![Wikimedia's AI Partnerships: How Wikipedia Powers the Next Generation of AI [2025]](https://tryrunable.com/blog/wikimedia-s-ai-partnerships-how-wikipedia-powers-the-next-ge/image-1-1768491471389.jpg)
Introduction: When Wikipedia Became an AI Asset
There's a moment that defines generational shifts in technology. For Wikipedia, that moment arrived quietly in January 2025, when the Wikimedia Foundation announced partnerships with some of the world's biggest AI companies. Amazon, Meta, Microsoft, Perplexity, Mistral AI, and others now have formal agreements to use Wikipedia content at scale through a commercial product called Wikimedia Enterprise.
This isn't just another licensing deal. It's a fundamental pivot for one of the internet's oldest and most trusted institutions. For 25 years, Wikipedia survived on donations and volunteer work. Now, as AI companies rake in billions while training on freely available knowledge, Wikipedia is finally saying: if you're building products on our content, you're going to pay for it.
But here's what makes this interesting. This isn't about Wikipedia abandoning its mission or turning greedy. It's about sustainability. When Chat GPT, Claude, and Perplexity answer your questions with factual information, they're often drawing from Wikipedia. The companies building these tools are worth hundreds of billions. Wikipedia's annual budget is around $150 million for a global operation that serves 5 billion people. The math doesn't work.
So what exactly are these partnerships? What do they mean for AI companies, for Wikipedia users, and for the future of knowledge on the internet? Let's dig in.
The source material here is the Wikimedia Foundation's own announcement during their 25th birthday celebration, but what's really interesting is what lies beneath this news. It's a story about power dynamics, sustainability, the future of knowledge, and how open-source projects survive when their value suddenly becomes undeniable to billionaires.
The Wikimedia Enterprise Model: Wikipedia Gets Paid
Wikimedia Enterprise is the engine behind these new partnerships. It's not a new product, but it's now the centerpiece of how Wikipedia generates revenue from AI companies.
Here's how it works: Instead of scraping Wikipedia's public pages (which anyone can do), companies using Wikimedia Enterprise get structured, cleaned data. They get access to Wikipedia's full content database, metadata, revision history, and language versions. They get it at scale, with guaranteed uptime and performance. Think of it like the difference between manually copying information from a website versus having a direct database connection.
For AI companies, this is valuable. When training large language models, data quality matters enormously. Garbage in, garbage out. Wikipedia's content is human-edited, fact-checked, and sourced. It's worth more than raw web scrapes. Wikimedia Enterprise gives companies confidence that they're using reliable, authorized content.
Wikimedia Foundation started offering enterprise access years ago, but it remained relatively quiet. The founding partnership with Google in 2022 was public, but then... silence. Why? Probably because these deals are sensitive. They involve negotiations around pricing, exclusivity, and the optics of selling Wikipedia to tech giants.
Now, 25 years into Wikipedia's existence, the foundation is being transparent. Amazon, Meta, Microsoft, Perplexity, Mistral AI, Ecosia, and others have signed on. The foundation is finally comfortable discussing this revenue stream publicly.
What does Wikimedia Enterprise actually provide beyond raw content? It includes real-time data feeds, API access optimized for machine learning workflows, quality assurance, language-specific datasets, and technical support. For companies training models on billions of documents, having a reliable source of high-quality, authorized content is worth paying for.
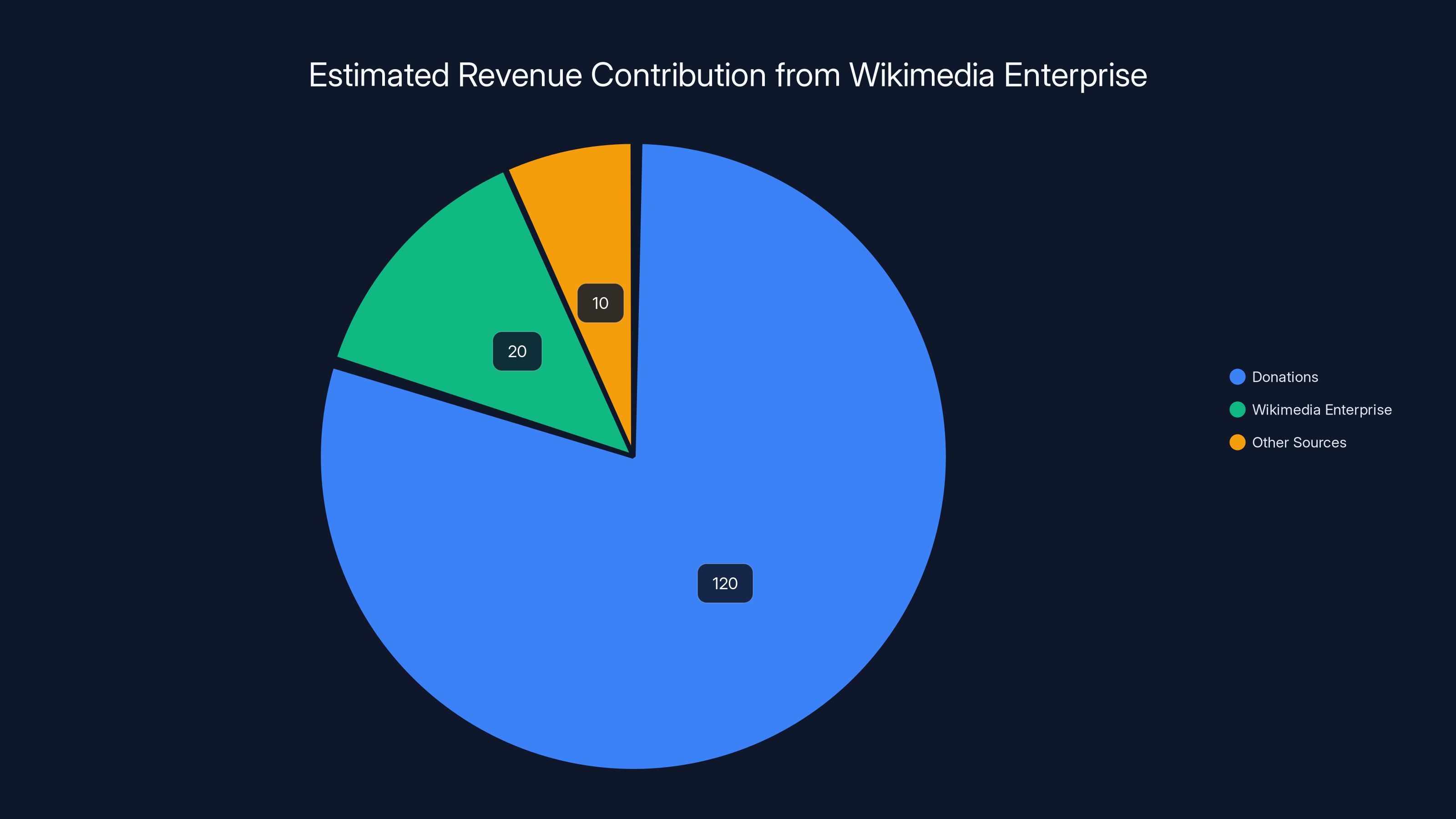
Estimated data suggests Wikimedia Enterprise could contribute around
Why Wikipedia's Business Model Is Broken (And Why That Matters)
Let's be honest about Wikipedia's situation before these partnerships. The Wikimedia Foundation operates one of the top-ten most-visited websites globally. Over 65 million articles. 300+ languages. Nearly 15 billion page views per month. It's the fifth-most trafficked website on the internet, behind only Google, YouTube, Facebook, and Reddit.
