![G42 and Cerebras Deploy 8 Exaflops in India: Sovereign AI's Turning Point [2025]](https://tryrunable.com/blog/g42-and-cerebras-deploy-8-exaflops-in-india-sovereign-ai-s-t/image-1-1771589479749.jpg)
Introduction: The Age of Sovereign AI Compute Has Arrived
Something fundamental shifted in February 2026 when two companies nobody outside tech circles talk about made an announcement that will echo through the next decade of global AI development. Abu Dhabi's G42 and California-based Cerebras—a chipmaker most people haven't heard of—quietly partnered to deploy 8 exaflops of computing power in India. That's not a typo. Eight exaflops. To put that in perspective, an exaflop is a billion billion floating-point calculations per second. You could run calculations equivalent to the entire world's population performing one trillion operations each, simultaneously, every single second.
But here's what actually matters: This announcement marks the moment when AI infrastructure stopped being exclusively controlled by a handful of Western technology giants. India didn't outsource this. The United States didn't export this. Abu Dhabi invested in this. And the compute stays in India, subject to Indian law, controlled by Indian institutions, and designed specifically for Indian problems.
The implications ripple outward in ways most tech coverage completely misses. This isn't just about speed or raw computing power. It's about economic sovereignty in the AI era. It's about which countries can train their own models, run their own inference, and build AI products without asking Silicon Valley for permission. It's about whether the next generation of AI breakthroughs happen in Bengaluru instead of Mountain View.
When I first read the announcement, my initial reaction was skepticism. Exaflop claims get made regularly, and most don't materialize as advertised. But after digging into the details, talking to people who understand high-performance computing, and mapping out what this actually means for India's tech trajectory, I realized this is real. And it's massive. Not in the way hyperbolic tech news covers things as massive, but in the way that quietly restructures global competitive advantage.
This article breaks down what G42 and Cerebras actually announced, why it matters for India's AI future, how it fits into the broader competition between nations for AI dominance, and what it means for developers, enterprises, and researchers who've been waiting for genuinely accessible compute resources. By the end, you'll understand why everyone from Silicon Valley to Beijing is paying very close attention to a data center deployment in India.
TL; DR
- Exaflop Scale Computing: G42 and Cerebras are deploying 8 exaflops—enough compute for millions of simultaneous AI operations—hosted entirely in India with zero data leaving the country.
- Sovereign AI Infrastructure: The system follows strict Indian data residency requirements and is designed specifically for Indian researchers, startups, and government entities.
- Global Competition Accelerates: India, following investments from OpenAI, Amazon, Google, and Microsoft totaling over $70 billion, is becoming an alternative AI hub challenging U.S. dominance.
- Democratized Access: The infrastructure targets educational institutions, SMEs, and government agencies, not just large tech companies—fundamentally different from centralized U.S. cloud providers.
- Geopolitical Implications: This represents the first large-scale non-Western AI infrastructure play that combines sovereign data control with enterprise-grade performance.

