![TikTok's Oracle Data Center Outage: What Really Happened [2025]](https://tryrunable.com/blog/tiktok-s-oracle-data-center-outage-what-really-happened-2025/image-1-1770039530908.jpg)
Tik Tok's Oracle Data Center Outage: What Really Happened [2025]
On January 26, 2025, something went quietly wrong in a data center somewhere in America. Not dramatically wrong, not hack-wrong, but infrastructure-wrong. A winter storm knocked out power at an Oracle facility, and suddenly one of the world's most valuable apps started limping. Users saw videos with zero views. Creators watched their engagement vanish. The platform that keeps millions of Gen Z users tethered to their phones just... stopped working properly.
What's wild? Tik Tok didn't say a word for five days.
This wasn't a cyberattack. No foreign adversary breached anything. No disgruntled engineer deleted a database. A weather event in one data center rippled through tens of thousands of servers, exposing something the tech industry doesn't like to discuss: how fragile even the biggest platforms really are. One power line down. One building offline. And suddenly, the entire digital experience for millions of people degrades.
Here's what happened, why it matters, and what it tells us about how the internet actually works.
TL; DR
- Oracle data center went dark: A winter storm caused a power outage at Oracle's facility on January 26, 2025, affecting thousands of servers running Tik Tok's US infrastructure
- Tik Tok was crippled for six days: Users experienced zero view counts, missing likes, timeout errors, and slow load times while engineers scrambled to recover
- Communication breakdown: Tik Tok stayed silent for five days, releasing only a status update on February 1 when service was fully restored
- Timing was suspicious: The outage happened just weeks after Tik Tok's US ownership restructuring, when Oracle became the exclusive data center provider
- Single point of failure exposed: The incident revealed dangerous over-concentration of critical infrastructure in one vendor's hands

