![AI Factories: The Enterprise Foundation for Scale [2025]](https://tryrunable.com/blog/ai-factories-the-enterprise-foundation-for-scale-2025/image-1-1767886616472.jpg)
AI Factories: The Enterprise Foundation for Scale
Your organization has probably already run a successful AI pilot. The spreadsheet looks great. The ROI projections look even better. Everyone's excited. Then reality hits: you need to scale this thing across the enterprise.
Suddenly you're juggling incompatible tools, managing different GPU generations, dealing with shifting software stacks, and trying to keep your security and compliance teams happy. The chaos is real. Teams are building AI silos. One department uses TensorFlow, another uses PyTorch. Data residency requirements vary by region. Nobody can agree on how models should be versioned, monitored, or retired.
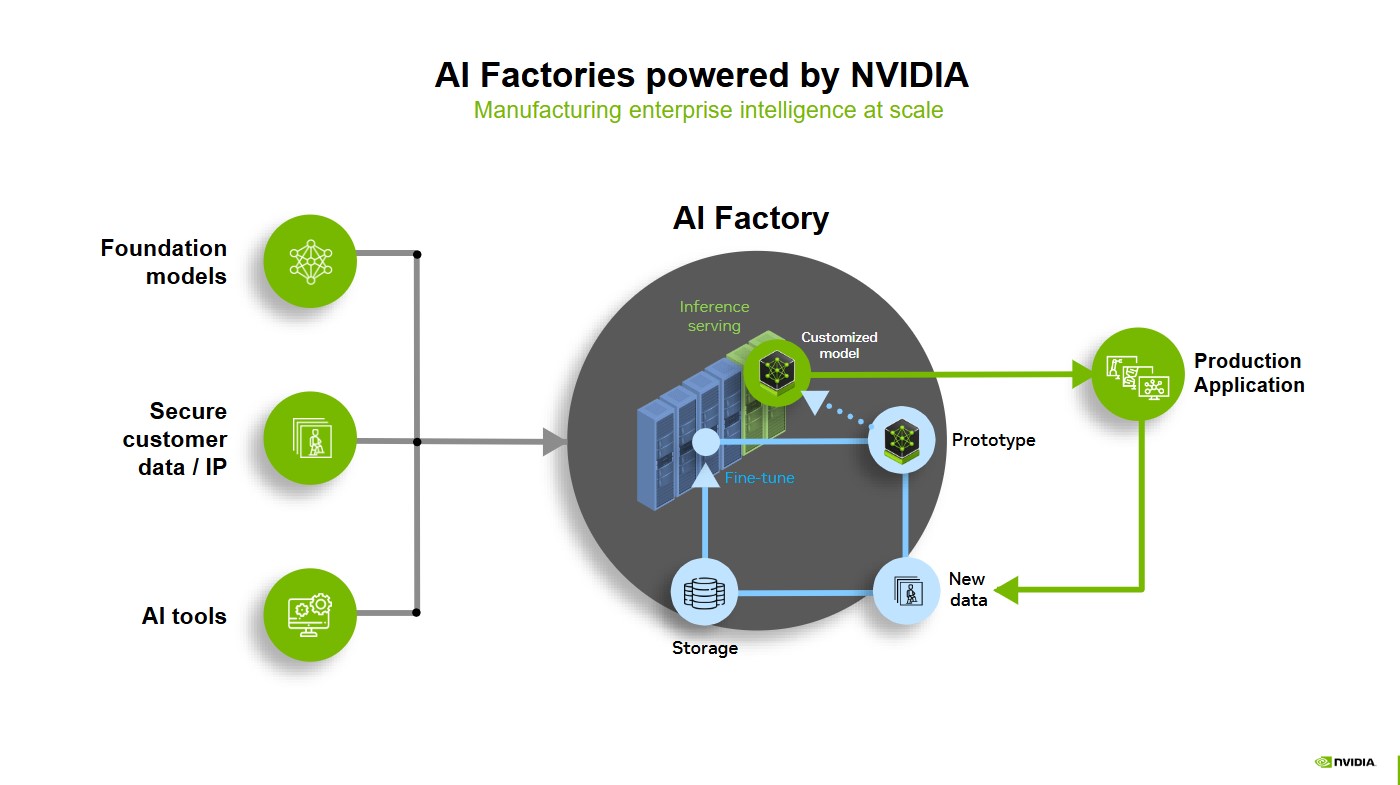
This is where AI factories come in. They're not a product you buy. They're an architectural pattern, a way of thinking about infrastructure that transforms AI from a chaotic collection of experiments into a predictable, managed capability. An AI factory is the organized foundation that lets your entire organization build, deploy, and operate AI systems reliably, securely, and at scale.
Let me be clear: this isn't theoretical. Companies doing serious AI work—financial services firms processing millions of transactions, healthcare organizations handling sensitive patient data, manufacturers running production systems—they're all converging on this pattern. Not because it's trendy, but because it's the only way to handle the complexity without burning out your teams.
Here's what separates a mature AI operation from one that's still struggling: the mature ones treat AI infrastructure like they treat their applications. They don't allow every team to build their own database. They don't let engineers deploy servers however they want. They standardize. They govern. They automate. That's what an AI factory does for machine learning.
In this article, I'm going to walk you through what an AI factory actually is, why it matters, and how to start building one at your organization. We'll cover the architectural components, the operational benefits, the security implications, and the common mistakes teams make when they try to build this stuff without a clear blueprint.
TL; DR
- AI factories unify fragmented AI infrastructure into a single, standardized platform across accelerated computing, Kubernetes, data governance, and security
- Enterprise AI at scale fails without operational maturity: silos, manual orchestration, and inconsistent governance create technical debt and slow deployment cycles
- Multi-tenant governance enables shared AI services: rather than siloed projects, organizations create internal AI marketplaces where models are versioned, deployed, and accessed through policy