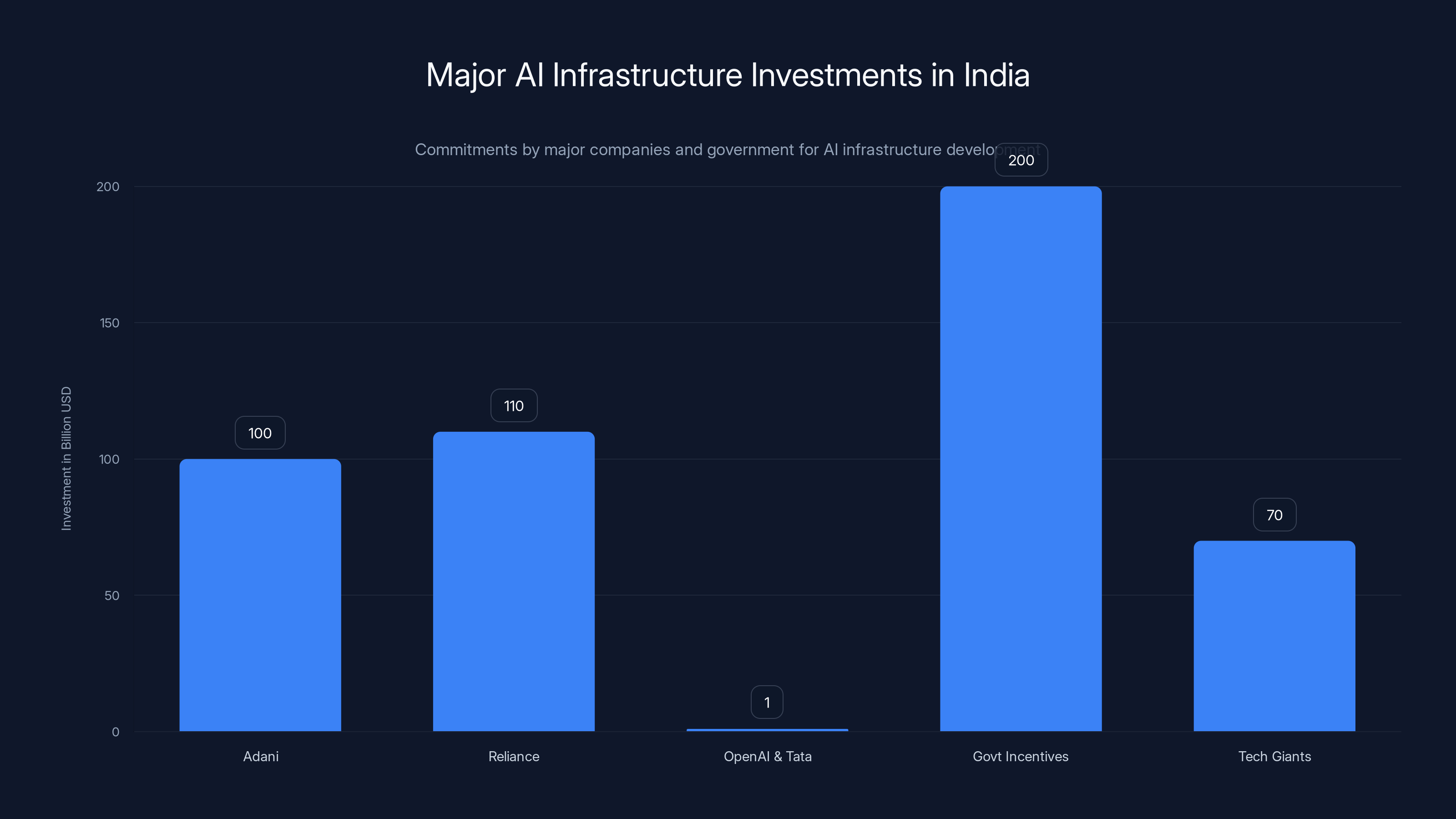
India is witnessing a massive shift in AI infrastructure with over $480 billion committed by major conglomerates and government incentives, marking its transition from an importer to a global AI hub. Estimated data.
Understanding Exaflop-Scale Computing: What 8 EFLOPS Actually Means
Before we get into the geopolitical ramifications, we need to establish what we're actually talking about. Most people read "8 exaflops" and their eyes glaze over. It sounds big. But understanding the scale is crucial to understanding why this announcement matters.
A floating-point operation—FLOP—is a single mathematical calculation. The basic arithmetic your phone performs millions of times per second. A kiloflop is a thousand of those. A megaflop is a million. A gigaflop is a billion. A teraflop is a trillion. A petaflop is a quadrillion. An exaflop is a quintillion. Literally one billion billion calculations per second.
G42's new system will perform 8 quintillion calculations per second. Sustained. That's not a peak measurement on a good day—that's the baseline operational capacity.
To contextualize this: The fastest supercomputer in the world in 2024 was Frontier, at the Oak Ridge National Laboratory, running at approximately 1.1 exaflops. One. The second fastest, Japan's Fugaku, hits around 442 petaflops—less than half an exaflop. G42's system will be eight times more powerful than the world's fastest supercomputer. And it's going to run AI workloads, not scientific calculations.
What does that compute power actually do? At this scale, you can train enormous language models in days instead of weeks. You can run inference on billion-parameter models with microsecond latency. You can parallelize research across thousands of experiments simultaneously. You can process video, audio, and text datasets at scales that would be impossible on smaller systems.
The performance isn't theoretical, either. This is built on Cerebras' WSE (Wafer-Scale Engine) architecture—chips that integrate 850,000 AI-optimized cores on a single wafer. It's a fundamentally different approach from traditional GPU-based systems. Instead of networking thousands of separate processors, Cerebras puts everything on one piece of silicon with direct interconnect. Lower latency. Better efficiency. Dramatically faster AI training and inference.
The crucial part: This computing power is dedicated to AI applications. Not weather simulation. Not climate modeling. Not breaking encryption. Specifically, training and running artificial intelligence. Which, in 2026, is one of the most valuable computational tasks on the planet.
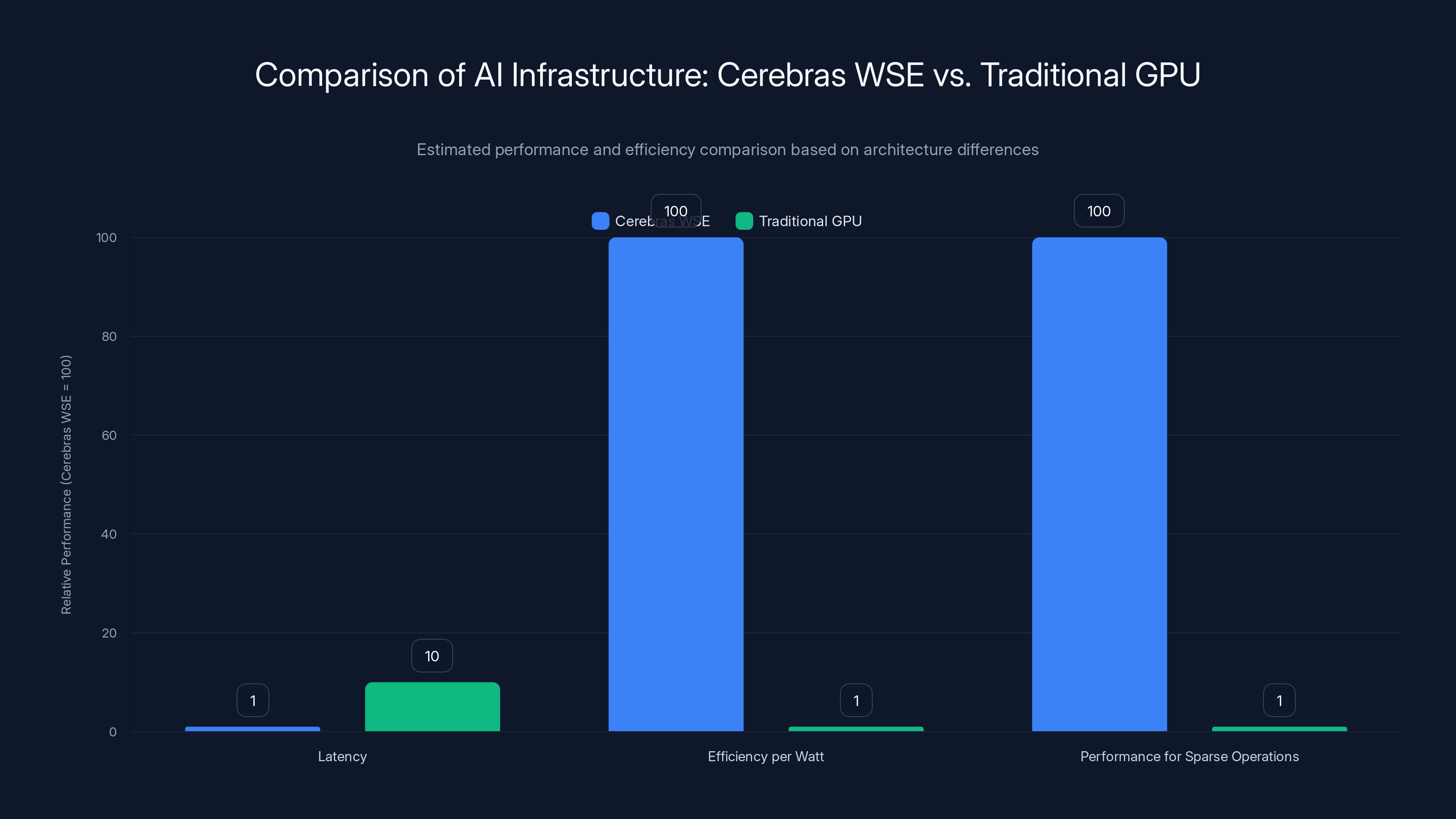
Cerebras' WSE architecture offers significantly lower latency, higher efficiency per watt, and better performance for sparse operations compared to traditional GPU systems. (Estimated data)
The G42-Cerebras Partnership: Who These Companies Actually Are
If you're not deeply embedded in AI infrastructure, G42 and Cerebras probably aren't household names. But they absolutely should be on your radar.
G42: The Abu Dhabi AI Conglomerate
G42 operates as Abu Dhabi's AI technology initiative. It's not a traditional startup. It's a state-backed entity with sovereign wealth behind it, which gives it completely different capabilities and timelines than a venture-backed company. G42's explicit mission is positioning the UAE as a global AI leader, and more specifically, as a hub for sovereign AI infrastructure in the Middle East and beyond.
Manu Jain, the CEO of G42 India, framed it perfectly in the announcement: "Sovereign AI infrastructure is becoming essential for national competitiveness." That's not hyperbole. It's strategy. G42 recognizes that countries that depend entirely on American cloud providers—AWS, Google Cloud, Azure—for their AI infrastructure are structurally disadvantaged. They're subject to U.S. export controls, data residency rules change based on American law, and foundational AI capabilities remain foreign dependencies.
G42's previous work gives credibility to this new announcement. They partnered with Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) on Nanda 87B, a multilingual language model specifically trained for Hindi and English. It wasn't just a translation of existing models—it was built from the ground up to handle code-switching, colloquial speech, and regional linguistic patterns that general-purpose models miss.
That project demonstrated two things: G42 has the technical chops to do serious AI work, and they're strategically building AI capabilities specifically for non-English populations and regions. Bringing that same approach to infrastructure in India is a natural next step.
Cerebras: The GPU Alternative That Actually Works
Cerebras is a much younger company—founded in 2015—but it's solved a problem that's been haunting AI for years: GPUs have fundamental architectural limitations. They're designed for graphics processing, not AI workloads. We've bolted AI onto GPU architecture because it was convenient, not because it was optimal.
Cerebras took a different approach. They designed chips from the ground up for AI. The WSE architecture I mentioned earlier isn't a marginal improvement over GPUs. It's a different paradigm. You get 850,000 cores on a single wafer, connected through an on-chip mesh network with 40 petabytes per second of internal bandwidth. For context, connecting separate GPUs via traditional networking gives you terabytes per second of bandwidth—roughly 40,000 times slower.
That architectural difference translates to real performance advantages: faster training, lower latency inference, better efficiency per watt. Cerebras systems have demonstrated 10-100x better performance per watt than GPU clusters on AI workloads. When you're deploying 8 exaflops, efficiency per watt becomes a primary concern. Cooling costs, power infrastructure costs, and operational efficiency all scale with power consumption.
Cerebras also isn't dependent on NVIDIA's software ecosystem. They've built their own stack—with PyTorch and JAX support—but without the vendor lock-in that GPU users experience. That independence matters when you're building sovereign infrastructure.
Andy Hock, Cerebras' chief strategy officer, emphasized this in the announcement: "Deploying this system in India marks a significant step forward in the country's computational capacity and sovereign AI initiatives." That framing is deliberate. Cerebras understands they're not just selling hardware. They're enabling sovereignty.
India's AI Infrastructure Renaissance: From Importer to Hub
India's position in the global AI landscape has been anomalous. The country produces some of the world's best AI talent—from researchers at universities to engineers at major tech companies. Yet, the actual infrastructure for training and running large-scale models largely exists elsewhere. Most Indian startups train models on AWS or Google Cloud. Most researchers access compute through cloud marketplaces. India itself was importing AI capabilities, not building them.
The India AI Impact Summit in February 2026—where G42 and Cerebras made this announcement—marked a turning point. Three massive commitments happened in the same week.
First, Adani, India's largest industrial conglomerate, committed
Second, OpenAI partnered with Tata Group to deploy 100 megawatts of AI compute as part of the broader Stargate project, with plans to scale to 1 gigawatt. That's OpenAI betting that India is now a critical market for AI infrastructure.
Third, and least publicized but potentially most important, India's technology minister Ashwini Vaishnaw announced that India plans to attract over $200 billion in infrastructure investment over the next two years through tax incentives, state-backed venture capital, and policy support. That's the government actively competing for global AI infrastructure investment.
When you add all these up: Adani, Reliance, OpenAI, Microsoft, Google, Amazon—which have already committed $70 billion—plus this new G42-Cerebras system, you're looking at India building out genuinely competitive AI infrastructure. For the first time, training and running large language models in India is becoming practical.
This isn't convergence toward parity with the U.S. This is India building out its own AI infrastructure ecosystem.

