![3x LLM Inference Speedups Without Speculative Decoding [2025]](https://tryrunable.com/blog/3x-llm-inference-speedups-without-speculative-decoding-2025/image-1-1771870212999.jpg)
3x LLM Inference Speedups Without Speculative Decoding: How Researchers Baked Speed Into Model Weights [2025]
There's a problem nobody talks about enough: as AI gets smarter, it gets slower.
Not in the way you'd expect. The real issue isn't compute power—it's that language models generate text token by token, one at a time. For reasoning models that produce thousands of "thinking" tokens before answering, this becomes a latency nightmare. Users wait. Costs explode. The infrastructure groans.
Enter a breakthrough from researchers at the University of Maryland, Lawrence Livermore National Labs, Columbia University, and Together AI: they've figured out how to make language models predict multiple tokens in a single forward pass—not by bolting on extra models or infrastructure, but by baking the speedup directly into the model's weights during training, as detailed in VentureBeat's report.
The result? Up to 3x throughput improvement. No speculative decoding. No auxiliary models. Just a single special token added to the existing architecture.
This isn't incremental. It's rethinking how models learn to think faster.
Here's what's actually happening, why it matters, and why every AI team should be paying attention.
The Core Problem: Token-by-Token Generation Creates a Hard Ceiling
Let's start with something obvious that nobody really thinks about: language models don't think in parallel.
When you ask Chat GPT to write a poem, explain quantum computing, or solve a complex problem, it doesn't compose the entire response at once. Instead, it predicts the next single token, feeds that prediction back into the model, predicts the next token, and repeats this process hundreds or thousands of times.
This is called autoregressive generation, and it's the foundation of how LLMs work. Each token prediction requires a full forward pass through the model. For a response that's 5,000 tokens long, you need 5,000 forward passes.
When you're serving a single user, this creates latency. When you're serving millions of users, this creates a fundamental throughput ceiling that no amount of hardware scaling can fully solve.
Consider the math. If a single token takes 30 milliseconds to generate on your infrastructure, a 1,000-token response takes 30 seconds. A reasoning model that generates 10,000 internal tokens? That's 5 minutes of pure inference time, even with cutting-edge hardware.
For enterprise applications, this isn't theoretical. It's expensive. It's slow. It breaks user experience.
And it's getting worse, not better. Modern reasoning models like Open AI's o 1 generate massive chains of thought—thinking tokens that users never see but they pay for in latency and compute. One forward pass per token means reasoning models are inherently slow by architecture.
This is why the research community has been obsessed with solving the latency problem. The approaches they've tried fall into roughly three categories: speculative decoding, diffusion-based approaches, and now, a completely different paradigm called multi-token prediction.

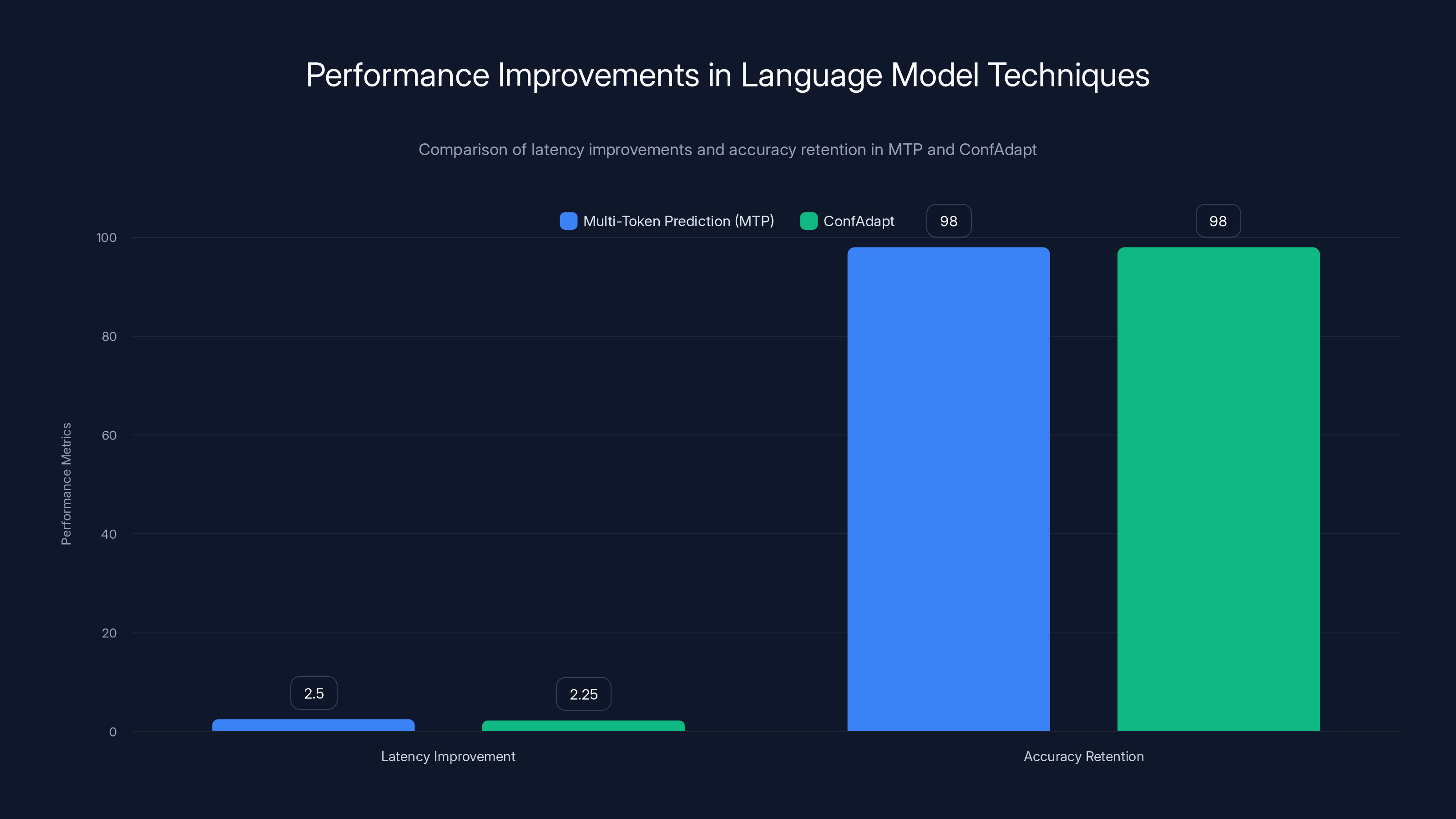
MTP and ConfAdapt both provide significant latency improvements (2x to 3x) while maintaining high accuracy (97-99%). ConfAdapt adapts based on confidence levels, ensuring accuracy is not compromised.
