![AI Failover Systems: Enterprise Reliability in 2025 [Guide]](https://tryrunable.com/blog/ai-failover-systems-enterprise-reliability-in-2025-guide/image-1-1769004468328.webp)
AI Failover Systems: Why Enterprise AI Applications Need Automatic Rerouting [2025]
Last December, an Open AI outage took down a pharmacy's prescription refill system for hours. Real patients couldn't access their medications. Revenue tanked. The scary part? This wasn't a freak accident. It was a preventable crisis.
Enterprise AI systems have become mission-critical infrastructure. They power prescription refills, generate sales proposals, review contracts, and handle customer support. When they go down, the costs are brutal: thousands of dollars per minute in lost revenue, frustrated customers, SLA violations, and sometimes real human consequences.
Here's the problem nobody talks about enough. Unlike traditional cloud services from AWS or Azure, which have been perfecting reliability for decades, AI model providers are still figuring it out. Open AI, Anthropic, Google, and others operate mind-bogglingly complex systems that fail more often than enterprises expected. And when they do, there's no magic safety net. Your entire application stops working.
That's where AI failover systems come in. These are automated infrastructure layers that detect when a model provider goes down or degrades, then instantly reroute traffic to backup models without your users noticing anything happened. It's like having a backup power generator that switches on automatically before the lights even flicker.
The technology matters because the stakes keep getting higher. Companies aren't experimenting with AI anymore. They're betting their business on it. And that means reliability can't be an afterthought.
This guide covers everything you need to know about AI failover systems: how they work, why enterprises need them, what to look for when choosing one, and how to implement them without breaking your existing code. If you're building AI applications for production use, understanding this technology could save your company from a crisis you haven't anticipated yet.
TL; DR
- AI providers fail regularly: Major LLM services experience outages, slowdowns, or quality degradation every few weeks or months, affecting thousands of dependent businesses
- Single-provider dependency is risky: Unlike traditional cloud services with decades of reliability engineering, AI model providers operate newer systems prone to unexpected failures
- Failover goes beyond routing: Modern AI failover must handle output quality preservation, prompt adjustment, latency monitoring, and multi-region distribution simultaneously
- Degradation monitoring is critical: The most damaging failures aren't complete outages, they're partial degradations where systems stay up but performance silently erodes
- Automatic switching saves time and revenue: Enterprises implementing failover solutions can reroute traffic in minutes instead of hours, preventing thousands of dollars in losses
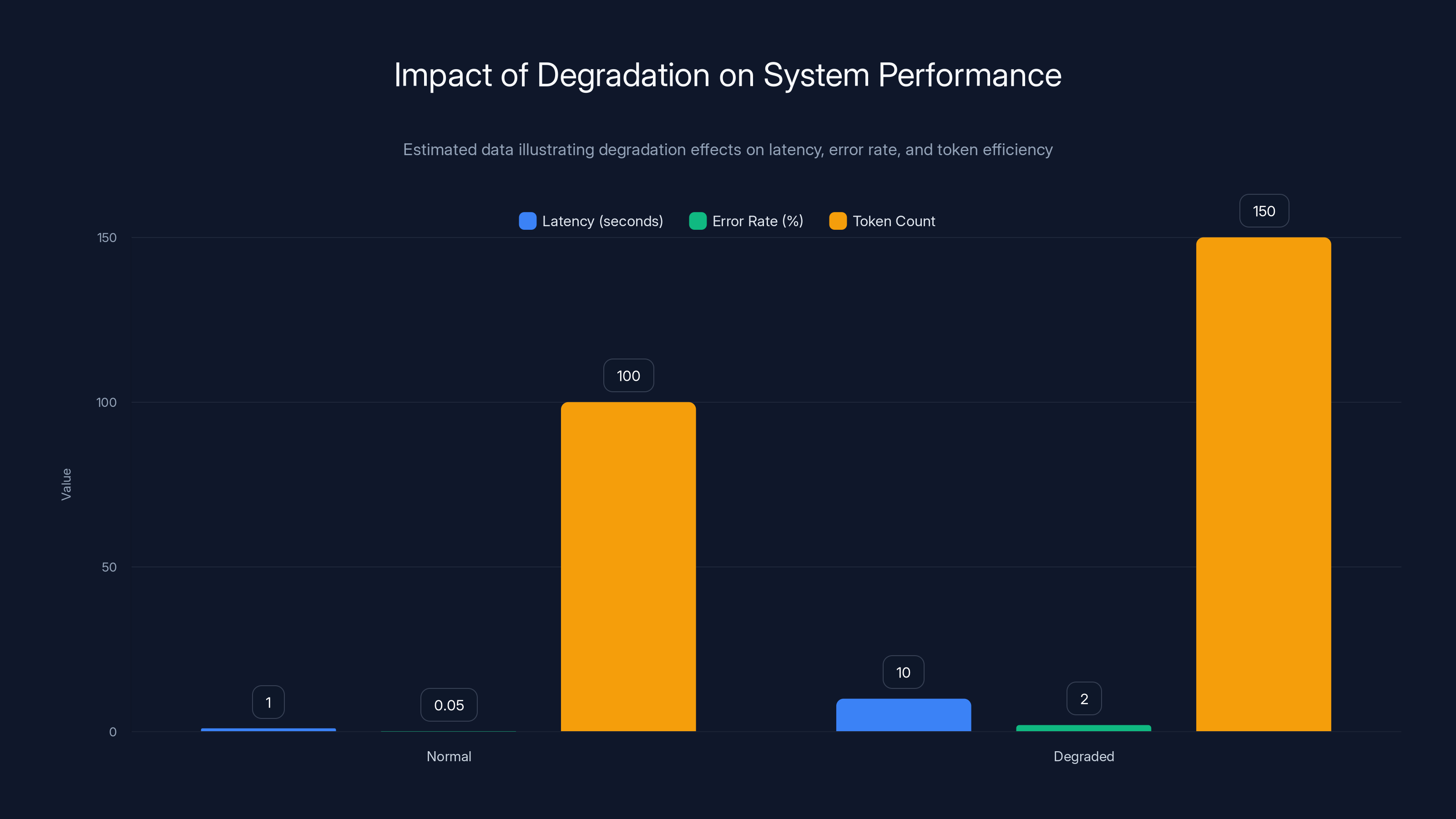
Estimated data shows significant increases in latency and error rates, and a rise in token count during degradation, indicating performance issues.