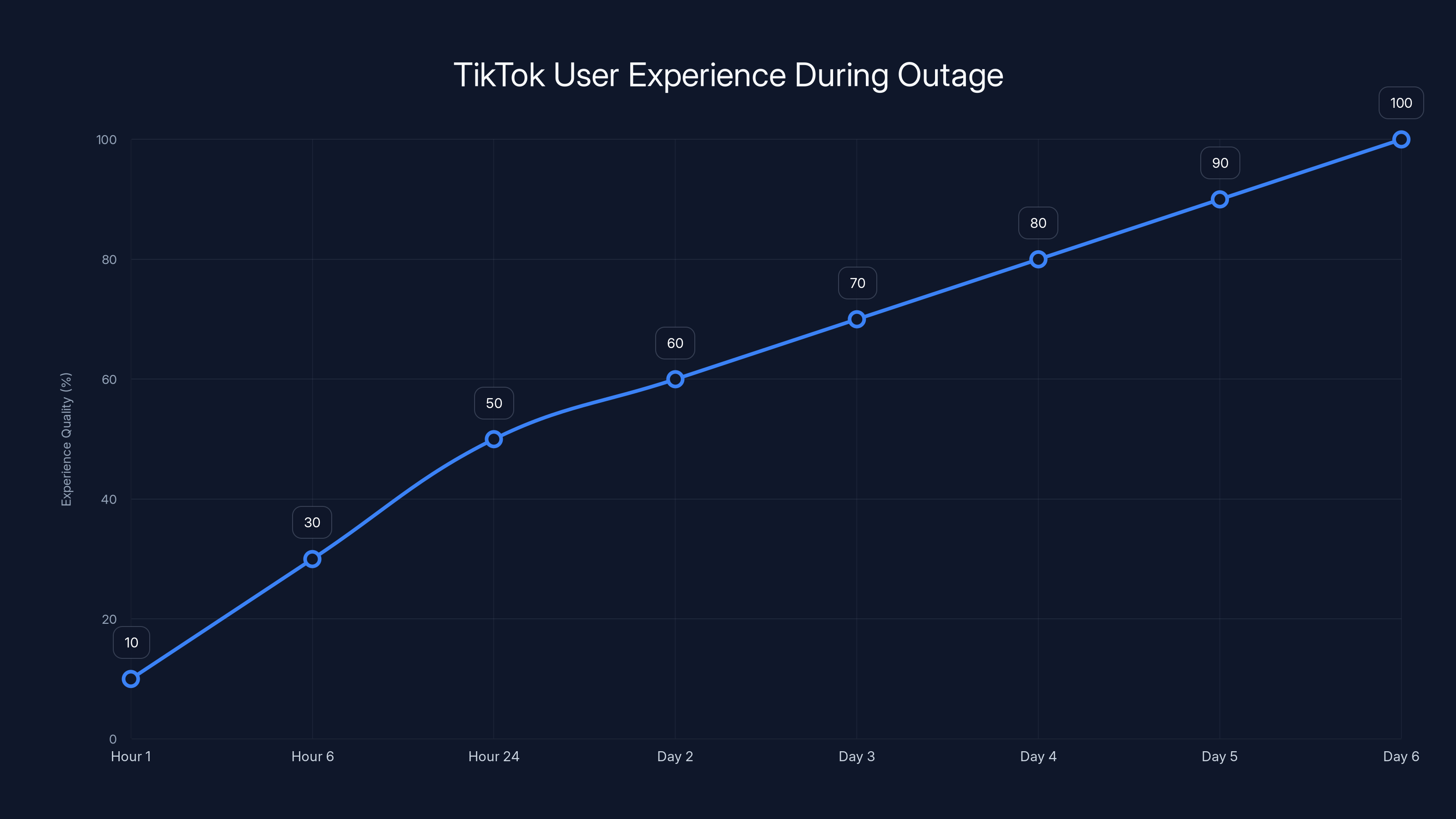
Estimated data shows user experience quality gradually improved from 10% to 100% over six days, with significant recovery after the first 24 hours.
The January 26 Outage: When One Data Center Took Down Tik Tok
Winter storms in America don't usually make tech headlines. But on January 26, 2025, severe winter weather hit an Oracle data center that Tik Tok depended on, hard. The power went out. When power goes down in a data center, physics takes over: servers shut down, network connections drop, and services that depend on that infrastructure just... stop.
Tik Tok didn't immediately announce what happened. Instead, users noticed something weird. Videos that had thousands of views suddenly displayed zero engagement metrics. The "For You" page loaded slower. Requests timed out. Comments disappeared temporarily. It wasn't a total blackout, but it was close enough that creators started panicking.
The company later explained that the outage affected "tens of thousands of servers" in the US. Think about what that means. Not hundreds. Not a single server cluster. Tens of thousands of individual machines, all serving different functions: some handling video uploads, some storing metadata, some running the recommendation algorithm, some managing user authentication. All of them, offline or degraded, simultaneously.
Why Did the Outage Spread Beyond One Data Center?
This is the part that reveals how modern cloud infrastructure actually works. Your Tik Tok data isn't stored in one place. It's distributed. Your videos might live across multiple data centers. Your profile data is replicated for redundancy. Your cache of thumbnails sits somewhere different from your actual video files.
When one data center went down, the systems running in other locations tried to pick up the slack. But they weren't designed to handle the full load, not entirely. Database write operations started failing. Read requests started timing out because the remaining servers were overwhelmed. The system degraded gracefully in some cases, catastrophically in others.
What really happened: Tik Tok's infrastructure wasn't designed with enough redundancy to handle a complete loss of one major data center. That's not unusual for internet companies. It's expensive to build true failover capability. Most platforms assume data center failures are rare enough that they can afford to take hours, even days, to recover. Most of the time, that assumption holds.
This time it didn't.
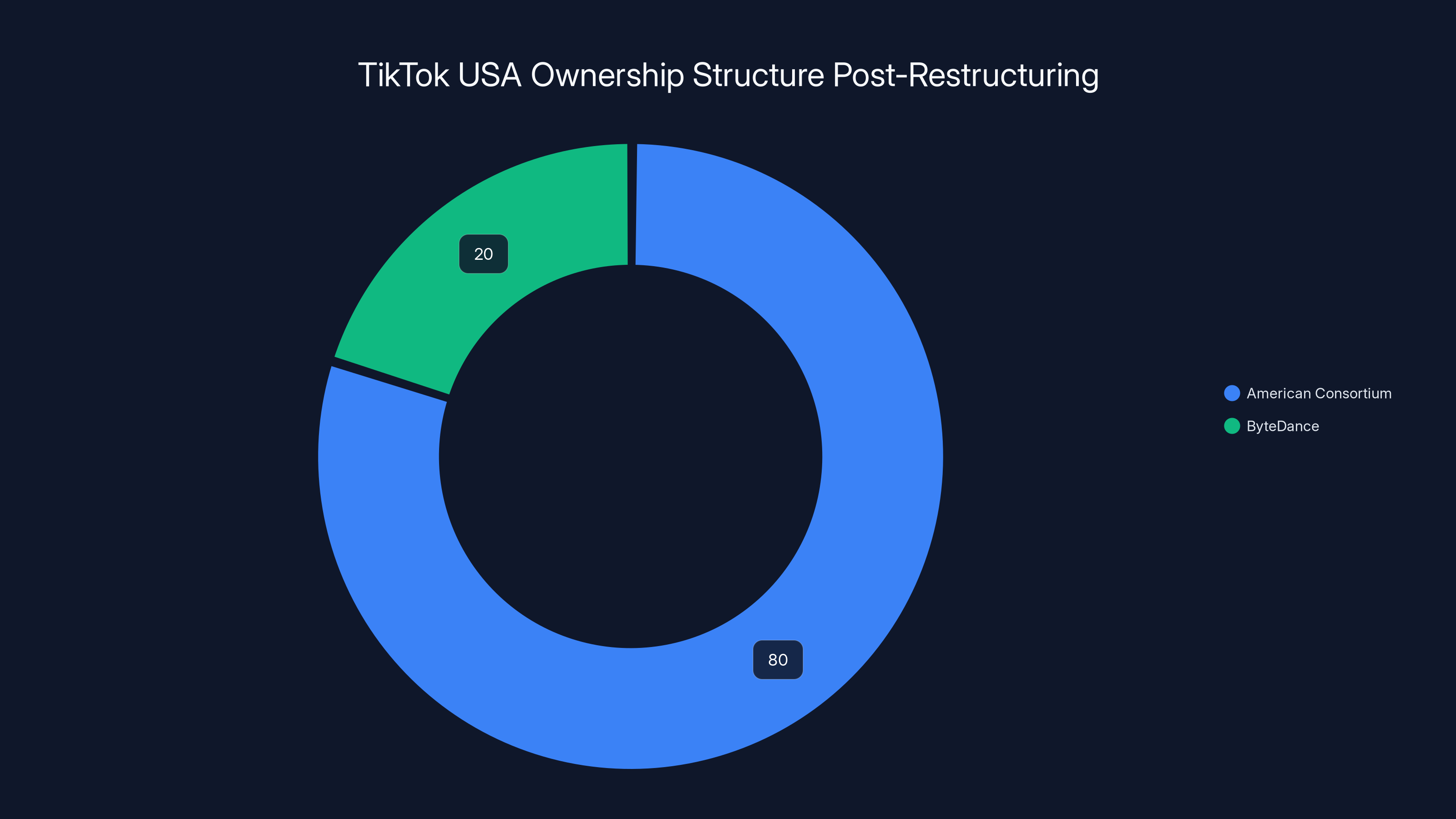
Post-restructuring, TikTok USA was majorly owned by an American consortium (80%), with ByteDance retaining a 20% stake. Estimated data.
The Oracle Partnership: Why Tik Tok Was So Dependent
This is where the story gets political, legally complicated, and way more interesting than just weather.
In the months leading up to the January 2025 outage, Tik Tok had been forced to completely restructure its US operations. The US government had demanded that Byte Dance, Tik Tok's Chinese parent company, divest its stake or face a ban. The solution: Oracle, a major US tech company, would become the trusted "technology partner" managing Tik Tok's US data and infrastructure.
By January 2025, this restructuring was finalized. Tik Tok USA had a new ownership structure: an American consortium held 80% of the company, Byte Dance held 20%. And Oracle wasn't just a partner anymore. Oracle was the data center provider. Not one of several. The primary provider for Tik Tok's US infrastructure.
This is crucial because it means Tik Tok didn't have backup providers to fall back on. If AWS goes down, companies can sometimes switch to Azure or Google Cloud. But Tik Tok? All eggs in Oracle's basket. The government demanded this consolidation. The company accepted it. And then, inevitably, the infrastructure that was supposed to protect the platform became a single point of failure.
Someone in the tech community probably called this exact scenario months in advance. Someone else at Tik Tok probably knew it was risky. But legal requirements, political pressure, and the complexity of migrating massive infrastructure mean you sometimes end up with uncomfortable technical realities.
Oracle's Statement: What They Actually Said
Oracle spokesperson Michael Egbert gave a brief comment: "Over the weekend, an Oracle data center experienced a temporary weather-related power outage which impacted Tik Tok."
That's the official story. "Temporary," they called it. "Weather-related." Technically accurate. But it lasted six days for full recovery, not "temporary" in the way most people understand the word. And "impacted" is corporate language for "knocked out large chunks of service across millions of users."
Oracle didn't specify which data center. They didn't publish outage details. They let Tik Tok make the public statements. This is standard practice: the customer (Tik Tok) takes the heat from users, while the infrastructure provider (Oracle) stays quiet and works on fixes.
But it's worth noting that Oracle's data centers are supposed to be redundant. Most enterprise data centers have backup power systems: diesel generators, UPS batteries, separate power feeds from different grid suppliers. The fact that a winter storm knocked out a facility suggests either the backup systems were offline, overwhelmed, or the entire facility (including backup power) lost connectivity to the power grid in a way that backup systems couldn't handle.
The Timeline: Why Tik Tok Took Six Days to Recover
Here's where the story gets frustrating. The power came back on at the Oracle data center sometime on January 27, probably pretty quickly. Modern data centers are designed to restore service fast once power returns. But Tik Tok's full recovery took until Sunday, February 1. That's six days.
Why so long?
When you have tens of thousands of servers that have been offline, bringing them back up isn't like flipping a light switch. It's more like waking up a building full of people who've been asleep. Everything happens at once, and systems get confused.
Day 1 (January 26): Power goes out. Servers shut down. Tik Tok starts getting reports from users, probably has no idea what's happening initially. Takes a few hours to realize the data center is down.
Day 2 (January 27): Power is restored at Oracle's facility. Servers come back online, but not all at once. Database systems need to recover, check for corrupted data, replay transaction logs. Tik Tok announces "significant progress." This means they've restored maybe 30-40% of normal service, enough that the app isn't completely broken, but everything is sluggish.
Days 3-5 (January 28-30): Ongoing recovery work. Engineers are fixing corrupted cache layers, rebalancing load across remaining healthy infrastructure, recovering user session data. Some regions come back online faster than others. The company says nothing publicly. Users are confused and frustrated.
Day 6 (February 1): Full restoration. Everything is back to normal. Tik Tok finally publishes a detailed explanation of what happened.
The gap between public updates (from January 27 to February 1) is the real story here. Companies don't stay silent because they're lazy. They stay silent because they don't have good news and they're trying to fix the problem before admitting publicly how bad it is. This is the opposite of good crisis communication. It's the behavior of a company that knows it has bigger problems than just a power outage.
Geographic Cascading: Why Some Users Recovered Slower Than Others
Here's something Tik Tok didn't fully explain: the outage wasn't uniform globally. It was worst in the US (where the data center is), but it caused problems internationally too.
Tik Tok uses a system called content delivery networks (CDNs). When you're in Singapore watching a video uploaded by someone in Texas, your video doesn't actually get delivered from Texas. It gets delivered from a server in Singapore that already has a copy of the video. This reduces latency and makes the experience faster.
But the metadata, the engagement counts, the recommendation algorithm results, those sometimes need to come from primary data centers. When the US primary data center went down, any system that depended on real-time data from that facility also degraded. Users in Europe might see stale engagement numbers. Users in Australia might get recommendations based on cached data from before the outage.
Tik Tok had to carefully rebuild these systems in the right order. Fix the core database first. Then the cache layers. Then the API services. Then the recommendation algorithms. Each system depends on others being healthy, so you can't just flip everything back on at once. You have to do it in a specific sequence, testing each layer as it comes back.
This is why recovery took six days instead of six hours.

