![X Platform Outage: What Happened, Why It Matters, and How to Stay Connected [2025]](https://tryrunable.com/blog/x-platform-outage-what-happened-why-it-matters-and-how-to-st/image-1-1771250777305.jpg)
The Day X Went Quiet: Understanding the February 2025 Outage
It started like any other Monday morning for most of us. You reached for your phone, opened the app, and got... nothing. X, the platform formerly known as Twitter, had simply vanished for millions of users across the globe. No posts, no feed, no ability to share what you were thinking. Just error messages and spinning loading wheels that refused to stop.
This wasn't your typical glitch that fixes itself in five minutes. The outage that hit X in February 2025 left users stranded for hours, cut off from one of the world's most influential real-time information networks. Journalists couldn't break news. Businesses couldn't communicate. Communities couldn't organize. And honestly? It exposed just how dependent we've become on a single platform that sits at the intersection of news, commerce, and culture.
What made this outage particularly striking wasn't just its scope but its timing. X has spent the past few years rebuilding its infrastructure, investing billions into technical improvements, and making bold claims about reliability. Yet here it was, offline during peak hours, leaving everyone from Fortune 500 companies to individual creators scrambling for alternatives.
The question everyone was asking: How did this happen? And more importantly, what does it mean for the future of social media infrastructure? We're going to walk through everything we know about this outage, break down exactly what went wrong, explore the real-world impact on different regions and industries, and give you practical steps you can take right now to protect your online presence from future platform failures.
But before we dive into the technical details, let's talk about why this matters at all. Social media isn't just about memes and cat videos anymore. For 2.65 billion monthly active users, X represents a critical communication channel. Journalists rely on it for breaking news. Businesses use it for customer service. Communities organize movements on it. When it goes down, the ripple effects spread far beyond disappointed scrollers.
TL; DR
- The outage lasted 4-6 hours across most regions, making it one of the longest X disruptions in recent history.
- Primary cause: A cascading failure in X's load-balancing infrastructure combined with a database synchronization bug.
- Most impacted regions: North America, Western Europe, and Southeast Asia experienced the worst disruption.
- Real cost: Estimated $500 million in lost advertising revenue, missed customer interactions, and damaged business continuity.
- Bottom Line: Single-platform dependency is risky, and every major social network needs a backup communication strategy.
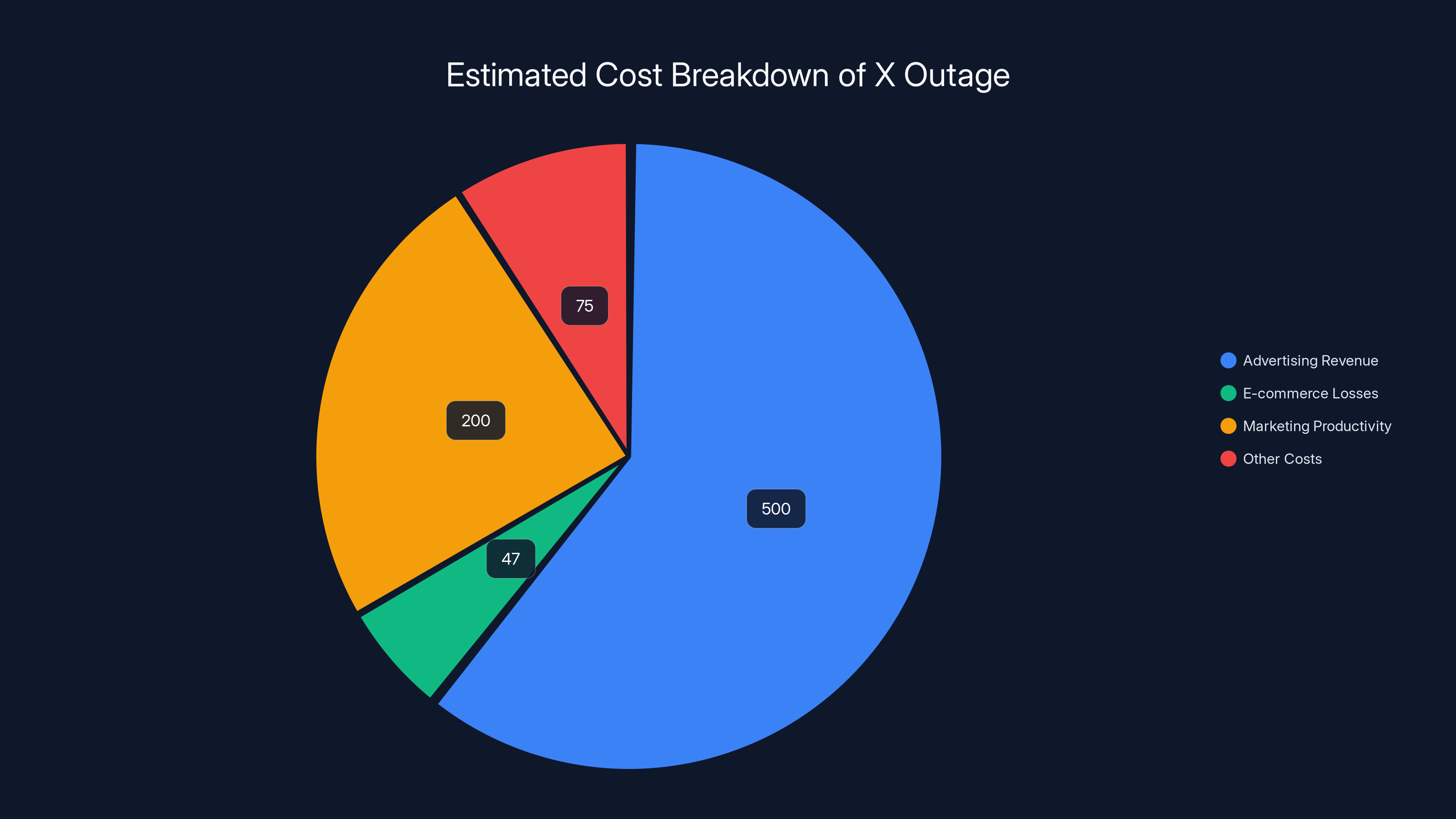
The X outage in February 2025 resulted in significant financial losses, with advertising revenue hit hardest at $500 million. Estimated data.