The Hidden Crisis: Why Single-Provider AI Infrastructure is Dangerously Fragile
When people talk about cloud reliability, they reference five-nines availability: 99.999% uptime, meaning roughly five minutes of downtime per year. AWS and Azure have spent decades building redundancy, failover mechanisms, and monitoring systems that make this standard feel normal.
But AI model providers? They're operating from a completely different playbook. These systems are newer, more resource-intensive, and less predictable. Open AI has experienced multiple significant outages in the past year alone. Google's Gemini API has had slowdown episodes. Anthropic's Claude experiences occasional performance degradation under heavy load. These aren't failures of unreliable companies. They're inherent to how modern LLM systems work.
Here's what makes AI systems uniquely fragile compared to traditional cloud infrastructure. Large language models run on shared clusters of expensive GPU and TPU hardware. When demand spikes for one customer, it can affect all customers sharing that hardware. The systems are probabilistic, meaning they're inherently harder to predict and test. Inference loads are highly variable and impossible to forecast accurately. And the sheer computational complexity means cascading failures can occur in unexpected ways.
Take the December Open AI outage that affected the pharmacy in our earlier example. The company had built a critical business process around Chat GPT's reliability. They'd tested the integration thoroughly. The system worked perfectly in production for months. Then one day, without warning, Open AI went down. Not their fault. Not the pharmacy's fault. Just the reality of depending on infrastructure you don't control.
The economic impact is staggering. For a healthcare company processing hundreds of prescriptions per hour, even a two-hour outage means thousands of dollars in lost revenue. For a customer support operation, every minute of downtime is customers sitting in a queue getting frustrated. For a financial services company using AI to generate trading insights, an outage could mean missed market opportunities worth millions.
Worse than complete outages are the partial failures. These are the silent killers. A model provider might not be fully down, but responses start taking 30 seconds instead of 2 seconds. Error rates spike from 0.1% to 2%. Quality degrades subtly. The service is "up" so traditional monitoring doesn't alert. But user experience tanks. SLA violations accumulate. Revenue leaks out slowly instead of stopping all at once.
The root cause of this fragility is architectural. Enterprise infrastructure like AWS is designed with redundancy baked in. Multiple availability zones. Automatic failover. Circuit breakers. Rate limiting. Years of observability. AI model providers are still building these capabilities. They're adding redundancy, but they're doing it in parallel with billions of requests hitting their systems. It's like rewiring an electrical grid while people are still flipping light switches.
This is why single-provider AI infrastructure is essentially asking for a crisis. It's not a question of if your primary AI provider will experience issues. It's when. And when it happens, every second without a failover strategy becomes increasingly expensive.
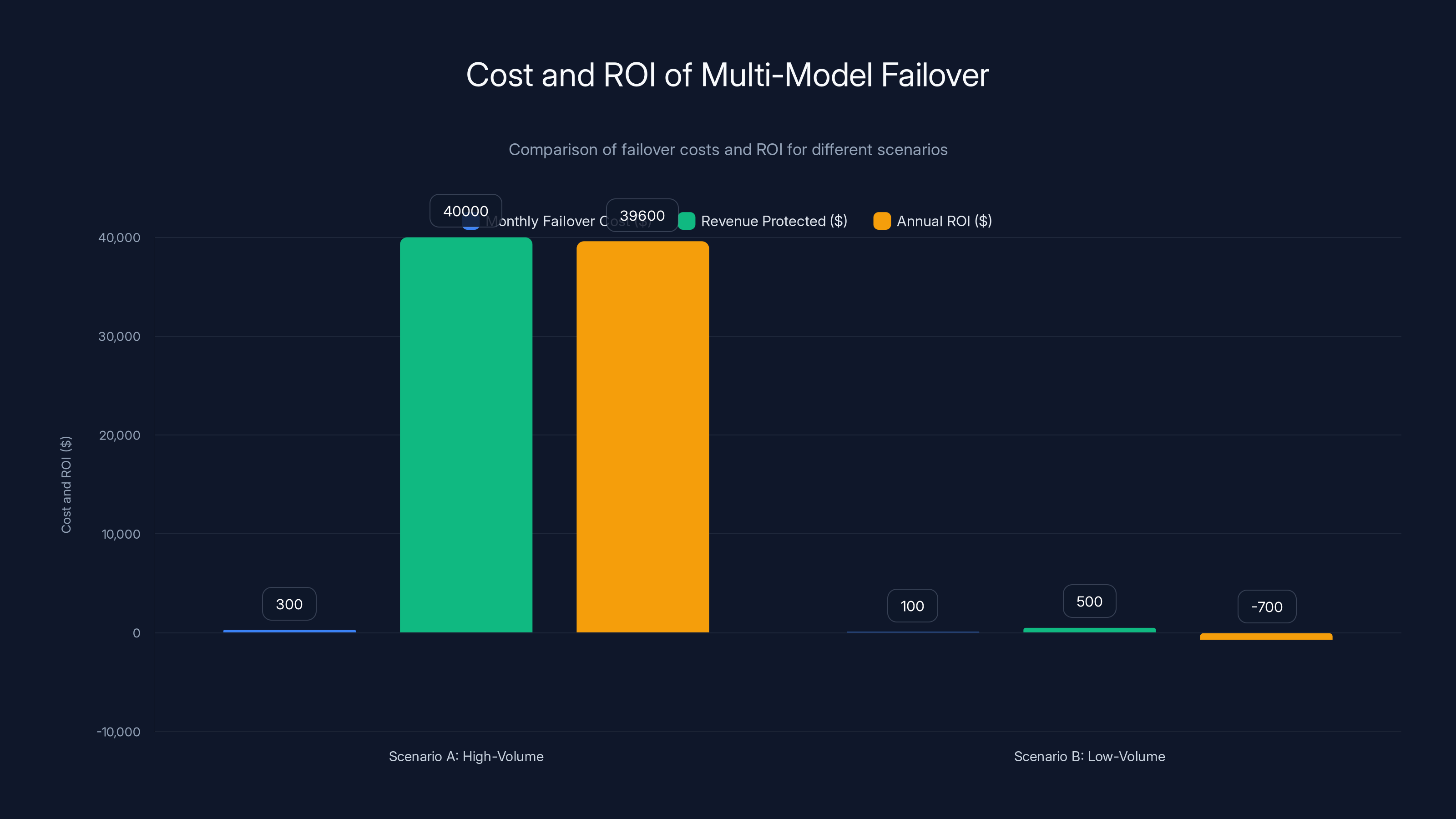
Scenario A shows a high ROI due to significant revenue protection, justifying failover costs. Scenario B has a negative ROI, indicating failover is not economically viable.
