![TikTok's US Data Center Outage: What Really Happened [2025]](https://tryrunable.com/blog/tiktok-s-us-data-center-outage-what-really-happened-2025/image-1-1769445623257.jpg)
Introduction: When a Social Media Giant Goes Dark
Imagine this: it's Sunday morning, and millions of Americans wake up to find they can't upload videos to TikTok. The For You page isn't refreshing. Their feeds look frozen. It's not a bug in the app on their phone. It's not a software glitch. It's something bigger: an entire data center, somewhere in the US, lost power.
That's exactly what happened in early 2025 when TikTok's newly restructured US operations experienced significant service disruptions. The company, now operating under a fresh ownership structure with Oracle as its infrastructure partner, issued a brief statement: a power outage at a US data center had knocked services offline.
But here's the thing: this outage reveals something much deeper about how TikTok works, how dependent we've become on these platforms, and what happens when one of the world's most-used apps suddenly stops working. It also raises uncomfortable questions about the infrastructure supporting billions of daily active users, about redundancy (or the lack thereof), and about what caused the outage in the first place.
The weekend disruptions were more than just an inconvenience. They exposed vulnerabilities in TikTok's freshly restructured US infrastructure. Creators couldn't post. Users couldn't see new content. The algorithmic engine that TikTok has spent years perfecting seemed to reset for some users. And the company's initial response, while honest, was also somewhat vague. They blamed "a power outage at a U.S. data center." But where? Why did it happen? How long will it take to prevent this again?
This article digs into exactly what went wrong, why it matters, and what the TikTok outage reveals about the state of social media infrastructure in 2025. We'll explore the technical factors behind the disruption, the business implications for TikTok's new ownership structure, the impact on creators and users, and the broader lessons about data center resilience that this incident teaches us.
TL; DR
- What happened: TikTok experienced a major service outage affecting US users Sunday morning, caused by a power failure at a data center
- Impact: Users reported inability to upload videos, disrupted For You algorithms, and frozen feeds across the platform
- Root cause: A US-based data center lost power, affecting both TikTok and other apps operated by the company
- Response: TikTok USDS acknowledged the issue and stated they were working with data center partners to stabilize services
- Bottom line: The outage exposed infrastructure vulnerabilities in TikTok's newly restructured US operations under Oracle partnership

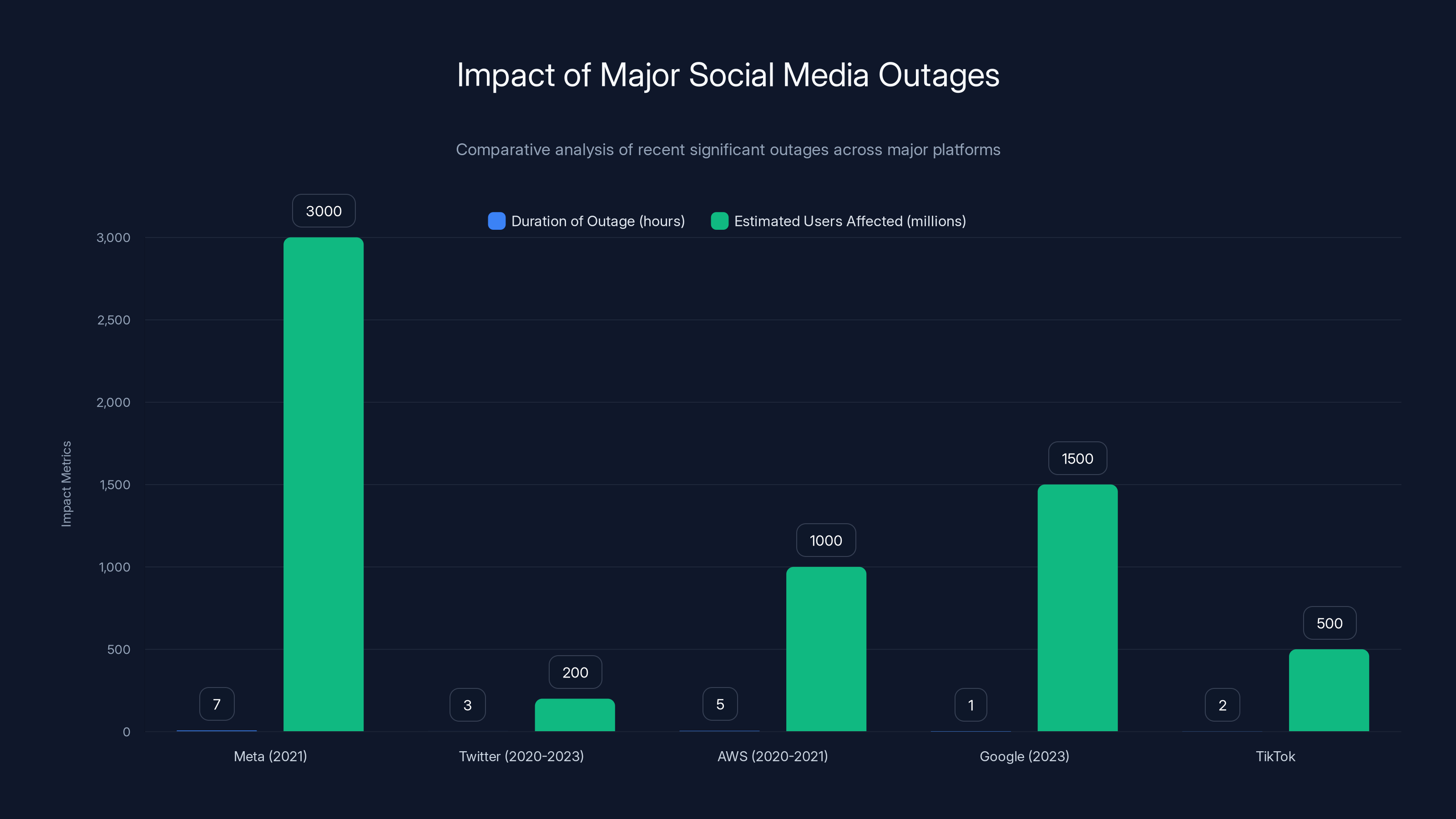
Meta's 2021 outage was the longest and affected the most users, while TikTok's recent outage was relatively modest in both duration and impact. Estimated data for TikTok.
The Timeline: How the Outage Unfolded
The outage didn't happen all at once. Instead, it rolled out gradually across the US on Sunday morning, starting early in the day and affecting different regions at slightly different times. This phased failure actually tells us something important about how TikTok's infrastructure is distributed.
By mid-morning Sunday, reports started flooding social media (ironically, on platforms that were still working). Users on Twitter, Reddit, and Instagram began documenting that TikTok wasn't functioning properly. Videos wouldn't upload. Feeds weren't refreshing. Some users saw blank screens where new content should have appeared.
