![The Three Frontiers of AI Model Capability: Beyond Raw Intelligence [2025]](https://tryrunable.com/blog/the-three-frontiers-of-ai-model-capability-beyond-raw-intell/image-1-1771875368874.png)
The Three Frontiers of AI Model Capability: Beyond Raw Intelligence [2025]
When you ask a developer what they want from an AI model, you'll probably hear "better performance." But that word means something completely different depending on who's asking.
For a software engineer writing code, performance might mean model intelligence. Give them the smartest model available, even if it takes 45 minutes to generate a response. They'll wait. They're going to review that code anyway, integrate it into their codebase, and maintain it for months. Raw capability matters more than speed.
But ask a customer support agent the same question, and they'll tell you something different. They need intelligence, sure, but only within a strict latency budget. If a policy lookup takes 45 minutes, the customer hung up 44 minutes ago. The best answer in the world doesn't help when it arrives too late.
Then there's the third scenario, the one that doesn't fit neatly into either box. When a platform like Reddit or Meta wants to moderate billions of posts across unpredictable traffic spikes, they face a fundamentally different constraint. They have a fixed budget. They have no idea how many moderation requests will arrive tomorrow. They need intelligence, but only as much intelligence as they can afford to scale infinitely.
These three scenarios aren't edge cases. They represent three distinct frontiers that AI models are pushing against simultaneously. And understanding how they work, how they compete, and how they're reshaping enterprise AI deployment is critical for anyone building with AI in 2025.
Let's break down what's actually happening in the market, why it matters, and what it means for the future of model development.
TL; DR
- Three distinct model optimization frontiers: Raw intelligence (code generation), response latency (customer support), and cost-effective extensibility (content moderation at scale)
- Different frontiers require different architectures: Smaller specialized models often outperform larger general models within specific latency or cost constraints
- Enterprise adoption is infrastructure-limited, not capability-limited: Missing patterns for auditing, authorization, and human-in-the-loop processes are holding back agentic AI deployment
- Software engineering leads adoption: Development workflows naturally fit agentic patterns because they have existing testing, review, and promotion pipelines
- Vertical integration matters: Companies with control across the entire stack (chips, models, inference, APIs, interfaces) can optimize for all three frontiers simultaneously
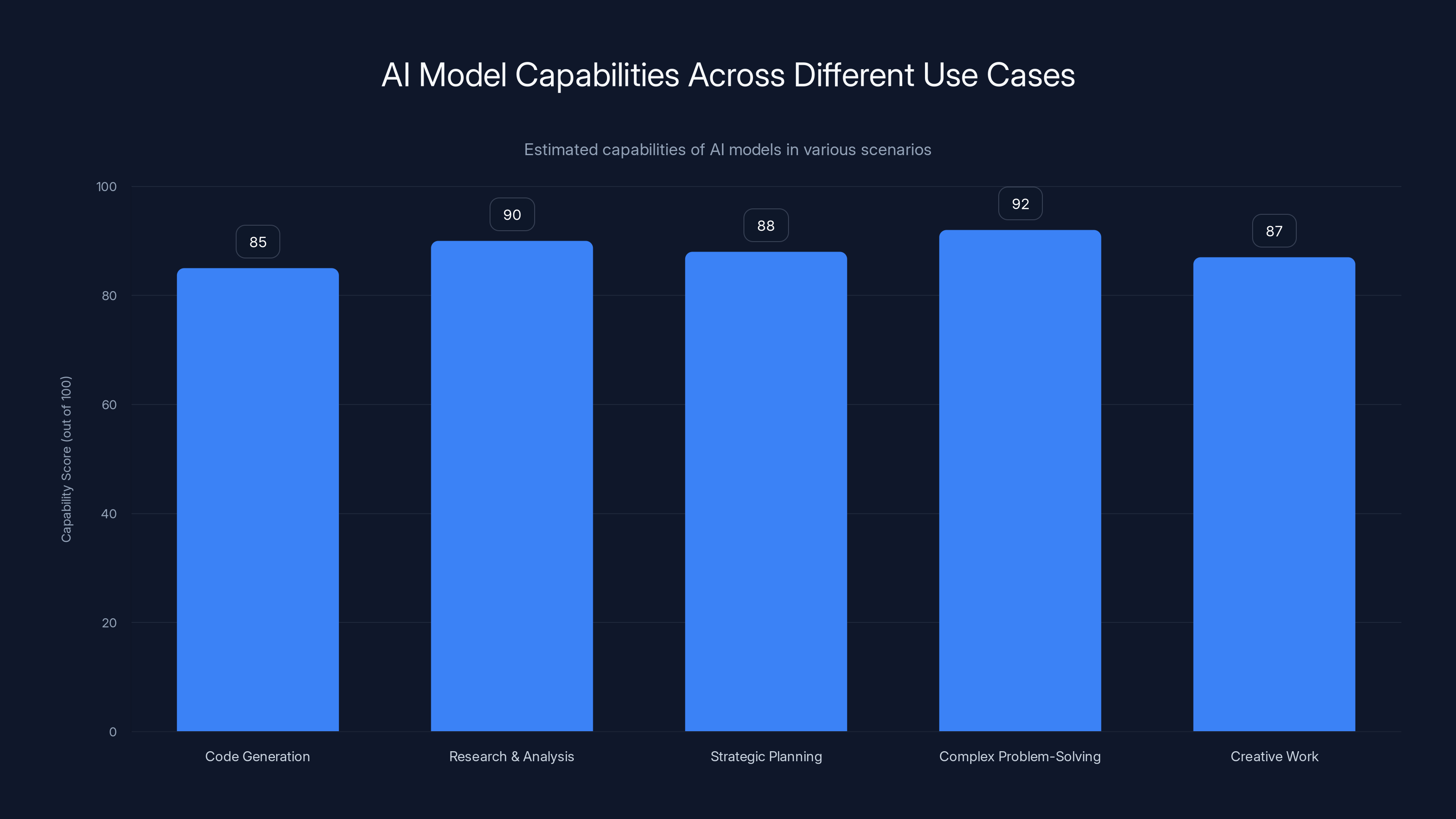
AI models show varying capabilities across different use cases, with complex problem-solving and research analysis scoring the highest. Estimated data.