And it's almost entirely volunteer-powered.
The foundation's budget of approximately $150 million annually is funded primarily through donations. Yes, donations. They run banner campaigns during Wikipedia's "Wikipedian birthday" asking people to contribute money. These campaigns work surprisingly well, but they're also not scalable.
Meanwhile, every major tech company has been happily using Wikipedia content without paying for it. Google indexes Wikipedia. Chat GPT trained on Wikipedia. Perplexity uses Wikipedia to provide quick answers. These companies collectively are worth over $10 trillion in market capitalization. They're using one of humanity's most valuable knowledge bases for free.
This is the core tension. Wikipedia provides an enormous public good, but the financial model never matched the value being extracted. Volunteers write articles. Volunteers edit and fact-check. The foundation maintains servers. And everyone else profits.
Selena Deckelmann, Wikimedia Foundation's Chief Product and Chief Technology Officer, acknowledged this in the foundation's announcement: "Wikipedia shows that knowledge is human, and knowledge needs humans. Especially now, in the age of AI, we need the human-powered knowledge of Wikipedia more than ever."
Translation: Wikipedia is more valuable than ever, and Wikipedia's volunteers deserve better funding than a once-a-year donation drive can provide.
The Wikimedia Enterprise partnerships solve this partially. Not completely. The foundation isn't disclosing the terms of these deals, which means we don't know if Microsoft is paying millions per year or thousands. But having legitimate revenue sources from companies actually using the content is a step toward financial sustainability.
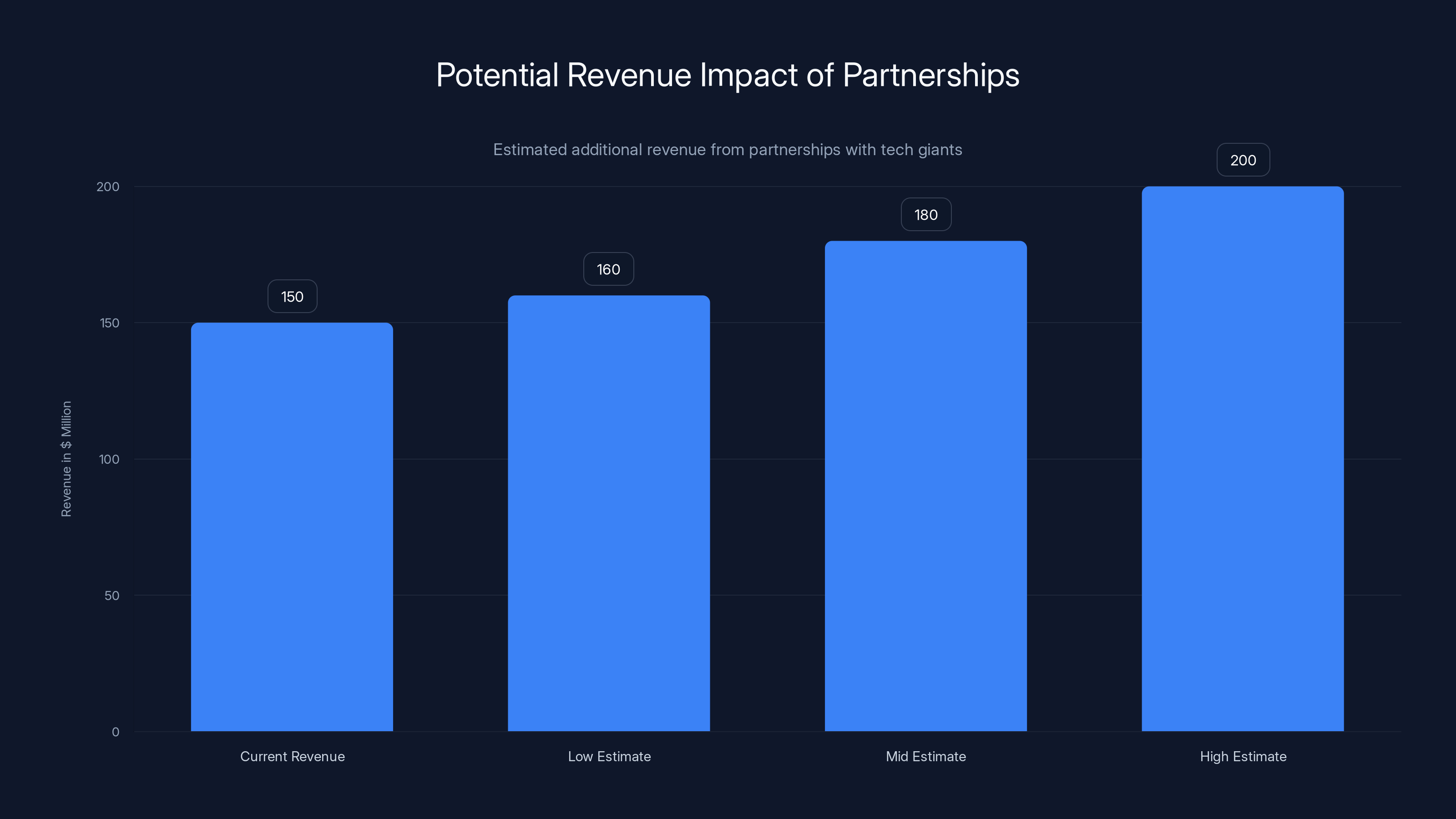
Estimated data: Potential partnerships could increase Wikimedia's revenue by $10-50 million, significantly impacting its budget.
The Partners: Who's Paying for Wikipedia?
Let's break down who signed these deals and what they might be using Wikimedia Enterprise for.