What made this outage particularly notable was the specificity of the symptoms. This wasn't a case where the app crashed for everyone equally. Instead, users experienced varied problems: some couldn't upload, others couldn't see new videos, still others saw their personalized algorithms completely reset. This pattern suggested a backend infrastructure problem rather than a frontend app issue.
The company first acknowledged the problem through an official statement posted to their newly created X (formerly Twitter) account, which TikTok USDS (the new US-based joint venture) had just established. The Verge received confirmation from a TikTok USDS spokesperson named Jamie Favazza, who pointed to that statement as the official explanation.
By Sunday afternoon, the company was actively working on restoration. However, the process of bringing a major data center back online isn't like restarting your home router. It involves cascading services, database synchronization, caching layer resets, and verification that all systems are functioning correctly. This is why what might seem like a simple "turn it back on" process actually takes hours.
Interestingly, the outage affected not just TikTok but also "other apps we operate," according to the company's statement. This detail is significant because it tells us that TikTok operates other services beyond just the main social media platform, and these services shared infrastructure with TikTok itself.

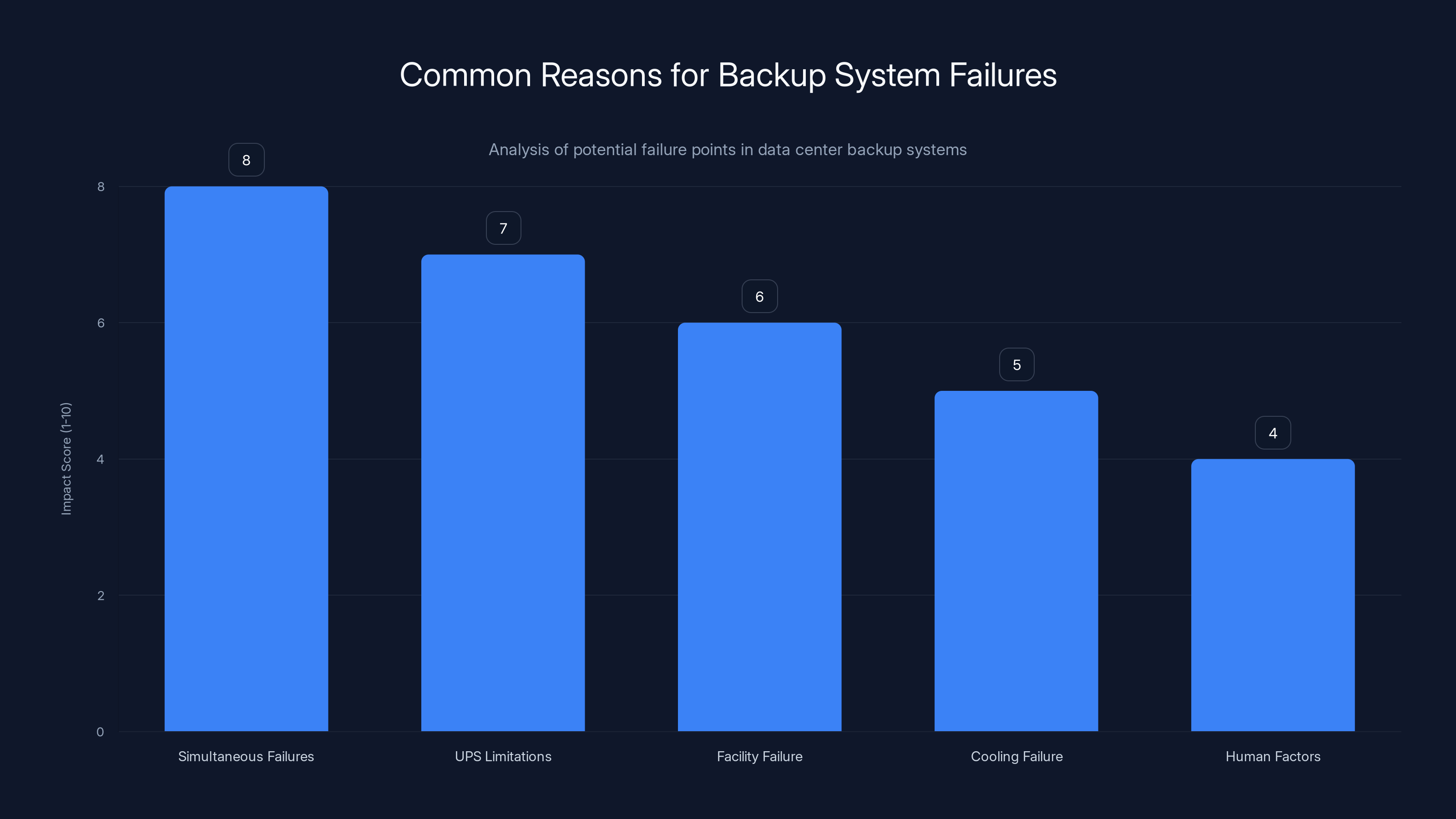
Simultaneous failures and UPS limitations are the most impactful reasons for backup system failures, highlighting the need for regular testing and maintenance. Estimated data.
Understanding Data Centers: The Invisible Infrastructure
Most people don't think about data centers. They upload a TikTok video and it appears on their followers' feeds instantly (or so it seems). But that instant experience depends on one of the most complex pieces of infrastructure on Earth: a data center.
A modern data center is essentially a massive, climate-controlled warehouse filled with thousands of servers. These servers store data, process requests, run algorithms, and serve content to billions of people. The largest data centers can consume as much power as a small city. Google, Amazon, Microsoft, Meta, and yes, TikTok all operate dozens of these facilities around the world.
For TikTok specifically, the infrastructure picture became significantly more complicated in early 2025. Previously, TikTok used data centers from multiple providers. But when the new US ownership structure took effect, Oracle became the primary infrastructure partner. Oracle operates a global network of data centers designed for enterprise applications, databases, and cloud services.
The deal meant that user data from US-based TikTok users would route through Oracle infrastructure. Additionally, TikTok's algorithm (which has been trained on billions of user interactions to determine what videos show up on your For You page) would be retrained using only US user data and would run on US infrastructure.
This is a critical detail because it means the new US data center infrastructure is comparatively fresh. Unlike Amazon's AWS, which has been refined over 15+ years, or Google Cloud's infrastructure, which has been battle-tested by the search giant's massive scale, the TikTok/Oracle arrangement is newer and potentially less mature from an operational standpoint.
Data centers aren't isolated buildings. They're connected to power grids, internet backbone networks, and other facilities. A power outage at one data center can be caused by:
- Grid failures: Problems with the electrical utility supplying power
- Equipment failure: Failures in backup generators, uninterruptible power supplies (UPS), or cooling systems
- Natural disasters: Severe weather like the massive snowstorm that coincided with the TikTok outage
- Human error: Configuration mistakes or maintenance accidents
- Cascading failures: When one system fails, it overloads others, causing a domino effect
The snowstorm that was happening across much of the US during the outage is worth examining. Extreme weather is actually one of the most common causes of data center outages. Heavy snow can knock down power lines. Ice storms can overload electrical systems. Flooding can damage equipment. Wind can disrupt power transmission.