The Intelligence Frontier: When Capability Is Everything
The intelligence frontier is what most people think about when they think about AI models competing. This is where raw capability matters most, and where bigger models generally win.
Picture a software engineer who needs to generate complex production code. They're not in a hurry. The code will be reviewed by at least two people at a major tech company. It needs to be correct, efficient, and maintainable. In this scenario, response time is almost irrelevant. If you can give them code that requires 30% fewer revisions and integrates more smoothly with the existing codebase, that's worth waiting for.
This is why the intelligence frontier looks like a traditional "bigger is better" arms race. Deep Seek, Anthropic, Open AI, and Google Deep Mind are all competing to build the most capable models. They're investing in better training data, longer context windows, improved reasoning capabilities, and multi-modal understanding.
The intelligence frontier isn't just about code generation, either. It applies to any use case where quality matters more than speed:
Research and analysis: A researcher generating a comprehensive literature review doesn't care if the model takes 10 minutes per section. They need depth, nuance, and accuracy.
Strategic planning: An executive team working through a five-year roadmap wants the most thorough analysis available, even if it takes hours to generate.
Complex problem-solving: When you're trying to debug a subtle architectural issue or design a new system, raw intelligence beats fast approximations.
Creative work: Writers, designers, and strategists often want the most capable model available because the output quality directly affects their work product.
The intelligence frontier drives a lot of the media attention around AI. When Open AI released O1, with its reasoning capabilities, or when Deep Seek announced better performance at lower cost, these were intelligence frontier breakthroughs. They expanded the kinds of problems models could actually solve.
But here's the catch: optimizing purely for intelligence usually means accepting longer inference times. You can't get the absolute best answer in milliseconds. The model needs time to think, explore multiple approaches, and refine its response. That's fine if you're willing to wait. It's catastrophic if you're in a real-time interaction with an impatient human.
That's where the second frontier comes in.
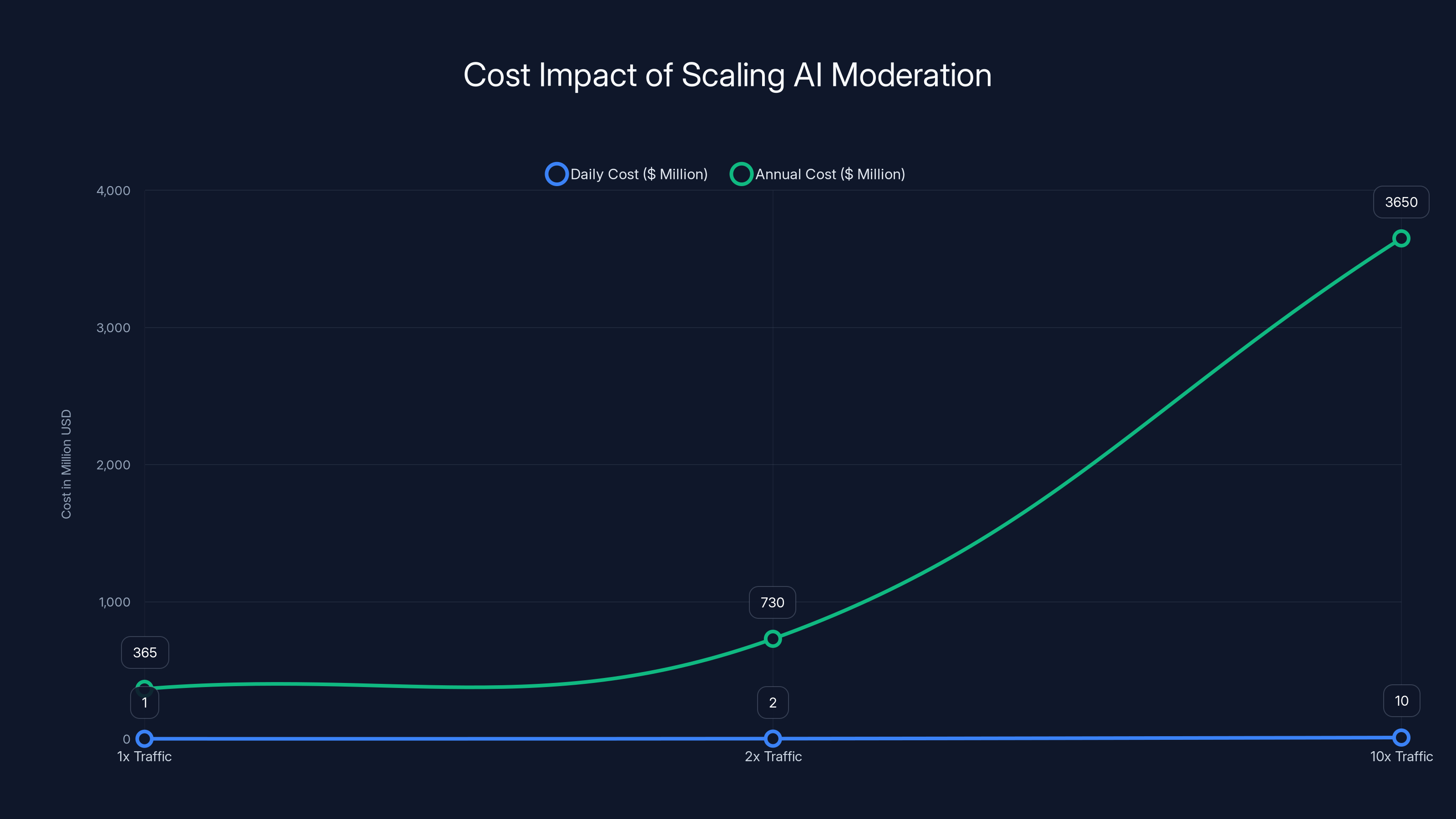
Estimated data shows that as traffic scales from 1x to 10x, daily moderation costs can rise from
The Latency Frontier: Intelligence Within a Time Budget
Now imagine a different scenario entirely. You're calling your airline to upgrade your seat. You ask, "Can I upgrade to first class?" The agent needs to:
- Check your current booking
- Look up seat availability
- Review applicable policies (some seats have restrictions)
- Determine pricing
- Execute the transaction
All of this requires intelligence. The agent needs to understand the policy, apply it correctly, and make decisions based on your specific situation. But here's the critical part: it needs to happen in under 30 seconds. Maybe 60 seconds if the customer is patient. More than that, and you've lost them. They're frustrated, considering competitor airlines, and definitely not upgrading.
