality gates, close collaboration with customer validation programs, and rapid response capabilities if issues emerge. Samsung's manufacturing expertise and previous HBM success suggest these risks are manageable, but real-world data will clarify actual reliability profiles.
Supply Continuity and Geopolitical Considerations
Semiconductor manufacturing, particularly advanced node processes, faces geopolitical risks. Samsung's South Korean location, advanced fabs, and dependence on specific equipment suppliers and material sources create vulnerability to international disputes, export restrictions, or natural disasters. While diversification with SK Hynix (also South Korean) provides only partial mitigation, it's superior to single-supplier dependency.
Organizations heavily dependent on HBM4 should monitor geopolitical developments and consider supply chain resilience in strategic planning. Maintaining relationships with multiple suppliers, diversifying supply geographies where possible, and maintaining modest strategic reserves of critical memory represent prudent risk management.
Technology Obsolescence and Rapid Evolution
If HBM4E appears faster than expected or demonstrates substantially superior economics, early HBM4 adopters might face systems with abbreviated useful lives before replacement becomes attractive. However, this risk is inherent in technology decisions and doesn't argue against HBM4 adoption—rather, it argues for accepting depreciation risk as normal cost of leadership position.
Organizations valuing certainty over performance leadership should consider waiting for HBM4E production readiness before major commitments. Those prioritizing performance will accept shorter useful lives in exchange for capability leadership.

Recommendations for Decision-Makers and Strategic Planning
For Hyperscale Data Center Operators
Hyperscalers operating massive AI infrastructure at millions of GPU scale should prioritize HBM4 adoption immediately. The combination of performance improvements, efficiency gains, and strategic benefits of supplier relationships justifies early integration. These organizations benefit most from performance advantages and have sufficient scale to weather initial yield learning curves and premium pricing. Collaborative relationships with Samsung and GPU manufacturers on HBM4 development create competitive advantages worth pursuing.
Capital budgeting should allocate HBM4 adoption across 2025-2026 refresh cycles, with phased deployment allowing gradual learning and optimization. Maintaining supplier diversity—integrating both Samsung and SK Hynix HBM4 into systems—ensures supply security and pricing competitiveness.
For Enterprise IT Organizations
Traditional enterprise IT evaluating AI infrastructure for internal operations or customer service should evaluate HBM4 adoption based on specific application requirements. If applications are genuinely memory-bandwidth-limited and performance is strategically important, HBM4 adoption in 2026-2027 makes sense. If applications are computationally bound or cost is paramount, HBM3E systems or cost-optimized alternatives might remain superior.
Enterprise organizations benefit from waiting 12-18 months for HBM4 ecosystem maturation, pricing stabilization, and broader vendor compatibility. By late 2026, HBM4 systems will be more thoroughly tested, competing suppliers will have qualified products, and cost premiums will have narrowed.
For Research and Academic Institutions
Universities and research organizations should prioritize HBM4 adoption for serious computational research. Scientific computing applications typically represent ideal use cases where memory bandwidth directly translates to research capability. Budget for HBM4 systems in infrastructure planning, seeking grant funding and capital equipment appropriations to support cutting-edge infrastructure.
Academic partnerships with equipment manufacturers might yield favorable terms or early access to new systems in exchange for publication of research results and performance benchmarks.
For Emerging AI Startups
Startups building AI products face different constraints: limited capital, need for rapid iteration, and uncertainty about specific performance requirements. These organizations should initially focus on business model validation using available systems—whether HBM3E based or other alternatives—rather than optimizing for cutting-edge memory performance. As products mature and specific performance bottlenecks emerge, upgrade infrastructure accordingly.
Startups should avoid capital-intensive HBM4 commitments until business fundamentals justify premium hardware investments. However, developers should understand HBM4 characteristics and assume future infrastructure will incorporate them, designing software appropriately.

Conclusion: Strategic Implications and Looking Ahead
Samsung's commercial HBM4 shipment and aggressive roadmap extending through HBM4E and custom variants represent a significant inflection point in AI infrastructure evolution. The combination of 11.7 Gbps speeds, 3.3TB/s bandwidth, 40% power efficiency improvements, and advanced process node manufacturing positions HBM4 as the standard for next-generation AI accelerators and data center systems.