TikTok never explicitly stated whether the snowstorm caused the power outage, but the timing and geographic distribution of the problem suggest weather might have played a role. This is important context because it means the outage might not have been entirely preventable through better engineering—sometimes nature wins.

Why Didn't TikTok's Backup Systems Work?
This is the question that probably frustrated TikTok executives more than anyone else. Every modern data center is supposed to have backup power systems for exactly this scenario.
Proper data center redundancy works like this: if the primary power supply fails, an uninterruptible power supply (UPS) instantly kicks in. The UPS is essentially a massive battery system that can power the facility for several minutes. During those minutes, backup diesel generators start up and take over. In theory, users never experience an interruption.
But there are several reasons why backups fail:
1. Simultaneous failures: If the power grid fails AND the backup generator doesn't start, you have a cascading problem. Backup systems sometimes fail because they haven't been tested recently, fuel hasn't been maintained, or the startup sequence encounters an unexpected error.
2. UPS capacity limitations: No data center's UPS can sustain full operations indefinitely. If backup generators take too long to start, or if there's an unexpected issue ramping them up, you can exceed the UPS capacity and lose power anyway.
3. Multiple facility failure: If TikTok's infrastructure wasn't properly distributed across multiple data centers (a concept called geographic redundancy), then a single facility failure could take down services.
4. Cooling system failure: This is sneaky but critical. If the power loss damages cooling systems and they can't be quickly restored, the data center's equipment starts overheating. After 30-60 minutes without active cooling, servers can suffer physical damage. Even after power is restored, damaged equipment needs to be replaced.
5. Human factors: During an emergency, there's often confusion about what happened and what should be done. Recovery procedures might not be clear. Staff might make decisions that inadvertently cause further problems.
TikTok's statement that they were "working with our data center partner to stabilize our service" is interesting because it suggests the problem might not have been entirely within TikTok's control. If Oracle's data center had the outage, then TikTok had to work at Oracle's pace to restore service. Oracle has world-class engineers, but the fact that it took hours to restore suggests something more serious than a simple power glitch.
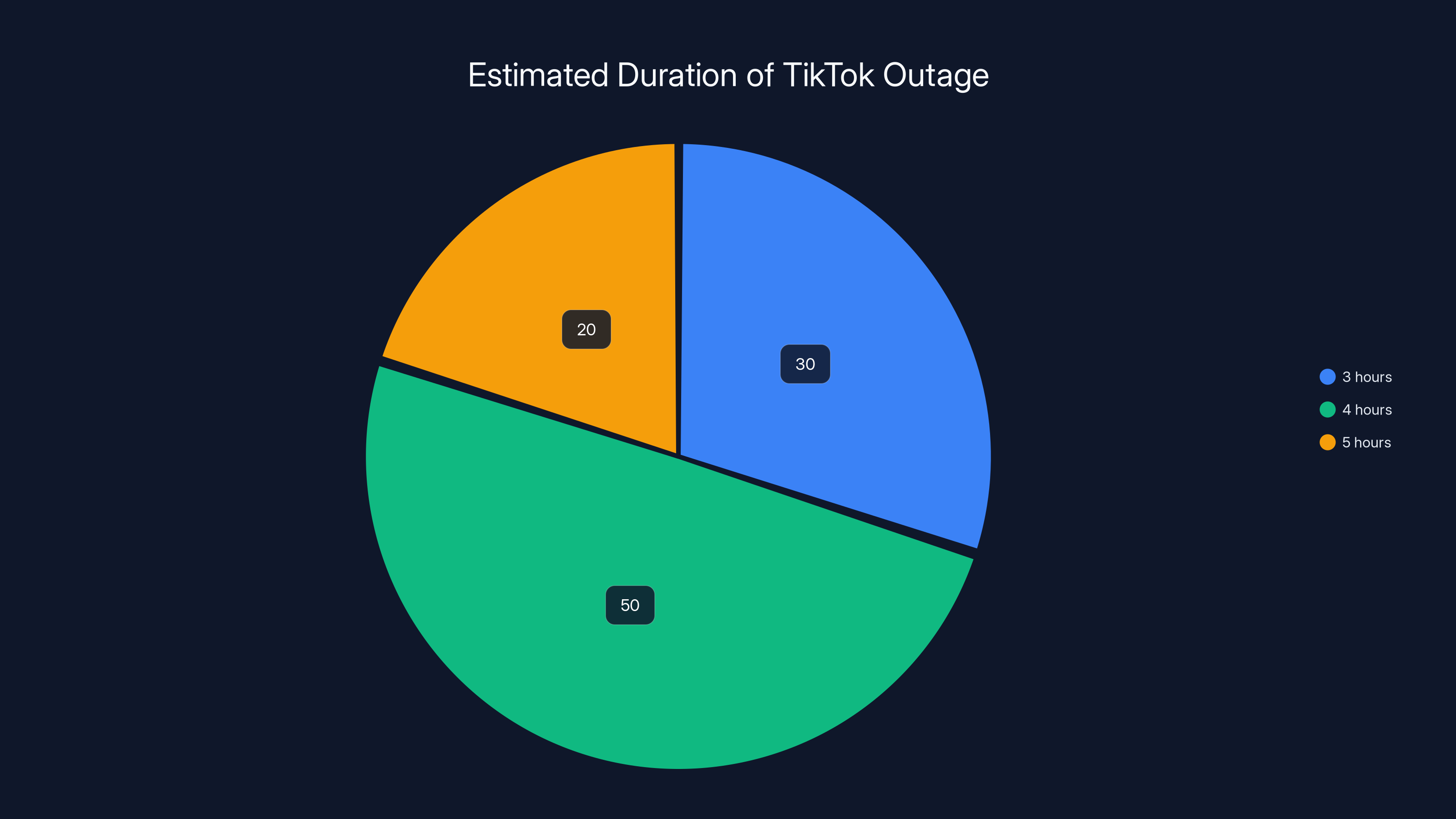
Estimated data suggests the majority of users experienced the TikTok outage for approximately 4 hours, based on user reports and discussions.
Impact on Creators: The Real Cost of Downtime
When TikTok goes down, the impact isn't evenly distributed. Most people are inconvenienced. But for creators who depend on the platform for income, a multi-hour outage is an actual financial loss.
TikTok's creator economy is worth billions of dollars. Creators earn money through:
- Creator Fund: Direct payments from TikTok for video views
- Live gifts: Tips from viewers during live streams
- Brand partnerships: Companies paying creators to promote products
- Link in bio sales: Directing followers to external stores or services
When TikTok is down, all of these revenue streams stop. A creator doing a live stream loses the opportunity to earn gifts. A creator who can't upload loses potential Creator Fund revenue. And perhaps most importantly, the algorithm stops working, which means new videos don't get recommended to viewers.
