![Meta and Nvidia Partnership: Hyperscale AI Infrastructure [2025]](https://tryrunable.com/blog/meta-and-nvidia-partnership-hyperscale-ai-infrastructure-202/image-1-1771704399241.jpg)
Meta and Nvidia's Historic Partnership: Building the AI Infrastructure for Billions
In 2025, technology doesn't move slowly anymore. Partnerships that would have taken months of negotiation a decade ago now happen at the speed of innovation itself. When Meta announced its multi-year partnership with Nvidia, it wasn't just another tech collaboration. This was a declaration that the race for hyperscale AI infrastructure had entered a new phase.
Here's the thing: AI at Meta's scale isn't theoretical anymore. The company runs personalization engines that serve billions of users daily across Facebook, Instagram, WhatsApp, and Threads. Each recommendation, each ad placement, each content ranking decision involves machine learning systems operating at a scale that most companies can't even comprehend. When Nvidia's CEO Jensen Huang said "no one deploys AI at Meta's scale," he wasn't exaggerating. He was describing a technical reality, as noted in Nvidia's announcement.
This partnership represents something bigger than just hardware procurement. It's the alignment of two companies recognizing that the future of AI infrastructure requires deep integration across CPUs, GPUs, networking, software, and memory systems. Meta needed raw computational power, but it also needed optimization at every layer. Nvidia needed a flagship customer that could push its technology to breaking points and then ask for more.
What makes this deal particularly significant is the timing. We're in an era where AI capabilities are expanding faster than infrastructure can support them. Companies like OpenAI and Anthropic are building larger models. Google DeepMind is working on systems that could transform entire industries. Everyone's competing for GPU capacity, and the infrastructure bottleneck is real.
Meta's move changes the equation. By securing millions of Nvidia GPUs and committing to a multi-year partnership, the company is essentially betting that the most defensible competitive advantage in AI won't be the models themselves, but the infrastructure running them, as highlighted in Engadget's report.
TL; DR
- Scale and Scope: Meta and Nvidia are deploying millions of GPUs and Arm-based CPUs across unified on-premises and cloud infrastructure to handle some of the largest AI workloads globally.
- Technical Integration: The partnership integrates Nvidia's GB300 systems, Spectrum-X Ethernet, and Grace CPUs with Meta's production workloads, optimizing performance per watt.
- Privacy Innovation: Meta is implementing Nvidia Confidential Computing for WhatsApp and other services, allowing AI models to process user data while maintaining privacy.
- Unified Architecture: The companies are building a single architecture spanning data centers and Nvidia cloud partner deployments, simplifying operations while maintaining massive scale.
- Future Roadmap: Mark Zuckerberg's vision for "personal superintelligence" requires infrastructure that can handle next-generation AI models at unprecedented scale.

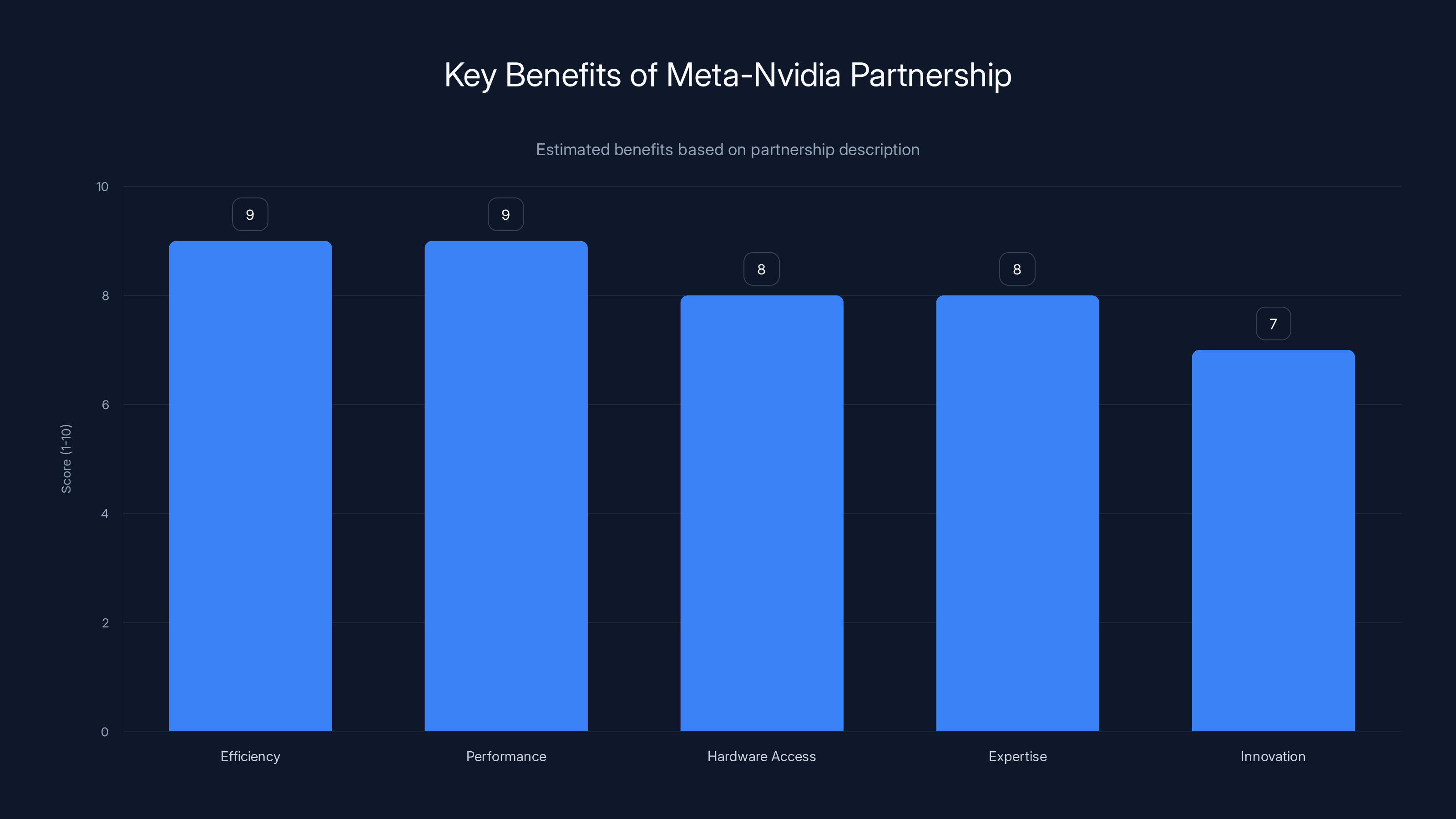
The partnership between Meta and Nvidia is estimated to significantly enhance efficiency and performance, with high scores in hardware access and expertise, facilitating innovation. Estimated data based on qualitative insights.
Understanding the Scale: What "Hyperscale" Actually Means
When tech executives use the term "hyperscale," they're usually describing infrastructure that operates in a completely different category from normal enterprise systems. But what does that actually mean in practical terms?
For Meta, hyperscale means serving 3 billion monthly active users with personalized content. That's not an exaggeration. The company's platforms include Facebook, Instagram, WhatsApp, and Threads, each with hundreds of millions to billions of users. Every single interaction—every scroll, every like, every comment—feeds data into recommendation systems that need to make split-second decisions about what content to show next, as detailed in Marketing4eCommerce.
Think about the math. If Facebook has 2 billion daily active users, and each user's feed requires 50-100 content ranking decisions per session, that's hundreds of billions of inference operations per day. Each operation needs to run in under 100 milliseconds to avoid degrading user experience. The latency budget is brutal. There's no room for slow responses.
The infrastructure challenges multiply. You don't just need GPU compute power. You need networking that can move data between thousands of GPUs without bottlenecks. You need memory systems that allow models to operate on massive datasets without constant storage I/O delays. You need software stacks that optimize everything from the silicon up through the application layer.
Nvidia has spent the last decade building exactly this kind of integrated ecosystem. The company's strategy shifted from selling standalone GPUs to selling complete infrastructure stacks. That's why the partnership makes sense. Nvidia's software ecosystem—CUDA for compute, cuDNN for neural networks, NCCL for distributed communication—is designed specifically for problems at Meta's scale, as noted in Nvidia's announcement.
Mark Zuckerberg's vision of "personal superintelligence" adds another layer of complexity. The company isn't just running inference on existing models. It's training new models continuously, fine-tuning them for specific use cases, and deploying them across multiple services. That requires both training infrastructure and inference infrastructure, and they need to coexist in the same architecture.