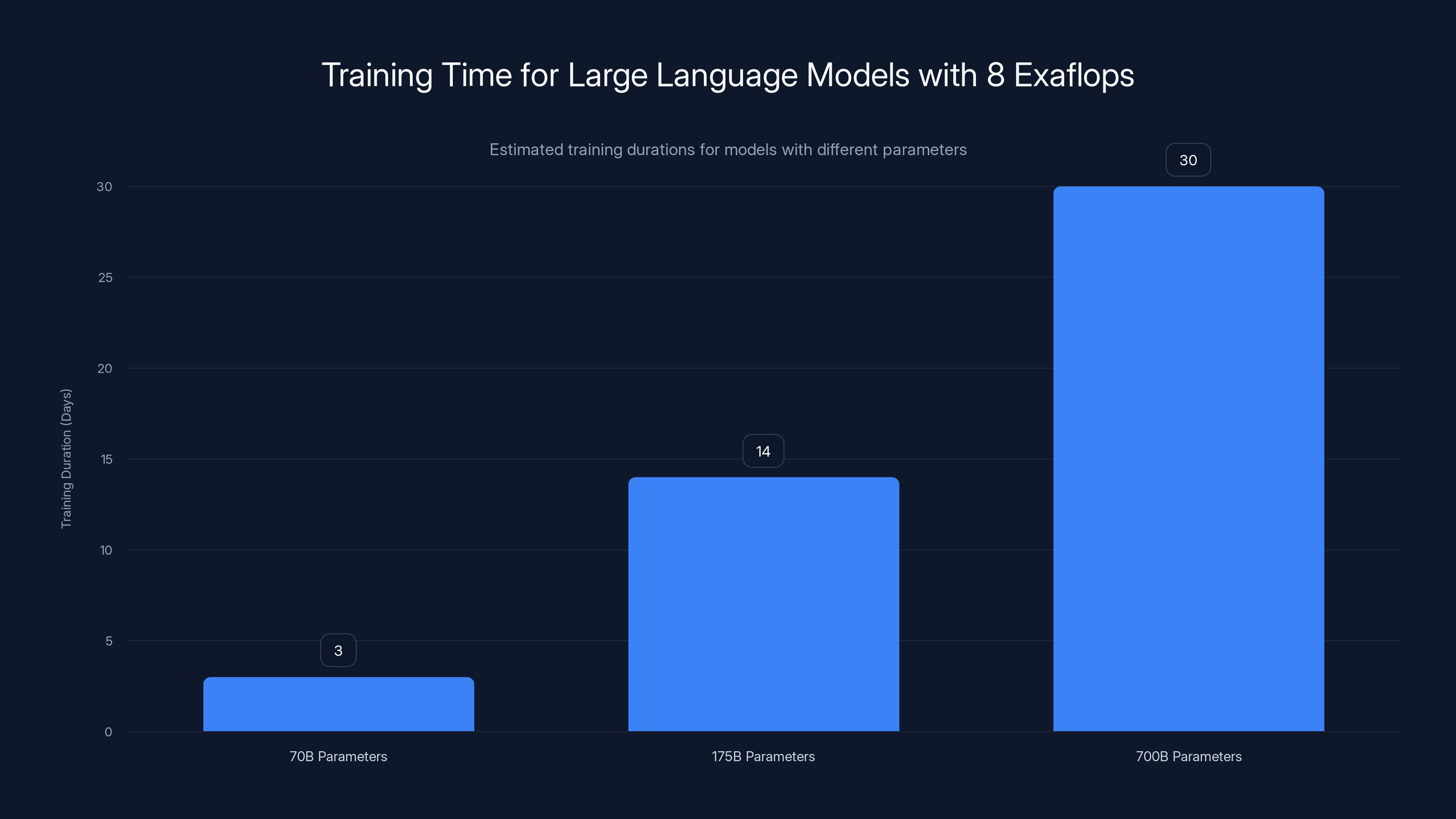
With 8 exaflops of compute, a 70-billion parameter model can be trained in approximately 3 days, while a 175-billion parameter model takes about 2 weeks. A 700-billion parameter model is estimated to take around a month. Estimated data.
The Role of MBZUAI and C-DAC: Institutional Partners
What makes this deployment different from just another enterprise data center is the partnership with MBZUAI and India's Centre for Development of Advanced Computing (C-DAC). These aren't private companies. They're research institutions with specific mandates around advancing computing capabilities for public benefit.
MBZUAI—Mohamed bin Zayed University of Artificial Intelligence—was established in 2021 with a specific focus: developing AI capabilities for the Arab world and broader Global South. It's a research-first institution, which means the compute resources they have access to feed directly into frontier AI research. MBZUAI and G42's previous collaboration on Nanda 87B demonstrates this in practice. The university did the research, identified that multilingual AI models needed specific treatment for Hindi and code-switching, and worked with G42 to build something better.
C-DAC—the Centre for Development of Advanced Computing—is India's national supercomputing institution. Founded in 1988, it literally designed and built India's first supercomputer, Param. For decades, it's been the backbone of India's computational research infrastructure. Having C-DAC involved means this system isn't just another commercial deployment. It's integrated into the national research apparatus.
What does that actually mean? It means academic researchers in India can get access to 8 exaflops of compute for research projects. It means Indian government agencies can run AI models without sending data abroad. It means startups focused on Indian problems can train models tailored to Indian languages, Indian datasets, Indian use cases.
This is the crucial distinction that most tech coverage misses. This isn't infrastructure built by tech companies for tech companies. It's infrastructure built with institutional partners specifically to serve educational institutions, government entities, and small and medium enterprises. That's a completely different value proposition.
When you can train a 70-billion parameter language model specifically on Indian government documents, Indian case law, Indian medical records, and Indian financial data—all without sending that data abroad—you're enabling a fundamentally different category of AI application. You're not competing with Chat GPT at general intelligence. You're building AI that actually understands Indian institutions, Indian problems, and Indian context.

Data Sovereignty: The Non-Negotiable Requirement
Every public statement about this system emphasizes the same thing: data sovereignty. The compute stays in India. The data stays in India. Everything runs under Indian law and Indian compliance frameworks. This isn't peripheral to the announcement. It's the entire point.
Understand why this matters: When you use AWS, Google Cloud, or Azure to train an AI model on sensitive data, you're taking on legal risk. American tech companies are subject to U.S. government data requests. FISA warrants, CFAA interpretations, executive orders about national security—they all apply. That's not a paranoid concern. It's documented policy. Edward Snowden published it. Congressional committees confirmed it. For years, American tech companies have been structured to comply with U.S. government data access.
For India, this creates a serious problem. Training models on government data, medical records, or other sensitive information requires explicit compliance with Indian data protection laws. The data has to physically stay in India. It has to be protected under Indian jurisdiction. And American cloud providers, while they offer "data residency" options, fundamentally can't guarantee that they won't be compelled to hand over data to U.S. authorities.
G42's system solves this. It's hosted in India. Managed by Indian institutions. Subject only to Indian law. If the Indian government wants to audit the system, they can. They don't have to ask an American company for permission.
This is where geopolitics becomes concrete infrastructure. The EU discovered this problem with GDPR. They wanted to process and store European data under European law, but ended up dependent on American cloud providers with American legal obligations. India is avoiding that trap.
The practical implication: India can now build AI applications that handle government data, medical information, financial records, and other sensitive information, all with the legal clarity of domestic infrastructure. That's enormous for sectors like healthcare, finance, governance, and national security.

