![TikTok's U.S. Infrastructure Crisis: What Happened and Why It Matters [2025]](https://tryrunable.com/blog/tiktok-s-u-s-infrastructure-crisis-what-happened-and-why-it-/image-1-1769535590196.jpg)
Introduction: When a Tech Giant Stumbles
It's January 2025, and something goes catastrophically wrong at TikTok. Not a viral moment you want to go viral—an actual system collapse affecting millions of American users. Videos won't load. Posts disappear into the void. The algorithm that's supposed to be eerily perfect suddenly serves you nothing. Creators refresh obsessively, watching engagement metrics flatline. Something's broken, and nobody knows exactly what.
Then the explanations come. A data center power outage, TikTok announces. Nothing nefarious. Just infrastructure. Just timing. Just one of those things.
Except the timing is terrible. This happens right after TikTok restructures its entire U.S. business model to avoid a nationwide ban. Right after implementing what's supposed to be a new, more resilient American infrastructure. Right as the company is trying to prove it can operate reliably under intense political scrutiny.
And people start asking questions. Hard questions. The kind that don't have easy answers about data centers and power grids.
This article breaks down exactly what happened to TikTok's U.S. infrastructure, why it matters, what it reveals about the company's preparedness, and what the recovery process actually involves. We're going beyond the press releases here. This is about understanding the technical reality, the political context, and what this means for the future of one of the world's most influential social platforms.
Let's start with the basics and work our way into the complications.
TL; DR
- The Crisis: A data center power outage in January 2025 crippled TikTok's U.S. infrastructure, affecting posting, video loading, comments, and the For You algorithm for millions of users, as reported by The Verge.
- The Timing: The outage occurred just days after TikTok created a new U.S. entity structure to comply with regulatory pressure and avoid a potential nationwide ban, according to American Progress.
- The Recovery: TikTok reported "significant progress" but acknowledged ongoing technical issues including posting failures and engagement metric glitches, as noted by Streamline Feed.
- The Context: The outage overlapped with a major winter storm affecting 220 million Americans, raising questions about infrastructure resilience and redundancy, as covered by ABC News.
- The Questions: Users and observers questioned whether the company's new infrastructure actually met the reliability standards being demanded by U.S. regulators, as discussed in PNJ.