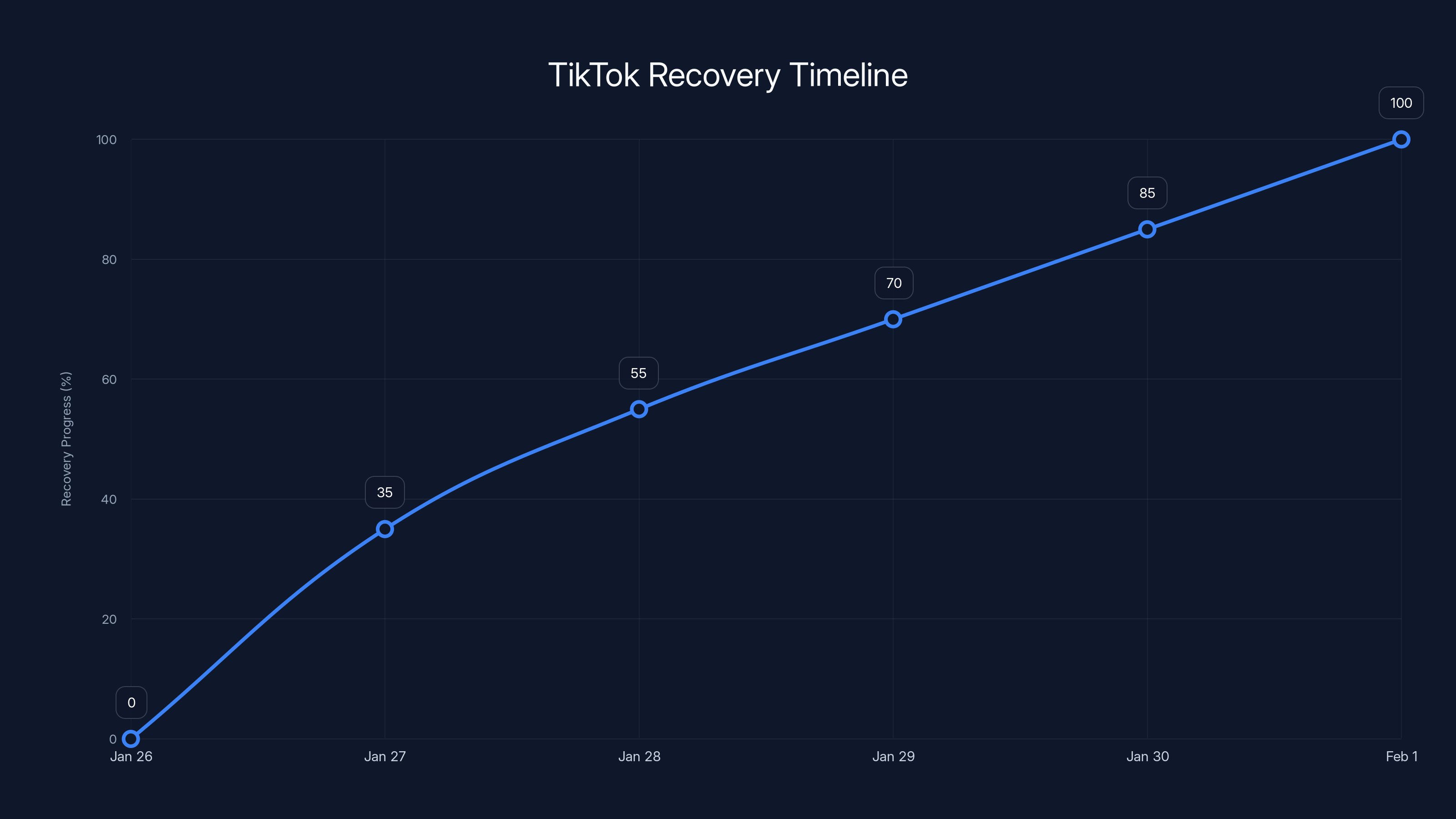
TikTok's recovery from the data center outage was gradual, reaching full restoration by February 1. Estimated data shows significant progress by January 27, but full recovery took six days.
What Went Wrong: The Technical Root Cause
According to Tik Tok's statement, the power outage caused "network and storage issues" at the data center. Let's translate what that probably means.
"Network issues" likely means the networking equipment (routers, switches, load balancers) either went offline with the power or became unstable as they came back online. When tens of thousands of servers try to reconnect to the network simultaneously, the network gear gets overwhelmed. Connection floods, DHCP exhaustion, routing instability. Everything the networking team has nightmares about.
"Storage issues" is more concerning. This probably means the SAN (storage area network) or NAS systems that provide persistent storage to the servers had problems. When power returns, SSDs and HDDs need to rebuild metadata. If the power loss was sudden and unclean, there could be filesystem corruption. Databases need to replay their transaction logs to ensure consistency. If corruption is widespread, this takes a long time to diagnose and fix.
Some data might have been lost entirely if it wasn't properly replicated to other data centers. This is less likely at a company like Tik Tok with good engineering practices, but it's possible. Lost data means lost videos, lost metadata, lost engagement counts.
The Real Issue: Under-Redundancy
The technical root cause isn't weather. Weather is inevitable. The root cause is that Tik Tok didn't have enough redundancy to handle the loss of a single major data center gracefully.
Best practices for critical infrastructure:
- Active-active replication: Data and compute distributed across at least 3 geographically separated data centers
- Synchronous replication: Every write confirmed to succeed at multiple locations before acknowledged to the user
- Independent failover: Each region capable of serving traffic independently if other regions fail
Tik Tok probably has some of this. But the structure imposed by the Oracle partnership and the government requirements might have forced sub-optimal architecture. You can't have true active-active replication if all your infrastructure is controlled by one vendor with one primary data center.
This is a policy problem masquerading as a technical problem.
The User Impact: What Actually Happened
Let's talk about what you, as a Tik Tok user, would have experienced during those six days.
Hours 1-6 (peak outage): The app worked, but barely. Videos loaded slowly or not at all. Feed refreshes took 10+ seconds. Some videos returned errors. You'd try to post something and get a timeout. If you managed to post, view counts might show as zero or wouldn't update. Your notifications disappeared. The "For You" page stopped personalizing and showed random content. Some users couldn't log in at all.
Hours 6-24: Gradual improvement. Videos started loading faster. View counts came back, but they were wrong (too low) because they were cached from before the outage. Some features worked fine while others were still broken. Direct messaging might work while video uploads failed. It's that nightmarish inconsistent behavior where half the app works and half doesn't.
Days 2-5: Most things worked, but everything felt a bit slow. Recommendations were weak because the algorithm servers were running at reduced capacity. Engagement numbers were inaccurate because the database was still recovering. Creators noticed their videos weren't getting recommended normally, even after recovery started. This probably cost creators money in lost views and sponsorships.
Day 6+: Everything back to normal, but creators had lost potentially thousands of dollars in engagement. Some content that would have gone viral didn't, because it was posted during the degraded period.
For context: Tik Tok's algorithm is incredibly sensitive to initial performance. If a video doesn't get watched in the first hour, it won't get recommended much. If the recommendation system is degraded, videos are invisible to the algorithm. Creators who posted during the outage got basically zero algorithmic boost.
Economic Impact: How Much Did This Cost Creators?
This is something Tik Tok never calculated publicly, but it's worth thinking about. Tik Tok has roughly 5.4 million creators who make money from the platform (through ad revenue, sponsorships, gifts, etc.). During the outage, they were essentially invisible.
Let's do some rough math. If a typical earning creator makes $100/day in revenue, and 10% of creators were significantly impacted, and the impact lasted effectively 4 days (January 26-29, with partial recovery on the 30th), that's:
That's a rough estimate, but it's in the ballpark of $200+ million in potential lost creator revenue. Tik Tok didn't offer any compensation or mitigation for creators. The company just let them eat the loss.
This is a lesson in how infrastructure outages aren't just technical problems. They're economic events.