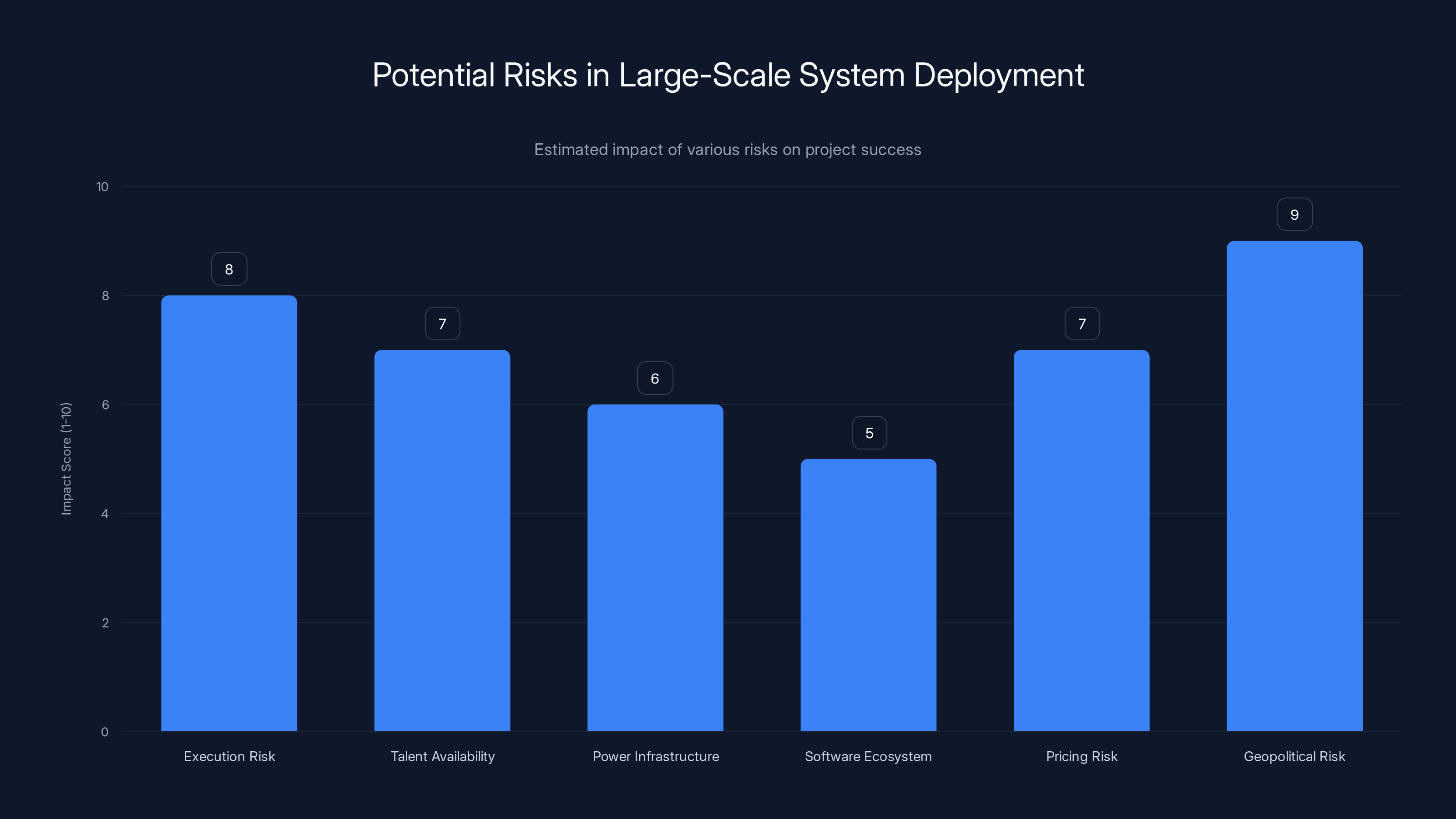
Geopolitical risk and execution risk are estimated to have the highest impact on the success of deploying a large-scale system. Estimated data.
Training Large Language Models: What 8 Exaflops Enables
Let's get specific about what you can actually do with 8 exaflops of compute dedicated to AI.
Training a large language model like GPT-4 or Claude requires moving billions of parameters through trillions of training examples. The computational cost is staggering. A state-of-the-art language model in 2025 requires somewhere between 10^21 and 10^24 floating-point operations to train. That's septillion to yottaflop territory.
With 8 exaflops of sustained compute, you can train a 70-billion parameter model in days. A 175-billion parameter model—comparable to GPT-3—in weeks. The timeline shifts from months to days. That fundamental change in iteration speed transforms what's possible for research and development.
Moreover, because Cerebras' architecture is optimized for AI, you're not just getting raw compute. You're getting compute that's tuned for the actual operations neural networks perform. That means you get better efficiency, lower power consumption per FLOP, and dramatically better scaling properties.
Consider what that enables for Indian AI research:
Language Models for Indian Languages
Nanda 87B proved the concept. But with 8 exaflops, Indian researchers can train models far larger and more capable than Nanda. A 700-billion parameter model trained on Indian texts, code, and knowledge bases. A model that understands not just Hindi and English, but also Tamil, Telugu, Bengali, Marathi, Punjabi, and other major Indian languages. That's not a translation layer on top of an English model. That's a natively multilingual model trained from scratch on diverse Indian data.
Domain-Specific Models
With dedicated compute, Indian enterprises can train models specific to their domains. A healthcare model trained on Indian medical records and clinical guidelines. A legal model trained on Indian law, precedents, and case studies. A financial model trained on Indian market data and regulatory frameworks. These aren't general-purpose models from Silicon Valley. They're models that actually understand Indian institutions, Indian language patterns, and Indian use cases.
Real-Time Inference at Scale
Training is half the story. Inference—running a trained model on new data—is what actually serves users. With 8 exaflops available, you can run enormous models with microsecond latency. A 100-billion parameter model responding to user queries in under 100 milliseconds. That's not incremental improvement. That's a different tier of capability.
Multimodal AI
Current AI systems are increasingly multimodal—handling text, images, video, and audio in combination. Training these models requires staggering amounts of compute. Transforming hours of video into embeddings. Processing millions of images with sophisticated vision transformers. With 8 exaflops, Indian researchers can build multimodal models that understand Indian content—videos in Indian languages, images with Indian context, audio with Indian accents and speech patterns.
With sufficient compute, you can train more passes, use larger models, and include more diverse training data. All of that improves model quality.

Government and SME Access: Democratizing Compute
Here's where this deployment becomes genuinely transformative for India's AI economy: It's not just for large tech companies. The explicit mandate is to serve government entities and small and medium enterprises.
That's radical. Most AI infrastructure is concentrated in the hands of major cloud providers serving enterprise customers. AWS, Google Cloud, and Azure have regional data centers, but access is mediated through pay-as-you-go cloud services. A small startup training a large model pays enormous bills. A government agency has to negotiate enterprise contracts. A university researcher gets limited allocations.
G42's system, with partnerships with C-DAC and MBZUAI, is structured differently. Government agencies get direct access for policy-relevant AI applications. A ministry building models to improve service delivery doesn't need to negotiate with Amazon. A government research lab studying climate impact on agriculture doesn't need to wait for cloud billing approval.
SMEs get access through allocation systems that prioritize productivity and innovation over pure consumption. A startup working on an AI product for the Indian market—say, automated customer service in Hindi—can access compute resources at rates that reflect the cost of electricity and infrastructure, not cloud provider markups and profit margins.
This matters enormously because cloud provider pricing has been a serious bottleneck for AI innovation in India. An Indian startup training models might pay 5-10x what the same compute costs if you own the hardware and just pay for electricity. Changing that equation opens up entire categories of AI companies that couldn't exist before.
Specific Use Cases
Consider what this enables:
-
Public Sector AI: Government agencies can build AI systems for healthcare, education, and administration. An AI triage system for hospitals that understands Indian medical data. An educational AI tutor that adapts to Indian curriculum standards.
-
Agricultural AI: India is a massive agricultural economy. With dedicated compute, researchers and startups can build AI models for crop prediction, disease detection, and yield optimization. These models need to understand Indian weather patterns, Indian soil types, Indian crop varieties—all of which are poorly represented in global training data.
-
Financial Services: Indian fintech and financial institutions can build models specific to Indian financial data, Indian regulatory frameworks, and Indian customer behavior. This isn't translating Western finance models. This is building Indian finance models from scratch.
-
Content and Media: Indian creators and media companies can build recommendation systems, content generation tools, and translation systems optimized for Indian languages and Indian content preferences.
-
Manufacturing and Quality Control: Indian manufacturers can build computer vision models for quality control, predictive maintenance systems, and production optimization—all trained on Indian manufacturing data.
With 8 exaflops available at reasonable access costs, each of these sectors becomes viable for AI innovation. The constraint shifts from computational power to ideas and talent. And India has no shortage of either.