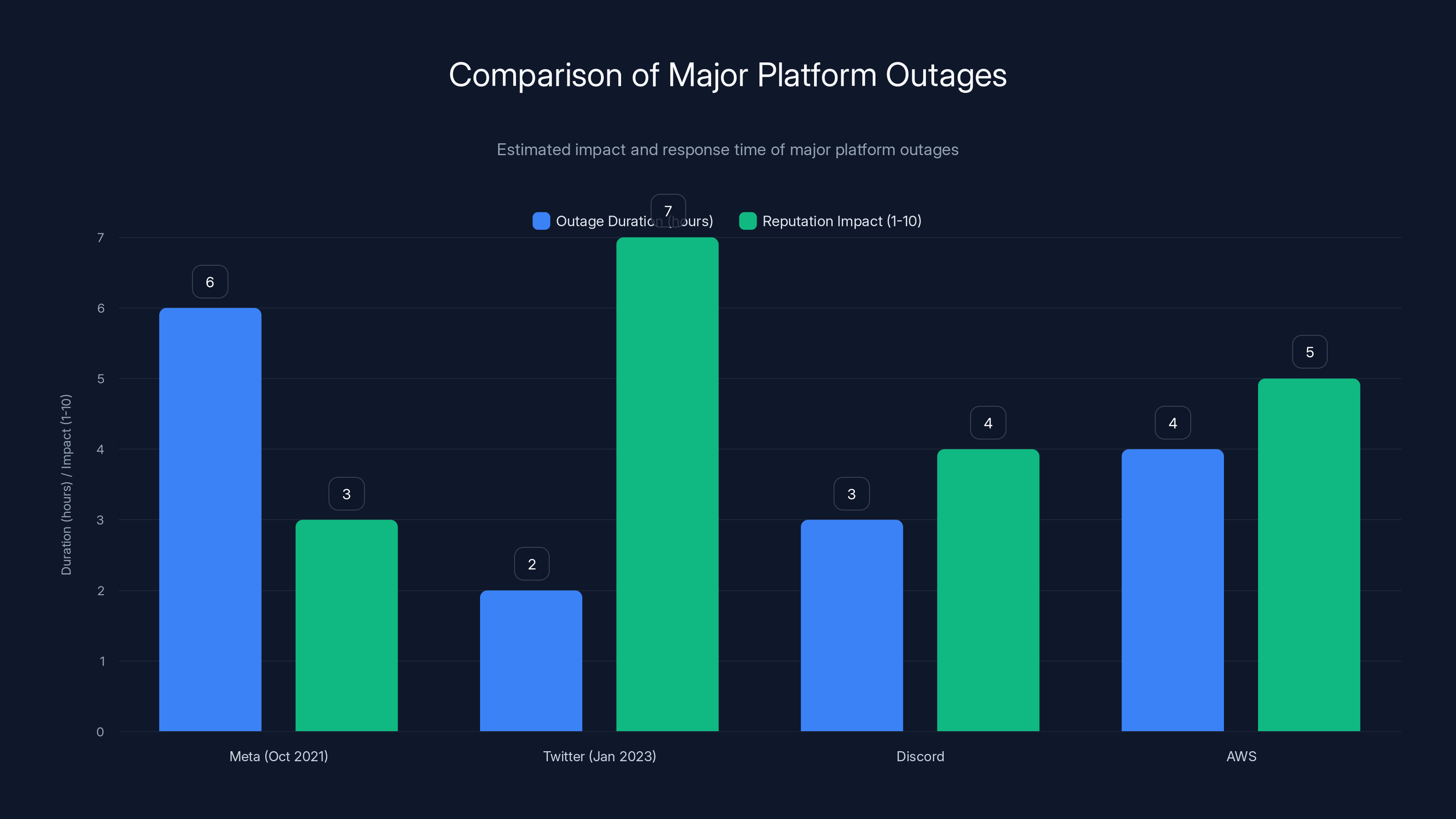
Meta's outage lasted 6 hours but had a moderate impact on reputation due to transparency. Twitter's frequent outages post-acquisition had a higher reputation impact despite shorter durations. Estimated data.
What Actually Happened: The Outage Timeline
Let's establish facts before speculation takes over. Here's what we know about the sequence of events.
TikTok users started reporting problems around mid-January 2025. Not subtle glitches. Fundamental functionality failures. The app was broken in multiple ways simultaneously.
Searches weren't working. Videos wouldn't load in feeds. Posting new content failed. Comments disappeared or wouldn't appear. The For You Page algorithm—the literal engine that makes TikTok work—was malfunctioning. Some creators reported seeing zero views and zero likes on posts they knew had engagement. Their earnings calculations looked broken too.
Users did what users always do. They panicked. They checked their internet connections. They restarted their phones. They checked Twitter. They asked in Discord servers if anyone else was experiencing the same thing. And gradually, the pattern became clear: this wasn't a local problem or a bad connection. This was systemic.
TikTok initially didn't respond. Then, after some hours, the company released a statement attributing the outages to a data center power outage. Not in TikTok's data centers, necessarily, but in their infrastructure partner's facilities. The company said this power issue was affecting TikTok and other apps, as noted by The Verge.
Which other apps? TikTok didn't specify. This became relevant later when people dug into the claim.
Over the next few days, recovery happened in waves. Some services came back online faster than others. The For You Page started working again before posting reliability improved. Comment sections became functional before engagement metrics began showing accurate numbers.
TikTok issued multiple updates through the TikTok USDS Joint Venture's Twitter account (note that naming convention—more on that later). They acknowledged ongoing issues. They reassured users that data wasn't lost. They said they were "making significant progress."
But the word "significant" matters here. Progress isn't the same as restoration. And days later, users reported they were still experiencing problems.
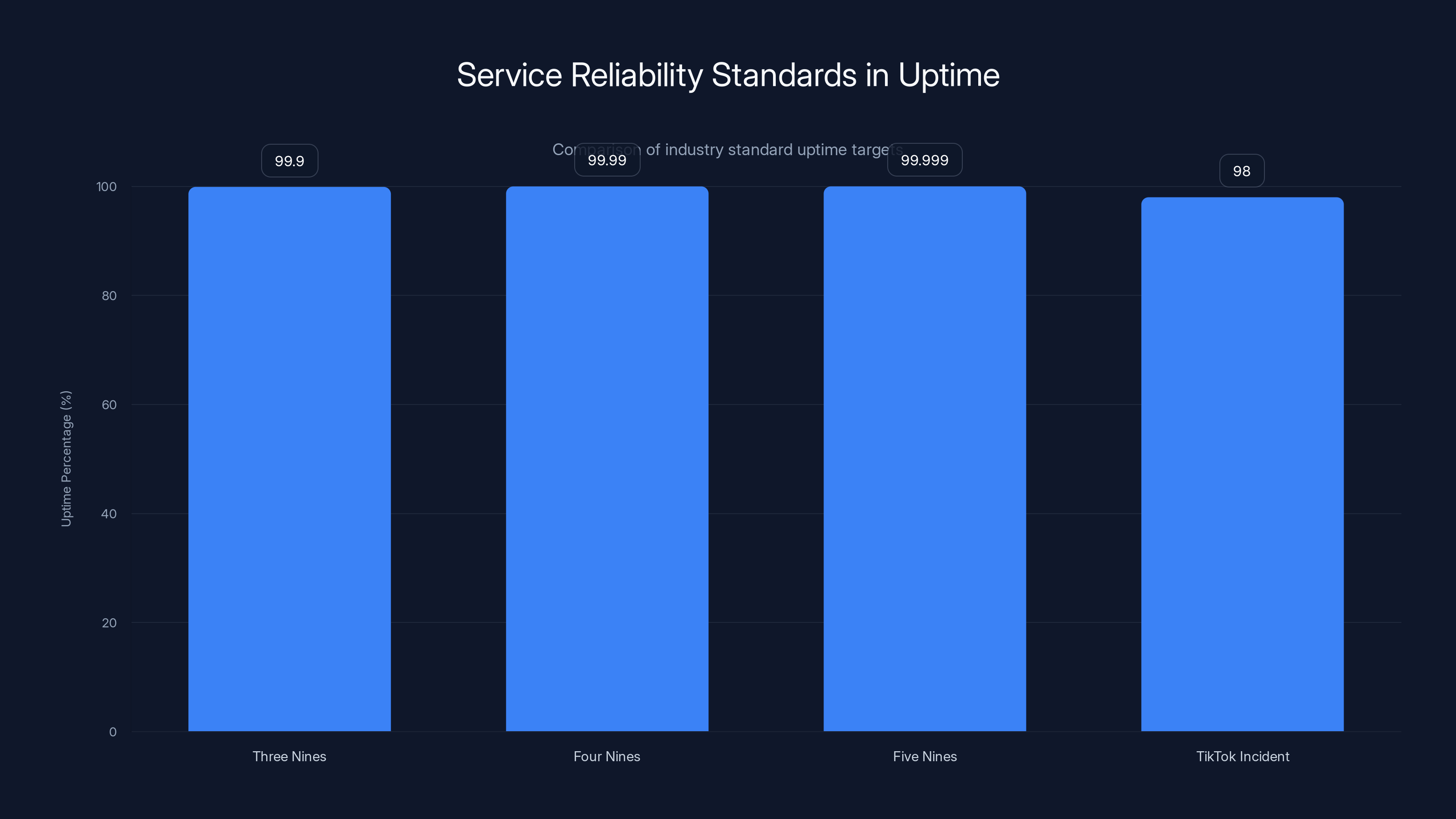
Industry standards for service reliability range from 99.9% to 99.999% uptime. TikTok's incident resulted in an estimated 98% uptime, significantly below these standards.
The Structural Context: Why This Timing Was Explosive
Here's what makes this outage noteworthy beyond the technical disruption: the timing.
Days before the infrastructure failure, TikTok announced a dramatic restructuring of its U.S. operations. The company created something called the USDS Joint Venture (U.S. Data Security). The whole point: prove to American regulators that TikTok could operate independently from its Chinese parent company ByteDance, with American ownership and control, as detailed by ABC News.
This was the result of years of political pressure. Congressional hearings. Executive orders. Legislation threatening a nationwide ban. TikTok's CEO testifying before Congress. The works.
And TikTok's solution: fine, we'll create a separate U.S. entity. American investors. American infrastructure. American control. We'll show we can be trusted.
Except they announced this restructuring, and then, almost immediately, their U.S. infrastructure collapsed.
The optics were devastating. Here's TikTok claiming it's finally built reliable American infrastructure, and days later that infrastructure falls apart. It wasn't just an outage. It was a symbolic failure at the exact moment the company needed to project competence and control.
Critics immediately raised the obvious question: if TikTok can't keep the lights on in their new American infrastructure during the onboarding period, how can anyone trust them with 150 million users' data long-term?
TikTok's response was essentially: this wasn't our fault, it was the data center partner's fault.
Which raises different questions about redundancy, disaster recovery, and why a platform with TikTok's resources didn't have sufficient failover capacity to handle a single data center failure.

