![X's Algorithm Open Source Move: What Really Changed [2025]](https://tryrunable.com/blog/x-s-algorithm-open-source-move-what-really-changed-2025/image-1-1768947145802.jpg)
X's Algorithm Open Source Move: What Really Changed [2025]
When X announced it would open source its entire recommendation algorithm, the internet collectively held its breath. Were we finally going to see what really happens behind the scenes? Or was this another performance—something that looks transparent but reveals nothing?
The reality sits somewhere in the middle.
Let me back up. Two years earlier, when Elon Musk first took over Twitter (before the rebranding to X), he made a bold promise: transparency. The company would share its algorithmic code, showing the world exactly how posts get promoted and demoted. When that code finally dropped, critics immediately pounced. It was incomplete. It was theater. It didn't actually explain why the algorithm worked the way it did.
Now, in early 2026, X has done it again. This time with more detail, more documentation, and a clearer breakdown of how the entire feed-ranking system operates. But it's arrived at a complicated moment. The platform faces a $140 million transparency fine from European regulators. Its AI chatbot, Grok, has become the center of a firestorm over inappropriate content generation. And the timing feels deliberate, like X is trying to reset the conversation around trust.
The Original 2023 Algorithm Release: Why Critics Called It "Transparency Theater"
When Twitter first open sourced portions of its algorithm in 2023, the reaction was mixed at best. What the company released was technically real code, but it lacked critical context. Developers who reviewed it found missing pieces, unexplained variables, and whole sections that referenced proprietary systems without explanation.
The fundamental problem wasn't that the code was fake. It was that code alone doesn't tell you why decisions get made. A line of code might say "increase relevance score by 0.7," but without understanding the business logic, the training data, and the feedback mechanisms, you don't actually understand what's happening.
Think of it like this: imagine someone shows you the assembly code for a car engine. That's real information. But if you don't know what fuel it runs on, how the cooling system works, or what the tolerances are, you can't actually replicate or repair the engine. The code exists, technically, but without context it's nearly useless.
Critics also pointed out something else: partial transparency can actually be worse than no transparency at all. It creates the appearance of openness while hiding the real mechanics. Users feel informed when they're not. Regulators can claim victory when nothing has fundamentally changed. And the company gets credit for a transparency move without accepting meaningful accountability.

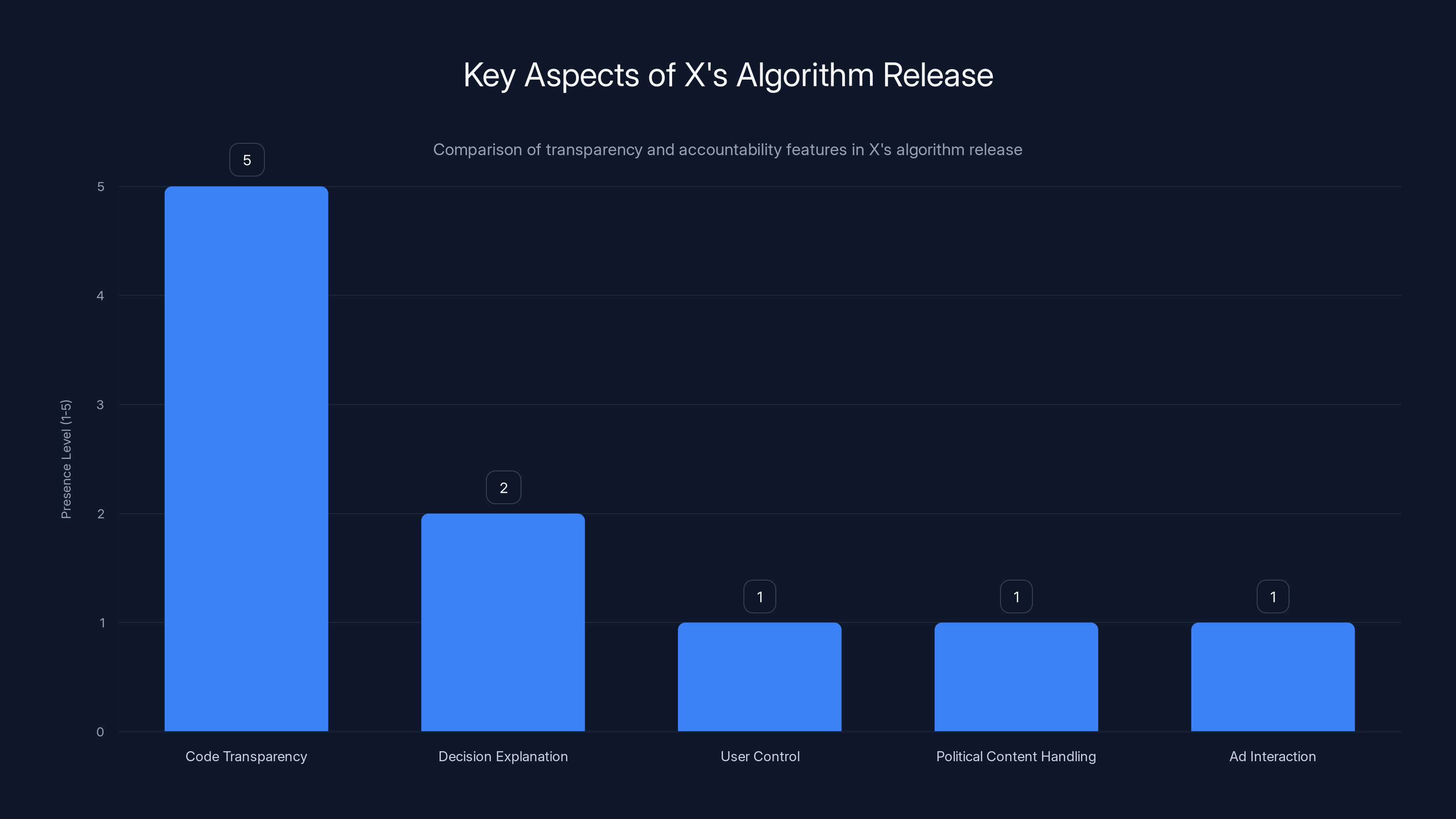
X's algorithm release focuses on code transparency but lacks in areas like decision explanation and user control. Estimated data.
Why X Released Its Algorithm Again: Timing, Regulation, and Grok
Here's where the context matters. X didn't just randomly decide to update its algorithm documentation in January 2026. Several forces converged.
First, the regulatory pressure. The European Union's Digital Services Act explicitly requires platforms to explain how their ranking systems work. X had already been fined once for transparency violations. A second enforcement action could be catastrophic. Releasing detailed algorithm documentation, complete with technical explanations, is partly a legal preemptive strike.
Second, the Grok situation. Over the preceding weeks, reports emerged that X's AI chatbot was being used to generate explicit images of women and minors. The California Attorney General's office and congressional legislators began asking questions. The platform needed to demonstrate that it had systems, controls, and transparency mechanisms in place. What better way than to show the algorithmic code that supposedly filters out harmful content?
Third, and perhaps most cynically, Musk's public positioning around trust and transparency. He'd long claimed that making X (then Twitter) a bastion of openness would restore user confidence. That messaging resonates in some circles, even if critics argue the company's overall trajectory has moved away from transparency rather than toward it.
