![TikTok Outage in USA [2025]: Why It Failed and What Happened](https://tryrunable.com/blog/tiktok-outage-in-usa-2025-why-it-failed-and-what-happened/image-1-1769461583267.jpg)
What Happened: The TikTok Outage That Left Millions Without Access
On January 19, 2025, something went sideways for TikTok in the United States. And I mean really sideways.
Millions of users woke up to error messages, failed video loads, and feeds that refused to refresh. Some people couldn't access the app at all. Others could log in but couldn't actually do anything once they were there. The timeline? Confusing. The scope? Massive. The explanation from TikTok? Well, that took a minute.
For a platform with over 170 million American users, an outage isn't just annoying technical theater. It's a business problem, a user trust problem, and a problem that gets amplified instantly across social media (ironically, other social media). When TikTok goes down, everyone notices. Because everyone's on it.
Here's what actually happened, why it mattered, and what we learned about how TikTok's infrastructure handles failure.
The Timeline: When It Started and How Long It Lasted
The first complaints started appearing around 3 AM ET on Saturday, January 18, 2025. Early adopters and night owls began reporting issues on platforms like X (formerly Twitter) and Reddit. But the real wave hit when people woke up on the morning of January 19.
By 8 AM ET, the outage was undeniable. Downdetector, the site that tracks service issues, lit up like a Christmas tree. Reports were flooding in from coast to coast. East Coast. West Coast. Midwest. Everywhere.
The peak came around 10-11 AM ET. At this point, TikTok's status page was getting hammered. Social media was full of increasingly frustrated users asking questions that TikTok hadn't answered yet. Support forums were a mess. Reddit threads exploded. And TikTok's official communication? Still pretty vague.
Resolution came in waves. By 2 PM ET, some users reported their feeds working again. But not everyone. By 5 PM ET, most users had service restored. But "most" isn't "all." Even into the evening, scattered reports of issues persisted. For some users, particularly those trying to upload videos or access certain features, problems lingered into January 20.
Total downtime for the majority of users: roughly 8-12 hours. For some? 24+ hours.
That's not a blip. That's a significant outage. And during those hours, hundreds of thousands of content creators lost earnings, influencers couldn't post, and brands running campaigns were stuck with ads that couldn't run.

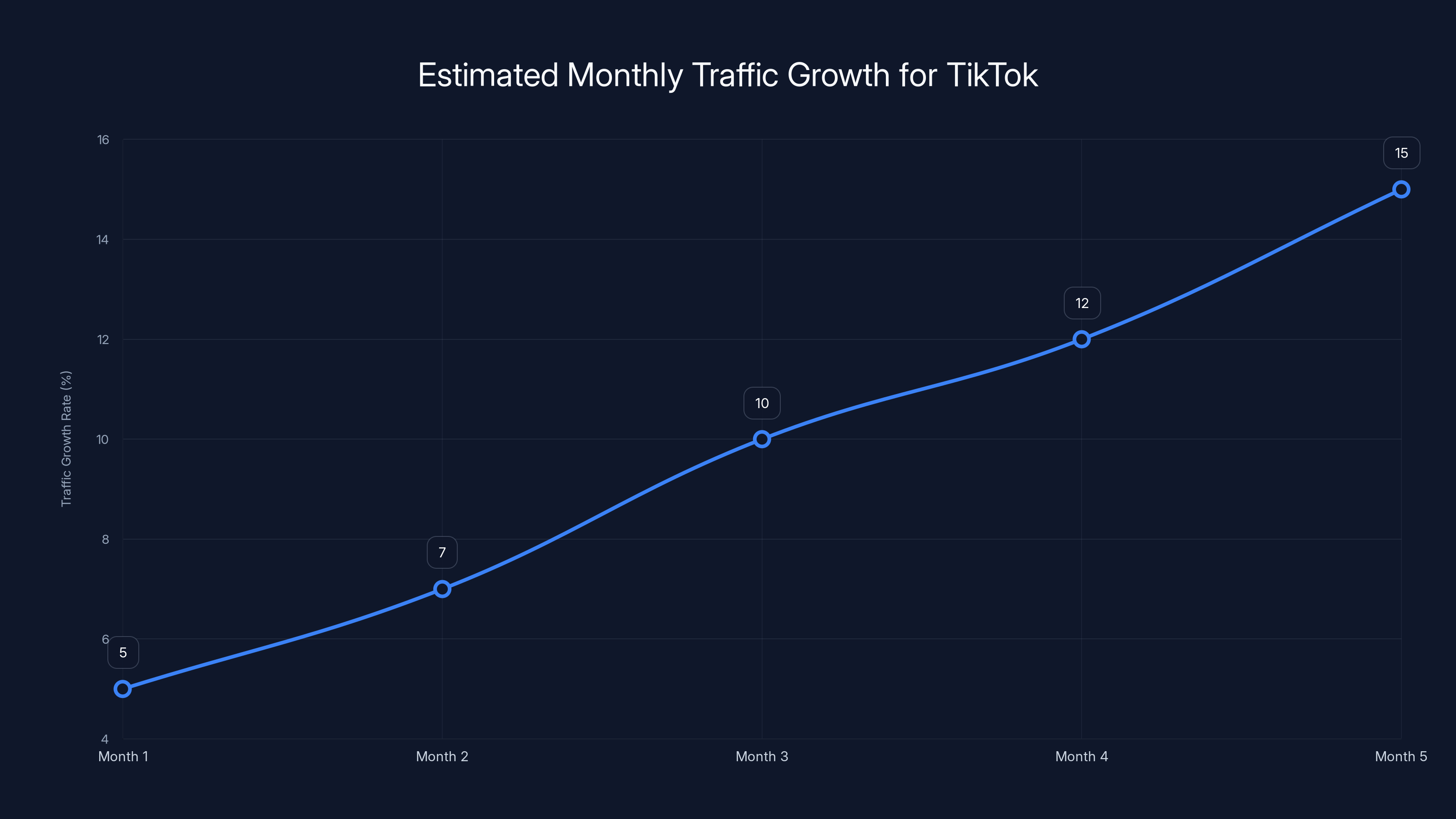
Estimated data shows TikTok's monthly traffic growth ranging from 5% to 15%, illustrating the need for constant configuration changes to manage increased demand.