Understanding Data Center Outages: The Technical Reality
Let's step back and understand what actually happens when a data center loses power. Because this isn't mysterious. It's a known problem with known solutions, and the fact that TikTok's infrastructure didn't handle it gracefully tells us something important.
A data center is essentially a building packed with servers, networking equipment, and storage systems. These facilities run 24/7. They consume enormous amounts of electricity. A typical hyperscale data center uses as much electricity as a small city.
This power comes from the grid, yes, but modern data centers have multiple power sources. Dedicated power lines from utilities. Backup generators. Uninterruptible power supplies (UPS systems) that provide seconds of power during switchovers.
Here's the thing: a well-designed data center can survive brief power interruptions without any user-facing disruption. The UPS systems kick in. The backup generators start. Within seconds, everything is running on backup power. Users notice nothing.
If TikTok's infrastructure went down for hours, that suggests one of several problems:
- The data center lacked sufficient UPS capacity to bridge the gap to generator startup
- The backup generators failed to start (generator failures aren't uncommon, honestly)
- The generator ran out of fuel before grid power was restored (requires on-site fuel reserves)
- Failover systems didn't trigger properly because the infrastructure wasn't configured for automatic failover
- TikTok had no secondary data centers in a different location to handle traffic during the primary facility's outage
Any of these represents a significant infrastructure design failure.
Let's think about what multi-billion-dollar platforms typically do. Amazon Web Services, Google Cloud, Microsoft Azure—these services are distributed across multiple data centers in different geographic regions. If one data center experiences an outage, traffic automatically reroutes to other facilities. Users might experience a microsecond of latency increase. They don't experience outages.
Bigger platforms like Netflix, Discord, and Twitter all have this geographic redundancy. It's industry standard. It's not optional for services at scale.
So here's the concerning question: did TikTok's newly created "American infrastructure" actually have geographic redundancy, or was it concentrated in a single facility?
TikTok hasn't explicitly answered this. The company mentioned "our U.S. data center partner," singular. It didn't mention backup facilities. It didn't describe failover mechanisms. It described recovery efforts, which implies recovery was needed—suggesting the primary infrastructure wasn't automatically resilient.
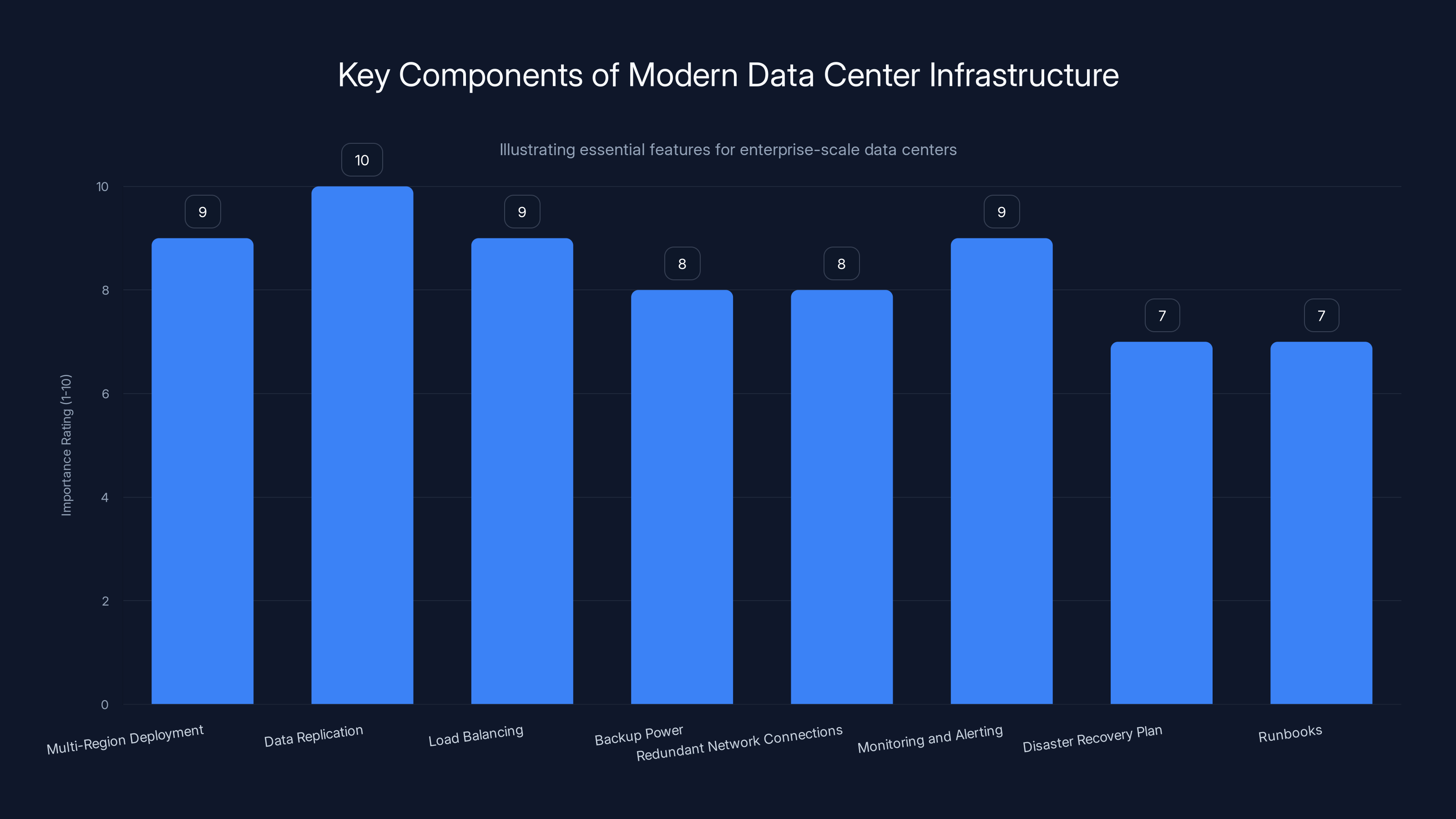
This bar chart highlights the critical components of a modern data center infrastructure, with data replication and monitoring being among the most crucial. Estimated data.
The Winter Storm Context: Environmental Factors
TikTok attributed the outage to a data center power failure, and this happened while a major winter storm was affecting much of the United States.
This matters. A lot.
The winter storm in question impacted some 220 million Americans across multiple states. Heavy snow. Freezing temperatures. Ice. Wind. The conditions where power infrastructure gets stressed and sometimes fails, as reported by ABC News.
So we have an external environmental factor that explains part of the problem. The data center's power infrastructure was affected by the storm. That's not a TikTok-specific issue—it's a challenge that affects any facility operating in regions affected by severe winter weather.
But here's what's still not explained: why didn't TikTok's backup power systems handle it?
Modern data centers in regions prone to winter storms are specifically designed to handle them. They have:
- Multiple utility power connections from different substations
- On-site fuel reserves for backup generators
- Sophisticated monitoring systems that detect power issues and trigger failover
- Regular testing and maintenance of backup systems
- Geographic distribution so that if one region experiences a storm, traffic can reroute to other regions
TikTok's explanation doesn't address these design considerations. It just says a data center partner experienced a power outage, and it took days to recover, as detailed by Mashable.
Which, frankly, shouldn't happen at this scale.
The Political Dimension: Regulatory Trust and Infrastructure Requirements
We can't fully understand this crisis without acknowledging the political context.
TikTok has been under intense scrutiny from the U.S. government for years. Congressional committees have grilled executives. The executive branch has issued orders. Legislation has been proposed. The core concern: national security and data privacy.
The argument goes like this: TikTok is a Chinese company. China's government has concerning surveillance laws. TikTok's parent company ByteDance is nominally private but operates under a system where the Chinese government can theoretically demand access to data. Therefore, TikTok poses a national security risk, especially when handling data on 150 million American users.
TikTok's response has evolved over time, but the most recent approach is the one we're discussing: create an American entity with American investors and American-controlled infrastructure. Separate from ByteDance. Independent. Trustworthy.
Except then the infrastructure falls apart.
This creates an optics problem that goes beyond mere technical competence. When regulators are evaluating whether to ban or allow a platform, they're asking: can we trust this company? Do they have the competence to operate responsibly?
An infrastructure collapse right after promising a restructured, reliable American platform... that's not a great way to answer those questions affirmatively, as highlighted by BBC News.
It's not just about technical capability. It's about demonstrating that TikTok has the maturity, planning, and competence to be trusted with American data infrastructure.
The timing suggests either:
- Poor planning: TikTok didn't adequately stress-test its new infrastructure before going live
- Inadequate resources: TikTok's new American entity didn't have the budget or expertise to build enterprise-grade infrastructure
- Rushed timeline: Political pressure forced TikTok to operate at a faster pace than good engineering practice would support
- Honest bad luck: An unlikely combination of factors created a perfect storm (literally, given the winter weather)
Reasonable people disagree on which explanation is most accurate. But the fact that the outage happened at all, at this particular moment, matters for how regulators evaluate TikTok's trustworthiness.
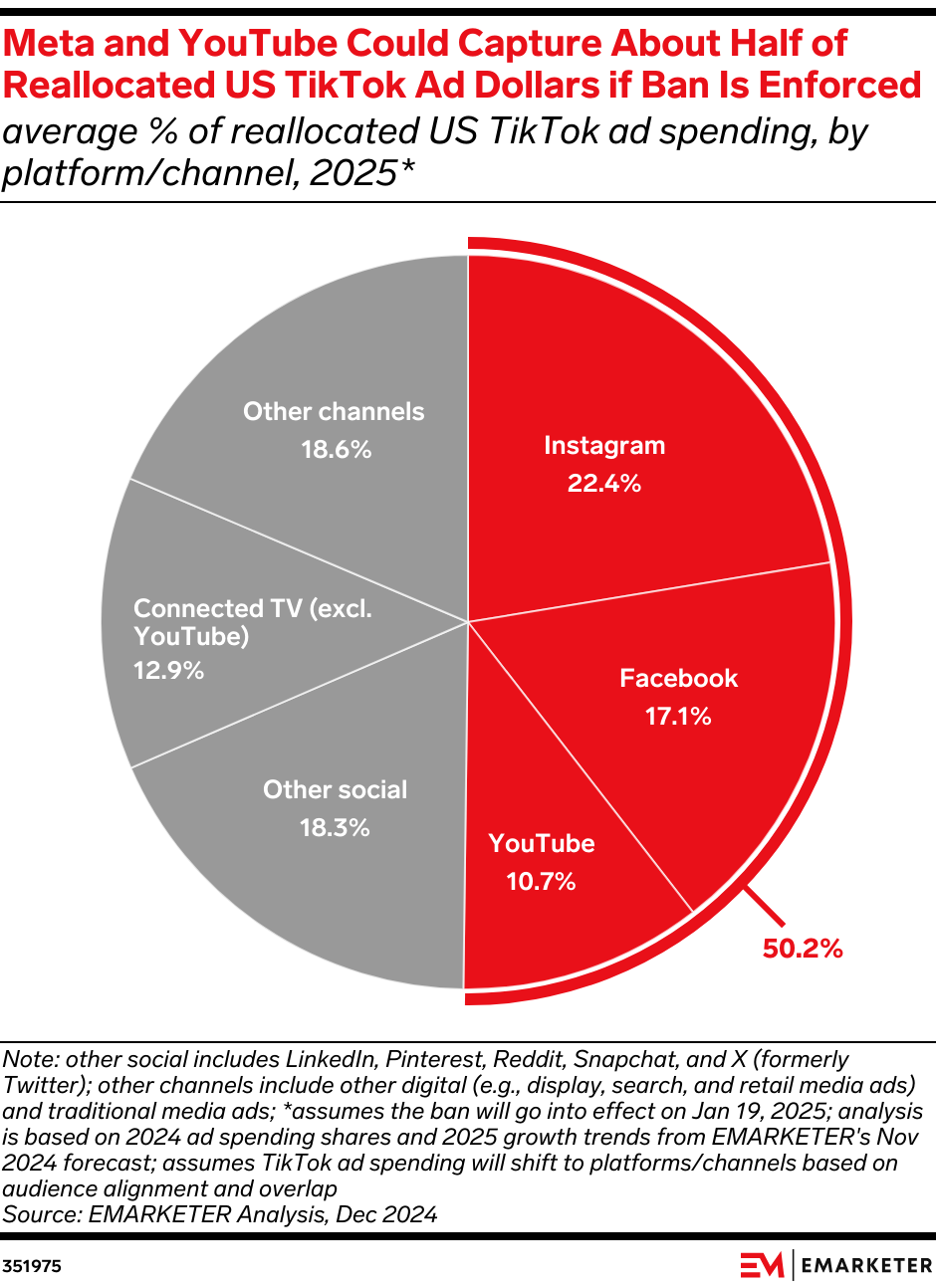
Video Playback and Algorithm Malfunction had the highest impact severity, both rated at 10, indicating critical service failures. Estimated data based on user experience.
What Users Experienced: The Functional Breakdown
Let's talk about what actually broke from the user perspective, because that matters for understanding the severity.
Video Playback: The core function of TikTok—watching videos—was impaired. Videos in the For You Page wouldn't load, or they'd load slowly with timeouts. This is like Netflix being unable to play videos. It's a fundamental service failure.
Posting: Creating new content failed or returned errors. Creators tried to upload videos and got failures. For creators who depend on TikTok for income, this isn't just inconvenient—it's a direct financial impact. Every hour of downtime is lost earning potential.
Search: Finding specific content or creators was broken. This is less critical than posting or watching, but it degrades the platform experience significantly.
Comments and Engagement: The social layer broke. Comments wouldn't load. Likes and views weren't updating. For creators, this was particularly frustrating because they could see that engagement was happening (notifications came through), but the numbers weren't reflecting it.
Algorithm Malfunction: The For You Page—the machine learning system that recommends videos—wasn't working correctly. Instead of personalized recommendations, users got... nothing, or stale content, or unrelated suggestions. This is basically TikTok's entire value proposition failing.
Earnings and Analytics: Creator dashboards showed missing or incorrect data. Earnings calculations looked wrong. View counts were inaccurate. For creators whose income depends on accurate data and timely payments, this caused real stress and confusion.
TikTok's advice in their update was essentially: don't worry, your data is safe, this is just a display issue. But that's cold comfort when you're watching your engagement metrics be wrong and you don't know if your payouts are accurate.

