![Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]](https://tryrunable.com/blog/wikipedia-s-enterprise-access-program-how-tech-giants-pay-fo/image-1-1768468032095.jpg)
Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]
TL; DR
- Wikimedia Enterprise: Microsoft, Meta, Amazon, Perplexity, and Mistral AI now pay for premium Wikipedia API access launched in 2021
- Why It Matters: Tech giants need reliable, structured data for AI training; Wikipedia gets sustainable funding to support 400+ projects
- The Deal: Companies pay undisclosed fees for "tuned" Wikipedia versions with custom features, better data formatting, and priority support
- The Sustainability Play: The Wikimedia Foundation argues this creates mutual benefit, keeping Wikipedia healthy while giving AI companies verified content sources
- Bottom Line: AI training costs are shifting toward paying for quality data rather than scraping freely available information
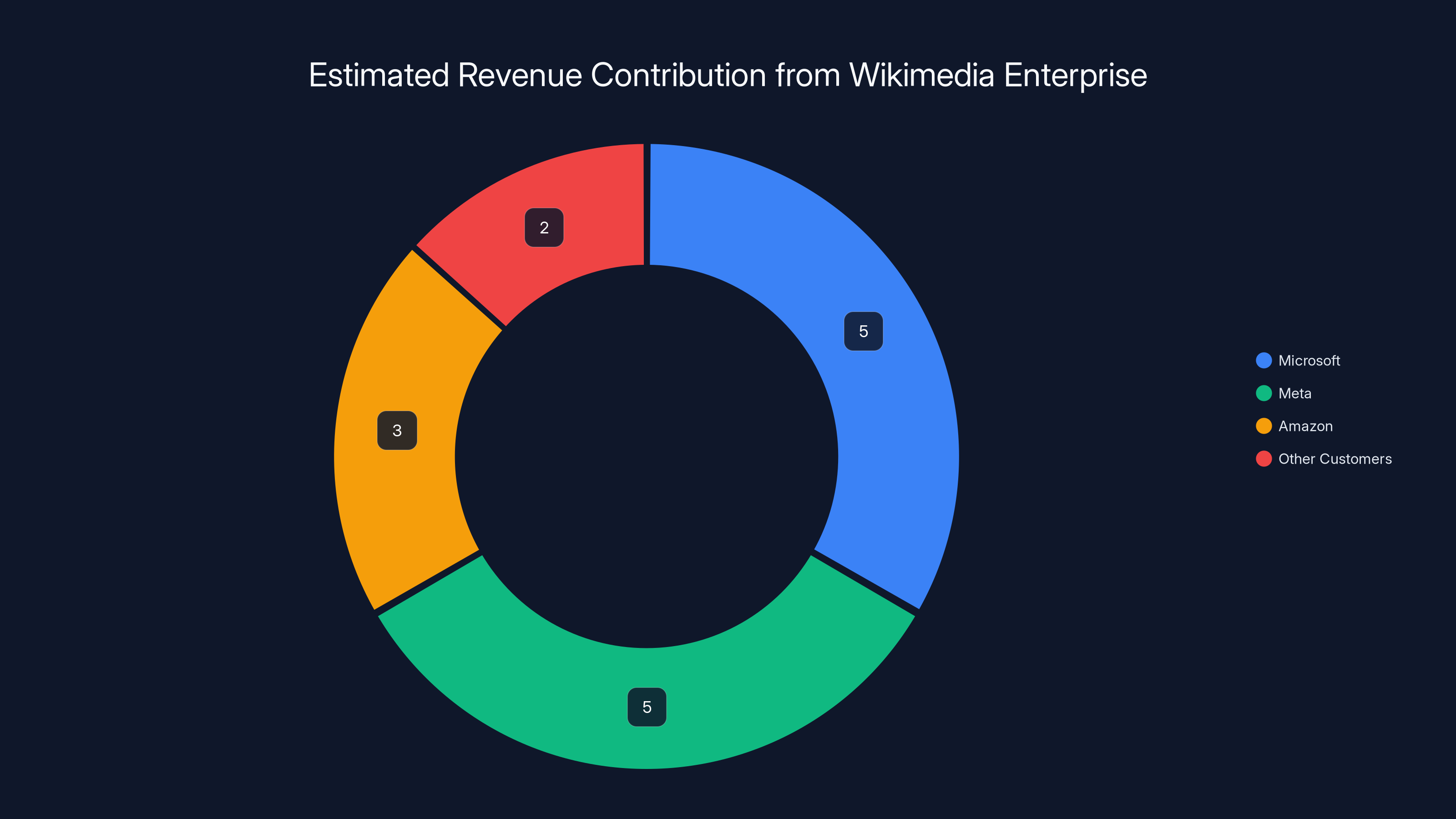
Estimated data suggests that major companies like Microsoft, Meta, and Amazon contribute significantly to Wikimedia's budget, potentially accounting for 10-15% of its annual operating budget. Estimated data.
Introduction: The Day Wikipedia Became an Enterprise Product
For 25 years, Wikipedia operated on a simple promise: free knowledge for everyone. Volunteer editors built it, readers accessed it for nothing, and tech companies scraped it without asking permission. But that era's quietly ending. On Wikipedia's 25th anniversary in 2025, the Wikimedia Foundation announced something that would've seemed unthinkable a decade ago: Microsoft, Meta, Amazon, Perplexity, and Mistral AI are now paying for special access to Wikipedia.
The numbers aren't public. The deals aren't detailed. But the trend is unmistakable. The world's largest AI companies—the ones training models that'll shape how billions of people interact with information—are now opening their wallets to one of the internet's most important knowledge repositories.
This isn't about slapping ads on Wikipedia. It's about something more fundamental: the commodification of reliable data in the AI age. As large language models become increasingly central to everything from customer service to drug discovery, the data they're trained on matters enormously. Bad data means biased models. Unreliable data means confidently wrong answers. And free data, it turns out, comes with hidden costs.
The Wikimedia Foundation's Lane Becker—the outfit's senior director of earned revenue—frames it differently. He describes Wikimedia Enterprise as a mutual-survival strategy. Wikipedia depends on donations and grants to sustain 400+ projects in dozens of languages. AI companies depend on high-quality, verified information to build models people can trust. When Microsoft pays for enterprise access, they're not buying Wikipedia. They're buying reliability, structure, and the knowledge that comes from millions of volunteer editors working for free.
But here's what makes this fascinating: it reveals something uncomfortable about how AI is actually built. These companies aren't paying because they're nice. They're paying because they need to. And the fact that they do, publicly and at scale, tells us something important about the future of AI training data, content licensing, and what it means to build intelligence at scale.
This article digs into what actually happened, why it matters, and what it means for everyone building with AI—including platforms like Runable, which uses similar data sourcing strategies for AI-powered content generation.
The Wikimedia Enterprise Program: A Brief History
The Wikimedia Enterprise initiative didn't materialize overnight. It launched quietly in 2021, four years before these major announcements. The original vision was pragmatic: create a premium tier of access to Wikipedia's API (Application Programming Interface) that gave large organizations additional features, better data formatting, and dedicated support.
Think of it like software subscription models. Open source databases like Postgre SQL are free, but companies like Amazon offer managed Postgre SQL services you pay for. You get the same underlying database, but with monitoring, backups, scaling, and support baked in. Wikimedia Enterprise works similarly—the content is the same, but the delivery is optimized for commercial users with specific technical needs.
The program's early years were quiet. Google signed on as the first major customer, which made strategic sense. Google's search index already crawls Wikipedia heavily; paying for enterprise access gave them cleaner data pipelines and probably custom features for their specific use cases.