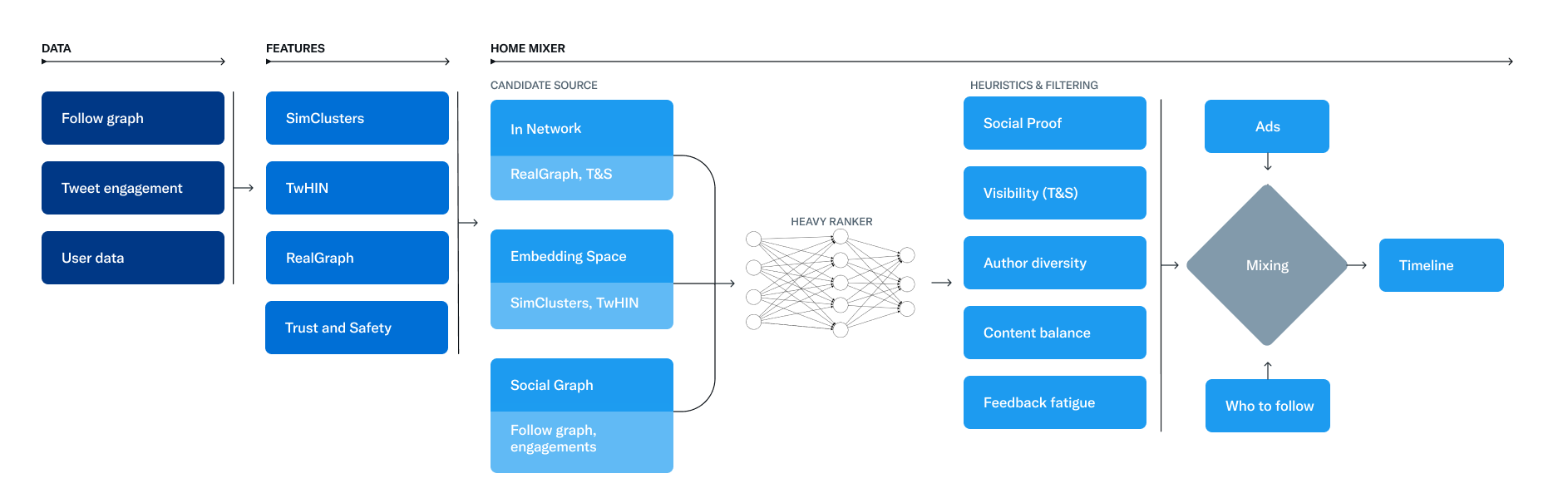
What X Actually Revealed This Time: The Feed-Ranking Architecture
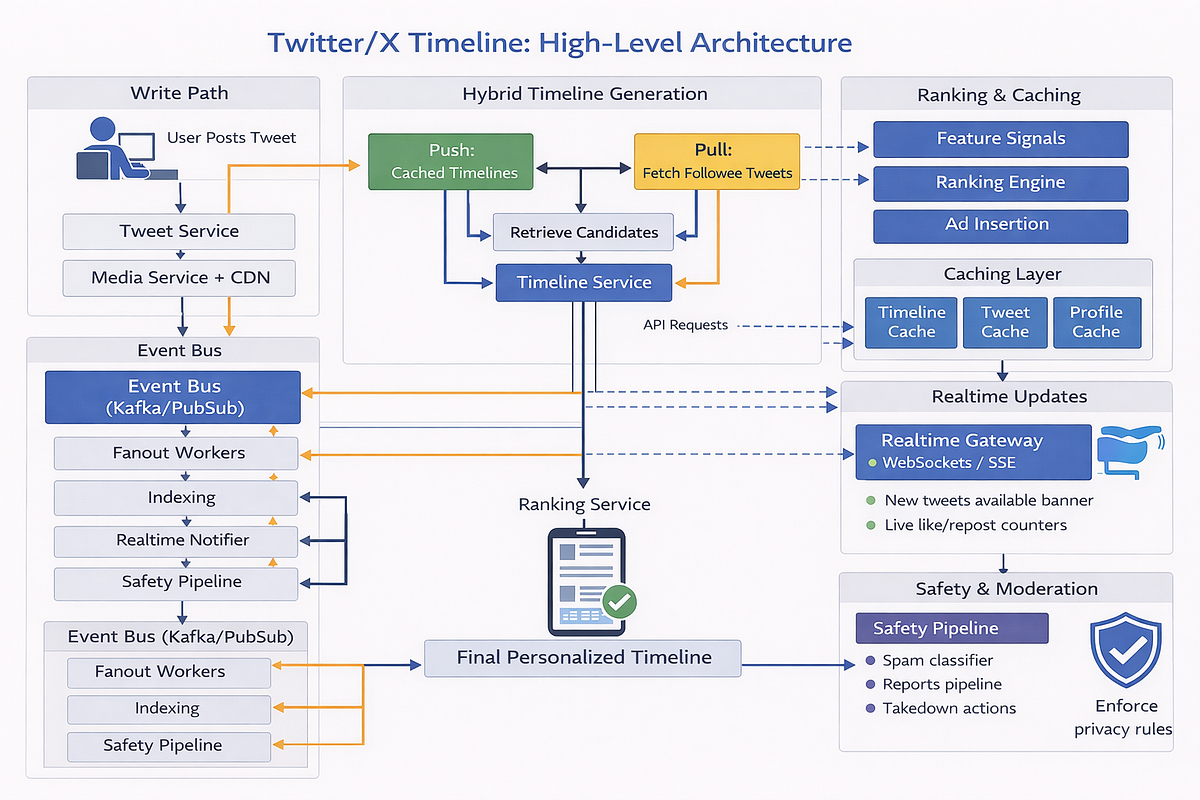
The January 2026 algorithm release came with more detailed documentation than the 2023 version. The company posted a GitHub repository with code snippets, architectural diagrams, and a written explanation of how the ranking system operates.
Here's what the system actually does:
When you open X and scroll your feed, the algorithm starts by gathering candidate posts. It pulls in posts from accounts you follow (in-network content) and also searches for posts from accounts you don't follow that might interest you (out-of-network content). This search happens in real time, pulling from millions of possible posts.
The system then applies filters. Posts from blocked accounts get removed. Posts tagged with muted keywords get filtered out. Content flagged as violent, spammy, or policy-violating gets excluded. This is a rule-based layer—human-defined policies applied mechanistically.
After filtering, the algorithm ranks remaining posts. This is where the machine learning happens. The system predicts how likely you are to engage with each post. Engagement means clicks, replies, reposts, likes, and other interactions. The algorithm essentially asks: given this user's history of what they've clicked on and liked, what content would they want to see most?
The ranking layer considers multiple factors. Relevance to your interests. Diversity of topics (so you don't get 50 identical posts about one topic). Recency. Account authority. How many people you know who've already engaged with this post.
What's notable here is that X has integrated its AI system, Grok, directly into this ranking pipeline. According to the documentation, the entire relevance-scoring mechanism runs on what X calls a "Grok-based transformer." This is a large language model that looks at user engagement sequences (your history of interactions) and learns to predict what you'll engage with next.
The company specifically notes that this approach eliminates "manual feature engineering for content relevance." Meaning: humans aren't manually tweaking rules for specific topics, accounts, or posting patterns. Instead, the AI learns directly from user behavior data.