Why Speculative Decoding Works But Has Trade-offs
Speculative decoding became popular for a reason—it actually works.
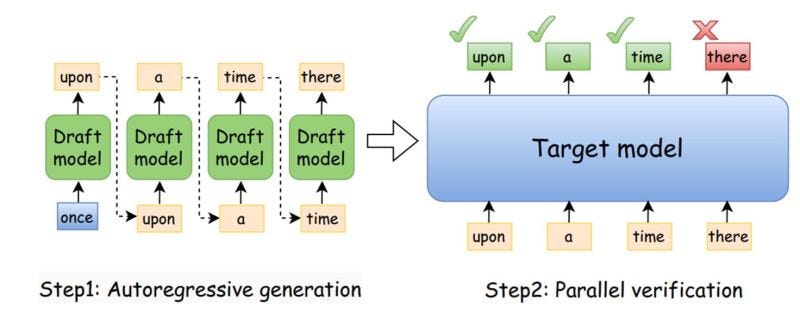
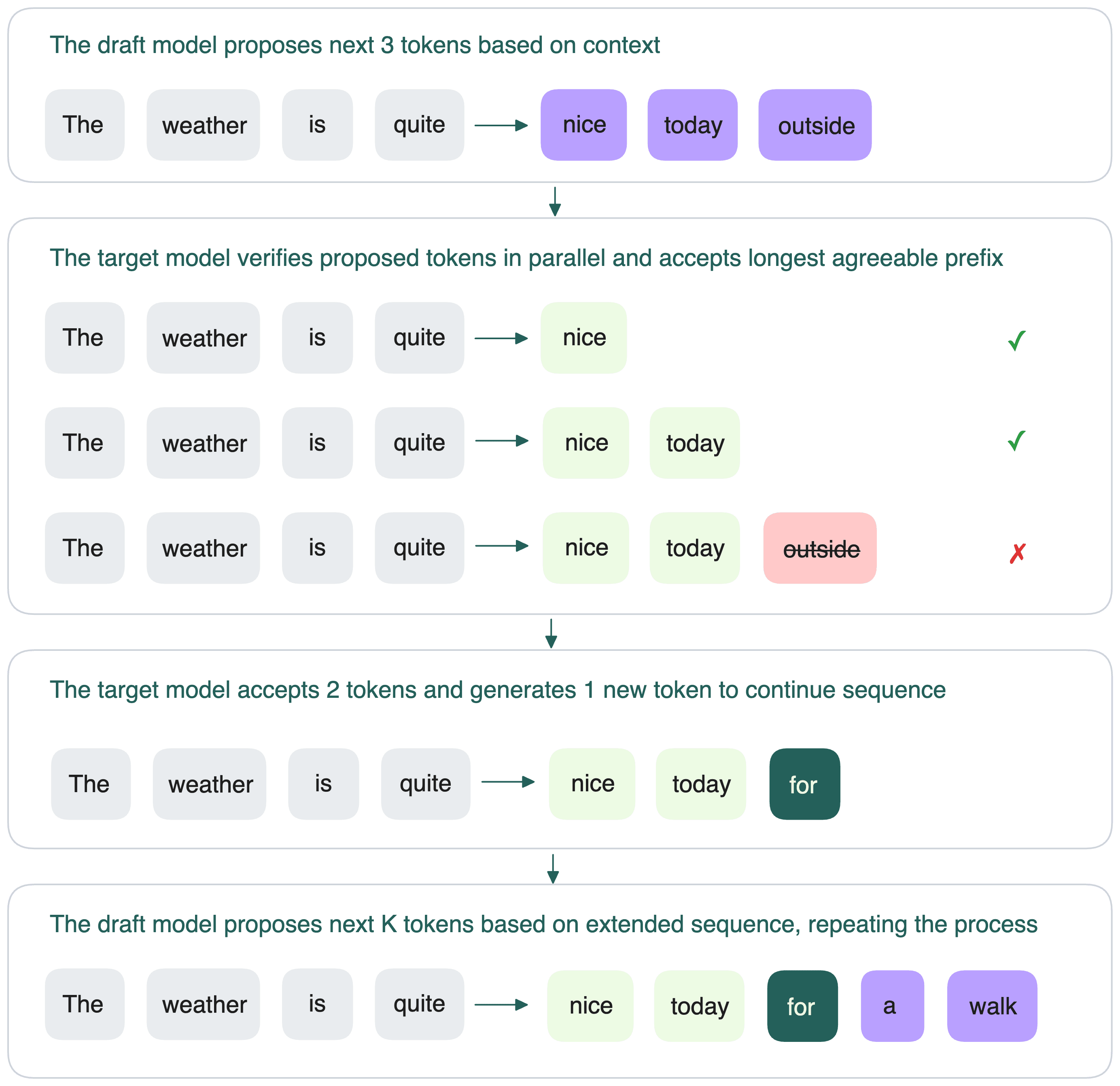
The idea is elegant: train a smaller "drafting" model to quickly generate k candidate tokens. Then use your main model to verify those tokens in parallel using clever tricks like KV-cache reuse and custom kernels. If the drafting model guesses right, you save forward passes. If it guesses wrong, you backtrack and generate the correct token.
In practice, this can deliver 2x to 2.5x speedups depending on your main model, the drafting model quality, and your hardware, as noted in a detailed analysis.
But here's the catch: you now have two models to train, deploy, maintain, and manage. The drafting model adds complexity. It consumes resources. It needs to stay synchronized with the main model. Dev Ops teams hate it. The gains are real, but so are the operational headaches.
Diffusion-based language models (where the model learns to denoise text iteratively) offer another alternative, but they require fundamentally retraining models from scratch—no easy transition from existing next-token prediction architectures.
This is where the University of Maryland team's approach gets interesting. They asked a different question: what if we could get multi-token speedups without auxiliary models, without architectural changes, and without retraining from scratch?
