![AI Agent Training: Why Vendors Must Own Onboarding, Not Customers [2025]](https://tryrunable.com/blog/ai-agent-training-why-vendors-must-own-onboarding-not-custom/image-1-1769787522083.jpg)
The Seismic Shift in Enterprise AI Adoption
Remember 2019? Enterprise software sales looked like this: a rep shows up, demos the tool, you sign. Then you call Accenture. Nine to twelve months of consulting, implementation, configuration. Half a million dollars later, you're live.
That playbook is dead for AI.
Nobody's tolerating a six-month ramp period to see value from an AI agent. Not in 2025. Not ever again. The timeline has compressed so radically that time-to-value now happens before the contract even gets signed. I'm watching this play out across portfolio companies and fastest-growing AI startups, and it's one of the most fundamental shifts I've observed in how enterprise software gets built, sold, and deployed.
The uncomfortable reality? Your AI agent will fail if nobody properly trains it. And that "nobody" can't be your customers. It has to be you.
This isn't theoretical. I'm running 20+ AI agents at my company right now. The ones that work—the ones generating actual ROI—share a common pattern: their vendors invested heavily in training us during the first 30 to 60 days. The ones that don't work? Vendors who expected us to figure it out.
Let me be direct: if you're building an AI product and expecting customers to train the agent, debug edge cases, QA outputs, and iterate on prompts themselves, you're going to lose. And your customers will resent you for wasting their time.
Why Traditional Enterprise Software Playbooks Failed Fast
Enterprise software in 2019-2023 followed a predictable adoption curve. Month one to three, onboarding and basic setup. Months four to six, team adoption and workflow integration. Months seven to twelve, advanced features and expansion. Year two and beyond, optimization and scale.
This worked because customers could succeed with a lean customer success team. Adoption was gradual. Users learned incrementally. Early mistakes had time to be corrected without major business impact.
But AI agents operate under completely different physics.
An AI agent's quality is determined on day one, not day 90. A poorly trained agent creates immediate, terrible experiences that are almost impossible to recover from. Customers won't tolerate a "learning period" when they're replacing actual human workflows. One bad interaction with a poorly configured AI agent and trust evaporates.
The stakes are also different. When you deploy a traditional SaaS tool poorly, it just sits unused. When you deploy an AI agent poorly, it actively breaks things. It sends bad emails to customers. It schedules meetings at impossible times. It escalates support tickets incorrectly. The damage compounds.
This is why first impressions with AI are everything. Traditional software could afford stumbles in month two or three. AI can't. The initial deployment quality determines whether the customer ever trusts the system again.
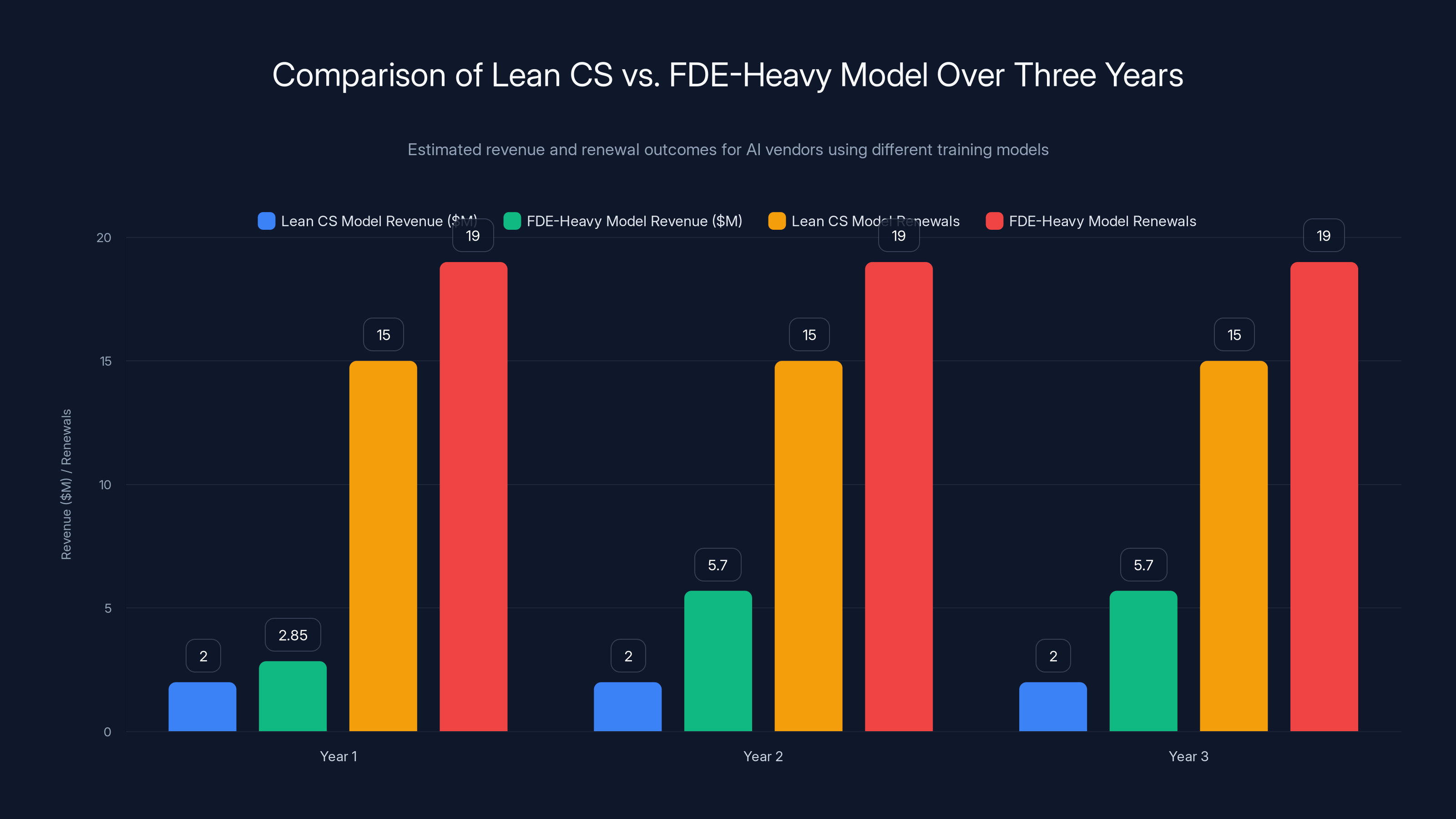
The FDE-heavy model, despite higher initial costs, significantly outperforms the lean CS model in revenue and customer renewals over three years. Estimated data.
The Forward-Deployed Engineer Model: Why It's Now Table Stakes
Palantir invented the forward-deployed engineer model. At first, it looked like a luxury consultancy play—having PhD-level engineers work directly with customers. Everyone thought it was overkill for SaaS.