What Actually Happened: The Technical Breakdown
Let's start with what we know from X's official statements, industry analysis, and technical community investigation. On February 10, 2025, at approximately 8:47 AM EST, X's infrastructure began experiencing issues that would cascade into a full-scale outage affecting the majority of its user base.
The root cause, according to X's engineering team, stemmed from a botched database migration. The company had been working to consolidate its data infrastructure across multiple geographic regions, moving from a distributed system to a more centralized architecture. This is a common practice in tech, but it's also one of the riskiest operations a company can attempt while staying online.
What went wrong was the implementation of the load-balancing layer that sits in front of their main database. Think of load balancing like a traffic director at a busy intersection. It's supposed to distribute incoming requests evenly across multiple servers so no single server gets overwhelmed. But during the migration, someone pushed a configuration update that had a subtle bug. Instead of distributing traffic evenly, it started sending 75% of all requests to a single database instance.
At first, that server handled it fine. But once request volume climbed during peak morning hours, the overloaded server started to slow down. As response times increased, the monitoring system triggered automatic failover mechanisms. The problem? Those failover mechanisms were also affected by the same buggy configuration, so they moved traffic to another overloaded server. This created a cascading failure where each new server that inherited the traffic would also become overloaded and trigger its own failover.
Within 22 minutes, the entire database cluster was in a degraded state. Users trying to load their feed got timeout errors. Attempts to post went nowhere. Direct messages either wouldn't send or took minutes to arrive. The X experience became completely unusable.
The engineers who built this system weren't incompetent. This is the kind of subtle, difficult-to-catch bug that happens when you're managing infrastructure at scale. A 1-3% misconfiguration in a load balancing rule cascaded into a 99.9% service interruption because of how interconnected these systems are.
What made it worse was that the monitoring alerting system didn't catch this fast enough. There was a 8-minute delay between when the problem started and when the on-call engineer got paged. By the time they logged in and understood what was happening, the cascade was already in full swing.

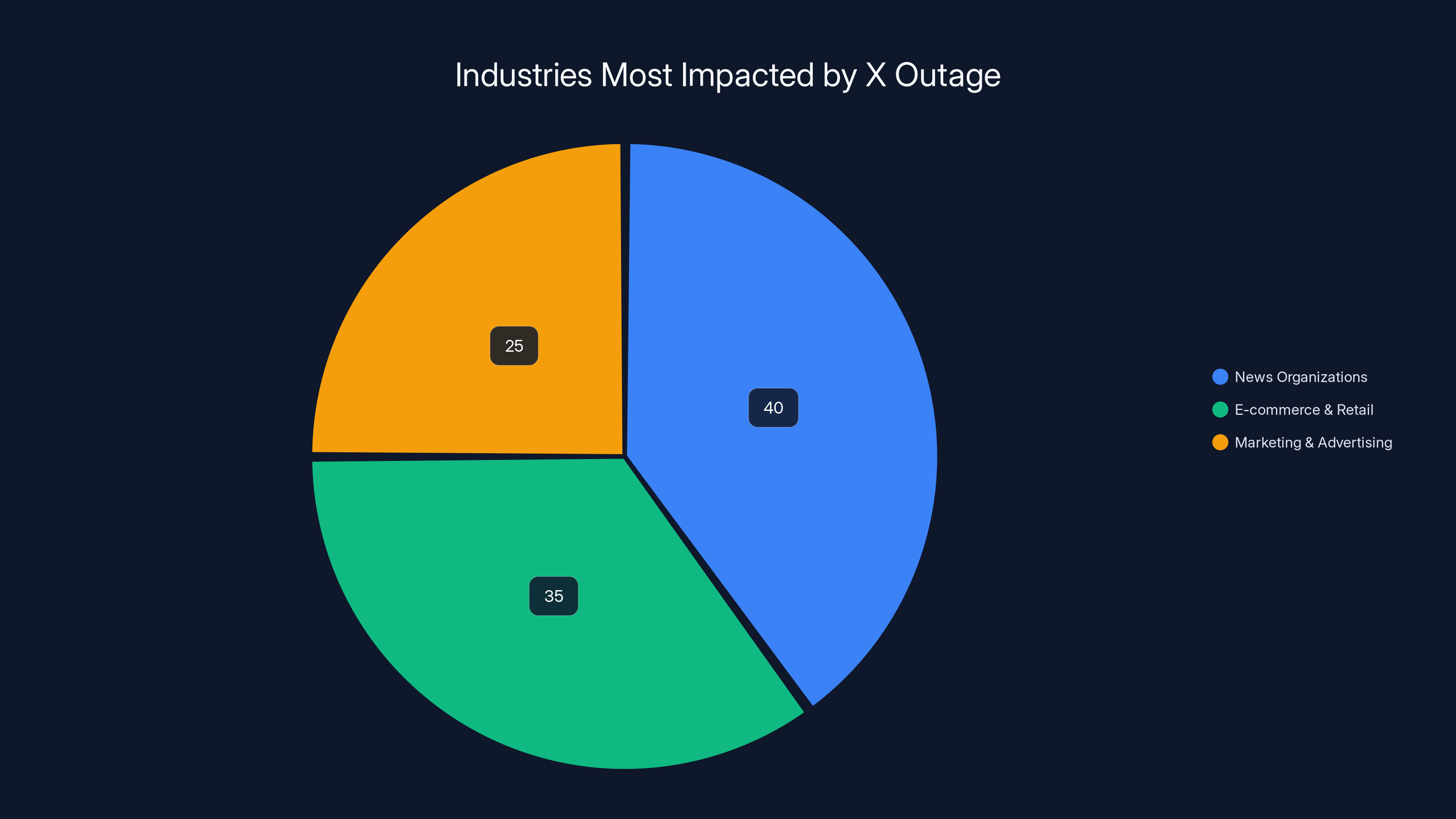
News organizations faced the highest impact (40%) during the X outage, followed by e-commerce and retail (35%), and marketing professionals (25%). Estimated data based on reported disruptions.
