![Vibe-Coding With LLMs: Building Real Tools Without Being a Programmer [2025]](https://tryrunable.com/blog/vibe-coding-with-llms-building-real-tools-without-being-a-pr/image-1-1770208558663.jpg)
Introduction: The Death of the Gatekeeper
There's a dirty little secret the programming community doesn't want you to know: you don't actually need a CS degree, ten years of experience, or the ability to recite syntax from memory to build working software anymore.
For decades, the gatekeepers of tech have maintained a fortress mentality. You either "know how to code" or you don't. You either spent years climbing the learning curve, suffered through Stack Overflow lectures about why your question was too simple, or you stayed out. The barrier to entry wasn't just high—it was deliberately maintained that way.
Then came large language models.
What we're seeing right now isn't just another iteration of software development tools. It's a fundamental shift in who can participate in building applications. And not the shallow "AI can generate a hello world" kind of participation. Real participation. Building actual tools that solve actual problems.
I'm not a programmer. Let me be clear about that. I can read code. I understand what conditionals do, what loops accomplish, why someone might reach for a variable instead of hardcoding a value. On a good day, I could explain what a pointer is (badly). But asking me to architect a complex application from scratch? To design database schemas? To handle edge cases across multiple files and modules? That was never happening.
Until I needed to.
My project was simple: a Python-based log colorizer. Nginx logs, raw and overwhelming, needed color-coding to make scanning through thousands of entries less exhausting for tired eyes. The off-the-shelf tools existed, but they didn't do exactly what I needed. They weren't my tool.
So I didn't build it the traditional way. I brought in Claude, asked it to construct the application, and followed a feedback loop of prompts and iterations. The result: a 400-line Python script that does exactly what I wanted, deployed and working right now.
This is what "vibe-coding" means. It's not haphazard. It's not sloppy. It's working with AI to bridge the gap between "I need a tool" and "here's a tool that works."
And I want to be honest about something else: it felt good. Not just "problem solved" good. It felt creative. It felt like I actually built something.
So let's talk about how this works, why it matters, and what it means for people who've always been locked out of software development.
TL; DR
- LLMs can handle complete software projects when scoped correctly, delivering working code without requiring formal programming expertise
- Context windows matter more than you think: Keeping projects small enough to fit within a single LLM context window eliminates fragmentation and makes iteration smoother
- Iterative prompting beats long specifications: Short feedback loops, testing results, and asking for adjustments works faster than trying to spec everything perfectly upfront
- The real skill isn't coding—it's debugging conversations: Knowing how to explain what went wrong and guide the LLM toward fixes is more valuable than memorizing syntax
- Small, focused projects are the sweet spot: A 400-line single-file application is far easier to manage and audit than sprawling multi-file systems

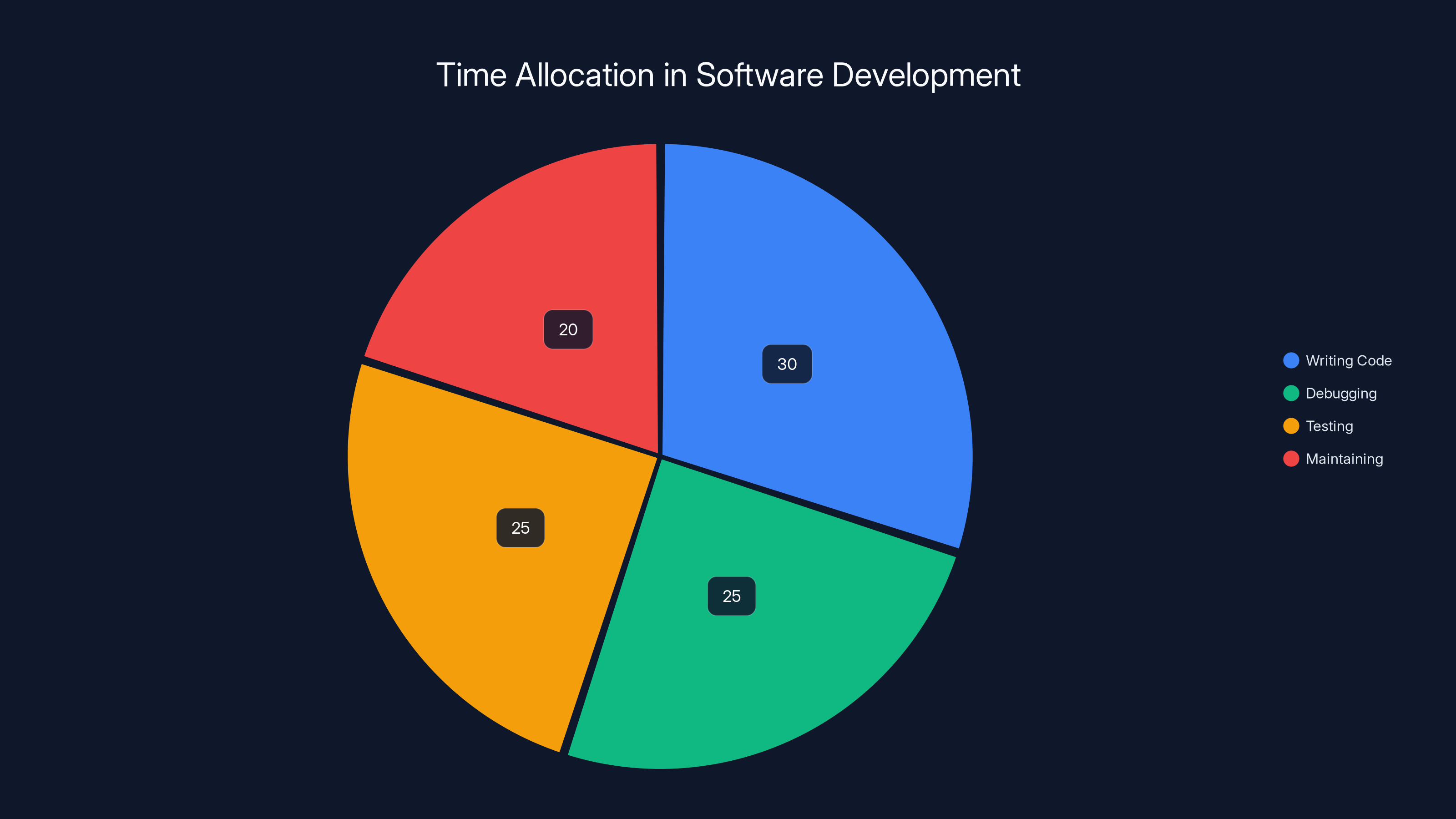
Developers spend 30% of their time writing code, with the remaining 70% split between debugging, testing, and maintaining. Automation tools like Runable can streamline these processes.
The Permission Problem: Why I Never Learned to Code
Let's be real. I'm not lazy. I'm not dumb. But I am finite, and my attention is finite too.
For most of my adult life, if I wanted to build software, the pathway was clear: spend 2-3 years learning programming fundamentals, dedicate another year to a specific language ecosystem, contribute to open-source projects to build a portfolio, apply for junior developer roles, and climb from there. It was a commitment that required neurodevelopmental plasticity (which I had, but lost), time (which I didn't have), and motivation (which I wasn't sure about).
There's a psychological thing that happens when the barrier to entry for a skill is that high. You stop seeing yourself as someone who "could" learn that skill. You're a different kind of person now. A non-programmer. It becomes identity.
And honestly? That was fine. I was good at other things.
But there were these small projects. Nagging little problems. Things that would take a programmer four hours to solve, but I couldn't solve them because I wasn't one. I'd see someone else tackle it with a neat little script or utility, and think: "Why didn't that exist?"
The answer was: because it wasn't worth anyone's time to build, and I couldn't build it myself.