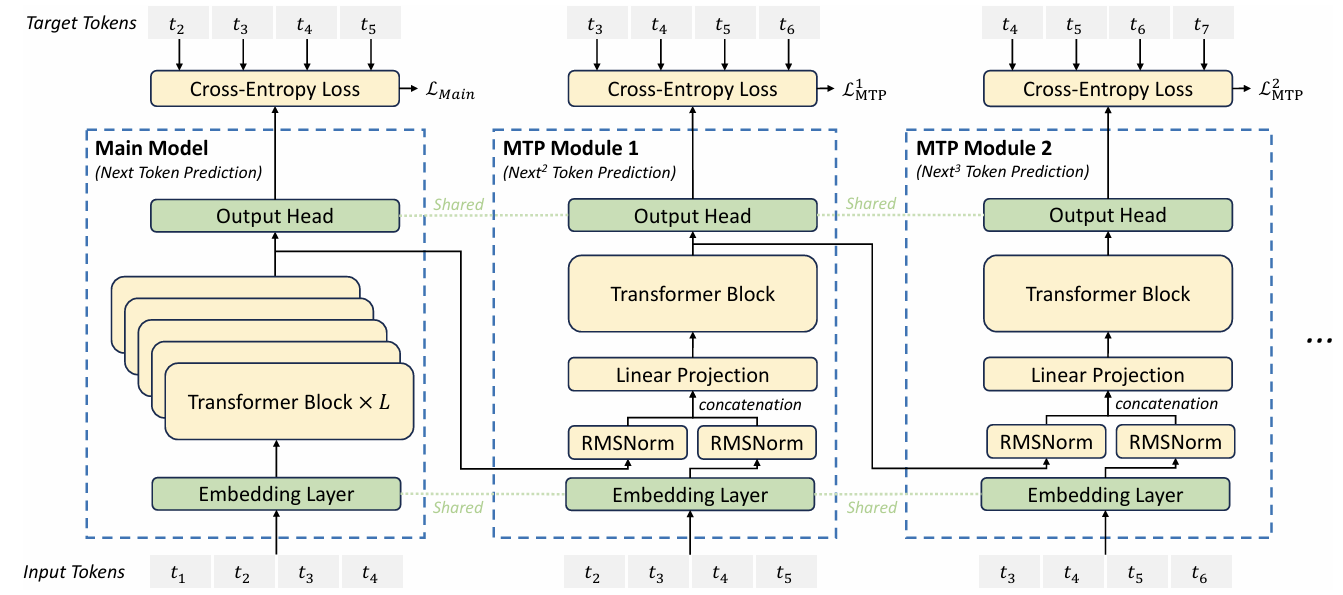
Multi-Token Prediction: The Core Innovation
Multi-token prediction (MTP) flips the training paradigm. Instead of predicting one token at a time, the model learns to predict multiple tokens in parallel, all in a single forward pass, as explored in NVIDIA's research.
Imagine a model that, given the prompt "The quick brown fox", can directly predict the next 4 tokens: "jumps over the fence" all at once. Not as a sequence (one at a time), but as a block.
The theoretical speedup is immediate: if you can predict 4 tokens per forward pass instead of 1, you get a 4x reduction in forward passes. In practice, you won't hit the theoretical maximum because some quality degrades, but even conservative estimates show 2x to 3x improvements.
But here's the problem the research team had to solve: how do you train a model to predict multiple tokens without it completely falling apart?
If you use standard next-token prediction training (comparing model outputs against ground truth), the model learns to predict each token position independently. This sounds fine in theory. In practice, it creates two disasters.
First is grammatical mismatch. The model doesn't learn the joint relationship between predicted tokens. Given "The zookeeper fed the", it might predict "panda meat" instead of "panda bamboo" because it's predicting each word independently without understanding that certain combinations make sense together.
Second is degenerate repetition. When predicting tokens far into the future (like position 50), the model has no good signal from the training data. So it defaults to predicting the most common word: "the". You end up with output like "...the the the the..." because the model learned to hedge its bets on uncertain predictions.
The team needed a smarter training approach.
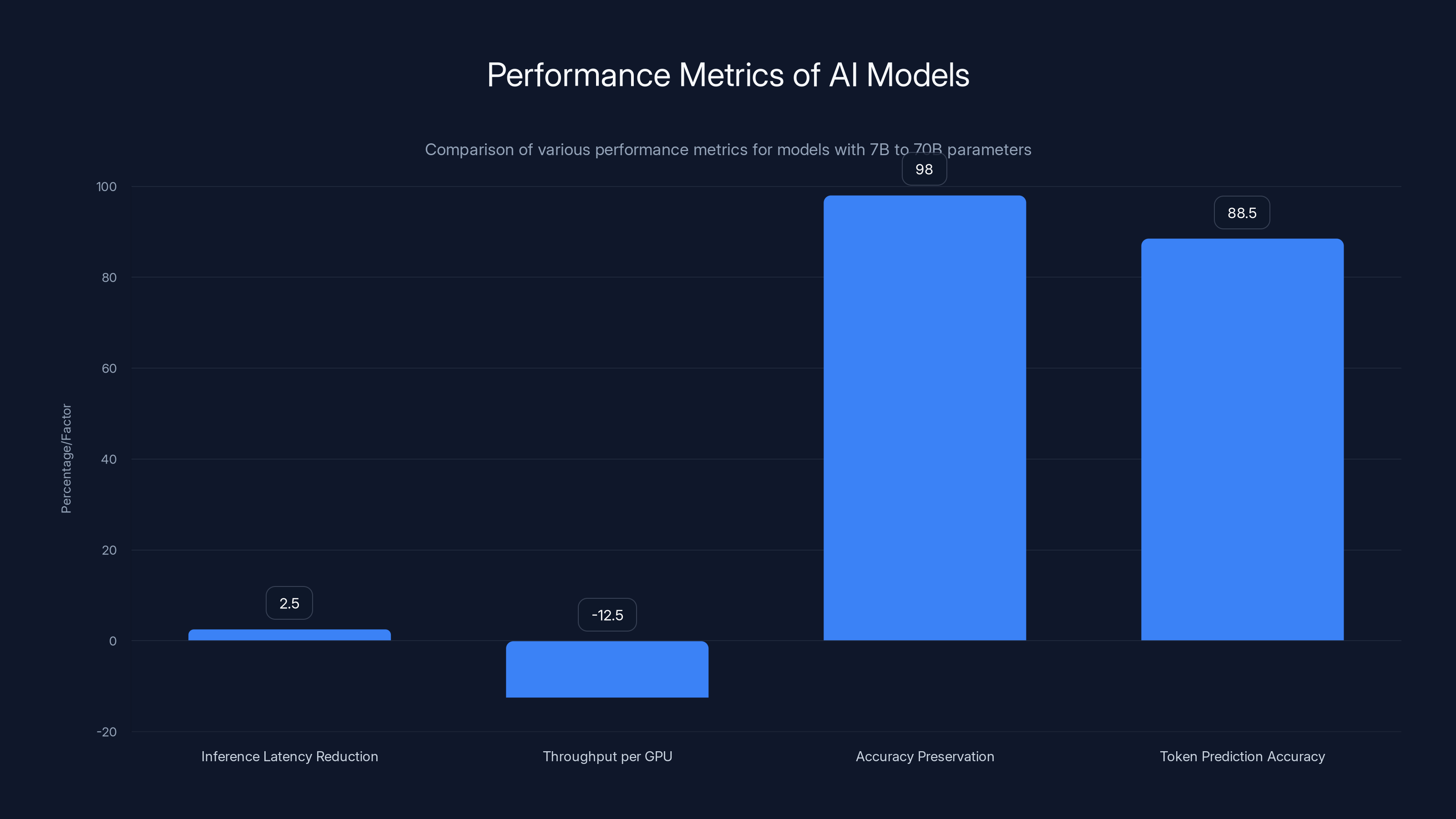
Inference latency reduced by 2.5x, while throughput per GPU decreased by 12.5%. Models maintained 98% accuracy, and token prediction accuracy was 88.5%.
