![YouTube Massive Outage February 2025: Complete Timeline & Impact [2025]](https://tryrunable.com/blog/youtube-massive-outage-february-2025-complete-timeline-impac/image-1-1771387550044.jpg)
YouTube Massive Outage February 2025: Complete Timeline & Impact
On the evening of February 17, 2025, something went wrong. Really wrong. Starting around 8 PM Eastern time, YouTube simply vanished for hundreds of thousands of people across the United States and beyond. One moment you're scrolling through videos, the next you're staring at an error page. No explanation. No countdown timer telling you when things might be back. Just nothing.
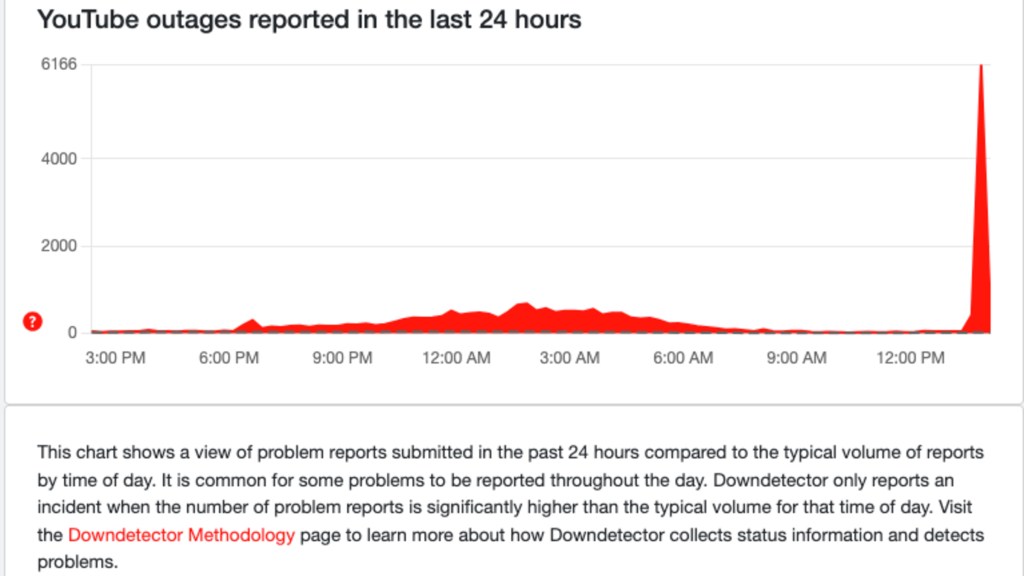
By 8:30 PM, outage tracking sites were flooded with reports. More than 338,000 people reported issues on Downdetector alone. That's not a small hiccup. That's a genuine crisis affecting millions of users worldwide.
What made this event particularly unsettling wasn't just the scale. It was the cascading failures. YouTube wasn't the only Google service that went down. Google's search functionality experienced issues. Google Home Assistant stopped responding. When one of the world's largest technology companies stumbles, it sends ripples across the entire internet ecosystem.
For nearly two hours, the YouTube recommendation engine was completely offline. The homepage came back online first, but users could only see a blank page where their personalized video suggestions should be. Imagine opening your favorite entertainment platform and finding absolutely nothing there. No suggestions. No algorithms working in the background. Just emptiness.
This incident raises critical questions. How does a service used by over 2 billion people go down? What infrastructure failures lead to such widespread outages? And perhaps most importantly: what can individuals and businesses do to prepare for the next one?
This article breaks down everything about the YouTube outage, why it happened, what the broader implications are, and how to build resilience into your digital life.
TL; DR
- YouTube went completely down on February 17, 2025, at 8 PM ET, affecting 338,000+ reported users in the US and multiple other countries
- Multiple Google services failed simultaneously, including YouTube, Google Search, and Google Home Assistant, suggesting a systemic infrastructure issue
- The outage lasted nearly two hours, with the homepage coming back online first while the recommendation system remained offline
- Geographic spread was global, with users in Canada, India, the Philippines, Australia, and Russia also experiencing access issues
- No official explanation was provided about the root cause, though Google acknowledged the problem and claimed full resolution by 10:12 PM ET

The YouTube outage likely affected hundreds of millions globally, with only a fraction reporting the issue. Estimated data based on 2 billion monthly active users.
What Actually Happened on February 17, 2025
The outage didn't begin with a dramatic announcement or a warning email. It started with confusion. Users opened YouTube on their phones, tablets, and computers and found nothing. The site wouldn't load. The app wouldn't respond. And they weren't alone.
The first signs of trouble appeared around 8 PM Eastern time. This is important timing to understand. Eight o'clock on a Monday evening meant that YouTube was experiencing peak traffic. Millions of people come home from work and settle in for the evening. They're catching up on content, watching gaming streams, listening to music. It's prime time for YouTube's engagement metrics.
Within minutes of the initial failures, social media erupted. Reddit's r/youtube filled up with thousands of posts. Twitter (now X) saw the term "YouTube down" trending within an hour. People were confused, frustrated, and searching for answers that nobody had.
Downdetector recorded a dramatic spike in reports. The website tracking service logs user-submitted complaints about service outages across various platforms. By 8:30 PM, they'd received over 100,000 reports. By 8:45 PM, the number had climbed to 338,000. This exponential growth suggested the problem was severe and affecting massive swaths of the user base simultaneously.
What made this particularly interesting was the pattern of the outage. It wasn't a clean total failure. Different users experienced different problems at different times. Some couldn't access the homepage. Others could see the homepage but got no recommended videos. Some users reported that the mobile app worked fine while the web version was completely broken. Others experienced the opposite.
This staggered failure pattern suggests the problem didn't originate from a single point of failure, but rather from multiple systems struggling simultaneously.
The Geographic Scope
YouTube isn't just an American platform. It's a global service with users on every continent. The outage reflected this reality. While the initial reports focused on the United States, reports soon came flooding in from other countries.
Users in Canada reported widespread access issues. India saw major service disruptions. The Philippines experienced significant problems. Australia reported widespread failures. Russia also had access issues, though this could have involved different factors given the geopolitical situation and existing internet restrictions.
This global spread told engineers and industry observers something critical: the problem was likely at YouTube's core infrastructure level, not at a regional data center or a content delivery network serving a specific geographic area. When multiple continents lose access simultaneously, you're dealing with a central system failure.
Google maintains redundant data centers across the world specifically to prevent this scenario. Each region has its own infrastructure. If one data center fails, traffic should automatically reroute to others. The fact that this didn't happen suggested either the failure was so comprehensive it affected all data centers simultaneously, or the routing systems that redirect traffic during outages weren't functioning properly.
Timeline of Events
Precise timing matters when understanding outages. Here's how the evening unfolded:
8:00 PM ET - First reports of YouTube being inaccessible begin appearing. Users from multiple regions start experiencing issues.
