![TikTok Power Outage: What Happened & Why Data Centers Matter [2025]](https://tryrunable.com/blog/tiktok-power-outage-what-happened-why-data-centers-matter-20/image-1-1769451180778.jpg)
TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
Introduction: When Your Favorite App Goes Dark
You open TikTok on a Sunday evening, ready to scroll through your "For You" page. Nothing loads. You refresh. Still nothing. You check your internet connection—it's fine. Twitter's working. Instagram works. But TikTok? Dead.
If you experienced this recently, you weren't alone. Millions of TikTok users across the United States hit a wall when the platform's service suddenly became inaccessible. Videos wouldn't load. The recommendation algorithm—the secret sauce that makes TikTok so addictive—stopped working entirely. Users complained about seeing generic content instead of personalized feeds. Others couldn't log in or upload videos.
Here's what actually happened: TikTok's infrastructure suffered a massive power outage at one of its data centers in the United States. Not a hack. Not a government shutdown (at least, not that day). Just a power failure that cascade-failed across the platform's American services, as reported by The Verge.
This incident reveals something crucial about how modern apps work. TikTok isn't some magical cloud service that exists everywhere and nowhere. It runs on physical servers in real buildings with real power cords. When those power cords get cut—accidentally or otherwise—millions of users instantly feel the impact.
The timing made it even more dramatic. This outage happened just days after TikTok finalized a deal to spin off its US business, following months of political pressure and regulatory threats, as noted by ABC News. So people weren't just frustrated about the app being down—they were speculating about whether this was connected to the broader shake-up happening behind the scenes.
In this article, we're diving deep into what caused this outage, why it happened, what the company did to fix it, and what it tells us about the infrastructure that powers your favorite apps. By the end, you'll understand data center failures in a way that makes you question how fragile the digital world actually is.
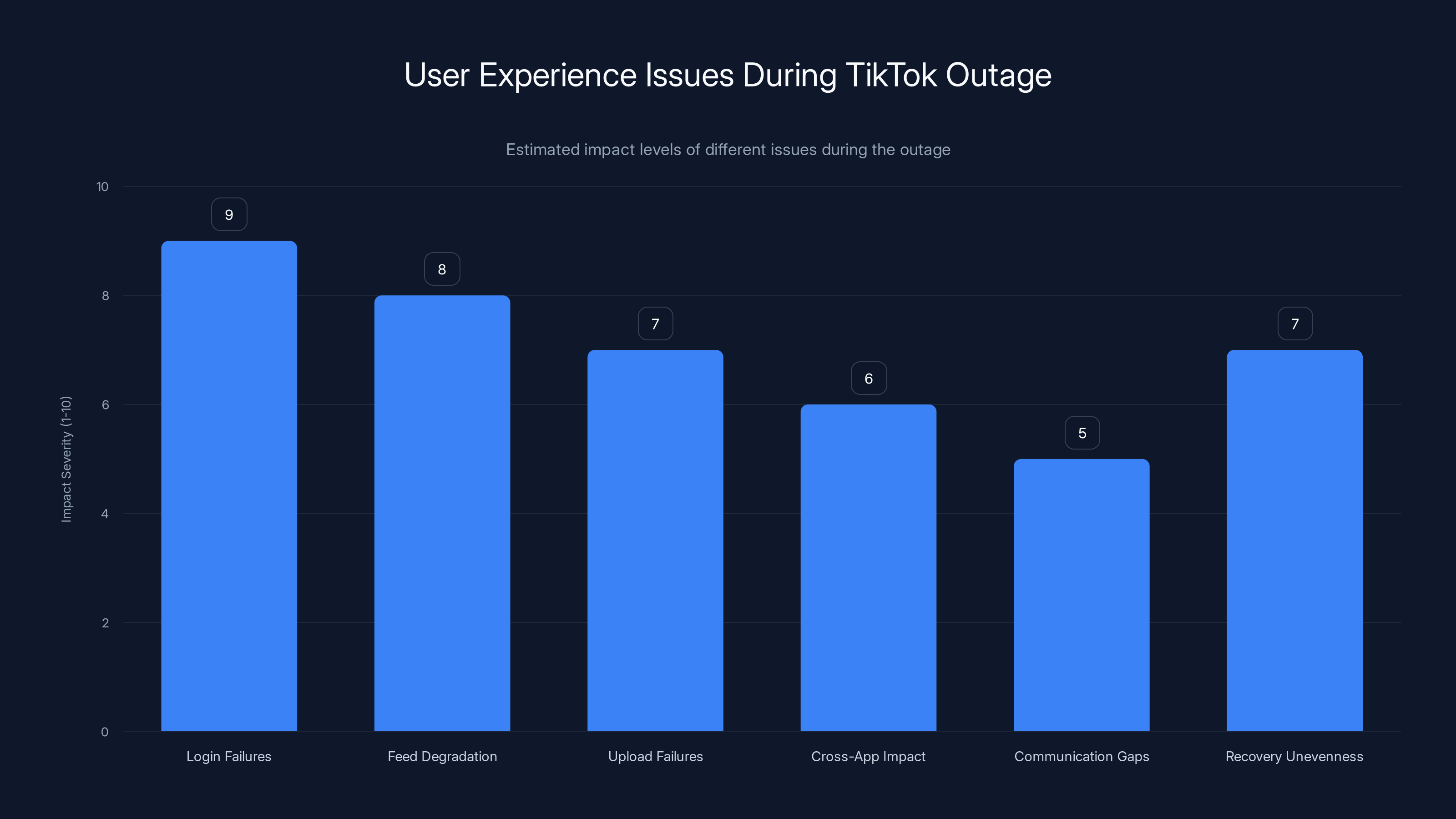
Login failures had the highest impact on user experience during the TikTok outage, followed by feed degradation and upload failures. Estimated data based on narrative analysis.
TL; DR
- What Happened: TikTok experienced a widespread service outage across the US caused by a power failure at one of its data centers
- User Impact: Millions couldn't log in, upload videos, or see personalized content in their feeds—the algorithm broke entirely
- Root Cause: A power outage at a single US data center that TikTok and other apps it operates depend on
- Company Response: TikTok worked with its data center partner to stabilize services and restore functionality
- Why It Matters: This reveals how dependent we are on physical infrastructure and how single points of failure can affect millions
What Exactly Happened That Day
On Sunday, January 12, 2025, TikTok users in the United States began reporting problems with the app around 2 PM Eastern Time. At first, it seemed random—maybe your connection, maybe a local issue. But the complaints kept flooding in. Reddit threads multiplied. Twitter exploded with screenshots of error messages.
The problems weren't uniform across the platform. Some users could access the app but couldn't upload videos. Others could watch content but the feed wasn't personalizing—instead of your usual hyper-targeted content mix, you got generic videos that made no sense for your interests. Some users reported seeing the same five videos repeat endlessly. One user tweeted they kept seeing a 45-second dance video from 2023 in different aspect ratios, as detailed by Cleveland.com.