The technical achievements underlying HBM4—utilizing sixth-generation 10nm-class DRAM and 4nm logic base dies without requiring design revisions during production scaling—demonstrate exceptional engineering and manufacturing control. These decisions carry risk, but Samsung's success in managing this risk creates competitive advantages that will persist until competitors achieve similar manufacturing competency.
From a strategic perspective, HBM4 adoption represents a milestone in the AI infrastructure arms race. Organizations and countries investing in advanced AI capabilities require access to cutting-edge memory technology. Samsung's early qualification and shipping position creates leverage with GPU manufacturers, hyperscalers, and government entities prioritizing technological leadership. This supplier relationship value extends beyond mere component sales to strategic technology partnerships shaping the future of AI systems.
The broader ecosystem impact extends to applications and algorithms. As memory bandwidth improves, new problem-solving approaches become feasible. Language models with longer context windows, multi-modal models incorporating richer sensory information, and scientific simulations at previously impossible scales all become practical with HBM4 and subsequent improvements. This represents genuine technological progress, not merely incremental marketing claims.
For organizations making infrastructure investment decisions through 2026, HBM4 warrants serious consideration. The technology is real, specifications are credible, and deployment timelines align with natural infrastructure refresh cycles. Early adopters will benefit from performance advantages and supply security. Those delaying until HBM4 ecosystem maturation and cost normalization accept modest competitive disadvantage in exchange for risk reduction and improved capital efficiency.
Looking forward, HBM4 represents a waypoint in memory technology evolution rather than an endpoint. HBM4E, custom variants, and future generations will continue improving performance and efficiency. However, the fundamental achievement of reaching 11.7 Gbps speeds with 3.3TB/s bandwidth and 40% power improvements establishes baseline expectations for AI infrastructure through the next 2-3 years. Organizations that understand these capabilities and limitations can make informed decisions about infrastructure investment, application development, and strategic positioning in the evolving AI landscape.
The convergence of performance, efficiency, manufacturing innovation, and market readiness makes this a consequential moment for AI infrastructure investment. Samsung's HBM4 execution successfully navigates these competing pressures, creating a foundation upon which the next phase of AI infrastructure development will build.

FAQ
What is HBM4 memory?
HBM4 (High Bandwidth Memory 4) is the fourth generation of specialized memory technology designed for AI accelerators and data center GPUs. Samsung manufactures HBM4 using advanced sixth-generation 10nm-class DRAM processes and 4nm logic base dies, achieving 11.7 Gbps operational speeds with maximum headroom to 13 Gbps. The memory is organized in vertically stacked DRAM dies connected through through-silicon vias, creating 3.3TB/s of bandwidth per stack—approximately 2.7 times higher than HBM3E generation.
How does HBM4 improve AI infrastructure performance?
HBM4 delivers 11.7 Gbps speed compared to 8 Gbps baseline for earlier generations, directly reducing memory latency and increasing bandwidth availability for AI accelerators. This improvement enables faster model training (potentially 25% reduction in training time), higher inference throughput (more tokens generated per second), support for longer context windows in language models, and improved multi-modal model processing capabilities. The 40% power efficiency improvement compared to HBM3E reduces electricity and cooling costs, improving total cost of ownership for equivalent performance levels.
What are the primary use cases for HBM4-based systems?
HBM4 excels in memory-bandwidth-intensive workloads including large language model training and fine-tuning, real-time inference serving at scale, multimodal model processing, long-context language model applications, and scientific computing workloads like molecular dynamics and climate simulations. Applications that are computationally bound rather than memory-bandwidth-limited experience less dramatic improvement from HBM4. Organizations should evaluate whether their specific workloads truly benefit from improved bandwidth before committing to HBM4 systems.
When will HBM4 systems become widely available?
Samsung began commercial HBM4 shipments in 2024, with production scaling expected through 2025 and sharp business growth anticipated in 2026. GPU manufacturers are currently integrating HBM4 into upcoming accelerator designs, with production systems expected to ship progressively through late 2025 and 2026. HBM4E sampling is planned for later 2025, suggesting next-generation options will become available before current HBM4 production matures. Wider market adoption with more competitive pricing should occur by 2026-2027 as multiple suppliers qualify products and production yields improve.