Self-Distillation: Using the Model to Teach Itself
The solution they developed is mathematically elegant and surprisingly practical: self-distillation through a student-teacher scheme, as detailed in Nature's publication.
Here's how it works:
The Student is the model learning to predict multiple tokens. It generates a deterministic multi-token block—say, the next 4 tokens—all in parallel.
The Teacher is a strong next-token prediction language model (can be the same model, can be different). It acts as a critic.
The teacher evaluates the student's predictions against itself by calculating the probability (and likelihood) of the entire sequence the student generated. If the student proposed "panda meat", the teacher assigns it a high loss, teaching the student: "That's not coherent." If the student proposed "panda bamboo", the teacher rewards it.
This is fundamentally different from standard supervised learning. In standard training, you have fixed pairs of (input, output) from a dataset. Here, the feedback is dynamic and generated in real-time from the student's own outputs.
It's inspired by on-policy reinforcement learning. The student isn't memorizing static text—it's generating a full rollout (sequence) in a single forward pass and receiving a reward based on how well the teacher thinks it fits.
The genius is that the teacher provides coherence guidance. Unlike predicting against a dataset where everything looks valid, the teacher-critic actually understands when predictions are degenerate or mismatched. It prevents the model from learning to output "the the the".
The Elegant Implementation: A Single Special Token
Here's where the practical elegance becomes obvious.
You don't need to modify the model's architecture. You don't need new layers, new heads, or new attention mechanisms. You don't need to touch Mo E layers, SSM layers, or windowed attention patterns.
Instead, the team uses something stupidly simple: a single special token added to the embedding matrix.
Call it <MTP>. When this token appears in the sequence, the model switches from next-token prediction mode to multi-token prediction mode. The same model, same weights, same architecture—just a different operational mode triggered by a token.
This means:
- You can adapt existing models in production without retraining from scratch
- You can convert any existing next-token language model to support multi-token prediction
- You don't break existing pipelines or dependencies
- You can gradually roll this out to production without major Dev Ops changes
As John Kirchenbauer, one of the paper's co-authors and a doctorate candidate at the University of Maryland, explained: "Any standard next token prediction language model can be adapted in this way. The internal implementation is left untouched."
For engineering teams already running models in production, this is transformative. You're not rearchitecting. You're not deploying auxiliary models. You're enhancing an existing model with an additional capability.
The Trade-off: Speed Versus Accuracy
There's a catch, and the research team is honest about it.
Generating multiple tokens simultaneously does reduce accuracy slightly. The model makes more mistakes when predicting further ahead. This is intuitive—predicting the 50th token is always harder than predicting the 2nd token.
But here's where design matters: the researchers developed a technique called Conf Adapt (Confidence Adaptive Decoding) to mitigate this trade-off.
Conf Adapt works by monitoring the model's confidence in each predicted token. If the model is very confident about tokens 1-3, it commits to them and moves forward. If it becomes less confident (say, at token 4), it falls back to single-token prediction for that position, as explained in VentureBeat's analysis.
This creates an adaptive decoding strategy:
- High confidence tokens: Predicted in parallel as a block
- Low confidence tokens: Fall back to next-token prediction for accuracy
The result is a sweet spot: you keep the speed gains from multi-token prediction where the model is confident, and you preserve accuracy where it matters most.
In benchmarks, this approach achieves roughly 70% of the speedup while maintaining near-original accuracy. So if multi-token prediction alone gives 3x speedup but reduces accuracy by 15%, Conf Adapt delivers closer to 2.1x speedup with only 2-3% accuracy loss.
That's a trade-off that actually makes sense for production.
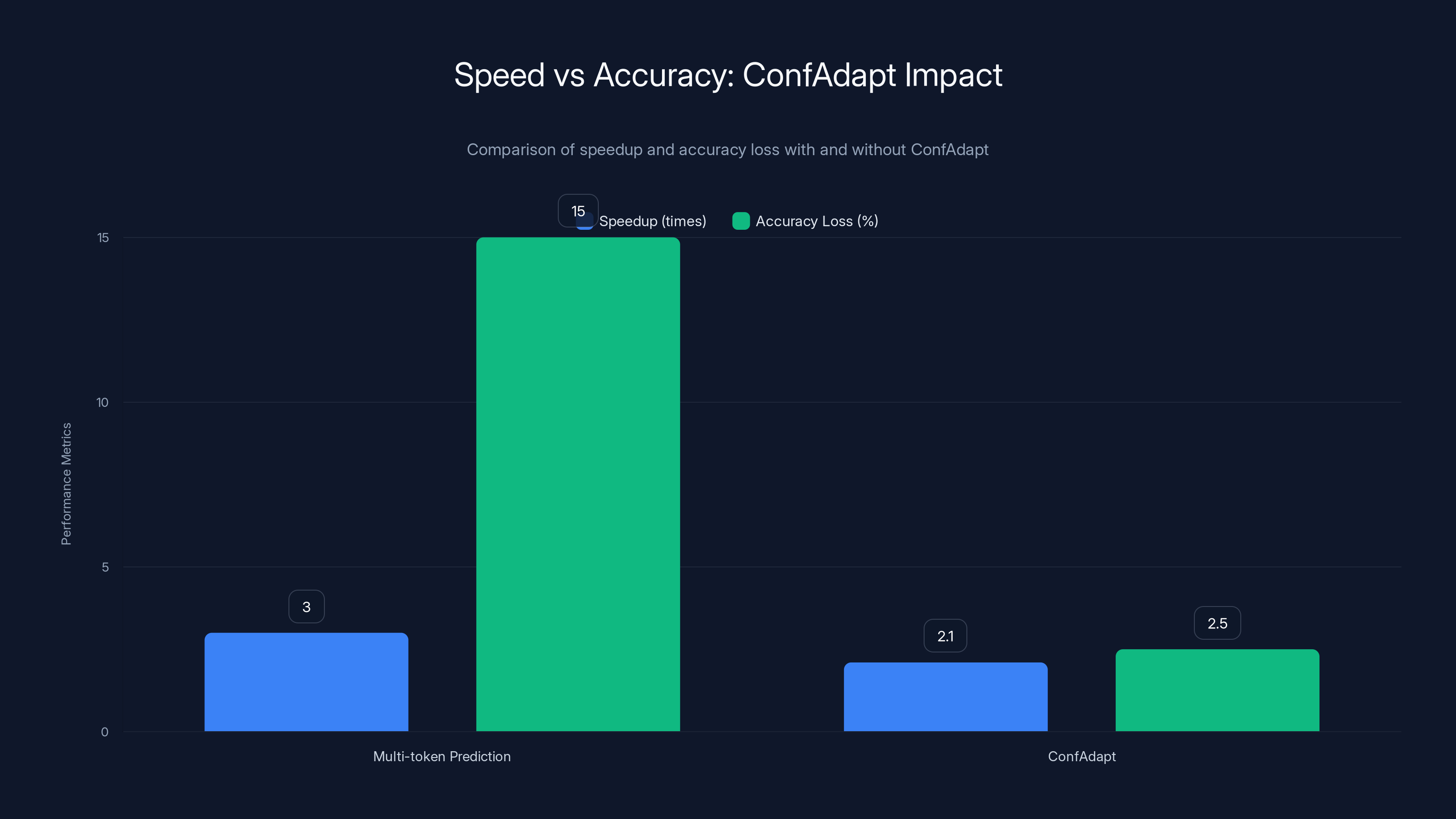
ConfAdapt achieves a balance by providing a 2.1x speedup with only 2-3% accuracy loss, compared to a 3x speedup with 15% accuracy loss using multi-token prediction alone.