8:15 PM ET - Downdetector begins receiving reports. Initial spike suggests widespread impact affecting major geographic regions.
8:30 PM ET - Reports peak at over 100,000. Social media platforms see massive increases in user complaints about YouTube.
8:45 PM ET - Downdetector records 338,000 reports. This becomes the highest point of reported failures.
9:00 PM ET - YouTube's official team acknowledges the problem via social media. They don't provide details about what's happening.
9:20 PM ET - Homepage starts coming back online for some users. However, the recommendation system remains offline.
9:33 PM ET - Users report partial restoration. They can access the homepage but aren't seeing any recommended videos or personalized content.
9:50 PM ET - Google services that went down simultaneously (search, home assistant) show signs of recovery for some users.
10:12 PM ET - YouTube's Team account posts that the issue has been completely fixed.
10:27 PM ET - Follow-up reports confirm most users have full access restored.
This timeline shows the outage lasted just over two hours from initial failures to full resolution. That might not sound like a long time, but consider how many people depend on YouTube every single hour. Two hours represents millions of hours of lost user time, lost engagement, lost ad impressions, and lost streaming revenue.
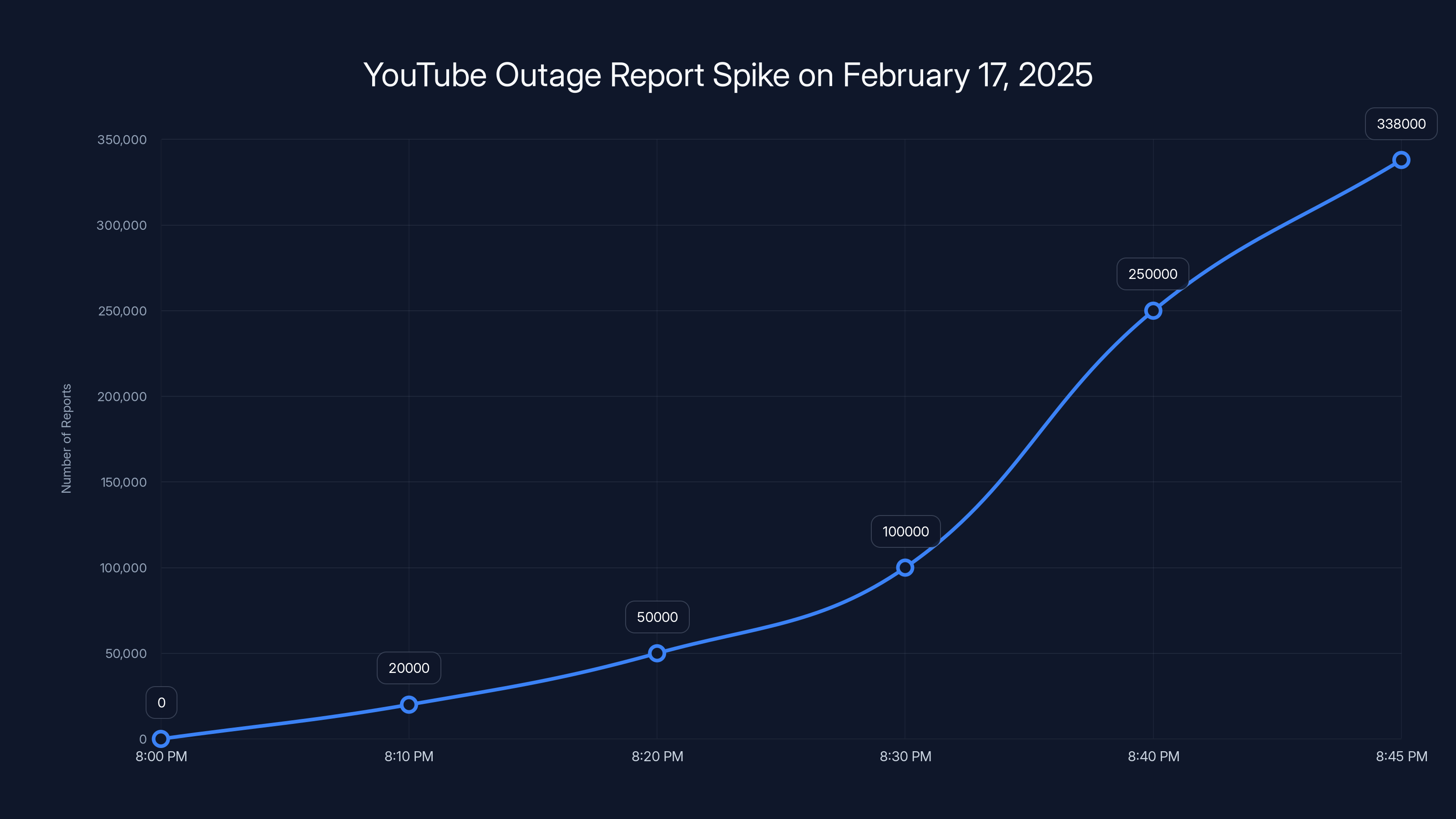
The number of outage reports on Downdetector spiked dramatically, reaching 338,000 by 8:45 PM, indicating a widespread issue affecting many users.
Why YouTube Going Down Is Worse Than You Think
YouTube isn't like your favorite social media app where you can simply switch to a competitor if things go wrong. YouTube has become infrastructure. It's woven into the daily life of billions of people.
Content creators depend on YouTube for their livelihoods. Thousands of professional YouTubers were in the middle of streaming sessions when the outage hit. Livestreams ended abruptly. Hours of streaming revenue vanished. Gaming channels mid-tournament broadcast lost their streams. Educational creators broadcasting to live classrooms went dark.
Businesses use YouTube for marketing. Companies had advertisements scheduled during that exact time window. Those ads never served. The impressions never counted. The campaigns essentially experienced a full blackout.
Musicians rely on YouTube for distribution. The platform serves as the modern-day radio station. An outage means no music playback for millions. The royalties that would have accrued during those two hours simply don't exist.
Parents use YouTube as an entertainment and educational tool. When it goes down, they're suddenly without a resource they've come to depend on. Schools that use YouTube for instructional content experience disruptions.
But here's what really matters: this wasn't an isolated failure. Google's own search engine went down partially. Google Home Assistant stopped responding to voice commands. These aren't YouTube-specific systems. They're core Google infrastructure.
When Google's core services fail, it reveals something uncomfortable. Even the most sophisticated technology companies with unlimited resources can experience cascading failures that knock out multiple services simultaneously. If it can happen to Google, with their legendary infrastructure team and redundancy systems, it can happen to any company.

Understanding Internet Infrastructure During Outages
To truly understand what happened, you need to grasp how massive internet services work. YouTube doesn't run on a single server in a single location. That would be absurd. One physical failure would destroy the entire service.