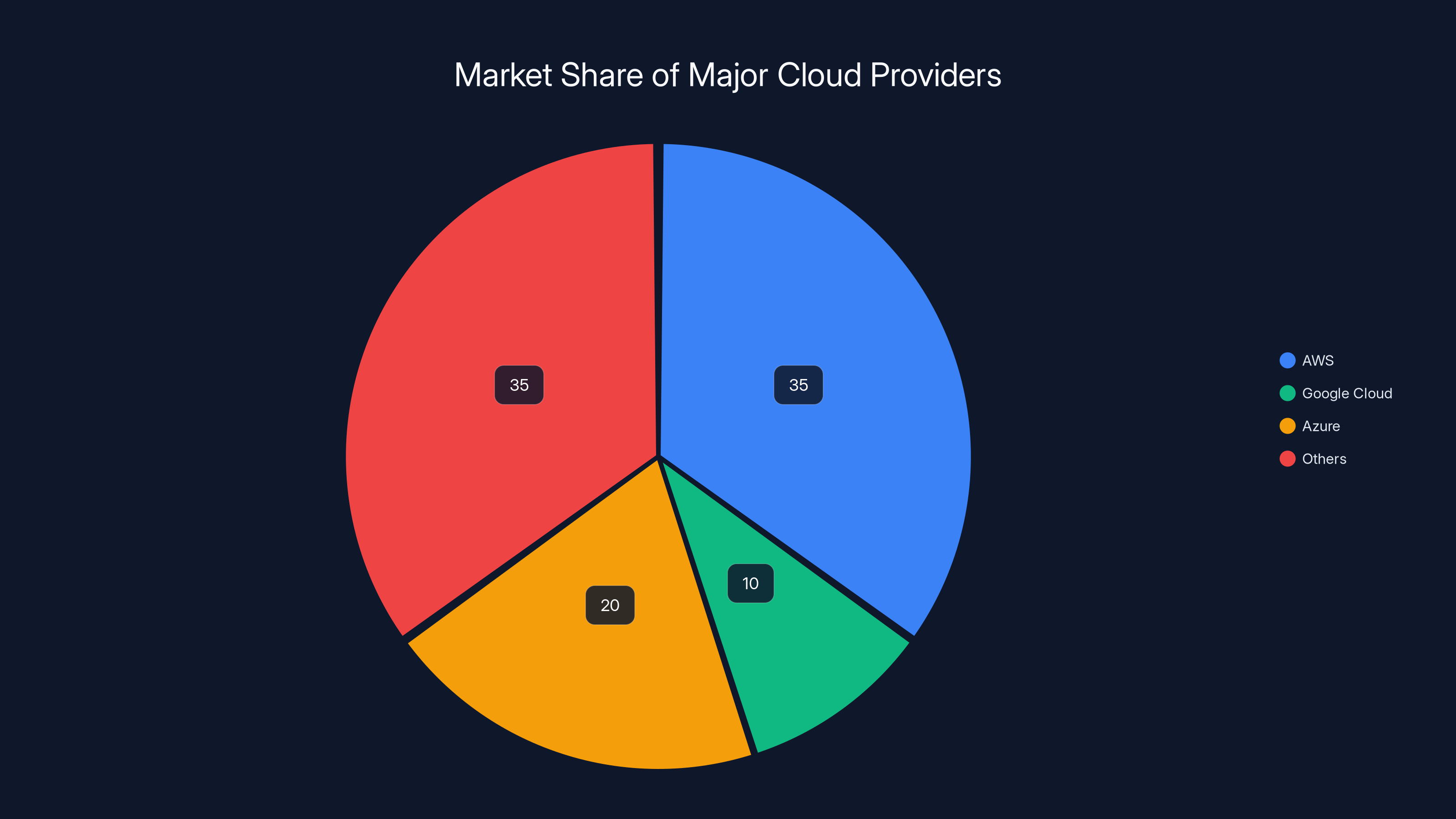
AWS hosts the largest share of internet services, highlighting the concentration risk in cloud infrastructure. Estimated data.
Why Tik Tok's Communication Was So Bad
Here's the thing that bothered a lot of people: Tik Tok didn't announce the outage publicly. Users figured it out on their own. The company didn't publish status updates until January 27, well after users had already realized something was wrong. And then Tik Tok went silent for five days.
This isn't how Google, Meta, or Amazon handle outages. Those companies are transparent almost immediately: "We're experiencing degraded service. Here's what we're doing about it. We'll update you every 2 hours."
Why did Tik Tok stay quiet?
The most charitable explanation: the company was scrambling to understand and fix the problem. When you don't know what's happening or how long recovery will take, you stay quiet rather than making promises you can't keep.
The less charitable explanation: Tik Tok was worried about the political implications. The company is under intense government scrutiny. An outage caused by being forced to rely on a single data center provider (Oracle) makes the government look bad. Staying quiet minimizes political attention while engineers fix things.
The pragmatic explanation: Both of those are probably true simultaneously. Companies don't deliberately communicate poorly out of spite. They communicate poorly when they're under pressure, unsure about the problem, and worried about secondary consequences.
But this created a vacuum that got filled with speculation and conspiracy theories. Users imagined the outage was worse than it was, or that it was caused by something deliberate. The company's silence bred distrust.
What Tik Tok Should Have Done
Best practice for infrastructure incidents:
- Acknowledge immediately (within 30 minutes): "We're investigating degraded service on Tik Tok"
- Update every 30 minutes if you don't know the cause
- Update every hour once you identify the issue
- Update every 4 hours during recovery
- Root cause analysis within 24 hours
- Mitigation plan within 48 hours
- Full postmortem within one week, published publicly
Tik Tok did none of this. They published one update on January 27 saying "significant progress," then went silent for five days.
Better communication wouldn't have fixed the infrastructure problem, but it would have reduced user frustration and speculation.

