![Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work [2025]](https://tryrunable.com/blog/gemini-3-1-pro-google-s-record-breaking-llm-for-complex-work/image-1-1771549623495.jpg)
Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work
Google just dropped something that's shaking up the AI model wars in a serious way. On Thursday, the company released Gemini 3.1 Pro as a preview, and the benchmark numbers are—honestly—wild. This isn't just a refresh or a slight improvement. This is Google making a statement that they're not letting OpenAI and Anthropic run away with the AI race unchecked.
But here's what actually matters: Gemini 3.1 Pro is being positioned as something different. It's built specifically for what's being called "agentic work." That's the industry term for AI systems that can break down complex problems into steps, reason through them independently, and execute multi-part tasks without constant human intervention. Think of it like the difference between asking an AI to write one sentence versus asking it to write a business proposal, execute research, pull data, synthesize findings, and present conclusions—all in one coherent workflow.
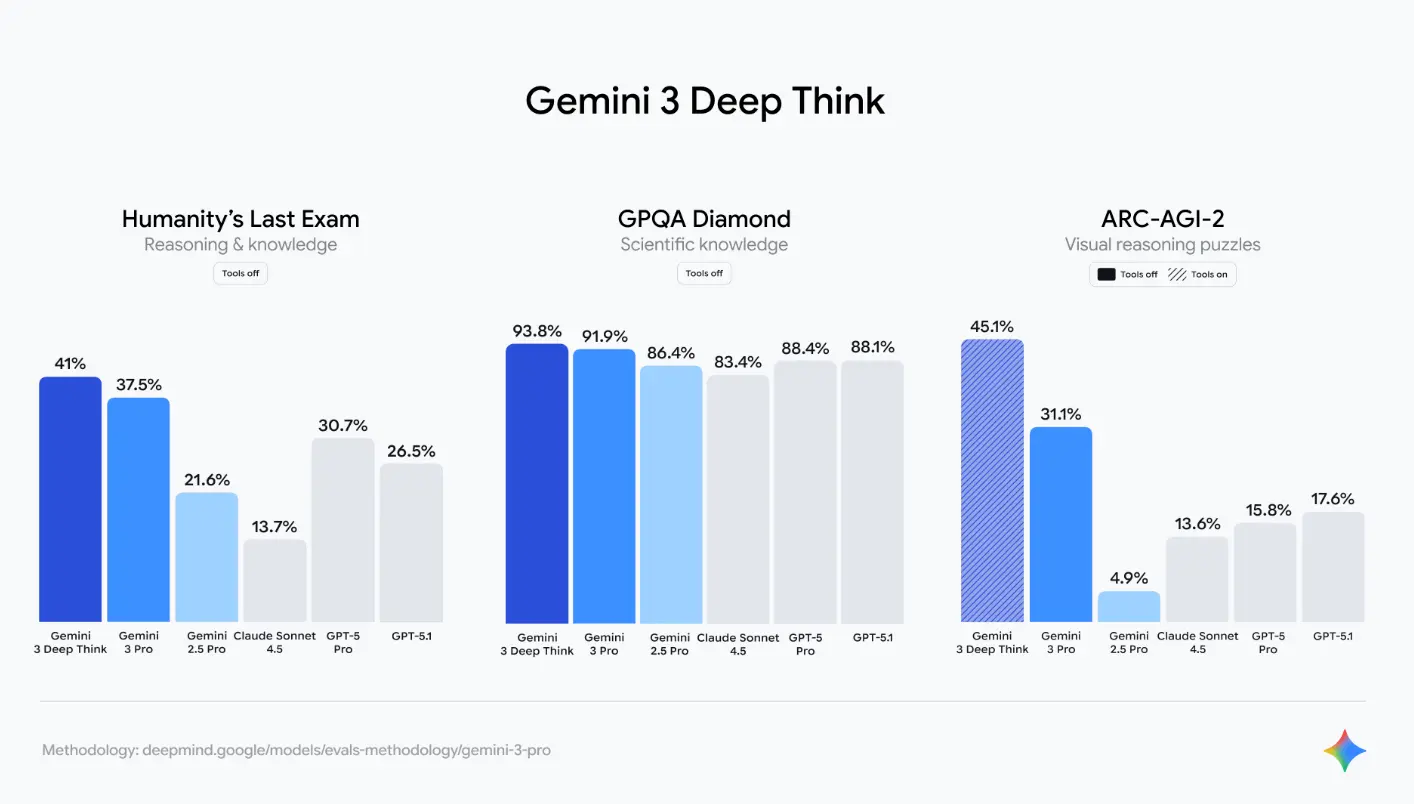
The numbers backing this up are coming from some pretty serious benchmarking systems. Humanity's Last Exam (a human-created benchmark designed to test AI reasoning) showed Gemini 3.1 Pro performing significantly better than Gemini 3. But what caught industry attention was how it performed on APEX-Agents, the benchmarking system created by Mercor. The company's CEO, Brendan Foody, publicly noted that Gemini 3.1 Pro hit the top of the APEX-Agents leaderboard—a ranking system specifically designed to measure how well AI models handle real professional tasks. That's not theoretical performance. That's practical, work-world capability.
This matters because we're at a moment where AI isn't just getting smarter in lab tests anymore. The competitive pressure is forcing companies to build models that solve actual business problems. And that shift is reshaping which AI tool becomes the default for developers, product teams, and enterprises. Let's break down what's happening with Gemini 3.1 Pro, why the benchmarks actually mean something, and what this means for the broader AI landscape.
TL; DR
- Gemini 3.1 Pro tops benchmarks: Record scores on Humanity's Last Exam and APEX-Agents, showing significant improvement over Gemini 3
- Built for agentic work: Designed specifically for multi-step reasoning, complex problem-solving, and independent task execution
- Real professional task performance: The model demonstrates practical capability for knowledge work, not just theoretical improvements
- Competitive pressure intensifying: OpenAI, Anthropic, and Google are in active competition to dominate the AI model space
- Preview now, general release soon: Gemini 3.1 Pro is available in preview with general availability expected shortly
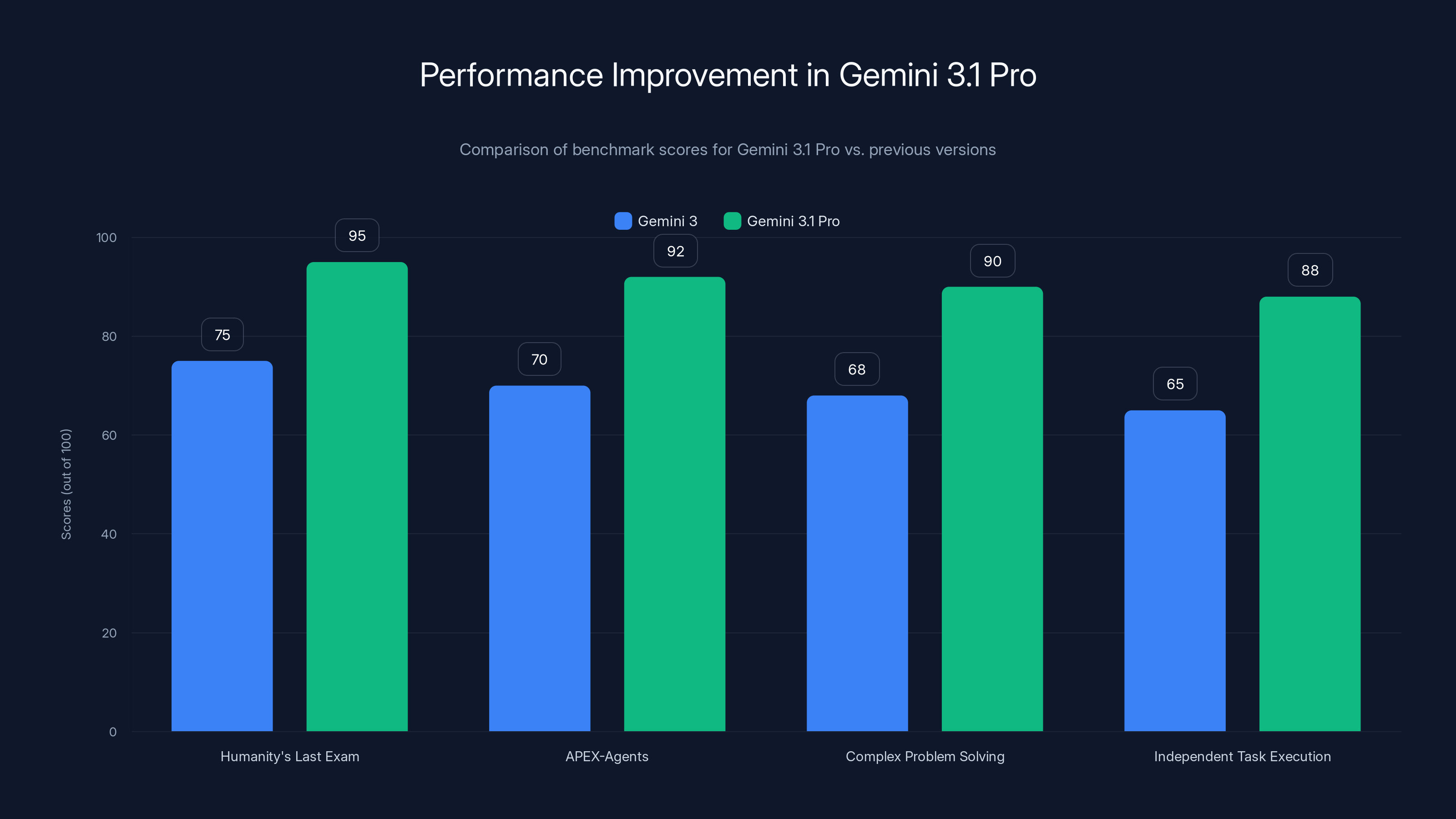
Gemini 3.1 Pro shows significant improvements over Gemini 3 in key benchmarks, indicating enhanced capabilities in reasoning and independent task execution. Estimated data.