This is where LLMs break the model completely. Not because they make coding "easy" in some dumbed-down sense. They don't. But because they collapse the learning curve. They eliminate the years of prerequisite knowledge. They let you skip from "I have a problem" to "here's a solution" without the ten-year intermission.
The permission shift is real. For the first time, I didn't need permission from the programming community to build something. I didn't need to prove I "deserved" to code. I had a tool. I used it.

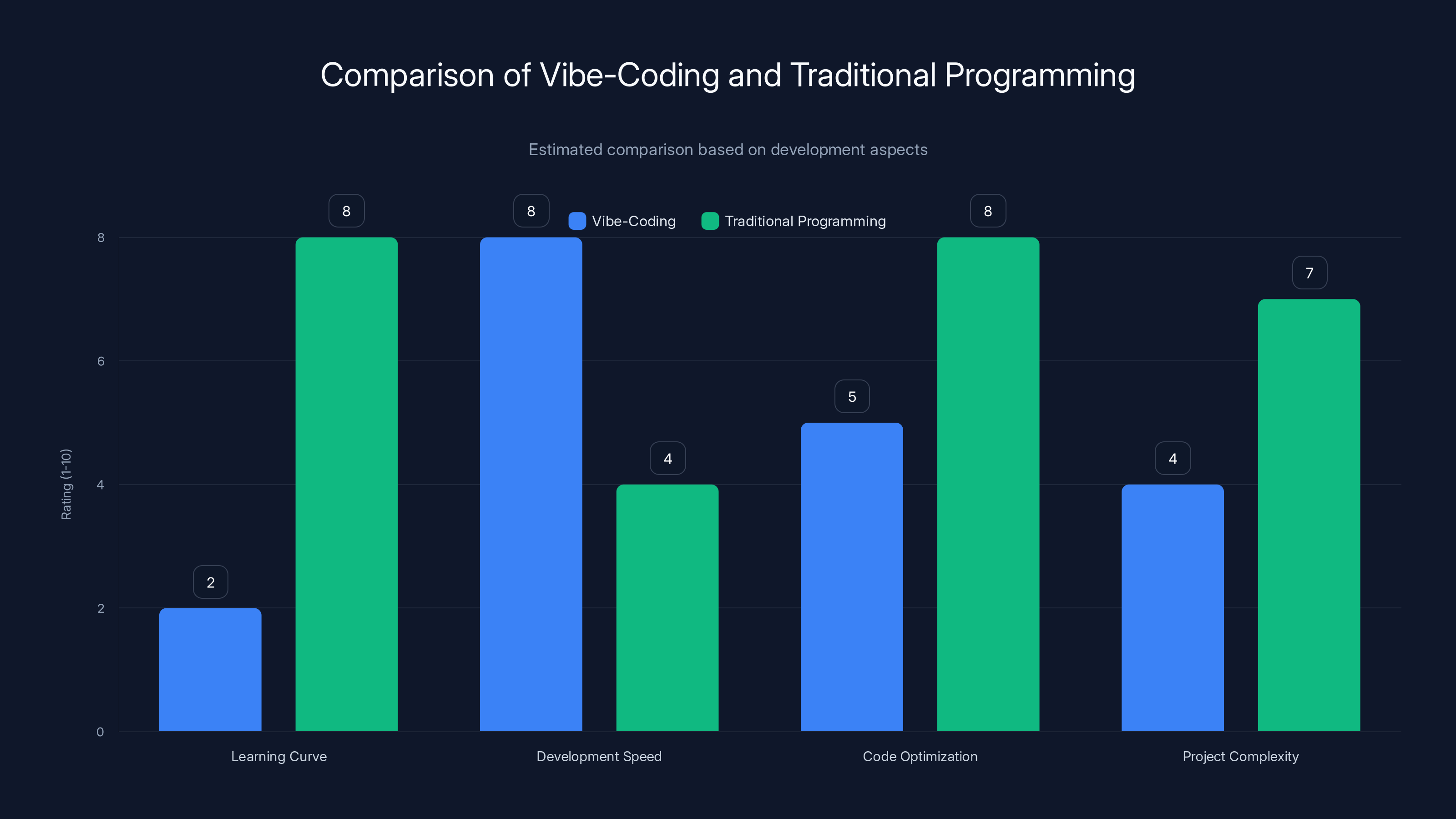
Vibe-coding offers a lower learning curve and faster development speed compared to traditional programming, though it may lack in code optimization and handling complex projects. Estimated data.
The Specific Problem: Caching Gone Wrong
Understanding the "why" behind the log colorizer requires understanding the underlying problem it helped me diagnose.
I run web hosting for Space City Weather, a Houston-area forecasting site built on Word Press. It's self-hosted on an AWS EC2 instance, fronted by Cloudflare for caching and performance. In August 2025, we added Discourse for comments, replacing Word Press's native comment system.
Then something strange started happening.
Every few weeks—not reliably, not consistently—a new post would go live with an old comment form cached at the bottom. Visitors would see disabled Word Press comments instead of the functional Discourse system. Hundreds of people would view the broken page until I manually flushed Cloudflare's cache or waited for the automatic expiration.
The problem would vanish. Weeks would pass. Then it'd come back.
This is the worst kind of production issue: intermittent. You can't reproduce it on demand. You change something to fix it, and suddenly it starts working, so you think you've won. Then three weeks later—boom—it happens again.
You question yourself. You question the universe. You start reading conspiracy theories about how Cloudflare might be cursed.
I spent time consulting LLMs about possible causes. One suggestion stood out: force "DO NOT CACHE" headers on post pages until Discourse has fully loaded its comments. That's a workaround, not a solution, but it worked. The stale cache pages disappeared.
For months, I left it alone.
Then in December, I disabled the workaround to see if the underlying problem had resolved itself. (Sometimes issues fix themselves—servers do weird stuff.)
Nope. The very next post went live without comments.
Now I needed actual answers.
The Debugging Deep Dive: Finding the Needle
Intermittent production issues require evidence. Evidence requires logs.
Cloudflare logs, Nginx logs, PHP logs, Word Press logs—all of them were potentially relevant. The problem is that when you're digging through server logs, you're swimming through an ocean of noise.
Every request. Every connection. Every 304 Not Modified response. Every cache hit and miss. Thousands upon thousands of lines per day.
My aging eyes don't scan raw logs well. The monochrome wall of text blurs together. By the time you've visually parsed twenty lines, you've lost the pattern. You need color. You need visual distinction between different types of events.
The existing colorizers—tools like ccze and others—worked okay for generic logs. But they weren't built for my specific logs with my specific needs. I wanted to distinguish between different HTTP status codes with different colors. I wanted to highlight certain patterns. I wanted the tool to be mine.
