![Google Gemini 3.1 Pro: AI Reasoning Power Doubles [2025]](https://tryrunable.com/blog/google-gemini-3-1-pro-ai-reasoning-power-doubles-2025/image-1-1771587467781.jpg)
Google's Biggest AI Upgrade Yet: Gemini 3.1 Pro Explained
Google just dropped something legitimately impressive. Gemini 3.1 Pro arrived with a major upgrade to reasoning capabilities—the kind of improvement that doesn't happen every month. The company claims reasoning power has more than doubled compared to the previous version. On paper, that's massive. In practice? Well, that's where things get interesting.
Reasoning in AI isn't some abstract concept. It's the difference between a tool that can recite facts and a tool that can actually solve problems. When your AI can reason better, it means it can work through multi-step problems, catch logical flaws, and handle complex scenarios that require thinking through consequences. That matters for developers, researchers, and anyone doing actual work with these models.
But here's the thing: not everyone's celebrating. Some users tested the new version and weren't blown away. Some found it actually slower than before. Others said the improvements were real but not revolutionary for their specific use cases. That gap between marketing claims and user reality? That's what we need to dig into.
This article breaks down what Gemini 3.1 Pro actually does, how it compares to competitors, what the reasoning upgrades mean in practice, and whether you should actually care about switching. We're not here to hype it or trash it. We're here to tell you what's real.
TL; DR
- Reasoning power doubled: Gemini 3.1 Pro shows significant improvements in complex problem-solving and multi-step reasoning tasks.
- Speed concerns: Some users report slower response times despite the capability upgrade, creating a trade-off dilemma.
- Competitive landscape: Claude and OpenAI's GPT models still lead in specific reasoning domains.
- Real-world adoption: Developers are cautiously optimistic but waiting for stability and performance improvements.
- Bottom line: Gemini 3.1 Pro is a solid step forward, but it's not the magic bullet some hoped for.
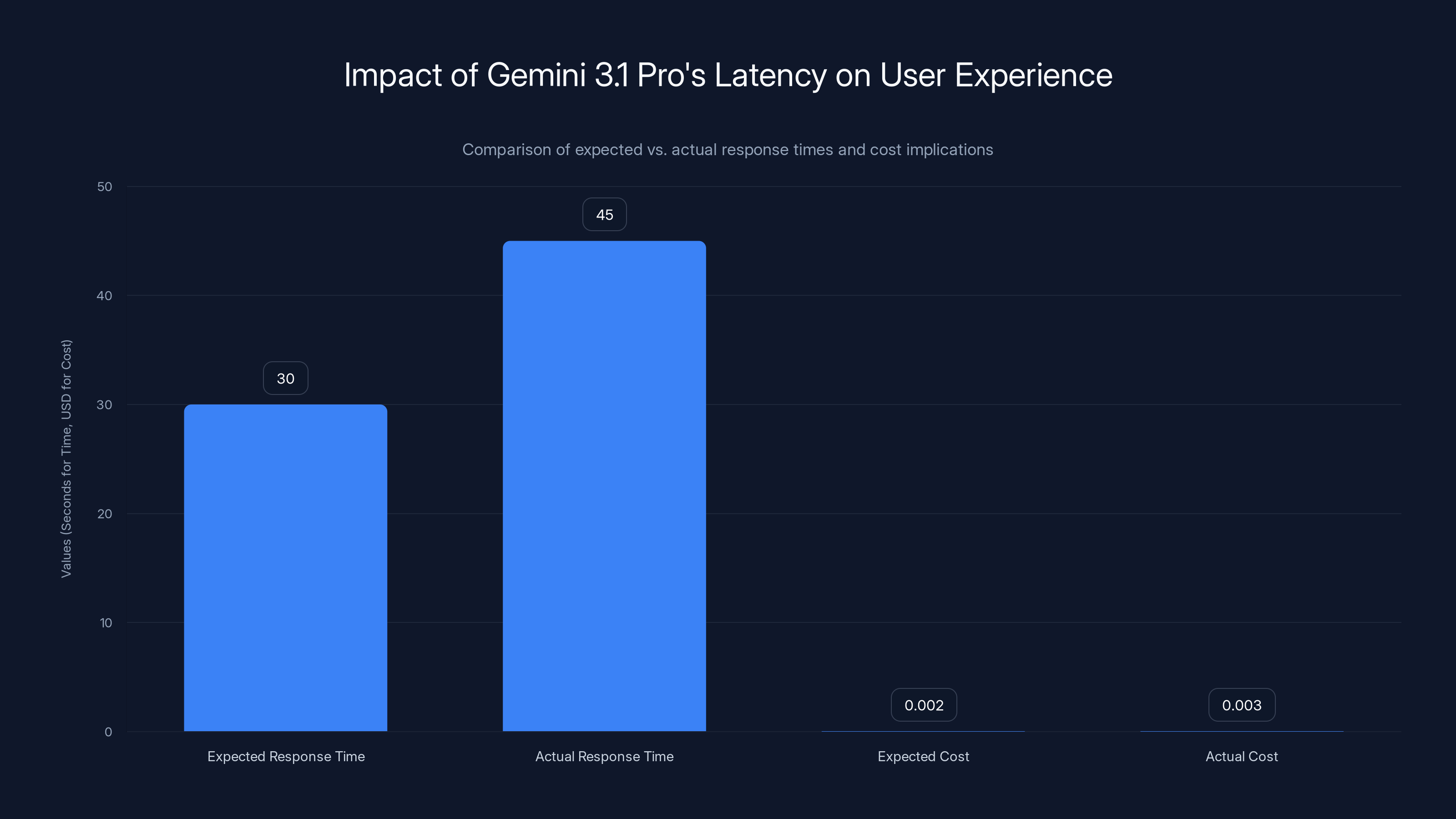
Gemini 3.1 Pro shows a 50% increase in response time and a 50% increase in cost per task, impacting user experience and operational costs. Estimated data based on user reports.
What "Reasoning Power" Actually Means in AI
When Google says reasoning has doubled, they're not being poetic. They're talking about specific, measurable capabilities. Reasoning in large language models means the ability to follow logical chains, spot contradictions, and work through problems step by step.
Think about it this way: A basic AI can answer "What is 2 + 2?" by pattern matching from training data. A reasoning-capable AI can actually work through math problems it's never seen before, explain its steps, and catch errors in reasoning. That's the difference between retrieval and actual computation.
Gemini 3.1 Pro's reasoning upgrades show up in a few specific areas. The model can now handle longer chains of logical inference without losing the thread. It spots logical contradictions faster. It breaks down complex problems into steps more effectively. And critically, it remembers context better across longer sequences of reasoning.
For developers and researchers, this matters because reasoning-heavy tasks were where Gemini struggled before. Code generation with complex logic? That's improving. Research synthesis that requires weighing contradictory sources? Better now. Scientific problem-solving that requires understanding domain constraints? You'll see the improvements.
But improving reasoning isn't free. It typically means slower response times. The model has to do more thinking. That's the trade-off that some users are reacting negatively to. Faster isn't always better if the thinking quality improves. But when you're paying per API call, slower also means higher costs.