Amazon and AWS
Amazon's interest makes sense on multiple levels. AWS offers AI services including Bedrock, their managed foundation model service. Training better models requires better data. Wikimedia Enterprise gives Amazon access to some of humanity's highest-quality knowledge content.
Amazon also operates Alexa, their voice assistant. Alexa answers questions. Using quality Wikipedia data helps Alexa provide more accurate answers. There's also potential for Amazon to integrate Wikipedia content into their e-commerce and search functions.
For AWS customers building their own AI applications, having access to clean, licensed Wikipedia data through Wikimedia Enterprise is a selling point.
Meta (Facebook, Instagram, WhatsApp)
Meta's use case is less obvious but equally important. Meta is investing heavily in AI, having created LLAMA (Large Language Model Meta AI), a series of increasingly capable open-source models. LLAMA models are trained on diverse data sources, and Wikipedia is among the highest-quality sources available.
Meta also runs Threads, their Twitter-like social network. Better AI models help with content moderation, recommendations, and anti-misinformation efforts. Accurate knowledge bases matter for these applications.
WhatsApp could also benefit. Meta is exploring ways to integrate AI into WhatsApp for customer service and other features. Quality knowledge helps these use cases.
Microsoft
Microsoft has Copilot, Bing, and Azure AI Services. They're building AI into Office applications, SQL Server, and enterprise tools. They also partnered with OpenAI years ago, and they integrate OpenAI's models into their products.
For all of these use cases, quality knowledge data matters. Microsoft likely uses Wikimedia Enterprise for training and for providing real-time knowledge to Copilot and Bing.
Perplexity
Perplexity is probably the most obvious use case. Perplexity is an AI search engine that answers questions by synthesizing information from web sources. Perplexity is explicit that it cites its sources. Using authorized, quality Wikipedia data through Wikimedia Enterprise is exactly what Perplexity needs.
Perplexity's entire business model depends on being able to provide accurate answers with proper attribution. Wikimedia Enterprise is a perfect fit.
Mistral AI
Mistral AI is a European AI company that competes with OpenAI and Meta. They create language models and tools. Like all foundation model companies, Mistral needs quality training data. Wikimedia Enterprise is a clean source.
The fact that Mistral signed on is interesting because it shows Wikimedia isn't playing favorites. They're happy to partner with any capable AI company, whether it's a Silicon Valley giant or a European startup.
Others: Ecosia, Pleias, Pro Rata, Nomic, Reef Media
These companies are less famous but equally interesting. Ecosia is a search engine. Pleias is an AI company. Pro Rata builds AI tools. Nomic creates machine learning infrastructure. Reef Media works in media and AI.
The diversity of partners shows that Wikimedia Enterprise isn't just serving OpenAI-style frontier AI labs. It's becoming infrastructure for the entire AI ecosystem.

The Scale of Wikipedia's Content: Numbers That Matter
Understanding the value of Wikimedia Enterprise requires understanding the scale of Wikipedia itself.
65 million articles across all Wikipedia language editions. That's not 65 million in English alone. English Wikipedia has about 6.7 million articles, which makes it the largest, but Spanish, French, German, and Chinese editions all have millions more. Italian, Japanese, Arabic, Portuguese—the list goes on.
300+ languages represented. This is crucial. A company training an AI model that needs to work globally can't just use English Wikipedia. They need knowledge in dozens of languages. Wikimedia's multilingual content is a genuine advantage.
Nearly 15 billion page views per month. That's 15 billion instances of humans accessing Wikipedia. Thirty million people visit Wikipedia per day. During exam season, it's probably higher. When there's a major news event, Wikipedia traffic spikes. This is real, constant usage at scale.
Top-ten website globally. Wikipedia consistently ranks among the ten most-visited websites in the world. Google, YouTube, and Facebook get more traffic, but Wikipedia competes with Amazon, Wikipedia, and Reddit. Not bad for an organization without a business model based on advertising or data sales.
These numbers give you a sense of why AI companies would pay for this. Access to knowledge that billions of humans trust and use daily is valuable. Very valuable.
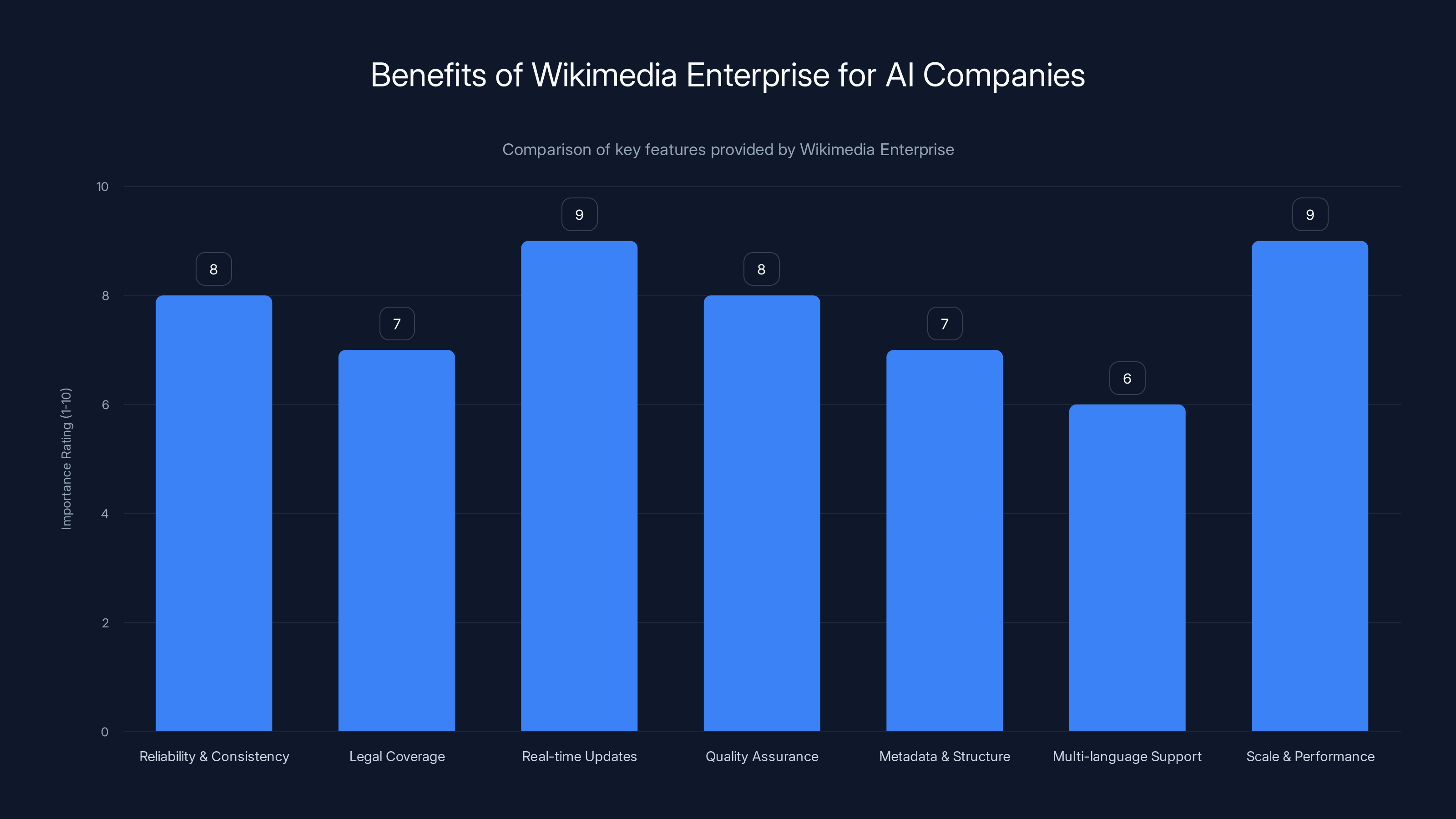
Wikimedia Enterprise offers AI companies critical features like real-time updates and scale performance, rated highly for their importance in AI model training. Estimated data.