Instead, YouTube's infrastructure looks something like this:
Content Delivery Networks (CDNs). YouTube's videos are stored in data centers across the world. When you request a video, your request goes to the nearest server, which sends you the content. This reduces latency and server load at any single location.
Load Balancers. These systems sit in front of your actual servers and distribute incoming traffic. If you have 10,000 people requesting the homepage simultaneously, the load balancer sends some to server A, some to server B, some to server C, and so on. This prevents any single server from being overwhelmed.
Redundancy at Every Level. If one data center goes down, traffic automatically reroutes to another. If one load balancer fails, a backup takes over. If one entire region goes offline, other regions can handle the traffic.
The Frontend and Backend. The homepage you see (frontend) is separate from the recommendation system (backend). The backend runs complex algorithms analyzing your viewing history, your likes, your subscriptions, your watch time, and millions of other data points to predict what you'd like to watch next. This is computationally intensive and runs on massive server farms.
When YouTube went down on February 17, something broke this entire system. The frontend came back faster than the backend, suggesting the problem might have affected the recommendation system specifically. Maybe a database crashed. Maybe an algorithm service failed. Maybe something in the backend infrastructure experienced a cascading failure that brought down recommendation serving.
One popular theory among engineers is that the outage might have been related to a failed deployment. Most large tech companies deploy new code continuously. Sometimes a deployment goes wrong. A bug in new code causes a service to crash. When the service crashes, the system tries to automatically roll back to the previous version. Sometimes that rollback fails too. Then you've got a situation where the service is dead and can't restart itself.
Another possibility is a database issue. YouTube's recommendation system requires access to massive databases. If a database becomes corrupted or locked, the service can't function. Recovery might require manual intervention.
Without Google providing detailed information about the root cause, we can only speculate. But the key point is that this wasn't a DNS issue or a network routing problem. This was something deeper in Google's infrastructure.
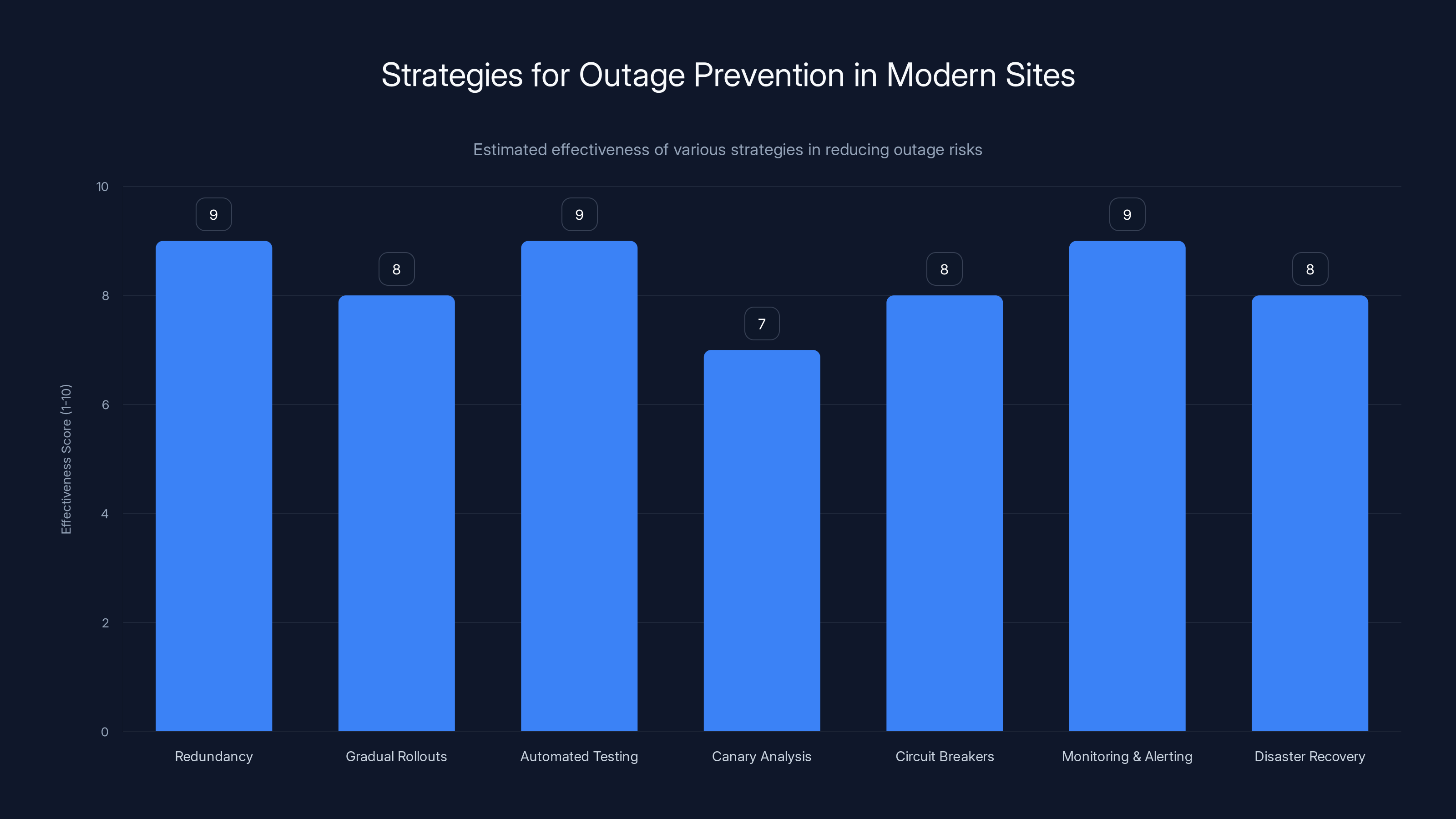
Redundancy, automated testing, and monitoring are among the most effective strategies in preventing outages, with scores of 9 out of 10. (Estimated data)
The Ripple Effects Across the Internet
When YouTube goes down, the consequences extend far beyond YouTube users who can't watch videos. The outage created shockwaves through multiple interconnected systems and businesses.
Streaming and Content Creation. Content creators were streaming live when the outage hit. Twitch streamers, TikTok creators, and especially YouTube Live broadcasters saw their streams terminate. This is particularly painful during events. If a major gaming tournament is being broadcast on YouTube, an outage during that tournament is catastrophic.
One creator might have been streaming a charity fundraiser with thousands of viewers. When the stream dies without warning, viewers can't donate. The fundraiser's goal goes unmet. Viewers are frustrated. The platform's reputation takes a hit.
Advertising Impact. Advertisers pay YouTube billions annually for ad placements. During the outage window, YouTube ads didn't serve. Advertisers lost money they'd paid for. YouTube lost potential revenue. It's a lose-lose situation for both parties.