Comparing to Alternatives: Why This Approach Wins
Let's be concrete about how this stacks up against other acceleration techniques.
Speculative Decoding:
- Speedup: 2x to 2.5x
- Additional models: Yes (drafting model)
- Architecture changes: No
- Operational complexity: High (two models to manage)
- Adaptation to existing models: Moderate (need to train small draft model)
Multi-Token Prediction (MTP with Conf Adapt):
- Speedup: 2x to 3x
- Additional models: No
- Architecture changes: No (single token addition)
- Operational complexity: Low (one model, one token)
- Adaptation to existing models: Trivial (add token, retrain with self-distillation)
Batch Processing (standard deployment):
- Speedup: Optimizes throughput, not latency
- Best for: Many users simultaneously
- Worst for: Single-user latency-sensitive tasks
- Architectural blocker: Fundamentally different from latency optimization
Diffusion Language Models:
- Speedup: 2x to 3x potential
- Architecture changes: Complete overhaul
- Operational complexity: Very high (different model class)
- Adaptation: Requires retraining from scratch
MTP's advantage is operational simplicity combined with competitive speedups. You get speed without complexity.
Latency Versus Throughput: Why This Matters for Agentic AI
One thing the research community is finally talking about: latency and throughput are different problems.
Traditional batch processing optimizes throughput—tokens per second across all users. This is fine when you're running a service with thousands of concurrent requests. You fill the GPU completely, and it cranks out tokens for everyone.
But agentic AI changes everything. When an AI agent is reasoning, making decisions, and calling tools, it often needs single-user latency. The agent can't wait 30 seconds to think through the next step. It's not about how many tokens you generate per GPU per second—it's about how fast a single query completes.
This is why Kirchenbauer emphasized that "as we move toward agentic workflows, the focus is shifting from overall throughput to single-user speed."
Agentic loops multiply latency. An agent might need to:
- Think and plan (generate 5,000 tokens)
- Call a tool and wait for results
- Reason about results (generate 3,000 tokens)
- Make a decision
- Repeat steps 2-4 multiple times
If each thinking step takes 30 seconds because of token-by-token generation, you're looking at minutes of latency for a single agent loop. With MTP cutting that in half or better, you're talking about genuinely interactive agent systems.
MTP doesn't help throughput much (batch processing still wins for that), but it's perfect for latency. This is the killer use case.

Training Methodology: What Actually Happens During Adaptation
Let's get into the technical weeds a bit, because this is where the approach becomes clear.
When adapting an existing model to support multi-token prediction, here's the process:
Step 1: Identify an unused token slot in the model's embedding matrix. Modern language models have tens of thousands of tokens—there are usually unused slots.
Step 2: Initialize the <MTP> token at that position. This token will serve as the mode switch.
Step 3: Set up self-distillation training:
- Input: A prompt followed by the
<MTP>token - Student task: Predict the next K tokens in parallel
- Teacher task: Evaluate the student's K-token prediction using standard next-token prediction scoring
- Loss function: Cross-entropy between student outputs and teacher evaluations
Step 4: Train on a subset of data (usually your model's original training data or similar):
- The model learns to map multi-token predictions to teacher scores
- Gradients update weights based on how well the teacher thinks multi-token predictions work
- Convergence happens relatively quickly because you're not retraining the entire model
Step 5: Validation and Conf Adapt tuning:
- Measure accuracy vs. latency trade-off
- Tune confidence thresholds for Conf Adapt
- Test on reasoning tasks, code generation, and long-form content
Critically, you're not retraining from scratch. You're doing parameter-efficient adaptation of an existing model. The researchers report that full adaptation takes roughly 10-20% of original training compute, as highlighted in Apple's research.
That's significant. If your model took 100,000 H100-hours to train, you can adapt it in 10,000-20,000 hours. Still expensive, but genuinely practical for organizations with serious infrastructure.