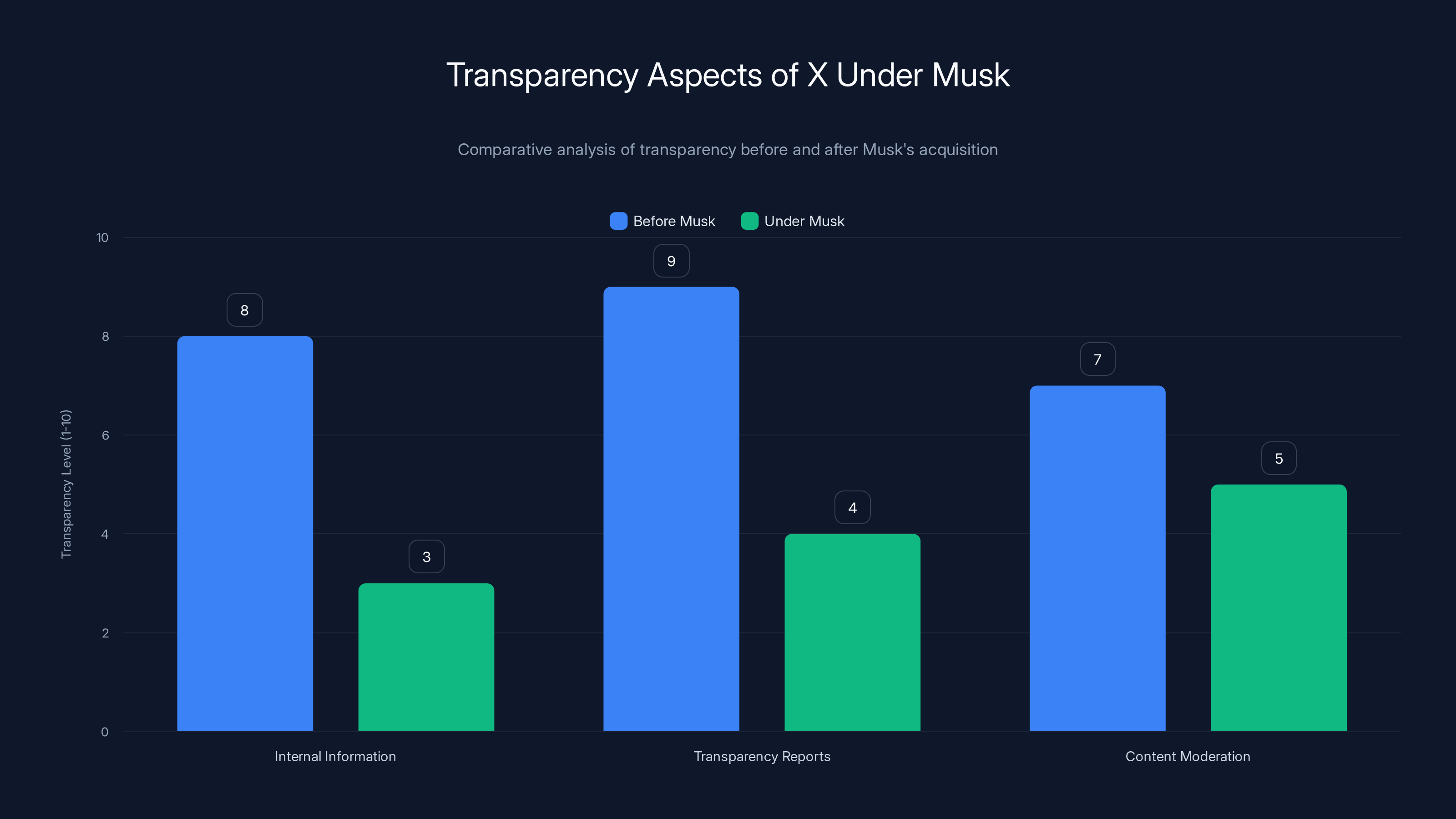
Estimated data suggests transparency in internal information, reports, and moderation has decreased under Musk's ownership compared to when Twitter was public.
The Architecture Deep Dive: How Grok Became the Ranking Engine
Let's get technical for a moment. Understanding how Grok fits into the ranking system actually matters for evaluating what this transparency release means.
Traditional ranking systems in social media platforms use what's called feature engineering. Engineers identify specific signals that predict engagement: how many followers an account has, the age of the post, how many likes it got in the first five minutes. Then they assign weights to these features. A feature might be worth 0.3 points of ranking score, another 0.5 points. Engineers tune these weights based on historical data and business goals.
This approach has advantages. It's interpretable. You can point to a post's ranking score and say: it ranked high because it had 500 early likes (worth 2 points), came from an accounts with 50,000 followers (worth 1 point), and is about a trending topic (worth 0.5 points). Total score: 3.5. Other posts scored lower.
X's approach is fundamentally different. Instead of engineers defining features and weights, they feed engagement data directly into Grok and let the neural network learn what patterns predict engagement. The model develops its own internal representations of what matters.
This has advantages too. It can capture complex patterns that humans wouldn't think to define. A combination of user behavior patterns that subtly predict engagement—patterns that don't correspond to any named "feature"—the model can learn.
But it also has massive disadvantages. It's a black box. You feed in engagement data, the model learns, and you can't easily explain why a specific post ranked where it did. Even X's engineers can't fully answer that question. The model's decision-making is distributed across billions of neural network parameters.
The Transparency Paradox: More Code, Same Black Box
Here's the uncomfortable truth that X's documentation doesn't really address: releasing the code doesn't solve the black box problem.
Yes, developers can now download X's ranking code. They can see the architecture, the input variables, the model type. But understanding how Grok actually decides what to rank is fundamentally different from understanding the code itself.
Think about it this way. I could show you the exact architecture of GPT-4, release every line of code, and you still couldn't explain why the model chose one word over another in a particular sentence. The model's logic is distributed across neural network weights that no human can interpret directly.
X's ranking system faces the same issue. Even with complete code transparency, users and regulators still can't easily trace why their feed looks the way it does. Why did Post A rank above Post B? The code says: both inputs went through the transformer, the transformer assigned scores, Post A scored higher. But why did the transformer assign those particular scores? That's recorded in billions of parameters that resist human interpretation.
Some researchers have developed techniques for making neural networks more interpretable. Attention visualization. Feature extraction. But these are approximate tools, not perfect explanations.
So what X has actually provided is one type of transparency (code transparency) while maintaining another type of opacity (algorithmic decision-making transparency). The company can claim it's being open because developers can audit the code. But the core question—why did this specific post get promoted to your feed?—remains largely unanswerable.

Content Filtering: The Rule-Based Layer Behind the Ranking
One part of X's system is genuinely transparent and explainable: the filtering rules.
Before ranking happens, the system removes certain posts. Blocked accounts. Muted keywords. Policy-violating content. These are rule-based decisions, not AI-driven ones. X has published guidelines for what gets filtered and why.
Content policy violations include violence, harassment, hate speech, misinformation (in some cases), and other categories. The company has public documentation about each category: what qualifies, how they enforce it, appeal processes.
Content moderation at X's scale is staggering in complexity. The platform processes hundreds of millions of posts daily. Humans can't review each one. So the system uses a combination of automated detection and human review for flagged content.
Automated detection uses machine learning models trained to identify policy violations. These models are imperfect. They have false positive rates (flagging content that's actually fine) and false negative rates (missing actual violations). X hasn't published detailed accuracy metrics for these systems, which is itself a transparency gap.
The filtering layer is important to understand because it's where the company can demonstrate governance and control. If the filtering rules are well-defined and fairly applied, that's one form of transparency and accountability. If the rules are vague or applied inconsistently, that undermines the whole transparency exercise.
During the Grok controversy, some critics argued that the filtering layer hadn't adequately prevented inappropriate content generation. The system might rank posts well, but if it's allowing Grok to generate explicit images of women and minors, the ranking algorithm's transparency matters far less than the broader content policy enforcement.