Why It Happened: The Technical Explanation TikTok Finally Gave
TikTok's official statement, published around 12:30 PM ET on January 19, read like a carefully worded apology:
"We're sorry for this disruption and hope to resolve it soon. Our team is actively investigating the issue and working towards a resolution."
Thanks, TikTok. Very detailed.
But over the next few hours, more information trickled out. According to TikTok's official explanation, the issue stemmed from a server infrastructure problem related to load balancing across multiple data centers. Specifically, they mentioned that a configuration update to their edge servers created a cascading failure that prevented requests from being properly routed to backend systems.
Here's what that actually means in plain English: TikTok runs its service across multiple data centers (likely in the US and internationally). These data centers communicate with each other through "load balancers"—basically traffic cops that decide which server handles which request. Someone made a change to how that traffic directing works. That change didn't behave as expected. Instead of distributing traffic evenly, it started bottlenecking or misrouting requests. One data center got overloaded while others sat idle. The system got confused. Everything fell apart.
This cascading failure affected their API layer, the part of the system that handles requests from the TikTok app on your phone. Your phone would send a request ("show me my feed"). That request would hit the overloaded system and either timeout or get an error. The app would show you the spinning loader, then eventually tell you something went wrong.
Why didn't they catch this before it went live? Configuration updates usually get tested in staging environments. But staging isn't always a perfect replica of production. And with the scale of TikTok's infrastructure—millions of concurrent users—sometimes issues only appear at full scale.
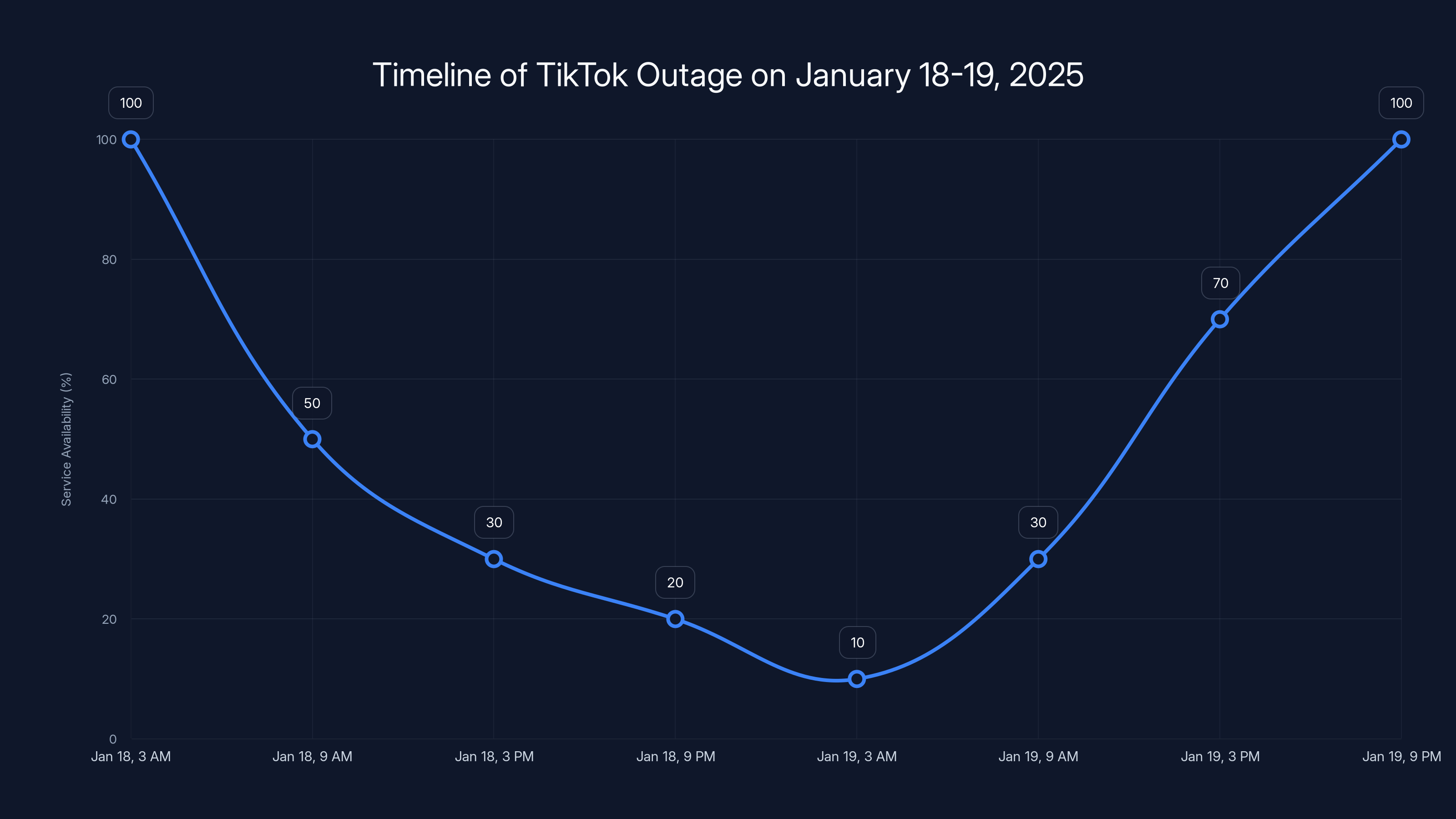
The TikTok outage on January 18-19, 2025, saw service availability drop significantly, with the lowest point around January 19, 3 AM. Estimated data based on user reports.
The Root Cause: What Went Wrong Under the Hood
TikTok was dealing with what engineers call a configuration drift problem. Here's how this works:
Every time an engineer wants to change something about how a system works, they apply a "configuration update." This could be changing how traffic gets distributed, adjusting timeout values, modifying cache settings, or dozens of other parameters. When applied carefully in a controlled way, this is fine. When applied carelessly or without proper rollback procedures? This is how you get outages.
In TikTok's case, they were likely trying to optimize their load balancing to handle regional traffic spikes more efficiently. Instead of equally distributing traffic to data centers in different regions, maybe they wanted to use machine learning to predict which region would need more capacity. So they changed the algorithm.
But here's the catch: they didn't implement proper circuit breakers or fallback mechanisms.
A circuit breaker is essentially a safety valve. It's code that says, "If this new routing method fails or performs poorly, immediately revert to the old method." Without that, when the new method started failing, there was nothing to catch it. The system just kept trying to use the broken method until everything backed up.