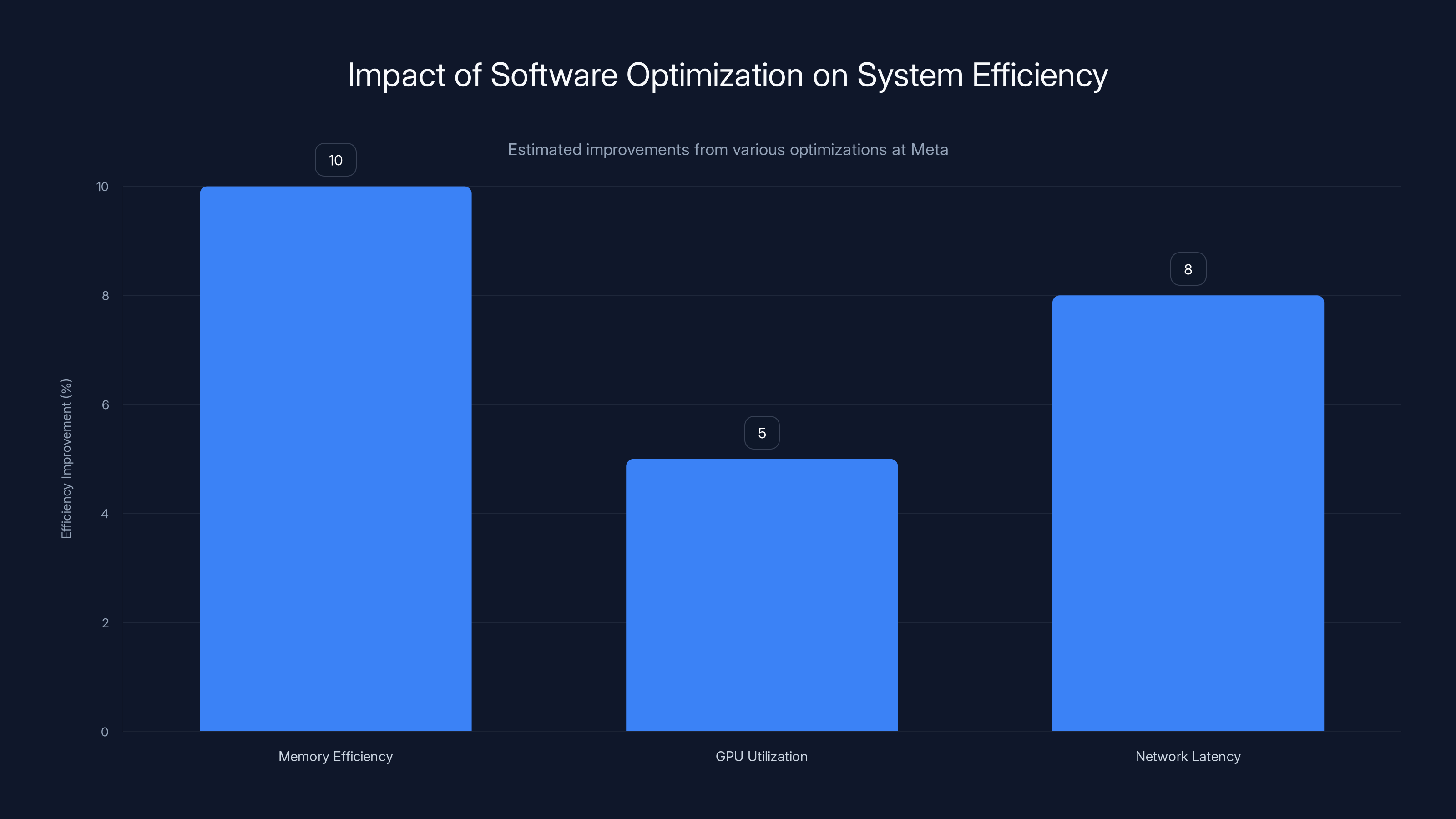
Estimated data shows that combined software optimizations can lead to a 25% overall system efficiency improvement at Meta, significantly reducing operational costs.
The Hardware Foundation: Nvidia's GB300 and Grace CPUs
At the heart of this partnership sits Nvidia's latest generation of AI processors. The GB300-based systems represent a major leap forward in GPU architecture, and the Grace CPU represents a bet that Arm-based processors can compete with x86 for AI workloads.
Let's start with the GPU side. The GB300 is Nvidia's latest flagship accelerator designed specifically for large language models and AI training. It brings substantial improvements over previous generations in terms of memory bandwidth, compute capability, and power efficiency. The architecture combines massive parallel processing capability with advanced memory hierarchies designed to handle the kind of attention mechanisms that power modern transformers.
What matters most isn't just raw compute. It's compute efficiency. In AI infrastructure, power consumption directly translates to operational costs. A system that's 20% more efficient means lower electricity bills, less cooling infrastructure needed, and smaller data center footprints. For a company operating at Meta's scale, a 20% efficiency gain translates to millions of dollars annually.
The GB300 achieves this through several architectural improvements. The memory system is redesigned to reduce data movement, which is often the bottleneck in AI workloads. The interconnect between GPUs is optimized for the all-to-all communication patterns required by distributed training. The power distribution is more efficient, reducing parasitic losses in the electrical system.
But here's where the partnership gets interesting. Nvidia added something new: tight integration with Arm-based CPUs. Enter the Grace CPU.
Traditionally, AI infrastructure has used x86 processors (from Intel or AMD) as host CPUs managing GPU clusters. The Grace CPU changes that equation by offering an Arm-based alternative specifically optimized for AI workloads. This is significant because Arm's efficiency advantage in mobile and low-power applications translates surprisingly well to data center environments when optimized properly, as detailed in Nvidia's announcement.
The codesign aspect is crucial. Nvidia and Meta's engineering teams didn't just pair existing components. They optimized them together. Software libraries were rewritten to take advantage of Grace's specific architectural characteristics. Memory hierarchies were tuned for the way Meta's models access data. Even the interconnect between CPUs and GPUs was optimized for Meta's specific workloads.
This kind of codesign work is expensive and time-consuming. It's only feasible when you have a customer like Meta with the scale to justify the investment. But when done right, it unlocks efficiency gains that generic optimization can't achieve.
Networking Innovation: Spectrum-X Ethernet
GPUs get most of the attention in AI infrastructure discussions, but networking is equally critical. The bottleneck isn't always compute. Often it's moving data between GPUs and between nodes.
Nvidia's Spectrum-X Ethernet is designed specifically for this problem. It uses Nvidia's NVLink technology integrated with Ethernet, creating a network fabric optimized for AI workloads. The result is predictable, low-latency communication between thousands of GPUs.
Why does this matter? Imagine you're training a large language model. The forward pass through the model might take 1 second. The backward pass to compute gradients might take another 1.5 seconds. But if your network can't efficiently synchronize gradients across 10,000 GPUs, the effective training time might double. Efficient networking prevents those synchronization bottlenecks.
Spectrum-X provides several advantages. It offers higher bandwidth than conventional Ethernet. It reduces latency variance, which is critical for synchronized operations. It includes intelligent congestion management so that one congested link doesn't slow down the entire network. It supports in-network computing, allowing network switches to perform certain operations like gradient reduction directly on the hardware.
Meta is expanding this networking throughout its data centers. That's a massive undertaking. It means replacing existing network infrastructure with Spectrum-X switches and cables. It means retraining network engineers on new management tools and configurations. It means updating software stacks to take advantage of the new network capabilities.
But the investment pays for itself. For training models at billion-parameter scale, the difference between a network that supports 500 Gbps all-to-all communication and one that supports 1.6 Tbps is literally the difference between training a model in 3 weeks or 6 weeks, as highlighted in Nvidia's announcement.