The most frustrating issue was the authentication failure. You'd try to log in and get a vague error message. Users with multiple accounts couldn't switch between them. New users couldn't create accounts. TikTok's sign-in servers simply weren't responding.
Within hours, the company publicly acknowledged the issue. TikTok posted a statement: "Since yesterday we've been working to restore our services following a power outage at a U. S. data center impacting TikTok and other apps we operate. We're working with our data center partner to stabilize our service. We're sorry for this disruption and hope to resolve it soon," as reported by Mashable.
That phrase "other apps we operate" was interesting. TikTok doesn't just run TikTok. ByteDance owns the parent company that operates numerous apps—Douyin in China, Hype, Vigo Video, and others. A single data center failure affected potentially hundreds of millions of users across multiple platforms.
The outage lasted roughly 12 hours before TikTok posted another update saying services were being restored. By Monday afternoon, most users reported normal functionality. But the algorithm took longer to fully recover—some people continued seeing suboptimal recommendations for another day or two as the system relearned user preferences, as noted by The Verge.
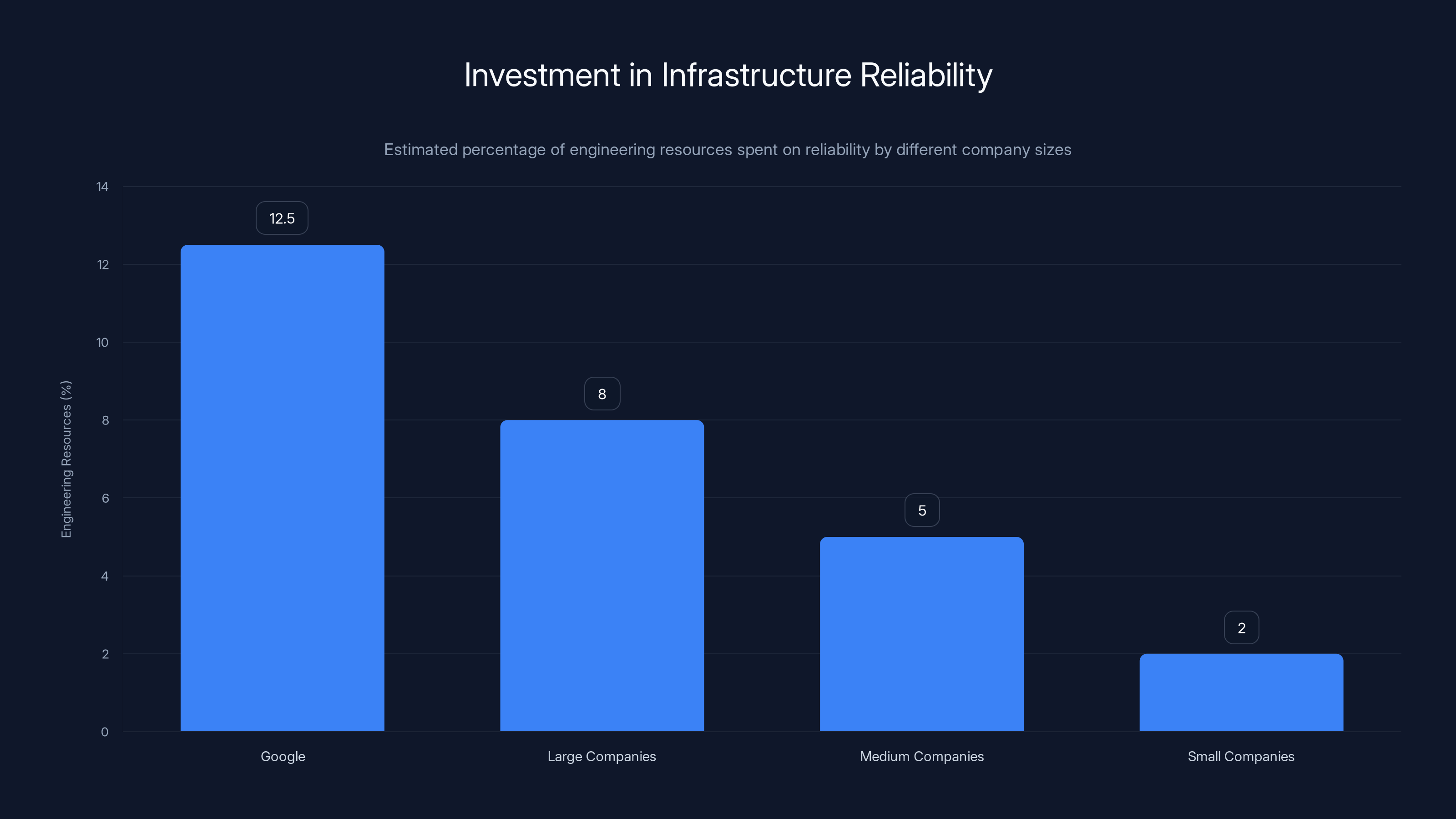
Estimated data shows Google invests significantly more in reliability compared to smaller companies, which leads to fewer outages. Estimated data.
The Data Center Connection: How One Building Powers Millions
Understanding this outage requires understanding data centers. A data center isn't mysterious. It's a building—sometimes massive, sometimes modest—filled with servers. Hundreds or thousands of computers stacked in racks, connected by fiber optic cables, cooled by industrial air conditioning, powered by industrial-grade electricity.
TikTok operates multiple data centers across the United States. We don't know the exact locations (companies keep this secret for security reasons), but TikTok has infrastructure in Virginia, California, Texas, and other major tech hubs. The idea is redundancy: if one data center goes down, traffic reroutes to others automatically, as explained by Britannica.
But here's the critical failure point: apparently, this particular data center wasn't fully redundant. Or the redundancy had a flaw.
When the power cut at one facility, several things could have happened. Best case: automatic failover kicks in, traffic redirects instantly to backup data centers. Users never notice. Worst case: the backup systems fail, or the backup capacity isn't large enough to handle the full load, or—most likely—there's a cascade failure where multiple systems try to simultaneously transition and overwhelm the remaining infrastructure.
When you have 130 million daily active users (TikTok's US number), even 60 seconds of service disruption creates chaos. The company's systems probably hit cascading failures: too many login attempts from users trying to reconnect overwhelming the remaining servers. Too many requests hitting backup systems that weren't designed for the full load. Cache systems emptying out. The algorithm's machine learning models struggling to make predictions without their usual data sources.
Data centers fail for obvious reasons: power surges, transformer failures, cooling system breakdowns, or sometimes human error during maintenance. They fail for weird reasons too: a water pipe bursting, a generator failing to kick in, or—I've actually seen this—a contractor accidentally drilling into a power cable during renovations.
TikTok didn't specify what caused the power failure. That's normal. Companies rarely publicize root causes immediately because they're still investigating. Possible causes range from weather (severe storms, extreme heat straining the grid) to equipment failure (a transformer at end-of-life finally gave up) to maintenance gone wrong.
Why The For You Algorithm Broke Completely
The most visible failure during this outage was the algorithm breaking. Users got generic content, repeated videos, recommendations that made no sense.