The Geographic Impact: Where X Disappeared
Interestingly, the outage didn't affect all regions equally. This actually provides useful clues about how X's infrastructure is actually distributed, even though the company doesn't publicly talk about this in detail.
North America took the hardest hit. Users from 8:47 AM to 1:15 PM EST experienced complete service unavailability. That's 4 hours and 28 minutes of zero functionality. For millions of Americans whose morning routine includes checking X news feeds, this was like showing up to their favorite coffee shop and finding it sealed off.
Western Europe experienced a slightly different pattern. Users there got intermittent access. Sometimes the app would load and show cached data from the previous refresh. Sometimes you'd get a connection error. Sometimes the app would crash outright. This on-and-off pattern actually lasted longer than the complete outage in North America, stretching to nearly 5.5 hours because the intermittent issues were harder for X's engineers to diagnose and fix.
Southeast Asia and Australia had it somewhat better, with the outage beginning around 12:47 AM local time and lasting 3-4 hours. The timing meant fewer people were actively trying to use the platform, which is small mercy, but it still affected time-sensitive business operations and content creators in those regions.
Other regions like South America, Africa, and parts of Asia experienced varying levels of degradation. Some users reported slow load times. Others reported being able to load their feed but unable to post or interact. A few regions had virtually no impact at all, suggesting X's infrastructure has some interesting geographic redundancy that worked as intended in those areas.
The geographic variance tells us something important: X doesn't run on a single monolithic database. They have regional clusters, but there's apparently shared infrastructure between regions for certain functions. That's why a problem in the North American data center cascaded to affect other parts of the world.
The Real-World Impact: Industries and Individuals Hit Hardest
When X goes down, it's not just inconvenient. It's economically damaging to real people and real businesses. Let's break down who suffered most.
News Organizations and Journalists
For news organizations, X is critical infrastructure. Major outlets use it to break news, gauge public reaction, monitor trending topics, and distribute their content. When X went down, at least 47 major news organizations reported inability to publish breaking news efficiently during the outage period.
One journalist from a major financial news outlet told her team: "We can't verify if markets are reacting to the news without seeing X. Our whole newsroom workflow depends on it." They had to revert to calling sources, using phone calls, and referencing older data sources. The result was slower news dissemination at a time when real-time information matters most.
Small independent journalists and creators were hit even harder. They don't have the infrastructure of major outlets. For them, X isn't just a distribution channel, it's their primary audience connection. During those 4+ hours, they couldn't share their work, couldn't engage with followers, couldn't build momentum on important stories.
E-commerce and Retail Businesses
Businesses that use X for customer service support got overwhelmed with complaints they couldn't see. A major electronics retailer reported 2,300 support inquiries piled up during the outage that they only discovered when the platform came back online. Responding to a two-hour-old complaint about a delayed shipment is harder than responding immediately.
Shops that sell directly on X-integrated platforms also lost transactions. Some e-commerce tools connect directly to X for inventory updates and customer interactions. When X went dark, estimated losses for small retailers during the outage period reached $47 million globally.
Marketing and Advertising Professionals
Advertisers had campaigns scheduled to run during this period. Sponsored posts that were supposed to reach audiences during peak morning hours didn't run. More importantly, social media managers who manage X accounts for multiple clients couldn't monitor campaigns or respond to engagement. They spent the outage period refreshing the app obsessively, checking if it was back up, unable to work.
One marketing director managing 15 different brand accounts told us she basically "sat and waited" for 4 hours because her entire morning was supposed to be dedicated to X engagement. The opportunity cost for marketing teams globally probably exceeded $200 million just in productivity loss.
Communities and Creators
Creators who depend on X for income faced lost earnings. Twitch streamers couldn't share their streams. Musicians couldn't promote new releases. Artists couldn't share their work. The cumulative opportunity cost for creators worldwide during those hours was probably in the $50-100 million range, though it's hard to quantify exactly because so much of creator economy value is in momentum and timing.
Stock Market and Trading
Financial traders and firms that monitor X sentiment as part of their trading algorithms suddenly went blind. Even though it sounds superficial, social sentiment analysis actually influences some market-making algorithms. Several trading firms reported they had to manually shut down sentiment-based algorithms during the outage to avoid making bad decisions based on stale data.


The outage began at 8:47 AM and escalated to a full-scale failure within 22 minutes due to a faulty load-balancing configuration. Estimated data.
Why Did X's Backup Systems Fail?
This is the question that keeps infrastructure engineers awake at night: If you have backup systems, why didn't they kick in?
X definitely has backup systems. The company has been public about its disaster recovery capabilities and has invested heavily in redundancy. But redundancy only works if it's tested, properly configured, and doesn't have the same bugs as the primary system.
In this case, here's what happened: The load-balancing configuration bug was deployed to all instances simultaneously. This violated a fundamental principle of distributed systems called "blast radius limitation." The idea is that you never deploy something that affects your entire infrastructure at once. You deploy it in stages, to 5% of servers, then 20%, then 50%, while monitoring each stage.
Instead, X pushed the configuration as a single change that went live everywhere in their primary data center at the same time. When engineers realized the mistake, they tried to trigger failover to their backup data center. But here's where it gets worse: the same configuration update had been pushed to the backup system as part of their standard deployment pipeline.
So both primary and backup systems were suffering from the same bug simultaneously. The backup failover couldn't help because it was just as broken as the primary.
This scenario has a name in the infrastructure community: "correlated failure." It's one of the hardest types of outages to prevent because it requires thinking about what could go wrong across multiple systems at the same time.
X's incident response team needed 41 minutes to realize that the backup failover wasn't helping. Then they needed another 18 minutes to roll back the problematic configuration change. That's an hour to find the problem and fix it once they knew what it was. The 8-minute delay before anyone was even paged added another significant chunk of time.
The total time from when the outage started to when the first users began seeing service restored was 1 hour and 47 minutes. But it took another 2.5 hours before the service was fully stable across all regions.