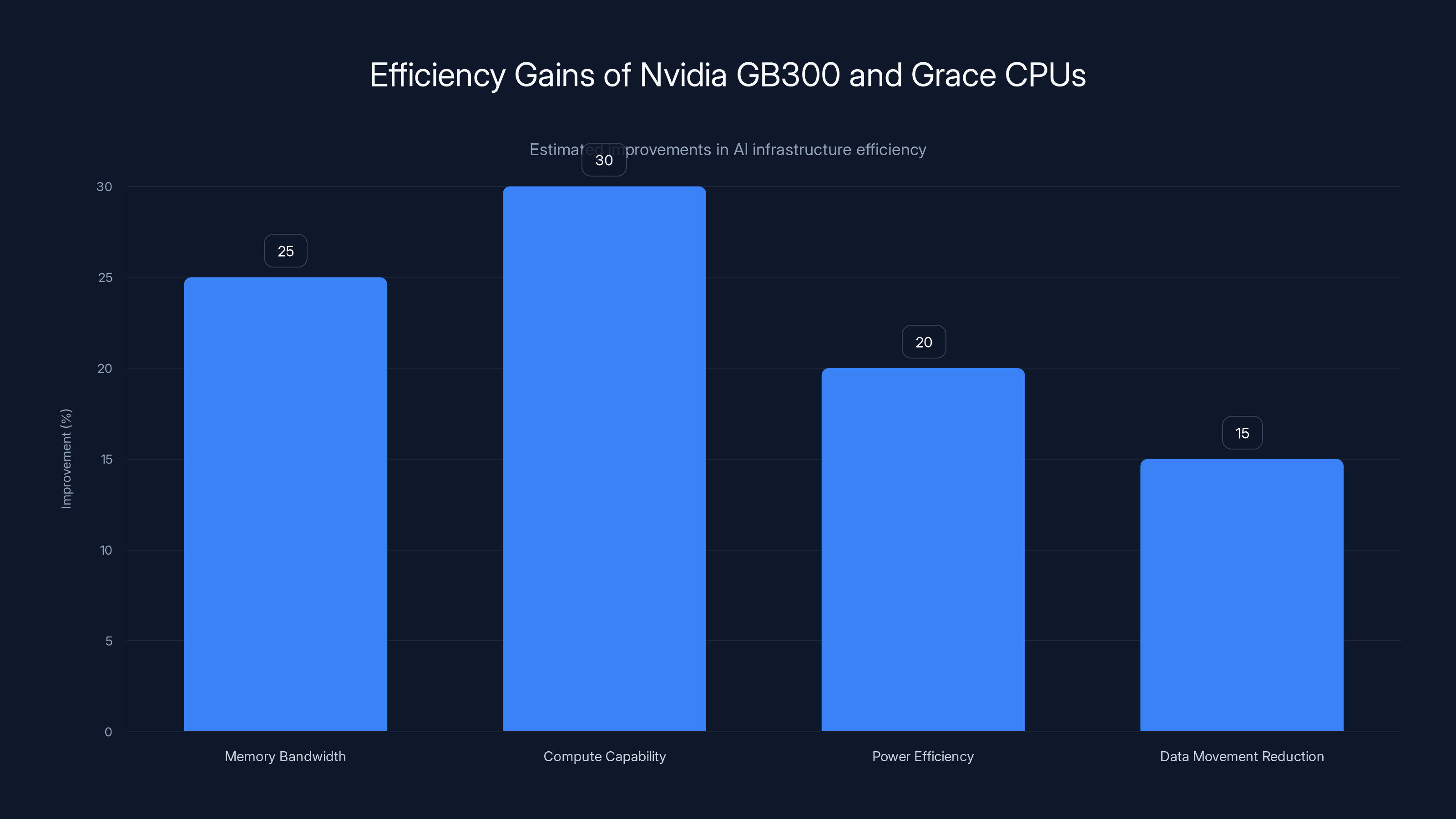
The Nvidia GB300 and Grace CPUs offer significant efficiency improvements, with up to 30% gains in compute capability and 20% in power efficiency. Estimated data.
Privacy-Preserving AI: Nvidia Confidential Computing
One of the most interesting aspects of this partnership is the focus on privacy. Specifically, Nvidia Confidential Computing, which allows AI models to process sensitive data without exposing that data to the underlying infrastructure operators.
This sounds abstract, but it's practically crucial for Meta. The company operates WhatsApp, a messaging service that needs to honor end-to-end encryption guarantees. But Meta also wants to add AI capabilities to WhatsApp—things like intelligent reply suggestions, content filtering, and translation features. The challenge: how do you run AI models on encrypted data without decrypting it first?
Nvidia Confidential Computing solves this using Trusted Execution Environments (TEEs). These are isolated execution spaces within the GPU where code and data are encrypted and can only be accessed by authorized processes. The host operating system and system administrators can't see what's happening inside the TEE. Even if someone compromises the data center physically or breaks into the system software, the encrypted data remains protected, as explained in Engadget's report.
The implications are significant. Meta can deploy AI models that process WhatsApp messages without actually being able to read those messages. The AI operates on encrypted data, produces results, and those results are the only thing that leaves the trusted environment. Users get personalized AI features while maintaining cryptographic guarantees about data privacy.
This is a substantial technical achievement. TEEs historically have been much slower than unrestricted execution because of the overhead of encryption and isolation. Nvidia optimized Confidential Computing specifically for the throughput requirements of AI inference. The company added hardware acceleration for cryptographic operations commonly used in TEE implementations.
Meta plans to extend this approach beyond WhatsApp. The partnership announcement mentions deploying Confidential Computing across multiple Meta services. Imagine running AI models on Instagram messages, on Facebook comments, on any text or data with privacy implications, with cryptographic guarantees that the infrastructure operators can't violate.