Understanding AI Failover: More Complex Than Traditional Failover
Traditional failover is relatively straightforward. Your database is down? Switch to the backup database. Your API server crashes? Route requests to a replica. The data is the same. The interface is the same. The experience is identical.
AI failover is messier. When you switch from Open AI's GPT-4 to Anthropic's Claude or Google's Gemini, you're not just switching connections. You're switching entirely different models with different training data, different instruction-following behavior, and different output patterns.
Consider a simple example. You have a sales proposal generator running on GPT-4. It uses a carefully engineered prompt that works perfectly. Now Open AI goes down. You failover to Claude. Same prompt. Completely different output. Claude formats the proposal differently. It organizes sections in a different order. The tone is different. To your users, it feels like the entire product broke, not just the backend.
There's more. Latency profiles are different. GPT-4 might respond in 800 milliseconds while Claude takes 2 seconds. If your users are accustomed to instant responses, the Claude failover feels slow even though it's working fine. Some models support features others don't. GPT-4 might support vision input while Gemini does but Claude doesn't. Switching models means handling feature incompatibilities on the fly.
Then there's the quality angle. Some models are better at certain types of tasks. GPT-4 might be excellent at reasoning but Claude might be better at creative writing. When you failover to a "worse" model for your specific use case, the quality of generated content might degrade enough that users notice immediately. Maintaining quality across model switches requires understanding the relative strengths of each model and being able to adjust prompts in real-time.
This is why naive failover approaches fail. Many teams think they can just implement basic model switching. You can't. Effective AI failover requires a system intelligent enough to:
- Detect not just complete outages but performance degradation
- Adjust prompts in real-time to work with different models
- Monitor output quality to catch degradation before users do
- Handle latency differences without breaking user experience
- Manage feature incompatibilities automatically
- Balance cost against quality when switching models
- Maintain consistency in responses across model switches
Building all of this manually is incredibly complex. That's why specialized failover systems exist. They abstract away this complexity and handle the hard parts automatically.

How Modern AI Failover Systems Work: The Technical Foundation
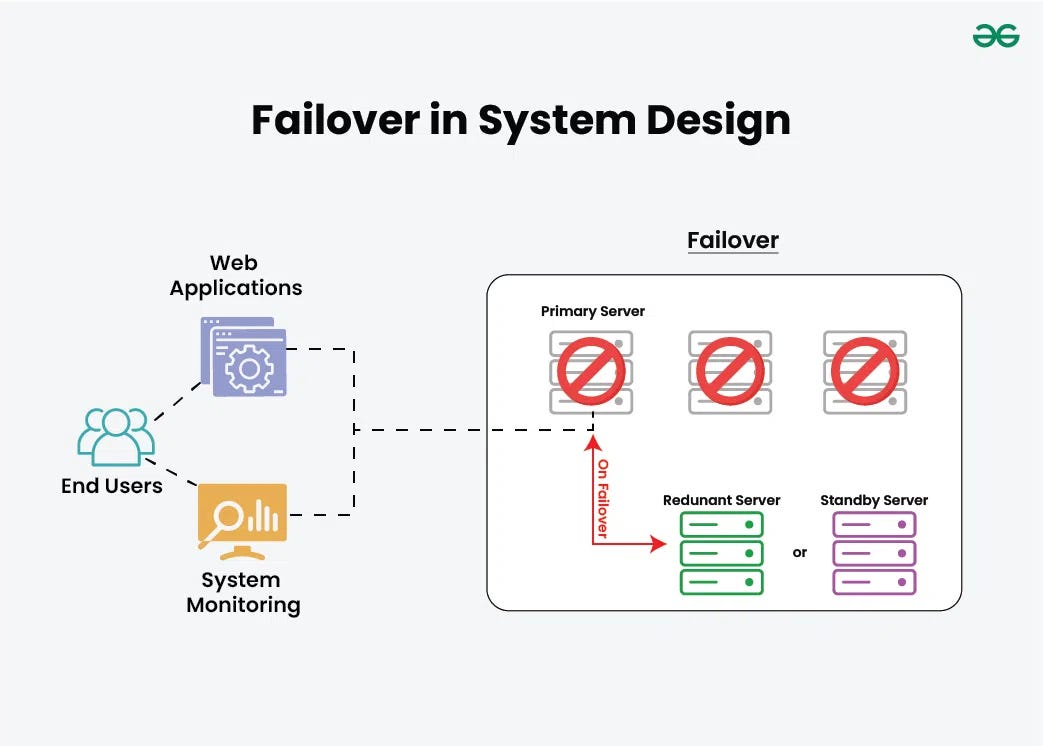
At its core, an AI failover system sits between your application and the AI model providers. It acts as an intelligent router and proxy that watches everything happening on the API calls and makes real-time decisions about where to send traffic.