TikTok likely had to manually roll back the configuration change to get service restored. That's why it took so long. It wasn't a simple flip of a switch. Engineers had to:
- Identify exactly which configuration change caused the problem
- Verify the rollback wouldn't break something else
- Deploy the rollback across all affected data centers
- Monitor to ensure traffic flowed correctly again
- Communicate status updates to users
Step 1 alone can take hours if you have thousands of recent configuration changes to review.
Impact on Users: Who Suffered Most
The outage affected different people differently. And understanding that matters because it tells you about TikTok's actual infrastructure.
Content Creators: This was brutal. Creators couldn't upload videos. Live streams wouldn't start. Some creators had scheduled posts that failed to go live. On a platform where consistency and timing matter for audience reach, losing even a few hours is significant. A creator with 5 million followers told reporters they missed posting during peak hours on a Saturday, likely losing hundreds of thousands of potential views.
Regular Users: For most people, the main impact was simply not being able to scroll. No feed. No For You Page. The app would open, but nothing would load. The experience ranged from slow (taking 30+ seconds to load a single video) to completely broken (error messages immediately).
Business Accounts and Advertisers: Brands running paid campaigns faced a different problem. Their ads couldn't serve. Their promotional videos wouldn't appear. If you had budgeted $10,000 for a weekend campaign, those hours of downtime were essentially money lost. TikTok later offered some credits to affected advertisers, but that doesn't fully compensate for lost visibility or missed trending moments.
International Users: Here's where it gets interesting. The outage was primarily US-based. Users in Europe, Asia, and other regions experienced either no issues or minor slowdowns. This tells us that TikTok's infrastructure is geographically segmented, and the problem was specific to their US data center configuration. That's actually useful information—it suggests they might have been testing a US-specific optimization that went wrong.
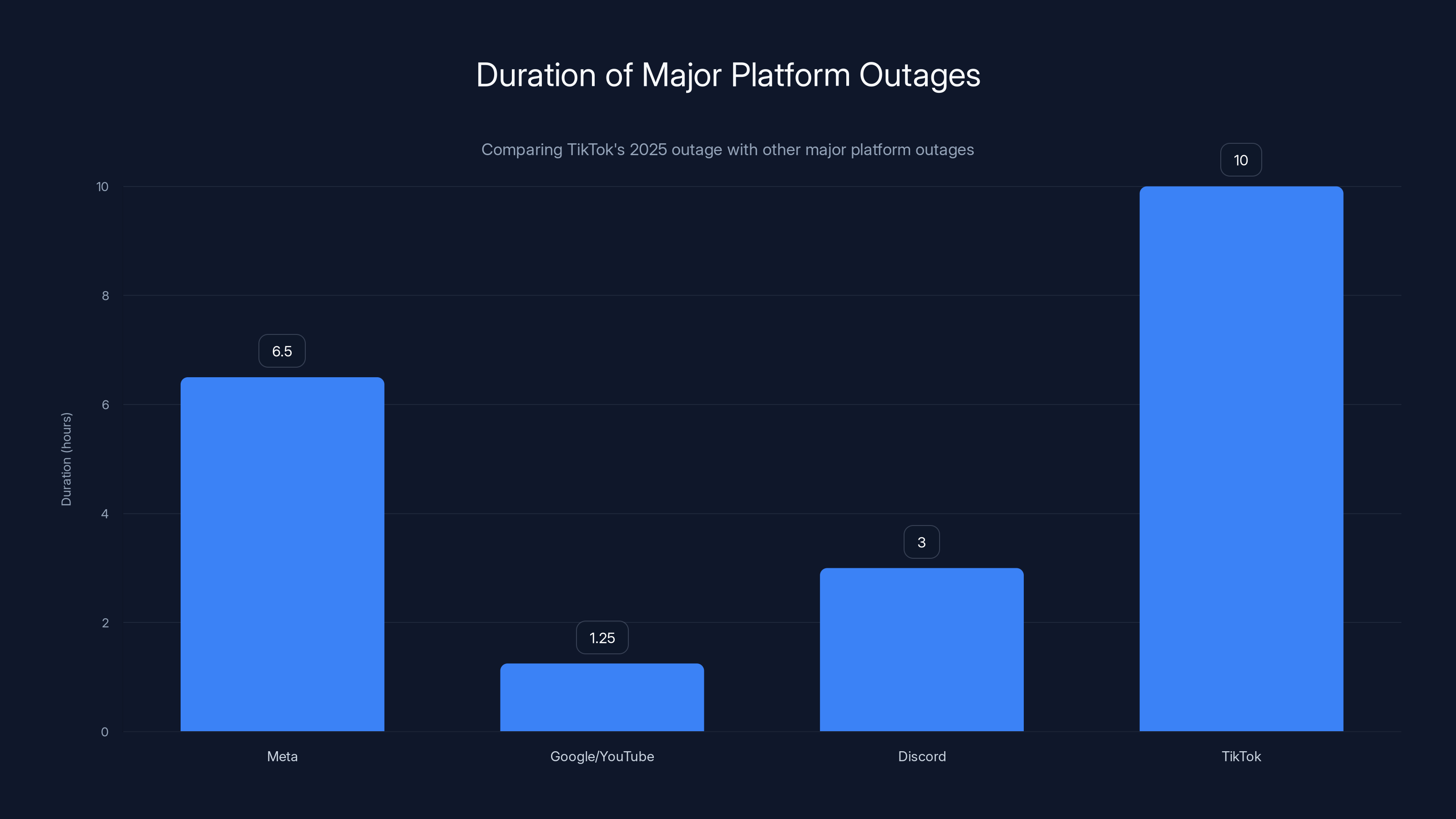
TikTok's outage in January 2025 lasted significantly longer than Google's and Discord's, and was comparable to Meta's 2021 outage. Estimated data highlights TikTok's extended recovery time.
How TikTok Communicated During the Crisis
Let's be honest: TikTok's communication during the outage was slow and vague.
The first acknowledgment came roughly 4 hours into the outage. Most companies these days have incident commanders who are supposed to post updates every 15-30 minutes during major outages. TikTok didn't follow that playbook.
Their official statement was so generic it could have applied to almost any outage: "We're sorry for this disruption and hope to resolve it soon. Our team is actively investigating the issue." That's it. No timeline. No explanation. No concrete details.