Unified Architecture: On-Premises and Cloud Integration
Most companies think of infrastructure as either on-premises or cloud-based. They pick one or the other and deal with the operational differences. Meta is taking a different approach: creating a truly unified architecture that spans both on-premises data centers and Nvidia cloud partner deployments.
This sounds simple, but it's architecturally complex. On-premises infrastructure is owned and operated by Meta directly. Cloud infrastructure is owned and operated by providers like AWS, Google Cloud, or Azure. They have different management tools, different upgrade procedures, different failure modes, and different operational characteristics.
A unified architecture means applications and workloads can move seamlessly between on-premises and cloud resources. A training job might start on premises but burst to cloud resources during peak training phases. An inference service might primarily run in one data center but automatically fail over to another location without downtime. Model deployments happen once and run everywhere.
Achieving this requires standardization at every layer. The hardware must be identical, whether in Meta's data centers or a cloud provider's facility. The network fabric must provide equivalent performance and latency characteristics. The software stack—from operating systems through container runtimes through model serving libraries—must behave identically everywhere.
Nvidia plays a crucial role here because the company's software ecosystem can run on Nvidia-based infrastructure anywhere. Whether a GB300 GPU is in Meta's Sacramento data center or Nvidia's Santa Clara facility, the CUDA runtime, cuDNN libraries, and networking stack work the same way. That consistency is what enables unified architecture.
The operational benefits are substantial. Meta gains flexibility to deploy workloads where it makes most sense—closer to users for lower latency, in locations with cheaper power, wherever data residency requirements mandate. If one data center fills up with infrastructure, new workloads automatically distribute to other locations without application changes, as noted in Nvidia's announcement.

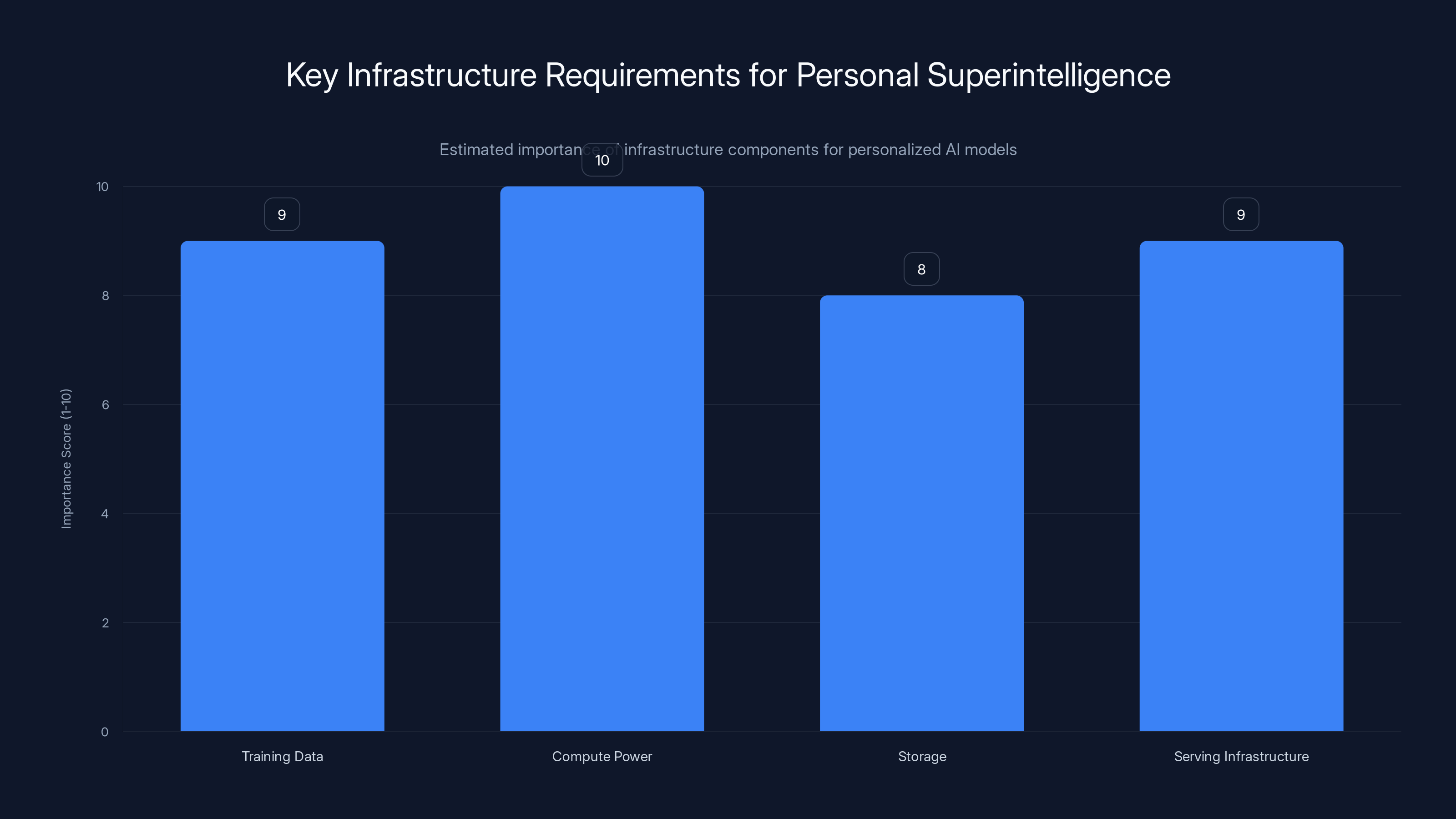
Compute power and serving infrastructure are crucial for implementing personalized AI models, with high importance scores. Estimated data.
The Software Layer: Optimization and Integration
Hardware is only half the story. The real differentiation happens in software.
Meta and Nvidia's engineering teams are doing something called "codesign across the full stack." That means CPU libraries are being rewritten to take advantage of Grace's specific characteristics. GPU kernels are being hand-tuned for Meta's workloads. Networking drivers are being optimized for the communication patterns in Meta's models. Memory management is being redesigned to reduce allocation latency.
This is painstaking work. It requires deep knowledge of both the hardware and the specific workloads. A software engineer needs to understand not just how to write correct code, but how to write code that maps efficiently onto the underlying hardware. They need to understand CPU pipeline behavior, GPU warp scheduling, memory hierarchy characteristics, and network topology.
Why is this worth the effort? Because incremental improvements compound. A 10% improvement in memory efficiency combined with a 5% improvement in GPU utilization combined with an 8% improvement in network latency adds up to something approaching a 25% overall system efficiency improvement. At Meta's scale, a 25% efficiency improvement is worth hundreds of millions of dollars in annual operational costs.
Meta is particularly focused on what's called "performance per watt." This metric measures how much useful computation you get for each watt of electrical power consumed. In data centers with thousands of GPUs, power consumption isn't just an operational cost—it's a constraint. Some data centers can't add more infrastructure because they've maxed out available electrical power. Others face limits from cooling systems. By optimizing performance per watt, Meta can train larger models in existing facilities without requiring new infrastructure buildouts.
The software optimizations span multiple areas. Matrix multiplication libraries are being tuned for the specific tensor dimensions in Meta's models. Sparse tensor operations are being optimized to skip zero-valued elements. Communication algorithms are being redesigned for the specific network topology. Memory allocation strategies are being changed to reduce fragmentation.
These aren't one-time optimizations. They're ongoing. As Nvidia releases new hardware generations, Meta's software needs to adapt. As Meta builds larger models, software bottlenecks emerge that require new optimization approaches. The partnership structure—with engineering teams from both companies working together—enables this continuous improvement cycle, as highlighted in Nvidia's announcement.