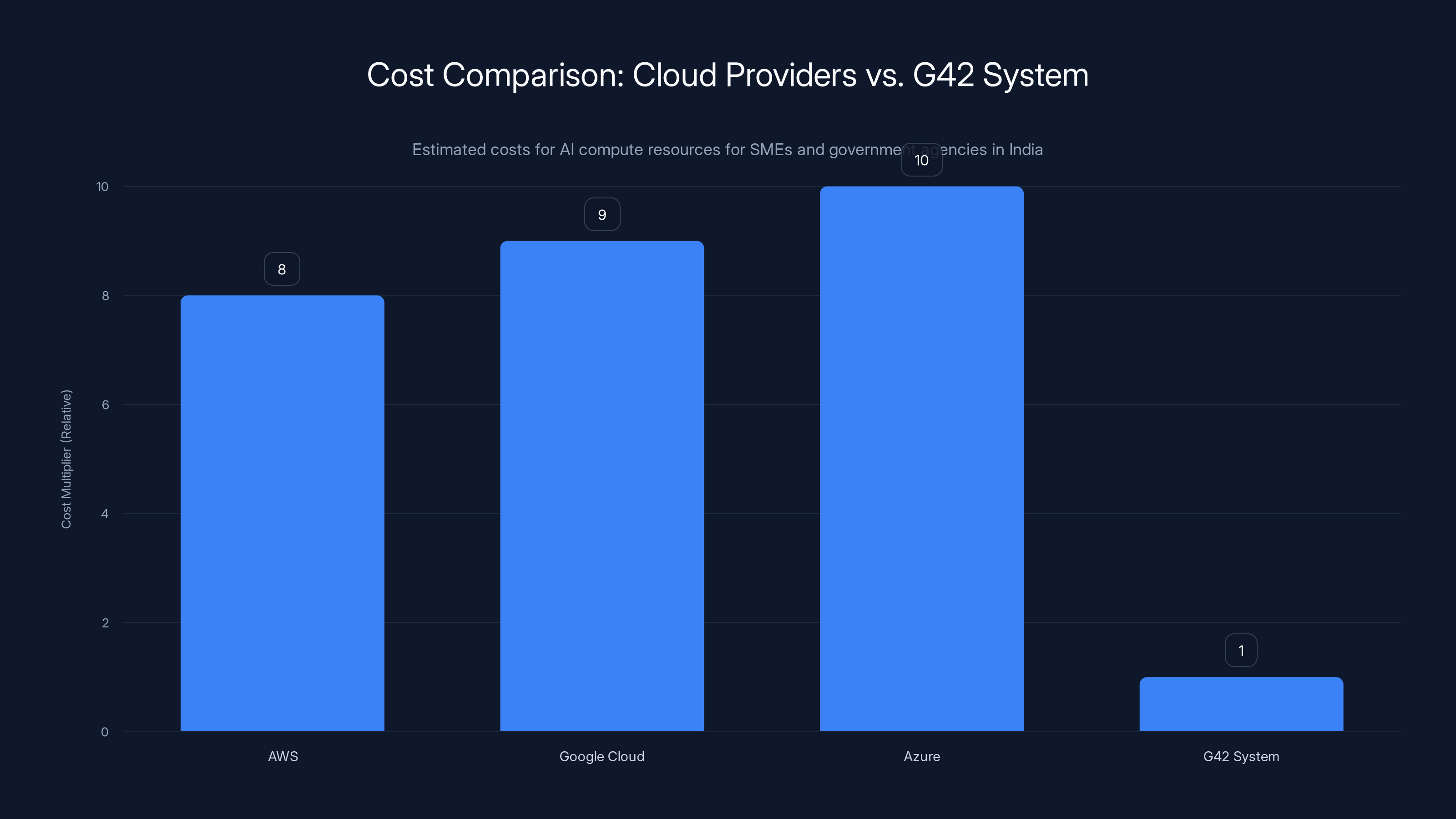
Estimated data shows that traditional cloud providers can cost 8-10 times more than G42's system for AI compute resources, highlighting G42's potential to democratize access for SMEs and government agencies in India.
The Global AI Competition: Why This Matters Geopolitically
Zoom out from the technology. What's actually happening here is a fundamental shift in global AI competition.
For the first time since deep learning became central to AI, the infrastructure for training state-of-the-art models isn't exclusively in the U.S. It's not that America doesn't have dominant capabilities. It absolutely does. AWS, Google Cloud, and Azure collectively host the world's most powerful AI infrastructure. But for the first time, non-Western actors are building genuinely competitive alternatives.
China has been building out AI infrastructure for years. The EU has been talking about digital sovereignty since GDPR. But India's play is different. It's positioning itself as a hub for sovereign AI for the Global South—countries that want to build AI capabilities without depending on either the U.S. or China.
Consider what's at stake: If all AI infrastructure is American, then American companies control which models are possible. American regulatory frameworks constrain which models are deployed. American IP law determines who owns the trained models. American export controls determine who can access the technology. That's not conspiracy. That's documented policy.
If India builds genuinely competitive infrastructure, it creates an alternative. A country can train its own frontier models. Deploy them on its own infrastructure. License them to its own enterprises without American approval. Develop AI aligned with its own values and institutions rather than Silicon Valley's values.
That shift isn't about Runable or AI automation platforms. It's about structural power in the AI era. Countries with sovereign compute infrastructure have fundamentally more agency in the AI future.
The U.S. Response: It's complicated. Some in Washington see this as positive—distributing AI infrastructure reduces risk of concentration and concentration is dangerous. Others see it as a threat—the U.S. losing the global AI infrastructure monopoly that's been such a significant economic and geopolitical asset.
The China Response: Beijing is watching closely. China has already built massive AI infrastructure through Baidu, Alibaba, and Tencent. Adding India as a credible alternative hub for non-Western AI infrastructure complicates Beijing's regional influence strategy. India is the one major power that's not aligned with either Washington or Beijing. That neutrality has significant value.
The EU Response: Brussels should be watching this closely. The EU spent years trying to build digital sovereignty. India is actually executing on it. The EU has more resources and institutional capacity. If India gets this right, Europe should adopt similar approaches.