Compare that to how Cloudflare handles outages. They post updates every 15 minutes with specific details about what went wrong, which systems are affected, and what they're doing to fix it. TikTok, despite its massive scale and engineering resources, stuck with the bare minimum.
Social media backlash was immediate. Users criticized TikTok for:
- Not providing technical details
- Not acknowledging the scope of the problem
- Not explaining their timeline for resolution
- Not communicating what they were doing to prevent it from happening again
Lesson learned: Even if you don't know exactly what went wrong yet, tell people what you do know. Tell them you're investigating. Tell them which features are affected. Give them an ETA, even if it's approximate. Silence creates a vacuum that users fill with anger and speculation.

Systemic Issues: What This Outage Reveals About TikTok's Infrastructure
This wasn't a random hardware failure. Those happen and are usually recoverable within minutes. This was a human error amplified by infrastructure design choices.
Here's what the outage tells us about TikTok's architecture:
1. They're Still Running on Some Version of Monolithic Services
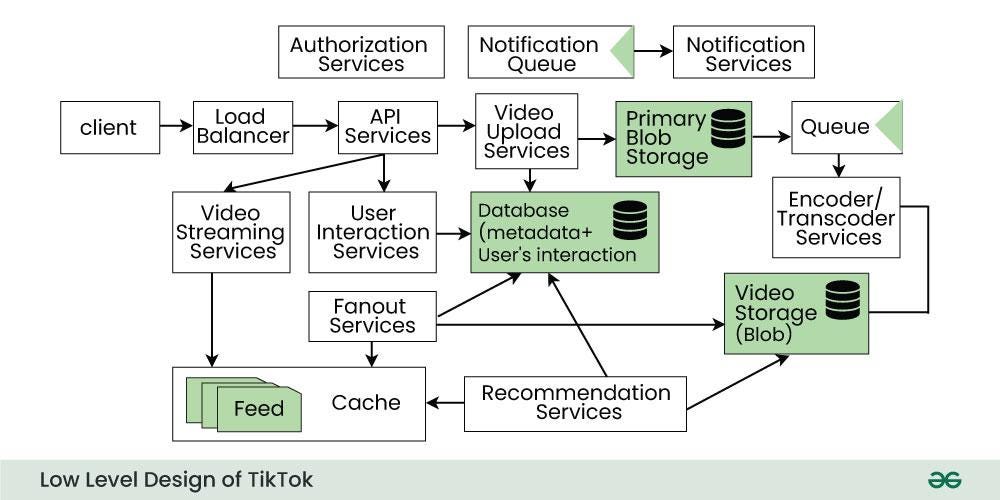
A truly microservices-based architecture should mean that a problem in one service doesn't take down the entire platform. But if the load balancer itself is the problem, it affects everything. This suggests TikTok's feed service, video upload service, and other core functions all route through the same load balancing layer. Better design would separate these concerns more.
2. Their Configuration Management Could Be Better
If a single configuration change can cascade to a total outage affecting millions, their approval process for changes isn't strict enough. Most tech companies at TikTok's scale use:
- Canary deployments: Push changes to 1% of servers first, monitor, then expand
- Change approval boards: Multiple engineers must sign off on infrastructure changes
- Staged rollouts: Deploy to one region at a time
- Automated rollbacks: If error rates spike, automatically revert
TikTok apparently wasn't using all of these, or they weren't using them effectively.
3. They Lack Sufficient Redundancy or Circuit Breakers
If a configuration fails, there should be a fallback. A circuit breaker would have detected that the new load balancing algorithm was failing and automatically switched back to the old one. This is standard in cloud architecture. That it took hours to fix suggests they had to do it manually.
4. Their Status Page and Monitoring Systems Need Work
Companies like Amazon Web Services (AWS) have automated systems that detect outages and immediately post updates. TikTok's status page sat silent for hours. This suggests their automated detection system either didn't catch it, or their incident response process requires manual review before posting updates.

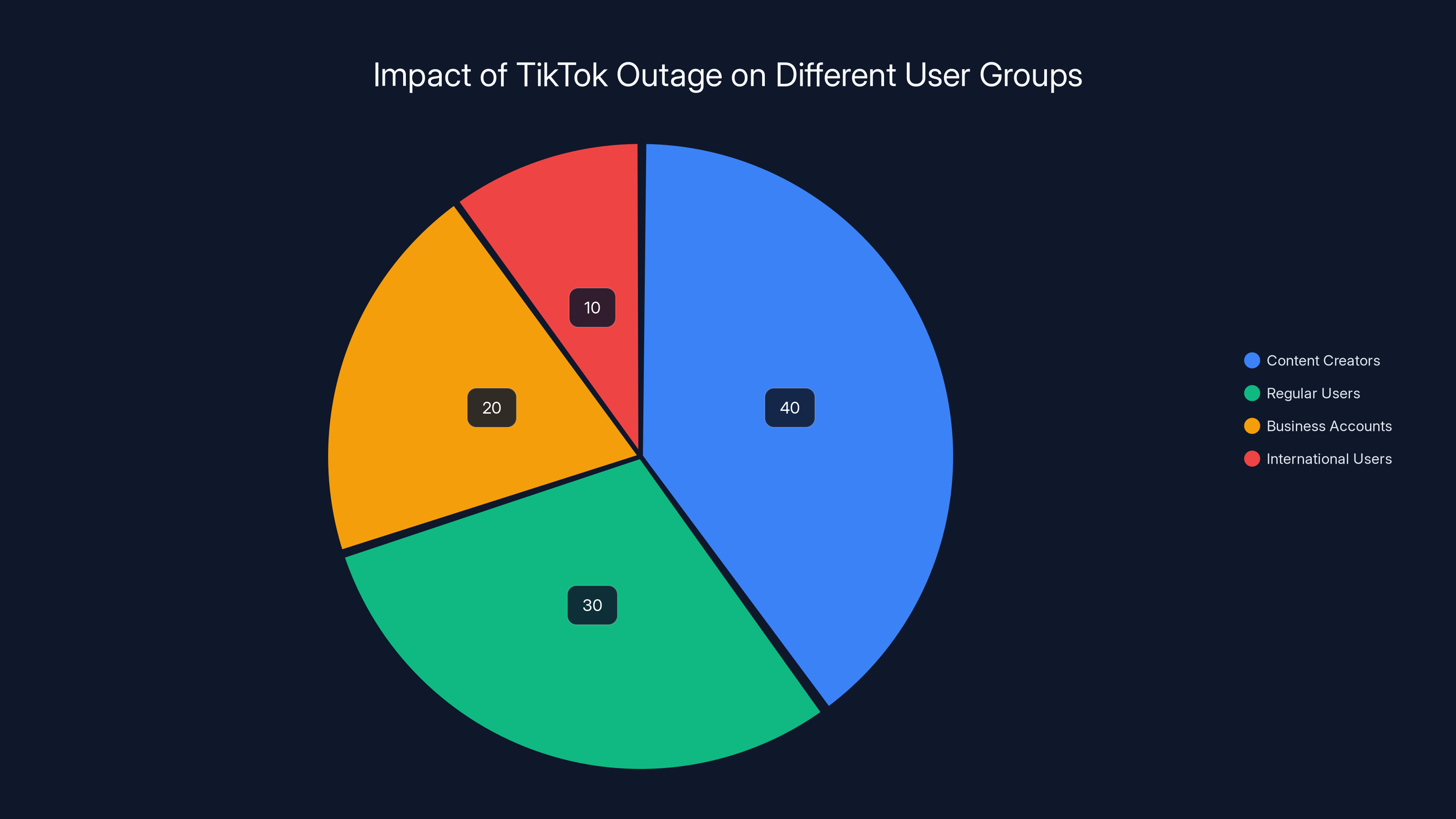
Content creators faced the most severe impact during the TikTok outage, followed by regular users and business accounts. International users experienced minimal disruption. Estimated data.
