![Startup's Check Engine Light On? Google Cloud's Guide to Scaling [2025]](https://tryrunable.com/blog/startup-s-check-engine-light-on-google-cloud-s-guide-to-scal/image-1-1771450589915.jpg)
The Startup Survival Signal Nobody's Talking About
Your SaaS is growing. Revenue's up 40% year-over-year. Slack's exploding with new hires. Everything feels like it's working.
Then the CEO pulls you aside at 11 PM on a Thursday and says, "Something doesn't feel right."
That gut feeling? That's your startup's check engine light.
Darren Mowry, Google Cloud's vice president of global startups, watches this moment play out thousands of times a year. He sits at the intersection of opportunity and chaos, watching founders navigate some of the most critical decisions of their company's life. The ones who listen to that check engine light? They scale. The ones who ignore it? They either plateau or collapse spectacularly.
What's fascinating is that the warning signs are usually invisible to the founders living inside the problem. The infrastructure groans under load. The database queries slow down mysteriously. The team spends more time debugging than building. The cloud bill becomes the elephant in the room that nobody wants to talk about.
But here's what most startup leaders don't understand: these aren't problems. They're signals. They're your company telling you that something fundamental needs to change before you can move to the next level.
This guide pulls together what we're seeing across the entire startup ecosystem right now, the tradeoffs that Mowry is helping founders navigate, and the frameworks that successful companies use to know when it's time to rebuild versus scale.
If your startup's check engine light is blinking, you're going to want to understand what it's trying to tell you.
TL; DR
- Infrastructure becomes your bottleneck before revenue does. The startups growing fastest are hitting scaling walls at $2-5M ARR, not later
- AI adoption costs money upfront but saves 300+ hours per quarter in developer productivity if implemented correctly
- **Cloud architecture decisions made at 10M ARR
- Founders ignore operational red flags an average of 6-8 months too long, costing 500K in technical debt
- Hiring the right infrastructure person is 3x more important than hiring another engineer right now

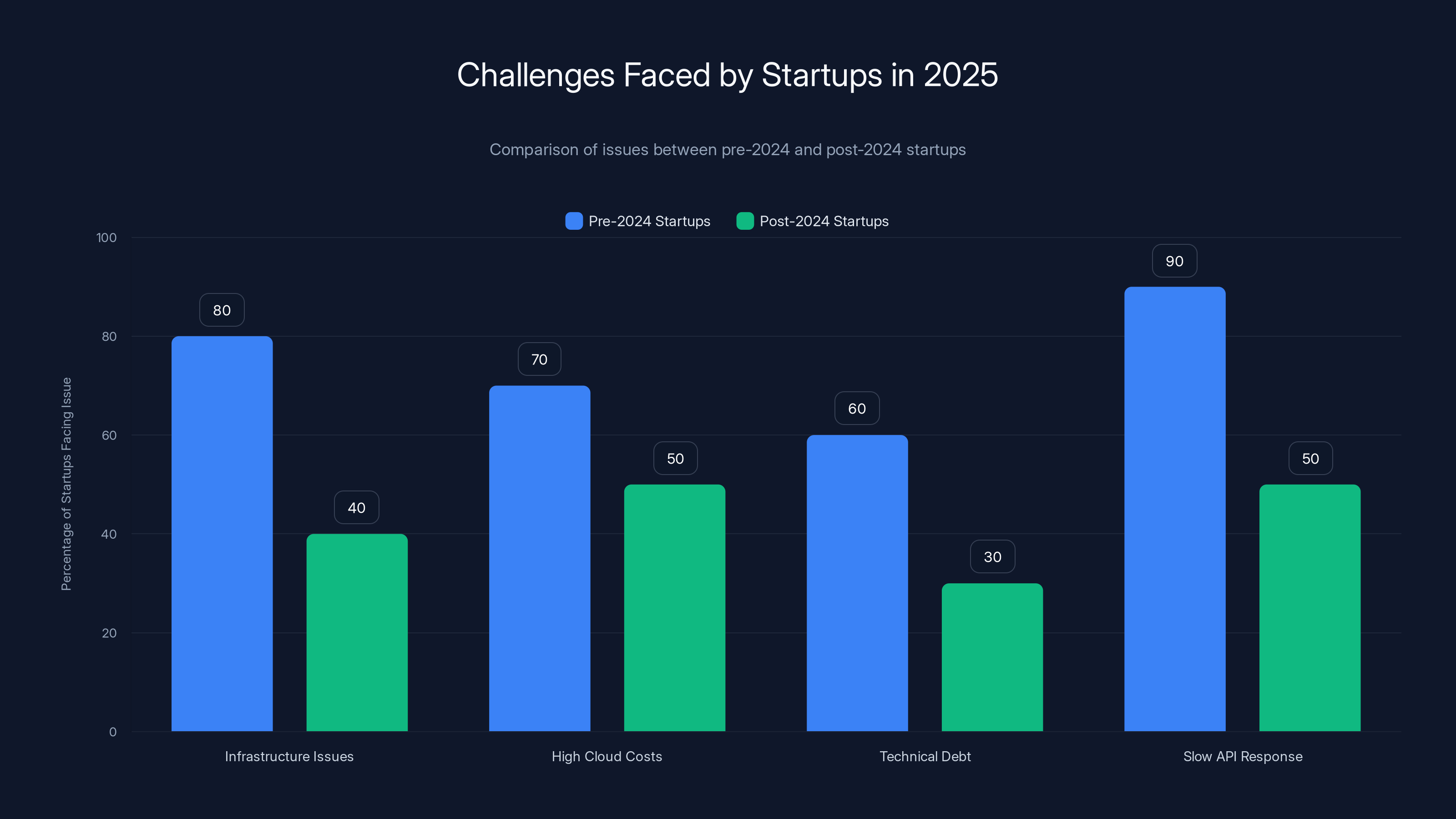
Estimated data shows pre-2024 startups face more infrastructure and technical debt issues compared to post-2024 startups, who are more deliberate in their approach.
What Mowry's Actually Seeing: The Real Startup Ecosystem in 2025
If you're only reading startup news from Tech Crunch headlines, you're missing the real story. The real story is happening in the conversations that VPs of global startup programs have with hundreds of founders every single month.
Mowry isn't seeing a healthy ecosystem. He's seeing a bifurcated one.
On one side, there are startups that raised in 2022-2023 when capital was cheap and easily available. These companies hired aggressively. They built on whatever infrastructure felt fast at the time. They prioritized growth metrics over operational health. They're the ones with check engine lights that are now screaming at full volume.
On the other side, there are the post-2024 startups that learned from watching those earlier companies get decimated. They're being deliberate about infrastructure from day one. They're hiring infrastructure engineers before they hire their third backend engineer. They're making architectural decisions at a
The gap between these two groups is massive.
What Mowry's seeing most frequently is startups hitting a specific wall around $2-5M in ARR. This is the point where you can't just throw more servers at the problem anymore. Your database is slow. Your API response times have crept from 100ms to 2 seconds. Your cloud bill is 25% of revenue and climbing. Your team is spending 40% of sprint capacity on technical debt instead of new features.