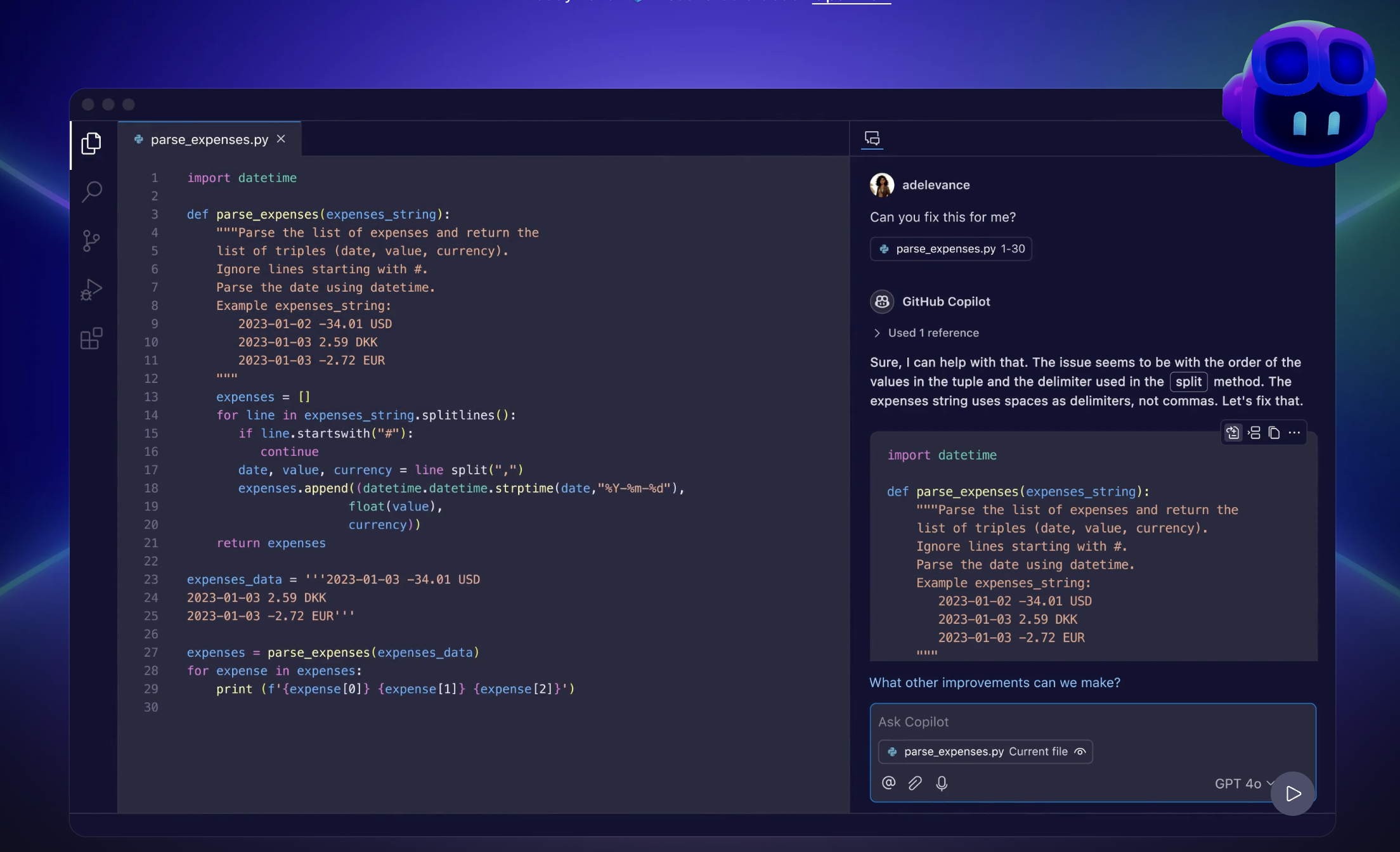
So instead of spending six hours learning Python properly, I asked Claude to write it.
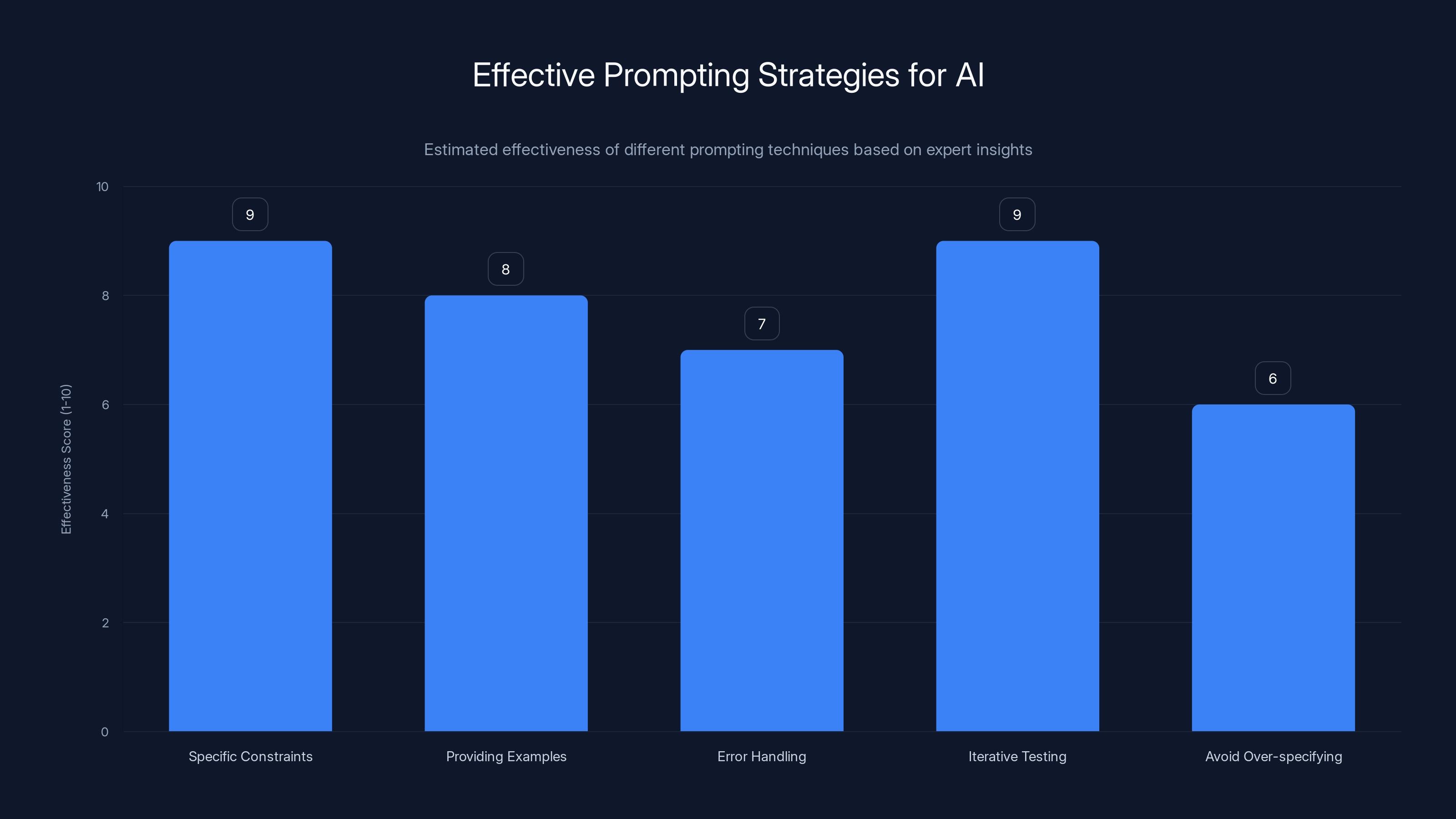
Specific constraints and iterative testing are highly effective strategies for prompting AI, while over-specifying can be less effective. Estimated data based on expert insights.
Vibe-Coding: What It Actually Means
"Vibe-coding" is a term that gets thrown around casually, but let me be precise about what it means in practice.
It's not random. It's not "type some words and hope the AI figures it out." It's methodical collaboration between a human (who understands the problem domain deeply) and an AI (that understands code syntax and patterns).
The process goes like this:
Step 1: Clear problem definition. You describe what you want with as much specificity as possible. Not "make a tool that colorizes logs." Instead: "I need to read Nginx access logs and color-code them so HTTP 200 responses are green, 404s are red, 5xx errors are bright red, and so on. The input is raw log lines on stdin, output is colored lines on stdout."
Step 2: Initial generation. Feed that into Claude Code or similar. It generates a complete, working implementation. For my colorizer, it created a full Python script with regex parsing, color output, and command-line argument handling.
Step 3: Testing and iteration. Run the code against real data. It probably won't be perfect. Maybe the regex misses some log formats. Maybe the color scheme isn't quite right. Maybe you want different behavior for edge cases.
Step 4: Targeted feedback. Instead of rewriting it yourself, describe what's wrong and ask for fixes. "The IPv 4 address parsing is failing on requests with no user-agent. Can you make the regex more forgiving?" The AI adjusts.