Why AI Companies Need Wikipedia (And Why They Should Pay)
Let's flip the perspective. Why do AI companies actually need this? Why not just scrape Wikipedia for free like they've been doing?
Actually, they can and have been. That's the whole problem. But there are good reasons to use Wikimedia Enterprise instead.
Reliability and consistency: Public Wikipedia changes constantly. Articles get edited, sometimes vandalized, sometimes corrected. When you need consistent training data, you need a stable snapshot. Wikimedia Enterprise provides this.
Legal coverage: Using public Wikipedia is fine legally under creative commons licenses, but working with Wikimedia Enterprise directly provides clearer terms. If there's ever a dispute, having a commercial agreement is safer than relying on interpreting Wikipedia's CC-BY-SA license.
Real-time updates: For AI systems that need current information, Wikimedia Enterprise provides data feeds. You don't need to re-scrape Wikipedia every day. The foundation handles distribution.
Quality assurance: Not everything on Wikipedia is equally reliable. Articles on popular topics are well-maintained. Articles on obscure topics might have errors. Wikimedia Enterprise includes metadata about edit history, article quality ratings, and revision stability. This helps companies identify which content is most trustworthy.
Metadata and structure: Beyond just text, Wikimedia Enterprise provides article relationships, categories, and internal link graphs. This structured data is valuable for training AI models that need to understand relationships between concepts.
Multi-language support: Getting high-quality knowledge in 50+ languages is hard. Wikimedia Enterprise provides this out of the box.
Scale and performance: Downloading all of Wikipedia takes time and bandwidth. Wikimedia Enterprise is optimized for high-volume, distributed access. For a company training massive models, this efficiency matters.
Attribution and provenance: If an AI model trained on Wikipedia knowledge needs to cite where it got information, Wikimedia Enterprise provides the metadata to do this. Perplexity values this. Other companies will too.
None of these reasons are deal-breakers individually. But together, they explain why paying for Wikimedia Enterprise makes sense rather than just scraping Wikipedia.
The Financial Impact: How Much is This Worth?
Here's what we don't know: the actual financial terms of these deals.
The Wikimedia Foundation hasn't disclosed how much Amazon, Meta, Microsoft, and others are paying. They haven't said whether these are one-time payments or recurring licensing fees. They haven't said whether there are volume-based pricing tiers.
But we can estimate.
Wikimedia Foundation's current revenue is approximately
If these deals are significantly larger—say, $50+ million annually—that would essentially double the foundation's revenue and fundamentally change its financial situation.
For context, consider what these companies spend on data and AI infrastructure:
- Microsoft's AI spending is estimated at billions per year
- Meta's AI research budget is estimated at $10+ billion annually
- Amazon's total R&D spending exceeds $100 billion per year
- Perplexity has raised $600 million in funding to build its AI search engine
Against these numbers, even a $100 million annual license fee from all partners combined is rounding error. It's trivially cheap for these companies.
This is why the Wikimedia Foundation has leverage. These companies need Wikipedia far more than Wikipedia needs any single company. The foundation's negotiating position is stronger than it's ever been.

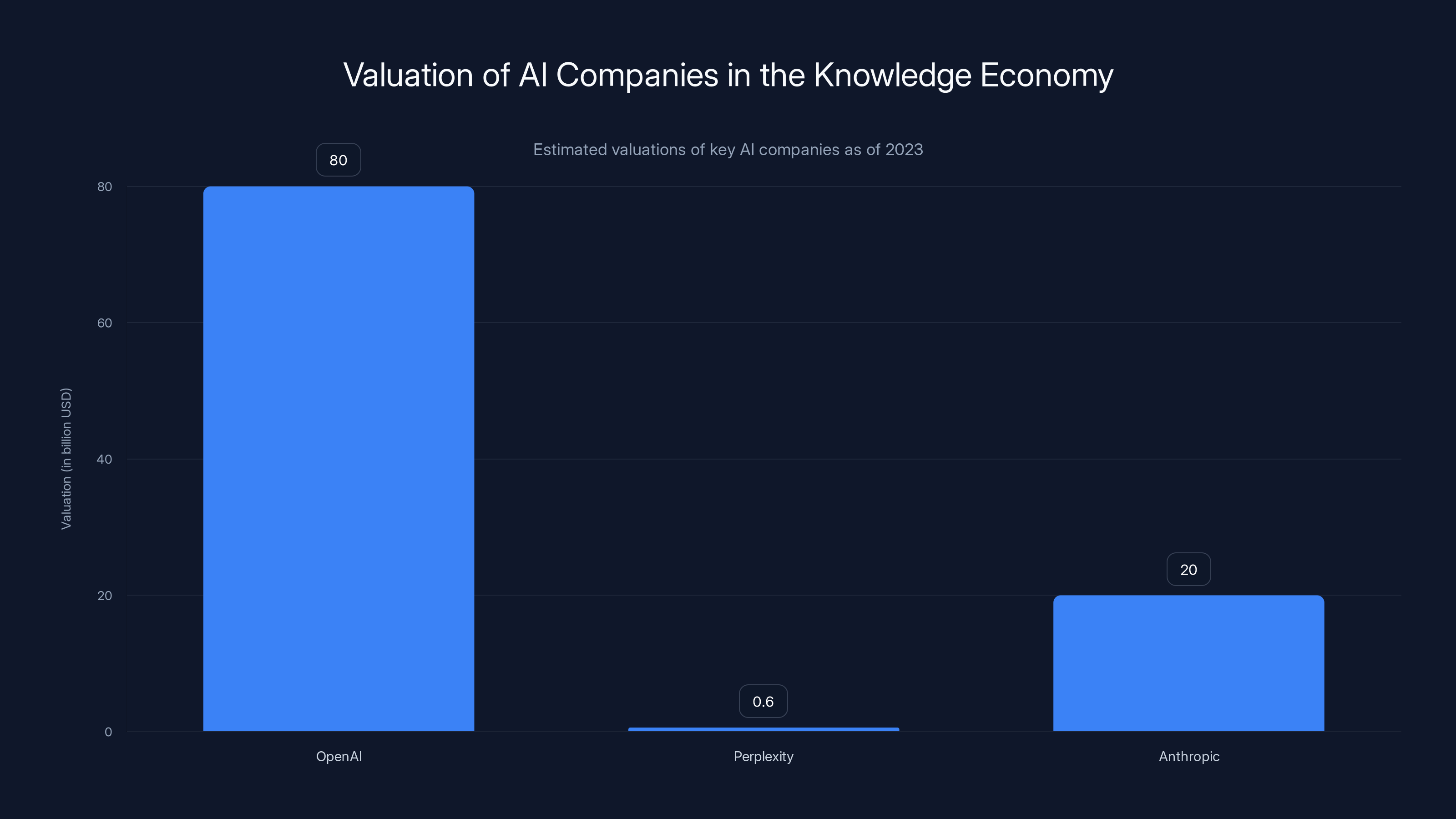
OpenAI leads with a valuation of $80 billion, highlighting the immense economic potential of knowledge in the AI era. Estimated data.