This is the latency frontier. Intelligence still matters, but only within a strict time budget.
Latency-constrained applications are incredibly common in production:
Customer support: Chatbots answering FAQ questions, policy clarifications, or troubleshooting steps need to respond within seconds, not minutes.
Real-time recommendations: E-commerce sites showing product recommendations when a customer lands on a page have perhaps 100-200 milliseconds before they've already scrolled past.
Content moderation decisions: Platforms reviewing content in real time need decisions in seconds, not minutes.
Ad targeting: Deciding which ad to show a user when they load a page happens in milliseconds.
Search and retrieval: Users expect search results to load in under a second.
The latency frontier creates a completely different optimization problem. You can't just use the biggest, smartest model. You need the most intelligent model that can respond within your latency budget. Sometimes that means using a smaller model. Sometimes it means using a specialized model trained on your specific domain. Sometimes it means breaking the problem into multiple steps, with different models handling different parts.
This is why Anthropic developed models at different size tiers, why Open AI offers GPT-4o mini for faster inference, and why companies are investing heavily in model distillation and optimization techniques.
The latency frontier also creates opportunities for innovation beyond just using smaller models. You can:
Use speculative decoding: Generate multiple possible next tokens in parallel, then verify which path the model would have taken. This can significantly reduce latency for token generation.
Implement retrieval-augmented generation (RAG): Replace some of the model's knowledge with fast database lookups. Instead of asking the model to recall information, give it the information and ask it to apply reasoning.
Route requests to specialized models: A small routing model determines which specialized model should handle the request, potentially reducing overall latency.
Cache partial results: For common queries, cache the model's reasoning and only generate novel responses when necessary.
Companies optimizing for the latency frontier often end up with completely different architectures than those optimizing for pure intelligence. A bank's fraud detection system and a research institution's code generation platform might use the same underlying model technology, but their deployment, routing, and optimization strategies would be almost completely different.
The Extensibility Frontier: Scaling to Infinite Demand
Now consider a third scenario. You're a platform with massive scale. Reddit, with its 500 million posts per month. Meta, with its billions of user-generated posts. A content moderation platform trying to review all the content across the internet.
You have a budget. Maybe a large budget, but a budget nonetheless. You don't know how much content you'll need to moderate tomorrow. It might be 10x what you're moderating today. It might be 100x. Your costs can't scale linearly with demand, or you'll bankrupt yourself.
This is the extensibility frontier, and it's fundamentally different from both intelligence and latency. This is about intelligent capability that scales to theoretically unlimited demand while staying within a cost envelope.
The key insight here is that you don't necessarily want the smartest model. You want the smartest model you can afford to run at unlimited scale. That's a completely different optimization metric.
Consider the economics. If your most expensive model costs
No platform can absorb that kind of cost variance. So they optimize differently. They find the highest intelligence model they can afford to run at any scale, and they deploy that relentlessly.
The extensibility frontier isn't really about raw model capability. It's about finding the efficient frontier of capability-per-unit-cost. Sometimes that means using a smaller, cheaper model and accepting lower accuracy. Sometimes it means using a combination of models, where an expensive model only handles genuinely difficult cases and a cheaper model handles common cases.
There are specific industries and use cases where extensibility becomes the dominant concern:
Content moderation: Platforms need to review billions of pieces of content where the volume is completely unpredictable. One viral controversy could multiply moderation volume 10x.
Spam detection: Email providers, social platforms, and messaging apps face similar issues. Spam volume spikes during specific times and events.
Log analysis and security monitoring: Enterprises generate terabytes of logs daily. They can't afford to send all of them to expensive frontier models.
Recommendation systems: These run constantly, across billions of users, often generating predictions thousands of times per second.
Data processing pipelines: Organizations processing large datasets need consistent, predictable costs regardless of data volume.
The extensibility frontier drives different architectural choices entirely:
Model selection strategies: Companies choose models based on cost per inference rather than raw capability, using specialized models for specific classification tasks rather than general-purpose models for everything.
Batching and async processing: Instead of processing requests one at a time, group them together and process in batches, which reduces per-token costs and improves hardware utilization.
Tiered routing systems: Send simple requests to cheap models, reserve expensive models for genuinely difficult cases. Some systems might use five or six different models, each optimized for different complexity levels.
Fine-tuning and customization: Train specialized models on domain-specific data to get better performance at lower costs than using expensive general-purpose models.
Quantization and optimization: Run models on optimized hardware, use lower-precision arithmetic, and apply other techniques to reduce inference costs without losing significant accuracy.