The outage occurred during a Sunday morning in the US, which is actually a relatively less busy time for the platform compared to evenings. If it had happened during peak hours (typically 6-10 PM), the impact would have been significantly larger. Creators uploading videos during evening hours would have lost reach. Peak earning hours during live streams would have been missed.
But here's what's particularly frustrating for creators: they have no recourse. TikTok doesn't compensate creators for outages. There's no service level agreement (SLA) protecting creators' ability to earn. It's just a loss.
This is different from how professional cloud services work. If Amazon's AWS has an outage, companies affected get service credits. If Heroku or Digital Ocean loses service, customers receive credits. But TikTok operates under a different model where creators are not customers with contractual protections—they're users of a free service.
The Algorithm Reset Problem
Many users reported that their TikTok algorithm seemed to reset during the outage. This is worth understanding because it reveals something important about how TikTok's recommendation system works.
TikTok's algorithm is one of its most closely guarded secrets. But we know from various sources that it works something like this:
Every time you interact with a video (watch it, like it, share it, comment on it, or skip it), that interaction is recorded and sent to TikTok's servers. These interactions are aggregated with interactions from millions of other users. The algorithm analyzes patterns in these interactions and predicts what content you're most likely to engage with.
The For You page (FYP) you see is actually highly personalized. Your FYP is completely different from your friend's FYP, based on your unique pattern of interactions.
Maintaining this algorithmic system requires constant synchronization between:
- User interaction databases: Records of what everyone has watched and liked
- Content metadata: Information about each video (duration, category, creator, etc.)
- Model coefficients: The machine learning weights that determine recommendations
- Cache layers: Fast-access copies of frequently used data
If a power outage interrupts this system, there's a significant risk of data inconsistency. The main database might have recorded an interaction, but that interaction might not have been processed by the recommendation algorithm. The cache layer might be out of sync with the database.
When the system comes back online, engineers have to carefully verify that everything is consistent. In some cases, they might need to replay recent transactions to ensure nothing was lost. This process, called "crash recovery," can take significant time.
It's possible that during crash recovery, some systems were reset to a previous consistent state, which could explain why some users felt their algorithm had been reset. This is generally a safe approach (prioritizing data integrity over lost interactions), but it means some user interactions during the hours leading up to the outage might have been discarded.

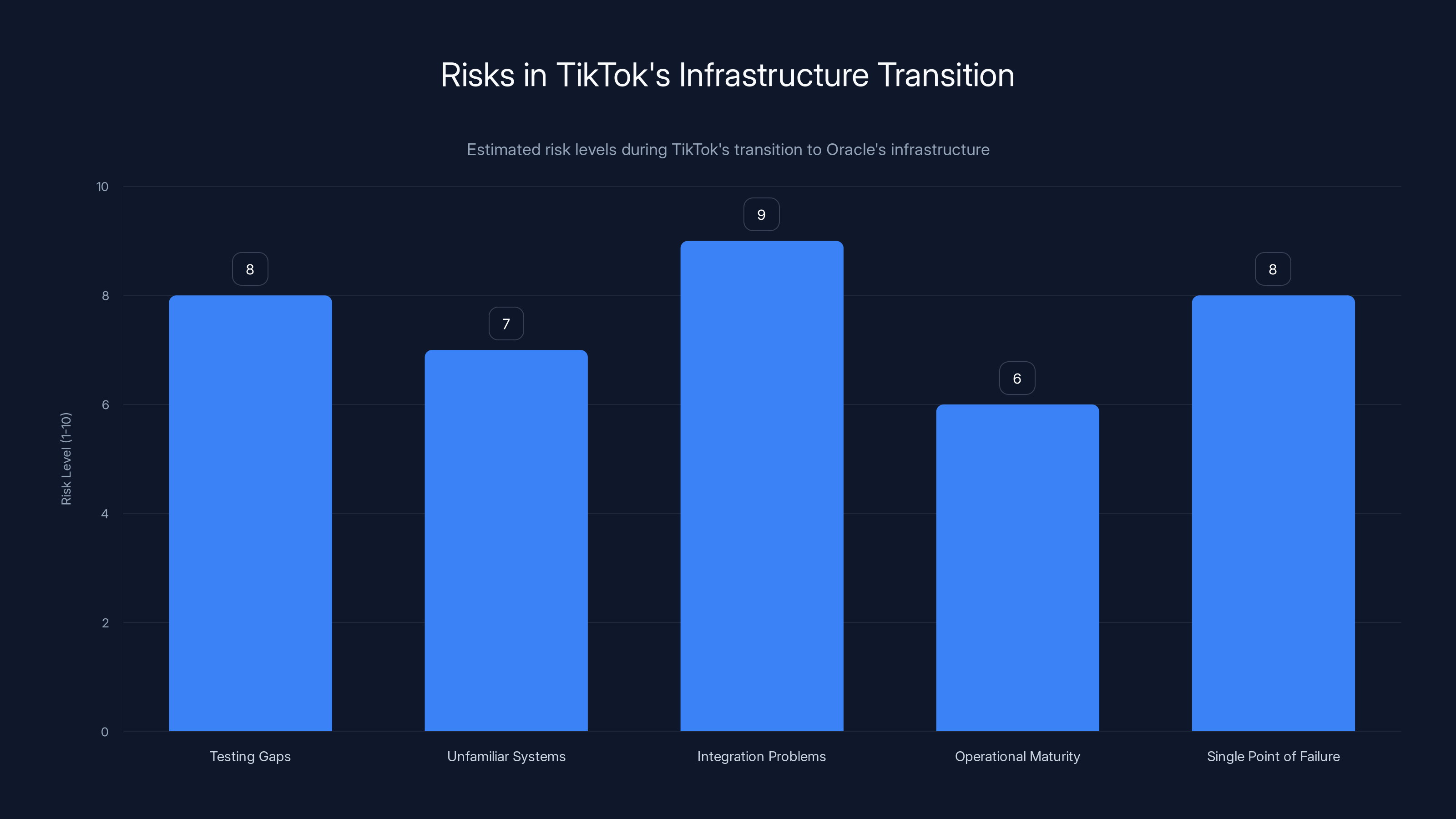
Estimated data shows that integration problems pose the highest risk during TikTok's transition to Oracle's infrastructure, followed by testing gaps and single points of failure.
TikTok's New Ownership Structure and Infrastructure Challenges
To understand why this outage matters, you need to understand what changed for TikTok in early 2025.
For years, TikTok operated using a complex arrangement of data centers, some owned by TikTok's parent company ByteDance (now based in China's Beijing), and some rented from other cloud providers. This arrangement was controversial because US politicians and national security officials worried that user data could be accessed by the Chinese government.
The new structure, created to address these concerns, places Oracle in a central role. Oracle operates the data centers. Oracle runs the infrastructure. US user data stays within US-based Oracle facilities.
This change is massive from an operational perspective. It's not just a contract renegotiation—it's a fundamental restructuring of how TikTok's US operations work.
When you make this kind of infrastructure change, you're essentially rebuilding while running. You can't take TikTok offline for weeks to migrate everything to new systems. You have to do it gradually, with parallel systems, failovers, and extensive testing.