The Precedent: How This Changes Everything
These partnerships establish something important: a precedent that AI companies should pay for high-quality data.
For years, the AI industry operated under the assumption that internet-scale training data was free for the taking. Scrape away. Train away. Make billions. Everyone else figures out their own business model.
But Wikipedia's partnerships suggest this is changing. If Meta is paying for Wikipedia, why shouldn't they pay for other quality content sources? If Microsoft is licensing Wikipedia through Wikimedia Enterprise, shouldn't they also be paying news organizations, academic institutions, and authors?
This is already happening to some degree. OpenAI faced legal challenges about training on copyrighted material. The publishing industry is now negotiating with AI companies. News organizations are demanding compensation. Academic institutions are asking why their research is being used to train commercial AI without their knowledge.
The Wikimedia partnerships are a high-profile example of the right approach: transparent agreements with clear terms and mutual benefit.
Now, Wikimedia was in a unique position. Wikipedia is explicitly under a Creative Commons license. Companies can legally use it. But Wikimedia still negotiated for compensation because they understood their leverage.
Other institutions might learn from this. If you control valuable knowledge or content, don't assume it's fine for AI companies to use it for free. These companies are making billions. You can negotiate for a piece of that value.
Conversely, for AI companies, licensing quality data from legitimate sources is better than trying to navigate the legal and ethical minefield of using content without clear permission.
The Wikimedia partnerships are a healthy precedent.
Wikimedia's Approach to AI: Not Just Selling Content
It's worth noting that Wikimedia Foundation isn't just monetizing Wikipedia. They're also building their own approach to AI.
In their 25th anniversary announcement, the foundation discussed their "own approach to AI." This is vague, but it suggests they're thinking about how Wikipedia itself uses AI to improve its operations and mission.
Wikipedia's volunteers are aging. The median age of an active Wikipedia editor is in the 50s. They're not getting a large influx of young editors. This is a problem for sustainability.
AI could help. Automated tools could assist editors with research, citation finding, and fact-checking. AI could help translate articles between languages, making knowledge available to more people. AI could help identify vandalism and problematic edits. AI could help detect gaps in Wikipedia's coverage—topics that are missing or under-represented.
The foundation is also experimenting with games and short-form video content. This is a bet that younger audiences engage with knowledge differently than older audiences. Instead of long-form encyclopedia articles, maybe they want interactive games about history. Maybe they want 30-second videos explaining concepts.
These experiments are separate from the corporate partnerships, but they show Wikimedia is thinking broadly about how to sustain Wikipedia's mission in a changing media landscape.

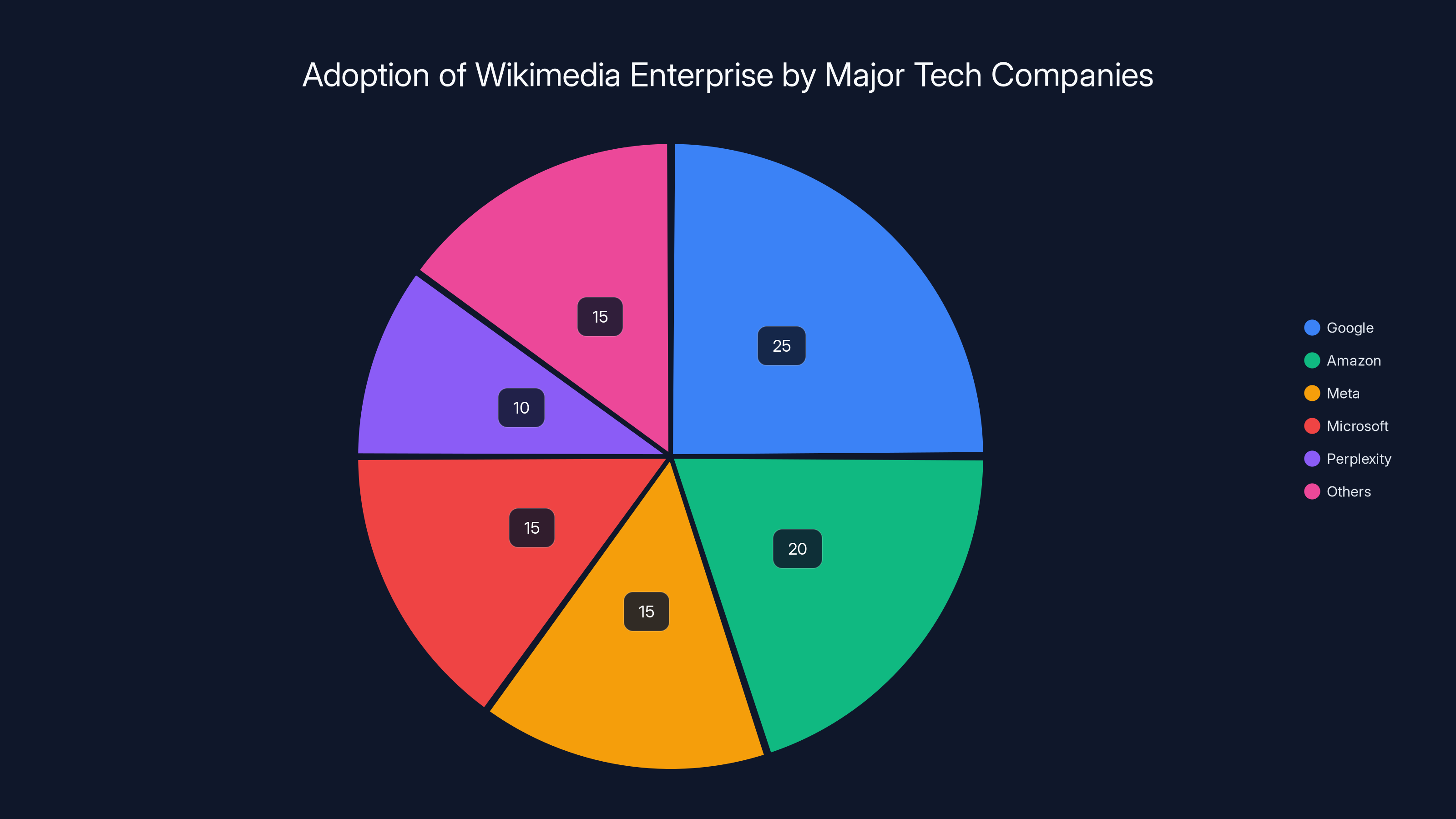
Estimated data shows Google leading in Wikimedia Enterprise adoption, followed by Amazon and Meta. This highlights the strategic importance of reliable data sources for AI development.