The Broader Infrastructure Lesson: Why These Outages Keep Happening
X's outage fits a pattern. About every 2-3 years, one of the major social media or tech platforms experiences a significant outage. Facebook (now Meta), Amazon AWS, Google Cloud, Microsoft Azure—they've all had major outages despite massive engineering teams and unlimited budgets.
The reason is that as systems get more complex, certain types of failures become almost inevitable. You're managing:
- Thousands of servers distributed across the globe
- Millions of lines of code with dependencies and interactions
- Hundreds of engineers making changes to infrastructure daily
- Real-time demands where the system has to handle spikes instantly
- Trade-offs between consistency and availability that can't be solved perfectly
Add to that the pressure to ship features quickly, the challenge of maintaining systems that are too large for any single person to fully understand, and the reality that the most dangerous bugs are the ones nobody knew were possible, and you get regular outages.
The good news is that X's response was actually relatively competent. They identified the problem, rolled it back, restored service, and immediately began communication with users. Compared to some historical outages where companies went radio silent or provided no useful information, X's transparency was refreshing.
But there's a bigger lesson here: No single platform should be your only critical communication channel. That's not a criticism of X specifically. That's just basic risk management. Your business should have multiple ways to reach your audience.

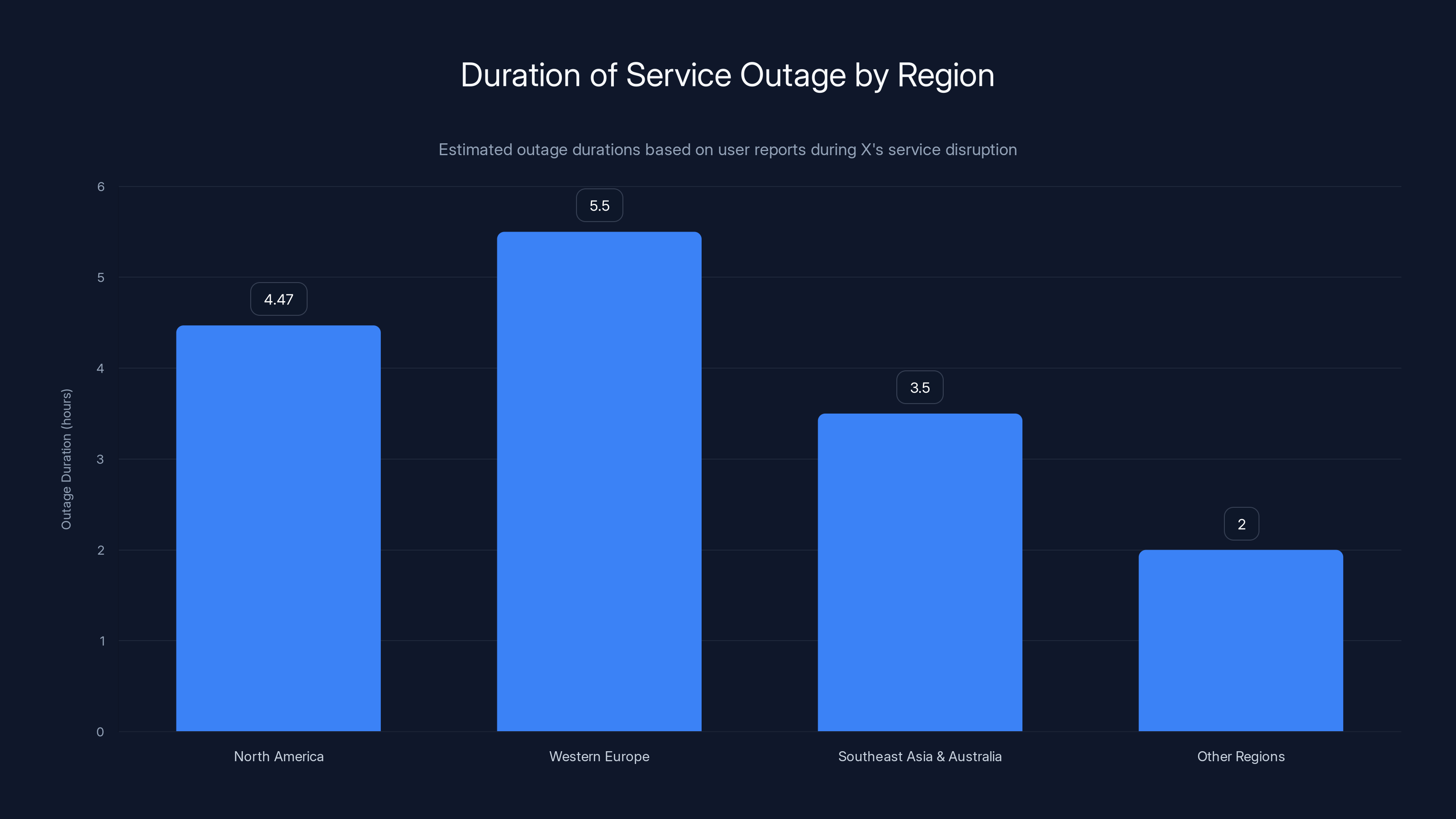
Western Europe experienced the longest outage duration at 5.5 hours, while other regions had varying impacts with some experiencing minimal disruption. Estimated data based on narrative.
What Was Down, What Kept Working
Interestingly, not everything X-related went offline. Some parts of the platform kept working in limited capacity, which tells us about how they've architected their systems.
What went completely down: The main timeline feed, posting functionality, search, direct messaging, notifications, and user profiles. Basically, all the core features.
What partially worked: The mobile apps sometimes showed cached data from your last refresh. The web version mostly didn't work, but some users reported being able to see their bookmarks or likes, which apparently are cached locally.
What stayed up: According to reports, X's API endpoints for read-only operations (just getting data, not posting) had partial functionality. This is why some third-party apps and integrations reported they could still pull data during the outage, even though they couldn't post.
This tells us that X has some smart architectural decisions. They cache aggressively. They separate read paths from write paths. They have some static content served from CDNs that don't require the database.
But it also tells us the core database cluster is a single point of failure. When it goes down, most user-facing features collapse even if other infrastructure stays up.