Step 5: Repeat until done. Usually this takes 3-5 iterations for a project this size.
What makes this different from traditional programming:
- You're not learning syntax. You're not debugging your own typos. You're not fighting with indentation and import statements.
- You're applying domain knowledge (what you know about your logs) to the AI's technical knowledge (how to parse strings and apply colors).
- The feedback loop is tight and focused, not sprawling.
- You maintain agency over the direction while outsourcing execution.
The skill isn't "being a programmer." It's being able to articulate what you want, test whether you got it, and explain why the result isn't quite right yet.
The Technical Reality: 400 Lines of Pure Utility
The final colorizer ended up being about 400 lines of Python. Not small, but not large. Small enough to fit entirely in Claude's context window, which matters more than you'd think.
When your entire codebase fits in context, you avoid a common fragmentation problem: the AI loses sight of how functions interact, or forgets what globals you defined earlier. It works on the whole picture.
The colorizer does several things:
Regex-based log parsing. It takes raw Nginx log lines and breaks them into components: IP address, timestamp, HTTP method, URL, status code, response size, user agent, and more.
Conditional coloring. Different status codes get different colors. 2xx responses are green. 3xx redirects are cyan. 4xx client errors are yellow. 5xx server errors are red.
Pattern matching for special cases. Certain URLs get highlighted differently. Certain user-agents are color-coded. The idea is to make patterns visually obvious instead of requiring you to read every single line.
IPv 4 and IPv 6 handling. You can filter logs to show only IPv 4 or IPv 6 traffic, which is useful when you're debugging a specific connectivity issue.
Output control. You can pipe logs directly into it via stdin, or point it at a file. It writes colorized output to stdout.
None of this is rocket science. It's not machine learning or distributed systems or database optimization. It's straightforward procedural code that does one thing: make logs easier to read.
But here's the thing: if I'd had to write this myself from scratch, I wouldn't have. The friction was too high. The motivation wasn't strong enough. The tool wouldn't exist.
With LLM assistance, I had a working version in an afternoon.
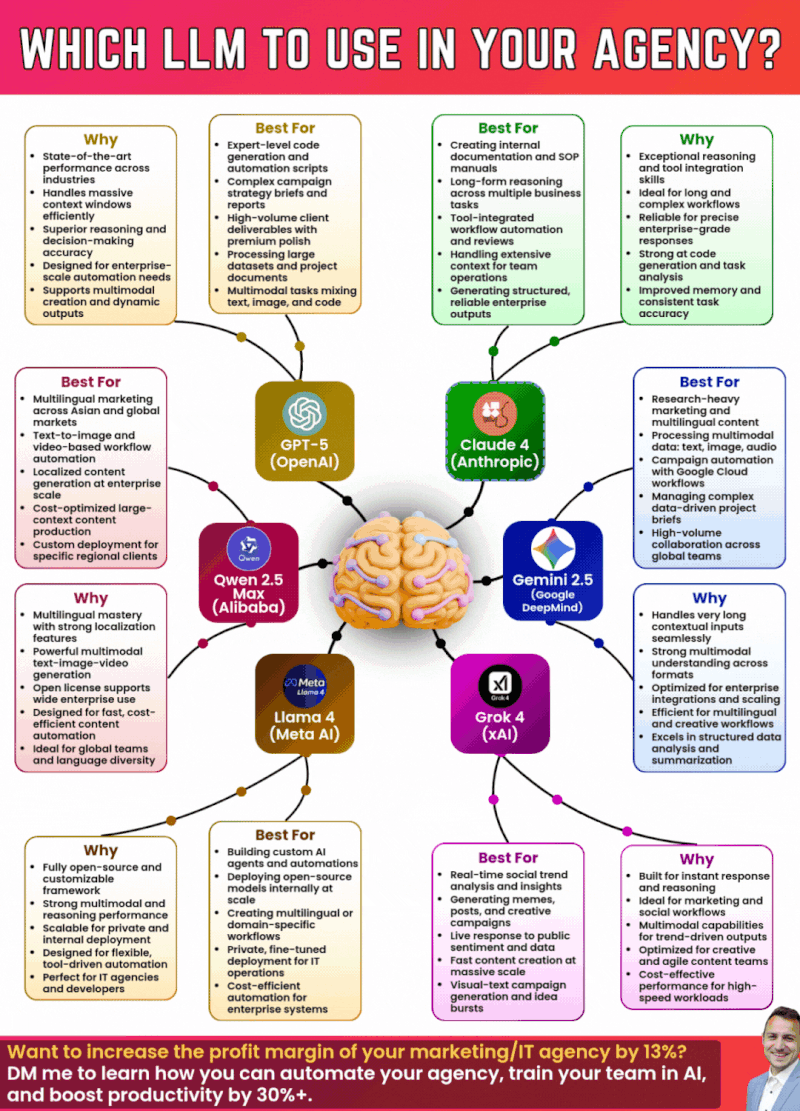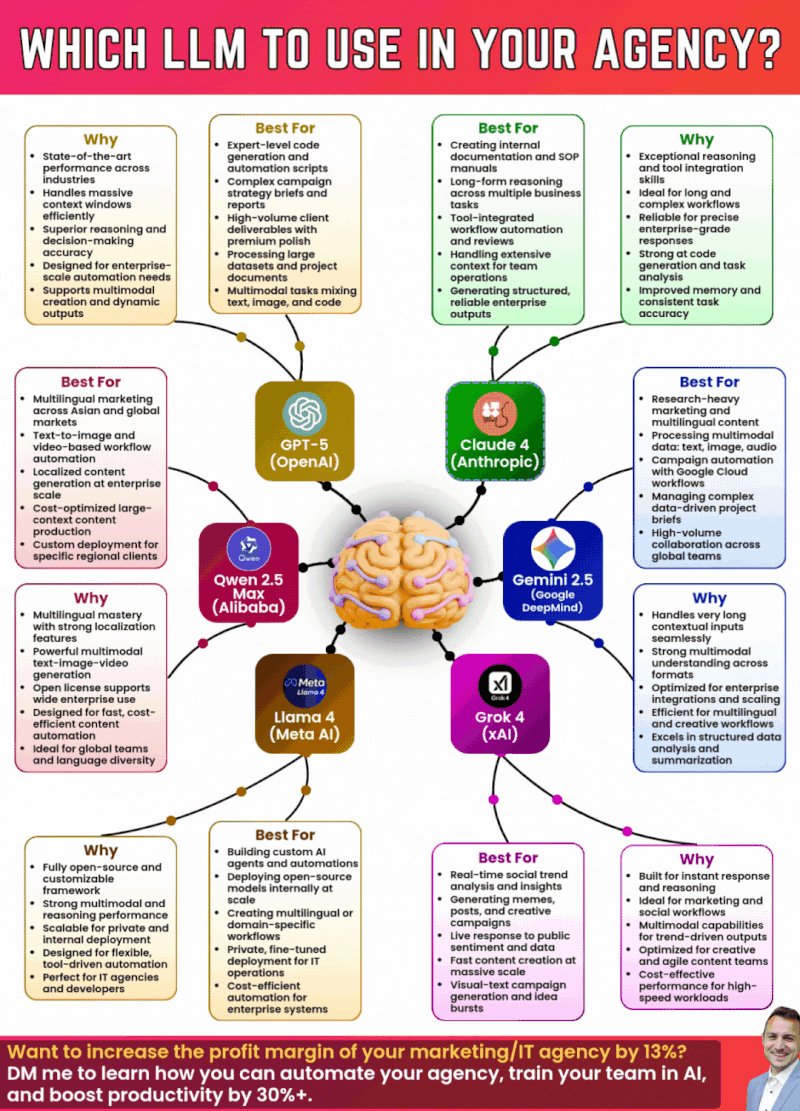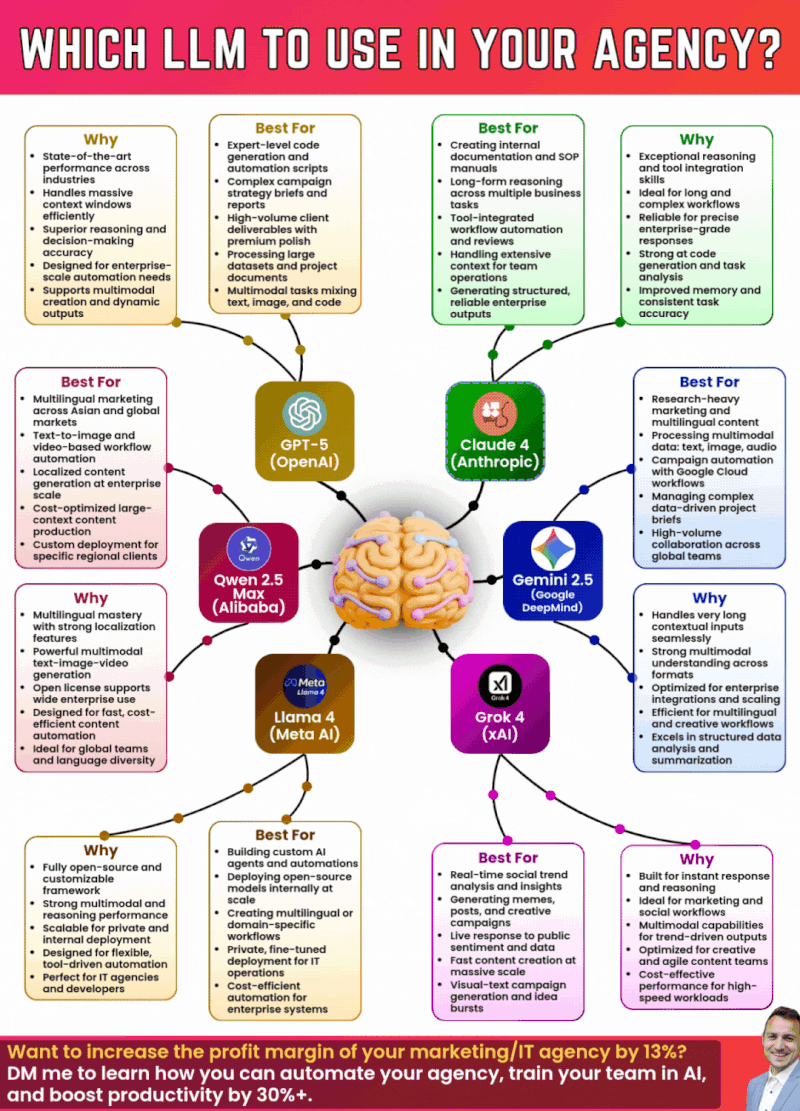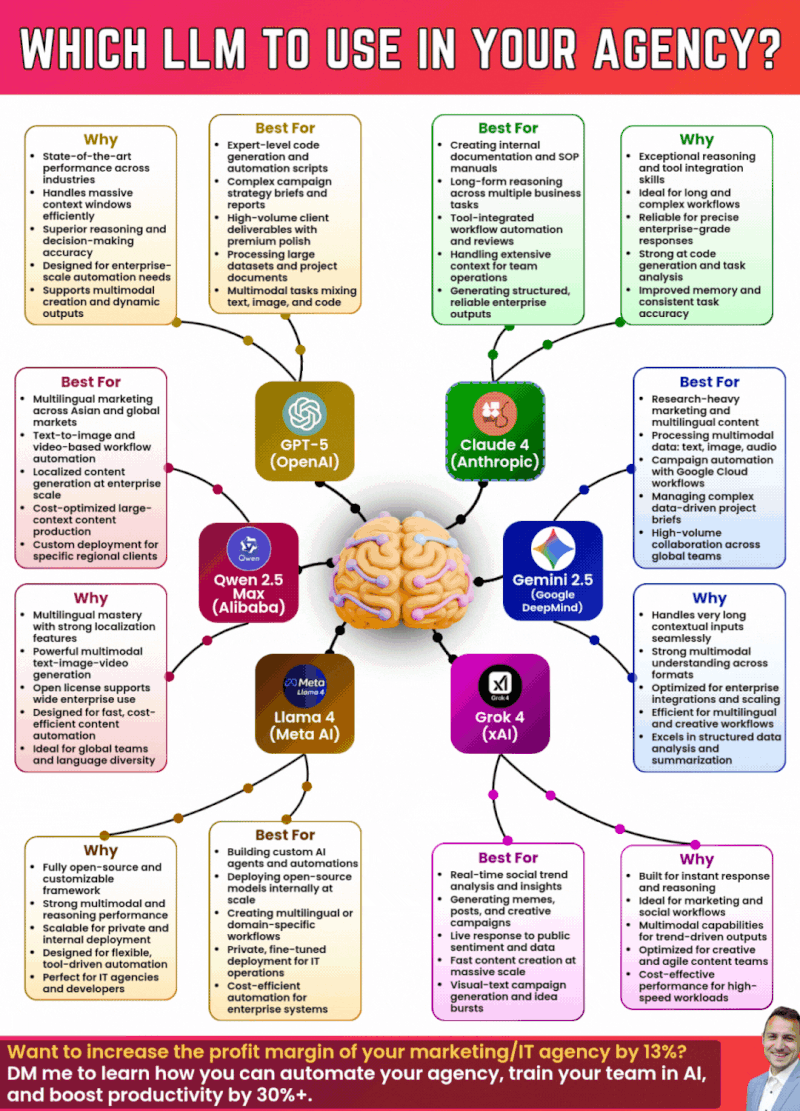
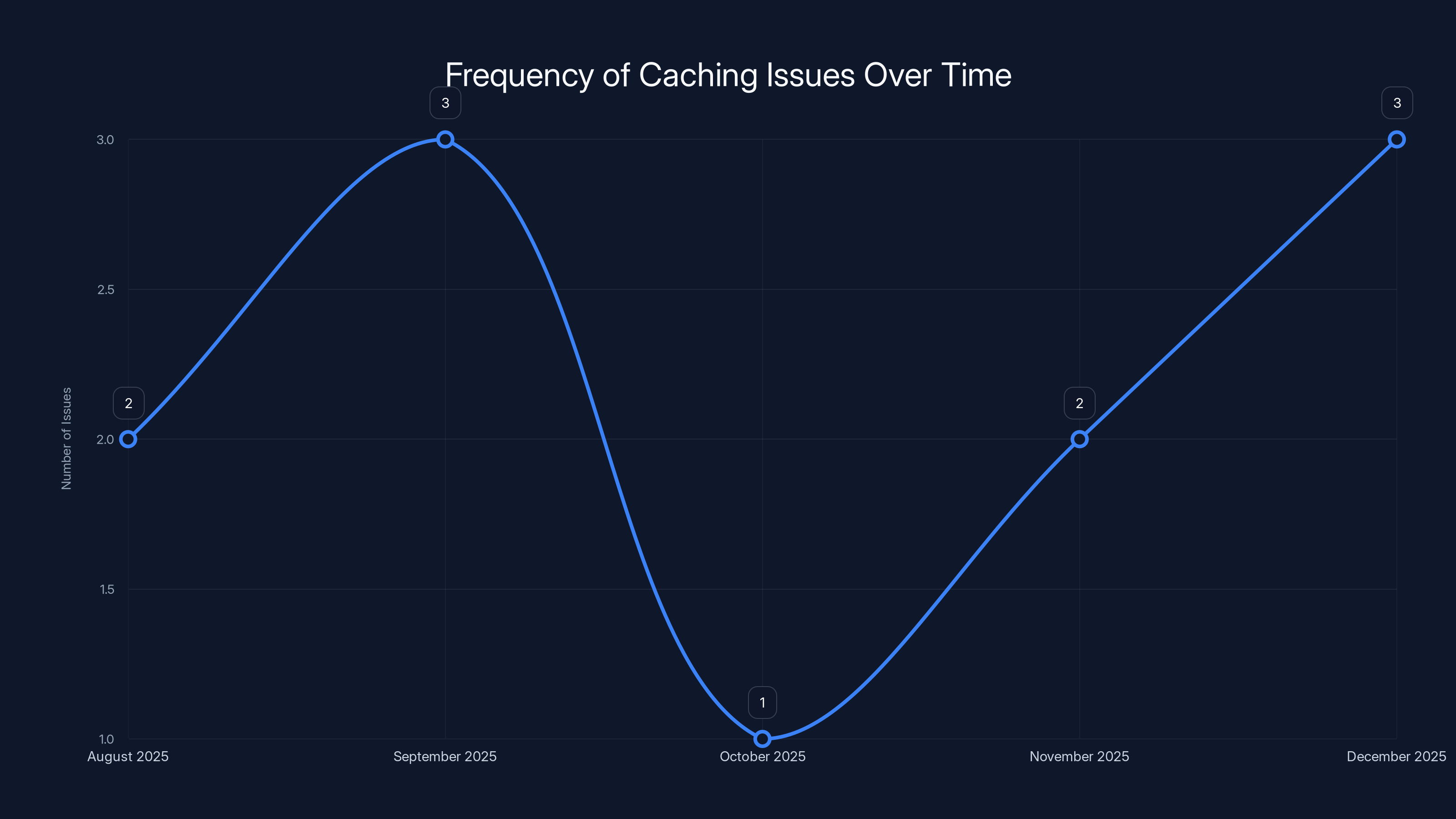
The chart shows an estimated frequency of caching issues from August to December 2025. Despite attempts to resolve the problem, issues persisted intermittently.