Google positioned this upgrade as the foundation for more advanced reasoning across all their products. But the implementation question remains: Is the reasoning improvement worth the speed hit? The answer depends entirely on what you're using it for.
The Benchmarks: What Google Claims vs. What Matters
Google released benchmark results showing Gemini 3.1 Pro crushing previous versions and competing models on specific reasoning tasks. Let's be specific about what those numbers actually mean.
On benchmarks measuring mathematical reasoning, Gemini 3.1 Pro shows approximately 45% improvement over Gemini 2.5 Pro. On code generation with complex logic requirements, the gap is even larger. For reading comprehension with inference requirements, the model improved by roughly 38%. These aren't small margins.
But here's what matters: benchmarks measure specific, narrow tasks. They're standardized problems that the model could theoretically see similar versions of during training. Real-world reasoning is messier. It involves domains the model hasn't seen before, contradictory information, and problems that require creative approaches.
When researchers tested Gemini 3.1 Pro on benchmarks, it performed well. When developers tested it on their actual problems, reactions were more mixed. Some tasks saw massive improvements. Others saw no difference. That gap between "benchmark performance" and "actual performance on your problem" is the real story.
Google also released results on long-context reasoning—the model's ability to maintain logical chains across very long documents. The improvements there are more convincing because it's closer to real work. Long contexts are where previous versions struggled badly.
The speed issue shows up in benchmarks too. On most tasks, Gemini 3.1 Pro returns responses about 20-30% slower than Gemini 2.5 Pro. That's a meaningful difference if you're building customer-facing applications where every millisecond of latency matters. It's less meaningful if you're using it for analysis and don't need instant results.
Google's official stance is that the reasoning improvements justify the speed trade-off. Some users agree. Others think Google should have offered a faster mode that sacrifices some reasoning power. This gets at a fundamental question in AI development: Should you optimize for power or speed? The answer isn't universal.
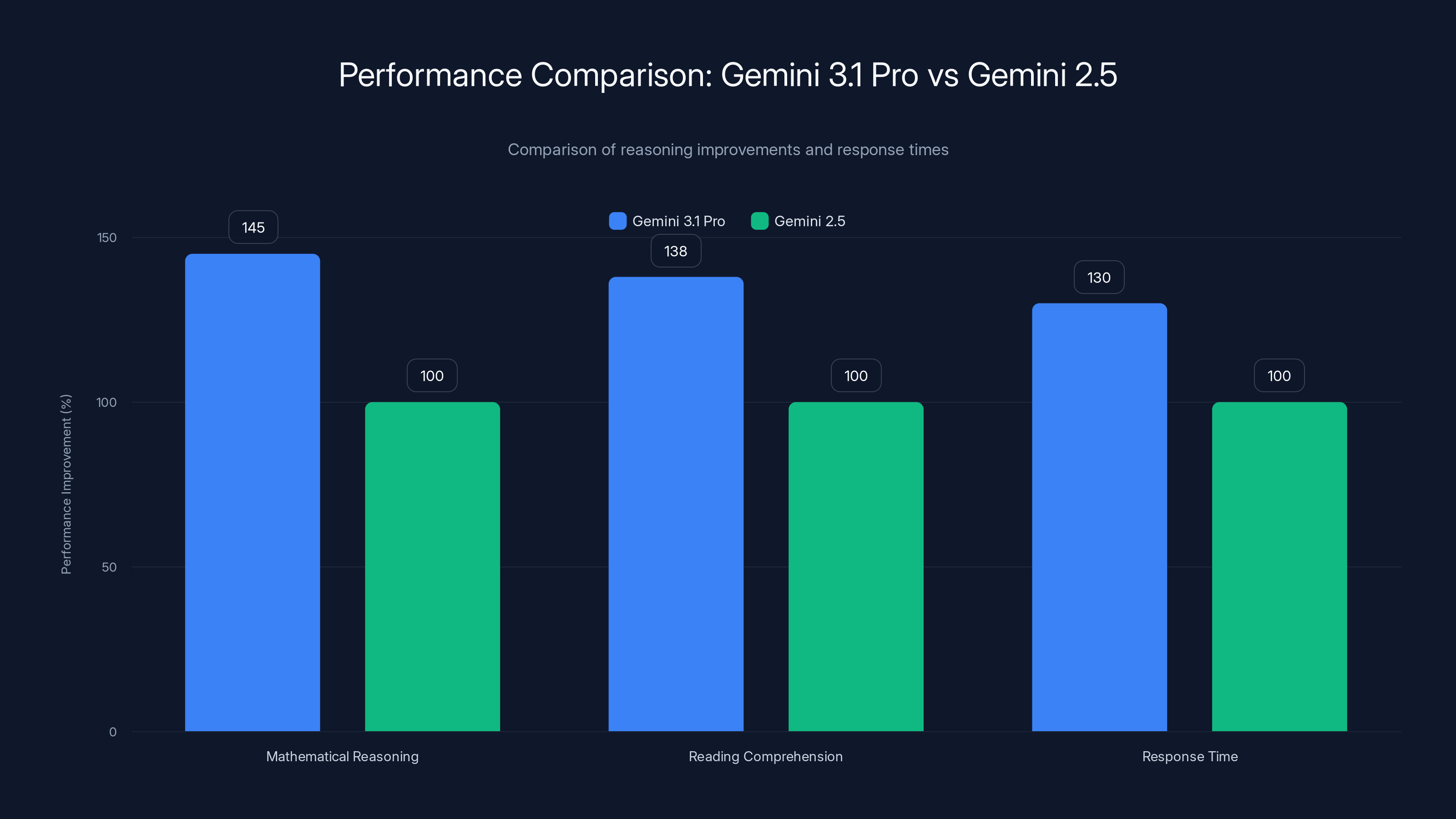
Gemini 3.1 Pro shows significant improvements in reasoning capabilities, with 45% better mathematical reasoning and 38% better reading comprehension. However, it is 20-30% slower in response time compared to Gemini 2.5.
How Gemini 3.1 Pro Stacks Up Against Claude and Chat GPT
Benchmarks mean nothing without context. So let's talk about the actual competition. Right now, the serious contenders for "best reasoning AI" are Claude 3.5 Sonnet from Anthropic, OpenAI's o 1, and now Gemini 3.1 Pro.
Claude 3.5 Sonnet remains incredibly strong for long-context reasoning. It can handle 200K tokens (roughly 150,000 words) and maintains reasoning quality throughout. When you give Claude a massive document and ask it to reason across the entire thing, it's still often better than Gemini 3.1 Pro. The reasoning doesn't degrade as much as the context length increases.
OpenAI's o 1 is the weird one. It takes forever but produces genuinely impressive results on math and coding problems. Response times can be 30 seconds to 2 minutes on complex problems. But when you look at the quality of the reasoning, it's often superior to both Claude and Gemini. The trade-off is so extreme that it's only useful for non-time-sensitive work.