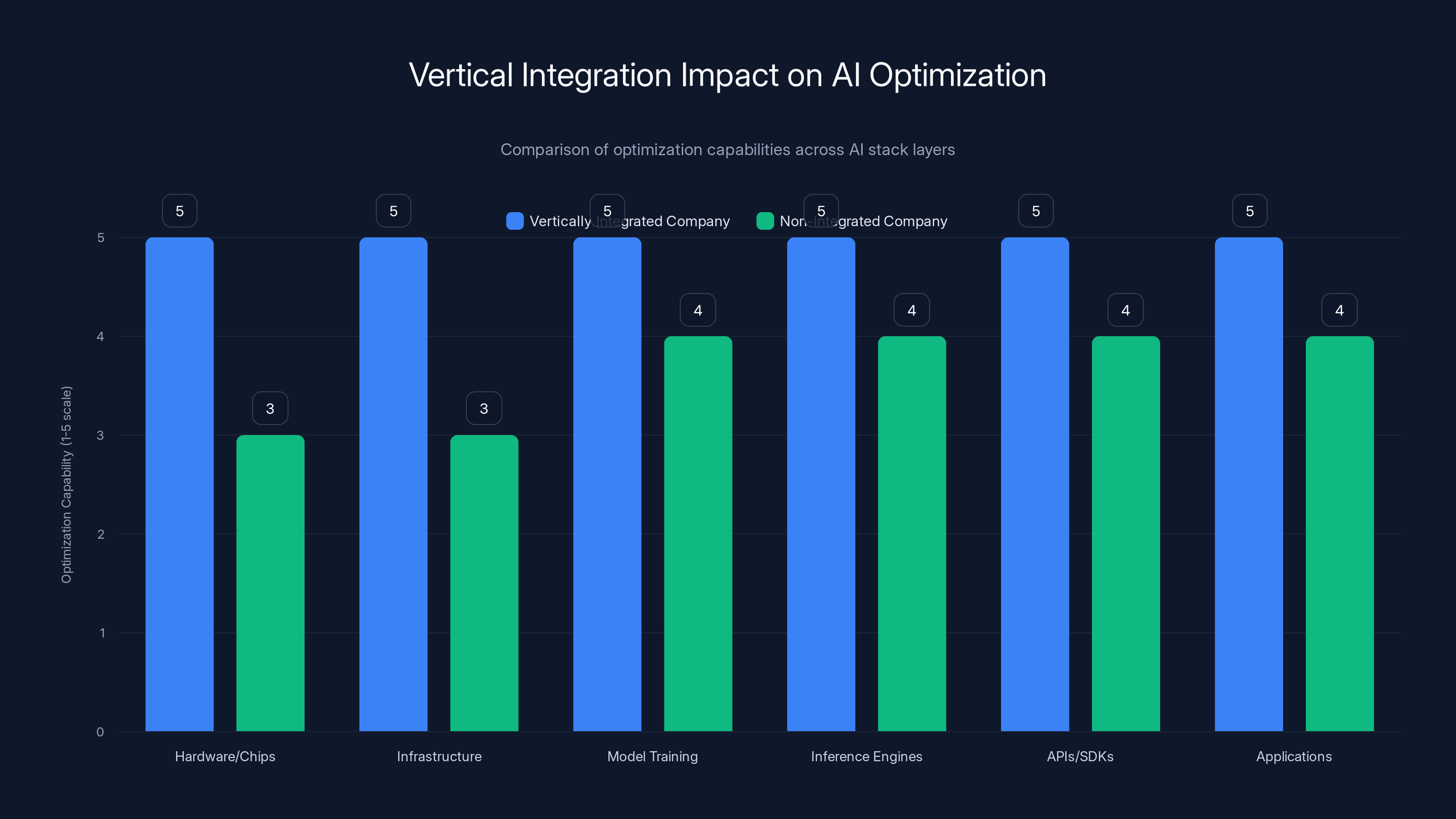
Vertically integrated companies can optimize all layers of the AI stack more effectively, providing a competitive advantage. Estimated data.
The Three Frontiers Framework: How Companies Actually Optimize
Understanding these three frontiers changes how you think about AI deployment entirely. Most companies aren't just buying access to the smartest model. They're selecting models based on where they sit within the three-dimensional space defined by intelligence, latency, and cost-extensibility.
Let me put this more concretely. Imagine you're building an AI customer support system. You have three options:
Option 1: Deploy a frontier model
Use the absolute best, most capable model available. Cost: expensive per request. Latency: 5-10 seconds. Performance: 98% accuracy on complex queries.
Option 2: Deploy a fine-tuned smaller model
Train a smaller model specifically on your support documentation and common questions. Cost: cheaper per request. Latency: 500-800ms. Performance: 94% accuracy on your specific domain.
Option 3: Hybrid routing
Use a fast classification model to route simple questions to a cheap model (95% accuracy, 200ms latency) and complex questions to a more expensive model (97% accuracy, 3 seconds). Blended cost and latency between options 1 and 2.
The right choice depends entirely on where you need to optimize. A financial institution doing technical support might choose Option 1 because a wrong answer costs them. A high-volume retailer might choose Option 2 or 3 because they need to keep costs predictable across millions of interactions.
This framework also explains why we're seeing such explosive growth in specialized models. Anthropic, Together AI, Mistral, and others are building models optimized for specific frontiers or use cases. They're not trying to beat frontier models at everything. They're trying to find niches where they can dominate on their chosen frontier.
Companies with vertical integration across chips, infrastructure, models, and APIs have a significant advantage in this space. They can optimize the entire stack for their chosen frontiers. When you control the silicon, you can optimize inference patterns. When you control the model training, you can target specific capabilities. When you control the deployment infrastructure, you can implement advanced routing and batching strategies that standalone API providers can't match.
This is one reason Google's position is interesting. They can build custom chips optimized for their models, optimize model architecture for their hardware, and deploy on infrastructure they control completely. This vertical integration translates directly to better efficiency across all three frontiers.

Why Agentic AI Adoption Is Slower Than Expected
Here's something that should surprise you: despite incredible model improvements over the last year, we're not seeing the massive productivity gains in production systems that benchmarks would suggest.
The models are definitely smarter. Benchmarks show consistent improvements. But enterprise adoption of agentic AI systems is significantly slower than the technology would predict. Why?
The answer isn't about model capability. It's about infrastructure and operational patterns.
Building a working AI system in a research setting is one thing. You can prompt-engineer, iterate, and debug to your heart's content. Building an AI system in production is completely different. You need:
Auditing patterns: How do you review what an AI agent did? When an agent makes a decision, you need to understand its reasoning and verify it was correct. For simple tasks, this is straightforward. For complex decisions with millions of variables, this becomes incredibly hard.
Authorization patterns: Who can authorize an agent to take actions? If an AI agent is going to modify your database, transfer funds, or publish content, you need clear policies about what it can and can't do. These patterns don't exist yet at scale.
Monitoring and alerting: How do you know when an agent is behaving incorrectly? Traditional monitoring looks for crashes and errors. Agents can behave incorrectly in subtle ways that don't trigger standard alerts.
Rollback and recovery: If an agent makes a mistake, how do you fix it? For some systems, this is straightforward. For others, the damage is distributed across thousands of records and hard to reverse.
Human-in-the-loop processes: In many cases, you don't want agents to act autonomously. You want them to gather information and present it to humans for decision-making. Building these interaction patterns is non-trivial.
Compliance and governance: If your system is regulated (financial services, healthcare, etc.), you need to document everything the agent does and prove it followed the rules. Current agent architectures don't make this easy.