The architecture typically looks like this:
Your application → Failover gateway → Model provider APIs
Instead of your code directly calling Open AI or Anthropic, it calls the failover system. The failover system maintains connections to multiple model providers. It forwards your request to the primary model but continuously monitors what happens. If problems occur, it transparently reroutes to backup models without your application noticing.
Let's walk through what happens when a provider fails.
Detection: The failover system monitors several signals simultaneously. It watches response latency. It tracks error rates. It measures output quality through various heuristics. It checks if responses are degrading in subtle ways. Most importantly, it doesn't rely on a single signal. When response times spike AND error rates increase AND quality metrics dip, that's when the system knows something is wrong. Individual signals can be noisy, but multiple signals together form a clear picture.
Decision Making: Once problems are detected, the system evaluates available backup options. Which backup model is available right now? How is its quality for this specific use case? What's the latency? What's the cost? The system quickly ranks alternatives and selects the best option. If multiple backups are equally good, it might load-balance between them.
Execution: The system forwards the request to the selected backup model. This is where prompt adjustment happens. If the backup model needs the prompt slightly reworded for best results, the system handles it. If the backup model doesn't support certain features, the system adapts. The user's application code doesn't change at all.
Monitoring: The failover system continues monitoring the backup model's performance. If the backup starts failing too, it can chain failovers, rerouting to a third model if needed. This ensures your application stays online through cascading failures.
Learning: Over time, the system learns which models work best for different types of requests. It builds profiles showing that GPT-4 is best for reasoning tasks, Claude for creative writing, Gemini for multimodal analysis. This historical learning improves future routing decisions.
Implementing this properly requires sophisticated infrastructure. Most teams can't build it from scratch and maintain it. That's why specialized solutions exist.
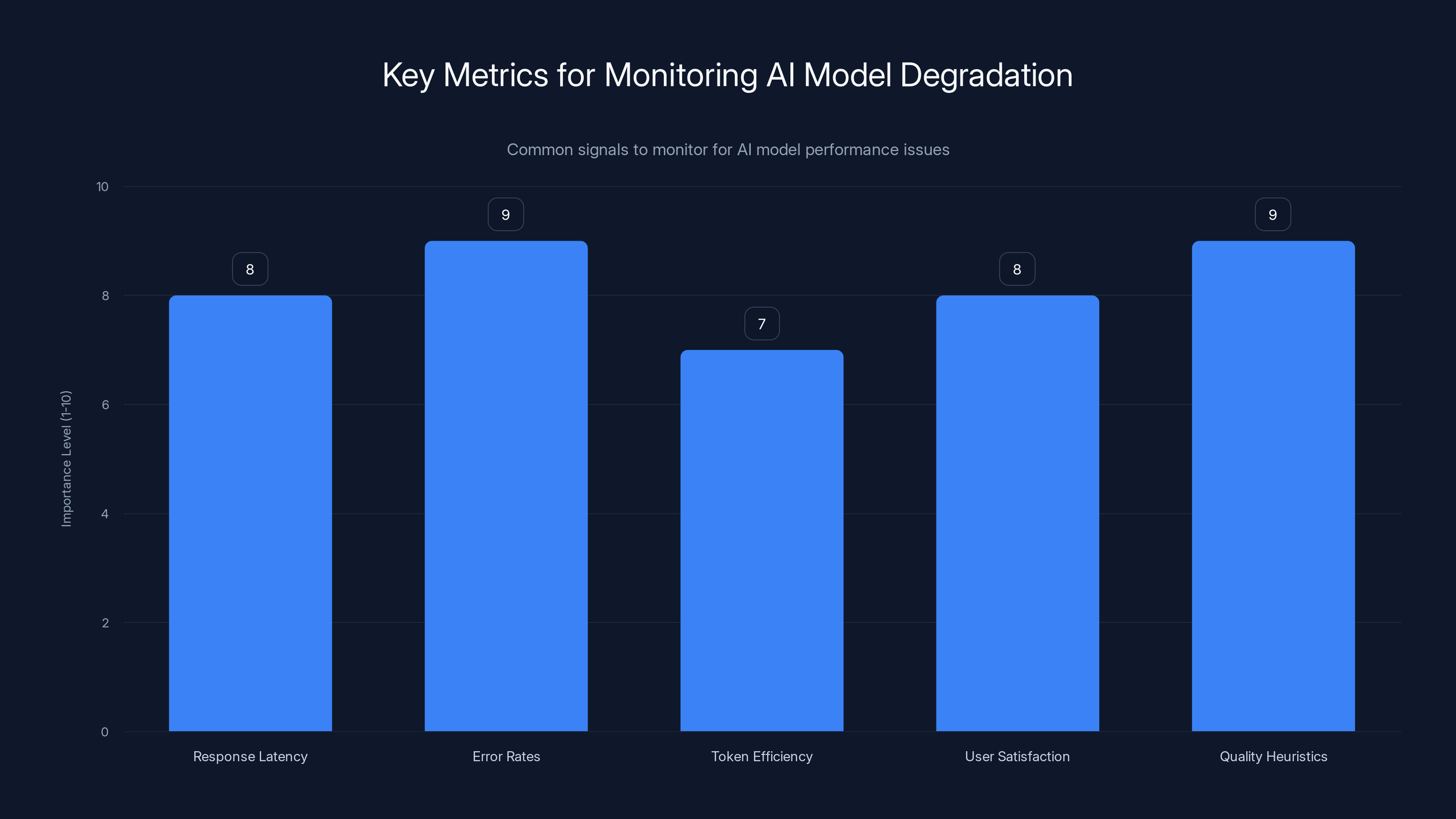
Monitoring multiple signals such as error rates and quality heuristics is crucial for detecting AI model degradation. Estimated data based on typical monitoring practices.