SEO and Indexing. Google's search engine uses web crawlers to discover and index content. During the outage, Google's crawlers couldn't access YouTube content. This might have affected how quickly new YouTube videos show up in Google Search results.
API Dependencies. Thousands of applications integrate with YouTube's API. Analytics platforms that pull YouTube metrics couldn't refresh their data. Aggregators that compile YouTube videos from multiple channels experienced failures. Any application that depended on accessing YouTube data went dark.
Smart Home Ecosystem. Google Home products couldn't function normally. People with smart displays expecting to play YouTube videos on them experienced failures. The smart home ecosystem is becoming increasingly intertwined with YouTube for entertainment.
Enterprise Tools. Companies using Google Workspace experienced issues. Google Sheets, Google Drive, and other Google services experienced cascading failures as the core infrastructure struggled.
This interconnection demonstrates a troubling reality: we've built a digital world where the failure of a single company's infrastructure can create widespread problems across multiple industries and services.

How Google Responded and What They Said
Google's response to the outage was measured but minimal. The company didn't immediately come forward with an explanation. Instead, they acknowledged the problem existed and assured users they were working on a fix.
Around 9 PM ET, approximately one hour into the outage, Team YouTube posted on X (formerly Twitter) that they were aware of the problem. This simple acknowledgment is important. Users want to know that the company knows something is wrong. Radio silence would have been worse.
About 20 minutes after the initial acknowledgment, they posted another update noting that their recommendation system was experiencing issues. This was the first concrete detail provided. Users now knew it wasn't a complete shutdown. The servers were accessible, but the algorithms generating personalized recommendations weren't working.
At 10:12 PM ET, Team YouTube posted that the issue had been completely resolved. All systems were back online. Services were fully restored. Everything was normal again.
What notably didn't happen: Google never explained what caused the outage. They never detailed the specific systems that failed. They never provided information about what went wrong or how they fixed it. They never discussed whether data was lost or if content was affected.
This is standard practice for major tech companies. Detailed explanations of how infrastructure fails can reveal security vulnerabilities. Competitors could potentially learn how to exploit similar weaknesses. Users might lose confidence if they understand the fragility of the systems they depend on.
But from a transparency standpoint, users would appreciate more information. Why did it happen? How long did you know about it before responding? What systems were affected? What changes are being made to prevent this in the future?
Google likely published a more detailed incident report internally. This document would go to the company's incident response team, the engineering teams involved, and potentially regulatory bodies. The public got the condensed version that amounts to: "Something broke, we fixed it, everything's fine."
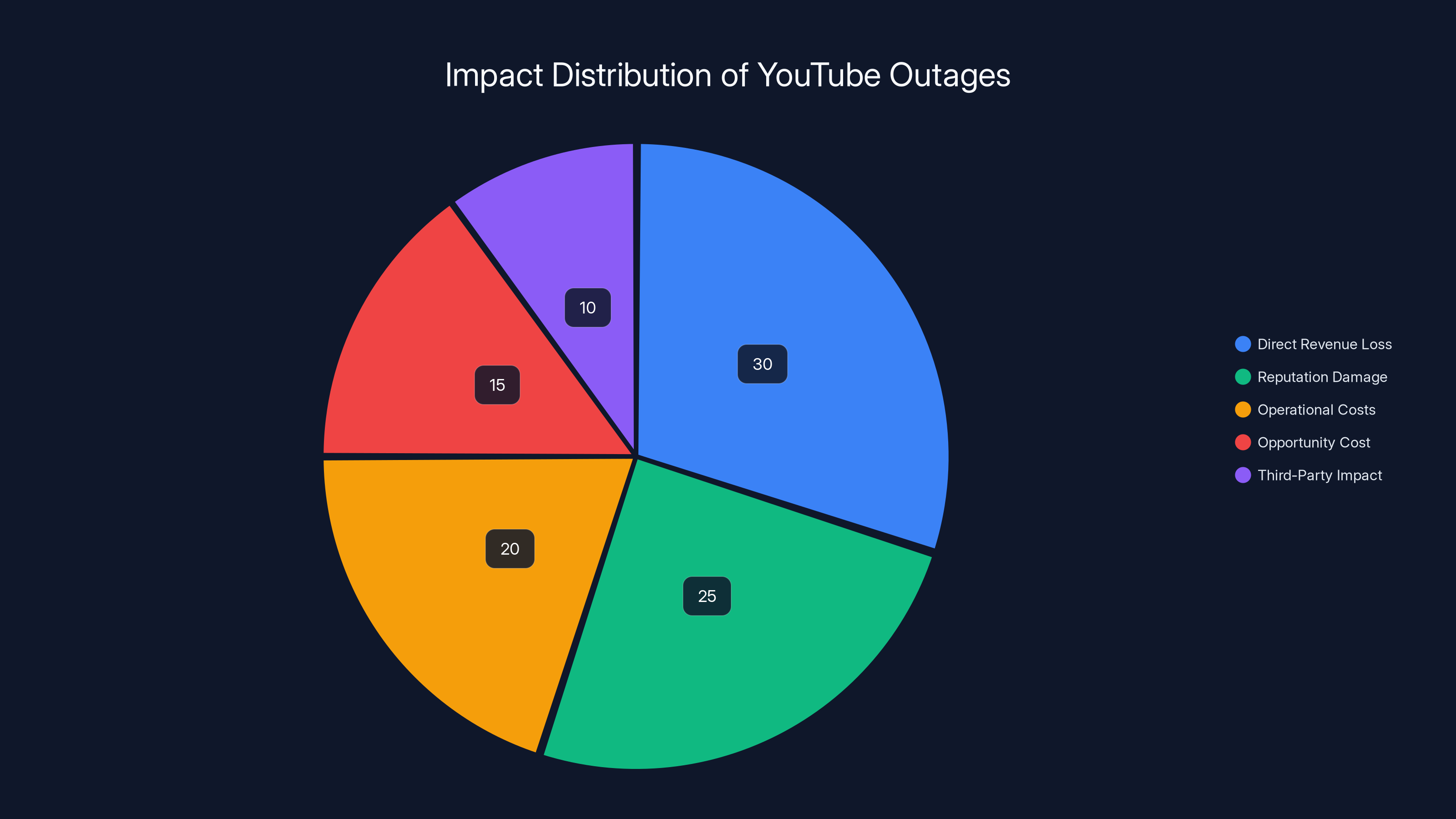
Estimated data shows that direct revenue loss and reputation damage are the largest impacts of YouTube outages, highlighting the importance of reliability engineering.
The Scale of YouTube's Operations
Understanding why this outage mattered requires understanding just how massive YouTube's operations are.
YouTube serves over 2 billion logged-in users monthly. That's roughly one quarter of the entire world's population. On any given day, hundreds of millions of people are watching videos on the platform. At any given moment during peak hours, tens of millions of concurrent viewers are streaming content.