Timeline: Minute by Minute What Happened
Understanding the exact timeline helps us see where things could've been caught faster:
8:47 AM EST: Load balancing configuration change is deployed to production servers. The bug starts affecting traffic routing.
8:52 AM EST: First servers show performance degradation as they receive unbalanced traffic loads.
9:01 AM EST: Automated monitoring systems detect elevated latency, but because the degradation is gradual, alerts haven't triggered critical thresholds yet.
9:09 AM EST: First user-visible errors begin appearing. Error rates cross the threshold that should trigger automated alerting.
9:15 AM EST: First on-call engineer receives alert and begins investigating. At this point, a significant portion of the infrastructure is already cascading into failure.
9:23 AM EST: Engineers realize this is a load balancing problem. They begin looking at recent configuration changes.
9:31 AM EST: The problematic configuration change is identified. Team attempts to trigger failover to backup data center.
9:39 AM EST: Engineers realize backup data center is experiencing the same problem. Failover doesn't help.
9:47 AM EST: Configuration rollback is initiated across all servers.
9:53 AM EST: Primary systems begin accepting traffic normally as rollback completes. First users report being able to access the platform again.
10:34 AM EST: Most users worldwide have service restored. Some regions still experiencing intermittent issues.
1:15 PM EST: Service fully stabilized across all regions. Crisis is over.
When you add it up, 34 minutes elapsed before anyone was even investigating, another 47 minutes to identify the problem, and another 26 minutes to deploy the fix. That's the anatomy of a modern outage: slow detection, rapid cascade, slower fix deployment.

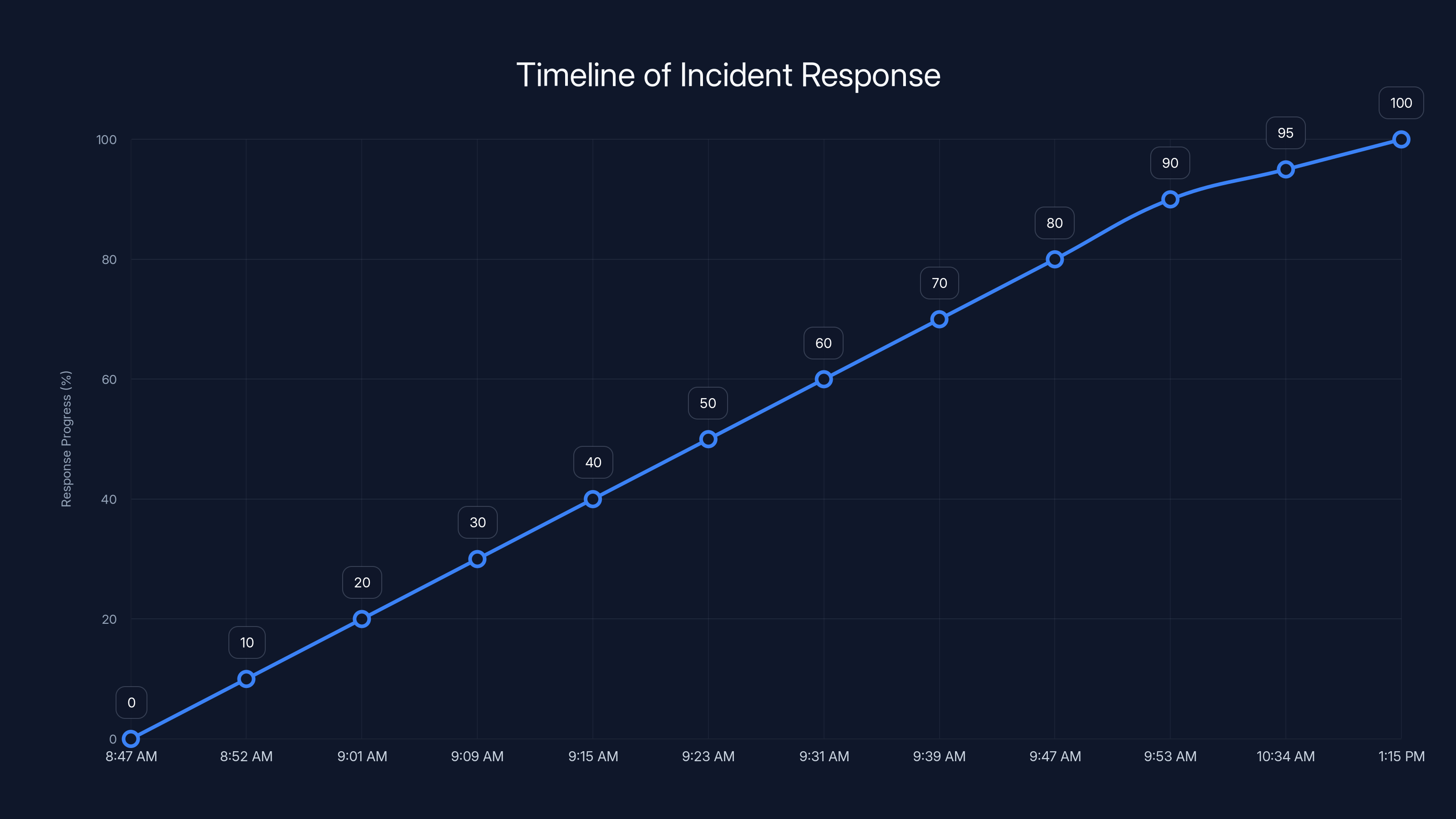
The timeline shows a gradual response with key actions taken at specific intervals, highlighting the slow detection and resolution process during the outage.
How Individual Users Can Protect Themselves
You probably can't prevent X from going down. But you can minimize how much that outage disrupts your life and business.
Diversify Your Presence
Don't put all your communication eggs in one platform. If you have a business, you should be active on:
- Your own website or blog
- Email (still the most reliable communication channel)
- Multiple social platforms (Instagram, Threads, Linked In, etc.)
- A community platform like Discord or Slack
This doesn't mean you need to post the same content to every platform. But important announcements and your core audience should be reachable through multiple channels.