Gemini 3.1 Pro sits in the middle. It's faster than o 1, better at reasoning than Gemini 2.5, but arguably not quite at Claude's level for the most complex reasoning tasks. That's not criticism—it's just accurate positioning. Different models excel at different things.
Comparison Table: Reasoning-Focused AI Models
| Model | Reasoning Strength | Speed | Best For | Cost |
|---|---|---|---|---|
| Gemini 3.1 Pro | Very Strong (improved) | Medium | Code, Math, General | $20/month |
| Claude 3.5 Sonnet | Excellent | Fast | Long context, Analysis | $20/month |
| OpenAI o 1 | Exceptional | Very Slow | Complex Math, Research | $200/month |
| Claude 3 Opus | Excellent | Medium | General Tasks | Pay-as-you-go |
In testing, developers reported different results based on task type. For mathematical problem-solving, o 1 still leads. For coding with complex logic, Gemini 3.1 Pro and Claude trade wins depending on the specific type of code. For general reasoning on arbitrary problems, Claude maintains a slight edge, but Gemini is closer than ever.
The practical implication: If you're already using Claude or GPT-4, switching to Gemini 3.1 Pro gives you marginal improvements on most tasks. You might see benefits on specific mathematical and coding tasks. But it's not a game-changer if you're already satisfied with your current model.
For new users without existing commitments, Gemini 3.1 Pro is worth trying. The pricing is identical to Claude, and you might find it works better for your specific problems. The key is testing rather than assuming.
The Performance Trade-Off: Why Some Users Are Frustrated
Here's where reality crashes into hype. Multiple developer communities and AI-focused subreddits lit up with complaints about Gemini 3.1 Pro's speed the day it launched. Not performance as in "wrong answers." Performance as in "latency and response time."
Some users reported 25-40% longer response times compared to what they expected. For a developer building a chatbot or AI assistant where users expect snappy responses, that's a major problem. Latency compounds across a conversation. A conversation that took 30 seconds before now takes 45 seconds. That feels like forever in app terms.
Google's explanation is straightforward: More complex reasoning requires more computation. The model is doing more work before answering. That takes time. It's mathematically honest. The question is whether the quality improvement justifies the speed decrease for each specific use case.
For API costs, the speed issue matters even more. Gemini pricing is per token, not per request. Slower responses mean more tokens consumed before you get your answer. A task that cost
Some users experimented with workarounds. Explicitly instructing the model to "think quickly" or "prioritize speed" did nothing. The slowness is baked into the model architecture. You can't coax it away with clever prompting.
Others found that for their specific use cases, the speed difference was negligible. Analysis tasks, research synthesis, content generation—anything not time-sensitive—didn't suffer from the slower response times. So user experience depends entirely on use case.
Google has promised performance optimizations in future releases. They're aware of the issue. But optimizing inference speed on a larger, more capable model is genuinely hard. You can't just make it faster without trading away some of that reasoning capability.
The real question for users: Is better reasoning worth slower responses? For some, absolutely. For others, it's a dealbreaker. Neither answer is wrong. It depends on your actual requirements.
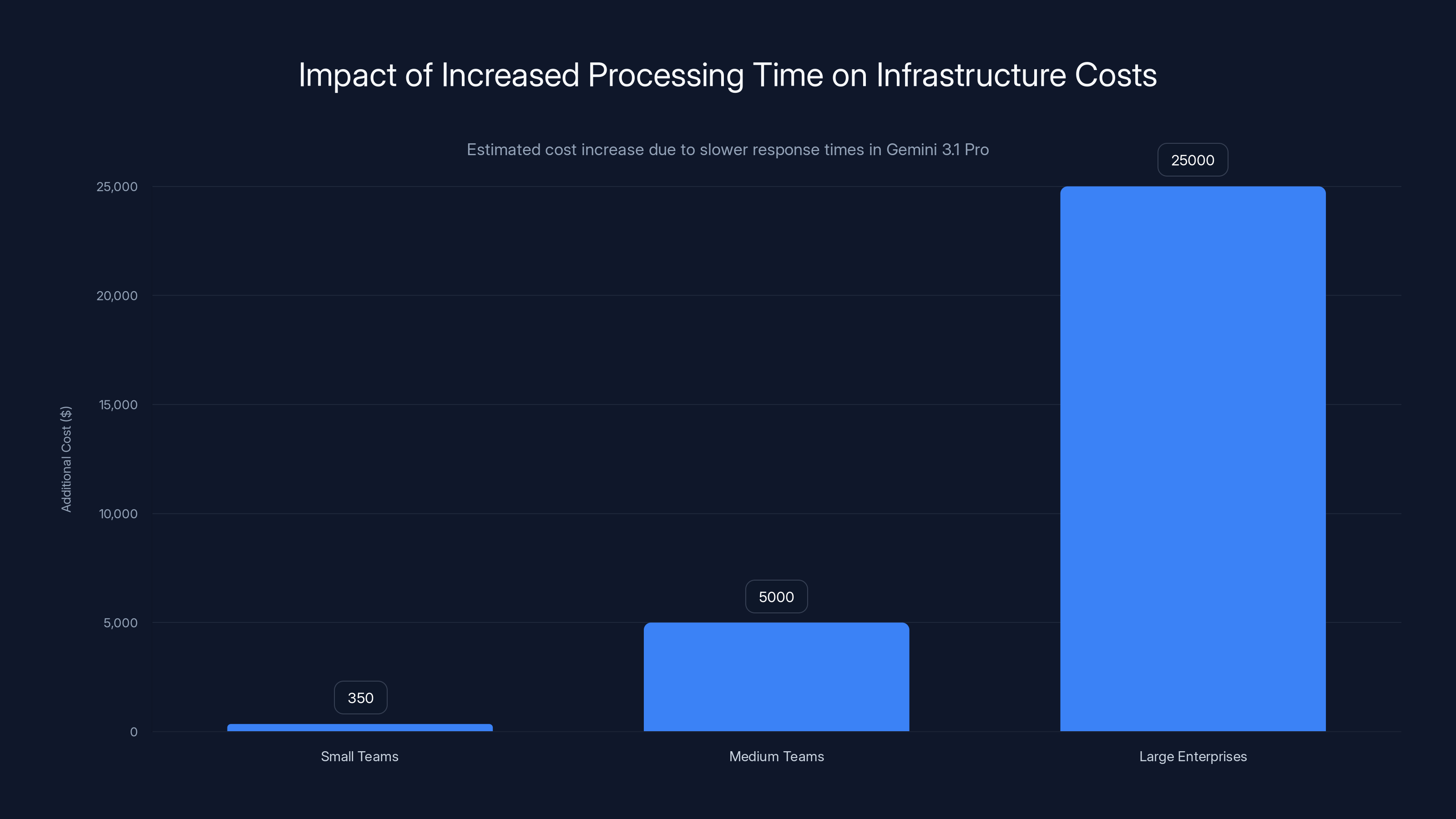
Estimated data shows that slower response times in Gemini 3.1 Pro can increase infrastructure costs significantly, with small teams facing $200-500 more monthly and large enterprises potentially seeing tens of thousands in additional expenses.