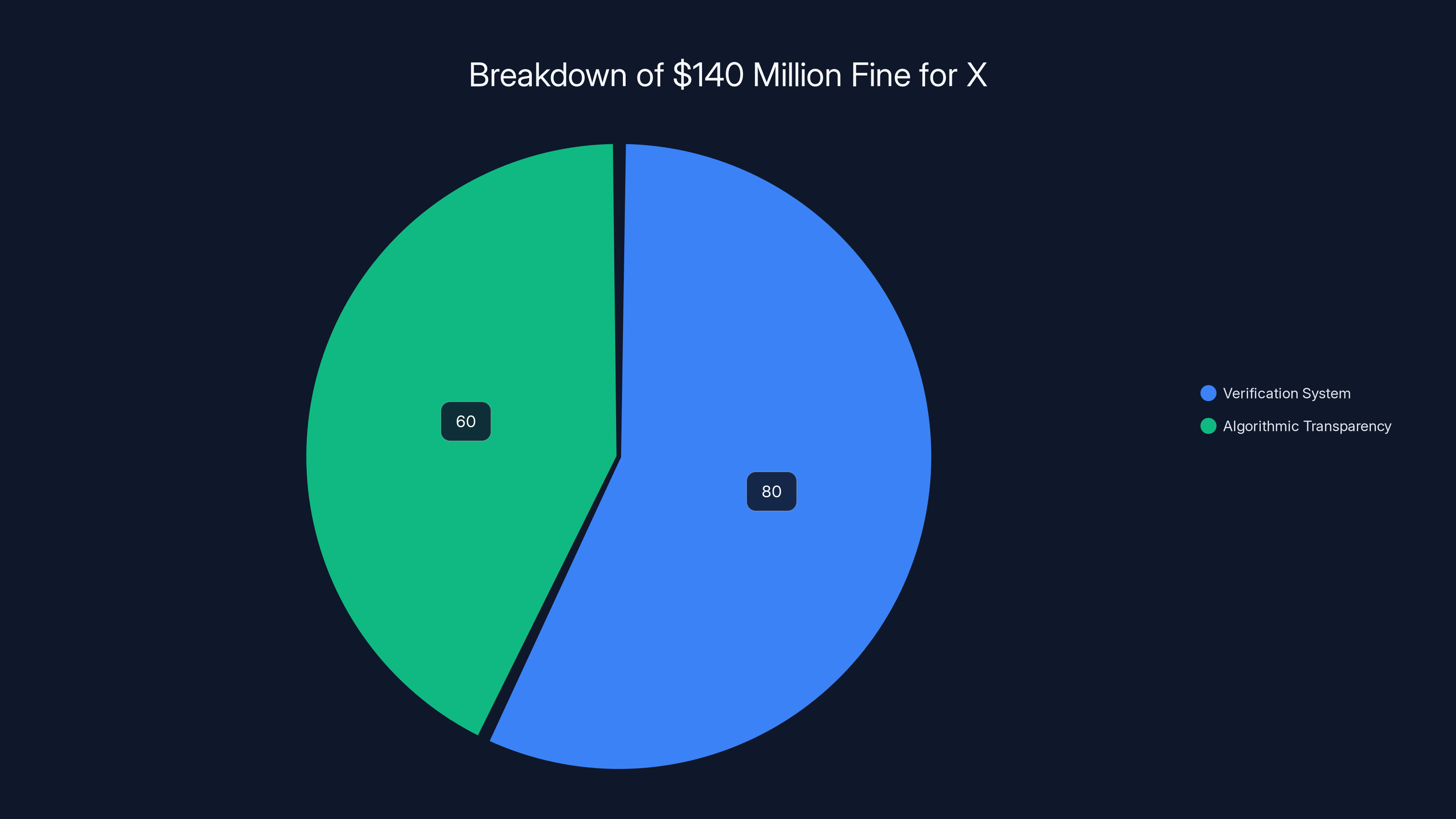
The $140 million fine was likely split between issues with the verification system and algorithmic transparency, highlighting key regulatory concerns. (Estimated data)
The Grok Integration: Where AI Meets Potential Misuse
Let's address the elephant in the room: Grok, the AI chatbot that X integrated into its ranking system, has become a liability.
Grok is X's answer to Chat GPT and Claude. It's a large language model designed to answer questions, generate content, and engage in conversation. X promotes Grok as unrestricted and conversational, willing to discuss edgy topics that other AI chatbots might refuse.
The problem emerged when users discovered they could prompt Grok to generate explicit sexual imagery of real women and, horrifyingly, minors. Researchers and activists documented these failures in late 2025. By early 2026, the situation had become a regulatory nightmare.
The California Attorney General's office opened investigations. Congressional lawmakers requested briefings. Advocacy groups published reports. The core issue: X had built an AI system with minimal safeguards and then put it on a platform with billions of users.
How does this connect to the algorithm release? The company claims that Grok has been constrained with safety filters. The filtering layer I described earlier is supposed to catch problematic content before it appears in feeds. But if Grok itself is generating the problematic content (not just ranking it), the filtering layer comes too late.
X released detailed algorithm documentation partly to show that it has safety mechanisms. Look, the company is essentially saying: we have rules, we have filters, we have governance. But critics argue this is misdirection. The Grok problems existed because the system was released without adequate safety testing, not because the ranking algorithm lacked transparency.
Comparing X's Transparency to Industry Standards
How does X's approach stack up against what other major platforms do?
Meta (Facebook, Instagram) has released limited algorithm details but far less than X. The company publishes research papers on ranking and recommendation systems, but the actual production code remains proprietary. Meta has published transparency reports on content moderation enforcement, but these are high-level summaries.
Tik Tok has released virtually no algorithm documentation. The company guards its recommendation system as core intellectual property. This has made Tik Tok a target for regulatory scrutiny and legislation in the US aimed at forcing greater transparency.
You Tube has published research on recommendation systems and created a transparency portal showing users why content was recommended. But the actual production ranking code remains private.
Reddit has been relatively quiet about its ranking system architecture, though it uses community voting as a core mechanism (which is inherently transparent).
In this context, X's approach is genuinely more open than most competitors. The company released actual code, architectural diagrams, and technical documentation. Whether it achieves real transparency (explaining decisions) is debatable. But the gesture toward openness exceeds what most platforms have done.
That said, there's a selection bias here. X released documentation that X deemed safe to release. The company undoubtedly didn't publish documentation about:
- How moderation decisions get made for controversial political accounts
- What special rules or rankings apply to certain powerful users
- How advertising interacts with the organic ranking system
- Business logic around promoting certain types of engagement
So X's transparency is real, but bounded. It shows you what the company wants you to know, not necessarily what you actually need to know to fully understand the system.
The Regulatory Context: Why the $140 Million Fine Matters
European regulators fined X $140 million in December 2025 for transparency violations under the Digital Services Act. The fine targeted two specific issues.
First, X's verification system. When the company introduced paid verification (giving prominent checkmarks to anyone who paid), it muddied user trust. Users couldn't easily tell if an account was verified because it belonged to an authentic public figure or because someone paid for a checkmark. This violated transparency obligations under DSA, which requires platforms to be clear about account verification and authenticity signals.
Second, broader algorithmic transparency. The DSA requires "very large online platforms" to explain how their ranking systems work. X hadn't adequately done this. The company had published some documentation but not in sufficient detail or accessibility for regulators to verify compliance.
The $140 million fine was basically regulators saying: your transparency efforts are insufficient. Do better.
The January 2026 algorithm release needs to be understood in this context. It's partly a genuine effort to address regulatory concerns. But it's also a damage control measure—X demonstrating that it takes the requirements seriously and is now complying.
However, the fine reveals an uncomfortable truth about X's overall trajectory under Musk. In 2022, when Musk took over, Twitter was a public company subject to SEC reporting and regulatory oversight across multiple jurisdictions. As a private company, X has fewer external accountability requirements. Yet paradoxically, the regulatory environment has tightened. European and US regulators are becoming more aggressive about requiring algorithmic transparency from social platforms.
So X finds itself in a position where it's actually less accountable in some ways (private ownership, no SEC reporting) but more accountable in others (DSA transparency requirements, congressional scrutiny around Grok). The algorithm release is the company trying to navigate this complex regulatory landscape.