Grace CPU Deployment: A Flagship Implementation
Meta's commitment to large-scale Grace CPU deployment is notable because it's the first major production deployment of Arm-based processors at this scale specifically for AI workloads.
This matters because it signals to the industry that Arm can compete with x86 for data center AI workloads. For decades, x86 processors from Intel dominated data centers. AMD disrupted that with more efficient x86 designs. But Arm has always been considered a mobile and low-power processor architecture. Meta's deployment essentially says: Arm can do data center AI, and it can do it better than x86 in some scenarios.
The Grace CPU brings several advantages. It uses a more efficient instruction set than x86, which translates to lower power consumption for equivalent work. It has a different cache hierarchy that can be optimized for how AI workloads access memory. It includes specialized instructions for operations common in machine learning, like matrix operations and reductions.
But more importantly, Grace was codesigned specifically for AI data centers. Nvidia didn't just port its ARM cores into a data center form factor. The company built Grace from the ground up to be an AI-optimized processor. That's visible in the memory bandwidth characteristics (optimized for feeding data to accelerators), the interconnect design (optimized for GPU communication), and the power delivery system (optimized for sustained high-utilization workloads).
For Meta, this means the host CPU isn't a bottleneck. Traditional data center designs often have CPU-GPU imbalances. The CPU might finish its work and have to wait for the GPU, or the GPU might finish and wait for the CPU to prepare the next batch of data. With Grace optimized specifically for GPU acceleration, these imbalances are minimized.
Meta's large-scale deployment also creates a feedback loop. As the company uses millions of Grace CPUs, performance characteristics emerge that Nvidia didn't anticipate. Nvidia can then optimize future iterations based on real-world workload data. It's a mutual benefit arrangement that accelerates both companies' innovation cycles, as noted in Nvidia's announcement.

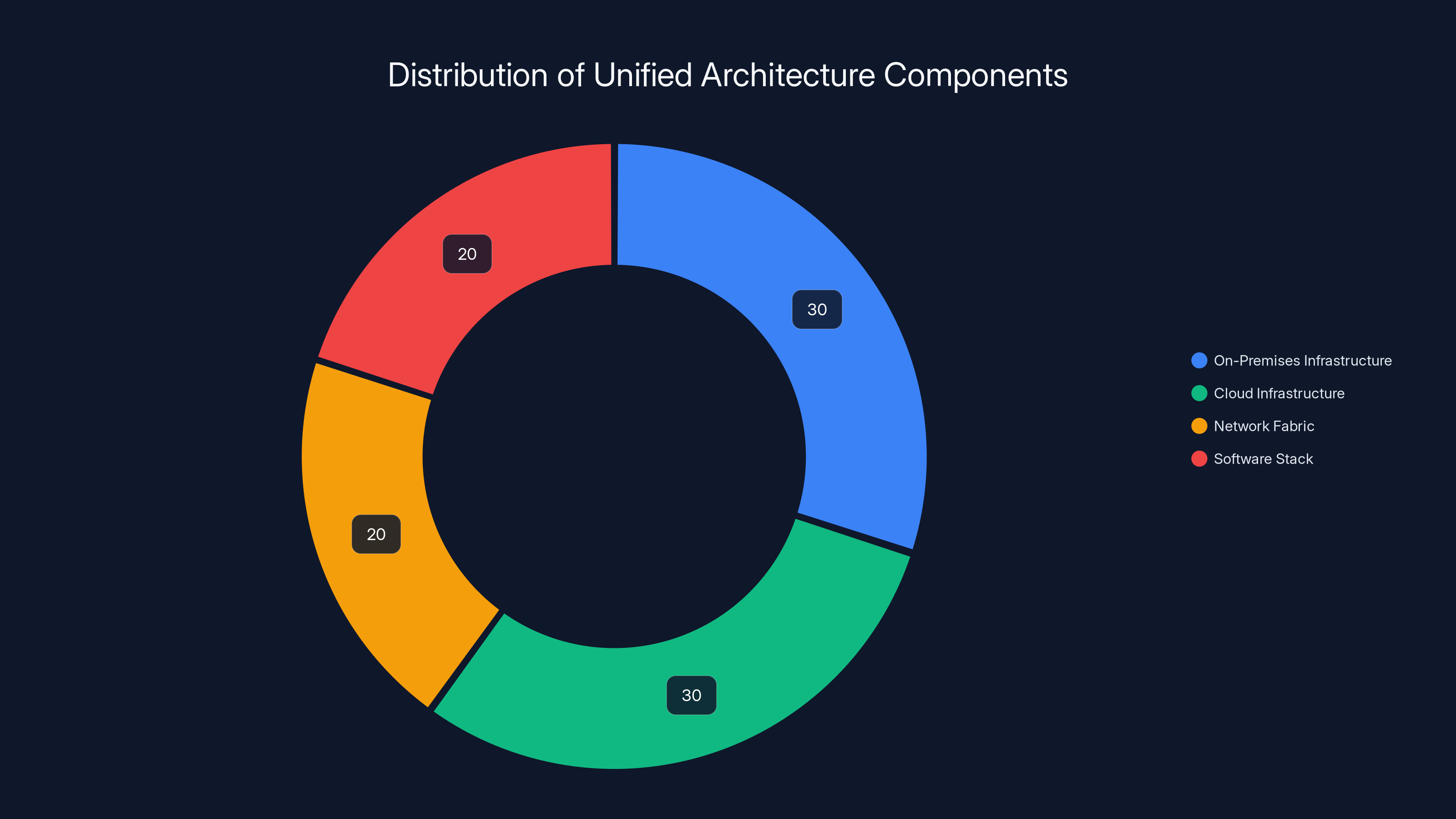
Estimated data shows a balanced distribution of components in a unified architecture, with equal emphasis on on-premises and cloud infrastructure, and significant focus on network and software standardization.
Model Training and Inference: Dual Optimization
Meta's infrastructure needs to handle two distinct workloads: training and inference. They have completely different characteristics, and optimal infrastructure for one isn't always optimal for the other.
Training involves processing massive amounts of data, computing gradients, and updating model parameters. It's throughput-optimized work. You care about processing as much data as possible per unit time. Latency matters less because you're not in a real-time deadline situation. A training job running 5% slower because of a 10-millisecond latency hiccup doesn't matter much. A training job running 5% slower because it's compute-bound does matter, a lot.
Inference is the opposite. You're running a trained model on new data to generate predictions. It's latency-optimized work. Users waiting for a response care deeply about how long the inference takes. A 10-millisecond latency improvement in inference affects user experience immediately. A 10-millisecond latency improvement in training affects overall training time, but the impact is proportional to the fraction of time spent in communication versus compute.
Meta's infrastructure needs to support both efficiently. The partnership with Nvidia enables this through several mechanisms.
First, the hardware itself is flexible. GPUs can operate in training or inference modes, and software can optimize for each. Training workloads use batching to get high throughput. Inference workloads use low-latency serving to keep response times minimal. The same underlying GPU can be time-sliced between these different workload types.
Second, the networking infrastructure supports both patterns. Training requires all-to-all communication during gradient synchronization. Inference requires client-to-server communication with specific latency budgets. Spectrum-X Ethernet can optimize for both patterns, prioritizing gradient synchronization when training jobs are active and minimizing tail latencies for inference queries.
Third, the software stack is optimized for both. Libraries like cuDNN have training-optimized kernels and inference-optimized kernels. Model serving software like TensorRT is designed specifically for low-latency inference. Training frameworks like PyTorch are optimized for distributed training. These tools allow the same hardware to be used effectively for completely different purposes.
Meta actually needs both capabilities urgently. The company is training new models continuously (to stay competitive with OpenAI, Anthropic, and Google), while simultaneously serving inference from billions of personalized models (one for each user's feed, essentially). The infrastructure must support massive scale on both fronts, as highlighted in Nvidia's announcement.