But Google paying for Wikipedia access barely made headlines. It felt expected. Tech giants buy access to all kinds of data and services. What changed in 2025 is the sheer scale and specificity of who's paying, and—crucially—for what purpose.
Microsoft joining the program signals something deeper. Microsoft has its own LLMs, its own data infrastructure, and partnerships with Open AI. If even Microsoft thinks paying for structured Wikipedia access is worth it, other AI companies follow quickly. Perplexity, a search engine built on LLMs, needs reliable sources to cite. Mistral AI, a French LLM company, needs training data that doesn't introduce European regulatory complications. Meta, with its own LLM research, likely needs the same thing everyone else does: verified, cleanly formatted information they can train on without legal headaches.
Amazon's involvement is particularly interesting. The company, through AWS, already serves massive amounts of data. But for its AI initiatives—Bedrock, Q, and various enterprise AI services—Amazon probably wants to offer customers Wikipedia-sourced answers with verified sourcing. That requires clean pipelines and rights clarity.
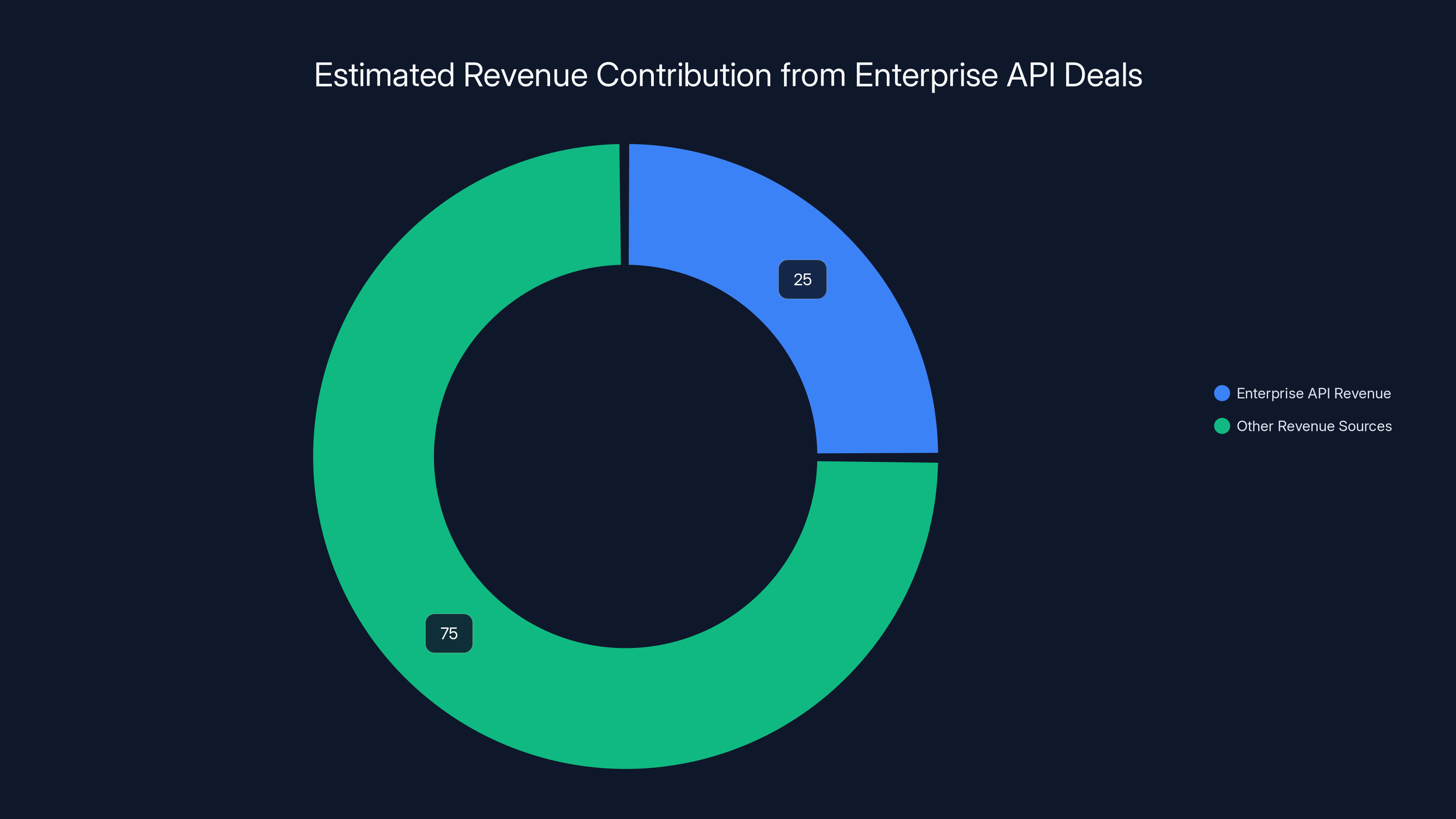
Estimated data suggests enterprise API deals could contribute up to 25% of Wikimedia's budget, marking a significant shift towards a more sustainable revenue model.
Why Companies Are Paying: The True Cost of Data Quality
Here's a question worth asking: Why would Microsoft pay for Wikipedia when they could just scrape it for free? They already have the infrastructure. They have the scale. They have lawyers who know how to navigate IP law. So why hand over money?
The answer reveals something crucial about modern AI: data quality matters more than quantity. You can train a model on a billion low-quality documents and end up with something that sounds fluent but makes up facts confidently. Or you can train on a smaller set of verified, carefully edited content and get something more reliable. The latter is what enterprise customers actually want to buy.
Wikipedia represents something rare: a massive knowledge base that's been edited by millions of volunteers, fact-checked across overlapping sources, and continuously refined. An article on molecular biology might've been touched by 50+ editors over 15 years. Bad information gets corrected. Biases get flagged. Citations get verified. It's not perfect, but it's significantly better than average internet content.
When Becker says the enterprise version is "tuned" for commercial use, he means several things. First, the data is structured differently. Wikipedia articles, when you scrape them, come as messy HTML. For an AI model, you want clean data: structured metadata, labeled sections, clear citation markers, and linked references. That's not something you get from a basic Wikipedia crawl. Someone has to process it.
Second, enterprise access probably includes API features that don't exist in the public version. Real-time update feeds so you know when information changes. Batch download capabilities for model training. Possibly even custom data extraction—if Meta wants all Wikipedia articles about advertising formats with specific metadata fields, Wikimedia can build that without making it public.
Third, there's the legal clarity. When you scrape Wikipedia without permission, you're technically in a gray area. Wikipedia's content is under Creative Commons licenses, but the terms have complexity. Paying for enterprise access means explicit rights, terms of service, and legally defensible use. If a Wikimedia Foundation official explicitly says "You have our permission to train your model on this data," that's worth something to a legal team.
But there's another layer. Training modern LLMs requires immense computational resources. A single training run can cost millions of dollars in compute time. In that context, paying a few million dollars annually for Wikipedia access is insurance. You're making sure the data going into that expensive training process is as good as possible. Garbage in, garbage out—even at billion-dollar scales.
Final point: these companies need to cite their sources. When Perplexity shows you an answer from Wikipedia, it links to the Wikipedia article. When Microsoft builds features into Copilot or search products that reference Wikipedia, they need to know exactly what they're citing and maintain links. That requires more sophisticated access than a basic scrape provides.
The Sustainability Argument: Why Wikipedia Needs This Money
The flip side of this deal is worth understanding, because Becker's framing—that this is mutual survival—isn't just rhetoric. It's probably true.