Then AI happened. Suddenly, every growing AI company started hiring armies of forward-deployed engineers.
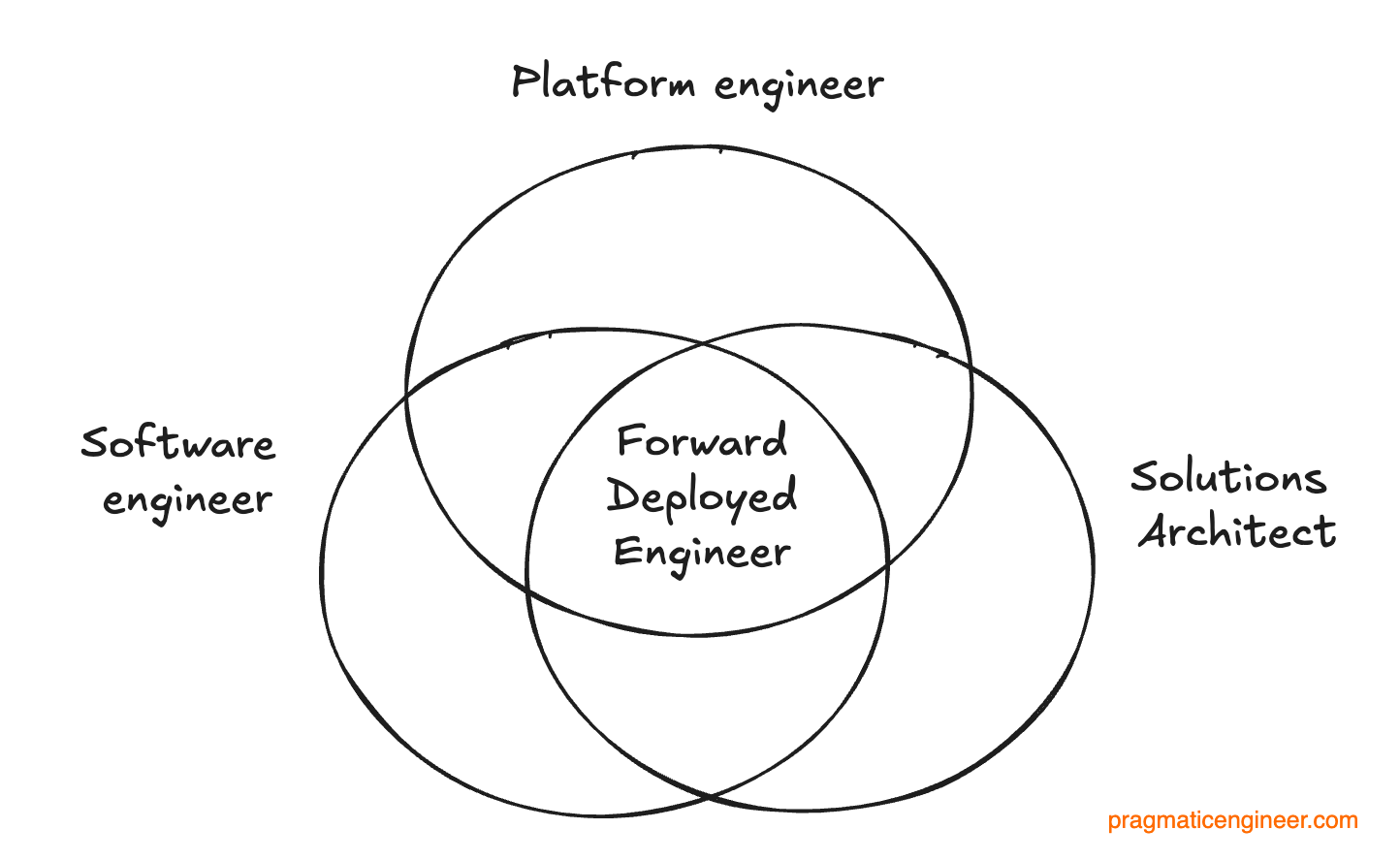
Here's what FDEs actually do: they work directly inside your business to understand specific processes. They build end-to-end workflows and take them to production. They handle model training and iteration until the agent works. They solve real-world implementation problems daily—not quarterly in a steering committee.
They're simultaneously engineers, consultants, and AI trainers. You can't outsource that role. It requires deep product knowledge, AI expertise, and the ability to sit in your workflows and understand edge cases before you discover them the hard way.
The FDE model works at scale if your ACV is $50,000 or higher. You can hire dedicated engineers to do training and handle edge cases. The math works.
But what about companies with $5,000 ACV? Who's doing 30 days of intensive training for each SMB customer? That's where most AI companies get stuck. They've figured out the high-ACV playbook. They haven't figured out how to systematize it for lower-ticket deals.
The companies cracking this will win the SMB market. They'll capture the expert knowledge once, then deploy it at scale. They'll systematize what their FDEs learned from 100 customer implementations, bake it into the product, and then deliver that accumulated knowledge to new customers automatically.