The Prompting Strategy: How to Talk to AI
Getting good results from LLMs requires a specific approach to prompting. It's not magic words. It's structure.
Be specific about constraints. Don't just say "write a log colorizer." Say: "I need to parse Nginx access logs in this exact format: [timestamp] [IP] [method] [URL] [status] [size] [user-agent]. The output should be colored ANSI escape sequences." Constraints breed better solutions.
Provide examples. Show the AI what good input looks like. Paste in a few sample Nginx log lines. Say: "Here are three example logs. I want 200 responses in green, 404s in yellow, and 5xx errors in red. Can you write a Python script that does this?"
Ask for specific error handling. Most generated code is fragile if you don't tell it otherwise. "What happens if a log line is malformed? Can you add error handling that skips invalid lines instead of crashing?"
Test iteratively. Run the code. When it fails, describe the failure precisely. "When I run this against my actual Nginx logs, the user-agent field isn't parsing correctly on lines where the user-agent is missing. Can you adjust the regex to handle that case?"
Avoid over-specifying. The temptation is to detail every single aspect upfront, like writing a comprehensive requirements document. Don't. High-level direction + iterative feedback works better than trying to predict every edge case.
What you're really doing is having a conversation where the AI does the typing, but you maintain creative direction.

The Productivity Multiplier: What Changed
Let me quantify this in terms of my time.
Writing a 400-line Python script from scratch, including debugging and testing, would have taken me roughly 8-12 hours if I already knew Python well. Since I don't, it would have been 20-30 hours of learning + coding + debugging.
Using Claude, it took me about 3 hours from "I want a tool" to "tool works and solves my problem."
That's roughly a 6-10x time compression.
But here's what's important: that time savings isn't about me becoming a programmer faster. It's that the project became tractable. It went from "too much work, I'll live without it" to "done by lunch."
For anyone managing their own time—and that's most knowledge workers—tractability is everything.
Multiply this across a team. If a developer usually spends a week on utility scripts and internal tooling, and LLM assistance cuts that to a day, you've recovered a week of productive capacity. Per person. Per week.
The compounding effect at scale is enormous.

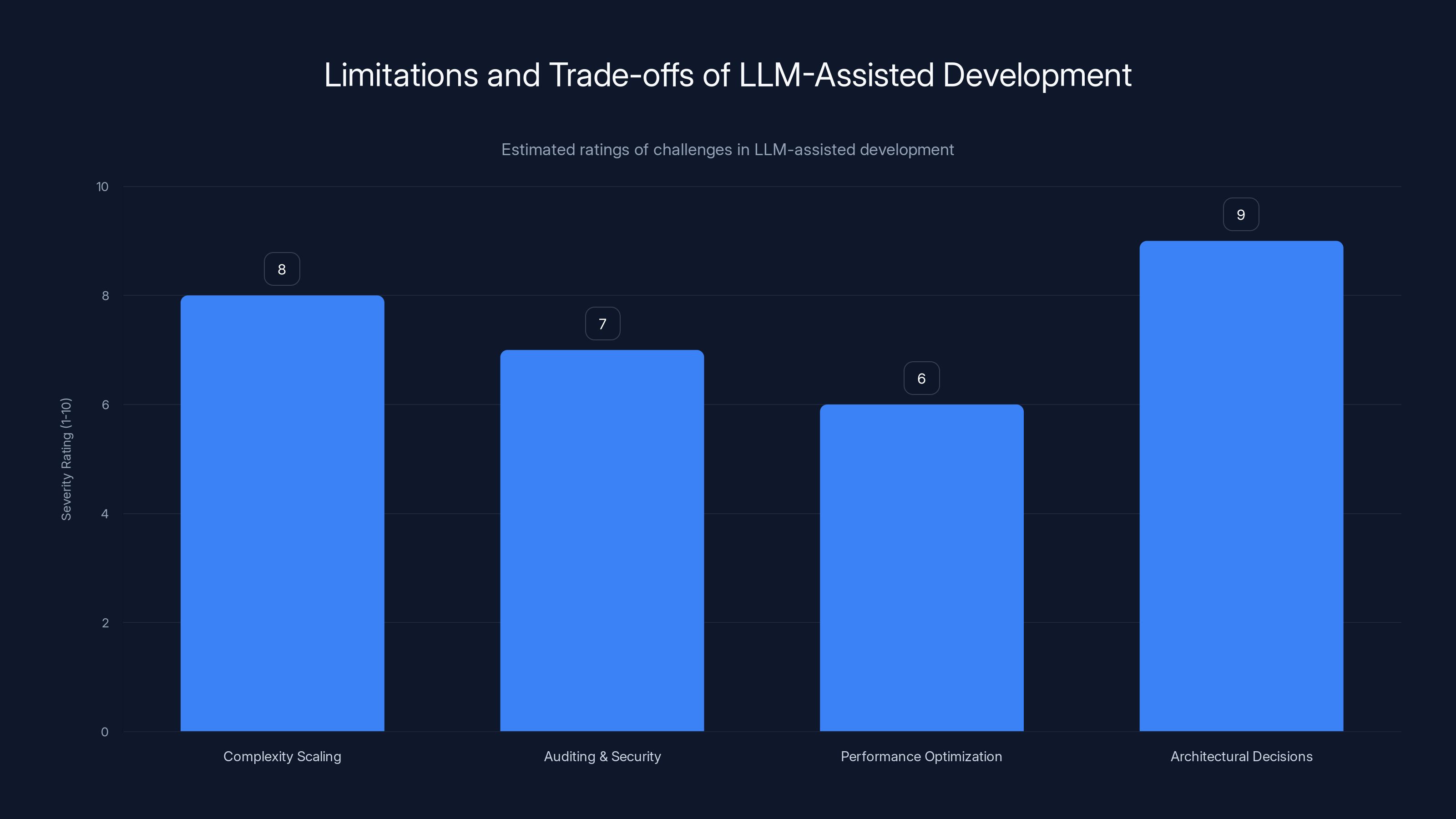
Complexity scaling and architectural decisions pose the greatest challenges in LLM-assisted development. Estimated data.