The risks of this transition are significant:
Risk 1: Testing gaps: The new infrastructure might not have been tested under real-world load conditions. You can't fully replicate a billion daily active users in a test environment.
Risk 2: Unfamiliar systems: TikTok engineers might not be fully familiar with Oracle's infrastructure patterns, deployment procedures, and monitoring systems.
Risk 3: Integration problems: Connecting TikTok's systems to Oracle's infrastructure requires integration work at many levels, and integration is where bugs hide.
Risk 4: Operational maturity: New operational setups often have hidden assumptions and undocumented procedures. When something goes wrong, people aren't sure what to do.
Risk 5: Single point of failure: If all US TikTok traffic goes through Oracle's data centers, and those data centers have an outage, there's no fallback.
The outage we're examining might actually be a relatively minor issue given the complexity of the infrastructure change. But it's a sign that the new setup might not be as resilient as the previous arrangement.

Comparing TikTok's Outage to Other Social Media Incidents
The TikTok outage wasn't the first time a major social media platform experienced service disruptions, and comparing it to previous incidents provides useful context.
Meta's 2021 Outage: In October 2021, Facebook, Instagram, and WhatsApp all went offline simultaneously for about 7 hours. The cause was an error in Border Gateway Protocol (BGP) configuration that made Meta's data centers unreachable from the internet. This was essentially a networking infrastructure problem. The outage affected nearly 3 billion people and cost Meta somewhere in the range of $50-100 million in lost advertising revenue. The incident revealed that even the world's most sophisticated tech companies can make configuration mistakes with massive consequences.
Twitter's Service Issues (2020-2023): Twitter experienced various outages and performance problems, particularly around major events. In 2020, during the US presidential election, Twitter experienced several periods where tweets wouldn't load or post. The causes varied from database scaling issues to network congestion. Twitter's infrastructure was not as resilient as some competitors.
AWS Outages: Amazon Web Services has experienced multiple significant outages despite being one of the most mature cloud infrastructure providers. In 2021, a metadata service failure caused widespread AWS problems. In 2020, an AWS outage in us-east-1 took down many internet services. These incidents show that even market-leading infrastructure providers with decades of experience have failures.
YouTube and Google Services (2023): Google's services experienced a brief outage in November 2023 affecting YouTube, Gmail, and other services. The cause was never fully disclosed but suggested authentication system issues. Google resolved it within about an hour.
TikTok's outage, in comparison, seems relatively modest in scope (affected primarily uploads and feeds, not the entire platform) and duration (resolved within a few hours). But the fact that it happened during TikTok's relatively early days with its new infrastructure is concerning.

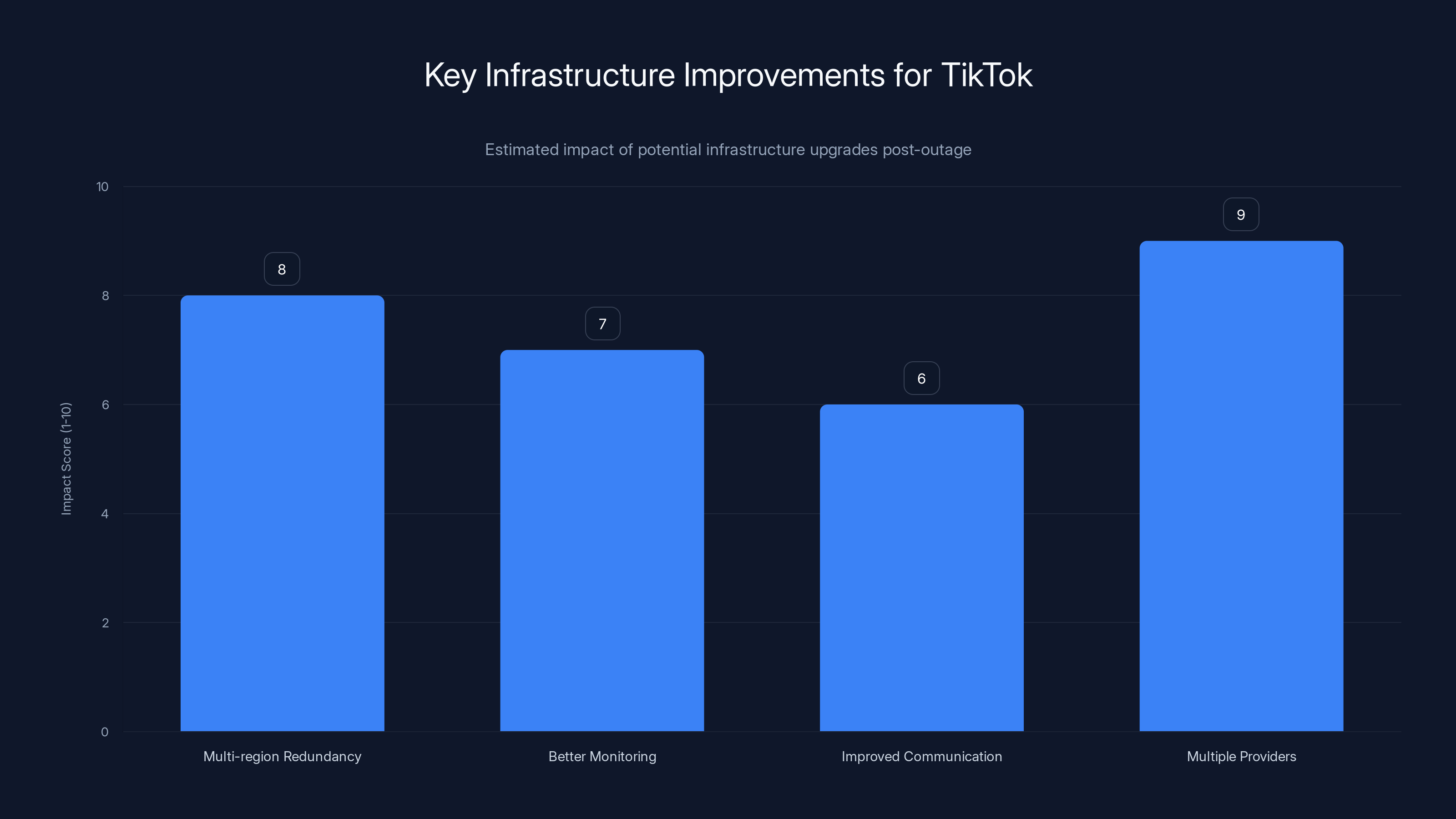
Estimated data suggests that implementing multiple infrastructure providers could have the highest impact on reducing future outages for TikTok.
What the Outage Reveals About Social Media Dependency
Here's something unsettling that becomes clear whenever a major platform goes down: we've built an enormous amount of economic activity on top of services that can fail.
TikTok isn't just entertainment. For hundreds of thousands of creators, it's their primary income source. For small businesses, it's a critical marketing channel. For media companies, it's a distribution platform. For teenagers, it's essentially their social life.