These aren't theoretical problems. They're practical blockers preventing companies from deploying agentic systems at scale.
Interestingly, software engineering has seen much faster adoption of agentic patterns. Why? Because software development already has all these patterns in place.
When an AI agent writes code:
- There's a dev environment where it's safe to break things
- The code automatically goes to tests that verify correctness
- Code review is already part of the workflow (at least two people review and approve)
- There's a staging environment before production
- Rollback is built into version control
- Everything is tracked and auditable
Software engineers basically got agentic AI "for free" because their existing development process was already designed to handle untrusted code.
Other industries don't have equivalent infrastructure. A customer support agent can't operate in a "dev environment" the same way. A financial system can't have automatic testing of policy decisions. A content moderation system can't easily rollback moderation decisions after they've been made.
Building these patterns is the real work holding back agentic AI adoption. It's not about making smarter models. It's about building the operational and governance infrastructure to safely deploy smart systems.
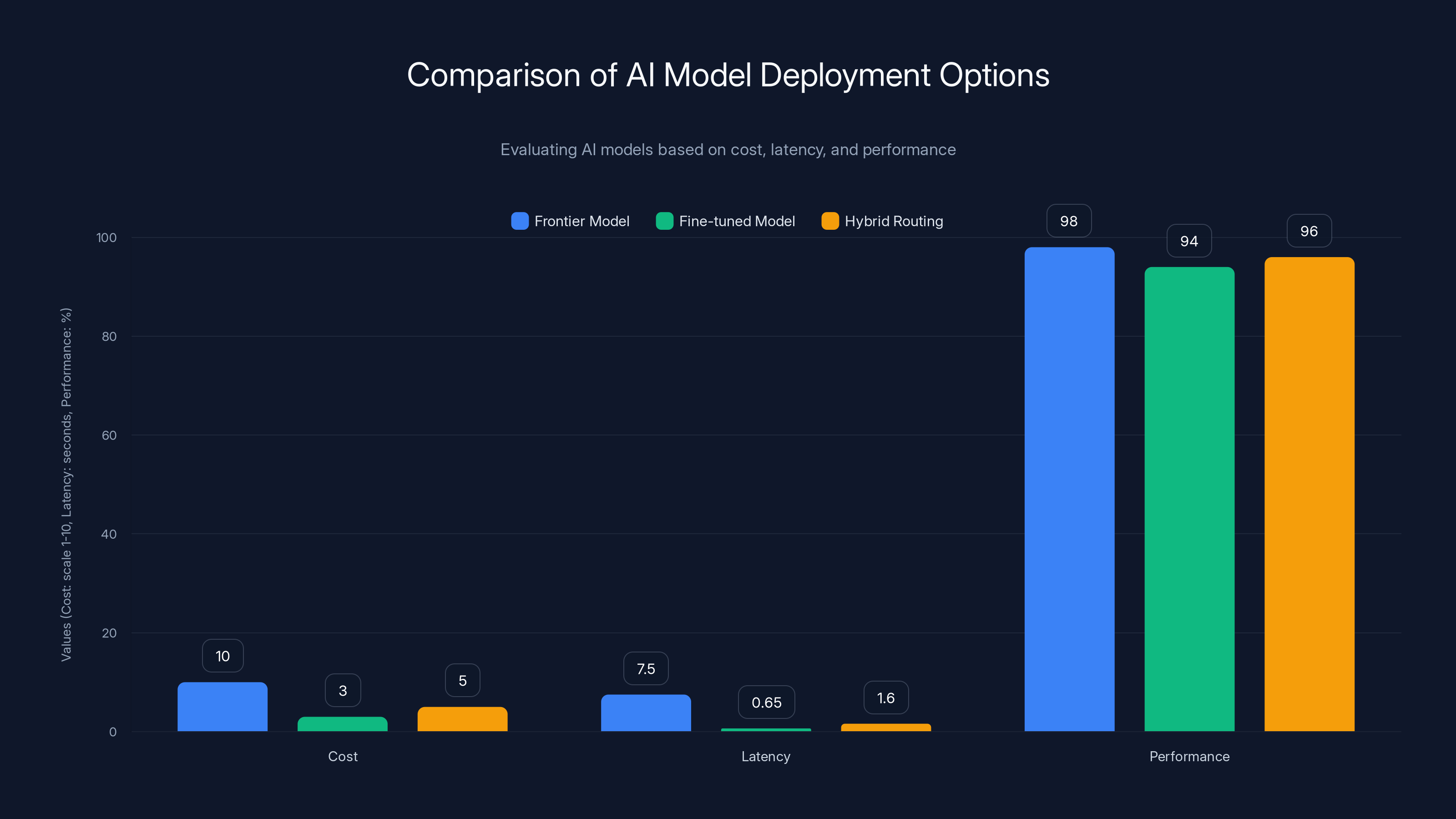
The chart compares three AI deployment options. The Frontier Model excels in performance but is costly and slower. The Fine-tuned Model is cost-effective with moderate performance. Hybrid Routing balances cost, latency, and performance.
The Infrastructure Gap: What's Actually Missing
Let's get specific about what's missing.
Audit trails and explainability: We need standardized ways to record what an AI agent did and why. This includes the inputs it received, the reasoning process it followed, and the outputs it generated. Current logging systems weren't designed for this level of detail.
Authorization frameworks: We need policies that specify exactly what actions an agent can take. This isn't just about role-based access control. It needs to understand context. "This agent can approve expenses under $10,000" is different from "this agent can approve any expense as long as it's from the approved vendor list."
Monitoring and alerting: We need to detect when agents are behaving abnormally or violating policies. This requires understanding what normal behavior looks like for your specific agents and systems.
Testing frameworks: We need ways to test agent behavior safely before deploying to production. This includes both unit testing (does the agent handle this specific case correctly) and integration testing (does the agent play nicely with other systems).
Deployment and versioning: We need ways to safely deploy new versions of agents, roll back if something goes wrong, and maintain multiple versions simultaneously.
Monitoring at scale: As you deploy more agents, you need centralized monitoring that lets you understand what's happening across your entire fleet of agents.
Some companies are building internal frameworks to address these gaps. But there's no industry standard yet. Every company is solving these problems independently, which is expensive and slow.