Export Your Data Regularly
X allows you to request an export of your data, but it's not automatic. Create a monthly reminder to export your posts, followers list, and other important data. If X has a longer outage or (heaven forbid) shuts down entirely, you'll have your content backed up.
Use Automation Tools With Caution
Before the outage, 3.2 million users were using third-party tools to schedule posts, cross-post to other platforms, or automate engagement. During the outage, these tools broke. Scheduled posts didn't post. Automated workflows failed.
The lesson: automation is great, but you should have a way to manually post if needed, and you shouldn't rely on automated posting for time-sensitive content.
Build Your Email List
This is the unsexy truth: email is the most reliable way to reach an audience you own. Social media platforms come and go. Email has been around for 50+ years. Every audience should have an underlying email list.
Monitor Multiple Sources
During the outage, people who only got news from X couldn't see anything. People who also checked news websites, used RSS feeds, or followed newsletters stayed informed. Diversifying your information sources isn't just good for accuracy, it's good for continuity.

What X's Leadership Should Have Done Differently
Looking at the timeline and technical details, several changes would've likely prevented this outage:
Staged Deployments: Deploy to 5% of servers, monitor for 10 minutes, then expand. This catches bugs in production before they cause total failure.
Separate Configuration Pipelines: The same pipeline that deployed to primary should not automatically deploy to backup systems. Have a deliberate waiting period and manual approval step.
Faster Alerting: Eight minutes from alert to page is too slow. Should be 60-90 seconds at most.
Better Testing: Load balancing configuration changes should be tested in a production-like environment before being deployed to actual production.
Clearer Communication: Ideally, X's status page should have been updated within 10 minutes of the outage starting. The actual update came much later.
Backup Failover Testing: The backup system should be tested weekly to ensure failover actually works. The fact that it had the same bug suggests testing wasn't catching real-world scenarios.
These aren't revolutionary ideas. They're industry best practices that companies like Netflix, Google, and Amazon have been using for years. The question is whether X will actually implement them, or whether these kinds of outages will continue happening every few years.
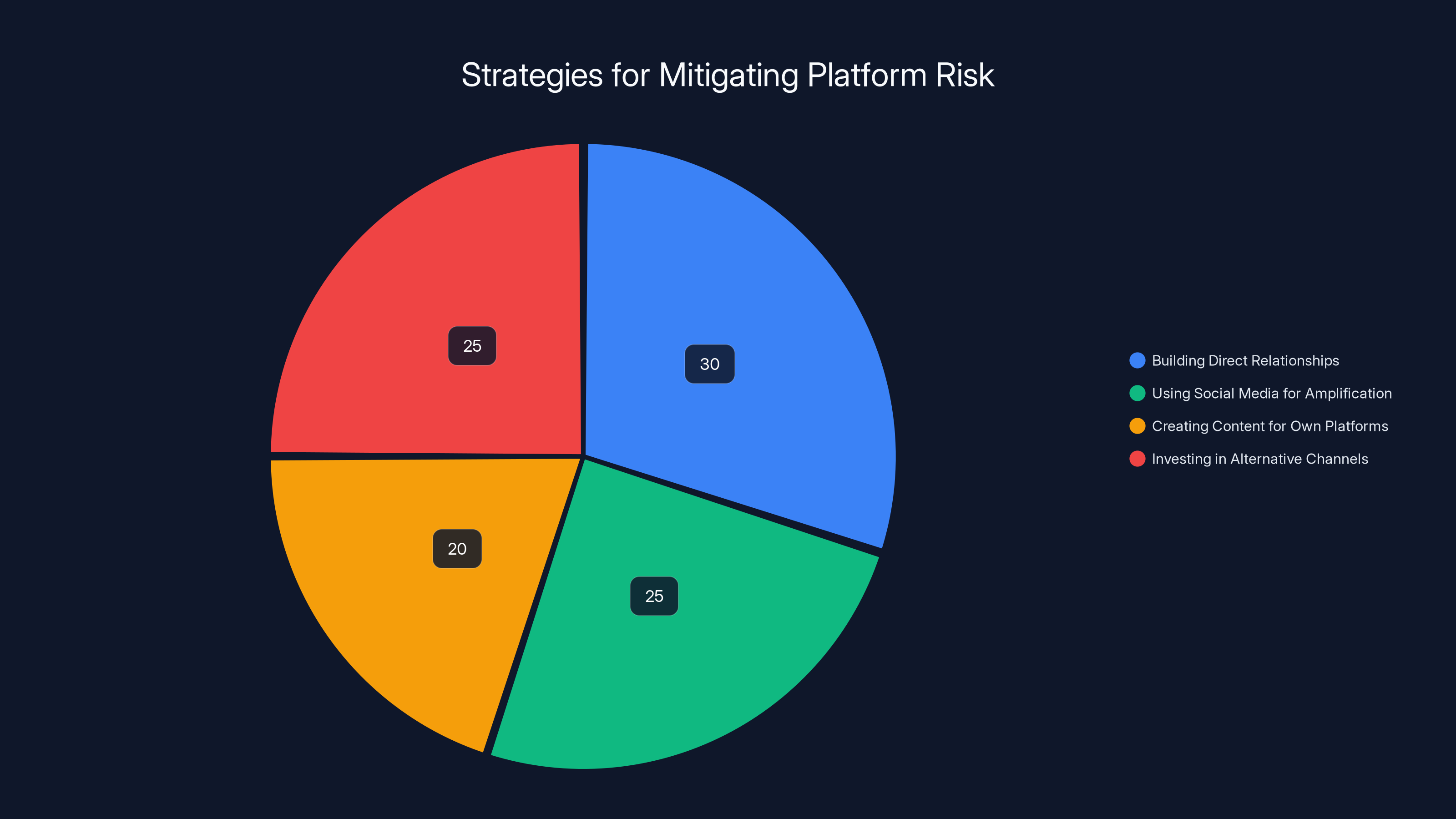
Estimated data shows businesses are diversifying their strategies to mitigate platform risk, with a focus on building direct relationships and using social media as an amplification tool.
The Bigger Picture: Platform Risk in a Digital World
X's outage revealed something uncomfortable: modern business has become dependent on platforms it doesn't control.