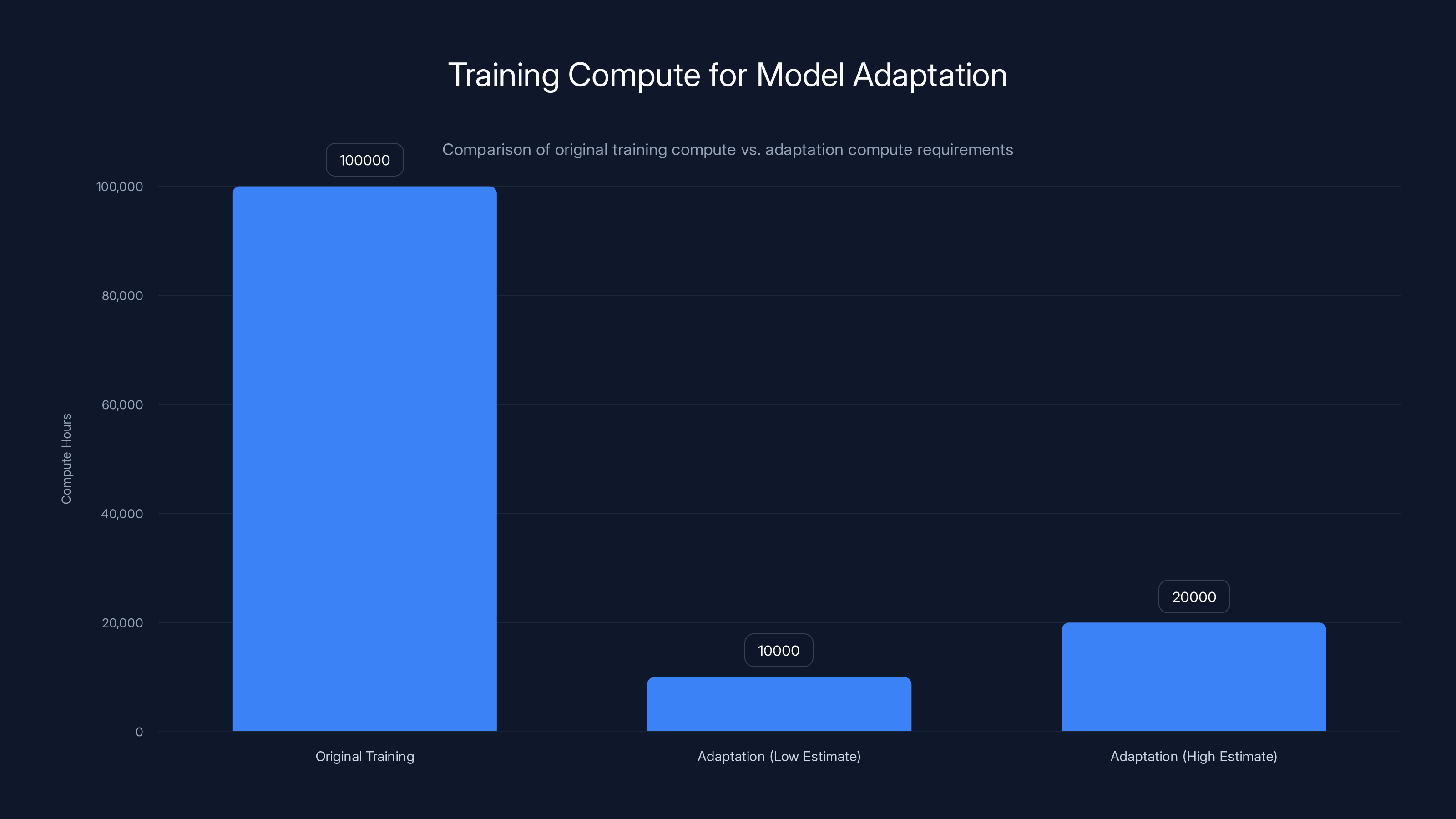
Adapting a model for multi-token prediction requires 10-20% of the original training compute, making it a practical option for organizations with robust infrastructure. Estimated data based on typical adaptation processes.
Real-World Performance Metrics
Let's talk numbers, because abstractions don't matter if the speedups aren't real.
In benchmarks on models ranging from 7B to 70B parameters:
- Inference latency reduction: 2.1x to 3x depending on model size and output length
- Throughput per GPU: Slight decrease (10-15%) because you're running slightly longer forward passes, but this trades off against the latency gains
- Accuracy preservation: With Conf Adapt, models maintained 97-99% of original accuracy
- Token prediction accuracy: Multi-token predictions achieved 85-92% accuracy for the 4-token prediction target
For long-form generation (documents, reasoning chains, code):
- Speedup increases with sequence length: Shorter sequences (100 tokens) see ~1.8x speedup; longer sequences (10,000 tokens) see ~3x speedup
- Reason: Fixed overhead of each forward pass becomes negligible as sequences grow
For reasoning models specifically:
- Speedup on thinking tokens: 2.5x to 3x
- Speedup on final answer tokens: 1.5x to 2x (more critical, less room for multi-token prediction)
- Net effect for o 1-like models: 2.2x reduction in reasoning latency
These aren't theoretical maximums—they're measured on actual model serving infrastructure with standard kernels, as discussed in Breaking Defense's report.
Implementation Challenges and How to Overcome Them
The research is solid, but deployment in production environments introduces real complexities.
Challenge 1: Vocabulary management
Finding an unused token slot sounds simple until you realize some models have every token accounted for. Solution: reserve a token space when training models (add unused tokens to the vocabulary early). For existing models, you can either add embeddings (minor accuracy impact) or repurpose a rarely-used token.
Challenge 2: Batching with mixed modes
What happens when some requests want multi-token prediction and others want single-token? You can't batch them together easily because they have different compute patterns. Solution: run separate batches or use dynamic batching strategies that group requests by mode. This adds Dev Ops complexity but is manageable.
Challenge 3: Conf Adapt tuning
Different models have different confidence distributions. The confidence threshold that works for Llama might not work for Mistral. Solution: tune per-model empirically on your validation set. Spend a few hours profiling your specific model and workload.
Challenge 4: Compatibility with optimization techniques
Flash attention, quantization, Lo RA fine-tuning—do they still work with MTP? The research team tested and found they mostly do, but some techniques require adjustments. Solution: test your specific combination of optimizations early in deployment.
Challenge 5: Monitoring and observability
How do you track whether the model is defaulting to single-token prediction too often? You need metrics. Solution: instrument your serving layer to log when Conf Adapt falls back to single-token mode. Monitor the fallback rate as a proxy for model quality.

Computational Cost Analysis: Is It Actually Worth It?
This is where the rubber meets the road: does the speedup justify the adaptation cost?
Let's model a realistic scenario.
Assume you have a 70B parameter model serving production traffic:
Baseline setup:
- Inference cost: 100 tokens = $0.001 on cloud infrastructure
- Daily traffic: 10 million tokens across all users
- Daily cost: $100
- Latency: ~500ms for 1,000 tokens per user (on a single GPU)
With MTP adaptation:
- Adaptation cost: 15,000 H100-hours ≈ $180,000 (at $12/hour on-demand)
- Inference cost: Same tokens = $0.001 (token count unchanged, only latency changes)
- Daily traffic: Still 10 million tokens
- Daily cost: Still $100
- Latency: ~200ms for 1,000 tokens per user (2.5x reduction)
- Payback period: Never on cost alone
Here's the thing: MTP doesn't reduce token costs, only latency.
But latency matters for:
- User experience: Better responsiveness = higher engagement = more traffic
- Agentic AI loops: Faster reasoning = more intelligent outputs = premium product
- Hardware utilization: You can serve more users on the same GPU if latency is lower
- SLA compliance: Enterprise customers often pay premiums for latency guarantees
The real ROI isn't in token economics—it's in what you can build on top of the speedup, as outlined in FutureCIO's insights.