That's not a failure. That's actually the exact moment most startups need to completely rethink their infrastructure approach.
The problem is that most founders have never done this before. They scaled their startup the first time by sheer force of will and a lot of coffee. They don't have a mental model for what healthy scaling looks like at a different order of magnitude.
So they panic. They either throw money at it (spinning up expensive managed services they don't fully understand), or they go the other direction and decide to rebuild everything from scratch (burning 6-12 months of engineering capacity).
Neither is optimal.
The AI Startup Shakeout Nobody Expected
Two years ago, every startup founder wanted to build AI. Three months ago, every founder wanted to build on top of AI. Right now, every founder wants to deploy AI into their existing product and hopes it sticks.
Mowry's seeing a profound shift in how startups think about artificial intelligence, and it's not what the hype cycle predicted.
The startups that jumped early into AI infrastructure (thinking about GPUs, CUDA, model serving, vector databases) are now sitting on enormous unutilized capacity. They built for a scaling scenario that never materialized the way they expected. Some of them are pivoting the entire business just to use the infrastructure they already paid for.
Meanwhile, startups are discovering that you don't actually need to host your own models. You can call APIs. You can use Open AI's API for most use cases. You can leverage Claude's API. You can use Vertex AI. The infrastructure complexity gets outsourced, and your startup stays lean.
But here's where it gets interesting: the startups that are winning are the ones that figured out how to reduce developer operational burden while using AI. They're deploying AI automation platforms like Runable to handle repetitive tasks—generating documentation, creating presentations, building reports—so their engineers can focus on differentiating product work.
The pattern is clear. AI isn't about custom models anymore. It's about integration. It's about reducing human cognitive load on routine tasks. It's about letting your three engineers do the work that previously required eight.
This is reshaping how startups think about hiring, burn rate, and runway.
A startup that previously needed eight engineers to maintain infrastructure, write documentation, and generate reports might now need five engineers and a strategic deployment of AI tooling. The math gets genuinely different.

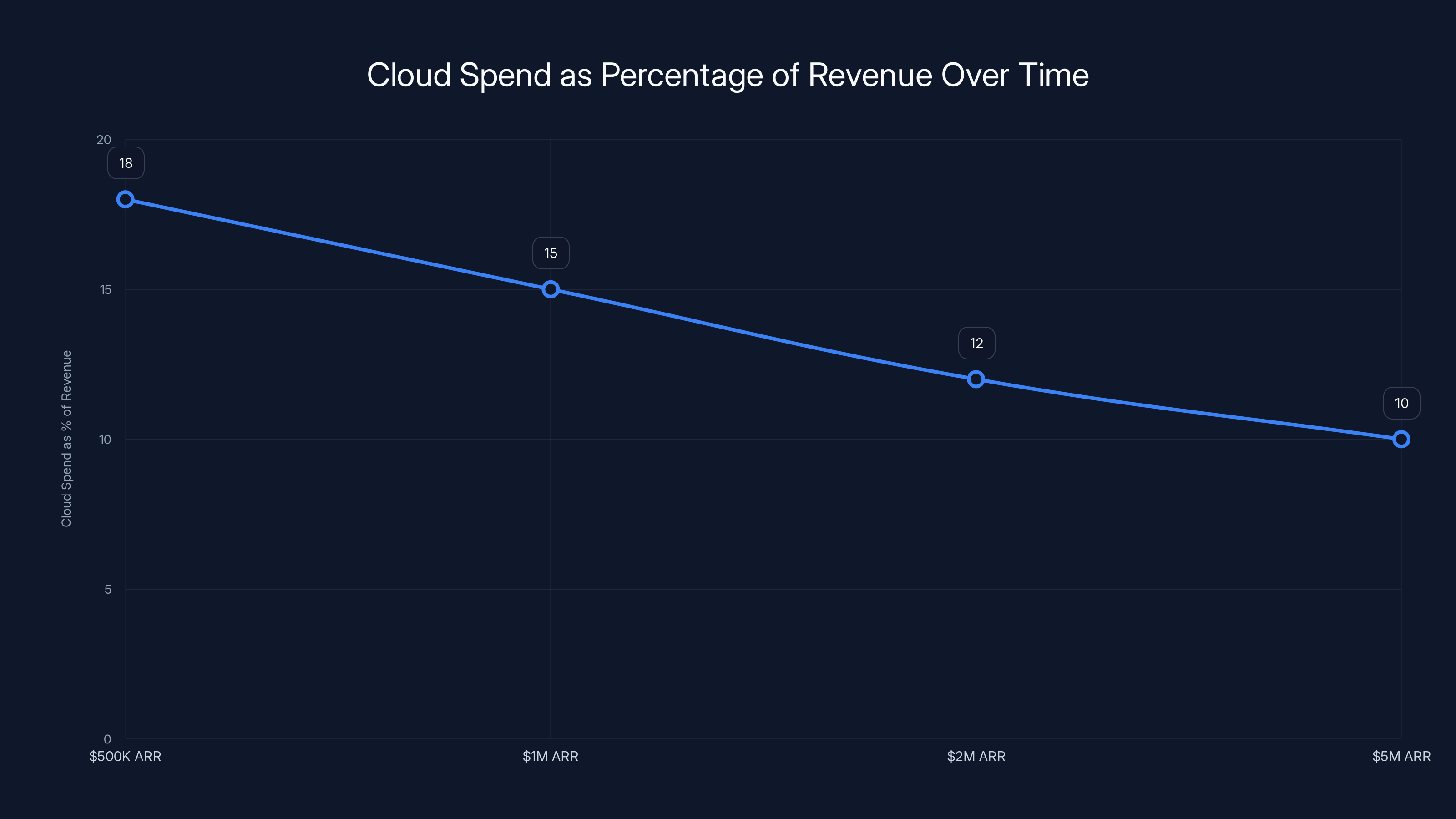
Estimated data shows that cloud spend should decrease from 18% at
Competing for AI Talent in a Market That's Completely Inverted
Two years ago, the advice was "move to San Francisco, get funded, hire the smartest people you can find."
Today? That advice gets you into a bidding war where you lose.
The AI talent market has completely inverted. The people building the most important AI infrastructure work aren't competing for startup opportunities. They're staying at Open AI, Deep Seek, and Anthropic because those are the only places where they can move the needle on fundamental AI capability.
So startups have to get creative. The winners are the ones thinking about what they can offer that a big lab can't: autonomy, equity upside that actually means something, and the ability to see your work impact customers directly.
Mowry's watching startups compete for talent using three strategies:
First, the infrastructure angle. They're hiring people who want to build the systems that make AI work, not necessarily people who want to advance AI itself. This is actually a huge opportunity because there's a shortage of people who understand how to actually deploy, scale, and operate AI systems in production. This is less glamorous than "building AGI" but it's more valuable to an early-stage startup.
Second, the specialization angle. Instead of trying to hire someone amazing at everything, startups are hiring people who are phenomenally good at one specific thing: RAG (retrieval augmented generation), fine-tuning, vector search, inference optimization. Deep specialists. People who can solve your one hardest problem and then move on. This is a different hiring profile than the generalist AI engineer that everyone was chasing two years ago.