Understanding Gemini's Evolution: From 3.0 to 3.1
Gemini's journey has been interesting to watch. When Google released Gemini 3 back in November, the tech community was impressed. It was a genuinely capable model that could compete with the best systems available. But let's be honest: it wasn't setting records at that point. It was solid, reliable, and capable—which is exactly what enterprises want, but not what gets headlines.
Then, just a few months later, Gemini 3.1 Pro comes out and immediately jumps to the top of multiple leaderboards. The jump from 3.0 to 3.1 suggests Google wasn't just fine-tuning around the edges. Something structural changed. That's either a training methodology breakthrough, significantly more compute resources, or better data curation. Probably all three.
The key distinction here is that Gemini 3.1 Pro isn't positioned as a marginal improvement. Google explicitly framed this around the ability to handle complex, multi-step reasoning tasks. That's code for: this model can break down a problem, create a plan, execute steps sequentially, and handle dependencies between tasks. It's the difference between a smart calculator and a problem-solving agent.
What makes this relevant is timing. We're in the middle of an AI capability race where companies are measuring success not just on raw benchmarks, but on whether models can actually replace or augment human professional work. A model that can write a paragraph is interesting. A model that can manage a workflow, pull data from multiple sources, synthesize findings, and generate reports automatically—that's business-changing.
The Benchmark Story: What the Numbers Actually Tell Us
Here's the thing about AI benchmarks: they've become a bit of a proxy war. Every company claims their model is the best, every benchmarking system has subtle biases, and the public gets confused about what these scores actually mean. But some benchmarks are genuinely more useful than others.
Humanity's Last Exam is one of the more interesting ones because it's designed by humans who intentionally created problems that are difficult for AI. These aren't softball questions. They're problems that require reasoning, context switching, and multi-disciplinary knowledge. When Gemini 3.1 Pro shows significant improvement on this benchmark, it's saying something real: the model is better at reasoning through hard problems.
But the APEX-Agents leaderboard is where things get practical. Mercor created this system to test how well models perform on actual professional tasks. Think real work scenarios: analyzing data, writing reports, solving engineering problems, managing projects. This isn't theoretical. Companies like Mercor specifically built this to measure what humans care about: can this AI actually do useful work?
The fact that Gemini 3.1 Pro topped the APEX-Agents leaderboard is significant because it means Google's model is being recognized by an independent benchmarking system as the best at executing real professional work. That's different from claiming "we have the highest score." An independent system says: "We tested these models on real tasks, and this one performed best."
Now, the important caveat: benchmark performance doesn't always translate directly to your specific use case. A model that's best at general professional tasks might not be best for specialized domains like legal analysis or code generation. But when multiple independent benchmarks align on the same winner, you start seeing a pattern.
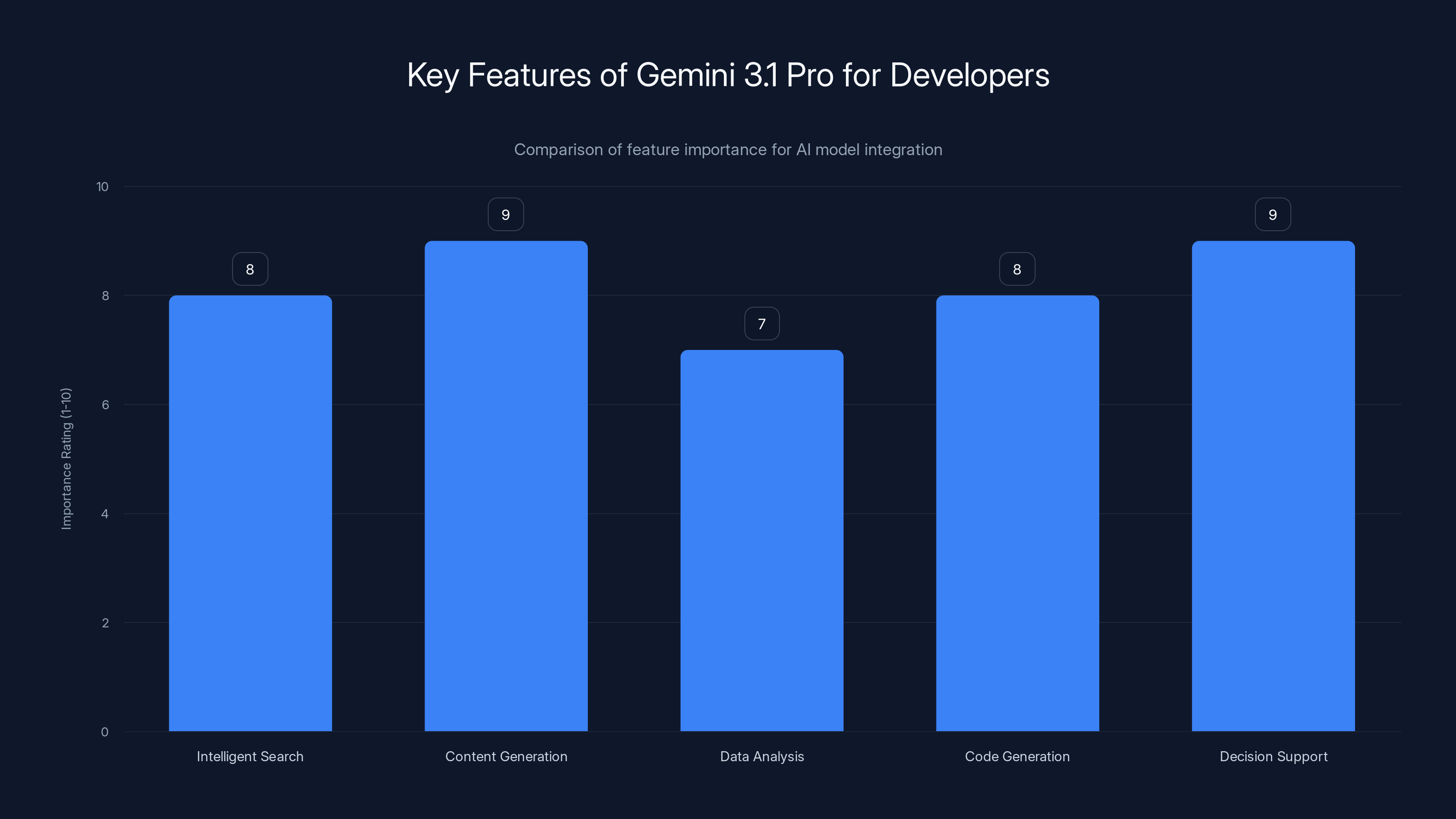
Gemini 3.1 Pro excels in content generation and decision support, making it a strong candidate for complex AI integrations. Estimated data.