This is why we're seeing so much investment in AI operations platforms. Companies like Humanloop, Gretel, and others are building tools to address the operational gaps. These tools don't make models smarter. They make it practical to deploy smart models safely and at scale.
Vertical Integration as Competitive Advantage
Companies with vertical integration across the entire AI stack have significant advantages when optimizing for the three frontiers.
Consider the typical AI deployment stack:
- Hardware/chips: Processors optimized for AI inference
- Infrastructure: Data centers, networking, deployment systems
- Model training: Creating and fine-tuning models
- Inference engines: Running models efficiently
- APIs and SDKs: Developer interfaces
- Applications: End-user products
When a company controls all of these layers, they can make joint optimizations that companies controlling only part of the stack can't make.
For example, suppose you want to optimize for the latency frontier. You have several options:
- Use a smaller model (affects quality)
- Optimize the inference engine (requires control over hardware and software)
- Build custom hardware (requires chip design capability)
- Change the model architecture (requires training capability)
- Batch requests and use speculative decoding (requires API design flexibility)
A vertically integrated company can do all of these simultaneously. A company that only provides an API can maybe do some of them.
This is relevant because Google has this vertical integration. They design chips (TPUs). They build infrastructure. They train models (Gemini). They operate inference systems (Vertex AI). They build APIs. They have consumer products (Gemini). They can optimize the entire stack for different frontiers simultaneously.
Competitors without this vertical integration have to make harder trade-offs. If you're Open AI, you can't change the chip design if your inference isn't fast enough. You're limited to optimizing the model and the software. That's still significant, but it's not as much leverage.
Vertical integration also matters for the cost-extensibility frontier. If you control everything, you can optimize end-to-end efficiency. Google can make sure their chips are optimized for Gemini. They can optimize the Gemini architecture for their hardware. They can optimize the inference engine to squeeze every bit of performance. They can optimize the Vertex API to route requests efficiently.
This kind of end-to-end optimization is hard for companies that have to buy hardware from someone else, use inference engines from the open source community, and rely on third-party infrastructure.

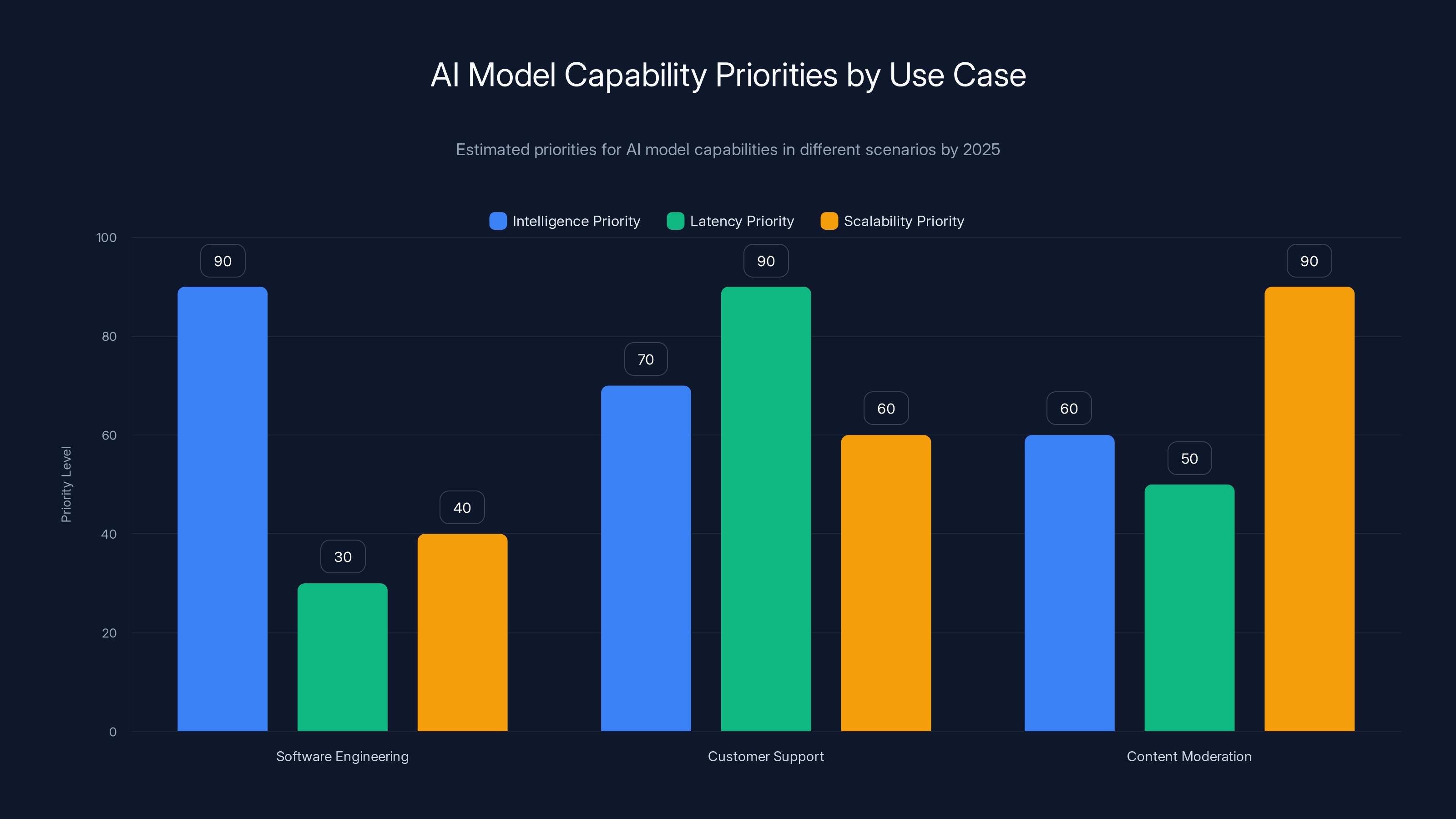
Different use cases prioritize AI model capabilities differently: software engineering values intelligence, customer support prioritizes low latency, and content moderation focuses on scalability. Estimated data.
Specialized Models vs. General Models: A Changing Landscape
The three frontiers framework helps explain a trend we're seeing: the rise of specialized models.