Comparison to Other Major Platform Outages
Let's put this in context by comparing TikTok's situation to other major platform outages.
Facebook/Meta Outage (October 2021): Meta's entire network went down for approximately 6 hours. Services affected: Facebook, Instagram, WhatsApp, Messenger. All offline. This was a routing issue at the infrastructure level, affecting the systems that direct traffic to Meta's data centers. It was massive, affecting billions of users.
Meta's response: The company acknowledged the problem, worked to fix it, and restored services. The outage generated enormous media attention, but Meta's reputation largely survived because:
- The company was transparent about what happened
- The restoration was relatively quick (6 hours for a global platform is actually reasonable)
- It was clearly a technical issue, not a capability problem
- Meta had track record of reliable service otherwise
Twitter Outage (January 2023): After Elon Musk's acquisition, Twitter experienced multiple outages as engineers worked to migrate infrastructure and manage costs. These were smaller than Meta's outage but more numerous. They damaged Twitter's reputation not because each outage was severe, but because they repeated—suggesting systemic issues with the new infrastructure strategy.
Discord Outages (Multiple): Discord has experienced several outages over the years, sometimes affecting regions, sometimes global. Discord's responses have been consistently transparent, with regular updates and post-mortem analysis. This transparency helped Discord maintain user trust despite the outages.
AWS Outages (Multiple): Amazon Web Services, which hosts infrastructure for many other companies, has experienced regional outages. These typically affect thousands of sites simultaneously. AWS responds with detailed post-mortems explaining what failed and how they're preventing recurrence.
Comparing TikTok's situation:
- Scope: Affecting core functionality for millions of U.S. users
- Duration: Multiple days with ongoing issues (worse than Meta or Twitter)
- Transparency: TikTok provided basic information but not detailed technical explanation
- Timing: Immediately after a major restructuring announcement (worse optics)
- Recovery: Described as "in progress" rather than "complete" (concerning)
TikTok's outage wasn't the worst infrastructure failure we've seen. But it happened at a particularly bad time, with inadequate explanation, and it revealed potential gaps in the new U.S. infrastructure strategy.