This creates staggering infrastructure demands. Imagine building a system that simultaneously serves video to 10 million people. Now imagine doing that reliably, with minimal buffering, across different continents, on different devices, with different internet speeds.
YouTube's data centers contain millions of servers. The bandwidth consumed by YouTube is estimated at 1 billion hours of video watched per day. That's not a typo. Every single day, people collectively watch a billion hours of YouTube video. To put this in perspective, that means about 115,000 years worth of content viewed in a 24-hour period.
The recommendation system alone is one of the most complex software systems ever built. It analyzes thousands of signals about your behavior and predicts with reasonable accuracy what you'd like to watch next. This system must make those predictions in milliseconds for billions of users.
Google maintains data centers in multiple countries. The exact number isn't public, but industry estimates suggest over 30 major data centers globally. Each one contains thousands of servers. The capital investment is in the tens of billions of dollars.
When something goes wrong in a system this complex, the failure can propagate quickly. One problem in one system can cascade to another. If the recommendation system crashes, it might cause load balancers to become overwhelmed trying to restart it. That might cause the frontend servers to become overloaded. That might cause the entire service to go down.
This is why large tech companies invest so heavily in infrastructure engineering. They employ thousands of engineers whose sole job is to prevent exactly this scenario. And yet it still happens.
Comparing This to Previous YouTube Outages
YouTube has experienced outages before, though they're relatively rare given the scale and engineering investment. Looking at historical incidents provides context.
In 2018, YouTube experienced a significant outage affecting various regions. Similarly, Google services including Gmail, Photos, and Drive went down. The duration was under an hour, but it still affected millions.
In 2020, a widespread Google outage affected Gmail, YouTube, Drive, and other services simultaneously. This was particularly notable because it happened during the COVID-19 pandemic when remote work and online education were critical.
In 2022, a major YouTube outage affected viewing across multiple regions. Users couldn't stream video, though uploads and other functionality remained available.
Each outage provides learning opportunities. Google's post-incident processes likely resulted in infrastructure changes. They add redundancy. They improve monitoring. They implement faster recovery mechanisms.
But the interesting observation is that these outages are becoming less frequent, not more. As Google's infrastructure becomes more mature and more redundant, the likelihood of complete failures decreases. However, when they do happen, they affect more people because YouTube's user base keeps growing.
The February 17, 2025 outage was notable for affecting both YouTube and other Google services simultaneously. This suggests the problem was in shared infrastructure, not isolated to YouTube specifically.
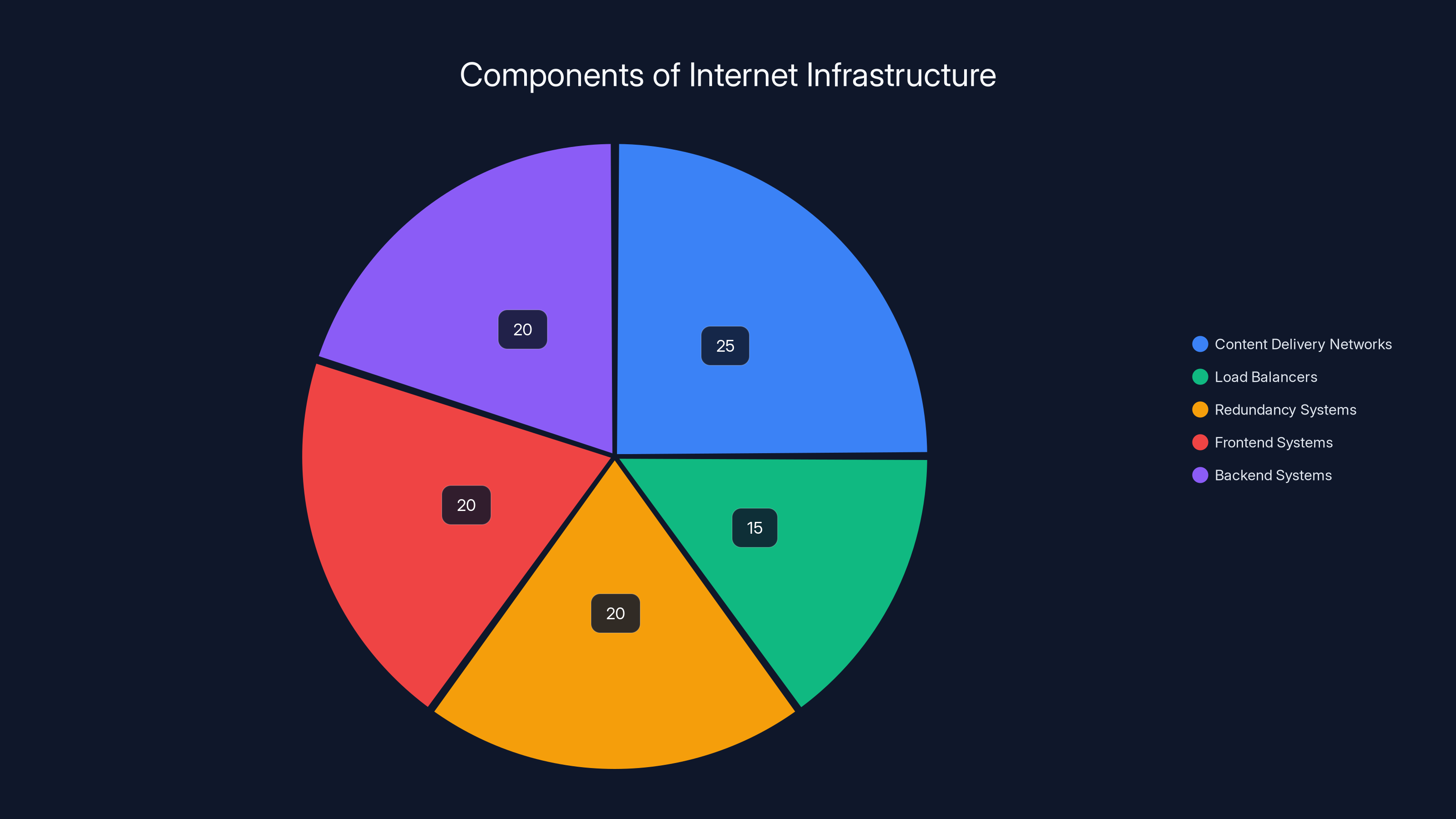
Estimated data showing the distribution of key components in internet infrastructure. CDNs and redundancy systems are crucial for minimizing latency and ensuring service continuity.
What This Reveals About Digital Dependency
The YouTube outage serves as a broader mirror reflecting how dependent our society has become on a handful of large technology companies.
Think about what YouTube provides: entertainment, education, documentation, music, gaming, fitness instruction, and thousands of other services. For many people in developing countries, YouTube is the primary way they learn new skills and access information.