When TikTok goes down, all of that stops.
This raises uncomfortable questions:
Question 1: Should critical infrastructure (and TikTok arguably qualifies given its economic importance) have more stringent reliability requirements?
Question 2: Should creators be protected by service level agreements that guarantee availability and compensate them for outages?
Question 3: Should there be more transparency about outages and their causes?
Question 4: Should social media platforms be required to have truly redundant infrastructure across different providers, not just different data centers of the same provider?
Question 5: Who is responsible when an outage causes financial losses for creators?
These aren't just theoretical questions. They're increasingly practical business and policy questions that governments, companies, and creators are all asking.

The Role of Weather in Data Center Outages
TikTok's outage coincided with a massive winter snowstorm that blanketed much of the United States. While TikTok didn't explicitly blame the weather, the timing strongly suggests it was a contributing factor.
Weather causes a surprisingly large percentage of data center outages. According to reliability studies:
- 30-40% of data center outages are weather-related
- Heavy snowfall causes power grid failures and transmission line damage
- Ice storms overload electrical systems
- Flooding damages equipment and disrupts operations
- High winds can knock down power lines
- Extreme heat can overwhelm cooling systems
While data centers are designed to operate in any weather, they're still ultimately connected to power grids and networks that are exposed to weather. A snowstorm doesn't have to hit the data center directly—it just has to hit the power lines supplying it.
This raises an important point: as climate change makes severe weather more frequent, data center resilience becomes increasingly important. A data center designed for 20th-century weather patterns might not be sufficient for 21st-century conditions.
Some of the world's most advanced data center operators have started moving facilities to geographically diverse locations with lower weather risk. However, this is expensive and isn't always possible given the need for low-latency connections to users.

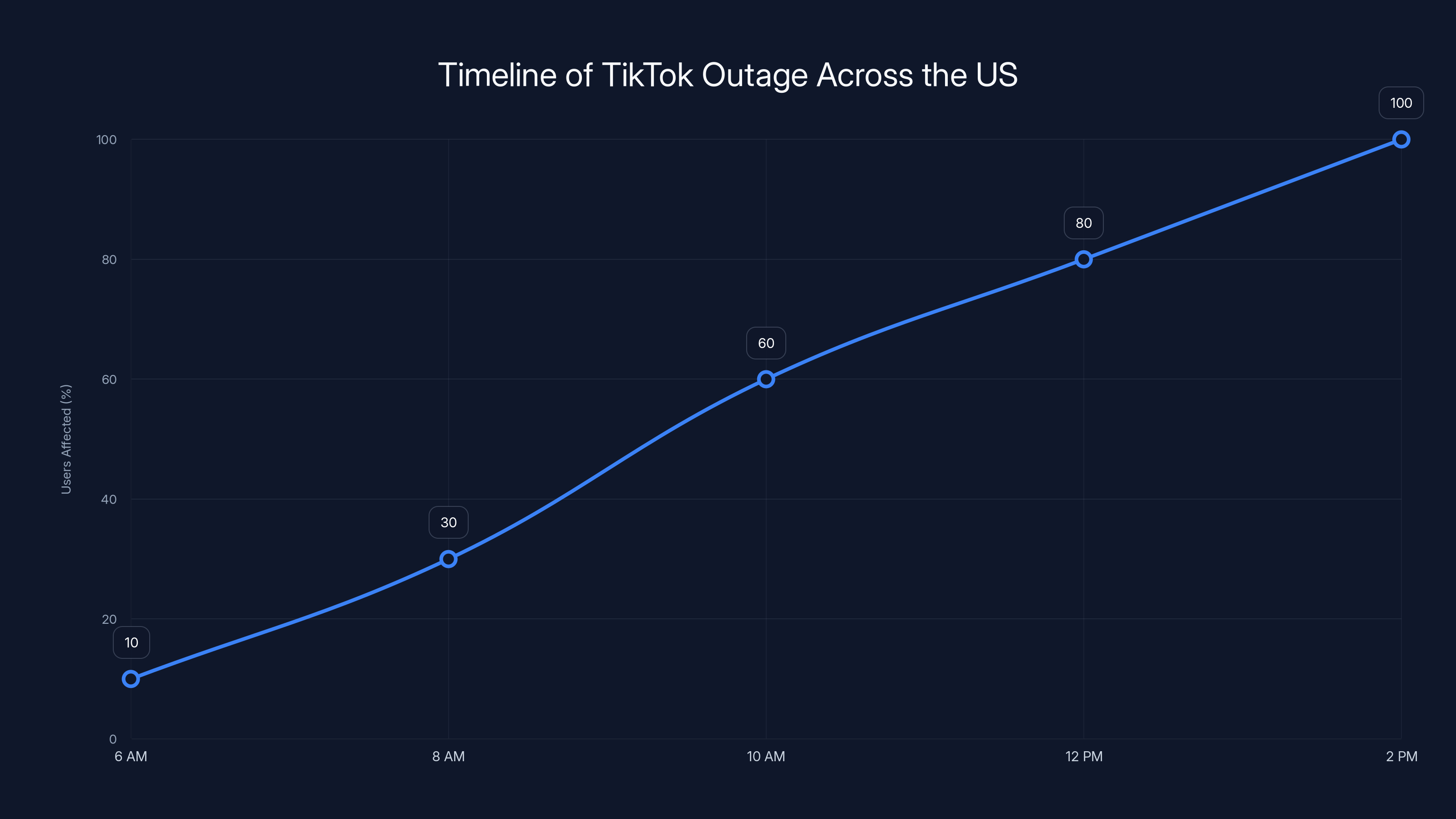
The outage began early Sunday morning and gradually affected more users, peaking by afternoon. Estimated data reflects typical outage progression.
Comparing Data Center Infrastructure: Oracle vs. Competitors
Understanding why TikTok chose Oracle requires understanding Oracle's data center capabilities compared to alternatives.
Oracle Cloud Infrastructure (OCI): Oracle's cloud platform has grown significantly in recent years. It's particularly strong for databases and enterprise applications. Oracle operates data centers globally, including multiple facilities in the US. However, OCI is not as comprehensive as AWS or Google Cloud for general-purpose web applications. OCI's infrastructure is newer and has less operational maturity than AWS.
Amazon Web Services (AWS): AWS operates the largest cloud infrastructure globally with over 30 regions and multiple availability zones per region. AWS has been refined over 15 years and has industry-leading reliability. However, AWS is owned by Amazon, and there were political concerns about relying on Amazon for critical TikTok infrastructure.
Google Cloud Platform (GCP): Google's cloud infrastructure is extremely sophisticated, built on the same systems that power Google's massive search and advertising operations. However, like AWS, Google Cloud raised political concerns about relying on another major tech company.
Microsoft Azure: Microsoft's cloud platform is comprehensive and globally distributed. Azure has enterprise-grade reliability. However, Microsoft also raised political concerns.