Multi-Model Failover: The Foundation of AI Resilience
Multi-model failover is the simplest form of AI failover and it's also the most essential. The basic principle is straightforward: configure your primary model, define one or more backup models, and let the system switch automatically if the primary fails.
But implementing this effectively involves more complexity than it appears. First, you need to choose your backup models strategically. You shouldn't just pick random alternatives. Consider these factors:
Capability alignment: Your backup model should be capable of handling the same types of requests as your primary. If your primary is GPT-4, Claude 3 Opus is a good backup because it's similarly capable. Mistral 7B would be a weaker choice because it's significantly less sophisticated.
Cost considerations: When you failover to a backup, you might be accepting higher costs per request. Claude is more expensive per token than some alternatives. Gemini 1.5 Flash is cheaper than GPT-4. Understanding the cost implications of each failover helps you make informed decisions about which backups to use.
Provider independence: Ideally, your backups come from different companies. Having Open AI as primary and Azure Open AI as backup isn't real redundancy because they're the same underlying model. Having Open AI, Anthropic, and Google creates real provider independence.
Availability zones: When choosing backups, consider geographic distribution. If your primary model provider is experiencing regional issues, you want backups in different regions. Some providers run distributed infrastructure, but knowing their backup locations helps you make better decisions.
Feature support: Different models support different features. Vision, tool use, JSON output, thinking tokens, etc. When selecting backups, verify they support the features your application needs.
Once you've selected your backups, the failover system needs to be configured with fallback chains. Your primary choice goes here, then your first backup, then your second backup, etc. The system will work down this chain until it finds an available model.
A good fallback chain might look like:
- Primary: Open AI GPT-4 (most capable, best quality)
- Backup 1: Anthropic Claude 3.5 Sonnet (equally capable, good quality)
- Backup 2: Google Gemini 2.0 (capable, slightly lower quality for some tasks)
- Backup 3: Mistral Large (decent fallback, significantly cheaper)
- Final: Self-hosted model (always available, lower quality)
When Open AI is healthy, all requests go to GPT-4. If Open AI starts experiencing issues, the system automatically tries Claude. If Claude is also having problems, it moves to Gemini. And so on.
The beauty of this approach is that application code doesn't change. Your code still calls the same API endpoint. The failover system handles all the switching transparently. This is crucial for production systems where you can't afford to change code in the middle of an incident.
Multi-model failover has limitations though. It doesn't help if all major providers are down simultaneously, which is rare but possible. It assumes you have access to multiple paid APIs, which adds cost. And it requires upfront knowledge of which models will work best for your use cases, which demands testing and experimentation.
But as a foundation, multi-model failover is non-negotiable. Every enterprise AI application should have at least one backup model configured and tested.

Degradation-Aware Routing: Catching Problems Before Users Do
Complete outages are obvious. The model provider's API returns errors. The system can't miss it. Way more common and way more dangerous are the partial failures where everything appears to work but performance is degrading silently.
A model might slow down from 1-second responses to 10-second responses. Technically it's working. Error rates might increase from 0.05% to 2%, but 98% of requests still succeed. Quality might subtly degrade, with responses becoming less helpful or more generic, but not catastrophically. These scenarios devastate user experience while evading traditional monitoring that only looks for hard failures.
Degradation-aware routing solves this by monitoring a combination of signals that together indicate when a model is having problems:
Latency monitoring: The system measures how long each request takes from submission to response. It compares current latency against historical baselines. When responses start taking 5x longer than normal, that's a signal something's wrong. But latency alone isn't enough because different requests naturally take different times. A complex question might legitimately take longer than a simple one.
Error rate tracking: The system counts how many requests fail versus succeed. A sudden spike from 0.1% errors to 5% errors indicates problems. But error rate in isolation can be misleading too. If users are sending bad prompts, error rates might spike legitimately. The system needs context.
Token efficiency: For language models, tokens matter. Some models are more verbose than others. A model starting to produce longer responses than it did historically might indicate quality degradation. The system tracks average token counts and flags when they deviate significantly.
Quality heuristics: The system can apply various heuristics to detect quality degradation. If responses are becoming repetitive, that's a signal. If they're becoming off-topic, that's another signal. If they're becoming less helpful based on feedback signals, that matters too.
User satisfaction signals: The best signal is actual user feedback. If users are rating responses lower than historical averages, that's the clearest sign quality is declining. Some systems integrate user thumbs-up/thumbs-down feedback as explicit quality signals.
The key insight is that no single signal tells the whole story. But when multiple signals move in the same direction simultaneously, the picture becomes clear.
Consider this scenario: Response time increases 2x AND error rate increases 3x AND user satisfaction drops 15% AND token counts jump 20%. Individually, any one of these could have an explanation. Together, they signal that the model is degraded and needs failover.
Degradation-aware routing requires machine learning or sophisticated rule engines to weight these signals correctly. Too sensitive and you'll failover for normal variations. Too insensitive and you'll miss real problems. Good systems learn from historical data to set appropriate thresholds.