Agentic Work: What It Means and Why It Matters
There's a lot of industry buzz around "agentic AI" right now, and it's worth understanding what that actually means because it's fundamentally different from how most people interact with AI today.
When you use Chat GPT or Claude, you're having a conversation. You ask a question, the model responds, you ask a follow-up, and so on. That's reactive AI. You're directing it step by step.
Agentic work is different. You give the AI a goal, maybe some constraints, and it figures out the steps needed to achieve that goal independently. It might need to search for information, pull data from multiple systems, synthesize findings, identify gaps, ask clarifying questions, and then deliver a result. All without you having to guide it through each step.
A practical example: imagine you ask agentic AI to "analyze our Q4 sales performance and identify which regional sales teams exceeded targets by more than 15%, then write a brief summary of their strategies for the team." An agentic system would:
- Access the sales database
- Pull Q4 regional performance data
- Calculate which teams exceeded 15% targets
- Research or retrieve information about those teams' strategies
- Synthesize findings into a coherent summary
- Deliver results with citations and confidence levels
A non-agentic system would handle one step at a time and ask for your input or clarification between steps. The difference might sound small, but it compounds. Agentic systems can handle jobs that would take humans hours to complete—pulling data, researching, analyzing, and writing—in minutes.
Gemini 3.1 Pro's emphasis on being built for agentic work means Google is specifically training this model to handle multi-step reasoning. The architecture, training data selection, and fine-tuning are all optimized for this capability rather than generic conversational ability.
For developers building AI systems, this matters enormously. A model built for agentic work has better support for:
- Tool use and function calling: The model can learn to use APIs and tools as part of its reasoning
- Long context understanding: It can hold multiple pieces of information in mind while working through a problem
- Iterative refinement: It can evaluate its own work, spot mistakes, and correct them
- Structured output: It can format results in ways that other systems can consume
How Gemini 3.1 Pro Compares to Competing Models
The AI model landscape right now is genuinely competitive. A year ago, OpenAI had clear dominance. Today? It's messier. Multiple companies have genuinely strong models, and the leader is determined mostly by what you're measuring.
OpenAI's GPT-4 and the newer GPT-4o remain solid performers, particularly for reasoning tasks and code generation. But OpenAI has been slower than competitors at releasing improvements. That creates opportunities for Google and Anthropic to advance their offerings.
Anthropic defines itself around safety and has been building Claude with explicit focus on being helpful, harmless, and honest. Claude 3 models are genuinely good, particularly for analysis and writing tasks. But Anthropic has been more conservative about claims, which sometimes makes it look like they're trailing when they're actually just not marketing as aggressively.
Google's advantage is infrastructure. The company literally invented the transformer architecture that powers modern LLMs. Google has access to massive compute, best-in-class data pipelines, and the ability to integrate AI models directly into products like Search, Gmail, and Workspace. When Google says Gemini 3.1 Pro is ready for complex work, they're backing it up with deployment at massive scale.
The competitive dynamics are shifting from "who has the smartest model" to "who can integrate AI most effectively into workflows people actually use." That's a different game, and it plays to Google's strengths. If Gemini 3.1 Pro becomes the default model in Google Workspace, Google Cloud, and search products, it doesn't matter if it's 2% smarter than alternatives—people will use it because it's already there.
That's not cynical; that's market reality. The companies winning the AI race aren't necessarily the ones with the smartest models. They're the ones with the smartest integration and the most integrated ecosystems.
Real-World Applications: Where Gemini 3.1 Pro Changes Things
Benchmark scores are interesting, but what actually matters is whether improved capability translates to better outcomes for real work. Let's walk through where Gemini 3.1 Pro's capabilities matter practically.
Complex Data Analysis
Consider a financial analyst who needs to prepare a quarterly report. Traditionally, this involves: accessing multiple data sources, cleaning data, running analyses, interpreting results, and synthesizing findings. With a non-agentic model, the analyst asks questions one at a time. With an agentic system like Gemini 3.1 Pro, the analyst could say "Prepare a quarterly financial report analyzing revenue trends, customer acquisition cost, and churn rates" and the system would handle the entire workflow.
The time savings here are substantial. What takes a human 4-6 hours might take agentic AI 30 minutes. That's not just faster; that's fundamentally changing how work gets organized.
Software Development and Code Review
Developers spend significant time on code review, documentation, and refactoring. An agentic model could be given a codebase and asked to "identify technical debt, propose refactoring priorities, and generate updated documentation." The model would analyze code structure, identify patterns, understand dependencies, and deliver structured recommendations. This is genuinely useful work that currently requires senior engineers.
Research and Synthesis
Research professionals spend hours pulling information from disparate sources, synthesizing findings, identifying contradictions, and drawing conclusions. Agentic AI can do this at scale. "Research the current state of transformer optimization techniques, identify which companies are leading development, and summarize the key innovations of the past six months." A capable agentic system handles this efficiently.
Customer Service and Support
Support teams could give an agentic system access to documentation, knowledge bases, and previous tickets, then have it handle complex customer issues. The system would research the problem, pull relevant documentation, check for similar issues, and provide thorough responses.
Project Management and Planning
Agentic systems could manage complex project workflows. "Create a detailed project plan for launching a new product," including tasks, dependencies, resource allocation, risk identification, and timeline. The model would break down the problem, identify required steps, and deliver a structured plan.
What ties all these together is that they're not hypothetical use cases. Companies are actively building these workflows with current agentic AI systems. The question is whether Gemini 3.1 Pro's improvements make it the preferred foundation for these applications.
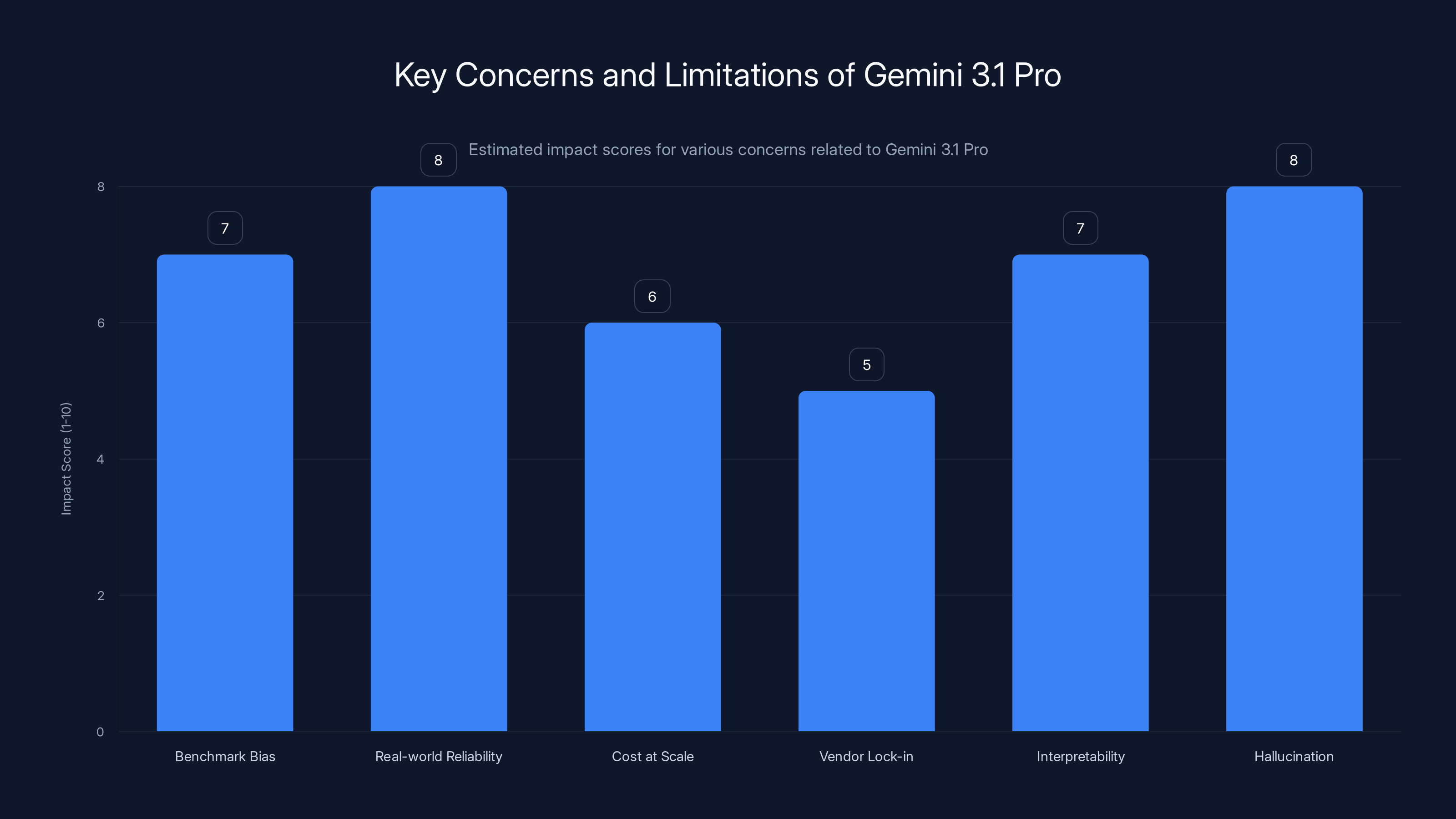
This bar chart estimates the impact of various concerns related to Gemini 3.1 Pro. Real-world reliability and hallucination issues are rated highest, indicating significant challenges in practical applications. Estimated data.