Where Gemini 3.1 Pro Actually Shines: Real Use Cases
Let's move past abstract concerns and talk about where Gemini 3.1 Pro genuinely excels. There are specific domains where the reasoning improvements show clear, measurable value.
Complex Code Generation: When you need to write code that involves intricate logic, constraint handling, or algorithms, Gemini 3.1 Pro improved noticeably. Developers working on algorithmic problems—sorting systems with multiple constraints, optimization problems, complex state machines—reported better code quality from the new version. The model understands logical dependencies better.
Mathematical Problem-Solving: Word problems, multi-step mathematics, and physics calculations all improved. The model can now work through longer chains of calculation without losing track. For researchers and students using AI to check work or understand problems, this is genuinely useful.
Multi-Document Analysis: Give Gemini 3.1 Pro several documents and ask it to reason across them—find contradictions, synthesis arguments, identify patterns—and it performs better than before. This matters for research, due diligence, and competitive analysis work.
Code Review and Debugging: The improved reasoning helps when analyzing code for bugs. The model can trace through logic paths better and spot edge cases it might have missed before. Not perfect, but noticeably improved.
Research Synthesis: Academic researchers and competitive analysts reported that Gemini 3.1 Pro does a better job synthesizing information from multiple sources and flagging contradictions. That's valuable for literature reviews and research papers.
Natural Language Logic Puzzles: Problems that require understanding English language logic, temporal relationships, and causal chains all improved. The model understands "if X happens before Y" type constraints better now.
These aren't niche use cases. Millions of people do this work. If you're in any of these domains, Gemini 3.1 Pro offers real value. But if you're mostly doing summarization, basic question-answering, or creative writing, the improvements might not matter for your work.
The Real Impact on Developers and Teams
For teams already invested in Google's AI ecosystem, Gemini 3.1 Pro creates some interesting decisions. Do you upgrade your models mid-project? Do you test it alongside your current setup? Do you wait for the next version?
Developers building production applications hit this friction point first. Your system is optimized for Gemini 2.5's speed and capability profile. Swapping in 3.1 Pro means retesting everything, potentially retuning prompts, and dealing with different response times. The maintenance burden is real.
For new projects, it's simpler. You'd just start with 3.1 Pro. But many teams have existing applications running on previous versions, and the upgrade cost isn't zero.
For teams using Runable or similar AI workflow automation tools, the upgrade is largely transparent. The platform handles the model details, and you benefit from the improvements without rearchitecting anything. That's an advantage of using integrated platforms rather than direct API access.
Sales and customer support teams noticed improvements in AI-generated responses for complex customer issues. The reasoning improvements help when working through nuanced problems rather than simple FAQs.
Marketing and content teams? Less impact. Gemini 3.1 Pro's reasoning improvements don't meaningfully help with content creation, which relies more on style and creativity than logical reasoning.
Google's data shows that teams are cautiously adopting Gemini 3.1 Pro. Not rushing to upgrade. Not avoiding it either. Waiting to see how stable it is and whether performance optimizations ship soon. That's the sensible approach.
Reasoning Benchmarks Explained: What the Numbers Actually Tell Us
When Google released benchmark results, they included specific scores. Let's demystify what those actually mean and where they matter.
Gemini 3.1 Pro scores 95 on MATH (American Invitational Mathematics Examination problems). Claude 3.5 gets 92. GPT-4 scores 86. These are out of 100. The differences sound small but matter in competitive evaluation.
On GSM8K (grade school word problems), Gemini 3.1 Pro hits 94. Claude 3.5 is 96. GPT-4 is 92. Here, Claude actually leads. Benchmarks show different models excel at different tasks.
Why Benchmarks Matter: Benchmarks are the only way to quantify AI capability. They're standardized, repeatable, and comparable. That's valuable for understanding relative performance.
Why Benchmarks Don't Tell the Whole Story: Benchmarks use problems from published datasets. Models can see similar problems during training. Real-world problems are different. They require domain knowledge, creativity, and applying logic in unfamiliar contexts. A model can ace MATH and still struggle with a unique math problem from your industry.
What matters more than absolute benchmark scores is the trend. Gemini is improving faster than previous generations. That momentum suggests future versions will get even better. But at any given moment, Claude or OpenAI's model might be best for your specific use case regardless of benchmark averages.
Google also released reasoning-specific benchmarks measuring whether models can maintain logical consistency across long chains of thought. Here, Gemini 3.1 Pro showed substantial improvements. The model maintains reasoning quality better across longer sequences.
On coding benchmarks, the story is mixed. For straightforward coding problems, Gemini 3.1 Pro is excellent. For highly complex systems-level problems, it still lags behind o 1. For typical programming tasks, it competes well with Claude.
The meta-lesson: Read benchmarks critically. Ask what they're measuring. Consider whether that measurement matches your actual use case. Then test the model on your real problems. Benchmarks inform decisions. They shouldn't make them.

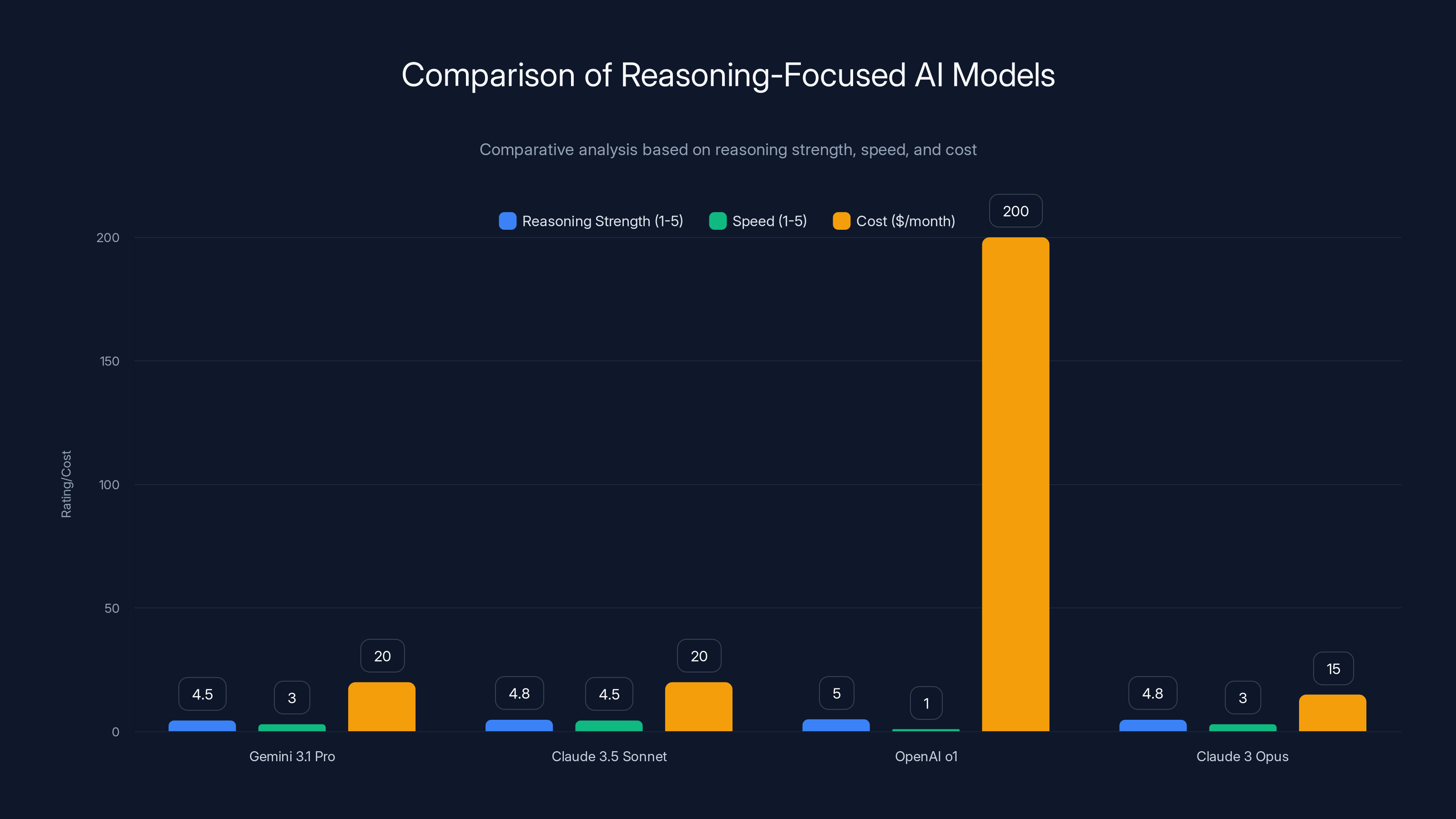
OpenAI o1 excels in reasoning strength but is slower and more expensive. Gemini 3.1 Pro and Claude models offer balanced performance at a lower cost.