Third, the tool angle. Startups are using AI tools themselves to reduce the operational burden on the humans they hire. Instead of hiring someone to manage infrastructure, they're using automation to handle routine tasks and hiring someone to set up the automation and respond to edge cases. The leverage changes completely.
The startups that Mowry sees winning at talent acquisition right now are the ones who've been deliberate about this shift. They've stopped trying to be a mini-version of an AI lab. They've started asking: "What is the specific problem we're solving that requires human expertise, and what can we automate?"
That distinction is showing up in hiring success rates.
The Infrastructure Conversation That Founders Are Avoiding
This is the one that Mowry brings up in almost every conversation with founders that are scaling past $2M ARR.
Most founders treat infrastructure like a necessary evil. They want to think about product. They want to think about growth. Infrastructure is the thing that gets in the way if it breaks, and the thing that gets ignored if it works.
The most successful scaling stories? They flip this script entirely.
Infrastructure becomes a competitive advantage when you start thinking about it early. Here's what that looks like:
You're at
Most founders don't. They wait until they hit
By then, you've already locked in architectural decisions that you're going to pay for for years.
Here's what the founders who get this right do:
They make a list of the decisions that are actually irreversible. Or at least, very expensive to reverse. What's your persistence layer? What's your caching strategy? How are you splitting data between services? Are you using a monolith or microservices, and what's your threshold for splitting?
They think through this at a
They also run an honest audit of technical debt. Not the stuff that's broken. The stuff that's slow. The stuff that's fragile. The stuff that requires institutional knowledge to deploy. The stuff that scares you when someone goes on vacation.
Then they ask: which of these is going to kill us in the next 12 months if we don't fix it? That's the stuff you fix. Everything else, you live with and plan for later.
The mistake is trying to fix everything, or fixing nothing. The middle path—being strategic about which infrastructure debt actually matters—is what separates the startups that scale smoothly from the ones that hit a wall.
Mowry's literally seeing founders ignore obvious infrastructure warnings and then spend six months on technical debt work that they would have spent six weeks on if they'd fixed it earlier. The cost isn't just the six months. It's the opportunity cost. It's the feature set you didn't build. It's the market you didn't capture. It's the competitor that moved faster because they had better infrastructure decisions at the $1M stage.

Cloud Spend: The Financial Metric Nobody's Actually Optimizing
Want to know what correlates almost perfectly with startup failure? Cloud spend as a percentage of revenue that's still climbing at $5M ARR.
For most SaaS startups, this should be declining from 15-20% at
Mowry sees a lot of startups running profoundly inefficient infrastructure. Not because they're stupid. But because they were optimizing for the wrong thing.
At $500K ARR, you optimize for speed. You spin up resources. You don't worry about it. That's correct. That's the right call.
At $2M ARR, you should have made the transition to efficiency. You should have someone looking at your cloud spend. Understanding where it's going. Finding the easy wins.
But most startups haven't. They've hired someone to manage infrastructure or they've made one person responsible for it, but they haven't actually given them the tools or the mandate to optimize.
Here's what the good startups do:
They implement cost tracking at a granular level. They know how much the API costs to run. They know how much the background jobs cost. They know how much the front-end serving costs. They can see, at a glance, where the money is going.
Then they apply simple optimization heuristics:
- Reserved instances for baseline load (3-year commitments reduce costs 40-60%)
- Spot instances for burst capacity (70% discount but interruptible)
- Caching aggressively to reduce compute
- Archiving old data instead of querying it
- Rightsizing resources instead of over-provisioning
None of this is rocket science. All of it requires someone to actually look at the data.
Mowry's seeing startups save
For a startup with a $200K monthly burn, that's 15-50% of your burn gone. That's the difference between running out of cash in 10 months and running out of cash in 16 months. That's time to hit product-market fit. That's time to get to profitability.
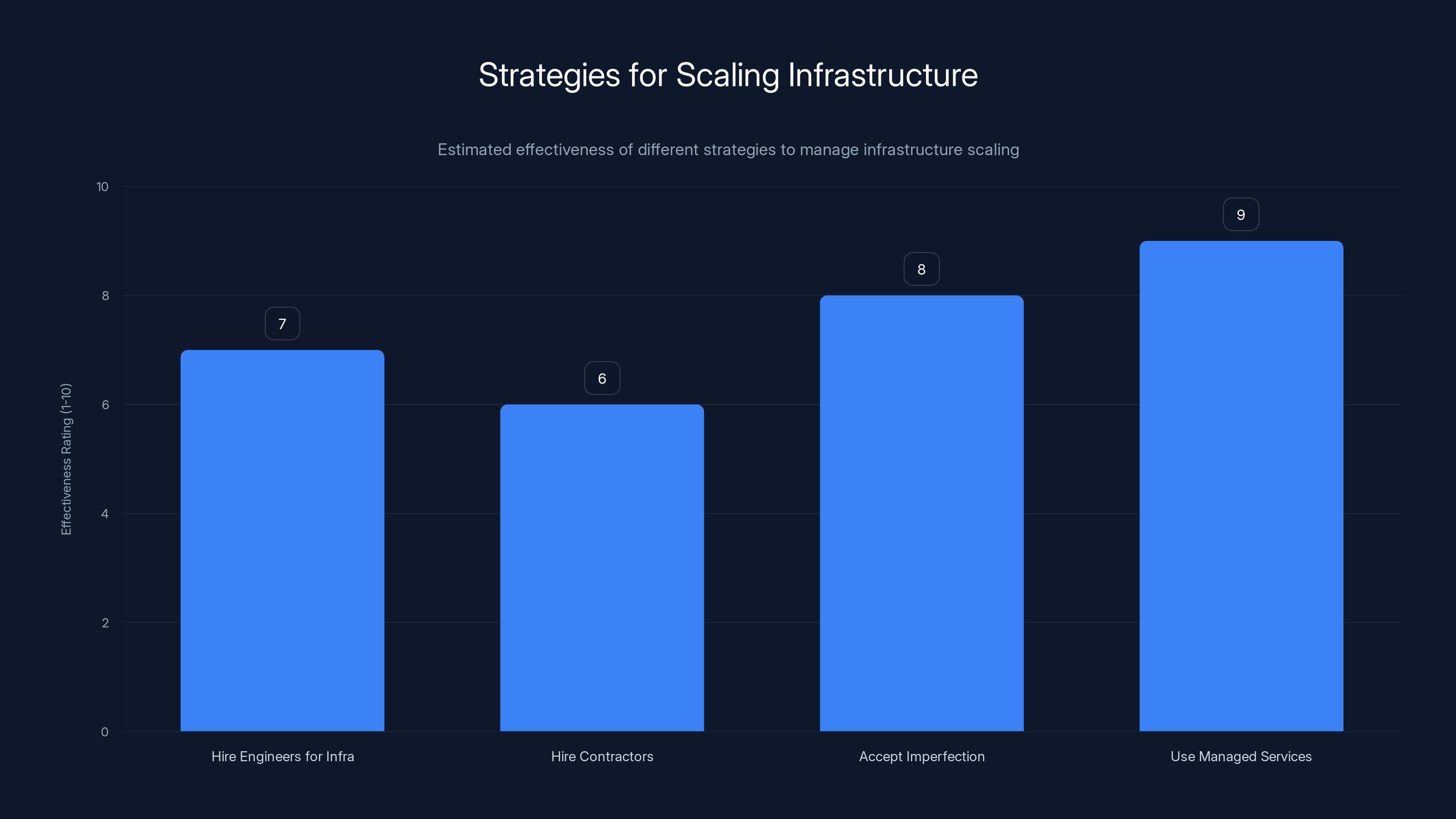
Using managed services is often the most effective strategy for scaling infrastructure, followed by accepting imperfections and working in parallel. Estimated data.