- Security and sovereignty must be embedded from day one: FIPS encryption, audit trails, fine-grained access controls, and data residency requirements are non-negotiable for regulated industries
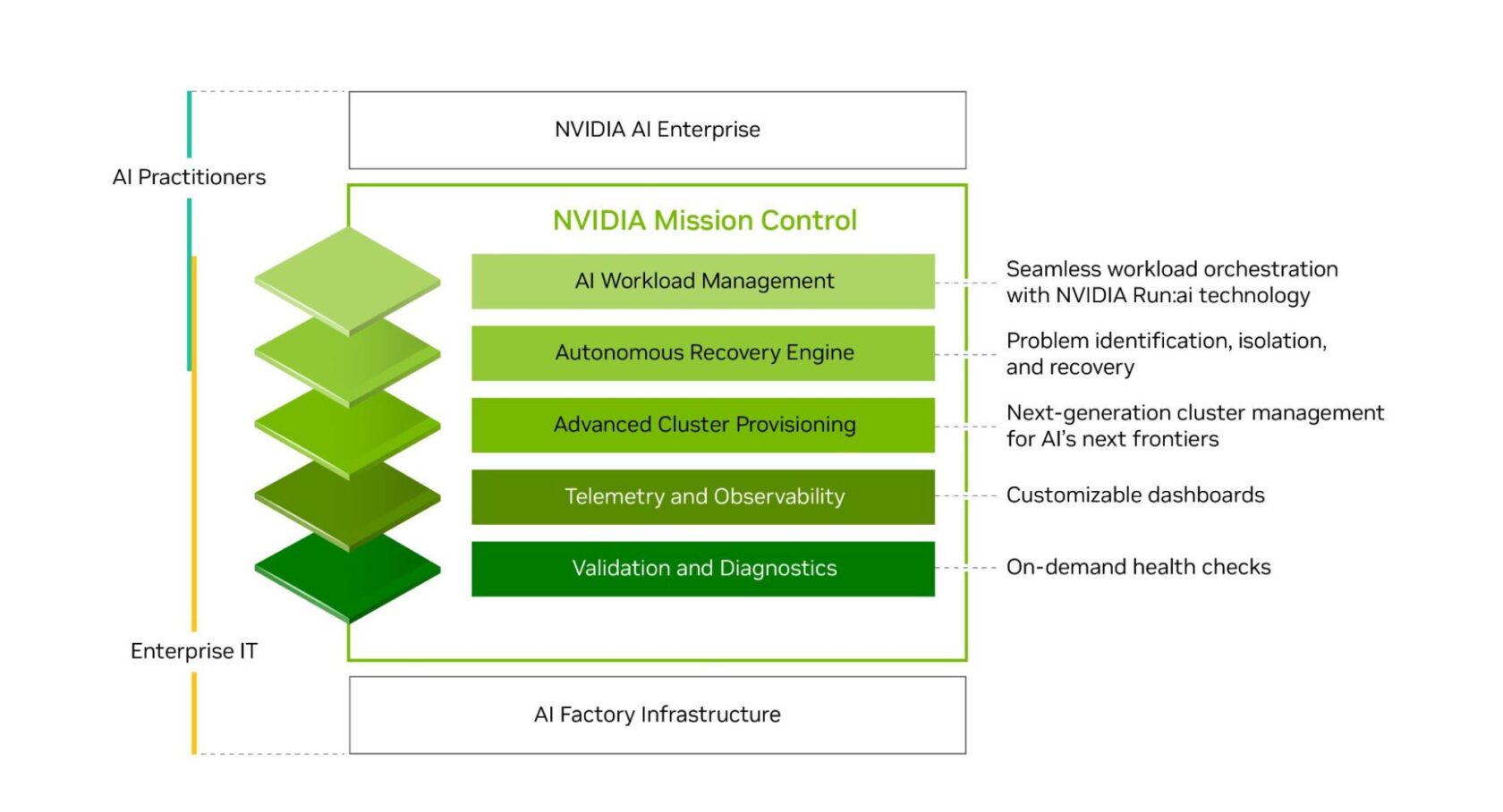
- Kubernetes simplification is critical: production-grade Kubernetes abstracts GPU scheduling, dependency management, and lifecycle control, freeing teams to focus on AI innovation rather than infrastructure maintenance

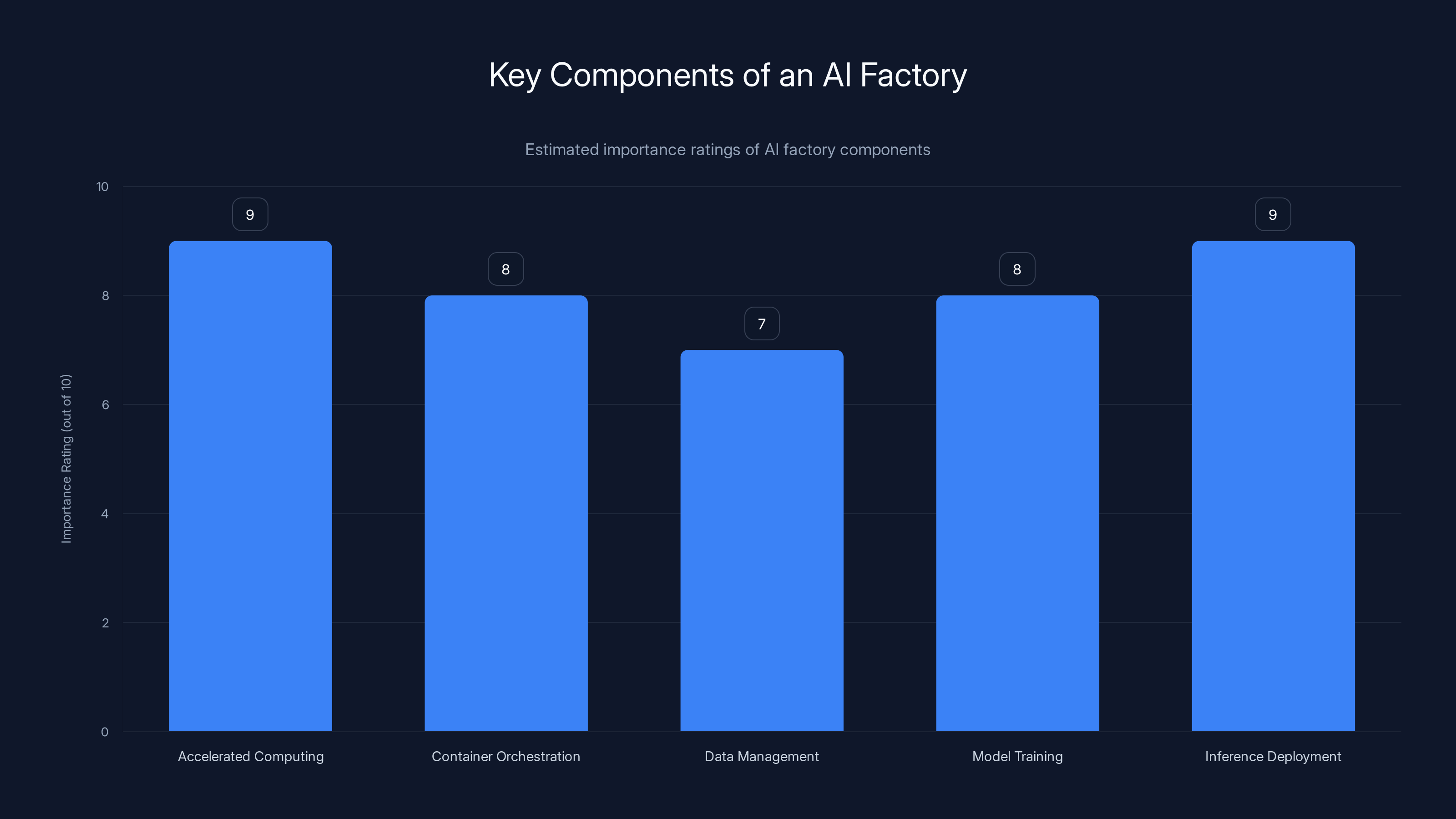
Accelerated computing and inference deployment are crucial components of an AI factory, each rated at 9/10 for their importance in handling AI workloads. Estimated data.
What Exactly Is an AI Factory?
Let's start with a definition that actually makes sense. An AI factory is an integrated platform that brings together several critical pieces:
Accelerated computing infrastructure that supports current and future hardware generations, whether GPUs, TPUs, or specialized AI accelerators. This isn't just buying hardware—it's managing diverse architectures, handling refresh cycles, and ensuring workloads can move between hardware without rewriting code. For instance, NVIDIA's Rubin platform exemplifies this with its support for multiple hardware generations.
Production-grade Kubernetes orchestration that abstracts the complexity of scheduling AI workloads, managing resources, and handling failures. Most enterprises underestimate Kubernetes complexity when AI enters the picture. Standard Kubernetes works fine for stateless applications. AI workloads are different—they're resource-intensive, they're often stateful, and they require specialized scheduling logic for GPUs and other accelerators.
Multi-tenant data governance and access control that lets different teams securely access shared data, models, and compute resources without stepping on each other. This is where a lot of organizations get tripped up. They build the infrastructure, but they don't build the governance layer. Then you get situations where one team's misconfiguration brings down everyone else's workloads.
Validated model environments where you can standardize the software stack, dependency versions, and runtime configurations. Model drift is a real problem. You train a model in one environment with version 2.8 of some library, deploy it in production with version 3.1, and suddenly your accuracy drops 15%. AI factories prevent this through containerization, versioning, and validated environments.
Security and compliance infrastructure embedded into the foundation: encryption at rest and in motion, audit logging, vulnerability scanning, FIPS compliance, and data residency controls. This isn't a layer you add later. It has to be baked in from day one.
The key insight here is that these components aren't independent. They work together. You can't have a truly scalable AI operation without standardized infrastructure. You can't have governance without visibility. You can't have security without infrastructure controls.