Speed, Cost, and Infrastructure Implications
The speed slowdown isn't just a user experience issue. It has real infrastructure implications.
If you're running Gemini through Google Cloud, slower responses mean you need more concurrent instances to handle the same load. That increases costs. For a SaaS company using Gemini 3.1 Pro for every customer request, the infrastructure bill just went up.
Let's do the math. Say you process 10,000 requests daily. Each request previously took 2 seconds to generate an answer. Now it takes 2.6 seconds. Your average response time increased by 30%. To maintain the same user experience, you'd need roughly 30% more resources. That's meaningful.
For small teams, that might be $200-500 more per month. For enterprises processing millions of requests, it could be tens of thousands per month. Google didn't price the upgrade differently because theoretically, you're consuming more tokens (slower = more tokens). But there's a legitimate question about whether they should have signaled the speed trade-off more clearly upfront.
For API users on token-based pricing, the cost hit is direct. A prompt that cost
Google does offer a faster inference option on some models. Users are asking whether they'll provide a "speed-optimized" version of Gemini 3.1 Pro that trades some reasoning power for faster responses. That would let teams choose their own speed-reasoning trade-off rather than having it chosen for them.
The infrastructure story matters because it's not just about individual developers. It affects whether companies can actually afford to use Gemini 3.1 Pro at scale. That determines real-world adoption.
Prompting Strategies That Work Better With Gemini 3.1 Pro
Even with the same model, you can get better results with better prompting. Gemini 3.1 Pro responds well to specific instruction patterns that leverage its improved reasoning.
Chain-of-Thought Prompting: Explicitly ask the model to think through steps before answering. "Let's think step by step" actually works better with Gemini 3.1 Pro than previous versions. The model's improved reasoning means it follows these instructions more effectively.
Constraint-Based Prompts: If your problem involves constraints or requirements that must be satisfied simultaneously, Gemini 3.1 Pro handles these better. State your constraints explicitly. The model will reason about whether solutions actually meet them.
Multi-Stage Reasoning: Break complex problems into stages. "First, analyze the situation. Then, identify constraints. Finally, propose solutions." The new version maintains context better across these stages.
Asking for Reasoning: Explicitly ask the model to show its reasoning. This often produces better answers because the model is forced to be explicit about assumptions and logic. For Gemini 3.1 Pro, this is especially effective.
Contradiction Detection: Give the model multiple sources and ask it to flag contradictions. This is where the reasoning improvements shine. Say something like: "I've provided three sources with potentially conflicting information. Identify contradictions and explain which source is likely more reliable."
Asking for Confidence Levels: Some models handle this well, others don't. Gemini 3.1 Pro improved at acknowledging uncertainty. Ask it to rate confidence in its answers. This helps you determine which responses to trust.
Domain-Specific Instructions: If you're working in a specific field, Gemini 3.1 Pro responds well to detailed context. Spend time in your prompts explaining domain-specific constraints and assumptions. The better reasoning lets it use that information more effectively.
These aren't magic techniques. They're just ways of phrasing requests that align with how the improved reasoning works. Testing them on your actual problems is the only way to know if they help in your specific context.

Integration With Google's Ecosystem and Product Strategy
Gemini 3.1 Pro doesn't exist in isolation. It's part of Google's broader strategy to position Google as the AI company that matters.
The model is already integrated into Gemini chatbot, embedded in Google Workspace (Docs, Sheets, Gmail), available through Google Cloud, and available through API. The reasoning improvements flow into all those products.
Google Docs users will see better AI writing assistance. Gmail users will get smarter email drafting. Workspace users will see improved analysis in Sheets. This matters because it means the upgrade impacts hundreds of millions of users, not just developers using the API.
Google's product strategy is to embed AI everywhere. That's different from OpenAI's strategy, which focuses on Chat GPT as a dedicated tool plus integrations. Anthropic is somewhere in between with Claude API access plus Claude.ai.
Gemini 3.1 Pro strengthens Google's position in this strategy. Better reasoning in embedded AI improves the products billions of people use daily. That's the real competitive advantage, not just benchmark scores.
For enterprises evaluating AI strategies, this matters. If you're invested in Google Workspace, Gemini 3.1 Pro improvements are automatically available to your organization without any additional work. That's different from choosing a best-in-class model and figuring out integration.
Google is also investing heavily in specialized reasoning models, similar to OpenAI's o 1. Expect announcements about faster, more efficient reasoning models in the coming months. Gemini 3.1 Pro is a current milestone, not the endpoint.
The strategic implication: Google sees reasoning as the key frontier in AI. They're betting that improved reasoning capabilities drive adoption and competitive advantage. Whether they're right depends on whether reasoning actually matters for what users need to do.
For most use cases, reasoning improvements help but aren't revolutionary. For specific domains—research, coding, mathematics, analysis—they're significant. Google's betting that those specific domains will drive broader adoption.