Once degradation is detected, the system doesn't necessarily failover immediately. Instead, it might:
- Start load-balancing new requests between primary and backup
- Send a subset of traffic to the backup to test it
- Gradually shift more traffic to the backup if it performs better
- Only full failover if degradation becomes severe
This graduated approach reduces the risk of failover to a lower-quality backup. If the primary is experiencing a temporary blip that resolves in seconds, you don't want to have fully switched to a worse model.
The challenge is calibrating these systems correctly. Set thresholds too high and you miss problems. Set them too low and you failover constantly for normal variations. Most systems require several weeks of baseline data before they can detect degradation accurately.

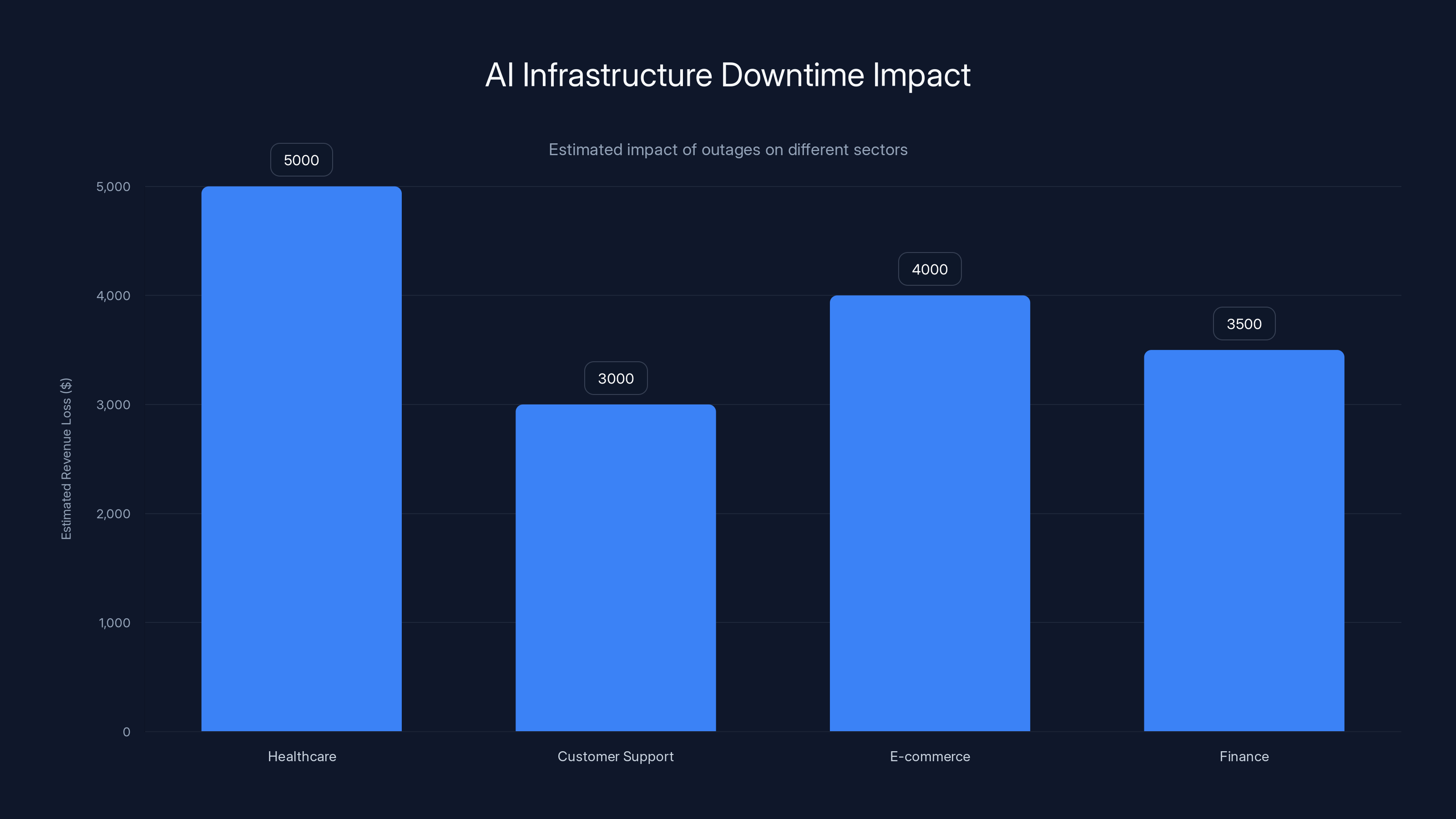
Estimated data shows that AI infrastructure outages can lead to significant revenue losses across various sectors, with healthcare potentially losing up to $5000 in just two hours.
Multi-Region and Multi-Cloud Resilience: Geographic Distribution Matters
Many enterprises serve customers globally. They need AI responses in milliseconds, not seconds. This creates an architecture problem: where should the AI processing happen? If everything routes through a single data center in one region, latency for distant users becomes problematic.
Multi-region resilience addresses this by deploying AI endpoints in multiple geographic locations. Your primary might be in us-east-1, but you have backups in eu-west-1, ap-southeast-1, etc.
Why does this matter for failover? Consider a scenario where Google Gemini's us-east-1 infrastructure experiences issues but their eu-west-1 region is fine. With multi-region awareness, the failover system can route traffic to Gemini eu-west-1 instead of completely switching to a different provider. This preserves the primary model choice while avoiding the degraded region.
Multi-cloud resilience takes this further. Instead of relying on one provider's infrastructure, you distribute across multiple cloud providers. Your primary might run on AWS, your backup on Google Cloud, and your tertiary on Azure. This protects against not just model provider issues but entire cloud infrastructure failures.
Implementing this requires several architectural pieces:
Geographic routing: The failover system must know where requests originate and route to the nearest healthy endpoint. This reduces latency and distributes load geographically. If a request comes from Singapore, route to the ap-southeast-1 endpoint. If it comes from Frankfurt, route to eu-central-1.