A few years ago, the assumption was that bigger general models would eventually beat specialized models at everything. One model to rule them all.
But that hasn't happened. Instead, we're seeing a more nuanced picture where specialized models often beat general models within specific frontiers or use cases.
A specialized model fine-tuned for your domain might:
- Provide better accuracy for your specific task
- Cost less to run because it's smaller
- Run faster because it's optimized for your use case
- Be easier to integrate into your workflows
The trade-off is that it only works well for your specific domain. It won't generalize to other tasks.
For companies deploying AI systems, this creates strategic flexibility. You're not stuck choosing between one big expensive model or a bunch of cheap weak models. You can build a portfolio of specialized models, each optimized for different tasks.
Some companies are building model marketplaces where you can find models optimized for specific tasks. Others are building fine-tuning services that let you quickly create specialized versions of general models.

Where We're Headed: The Next Evolution
If the current frontier is about optimizing within three dimensions (intelligence, latency, extensibility), what's the next frontier?
I'd argue it's about composability and modular AI systems. Instead of deploying monolithic models, companies will increasingly deploy systems made up of multiple specialized models, each optimized for specific aspects of the problem.
This requires new infrastructure for:
- Model orchestration: Routing requests to the right model at the right time
- Result composition: Combining outputs from multiple models into a coherent response
- Caching and memoization: Reusing results from previous similar queries
- Cost optimization: Making sure the overall system stays within budget while maintaining quality
Companies that get really good at building these modular systems will have significant advantages. They'll be able to optimize for multiple frontiers simultaneously, respond quickly to changing requirements, and reduce costs through specialization.
The companies that remain dependent on monolithic general models will find themselves increasingly outcompeted in cost, latency, and reliability.
This shift is already happening in some domains. Search systems have moved from monolithic information retrieval to multi-stage ranking pipelines. Recommendation systems use different models for different stages. Financial systems use specialized models for different types of decisions.
AI systems will follow the same pattern. The future isn't one giant superintelligent model. It's a fleet of specialized models, each optimized for specific tasks, orchestrated together to solve complex problems.
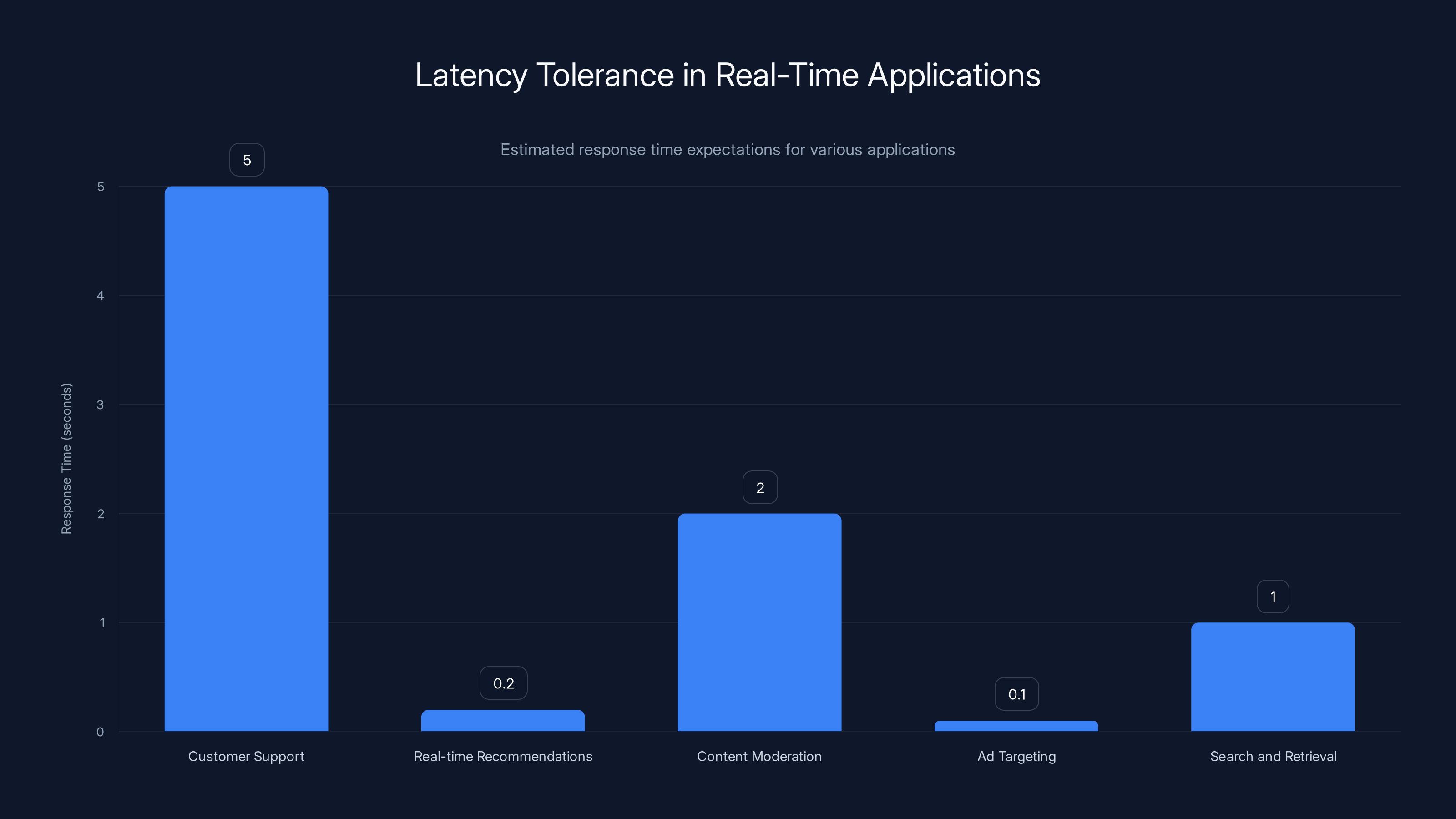
Different applications have varying latency expectations, with ad targeting and real-time recommendations requiring responses in milliseconds. Estimated data.
Implications for Your Organization
If you're building AI systems, this framework should change how you think about model selection and deployment.