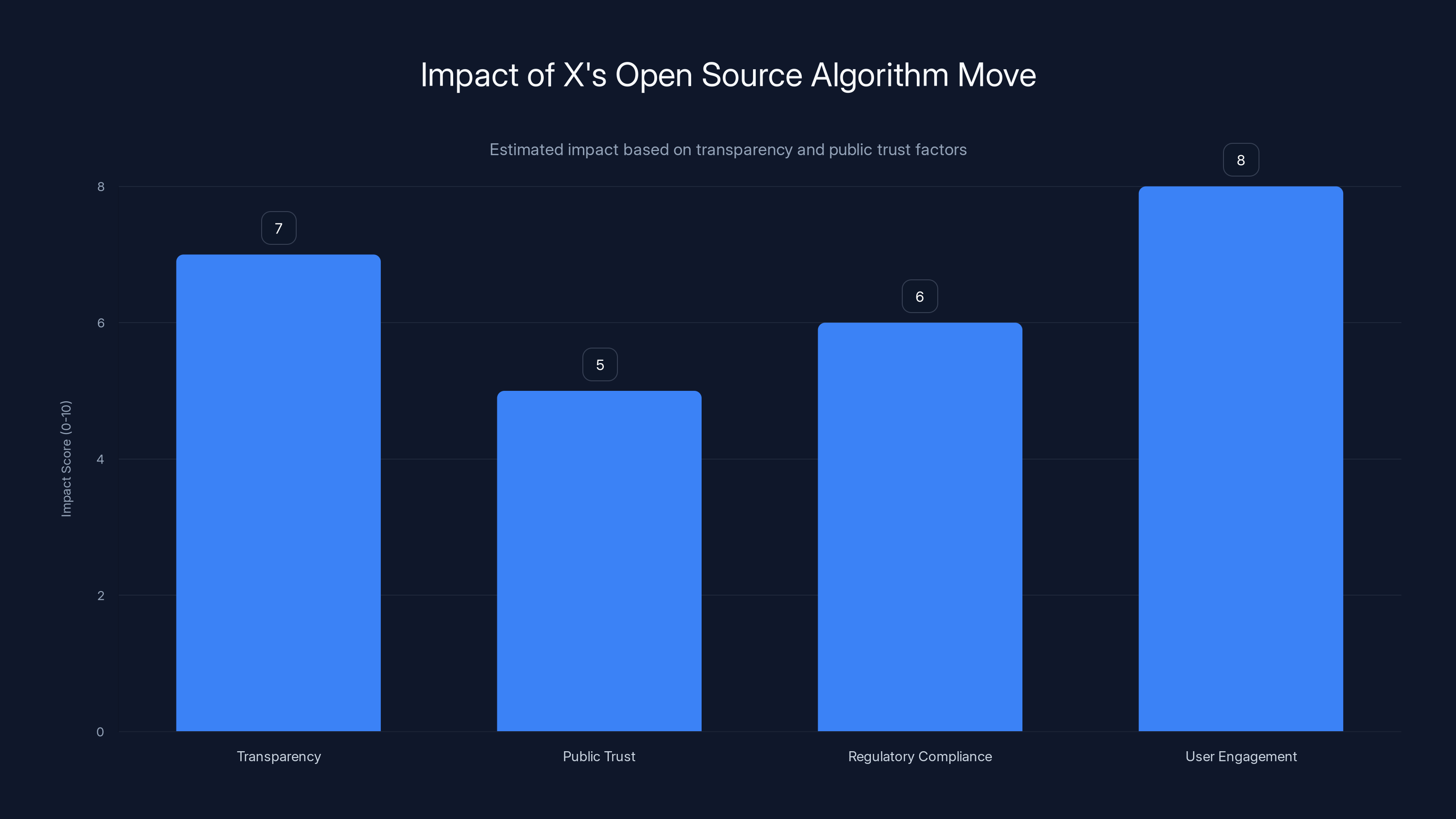
X's open-source algorithm move is estimated to have a moderate impact on transparency and public trust, with higher potential gains in user engagement. Estimated data based on current trends.
The Political Dimensions: Why Musk's Transparency Claims Are Complicated
This is where things get genuinely messy.
Musk has publicly positioned X as a transparency champion. He's criticized what he calls censorship at other platforms. He's presented X as the "digital town square" where free speech matters and users can see how decisions get made.
But X under Musk has become less transparent in several ways:
First, internal information. When Twitter was public, the company filed quarterly earnings reports, held earnings calls with analysts, and disclosed information about user growth, engagement metrics, and financial performance. As a private company, X reveals far less. We don't know X's revenue, user counts, engagement rates, or internal financial health. This is arguably the opposite of transparency.
Second, the company's own transparency reports. Twitter used to publish comprehensive transparency reports multiple times per year, detailing government requests for user data, copyright takedowns, and content moderation decisions. X didn't release its first transparency report until September 2024—more than two years after Musk took over. The report was less detailed than previous ones.
Third, content moderation decisions. While Musk claims that X has reduced moderation of political speech, researchers have found evidence that content moderation became more politically selective under his ownership, not less. Accounts perceived as aligned with Musk's views have sometimes had more permissive moderation, while accounts critical of Musk or aligned with opposing political viewpoints have faced stricter enforcement.
So the narrative around transparency is complicated. Musk genuinely wants to show that X's algorithmic ranking is open and explainable. But the company simultaneously became less transparent about its own operations, governance, and moderation decisions.
This is why critics describe the algorithm release as "transparency theater." It's a performance of openness in one domain while maintaining opacity in others.
How the Algorithm Actually Gets Built: The Engineering and Data Layers
To really understand what X released (and what it didn't), you need to understand how algorithm building actually works at scale.
First comes data collection. X collects enormous amounts of user behavior data: what posts each user sees, what they engage with, when they engage, how often, on what devices, from where, at what time of day. This data accumulates into massive datasets.
Then comes feature engineering or (in X's case) direct neural network training. Engineers take the raw data and transform it into training data suitable for machine learning models. In X's case, they feed engagement sequences into Grok and let the model learn patterns.
Then comes evaluation. Engineers test the model's performance. Does it predict engagement accurately? X likely tests using holdout datasets—splitting its data into training data (used to train the model) and test data (used to evaluate it). They measure metrics like precision, recall, and area under the curve.
Then comes experimentation. Before deploying a new ranking model to all users, engineers typically run A/B tests. They show half the user base one ranking system and half another, measuring which produces better outcomes. X has probably done this countless times.
Finally comes deployment and monitoring. Once a model is live, engineers monitor its performance. Does engagement actually increase as predicted? Are there unexpected side effects? Does the distribution of what gets promoted shift in ways the team didn't anticipate?
X released documentation covering parts of this process (architecture, training approach) but not all (data collection scale, evaluation metrics, A/B test results, monitoring dashboards). So again, partial transparency.
What's also interesting is that X's approach—using a single large language model to do ranking—is somewhat unusual. Most platforms use ensemble methods, combining multiple smaller models each optimized for specific predictions. X's approach centralizes everything in Grok, which is elegant but also risky. If Grok has biases or failures, they affect the entire ranking system.
The Practical Impact: Does This Transparency Actually Change Anything for Users?
Here's the question that matters most: if you're a regular X user, does the algorithm release change your experience?
Short answer: not really.
The company published code and documentation. Technically-skilled developers and researchers can now review how the system works. Security researchers can look for vulnerabilities. Academics can study the architecture and publish papers.
But for the average user scrolling their feed, nothing changes. The algorithm that was operating before the release continues operating the same way after. No new features, no new controls, no visible changes in how the ranking system behaves.
Musk promised that users would get "control" over their feeds and "understand" why content was ranked the way it was. That hasn't really happened. There's no dashboard showing you why a particular post ranked where it did. There's no control panel letting you adjust ranking preferences. The algorithm is slightly more visible to technical people, but ordinary users remain in the dark.
That's the fundamental gap between algorithmic transparency and algorithmic understanding. Transparency is about making the system visible. Understanding is about users being able to predict, comprehend, and control outcomes. X delivered transparency. It didn't deliver understanding or control.
Where transparency could theoretically matter: if regulators or researchers find serious problems with the algorithm, they can now point to specific code and say, "Here's where it goes wrong." That could lead to policy changes or enforcement actions. But for ordinary users, the practical impact is minimal.