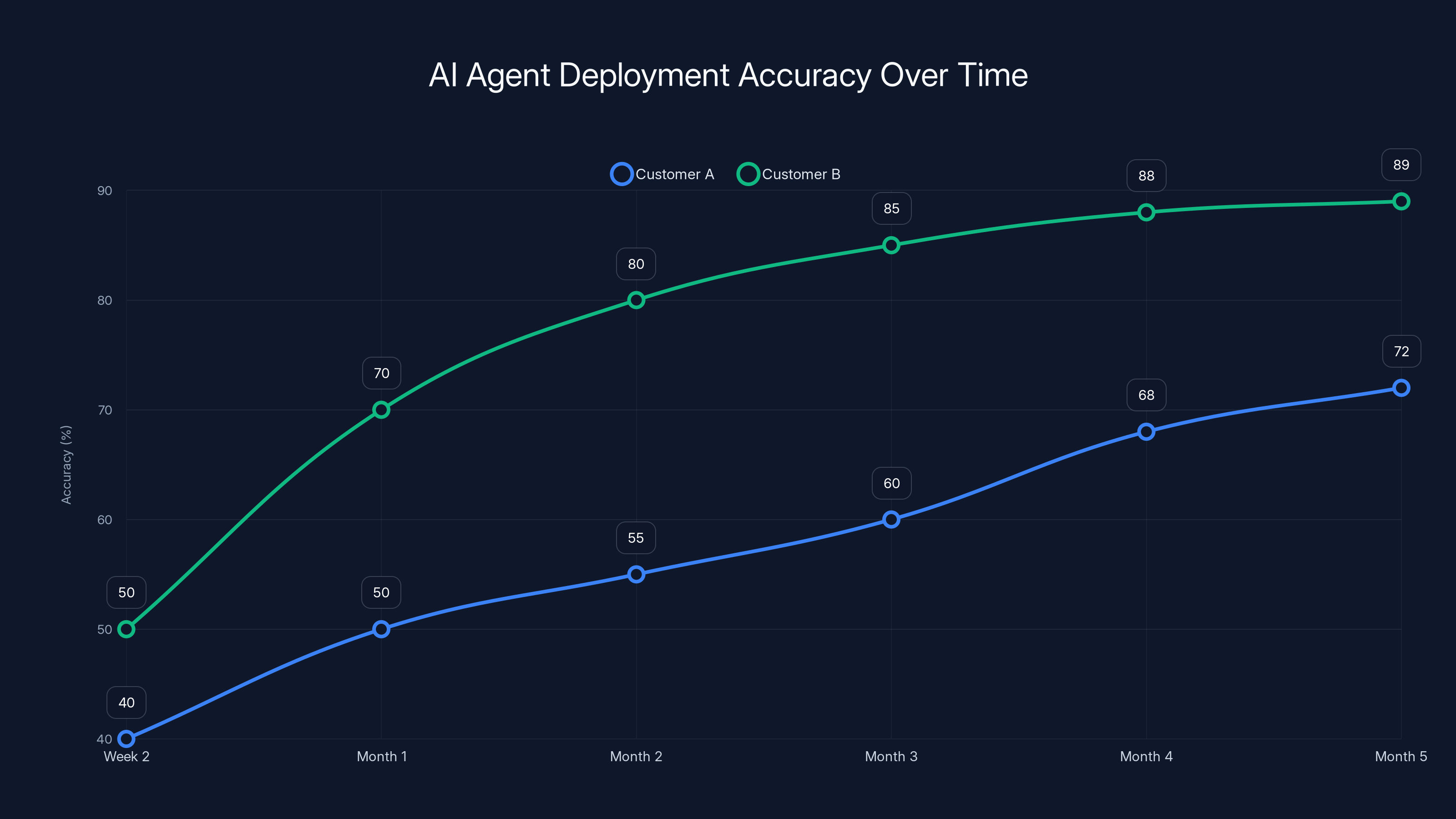
Customer B achieved higher accuracy faster due to dedicated resources, reaching 89% by week eight, compared to Customer A's 72% by month five. Estimated data based on case study.
What the Winning AI Vendors Are Actually Doing
I've worked with dozens of AI tools in the last 18 months. The vendors that deliver results share a specific pattern during the first 60 days:
Daily check-ins. Not weekly standups. Not monthly business reviews. Daily. They're identifying problems in real time, not in a quarterly retrospective. They're iterating daily on model outputs, data quality, workflow optimization.
Custom training on your specific data and workflows. They're not running a generic onboarding script. They're sitting in your systems, understanding your unique data structure, your edge cases, your business logic. They're building custom training datasets from your historical data. They're hardening the model against your specific failure modes.
Proactive edge case identification. Before you hit a problem, they've already spotted it. They're running simulations against your data, finding scenarios where the model might fail, and fixing them preventatively. You discover workarounds. They discover root causes.
Real-time iteration when something isn't working. They're not waiting for you to file a support ticket. They're monitoring outputs continuously, and the moment something drifts, they're investigating and fixing it.
Most customers achieve 60 to 70% of potential agent performance. Top performers get 90 to 95%. That 25 percentage point gap isn't magic. It's vendor partnership intensity.
At my company, we're the number one performing customer for both Artisan and Qualified across their entire customer bases. That's not because I'm smarter than other customers or our data is somehow magically clean. It's because their teams invested heavily in our training and daily optimization. We were a forcing function for them to build better, more systematic training processes.

The Uncomfortable Truth: It's On You, Not Your Customer
Here's what founders building AI products need to hear, even if it's uncomfortable: your customer's job is to use the agent. Your job is to make sure it works.
If you're building an AI product and expecting customers to train the agent themselves, you're going to fail. Not because customers are lazy. Because you've misunderstood the market dynamics.
Traditional software could push configuration complexity to customers because there was a long adoption window and customers had time to learn. AI doesn't work that way. The adoption window is weeks, not months. Customers need production-ready agents immediately.
The vendors who understand this treat customer success like product development. Every customer deployment is a research opportunity. Every edge case your customer hits, you fix in the product so the next customer doesn't hit it. Every training document you create, you systematize for scale. Every workaround a customer invents, you bake into the core product.
This is the opposite of the traditional SaaS model, where customer success is separate from product development. Customer success was about adoption and retention. Product development was about building features.
In AI, customer success IS product development. You're using live customer deployments to make your underlying model better. You're treating every customer implementation as a data point for improving your training process. You're capturing institutional knowledge from one customer and deploying it to the next.
The vendors who nail this win. The ones who don't, lose.
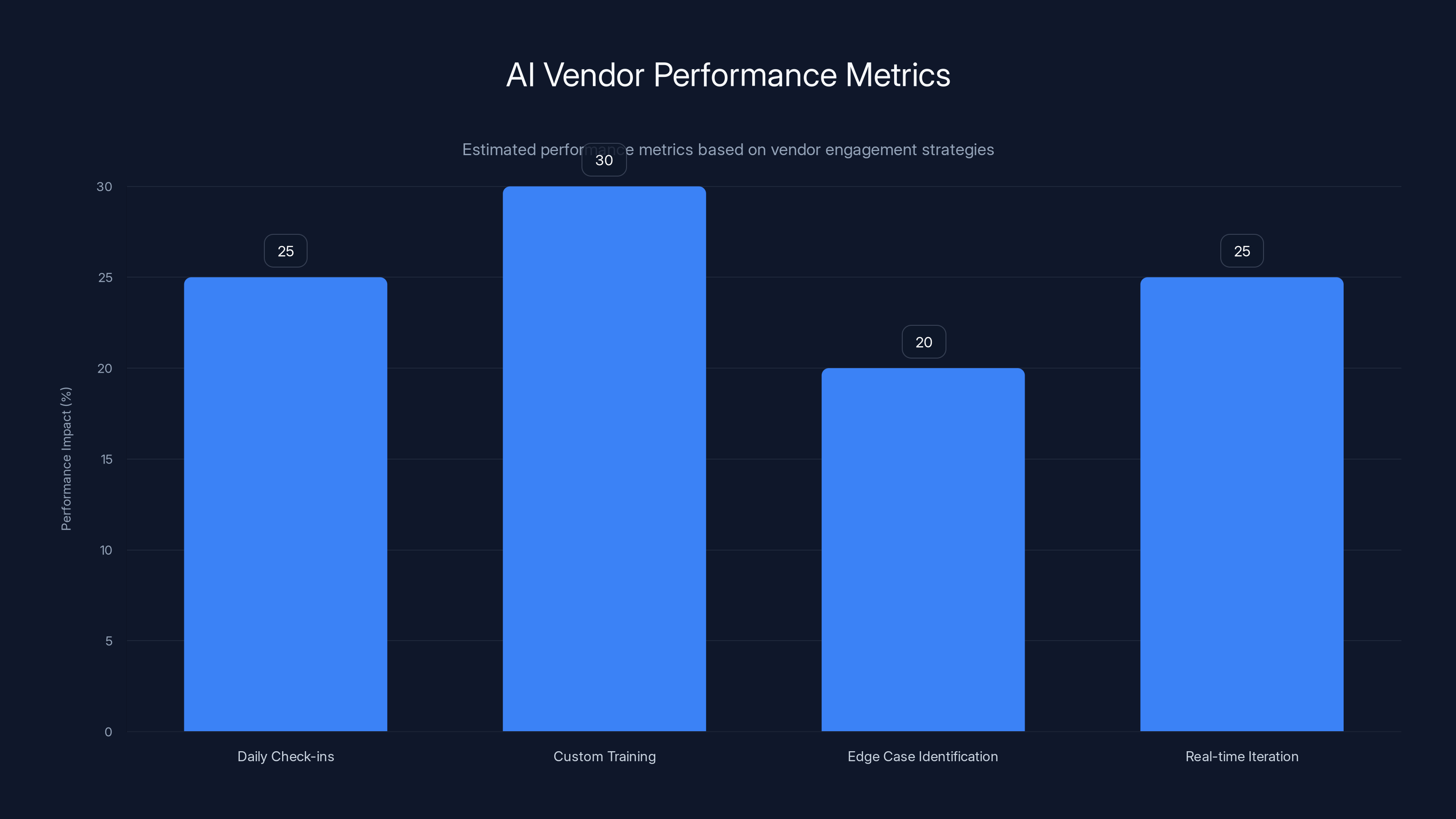
AI vendors focusing on daily check-ins, custom training, edge case identification, and real-time iteration can improve performance by up to 25-30%. Estimated data.