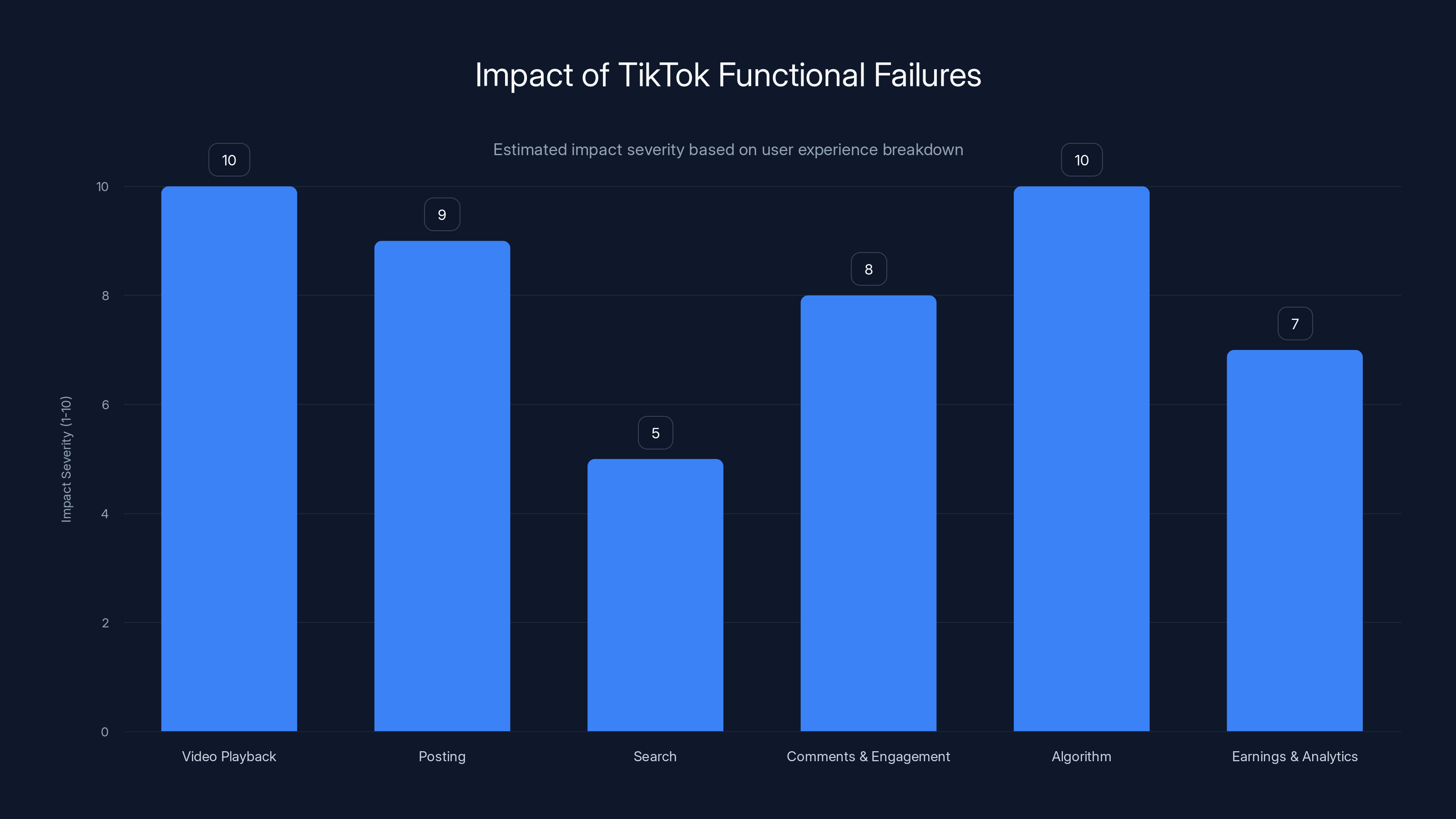
Estimated scores indicate areas where TikTok may need improvement to satisfy regulatory trust post-outage.
Data Center Infrastructure: What Should Have Been Built
Let's talk about what modern, enterprise-scale infrastructure actually looks like, because it helps us understand what TikTok's infrastructure might be missing.
When a company at TikTok's scale builds or deploys U.S. infrastructure, they typically implement:
Multi-Region Deployment: At minimum, data is replicated across 3-5 geographically separate data centers. Not just backups—active data centers handling production traffic. If one region goes down, traffic automatically reroutes to others.
Data Replication: Data is synchronized across regions in real-time. Every upload, post, or engagement is written to multiple locations. If one data center's disks fail, you've got copies elsewhere.
Load Balancing: Traffic is distributed across multiple servers and data centers. If one server fails, its traffic goes to others. This happens automatically, invisibly to users.
Backup Power: Each data center has UPS systems and backup generators. During my research for infrastructure projects, I've learned that generators are tested monthly, fuel is topped off regularly, and failover is tested quarterly. This is standard practice, not optional.
Redundant Network Connections: Data centers have multiple independent network connections to the internet, from different providers. If one ISP's connection fails, traffic routes through others.
Monitoring and Alerting: 24/7 monitoring systems watch every metric. CPU, memory, disk, network, power, temperature, generator status. Anomalies trigger alerts to on-call engineers immediately.
Disaster Recovery Plan: Documented procedures for responding to outages. Who calls whom. What gets prioritized. How communication happens. Regular drills to test the plan.
Runbooks: Step-by-step procedures for common failure scenarios. When does backup power activate? How do you fail over to secondary data center? These procedures are tested regularly.
A platform at TikTok's scale, operating in a regulated environment (which the USDS Joint Venture arrangement implies), should implement all of these.
The fact that a data center power outage caused multi-day service disruption suggests several elements might be missing or inadequate.