This happened because TikTok's recommendation algorithm—the actual artificial intelligence model that decides which videos you see—relies on real-time data processing. Every time you watch, like, comment, or share a video, that data feeds into machine learning models running on TikTok's servers. These models are constantly updating, learning your preferences, comparing your behavior to millions of other users.
When the primary data center went down, those models became unreachable. TikTok's app has some fallback logic—it doesn't completely break. Instead, it falls back to simpler algorithms: recently trending videos, random popular content, videos that performed well yesterday.
That's why users saw generic content. The app was serving you something instead of nothing, but it wasn't the sophisticated personalization that makes TikTok addictive.
One user reported the same three-minute dance video showing up 47 times in her feed before she gave up scrolling. Another saw cat videos (not their usual content) repeated endlessly. This happens because without the main algorithm, the fallback system might use crude matching—"this person watched videos with music, so give them all music videos" or "this person watches dance, so here's every dance video from the past week."
The repeated videos specifically tell us the app's caching system was probably running on the failed data center too. Caching means TikTok stores the most popular and recently viewed videos in super-fast local memory so they load instantly. When that cache went offline, the app had to fall back to a more limited selection of videos it could confidently serve.
Even as the data center came back online, the algorithm needed time to recalibrate. The models had been offline. They needed to reprocess data, recalculate weights, and re-index the user behavior data. This isn't instant. Modern machine learning models running on billions of data points need minutes to hours to fully synchronize after an outage.

The Timing: Why This Happened Days After the Spin-Off Deal
The outage hit just days after TikTok finalized a deal that would separate its US operations from its Chinese parent company, ByteDance. This timing sparked wild speculation on social media.
Some people thought it was intentional—maybe the Chinese government was sabotaging things during the transition. Others wondered if ByteDance was failing to properly maintain infrastructure now that a sale was imminent. Some just thought the universe had terrible timing.
Likely? This was coincidence. Infrastructure failures happen constantly. The difference is, most companies don't have millions of users watching simultaneously, so when a failure happens, fewer people notice.
But the timing did highlight something real: during major corporate transitions, infrastructure stability can take a backseat. When you're negotiating a multibillion-dollar spinoff, your engineering teams are sometimes distracted. Staff might be uncertain about their roles. Resources get reallocated. Maintenance schedules get postponed waiting to see what the new organizational structure will be.
We don't know if that happened here. But it's a pattern in tech industry history. During the Yahoo/AOL transition, during Elon's Twitter takeover, during the Meta restructuring—reliability often dipped because the organization's attention was divided.
TikTok didn't acknowledge any connection, and we have no evidence of one. The company said it was coordinating with its "data center partner" to resolve things, suggesting it was a partner company's facility, not TikTok's own data center. This could mean the outage was the partner's responsibility, which might explain why TikTok was less forthcoming about details.
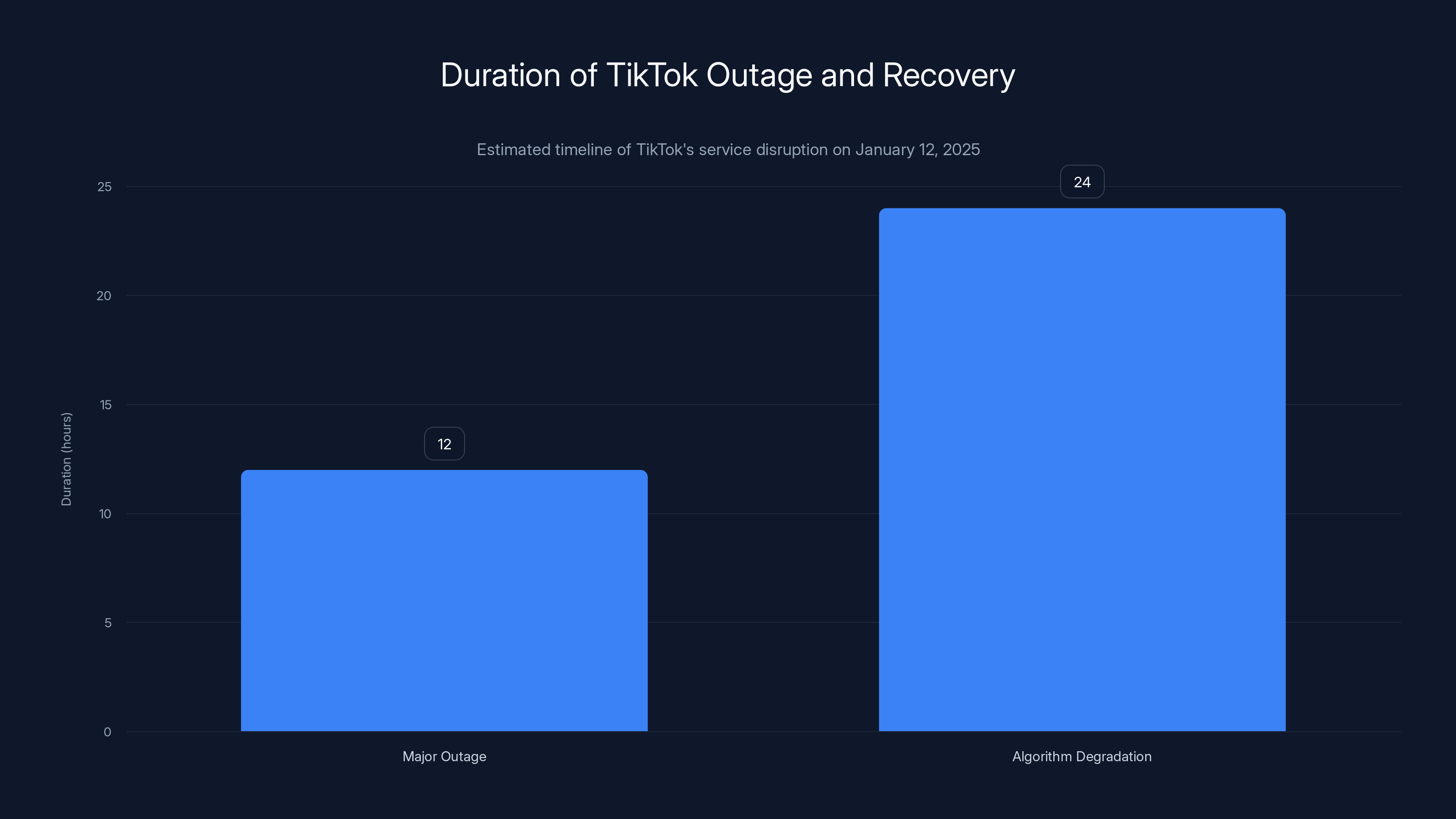
TikTok experienced a major outage lasting 12 hours, followed by 24 hours of algorithm degradation as systems recalibrated. Estimated data.