Why Agent Quality Fails When Vendors Skip Training
Let me walk through what actually happens when a vendor ships an AI agent without doing proper training.
Day one: customer gets access, spins up the agent with demo data. Looks good in the sandbox. They're excited.
Day three: agent hits real data. Edge cases everywhere. The model wasn't trained on your data distribution. It doesn't understand your business logic. Outputs are confidently wrong.
Day seven: customer is frustrated. They're spending cycles debugging, trying different prompts, rebuilding training data. They're calling it a "proof of concept" internally, but they're already mentally checking out.
Day 30: customer has built workarounds. They're not using the agent for critical workflows anymore. They're using it for low-risk stuff. ROI is underwater.
Day 90: customer is in churn conversations. They're not blaming the vendor (usually). They're saying "it's not ready for production." But what they mean is "nobody helped us make it production-ready."
This is preventable. A vendor investing 60 days of training would catch these problems on day two, not day 30.
The reason vendors skip this is obvious: it's expensive. It requires senior engineers, not support tickets. It requires patience and daily iteration. It's hard to scale. It cuts into margins.
But the vendors who do it anyway win. Because they're solving a fundamentally different problem than everyone else. They're not selling software. They're selling outcomes. And outcomes require training.
The Economics of Vendor-Led Training vs. Customer-Led Training
Let's do the math. Say you're an AI vendor with $100,000 ACV and your target is 20% gross margin after customer success costs.
If you use the old model (minimal training, lean CS team), you might have $15,000 in CS costs per customer. You hit your margin targets. But your logo churn is 25% because half your customers don't see ROI.
If you invest
Over three years:
Lean CS model: 20 customers, 5 churn after year one, 15 renew, ACV growth minimal. Revenue: $2M.
FDE-heavy model: 20 customers, 19 renew after year one, expansion drives ACV to
The math flips hard in year two. The initial margin hit looks terrible on a spreadsheet. But on a unit economics basis, the FDE model destroys the lean CS model over any reasonable time horizon.
The best AI companies have figured this out. They're not optimizing for year-one margins. They're optimizing for customer outcomes because outcomes drive retention, expansion, and referrals.
This is why Palantir's model, once thought to be boutique and unscalable, turned out to be the template for the AI era. It wasn't about being premium. It was about being right.
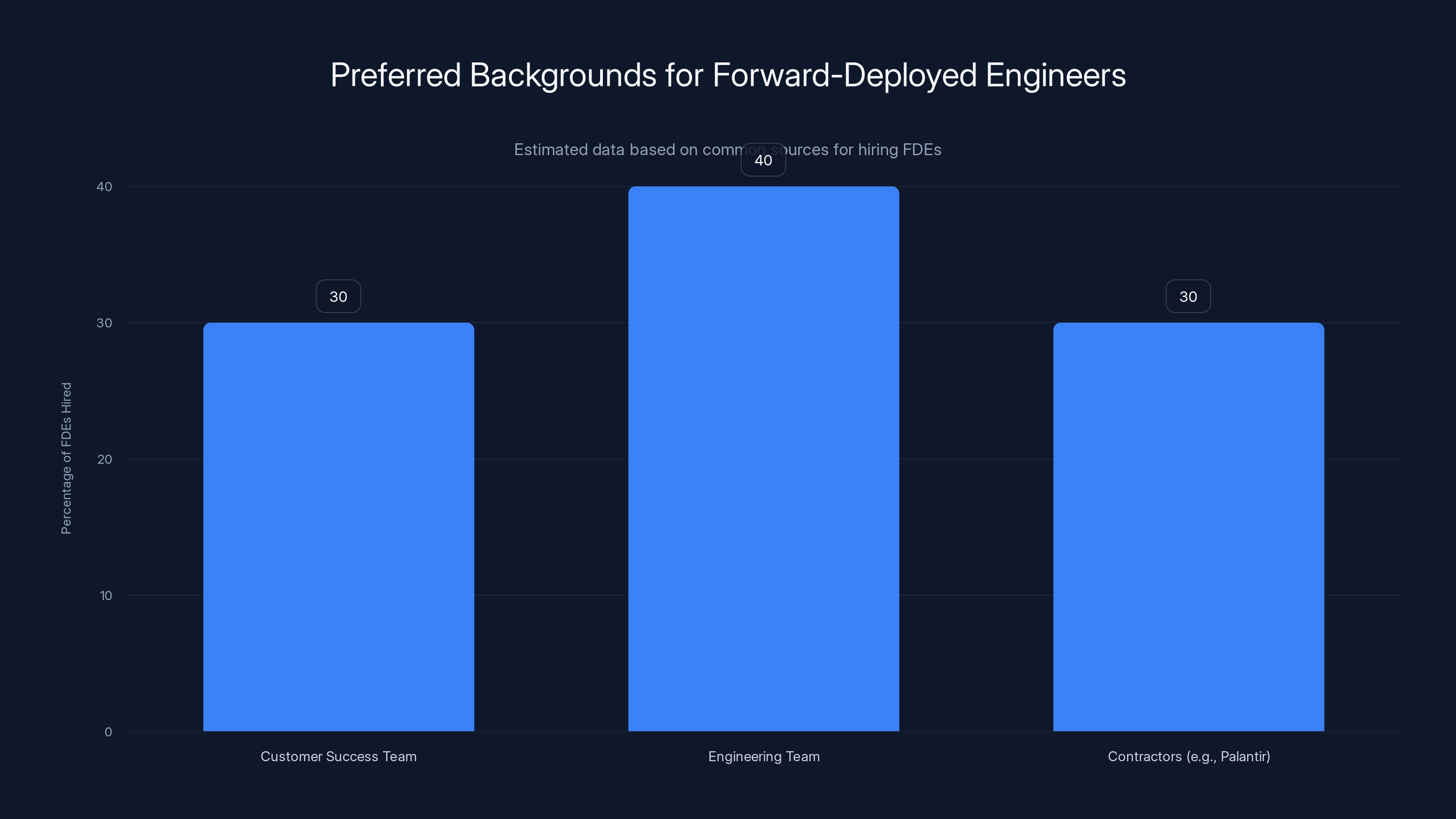
Estimated data suggests that engineering teams are the most common source for hiring forward-deployed engineers, followed by customer success teams and contractors.