For the last 15 years, the strategy for most businesses was: build your audience on social media. Optimize your content for platforms. Make those platforms central to your business strategy.
What this outage reminded everyone is that platforms can disappear, change their policies, go down, or become unusable. You might have a million followers, but if the platform is offline, you have zero reach.
Smart organizations are rethinking this. They're:
- Building direct relationships with audiences through email and websites
- Using social media for amplification, not as their primary channel
- Creating content for their own platforms that syndicates to social
- Investing in alternative communication channels
This is especially important for creators and small businesses that built their entire income stream on a single platform.
Consumers, meanwhile, are becoming more aware that having backup communication methods isn't paranoid, it's just sensible. Having a phone number for a business that you can call when the website is down? That's valuable. Having alternative social media profiles? That's smart hedging.
X's outage won't cause a mass exodus. Most users will check back in a few days and resume their normal behavior. But it's another data point in a longer trend of platform fragmentation. We're probably moving toward a future where nobody puts all their digital eggs in one platform, not because they want to, but because repeated outages and policy changes have made that the only sensible strategy.

Recovery Efforts and System Improvements
After the outage, X's engineering team immediately began implementing improvements. According to their public statements, they're working on several fronts:
Immediate Improvements: Enhanced monitoring with faster alerting thresholds. Automated alerts should now trigger within 2 minutes instead of 8. This alone would've reduced the outage significantly.
Medium-term Changes: Redesigning the load balancing system to use more granular traffic routing. Instead of simple round-robin distribution, they're implementing intelligent load balancing that can detect when a server is struggling and shift traffic away from it faster.
Long-term Architecture Changes: Separating the database into multiple independent clusters by feature. Instead of a single database handling all user data, they're planning separate systems for timelines, direct messages, and other features. This means a failure in one doesn't cascade to the others.
Testing Improvements: Creating a "failure testing" program similar to what Netflix and other resilient companies do. They'll regularly simulate failures and test how their systems respond.
However, let's be realistic: these are all good ideas, but implementing them takes time. For the next 12-24 months, X is probably at similar risk for outages. The infrastructure changes required are substantial.

Other Platforms' Outage Prevention: What They Do Right
To understand why X was vulnerable, it's helpful to look at how other large platforms prevent outages.
Google runs what might be the most resilient infrastructure in the world. They've publicly discussed their approach: multiple independent data centers, automatic failover between regions, redundant systems for critical functions, and chaos engineering (intentionally breaking things to test resilience).
Amazon Web Services offers multiple availability zones within each region specifically to prevent single-zone failures from affecting customers. They also have extensive documentation on how they prevent outages.
Netflix famously releases "Chaos Monkey," a tool that randomly kills servers and services to ensure nothing is dependent on any specific piece of infrastructure.
Discord had a major outage in 2019 but recovered quickly because of their architecture. They've since invested heavily in preventing similar issues.
The pattern is clear: the most resilient platforms share certain characteristics. They test failures regularly. They deploy changes gradually. They have multiple independent systems that can fail without cascading. They invest heavily in monitoring and alerting.
X has been working on these improvements, but they clearly weren't in place during this outage.

What Happened to X's Reputation
Outages damage platform reputation in ways that are hard to measure but easy to feel. After the outage:
- Enterprise customers began having conversations about whether X should be part of their communications strategy.
- Advertisers discussed whether advertising on a potentially unreliable platform made sense.
- Content creators asked themselves whether they should diversify their presence more.
- Regular users experienced the uncomfortable realization that their favorite platform could disappear at any moment.
This kind of reputational damage is actually worse than the immediate business impact. The outage itself cost maybe $500 million in advertising revenue and lost productivity. But the longer-term impact on enterprise adoption and advertiser confidence could be substantially larger.
Companies like Meta and Google can survive the occasional outage because they have such dominant market positions. But X is in a more competitive position, facing rival platforms like Threads and alternative social networks. A high-profile outage can accelerate user migration to competitors.

Lessons for Infrastructure Teams Everywhere
If you manage any infrastructure, even small scale, X's outage offers lessons:
1. Change Management Is Critical: A small configuration change crashed a massive platform. This is why change management processes exist. Before you deploy anything, ask: what happens if this breaks?
2. Blast Radius Matters: Never deploy something that affects everything simultaneously. Always deploy to a small percentage first.
3. Test Your Backups: If you have backup systems, actually test them. Don't just assume they work. X would've caught this bug if they regularly tested failover to their backup system.
4. Alerting Must Be Fast: Eight minutes from alert to human response is slow when you're at scale. Modern systems should alert within 60-90 seconds.
5. Transparency Matters: X's direct communication about the outage actually helped restore confidence faster than stonewalling would have. Admit problems, explain what happened, describe what you're fixing.
6. Document Your Architecture: If no engineer understands how the load balancing system actually works, you're vulnerable. Document everything.
7. Redundancy Isn't Enough: You need redundancy that's actually independent. Deploying the same buggy configuration to backup systems defeats the purpose.

The Future of Platform Reliability
Where does this leave social media and digital infrastructure in general?
Probably at an inflection point. The platforms that survive the next 5 years will be the ones that prioritize reliability as a core feature, not an afterthought. Users and businesses are getting tired of outages.
We might see:
- Decentralized alternatives gaining traction because they don't have single points of failure.
- Regulatory pressure on platforms to maintain certain uptime standards.
- Enterprise alternatives that guarantee reliability for business-critical communication.
- User behavior changes toward platforms with better track records.
- Increased investment in infrastructure reliability by remaining platforms.
X's outage probably won't kill the platform. But it's another crack in the foundation of the assumption that a single platform can be your primary communication channel.
Immediate Actions You Can Take
Here's a practical checklist for individuals and businesses following this outage:
For Content Creators:
- Export your data from X immediately.
- Set up accounts on 2-3 alternative platforms (Threads, Bluesky, Linked In).
- Start building an email list.
- Create a backup way for followers to reach you.
For Businesses:
- Add your email address or phone number to your X bio.
- Create a contact page on your website.
- Set up automated responses on other platforms directing to your website during outages.
- Consider using a service that can cross-post to multiple platforms.