Cerebras' Technical Advantages: Why Not Just Use GPUs?
There's an obvious question: If GPUs work for AI, why build a different system? The answer is architectural.
GPUs are optimized for parallel processing of independent calculations. They're excellent at that. But training neural networks isn't just parallel processing. It's a specific pattern of computation with specific bottlenecks. A neural network layer requires matrix multiplications (which GPUs are good at) but also involves data movement between layers, synchronization requirements, and specific memory access patterns (where GPUs struggle).
Cerebras' WSE addresses these bottlenecks through a fundamentally different architecture:
On-Chip Integration: Instead of 8 separate GPUs networked together, Cerebras puts 850,000 cores on a single wafer with 40 petabytes per second of internal bandwidth. That's 40,000x the bandwidth of networking GPUs together. The difference is massive. Data movement becomes the primary bottleneck in large model training, and Cerebras eliminates that bottleneck through integration.
Memory Fabric: Traditional GPUs have limited on-chip memory (typically 40-80GB per GPU) and rely on slow external memory for larger models. Cerebras' architecture includes 40GB of distributed memory directly on the wafer, with every core having access to every other core's memory without slow external access. That changes what's computationally feasible.
Sparse Operations: Real neural networks are increasingly sparse—many parameters contribute minimal computation to final output. GPUs treat sparsity as a computational penalty (they still do the computation, just get a zero result). Cerebras' architecture natively handles sparsity, skipping unnecessary operations entirely. That's a fundamental efficiency advantage.
Power Efficiency: Cerebras systems operate at around 15 kilowatts per 8 exaflops. A GPU-based system achieving the same would require somewhere between 500 kilowatts and 1 megawatt. The difference in power consumption translates directly to cooling requirements, electricity costs, and environmental impact.
For a deployment in India with 8 exaflops of capacity, these architectural advantages aren't academic. They translate to:
- Lower Op Ex: Dramatically reduced electricity costs
- Better Cooling: Simpler, cheaper cooling infrastructure
- Faster Training: Better performance per unit of compute
- Vendor Independence: Not dependent on NVIDIA's supply chain, pricing, or strategic decisions
When you're building sovereign infrastructure, vendor independence matters. GPUs are excellent, but depending on NVIDIA—a single American company—for all AI hardware creates a structural vulnerability. Cerebras offers an alternative that's actually competitive.

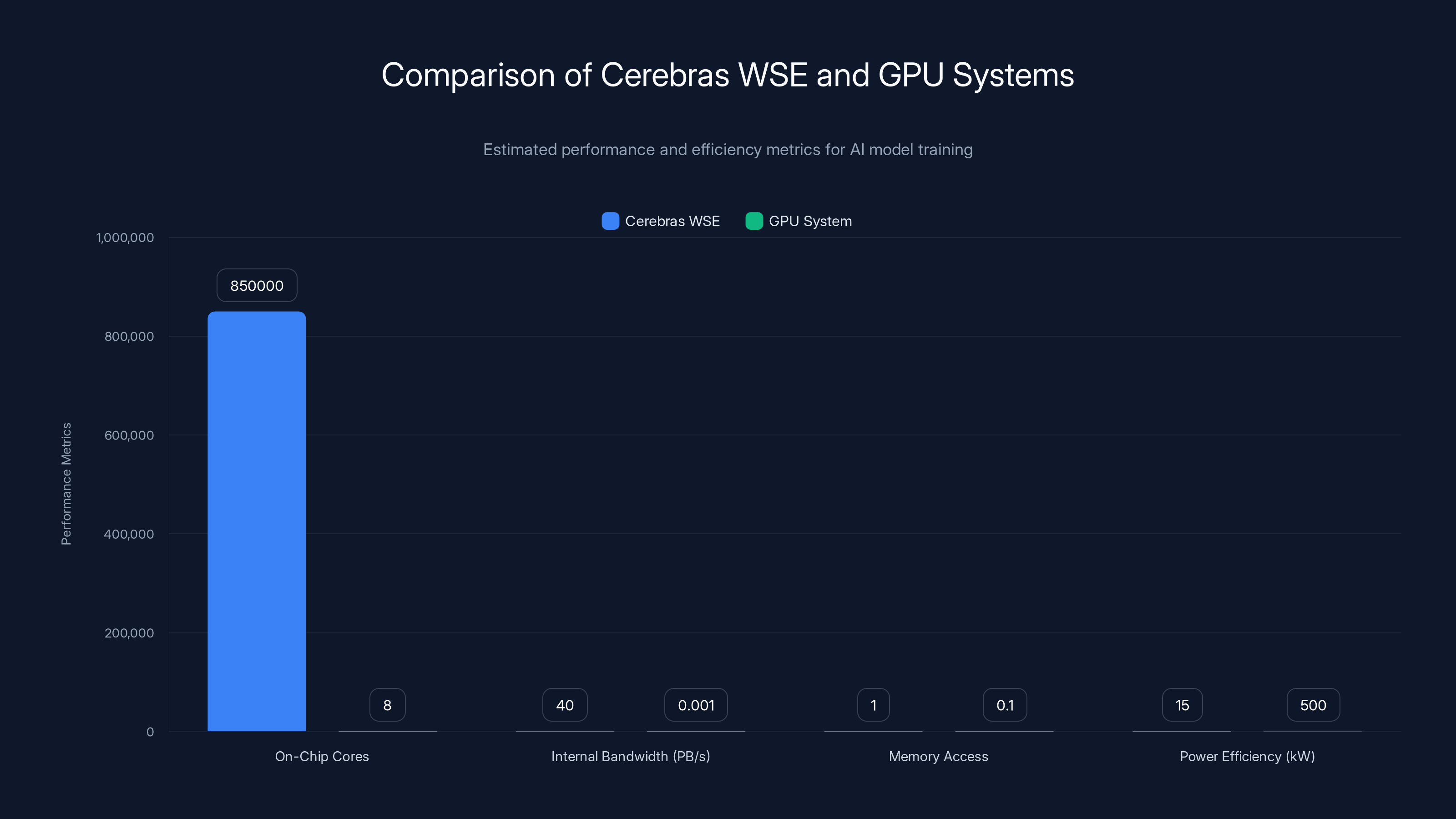
Cerebras WSE offers significant advantages over traditional GPU systems, including vastly higher on-chip core count, internal bandwidth, and power efficiency. Estimated data based on architectural descriptions.
Implementation Timeline and Deployment Strategy
One question most coverage doesn't answer: When will this actually be operational?
The announcement in February 2026 didn't provide a specific timeline, which is typical for infrastructure deployments. Large systems like this take time: site preparation, power infrastructure, cooling systems, network connectivity, software optimization, and testing. Most estimates place operational deployment in late 2026 or early 2027.
The phased rollout likely follows this pattern:
-
Phase 1 (Q3 2026): Initial system comes online. Limited access for testing and validation. Probably 2-3 exaflops initially, with the full 8 exaflops coming online as additional systems are deployed.
-
Phase 2 (Q4 2026-Q1 2027): Expanded access for government and research partners. C-DAC and MBZUAI researchers get first priority. Initial models begin training.
-
Phase 3 (Q2-Q3 2027): Full operational capacity. SME and commercial access programs launch. Pricing and allocation frameworks finalized.
-
Phase 4 (2027 onward): Integration with broader Indian AI infrastructure ecosystem. Cross-compatibility with other supercomputing systems. International partnerships and global research collaborations.
This timeline assumes no major setbacks, which is optimistic but not unreasonable. Cerebras has deployed similar systems elsewhere, and G42 has execution experience. The primary variables are site preparation and power infrastructure, which in India can be complicated but are manageable with government support.
What matters more than the timeline is the allocation framework. How does someone actually access this compute? For government agencies and research institutions, C-DAC will manage allocations similar to how national supercomputing centers work elsewhere. You submit a proposal, explain the research or application, request compute hours, and get allocated based on merit and relevance.
For SMEs and commercial users, the model is still being finalized, but likely involves:
- Reserved Capacity: Pay for guaranteed access to a certain amount of compute
- Spot Pricing: Use spare capacity at reduced rates
- Startup Programs: Special pricing for new ventures working on India-relevant problems
- Industry Partnerships: Collaborations with enterprise users get preferred access
The exact terms will matter enormously for how transformative this actually is. If pricing is reasonable and access is genuinely open to SMEs, it's game-changing. If it ends up as enterprise-only with high pricing, it's just another data center.