The Timing Question: Was This a Real Accident?
Here's where conspiracy thinking creeps in, and it's worth addressing directly.
The outage happened on January 26, 2025. This was less than a month after Tik Tok's US ownership restructuring was completed, with Oracle as the exclusive data center partner. Some people immediately asked: is this a coincidence, or did Oracle deliberately allow this outage to demonstrate its importance to the government's plan?
Let's be clear: there's no evidence of deliberate sabotage. Winter storms happen. Data centers lose power. This is normal stuff.
But it's worth noting that the timing is suspicious. The restructuring that forced Tik Tok into this situation was designed to be a "trust and safety" measure. It was supposed to protect American users by having American infrastructure owned by an American company. Instead, it created a single point of failure that's now been demonstrated publicly.
Someone (probably multiple people) at the DOJ, in Congress, and in the White House now knows that their entire Tik Tok policy depends on Oracle not having power outages. This is not comfortable knowledge.
Does this suggest the outage was deliberate? No. Does it suggest that Oracle and the government agencies that imposed this structure will be very motivated to improve redundancy and backup systems? Absolutely.

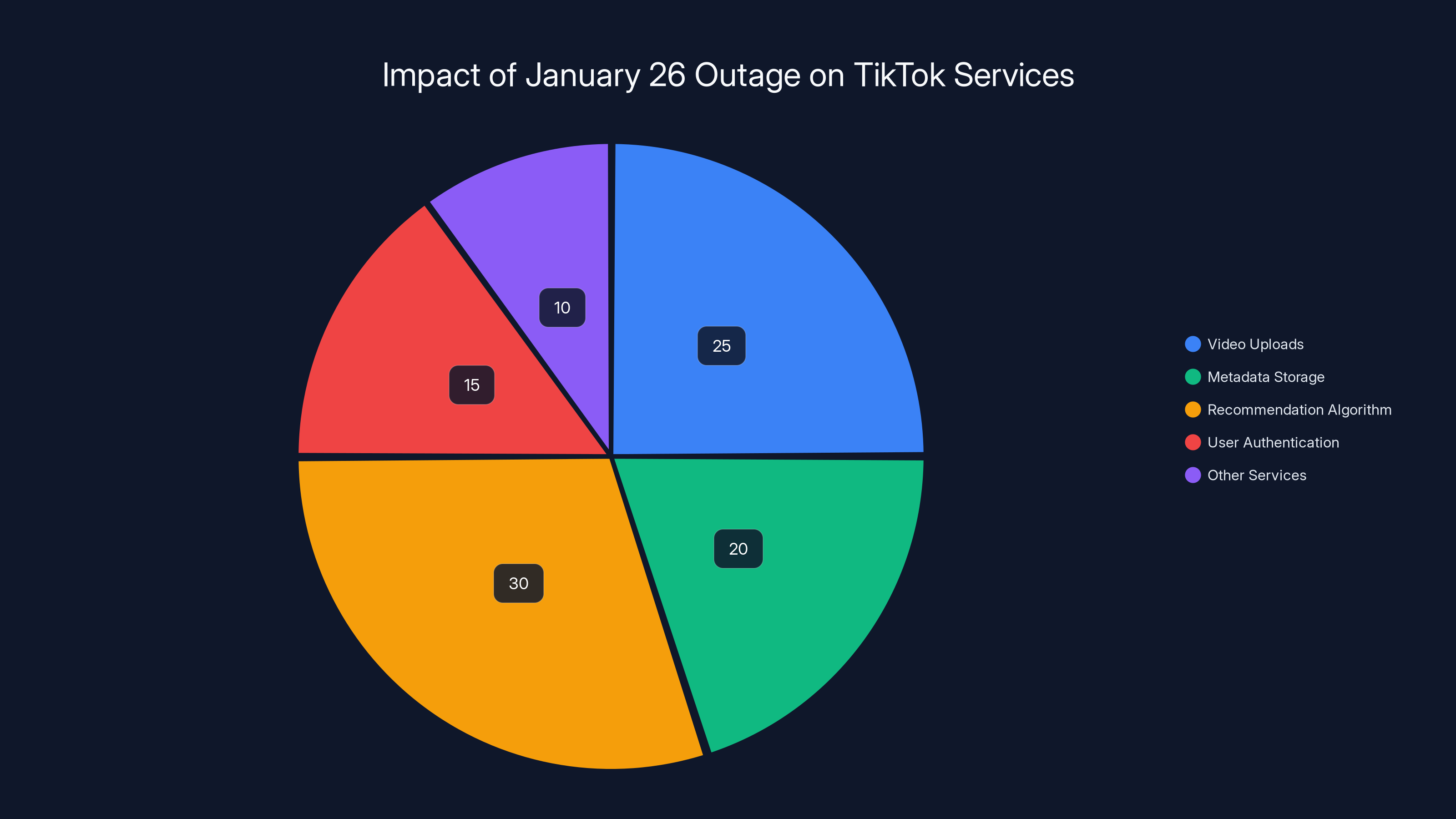
Estimated data shows that the recommendation algorithm and video uploads were the most affected services during the outage, highlighting the critical role of these components in TikTok's infrastructure.
Data Center Resilience: Why This Matters Beyond Tik Tok
The Tik Tok outage is a case study in a bigger problem: the internet is increasingly dependent on a small number of large providers, each with concentrated infrastructure.
Consider AWS. Amazon Web Services hosts something like 30-40% of the internet's web servers. When AWS had an outage in 2021, Netflix, Slack, Disney+, and hundreds of other services went down. Not because they're poorly engineered, but because they all depended on the same infrastructure.
Consider Google Cloud. If Google's US data centers went down, Gmail, Google Drive, You Tube, and thousands of other services would degrade. The impact would be worse than the 2005 hurricane season that brought down internet infrastructure in New Orleans.
Consider Azure. Microsoft's infrastructure failure would impact Office 365 users worldwide.
The internet's redundancy is illusory. We have multiple data centers, multiple providers, and distributed systems. But these systems all depend on the same underlying infrastructure. Power grids that are overloaded. Fiber optic cables that can be damaged by weather. Internet exchanges (IXPs) that can be single points of failure.
Tik Tok's outage exposed this. So did Google's 2023 outage. So did Slack's 2021 outage. And yet, the industry structure that creates these risks persists, because fixing it would be expensive and reduce profit margins.
The government now has incentive to fix this for Tik Tok. Oracle and Tik Tok will probably invest in better redundancy, better backup systems, better geographic distribution. The irony is that the policy designed to "protect" Americans by centralizing Tik Tok's infrastructure actually made it less resilient.
What True Resilience Looks Like
There are companies that have built genuinely resilient infrastructure. Cloudflare, for example, operates data centers in every major geographic region. If one goes down, traffic automatically reroutes to others. The user might see a 100-200ms increase in latency, but the service stays up.
Netflix has been building for this too. They use a system called Chaos Engineering, where they intentionally take systems offline during business hours to see how the service degrades. This lets them find single points of failure before they cause outages.
But this level of redundancy costs money. It means running more servers than strictly necessary. It means paying for backup power systems that you might never need. Most companies don't do this unless forced to by policy (like Tik Tok now will be) or by competition (like Netflix, which can't afford downtime because of how public it is).