The Debugging Revelation: Finding the Root Cause
But the colorizer wasn't just a nice-to-have tool. It was actually useful for solving the intermittent caching problem.
With color-coded logs, patterns became visible that were invisible before.
I could see that on days when the caching failure happened, certain sequences of requests were clustered together in ways they weren't on normal days. The timing was slightly off. Discourse comment section loads happened after Cloudflare cached the page instead of before.
The root cause wasn't a bug in Cloudflare, or Word Press, or Discourse specifically. It was a race condition in how the three systems interacted. Under normal timing, Discourse would load, inject its comments, and then the page would get cached. But under certain network conditions—maybe slightly higher latency to wherever Discourse was running—the sequence could get inverted.
Cloudflare would cache the page before Discourse finished decorating it.
The workaround I'd implemented (forcing "do not cache" headers until Discourse confirms it's ready) was actually the right long-term fix for this architecture. It's not fixing the race condition—it's preventing the race condition from having consequences.
But I wouldn't have figured that out without being able to visually parse the logs quickly. The colorizer made that possible.

The Honest Assessment: Limitations and Trade-offs
Let me not oversell this. LLM-assisted development has real limitations.
Complexity scaling. The colorizer is small and self-contained. It's straightforward procedural code. If you wanted to scale this to something with a database, authentication, a web interface, and multiple interdependent modules, the story changes. Larger projects fragment across more files, more context windows, more iteration cycles. They become harder to keep coherent.
Auditing and security. Even though I wrote this tool and tested it, I haven't done a thorough security audit. I trust Claude's code more than I'd trust random internet code, but if this were handling sensitive data at scale, I'd want a professional review. The LLM-assisted approach works best when the stakes are low.
Performance optimization. The code works. It's not slow. But if I needed to optimize it to process gigabytes of logs per second, that's the kind of specialized work where you actually need deep technical expertise. LLMs are good at generating working code. They're less reliable at generating fast code.
Architectural decisions. The colorizer is a command-line tool that reads stdin and writes stdout. That's a straightforward choice. But if the project needed to be a microservice, or a web app, or something that interfaced with multiple APIs, the architectural decisions would multiply. Those decisions require human judgment and experience.
So vibe-coding isn't "AI replaces programmers." It's "AI eliminates friction for non-programmers on small, well-scoped projects."


Building in public with LLM assistance fosters collaboration, with an estimated 75% of projects receiving community engagement through forks, feature additions, or adaptation requests. Estimated data.
The Broader Shift: What This Means for Software
We're watching a fundamental change in who can participate in building software.
For decades, programming was gatekept. Not entirely intentionally in all cases, but the effect was real. High barrier to entry. Multi-year commitment to learning. You had to choose: become a programmer, or use software other people built for you.
Now there's a middle path. You can be a domain expert—someone who understands your problem deeply—and use AI to bridge the gap to implementation.
The science fiction writer can write a tool to analyze narrative structure without learning algorithms. The researcher can write utilities to process datasets without learning data structures. The systems administrator can write monitoring scripts without years of programming experience.
For some categories of projects, this is transformative.
For larger, more complex systems—the kind that require real software architecture, team coordination, and long-term maintenance—we'll still need professional programmers. Maybe more than ever, actually, since there'll be more software tools in the world than there used to be.
But for the long tail of small utilities, one-off scripts, and domain-specific tools? That's going to come from everywhere. From people who never intended to be programmers.

The Neurodiversity Angle: Accessibility Matters
There's something worth mentioning that doesn't get talked about enough: this changes the accessibility equation.
Learning to code as a traditional pathway requires specific cognitive strengths and neurotypes. Linear, sequential thinking helps. The ability to maintain context across multiple files helps. Working memory capacity matters. Pattern recognition helps.
Not everyone has those strengths in equal measure. Some people think in ways that are completely incompatible with traditional programming but would be great at using LLMs to build software. They think in analogies. They think in stories. They can explain a problem but not code a solution.
For neurodivergent folks—people with ADHD, dyslexia, autism spectrum conditions—the traditional "learn programming the right way" pathway can be needlessly hard. Not impossible, but unnecessarily difficult.
LLM-assisted development might actually be more accessible for people who think differently. You don't need to memorize syntax. You don't need perfect written language (you can describe something conversationally). You don't need to hold complex multi-file architecture in working memory.
You just need to understand your problem domain and be able to iterate on solutions.
Building in Public: Community and Learning
One interesting side effect of all this: I'm more likely to share what I build.
When I write code, I'm weirdly self-conscious about it. I feel like I'm exposing incompetence. An actual programmer would do this better. More elegantly. More efficiently.
But code I vibe-coded with an LLM? I'm less defensive about it. It's not pretending to be expert work. It's a practical solution generated by a tool, then refined by iteration. There's less ego attached.
I published the colorizer on Git Hub. A couple of people forked it and added features. Someone asked if they could adapt it for a different log format. That conversation wouldn't have happened if I'd just kept it private because I was embarrassed.
Software built this way—LLM-assisted, pragmatic, not trying to be perfect—might actually foster more collaborative development than the gatekept model ever did.

The Wider Ecosystem: Tools That Enable This
The reason vibe-coding even works is because of better tooling for LLM interaction.
Claude Code is a genuinely useful interface. You describe what you want, and it maintains the full codebase in a view where you can see everything, run it, test it, and give feedback. The context is preserved. You're not copy-pasting code between windows.
Other options exist. Git Hub Copilot integrates directly into IDEs like VS Code. Jet Brains IDEs have AI assistance built in. Cursor is literally an IDE optimized for AI-assisted development.
Each approach has trade-offs. What matters is that the infrastructure for human-AI collaborative development keeps getting better.
We're moving past the phase where LLM coding is novelty. It's becoming boring infrastructure. The way you do certain classes of work now.
Automation as a Multiplier: The Runable Connection
Once you've built a tool—even a small one—the next question is: can it be automated?
Some tools you run once. Others become part of your regular workflow. The colorizer is useful when I'm actively debugging. But imagine if I wanted to run it continuously, process logs in real-time, and send alerts when certain patterns appeared.
That's where automation platforms become relevant. Tools like Runable let you build automated workflows without traditional coding. You can trigger scripts on schedules, chain processes together, and generate reports automatically.
For someone building their own infrastructure, this becomes powerful quickly. You vibe-code a utility. Then you automate its execution. Then you add reporting. Before you know it, you've built a legitimate monitoring system—not because you're a Dev Ops expert, but because the tools got out of your way.

The Future: Where Vibe-Coding Goes
Right now, vibe-coding is still collaborative. Humans provide direction. AI provides implementation. It's a conversation.
As LLMs improve—better reasoning, larger context windows, more reliable code generation—the friction will decrease further. You'll be able to vibe-code more complex projects. Multi-file applications. Systems with databases and APIs. Things that require more sophisticated architecture.
At some point, the boundary between "thing I can vibe-code" and "thing I need a professional programmer for" will shift significantly.
I don't think this means professional programmers become obsolete. Complex systems still need thoughtful architecture. Teams need coordination. Security and performance optimization still require expertise.
But the number of professional programmers needed for every line of code written will probably decrease. A lot of the work they do—maintenance scripts, internal tools, small utilities, debugging helpers—that work will migrate to domain experts using AI assistance.
The programmer role might shift from "someone who writes code" to "someone who architects systems, reviews AI-generated code, and handles the complex parts that can't be vibe-coded."
We're in transition. That's what's interesting about right now.

Practical Takeaways: How to Start
If you want to try vibe-coding your own projects, here's the framework that worked for me:
Choose the right project. Small. Well-scoped. Single-file if possible. Something you understand deeply but don't know how to code. The colorizer was perfect—I understood logs, understood what I wanted to see, didn't know Python.