Oracle was chosen partly for technical reasons (Oracle's data centers are adequate for TikTok's needs) and partly for political reasons. Oracle has been less controversial in US political discussions and has cultivated relationships with the Trump administration. Founder Larry Ellison has been politically favorable to the administration.
This choice of infrastructure based partly on political considerations, rather than purely on technical merit, might be a factor in why the outage occurred. If TikTok had chosen AWS or Google Cloud, the outage might have been less likely or less severe, because those providers have more mature operational processes.
But that's speculation. The reality is that Oracle's infrastructure is adequate for TikTok's needs—this one outage doesn't invalidate the choice. However, it does suggest that TikTok should invest in improving infrastructure resilience.

The Path to Better Infrastructure: What TikTok Should Do
If I were advising TikTok's leadership on how to prevent future outages, I'd recommend several approaches:
1. Multi-provider redundancy: Don't put all US traffic through Oracle. Distribute traffic across Oracle and at least one other major cloud provider (AWS, Google Cloud, or Azure). If one provider has an outage, the other takes over.
2. Geographic distribution: Within the US, distribute TikTok's services across multiple data centers in different regions. An outage in one facility shouldn't affect the entire US.
3. Better testing: Conduct regular disaster recovery exercises. Simulate data center failures. Practice failover procedures. Make sure teams know exactly what to do when something goes wrong.
4. Improved monitoring: Implement sophisticated monitoring that detects problems before they impact users. Monitor power systems, network connectivity, database health, and application performance.
5. Transparent communication: When outages occur, communicate clearly and frequently with users and creators. Provide ETAs for restoration. Explain what went wrong. This builds trust.
6. Creator compensation: Consider implementing a service level agreement for creators. If TikTok is down during peak hours, compensate affected creators.
7. Incident postmortems: After each outage, conduct a thorough investigation. Publish findings (at least internally, and ideally publicly in redacted form). Fix root causes, not just symptoms.
These aren't revolutionary suggestions. They're standard practices at major cloud providers. But implementing them requires investment, engineering effort, and organizational commitment.
The Broader Implications for Social Media Infrastructure
TikTok's outage is just one incident, but it illustrates broader challenges facing all social media platforms in 2025.
Social media has become critical infrastructure. Billions of people depend on these platforms for communication, entertainment, commerce, and information. The economic value created on top of social media platforms is enormous—billions in creator income, advertising revenue, and commerce transactions.
Yet social media platforms remain relatively fragile. They can go down. They do go down. And when they do, the consequences ripple through the entire economy.
Governments around the world are starting to regulate this. The EU's Digital Services Act requires platforms to maintain certain reliability standards. The US is considering similar regulations. This regulatory pressure will force platforms to invest more in infrastructure resilience.
TikTok's situation is particularly complex because of the political dimensions. The infrastructure restructuring was driven by national security concerns, not purely by technical or business considerations. This might create suboptimal technical outcomes if political requirements force architectural decisions that engineers wouldn't recommend.
But TikTok isn't unique in this regard. All major platforms face some combination of technical, business, and regulatory requirements. How well they balance these competing demands determines how reliable they are.

User Experience Impact: What Happened On Your Phone
Let's get concrete about what the outage actually felt like for users, because the user experience is ultimately what matters.
Symptom 1: Upload failures: Users tried to upload videos and received error messages. These might have been generic "please try again" messages or more specific "service temporarily unavailable" messages. For creators used to smooth uploads, this was confusing.
Symptom 2: Feed not refreshing: The For You page stopped showing new videos. Pulling to refresh often just showed the same videos repeatedly. This broke the core TikTok experience.
Symptom 3: Algorithm reset: Some users reported that their personalized For You page became significantly less personalized. Videos they normally saw were replaced with generic content. This suggests that the recommendation system, at least temporarily, fell back to less sophisticated algorithms.
Symptom 4: Messaging issues: If TikTok's direct message system runs on the same backend infrastructure, messages might not have been sending or receiving properly.
Symptom 5: Live streaming problems: Creators attempting to go live probably encountered issues. Either they couldn't start a live stream, or the stream was interrupted.
Partial availability: Interestingly, not all users experienced all symptoms simultaneously. Some users were barely affected while others had severe issues. This suggests that the outage was not a complete platform blackout, but rather partial infrastructure failures affecting specific services or regions.
This pattern of partial failures is actually more complicated to diagnose and fix than a complete outage. When everything is down, it's clear something catastrophic happened. When some things work and others don't, it's much harder to determine the scope of the problem and prioritize which systems to restore first.

The Response: TikTok USDS's Communication Strategy
How TikTok communicated about the outage says something important.
The company posted a statement to their X account. They also provided a statement to The Verge. The messaging was honest but brief:
- Acknowledged the power outage
- Stated they were working to restore services
- Thanked people for their patience
- Didn't over-promise on timing
This is actually a reasonable communication approach. Many companies either stay silent during outages (which creates panic and speculation) or over-promise on recovery times (which looks bad when recovery takes longer).
However, the communication could have been better:
- More specificity: Which data center? Which geographic regions most affected? What's the estimated recovery time?
- More frequent updates: One statement and then silence is less helpful than periodic updates every 30 minutes.
- Technical details: What caused the power outage? Was it weather-related? Was it equipment failure? (This might be operationally sensitive, but some transparency would help)
- Impact summary: How many users affected? How many creators unable to upload? This context helps people understand the scope.
- Compensation: Will creators be compensated for lost revenue? Will users be given any service credits or benefits?
Compare this to how Amazon communicates during AWS outages. Amazon publishes detailed incident reports on their status page, with timeline details, root cause analysis (eventually), and steps being taken to prevent recurrence. This transparency builds trust.
TikTok's vague communication was probably a safe choice politically and legally, but it probably left users, creators, and investors wanting more information.

Lessons Learned: What This Outage Teaches Us
If there's one thing we can take from the TikTok outage, it's that even the most valuable and well-funded social media platforms can experience infrastructure failures.
This teaches several lessons:
Lesson 1: No amount of money guarantees perfect uptime: TikTok has basically unlimited resources. Oracle has some of the smartest engineers in the world. Yet they still had an outage. Uptime is hard.
Lesson 2: Political requirements can drive architectural decisions: TikTok's infrastructure restructuring was driven partly by regulatory and political pressure. This might not have been the most technically optimal path, and the outage might be a consequence.
Lesson 3: Infrastructure transitions are risky: Moving from one infrastructure setup to another is inherently dangerous. Gradual migrations reduce risk but take longer. This is a trade-off that's difficult to balance.
Lesson 4: Geographic redundancy is critical: If TikTok had backup systems in different regions, this outage probably wouldn't have affected so many users.
Lesson 5: Weather remains a threat: Modern technology can fail when nature strikes. Climate change makes this an increasingly important consideration.
Lesson 6: Transparency matters: Companies that communicate clearly during outages build more trust than those that stay silent.
Lesson 7: Dependency on single platforms is risky: For creators, businesses, and individuals, relying entirely on one platform is risky. Diversification reduces vulnerability.