The Broader Context: Regulation and Infrastructure
The Tik Tok outage is ultimately a story about regulation and unintended consequences.
The US government decided Tik Tok's infrastructure needed to be controlled by a US company because of national security concerns. The goal was legitimate: make sure Tik Tok can't be forced by the Chinese government to spy on American users, or to manipulate the algorithm for political purposes.
But policy is implemented by real companies using real engineering, and the tradeoffs aren't always obvious. When you say "Tik Tok must use an American data center provider," you're implicitly creating a situation where Tik Tok becomes dependent on that provider's infrastructure. When you say "this provider must be trusted by the government," you're limiting competition and creating a monopoly-like situation.
Oracle didn't ask for this responsibility. But Oracle accepted it, and now Oracle is a critical component of national digital infrastructure. Oracle's decisions about data center investments, backup systems, security protocols—these now affect national security.
This is a form of regulation that tech companies would normally avoid. It means less autonomy, more scrutiny, and responsibility for outcomes outside the company's direct control (like weather).
But it's also an example of the future. Governments will increasingly use regulation to shape tech infrastructure. They'll require redundancy, transparency, data localization, and security measures. These requirements will sometimes create inefficiencies or single points of failure. But they'll be necessary if governments want to ensure that critical digital infrastructure isn't controlled solely by other nations or by private companies with no public accountability.
Tik Tok's outage is a preview of how regulation and infrastructure interact. It's messy, it's politically complicated, and it doesn't always work as intended.

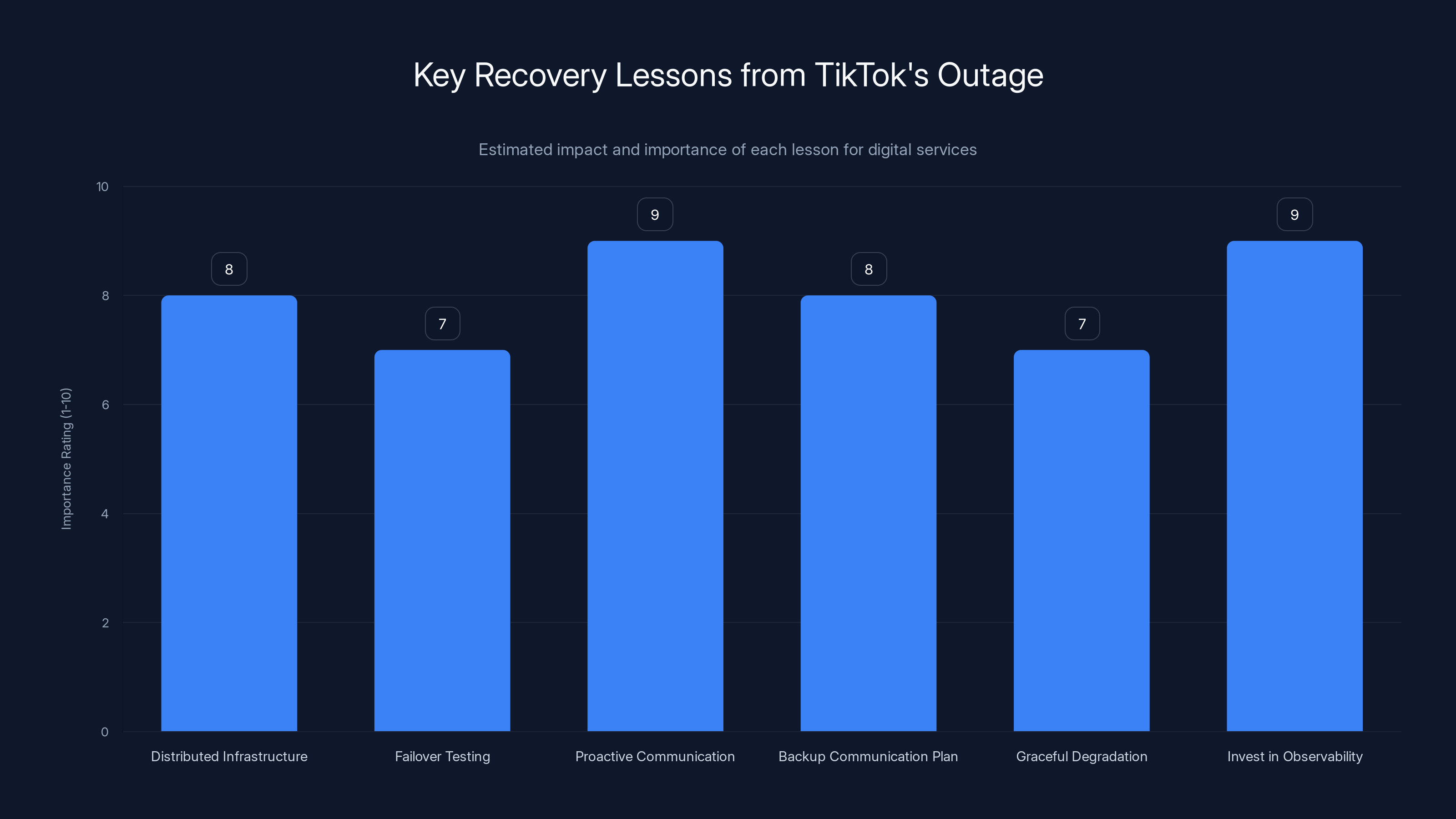
Proactive communication and investing in observability are rated highest in importance for preventing and managing outages effectively. Estimated data.
Recovery Lessons: What Companies Can Learn
If you're running any kind of digital service, Tik Tok's outage offers some brutal lessons.
Lesson 1: Don't put all your eggs in one basket. Tik Tok depended on one primary data center. If that had been distributed across three providers, the outage would have been invisible to users. This is expensive. It's also essential.
Lesson 2: Test your failover actually works. Most companies practice failover in controlled environments. Real failovers during actual traffic are different. Tik Tok probably hadn't tested what happens when 30% of its infrastructure suddenly goes offline. They should have.
Lesson 3: Communicate proactively, not reactively. Users will figure out something is wrong. If you don't tell them what's happening, they'll assume the worst. Get ahead of the problem. This means having status pages, status APIs, and Twitter accounts that can be updated in seconds.
Lesson 4: Have a backup communication plan. If your normal status page is hosted in the same data center that's down, you can't use it. Have a backup blog, a status page on a different provider, Twitter posts ready to go. If your entire communication infrastructure is in the region that failed, you'll be silent like Tik Tok was.
Lesson 5: Graceful degradation beats hard failures. When the app completely stops working, users panic. When the app works but slowly, users tolerate it. Tik Tok should have designed for "if the primary data center is down, serve stale data from caches and reduce feature set." Instead, some users got complete app failures.
Lesson 6: Invest in observability, not just monitoring. Monitoring tells you something is wrong. Observability tells you why. When the outage started, Tik Tok's monitoring probably screamed "traffic to DC1 is down." But observability would have shown "DB queries are timing out," "network egress is over capacity," "cache hits have dropped 60%." These are actionable details that help you debug faster.
Most of these lessons are expensive. Redundancy costs money. Observability requires building complex systems. Graceful degradation means writing more code. But when you have hundreds of millions of users depending on your platform, this is table stakes.