Region-aware failover: When an endpoint in one region has problems, failover to a different endpoint in the same region first, then to other regions only if necessary. This keeps latency low while avoiding failed infrastructure.
Load balancing across regions: Even when everything is healthy, distributing requests across regions reduces load on any single endpoint and improves resilience. If one region has issues, the others can handle overflow.
Latency monitoring: The system must measure latency to each region and prefer low-latency paths. A failover to a geographically distant endpoint is better than an outage, but routing to a close endpoint is better still.
Multi-cloud setup adds complexity but significantly improves resilience. The trade-off is cost and operational overhead. You're maintaining relationships with multiple cloud providers and infrastructure in multiple regions.
A practical multi-region setup might look like:
Primary: Open AI GPT-4 on AWS us-east-1 Region failover: Open AI GPT-4 on AWS eu-west-1 (same model, different region) Model failover: Anthropic Claude on AWS us-east-1 (same region, different model) Full failover: Gemini on Google Cloud us-central 1 (different provider, different region)
This chain handles regional outages, model-specific issues, and complete provider failures.
Prompt Adaptation and Quality Preservation During Failover
Here's a problem most people don't anticipate until they hit it in production. You've carefully crafted a prompt that works perfectly with GPT-4. It has specific instructions formatted exactly how GPT-4 understands them. It includes few-shot examples. It uses system prompts in a particular way.
Now you failover to Claude. Same exact prompt. Completely different output. Not because Claude is worse. Just because Claude was trained differently and interprets instructions differently.
Quality preservation during failover requires the system to adapt prompts in real-time to work well with backup models. This is harder than it sounds because you're trying to solve a complex problem instantly in production.
One approach is prompt templates with model-specific variants. Instead of a single prompt, you have a template that can be rendered for different models:
GPT-4 version:
"You are a sales expert...[specific instructions GPT-4 likes]"
Claude version:
"You are a sales expert...[slightly different phrasing Claude prefers]"
Gemini version:
"You are a sales expert...[structured format Gemini prefers]"
When the failover system switches models, it also switches to the appropriate prompt variant. This preserves output quality because each prompt is optimized for its model.
Developing these variants requires experimentation. You need to test your prompt with each backup model, observe the output quality, and iterate until all variants produce acceptable results. This is ongoing work because model versions change, training data changes, and what works today might not work tomorrow.
Another approach is using a language model to transform prompts. You could have a system prompt that says "translate this prompt to work optimally with Claude 3.5 Sonnet." The system uses a small, fast model to do this translation in real-time before sending to the backup model. This is clever but has latency costs.
Some systems use output post-processing to improve quality after failover. If the backup model produces output that's too verbose or formatted incorrectly, a post-processing step cleans it up before returning to the user. This is less elegant than prompt adaptation but easier to implement.
The most sophisticated systems combine multiple approaches. They have model-specific prompt variants for common use cases, plus a fallback transformation system for unusual cases, plus output normalization as a final safety net.
Testing is critical here. Before relying on failover in production, run extensive tests with your actual prompts against all backup models. Compare outputs. Measure quality. Iterate until you're confident the failover experience is acceptable to your users.
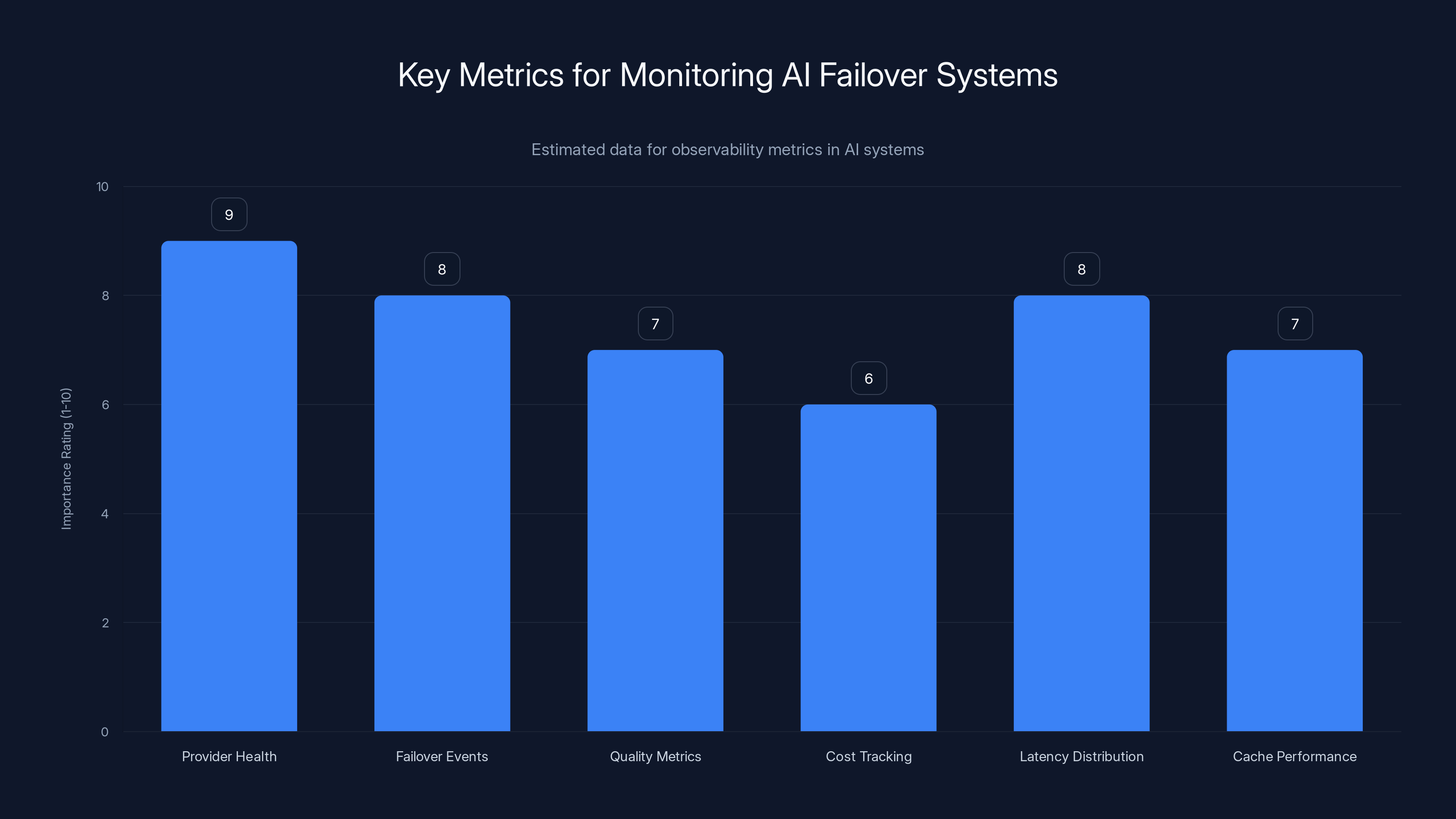
Provider health and failover events are rated as the most critical metrics for monitoring AI failover systems, followed by latency distribution. Estimated data.