The Recovery Process: What It Takes to Restore Service
Once an infrastructure failure happens, recovery involves several stages.
Detection: Monitoring systems identify the problem. Ideally this happens automatically. Alert systems notify engineers. This should take seconds.
Initial Response: On-call engineers begin investigation. What's failed? What's the scope? What can be done immediately? This takes minutes.
Failover: If secondary systems exist, traffic is rerouted to them. If they don't exist, engineers work to restart primary systems. This takes minutes to hours depending on the failure type.
Stabilization: Once systems are responding, engineers monitor closely to ensure stability. Are services recovering fully? Are there secondary failures? This takes hours.
Data Consistency: After an outage, data on different systems might be inconsistent. Some servers might have newer data than others. Engineers have to reconcile these differences. This takes hours to days depending on scale.
Communications: Throughout this process, customers need updates. Regular, honest updates about what's happening and when service should be restored. This reduces panic and maintains trust.
Post-Mortem Analysis: After service is restored, the team investigates root causes and develops fixes to prevent recurrence.
For TikTok's outage, we know:
- Detection and alert: Worked (users reported issues, TikTok responded relatively quickly)
- Initial response: Took hours (no immediate statement from TikTok)
- Failover: Apparently didn't exist, or wasn't triggered automatically
- Stabilization: Took multiple days
- Data consistency: Still ongoing (engagement numbers were still incorrect days later)
- Communications: Minimal updates, mostly reassurance without technical detail
- Post-mortem: No public analysis has been released
This pattern suggests the new U.S. infrastructure was built with less redundancy than best practices would recommend.

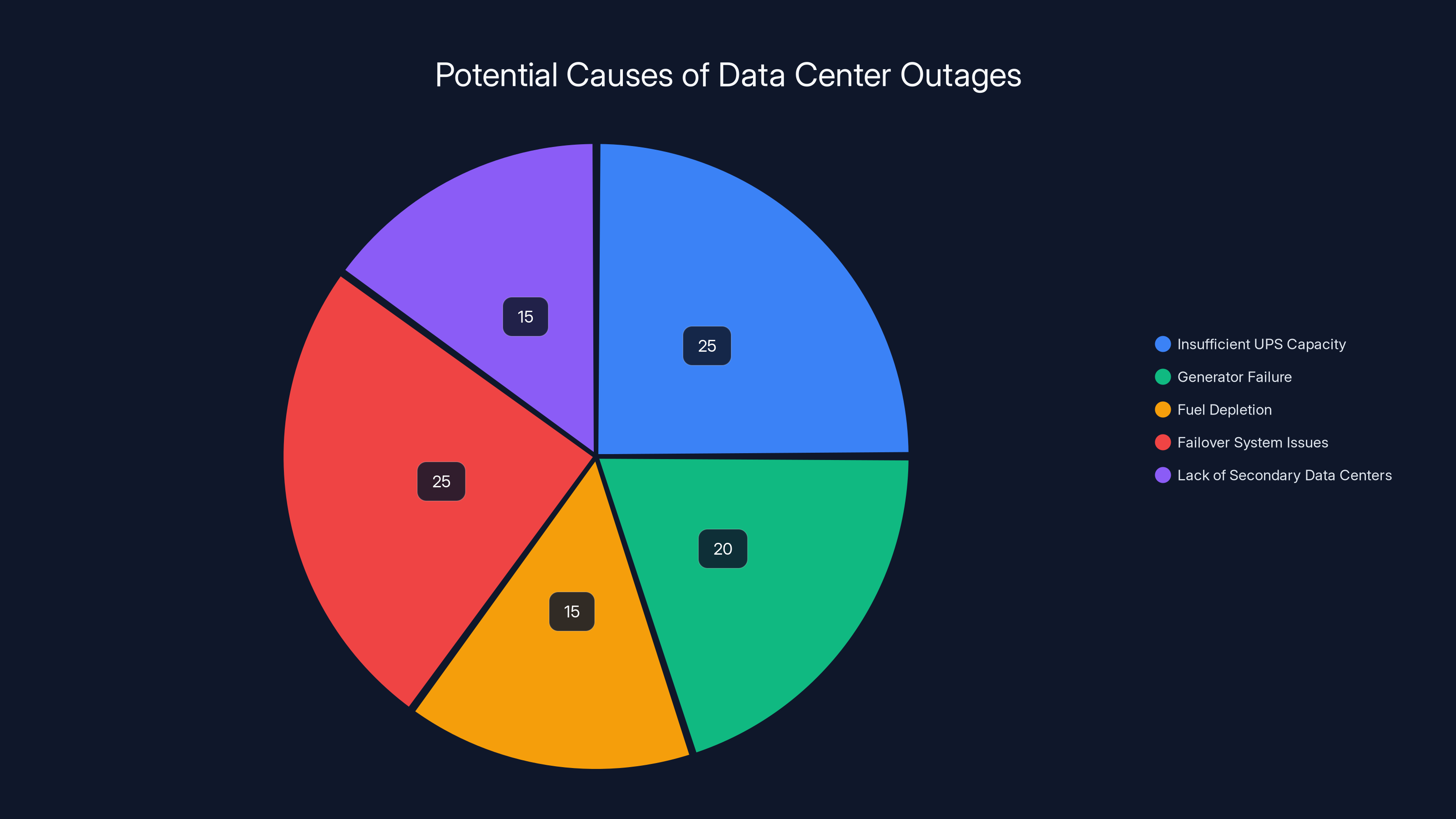
Estimated data shows that insufficient UPS capacity and failover system issues are the most common causes of data center outages, each accounting for 25% of failures.
Questions That Still Don't Have Answers
Days after the initial outage announcement, significant unanswered questions remained.
Why no geographic redundancy? TikTok never explained whether the new U.S. infrastructure had multiple active data centers or was concentrated in a single facility. If a company restructures its entire U.S. operations, you'd expect geographic distribution as a baseline requirement.
Which data center partner? TikTok mentioned "our U.S. data center partner" but never named them. Was it Amazon AWS? Google Cloud? Microsoft Azure? A dedicated facility like Equinix or CoreWeave? This matters because different providers have different reliability track records.
Why did recovery take multiple days? For some service degradation, this is normal. But for a simple power outage at a facility with proper backup systems, multi-day recovery suggests either:
- The backup systems failed
- The facility lacked modern infrastructure standards
- Data consistency issues were more severe than acknowledged
What was the actual impact magnitude? TikTok's statements were vague about how many users were affected, for how long, and what services were most impacted. This matters for assessing severity.
How were the newly separated U.S. operations affected? The USDS Joint Venture was supposed to be independent. Were the new American executives able to take decisions independently, or was ByteDance involved in the response? This matters for assessing whether the separation was real or nominal.
Will this happen again? TikTok didn't explain what changes they're making to prevent recurrence. Without those details, we can't assess whether the outage was a one-time incident or symptomatic of ongoing infrastructure problems.
What about user data integrity? TikTok said data was safe, but experiencing days of sync issues between databases... that's concerning. Did any data actually get lost or corrupted? Were there any consistency issues?