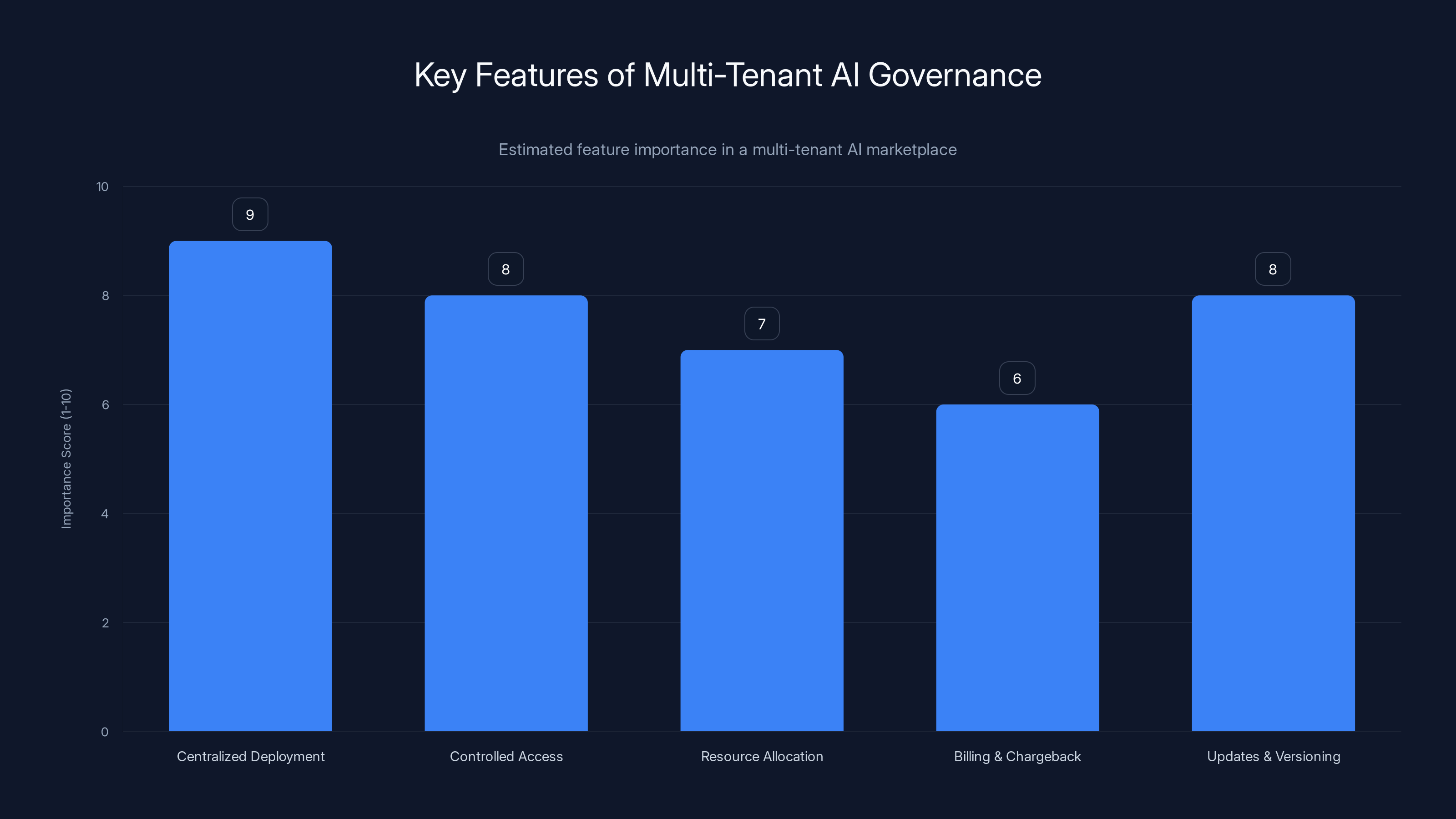
Centralized deployment and controlled access are crucial for effective multi-tenant AI governance, ensuring efficient resource use and secure operations. Estimated data.
Why Enterprise AI Fails Without This Architecture
I've watched this happen more times than I can count. A company gets excited about AI. They fund three or four proof-of-concept projects. The pilots are successful. Great results, real ROI, the business is thrilled.
Then someone asks: "Okay, so how do we do this across the whole organization?"
That's when everything breaks.
Without a unified factory model, enterprises end up with what I call "AI silos." Each team builds their own ML infrastructure. Data science team A uses on-premises hardware. Team B rents GPUs from a cloud provider. Team C uses a different cloud provider because they need specific compliance certifications. Nobody talks to each other. Nobody shares models. Nobody has a consistent way to monitor, version, or update anything.
This creates several predictable problems:
Cost overruns. When you're not standardizing, you're not negotiating volume discounts. You're not consolidating infrastructure. You're not sharing compute resources. A company I worked with had five different teams renting GPU capacity independently. They were paying 30% more than they would have if they'd pooled resources. When they standardized on an AI factory approach, they cut costs by nearly $2 million annually without reducing capability.
Security and compliance nightmares. Different teams have different security requirements. One team's models handle financial data that requires FIPS-140-2 encryption. Another team's models are less sensitive. Without a unified security architecture, you either over-secure everything (expensive and slow) or under-secure some workloads (massive risk). An AI factory standardizes security to a level that meets the highest requirements while not over-engineering everything.
Model drift and reliability issues. I mentioned this earlier, but it's worth emphasizing. Without standardized environments, you get situations where models work great in development but fail in production. The software versions are different. The hardware is different. The data format is different. Your team spends weeks debugging, and the root cause is something stupid like a library version mismatch.
Slow innovation. This might sound counterintuitive, but more standardization actually speeds up innovation. Here's why: when your teams aren't spending 80% of their time managing infrastructure and solving the same problems over and over, they have time to actually innovate. An AI factory gives your data scientists a clean, simple way to deploy models. They don't have to learn Kubernetes. They don't have to manage GPUs. They just upload a model and it works.
Governance collapse. As you scale AI, you need to answer questions like: Who has access to which models? Which data are these models allowed to use? Who approved this model for production? How do we audit which predictions are being made? Without a unified governance layer, the answer to all these questions is basically "nobody knows."
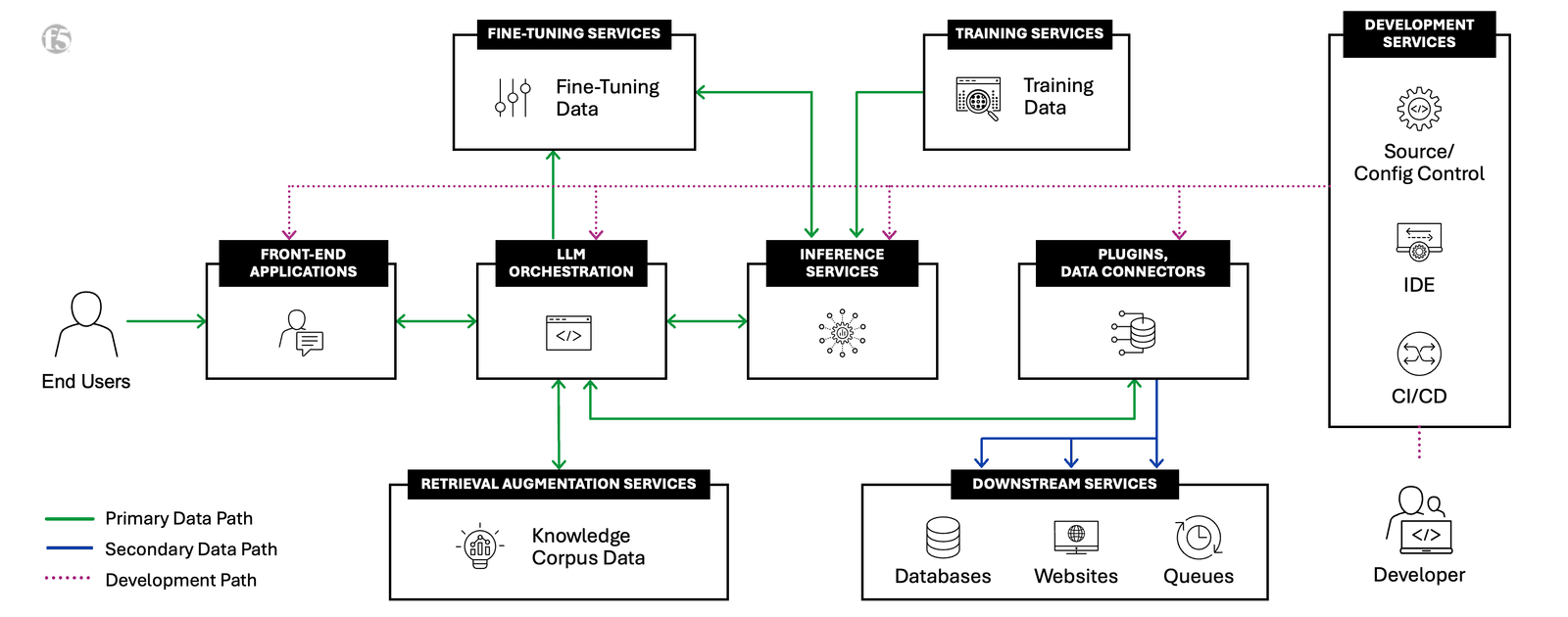
The Core Components of an AI Factory
Let's get into the actual architecture. An AI factory has five main components. Think of them as layers that build on top of each other.
Layer 1: Accelerated Computing Infrastructure
This is the foundation. You need compute hardware optimized for AI workloads—GPUs, TPUs, specialized inference accelerators, or a combination of all three.
Here's the tricky part: there's no single best hardware for all AI workloads. Training models benefits from high memory bandwidth and compute density. Inference benefits from latency optimization. Large language models need massive parallelization. Computer vision models often run on completely different hardware than natural language processing models.
A mature AI factory supports multiple hardware generations simultaneously. You can't replace every GPU in your organization every 18 months. You'll have a mix of NVIDIA A100s, H100s, L40s, and older hardware from previous generations. The infrastructure layer needs to abstract this diversity away. A data scientist shouldn't need to know which GPU their workload is running on.
You also need to think about capacity planning. How much GPU time do you actually need? This is harder than it sounds because demand is unpredictable. You might have periods where inference traffic spikes dramatically. You might have large training runs that tie up resources for weeks. The infrastructure needs to be flexible enough to handle this variability without requiring humans to constantly provision and deprovision resources.
Layer 2: Container Orchestration and Kubernetes
Kubernetes is the de facto standard for container orchestration in 2025. But running Kubernetes at enterprise scale, especially with GPU workloads, is genuinely hard.