The Volunteer Perspective: Does This Help or Hurt?
Here's a question that doesn't get asked enough: How do Wikipedia's volunteer editors feel about corporations paying for Wikipedia content?
There are a few perspectives:
The positive take: Any revenue that helps sustain the Wikimedia Foundation is good. More funding means more support for volunteers. The foundation can hire people to do community outreach, support editors, and improve tools. This benefits the volunteer community.
The skeptical take: Why are we selling our work to make corporations richer? We wrote these articles as volunteers. Now Microsoft and Amazon are licensing them to train AI systems that will compete with human creators. Where's our cut?
The pragmatic take: This is reality. Companies were already using Wikipedia. At least now there's some compensation and oversight instead of just free scraping.
The truth is probably somewhere in the middle. For Wikipedia's volunteers to continue contributing, the project needs to be sustainable. If the Wikimedia Foundation can't fund its operations, it dies. The partnerships help with this.
But the volunteer community might reasonably ask whether they should get a direct share of licensing revenue. Currently, all licensing revenue goes to the foundation's general budget. It doesn't benefit individual editors.
Some Wikipedia editors have proposed paying volunteers, but the foundation has resisted this historically. The idea is that Wikipedia is a labor of love, a gift economy. Once you start paying people, it changes the dynamics.
But this might be worth revisiting. If the foundation is generating tens of millions of dollars in licensing revenue, perhaps some portion should go back to the most prolific editors. This could help attract and retain younger volunteers.
For now, this remains an open question.

The Future of Knowledge: Wikipedia vs. AI
There's a bigger story here about the future of knowledge itself.
For 25 years, Wikipedia has been humanity's best free encyclopedia. But now AI is changing how people access information. Instead of searching for an article and reading it, people ask AI assistants. The AI reads hundreds of sources and synthesizes an answer.
This is generally good. It's faster and more convenient. But it also means fewer people visit Wikipedia directly. Wikipedia's traffic might stay flat or grow, but the growth will come from AI systems querying Wikipedia, not from humans reading articles.
The question is: What's the long-term sustainable model for Wikipedia in a world where most knowledge access goes through AI intermediaries?
Option 1: Wikipedia becomes a data source for AI companies, funded by licensing agreements. Wikipedia's public website continues to exist, but it's increasingly a content creation platform for AI training rather than a direct-to-consumer product.
Option 2: Wikipedia figures out how to integrate AI into its own experience. Instead of articles, Wikipedia offers interactive AI-assisted learning. You ask Wikipedia a question, and it synthesizes an answer from across its content. Wikipedia competes with Chat GPT and Perplexity directly.
Option 3: Wikipedia doubles down on its volunteer mission, remains primarily donor-funded, and treats AI partnerships as supplementary revenue. This is essentially the current path.
The Wikimedia Foundation seems to be pursuing a mix of these strategies. The partnerships generate new revenue (Option 1). The experiments with games and video suggest they're exploring how to engage new audiences differently (Option 2). And donations remain a core funding source (Option 3).
Over the next five years, we'll see which approach actually works. One thing is certain: Wikipedia's role in the knowledge ecosystem is changing, and these partnerships are just the beginning.