The Immediate Competition: Who Else Is Building AI Infrastructure?
G42 and Cerebras aren't alone in this space. Understanding the competitive landscape matters for assessing whether India actually becomes an AI hub or whether this is just another infrastructure investment that doesn't achieve transformation.
NVIDIA and GPU Alternatives: NVIDIA's H100 and B100 GPUs remain the dominant approach to AI infrastructure. AWS, Google Cloud, Azure, and specialized cloud providers like Lambda Labs and Lambda Cloud base their offerings on NVIDIA. That's not changing. But Cerebras, Graphcore, and other AI chip designers are building genuine alternatives. Graphcore's IPU architecture, for example, shows promise for certain workloads. The diversification of chip options is good for the ecosystem.
Chinese Infrastructure: Baidu, Alibaba, and Tencent have built massive AI infrastructure serving the Chinese market. They're not building for export or international use (Chinese regulations restrict that), but they represent competitive alternative infrastructure. China's AI capabilities are world-class, and that competition drives everyone else forward.
European Initiatives: The EU has been investing in sovereign AI infrastructure through initiatives like GAIA-X. Progress has been slower than hoped and more expensive than anticipated, but it's happening. European compute infrastructure remains more expensive and less available than U.S. cloud providers, but that's improving.
Emerging Markets: Brazil has announced plans for AI infrastructure. Southeast Asian nations are exploring partnerships with everyone from China to Singapore to various American companies. The global competition for AI infrastructure investment is heating up.
In this context, India's G42-Cerebras deployment is significant because it's actually happening at scale. Announcements and plans are common. Actual 8-exaflop deployments are rare. The question is whether India can actually execute this and make it operationally excellent.
Based on C-DAC's track record and G42's previous work, I'm cautiously optimistic. This isn't vaporware. It's real infrastructure with real partners and real funding. Whether it achieves the transformative impact India hopes for depends on execution, pricing, and how effectively they democratize access.

Real-World Applications: What Researchers Can Actually Build
Let's get concrete about what this compute enables in practice.
Healthcare AI: India has about 1.4 billion people and a healthcare system that's stretched across that population unevenly. AI models that help diagnose diseases, predict patient outcomes, and optimize treatment could save enormous numbers of lives. Training these models requires massive amounts of patient data and compute. With sovereign infrastructure, Indian healthcare institutions can train these models without leaving sensitive data abroad.
Consider a specific use case: Tuberculosis diagnosis and treatment in rural India. Building an AI system that understands regional variation in symptoms, local antibiotic resistance patterns, and population-specific health factors requires training on Indian medical data. You don't get there by fine-tuning a model trained on American medical records. You need to train from scratch on Indian data. That's computationally expensive and requires sovereign infrastructure.
Agricultural Optimization: Indian agriculture is the backbone of the economy and incredibly sensitive to climate variation. AI models that predict crop yields, identify diseases early, and optimize irrigation could dramatically improve agricultural productivity. Again, these models need Indian-specific training. Monsoon patterns, soil types, crop varieties, and farming practices in India are sufficiently different from the rest of the world that models trained globally underperform.
A specific example: Precision agriculture in cotton farming. Cotton yields vary dramatically based on rainfall, temperature, pest pressure, and farming practices. An AI system trained to predict cotton yields in India—using Indian weather data, Indian farming practices, Indian pest patterns—would be dramatically more valuable than a generic agricultural AI model.
Financial Risk Models: Indian banks and financial institutions need models to assess creditworthiness, predict default risk, and detect fraud. These models work better when trained on Indian financial data, Indian customer behavior, and Indian economic patterns. A fintech company building lending AI for India can't just use models trained on American loan data. It needs models trained on Indian data, requiring computational resources Indian institutions now have.
Government Services AI: The Indian government runs massive programs—subsidy distribution, tax collection, benefit administration, law enforcement. AI could improve every aspect of these systems. But training these models requires running them on sensitive government data. That requires infrastructure the government controls. Sovereign compute enables government AI in ways cloud providers can't match.
Manufacturing Quality Control: India's manufacturing sector is enormous and increasingly competing globally. Computer vision AI for quality control, predictive maintenance, and process optimization requires training on actual manufacturing data. Indian manufacturers can now build these systems domestically rather than relying on cloud providers or international consultants.
The pattern is clear: In every sector where India has specific characteristics—different diseases, different climate, different financial systems, different manufacturing practices—AI trained on Indian data and deployed on Indian infrastructure will outperform globally generic approaches. This infrastructure enables that entire category of innovation.

Challenges: What Could Go Wrong?
I've been bullish so far, and the potential is real. But let's acknowledge the risks.
Execution Risk: Building and operating a system of this scale is genuinely difficult. There's real risk of project delays, cost overruns, or operational problems. India has executed large infrastructure projects successfully, but not all of them. Telecom towers work. Highway construction is improving. But some projects languish.
Talent Availability: Running an 8-exaflop system requires world-class expertise in high-performance computing, systems administration, and AI optimization. India has talent, but recruiting and retaining the best people is competitive. Losing key staff could degrade the system's performance.
Power Infrastructure: A system drawing 15 kilowatts continuously requires stable, reliable power. Most of India has adequate power, but some regions remain problematic. This infrastructure will likely be deployed in major tech hubs with good power grids, but that's still a risk factor.
Software Ecosystem: Cerebras systems need custom software optimization. Getting standard machine learning frameworks to perform well on WSE architecture requires engineering work. That's solvable, but it's not plug-and-play like GPUs are. The software ecosystem around Cerebras is maturing but less mature than NVIDIA's CUDA ecosystem.
Pricing Risk: If the system ends up priced like commercial cloud services, adoption by SMEs and research institutions will be limited. If it's priced too cheaply, the system won't be self-sustaining and will require ongoing government subsidy. Finding the right price point is crucial and nontrivial.
Geopolitical Risk: U.S. export controls on advanced semiconductors and AI technology could complicate operation. The regulations are murky, and there's risk of restriction. Cerebras is American, and the WSE chips require advanced semiconductor manufacturing. If the U.S. restricts exports, this entire project becomes problematic.
Competition Risk: By the time this system is fully operational in 2027, other infrastructure alternatives may have matured. Faster GPUs, better AI chips, or cloud services with equivalent performance at lower cost could undermine the value proposition.
None of these risks are catastrophic, and the Indian government is aware of them. But they're real variables that will determine whether this becomes transformative or just a well-intentioned infrastructure project.

Integration with India's Broader AI Strategy
This deployment doesn't exist in isolation. It's part of a broader Indian strategy to build AI capabilities.
The National AI Strategy, released in 2021, identified areas where India should focus AI investment: healthcare, agriculture, education, criminal justice, and smart cities. G42's infrastructure supports all of these. With compute power, Indian researchers and entrepreneurs can build AI systems in these priority areas.
Simultaneously, India has been building out the policy and institutional framework. MEITY (Ministry of Electronics and Information Technology) is coordinating infrastructure, research, and policy. DPIIT (Department for Promotion of Industry and Internal Trade) is supporting startup ecosystems. Various universities are ramping up AI research programs.
What's missing so far has been computational infrastructure. India had supercomputing centers through C-DAC, but they're oversubscribed and not optimized for AI workloads. Researchers and startups had to use cloud services, which meant international dependencies and higher costs. This changes that equation dramatically.
The strategic timing matters. India is becoming a AI-capable nation exactly when AI is becoming the central competitive technology. That alignment is valuable. Every year matters in the race to establish credible alternatives to American AI dominance.

Looking Forward: The Next Five Years
If this project executes well, what does the Indian AI landscape look like in 2030?
Scenario 1: Successful Execution India has world-class AI infrastructure. Companies and researchers use it instead of cloud services. Models trained in India become globally competitive. Indian AI products outcompete global alternatives in Indian markets and increasingly in global markets. Export of AI models and services becomes significant. Tax revenue and intellectual property rights flow back to India. This becomes the template that other countries adopt.
Scenario 2: Partial Success The system works technically but isn't widely adopted. Access remains bureaucratic or expensive. India builds some good models but remains dependent on cloud services for most use cases. International recognition is modest. This becomes another underutilized government infrastructure investment.
Scenario 3: Delayed Execution The system comes online years late and over budget. By the time it's operational, competitive alternatives have emerged. Global AI infrastructure has become cheaper and more distributed. The project becomes less relevant than anticipated.
I think Scenario 1 is most likely, maybe 50-60% probability. Scenario 2 is possible at maybe 25-30%. Scenario 3 at 15-20%.
What tips the odds toward Scenario 1: The institutional partners (C-DAC, MBZUAI) are credible. G42 has proven capability. The government has strong incentives to make this work. Indian talent and entrepreneurship will find ways to use this if it's available. The use cases are compelling.