Industry Standards for Service Reliability
Let's talk about what reliability actually means in the industry, because TikTok's recovery didn't meet basic standards.
Reliability is measured in "nines": how much uptime a service maintains.
Three nines (99.9% uptime): 43 minutes of acceptable downtime per month. Small startups often target this.
Four nines (99.99% uptime): 4 minutes of acceptable downtime per month. Enterprise services target this.
Five nines (99.999% uptime): 26 seconds of acceptable downtime per month. Major platforms target this.
TikTok, as a platform serving 150 million Americans and considered critical infrastructure by many, should target at least four nines. Probably five.
A multi-hour outage affecting core functionality means:
- TikTok is operating at approximately 98% uptime during the incident, way below standards
- This single outage eats up the annual allotment for four-nines target
- Multiple days of degraded service (posts posting slowly, engagement not updating) extends the impact
When companies commit to reliability standards, they build redundant infrastructure to support it. TikTok's infrastructure apparently lacks this redundancy.
Now, TikTok hasn't publicly committed to specific uptime SLAs (Service Level Agreements). It's a free service, not enterprise infrastructure. So technically, TikTok has no obligation to maintain any specific reliability.
But when you're asking the U.S. government to trust you with operational independence, and you've been under scrutiny about trustworthiness, failing to maintain basic reliability standards is... a problem.

Lessons from Infrastructure Modernization
I've worked with teams going through infrastructure migrations, and TikTok's situation reflects common patterns.
When you're redesigning infrastructure under deadline pressure, corners get cut. Often unknowingly. The team knows they need to be live by a certain date, so they:
- Deploy to a single data center first (simpler to manage)
- Plan to add geographic redundancy "in phase 2"
- Use a managed service provider for initial deployment (to move faster)
- Skip some stress testing (because there's no time)
- Launch with fewer than ideal monitoring and alerting systems
Each of these individually is defensible as a timeline tradeoff. Together, they create fragile infrastructure that works fine until it doesn't.
When the first failure happens, it's often worse than it would have been if you'd spent the time up front. Because now you have all these dependency chains you didn't fully understand, and a single failure cascades.
TikTok's outage might reflect this pattern. Not negligence necessarily, but the compressed timeline of having to stand up American infrastructure fast, under regulatory pressure, while minimizing disruption to existing operations.
That doesn't excuse the outage. But it explains how it happened.

The Regulatory Implications
We need to think about what this outage means for TikTok's regulatory status.
The company's pitch to regulators is basically: "We've restructured. We have American infrastructure now. You can trust us."
But the outage forces regulators to ask: "Wait, can we actually trust you with this responsibility?"
This isn't about technical expertise necessarily. TikTok obviously employs talented engineers. But it's about demonstrating:
- Planning capability: Did you think through infrastructure requirements for a 150-million-user platform?
- Execution capability: Did you build systems that actually meet those requirements?
- Operational responsibility: Do you maintain and monitor systems properly?
- Communication: Do you transparently explain problems to users and regulators?
The outage creates doubt about all four.
TikTok is essentially being evaluated on whether it should be allowed to continue operating in the U.S. The company's argument is that it can be trusted to operate responsibly under American oversight. An infrastructure crisis right after announcing the restructuring undermines that argument.
This doesn't mean TikTok will get banned. The outage alone won't do that. But it's a data point regulators will consider.
Regulators are asking: If this is what TikTok's infrastructure looks like after careful planning and restructuring, what was it like before? And that's a concerning question if you're trying to make a trust-based argument.

Preventative Measures for Future Outages
Let's talk about what TikTok should do to prevent this from happening again. Whether they'll actually do it is another question, but here's what sound engineering practice would suggest.
Immediate (Weeks):
- Deploy to at least one secondary data center in a different geographic region
- Configure automatic failover so that if one facility loses power, traffic routes to the other within seconds
- Implement geographic load balancing at the DNS and application layer
- Conduct disaster recovery drills weekly for at least one month
Short-term (Months):
- Implement comprehensive redundancy for all critical systems
- Deploy to at least three geographic regions (one on each coast, one central)
- Add backup power testing to monthly maintenance procedures
- Document detailed runbooks for every conceivable failure scenario
- Hire or contract with infrastructure specialists who've managed large-scale distributed systems
Medium-term (Quarters):
- Achieve and publicly commit to four-nines uptime (99.99%)
- Implement automated chaos engineering—intentionally breaking systems to test recovery
- Achieve vendor diversity (use multiple data center providers, not just one)
- Build internal disaster recovery team with on-call rotations
- Implement comprehensive monitoring and alerting for every infrastructure component
Long-term (Years):
- Target five-nines uptime (99.999%)
- Achieve true multi-region distribution where no single facility can take down the platform
- Build internal data center expertise rather than relying on partners
- Implement predictive maintenance to identify failures before they happen
Will TikTok do all of this? Unknown. Will they do some of it? Probably. The regulatory environment ensures that the company is thinking carefully about infrastructure going forward.

The Cost of Infrastructure Resilience
Here's the uncomfortable truth about fixing this: it's expensive.
Building and operating multiple geographic data centers, with redundant systems, monitoring, and expertise, costs real money. Millions annually, even for internal infrastructure.
For a platform like TikTok, which operates at massive scale and makes money through advertising, infrastructure costs are significant but manageable. However, they're not free.
There's a natural tradeoff between:
- Infrastructure resilience (expensive, prevents rare outages)
- Feature development (revenue-generating, makes users happy)
- Profitability (investors care about this)
TikTok has presumably allocated resources based on their risk tolerance and expected revenue. The outage suggests their allocation was insufficient.
Going forward, the regulatory environment will force TikTok to invest more in resilience than pure business logic might dictate. That's not a bad thing—users benefit from more reliable platforms. But it's a real cost.

Questions for the Future
As we move forward from this crisis, several big questions remain unanswered.
Will the public trust TikTok after this? Users are remarkably forgiving of technical failures if companies are transparent and fix the problems. TikTok's vague communication might have damaged trust more than the outage itself.
Will regulators use this as evidence? In ban-or-not-ban discussions, every data point matters. This outage will come up. How much weight it carries depends on how TikTok responds and what changes they make.
Does this mean TikTok's restructuring was insufficiently planned? It's possible. Or it's possible this was genuinely bad luck—a data center failure coinciding with a once-in-a-decade winter storm. The pattern of communication suggests the former, but we can't know for sure.
How will competitors respond? Instagram Reels and YouTube Shorts are TikTok's primary competitors. They'll be watching to see if TikTok's infrastructure problems recur, because reliability is a competitive advantage.
What does this mean for creator confidence? Creators depend on TikTok for income. An outage that makes their engagement metrics incorrect and breaks their posting ability for days creates anxiety. Some creators might diversify to other platforms as a result.
Will TikTok's costs increase significantly? Building proper infrastructure redundancy costs money. This might hit TikTok's profitability or force changes to the business model.