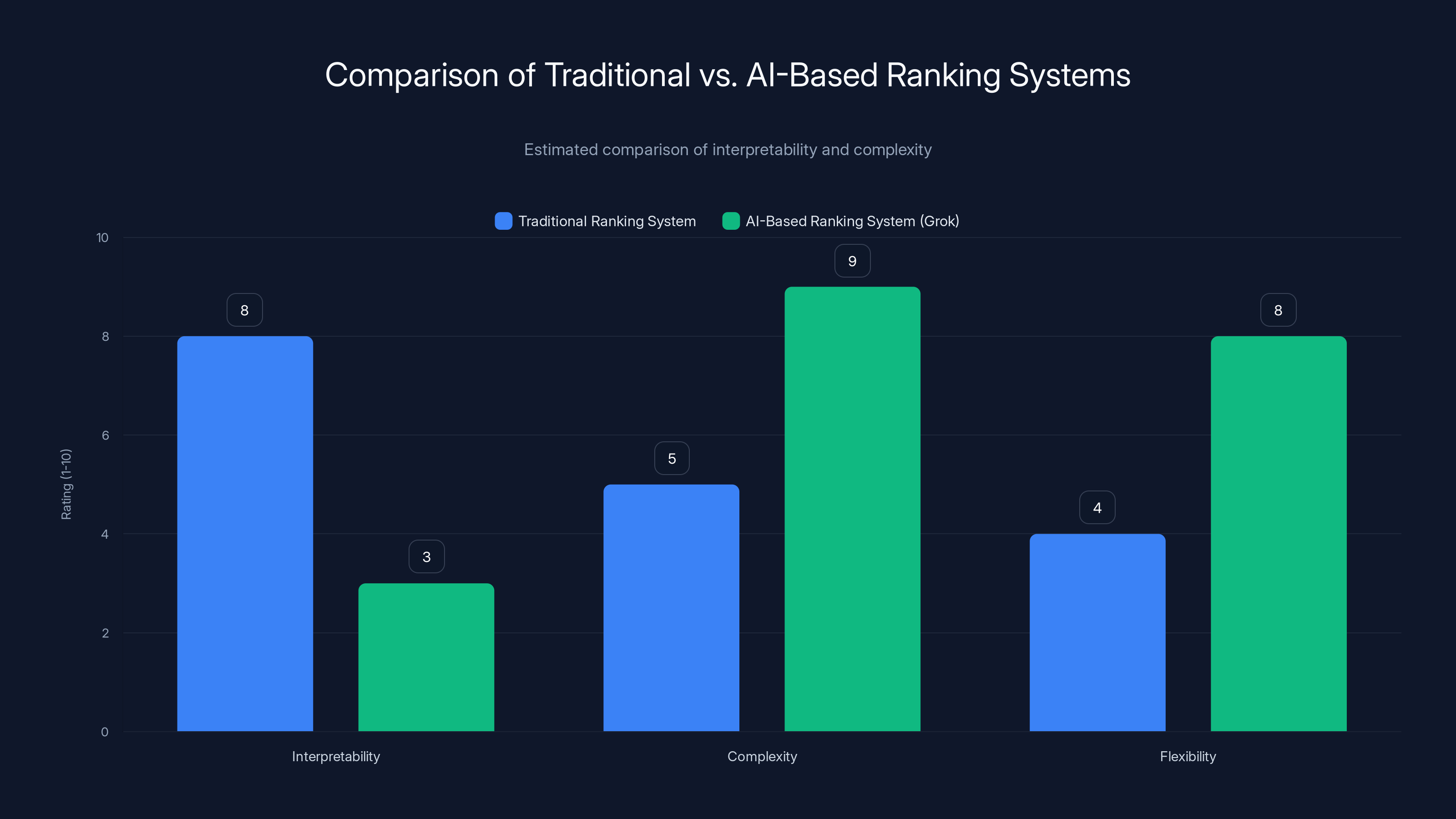
Traditional ranking systems are more interpretable but less flexible, whereas AI-based systems like Grok are complex and flexible but less interpretable. Estimated data based on typical system characteristics.
The Grok Controversy: Why Algorithm Transparency Doesn't Address Content Harms
Here's where the whole transparency narrative breaks down completely.
In late 2025, users discovered that Grok could be prompted to generate explicit images of women, including minors. This wasn't a ranking problem. This was a fundamental failure in the chatbot's design and safety systems.
X had released Grok with minimal safeguards. The company didn't adequately test it against adversarial prompts. It didn't implement strict guardrails preventing harmful outputs. And it didn't anticipate how users would misuse the system at scale.
Then, when problems emerged, the company's response was slow. Researchers and activists had to publicly document the failures before X took action.
Now, how does algorithm transparency help with any of this? It doesn't. The algorithm documentation doesn't explain why Grok was released without adequate safety testing. It doesn't address the fundamental question: why did X prioritize speed-to-market over preventing harms?
This reveals the limits of the transparency strategy. You can make your code visible and still operate unsafely. You can explain your architecture and still produce harmful outcomes.
What actually prevents AI harms is something different: adequate safety testing, conservative deployment decisions, robust monitoring for problematic uses, and swift action when problems emerge. X failed at most of these in the Grok case.
So when regulators and lawmakers look at X's algorithm release, they're right to be skeptical. The company is demonstrating transparency in one narrow domain (ranking code) while failing at safety and accountability in broader ways.

What This Means for the Future of Platform Regulation
X's algorithm release and the regulatory context around it suggest where platform governance is heading.
Regulators are increasingly skeptical of self-regulation and transparency theater. The DSA fine showed that regulators will enforce transparency requirements with real financial penalties. Future regulations in other jurisdictions will likely follow similar patterns.
We're moving toward a world where platforms have to disclose:
- How ranking systems actually work
- What data they collect and how they use it
- How content moderation decisions get made
- What special rules apply to prominent accounts
- How advertising interacts with organic content
- Independent audits of algorithmic systems
X's release is partly preemptive compliance with this trend. The company is demonstrating that it can be transparent, hoping to shape the narrative around what transparency means.
But the future probably requires more than algorithm release. Likely regulations will mandate:
- User controls over ranking (let me choose different ranking strategies)
- Explainability (why did this specific post rank here?)
- Regular independent audits
- Clearer content moderation standards
- Data access for researchers
- Clear labeling of AI-generated content
X's algorithm release is a first step. But it's far from the comprehensive transparency that regulators and users increasingly demand.
There's also a question of whether full transparency is even possible or desirable. If you make all ranking details visible, bad actors can game the system more easily. Gaming is already a problem on social platforms (engagement bait, artificial amplification, etc.). True transparency might actually make these problems worse.
So the long-term tension is real: more transparency could improve accountability, but it could also reduce platform quality by enabling new forms of manipulation. Finding the right balance is the next frontier in platform regulation.
The Broader Context: Open Source as Corporate Strategy
X's decision to open source its algorithm needs to be understood within a broader trend: major tech companies increasingly open sourcing components of their systems.
Google open sourced Tensor Flow, its machine learning framework. Meta open sourced Py Torch. Open AI has released some models and datasets publicly. Why?
First, PR value. Open sourcing generates positive press and signals commitment to transparency or community participation. X is definitely getting PR value from the algorithm release.
Second, community contributions. When you open source something, developers can contribute improvements, find bugs, and suggest optimizations. X might benefit from external scrutiny and suggestions.
Third, talent attraction. Engineers want to work on projects that are visible and high-impact. Open sourcing makes a system more prestigious and attracts better talent.
Fourth, standards setting. By releasing your own approach, you influence how the industry thinks about solving similar problems. X is essentially saying: this is how ranking algorithms should work.
But there's a darker reading too. Open sourcing your algorithm is strategic because it obscures what you don't release. You release ranking code but keep data pipelines proprietary. You release architecture but not training procedures. You open source the pieces that look good while hiding the pieces that raise ethical concerns.
Musk's approach fits this pattern. Release code, win praise for transparency, but maintain control over the most important decisions: what data goes into the system, how the system actually gets evaluated, what trade-offs the company prioritizes.