Be specific in your requests. Don't say "make a tool." Say: "I need a script that takes a CSV file with these columns, filters rows where column X is greater than Y, calculates a sum of column Z grouped by column W, and outputs the results as a table."
Test as you iterate. Don't wait until the end to try running the code. Ask for the first piece. Test it. Ask for the next piece. Build incrementally.
Don't optimize early. Does the code work? Great. Does it work fast enough? If yes, you're done. Premature optimization is noise.
Share what you build. Put it on Git Hub. Ask for feedback. Let others adapt it. The collaborative nature of this kind of development benefits from transparency.
Learn enough to understand failures. You don't need to know Python deeply. But you should understand enough to read an error message and describe what went wrong to the AI.
Those six things will get you further than you'd expect.

The Personal Element: Why This Matters
Let me circle back to the beginning, because the practical stuff is only half the story.
Building this tool—even with AI assistance, even though the code isn't mine in the traditional sense—made me feel like I'd accomplished something. Not in a grandiose way. It's a log colorizer. It's maybe useful to a few dozen people.
But it solved a problem that was genuinely bothering me. I went from "I wish this tool existed" to "I built this tool" in an afternoon.
That's new. For most of my adult life, my relationship with software was consumer-based. I used tools other people built. I submitted feature requests. I waited for updates. I was on the receiving end.
Now I can be on the building end, even at scales where it wouldn't have been worth learning to code traditionally.
There's something deeply satisfying about that. It's the kind of satisfaction that comes from agency. From taking something you wanted to exist and making it exist.
Software should be more like that. Not "things that are possible only for specialists," but "things that anyone with a problem can solve."
Vibe-coding isn't perfect. It has limits. But it's a step in that direction.
And honestly? I feel good about where it's going.

FAQ
What is vibe-coding?
Vibe-coding is collaborative software development where a human with deep domain knowledge works iteratively with an LLM to build working applications. You describe what you want, the AI generates code, you test it, you provide feedback on what's wrong, and the AI refines it. It's called "vibe-coding" because it prioritizes getting something working that solves your problem over writing perfectly optimized or architecturally pure code.
How does vibe-coding differ from traditional programming?
Traditional programming requires learning syntax, architecture patterns, debugging skills, and how to handle edge cases—a multi-year learning curve. Vibe-coding lets you skip the learning curve by using an LLM's code generation as a tool, similar to how you'd use a library or framework. You maintain creative direction and domain expertise while the AI handles implementation details. The feedback loop is tight and iterative rather than requiring you to write and debug code in isolation.
What kinds of projects work best for vibe-coding?
Projects work best for vibe-coding when they're small, well-scoped, and fit within an LLM's context window. Command-line utilities, data processing scripts, log analysis tools, and single-file applications are ideal. Projects that sprawl across multiple files and require deep architectural decisions are harder. Projects that need real-time performance optimization or security audits are challenging. The sweet spot is something a professional programmer would spend a few hours on, but you'd need weeks to learn enough to build.
Can vibe-coded tools be used in production?
Yes, vibe-coded tools can be used in production if they're simple enough to audit and test thoroughly. A 400-line single-file Python script is auditable. You can read through the entire codebase and understand what it does. Larger, more complex systems generated by LLMs are harder to be confident about. For mission-critical systems, professional code review is advisable. For internal utilities and monitoring scripts, vibe-coded tools work well as long as you test them thoroughly with real data.
What's the learning curve for getting started with vibe-coding?
The learning curve is minimal if you understand your problem domain well. You don't need to know programming—you need to know how to describe what you want clearly, test whether you got it, and explain why the result isn't quite right. These are skills most people already have. You might spend an hour getting comfortable with the interface (Claude Code, Copilot, Cursor, etc.), then you're ready to start. The main challenge isn't technical—it's being specific enough in your requests that the AI understands what you're asking for.
How do you handle bugs in vibe-coded software?
Debugging vibe-coded software is different from debugging traditional code. You don't need to learn to read a stack trace and figure out what went wrong yourself. Instead, you describe the symptoms to the AI: "When I run it with this input, I get this output, but I expected this other output instead. Can you fix it?" The AI investigates the code and suggests fixes. You test again. The iterative cycle continues until it works. This is often faster than traditional debugging because you're not fighting with syntax and environment setup.
Will vibe-coding make professional programmers obsolete?
No. Professional programmers will remain essential for complex systems, architectural decisions, security-critical applications, and code that needs optimization. What will change is the distribution of work. A lot of the routine coding tasks—internal tools, monitoring scripts, utilities—will migrate to domain experts using AI assistance. Professional programmers may shift more toward architecture, code review, and the hard problems that require deep expertise. There will likely be more software tools built in total, but fewer programmer-hours per tool.
How do you know when something is too complex to vibe-code?
A few signals suggest you need professional programmers: (1) The project requires careful architectural decisions upfront. (2) It spans multiple interconnected files and modules. (3) It needs real-time performance optimization. (4) It handles sensitive data that requires security audits. (5) It's mission-critical infrastructure where failure causes serious damage. (6) A professional programmer estimates it would take more than a few weeks to build. If you're uncertain, vibe-code a prototype and see if you run into limitations. Often you'll hit a wall where the system gets too complicated for iterative prompting. That's when you know you need different expertise.
Conclusion: The Democratization of Making
We're living through a fascinating transition. For the first time in the history of computing, the barrier between "someone who uses software" and "someone who builds software" is actually coming down.
Not all the way. Complex systems still require expertise. But the long tail of small problems—the things that would take a professional programmer a day to solve but you'd never pay for—those are becoming tractable for anyone with domain knowledge and access to an LLM.
That matters more than the tech world tends to acknowledge.
Software is increasingly how we solve problems, automate our work, and make sense of data. For most of history, the ability to build software tools was gatekept by people who'd invested years in learning to code. That was fine when software projects required teams of specialists. But for the long tail of small utilities and domain-specific tools, it was wasteful.
All that unbuilt software. All those problems that didn't quite justify hiring someone to solve them.
Vibe-coding doesn't solve everything. It has real limits. But it shifts the economics of tool-building in a way that's going to matter.
The scientist can write a script to analyze experimental data. The researcher can build utilities to process documents. The operations person can write monitoring tools without waiting for engineering tickets. The domain expert becomes the tool builder.
That's genuinely new.
Personally, I'm glad I'm living through this transition. I'm glad I don't have to choose between "become a programmer" and "use tools other people built." I'm glad I can spend an afternoon with an LLM and end up with a tool that solves my actual problem.
And honestly? Despite all my hedging and caveats, I do feel good about it.
The tool works. The problem is solved. And I built it.
That's not nothing.
Key Takeaways
- Vibe-coding democratizes software building by letting domain experts collaborate with LLMs instead of requiring years of programming education
- Small, focused projects within a single LLM context window are the sweet spot—complex multi-file applications are much harder to maintain
- Iterative prompting with clear examples and specific testing feedback is far more effective than trying to specify everything upfront
- LLM-assisted development collapses 20-30 hours of traditional learning and coding into 3-4 hours of collaborative iteration
- The skill isn't memorizing syntax—it's understanding your problem deeply and knowing how to describe failures so the AI can fix them
Related Articles
- Xcode Agentic Coding: OpenAI and Anthropic Integration Guide [2025]
- Xcode 26.3: Apple's Major Leap Into Agentic Coding [2025]
- Apple Xcode Agentic Coding: OpenAI & Anthropic Integration [2025]
- Take-Two's AI Strategy: Game Development Meets Enterprise Efficiency [2025]
- MacBook Pro M5 24GB RAM Deals: The Best Value Configuration [2025]
- Agentic Coding in Xcode: How AI Agents Transform Development [2025]