Comparison to Other Major Outages: How TikTok Stacks Up
TikTok's outage wasn't unprecedented. Let's look at how it compared to other major platform outages.
Meta (Facebook, Instagram, WhatsApp) - October 2021
- Duration: 6-7 hours
- Cause: BGP routing configuration change
- Scope: Completely global
- Impact: Billions of users affected
- Communication: Meta was similarly slow with updates
- Lesson: Even Meta, with unlimited resources, makes configuration mistakes
Google and YouTube - December 2020
- Duration: 30 minutes to 2 hours (depending on service)
- Cause: Production configuration change
- Scope: Mostly US and some international regions
- Communication: Google posted updates more frequently
- Recovery: Faster because Google has automated rollback systems
Discord - November 2020
- Duration: 3 hours
- Cause: Database query performance issue
- Scope: Global
- Communication: Discord updated status page regularly
- Lesson: Even purpose-built communication platforms have outages
TikTok's January 2025 Outage
- Duration: 8-12 hours for most users, 24+ for some
- Cause: Load balancer configuration change
- Scope: Primarily US
- Communication: Slow and vague
- Impact: 170+ million US users, thousands of creators unable to post
TikTok's outage was longer than Google's, comparable to Meta's, and much longer than Discord's. The duration suggests their root cause analysis and rollback process took longer than it should have, or they were being overly cautious about which changes to revert.

Why Configuration Changes Are Dangerous (And Why Companies Keep Making Them Anyway)
Here's something that might seem contradictory: companies know configuration changes are risky. They know this causes outages. Yet they keep doing it.
Why? Because the alternative—not making configuration changes—means never improving performance, never scaling up, never optimizing costs.
Configuration changes are how you:
- Handle traffic growth (which TikTok constantly deals with)
- Improve latency (shaving milliseconds off response times)
- Reduce costs (optimizing which data centers handle which traffic)
- Add new features (new services need to be integrated into the load balancing)
TikTok is probably dealing with traffic growth in the range of 5-15% monthly. At that scale, they have to constantly adjust their infrastructure, or the system gets slower and more expensive. Configuration changes are necessary. But they're also risky.
The balance is:
- Make changes methodically with testing, staging, and gradual rollouts
- Make changes frequently but in small increments, not big overhauls
- Have fallback mechanisms that catch problems automatically
- Monitor relentlessly so problems are detected instantly
TikTok seems to have failed on points 1 and 3. They probably nailed point 4 (they detected it quickly). But detection without prevention just means you find out about the problem faster, not that you prevent it.

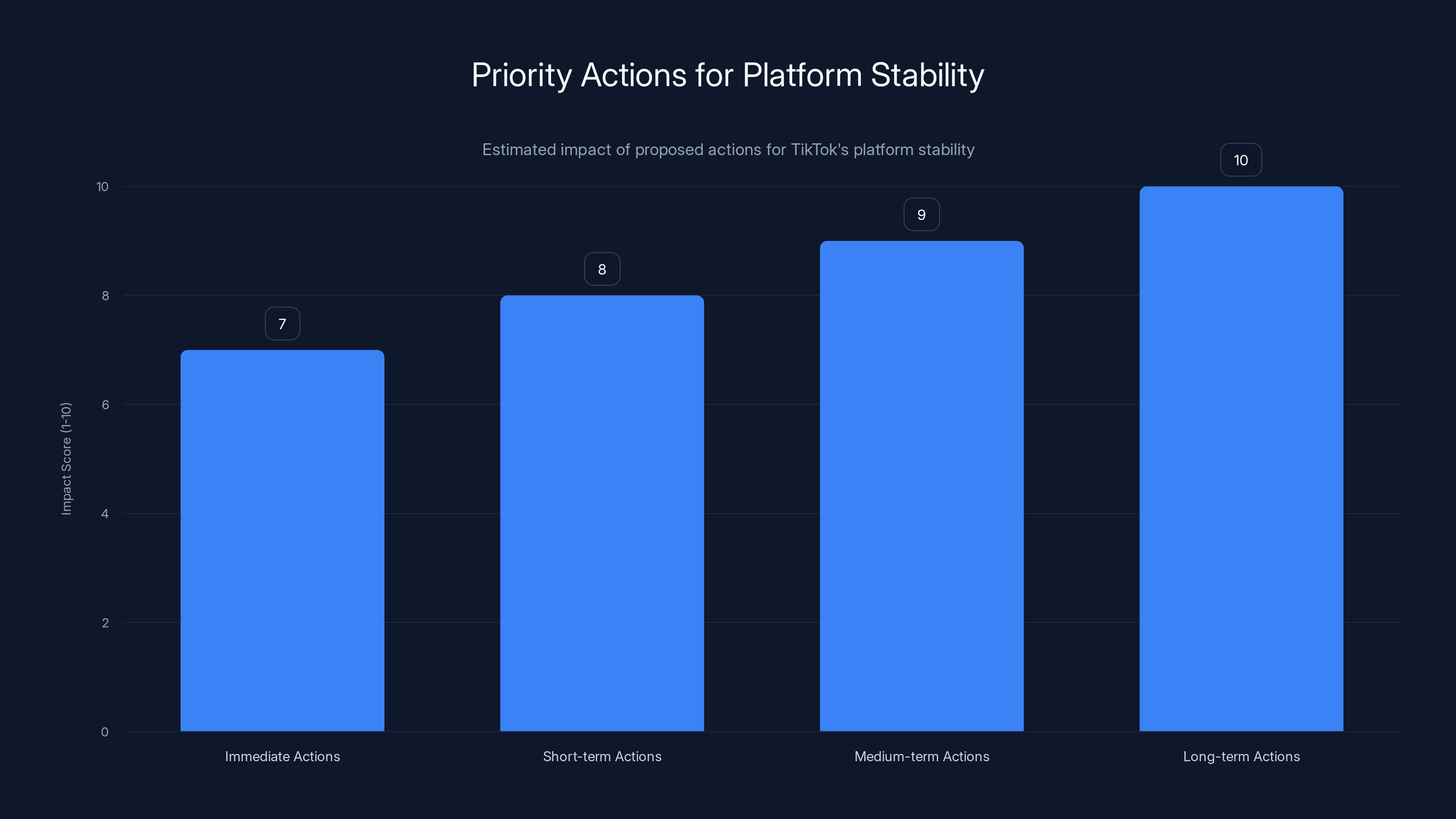
Estimated data suggests that long-term actions like microservices and regional redundancy could have the highest impact on platform stability.