How to Systematize Training at Scale Without Exploding CS Costs
The real insight isn't that training matters. Of course training matters. The insight is how to systematize it without hiring an unlimited army of FDEs.
Here's the framework:
Phase one is manual. Your FDEs do training for your first 20-30 customers. They're learning what works, what doesn't, where edge cases live. It's expensive and slow. But they're building the knowledge base.
Phase two is documentation. Those 30 customer implementations become templates. You document the training process, the common questions, the debugging workflows. You're capturing institutional knowledge.
Phase three is partial automation. Specialized CS people (not engineers) can now execute the training playbook with 80% of the quality of FDEs. It's systematic, reproducible, cheaper.
Phase four is scaled automation. You build tooling that handles the routine parts. Customers do automated data discovery. The system builds a training dataset automatically. You've reduced FDE time from 60 days to maybe 15 days of reviews and iteration.
Phase five is pure product. The training knowledge gets baked into the product itself. New customers get a wizard that builds training data automatically. The product itself adapts to their data distribution. You've gone from needing 60 days of manual training to needing 5 days of setup.
The companies doing this well are already at phase three or four. They've hired enough FDEs to handle current volume, but they're spending engineering effort on tooling to reduce FDE dependency over time. They're treating training as a product problem, not just a CS problem.
The companies that will win are moving to phase five. They're embedding training into the product architecture itself. A customer spins up an agent, feeds it data, and the product handles model training automatically. No FDE required. But it took three years to get there.
The Measurement Problem: How to Know If Training Is Actually Working
Here's where most vendors go wrong: they measure training by "did we do it," not by "did it work."
The right way to measure training effectiveness:
Agent accuracy on day one vs. day 60. You should see measurable improvement. If you're not seeing 20-30% better accuracy by day 60, something's wrong.
Edge case discovery and resolution. By day 60, how many of the customer's known failure modes have you found and fixed? If you've only found the obvious ones, you didn't dig deep enough.
Time to production. How long did it take from kickoff to real data, real workflows? If it's longer than 45 days, your training was too theoretical.
Customer independence. After 60 days, can the customer make changes without calling you? If they're completely dependent on your team, you didn't actually train them. You just maintained the agent for them.
Expansion rate. This is the ultimate metric. If the customer sees ROI in 60 days, they're going to ask "what else can this agent do?" Expansion revenue is the true signal of successful training.
Most vendors measure training by attendance or hours logged. That's missing the point entirely. Training that doesn't result in measurable agent performance improvement is just theater.
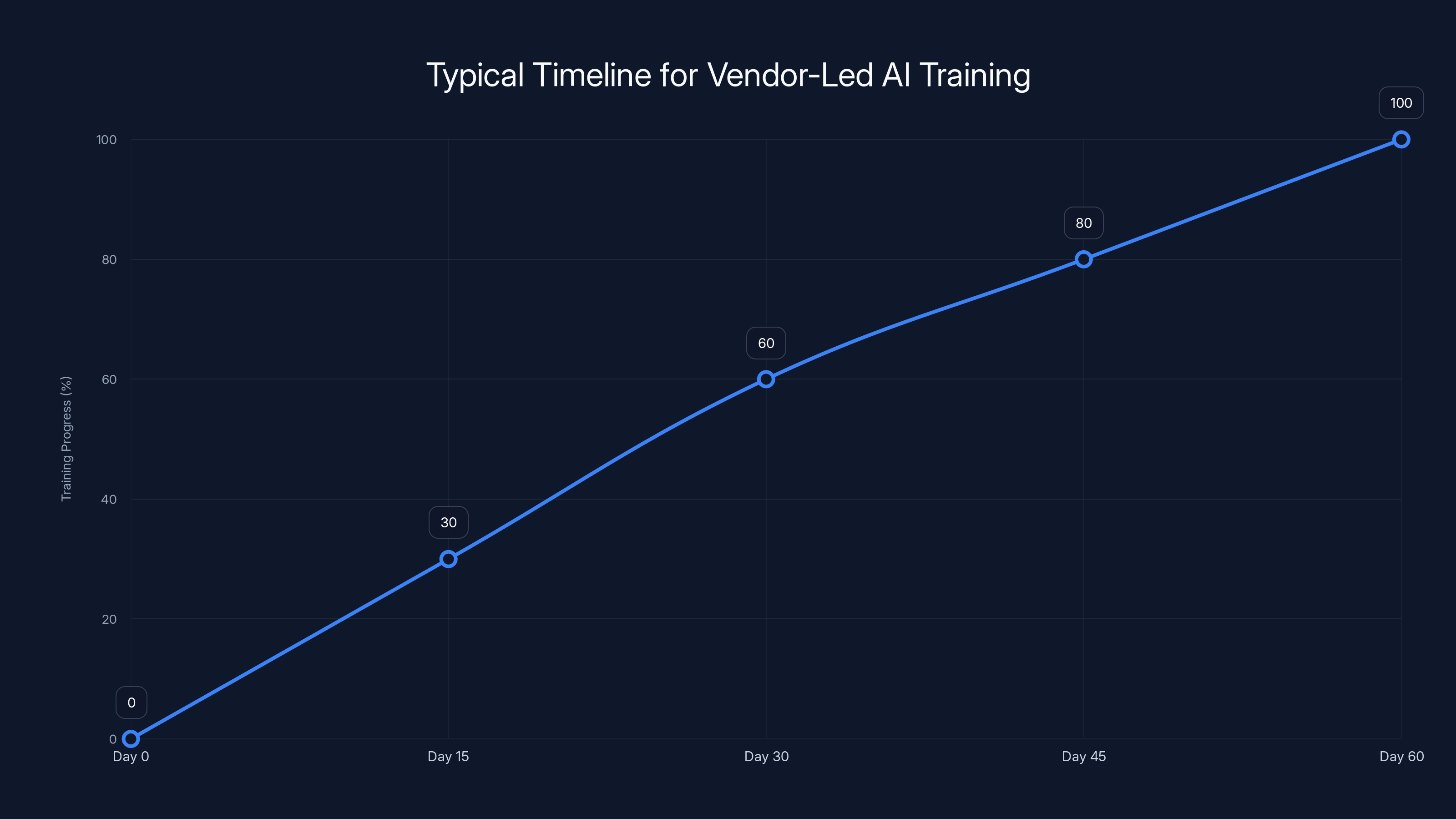
Vendor-led AI training progresses from data discovery to production deployment over 60 days, with significant milestones at days 15, 30, and 60. Estimated data based on typical implementation phases.