Cascade Failures: How One Power Outage Broke Everything
Here's what probably happened technically, based on how distributed systems fail:
Phase 1: Initial Power Loss
The power went out at the primary data center. Backup power systems (generators) should have kicked in within seconds. But something failed—either the generators didn't start, or they started but couldn't handle the full load, or there was a surge that damaged equipment.
Phase 2: Overflow to Backup Infrastructure
Immediately, TikTok's load-balancing systems tried to redirect all traffic from the failed data center to backup facilities. Imagine suddenly telling all 130 million active US users to use servers that were only built to handle a fraction of that load. The backup systems got crushed.
Phase 3: Cache Invalidation
Once a request hits a server that's not the primary one, the cached data becomes unreliable. Is that video thumbnail still accurate? Is that trending data still current? The system has to decide: serve potentially stale data or reject the request and make the user wait.
With millions of simultaneous requests, the system probably chose to serve what it could, creating the degraded experience users saw.
Phase 4: Database Lock-Ups
All those requests trying to hit backup systems created connection storms at the database level. Database connections are finite resources. When you hit the limit, new connections fail. The app would show "connection error" to users.
Phase 5: Cascading Failures
Now you've got failures cascading: the recommendation algorithm can't query user data (databases are overloaded), so it fails gracefully to fallback algorithms. The upload system can't write to primary storage, so uploads queue up and eventually timeout. The authentication system can't reach session storage, so logins fail.
One failure creates five more failures creates twenty more failures. This is why a single data center problem took down the entire US service.

How TikTok (Partially) Recovered So Quickly
The outage lasted about 12 hours. By tech industry standards, that's actually pretty fast recovery. Some companies take 24+ hours to fully restore service.
TikTok recovered relatively quickly because:
Automated Failover Systems: TikTok likely has automated monitoring that detects when a data center is unavailable and reroutes traffic within seconds. The company didn't need to manually intervene to redirect requests.
Geographically Distributed Infrastructure: Having multiple data centers means you don't lose everything. TikTok's other US facilities were still running, so the platform wasn't completely dark—just degraded.
Capacity Planning: TikTok probably sized its backup capacity to handle a percentage of traffic, like 30-50% of peak load. That's why backup systems could take on traffic (though degraded) rather than completely failing.
Rapid Communication with Data Center Partner: TikTok mentioned working with its "data center partner," suggesting this wasn't TikTok's own facility but a third-party provider like Equinix or Digital Realty. These partners have their own incident response procedures and can mobilize technicians faster than most companies.
Parallel Recovery: While power was being restored, TikTok was probably also doing several things simultaneously—validating backup systems, running diagnostic checks, preparing to gradually shift traffic back once the primary facility was ready.
The algorithm taking longer to fully recover (users reported suboptimal recommendations for another day) makes sense. Machine learning models are resource-intensive. Retraining them or resyncing them across multiple data centers takes time. TikTok probably decided to restore basic functionality first (let users log in and view content) before optimizing the recommendation algorithm.
What This Reveals About Platform Fragility
This incident exposes something uncomfortable: the digital services we depend on are fragile in ways most people don't realize.
TikTok isn't unique. Every major platform—Instagram, Netflix, YouTube, Spotify—depends on physical infrastructure. A power outage, a cooling system failure, a technician accidentally unplugging the wrong cable, and suddenly millions of people lose access to services.
We've built a society where an enormous amount of economic and social value depends on continuous operation of data centers. Companies spend billions trying to make this reliable, but reliability is extremely hard at scale.
Consider the numbers: A single data center might contain 50,000 servers. Each server is a potential failure point. Thousands of power distribution systems, hundreds of cooling units, miles of fiber optic cable, massive batteries for backup power—any one of these failing can take down the whole facility.
And here's the kicker: most people don't even know which data center their favorite app uses. Users don't know that by clicking "open TikTok," they're sending requests to physical hardware in a specific geographic location. They don't know that a weather event, a power grid failure, or a contractor's mistake could affect their service.
This is why companies obsess over something called "availability zones." Instead of just having backup data centers, they spread those backups across different cities, sometimes even different power grids. Google's infrastructure is spread across multiple continents specifically so that no single failure can take down the whole service.
But redundancy costs money. Lots of money. So not every company does it equally well, and some companies (especially startups) don't do it at all. If your favorite app doesn't have geographically distributed backups, a single power outage could take it offline completely.

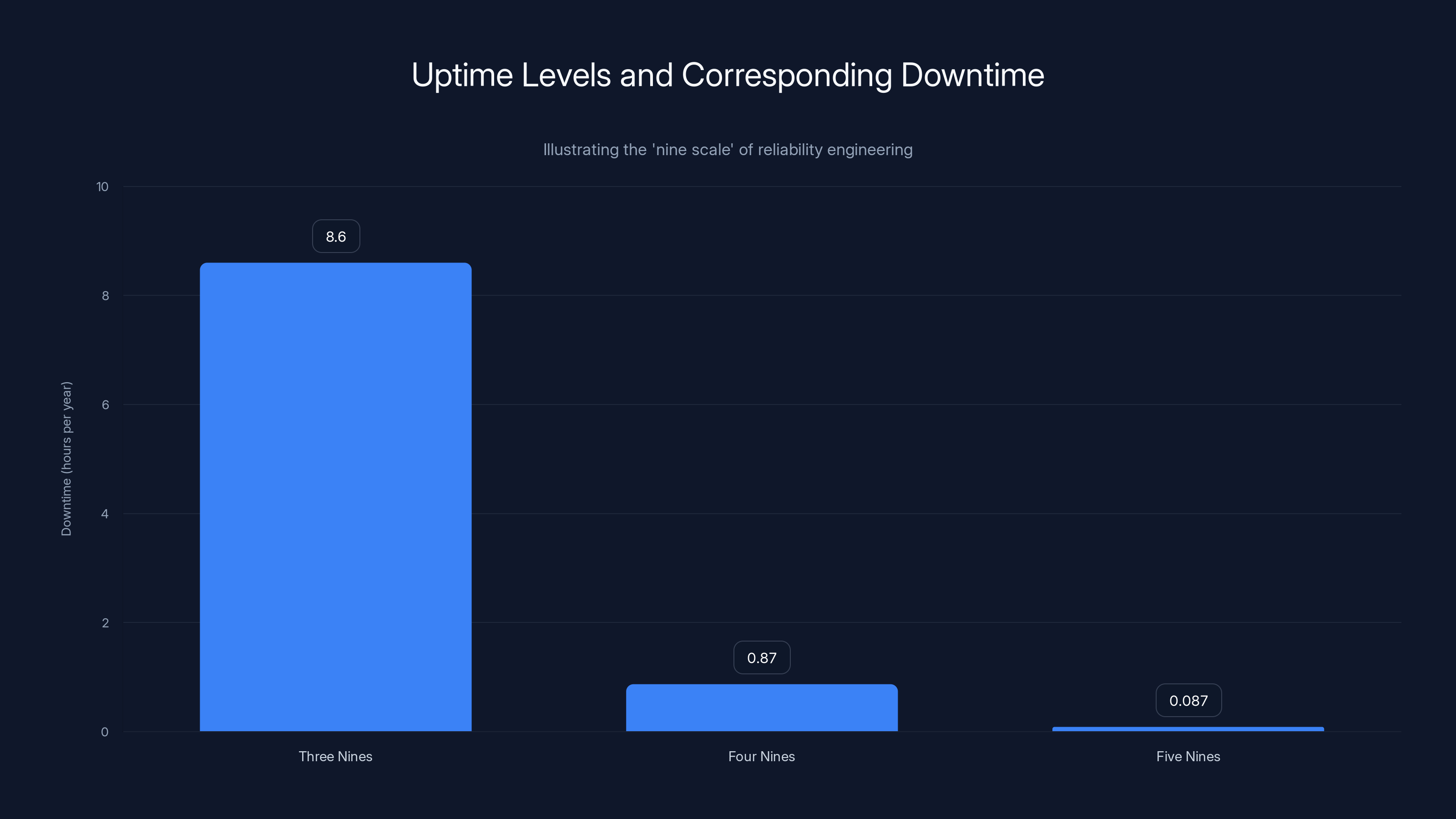
The chart shows how downtime decreases significantly as uptime improves from three to five nines, but achieving higher reliability comes with exponentially increasing costs. Estimated data.