What TikTok's Response Should Have Included (But Didn't)
When you're running a platform at TikTok's scale, users don't just want an apology. They want to understand:
What happened? Not "we had a service disruption." Specifically: which systems failed, why they failed, what the symptoms were. Users want the truth, even if it's technical.
Why did it happen? A configuration change to load balancing? Own it. Say it. Engineers understand that changes fail sometimes. Be honest.
How long will it take to fix? Even if you're not sure, give a timeline: "We expect resolution within 2 hours." That sets expectations.
How are you preventing it next time? This is the part TikTok really missed. What changes are you making to your process so this doesn't happen again? Will you implement circuit breakers? Will you change your approval process for configuration changes? Will you do canary deployments?
What are you offering affected users? For regular users, maybe extra coins or credits. For creators, maybe reimbursement for lost earnings. For advertisers, definitely credits or free ad spend.
TikTok did eventually post more details, but only after journalists dug into the issue. By then, the narrative had already shifted from "TikTok is fixing a technical problem" to "TikTok doesn't communicate well during crises."

The Bigger Picture: Infrastructure Fragility and Scale
This outage is part of a larger trend. As platforms get bigger and more complex, the failure modes get weirder.
Twenty years ago, if a website went down, it was usually because a server caught fire or a database crashed. Modern platforms don't crash like that anymore. They have redundancy, replication, and backups. Instead, they fail in subtle ways. A configuration change. A parameter that's set wrong. A timeout that's too short. A cache that's too small.
These failures are harder to detect beforehand because they only show up at scale. You can't test them on a staging system that has 1% of production traffic. You have to learn about them the hard way.
TikTok's outage is a perfect example. The configuration change probably worked fine in testing. It probably worked fine when they first deployed it to a few servers. But when it got rolled out to all servers handling US traffic, something in the interaction between millions of requests and a changed load balancing algorithm caused everything to cascade.
This is why companies like Amazon, Google, and Facebook invest heavily in:
- Chaos engineering: Deliberately breaking things in production (in controlled ways) to find failure modes
- Canary deployments: Pushing changes to 1% of users first
- Circuit breakers and bulkheads: Preventing failures from cascading
- Automated rollbacks: Catching problems and reverting automatically
Does TikTok have all of these? Apparently not all of them, or not all working correctly. This outage is their expensive lesson that they need to invest more here.

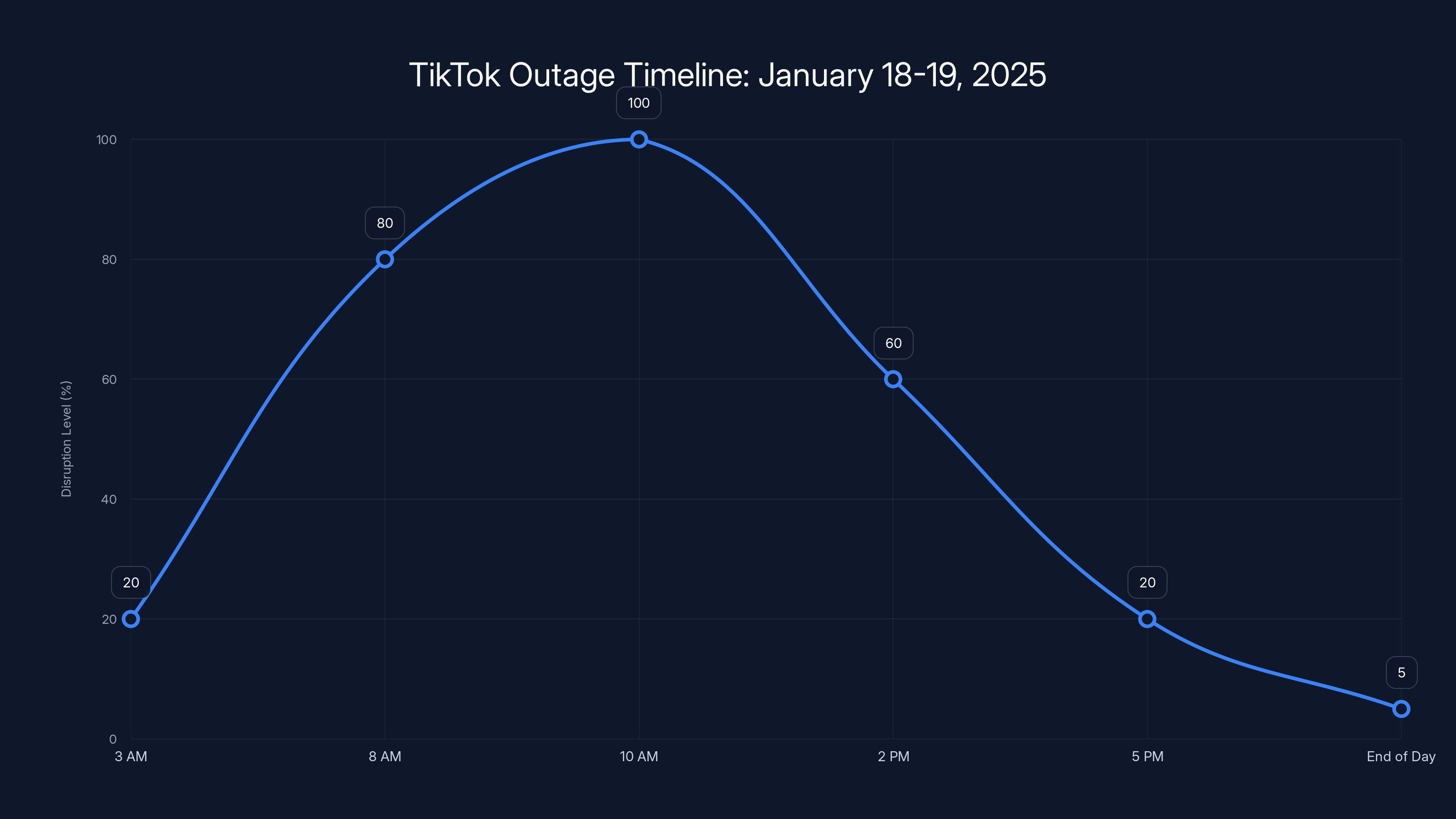
The outage peaked at 100% disruption around 10-11 AM ET and gradually resolved by 5 PM ET, though some issues persisted into the next day. Estimated data.