Zuckerberg's Vision: Personal Superintelligence
Mark Zuckerberg's recent messaging focuses increasingly on "personal superintelligence." It's not hyperbole. It's the guiding vision for what Meta's building.
The idea is that in the near future, AI systems will be capable enough and personalized enough that they essentially become digital extensions of each user's intelligence. Instead of searching for information, your AI assistant proactively suggests relevant content, answers questions before you ask them, and handles tasks on your behalf.
Implementing this vision requires infrastructure at scales that currently don't exist. A truly personalized AI assistant can't be the same model for everyone. Each person needs a model (or multiple models) fine-tuned to their preferences, goals, knowledge base, and communication style. If Meta serves this to billions of users, the infrastructure requirements become astronomical.
Each personalized model needs training data (your messages, your activity, your preferences). It needs training compute (to fine-tune on your specific data). It needs storage (to keep your personalized model weights). And crucially, it needs serving infrastructure (to run inference when you query it).
Traditional infrastructure can't support this. You'd need custom hardware and software for each user, which is obviously impractical. Instead, Meta is building infrastructure that can serve billions of custom models efficiently through shared compute resources, careful memory management, and optimization techniques like low-rank adaptation.
This is technically ambitious. It requires models that can be personalized with minimal training time and compute. It requires serving systems that can switch between billions of different models without massive latency penalties. It requires networking and storage that can handle billions of personalized data streams. And it requires power and cooling infrastructure that can support all of this simultaneously.
The Nvidia partnership directly enables this vision. The massive GPU and CPU capacity provides training resources. The optimized software stack ensures training and serving are efficient. The unified architecture allows flexibility in where different workloads run. The privacy-preserving computing ensures users' personalized data is protected, as noted in Nvidia's announcement.
Zuckerberg's commitment is clear: "tens of gigawatts this decade, and hundreds of gigawatts or more over time." That's an enormous amount of computational power. To put it in perspective, the entire world's total electricity generation is roughly 29 terawatts. Zuckerberg is talking about Meta building infrastructure consuming hundreds of gigawatts—that's a scale usually associated with national power grids. It underscores how seriously the company is taking this vision.

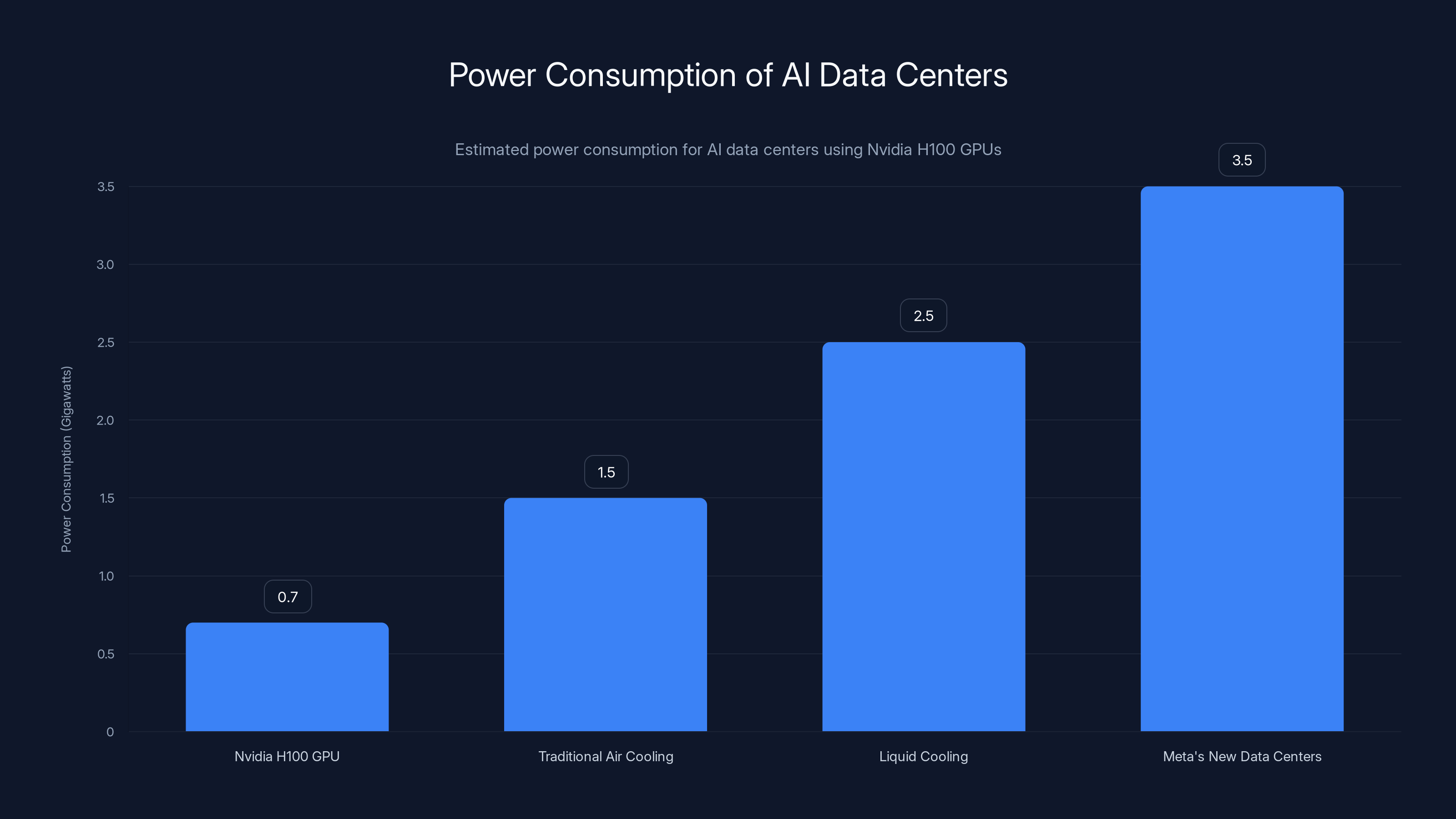
Estimated data shows that advanced cooling systems and new data center designs significantly increase power consumption to support AI infrastructure.
The Competitive Landscape: Why This Deal Matters
Understanding why this partnership matters requires understanding the competitive dynamics in AI infrastructure.
Google, Amazon, and Microsoft are all building massive AI infrastructure. Google has its own TPU processors. Amazon is developing its own AI chips through Trainium and Inferentia. Microsoft is investing heavily in OpenAI infrastructure.
By securing a long-term partnership with Nvidia and committing to massive deployment of the latest hardware, Meta is essentially raising the stakes. The company is saying: we're going to compete at the frontier of AI infrastructure, and we're going to have the compute power to do it.
This is particularly significant for Nvidia. The company's entire business model depends on being the dominant provider of GPU infrastructure for AI. If major tech companies build their own chips (like Google with TPUs or Amazon with Trainium), Nvidia's market shrinks. By securing Meta as a long-term customer and partner, Nvidia ensures that one of the world's largest AI infrastructure consumers remains dependent on Nvidia hardware.
For Meta, the partnership is defensive and offensive. Defensively, it ensures the company has secure access to cutting-edge hardware when GPU supply is constrained globally. Offensively, it signals to investors and employees that Meta is serious about competing in the AI era despite past missteps.
The deal also has geopolitical implications. Nvidia, Google, and Meta are all U.S. companies. China has been trying to develop competitive AI infrastructure but faces export restrictions on advanced semiconductors. By deepening partnerships between American tech companies and Nvidia, the U.S. strengthens its position in what's increasingly a strategic technology domain.