The Technical Architecture Behind the Improvements
Google didn't reveal detailed architecture changes, but we can infer some things from what we know about model scaling and the benchmark improvements demonstrated.
First, scale matters. Larger models generally perform better. If Gemini 3.1 Pro is showing significant improvement over Gemini 3, it's likely larger. Google has the compute resources to train genuinely massive models, and they've been investing heavily in their tensor processing unit (TPU) infrastructure. A model trained on more compute generally performs better.
Second, training data quality and curation probably changed. Google has access to enormous amounts of data—web content, academic papers, code repositories, and proprietary data. How that data is selected, cleaned, and weighted during training affects model behavior. If Google improved how they curate data for reasoning tasks and agentic work, that alone could explain improvements.
Third, fine-tuning and reinforcement learning approaches matter. Modern models are often trained in stages: initial training on massive data, then fine-tuning on specific tasks, then optimization using human feedback or other signals. Gemini 3.1 Pro might have more sophisticated fine-tuning specifically for reasoning tasks.
Fourth, architectural innovations could include better mechanisms for:
- Attention mechanisms: How the model weights different parts of input when generating output
- Tool integration: Systems for calling external tools and integrating results
- Long context handling: Processing longer sequences of information
- Chain-of-thought reasoning: Breaking complex problems into steps
Google has published research on several of these topics, so they're actively innovating here.
The reality is that modern AI performance comes from a combination of scale, data quality, training methodology, and architecture. Google has advantages in all four areas. That's why Gemini 3.1 Pro is competitive.
Benchmarking in Practice: APEX-Agents Deep Dive
The APEX-Agents leaderboard deserves special attention because it's different from most AI benchmarks. Rather than theoretical tests, it measures how well models perform on simulated professional tasks.
Mercor designed APEX to test agent behavior. The system creates scenarios that require models to:
- Understand complex goals: Parse what's being asked, identify unstated requirements
- Plan multi-step workflows: Break complex goals into steps, order them logically
- Use tools and APIs: Call external systems, integrate results
- Handle uncertainty: Make decisions when information is incomplete
- Iterate and refine: Evaluate results, identify mistakes, make corrections
- Communicate results: Present findings clearly with appropriate context
A model might score well on traditional benchmarks by having good general knowledge but fail on APEX-Agents if it can't plan workflows or integrate tool outputs effectively. That's why APEX-Agents is more predictive of real-world usefulness.
Gemini 3.1 Pro's top ranking on APEX-Agents specifically indicates it's good at these practical agent behaviors. That's more meaningful than raw reasoning scores for predicting how well it'll perform when you put it into production.
CEO Brendan Foody's public statement that "Gemini 3.1 Pro is now at the top of the APEX-Agents leaderboard" and that this shows "how quickly agents are improving at real knowledge work" carries weight because Mercor has skin in the game—they're not Google, so their endorsement isn't self-interested.
Industry Context: The AI Model Wars Heating Up
Gemini 3.1 Pro's release isn't happening in a vacuum. This is the latest move in an increasingly intense competitive race between the major AI companies.
OpenAI has been relatively quiet on major new releases, though they're constantly iterating on GPT-4o. The company seems focused on integrating AI into product experiences rather than announcing new flagship models. That's strategic—making AI useful matters more than having the headline-grabbing model. But it also creates an opening for competitors to claim leadership.
Anthropic is methodically improving Claude, with recent releases showing steady gains. The company's approach is more measured—they're investing heavily in safety research and interpretability alongside capability improvements. Anthropic claims Claude 3.5 Sonnet is competitive with GPT-4o on many benchmarks, and their analysis shows it excels on reasoning tasks.
Google is bringing the full weight of its infrastructure and distribution. Gemini 3.1 Pro is interesting not just because it's good, but because Google can integrate it across its entire ecosystem. Gmail, Workspace, Cloud, Search—all of these will eventually have Gemini AI capabilities baked in. That integration matters more for market dominance than having the theoretically smartest model.
Meta has been quieter but released models like Llama that compete well. Amazon is investing heavily through AWS Bedrock. Microsoft has been integrated with OpenAI but is developing its own models. The field is crowded, and everyone is innovating rapidly.
What's changing is that the benchmarks are converging. A year ago, there was clear separation. Now multiple models perform comparably on many benchmarks, with different models leading in different areas. That means the competitive differentiation is shifting from raw capability to:
- Integration and accessibility: Can you actually use this model easily?
- Cost and efficiency: How much does it cost to run?
- Specialization: Is it optimized for your specific use case?
- Trust and safety: Can you rely on its outputs?
- Integration with your existing systems: Does it work with what you already use?
Gemini 3.1 Pro is competitive on capability. Its real advantage is that it's coming from Google, which can integrate it everywhere.