The Business Side: Data Center Partnerships and Responsibility
TikTok's statement mentioned working with its "data center partner," which tells us something important: TikTok doesn't necessarily own or operate all its own data centers.
This is super common. Companies like Equinix, Digital Realty, and Core Weave operate massive data centers and rent out space to tech companies. TikTok books space in these facilities, installs its servers, and the data center company handles physical infrastructure—power, cooling, security, fiber optic connections.
This arrangement has benefits: TikTok doesn't have to manage generators and power distribution. It has benefits for the data center company too: they can sell space to multiple customers, spreading costs.
But it creates accountability questions. When the power fails, whose fault is it? Is the data center partner responsible for maintaining generators? Did TikTok properly specify their requirements? Did TikTok have contractual guarantees about uptime?
Most data center contracts specify an "SLA" (Service Level Agreement) that guarantees a certain uptime percentage, usually 99.9% or higher. If the partner fails to meet this, TikTok gets credits. But for a company like TikTok with massive revenue, an SLA credit is probably negligible compared to the actual business impact.
What probably happened: the data center partner will investigate the root cause, probably find some equipment failure or maintenance issue, fix it, and hand TikTok a detailed report. TikTok will issue a press statement saying everything's been resolved. And life goes on until the next data center fails.
Redundancy and Failover: Why Perfect Reliability Is Impossible
Some people asked: why didn't TikTok's backup systems work?
They did work, partially. That's why the service degraded rather than went completely offline. But they didn't work perfectly because perfect reliability is mathematically impossible.
There's something in reliability engineering called the "nine scale." When we talk about "five nines" of availability, we mean 99.999% uptime. That sounds incredible, but here's what it means in practice:
- 99.9% uptime = 8.6 hours of downtime per year ("three nines")
- 99.99% uptime = 52 minutes of downtime per year ("four nines")
- 99.999% uptime = 5.2 minutes of downtime per year ("five nines")
Achieving five nines is extremely expensive. It requires redundancy everywhere: redundant power supplies, redundant cooling, redundant network connections, redundant data centers, redundant backup systems for the backup systems.
As you add redundancy, costs don't increase linearly. They increase exponentially. Going from three nines to four nines might double costs. Going from four nines to five nines might triple costs.
Where should a company like TikTok aim? Probably somewhere between four and five nines. That means accepting that the service might go down for about an hour per year. Users think that's unacceptable, but the economics don't support better.
Moreover, redundancy doesn't eliminate human error. A technician might misconfigure a failover system. Code might have a bug that prevents automatic failover. The backup system might have never been tested under full peak load, so when it actually needs to handle 130 million users, it melts down. These things happen.
This is why even the best companies experience outages. Microsoft Azure goes down. Amazon AWS goes down. Google Cloud goes down. Perfection is impossible when you're managing billions of requests per second across complex infrastructure.

User Experience During the Outage: What Went Wrong
Focus on what users actually experienced, because that's what mattered.
Login Failures: Users couldn't authenticate. This is the worst-case scenario for a social media app. You can't even access your account to see what's happening.
Feed Degradation: Instead of seeing the personalized "For You" page that makes TikTok addictive, users saw generic trending videos. Some reported seeing the same video repeatedly. Others saw content completely unrelated to their interests.
Upload Failures: Content creators couldn't upload videos. For users whose income depends on TikTok (influencers, creators with sponsored content), this was economically damaging. Missing a few hours of content creation can affect growth metrics and sponsorship deals.
Cross-App Impact: Because TikTok's data center failure affected "other apps" that ByteDance operates, users of Vigo, Hype, and other platforms were also affected. This expanded the impact beyond just TikTok's user base.
Communication Gaps: TikTok's initial communication was sparse. The company posted a brief statement but didn't provide regular updates about progress or estimated time to resolution. Users were left refreshing the app, checking social media for news, and speculating wildly.
For comparison, when other services go down, better-managed companies provide granular updates: "We've identified the root cause. 30% of services are now restored. We estimate full restoration in 2 hours." TikTok's communication was more vague.
Recovery Unevenness: Recovery wasn't instant for everyone. Some users got service back after 6 hours. Others were still experiencing issues after 12 hours. This suggests TikTok was bringing systems back online gradually, probably in a specific order: authentication first, then basic content delivery, then algorithm and recommendations.