Instead of asking "What's the best model?" ask "Where do I need to optimize?" Then select models and build infrastructure to optimize for those specific frontiers.
If you're optimizing for intelligence, you might use a frontier model and accept longer latency. You might invest in fine-tuning to get better performance on your specific tasks. You might build a robust evaluation framework to verify the model is producing good results.
If you're optimizing for latency, you might use a smaller model and spend time on prompt engineering and retrieval-augmented generation to make it smarter. You might build a fast classification layer that routes simple requests to cheap models and complex requests to expensive models.
If you're optimizing for cost-extensibility, you might use a portfolio of models, with different models handling different complexity levels. You might invest heavily in fine-tuning to get better performance from smaller models. You might implement aggressive batching and caching.
The key insight is that there's no one right answer. The right answer depends on your specific constraints and requirements. Understanding the three frontiers gives you a framework for making these decisions systematically rather than just chasing the latest model benchmarks.
FAQ
What are the three frontiers of AI model capability?
The three frontiers are: raw intelligence (capability and accuracy), response latency (speed of generating responses), and cost-effective extensibility (ability to scale to massive, unpredictable demand while maintaining cost predictability). Each frontier represents a different optimization target, and different applications prioritize different frontiers based on their specific requirements.
Why does latency matter more than intelligence in some applications?
Latency matters because human users have finite patience. In customer support scenarios, if an AI agent takes 45 minutes to answer a policy question, the customer has already left. An intelligent answer that arrives too late provides no value. For latency-constrained applications, intelligence matters only within the time budget available. A good-enough answer in two seconds beats a perfect answer in two minutes.
How does the extensibility frontier differ from the other two?
The extensibility frontier focuses on cost predictability at massive scale rather than raw capability or speed. When platforms like Reddit or Meta need to moderate billions of posts across unpredictable traffic spikes, they can't use the most expensive model available. They need the most intelligent model they can afford to run at any scale. This creates fundamentally different architectural requirements than optimizing for intelligence or latency alone.
Why is software engineering seeing faster adoption of agentic AI than other industries?
Software development already has infrastructure patterns that agentic AI needs: development environments where it's safe to break things, automatic testing, code review processes, staging environments, and version control with rollback capabilities. Other industries lack these built-in safety and governance patterns, making it harder to deploy AI agents safely. Building these patterns in other industries is the actual blocker to agentic AI adoption.
What infrastructure is missing for widespread agentic AI adoption?
Key missing pieces include standardized audit trails and explainability mechanisms, authorization frameworks that understand context, monitoring and alerting systems designed for AI agents, testing frameworks for agent behavior, deployment and versioning systems for managing multiple agent versions, and centralized monitoring for fleets of agents. These operational and governance capabilities are necessary before companies feel confident deploying AI agents to handle consequential decisions.
How does vertical integration give companies advantages in optimizing for these frontiers?
Companies with control over chips, infrastructure, model training, inference engines, and APIs can make joint optimizations that specialized companies can't. They can optimize hardware for specific model architectures, design models for their hardware, optimize inference engines, and route requests efficiently across their entire system. A company controlling only the API layer or only the model training has less flexibility to optimize across all three frontiers simultaneously.
Will specialized models eventually outcompete general models?
Specialized models are increasingly competitive within specific domains and frontiers. A specialized model fine-tuned for your use case might provide better accuracy, lower cost, and faster inference than a larger general model, even if the general model is technically more capable. However, general models retain advantages for novel or unexpected tasks. Most organizations will likely use a portfolio of models, with general models handling unexpected cases and specialized models optimizing for specific, well-defined tasks.
How should organizations choose between optimizing for intelligence, latency, or cost?
The choice depends on your specific application and constraints. Ask: Does quality matter more than speed? Do you have strict time budgets for responses? Is cost or demand predictability the primary constraint? Different answers lead to different optimization strategies. Most organizations optimize for multiple frontiers simultaneously, but understanding which frontier matters most for each use case helps prioritize engineering efforts and model selection.
What's the role of model distillation in the three frontiers?
Model distillation training a smaller model to mimic a larger model's behavior is a key technique for optimizing latency and cost frontiers. A smaller distilled model can sometimes match a larger model's accuracy while running 5-10x faster and costing significantly less. This makes distillation particularly valuable for applications where you need high accuracy but have strict latency or cost constraints.
How do retrieval-augmented generation and fine-tuning affect frontier optimization?
Both techniques can improve intelligence-per-dollar and intelligence-per-millisecond. Retrieval-augmented generation replaces some of the model's need for memorized knowledge with fast lookups, improving latency and reducing model size requirements. Fine-tuning adapts models to specific domains, often improving accuracy while potentially reducing model size needs. Both techniques are especially valuable for latency and cost-extensibility frontiers.
The evolution of AI models isn't just about raw intelligence anymore. It's about understanding what intelligence actually means in your specific context, and optimizing for the frontiers that matter to your business. The companies that master this three-dimensional optimization problem will build AI systems that are cheaper, faster, and more practical than companies stuck optimizing for a single dimension.
Key Takeaways
- AI models compete simultaneously on three distinct frontiers: raw intelligence, response latency, and cost-effective extensibility at scale
- Different applications require different optimization strategies. Code generation prioritizes intelligence; customer support requires latency constraints; content moderation needs cost predictability
- The infrastructure gap, not model capability, is the primary blocker to agentic AI adoption. Missing audit trails, authorization patterns, and human-in-the-loop workflows prevent production deployment
- Software engineering leads agentic AI adoption because development workflows already include the testing, review, and promotion patterns that safe AI deployment requires
- Vertical integration across chips, infrastructure, models, and APIs enables simultaneous optimization across all three frontiers that specialized companies cannot achieve
Related Articles
- The Future of AI Hardware: Why GPUs Won't Dominate Data Centers by 2036 [2025]
- India's Sarvam Launches Indus AI Chat App: What It Means for AI Competition [2025]
- G42 and Cerebras Deploy 8 Exaflops in India: Sovereign AI's Turning Point [2025]
- AI Energy Consumption vs Humans: The Real Math [2025]
- Meta and Nvidia Partnership: Hyperscale AI Infrastructure [2025]
- AI Agents in Production: What 1 Trillion Tokens Reveals [2025]