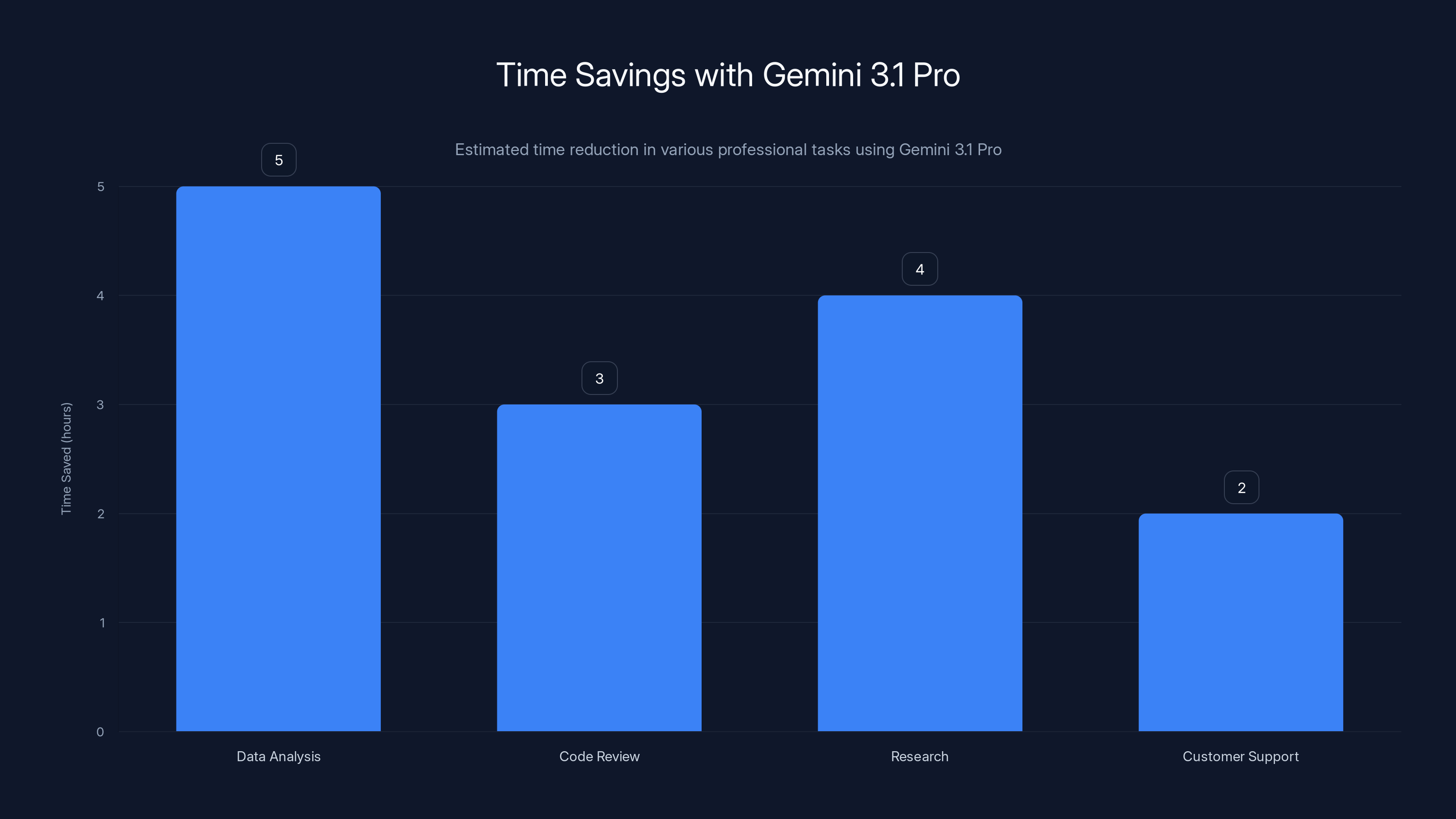
Gemini 3.1 Pro significantly reduces time spent on complex tasks, saving up to 5 hours in data analysis alone. Estimated data.
Practical Implications for Developers and Teams
If you're a developer or tech lead evaluating AI models for your products or internal workflows, Gemini 3.1 Pro's improvements matter, but they matter in specific ways.
For product integration: If you're building an AI feature into your product, Gemini 3.1 Pro is now a credible option. The benchmark performance suggests it can handle complex reasoning tasks, which means it can power features like:
- Intelligent search and discovery
- Automated content generation and summarization
- Data analysis and insights
- Code generation and refactoring
- Complex decision support
For workflow automation: If you're using AI to automate internal workflows, agentic capability matters more than raw benchmark scores. You need a model that can plan, execute, and iterate. Gemini 3.1 Pro's agentic focus means it's worth testing for workflows that would previously require human orchestration.
For cost considerations: Model choice has real cost implications. Larger, more capable models often cost more to run. Google typically prices competitively with OpenAI's API, but you should evaluate total cost of ownership including:
- Per-token pricing
- Prompt caching and efficiency
- Required context length
- Latency requirements
- Accuracy (fewer mistakes = lower correction costs)
For multi-model strategies: Smart teams are moving toward multi-model approaches, using different models for different tasks. Gemini 3.1 Pro might be ideal for complex reasoning while a smaller, faster model handles simple queries. This optimizes cost and performance.
Concerns and Limitations Worth Considering
While Gemini 3.1 Pro's performance is genuinely impressive, it's important to think critically about limitations and concerns.
Benchmark bias: All benchmarks have biases. A model can score well on APEX-Agents but might not perform well on your specific tasks. Benchmark dominance predicts capability, but doesn't guarantee it works for your use case.
Real-world reliability: Benchmark performance is measured under ideal conditions. Real-world usage involves edge cases, unclear prompts, incomplete data, and domains the model hasn't seen during training. A model's benchmark score doesn't tell you how often it'll be confidently wrong.
Cost at scale: If benchmarks show Gemini 3.1 Pro is more capable, Google will likely price it accordingly. Cost per token might be higher than simpler alternatives, and you need to evaluate whether the capability improvement justifies the cost for your specific use case.
Vendor lock-in: Choosing Google means integrating with Google's ecosystem. That has benefits (seamless Workspace integration, for example) but also risks. If Google changes pricing, discontinues the product, or makes design decisions you don't like, you're affected.
Interpretability and control: More capable models are often less interpretable. Agentic systems that break down complex problems into steps might make decisions that are hard for humans to understand or verify. That creates challenges for regulated industries like finance, healthcare, or legal.
Hallucination and accuracy: No matter how good a model is, it still generates false information with confidence sometimes. Gemini 3.1 Pro is probably better at avoiding hallucinations than predecessors, but it's not solved. For high-stakes applications, you need verification systems and human oversight.

The Competitive Landscape: Where This Fits
Gemini 3.1 Pro's release is significant for market dynamics. Here's what it means for the competitive landscape:
For Google: This is a statement of intent. The company is signaling that Gemini is competitive with the best models available. Google can now credibly position Gemini as the default AI choice for enterprises, and they'll integrate it throughout their product ecosystem. That's powerful for market share, even if some competitors have equally good or better models.
For OpenAI: This is pressure to innovate faster. OpenAI remains the market leader in terms of enterprise adoption and brand recognition, but allowing competitors to claim benchmark leadership is strategic risk. Expect OpenAI to announce improvements or new capabilities soon.
For Anthropic: This validates their strategy of focusing on capability and safety simultaneously. If Claude is competitive with or better than Gemini on reasoning tasks while maintaining safety focus, that's a strong positioning for enterprises that care about reliability and responsible AI.
For smaller players and open-source: This demonstrates that you need massive resources to compete at the frontier. Training and optimizing models at this scale requires compute, data, and talent that only big tech companies have. This consolidates the market at the top.
For enterprises: This is actually good news. More competition means more choice, better pricing, and faster innovation. Enterprises should test multiple options rather than assuming one provider is definitively best.
The landscape is becoming one where a few companies have genuinely competitive frontier models, and differentiation comes from integration, pricing, support, and specialization rather than raw capability. That's healthier than a single dominant player.