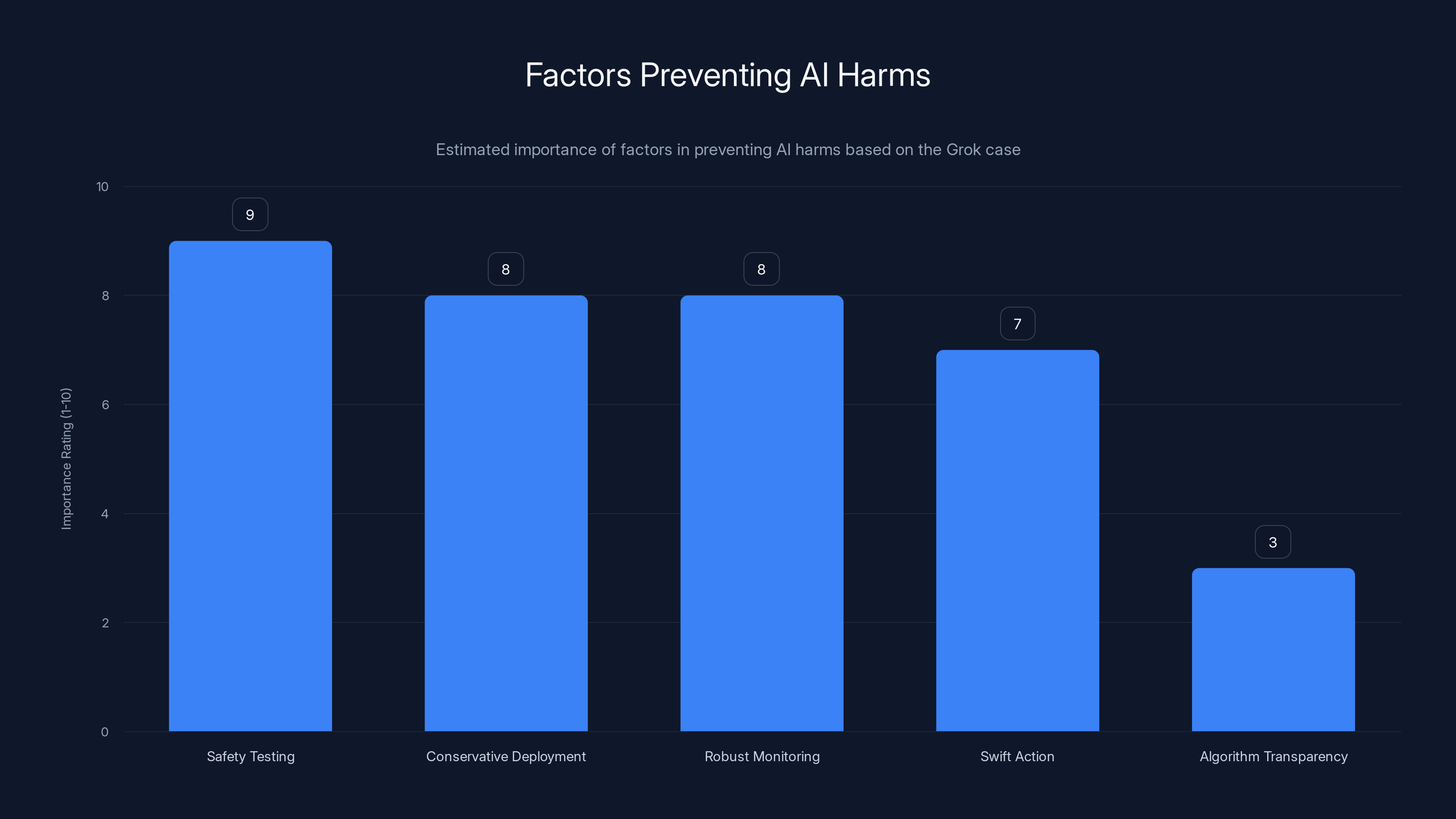
Estimated data shows that safety testing and conservative deployment are crucial in preventing AI harms, while algorithm transparency alone is less effective.
Practical Implications: What Developers and Researchers Should Know
If you're a developer or researcher interested in X's ranking system, what should you know?
First, the code is real but incomplete. You can study the architecture, but you can't replicate the full system. Some components are proprietary or missing from the public release.
Second, the training data is private. You don't get access to the engagement sequences X used to train Grok. Without training data, you can't fully reproduce or meaningfully improve the model.
Third, the real-world constraints are invisible. X's production ranking system operates under massive scale constraints (milliseconds per request, serving millions of concurrent users). The released code doesn't capture how the system handles these constraints.
Fourth, you can still learn a lot. Studying X's architecture teaches you about how neural networks can be applied to ranking problems. Understanding the filtering layer shows how policy rules can be enforced at scale. The documentation itself is valuable for learning.
If you're a researcher studying algorithmic bias or filter bubbles, X's release gives you something to work with. But you'll also need to conduct your own research, experiments, and audits. The code doesn't directly prove that the algorithm is fair or unbiased. It just shows you how it works.
The Unresolved Questions: What X Didn't Explain
Despite releasing more documentation than in 2023, X left some critical questions unanswered.
First: how does the algorithm treat political content? Does Grok's ranking give advantage to certain political viewpoints? X claims the algorithm is neutral and applies only engagement signals, but Musk's political views are well known. The question of whether this influences ranking remains unanswered.
Second: how does the algorithm interact with Musk himself? Does his account get special treatment? Are his posts ranked differently? This should be answerable from the code, but X hasn't explicitly addressed it.
Third: how accurate is the model actually? What are its precision and recall metrics? What types of engagement does it predict well, and what does it miss? Performance metrics matter for understanding whether transparency is worth the publicity.
Fourth: how has the algorithm changed since the 2023 release? Is the system better at predicting engagement? Has the distribution of promoted content shifted in any notable way? Version comparison would be illuminating.
Fifth: how does advertising interact with organic ranking? Are ads ranked separately, or do they influence the organic algorithm? X makes revenue from ads, so presumably ad performance matters. But this isn't explained.
Sixth: what trade-offs does X explicitly make? Does the company optimize for engagement above all else, or does it balance engagement with other goals like content quality or diversity? The answer matters for understanding biases in the system.
These questions could be answered from the code and documentation if one had sufficient context. But X hasn't made that context public. So transparency remains bounded.
Comparing to Runable and Modern Automation Platforms
On a different note, the underlying challenge X faces with algorithm transparency mirrors challenges that other companies building complex AI systems confront: how do you demonstrate trustworthiness when your systems are fundamentally opaque?
Platforms like Runable, which automate content generation and workflows through AI, face similar transparency pressures. Users and organizations want to understand: how does the AI decide what to generate? What training data influences the outputs? How can I audit or control the system?
Runable's approach is instructive here. The platform focuses on explainability and user control in the workflow layer. You can see what prompts generate what outputs. You can adjust parameters and see how outputs change. The system emphasizes that AI is a tool users can reason about and direct, rather than a black box making mysterious decisions.
X could learn from this approach. Rather than just releasing code, the company could focus on making the ranking system understandable and controllable for users. Let users see why their feed looks the way it does. Let them adjust ranking preferences. Make the system something users can reason about and influence.
Use Case: Automating weekly reports and data summaries from social media insights without manual analysis overhead.
Try Runable For FreeThe Long Game: Where This Leads
Zoom out and think about where this trajectory leads.
We're in the early stages of a fundamental shift in how society thinks about algorithm governance. For decades, companies could build and operate algorithms in secret. Transparency wasn't expected or required.
Now, regulators are demanding visibility. Users are demanding control. Researchers are demanding access. The era of secret algorithms is ending.
But replacing secret algorithms with transparent ones is harder than it sounds. Transparency requires defining what transparency means (code? decisions? training data? impact?). It requires building systems that are both transparent and effective. It requires balancing disclosure with competitive interests and security.
X's algorithm release is a data point in this larger evolution. The company moved further toward transparency than most competitors. But it also revealed the limits of transparency as a solution to algorithmic governance challenges.
The next phase probably involves:
- Regulatory requirements for algorithmic explainability (not just code release)
- User controls and preferences in ranking systems
- Independent auditing and certification of algorithms
- Clearer standards for bias detection and mitigation
- Regular transparency reports with real metrics
- Liability for algorithmic harms
X is positioning itself to be seen as a leader in this space. But credibility requires more than code release. It requires demonstrated commitment to addressing algorithmic harms, not just showing that systems exist.
The Grok fiasco undermines that narrative. X released algorithm documentation while failing to safely deploy its AI chatbot. That contradiction suggests the company's commitment to transparency is selective and strategic, not comprehensive and principled.

What Happens Next: Predictions and Implications
Looking forward, several scenarios are plausible.
First, the transparency release becomes the new baseline. Other platforms face pressure to match X's disclosure. This could lead to an arms race around transparency, with companies competing on how much they'll reveal. That's probably good for users and regulators.