Standard Kubernetes works great for stateless services. You can spin up containers, route traffic, scale horizontally, and let failures happen—the system recovers automatically. AI workloads are different. They're stateful. Training runs take hours or days. If something fails halfway through, you've wasted enormous amounts of compute and time.
A production-grade Kubernetes setup for AI needs specialized components:
GPU scheduling and resource management that understands GPU memory, bandwidth requirements, and which workloads can share GPUs and which need exclusive access. You can't just treat GPUs like regular CPU resources. A workload that needs 80GB of GPU memory can't run on a node with only 40GB available. You also need specialized drivers, CUDA versions, and sometimes kernel configurations.
Job orchestration and workflow management so that complex multi-step AI pipelines can run reliably. A typical ML workflow involves data preprocessing, training, validation, and inference. These steps often run sequentially or in complex DAGs (directed acyclic graphs). You need a system that can manage dependencies, handle retries, and provide visibility into what's running where.
Persistent storage and data access that lets your training jobs and inference services access data consistently and reliably. Kubernetes by default is stateless. For AI, you need managed storage solutions that work well with Kubernetes, provide high performance for data-intensive workloads, and support caching and replication.
Observability and monitoring across all layers so you can see what's happening when things go wrong. With AI workloads, traditional metrics aren't always enough. You need to understand GPU utilization, memory usage, temperature, and which workloads are causing contention.
Most enterprises don't build this from scratch. They use distribution or commercial platforms built on top of Kubernetes that add these AI-specific capabilities. Think of it like this: Kubernetes is the Linux kernel for cloud infrastructure. It's powerful but low-level. Most organizations use a distribution or platform that makes it easy to actually use.
Layer 3: Data Governance and Access Control
Here's something that's easy to underestimate: the governance layer is as important as the compute layer. Without it, you don't have an AI factory. You have compute infrastructure with an AI problem on top of it.
Data governance for AI is different from traditional data governance. It needs to answer questions like:
-
Who can access which models? Not everyone in the organization should have access to every model. Financial models should only be accessible to authorized financial systems. Customer data models should be restricted.
-
Which datasets can be used for training? Some data is sensitive. Some has licensing restrictions. Some is proprietary. You need to track this and enforce it automatically.
-
How do we version and track models? When a model is deployed to production, we need to know exactly which training data was used, which version of the training code, which dependencies, and when it was deployed. If something goes wrong, we need to roll back.
-
What are the lineage and dependencies? This model was trained on that dataset and uses these three other models as feature transformers. You need to track all of this so that when a dependency changes, you can identify which models might be affected.
-
How do we implement access controls? In a multi-tenant environment, you need fine-grained access controls. One team's confidential models shouldn't be visible to another team. But shared infrastructure models should be available to everyone.
A good data governance layer in an AI factory typically includes:
- Model registry with metadata, versioning, and access controls
- Data catalog with lineage, sensitivity classification, and usage tracking
- Access control policies that are enforced automatically
- Audit trails that log who accessed what and when
- Data quality checks that run automatically
Layer 4: Model Management and Lifecycle
Models have lifecycles just like software does. They're developed, tested, deployed, monitored, updated, and eventually deprecated. Without a structured process, things get chaotic.
A model management system needs to handle:
Model versioning and promotion. A model typically goes through several versions. Version 1.0 is the initial deployment. Version 1.1 includes a bug fix. Version 2.0 is a retraining with new data. You need to track all of this, be able to compare versions, and roll back if something goes wrong.
Environment management. Models need to run in development, staging, and production. Each environment needs to be configured identically from a software perspective but might have different hardware, data, or scale. The model management system should make it easy to promote a model through these environments while ensuring consistency.
Performance monitoring. Once a model is in production, you need to monitor its performance. Not just technical metrics like latency and throughput, but business metrics. Is the model still accurate? Have the input distributions changed? Is the model still profitable? Are there fairness issues?
A/B testing and canary deployments. You rarely want to deploy a new model to 100% of traffic immediately. You want to test it on a small percentage of traffic first, compare its performance to the existing model, and gradually roll it out. This requires infrastructure for traffic splitting and result comparison.
Automated retraining. Some models need to be retrained regularly. As new data arrives, the model's accuracy drifts. You need an automated pipeline that can detect drift, retrain the model, validate the new version, and deploy it automatically if it passes validation.
Layer 5: Security and Compliance Infrastructure
This is where a lot of organizations falter. They build the compute and orchestration layers, but they treat security as an afterthought. That's a mistake.
Security needs to be embedded into every layer of an AI factory:
Encryption. Data should be encrypted in transit (between services) and at rest (in storage). You should support multiple encryption standards to comply with different regulations. FIPS-140-2 compliance is required in many industries.
Authentication and authorization. Users and services need to be authenticated (prove who they are) and authorized (have permission to do what they're trying to do). This needs to work across multiple systems—Kubernetes, the model registry, data access, monitoring, etc.
Network isolation. Your AI infrastructure shouldn't be directly accessible from the internet. You need network segmentation, firewalls, and careful management of which systems can talk to which other systems. In a sensitive environment like healthcare or finance, you might want complete air-gapping.
Audit logging. Every significant action should be logged: who deployed what model when, which data was accessed and by whom, which predictions were made. These logs need to be tamper-proof and retained for compliance purposes.
Vulnerability management. Your infrastructure needs continuous scanning for known vulnerabilities. This happens at multiple levels: container image scanning, dependency scanning, infrastructure scanning. You need automated patching where possible and manual review and testing for critical patches.
Data residency and sovereignty. In regulated industries and specific jurisdictions (especially Europe under GDPR), you need to ensure data doesn't leave the jurisdiction. An AI factory needs to support this through policy enforcement and potentially isolated infrastructure deployments.
Model security. Models themselves can be attacked. Model extraction attacks try to steal your model's knowledge. Poisoning attacks try to corrupt the model's training data. Adversarial attacks try to trick the model into making bad predictions. These threats are real and you need defenses.

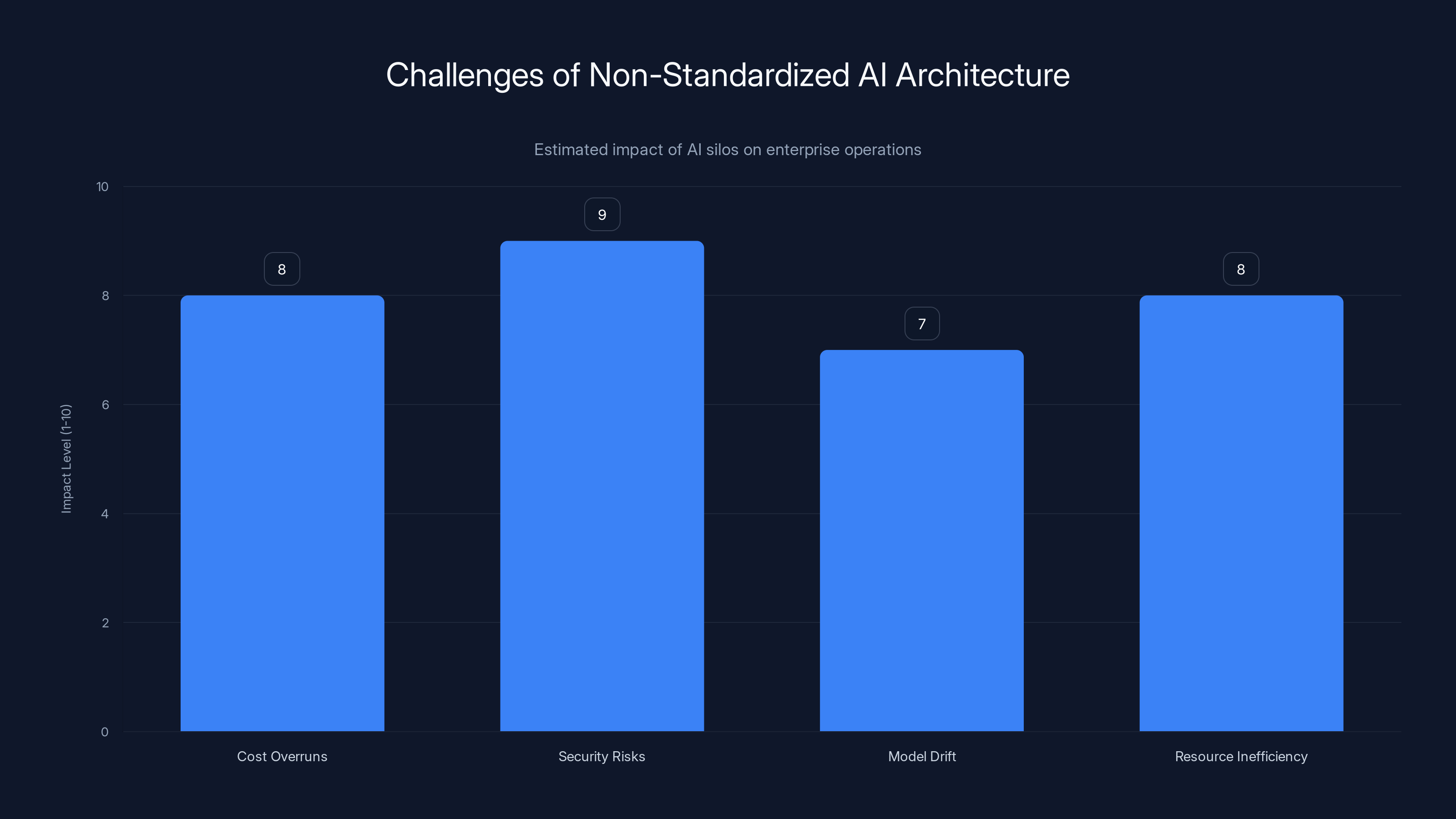
Non-standardized AI architectures lead to significant challenges, with security risks and cost overruns being the most severe. Estimated data based on typical enterprise scenarios.