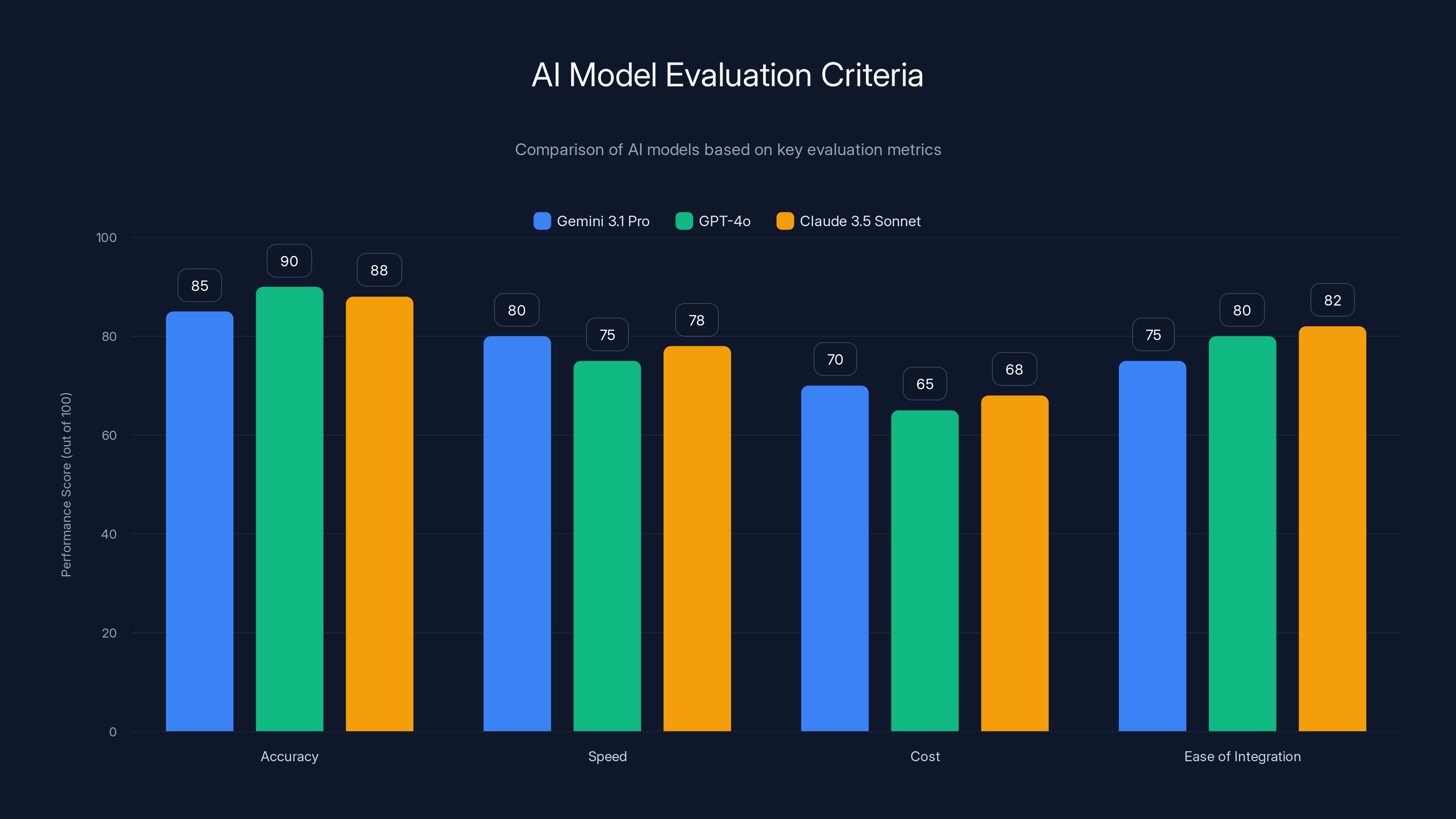
This chart compares AI models based on key evaluation metrics such as accuracy, speed, cost, and ease of integration. Estimated data provides a visual framework for selecting the most suitable model.
Looking Forward: What's Next in the AI Model Race
Where does this lead? A few observations about the trajectory of AI models in 2025 and beyond.
Capability plateau: There's only so much improvement possible with scaling. At some point, we hit diminishing returns where more compute yields smaller capability gains. We might be approaching that point, which means innovation will shift from raw scale to architecture, training methodology, and specialization.
Specialization: Rather than one model doing everything, we'll see specialized models optimized for specific domains. A model fine-tuned for medical diagnosis will outperform a general model, even if the general model is larger.
Cost efficiency: As models mature, the competitive focus shifts to cost and efficiency. Who can deliver 95% of capability at 50% of the cost? That becomes the winning question.
Integration into workflows: The real competitive advantage isn't model quality—it's being integrated into the tools people actually use. Gemini's advantage isn't that it's theoretically smarter; it's that Google will put it in Search, Workspace, and Drive.
Safety and interpretability: As AI capability increases, the demands for safety, interpretability, and control become more critical. This is where Anthropic's focus on safety becomes increasingly valuable.
Open versus closed: Open-source models are improving rapidly. They might not compete at the frontier, but for many applications, a smaller, open-source model is better than depending on a closed API. This creates competitive pressure on the big companies.
Multi-model stacks: Smart organizations will use multiple models—different tools for different jobs. That creates openness to newer, specialized models even if they're not the "best" overall.
Gemini 3.1 Pro is impressive, but it's a snapshot in a rapid evolution. The model that's best today might be adequate in six months and obsolete in a year. That's the pace of AI innovation right now.

How to Evaluate AI Models for Your Needs
Given the competitive landscape and rapid change, how should you think about model selection? Here's a framework.
Step 1: Define your use case specifically. Don't evaluate models based on benchmarks. Evaluate them on your actual tasks. What problems are you trying to solve?
Step 2: Identify required capabilities. Do you need reasoning ability? Code generation? Long-context understanding? Agentic behavior? Different models have different strengths.
Step 3: Test multiple options. Create a small test set of your actual problems. Run them through different models (Gemini 3.1 Pro, GPT-4o, Claude 3.5 Sonnet, etc.). Measure accuracy, speed, and cost.
Step 4: Consider total cost of ownership. Don't just look at per-token pricing. Include:
- Development time (some APIs are easier to work with)
- Integration complexity
- Accuracy (mistakes cost money to fix)
- Latency (slow responses might not work for your use case)
- Revision rates (models that require fewer corrections are cheaper)
Step 5: Think about lock-in. How much effort would it take to switch providers? If switching is easy, you have more leverage. If it's expensive, that affects the value of any provider.
Step 6: Plan for change. New models arrive frequently. Build your system to be model-agnostic if possible. Use a common API layer that makes switching providers easy.
Step 7: Evaluate emerging alternatives. Don't assume the best model today is the best model next quarter. Stay aware of what Stability AI, LMSYS, and research labs are doing.
Gemini 3.1 Pro should be on your evaluation list, especially if you're using Google Cloud or Workspace. But it shouldn't be your only evaluation.
Making the Transition: Practical Steps for Adoption
If Gemini 3.1 Pro looks promising for your use case, how do you actually adopt it?
Start with pilot projects. Don't migrate everything at once. Pick a non-critical workflow where you can test Gemini 3.1 Pro for 2-4 weeks. Measure performance against your current approach.
Create a comparison matrix. Document specific metrics:
- Task completion accuracy
- Time to completion
- Cost per task
- User satisfaction (if applicable)
- Error rates and types of errors
Build fallback systems. Agentic AI systems sometimes fail silently or produce incorrect results with confidence. Build monitoring and verification systems that catch problems.
Document your prompts and workflows. AI model behavior depends heavily on how you prompt it. Document what works, why it works, and how to adjust prompts when behavior changes after model updates.
Plan for migration complexity. If you're switching from another provider, you'll need to:
- Retest and optimize prompts
- Adjust integration code
- Retrain teams on different interfaces
- Establish new SLAs
These aren't enormous tasks, but they require planning.
Monitor performance over time. After adoption, keep measuring. Models get updated, competitors improve, and your needs change. Quarterly evaluation of whether you're still using the best tool for the job is good practice.