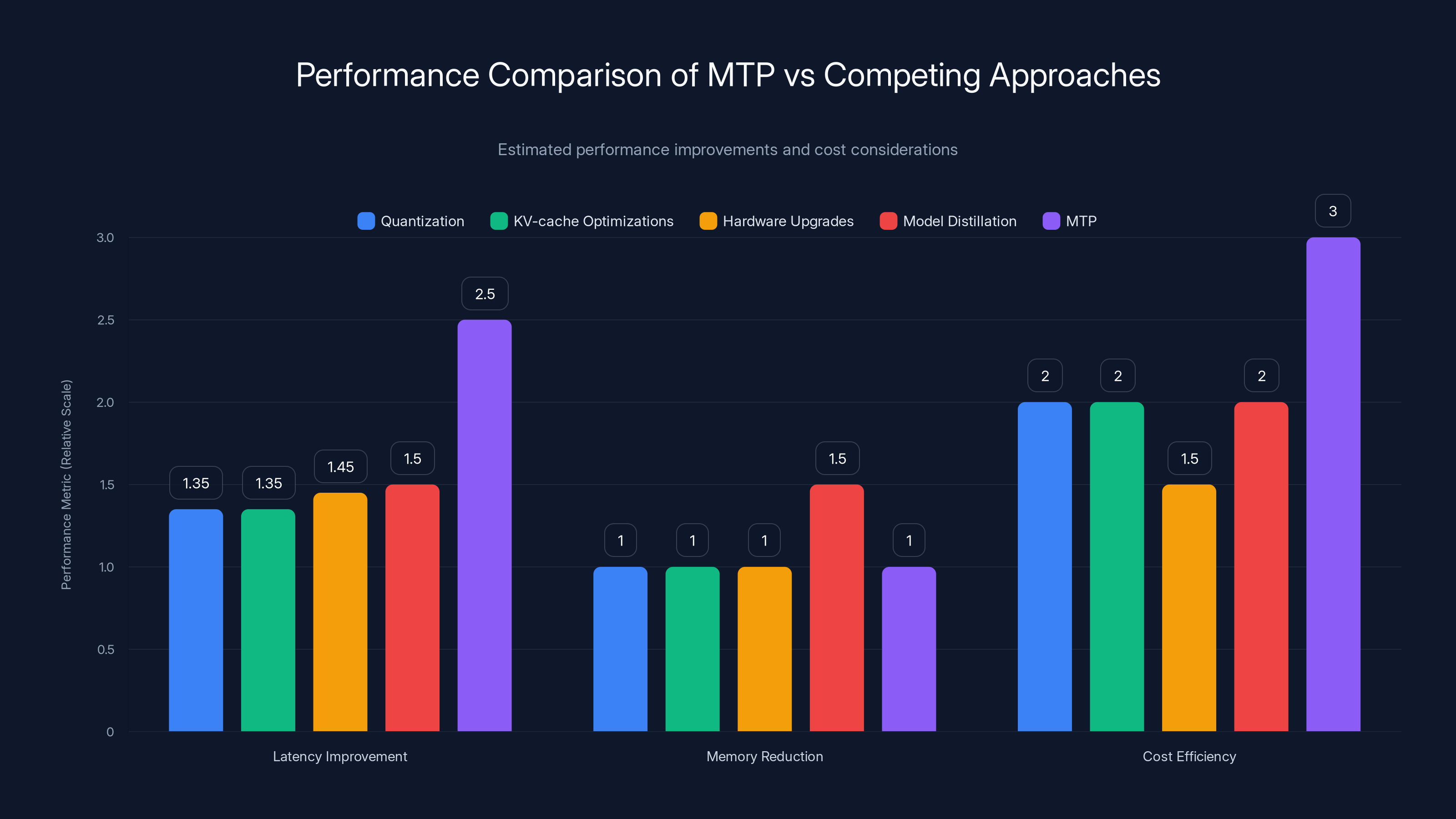
MTP offers the highest latency improvement and cost efficiency compared to other approaches, though it doesn't reduce memory usage. Estimated data.
Comparison with Competing Approaches
Let's be practical about how MTP stacks against other solutions teams are actually deploying.
Versus quantization (4-bit, 8-bit):
- Quantization: Reduces memory footprint and improves latency by 1.2x to 1.5x, slight accuracy loss
- MTP: Improves latency by 2x to 3x, no memory reduction
- Best practice: Use both together. Quantize your model, then apply MTP adaptation.
Versus KV-cache optimizations:
- KV-cache improvements (paging, compression): 1.2x to 1.5x speedup for longer sequences
- MTP: 2x to 3x speedup, better for all sequence lengths
- Best practice: Implement both. They're not mutually exclusive.
Versus hardware upgrades (H100 to H200):
- New hardware: Often 1.3x to 1.6x faster, costs $40K+ per GPU
- MTP adaptation: 2x to 3x faster, costs $180K once
- Math: MTP is more cost-effective per unit latency improvement
Versus model distillation:
- Distillation: Creates a smaller, faster model that's useful for edge deployment
- MTP: Speeds up existing models, no size reduction
- Tradeoff: Distillation is great if you need portable models; MTP is better if you're running on servers

Practical Deployment Strategy
If you were deploying this today, here's how you'd do it:
Phase 1: Assessment (Week 1)
- Identify your bottleneck latency metric (p 50, p 95, p 99)
- Measure current token generation time
- Estimate adaptation cost and benefit
Phase 2: Prototype (Weeks 2-4)
- Get the paper's code (likely to be released)
- Adapt a smaller model (7B to 13B) as a proof of concept
- Measure latency and accuracy on your real workload
Phase 3: Tune (Weeks 5-8)
- Optimize Conf Adapt thresholds for your specific use case
- Test with your actual inference infrastructure
- Measure impact on throughput and cost
Phase 4: Scale (Weeks 9-12)
- Adapt your main production model
- Implement serving layer changes (batching by mode, monitoring)
- Canary deploy to a subset of traffic
Phase 5: Monitor (Ongoing)
- Track latency improvements
- Monitor accuracy on production data
- Measure Conf Adapt fallback rates
- Iterate on confidence thresholds
Full deployment: 3 to 4 months, maybe longer depending on your infrastructure and risk tolerance.

Future Directions: What Comes Next
The research community is already pushing this further.
Next-generation improvements being explored:
Adaptive prediction length: Instead of always predicting 4 tokens, the model learns to predict 2 tokens when uncertain, 8 tokens when very confident. This optimizes the speed-accuracy trade-off dynamically.