The Operational Benefits: Why This Matters in Practice
Let me connect this back to reality with some concrete benefits you get from an AI factory architecture.
Massive Reduction in Time-to-Deployment
Without an AI factory, deploying a model takes weeks or months. You need to coordinate with infrastructure teams, provision hardware, install software, configure security, set up monitoring, integrate with existing systems. Multiple teams are involved. Communication is slow. Coordination is hard.
With an AI factory, you can deploy a model in hours. Your data scientist packages the model as a container, submits it to the model registry, specifies which dataset it needs access to, and approves it for production. The system handles everything else automatically. Kubernetes schedules it on appropriate hardware. The security system configures access controls. Monitoring agents attach themselves. The model is live.
I've seen organizations reduce their mean time to deployment from 12 weeks to 2 days. That's not hyperbole. The difference is whether they had a structured platform or not.
Dramatic Cost Optimization
When you have an AI factory, you can optimize costs in ways that are impossible with siloed infrastructure:
Resource consolidation. If teams are managing their own hardware, they each maintain peak capacity for their own needs. If inference traffic varies, one team might have idle GPUs while another needs more. With consolidation, you use one big pool. If one team is quiet, another team can use that capacity. Total capacity requirements drop by 30-40%.
Right-sizing. An AI factory can automatically scale resources based on actual demand. Training workloads spike then fall. Inference traffic varies by hour. Without automation, you're either over-provisioned (wasting money during low-traffic periods) or under-provisioned (missing capacity during spikes). With automation, you buy exactly what you need.
Hardware efficiency. An AI factory can pack workloads intelligently onto hardware. Maybe a GPU can run two small inference models without performance degradation. Without automated scheduling, humans make these decisions and often get them wrong. Automated systems are more efficient.
Reduced duplicate work. When every team builds their own infrastructure, there's massive duplication. Team A invests in building a data pipeline. Team B builds the same thing slightly differently. Team C builds it a third way. An AI factory eliminates this through shared infrastructure.
Operational Reliability and Visibility
Silos create visibility problems. When a model fails in production, debugging is hard because the model owner doesn't fully understand the infrastructure it's running on. When performance degrades, you don't know if it's the model, the hardware, the data, or something in between.
With an AI factory:
Full observability. Every layer is instrumented. You can see exactly what's happening at every stage. When something goes wrong, you have the information you need to diagnose and fix it.
Automated alerting. Monitoring systems can detect problems before they impact users. If GPU memory is creeping up, the system alerts you. If latency is degrading, you know immediately. If accuracy is drifting, the system detects it.
Incident response. When something does go wrong, you have playbooks and automated responses. A model behaving badly? Automatically roll back to the previous version. A hardware node failing? Automatically reschedule workloads. These systems can respond in seconds—humans would take hours.
Audit trails. For compliance and debugging, you have complete records. Who changed what? When? Why? What were the results? This is invaluable for troubleshooting and for regulatory compliance.

Security and Sovereignty: Non-Negotiable for Regulated Industries
I want to spend some time on this because it's genuinely important and often overlooked.
Regulated industries—healthcare, financial services, energy, government—face increasing regulatory pressure around AI. GDPR in Europe, emerging AI regulations globally, industry-specific regulations for healthcare and finance. The regulations are getting stricter, not looser.
An AI factory is essentially a compliance device. It embeds controls that make it possible to meet these requirements:
Data Residency and Sovereignty
Many jurisdictions require data to stay within borders. Europe requires European data to stay in Europe. China requires Chinese data to stay in China. If you're training models on sensitive data, you can't just dump it in a public cloud region that happens to be cheaper.
An AI factory can enforce data residency policies. You can configure it to only use specific infrastructure deployments for specific data. European models run on European hardware. Chinese operations run on Chinese infrastructure. The system enforces this automatically.
Encryption and Key Management
Regulations often specify encryption requirements. HIPAA in healthcare. PCI DSS in finance. FIPS-140-2 for federal systems. These regulations dictate encryption algorithms, key length, key rotation schedules, and how keys are stored.
An AI factory can enforce these policies. Encryption is applied consistently across all data access. Keys are managed securely. Rotation happens automatically. Auditing confirms compliance.
Access Controls and Audit Logging
When sensitive data is involved, you need to know exactly who accessed what. Why? For debugging? For analytics? For what specific purpose? And you need to log this activity for auditing.
An AI factory implements fine-grained access controls. A researcher can access a specific subset of data for a specific project. Another researcher cannot see that data. The system logs both access and denial attempts. If there's a breach, auditors can review logs to understand what happened.
Model Governance
Increasingly, regulations require governance around model deployment. You need documented evidence that the model was validated before production. You need to know what data was used in training. You need to be able to remove specific data and retrain if requested. You need to understand model behavior and ensure it doesn't exhibit unlawful bias.
An AI factory provides this through model registries that capture comprehensive metadata, versioning systems that track what changed and why, and validation systems that enforce testing before deployment.
Vulnerability Management
Regulations increasingly require vulnerability scanning and patch management. You need to know that every component of your system is scanned for known vulnerabilities. You need to know that critical patches are applied. You need evidence of this for auditors.
An AI factory has automated vulnerability scanning built in. Container images are scanned as they're built. Dependencies are analyzed. Infrastructure is scanned continuously. Critical vulnerabilities generate automatic alerts and can trigger automatic patching.
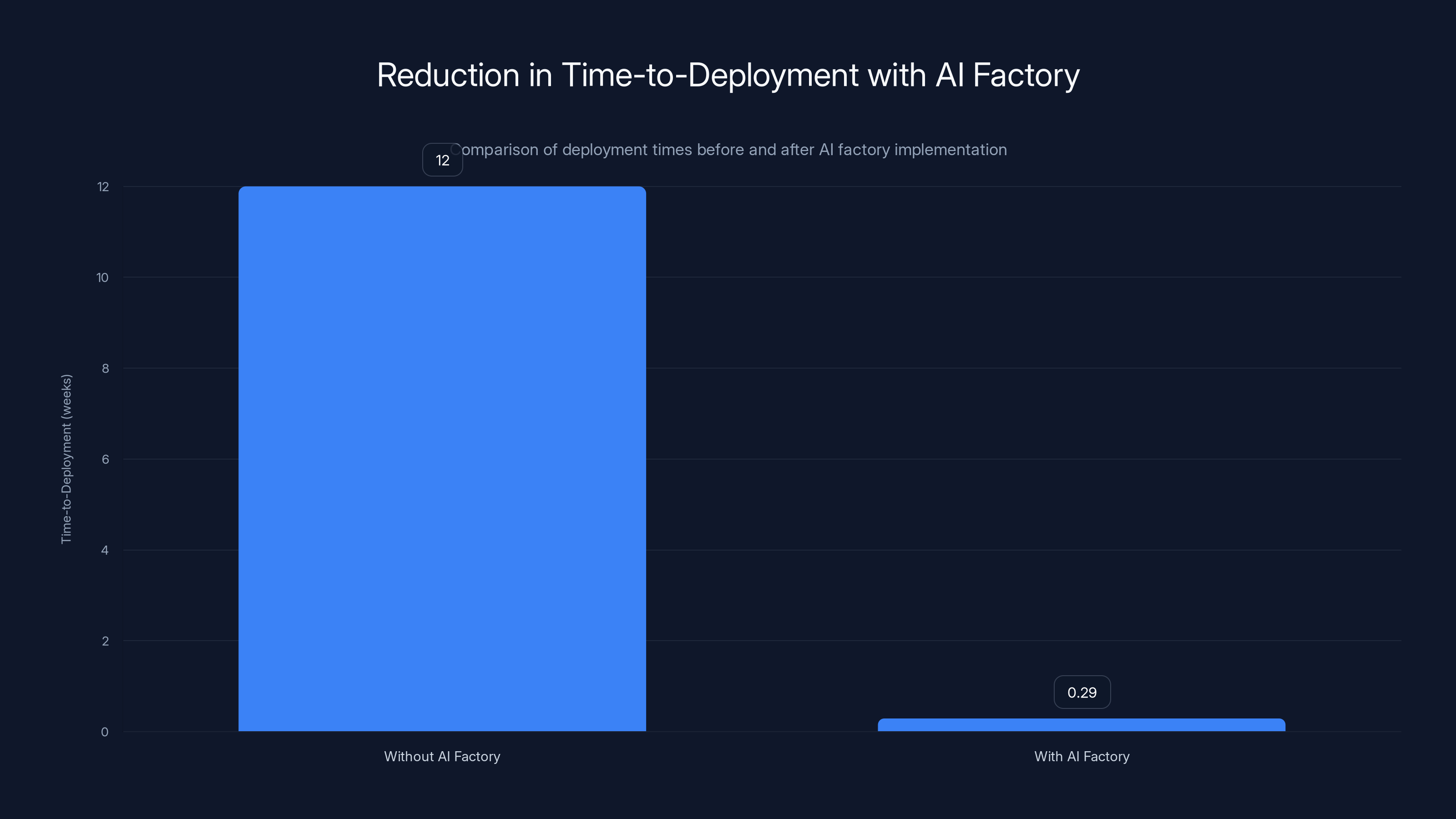
Organizations can reduce their mean time to deployment from 12 weeks to just 2 days with an AI factory, highlighting significant operational efficiency gains.