When YouTube goes down, these people lose access to that opportunity. A student in India who was watching an educational video explaining advanced mathematics suddenly can't continue their learning. A person in the Philippines learning English through YouTube videos can't progress. A creator in Brazil building an audience goes dark.
This concentration of services means that the decisions YouTube makes directly affect billions of people's daily lives. If YouTube decides to change its algorithm, it affects what billions of people see. If YouTube's service is unreliable, billions of people experience disruption.
The outage also revealed something about modern internet culture. The first response from users was to check social media. Twitter filled up with people asking, "Is YouTube down for you?" Reddit's outage status threads became the de facto source of information. YouTube's own official communication came later.
This demonstrates how we've outsourced the monitoring of service health to the community. Individual users are better at discovering and reporting outages than the companies operating the services. That's both amusing and alarming.
From a business perspective, the outage probably cost Google millions in lost revenue, lost advertising impressions, and potential damage to reputation. From a user perspective, it reminded us that no service is guaranteed to always be available.

Building Resilience: What Individuals Should Know
As someone who uses YouTube, you probably can't do much if the service goes down. But you can build resilience into your digital life.
Diversify Your Content Sources. Don't rely solely on YouTube. Follow creators on alternative platforms. If a creator you follow is on YouTube, check if they're also on Patreon, TikTok, or their own website.
Download Important Content. If there's a video you really care about, download it (assuming it's legal to do so). Don't assume it'll always be available for streaming.
Use Multiple Platforms. Stream from multiple sources. Use Spotify for music instead of relying entirely on YouTube Music. Use Vimeo or your own website for video hosting if you create content.
Monitor Service Status Pages. Most major services maintain status pages showing service health. Bookmark them so you know where to check if something seems broken.
Have Offline Alternatives. Keep books, downloaded articles, and other offline resources. When the internet fails, you've still got access to information.
Understand the Risks. Recognize that any online service can fail. The question isn't whether it will fail, but when. Prepare mentally for that eventuality.
For Content Creators: Have a Backup Plan. If you make a living from YouTube, develop alternative revenue streams. Live stream on multiple platforms simultaneously. Maintain a newsletter. Build direct relationships with your audience.
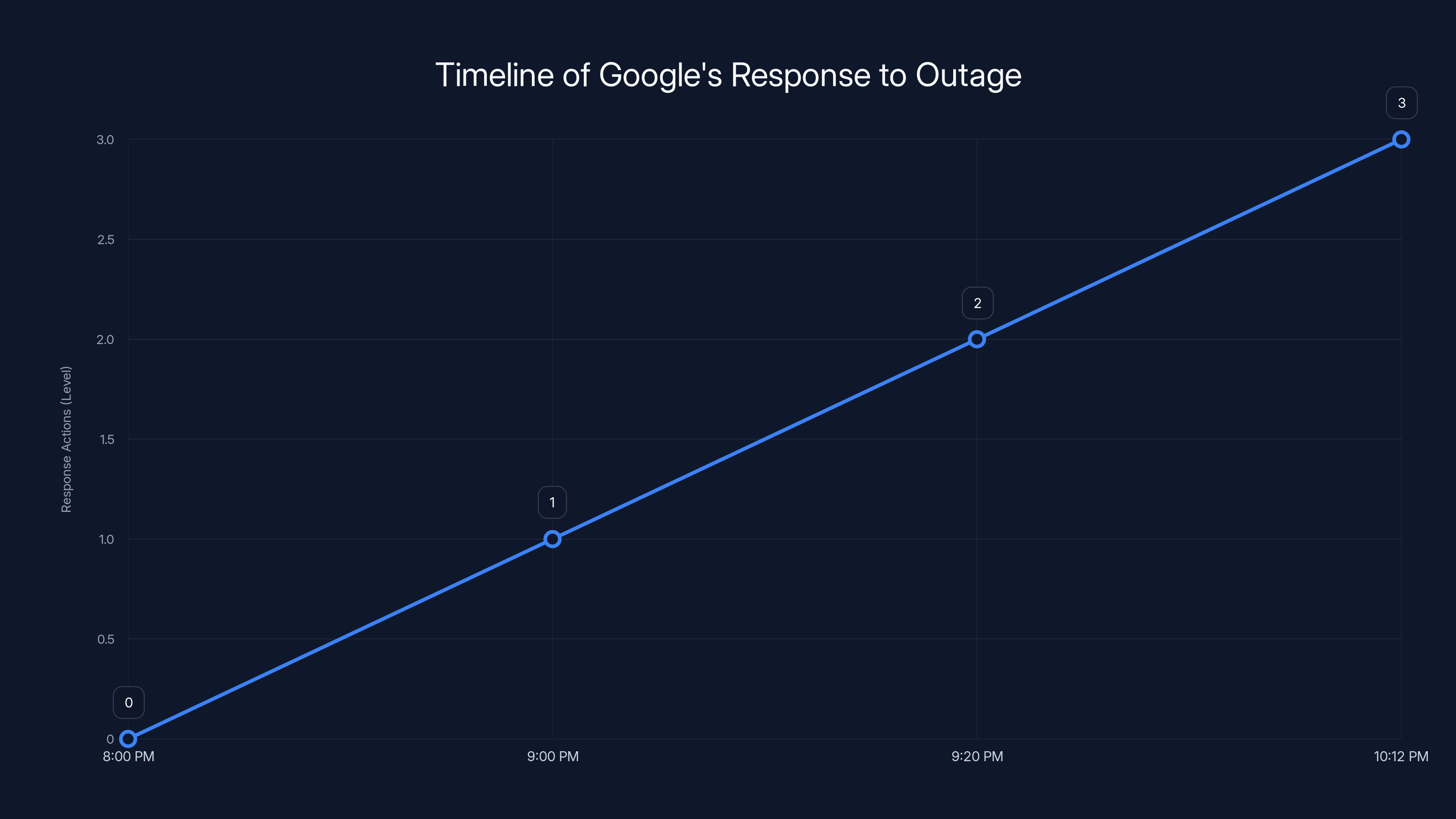
Google's response to the outage progressed from acknowledgment to resolution within a little over two hours. Estimated data based on typical response patterns.
The Business Impact of Outages
For YouTube as a business, outages create multiple types of costs.
Direct Revenue Loss. YouTube lost advertising revenue during the outage. Ads weren't served. Creators didn't earn their share of revenue. The direct financial impact was immediate and measurable.
Reputation Damage. Every user who experienced the outage was reminded that YouTube is fallible. Some might have tried alternatives. Some might have been frustrated enough to reconsider their reliance on the platform.
Operational Costs. The outage triggered incident response procedures costing engineering time, management attention, and data center resources as systems restarted.
Opportunity Cost. YouTube couldn't capture new viewers during the outage window. Growth metrics for that day likely took a hit.