The Founder Skill Gap That's Become Critical
Here's something Mowry has noticed that's rarely discussed in public: founders have gotten progressively worse at understanding their own infrastructure.
Ten years ago, a founder either built the infrastructure themselves or they built it closely with someone who understood it deeply. They could explain how their system actually worked. They understood the tradeoffs.
Today? Most founders can't explain how their system works. They trust their engineers, which is good. But they can't understand whether the engineers are making good decisions or bad decisions. They can't sense the check engine light until it's too late.
This creates a huge vulnerability. The company is vulnerable to a key person leaving. The company is vulnerable to infrastructure debt compounding unchecked. The company is vulnerable to cloud costs spiraling. The company is vulnerable to hiring infrastructure people who overcompress complexity in one direction (too much managed services) or overindex on custom complexity in another (rebuilding everything custom).
So here's what Mowry advocates for, and what we're seeing the best founders do:
Learn enough infrastructure to understand the tradeoffs, but not enough to think you should be building it.
That means you should be able to understand these concepts:
Databases: You should understand the difference between a relational database and a NoSQL database. You should understand indexing, query optimization, and replication. You don't need to be able to optimize a query yourself, but you need to understand that query optimization is a thing that matters and can be worth significant engineering time.
Caching: You should understand that caching exists and why it matters. Redis vs memcached. Database caching vs application caching vs edge caching. You don't need to implement it, but you need to understand that if your API is slow, caching is probably a solution.
Scalability patterns: You should understand that a monolith is fine until it isn't. That microservices aren't inherently better, just different. That there are multiple ways to split a system and different tradeoffs. You should be able to ask good questions about why your infrastructure team chose the architecture they chose.
Cost dynamics: You should understand how cloud providers charge. Compute, storage, data transfer. You should understand that some architectural choices make things cheaper and some make them more expensive. You should be able to read your cloud bill.
You don't need to be an infrastructure expert to understand these things. You need to spend maybe 20 hours learning them and then stay current as your business changes.
The founders who do this have a completely different relationship with their infrastructure teams. They ask better questions. They catch problems earlier. They make better hiring decisions. They understand when they're being told the truth and when they're being given explanations that are technically correct but strategically wrong.
The Hiring Decision That Becomes a Bottleneck
Mowry sees a specific hiring mistake that repeats across hundreds of startups.
They hire product engineers first. That's right. They hire backend engineers. They hire frontend engineers. They hire QA. That's all correct.
Then, when they hit the scaling wall, they say "we need an infrastructure person."
Too late. You should have hired the infrastructure person at
The infrastructure person isn't a separate category of engineer. They're a category of mind that thinks about systems holistically. They ask questions like: "What's going to break first as we scale? What should we fix now versus later? What are the architectural decisions that are going to bite us in 18 months?"
If you wait until $3M to hire this person, they spend their first year fixing mistakes that could have been prevented. You lose an entire year of efficiency gains that you could have captured.
The best infrastructure-minded people at early startups are usually hired as "senior backend engineer" or "tech lead." They're not necessarily siloed into infrastructure. But they have a particular way of thinking about problems that's oriented toward systems and scalability rather than just feature delivery.
What Mowry advocates for is being intentional about this hire. At around $1M ARR or 6-8 people, you should be looking for someone who thinks systematically about infrastructure. Not necessarily someone who is an infrastructure expert (those people are rare and expensive). Someone who thinks that way.
Then you give them 20-30% of their time (at least) to work on infrastructure debt, optimization, and architectural decisions that will pay dividends later. You don't give them a 100% infrastructure role because you're too small. But you do make sure that someone is thinking about these problems.
The startups that do this end up with founders who have a built-in advisor for infrastructure decisions. They end up with a team that makes better architectural choices early. They end up avoiding the full-team crisis at $5M where suddenly everything needs to be rebuilt.
The startups that don't do this? They end up where Mowry sees them most frequently: stuck at $3-4M ARR with an infrastructure crisis and no clear path forward that doesn't involve significant pain.
The Database Decision That Will Haunt You or Save You
One specific decision that Mowry brings up constantly: database choice.
This seems like a boring infrastructure decision. It's actually one of the most consequential decisions you'll make.
Why? Because it's expensive and disruptive to change later.
Most startups default to PostgreSQL because it's free, it's solid, it handles basically everything. For most startups, PostgreSQL is correct. It will take you from
But around $2-5M ARR, some startups start hitting PostgreSQL walls that shouldn't happen. They hit them because they didn't make good choices about indexing, query optimization, and data modeling early.
They also hit them because they're using PostgreSQL the way you'd use a MongoDB, storing arbitrary JSON in columns and querying it at scale. That's not how PostgreSQL wants to be used.
The startups that Mowry sees scaling smoothly usually made good database decisions at the $500K ARR stage: they normalized their schema, they indexed strategically, they thought about query patterns before they had to.
The startups that hit walls made the opposite choices: they stored anything in columns called "data", they didn't think about how the data would be queried, they optimized for developer speed at the cost of database efficiency.
Both are valid strategies at
This is a situation where "good enough" really isn't good enough. A startup that makes good database choices at
The fix, when it comes, is usually 2-4 months of engineering work that could have been avoided.