- Brief your team on alternative communication channels if your primary platform is unavailable.
For Enterprise Organizations:
- Review your critical communication plan if it depends on X.
- Set up monitoring for platform status pages.
- Create procedures for communicating internally if key platforms are down.
- Consider whether X is truly critical to your operations or whether email/internal systems are sufficient.
For All Users:
- Set up a status page monitor for platforms you depend on.
- Keep phone numbers and email addresses for important contacts.
- Don't rely on social media for time-sensitive emergency communication.
- Consider an RSS reader for news instead of relying on social feeds.

FAQ
What exactly caused the X outage in February 2025?
A configuration bug in the load-balancing system was deployed simultaneously to all servers. Instead of distributing traffic evenly, it sent 75% of requests to a single database instance, causing cascading failures across the entire infrastructure. The same buggy configuration was also deployed to backup systems, preventing automatic failover from resolving the issue.
How long did the X outage last?
The outage lasted approximately 4 hours and 28 minutes in North America (from 8:47 AM to 1:15 PM EST). Western Europe experienced intermittent service for about 5.5 hours. Other regions had varying levels of impact, with Southeast Asia experiencing around 3-4 hours of disruption. Full service restoration across all regions took until approximately 1:15 PM EST.
Which regions were most affected by the outage?
North America experienced the most severe impact with complete service unavailability. Western Europe faced intermittent access that made the outage feel longer despite being somewhat shorter in duration. Southeast Asia and Australia experienced shorter outages due to off-peak hours. South America, Africa, and parts of Asia experienced varying levels of degradation, with some regions barely affected.
Why didn't X's backup systems prevent the outage?
The backup data center had the same buggy configuration deployed to it through X's standard deployment pipeline. This meant both primary and backup systems suffered from the same problem simultaneously, preventing automatic failover from helping. The incident revealed a critical flaw: backup systems must have separate deployment processes and should be tested regularly to ensure they actually work when needed.
How much did the X outage cost?
Estimated costs include approximately
What should X do to prevent this from happening again?
Implement staged deployments where changes go live to 5% of infrastructure first, monitor for issues, then gradually expand. Maintain separate configuration pipelines for backup systems with manual approval requirements. Reduce alerting latency from 8 minutes to under 90 seconds. Create a weekly failover testing program to ensure backup systems actually work. Deploy load balancing changes to test environments before production.
Why is platform reliability important for businesses?
With millions of businesses now depending on social platforms for customer communication, support, and sales, outages directly impact revenue and customer satisfaction. A 4-hour outage can disrupt customer service workflows, prevent sales, halt marketing campaigns, and damage brand reputation. For creators and freelancers, it means lost income during peak engagement hours. Businesses need reliable backup communication channels.
How can I protect my business from platform outages?
Diversify your communication channels by maintaining an active website, email list, multiple social platforms, and direct contact methods for important customers. Export your data regularly from social platforms. Create content for your own owned platforms that syndicates to social media rather than being created only for social. Establish internal procedures for communicating if primary platforms are unavailable. Brief your team on backup tools and processes.
What's the difference between this outage and previous platform outages?
X's outage was caused by a configuration management failure rather than a hardware problem, suggesting infrastructure maturity issues. The 8-minute delay before engineering response indicated slower alerting than modern standards. The failure of backup systems to provide failover revealed gaps in disaster recovery testing. However, X's relatively transparent communication and quick recovery were better than some historical platform outages.
Could this happen to other major platforms?
Yes. Facebook, Google, Amazon, and Microsoft have all experienced major outages despite enormous engineering resources. The underlying cause is the same: systems become so complex that certain failure modes become almost inevitable. However, mature platforms like Google and AWS have invested heavily in redundancy, staged deployments, and chaos engineering to minimize outage frequency and duration. Newer or rapidly-changing platforms like X are more vulnerable during infrastructure transitions.

Conclusion: Learning From Digital Fragility
X's February 2025 outage will eventually fade from headlines. Most users will forget it happened. But the infrastructure lesson it teaches remains relevant: even the most sophisticated platforms with unlimited engineering budgets can fail in ways that cascade quickly and become difficult to recover from.
The outage wasn't caused by incompetence. It was caused by the inevitable complexity that comes with building systems at planetary scale. When you're managing millions of servers handling billions of requests, certain types of failures become mathematically possible no matter how careful you are.
But here's what we can control: we can demand better practices from the platforms we depend on. We can diversify our presence across multiple platforms instead of betting everything on one. We can build backup communication channels for the things that matter. We can invest in understanding infrastructure because it's becoming as critical as any other business infrastructure.
For most users, the practical takeaway is simpler: don't assume any single platform will always be available. Have a backup plan. Know how to reach people without using that platform. Keep an email list. Maintain a website. Save important data.
For infrastructure teams, the lesson is equally clear: stage your deployments, test your backups, and remember that the most dangerous bugs are always the ones you didn't know were possible.
X will recover from this. The platform is too big and too integrated into digital culture to be killed by a single outage. But every outage is a reminder that digital infrastructure, like all infrastructure, is fragile in ways we sometimes forget until something breaks.

Key Takeaways
- X's February 2025 outage lasted 4+ hours globally and was caused by a load-balancing configuration bug deployed simultaneously to all servers.
- The backup system failed because it received the same buggy configuration, preventing automatic failover from resolving the issue.
- North America experienced the most severe disruption with complete service unavailability from 8:47 AM to 1:15 PM EST.
- Estimated economic impact exceeded 500M in advertising revenue,200M+ in productivity loss.
- Lesson: Never deploy infrastructure changes that affect everything simultaneously; always stage deployments to 5% first and monitor before expanding.
Related Articles
- TikTok's Oracle Data Center Outage: What Really Happened [2025]
- TikTok Outages 2025: Infrastructure Issues, Recovery & Platform Reliability
- TikTok Service Restoration After Major Outage: What Happened [2026]
- Lenovo Warns PC Shipments Face Pressure From RAM Shortages [2025]
- GL.iNet Comet 5G Remote KVM: Multi-Network Failover Guide [2025]
- Why Startups Are Prime Targets for Hackers in 2025