Kubernetes Simplification and Operational Excellence
I know I mentioned Kubernetes earlier, but this deserves deeper treatment because Kubernetes is often the biggest operational challenge when building an AI factory.
Here's the thing about Kubernetes: it's incredibly powerful but also incredibly complex. Running Kubernetes at enterprise scale requires significant expertise. Add AI workloads on top and the complexity multiplies.
The Kubernetes Challenge for AI
Standard Kubernetes was designed for stateless, cloud-native applications. Services are deployed as containers. Traffic is load-balanced. Instances fail and are replaced. Everything is replaceable.
AI workloads break this model:
They're resource-intensive. A training job might need multiple GPUs and hundreds of GB of memory. Standard Kubernetes resource management isn't designed for this scale of resource requirements.
They're long-running. A training job might run for a week. Standard Kubernetes is designed for quick recovery—if something fails, restart it. For long-running jobs, you need more sophisticated fault tolerance.
They're stateful. A training job has state—checkpoints, intermediate results. If a node fails, you might need to recover from a checkpoint rather than starting over. Standard Kubernetes doesn't handle this well.
They have complex dependencies. A training job depends on specific CUDA versions, specific library versions, specific kernel configurations. Getting all of this right in a containerized environment requires care and testing.
They require specialized scheduling. GPUs can't be shared arbitrarily like CPUs. Some workloads need exclusive GPU access. Others can share. Some workloads have affinity requirements—they need to run on nodes with specific hardware. Kubernetes' default scheduler doesn't understand any of this.
The AI Factory Solution
A mature AI factory simplifies Kubernetes operations by providing abstraction layers:
A Kubernetes distribution or platform optimized for AI workloads. This typically includes specialized schedulers, GPU management, and job orchestration that understands AI-specific requirements.
Simplified interfaces for common operations. Rather than requiring teams to write complex Kubernetes YAML configurations, the platform provides simple interfaces. "Deploy this model for inference." "Run this training job." The platform translates these high-level requests into Kubernetes configurations.
Automatic resource management. The platform handles resource allocation. You specify requirements ("I need 2 GPUs and 64GB of memory") and the system handles finding appropriate hardware, provisioning it, and managing it.
Lifecycle management. From creation to completion to cleanup, the platform manages the entire lifecycle. Training jobs generate artifacts. These artifacts are stored, versioned, and made available to other systems. When a job completes, resources are freed and made available to other workloads.
Observability and debugging. Rather than requiring teams to debug Kubernetes networking, resource contention, and GPU issues, the platform provides high-level observability. You can see what your workload is doing, why it's slow, where it's running, and how to make it faster.
The result is that data scientists and engineers can deploy AI workloads without needing to become Kubernetes experts. They focus on their AI work, not infrastructure.
Multi-Tenant Governance: Creating an Internal AI Marketplace
One of the most important shifts enabled by an AI factory is moving from siloed projects to shared AI services.
Think about how your organization handles databases. You don't let every team maintain their own database. You have a database team that manages databases. Other teams use them. There's a request process. Databases are provisioned with appropriate resources. Access is controlled.
AI should work the same way. Instead of every team building their own models, you create shared AI services that any team can use.
The Multi-Tenant Model
In a multi-tenant AI factory:
Model deployment is centralized. Data science teams build and validate models. When a model is ready, they submit it to the model registry. The system handles deployment, scaling, monitoring, and updates.
Access is controlled through policy. Teams don't directly access models. They access them through APIs. Access is controlled by policy. Maybe the fraud detection model is accessible only to financial systems. The recommendation model is accessible to all customer-facing systems.
Resource allocation is managed. Multiple teams might use the same model. When GPU resources are scarce, the system allocates them fairly. One team can't monopolize resources.
Billing and chargeback is possible. If you want to charge teams for their AI usage (internally), a multi-tenant system makes this possible. You track which team used which model, how much compute they consumed, and invoice them.
Updates and versioning happen transparently. When a new version of a model is deployed, it can be rolled out gradually. Clients continue using the old version initially. The new version is tested. Once validated, clients are migrated. If something goes wrong, rollback is automatic.
Building an AI Marketplace
This is where things get interesting operationally. Instead of individual projects, you're building an internal AI product. Models are products. Users are customers. You need to think about:
Discovery. How do teams find available models? You need a catalog with metadata, documentation, and examples of how to use each model.
Onboarding. How does a new team start using a model? This should be simple—request access, get approved, start making predictions.
SLA management. Different models have different performance requirements. One model might be critical for fraud detection and need 99.99% uptime. Another is experimental. Your system should reflect these different requirements.
Cost transparency. Teams should understand what their AI usage costs. This creates incentives for efficiency. Teams are more careful about using experimental models if they know they're paying for it.
Feedback loops. As teams use models, they learn things. That feedback should flow back to model owners. "This model often makes mistakes on this type of input. Can you investigate?" These feedback loops improve models over time.
Governance. As an AI marketplace grows, you need governance. Which models are approved for sensitive use? Which models need additional validation? How do you retire models that are no longer useful?

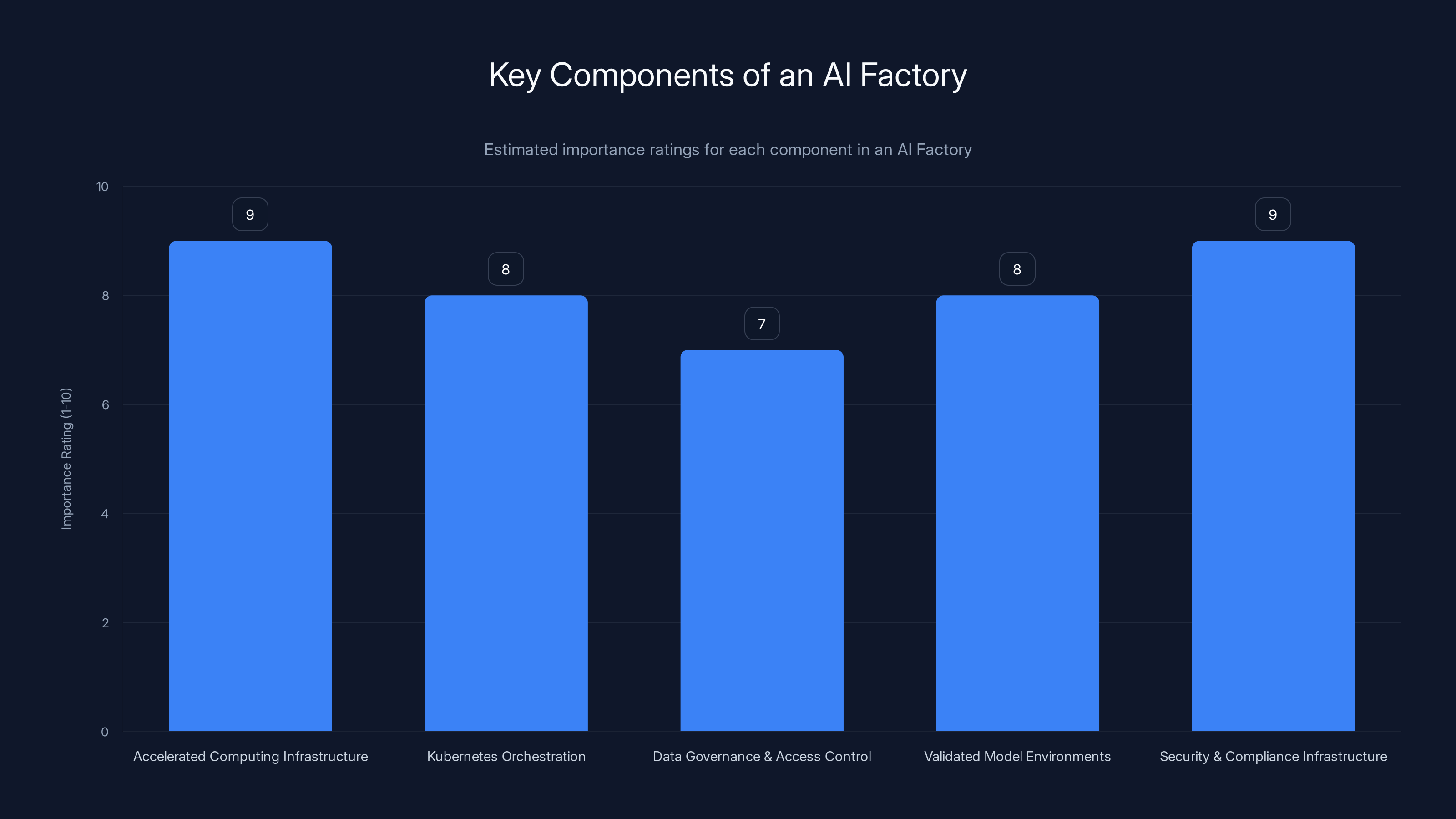
Accelerated computing infrastructure and security are rated highest in importance for AI factories, highlighting their critical roles. Estimated data.