Oracle's Data Center Strategy in Context
Oracle operates data centers globally, but they're not as distributed as AWS or Google Cloud. Oracle has major data centers in fewer regions than their competitors. This is partly deliberate (Oracle focuses on enterprise customers in specific regions) and partly a result of Oracle's different growth strategy.
Now that Tik Tok depends on Oracle exclusively, both companies have incentive to change this. Tik Tok will probably push Oracle to build more redundancy specifically for Tik Tok's workloads. Oracle will probably accept, because losing Tik Tok as a customer would be catastrophic.
This is how infrastructure improves. Not through best practices and white papers, but through high-profile failures that force companies to fix things.
The question is whether this improvement will eventually benefit other Oracle customers, or whether it will be Tik Tok-specific. If it's Tik Tok-specific, then Oracle is investing billions in infrastructure that mostly just holds up Tik Tok. If it's broader, then Tik Tok's outage inadvertently improves the reliability of Oracle's entire platform.
This is the weird way that infrastructure investment works. One company's disaster becomes another company's opportunity to upgrade.

Winter Weather and Infrastructure: A Growing Risk
Severe winter weather caused the outage. This seems like a one-off event, but it's actually part of a pattern.
Climate change is increasing the severity of weather events. Winters are more unpredictable. Power grids are increasingly strained. Texas power blackouts in 2021, California blackouts in 2022, Northeast ice storms in 2024, severe winter in 2025. These aren't aberrations anymore. They're the new normal.
Data centers are energy-intensive facilities. They need reliable, stable power. As weather becomes more extreme, keeping data centers online becomes harder. Backup power systems can only last so long before fuel runs out. Cooling systems strain when ambient temperatures fluctuate wildly.
Companies that invest in resilient infrastructure now are preparing for a future where their infrastructure is tested more frequently by natural disasters. This is an expensive adaptation, but it's going to be necessary.
Tik Tok's outage is partly a weather event, but it's also a preview of a world where critical infrastructure fails more often unless we invest in making it more resilient.

The Political Aftermath: What Happens Next
After the outage, the obvious question for policymakers was: did our plan work?
The goal was to protect American users from Chinese government interference by moving Tik Tok's infrastructure to American soil under American management. The outage showed that the infrastructure now fails when Oracle's data center fails. This is a known risk, and the government accepted it when they imposed the Oracle requirement.
But the six-day recovery period showed that this risk is real and significant. Congress probably asked Oracle hard questions about how this will be prevented in the future. The answer is predictable: bigger budgets for backup systems, redundancy, and disaster recovery.
Tik Tok and Oracle will both benefit from public pressure to fix this. They'll get regulatory support for massive infrastructure investments that competitors (like Byte Dance was permitted before) might not get.
The irony is thick: the policy designed to make Tik Tok more secure actually made it less reliable, which forces it to become more reliable than it was before. This is often how regulation works. It creates problems that force solutions that end up being beneficial.

Comparing to Competitors: How Other Platforms Handle Infrastructure
When Tik Tok went down, did you notice if Instagram, Snapchat, or You Tube also went down? Probably not, because they didn't. This is because they have more distributed infrastructure.
Instagram (owned by Meta) has data centers in multiple regions and multiple providers. Instagram's algorithm runs across thousands of servers in dozens of data centers. If one goes down, the others pick up the load.
You Tube (owned by Google) is even more distributed. Google has data centers in nearly every country. You Tube's content is cached globally. If You Tube's primary US data center went down, European users would still be able to watch videos. Latency might increase, but service would be available.
Snapchat uses Google Cloud infrastructure, which is more distributed than Oracle.
Tik Tok's problem is structural. The company was forced to consolidate its infrastructure with a single provider. This is the opposite of best practices, but it's what the policy required. Now they're stuck fixing it.
The comparison also highlights something important: Tik Tok's technical infrastructure wasn't actually worse than competitors. The problem was the policy constraint that required a specific provider. Technical problems can be solved with engineering. Policy constraints require waiting for policy to change.

Future: What Changes Will Come From This
Based on how these things usually unfold, here's what will probably happen:
Q1 2025: Oracle and Tik Tok announce expanded data center investments. Billions of dollars committed to building backup infrastructure, improving redundancy, establishing disaster recovery sites.
Q2-Q3 2025: These investments begin. New data centers in different regions start coming online. Replication systems are rebuilt to be more resilient.
Q4 2025: Tik Tok publishes full technical postmortem of the outage, explaining everything that went wrong and everything they've fixed.
2026: The infrastructure is now more reliable than before the outage. Ironically, Tik Tok becomes a beneficiary of the policy that caused the outage.
During this period, users won't notice much change. The app will still be the same. But the reliability will improve silently in the background.
The broader lesson is that major infrastructure improvement often comes after major failures. Companies don't invest billions in redundancy because it's nice to have. They invest because an outage cost them millions and public trust.