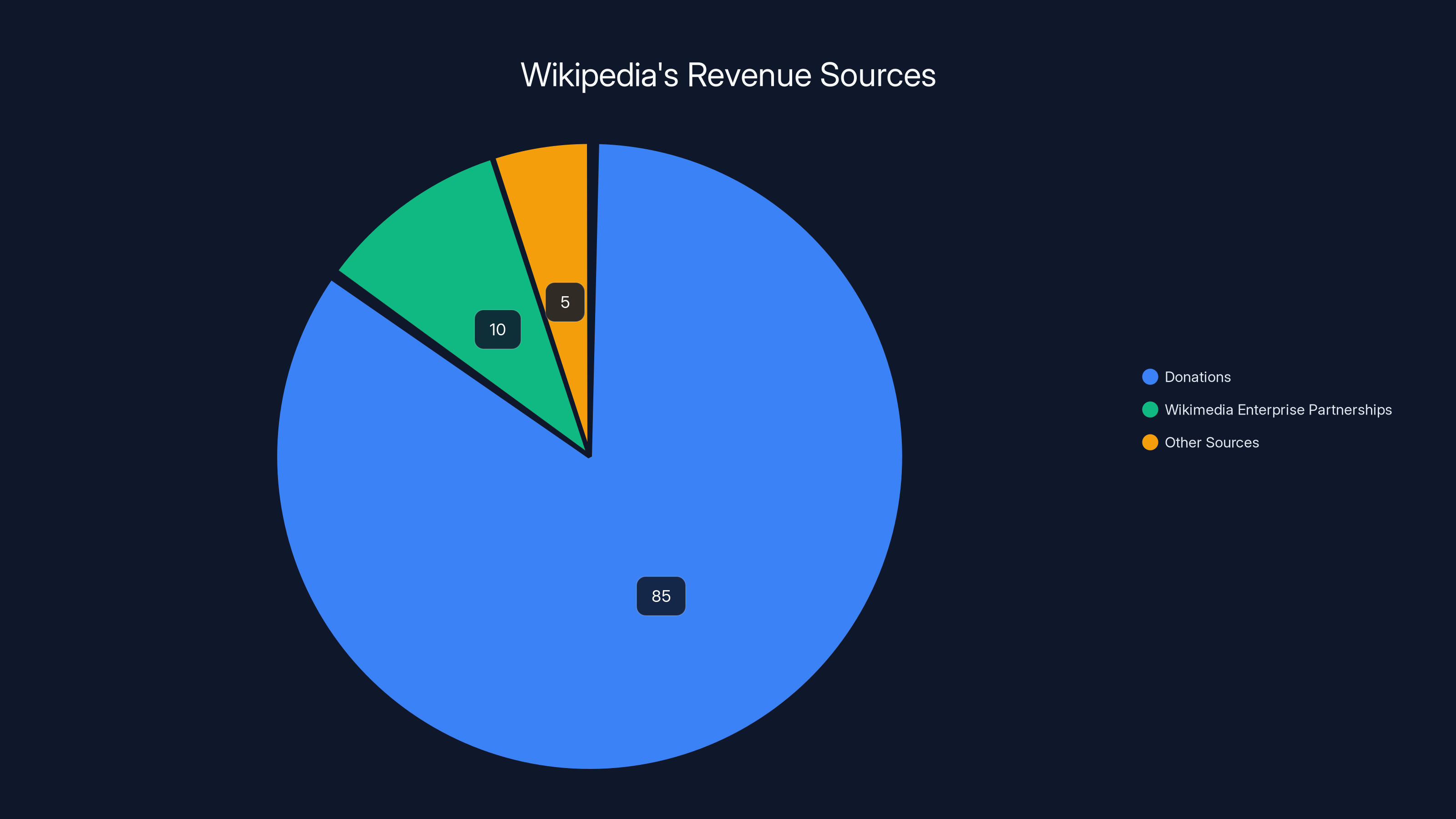
Estimated data shows that the majority of Wikimedia Foundation's budget is funded through donations, with a smaller portion coming from new enterprise partnerships and other sources.
The Legal and Ethical Dimensions
Wikimedia's partnerships raise some interesting legal and ethical questions.
From a legal perspective, Wikipedia's Creative Commons license allows commercial use. Companies can legally use Wikipedia content to train AI models. But the license requires attribution. When an AI model trained on Wikipedia knowledge provides an answer, should it cite Wikipedia? Currently, most models don't.
Wikimedia Enterprise agreements could require attribution, making the license terms explicit. This would be a benefit to Wikimedia—better visibility for Wikipedia as a knowledge source—and potentially useful for users who want to verify where information comes from.
From an ethical perspective, the question is whether it's right for companies to use volunteer-created knowledge to train commercial AI systems without explicit consent or compensation.
Wikipedia's Creative Commons license allows this. But did the volunteers who wrote articles understand that their work would be used to train AI systems? Probably not. Many Wikipedia articles were written before AI became a mainstream concern.
Some would argue this is fine. The license is clear. Volunteers accepted it. If they didn't want their work used commercially, they shouldn't have contributed under Creative Commons.
Others would argue that even if it's legally permissible, it's not quite right ethically. Volunteers poured effort into creating knowledge expecting it to benefit humanity generally, not to enrich specific corporations.
Wikimedia Enterprise provides a compromise. Companies compensate the foundation. The foundation can then use that money to support volunteers and the mission. It's not direct compensation to individual editors, but it's better than nothing.
But don't expect this to fully resolve the ethical concerns. The tension between "open knowledge should benefit everyone" and "companies are profiting from volunteers' work" will persist.
Practical Implications for Developers and Data Teams
If you're building AI applications or working with data, what should you take from this story?
First: Consider using licensed data sources like Wikimedia Enterprise. Yes, it costs money. But it's cleaner than scraping, legally safer, and ethically justified. For a company that might be worth billions, licensing Wikipedia is trivial. The PR risk of using unlicensed data is much higher.
Second: Understand that public data isn't free forever. Even openly licensed content might have licensing terms you should respect. As AI becomes more valuable, expect more data sources to shift from free to paid.
Third: If you're creating data—writing content, building datasets, publishing research—think about how you want it to be used by AI systems. Do you want to be compensated? Do you want to be cited? Add explicit terms. Don't assume Creative Commons is sufficient if you care about these issues.
Fourth: Think about data lineage and attribution. Wikimedia Enterprise helps with this. Users of Wikimedia-trained models can see where knowledge came from. As AI becomes more important in critical domains like healthcare and law, attribution and traceability will matter.

Wikimedia's 25th Anniversary: More Than Just Partnerships
The AI partnerships are the headline, but Wikimedia Foundation's 25th anniversary announcement included other interesting developments.
The foundation launched a birthday campaign with a new video docuseries showcasing Wikipedia volunteers around the world. This is a bet on storytelling and human interest. Foundations don't fund themselves. People do. People donate when they connect with the mission emotionally.
The foundation also created a "25 Years of Wikipedia" time capsule exploring the site's past, present, and future, with narration from founder Jimmy Wales. This is both a celebration and a statement about Wikipedia's place in history.
Wikipedia's infrastructure also received upgrades. The foundation is modernizing its tech stack to handle more traffic and to enable new features.
The experiments with games and short-form video suggest Wikimedia is thinking creatively about reaching new audiences. Younger people might not use Wikipedia, but they might play a trivia game or watch a historical explainer.
Taken together, these announcements show a foundation that's mature enough to monetize (partnerships) while still committed to its mission (celebrating volunteers, experimenting with engagement).

The Bigger Picture: Knowledge Economics in the AI Era
If you step back, the Wikimedia partnerships are part of a much larger story about knowledge economics in the AI era.
For the first time in history, knowledge has become the primary economic asset. Companies that can access, understand, and apply knowledge have unlimited growth potential. OpenAI is worth
All of these companies depend on knowledge. They scrape the internet, they license data, they build on publicly available information. And for the most part, they don't pay the people or institutions that created that knowledge.
Wikipedia's partnerships are a crack in that model. They show that institutions can negotiate for compensation. They show that companies understand they should pay for quality data.
Will this scale? Will universities start licensing their research to AI companies? Will news organizations demand payment for content used to train models? Will individual creators get compensated when their work is used to train AI?
If the Wikimedia partnerships are a successful precedent, maybe. The next five years will be interesting.
For now, Wikimedia Foundation has found a way to sustain itself in the AI era. Other institutions would be wise to learn from their approach.