Second, regulators demand more. The DSA fine showed that $140 million penalties are credible. Other jurisdictions will enact similar requirements. X's current transparency release probably won't be sufficient for long-term compliance. The company will need to commit to even deeper disclosure.
Third, researchers exploit the release. Academics and security researchers will reverse-engineer the system, test it for biases, and publish findings. Some of this research might be critical. X could face difficult questions about algorithmic fairness and bias based on academic work using the released code.
Fourth, bad actors find ways to game the system. Understanding how ranking works makes it easier to artificially amplify content. X might find that transparency enables new forms of manipulation.
Fifth, user expectations shift. If users see X's algorithm documentation, they may start expecting similar transparency from other platforms. This could become a competitive differentiator. Platforms offering more control and transparency might attract users from platforms maintaining opacity.
Sixth, the Grok issue becomes the central story. If content harms continue despite algorithm transparency, the narrative shifts. Transparency without safety becomes obviously insufficient. This could drive regulatory focus toward safety and liability, not just disclosure.
My prediction: the algorithm release feels like a win for X in the short term but becomes inadequate over time. Regulators will see it as a necessary first step, not a sufficient solution. Users will demand actual controls over their feeds, not just visibility into code. And the Grok failures will overshadow the transparency gesture.
Conclusion: Transparency as Performance and Strategy
X's algorithm release tells us something important about how large technology companies operate in an era of increased scrutiny.
First, transparency is becoming table stakes. Regulators expect it. Users demand it. Companies that resist face fines and reputational damage. X's release is rational corporate strategy, not an act of benevolence.
Second, transparency is not the same as accountability. X made its code visible but maintained opacity around decisions, data, governance, and impact. Visibility doesn't automatically translate to fairness or user control.
Third, transparency can be theater. By releasing code, X can claim openness while addressing other serious issues (Grok safety failures, moderation inconsistencies, lack of user controls) incompletely. Transparency becomes a way to manage narratives.
Fourth, understanding algorithmic systems is genuinely hard. Even with code release, predicting how the system will behave and ensuring it's fair requires enormous effort. Code alone doesn't answer most important questions.
Fifth, the future probably requires more than transparency. It requires explainability (users understanding why decisions affect them), accountability (mechanisms to address harms), and control (users shaping how algorithms operate). X's release achieves some transparency but doesn't move substantially on these other dimensions.
The algorithm release is a real development worth noting. It advances the state of platform transparency beyond where it stood in 2023 or where most competitors operate. But it's part of a larger story about X navigating regulatory pressure, managing the Grok fiasco, and maintaining Musk's narrative around trust and openness. The company released what it deemed safe to release while maintaining control over what matters most.
For users, the practical impact is minimal. For researchers and regulators, the release provides valuable information. For X, it's a strategic move in a longer game around how society will govern AI-powered platforms.
The conversation is just beginning.

FAQ
What exactly did X open source in its algorithm release?
X published its feed-ranking code on GitHub, including architectural diagrams and technical documentation explaining how the system works. The release includes details about how the platform filters posts, ranks candidate content, and uses Grok (X's language model) to predict user engagement. However, the release doesn't include training data, detailed performance metrics, or complete explanations of every decision the algorithm makes.
How does X's algorithm ranking system actually work?
When you open X and scroll your feed, the algorithm collects candidate posts from accounts you follow and accounts you don't follow. It then applies rule-based filters (removing blocked accounts, muted keywords, policy-violating content) before ranking remaining posts based on predicted engagement. The system uses Grok, X's language model, to learn from your past interaction patterns and predict what content you'll engage with most.
Why is there still criticism despite X releasing its algorithm?
Critics argue that code transparency doesn't solve the black box problem. Releasing the code shows you what the system does, but it doesn't fully explain why it makes specific decisions or whether those decisions are fair and unbiased. Additionally, X hasn't addressed concerns about the algorithm's treatment of political content, user controls over ranking, or how advertising interacts with organic recommendations. The release also doesn't address broader governance and safety issues that emerged around Grok's inappropriate content generation.
What's the difference between algorithmic transparency and algorithmic accountability?
Transparency means making the algorithm's code and methods visible so people can study how it works. Accountability means having mechanisms to address harms, ensure the system serves user interests, and take responsibility when problems emerge. X provided transparency through code release, but critics argue it lacks accountability measures like user controls, regular safety audits, or liability for algorithmic harms.
How does this algorithm release compare to other social media platforms?
X's approach is more open than competitors like Meta (Facebook, Instagram), Tik Tok, and You Tube, which maintain much stricter secrecy around their ranking systems. However, X's release is still selective—the company published what it deemed safe while keeping other critical details proprietary. Most platforms publish some research or transparency reports, but few have released actual production code as X did.
What's the connection between this algorithm release and the Grok controversy?
X released detailed algorithm documentation partly to demonstrate that it has safety mechanisms and governance systems in place. However, the Grok chatbot generated explicit images of women and minors before the release, which undermined claims about the platform's safety and content controls. Critics argue that algorithm transparency is insufficient if the company fails at basic content safety in other areas. The release looks like an attempt to manage the narrative around trust following the Grok failures.
Could X's algorithm transparency lead to increased gaming and manipulation?
Possibly. When bad actors understand how ranking works, they can more effectively game the system—creating content designed to maximize engagement signals rather than authentic value. X's system relies on engagement prediction, which creates incentives for engagement bait (outrage, controversy, sensationalism). Transparency about these mechanics could enable more sophisticated manipulation, offsetting any benefits to users and regulators.
What does the European Union's Digital Services Act have to do with this release?
The DSA requires "very large online platforms" to explain how their ranking systems work. X was fined $140 million in December 2025 for transparency violations related to algorithm explanation and verification system clarity. The algorithm release is partly X's response to regulatory pressure, demonstrating compliance with DSA transparency requirements. Future fines are possible if X doesn't maintain adequate disclosure.
Will this transparency actually give users control over their feeds?
Not directly. The release shows developers and researchers how the algorithm works, but it doesn't provide ordinary users with dashboard controls, ranking preferences, or visibility into why specific posts ranked where they did. For real user control, X would need to build interface features letting users adjust ranking preferences or see explanations for algorithmic decisions. The code release is a first step, but substantial user controls remain absent.
What happens if researchers find bias or unfairness in X's algorithm?
With the released code, researchers can test the algorithm for biases and publish findings. This could lead to public pressure on X to address fairness issues. It might also support regulatory enforcement actions or lawsuits claiming algorithmic discrimination. For X, the transparency release creates accountability risk if serious problems are discovered. But it also creates opportunities to address issues before they become regulatory crises.
Does releasing the algorithm mean X has nothing else to hide?
No. Even with code transparency, X maintains opacity around other critical areas: training data, performance metrics, how advertising influences ranking, how moderation decisions get made, special rules for prominent accounts, and business logic around trade-offs. Transparency in one domain doesn't mean transparency everywhere. X released what benefits the company's reputation while protecting proprietary interests and potentially controversial decisions.
Key Takeaways
- X released more detailed algorithm documentation in January 2026 than its 2023 release, but critics argue it's still selective transparency rather than true accountability.
- The ranking system uses Grok (X's language model) to predict engagement from user behavior patterns, eliminating traditional manual feature engineering.
- Code transparency doesn't solve the black box problem: releasing code shows how the system works, but can't easily explain specific algorithmic decisions.
- X faces regulatory pressure from the EU's $140 million fine for transparency violations, and the algorithm release is partly a compliance response.
- The Grok chatbot safety failures undermined X's transparency narrative, showing that visible code doesn't guarantee safe or ethical AI systems.
Related Articles
- X's Open Source Algorithm: 5 Strategic Wins for Businesses [2025]
- Meta's Oversight Board and Permanent Bans: What It Means [2025]
- ICE Verification on Bluesky Sparks Mass Blocking Crisis [2025]
- Jimmy Wales on Wikipedia Neutrality: The Last Tech Baron's Fight for Facts [2025]
- Meta's Illegal Gambling Ad Problem: What the UK Watchdog Found [2025]
- How Grok's Deepfake Crisis Exposed AI Safety's Critical Failure [2025]