Wikipedia's funding model has always been precarious. The Wikimedia Foundation raises money through donations (many small), grants from foundations, and limited corporate partnerships. The annual operating budget for all 406 Wikimedia projects is around $180-220 million. That sounds large until you realize it covers:
- Server infrastructure serving 20+ billion monthly page views
- Staff across multiple countries and time zones
- Tools and services for millions of volunteer editors
- Community moderation and anti-vandalism systems
- Localization into 300+ languages
- Mobile apps, API infrastructure, and data backups
Break that down per page view and you're talking about pennies. Wikipedia is, by any reasonable measure, radically underfunded relative to its importance.
Meanwhile, the AI boom is creating new demands. Search engines like Google and Perplexity query Wikipedia constantly. AI training pipelines consume huge amounts of data. Every LLM improvement cycle means more data consumption. Wikipedia's servers feel this pressure directly.
Becker's argument is straightforward: companies building AI products that depend on Wikipedia should contribute to its sustainability. Not because they're legally required, but because they have aligned incentives. If Wikipedia collapses, these companies lose a critical information source. If Wikipedia thrives, they have access to verified, high-quality content.
This is actually a more honest arrangement than what happens with most internet data. Google, Meta, and Amazon make billions training models on freely scraped content created by others. Teachers write lesson plans. Journalists write articles. Engineers write code comments. All of it gets vacuumed up for model training with minimal compensation to creators.
Wikipedia's model—where creators are volunteers who explicitly chose that role—is different. But the principle's similar. The Wikimedia Foundation is basically saying, "If you're going to profit from Wikipedia, help us sustain it." It's not regulation or law. It's a negotiated business relationship.
Does the money go back to volunteer editors? Mostly no. It goes to infrastructure and operations. Wikipedians have debated this. Some volunteers argue the money should directly compensate the people who write and edit. Others argue that would fundamentally change Wikipedia's culture, potentially introducing incentives to gaming the system. The current model keeps Wikipedia as a labor-of-love project while using corporate money to build better tools and infrastructure.
What Microsoft, Meta, and Amazon Actually Get
The exact features each company receives aren't public, and that's deliberate. But we can infer quite a bit from what enterprise API access typically includes.
For Microsoft, enterprise access to Wikipedia serves several purposes. Copilot, Microsoft's AI assistant, now powers features across Windows, Office, and Azure. Some of those features benefit from Wikipedia sourcing. Microsoft Bing uses Wikipedia as a ranking signal. And broadly, any Microsoft product using LLMs benefits from cleaner training data.
What does Microsoft probably get with enterprise access?
- Dedicated support: A Wikimedia contact they can reach when they need changes or have integration questions
- Custom data formats: Wikipedia structured in ways that work better for their model training pipelines
- Real-time updates: Feeds telling them when articles change, so their training data stays current
- Batch data delivery: The ability to download specific subsets (e.g., all science articles, all historical documents) without scraping
- Commercial licensing clarity: Explicit rights to use Wikipedia content in commercial products
For Perplexity, the need is more obvious. Perplexity's entire business model depends on citation. When you ask Perplexity a question, it searches the web, finds relevant sources, and synthesizes them into an answer—with links back to the original sources. Wikipedia is one of their most valuable source types because Wikipedia articles are well-researched, well-structured, and mostly reliable.
Perplexity probably gets:
- Fast, reliable API access without rate limits
- Enhanced search capabilities specific to Wikipedia's structure
- Rights to display Wikipedia content with proper attribution
- Access to article metadata (edit history, reliability ratings, citations)
For Meta, the motivation is more opaque because Meta's AI strategy is less visible to the public than Microsoft's. But Meta runs:
- LLa MA, an open-source LLM used by researchers and startups
- Internal AI systems for content moderation, recommendation, and generation
- Research initiatives around AI safety and alignment
- Future products using AI that aren't publicly announced yet
Meta likely wants Wikipedia access for training data, but also as a knowledge base their AI can reference. If your AI system can cite Wikipedia accurately, users trust it more.
Amazon (through AWS) is probably the most commercially motivated. Amazon offers Bedrock, a service that lets customers build AI applications using various LLMs. Some customers will want models trained on Wikipedia. Amazon likely pays for enterprise access to offer this as a premium service.
Amazon also runs Q, an enterprise AI assistant. Having legitimate access to Wikipedia data, properly licensed, makes that product more defensible legally.
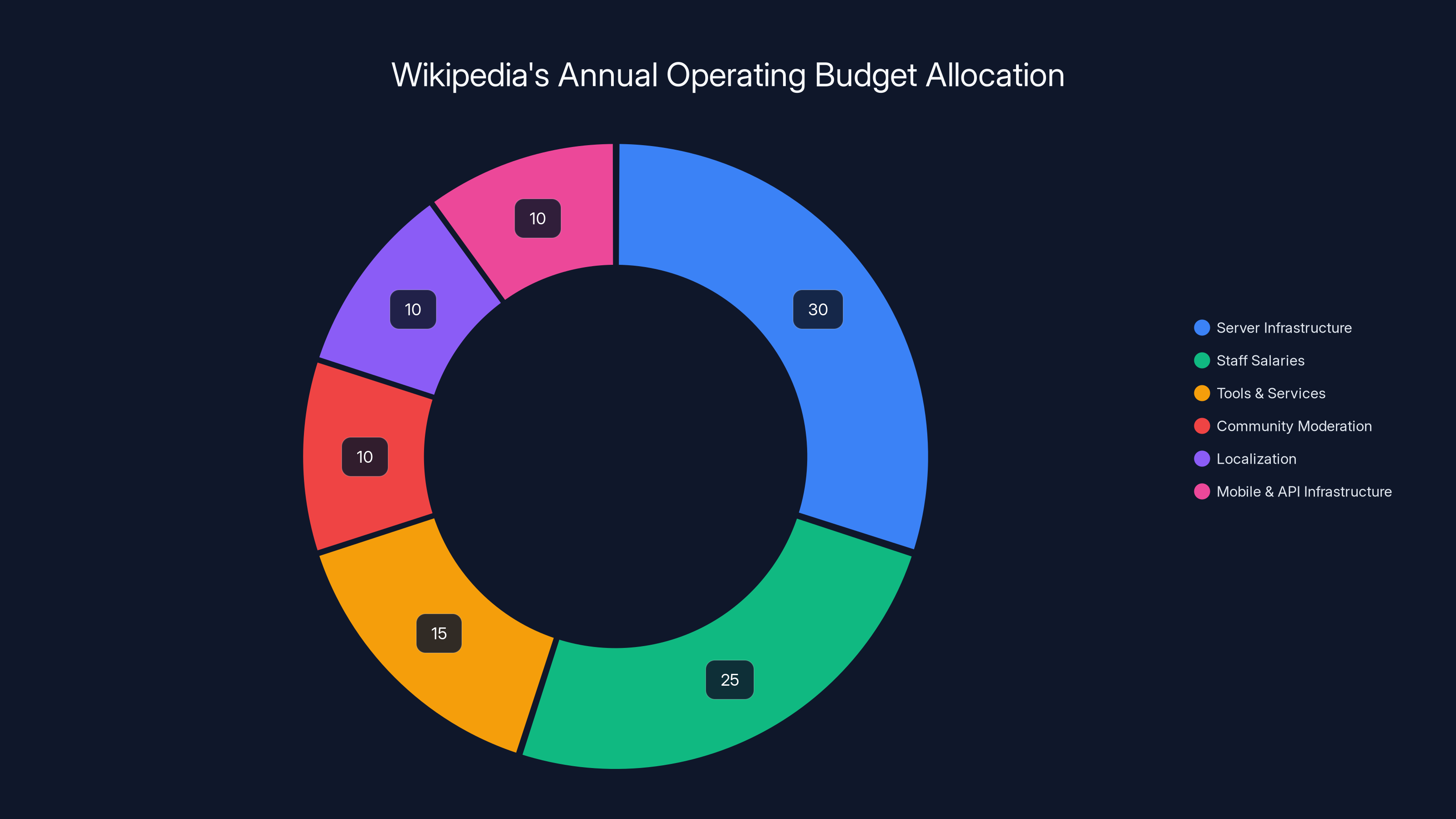
Estimated data shows server infrastructure and staff salaries consume the largest portions of Wikipedia's budget, highlighting the extensive resources needed to maintain its global operations.