How does HBM4 cost compare to previous generations?
HBM4 commands premium pricing during initial production phases due to advanced manufacturing processes and limited supply. Historical HBM transitions suggest 15-30% price premiums for new generations initially, declining as production scales and manufacturing learning curves improve. By 2026-2027, HBM4 pricing should normalize closer to HBM3E's current levels. Organizations prioritizing performance should expect to pay premiums for early adoption; those focused on cost optimization should wait 12-18 months for prices to stabilize.
What competitive alternatives to HBM4 exist?
SK Hynix represents the primary alternative HBM4 supplier, with products expected in 2025-2026. Series Memory technology, currently in development by industry partners, promises cost-effective alternatives for applications not requiring peak bandwidth. Hybrid Memory Cube (HMC) technology persists for niche applications, and some custom accelerator designs incorporate alternative memory architectures. For most mainstream AI infrastructure, Samsung HBM4 and SK Hynix HBM4 will dominate, with alternatives serving cost-conscious or specialized applications. For developers and teams focused on optimizing AI workflow automation and content generation without requiring specialized hardware, Runable offers AI-powered automation platforms ($9/month) that reduce operational overhead for machine learning pipeline management and model deployment without requiring hardware-intensive memory solutions.
What manufacturing risks does HBM4 face?
Advanced process node manufacturing introduces complexity including tighter process tolerances, higher sensitivity to variations, and electrical integrity challenges at smaller feature sizes. Samsung's claim of achieving stable yields without design revisions during production ramp suggests successful risk management, but real-world validation through independent testing remains pending. Potential risks include: thermal margin insufficiency requiring operating speed reductions, reliability issues appearing after months of deployment, packaging defects affecting yield, and geopolitical supply chain interruptions. Third-party testing and gradual production ramp with quality gates help mitigate these risks.
How long will HBM4 remain the performance standard before being superseded?
HBM4E, expected for sampling in late 2025, represents the immediate successor with potentially higher speeds or lower power consumption. Subsequent generations (HBM4X variants, custom configurations) will emerge through 2027. Based on historical HBM evolution, HBM4 will likely remain mainstream through 2026-2027 before HBM4E becomes the default choice. However, organizations commissioning infrastructure now should plan for useful life through 2027-2028, accepting that newer memory generations will arrive but HBM4 will continue delivering acceptable performance throughout that period.
Should organizations upgrade from HBM3E to HBM4 immediately?
Immediate HBM4 adoption makes economic sense for hyperscalers operating at massive scale where performance improvements translate directly to cost reduction and revenue enhancement. Enterprise organizations should evaluate specific application requirements—if memory bandwidth is genuinely limiting performance and performance improvements have strategic value, HBM4 adoption in 2026 makes sense. Those prioritizing cost should wait 12-18 months for ecosystem maturation and pricing normalization. Startups and research organizations should base decisions on whether specific workloads justify premium hardware costs versus available alternatives.

Key Takeaways
- HBM4 achieves 11.7Gbps speeds with 3.3TB/s bandwidth—2.7x improvement over HBM3E for memory-intensive AI workloads
- Samsung's use of sixth-generation 10nm DRAM and 4nm logic processes demonstrates advanced manufacturing achieving stable yields without design revisions
- 40% power efficiency improvement reduces electricity and cooling costs, improving total cost of ownership for AI infrastructure
- HBM4 directly benefits memory-bandwidth-limited applications like LLM training and inference, but offers less advantage for computationally-bound workloads
- Production scaling expected through 2025 with sharp business growth in 2026; HBM4E sampling planned for late 2025 and custom variants for 2027
- Organizations should evaluate specific application requirements before committing to premium HBM4 pricing in 2025; waiting 12-18 months enables more competitive pricing
- Hyperscalers and research institutions benefit from immediate HBM4 adoption; enterprise organizations should integrate into 2026 infrastructure refresh cycles
- SK Hynix represents primary competitive alternative; SeriesMemory and custom architectures provide specialized alternatives for cost-optimized applications
- HBM4 infrastructure decisions should account for useful life through 2027-2028 as HBM4E and subsequent generations emerge
- Strategic supplier relationships with Samsung and GPU manufacturers provide competitive advantages worth pursuing for organizations operating at scale