Implementing an AI Factory: The Practical Path Forward
Okay, so you're convinced that an AI factory is the right architecture. How do you actually build one? This is the hard part because every organization is different.
Phase 1: Assessment and Foundation
Before building, understand where you are:
Audit your current state. How many separate AI systems are you running? How many teams are managing their own infrastructure? How long does it take to deploy a model? What compliance requirements do you have?
Identify quick wins. There are probably some things you can fix quickly that will improve the situation. Maybe you can standardize on a single GPU type. Maybe you can create a shared data repository. These quick wins build momentum and prove the value.
Build leadership alignment. An AI factory requires coordination across multiple teams: infrastructure, security, data, applications. You need leadership buy-in. This is a structural change, not just a technology change.
Plan for change management. Implementing an AI factory changes how teams work. You need training, documentation, and support to help teams transition.
Phase 2: Core Infrastructure
Start with the foundation:
Deploy production-grade Kubernetes. Use a managed service if possible (AWS EKS, Azure AKS, Google GKE) rather than building from scratch. Add GPU support and appropriate scheduling.
Implement centralized storage. Your AI workloads need reliable, performant access to training data and model artifacts. Deploy a data lake or data warehouse designed for this purpose.
Set up basic monitoring and logging. You can't operate what you can't see. Deploy monitoring and logging infrastructure early.
Implement security controls. Encryption, authentication, authorization, audit logging. Do this now, not later. It's much harder to retrofit security.
Phase 3: Platform Layer
On top of the core infrastructure, build the platform:
Deploy a model registry. This is where models live, along with their metadata, versions, and access controls.
Implement model serving infrastructure. This is how models get served to applications. It should handle versioning, A/B testing, canary deployments.
Build training infrastructure. This is how models get trained. It should handle job submission, resource allocation, artifact management.
Create development tools and SDKs. Teams shouldn't have to write complex Kubernetes YAML. Provide simple tools that abstract this complexity.
Phase 4: Governance and Operations
Once the platform is working:
Implement data governance. Catalog your data, classify it by sensitivity, implement access controls.
Establish model governance. Define approval processes. Require validation before production deployment. Implement monitoring for production models.
Create operations runbooks. What do you do when a model fails? When inference latency spikes? When a security vulnerability is discovered? Document the answers.
Build a data science platform team. Someone owns this infrastructure. They maintain it, support users, and evolve it based on feedback.
Phase 5: Continuous Improvement
Implementing an AI factory isn't a project—it's a journey:
Measure and iterate. Track metrics: deployment time, cost per inference, SLA attainment, team satisfaction. Use these metrics to guide improvements.
Expand services gradually. Add new capabilities as the foundation stabilizes. Better monitoring. Better integration with applications. Better cost optimization.
Build community. Create forums, documentation, and training so teams can learn and share experiences.
Invest in automation. As you learn what works, automate it. Automated security scanning. Automated testing. Automated deployment.
Common Mistakes and How to Avoid Them
I've seen organizations mess this up in predictable ways. Here's what not to do.
Mistake 1: Building Everything from Scratch
Some organizations try to build an AI factory entirely with custom code. Big mistake.
Kubernetes is already hard. GPU scheduling is already hard. Model versioning is already hard. Don't solve these problems from first principles. Use existing platforms and tools. You'll move faster and avoid building things that others have already solved.
There's a place for custom development—integrating with your specific compliance requirements, automating your specific business processes. But the core platform should be built on existing technology.
Mistake 2: Treating Security as an Afterthought
Some organizations build the AI factory first, then think about security. This doesn't work.
Security needs to be designed in from the beginning. It's much harder and more expensive to retrofit. Building an AI factory that you then need to tear apart to add security is wasteful.
Mistake 3: Ignoring Change Management
Implementing an AI factory changes how teams work. Teams that previously managed their own infrastructure are now using shared infrastructure. Teams that previously trained models manually now use automated pipelines.
If you don't manage this transition carefully, you get resistance. Teams don't adopt the new system. They work around it. The platform becomes irrelevant.
Invest in training, documentation, and support. Have advocates in each team. Be willing to customize the platform to fit how teams naturally work.
Mistake 4: Under-Investing in Observability
Some organizations build an AI factory but don't invest in monitoring and logging. When something goes wrong, debugging is hard. You don't know what's actually happening in your system.
Observability should be comprehensive. Every component should be instrumented. Logs should be centralized and searchable. Metrics should be collected and visualizable. Traces should connect requests across service boundaries.
Mistake 5: Failing to Account for Total Cost of Ownership
An AI factory has significant operational costs. You need a platform team to maintain it. You need to train users. You need to evolve the platform over time.
Some organizations build the initial system then starve it of resources. The platform becomes outdated. Security patches lag. New requirements can't be met. The platform becomes a burden rather than a benefit.
Budget for ongoing operations. A typical organization of 100 engineers might need 3-5 full-time staff maintaining the AI factory. This is an investment that pays back through faster time-to-deployment, lower costs, and reduced incidents.

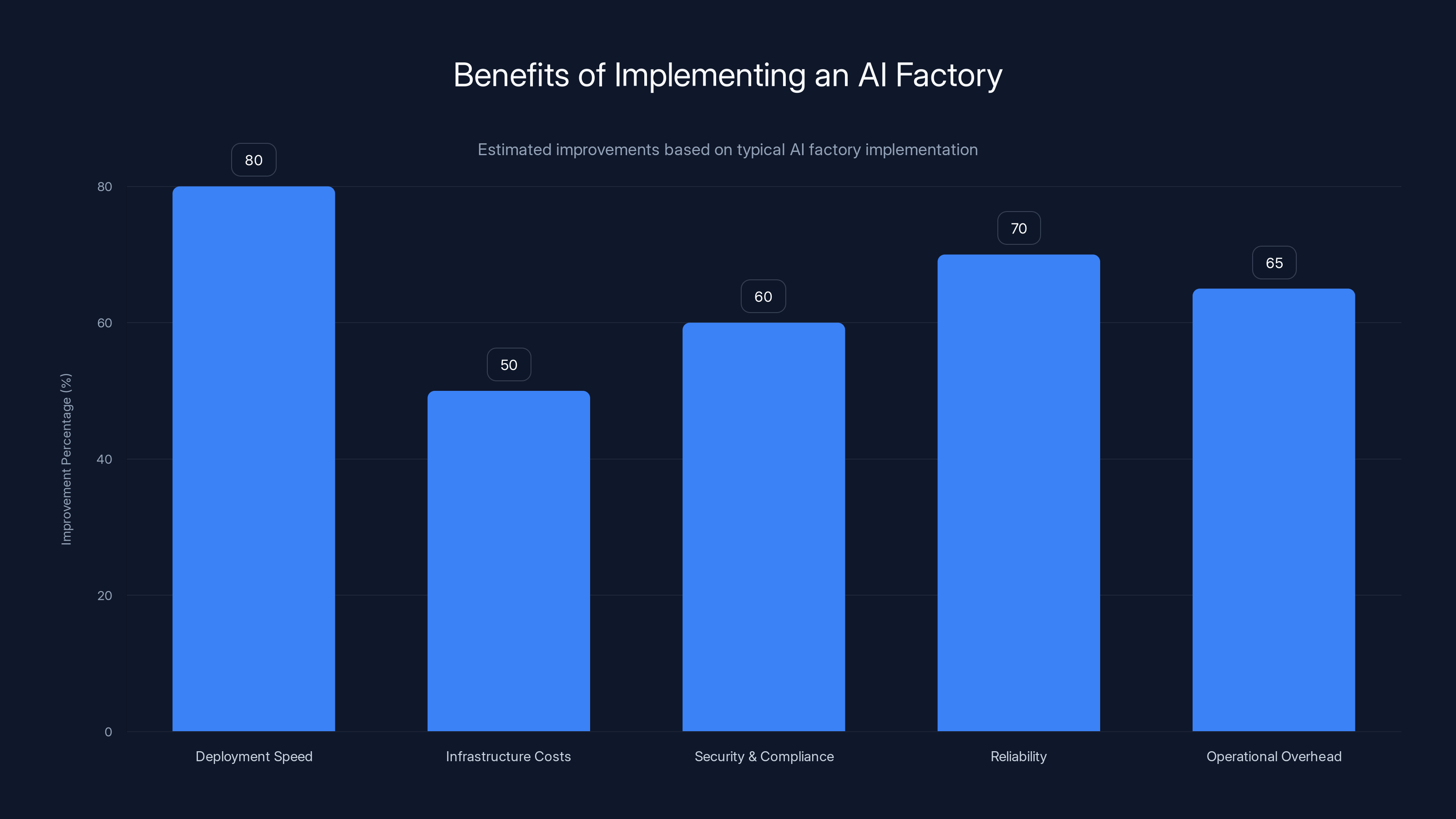
Implementing an AI factory can lead to significant improvements across various operational aspects, with deployment speed seeing the highest improvement at 80%. Estimated data.