The Broader Shift: Licensing vs. Scraping
These deals represent a fundamental shift in how AI companies source training data. For the first time decade, the assumption was "everything on the internet is training data." Companies built massive scrapers that pulled information from everywhere: websites, news sites, books (some legally, some... not), Reddit, Git Hub, You Tube transcripts.
This was cheap. You write a crawler, point it at the internet, wait for your hard drives to fill up, and suddenly you have gigabytes of training data for essentially zero marginal cost.
But there's friction now. Regulators care about data provenance. Copyright holders are suing. News outlets are negotiating payments for article usage. The New York Times sued Open AI. Authors sued Anthropic. Getty Images sued Stability AI over how they trained image models.
The legal and regulatory environment is tightening. Europe's AI Act requires transparency about training data. The Copyright Office is issuing guidance. State laws are starting to address AI training rights. In this environment, paying for data becomes less of a luxury and more of risk management.
Wikipedia Enterprise represents a early-stage, mature solution to this problem. Instead of scraping (cheap, legally gray), companies negotiate terms and pay (expensive, legally clear). This isn't just happening with Wikipedia. It's happening everywhere.
News organizations are starting to license their content to AI companies. Getty Images offers commercial licensing for training data. Publishers are negotiating with Anthropic and Open AI. This is the future: AI training shifts from extraction to licensing.
Wikimedia Foundation's move is actually ahead of the curve here. They're positioning Wikipedia as a premium data source. They're making explicit deals with major players. And they're doing it in a way that feels collaborative rather than adversarial, unlike the lawsuit-heavy approach other content creators have taken.
The Economics: How Much Are They Paying?
The Wikimedia Foundation hasn't disclosed pricing. But we can make educated guesses based on similar licensing deals and enterprise software pricing.
For enterprise API access, typical Saa S pricing looks like this:
- Base tier: 500K annually for medium usage
- High volume tier: 5M annually for heavy users
- Custom tier: $5M+ annually for companies with specific needs
Given that Microsoft, Meta, and Amazon are among the world's largest tech companies, they're probably not in the base tier. These are likely multi-million dollar deals. Not massive in absolute terms—Meta spends more on data centers monthly. But significant enough to matter for Wikimedia's budget.
Consider the math from Wikimedia's perspective. If they've signed 5-10 enterprise customers (not all announced), and each pays even
For the companies paying? It's a rounding error. Microsoft's annual revenue is
Here's where it gets interesting economically. If Wikipedia starts generating real revenue from these deals, it changes incentives. Currently, Wikipedia's survival depends on donations and grant funding from foundations. That's fragile. A economic downturn, a shift in foundation priorities, or a scandal could threaten funding.
But if Wikimedia can establish Wikipedia as a data commodity—something valuable enough that companies will pay for—they shift from a grant-dependent model to a sustainable business model. Not a high-margin business. But sustainable.
The risk, of course, is mission creep. Wikipedia's value comes from its volunteer community and neutrality. If commercialization ever compromises that—if Wikipedia starts favoring paid customers in content moderation, or if paid features leak into the main encyclopedia—it degrades the asset everyone's paying for.
Becker claims this won't happen. The enterprise program is separate from Wikipedia's editorial process. Volunteers still control what gets published. Companies just get special access to that content. So far, that distinction seems to hold.
Perplexity's Role: The Search Engine Built on Data Sourcing
Of the companies paying for Wikimedia Enterprise access, Perplexity deserves special attention. It's the smallest by market cap, the youngest, and also the most publicly vocal about Wikipedia's importance.
Perplexity is a search engine powered by LLMs. Instead of returning a list of blue links like Google, it synthesizes information from multiple sources and gives you a paragraph-length answer. The core experience is citation. Every claim in Perplexity's answer is attributed to a source with a clickable link.
This creates a hard dependency on source quality. If Perplexity cites Wikipedia inaccurately, users click to Wikipedia and notice the discrepancy. That breaks trust. So Perplexity needs reliable access to Wikipedia's data, and they need to know exactly how it's structured and when it changes.
Perplexity's business model is still evolving. The company offers a free tier and a Pro tier ($20/month). They haven't disclosed revenue. But their unit economics likely depend on keeping search results accurate and well-sourced. Wikipedia is one of their highest-value sources.
Perplexity's founder, Aravind Srinivas, has been publicly supportive of paying for content. In interviews, he's argued that AI companies should compensate creators and content sources rather than scraping everything for free. This isn't just altruism—it's enlightened self-interest. Perplexity's differentiation is reliability and sourcing. Paying for sources is part of that brand promise.
What's interesting is that Perplexity probably derives the most direct value from Wikimedia Enterprise of any company on the list. For Microsoft, Meta, and Amazon, Wikipedia is one data source among many. For Perplexity, it's potentially core infrastructure. They're probably among the most motivated to pay and get reliable, structured access.

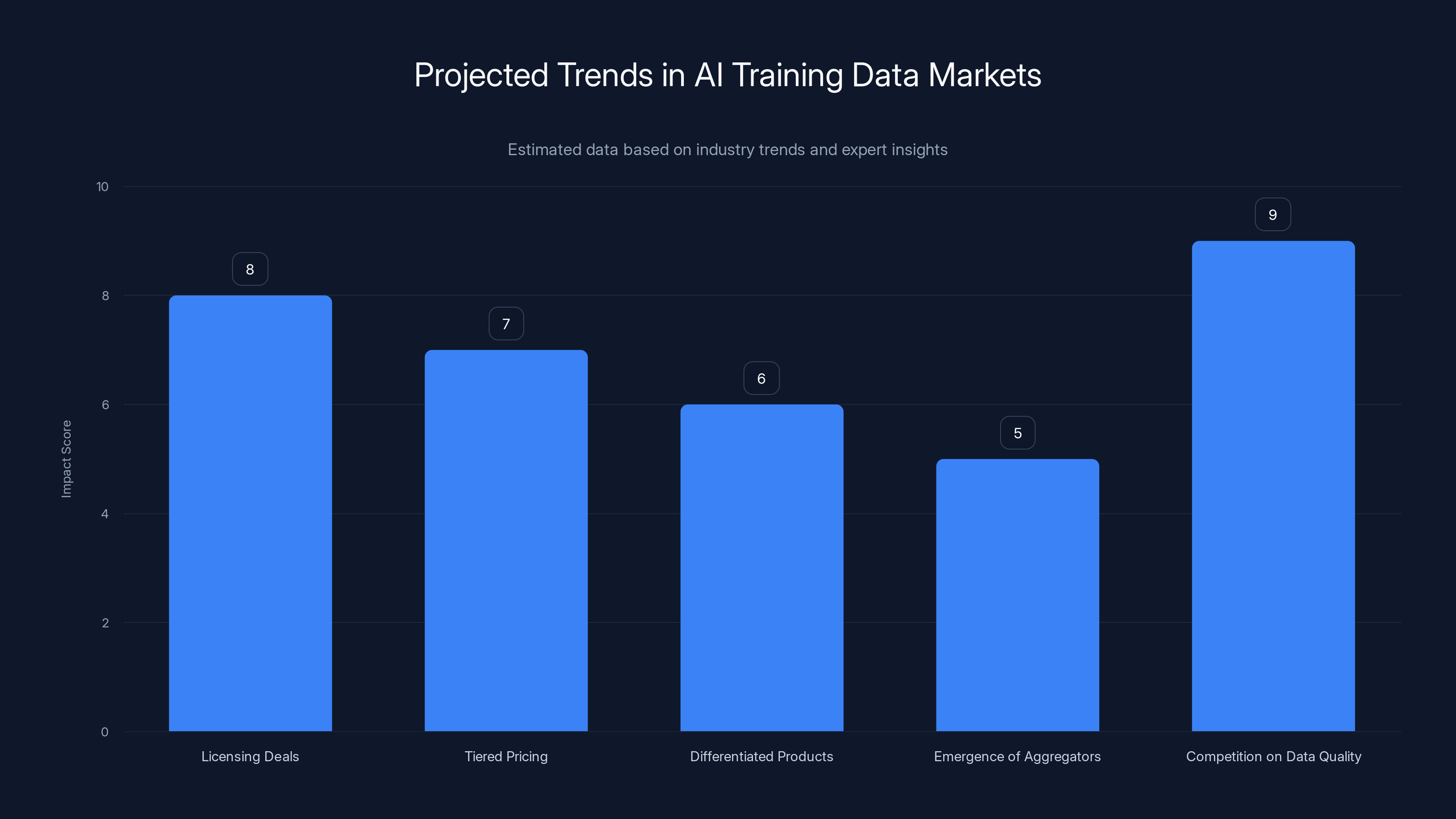
The AI training data market is expected to see significant changes, with competition on data quality and increased licensing deals having the highest impact. (Estimated data)
Mistral AI and Open-Source Implications
Mistral AI's participation in Wikimedia Enterprise is less visible but strategically interesting. Mistral is a European LLM company, and they're pushing against the dominance of Open AI and Anthropic in the proprietary LLM space.