The Future: What Comes Next for TikTok's Infrastructure
TikTok's engineers are almost certainly already working on preventing future outages. They'll conduct a thorough postmortem (internal investigation). They'll identify root causes. They'll implement fixes.
What we might expect to see:
Short-term fixes (weeks to months):
- Improved monitoring to detect problems faster
- Better documented recovery procedures
- Improved testing of backup systems
- Enhanced communication protocols during incidents
Medium-term improvements (months to a year):
- Deployment of backup systems in additional regions
- Better integration with multiple cloud providers
- Improved redundancy for critical systems
Long-term architectural changes (1-2 years):
- Complete redesign of infrastructure to be truly multi-region
- Potential diversification away from sole reliance on Oracle
- More sophisticated disaster recovery systems
The good news is that TikTok has the resources and technical talent to address these issues. The better news is that this outage, while disruptive, wasn't catastrophic. The platform came back online. No data was lost (as far as we know). Users were inconvenienced, but not permanently harmed.
FAQ
What exactly caused TikTok's power outage?
TikTok attributed the outage to a power failure at a US data center, but didn't specify whether this was caused by weather (a massive snowstorm was occurring), equipment failure, utility grid problems, or another factor. The vague statement suggests either that TikTok was still investigating the root cause, or that they chose not to disclose specific details publicly.
How long was TikTok down?
The outage lasted several hours from early Sunday morning until afternoon. TikTok didn't publish exact restoration times, but user reports and social media discussion suggest the platform was experiencing significant issues for approximately 3-5 hours before being fully restored.
Did this affect TikTok users outside the US?
No, the outage primarily affected US-based users. The statement mentioned it impacted "TikTok and other apps we operate," but international users reported normal service. This is because TikTok's new infrastructure under Oracle concentrates US user data in US data centers, while international users' data and services remain in separate infrastructure.
Why didn't TikTok's backup systems prevent the outage?
Data centers typically have backup power systems (batteries and generators), but these can fail due to simultaneous equipment failures, inadequate capacity, testing gaps, or maintenance issues. Without a public incident report from TikTok, we don't know why backups didn't prevent or minimize the outage, but possibilities include multiple simultaneous failures, generator startup issues, or cooling system damage.
Will TikTok compensate creators for lost income during the outage?
TikTok has not announced any compensation plans for creators affected by the outage. Unlike cloud service providers that offer service credits when infrastructure fails, social media platforms typically don't compensate users or creators for downtime, as they're free services with no service level agreements.
Could this outage happen again?
Yes, it could. No infrastructure is 100% reliable. However, if TikTok implements recommendations for better redundancy, geographic distribution, and improved monitoring, the probability and impact of future outages can be significantly reduced. The outage reveals that their current infrastructure has room for improvement.
Is TikTok less reliable than other social media platforms?
One outage doesn't establish a pattern. Meta, Twitter, YouTube, and other major platforms have all experienced outages. What matters is the frequency and severity of outages and how companies respond to them. TikTok's outage was significant but not unprecedented in the social media industry.
How does the Oracle partnership affect TikTok's reliability?
Oracle is a sophisticated infrastructure provider capable of supporting TikTok's needs. However, the transition to Oracle-controlled infrastructure is relatively new, and newer systems often have teething issues. Long-term reliability depends on how well TikTok and Oracle integrate their systems and implement redundancy.
Should TikTok have multiple data center providers for backup?
Yes, best practices suggest that critical infrastructure should not rely on a single provider. If TikTok distributed traffic across Oracle and another provider (AWS, Google Cloud, or Azure), a single provider's outage would have less impact. This would require architectural changes but would significantly improve resilience.
What should creators do to prepare for future outages?
Creators dependent on TikTok should diversify their platform presence by also uploading to YouTube Shorts, Instagram Reels, and other platforms. They should also build direct relationships with audiences through email lists, websites, or other channels not dependent on any single social media platform.

Conclusion: Infrastructure as an Invisible Necessity
The TikTok outage is a reminder that behind every app, every stream, every notification is an enormous invisible infrastructure of data centers, power systems, and network connections. When everything works, we don't think about it. But when it fails, the consequences are immediate and widespread.
For TikTok specifically, this outage occurs at a critical moment. The company is operating under a new ownership structure with new infrastructure partnerships. The transition from previous arrangements to the Oracle-based setup was always going to be risky. This outage is evidence that the transition still has rough edges.
But here's the important context: this was a relatively contained incident. It wasn't a platform-wide catastrophe. It was inconvenient for creators and users, but it was manageable. Recovery took a few hours, not days. No data was lost. The platform came back stronger.
Moving forward, TikTok has an opportunity to learn from this incident and invest in infrastructure resilience. Multi-region redundancy, better monitoring, improved communication, and potential use of multiple infrastructure providers would all reduce the likelihood and impact of future outages.
For everyone else, the lesson is clear: social media platforms are useful, but they're not reliable enough to be the sole foundation of a business or livelihood. Creators should diversify. Businesses should have backup channels. Individuals should have ways to communicate that don't depend on any single platform.
Technology is powerful and useful, but it remains fundamentally fragile. The more we depend on it, the more we need to understand its limitations and prepare for its failures. The TikTok outage of 2025 is just one example of why that preparation matters.
For teams looking to automate and manage complex operations across multiple platforms and systems, solutions like Runable offer automated workflows that can help coordinate activities across platforms when one experiences issues. Having backup automation in place helps teams maintain continuity when primary platforms experience downtime.
Use Case: Teams managing multiple social media platforms can use AI-powered automation to coordinate posting schedules and distribute content across backup platforms when primary channels experience outages.
Try Runable For Free
Key Takeaways
- TikTok experienced a significant power outage at a US data center that disrupted uploads, feeds, and algorithms for millions of users
- The incident occurred during the transition to new Oracle-based infrastructure, suggesting potential resilience gaps in the restructured setup
- Backup power systems failed to prevent user-facing disruptions, revealing possible inadequacies in redundancy architecture
- Weather likely contributed to the outage, as the incident coincided with a major US snowstorm affecting power infrastructure
- Better geographic redundancy across multiple data centers and providers would significantly reduce impact from future single-provider failures
- Creators lost potential income with no compensation mechanism, exposing the vulnerability of platform-dependent livelihoods
- TikTok's vague public communication contrasted with industry best practices from AWS and other providers regarding incident transparency
- Data center resilience remains critical infrastructure that requires investment, but no solution provides 100% uptime guarantee
Related Articles
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- Sandworm's Poland Power Grid Attack: Inside the Russian Cyberwar [2025]
- Wonder Man Marvel Release Strategy on Disney+: Why Full Drop Matters [2025]
- BBC's YouTube Strategy and the TV Licence Crisis [2025]
- Poland Energy Grid Wiper Malware Attack: What Really Happened [2025]
- Gmail Inbox Filtering Crisis: What's Breaking and How to Fix It [2025]