Third-Party Impact. Content creators who depend on YouTube lost income. This might drive some creators toward competitors or alternative platforms.
For Google overall, the impact was broader. Google Search is a more critical service than YouTube. If people lose trust in Google Search, that's existential. The fact that Google Search went down alongside YouTube suggests infrastructure problems that Google needs to address seriously.
This is why technology companies invest so much in reliability engineering. The cost of preventing outages is much lower than the cost of managing their consequences.

Technical Deep Dive: What Likely Happened
While Google didn't provide specifics, we can make educated guesses about what might have caused the outage based on typical failure patterns in large systems.
Scenario 1: Cascading Deployment Failure
Google likely deployed new code to production right before the outage started. This is statistically the most common cause of outages. New code has a bug. The service crashes. The system tries to automatically roll back to the previous version. But the previous version also has a problem, or the rollback itself fails. Now the service is stuck in a bad state.
The fact that the frontend came back before the backend suggests they might have rolled back the frontend code first, then needed to manually fix the backend.
Scenario 2: Database Failure
YouTube's recommendation system depends on large distributed databases. If a database becomes corrupted or locks up, the entire recommendation system can't function. Recovery might require database repair, which is time-consuming.
The fact that the homepage came back online while recommendations stayed offline supports this theory. The homepage requires minimal database access. Recommendations require intensive database queries.
Scenario 3: Cache Layer Failure
Large systems like YouTube use caching layers (systems like Redis or Memcached) to store frequently accessed data. If the cache becomes corrupted or overloaded, the underlying systems get overwhelmed. Requests pile up. The service becomes unresponsive.
Recovering from cache failures requires flushing and rebuilding the cache, which takes time and creates load on the underlying systems.
Scenario 4: Configuration Error
Sometimes an outage is caused by a configuration change, not a code change. Maybe a database connection string was updated incorrectly. Maybe a load balancer configuration was changed. Maybe firewall rules were modified. These configuration errors can take time to diagnose because the code looks fine.
Any of these scenarios would explain the timeline we observed. Google would have needed to identify the problem, implement a fix, and wait for the fix to propagate across their global infrastructure.
How Modern Sites Prevent Outages
Large technology companies employ multiple strategies to minimize outage risk.
Redundancy at Every Layer. Every component has backups. If one load balancer fails, another is ready. If one database node fails, other nodes have the data. If one data center goes offline, others handle the traffic.
Gradual Rollouts. When deploying new code, companies don't deploy to all servers simultaneously. They deploy to 1% of servers first. If nothing breaks, they deploy to 5%. If that works, 25%. Eventually 100%. If something goes wrong, the rollout stops affecting only a small percentage of users.
Automated Testing. Code is tested extensively before deployment. Unit tests, integration tests, load tests, security tests. The goal is to catch problems before they reach production.
Canary Analysis. After deployment, systems compare new code performance against the previous version. If the new code is slower, has higher error rates, or uses more memory, the system automatically rolls back.
Circuit Breakers. When one service is struggling, circuit breakers prevent other services from overwhelming it. If the recommendation system is slow, traffic to it is reduced, preventing cascading failures.
Monitoring and Alerting. Large systems have thousands of metrics being monitored. If error rates spike, latency increases, or disk space fills up, engineers are immediately alerted.
Disaster Recovery Plans. Companies regularly run simulations where they intentionally cause failures to practice recovery procedures.
Despite all these precautions, outages still happen. But they're less frequent and less severe than they would be without these measures.

The Broader Conversation About Internet Reliability
The YouTube outage sparked a broader conversation about internet infrastructure and service reliability.
In the United States and other developed countries, users have come to expect near-perfect uptime from critical services. When something goes down, it's shocking. But this expectation might be unrealistic. No system is perfect. All systems will eventually fail.
The question becomes: how much reliability is enough? Should YouTube guarantee 99% uptime? 99.9%? 99.99%? Each additional nine costs exponentially more money and engineering effort.
Google's infrastructure is already incredibly reliable. The fact that an outage affecting this scale of users is notable shows how rare they are. But even with Google's resources, achieving perfect uptime is impossible.
Society needs to have a conversation about acceptable service reliability. Users need realistic expectations. Regulators might need to establish minimum reliability standards. Companies need to communicate honestly about the trade-offs.
One perspective is that the internet's original design anticipated unreliability. The protocols were built assuming failures would happen. Routing systems would find alternate paths. Services would recover gracefully.
But modern services are built for convenience, not resilience. They depend on specific infrastructure being available. When that infrastructure fails, the service fails completely.
Learning from the Outage: Questions Worth Asking
The YouTube outage raises several important questions worth considering.
What Was the Root Cause? Google never publicly explained what caused the outage. A detailed explanation would help users understand the reliability of the service they depend on.
How Long Was the Service Partially Down? The timeline shows the homepage came back before recommendations. How long was the homepage available but recommendations offline? The outage severity depends on these details.
Did Any Data Get Lost? If systems crashed hard, was there data loss? Did anyone's watch history get reset? Did any uploads fail? Google didn't address this.
How Many Users Were Actually Affected? 338,000 reports on Downdetector is the number of people who went to the website to report it. The actual number of affected users is probably much higher.
What's the Long-Term Plan? Did this outage trigger architectural changes? Will YouTube's infrastructure be different in the future to prevent this?
How Does This Compare to Competitors? How often do Microsoft, Apple, or other major tech companies experience outages? Is YouTube better or worse than alternatives?
Without answers to these questions, users are left to speculate and trust that Google is doing the right thing behind the scenes.
What to Do If YouTube Goes Down Again
If you experience another YouTube outage, here's what to do.
First, Verify It's Not Your Connection. Check if other websites load. If not, your internet connection is the issue, not YouTube.
Check Your Device. Try accessing YouTube on a different device. If it works on one device but not another, the problem is device-specific.
Clear Your Cache. Sometimes cached data causes problems. Clear your browser cache and cookies, then try again.
Try a Different Network. If you're on Wi-Fi, try mobile data. If you're on mobile data, try Wi-Fi. Sometimes the problem is your local network.
Check the Status Pages. Visit YouTube's official status page or Google's status page to see if they've reported issues.
Use a VPN. In rare cases, regional issues might be resolved by using a VPN to connect through a different location.
Report It. If you believe there's a real outage, submit reports to Downdetector. This helps others know they're not alone.
Inform YouTube. Tweet at YouTube or submit a bug report through their official channels.
Wait and Refresh. In most cases, outages resolve within an hour. Patience and periodic refresh attempts are your best bet.
Future Outlook: Will Outages Become More or Less Common
There are competing trends affecting the likelihood of future outages.
Factors Making Outages Less Likely: Google continues to invest in infrastructure. Systems become more redundant. Monitoring becomes more sophisticated. As infrastructure matures, reliability typically improves.