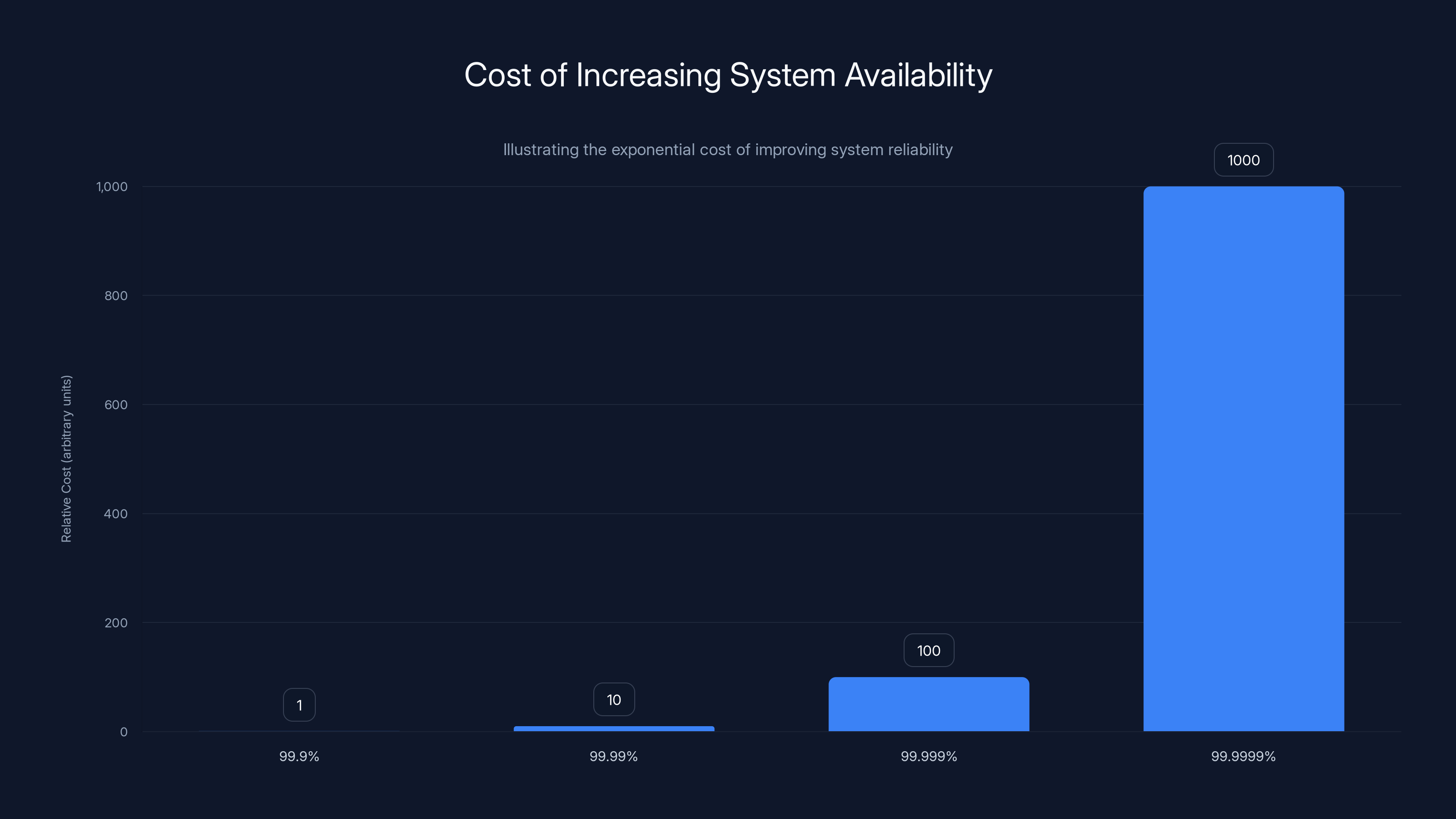
Increasing system availability from 99.9% to 99.9999% incurs exponentially higher costs due to the need for additional redundancy and monitoring. Estimated data.
The Broader Implications for App Reliability
This outage illustrates several broader themes in modern app infrastructure:
The Single Data Center Risk: Storing everything in one data center is corporate recklessness in 2025. But spreading infrastructure across multiple facilities costs significantly more. Companies constantly balance cost against reliability.
The Third-Party Dependency: TikTok depends on a third-party data center operator. If that operator has a catastrophic failure, TikTok goes down. The company can't unilaterally prevent this. They can only contractually require good practices and maintain backup systems.
The Algorithm Brittleness: Machine learning models are surprisingly fragile. Disconnect them from training data, restart them unexpectedly, or force them to handle degraded requests, and they break in weird ways. This is why users saw such strange recommendations during the outage.
The Cascade Problem: Modern distributed systems are incredibly complex. A failure at one layer cascades to multiple other layers. You can't just fix the power supply and have everything work—you need to carefully bring systems back online in the right order, testing each layer.
The Transparency Deficit: Most companies don't fully disclose infrastructure incidents. TikTok mentioned "a power outage at a U. S. data center," but didn't specify which data center, which components failed, whether it was a third-party error, or what will prevent future occurrences. Transparency helps customers and the industry learn from failures.

Lessons Learned: What Should TikTok Do Differently
If TikTok's engineering leadership is doing this right, they're currently working on several improvements:
Improve Geographic Redundancy: Ensure that a failure at any single data center doesn't affect US service. This might mean duplicating infrastructure in at least 3 separate geographic regions.
Test Failover Systems Regularly: The best backup systems are the ones that have actually been tested. TikTok should regularly simulate data center failures and verify that failover works correctly. Many companies don't do this because it's disruptive, but it's the only way to know if backups actually work.
Implement Graceful Degradation Better: The app should be smarter about serving when algorithms are unavailable. Instead of showing weird repeated videos, maybe show content from verified creators, or content that performed exceptionally well, or content the user explicitly subscribed to.
Enhance Communication Protocols: Have a plan for communicating during outages that includes regular updates to users, even if the updates are just "still working on it."
Decouple Critical Systems: The fact that the algorithm broke so completely suggests it's tightly coupled to the main data center. Critical systems should be more independent so that a failure in one layer doesn't break everything.
Post-Incident Transparency: After fully investigating, TikTok should publicly disclose what happened and what they're doing to prevent it. This helps the industry learn and shows users you take reliability seriously.
How This Compares to Other Major Outages
TikTok's 12-hour outage is significant, but it's not the worst in recent memory.
Instagram and Facebook Outage (2021): Facebook's infrastructure completely failed for about 6-7 hours. The outage was so complete that even internal tools stopped working—employees couldn't access company systems. Estimated impact: $100 million in lost ad revenue alone. Root cause: a configuration error during network maintenance cascaded into a complete failure.
Slack Outage (2024): Several brief outages hit different Slack regions. Most lasted less than 30 minutes, but in aggregate, Slack users experienced multiple disruptions in a single day. This is actually more damaging than a single long outage because users keep losing trust in the service working when they need it.
Amazon AWS Outages: AWS regularly experiences regional outages. The AWS infrastructure is so distributed that most customers don't notice because traffic reroutes automatically. But when outages do happen in AWS regions, they can take down thousands of third-party apps simultaneously.
TikTok's 12-hour outage puts it in the middle range. Not as severe as Facebook 2021 (which was catastrophic), but longer than most modern outages because most large companies have better geographic redundancy than TikTok apparently did.