Looking Forward: The Longer Narrative
This outage is a moment in a longer story about TikTok's relationship with the U.S. government, infrastructure resilience, and what it means for a foreign company to operate in a regulated market.
TikTok has been under scrutiny for years. The company has repeatedly promised to fix regulatory concerns, separate from ByteDance, create American infrastructure, and prove itself trustworthy.
This outage is the test. Not the only test, but an important one. If TikTok can respond by demonstrating real infrastructure improvements, transparent communication, and genuine operational responsibility, it survives this moment. If it responds with vague assurances and no concrete changes, the narrative shifts toward "TikTok isn't actually trustworthy."
The company's next moves matter more than this outage did.
From a user perspective, the outage is notable but probably not permanently damaging. Apps fail. Platforms have outages. Users generally tolerate this if it's infrequent and gets fixed quickly. TikTok's outage lasted days, which is longer than usual, but not unprecedented. The user base will largely move on.
But from a regulatory and business perspective, this outage created friction at exactly the wrong moment. It forced TikTok to defend its infrastructure reliability claims. It gave skeptics ammunition. It made the skeptical regulatory environment slightly more skeptical.
In the long run, that matters more than the outage itself.

FAQ
What caused TikTok's U.S. infrastructure outage in January 2025?
TikTok attributed the outage to a power failure at one of its data center facilities operated by a partner company. The failure occurred during a major winter storm that affected approximately 220 million Americans. The power outage cascaded into service failures across multiple TikTok functions including video loading, posting, comments, and the For You Page algorithm.
How long did the TikTok outage last?
The most severe outages lasted several hours, but service degradation continued for multiple days. Users experienced initial failures during the outage window, then intermittent issues with posting, engagement metrics, and algorithm functionality as systems recovered. TikTok's updates indicated "significant progress" but continued issues several days after the initial failure.
Why didn't TikTok's backup systems prevent the outage?
TikTok hasn't provided detailed technical information about backup systems, but the multi-day recovery suggests potential gaps. Modern data centers should have uninterruptible power supplies, backup generators, and geographic redundancy. If TikTok's infrastructure had comprehensive redundancy across multiple facilities, users shouldn't have experienced this level of disruption.
What does this outage mean for TikTok's regulatory status?
The outage occurred immediately after TikTok announced restructuring to create a separate U.S. entity with American oversight—a move designed to address regulatory concerns about the company's trustworthiness. The infrastructure failure undermines TikTok's argument that it can reliably operate under American regulatory scrutiny, providing skeptical regulators with evidence that the company's infrastructure planning may be insufficient.
How did the outage affect creators and users?
Creators couldn't post new content for extended periods. Users couldn't watch videos reliably. Engagement metrics were incorrect, and earnings calculations showed discrepancies. Comments wouldn't load consistently. The For You Page algorithm wasn't functioning. Users reported confusion about whether their data was safe and whether their engagement was being accurately tracked.
Has TikTok explained how it will prevent future outages?
TikTok hasn't released detailed post-mortem analysis or infrastructure improvement plans publicly. The company issued updates acknowledging the issue and thanking users for patience, but provided minimal technical explanation of what failed and what changes are being implemented to prevent recurrence. This lack of transparency is itself notable in the broader regulatory context.
Could this happen to other platforms like Instagram or YouTube?
Large platforms have similar infrastructure risks, but companies like Meta and Google have invested heavily in geographic redundancy and backup systems. An outage of TikTok's severity on those platforms would be extremely unusual. However, the winter storm was severe enough to affect multiple systems across infrastructure providers, suggesting the conditions were genuinely challenging for everyone.
What infrastructure best practices did TikTok's response reveal were missing?
The multi-day recovery suggests potential gaps including: single point of failure (possibly one primary data center), inadequate backup power systems or testing, lack of automatic geographic failover, insufficient data replication across facilities, and potentially inadequate monitoring and alerting systems that would trigger rapid response.

Conclusion: A Platform at a Crossroads
TikTok's infrastructure outage in January 2025 was more than just a technical failure. It was a moment where engineering realities collided with political expectations.
The company promised American regulators that it could be trusted to operate independently with restructured, reliable infrastructure. Days after making that commitment, the infrastructure fell apart.
That's not necessarily a permanent judgment. Technical failures happen. What matters now is how TikTok responds.
From a pure infrastructure perspective, the fixes are clear. Deploy to multiple geographic regions. Implement automatic failover. Add redundancy at every level. Test disaster recovery regularly. This is standard practice at scale. Expensive but well-understood.
From a communication perspective, TikTok needs to be transparent. Explain what failed. Publish detailed improvements being made. Commit to specific uptime standards. Demonstrate that the company takes responsibility seriously.
From a regulatory perspective, this outage is evidence. Evidence that either:
- TikTok's infrastructure wasn't adequately planned before launch (concerning)
- The timeline for restructuring was too compressed to implement proper redundancy (understandable but still concerning)
- The company's new American leadership lacked infrastructure expertise (fixable but reflects planning gaps)
None of these conclusions is certain, but they're all plausible based on the facts.
TikTok has survived larger crises. Congressional hearings. Executive orders. Bans that were announced then reversed. The company has shown resilience and adaptability.
But infrastructure resilience is different. It's not about public relations or regulatory navigation. It's about engineering competence and operational responsibility.
The outage was a test. Not the final test, but an important one. Users will largely forget about it within weeks. But the lesson—that TikTok's new American infrastructure has room for improvement—will linger.
The real question isn't whether this outage happened. It happened. The real question is what TikTok does next.
Do they invest seriously in infrastructure resilience? Do they become transparent about technical improvements? Do they demonstrate that they're taking operational responsibility seriously?
Or do they issue reassuring statements and hope the issue fades from memory?
Based on everything we know about TikTok and the regulatory environment it operates in, the company will likely invest significantly in infrastructure improvements. The reputational cost of not doing so is too high.
But those improvements will take time. Months at minimum. And during that time, users will be watching to see if problems recur. Regulators will be watching to evaluate the company's response. Competitors will be watching to identify vulnerabilities.
One outage doesn't determine a company's future. But how a company responds to a crisis often does.
TikTok's response to this infrastructure failure will reveal a lot about the company's true commitment to American operational independence and regulatory trustworthiness. That response, more than the failure itself, will shape the platform's future.
Watch for infrastructure announcements in coming weeks and months. Pay attention to whether TikTok's communication becomes more transparent or more defensive. Look for evidence of genuine operational improvement.
That's where the real story is headed.

Key Takeaways
- TikTok's January 2025 infrastructure outage affected 150+ million U.S. users, breaking core functions like posting, video loading, and the For You Page algorithm for multiple days
- The outage occurred immediately after TikTok announced restructuring into a separate U.S. entity with American oversight, severely damaging the company's credibility in regulatory discussions
- Multi-day recovery indicates potential gaps in infrastructure redundancy, backup power systems, and geographic distribution that should be standard for platforms at TikTok's scale
- The outage violated basic industry uptime standards (99.9%+ reliability is typical); multi-hour disruption suggests infrastructure wasn't built to enterprise resilience specifications
- TikTok's vague communication about root causes and recovery procedures undermined trust and raised questions about whether the new American operations truly have sufficient technical expertise
Related Articles
- TikTok's US Data Center Outage: What Really Happened [2025]
- TikTok's January 2025 Outage: What Really Happened [2025]
- TikTok Outage in USA [2025]: Why It Failed and What Happened
- TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
- TikTok Data Center Outage: What Really Happened [2025]
- TikTok Data Center Outage: Inside the Power Failure Crisis [2025]