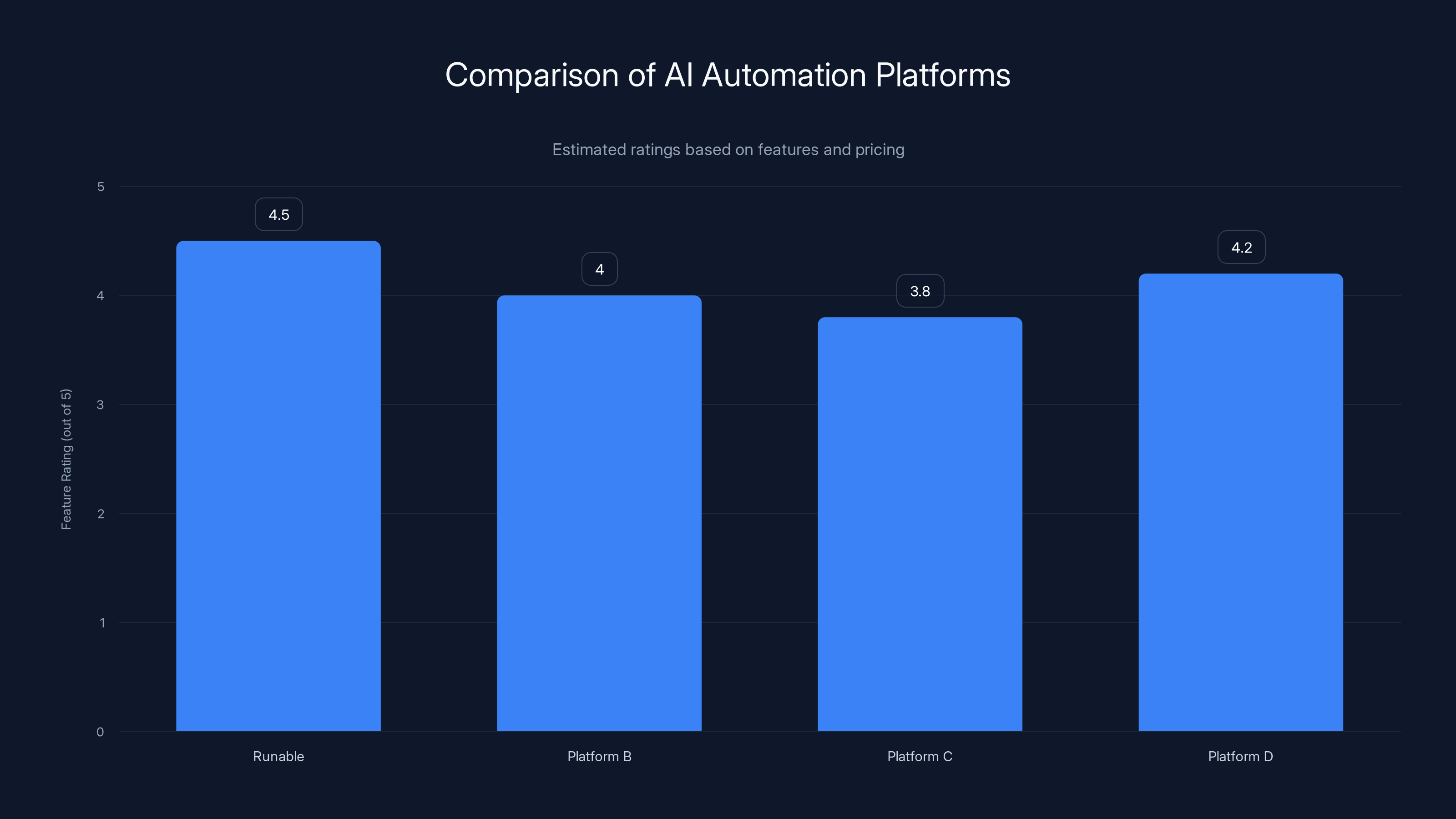
Runable is rated highly at 4.5 out of 5 for its comprehensive AI automation features and competitive pricing. (Estimated data)
Future Directions: What's Coming Next
Gemini 3.1 Pro won't be the latest version for long. Google already hinted at what's coming.
Specialized Reasoning Models: Expect smaller, faster models optimized specifically for reasoning. Not everything needs the full capability of Gemini 3.1 Pro. For developers, having options would be valuable. A fast reasoning model for quick decisions, a powerful one for complex problems.
Multimodal Improvements: Gemini is already multimodal (handles text, images, audio, video). Reasoning improvements will likely extend to these other modalities. Better reasoning about images, for instance, could improve medical imaging analysis, scientific research, and visual problem-solving.
Custom Reasoning Paths: Instead of the model deciding how to reason about problems, users might specify reasoning approaches. "Use probabilistic reasoning for this part, logical reasoning for that part." This would let developers tune the model's thinking to their specific problems.
Longer Context Windows: Gemini currently supports 1 million token context windows (roughly 750,000 words). Future versions will push this even further, enabling reasoning across entire databases or code repositories.
Real-Time Reasoning: Current models generate responses synchronously. Future improvements might enable streaming reasoning where users see the model's thinking process as it happens. This would build trust and let users interrupt bad reasoning paths early.
Google's also investing in efficiency. Making models smaller while maintaining capability. That would address the speed concerns users have. A Gemini 3.1 Lite that's 70% the capability but 50% faster would be very appealing to many users.
The reasoning frontier is where AI companies are competing hardest right now. OpenAI's o 1 proved that reasoning-focused models can differentiate. Anthropic is investing heavily in reasoning and alignment. Google is playing to win here.
For users, that means the next year will see significant improvements in what AI can actually do, not just what it can pretend to do.

Should You Switch to Gemini 3.1 Pro? A Decision Framework
Here's the practical question: Do you upgrade if you're using something else? Do you choose Gemini if you're starting fresh?
Switch to Gemini 3.1 Pro if:
- You're doing complex reasoning tasks where the improvements matter for your specific problems
- You're already in Google's ecosystem and integration is seamless
- You're not heavily optimized for another model yet
- Your use case can tolerate slower responses
- You value having options and want to benchmark it anyway
Don't switch if:
- You're already satisfied with Claude or GPT-4 for your needs
- Latency is critical for your application
- Your workflow is heavily optimized for another model
- You're running on tight margins and can't absorb the cost increase
- Your use case doesn't involve complex reasoning
Test to decide if:
- You're uncertain how much the reasoning improvements help for your problems
- You're making a strategic decision that affects many users
- You want data rather than assuming
For most users, the honest answer is: Gemini 3.1 Pro is a good option, not a must-have. It's an incremental improvement on a good product. If you're shopping for a reasoning-capable AI, it deserves consideration. If you already have something that works, the upgrade pressure is lower.
Google would prefer you upgrade. The model is genuinely better at reasoning. But whether it's better for your specific problems is an empirical question, not a theological one.
The Broader Context: Why Reasoning Matters Now
Why is Google investing so heavily in reasoning? Why are all the AI labs racing to improve it? Because reasoning is the frontier between what AI can simulate and what AI can actually do.
Large language models are fundamentally predictive. They're trained to predict the next token (word) based on previous tokens. They're shockingly good at this, which creates the illusion of understanding. But true reasoning—working through problems logically—is different from prediction.