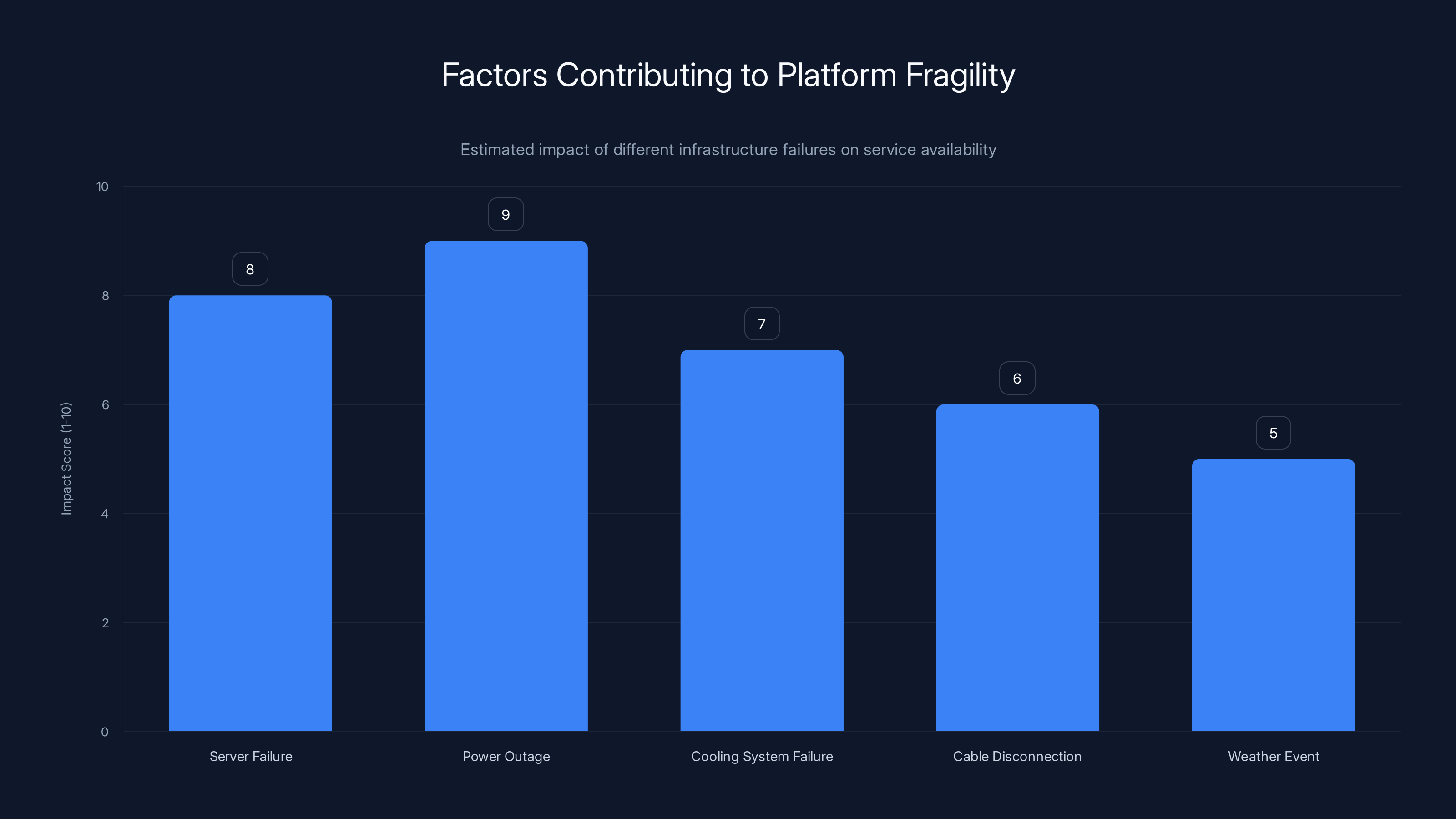
Estimated data shows that power outages and server failures have the highest impact on platform availability, highlighting the fragility of digital services.
The Future: Can We Build More Reliable Infrastructure
The tech industry is working on several innovations that could reduce outage severity:
Edge Computing: Instead of centralizing all processing in data centers, edge computing distributes computation closer to users. If one data center fails, users can be served from edge locations. This is why companies like Cloudflare and Fastly have become crucial infrastructure providers.
Kubernetes and Container Orchestration: Modern containerization makes it easier to quickly spin up new instances in different locations. If one server fails, Kubernetes automatically starts a replacement. This improves reliability but also increases complexity.
Multi-Cloud Strategies: Some companies now deliberately use multiple cloud providers (AWS, Google Cloud, Azure) so that a failure at one provider doesn't take them down. This adds complexity and costs, but improves resilience.
Machine Learning for Failure Prediction: Companies are using AI to predict equipment failures before they happen. If you can replace a cooling unit before it fails, you never experience the outage.
Improved Monitoring and Observability: Modern tools let companies understand their systems in real-time. When TikTok's data center went offline, they should have known within seconds. Better monitoring would enable faster response.
The challenge is that all these solutions cost money. And they compete with building new features. So companies have to choose: do we invest in reliability, or do we build new features users want? The market doesn't always reward reliability—users don't see it. Users only see it when it's missing.
The Data Center Industry Itself
To understand TikTok's outage, you also need to understand the data center industry that powers it.
Data centers are absurdly expensive to build and maintain. A modern hyperscale data center costs $1-2 billion to construct. Operating costs run into the tens of millions annually just for power and cooling.
This is why only a handful of companies own massive data center networks: Amazon (AWS), Google (Google Cloud), Microsoft (Azure), Meta, Apple, and a few others. Most companies lease space from third-party data center operators because they can't afford to build their own.
TikTok seems to use third-party operators for some infrastructure (based on their mention of working with a "data center partner"). This is economical but creates dependency. If your data center partner has catastrophic failures regularly, you need to switch partners or build your own infrastructure.
The data center industry is facing new challenges: power consumption is growing exponentially as AI becomes more compute-intensive. Cooling is becoming harder in hot climates. Supply chain issues mean replacing failed equipment takes longer. And increasingly, environmental regulations require data centers to use renewable energy, which adds complexity.
These industry-wide pressures mean outages might become more common before they become rarer.
Security Implications: Using Outages as Cover
While there's no evidence this happened with TikTok, it's worth noting that infrastructure outages can be used as cover for security breaches.
Imagine a scenario: someone hacks into your data center and steals user data. But instead of covering it up, they coordinate the theft with a power outage. While you're dealing with the service going offline, you're not investigating the data breach. By the time you discover the theft, the hackers are long gone.
This hasn't happened to TikTok (as far as we know), but it's a real concern in security circles. When there's an outage, companies should still maintain security investigations to ensure nothing else was compromised.
TikTok didn't mention any security concerns related to the outage, which suggests this was pure infrastructure failure, not a coordinated attack.
The Political Context
I'd be remiss not to acknowledge the political context. This outage happened days after TikTok finalized a deal to spin off its US operations from ByteDance, amid months of regulatory pressure and threats of a US ban, as highlighted by Britannica.
Some people speculated the outage was connected—that ByteDance was sabotaging the spinoff, or the Chinese government was punishing TikTok for complying with US orders, or something else political.
There's no evidence for any of this. Infrastructure failures happen constantly. The timing was unfortunate, but coincidence isn't proof of conspiracy.
That said, the timing did highlight how politically charged TikTok's infrastructure is in the US. If TikTok experiences frequent outages in the coming months, people will speculate about whether it's due to the spinoff disrupting operations, new management's inexperience, or reduced investment from ByteDance.
For TikTok's new US-focused leadership, reliability will be crucial. They need to demonstrate that US-based TikTok is as stable and reliable as any other social media platform. A series of outages would undermine confidence in the new structure.

Looking Ahead: What We Should Expect
More Detailed Root Cause Analysis: TikTok will likely publish a detailed post-mortem explaining exactly what failed and why. Look for this 1-2 weeks after the incident.