Why Your Customers Can't Do It Themselves (Even If They Want To)
You might be thinking, "Okay, but can't savvy customers just do this training themselves?"
Theoretically? Maybe. In practice? No.
Here's why: your customers are domain experts in their business, not in your AI model architecture. They don't know:
How your model weights training data. Feed it too much historical data and it overfits to past behavior. Feed it too little and it hallucinates. Most customers have no idea where that balance is.
What training data actually matters. There's a lot of data in your systems. But 80% of it is noise. A customer thinks "more data is better." Your ML team knows that data quality and distribution matter infinitely more than volume. That's not obvious unless you've built AI models before.
How to identify actual failure modes vs. expected variance. When an agent makes a mistake, is that a training problem or just unavoidable model uncertainty? A domain expert can tell you "this shouldn't happen." But figuring out why it happened requires deep product knowledge.
How to iterate safely. Customers are terrified of making changes that break things. So they don't change anything. They accept 70% performance because they're scared of 50%. A vendor who's trained 100 customers knows exactly what changes are safe and what changes require caution.
When to ask for features vs. working with what you have. Your product probably does 95% of what a customer needs. But they think they need the other 5%. A trained vendor knows which 5% isn't real requirements and which 5% actually matters.
The asymmetry is huge. Your vendor has 100 data points of learning from other implementations. Your customer has one. Asking them to do the training is asking them to reinvent what you already know.
The Competitive Moat: Training as Defensibility
Here's something interesting that's starting to emerge: training itself becomes a competitive moat.
Two AI vendors with almost identical product features but wildly different customer outcomes. What's the difference? The one with better training processes wins. And that training knowledge becomes nearly impossible for competitors to copy.
Why? Because training knowledge isn't in the code. It's in the playbooks, the debugging processes, the edge cases you've learned from 100 customer implementations. It's embedded in your FDEs' heads. It's hard to commoditize.
This is why some AI vendors have crazy logo density in certain verticals while competitors with similar features can't get traction. The winner figured out the training playbook for that vertical. The competitor didn't. And that advantage compounds because every new customer the winner gets is another data point improving the playbook.
The vendors who realize training is a product advantage (not a cost center) will build moats that last. The ones who see it as a necessary evil will get commoditized.
This is also why Palantir's model, often criticized for being unscalable, actually creates defensibility. You can't easily copy Palantir's FDE army and institutional knowledge about government workflows. You can copy their UI. You can copy their features. You can't copy their trained judgment from thousands of government implementations.
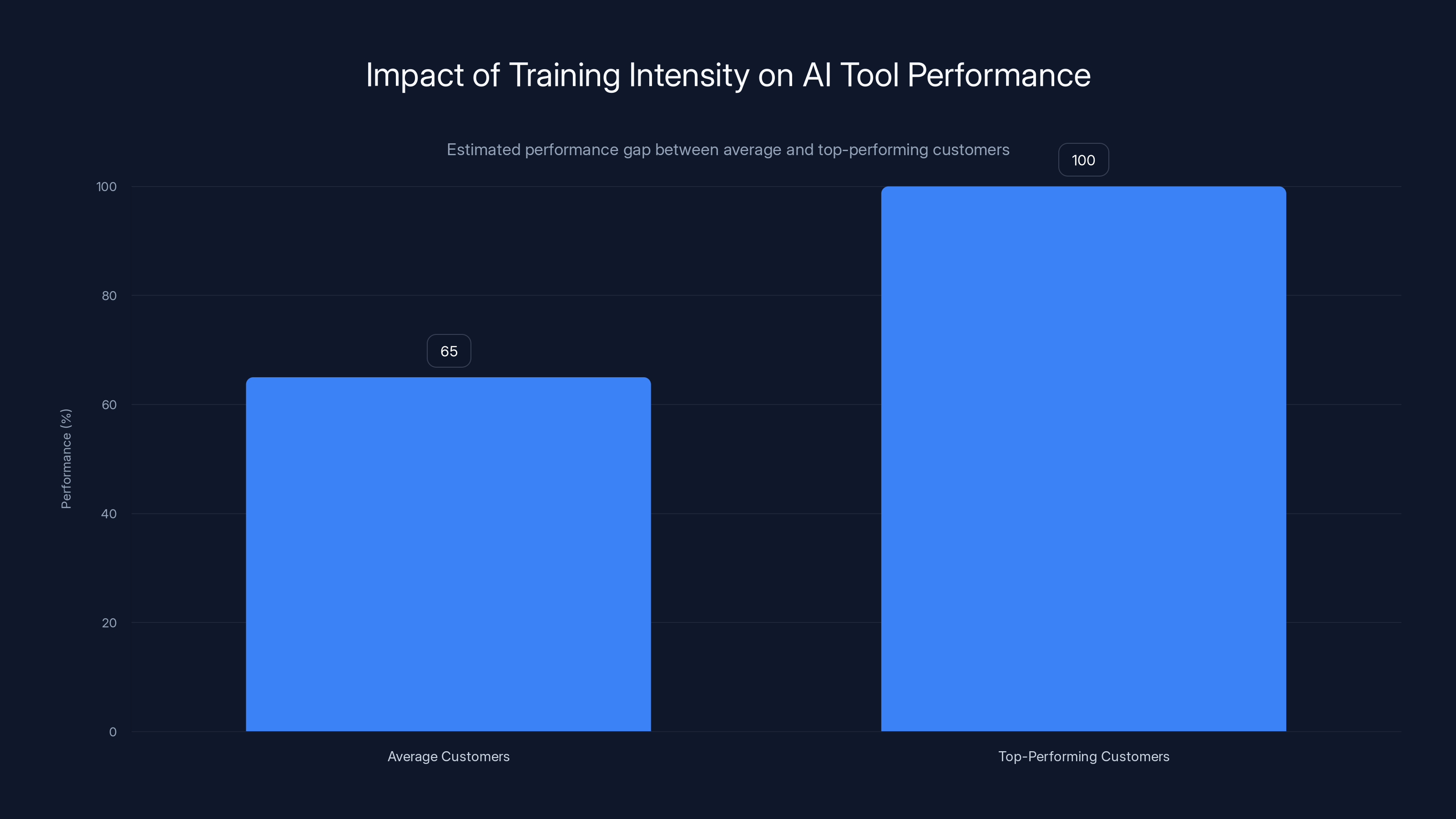
The performance gap between average and top-performing customers using the same AI tool is typically 30-35 percentage points, highlighting the impact of training intensity. (Estimated data)
Real-World Case Study: High Performance vs. Adequate Performance
Let me walk through two real customer implementations, anonymized but representative of what I'm seeing:
Customer A signed for a $120,000 ACV AI agent for customer service routing. Vendor assigned one part-time integration engineer. Gave them documentation and the implementation team was on their own. Customer spun up the agent in two weeks, deployed with 40% of customer service tickets being routed correctly. The other 60% fell through to manual handling. Customer spent four months debugging edge cases, building better training data, tweaking parameters. By month five, they hit 72% accuracy. They called it a success. It's in production now, but it's not moving the needle on business outcomes.