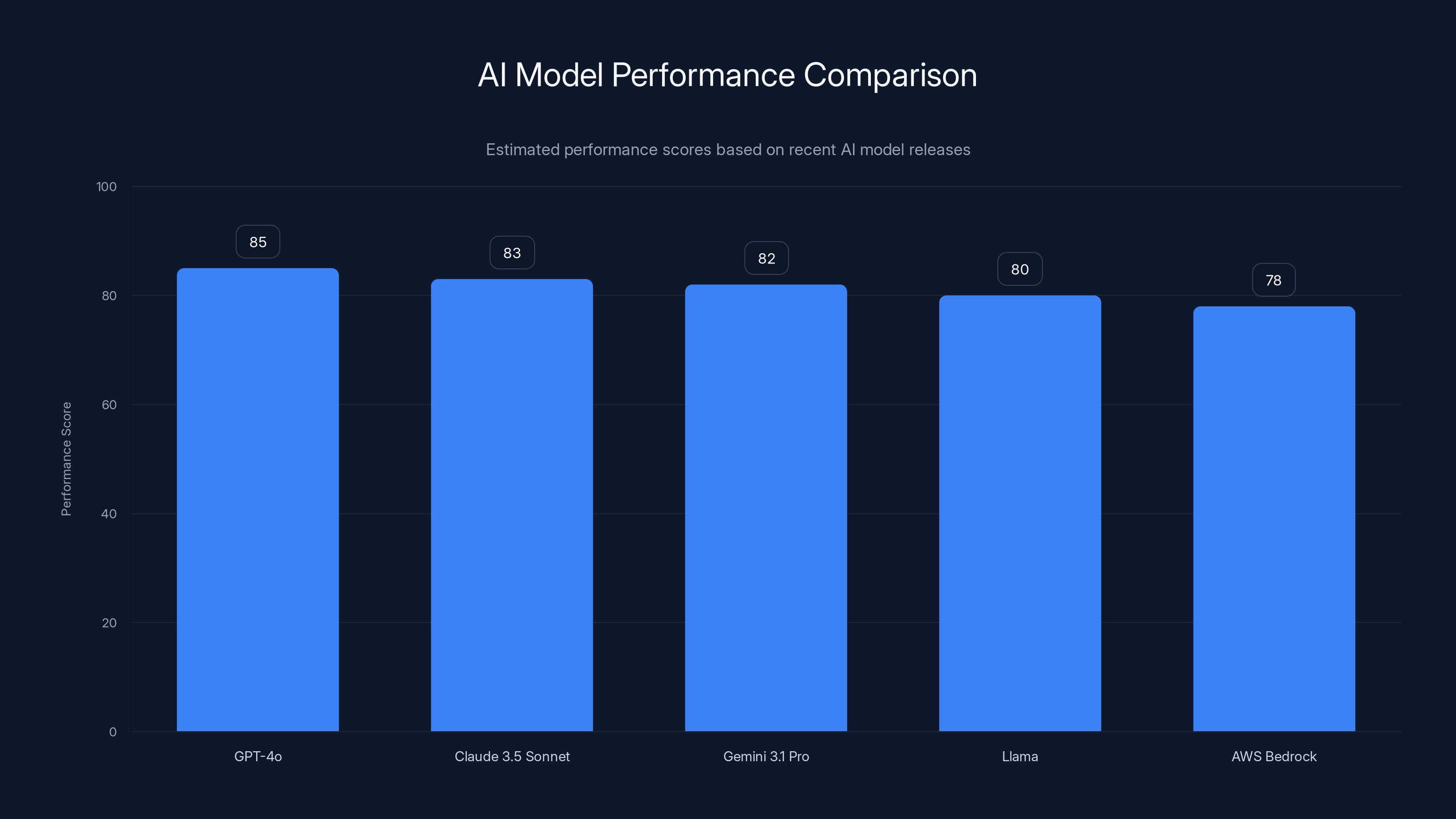
Estimated performance scores suggest that AI models like GPT-4o and Claude 3.5 Sonnet are leading the pack, with Gemini 3.1 Pro closely following. Estimated data based on industry trends.
Integration with Google's Ecosystem
One of Gemini 3.1 Pro's biggest advantages is that it's from Google. That means integration opportunities that competitors can't match.
Google Workspace: Gemini is integrated into Gmail, Docs, Sheets, and Slides. Gemini 3.1 Pro will power better suggestions, writing assistance, and automation throughout the suite.
Google Cloud: Cloud customers can use Gemini 3.1 Pro through the Vertex AI platform, with integrations to other Google Cloud services like Big Query, Cloud Storage, and Cloud Functions.
Google Search: Over time, Gemini will power more of Google's search experience. A more capable model means better search results and more sophisticated answer generation.
Android and Google Assistant: Google's assistant products will get better with improved Gemini capabilities.
For enterprises deeply integrated with Google, this ecosystem advantage is real. You can build end-to-end AI workflows that connect search, workspace, cloud infrastructure, and databases without switching between multiple AI providers.
For enterprises using competitor ecosystems (Microsoft with Office 365 and Copilot, for example), the advantage is less clear. Microsoft is closely integrated with OpenAI, so their ecosystem preference is different.
The Bigger Picture: What This Means for AI Strategy in 2025
Gemini 3.1 Pro is one release in a broader evolution. Here's what it represents for AI strategy:
AI capability is becoming table stakes. Companies can't compete without AI integration anymore. The question isn't "should we use AI?" but "how do we use AI better than competitors?"
The real competition isn't models. Multiple companies now have genuinely good models. The real competition is in:
- Making AI accessible to non-technical teams
- Integrating AI into existing workflows
- Building trust and reliability
- Cost efficiency
- Speed of innovation
Specialization will win. General-purpose models are useful, but specialized models for specific domains will outperform them. If you're in healthcare, legal, financial services, or manufacturing, look for AI solutions tailored to your industry.
Distribution channels matter more than raw capability. Google will win AI market share not because Gemini is theoretically smartest, but because it'll be available in everything Google users touch daily.
Open source is a genuine alternative. Models like Llama are improving fast. For many applications, an open-source model running on your infrastructure beats dependency on a closed API.
Multi-model strategies are the future. Using different models for different tasks, optimizing for cost and performance, becomes standard practice.
Gemini 3.1 Pro fits into this picture as a strong general-purpose model with competitive agentic capabilities, backed by Google's distribution and ecosystem. It's not a game-changing technological breakthrough—it's smart iterative improvement combined with strong strategic positioning.
Risks and Challenges to Understand
Before adopting Gemini 3.1 Pro or any new AI model, understand the risks.
Bias and fairness: Large language models can perpetuate biases present in their training data. For applications affecting people (hiring, lending, criminal justice), you need robust testing and mitigation strategies.
Hallucinations and misinformation: Models generate false information confidently. For fact-dependent applications, you need verification systems. Anthropic has published research on hallucination rates, which is worth reading.
Data privacy: If you're passing sensitive data to an API, understand what Google does with that data. Read their privacy policies carefully. For truly sensitive data, consider running models locally.
Regulatory compliance: Many industries have strict rules about AI usage. Financial services, healthcare, and legal services have specific requirements. Make sure any model you adopt meets your regulatory obligations.
IP and copyright: Models are trained on enormous amounts of data, including copyrighted material. There are ongoing legal questions about whether this is permissible. This might affect your liability if you depend on these models.
Dependency risk: If you build your product around a model API, you're dependent on that company. They can change pricing, modify the model, or discontinue service. That's acceptable for non-critical applications but risky for core business logic.
Security: AI systems are targets for attacks. Prompt injection, data extraction, and other security issues are real concerns. Build security into your AI applications from the start.
These aren't reasons to avoid using Gemini 3.1 Pro, but they're critical considerations that require planning.
Expert Perspectives and Industry Reception
How is the broader AI and tech community responding to Gemini 3.1 Pro?
Academic and research community: Researchers generally focus on methodological innovations more than model releases, but benchmark improvements attract attention. The fact that Gemini 3.1 Pro tops multiple independent benchmarks suggests real improvements.
Enterprise customers: Enterprises care about reliability, cost, and integration. Gemini 3.1 Pro is worth evaluating, particularly if you're already in Google's ecosystem. But enterprises aren't rushing to migrate—most are still figuring out how to best use current generation models.
Startups and product companies: Startups care about whether a model can power their product well and at what cost. For startups, Gemini 3.1 Pro is one option among several. Many are optimizing more for cost and speed than for absolute capability.
AI specialists: AI engineers and prompt engineers are curious about new models but pragmatic about adoption. They'll evaluate Gemini 3.1 Pro, test it, and use it if it's better for their specific application. Hype doesn't drive adoption in technical communities—capability and cost do.
Investors: The AI investment landscape is evaluating whether to invest in specialized AI companies or bet on the big tech companies. Gemini 3.1 Pro's strong performance reinforces the view that big tech has structural advantages in building frontier models.
Overall, the reception is positive but measured. Gemini 3.1 Pro is respected as a strong model, but it's not causing dramatic shifts in strategy. It's more like "oh good, another competitive option" than "everything changes now."

Future Developments and Trajectory
Where is all this heading? Some predictions and observations.
Model quality will plateau: Improvements will continue, but the gap between frontier models will shrink. In 2026, being "the best model" might only be 2-3% better than "the second-best model." That's less differentiation than we see today.