Mixture of experts with MTP: How do you apply multi-token prediction to models with conditional computation? Early experiments suggest it's possible but requires careful attention to load balancing.
Cross-layer prediction: Current MTP predicts at the output layer. What if you could predict at intermediate layers and use those for early exit? This could reduce forward pass cost further.
Integration with speculative decoding: Could you use a small drafting model to suggest multi-token blocks that the main model then verifies? This combines both approaches.
Application to vision-language models: Most work so far is on text. Extending to multimodal models is an open question.
Key Takeaways: Why This Research Matters
This isn't incremental. It's a fundamental rethinking of how we should train models for speed.
For decades, the paradigm was: faster models = simpler models = smaller models. Knowledge distillation, quantization, pruning. All pursuing the same logic.
This work says something different: the same model architecture, trained differently, can be fundamentally faster. You don't need to throw away intelligence to gain speed.
For teams building agentic AI, reasoning systems, and latency-critical applications, this is a game changer. You get 2x to 3x latency improvements without auxiliary models or architectural changes.
For organizations that have already deployed models: you can retrofit this. Add a token, retrain with self-distillation, and unlock speedups.
For infrastructure teams: this reduces the hardware arms race. You can serve more users on existing GPUs.
The research is real, the math checks out, and the practical implications are significant.
Looking Forward: Implications for AI Development
This research points to a future where inference efficiency becomes a first-class design consideration, baked into training methodology rather than bolted on afterward.
We're shifting from a world where you train for accuracy and optimize for speed separately, to a world where you train knowing exactly how the model will be used and optimizing for both simultaneously.
That's a subtle but profound change in how AI research works.
The teams shipping agentic AI will move fastest. The organizations that adapt their training pipelines to include multi-token prediction capabilities will have products that feel responsive and intelligent. Everyone else will be waiting for tokens.
This is one of those rare papers where the innovation is both intellectually interesting and practically useful. That combination is what shapes the future.

FAQ
What is multi-token prediction (MTP) in language models?
Multi-token prediction is a training technique that allows language models to predict multiple tokens simultaneously in a single forward pass, rather than generating text one token at a time. Instead of the traditional autoregressive approach where the model predicts token N, then token N+1, then token N+2, MTP enables the model to predict tokens N through N+K all at once, delivering 2x to 3x latency improvements for inference.
How does the self-distillation method work in MTP?
Self-distillation uses a student-teacher approach where the student model generates a block of predicted tokens in parallel, and a teacher model (often a standard next-token prediction model) evaluates the coherence and likelihood of that prediction block. The teacher provides dynamic feedback based on whether the predicted sequence makes linguistic sense, preventing the student from learning degenerate outputs like repeated words or grammatically mismatched phrases. This guidance ensures the model learns joint relationships between tokens rather than predicting each token independently.
What is Conf Adapt and why does it matter?
Conf Adapt (Confidence Adaptive Decoding) is a technique that monitors the model's confidence in each predicted token during multi-token prediction. When the model is very confident, it commits to multiple tokens in parallel. When confidence drops, it falls back to single-token prediction for accuracy. This creates an adaptive strategy that preserves most of the speed gains from MTP (2x to 2.5x) while maintaining 97-99% of original accuracy, making it practical for production systems where accuracy cannot be compromised.
How does MTP compare to speculative decoding?
Both achieve similar speedups (2x to 3x), but MTP requires no auxiliary drafting model while speculative decoding does. MTP adds only a single special token to existing architectures, whereas speculative decoding requires training, deploying, and managing a separate model. For operational simplicity and ease of adaptation to existing models in production, MTP is superior. However, speculative decoding's advantage is that it works with any existing model without retraining, whereas MTP requires adaptation training.
Why does latency matter more than throughput for agentic AI?
Agentic AI systems often require single-user latency optimization because agents need to reason and make decisions quickly within loops. Traditional batch processing optimizes throughput (total tokens per second across all users) but doesn't help single-user latency. When an AI agent must think through 5,000 tokens before making a decision, and that thinking takes 30+ seconds with standard token-by-token generation, the system feels slow and unresponsive. MTP cuts that latency in half or better, enabling genuinely interactive agent systems that can iterate faster.
What is the computational cost of adapting an existing model to support MTP?
Adapting an existing model requires parameter-efficient retraining using self-distillation, which typically costs 10-20% of the original model training compute. For a 70B parameter model that took 100,000 H100-hours to train originally, adaptation would cost 10,000-20,000 H100-hours, or roughly $120,000-$240,000 on cloud infrastructure. This is a one-time cost that creates permanent latency improvements for that model.
Can MTP be combined with other inference optimization techniques?
Yes. MTP is complementary to many other optimizations including quantization (4-bit, 8-bit), KV-cache optimizations, and hardware upgrades. The best practice is to combine multiple techniques: quantize your model first (for memory and some latency gains), then apply MTP adaptation (for additional latency gains), then deploy on optimized serving infrastructure (for further improvements). These approaches address different parts of the inference pipeline and stack multiplicatively.
How much accuracy loss occurs with multi-token prediction?
Standard MTP without Conf Adapt can reduce accuracy by 10-15% for long-form generation because predicting further-ahead tokens is fundamentally harder. However, Conf Adapt mitigates this by falling back to single-token prediction when confidence is low, achieving 97-99% of original accuracy while preserving most latency gains. The accuracy-latency trade-off is tunable per model and workload.
What types of models can be adapted for MTP?
Any language model using standard transformer architecture with next-token prediction can theoretically be adapted for MTP. This includes decoder-only models (GPT-style), encoder-decoder models, and models with various optimization techniques (Mo E, windowed attention, SSM layers). The approach requires no architectural changes, only the addition of a single special token and retraining using self-distillation, making it broadly applicable across the ecosystem.
What is the practical speedup you can expect in production?
Production speedups typically range from 1.8x to 3x depending on model size, output length, and workload characteristics. Shorter sequences see lower speedups (~1.8x) because per-forward-pass overhead dominates. Longer sequences and reasoning models see higher speedups (2.5x to 3x). With Conf Adapt tuning for your specific use case, expect 2x to 2.5x as a conservative estimate for typical production workloads.

Related Articles
- India's Sarvam Launches Indus AI Chat App: What It Means for AI Competition [2025]
- Google Gemini 3.1 Pro: AI Reasoning Power Doubles [2025]
- Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work [2025]
- Nvidia's Dynamic Memory Sparsification Cuts LLM Costs 8x [2025]
- AI Agents in Production: What 1 Trillion Tokens Reveals [2025]
- The OpenAI Mafia: 18 Startups Founded by Alumni [2025]