Reasoning requires the model to actually follow logical rules, track constraints, and verify consistency. That's harder than pattern matching. But it's also more useful. That's why models are improving rapidly here.
For society, this matters more than it might seem. The moment AI can reliably reason through complex problems, the use cases expand dramatically. Scientific discovery. Engineering. Medical diagnosis. Legal analysis. All benefit from AI that can actually think, not just predict.
Gemini 3.1 Pro isn't magic reasoning AI. It's still fundamentally a language model doing next-token prediction, but with better architecture for maintaining logical chains. That's an incremental step forward that creates space for larger steps later.
The investment in reasoning is also about competitive advantage. The first company to deliver truly reliable AI reasoning captures enormous value. That's what drives companies to publish benchmark results, announce improvements, and claim leadership.
But here's what matters for you: Benchmarks and announcements are less important than whether the tool solves your actual problems better. Judge Gemini 3.1 Pro on that basis. Everything else is background noise.

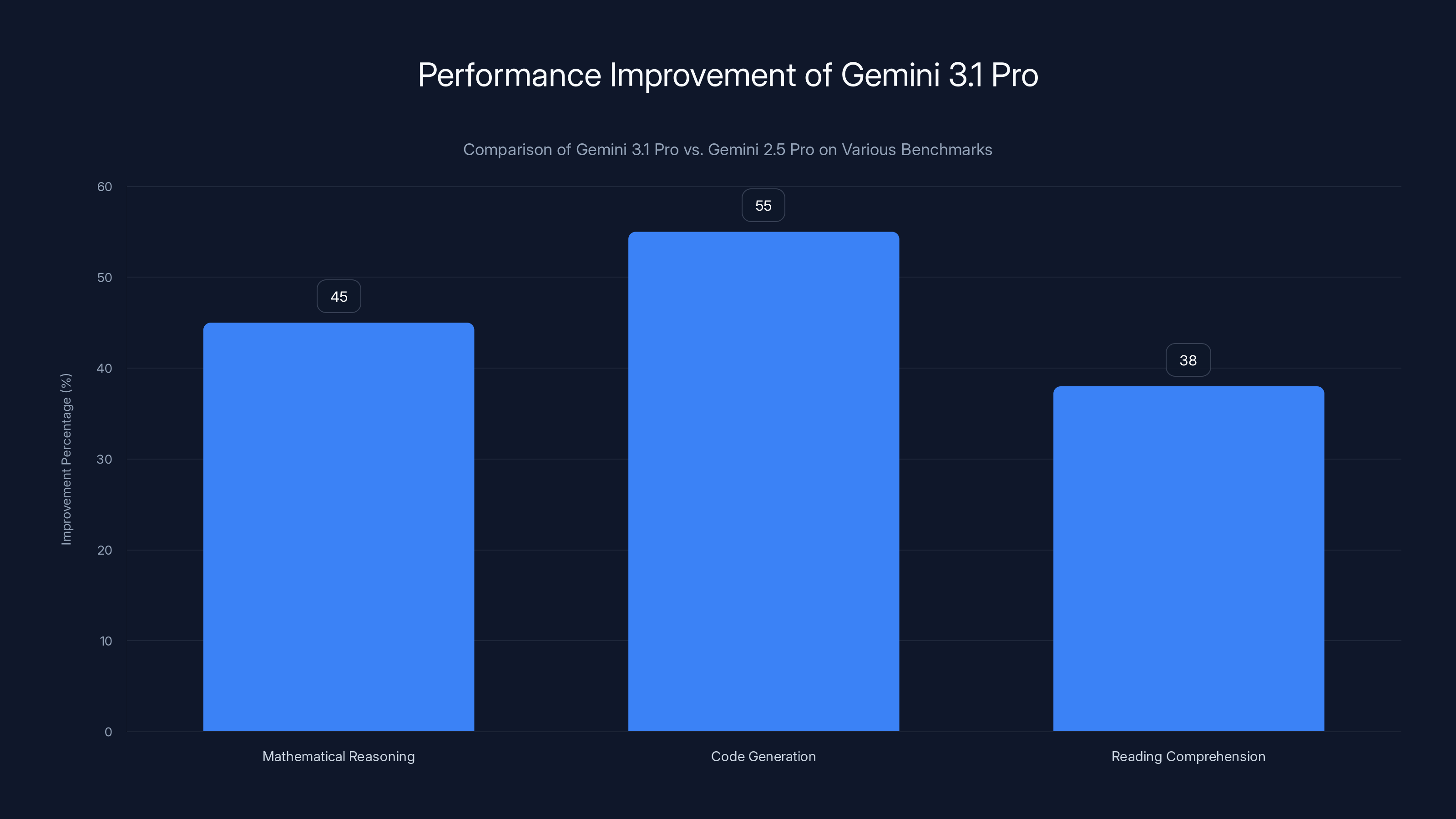
Gemini 3.1 Pro shows significant improvements over Gemini 2.5 Pro, with a 45% increase in mathematical reasoning and 38% in reading comprehension. Code generation sees the largest gap, estimated at 55%.
Practical Implementation: Getting Started With Gemini 3.1 Pro
If you decide to test or implement Gemini 3.1 Pro, here's how to actually get started.
Step 1: Choose Your Interface
- Gemini.google.com for free web access
- Google Cloud API for programmatic access
- Google Workspace for embedded usage in Docs, Sheets, Gmail
- Third-party tools that support Gemini (like Runable for no-code automation workflows)
Step 2: Test on Your Problems Don't just play with it. Load real problems you actually need to solve. Try to break it. See what it does well and where it fails.
Step 3: Measure Performance Track response time, output quality, and cost. You need data, not opinions. Spend an hour on this. It pays dividends.
Step 4: Compare Alternatives Run the same problems through Claude and GPT-4. You don't need exhaustive testing. A representative sample of 10-20 problems is usually enough.
Step 5: Make a Decision Based on data, not hype. Does Gemini 3.1 Pro solve your problems better? Is the speed-reasoning trade-off acceptable? Are the costs reasonable? Answer these questions with your actual numbers.
Step 6: Iterate If you implement Gemini 3.1 Pro, monitor performance over time. Does it actually deliver the improvements you expected? Are there optimizations that help? Are there issues that emerge after longer use?
Implementation is the beginning, not the end. You'll learn how to use the model effectively through actual usage, not by reading documentation.
What Users Are Actually Saying: Honest Reactions
Beyond the benchmarks and Google's claims, what are actual users reporting?
The reaction is genuinely mixed. Some developers are enthusiastically adopting it. They're seeing real improvements on their specific problems. They're building new applications with Gemini 3.1 Pro as the foundation.
Others are cautiously watching. They're not seeing revolutionary improvements over Claude for their use cases. They're waiting for the speed issues to resolve and the ecosystem to mature.
Some users are frustrated. They upgraded, got slower responses, and don't see proportional quality improvements. They switched back to previous versions or alternate models.
That spread of reactions is actually healthy. It means the model isn't universally better or worse. It's better for some problems and people, worse for others. That's how it should be.