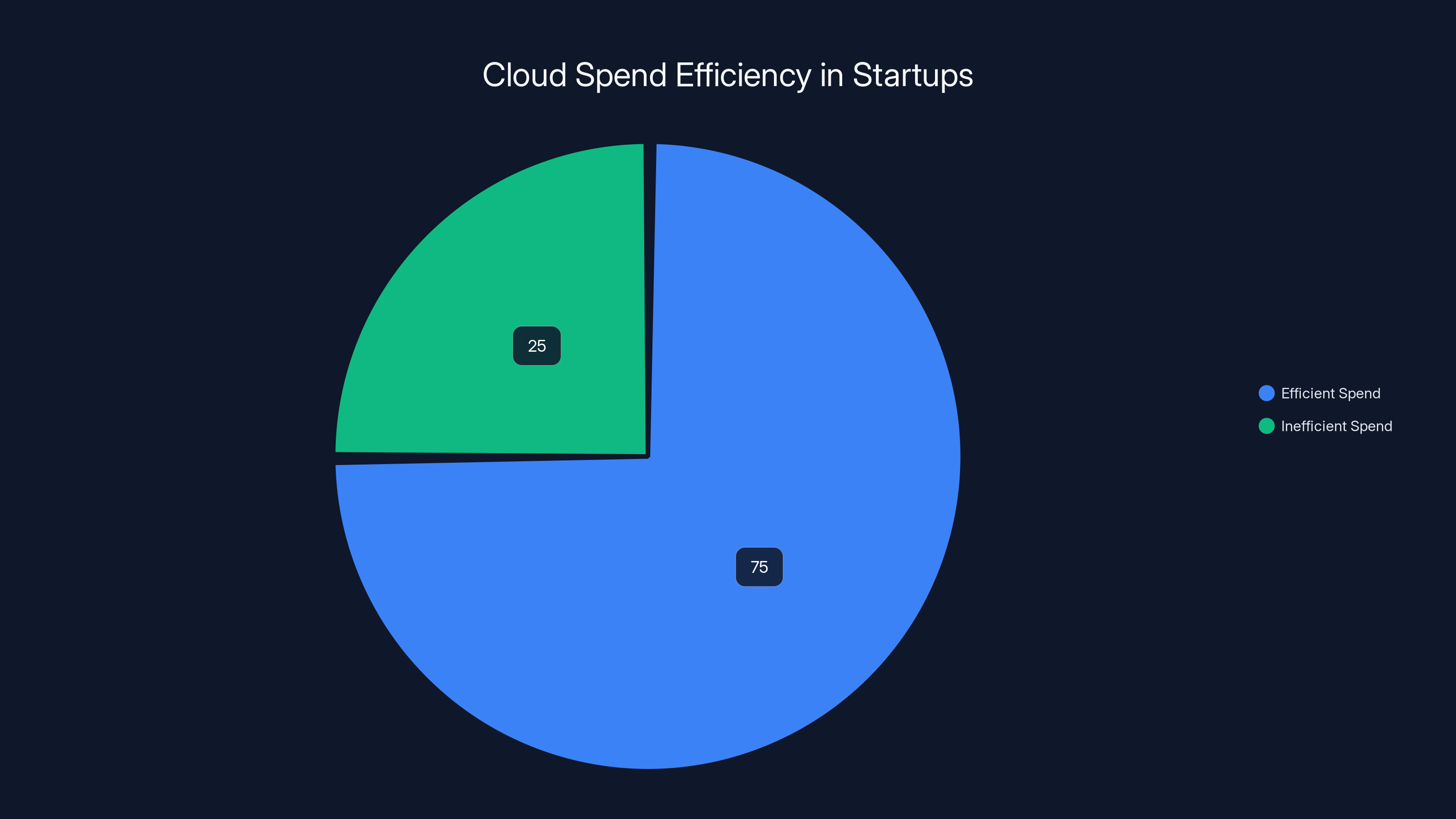
On average, startups have about 25% of their cloud spend categorized as inefficient or unnecessary, highlighting significant potential for cost savings.
When Your Team Needs to Double, But Your Infrastructure Can't Yet
This is the squeeze that Mowry sees most often in the $2-5M range.
You've hit product-market fit. You need to grow. To grow, you need to hire. To hire, you need more infrastructure. But your infrastructure isn't ready to scale, so suddenly you're hiring engineers into a broken system.
The vicious cycle is real.
What this looks like in practice:
You hire three engineers. Your infrastructure was barely keeping up with four. Now it's clearly breaking. The new engineers are hitting issues constantly. They're slow. They're frustrated. You're burning money on people who can't be as productive as they should be.
So you delay hiring new engineers while you fix infrastructure. But now you're falling behind on product development. Your sales team is frustrated because you can't ship features fast enough.
Mowry sees founders try to solve this in a few ways:
Option 1: Hire the engineers anyway and have them work on infrastructure instead of product. This is actually often correct, but it's painful because it requires the discipline to say "we're not shipping features this quarter." Most founders can't do this.
Option 2: Speed up infrastructure work by hiring contractors or renting expertise. This works if you're clear about what problem you're solving. It fails if you try to hire a "DevOps expert" to "make things better." That's too vague.
Option 3: Accept that your infrastructure isn't perfect and hire into that reality. Bring people in, be honest about the constraints, work on infrastructure in parallel with product work. This is actually usually correct but requires a high level of maturity in your engineering culture.
Option 4: Use more managed services to reduce operational burden on the humans you have. Instead of running your own Kubernetes cluster (operational burden), use a managed Kubernetes service. Instead of running your own Postgres database (operational burden), use a managed database. This increases costs but reduces the human burden.
The best founders make different choices based on their specific situation. The worst founders try to hire people into a broken system without acknowledging that it's broken.
The Myth of "We'll Optimize Later"
This is the core tension that Mowry sees in nearly every scaling conversation.
Founders want to move fast. Moving fast usually means building things that aren't optimized yet. This is correct up until a point. But that point comes earlier than most founders think.
The startups that scale smoothly are the ones that internalize a specific idea: optimization isn't something you do later when you have time. It's something you build into your practices from the beginning.
This doesn't mean over-engineering everything. It means being thoughtful about which things matter.
If you're building an API, response time matters. You should measure it from day one, not from when you hit scaling issues. If you're running background jobs, you should be monitoring how long they take. If you're storing data, you should be thinking about indexing and query patterns.
You don't optimize aggressively. You optimize enough so that you have visibility into what's happening. That visibility is what creates the check engine light signal. Without it, you don't know that something's wrong until it's catastrophic.
The best founders have a specific practice: every sprint, someone is looking at performance metrics. What got slower? What got faster? Why? Is there something we should fix? This is maybe 5-10% of engineering capacity. It's not expensive. It catches things early.
The alternative is what Mowry calls "optimization panics": the company hits a wall, everything slows down, you realize that nobody's been paying attention to performance, you need to spend three months fixing things that could have been prevented.

The Role of AI in Solving These Problems (And Creating New Ones)
Here's where it gets interesting and where the 2025 startup ecosystem is genuinely different from the 2024 ecosystem.
AI is solving some of these infrastructure problems. It's also creating new ones.
On the solving side: you can now use AI tools to automatically generate infrastructure code. You can ask an AI system to optimize a slow query. You can get suggestions for database indexing. You can have AI tools monitor your infrastructure and alert you to problems before they become catastrophic.
Platforms like Runable are helping startups reduce operational overhead in different ways. Instead of having someone manually write documentation, generate reports, or create presentations, AI handles the generation and humans focus on quality review. This isn't solving infrastructure problems directly, but it's freeing up engineering capacity to work on infrastructure problems that do exist.
On the creating new ones side: AI is increasing infrastructure complexity. If you're running inference at scale, that's a new class of problem that didn't exist five years ago. If you're using vector databases and semantic search, that's new infrastructure. If you're doing fine-tuning, that's a whole operational stack that's unfamiliar.
So the paradox is: AI is making some infrastructure problems easier to solve and some infrastructure problems more complex.
The startups that are navigating this well are the ones being selective. They're using AI where it genuinely reduces burden (documentation, reports, monitoring). They're avoiding custom AI infrastructure unless it's core to their product differentiation.
They're asking: "What's the actual business value of us running our own model vs. calling an API?" Most of the time, the answer is "calling an API is better."