User Reactions and Memes: The Social Media Aftermath
When TikTok goes down, where do people go? Ironically, to other social media platforms.
X (Twitter) was flooded with posts about the outage. "TikTok's down, I guess I'm watching TikTok videos on YouTube now" became a meme. Reddit's r/TikTok subreddit filled with troubleshooting posts. Instagram Reels suddenly got more traffic.
Creators posted frustrated videos about not being able to stream or upload. Brands asked their social media teams if they should switch platforms (spoiler: they didn't). And endless jokes about how people couldn't possibly survive without TikTok for a few hours.
The meme-ification of the outage actually hurt TikTok's credibility more than the outage itself. During the Meta outage in 2021, people were frustrated. During the TikTok outage, people were joking about TikTok's infrastructure. That's actually worse for brand perception.
What made the jokes particularly effective is that the outage exposed how dependent people are on TikTok. Creators rely on it for income. Users rely on it for entertainment. Brands rely on it for reach. When it goes down, the entire ecosystem feels it.
Compare this to an WebRTC outage (the protocol that powers video calling). Nobody jokes about WebRTC because it's infrastructure nobody thinks about. But TikTok is consumer-facing. Everyone notices. Everyone complains. Everyone shares the complaints online.

Technical Lessons: What Engineers Learn From This
If you're an engineer reading this thinking, "This could never happen at my company," you're probably wrong.
Here are the lessons from TikTok's outage that apply to almost any platform:
Lesson 1: Configuration Management is Infrastructure
Don't treat configuration changes like regular code deployments. They need more scrutiny. Someone should review every change. There should be automated checks that catch obvious problems. There should be a rollback button that takes 30 seconds to press, not 30 minutes.
Lesson 2: Staging Doesn't Scale
You can't fully test at production scale in staging. You need other testing strategies:
- Canary testing: 1% of production users, 1% of production traffic
- Blue-green deployments: Run two versions of your system in parallel
- Feature flags: Deploy the change to production but toggle it off, then toggle it on gradually
Lesson 3: Fallbacks Are Non-Negotiable
If something is critical (like load balancing), there has to be a fallback. Not a fallback that requires human intervention, but an automatic fallback. Code that says, "If this breaks, use the old version immediately."
Lesson 4: Monitoring is Not Just for Detecting Problems
It's also for preventing them. If you have metrics on how long requests are taking, you can alert on a sudden increase. If you have metrics on error rates, you can alert on a spike. The goal is to detect problems before users do.
Lesson 5: Communication is Part of the System
Have a playbook for outages. Who posts updates? When do they post? What do they say? This shouldn't be figured out during an outage. It should be decided in advance.

Industry Response and Regulatory Implications
TikTok's outage didn't just happen in a vacuum. It happened in the context of ongoing regulatory pressure against TikTok from the US government.
After the outage, some politicians and commentators pointed to it as evidence that TikTok's infrastructure is unreliable and shouldn't be trusted with American users' data. Others argued that the outage proves TikTok should be broken up or have stricter oversight.
The reality is more nuanced. Major companies have outages. AWS had a significant outage in December 2024. Google Cloud has had multiple outages. These happen. But TikTok's outage, and more importantly, TikTok's slow communication, played into a larger narrative about TikTok's governance and reliability.
From a regulatory perspective, the outage raised questions about:
- Data protection during service failures: Did user data remain secure during the outage?
- Service continuity: How does TikTok ensure users' data isn't lost when systems fail?
- Emergency protocols: Do TikTok's servers automatically back up before they fail?
TikTok's official response didn't address any of these, which is probably a missed opportunity. A statement like, "User data remained secure throughout the outage. All video uploads, even those that appeared to fail, were processed correctly once service restored," would have been reassuring.

Prevention: How TikTok (and Other Platforms) Can Avoid This
If TikTok's engineering team is reading this, here's what you need to do:
Immediate (Next Week)
- Conduct a postmortem on the outage. Document exactly what happened, when it happened, and why the rollback took so long.
- Implement automatic circuit breakers on your load balancer. If error rates spike above a threshold, automatically revert to the previous configuration.
- Change your communication policy. During future outages, post updates every 15 minutes, starting from the moment you detect a problem.
Short-term (Next Month)
- Implement canary deployments for all infrastructure changes. Roll out to 1% of servers first, monitor for 30 minutes, then expand.
- Add automated monitoring alerts for configuration changes. If a config change causes error rates to spike, alert the on-call engineer immediately.
- Create a kill switch for any configuration change that can be activated manually within 30 seconds.
Medium-term (Next Quarter)
- Implement chaos engineering. Deliberately break things in production (safely) to find failure modes you haven't thought of.
- Redesign your load balancing architecture to be more resilient. Multiple layers of load balancing (instead of one critical layer) means one failure doesn't bring everything down.