The Future of AI Infrastructure
AI factories are the foundation for enterprise AI in 2025. But they're evolving.
Emerging Trends
Distributed AI factories. As organizations expand globally, they're deploying AI factories in multiple regions, each handling local data and workloads while sharing models and best practices.
AI-optimized silicon. Custom accelerators designed for specific AI workloads. As demand grows, we're seeing more specialized hardware. This creates scheduling complexity that AI factories are designed to handle.
Federated learning integration. Training models on distributed data without centralizing the data. AI factories are evolving to support this pattern.
Real-time AI. As models become more sophisticated, they're being deployed for real-time decisions. AI factories are evolving to support ultra-low-latency inference at scale.
Multimodal models at scale. Models that handle text, images, video, audio. Training and serving these models requires significant infrastructure evolution.
How to Stay Ahead
If you're building an AI factory:
Design for flexibility. Your AI factory will need to evolve. Hardware will change. Software will change. Regulatory requirements will change. Design systems that can accommodate change without complete rebuilds.
Invest in talent. Platform engineering is specialized. Finding and retaining great platform engineers is hard. Invest in recruiting and developing this talent.
Stay current with industry standards. Join communities, attend conferences, participate in open source projects. Understanding where the industry is heading helps you make good architectural decisions.
Plan for scale. Start small but design for growth. An AI factory that works for 10 models might not work for 100 models. Design so that you can scale without fundamental redesigns.
FAQ
What is an AI factory?
An AI factory is an integrated platform that brings together accelerated computing infrastructure, Kubernetes orchestration, data governance, model lifecycle management, and security controls into a unified foundation for building, deploying, and operating AI systems at enterprise scale. It transforms AI from isolated projects into a standardized, managed capability that the entire organization can leverage.
How does an AI factory differ from traditional ML infrastructure?
Traditional ML infrastructure typically consists of separate tools and systems that teams assemble themselves. An AI factory integrates these components into a cohesive platform with standardized processes, governance, and operations. The key difference is that traditional approaches are decentralized and fragmented, while an AI factory is centralized and standardized, leading to better cost efficiency, faster deployment, and improved reliability.
What are the main benefits of implementing an AI factory?
The primary benefits include dramatically faster model deployment (weeks to hours), significantly lower infrastructure costs through consolidation and optimization, improved security and compliance through standardized controls, better reliability and monitoring, reduced operational overhead through automation, and the ability to share models and infrastructure across teams. Organizations typically see ROI within 12-18 months.
How long does it take to build an AI factory?
Implementation timelines vary based on organizational size and complexity, but a typical phased approach takes 6-18 months from assessment to production maturity. Phase 1 and 2 (foundation) typically take 3-6 months. Subsequent phases add capabilities gradually. Quick wins in the first 1-2 months help build momentum and demonstrate value.
What are the main challenges in implementing an AI factory?
Common challenges include the technical complexity of integrating multiple systems, organizational change management as teams transition from isolated projects to shared infrastructure, the need for specialized platform engineering talent, the complexity of multi-tenant governance, and the significant ongoing operational costs. Underestimating change management and the need for continuous investment are frequent mistakes.
Do we need to migrate existing AI systems to an AI factory?
This depends on your situation. New systems should be built on the AI factory from the start. Existing systems can either be migrated (which requires effort but provides benefits) or coexist with the factory initially. A phased migration approach often makes sense. Start with the AI factory for new work, then gradually migrate existing systems as they need updates.
How does an AI factory handle regulatory compliance?
An AI factory enforces compliance through multiple mechanisms: data residency policies ensure data stays in required jurisdictions, encryption standards are enforced consistently, audit logging provides complete records of access and changes, access controls implement fine-grained permissions, and governance processes ensure models are validated before production. This built-in compliance infrastructure is much more efficient than manually implementing compliance for each system.
Can small organizations benefit from an AI factory?
Small organizations can benefit, but the approach should be scaled to their size. Instead of building comprehensive infrastructure, they might use a managed platform (like a cloud provider's AI platform) that provides AI factory capabilities without the operational overhead. The architectural principles apply regardless of scale. The key is standardization, governance, and shared infrastructure rather than size.
How does an AI factory support multi-cloud and hybrid environments?
A mature AI factory abstracts the underlying infrastructure, allowing workloads to run on-premises, in different clouds, or in hybrid configurations. This requires careful architecture but provides significant benefits: you're not locked into a single cloud provider, you can optimize costs by using different clouds for different workloads, and you can meet data residency requirements by deploying infrastructure in specific locations.
What skills are needed to maintain an AI factory?
Successful AI factory operation requires a mix of skills: Kubernetes expertise, cloud infrastructure knowledge, data engineering, security and compliance, Python and other programming languages, DevOps and automation skills, and understanding of ML workflows. Most organizations need a dedicated platform team of 3-10 people depending on scale. This team should include platform engineers, cloud architects, security engineers, and DevOps specialists.

The Bottom Line
AI has moved past the experimentation phase for most enterprises. The pilots are working. The business value is clear. Now comes the hard part: scaling reliably, safely, and cost-effectively.
That's what an AI factory enables.
It's not a product you buy, though commercial platforms can help. It's an architectural pattern, a way of thinking about how to organize AI infrastructure and operations. It's about recognizing that as AI moves from projects to platforms, the infrastructure needs to mature accordingly.
The organizations that are succeeding with enterprise AI aren't the ones with the fanciest models. They're the ones with the most mature infrastructure. They can deploy models in hours instead of months. They have reliable, auditable systems that regulators trust. They can share models across teams and consolidate resources efficiently. They have visibility into what's happening and can respond to problems automatically.
These capabilities don't happen by accident. They happen through deliberate architectural choices and sustained investment.
If you're still managing AI through silos and manual processes, you're already behind. The competitive advantage goes to organizations that can reliably operationalize AI at scale. Building an AI factory is how you get there.

Key Takeaways
- AI factories unify fragmented AI infrastructure into standardized platforms, reducing deployment time from weeks to hours and cutting infrastructure costs by 30-50%
- Production-grade Kubernetes and GPU orchestration abstract operational complexity, enabling data scientists to focus on innovation rather than infrastructure management
- Multi-tenant governance creates internal AI marketplaces where validated models are shared across teams with fine-grained access controls and resource isolation
- Security and compliance must be embedded architecturally from day one; regulations increasingly require comprehensive audit trails, encryption standards, and data residency controls
- Successful implementation requires 6-18 months of phased development, dedicated platform engineering talent, and sustained investment in operations and evolution
Related Articles
- Nvidia Vera Rubin AI Computing Platform at CES 2026 [2025]
- AMD Instinct MI500: CDNA 6 Architecture, HBM4E Memory & 2027 Timeline [2025]
- GenAI Data Policy Violations: The Shadow AI Crisis Costing Organizations Millions [2025]
- Articul8 Series B: Intel Spinoff's $70M Funding & Enterprise AI Strategy
- AI Isn't a Bubble—It's a Technological Shift Like the Internet [2025]
- CES 2026: Everything Revealed From Nvidia to Razer's AI Tools