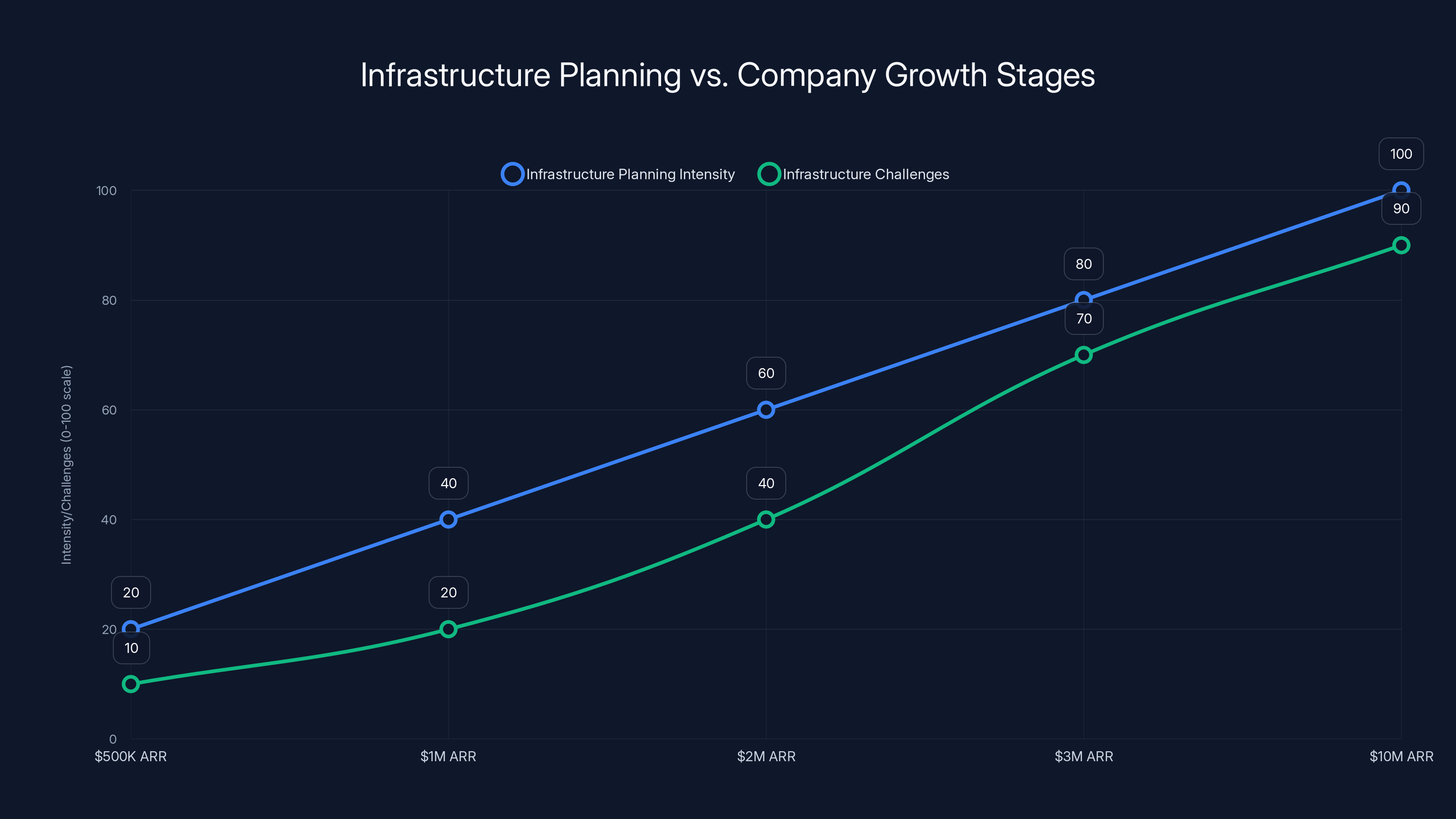
Successful founders address infrastructure planning early, ideally around
The Roadmap for Scaling Without Breaking Everything
If Mowry were to design the perfect infrastructure roadmap for a startup from
Here's the framework that he describes across his conversations:
$500K ARR: Nail the basics. Your database is normalized and indexed properly. Your code is deployed with confidence. You have basic monitoring so you know when things break. You can explain to a technical person how your system actually works.
$1M ARR: Start thinking about scalability. You should have one person thinking about infrastructure decisions. You should know what your cloud costs are and where the money goes. You should have identified the obvious inefficiencies and fixed them.
$2M ARR: Start stress-testing. You should know what your system looks like under 2x current load. You should have identified what will break first. You should have a plan to address it.
$3M ARR: Start implementing the plan. You should be actively working on the infrastructure changes that you identified earlier. This is a year of parallel work: building new infrastructure while running the old one, then gradually shifting traffic over.
$5M ARR: New baseline. Your infrastructure should be solid for the next stage of growth. You should be back to moving quickly on product, not spending all your time on infrastructure.
The difference between startups that follow this roadmap and startups that don't is honestly shocking. The ones that follow it hit
The investment is not actually that large. It's mostly about attention and discipline. Someone thinking about these problems. Someone making decisions. Someone saying "this is going to matter in 18 months, let's fix it now."

The Competitive Dynamics: Google Cloud vs. AWS vs. Azure for Startups
Why does Mowry's perspective on all of this matter? Because he works for Google Cloud, and they're trying to win at something that historically they haven't won at: being the cloud platform of choice for ambitious startups.
AWS is the default. Everyone's on AWS. It's where startups go because it's what they know. But AWS isn't optimized for startups, and it's definitely not optimized for simplicity. It's optimized for large enterprises that have dedicated teams.
Google Cloud is building something different. Fewer services (easier to understand), better defaults, more managed services out of the box. The strategy is: we're not going to win by having more services than AWS. We're going to win by making the right services the default and making them simple.
For startups, this matters because it means less infrastructure complexity that you have to manage yourself. Instead of running your own Kubernetes cluster (operational burden), you use a managed container service. Instead of managing your own databases, you use managed databases.
Azure is in a weird position where they're trying to serve enterprises and startups simultaneously, and they're probably not winning at either right now.
The reality for founders is: all three clouds are good. Pick one and commit. The switching costs are higher than you think. Don't try to be platform-agnostic. Go deep on one platform and become good at it.
For startups, the question isn't "which cloud is objectively best." It's "which cloud have I optimized my architecture for?" Once you've made that choice, switching is painful.
Mowry's pitch (because yes, he's making a pitch) is that Google Cloud requires fewer operational decisions upfront, which means you can focus on product instead of infrastructure. That's a legitimate advantage for early-stage startups.
The Myth of Monoliths vs. Microservices
This is one of Mowry's favorite topics to push back on, because he sees startups make terrible architectural choices based on religious beliefs about how systems should be structured.
The myth: "If you're at scale, you need microservices."
The reality: Monoliths scale to tens of billions of requests per year. Monoliths scale to hundreds of millions of users. The question isn't "does a monolith scale" (it does). The question is "what operational burden do you want to accept."