Factors Making Outages More Likely: As systems become more complex, there are more things that can go wrong. As YouTube adds features, the systems running them become more complicated. As the user base grows, the impact of failures increases.
Overall, we'll likely see outages continue to be rare but still possible. Google will continue investing in reliability. But society will also become more dependent on YouTube, making each outage more impactful.
The trend over the long term should be toward more reliable services. Companies that can't maintain reliability will lose customers to competitors. Natural selection favors reliability.
Taking Control of Your Digital Infrastructure
While you can't control YouTube's infrastructure, you can control your dependence on it.
Create Backups. If you have content on YouTube, back it up somewhere else. If you have playlists you care about, document them. If you have comments you're proud of, save them.
Build Relationships. Connect with creators through other channels. Follow their email lists, social media, or personal websites. Don't rely solely on YouTube's recommendation system to connect you.
Diversify Your Entertainment. Use multiple streaming services. Read books. Listen to podcasts. Play games. Don't put all your entertainment eggs in YouTube's basket.
Develop Skills Offline. If you learn through YouTube, supplement it with books and in-person instruction. Offline skills can't go down.
Support Decentralization. As services become more decentralized, reliability improves. Support platforms that distribute control rather than concentrating it.
The YouTube outage was a reminder that perfect reliability is impossible. But awareness and preparation can significantly reduce the impact when failures inevitably occur.
FAQ
What exactly happened during the YouTube outage on February 17, 2025?
YouTube went offline for hundreds of thousands of users across the United States and multiple other countries starting around 8 PM Eastern time. The service experienced multiple component failures, with the homepage coming back online before the recommendation system. The outage lasted nearly two hours before full restoration.
How many users were affected by the YouTube outage?
Downdetector recorded over 338,000 reports of the outage, but the actual number of affected users was likely much higher since not every user reports outages. Given YouTube's 2 billion monthly active users, the outage probably affected hundreds of millions of people globally.
Did YouTube explain what caused the outage?
No, YouTube never provided a detailed public explanation of the root cause. They acknowledged the problem existed, noted that their recommendation system was specifically affected, and confirmed when the service was restored. Internal incident reports likely contain more details, but these are rarely shared publicly due to security considerations.
Why did the homepage come back before recommendations?
This suggests the recommendation system and the homepage are architecturally separate, which is standard practice. The homepage requires minimal database queries and can be served from caches. The recommendation system is computationally intensive and requires extensive database access. If a failure affected the database or backend systems, recommendations would take longer to restore.
Could this happen to other tech companies like Microsoft or Apple?
Yes, outages can happen to any company. Microsoft Azure, Google Cloud, and AWS have all experienced major outages in their histories. Apple's services have gone down. Reliability is a function of investment and luck. Even with massive investment, perfect uptime is impossible.
What should I do to prepare for the next YouTube outage?
Diversify your content sources beyond YouTube. Download important videos (legally). Follow creators on multiple platforms. Use alternative streaming services. Understand that outages are inevitable and plan accordingly. For content creators, develop multiple revenue streams rather than depending entirely on YouTube.
Did anyone lose data because of the outage?
Google didn't provide information about potential data loss. In modern systems with proper redundancy, brief outages usually don't cause data loss because multiple copies of data exist in different locations. However, if systems crashed hard, some uncommitted data (like in-progress uploads) might have been lost.
How do I know if YouTube is down for me or if it's my internet?
Try accessing other websites. If other sites load, your internet works but YouTube might be down. Check YouTube's official status page or social media for announcements. Try accessing YouTube on a different device. Try using a different network (Wi-Fi vs mobile data). These steps help isolate whether the problem is your connection or YouTube's servers.
Why do outages like this happen if companies invest so much in reliability?
Because perfect reliability is impossible. All systems are complex. Complexity creates opportunities for failures. Companies make trade-offs between reliability, cost, speed of development, and new features. Pushing a system to 99.99% uptime costs far more than 99% uptime. Companies have to decide the right balance based on user needs and business constraints.
What's Google doing to prevent this from happening again?
While Google hasn't publicly detailed their response, companies typically implement more redundancy, improve monitoring, implement faster recovery procedures, improve testing of new code, and adjust architecture to prevent the specific failure that caused the outage. Over time, these incremental improvements lead to fewer and less severe outages.

Conclusion
The YouTube outage on February 17, 2025, was a reminder of an uncomfortable truth: the digital systems we depend on every single day are fragile. Despite billions of dollars invested in infrastructure, despite thousands of engineers working to prevent failures, despite multiple layers of redundancy and failover systems, outages still happen.
For nearly two hours, hundreds of millions of people lost access to one of the world's most important platforms. Content creators lost revenue. Advertisers lost impressions. Users lost access to entertainment and education. The incident demonstrated just how dependent modern society has become on a handful of technology companies.
But the outage also demonstrated something else: the resilience of the internet itself. The problem was fixed. The service came back. Life continued. No permanent damage. No data loss (as far as we know). Just a disruption.
What matters now is what we learn from this incident. Google will certainly conduct detailed internal reviews. Engineers will implement changes. Infrastructure will be upgraded. The next outage might be less severe or less likely.
For users, the lesson is to build resilience into your digital life. Don't depend entirely on any single service. Back up important content. Maintain relationships with creators across multiple platforms. Develop skills and maintain knowledge sources that don't depend on the internet.
The internet is an incredible system that has transformed human civilization. But it's also human-made, which means it's imperfect. Expecting perfection from the internet is like expecting the sun to never set. Instead, recognize that failures will happen, prepare for them, and continue building the future with eyes wide open to both the tremendous possibilities and the real limitations.
The YouTube outage wasn't a catastrophe. It was a disruption. But it was also a wake-up call about the world we've built and the dependencies we've created. Use that wake-up call wisely.
Key Takeaways
- YouTube experienced a major outage on February 17, 2025, affecting 338,000+ reported users across the US and multiple countries globally
- The outage revealed that even companies with massive infrastructure investment experience service failures when core systems break
- Multiple Google services went down simultaneously, suggesting systemic infrastructure failure rather than isolated YouTube problem
- Users are increasingly dependent on platforms like YouTube for entertainment, education, and income, making outages impact billions of people
- Building digital resilience requires diversifying content sources, backing up important data, and preparing for inevitable service disruptions
Related Articles
- YouTube and YouTube TV Outage: What Happened & How to Fix It [2025]
- X Platform Outage: What Happened, Why It Matters, and How to Stay Connected [2025]
- Living in AI Time: The Harsh Reality & Why We're Not Screwed [2025]
- New York Data Center Moratorium: What You Need to Know [2025]
- A16z's $1.7B AI Infrastructure Bet: Where Tech's Future is Going [2025]
- TikTok Outage in USA [2025]: Why It Failed and What Happened