Power and Cooling: The Hidden Challenge
When people talk about AI infrastructure, they focus on GPUs and networking. But power and cooling are equally critical constraints.
A single Nvidia H100 GPU can consume 700 watts under full load. Meta is deploying millions of these. Do the math: millions of GPUs times 700 watts per GPU equals many gigawatts of power consumption. That power has to come from somewhere. It has to be delivered reliably to data center facilities. And crucially, it has to be cooled effectively.
Data center cooling is a non-trivial engineering problem. Heat dissipation is the limiting factor for dense compute clusters. Traditional air cooling works at lower power densities. For extreme densities like AI data centers, you need liquid cooling. Nvidia's GB300 systems are designed with liquid cooling in mind, with the company providing specifications that allow data center operators to design cooling systems that can handle the thermal load.
Meta is committing to building new data centers specifically for this AI infrastructure. The company has announced massive capital expenditure plans. These new facilities will be designed from the ground up for high-power-density AI computing. They'll have dedicated power delivery infrastructure, advanced cooling systems, and network designs optimized for the specific workload patterns.
This is part of why the partnership extends beyond just hardware procurement. Nvidia's engineers are involved in designing these data centers. They're consulting on power delivery architecture, cooling system design, and network topology. They're ensuring that Meta's facilities can actually extract the full performance from GB300 systems without thermal throttling or power delivery bottlenecks.
The power consumption challenge also relates back to performance per watt. Every percentage improvement in power efficiency translates directly to facilities that can run at higher density, training larger models in smaller physical footprints, and reducing operational costs. This is why software optimization is worth the investment.

The Timeline and Phased Rollout
The partnership is a multi-year commitment, but it won't all happen overnight. Understanding the timeline provides insights into Meta's priorities and the complexity of the integration.
Initial deployments will focus on establishing the baseline infrastructure. This means installing GB300 systems, deploying Grace CPUs, and setting up Spectrum-X networking in Meta's existing data centers. This phase involves validating that all components work together as intended, identifying any hardware or software issues that need fixing, and establishing operational procedures.
During this phase, Meta will be training teams on the new infrastructure, developing internal expertise, and optimizing software for the specific deployment. This is tedious work but critical for subsequent phases.
The second phase involves scaling. Once the baseline is proven, Meta will rapidly expand deployments across multiple data centers. This is where economies of scale kick in. With established procedures, trained teams, and validated software, new deployments become faster and less risky.
The third phase involves optimization. With massive production deployments, Meta can identify bottlenecks and inefficiencies that weren't visible in smaller deployments. The company and Nvidia's teams will focus on improving performance per watt, reducing latency, and optimizing for specific workload patterns.
Crucially, this timeline overlaps with Nvidia's hardware roadmap. New GPU generations typically arrive every 18-24 months. The partnership structure allows Meta to integrate new hardware generations smoothly, upgrading data centers incrementally rather than requiring complete replacements. This provides a strategic advantage over companies that buy hardware infrequently and then are stuck with aging infrastructure.

Industry Impact: What This Means for Everyone Else
While this partnership is specifically between Meta and Nvidia, the implications ripple across the entire industry.
First, it signals that hyperscale AI infrastructure is a strategic necessity. Any company aspiring to compete in frontier AI can't do it cheaply with commodity hardware. You need the latest processors, optimized software, and deep engineering integration. This raises the barrier to entry for new competitors and strengthens the positions of incumbents who have the resources to invest in this level of infrastructure.
Second, it demonstrates Nvidia's continued dominance in AI accelerators. Despite competition from Intel, AMD, and custom chips from major cloud providers, Nvidia remains the architecture of choice for hyperscale AI. The company's ability to maintain this position depends on continuous innovation and deep partnerships with major customers like Meta.
Third, it shows that cloud providers who offer AI services need to continuously upgrade their infrastructure offerings. If AWS, Google Cloud, and Azure want to remain relevant for frontier AI workloads, they need access to the latest Nvidia hardware and strong partnerships with Nvidia to enable codesign and optimization.
Fourth, it suggests that the future of AI infrastructure is deeply integrated. Narrow specialization (just being a CPU company, or just a GPU company, or just a networking company) isn't sufficient. Success requires orchestrating across the entire stack. Nvidia's strategy of building CPUs, GPUs, networking, and software together is validated by Meta's partnership choice.
For companies running AI workloads, it raises important questions about infrastructure strategy. Should you build custom chips like Google? Should you rely on cloud providers? Should you develop long-term partnerships with infrastructure vendors? There's no single answer, but Meta's choice suggests that deep integration with a vendor like Nvidia can unlock significant performance and efficiency advantages.

Looking Ahead: The Future of AI Infrastructure
Meta and Nvidia's partnership is significant, but it's not the endpoint. It's a waypoint in the evolution of AI infrastructure.
Looking forward, several trends seem likely. First, AI accelerators will become increasingly heterogeneous. Rather than homogeneous clusters of identical GPUs, future data centers will mix different processor types optimized for different tasks. Some will be optimized for training, others for inference. Some will have specialized processors for specific operations like transformers, others for embedding operations or sparse operations.
Second, the integration between hardware and software will deepen. We'll see more codesign work, more domain-specific optimizations, and less generic tooling. The days of writing code that works well on any hardware are fading. The future involves hardware-conscious software design.
Third, infrastructure will become more distributed. Rather than concentrating all AI infrastructure in a few mega-clusters, we'll see distributed systems that span multiple data centers and cloud environments. This requires advances in distributed training, distributed serving, and cross-data-center networking.
Fourth, efficiency will become more critical. As model sizes grow and compute demands increase, the power consumption problem becomes harder. I expect we'll see more focus on techniques like quantization, pruning, and knowledge distillation that allow smaller models to replace larger ones. We'll see more focus on hardware that maximizes performance per watt.
Fifth, privacy will be built in at the infrastructure level, not bolted on afterward. We'll see more adoption of techniques like confidential computing, federated learning, and differential privacy as fundamental infrastructure capabilities rather than research projects.
Meta and Nvidia's partnership positions both companies well for these trends. Meta gets access to cutting-edge hardware and optimization expertise. Nvidia gets a flagship customer that pushes the boundaries of what's possible and provides real-world validation for new technologies.