If you build a monolith:
Pros: Single codebase. Easier to develop. Easier to deploy. Easier to understand. Transactions work across your whole system.
Cons: It's all or nothing on deployment. You can't scale a piece of it independently. When it breaks, everything breaks.
If you build microservices:
Pros: You can scale pieces independently. You can deploy independently. Different teams can own different services.
Cons: Distributed systems are hard. Debugging is harder. Transactions are complicated. You need sophisticated infrastructure.
For a startup at $1M ARR, there is almost no reason to choose microservices. You should build a monolith. You should get comfortable deploying it smoothly. You should add caching and monitoring. You should focus on product.
For a startup at $10M ARR with clear scaling needs in specific parts of the system, you might split out a service. A critical service that scales independently. A service that a separate team owns. But you shouldn't split out everything.
For a startup at $100M ARR, you might have a bunch of microservices. But even then, most companies find that a monolith with independent background jobs and caching layers works better than they expected.
The mistake is making this architectural choice based on what you think you'll need, instead of what you actually need. If you're at $2M ARR and you're running microservices, you're probably over-engineered. The infrastructure complexity is eating engineering capacity that you should be spending on product.
Mowry's advice: start with a monolith. When you have a specific scaling problem in a specific part of the system, solve it. Maybe that's a separate service. Maybe that's a cache layer. Maybe that's optimizing the existing monolith. Make the decision based on data, not on architectural religion.

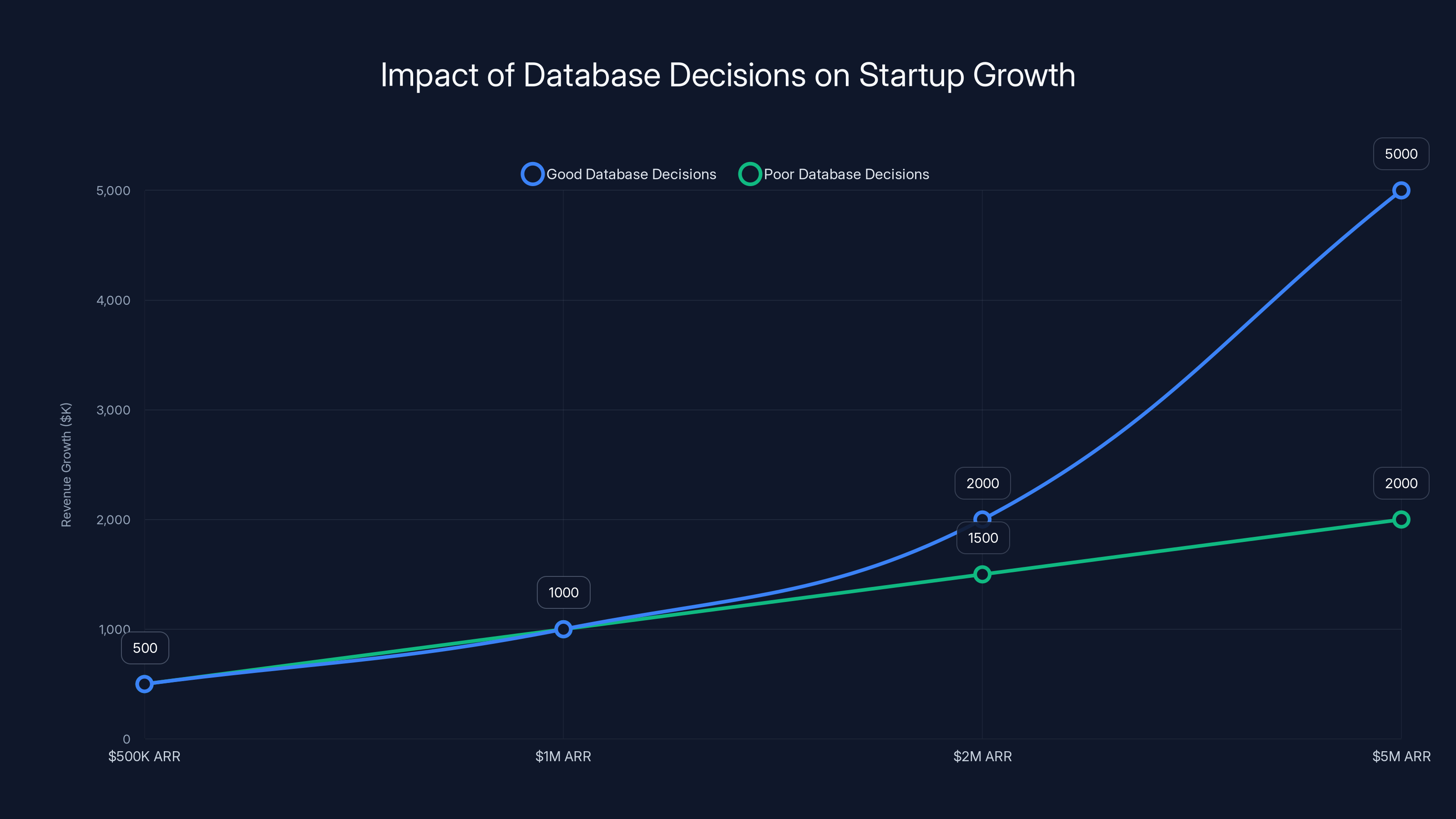
Startups with good database decisions scale efficiently from
The Warning Signs You're Actually Ignoring
Here's the tricky part: your check engine light is already on, but you're ignoring it.
Mowry describes some specific warning signs that he sees founders rationalize away:
"Our API is slow but we're in early access, so it doesn't matter yet." Wrong. Your slow API is a signal. It's telling you something about how you're accessing data or processing requests. If you fix it now when traffic is low, it's easy. If you ignore it and it becomes a scaling bottleneck, it's hard.
"Our cloud bill is high but we're growing fast." Partially true. Your cloud bill should be higher when you're growing fast. But it shouldn't be growing as a percentage of revenue. If it's growing from 10% of revenue to 20% to 30%, something's wrong. Something specific is inefficient.
"We have a lot of technical debt, but we're focused on product right now." Okay. But you need to be strategic about which debt matters and which doesn't. If there's a piece of technical debt that's actively slowing down development, fix it. If there's a piece that's lurking in the background, you can live with it for a while.
"Deployment takes an hour, but that's fine because we don't deploy very often." The fact that you don't deploy often is probably the problem. You should deploy constantly and safely. If deployment takes an hour, you're going to deploy less frequently, which means larger batches, which means higher risk, which means more breakage.
"Sometimes the database is slow, but we're not sure why." This is a problem. You should know why your database is slow. If you don't know, you don't have enough visibility. Add monitoring. Find out. Fix it.
The theme is: you're probably ignoring signals that are telling you something needs to change. The signals are quiet right now, but they're going to get louder. The sooner you listen, the less painful the fix.
The Framework for Making Strategic Scaling Decisions
Mowry describes a specific decision-making framework that the best founders use when they're trying to decide what to do about their infrastructure:
1. Inventory your actual constraints. Not your perceived constraints. Your actual constraints. Run a real performance test. Look at your real cloud costs. Understand your real bottlenecks. If you're guessing, you'll make bad decisions.