Why would an open-source-leaning company pay for Wikipedia access? A few reasons:
-
Training their base models: Mistral likely trains on Wikipedia data, and having enterprise access ensures legal clarity
-
Building products: Mistral isn't just a research org. They're building products like Codestral and consumer chat interfaces that might benefit from Wikipedia sourcing
-
European compliance: Mistral is based in France, subject to EU regulations. Having explicit licensing from Wikimedia is easier legally than arguing fair use for scraped data
-
Differentiation: In a crowded LLM market, being able to claim "trained on properly licensed, verified data sources" is marketing gold
Mistral's participation also signals something about the open-source LLM space. Even companies committed to open-source models and transparent training recognize the value of high-quality licensed data sources. You can't build great models on garbage data, even if your weights are open-source.
Google's Quiet Dominance and Why It Matters
Google was the first major company to join Wikimedia Enterprise, way back in 2021. But Google barely made headlines. Everyone kind of shrugged and moved on.
Looking back, that's probably the most important deal of them all. Google doesn't need Wikipedia the way a startup does. Google has its own massive knowledge graphs, its own crawl infrastructure, its own ranking algorithms. Google's search engine wouldn't break if Wikipedia disappeared tomorrow.
But Google pays anyway. Why? Probably because:
-
Knowledge Graph: Google's knowledge panels (the right-side boxes on search results with facts, dates, and summaries) are built partially from Wikipedia. Having enterprise access means cleaner, more reliable data to feed into those
-
Search quality: Wikipedia articles are among the highest-quality content on the internet. Using Wikipedia as a ranking signal, and as training data for ranking systems, improves search results
-
Generative AI features: Google's AI Overviews (launched 2024) synthesize information from multiple sources. Having reliable access to Wikipedia helps there
Google's deal probably shaped what Wikimedia Enterprise became. Google said, "Here's what we need, here's what we'll pay." Wikimedia built a product around that. Then other companies saw Google was paying and thought, "If Google thinks this is valuable, maybe we should do it too."
This is classic enterprise software market dynamics. A big customer (Google) validates a product. Other big customers follow. The market grows.
It's also worth noting that Google's deal with Wikimedia is less controversial than, say, Open AI's scraping of web content or Meta's data practices. Google is paying, Wikimedia is benefiting, and Wikipedia remains independent. That's a cleaner story than most Big Tech-content creator relationships.

The Content Creator Angle: Why This Matters for Smaller Players
Wikipedia's Wikimedia Enterprise model is interesting because it's essentially asking: how do online content creators get compensated when their content gets used for AI training?
Right now, that question is contentious everywhere. Creators on You Tube, Medium, Substack, and elsewhere see their content vacuumed up for model training with zero compensation. Even books—copyrighted, published works—are getting trained into models sometimes legally (through fair use arguments) and sometimes... less legally.
Wikipedia's model is interesting because it shows a path forward. Instead of suing, instead of blocking access, instead of fighting in courts, Wikipedia negotiated.
The structure is:
- Content stays freely available: Wikipedia's public version is still free. Everyone can read it.
- Commercial use gets licensed: Companies using it for commercial purposes pay.
- Money funds operations: Revenue helps Wikipedia scale and improve.
This isn't perfect. It doesn't pay individual editors (they remain volunteers). It doesn't solve the question of whether companies should need permission to train on all content (they probably should). But it's a pragmatic model that keeps Wikipedia independent while giving companies legal clarity.
Smaller content creators should pay attention. Blog networks like Medium, newsletter platforms like Substack, and community sites could adopt similar models. Instead of just blocking AI training or fighting it, they could monetize it.
Platforms like Runable, which use AI to generate content, might eventually need to license training data directly from content networks rather than scraping. The Wikimedia model shows what that could look like.