Customer B signed with a different vendor for the same problem and same price. Vendor assigned a dedicated FDE plus a CS engineer for 60 days. They spent two weeks on data discovery and training dataset construction. Week three, they deployed to a small segment. Spent weeks four through eight on iteration, edge case hardening, workflow integration. By week eight, accuracy was 89% on that segment. Customer was blown away. Rolled out to 50% of tickets. Now they're asking about deploying the agent to a second use case.
Both customers got an AI agent. Customer A spent
Who's more likely to expand? Who's more likely to refer? Who's going to churn and try competitor number three?
The economics look bad in year one for vendor B. Better in year two when customer B renews at
This is playing out across the AI industry right now. The winners are the ones who ate the training cost as part of the customer acquisition expense. The ones who are losing are trying to run lean customer success on a product that requires intensive training.

How to Hire and Deploy Forward-Deployed Engineers
If you're scaling an AI company and you need to hire FDEs, here's what actually works:
You need people who are simultaneously comfortable with code, comfortable with data, comfortable with your product, and comfortable with ambiguity. This is a specific phenotype. You can't hire them from a generic recruiter.
The best FDEs come from one of three places: your customer success team (promote the few who are technical enough), your engineering team (hire engineers who prefer customer interaction to shipping features), or contractors who've worked at Palantir or similar companies.
The job description matters. You're not hiring a support engineer. You're not hiring a consultant. You're hiring someone to live inside a customer's workflows for 30-60 days and make their AI agent great. They need to operate with partial information, make good judgment calls, and iterate continuously.
Compensation is critical. Your FDEs should be paid closer to senior engineers than support staff. Because they are senior engineers. The best FDEs could write code if they wanted. They're choosing to work with customers instead because they find it interesting.
Structure matters too. You don't want FDEs reporting to your VP of Customer Success. You want them reporting to your VP of Product or VP of Engineering. Because their job isn't support. It's to make your product better through direct customer work.
The bottleneck will be hiring more FDEs as you scale. This is where the systematization phase becomes critical. You have limited FDE capacity. You need to spend it on your highest-impact customers (the ones that will drive expansion) and then systematize what you learned so lower-volume customers can access 70% of that knowledge through scaled processes.
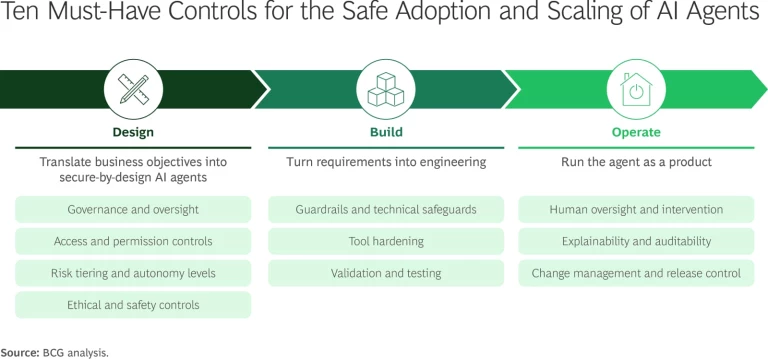
What Doesn't Work: Common Mistakes in Vendor Training
Let me walk through mistakes I see vendors making repeatedly:
Mistake one: Training is a support function. The vendor throws it at their customer support team. Support people aren't equipped to understand model behavior, data distribution, or architecture decisions. They can answer how-to questions, but they can't debug "why is this wrong." It shows. Customers notice.
Mistake two: Training is one-time. You do onboarding week one and then it's over. But the agent is learning and evolving. Your customer's data is changing. New edge cases emerge. Training should be continuous, at least for the first 90 days.
Mistake three: Training is generic. The vendor runs the same playbook for every customer. But every customer has different data, different workflows, different risk tolerance. Customization requires understanding the customer's specific situation. Templates don't scale understanding.
Mistake four: Training is documented but not practiced. The vendor writes a training manual but assumes the customer will follow it. But most customers won't prioritize reading a manual. They need hands-on coaching. Documentation is a reference, not a training method.
Mistake five: Training endpoints are arbitrary. You decide training ends after 30 days because that's your budget. But maybe your customer needs 45 days to get really good. Or maybe 20 days is enough. Training should end when the agent is actually good, not when the calendar says it should.
Mistake six: You measure training by effort, not by outcome. You count "hours trained" or "days of FDE time." But did the agent actually get better? Does the customer have expansion plans? Are they going to churn? You're measuring activity, not results.
Vendors who avoid these mistakes build customer success that actually works. The ones who fall into these traps lose deals that should have been wins.

The Technology Stack: Tools That Make Training Scalable
If you're going to train customers at scale without exploding FDE costs, you need tools that help.
Observability tools are essential. You need to understand why your agent is making specific decisions. Is it a data quality problem? Is it a model parameter problem? Is it a prompt engineering problem? Tools that let you trace execution and understand failure modes save months of debugging.
Data quality tools matter too. Your customer is probably working with messy data. They don't realize it's messy. You need tools that profile their data automatically, identify distributions, spot anomalies. This is 20% of the training time in most implementations.
Prompt management tools are underrated. You're going to iterate on prompts a thousand times during training. You need to version them, test them, understand what changed and when. Most vendors are doing this in spreadsheets, which is a disaster.
Model serving infrastructure that lets you iterate fast is critical. If you have to deploy a new model version every time you want to test a change, training takes forever. You need infrastructure that lets you test model variations in near real-time.
Customer success platforms that aggregate all customer interactions are helpful for prioritizing which edge cases to fix first. You should know what mistakes your agent is making across your customer base and prioritize fixes by frequency and impact.