2. Separate reversible decisions from irreversible ones. Some decisions you can change in a week. Some decisions will take months or years to reverse. Irreversible decisions deserve more thought. You shouldn't be casual about them.
3. Bias toward fewer, better decisions over more, fast decisions. You don't need to make 10 infrastructure decisions this quarter. You need to make 1-2 really good decisions that will pay dividends for years.
4. Default to the simplest solution that solves the actual problem. Not the fanciest solution. Not the most sophisticated. The simplest solution that actually solves your specific problem. If your database is slow because you're missing indexes, add indexes. Don't rebuild the database. If your API is slow because you're missing caching, add caching. Don't rebuild the API.
5. Have someone explicitly responsible. Not everyone. One person. One person is responsible for infrastructure decisions. One person is the tiebreaker when there are different opinions. This person might be your CTO. It might be your most senior engineer. But it's not a committee.
The startups that follow this framework end up making better infrastructure decisions. The startups that don't make decisions by crisis, which means they make bad decisions.

What the Next 18 Months Looks Like for Scaling Startups
Mowry's prediction for the startup ecosystem in 2025-2026 is that we're going to see significant separation between startups that are managing their infrastructure intelligently and startups that are just responding to crises.
The ones that are managing well are going to scale smoothly. They're going to be able to hire effectively. They're going to have headroom in their budgets. They're going to be able to think about product instead of constantly firefighting.
The ones that are responding to crises are going to hit walls. They're going to have months where they're essentially just doing infrastructure work instead of product work. They're going to have expensive hiring decisions that don't pan out because they're hiring into a broken system. They're going to be burning money inefficiently.
The separation is going to get more pronounced as the ecosystem matures.
What this means for you specifically:
If your startup is at
If your startup is at
If your startup is at $5M+ ARR and you haven't done the infrastructure work, you're going to have a painful 12-18 months. But you still have time to fix it. The sooner you start, the less painful it is.
The common thread is: this stuff requires attention now. It doesn't get easier if you wait.
The Reality Beyond the Hype: What Google Cloud Actually Offers
Mowry's job is to help startups succeed on Google Cloud, which means he's biased. But the underlying point is valid: the cloud you choose matters less than being intentional about the choice and committing to it.
Google Cloud's pitch to startups is: we've thought about what startups actually need. We've stripped away a lot of the complexity. We've made the default choices good choices. We've invested in making the simple path the right path.
Is this true? Partially. Google Cloud has fewer services than AWS, which is sometimes good (less choice paralysis) and sometimes bad (less flexibility). Google Cloud has managed services that are genuinely good, but so does AWS.
The real advantage is cultural. Google Cloud is building for simplicity. AWS is building for power users. Azure is building for enterprises. For startups, the simplicity-focused approach makes sense.
But here's the real talk: if you're on AWS and it's working for you, don't switch. The switching cost is higher than the benefit. Commit to AWS. Get good at it. You can scale to $100M+ on AWS completely smoothly.
If you're choosing a cloud for the first time, it's worth looking at all three. But don't overthink it. You're probably not going to run into the limits of any of them in your first five years. Pick one and commit.
The bigger decision is: are you going to think strategically about infrastructure, or are you going to respond to crises? That matters more than which cloud you're on.

FAQ
What is the "check engine light" in the context of startup infrastructure?
The check engine light is the warning signal that something in your system needs attention before it becomes catastrophic. In startup infrastructure, this can manifest as slowing API response times, climbing cloud costs, database query delays, or deployment friction. The key is recognizing these signals early and addressing them strategically before they force a crisis response that consumes months of engineering time and resources.
At what revenue stage should startups prioritize infrastructure planning?
The critical window is between
How much of my cloud bill is actually waste, and how do I find it?
The average startup has approximately 20-25% of cloud spend that's inefficient or unnecessary. Common areas include over-provisioned compute resources, unused storage, unoptimized data transfer, and lack of reserved instance utilization. Audit your spend by service, then focus on the three highest-cost items. Often, two weeks of focused analysis by someone with cloud expertise yields
Should we build a monolith or microservices?
Build a monolith at $1M ARR. When you have a specific service that needs to scale independently (proven by actual usage data), then split it out. Most companies find that a well-architected monolith with good caching, background jobs, and monitoring scales far beyond what they expected. Microservices add operational complexity that's rarely justified until you have a specific scaling problem to solve.
How do I know if my technical debt is actually going to hurt me later?
Focus on two categories: debt that's actively slowing down development right now, and debt that's creating visibility problems. If a piece of code is slow and you deploy it 10 times a day, the accumulated friction compounds quickly. If you have infrastructure that you don't have visibility into, that's dangerous. Most other technical debt is manageable and can be fixed later if needed.
What's the right way to hire infrastructure people at a startup?
At
Conclusion: Your Check Engine Light Is Already On
If there's one thing that stands out from Mowry's perspective on the startup ecosystem, it's this: most founders know something is wrong, but they're hoping it will go away if they ignore it long enough.
It doesn't go away.
The infrastructure problems that are causing friction now are going to cause crises later. The slow database that's making deployments take an hour now is going to create a bottleneck that slows your whole team later. The cloud bill that's creeping up as a percentage of revenue now is going to become a significant drag on profitability later.
But here's the hopeful part: these problems are solvable. They're not hidden. They're not mysterious. The tools to solve them exist. The expertise to solve them is available. The only requirement is that someone (usually the founder) decides to prioritize it.
That's the decision you need to make now. Not "are we going to be okay if we ignore this." You already know the answer to that (you won't be). The decision is: are we going to fix this proactively or reactively?
The startups that choose proactively are the ones that scale smoothly from
The startups that choose reactively end up in a crisis state where they're forced to rebuild infrastructure while trying to grow, which is the worst possible situation.
Your check engine light is on. It might be quiet right now, but it's on. Listen to it. It's trying to tell you something important about the future of your company.
Mowry's conversations with founders across thousands of startups point to one clear conclusion: the ones who listen to the warning signals early are the ones who scale. The ones who ignore them are the ones who hit walls that shouldn't exist.
You get to choose which category you're in.

Key Takeaways
- He sits at the intersection of opportunity and chaos, watching founders navigate some of the most critical decisions of their company's life
- That's actually the exact moment most startups need to completely rethink their infrastructure approach
- Three months ago, every founder wanted to build on top of AI
- Meanwhile, startups are discovering that you don't actually need to host your own models
- A startup that previously needed eight engineers to maintain infrastructure, write documentation, and generate reports might now need five engineers and a strategic deployment of AI tooling
Related Articles
- Samsung Galaxy Tab S10 Ultra: The 14.6-Inch Laptop Killer [2025]
- AI Music Generation: History's Biggest Tech Panic or Real Threat? [2025]
- Western Digital's 2026 HDD Storage Crisis: What AI Demand Means for Enterprise [2025]
- Netflix, Warner Bros., and Paramount Merger War [2025]
- Indian Pharmacy Chain Data Breach: How Millions Were Exposed [2025]
- Best Fitness Earbuds to Keep You Motivated Through Workouts [2025]