TL; DR
- Wikimedia Foundation announced partnerships with Amazon, Meta, Microsoft, Perplexity, and others to license Wikipedia content through Wikimedia Enterprise
- AI companies benefit from structured, authorized access to high-quality knowledge at scale, better than scraping Wikipedia publicly
- Wikipedia gets paid for content that AI companies have been using for free, creating a sustainable revenue stream beyond donations
- Scale matters: Wikipedia serves 5 billion people with 65 million articles in 300+ languages, accessed nearly 15 billion times per month
- This is a precedent showing that AI companies should pay for quality data, not assume everything on the internet is free to use
- Wikipedia's future is evolving from primarily volunteer-powered to a mix of partnerships, licensing, and experimentation with new engagement models

FAQ
What is Wikimedia Enterprise?
Wikimedia Enterprise is a commercial service provided by the Wikimedia Foundation that gives AI companies and other large-scale users authorized, structured access to Wikipedia and other Wikimedia projects. Rather than scraping publicly available Wikipedia, companies using Wikimedia Enterprise receive optimized data feeds, APIs, metadata about article quality and edit history, real-time updates, and technical support designed for machine learning and AI applications at scale.
How do the AI partnerships work?
Companies like Amazon, Meta, and Microsoft sign licensing agreements with the Wikimedia Foundation to use Wikimedia Enterprise. Instead of building and maintaining their own Wikipedia scraping infrastructure, they get official access to clean, structured data from Wikimedia's databases. The foundation provides guarantees about data consistency, quality, and legal coverage through formal commercial agreements. The exact financial terms aren't disclosed, but these are paid licensing relationships.
Why would AI companies pay for Wikipedia when they can scrape it for free?
While scraping Wikipedia is technically legal under its Creative Commons license, Wikimedia Enterprise offers significant advantages: guaranteed reliability and consistency, legal coverage through formal agreements, real-time data feeds optimized for machine learning, metadata about article quality and edit history, multi-language support in 300+ languages, and the ability to cite sources accurately. For companies training massive AI models, these benefits justify the licensing cost, which is trivial compared to the value they extract.
How much revenue do these partnerships generate for Wikipedia?
The Wikimedia Foundation hasn't disclosed specific financial terms for individual partnerships or total licensing revenue. However, these deals represent a meaningful new revenue stream for an organization with a
Does this compensation reach individual Wikipedia volunteers?
Currently, all licensing revenue goes into the Wikimedia Foundation's general operating budget, not directly to individual editors. The foundation has historically resisted paying volunteers, maintaining that Wikipedia operates on a volunteer labor-of-love model. However, improved funding from partnerships benefits volunteers indirectly through better foundation support, infrastructure, and community tools.
What does this mean for Wikipedia's independence?
Wikimedia Foundation remains independent, as it owns the partnerships and maintains editorial control through its nonprofit structure. The partnerships are licensing arrangements, not investments or acquisitions. Wikipedia's content and governance are controlled by volunteers and the foundation's board, not by Amazon, Meta, or Microsoft. However, as licensing becomes an increasingly important revenue source, the foundation will need to balance partnership relationships with maintaining editor independence.
Could these partnerships lead to Wikipedia being sold or becoming commercialized?
Unlikely. Wikimedia Foundation is a nonprofit with a mission-driven structure. Its bylaws prevent it from being acquired or converted to a for-profit entity. The partnerships are revenue sources, not steps toward commercialization. However, as more revenue comes from corporate partnerships rather than individual donations, the foundation will face ongoing challenges about maintaining its culture and mission.
How does this affect individual Wikipedia users?
For people who read Wikipedia directly through Wikipedia.org, nothing changes immediately. Wikipedia remains free, ad-free, and volunteer-powered. The partnerships happen behind the scenes and mainly affect companies building AI products. However, in the longer term, these partnerships fund Wikimedia Foundation operations, infrastructure improvements, and support for volunteer editors, which ultimately benefits the quality and sustainability of Wikipedia itself.

Conclusion: The New Economics of Knowledge
Wikipedia's 25th birthday brought more than just nostalgia and celebration. It brought a fundamental shift in how one of the internet's most important institutions sustains itself.
For a quarter-century, Wikipedia proved that a massive, high-quality encyclopedia could be built and maintained by volunteers with zero business model. That was remarkable. That was proof that knowledge could be decoupled from profit.
But times changed. AI changed everything. Suddenly, Wikipedia's content became incredibly valuable. Not just to individual users, but to corporations building AI systems worth tens of billions of dollars. Companies were already using Wikipedia extensively. The question became: Should they keep doing this for free?
Wikimedia Foundation's answer was reasonable and measured. They said: Yes, but you should pay us. The content is valuable. You're profiting from it. We should share in that profit so we can sustain our mission.
This is the future of knowledge economics. Not all content will follow Wikipedia's path. Some creators will continue sharing freely. Some will put content behind paywalls. Some will license to AI companies at premium prices.
But Wikimedia's partnerships establish an important principle: publicly useful knowledge created through public effort should be compensated when used for private profit. The companies creating AI aren't being hurt by paying for Wikipedia. It's trivial to them. And it's transformative for the Wikimedia Foundation.
If other institutions—universities, libraries, news organizations—follow this model, we might create a healthier ecosystem where knowledge creators are actually compensated for the value they create.
That would be worth celebrating.
For now, Wikipedia's partnerships are a victory. They're a sign that even volunteer-powered institutions can negotiate with tech giants and secure their futures. And they're a precedent that might reshape how AI companies source and value knowledge for the next 25 years.
Wikipedia got paid. And that changes everything.

Key Takeaways
- Wikimedia Enterprise partnerships with Amazon, Meta, Microsoft, Perplexity and others create new revenue stream for Wikipedia beyond donations
- AI companies benefit from licensed, structured access to high-quality Wikipedia data optimized for machine learning at scale
- These partnerships establish important precedent that AI companies should pay for knowledge, not assume internet content is free
- Wikipedia reaches 15 billion monthly page views across 300+ languages with 65 million articles, making it invaluable for AI training
- Wikimedia Foundation's $150 million annual budget could be significantly boosted by licensing deals worth tens of millions annually
Related Articles
- Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]
- Wikipedia's Existential Crisis: AI, Politics, and Dwindling Volunteers [2025]
- Wikipedia's 25-Year Journey: Inside the Lives of Global Volunteer Editors [2025]
- FTC Finalizes GM Data Sharing Ban: What It Means for Your Privacy [2025]
- Microsoft's $0 Power Cost Pledge: What It Means for AI Infrastructure [2025]
- Apple & Google's Gemini Partnership: The Future of AI Siri [2025]