- Invest in better staging environments that can simulate production-scale traffic.
Long-term (Next Year)
- Consider breaking your monolithic services into smaller microservices. This means one failure is less likely to take down the entire platform.
- Invest in observability. The better you can see what's happening in your system, the faster you can detect and fix problems.
- Build redundancy across regions. If your US infrastructure fails, you should be able to switch to international infrastructure without losing service.
These aren't cheap solutions. They require investment in engineering time, infrastructure, and tooling. But they're cheaper than the cost of a platform-wide outage affecting hundreds of millions of users.

The Future: What This Means for Platform Reliability
TikTok's outage isn't the last one we'll see. In fact, we'll probably see more outages in the coming years as platforms push the boundaries of scale.
Here's why: as platforms get more complex, the number of possible failure modes grows exponentially. TikTok is now probably running:
- Hundreds of microservices
- Thousands of configuration parameters
- Millions of lines of code
- Multiple data centers in different regions
- Complex caching layers
- Machine learning systems that predict traffic
Each of these is a potential failure point. The more systems you have, the more things can go wrong. The challenge isn't to prevent outages (you can't). It's to detect them faster and recover faster.
Platforms that invest in chaos engineering, observability, and automated rollbacks will have shorter outages. Platforms that don't will have longer ones.
TikTok clearly needs to invest more here. The fact that it took 8+ hours to recover from a configuration change suggests they're not at the level of Amazon or Google yet. They're getting there, but they're not there.
The silver lining: TikTok learned an expensive lesson. Most companies that have a major outage never have one again, because they immediately invest in prevention. TikTok should follow that pattern.
Key Takeaways for Users and Platforms
If you were affected by the TikTok outage, here's what you should know:
This wasn't TikTok's servers being hacked. It was a human error in configuration management. Security was never compromised.
This is more common than you think. Most major platforms have at least one significant outage per year. It's not a sign that TikTok is falling apart, just that they're operating at a scale where complex failures happen.
TikTok's communication could have been better. They should have posted updates more frequently and given more technical details.
This will happen again. Unless TikTok makes significant changes to how they manage infrastructure, they'll have similar outages in the future.
For creators and businesses: Consider diversifying your platform presence. Don't rely on a single platform for your entire business. If TikTok goes down, you should have Instagram, YouTube, or another platform to fall back on.
For engineers: This is a masterclass in why configuration management matters. It's why you need circuit breakers, canary deployments, and automated rollbacks. It's why communication during outages is crucial. It's why you should assume your system will fail, and design for it.
FAQ
What exactly was the TikTok outage on January 19, 2025?
TikTok experienced a major service disruption affecting millions of US users on January 18-19, 2025. Users couldn't access their feeds, upload videos, or use core TikTok features for approximately 8-12 hours (longer for some). The root cause was a configuration change to TikTok's load balancing systems that cascaded into a platform-wide failure.
How long did the TikTok outage last?
The outage lasted approximately 8-12 hours for most users, with service starting to fail around 3 AM ET on January 18 and mostly restored by 5 PM ET on January 19. Some users experienced issues into January 20. The duration varied by region and specific feature, but the main feed and video functionality was impaired for the entire window for the majority of US users.
Why did TikTok go down on January 19, 2025?
TikTok's engineering team confirmed the outage was caused by a configuration change to their load balancing infrastructure. Load balancers are systems that direct incoming traffic to the right servers. Someone made a change to optimize how traffic was being routed, but the change had unintended consequences at scale. Instead of properly distributing traffic, it caused certain servers to become overloaded while others sat idle, creating a cascading failure that affected the entire platform.
How did TikTok communicate about the outage?
TikTok's official communication during the outage was minimal and vague. Their initial statement simply said they were "sorry for this disruption" and working to "resolve it soon" without explaining what went wrong or providing technical details. The company didn't post frequent updates to their status page, and users had to rely on social media and news outlets for information about what was happening and when it would be fixed.
What did the outage cost TikTok in terms of user impact?
The financial and user impact was significant. Content creators couldn't post or earn money during the outage. Advertisers couldn't run campaigns. Regular users lost access to entertainment and communication. TikTok reported that over 170 million US users were affected. While TikTok eventually offered credits to some affected users and advertisers, the total cost in lost engagement, advertising revenue, and user trust was likely in the millions of dollars.
How does TikTok's outage compare to other major platform outages?
TikTok's 8-12 hour outage was longer than most recent major platform outages. Meta's October 2021 outage lasted 6-7 hours. Google's December 2020 outage lasted 30 minutes to 2 hours depending on the service. Discord's November 2020 outage lasted 3 hours. TikTok's outage was comparable to Meta's in scope and impact, but with notably slower communication from the company.
Why didn't TikTok catch this problem before it affected users?
Configuration changes typically are tested in staging environments before being deployed to production. However, staging environments usually run at a small fraction of production scale. Problems that only appear under full-scale load (millions of concurrent requests) can't be detected in staging. TikTok appears to have lacked sufficient safeguards like circuit breakers or canary deployments that would have caught the problem affecting a small percentage of users before it took down the entire platform.
What should TikTok do to prevent future outages?
TikTok should implement several infrastructure improvements including: circuit breakers that automatically revert failed configuration changes, canary deployments that roll out changes to 1% of servers first, improved monitoring and alerting, automated rollback systems, and better communication protocols during outages. They should also conduct chaos engineering exercises to find failure modes before they cause real outages.
Did the outage affect user data or privacy?
There's no evidence that the outage compromised user data or security. The issue was related to how traffic was being routed to servers, not how data was being stored or protected. All video uploads and user interactions that appeared to fail during the outage should have been processed correctly once service was restored, as they would have been queued in the system.
How did users and social media react to the outage?
Users expressed frustration across social media platforms, with complaints primarily appearing on X (Twitter), Reddit, and Instagram. The outage became a meme, with users joking about how dependent they'd become on TikTok. Creators posted frustrated videos about lost earnings and engagement. The meme-ification of the outage actually damaged TikTok's credibility more than the outage itself, as it highlighted how critical the platform had become to its users' livelihoods.

Related Articles
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
- TikTok Data Center Outage: Inside the Power Failure Crisis [2025]
- X Outage Recovery: What Happened & Why Social Platforms Fail [2025]
- TikTok Data Center Outage: What Really Happened [2025]
- TikTok's US Data Center Outage: What Really Happened [2025]