The vendors I'm seeing with strong training processes are investing in this infrastructure. They've automated away the "search through logs" part of debugging, which means their FDEs spend more time on actual problem-solving and less time on investigation.

The Future: Baking Training Into Product
Where this is headed is clear: training becomes automatic.
Future AI agents will have meta-learning capabilities. You feed them your data, they adapt. You give them feedback, they improve. The product itself learns what good looks like in your specific context. No human training required.
But we're not there yet. Today, training requires human judgment and embedded domain expertise. That's expensive. But it's also the competitive advantage for the next five years.
The vendors who nail customer training in 2025 will have built organizational muscle that competitors can't easily replicate. They'll have data and processes and institutional knowledge about how AI systems behave with real-world data at scale.
In 2028 or 2029, when products have baked training in, that advantage disappears. But for now, training is everything.
The best AI companies are treating 2025 like a window. Invest heavily in training, build the knowledge base, systematize the processes, embed it in the product. By 2027 when everyone expects training to be automatic, you're already there.
The Bottom Line: Your Responsibility
If you're building an AI product, here's what needs to be true:
You're treating customer success like product development because it is. Every customer implementation is a research opportunity. You're capturing what works, what doesn't, where the edge cases live.
You're investing in training as a customer acquisition expense, not a cost center. Better training means better outcomes, which means better retention, expansion, and referrals. The math works.
You're hiring FDEs or equivalent people who can actually make customers successful. Not support people. Not account managers. People who understand your product deeply and care about customer outcomes.
You're measuring training by outcome (did the agent get better, does the customer see ROI) not by effort (did we run training).
You're systematizing what you learn so you can scale training as you grow. Because you can't hire unlimited FDEs. You need to turn experience into process.
Do this, and you'll build something that lasts. Your customers will succeed. Your product will improve. Your retention will be incredible.
Skip this, and you'll compete on price and features and churn at 30% because your customers never see value.
The choice is yours. But the market is already choosing. The vendors doing training well are growing 3x faster than the ones shipping features and expecting customers to make it work.
FAQ
What is vendor-led AI training?
Vendor-led AI training is when the software vendor (not the customer) takes primary responsibility for configuring, testing, and optimizing your AI agent to work with your specific data, workflows, and business logic. This typically involves intensive work during a 30-60 day implementation period, often staffed by forward-deployed engineers or dedicated customer success specialists who understand both the product architecture and your business context.
Why can't customers just train AI agents themselves?
Customers lack the institutional knowledge of how your AI model behaves, what data quality matters most, where edge cases typically emerge, and how to safely iterate on parameters without degrading performance. Your vendor has trained 50 or 100 other customers, so they know the patterns and pitfalls. Your customer has trained zero. Asking them to learn on their own means they'll likely accept 70% agent performance when 90% is achievable with proper guidance.
How long does vendor-led training typically take?
Effective vendor-led training usually spans 30-60 days of intensive work with your implementation team. The first 15 days focus on data discovery and training dataset construction. Days 15-30 involve building and testing the agent. Days 30-60 center on edge case discovery, hardening against failure modes, and production deployment. After 60 days, maintenance transitions to standard support unless expansion work is underway.
What's the difference between forward-deployed engineers and regular support teams?
Forward-deployed engineers are senior technical staff who embed directly into your workflows during implementation. They combine deep product knowledge with AI expertise and the ability to debug complex problems in real-time. Regular support teams handle post-deployment questions and issues but lack the architectural understanding to solve training problems or optimize agent performance during implementation.
How do I measure whether AI training is actually working?
Measure training success by: (1) agent accuracy improvements from day one to day 60 (should see 20-30% improvement), (2) edge case discovery and resolution rates, (3) time to production deployment, (4) customer independence level after training (can they make changes without vendor support), and (5) ultimate expansion revenue (if training worked, customers will want more AI agents). Training that doesn't result in measurable performance improvement is theater, not results.
Can AI training be systematized and scaled without hiring unlimited forward-deployed engineers?
Yes, through a staged approach: start with manual FDE training for your first 20-30 customers, document what you learned into repeatable templates, hire specialized CS people to execute the playbook, build tooling to automate the routine parts, and eventually embed training capabilities into the product itself. The vendors winning in 2025 are at phase two or three. By 2027, the best will be at phase five, with training mostly automated in the product.
Why do some customers get 90% agent performance while others get 70% with the same tool?
The 20-point gap between top performers and average customers almost always comes down to implementation quality and training intensity. Top-performing customers had vendors invest 60 days in optimization and daily iteration. Average customers had minimal training or self-directed implementations. The tool is the same. The outcomes are completely different because the implementation depth was completely different.
What happens if a vendor doesn't offer sufficient training?
With insufficient training, AI agents underperform, customers experience bad results early on, trust erodes, and churn risk skyrockets. By month three, customers are likely exploring alternatives or shelving the tool entirely. By month six, they're in renewal conversations questioning whether to renew. The vendor loses an opportunity for expansion revenue and faces a significantly elevated churn risk that becomes hard to recover from.
Conclusion: The Future of AI Implementation Is Now
The enterprise software playbook from 2019 is completely broken for AI. That old model—minimal training, lean support, customers figure it out—was never going to work for AI agents because the stakes are too high and the learning curve is too steep.
The vendors who've figured this out are growing and keeping customers. The ones who are still trying to run lean customer success on AI products are struggling.
If you're building an AI company, your competitive advantage in 2025 isn't features. It's implementation. It's making your product work so well with your specific customer that they can't imagine switching. That only happens with intensive, systematic, vendor-led training.
Invest in it. Build the systems. Hire the people. Measure by outcomes. You'll build something that lasts.
The market is already making this choice. The next phase of AI adoption belongs to the vendors who take training seriously.
Use Case: Automate your vendor training documentation and create dynamic implementation guides from your agent performance data in minutes
Try Runable For Free
Key Takeaways
- AI agents require vendor-led training on day 1, not a gradual adoption process like traditional SaaS required in 2019-2023
- Forward-deployed engineers and intensive 60-day training programs are now table stakes, not luxury consulting options
- The 25-35 percentage point gap between average and top-performing customers using identical AI tools comes entirely from training quality
- Vendors who invest in training see 3x higher customer lifetime value by year three despite higher year-one CS costs
- Systematizing training through templates, tooling, and automation is the path to scaling without exploding FDE costs
Related Articles
- Microsoft's AI Strategy Under Fire: OpenAI Reliance Threatens Investor Confidence [2025]
- Claude Interactive Apps: Anthropic's Game-Changing Workplace Integration [2025]
- Enterprise Agentic AI Risks & Low-Code Workflow Solutions [2025]
- The AI Adoption Gap: Why Some Countries Are Leaving Others Behind [2025]
- Sam Altman's India Visit: Why AI Leaders Are Converging on New Delhi [2026]
- Realizing AI's True Value in Finance [2025]