FAQ
What is exaflop computing and why does it matter?
An exaflop represents one quintillion (10^18) floating-point operations per second. It matters because AI training and inference require enormous computational throughput. Eight exaflops means the ability to perform 8 billion billion calculations simultaneously, enabling training of massive AI models in days rather than weeks or months. For context, the world's fastest supercomputer runs at about 1 exaflop, making 8 exaflops extraordinarily powerful. At this scale, you can train frontier-class AI models, run sophisticated inference workloads, and handle complex research computations that would be infeasible on smaller systems.
How does Cerebras' WSE architecture differ from traditional GPU-based AI infrastructure?
Cerebras' Wafer-Scale Engine puts 850,000 AI cores on a single silicon wafer with 40 petabytes per second of internal bandwidth, compared to traditional GPU systems that must network separate processors with much slower external connections (terabytes per second). This fundamental architectural difference means WSE systems have dramatically lower latency, better efficiency per watt, and superior performance for sparse operations common in modern neural networks. The on-chip approach eliminates much of the data movement that constrains GPU-based systems, resulting in 10-100x better power efficiency for AI workloads compared to GPU clusters.
Why is data sovereignty important for India's AI infrastructure?
Data sovereignty ensures that sensitive information—whether medical records, government documents, financial data, or research data—remains physically and legally within Indian borders, subject only to Indian law. This is crucial because American cloud providers are subject to U.S. government data requests and surveillance programs. With sovereign infrastructure hosted in India, the country can train models on sensitive data without legal risk or foreign government access. This enables applications in healthcare, government, and finance that wouldn't be feasible on American cloud services, fundamentally expanding what AI applications are possible.
What specific AI models and applications will this infrastructure enable?
The 8-exaflop system enables training of massive multilingual models for Indian languages (Hindi, Tamil, Telugu, Bengali, and others), domain-specific models for Indian healthcare, agriculture, finance, and government, and real-time inference systems serving millions of users. Practically, researchers can build tuberculosis diagnosis systems trained on Indian patient data, agricultural prediction models for Indian crops and climate, financial risk models for Indian markets, and government service optimization systems. Because these models are trained on Indian-specific data rather than global datasets, they're dramatically more effective for Indian use cases than fine-tuned global models.
How will researchers and SMEs actually access this infrastructure?
Access will be managed through multiple channels: Government agencies and research institutions get priority allocation through C-DAC and MBZUAI. Academic researchers submit proposals outlining their computational needs and research questions, with allocation based on merit and relevance. SMEs access capacity through reserved allocations (paying for guaranteed compute), spot pricing for spare capacity, and dedicated startup programs offering preferential rates. The exact terms are still being finalized, but the explicit goal is democratizing access rather than restricting it to large enterprises, distinguishing this from commercial cloud services.
What are the risks that could prevent this project from succeeding?
Major risk factors include execution challenges (typical for infrastructure at this scale), talent recruitment and retention in high-performance computing, power and cooling infrastructure requirements, software ecosystem maturity on Cerebras systems (less mature than NVIDIA CUDA), pricing strategy determining whether it's accessible to SMEs and researchers, U.S. export controls on advanced semiconductors potentially restricting operation, and competitive alternatives emerging while the system is being built. None are show-stoppers, but they're real variables determining whether this becomes transformative or moderately successful.
How does this fit into India's broader AI strategy?
This deployment directly supports India's National AI Strategy priorities in healthcare, agriculture, education, criminal justice, and smart cities. It fills the critical missing piece: computational infrastructure. India has talent, research programs, and policy frameworks, but lacked access to frontier computing resources without international dependencies. This system integrates with MEITY's coordination, DPIIT's startup support, and university AI programs to create a complete ecosystem. Timing is strategic—India is building AI capability exactly when AI is becoming the central competitive technology globally.
What geopolitical implications does this have?
This represents the first large-scale non-Western AI infrastructure alternative combining sovereign data control with frontier computing capability. It signals India's intent to be an independent AI actor rather than dependent on American cloud providers. For the U.S., it means losing part of the infrastructure dominance that's been an economic and geopolitical advantage. For China, it complicates efforts to position itself as the leading alternative to American tech. For India, it opens options for independent AI development and international partnerships. For other nations seeking AI sovereignty, it provides a successful model to emulate.
When will this system actually be operational and available for use?
The announcement came in February 2026, with operational deployment likely phased through late 2026 and 2027. Initial systems probably come online in Q3-Q4 2026 with limited testing access, full operational capacity by mid-2027, and broad SME access expanding through 2027-2028. This timeline is typical for infrastructure of this scale, accounting for site preparation, power infrastructure, cooling systems, software optimization, and testing. Delays are possible but not inevitable given the experienced partners involved.

Conclusion: A Watershed Moment for Global AI Development
When the history of AI is written, February 2026 might show up as a turning point. Not because of breakthrough research or a novel algorithm, but because of something more fundamental: infrastructure shifting toward distributed capability and genuine alternatives to Western concentration.
G42 and Cerebras are deploying 8 exaflops of computing power into India. That's not a modest technical achievement. It's a statement. A country that imports most of its technology now has the computational capacity to train state-of-the-art AI models. Researchers who've relied on cloud services now have access to dedicated infrastructure. Startups that couldn't afford AI development can now build it domestically. Governments can run sensitive workloads without foreign dependencies.
The cynical take is that this is just another data center. One more pile of chips in one more building. That would be wrong. This matters because of where it is, who controls it, and what becomes possible because of it. A tuberculosis detection system trained in India on Indian medical data will outperform a generic system. Financial risk assessment trained on Indian market data will work better for Indian banks. Agricultural AI trained on Indian climate and crops will be more valuable to Indian farmers. This isn't theoretical.
The execution risks are real. Cerebras systems are less mature than GPU infrastructure. Access frameworks matter enormously. Power stability, software optimization, and talent retention are all important variables. But the fundamentals are sound. The partners are credible. The geopolitical incentives are aligned. The need is clear.
For Indian researchers, entrepreneurs, and government agencies: This changes what's computationally feasible. Start thinking about what you'd build if you had access to world-class AI infrastructure. By the time the system is operational, have your research questions and business cases ready.
For the global AI community: This is the first credible non-Western alternative to American infrastructure dominance. It won't replicate American capability immediately—the U.S. still has the most sophisticated ecosystem. But it's real competition, and that's healthy. Global AI development benefits from alternatives, redundancy, and different perspectives on problems. India bringing sovereign AI capability to the table makes the entire field stronger.
For governments watching this: India is showing how to execute on AI sovereignty. Not through rhetoric or regulation, but through actually building competitive infrastructure with institutional partners. If you want independent AI capability, this is the template.
The age of exclusive American dominance in AI infrastructure is ending. Not because America is declining—U.S. AI capability remains extraordinary. But because other nations are building genuine alternatives. That's not a threat to America. It's a maturation of global AI development. And it's good for the world.

Key Takeaways
- G42 and Cerebras are deploying 8 exaflops of AI compute in India—8x the world's fastest supercomputer—marking the first major non-Western sovereign AI infrastructure alternative.
- Data sovereignty and Indian data residency are non-negotiable, enabling AI on sensitive healthcare, government, and financial data without foreign dependencies.
- Cerebras' WSE architecture is 40,000x faster at data transfer than networked GPUs and 10-100x more efficient per watt, fundamentally reshaping AI infrastructure economics.
- This infrastructure democratizes access for Indian SMEs, researchers, and government agencies, shifting compute from exclusive cloud provider control to national capability.
- India's alignment of sovereign infrastructure with $200+ billion in committed investment creates genuine competitive alternative to American and Chinese AI dominance.
Related Articles
- OpenAI's 100MW India Data Center Deal: The Strategic Play for 1GW Dominance [2025]
- Nvidia and Meta's AI Chip Deal: What It Means for the Future [2025]
- Alibaba's Qwen 3.5 397B-A17: How Smaller Models Beat Trillion-Parameter Giants [2025]
- Google Gemini 3.1 Pro: AI Reasoning Power Doubles [2025]
- AI Agent Scaling: Why Omnichannel Architecture Matters [2025]
- General Catalyst's $5B India Bet: What It Means for AI & Startups [2025]