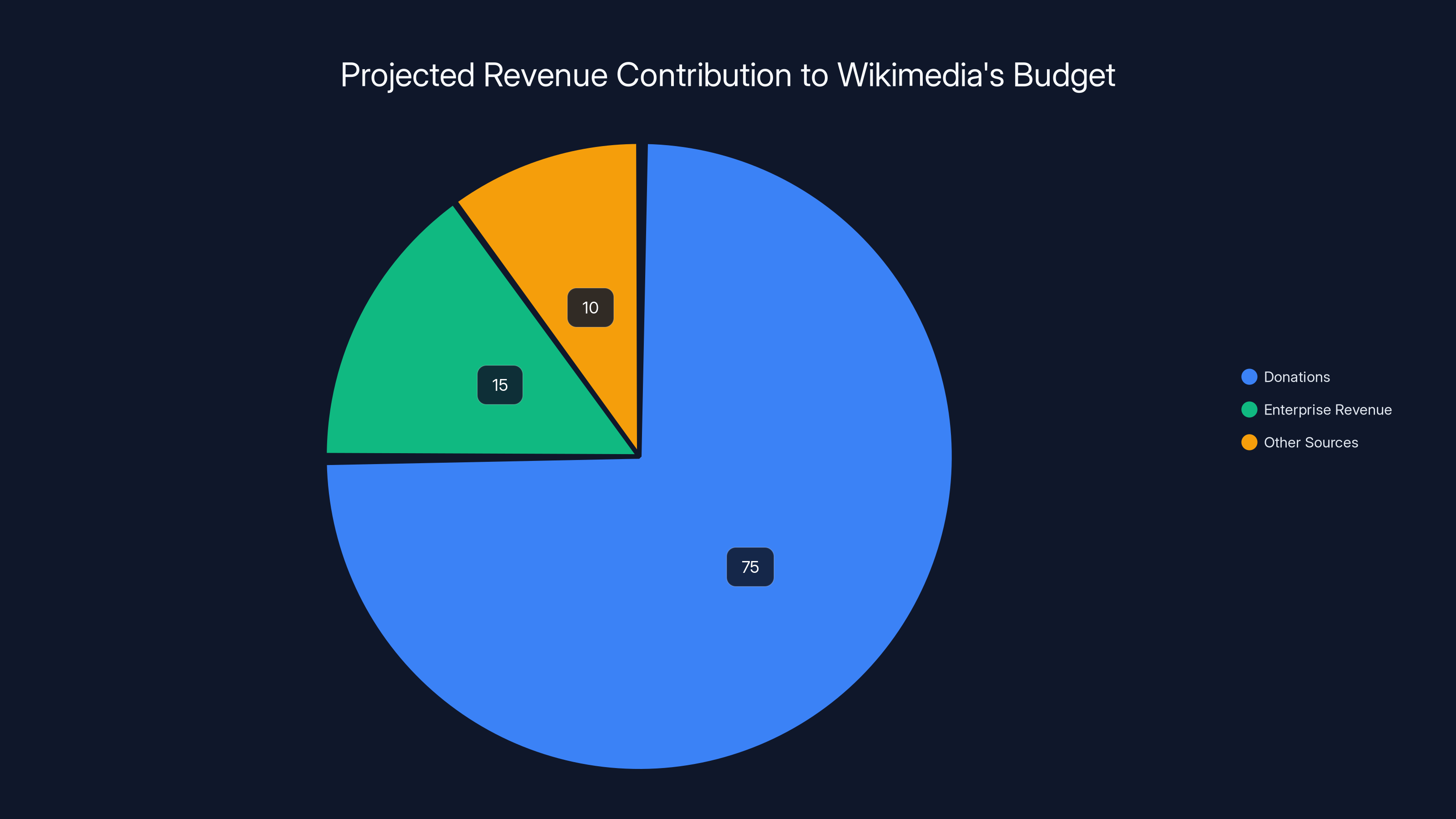
Estimated data shows that enterprise revenue from AI partnerships could contribute 10-15% to Wikimedia's budget, diversifying its income sources.
Regulatory Pressure: The SEC, EU, and Data Provenance
These Wikimedia Enterprise deals aren't happening in a regulatory vacuum. There's real pressure building around data provenance, copyright, and AI training transparency.
In the US:
- The Copyright Office issued guidance in 2023-2024 that AI companies should consider licensing content
- The FTC has launched investigations into data practices
- Congress has held hearings on AI training data
- Multiple lawsuits (Times v Open AI, Authors v Open AI, etc.) are pending
In Europe:
- The AI Act requires transparency about training data and sources
- GDPR compliance questions around scraped personal data
- Copyright Directive adds protections for publishers
- Some countries considering explicit AI tax on training data
In this environment, companies paying for data access can point to actual licensing agreements. It's regulatory insurance. When (not if) regulators ask, "Where did you source your training data?" companies like Microsoft can say, "We licensed it from Wikimedia Foundation and other reputable sources." That's stronger than "We scraped the internet."
For Wikimedia Foundation, being a licensed data provider also provides regulatory shelter. If regulators come asking about data provenance, Wikimedia can point to their enterprise program and say they're actively managing commercial use.
This is probably the real driver of these deals, even if companies don't say so publicly. It's not that Wikipedia was mysteriously valuable until 2025. It's that legal and regulatory landscape shifted, making data licensing more important than scraping.

What Happens When AI Models Train on Wikipedia
Let's get technical for a moment. What actually happens when an AI company uses Wikipedia for training?
Wikipedia data typically goes through a processing pipeline:
- Dump/extraction: Download Wikipedia's full database or specific articles
- Cleaning: Remove markup, templates, metadata
- Tokenization: Break text into tokens (words, subwords)
- Filtering: Remove low-quality articles, stubs, spam
- Deduplication: Remove duplicate or near-duplicate content
- Quality scoring: Rank articles by reliability metrics
- Embedding: Convert text into numerical representations
- Training: Feed into LLM training process
The more structured this data is, the better the model training. If Wikipedia provides pre-processed, cleaned, quality-scored data, steps 2-6 are already done. That saves computational resources and improves training quality.
For very large models like GPT-4 or Gemini, Wikipedia is probably 2-5% of the training data by weight. But it's disproportionately important because it's so high-quality. A model trained on 95% random internet text and 5% Wikipedia performs better than one trained on 100% random internet text, even though Wikipedia is smaller.
So when companies pay for Wikipedia access, they're essentially buying:
- Verified information: Reduces hallucinations in trained models
- Clean formatting: Saves preprocessing costs
- Structured metadata: Helps models understand article structure and importance
- Attribution chains: Models can learn to cite sources
This is why the Wikimedia Enterprise program is actually quite clever. They're not gatekeeping information (it's still free). They're just making it more useful to people who need to process it at scale. And they're charging for that convenience.
The Wikipedia 404 Risk: What Happens Without Sustainable Funding
Here's the uncomfortable truth that motivates these deals. Wikipedia could become unmaintained.
Volunteer-run projects are amazing, but they're fragile. Wikipedia's volunteer editor base has been declining for a decade. New editors are rarer. The median article probably hasn't been substantially revised in years. Some articles are outdated.
Server infrastructure is only getting more expensive. As usage grows (especially from AI training), bandwidth and storage costs increase. The Wikimedia Foundation's current funding model—mostly donations and foundation grants—is not keeping pace with growth.
Here's the scenario: Wikipedia continues operating, but with declining updates. Critical information stays wrong for months. Vandalism takes longer to catch. Mobile and API users experience slowdowns. Gradually, Wikipedia becomes less useful and less trusted.
For AI companies, this is catastrophic. Their models trained on outdated Wikipedia are degraded. Their citation links point to outdated information. Their users lose trust.
By paying for Wikimedia Enterprise, companies are making a bet that keeping Wikipedia healthy is worth it. They're essentially saying, "We'd rather pay for something working reliably than get it free and broken."
Becker frames this as mutual survival, and he's right. In a world where AI companies depend on verified information sources, keeping those sources healthy is not charity. It's infrastructure investment.
The risk is that without diverse funding sources, Wikipedia ends up dependent on a few large customers. If Microsoft suddenly decided to build its own encyclopedia, Wikimedia would lose a major client. That's why they're actively signing multiple partners—to diversify revenue and reduce single-customer risk.