Cost will become the primary competitive variable: As models reach capability plateau, companies will compete on price and efficiency. Who can deliver 95% of GPT-4o's capability at 50% of the cost? That question matters more than raw capability.
Integration and UX will determine winners: The best model in an API is less valuable than a decent model integrated into the tools you use daily. This favors Google, Microsoft, and Amazon more than specialized AI companies.
Specialization will accelerate: General-purpose models are cool, but specialized models that are fine-tuned for specific domains will outperform them on domain-specific tasks. Expect more specialized models from different vendors.
Open-source will be increasingly viable: Open models like Llama are improving rapidly. In 2-3 years, the open-source frontier might be close enough to closed models that cost and control factors make open-source preferable for many applications.
Regulatory pressure will increase: As AI systems become more critical to business and society, regulation will increase. This might slow innovation slightly, but it's necessary and probably inevitable.
Agentic AI will become practical for more use cases: As models improve at planning and reasoning, agentic AI systems will move from "interesting experiment" to "standard business practice."
Gemini 3.1 Pro is part of this trajectory. It's a strong move, but it's not an inflection point. The real shifts are more subtle and longer-term.
FAQ
What exactly is Gemini 3.1 Pro?
Gemini 3.1 Pro is Google's latest large language model, released in 2025, designed specifically for complex multi-step reasoning and agentic work. It significantly improves upon Gemini 3 in benchmark performance and can handle sophisticated tasks like data analysis, code generation, research synthesis, and workflow automation. The model is currently available in preview with general availability expected soon.
How does Gemini 3.1 Pro differ from previous Gemini versions?
The main difference is specialized capability for agentic work—multi-step reasoning, tool usage, and independent task execution. Gemini 3.1 Pro achieves record scores on benchmarks like Humanity's Last Exam and APEX-Agents, indicating it's better at breaking down complex problems and executing them independently. Previous versions were competent but less optimized for this specific use case.
What does "agentic work" mean in the context of AI models?
Agentic work refers to AI systems that can take a goal, break it into steps, execute those steps independently, integrate results, and handle dependencies between tasks. Instead of you directing the AI step-by-step, you give it an objective and it figures out the path forward. For example: "Analyze quarterly sales data and identify which regional teams exceeded targets by 15%" would be handled entirely by the agent without intermediate prompts from you.
What are the benchmarks showing, and why should I care about them?
Benchmarks like Humanity's Last Exam and APEX-Agents test how well models handle reasoning tasks and real professional work. Gemini 3.1 Pro scores at the top of these benchmarks, which predicts it will perform well on reasoning, analysis, and complex problem-solving in real-world applications. While benchmarks don't guarantee performance on your specific tasks, they indicate the model can handle sophisticated work.
How does Gemini 3.1 Pro compare to GPT-4o and Claude 3.5 Sonnet?
All three models are genuinely competitive and excel in different areas. Gemini 3.1 Pro leads on agentic work and some reasoning benchmarks. GPT-4o remains strong for code generation and has better real-world deployment experience. Claude 3.5 Sonnet focuses on reasoning and has strong safety characteristics. The "best" model depends on your specific use case, so testing with your actual tasks is essential.
Should I switch to Gemini 3.1 Pro from my current AI provider?
Not necessarily. Benchmark performance is one factor, but you should also consider cost, integration with your current systems, ease of switching, and whether it solves your specific problems better than alternatives. Create a test set of your actual tasks, compare performance and cost across multiple models, and make a decision based on data rather than hype. For many teams, multi-model strategies work better than switching entirely.
How much does Gemini 3.1 Pro cost?
Google hasn't announced final pricing for general release, but it typically prices competitively with OpenAI and Anthropic. Pricing will likely be per-token, with variations based on input/output tokens and usage volume. Check Google Cloud's Vertex AI pricing for current rates during preview.
What are the main limitations of Gemini 3.1 Pro?
The model can still hallucinate (generate false information confidently), requires careful prompt engineering for optimal performance, has knowledge cutoffs, and requires human oversight for critical decisions. It's also only available through APIs, so you depend on Google for availability and can't easily migrate if you want to. Like all AI models, it's best used as a tool to augment human judgment rather than replace it.
How do I actually use Gemini 3.1 Pro in my applications?
During preview, you can access it through Google Cloud via the Vertex AI API. You'll need a Google Cloud project, authentication credentials, and code to call the API. Google provides libraries in Python, Node.js, and other languages. For non-technical users, Google Workspace integration will eventually make it available directly in Gmail, Docs, and Sheets.
What types of tasks is Gemini 3.1 Pro actually good at?
Gemini 3.1 Pro excels at: complex data analysis, research synthesis, code generation and refactoring, generating structured reports, multi-step problem-solving, extracting insights from large documents, planning and project management, writing and editing complex content, and customer support automation. It's less suitable for specialized domains where general-purpose models haven't been fine-tuned.
How does Gemini 3.1 Pro affect the competitive landscape of AI?
It reinforces that the AI market is competitive with multiple strong models available. Rather than one dominant player, we're seeing Google, OpenAI, and Anthropic each with capable offerings that excel in different areas. This competition drives innovation and gives organizations real choices. It also consolidates market power at the big tech companies that can afford to train frontier models at scale.
Conclusion: Where AI Model Competition Leads
Gemini 3.1 Pro represents a significant milestone in AI capability, but it's important to understand it in perspective. The model is genuinely strong, with benchmarks showing it handles complex reasoning and agentic tasks better than predecessors. That matters. For organizations building AI applications, having access to multiple competitive models is healthier than market concentration.
But the release also highlights something important: the frontier of AI capability is consolidating to a few well-resourced companies. Training models at this scale requires massive compute, enormous datasets, and sophisticated training pipelines. That's not something startups can do. It's not even something mid-size tech companies can do. Only Google, Microsoft (with OpenAI), Amazon, Meta, and Anthropic have the resources to compete at the absolute frontier.
That has implications. It means competition will increasingly be about distribution, integration, and how companies embed AI into products and workflows rather than raw model capability. It means specialized AI startups need to either focus on specific domains, build on top of these models, or offer something fundamentally different (like open-source models).
For organizations using AI, the right approach is pragmatic. Test Gemini 3.1 Pro on your actual problems. If it's better than alternatives and the cost makes sense, use it. But don't assume it's the permanent solution. Model quality improves constantly, competitors iterate rapidly, and new approaches emerge. Build your systems to be model-agnostic where possible. Keep evaluating alternatives. Stay aware of new developments.
The AI model wars are real, they're competitive, and they're moving fast. Gemini 3.1 Pro is a strong move from Google. It's not game-changing, but it's solid innovation that improves the tools available to developers and organizations. That's exactly what you want in a competitive market.
The real excitement in AI right now isn't about individual model releases. It's about what people are building with these models, the agent systems that are becoming practical, and the workflows that are being automated. Gemini 3.1 Pro is a tool that makes building these systems more feasible. The impact will come from how it's used, not from the model itself.
Key Takeaways
- Gemini 3.1 Pro tops multiple benchmarks including APEX-Agents, showing significant improvement in complex reasoning and agentic work
- The model is specifically designed for multi-step reasoning and independent task execution, differentiating it from general-purpose competitors
- Multiple competitive models now exist (Google, OpenAI, Anthropic), making model selection more important than assuming one clear winner
- Real-world performance on your specific tasks matters more than benchmark scores; testing with actual workflows is essential before adoption
- The AI market is consolidating to well-resourced companies, but differentiation increasingly comes from integration and ecosystem rather than raw capability
Related Articles
- Google Gemini 3.1 Pro: The AI Reasoning Breakthrough Reshaping Enterprise AI [2025]
- Google I/O 2026: 5 Game-Changing Announcements to Expect [2025]
- Vibe-Coded Music Apps: How AI is Rebuilding the iTunes Future [2025]
- OpenAI's 850B Valuation Explained [2025]
- Enterprise Agentic AI's Last-Mile Data Problem: Golden Pipelines Explained [2025]
- Nvidia and Meta's AI Chip Deal: What It Means for the Future [2025]