FAQ
What is hyperscale AI infrastructure?
Hyperscale AI infrastructure refers to computing systems designed to handle artificial intelligence workloads at massive scale, serving billions of users simultaneously. This involves deploying millions of specialized processors, high-performance networking systems, and optimized software stacks that work together to train and serve AI models efficiently. Unlike traditional data centers designed for general computing, hyperscale AI infrastructure is specifically architected to handle the extreme compute, memory, and networking demands of large language models and recommendation systems at global scale.
How does the Meta-Nvidia partnership work technically?
The partnership combines Meta's extensive production AI workloads with Nvidia's hardware (GB300 GPUs and Grace CPUs) and software ecosystem (CUDA, cuDNN, networking drivers, and optimization libraries). Meta's engineers and Nvidia's engineers work together to codesign infrastructure, meaning they optimize hardware and software simultaneously rather than optimizing them separately. This integration spans everything from GPU kernels through networking drivers to high-level model serving software, creating a unified system optimized specifically for Meta's workloads rather than generic AI applications.
What are the key benefits of this partnership for Meta?
Meta gains access to the latest AI accelerators with codesign optimization specifically for the company's workloads, ensuring maximum efficiency and performance. The partnership provides secure access to cutting-edge hardware when GPU supply is globally constrained, critical for a company that needs millions of processors. Meta also gains expertise from Nvidia's engineering teams in optimizing infrastructure, reducing the company's time-to-productivity and enabling faster innovation cycles in AI capabilities.
What does Nvidia Confidential Computing do?
Nvidia Confidential Computing allows AI models to process sensitive data while maintaining cryptographic guarantees that the data remains protected. It works using Trusted Execution Environments (TEEs) within GPUs where data is encrypted and isolated from the host operating system and system administrators. This enables Meta to run AI features on WhatsApp and other services while honoring end-to-end encryption promises, since the AI operates on encrypted data without decrypting it in a way that infrastructure operators could access.
Why is unified architecture (on-premises and cloud) important for Meta?
Unified architecture allows workloads and applications to move seamlessly between Meta's owned data centers and cloud provider environments without requiring application changes. This provides flexibility to deploy work where it's most cost-effective, gives redundancy and disaster recovery capabilities, and allows the company to burst to cloud resources during peak demand periods. A truly unified architecture requires identical hardware, networking, and software stacks everywhere, which is why this partnership involves cloud provider deployments alongside on-premises infrastructure.
How does the partnership impact infrastructure competition?
The partnership strengthens Nvidia's market position as the dominant AI accelerator provider, validates the strategy of selling integrated hardware-software stacks rather than individual components, and suggests that custom chip development by other companies must be part of a broader infrastructure strategy. For companies considering AI infrastructure investments, it demonstrates that deep vendor partnerships enabling codesign and optimization can unlock significant advantages over generic, off-the-shelf solutions.
What is Zuckerberg's "personal superintelligence" vision?
Personal superintelligence refers to AI systems that are customized and personalized to each individual user, essentially becoming digital extensions of that person's intelligence. Rather than serving the same model to all users, Meta would have billions of specialized models, each fine-tuned to individual preferences, knowledge, and communication styles. This vision requires infrastructure capable of training and serving billions of custom models simultaneously, which is why Meta needs the level of compute resources that this partnership provides.
When will Meta's infrastructure upgrades be complete?
The partnership is structured as a multi-year commitment without a hard endpoint. Initial deployments are establishing baseline infrastructure in Meta's data centers, followed by phased scaling across multiple locations. The timeline overlaps with Nvidia's hardware roadmap, so new GPU generations arriving every 18-24 months will be integrated progressively rather than requiring wholesale replacements. Meta's publicly stated goal is to have "tens of gigawatts" of AI infrastructure operational this decade.
How much power will Meta's AI infrastructure consume?
Meta's stated ambition is to deploy infrastructure consuming "tens of gigawatts this decade, and hundreds of gigawatts or more over time." To provide context, one gigawatt of continuous power consumption costs roughly $600-800 million annually in electricity. This enormous scale reflects both the power density of modern AI workloads (each GPU consumes hundreds of watts) and the company's commitment to competing at the frontier of AI infrastructure globally.

Conclusion: The Future is Infrastructure
Meta and Nvidia's partnership represents something fundamental about where the AI industry is heading. It's not about clever algorithms or breakthrough research anymore. Those still matter, but increasingly the competitive advantage belongs to whoever can build and operate infrastructure at the largest scale most efficiently.
This shift has profound implications. It means that AI will increasingly be dominated by companies with the capital and scale to invest in massive infrastructure. It means that the infrastructure companies—processor manufacturers, networking vendors, power management specialists—are as important to AI progress as the companies actually building AI applications. It means that engineering excellence in infrastructure design will be as valuable as research breakthroughs.
Meta's partnership with Nvidia is ambitious, but it's also logical. Meta serves billions of users and has the financial resources to deploy infrastructure at extraordinary scale. Nvidia has spent decades building the software and hardware ecosystem that makes this scale practical. Together, they can build something neither could alone: infrastructure truly optimized for frontier AI workloads.
The implications extend beyond Meta and Nvidia. This partnership sets expectations for what's possible in AI infrastructure. It raises the bar for competitors. It demonstrates that integration across hardware, software, and workloads unlocks significant efficiency advantages. It shows that the future of AI infrastructure is deep optimization rather than generic solutions.
For companies building AI systems, watching this partnership and learning from the technical approaches Meta and Nvidia are pioneering will be valuable. The specific technologies—GB300 GPUs, Grace CPUs, Spectrum-X networking, Confidential Computing—might change, but the principles will persist: optimize across the entire stack, design hardware and software together, measure and improve efficiency continuously, and plan for workloads at scales you can barely imagine today.
Zuckerberg's vision of personal superintelligence might seem distant today, but the infrastructure is being built right now. Whether Meta achieves that vision or not, the infrastructure investments they're making will shape the AI landscape for the next decade. That's why this partnership matters: it's not just about deploying GPUs. It's about building the foundation for the next era of AI capabilities.
For technology leaders, the key lesson is this: in the age of AI, infrastructure isn't a commodity to be purchased off-the-shelf. It's a strategic asset that requires deep engineering, thoughtful partnerships, and continuous optimization. Meta gets this. Nvidia gets this. That's why their partnership is so significant.
Key Takeaways
- Meta and Nvidia's partnership involves deploying millions of GPUs and Arm-based CPUs in a unified architecture spanning on-premises and cloud infrastructure.
- The integration includes Nvidia's GB300 systems, Grace CPUs, and Spectrum-X networking, all codesigned specifically for Meta's workloads.
- Nvidia Confidential Computing enables Meta to run AI models on sensitive user data while maintaining cryptographic privacy guarantees.
- Meta's infrastructure commitment reflects Zuckerberg's vision of "personal superintelligence," requiring compute power reaching hundreds of gigawatts.
- This partnership signals that the future of AI competition depends on infrastructure scale, efficiency, and deep hardware-software integration.
Related Articles
- Can We Move AI Data Centers to Space? The Physics Says No [2025]
- G42 and Cerebras Deploy 8 Exaflops in India: Sovereign AI's Turning Point [2025]
- AI Data Centers & Energy Storage: The Redwood Materials Revolution [2025]
- AI Agents in Production: What 1 Trillion Tokens Reveals [2025]
- Facial Recognition Goes Mainstream: Enterprise Adoption in 2026 [2025]
- India's Sarvam Launches Indus AI Chat App: What It Means for AI Competition [2025]