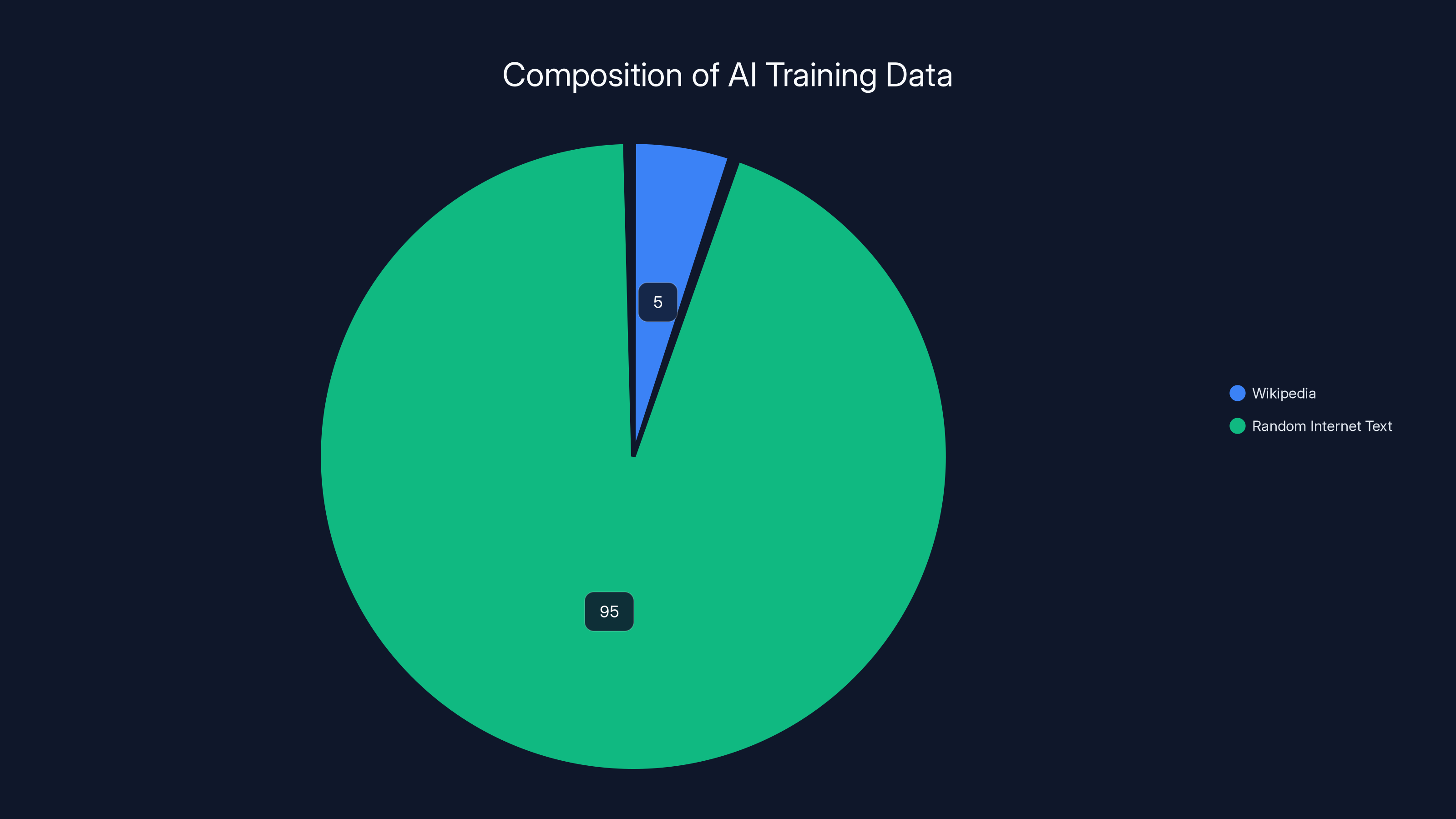
Estimated data shows Wikipedia comprises 5% of AI training datasets but significantly enhances model performance due to its high-quality content.
Transparency and Trust: The Public Critique
Not everyone is happy about these deals. Some Wikipedia volunteers and privacy advocates have raised questions:
Concern 1: Information asymmetry. We don't know what Microsoft or Meta are paying, what features they get, or how they use Wikipedia data. The deals are private. That makes it hard to evaluate whether Wikipedia is getting fair value.
Concern 2: Mission drift. There's a worry that chasing corporate money could gradually change Wikipedia's culture. Even if it doesn't now, will it in 10 years when corporate revenue is bigger than donations?
Concern 3: Who benefits? The companies paying (Microsoft, Meta, etc.) are some of the world's most profitable corporations. Why do they need Wikipedia subsidizing their AI infrastructure? Why not just pay for Wikipedia infrastructure directly without the licensing tier?
Concern 4: Global perspective. These deals are with massive US and European companies. What about Wikipedia contributions and users in the Global South? Do they benefit from revenue that mostly flows to the already-wealthy?
These are fair critiques. The Wikimedia Foundation's response is basically that transparency can improve over time, that corporate partnerships can coexist with mission, that these deals actually help fund Wikipedia's global operations, and that the alternative—letting Wikipedia deteriorate through underfunding—is worse.
They're probably right. But the tension is real, and it's worth watching.
The interesting meta-question is whether this becomes a competitive advantage for Wikipedia's future. If Wikipedia can be financially sustainable through a combination of donations plus strategic enterprise licensing, that's actually stronger than relying on either alone. It makes Wikipedia less vulnerable to funding swings.
Implications for AI Training Data Markets
These Wikimedia deals are early indicators of how AI training data markets might evolve.
Historically, data has been extracted, not bought. But as AI capabilities grow, as regulation tightens, and as content creators get savvy about their leverage, data licensing is becoming normal.
Expect to see:
-
More licensing deals: News organizations, publishers, and content platforms will all start licensing to AI companies
-
Tiered pricing: Just like Wikimedia, others will offer free access to individuals and paid access to companies
-
Differentiated products: Data providers will optimize different tiers for different use cases (training vs citation vs real-time, etc.)
-
Aggregators emerge: Companies that negotiate licenses on behalf of AI companies might appear, bundling rights to multiple sources
-
Competition on data quality: Since companies will be paying for data, providers will compete on quality, structure, and currency rather than quantity
For AI companies and startups, this means data sourcing becomes a material cost consideration. You can't just scrape everything for free. You need to understand licensing, negotiate terms, and budget for data.
For content creators and platforms, it means understanding your leverage. If your content is useful for AI training, you can monetize it. But you need to understand what companies actually want and what it's worth.
Wikipedia is ahead of the curve here. They understood their value, structured a sustainable model, and are executing it. Other content platforms should pay attention.

The Broader AI Data Problem: Quality Over Quantity
One more critical context: why is this happening now, specifically in 2025?
Part of it is regulatory (we discussed that). But part of it is practical. Early-stage LLMs could improve by just adding more data, any data. But we're reaching diminishing returns on scale.
Models like GPT-4 and Gemini are trained on terabytes of data. Adding another terabyte gives smaller improvements. But adding a high-quality, verified source like Wikipedia might give bigger improvements than a terabyte of mediocre web scraping.
This is called the "scaling laws" problem in AI. You can scale data, compute, and model size, but each has diminishing returns. To get real improvements, you need better data, not more data.
Companies are learning this. That's why they're paying for quality. That's why Wikipedia, with its volunteer-edited, fact-checked content, is valuable. That's why news organizations are getting licensing deals. That's why research papers and books are in demand.
It's also why some companies are starting to be more cautious about what data they train on. If your model hallucinates medical advice because it trained on a lot of bad health websites, that's bad. If it cites sources reliably because it trained on Wikipedia, that's good. Quality actually matters.
This is a healthy shift in AI development. For a while, the assumption was "more data = better models." Now we're learning it's actually "better data = better models."
Practical Takeaways: What This Means for AI Practitioners
If you're building with AI—whether at a startup, at a large company, or as an independent developer—these Wikimedia deals tell you something important:
1. Data sourcing is a strategic decision. Don't assume you can just scrape everything. Understand licensing, get legal review, and budget for data sourcing.
2. Quality trumps quantity. A model trained on 100 hours of high-quality data often beats one trained on 10,000 hours of noisy data. Be strategic about data selection.
3. Citation and sourcing matter. If your product cites sources (like Perplexity does), you need reliable, licensed sources. This is becoming table stakes for customer trust.
4. Regulatory risk is real. Companies that can demonstrate they licensed their training data have regulatory cover. Companies that scraped have exposure. Plan accordingly.
5. Infrastructure plays matter. Platforms like Runable that handle AI content generation need to think about data sourcing. As regulations tighten, they'll need clear, licensed data pipelines. Building that now is strategic.
6. Creator relationships matter. If you're building products that leverage creator content (code, articles, etc.), negotiate and compensate. It's better business long-term than fighting creators in court.