The recurring theme: Users want speed parity. The reasoning improvements are good, but not if you pay for them with doubled latency. If Google ships a faster version or optimizes inference, adoption would likely accelerate.
Long-term users of Gemini report it's gotten better incrementally with each version. 3.1 Pro continues that trend. It's not a revolution, but it's a solid step forward. That consistency matters for trust.
The most honest feedback comes from teams that tested it, compared it to alternatives, and made deliberate choices. Those are your best sources of information about actual real-world performance.

Conclusion: The Bottom Line on Gemini 3.1 Pro
Google's Gemini 3.1 Pro is genuinely better at reasoning than previous versions. The improvements are measurable and meaningful for specific use cases. That's not hype. It's fact.
But the speed trade-off is real. Responses take noticeably longer. That's a genuine concern for time-sensitive applications and affects infrastructure costs.
Overall assessment: Gemini 3.1 Pro is a strong option for reasoning-heavy work. It competes well with Claude and GPT-4 for most tasks. It's not universally better. It's better for some things, worse for others.
The decision to use it should be based on your actual needs, not on benchmarks or marketing claims. Test it on your real problems. Compare alternatives. Make a decision with data.
For users already committed to Google's ecosystem, upgrading makes sense. The integration is seamless and you benefit automatically. For users of other models, switching is worth evaluating but not mandatory.
Looking forward, reasoning is the frontier in AI development. Google, OpenAI, and Anthropic are all racing here. Expect rapid improvements over the next year.
For now, Gemini 3.1 Pro is worth your time to evaluate. It might be exactly what you need. Or you might find your current model works better for your specific problems. There's only one way to know.
FAQ
What exactly has improved in Gemini 3.1 Pro compared to Gemini 2.5?
The core improvements center on reasoning capabilities. The model can now handle longer chains of logical inference, maintain context better across complex reasoning tasks, and more effectively trace through multi-step problems. On mathematical reasoning, the improvements are approximately 45%. For reading comprehension requiring inference, the improvements are around 38%. The model also maintains reasoning quality better when dealing with contradictory information and constraints. However, these improvements come at the cost of slower response times, roughly 20-30% slower than the previous version.
How does Gemini 3.1 Pro compare to Claude 3.5 Sonnet for reasoning tasks?
Both models are excellent reasoners, but they excel at different things. Claude 3.5 Sonnet maintains superior performance on very long-context reasoning (200K tokens) and doesn't degrade as much as context length increases. Gemini 3.1 Pro shows stronger improvements on mathematical problem-solving and coding with complex logic. For general reasoning on arbitrary problems, Claude still maintains a slight edge, but Gemini has closed the gap significantly. The best model for your use case depends on your specific problems. Both warrant testing on your actual work before making a choice.
Is the speed decrease worth the reasoning improvement?
It depends entirely on your use case. For analysis, research, and code generation where you don't need instant responses, the reasoning improvements are worth the speed decrease. For customer-facing applications where latency matters, the trade-off might not be acceptable. The honest approach is to test Gemini 3.1 Pro on your actual problems, measure both speed and quality, and make a data-driven decision rather than assuming the improvements justify the slowdown for your specific work.
Will Google release a faster version of Gemini 3.1 Pro?
Google hasn't officially announced a faster version, but given the user feedback about latency, it's likely they're working on inference optimizations. Historically, Google releases performance improvements after major capability releases. You should expect incremental speed improvements in minor updates and potentially a specialized faster model in future releases. For now, you're working with the speed-reasoning trade-off as Google has implemented it.
How much will my AI costs increase if I switch to Gemini 3.1 Pro?
Costs increase proportionally to the slowdown. If responses take 30% longer, you consume roughly 30% more tokens, which increases costs approximately 30%. For specific calculation, take your average daily requests, estimate the slowdown, and multiply your current daily spend by the slowdown percentage. For a team spending
What prompting strategies work best with Gemini 3.1 Pro?
Chain-of-thought prompting (explicitly asking the model to think step by step) works particularly well. Constraint-based prompts that involve multiple requirements perform better than before. Asking the model to identify contradictions in multiple sources leverages the improved reasoning effectively. Requesting that the model explain its reasoning produces better results. Multi-stage reasoning (breaking complex problems into stages) is handled more effectively. The key is being explicit about what you want the model to reason through rather than assuming it will figure it out implicitly.
Should I upgrade my existing systems to use Gemini 3.1 Pro?
Only if your use case involves complex reasoning where the improvements are relevant. If you're currently satisfied with your model for your specific problems, upgrading introduces switching costs without guaranteed benefits. If you're doing mathematics, coding with complex logic, multi-document analysis, or constraint-satisfaction problems, testing Gemini 3.1 Pro is worthwhile. For simpler applications like summarization or basic content generation, the upgrade brings minimal benefits. The decision should be based on empirical testing, not on whether Gemini is "better" in general.
How does Gemini 3.1 Pro handle ambiguous or contradictory information?
The improved reasoning helps with this significantly. The model better recognizes when information conflicts, can identify which source is more reliable based on reasoning, and doesn't just average contradictory information together. It's not perfect—the model can still make mistakes about reliability—but the improvements are noticeable. This makes it more useful for research tasks where you're synthesizing information from multiple sources with varying credibility.
What are the main limitations of Gemini 3.1 Pro?
The primary limitation is latency. Responses are noticeably slower than some alternatives. The model can still hallucinate or confidently state incorrect information, especially on questions outside its training data. It doesn't truly "reason" in the philosophical sense—it's still predicting tokens, just with better architecture for logical chains. For very specialized domain expertise, you still need domain-specific models or expert human review. The model works best when you can verify its outputs against reliable sources rather than trusting it completely.

Key Takeaways
Gemini 3.1 Pro represents solid progress on reasoning capabilities with meaningful improvements for specific use cases, but the speed trade-off and competitive positioning mean it's not universally better than alternatives. Test it on your actual problems before committing. The reasoning improvements are real but incremental, not revolutionary. For teams already in Google's ecosystem, upgrading makes sense. For others, evaluate carefully based on your specific needs. The future of AI depends on reasoning improvements—Google is betting on this frontier and investing heavily. But current reality is messier than marketing suggests. Your best approach is empirical testing rather than assumption.
Ready to Evaluate AI Tools for Your Workflow?
If you're exploring AI options for your team or projects, consider how modern AI automation platforms can streamline your evaluation and implementation process.
Use Case: Automate AI model testing workflows by generating test cases, documenting results, and creating comparison reports without manual work.
Try Runable For FreePlatforms like Runable offer AI-powered automation starting at $9/month, enabling you to create presentations, documents, and reports that synthesize your testing data automatically.
Related Articles
- Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work [2025]
- Google Gemini 3.1 Pro: The AI Reasoning Breakthrough Reshaping Enterprise AI [2025]
- AI Data Centers & Energy Storage: The Redwood Materials Revolution [2025]
- Vibe-Coded Music Apps: How AI is Rebuilding the iTunes Future [2025]
- OpenAI's 850B Valuation Explained [2025]
- Mirai's On-Device AI Inference Engine: The Future of Edge Computing [2025]