Infrastructure Improvements: The company will probably announce investments in geographic redundancy and backup systems. These might be quiet operational changes rather than flashy marketing announcements.
Contract Renegotiations: TikTok will likely renegotiate its data center contracts to include stricter SLA guarantees and more robust backup power systems.
Monitoring Upgrades: TikTok will invest in better monitoring and alerting so that future failures are detected faster and users are informed quicker.
Stress Testing: The company should (and probably will) implement regular failover drills and stress tests to ensure backup systems actually work when needed.
Transparency Improvements: After the public relations hit from this outage, TikTok has incentive to be more transparent about future incidents.
The question is whether these improvements stick or whether they fade as the company's attention moves to other things. Tech companies often promise better reliability after outages but backslide once the crisis passes.
FAQ
What caused TikTok's outage on January 12, 2025?
A power outage at one of TikTok's US data centers caused the service failure. The exact facility and root cause of the power loss haven't been fully disclosed, but TikTok confirmed they were working with their data center partner to restore service following the failure.
Why did the "For You" algorithm break so completely?
TikTok's recommendation algorithm relies on real-time machine learning models running on their servers. When the primary data center went offline, these models became inaccessible. The app fell back to simpler algorithms serving generic trending videos and previously cached content, which is why users saw repeated videos and irrelevant recommendations.
How long did the outage last?
The major service disruption lasted approximately 12 hours, with the company acknowledging the issue Sunday and reporting recovery by Monday afternoon. However, some algorithm degradation persisted for another day as the system fully recovered and machine learning models recalibrated.
Did this affect other apps besides TikTok?
Yes. TikTok's statement mentioned that "other apps we operate" were affected by the same data center failure. ByteDance operates multiple apps including Vigo, Hype, and others, all of which likely depend on shared infrastructure. The exact number of affected apps wasn't disclosed.
Could this have been prevented?
Yes, partially. Better geographic redundancy would have prevented the complete service failure. If TikTok had infrastructure distributed across multiple data centers with automatic failover, users might have experienced degraded service but not complete outages. However, perfect prevention of all data center failures is impossible—redundancy has limits and costs increase exponentially.
What are data center SLAs and how do they protect users?
An SLA (Service Level Agreement) is a contract guarantee about uptime. Data center operators typically guarantee 99.9% to 99.999% uptime. If they fail to meet this, they provide service credits to their customers (like TikTok). However, credits are usually small compared to the actual business impact of outages, so SLAs are more about accountability than compensation.
Why didn't TikTok's backup systems work perfectly?
Backup systems did work partially—the service degraded rather than going completely offline—but perfect redundancy is extremely expensive and technically complex. Backup infrastructure might have been sized to handle 50% of peak traffic, not 130% (when primary systems fail and all traffic reroutes to backups). Additionally, cascade failures meant that bringing backup systems online created unexpected new failures.
How does this compare to other major app outages?
TikTok's 12-hour outage is significant but not unprecedented. Facebook's 2021 outage lasted 6-7 hours. AWS regularly experiences regional outages. AWS and Facebook typically have better geographic redundancy than TikTok apparently did, which is why their outages often affect specific regions rather than entire countries. TikTok's outage affected all US users simultaneously, suggesting insufficient geographic separation of their infrastructure.
Is TikTok less reliable than competitors like Instagram or Snapchat?
Based on publicly available information, TikTok has had fewer widely-reported outages than some competitors, but this particular incident suggests their backup systems might not be as robust as tech giants with massive infrastructure investment. Reliability depends on ongoing engineering investment, which varies by company and is hard to assess without internal data.
What should users do if major apps go down?
First, verify it's not just you by checking the company's status page (status.appname.com) or Down Detector. Check official company social media accounts for updates rather than relying on rumors. Accept that outages happen and give the company time to restore service. Use the outage time productively—read a book, go outside, anything other than endlessly refreshing the app.

Conclusion: When Digital Infrastructure Becomes Physical Reality
TikTok's power outage was a reminder that the digital world runs on physical infrastructure. Somewhere in America, in a building you've never seen, filled with equipment you couldn't name, there are servers. When those servers lose power, 130 million American users feel it immediately.
The outage lasted 12 hours. For TikTok users, it felt like an eternity. Content creators lost hours of productive time. Casual users were bored. But in the scheme of infrastructure failures, it wasn't catastrophic. The service came back. Data wasn't lost. No one got hurt.
What's interesting is what this reveals about how fragile modern services actually are. We've built an entire digital society on infrastructure that's dependent on: a steady power supply, multiple backup systems working correctly, software that doesn't have bugs, human technicians making no mistakes, and third-party partners acting responsibly.
One power outage can break all of this. Not because the infrastructure is fundamentally weak, but because modern systems are so complex and interconnected that failures cascade.
This is why companies obsess over reliability. It's also why reliability is so expensive. Every additional "nine" of availability (going from 99.9% to 99.99% to 99.999%) costs exponentially more in redundancy, monitoring, and engineering.
For TikTok specifically, this outage probably means increased investment in geographic redundancy, better monitoring, more regular testing of backup systems, and tighter SLA agreements with data center providers. These investments might not prevent all future outages, but they'll make them rarer and shorter when they do happen.
For users, the lesson is simpler: outages happen. They're frustrating, but they're not evidence of incompetence. They're evidence that you're using systems complex enough to occasionally fail. The best companies don't prevent all failures—they respond to failures quickly and transparently.
TikTok's response wasn't perfect. Communication could have been better. Recovery could have been faster. But a 12-hour outage and relatively quick recovery suggests the company has at least some operational competence.
In the coming weeks and months, pay attention to whether TikTok becomes more reliable or whether outages become a pattern. That's the real test of whether this incident led to meaningful improvements or was just a disruption that quickly faded from memory.
The digital infrastructure we depend on is only as strong as its weakest component. That power cable in a data center, that generator that failed to start, that configuration error during maintenance—any of these small failures can take down a service used by millions.
Understanding this fragility doesn't make you paranoid. It makes you realistic. The internet you use every day is an engineering miracle. That it works as often as it does is remarkable. That it sometimes fails is inevitable.
Key Takeaways
- A power outage at one US data center took TikTok completely offline for 12 hours, affecting 130M+ American users simultaneously
- The app's recommendation algorithm failed completely, forcing the system to serve generic trending videos and repeatedly cached content
- Cascade failures meant one infrastructure problem created multiple failures across authentication, caching, and data retrieval systems
- Perfect reliability is mathematically impossible—companies must choose between cost and achieving five nines of uptime
- TikTok's apparent lack of geographic redundancy suggests backup infrastructure was insufficient to handle full peak traffic during failover
Related Articles
- TikTok's US Data Center Outage: What Really Happened [2025]
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- TikTok Data Center Outage: Inside the Power Failure Crisis [2025]
- Sandworm's Poland Power Grid Attack: Inside the Russian Cyberwar [2025]
- Modernizing Apps for AI: Why Legacy Infrastructure Is Killing Your ROI [2025]
- Gmail Spam & Filtering Issues: Google's New Fix Explained [2025]