Conclusion: The Next 25 Years of Wikipedia and AI
Wikipedia's 25th anniversary gift to itself—formal partnerships with Microsoft, Meta, Amazon, Perplexity, and others—represents a maturation of both Wikipedia and AI.
For Wikipedia, it means shifting from a purely philanthropic model to a sustainable hybrid: donations plus enterprise revenue. That's healthier. Diverse revenue sources mean diversity of incentives and resilience against funding shocks.
For AI companies, it means moving from free extraction to legitimate licensing. That's also healthier. Data sourcing becomes a material cost, which encourages responsible practices. Companies start asking "Do we need this data?" instead of assuming everything is fair game.
The deals probably won't transform Wikipedia financially overnight. Even if each company pays $5 million annually, that's maybe 10-15% of Wikimedia's budget. Not transformative. But it's a foundation to build on.
What's most interesting is the signal it sends: major tech companies now believe it's cheaper and smarter to pay for data than to scrape it. That might seem obvious, but it represents a real shift. Five years ago, companies viewed data as a free resource to be maximized. Now they're licensing.
Becker's argument about mutual survival is actually the most important part. In a world where AI is central to technology, having reliable information sources is infrastructure. Wikipedia is infrastructure. Companies depending on that infrastructure should invest in it.
That's not altruism. It's enlightened self-interest. And honestly, that's a better motivator than charity.
The questions to watch going forward:
- Do other companies join? (Probably, as they recognize the value)
- Does Wikimedia maintain independence, or does corporate influence grow? (This is the real risk)
- Do other content creators adopt similar models? (They should)
- How does this affect AI regulation and data practices globally? (Significantly)
- Can Wikipedia scale to meet both volunteer editors and corporate demands? (This is the technical challenge)
For now, Wikipedia's 25th anniversary announcement is a quiet milestone. Not flashy. But significant. It marks the moment when the internet's most important reference work became both a public good and a commercial asset.
Both things can be true. And hopefully, that's sustainable.
FAQ
What exactly is the Wikimedia Enterprise program?
Wikimedia Enterprise is a commercial licensing initiative launched in 2021 that provides large organizations with premium API access to Wikipedia and other Wikimedia projects. Instead of accessing Wikipedia through basic public APIs, enterprise customers get optimized data formats, dedicated support, real-time update feeds, and explicit commercial licensing rights. This allows companies to use Wikipedia content for AI training, search products, and other commercial applications with clear legal terms and data structures tailored to their technical needs.
Why would companies pay for Wikipedia when they could scrape it for free?
Companies pay for several practical reasons. First, enterprise access provides structured, pre-cleaned data that saves significant preprocessing costs during model training. Second, it offers legal clarity and explicit licensing rights, which is increasingly important as regulators scrutinize AI training data sources. Third, companies get dedicated support and custom features. Most importantly, scraping is increasingly risky legally and regulatorily, while licensing provides defensible data provenance that protects companies from copyright and regulatory liability.
How much are Microsoft, Meta, and Amazon paying for this access?
The Wikimedia Foundation has not disclosed specific pricing for individual customers. However, enterprise API access programs typically range from $1-10 million annually depending on volume, features, and company size. For companies like Microsoft and Meta, payments are likely in the multi-million range, but represent a small percentage of their enormous budgets. For Wikimedia, even relatively modest payments from a few major customers can represent 10-15% of their annual operating budget.
What does this mean for Wikipedia's independence and editorial integrity?
Wikimedia Foundation emphasizes that the editorial process remains fully independent and volunteer-controlled. Enterprise customers don't influence which articles get written, what gets published, or how Wikipedia is edited. They only get special API access to content that Wikipedia publishes anyway. The separation between editorial and commercial operations is intentional to preserve Wikipedia's integrity. However, the tension between commercial revenue and editorial independence is real and worth monitoring long-term.
How does this affect the future of AI training data more broadly?
These deals signal a major shift from free data extraction to licensed data sourcing for AI companies. This trend is likely to accelerate as regulatory pressure increases and copyright holders gain leverage. We can expect more companies and content creators to adopt licensing models, similar to what Wikimedia pioneered. This makes AI training data a material cost for companies, which encourages more responsible and transparent data practices, but also means smaller startups and companies may face higher barriers due to data licensing costs.
Does Wikipedia get paid directly to volunteer editors?
No. Revenue from Wikimedia Enterprise goes to the Wikimedia Foundation's operations, infrastructure, and staff. Volunteer editors remain unpaid. This has been debated in the Wikipedia community, with some volunteers arguing that creators should benefit directly. However, Wikimedia maintains that direct payments would change Wikipedia's culture and create perverse incentives. The current model keeps Wikipedia as a labor-of-love while using corporate revenue to build better tools and infrastructure that benefit everyone.
What other companies might join Wikimedia Enterprise in the future?
Companies most likely to join include other AI and search companies (Google, Duck Duck Go, Chat GPT competitors), news aggregation services, recommendation systems, and enterprise software companies building AI features. Any company using Wikipedia as a training source or citation base has incentive to join for legal clarity and better data access. As regulations tighten around AI training data, joining will become increasingly attractive for risk management.

Conclusion: The Shift to Responsible Data Sourcing
Wikipedia's Wikimedia Enterprise program represents more than a business deal between a nonprofit and tech giants. It's a watershed moment for how AI companies source training data and how content creators monetize their work.
For decades, the internet's assumption was that data was free for extraction. Companies built AI systems on freely scraped content, texts, images, and code. Creators saw zero compensation. Regulators mostly looked the way.
That era is ending. These deals with Microsoft, Meta, Amazon, Perplexity, and others signal that responsible AI companies now see data licensing as normal operating cost. It's not altruism. It's regulatory hedging, risk management, and recognition that quality data actually improves AI performance.
For startups and smaller companies building with AI, this means budgeting for data costs upfront. For content creators, it means understanding your leverage and negotiating appropriately. For regulators, it means there's a emerging market-based solution to AI training data provenance without waiting for heavy-handed regulation.
Wikipedia itself benefits from revenue diversity and from companies investing in its long-term health. That's the real win here. Sustainable funding means better infrastructure, faster innovation, and a healthier encyclopedia for the next 25 years.
The deals aren't huge financial windfalls for Wikimedia. But they're proof of concept. They show that when companies have clear incentives—regulatory risk, quality requirements, citation needs—they'll pay for data. That's the future of AI training.
It's a future more aligned with the creators and content sources that actually produce knowledge. That's worth something.
Key Takeaways
- Wikimedia Enterprise represents a shift from free data extraction to legitimate licensing, with Microsoft, Meta, Amazon, Perplexity, and Mistral AI as major customers
- Companies pay for structured data, legal clarity, dedicated support, and regulatory insurance—not because Wikipedia is mysterious, but because licensing is smarter than scraping
- The deals signal that quality data matters more than quantity for modern AI training, addressing scaling law limitations with verified, high-reliability sources
- Revenue from enterprise partnerships helps Wikimedia maintain independence while keeping Wikipedia free for all users, creating a sustainable hybrid funding model
- Regulatory pressure around AI training data, copyright, and data provenance is accelerating adoption of legitimate licensing, establishing new market norms
Related Articles
- Meta Compute: The AI Infrastructure Strategy Reshaping Gigawatt-Scale Operations [2025]
- OpenAI's $10B Cerebras Deal: What It Means for AI Compute [2025]
- Grok AI Regulation: Elon Musk vs UK Government [2025]
- Why Grok's Image Generation Problem Demands Immediate Action [2025]
- AI's Real Bottleneck: Why Storage, Not GPUs, Limits AI Models [2025]
- Skild AI Hits $14B Valuation: Robotics Foundation Models Explained [2025]