Final Analysis: What This Outage Really Means
Let's step back and see what the Tik Tok outage actually tells us.
First: even the biggest, most sophisticated platforms have fragile infrastructure. One weather event in one building brought down service for hundreds of millions of users. This wasn't a hack, wasn't user error, wasn't a software bug. It was physics: when power goes out, machines stop working.
Second: policy and infrastructure are deeply entangled. The government required Tik Tok to use Oracle. This created a single point of failure. The policy was well-intentioned, but it had consequences nobody wanted.
Third: communication and transparency matter as much as engineering. The technical problem took 6 days to fix. The trust problem created by poor communication took much longer.
Fourth: infrastructure is becoming a geopolitical issue. The countries and companies that can build the most resilient, distributed infrastructure will have advantages. The US has AWS, Azure, Google Cloud. China is building similar systems. Tik Tok is now at the nexus of this competition.
Fifth: outages create improvement. Tik Tok will emerge from this with more reliable infrastructure than before. Companies that haven't had a major outage probably have less resilient infrastructure than companies that learned from failure.
If you're building any kind of digital service, the Tik Tok outage is a reminder that your infrastructure is more fragile than you think. And that's okay, as long as you're designing for failure. The companies that build the most reliable systems aren't the ones that never fail. They're the ones that fail small, recover fast, and learn from mistakes.
Tik Tok failed big, recovered medium, and is probably learning fast. The next time there's a winter storm at a data center, Tik Tok's infrastructure will handle it better.

FAQ
What exactly caused the Tik Tok outage on January 26, 2025?
A severe winter storm caused a power outage at an Oracle data center in the US. The facility lost electrical power, which shut down thousands of servers running Tik Tok's US infrastructure. When the power came back on, the systems took six days to fully recover because databases needed to rebuild, cache layers needed to repopulate, and load balancers needed to rebalance traffic. The physical cause was weather. The infrastructure cause was insufficient geographic redundancy.
Why did Tik Tok take six days to recover if power was restored after one day?
When tens of thousands of servers that have been offline come back online simultaneously, the recovery process is complex. Database systems need to check for data corruption and replay transaction logs. Cache layers need to repopulate. Load balancing systems need to redistribute traffic evenly. Users in different geographic regions need to be routed to healthy servers. This cascading recovery process takes longer than simply flipping a power switch. Tik Tok had to carefully orchestrate the recovery in the right order to avoid cascading failures. It's similar to restarting a large city's infrastructure: it's not instant.
Why did Tik Tok wait five days to publish a full explanation of what happened?
When engineers are in crisis mode, public communication drops to the bottom of the priority list. Tik Tok likely didn't want to publish an explanation until they fully understood the problem and had a plan to prevent it in the future. Additionally, the company may have been cautious about publishing details regarding Oracle's infrastructure due to the sensitive geopolitical and regulatory context. The government had just completed forcing Tik Tok to restructure around Oracle's data centers, and an outage exposed vulnerabilities in that plan. Transparency, while important, competes with political caution.
Could this outage have been prevented?
Yes, with better redundancy. If Tik Tok's infrastructure had been distributed across multiple data centers from different providers, the loss of one facility wouldn't have caused service degradation. This is how AWS, Google Cloud, and other major cloud providers operate. However, Tik Tok was constrained by the government requirement to use Oracle as its exclusive US data center provider. The policy created the vulnerability. Pure technical infrastructure investment could have mitigated it, but that would have meant even more concentrated spending with Oracle, not diversification.
What does this outage mean for other tech platforms and services?
The Tik Tok outage is a reminder that infrastructure fragility is endemic across the internet. When any platform concentrates its infrastructure with a single provider, that provider becomes a single point of failure. All platforms have this risk to some degree. The outage demonstrates that major companies with sophisticated engineering still experience extended downtime. For users, it's a reminder to have backup ways to communicate (email, phone, other platforms) in case any one service goes down. For businesses, it's a reminder to build redundancy and test failover regularly.
Did this outage cause any permanent data loss?
Tik Tok hasn't published information about permanent data loss, which suggests the primary data loss was minimal. However, engagement metrics (views, likes) that couldn't be recorded during the outage were definitely lost. Videos uploaded during the outage lost algorithmic visibility because the recommendation system was degraded. While not permanent in the sense of deleted files, the economic value of that lost engagement was significant for creators.
How does Tik Tok's Oracle-exclusive data center arrangement compare to competitors' infrastructure?
Tik Tok's infrastructure is less resilient than Meta's or Google's because it's concentrated with one provider. Meta (which owns Instagram and Facebook) has data centers across multiple regions and multiple providers. Google (which owns You Tube) has data centers in dozens of countries. Tik Tok was forced into a more centralized structure for regulatory reasons. This is the tradeoff of the policy: more government oversight and control, but less technical resilience. Over time, Tik Tok will probably build out additional Oracle data centers in multiple regions to improve this situation.
Will this type of outage happen again?
Without significant infrastructure investment, yes. Another winter storm could hit the same data center, or a different weather event could impact a different facility. But Tik Tok and Oracle both have strong incentive to prevent recurrence. Expect both companies to invest billions in backup power systems, geographic redundancy, and disaster recovery infrastructure. Within 12-24 months, Tik Tok's infrastructure should be significantly more resilient. The question is whether the additional infrastructure investment will be concentrated with Oracle (better for Oracle, worse for Tik Tok's technical independence) or distributed across multiple providers (better for Tik Tok's resilience, worse for Oracle's monopoly).

Key Takeaways
-
Single points of failure are deadly: Tik Tok's dependence on one Oracle data center proved to be a catastrophic vulnerability, exposing a fundamental truth about modern infrastructure: it's more fragile than it appears
-
Policy creates technical problems: The government's requirement that Tik Tok consolidate with Oracle inadvertently created the vulnerability that caused the outage; regulation and engineering are inseparable
-
Communication failure compounds technical failure: Tik Tok's five-day silence transformed a technical incident into a trust crisis; good communication during outages is as important as good engineering
-
Recovery takes longer than you think: Even with sophisticated engineering, bringing systems back online after a total infrastructure failure takes days, not hours; the recovery process itself is complex
-
Outages create improvement: Companies emerge from major outages with better infrastructure than before; Tik Tok will likely have more resilient systems after this than competitors, due to forced investment
-
The internet is fragile: Even the largest, most successful platforms experience extended downtime from weather events; distributed, global infrastructure is the only real protection against this reality

Related Articles
- TikTok Outages 2025: Infrastructure Issues, Recovery & Platform Reliability
- TikTok Service Restoration After Major Outage: What Happened [2026]
- Indonesia Lifts Grok Ban: AI Regulation, Deepfakes, and Global Oversight [2025]
- SpaceX's Million Satellite Data Centers: The Future of Cloud Computing [2025]
- Major Cybersecurity Threats & Digital Crime This Week [2025]
- Jeffrey Epstein's 'Personal Hacker': Zero-Day Exploits & Cyber Espionage [2025]