Caching and Load Shedding: Preventing Cascading Failures
One of the most insidious failure modes in AI systems is cascading failure. Your application gets popular. Traffic spikes. The primary model gets overwhelmed. Response times increase. Your system detects degradation and starts failover. But the backup is already overloaded because you're sending overflow traffic to it. So the backup fails too. Now you're out of options.
Caching prevents this by storing frequently requested responses. When traffic spikes and the primary model is struggling, the cache serves responses from historical data instead of hitting the primary. This reduces load and often lets the primary recover before failover is necessary.
Cache hit rates matter enormously. If your application asks the same questions repeatedly, caching can handle 30-50% of requests without touching any model. If your application asks unique questions constantly, caching might help only 5% of requests. Designing your prompts and questions to be cacheable improves resilience significantly.
Smart caching strategies include:
Semantic caching: Instead of exact-match caching, cache by meaning. If you've cached a response to "What is the capital of France?" you can serve that cache for "What's the capital of France?" even though the text is different. This requires semantic similarity matching but increases hit rates.
Tiered caching: Keep short-lived caches for very recent questions, medium-lived caches for popular questions, and long-lived caches for evergreen questions. Different questions need different cache durations.
User-specific caching: Some responses are personalized to users. Cache them in ways that respect privacy and user context.
TTL optimization: Balance freshness against hit rates. Responses cached for 1 hour might be stale. Responses cached for 1 minute might not improve hit rates. Find the sweet spot for your use case.
Load shedding complements caching by gracefully degrading service during extreme load. Instead of trying to process every request and failing on all of them, you process some requests with high quality and reject others with a clear message.
Load shedding policies might include:
- Priority queuing: Process requests from premium customers first, standard customers second
- Rate limiting: Limit requests per user, per application, or per region
- Circuit breakers: Stop accepting new requests when queues exceed thresholds
- Graceful degradation: Return cached or simplified responses instead of errors
Implementing load shedding requires clear policies about fairness and user expectations. Users need to understand why their requests are rate-limited or why they're getting cached responses instead of fresh ones. Most systems make this explicit with response headers and messages.
Combining caching, load shedding, and failover creates a comprehensive resilience strategy. Caching handles most failures by preventing them. Failover handles the failures caching misses. Load shedding ensures you never completely collapse even if everything else fails.

Monitoring and Observability: Knowing What's Actually Happening
You can have the best failover system in the world, but if you can't see what's happening, you're flying blind. Observability in AI failover systems means understanding:
- When providers are having issues
- Which requests are failover requests versus primary requests
- How quality changes during failover
- What's expensive and what's cheap
- Where latency is coming from
- Whether users are getting the experience you expect
Good observability requires dashboards showing key metrics:
Provider health: Which providers are up, degraded, or down. Response times for each provider. Error rates for each. This should be visible at a glance.
Failover events: How often failover is triggered. Which models trigger failover most frequently. How long failover events last. Whether failover successfully resolves issues.
Quality metrics: Are responses from backup models acceptable? Is user satisfaction maintained during failover? Are customers complaining more after failover?
Cost tracking: How much does using each provider cost? If you're failover to expensive models, how much extra is that costing? Can you optimize by choosing cheaper backups?
Latency distribution: What percentile of requests are fast, slow, very slow? Track 50th, 95th, and 99th percentile latencies. Failover to slower models should be obvious in latency metrics.
Cache performance: How many requests hit the cache? What's the hit rate? Is caching actually reducing load as expected?
Most importantly, monitoring should surface issues before they become crises. Alerts should trigger when:
- A provider's error rate exceeds thresholds
- Response latency spikes above historical norms
- Failover is triggered
- Cache hit rates drop suddenly
- Cost per request increases unexpectedly
- User satisfaction metrics degrade
The challenge is avoiding alert fatigue. Set thresholds too low and you get false alarms constantly. Set them too high and you miss real problems. Good monitoring takes calibration and iteration.
Observability should also track what users experience, not just what systems experience. If internal metrics look fine but users are complaining, something's wrong. Include user-facing metrics like:
- Response accuracy on test questions
- User satisfaction ratings
- Feature availability (can users do what they need to do?)
- Support ticket volume (more tickets might indicate issues)
- Session success rates (do user sessions complete or error?)
Integrating user experience metrics with technical metrics creates a complete picture of system health.
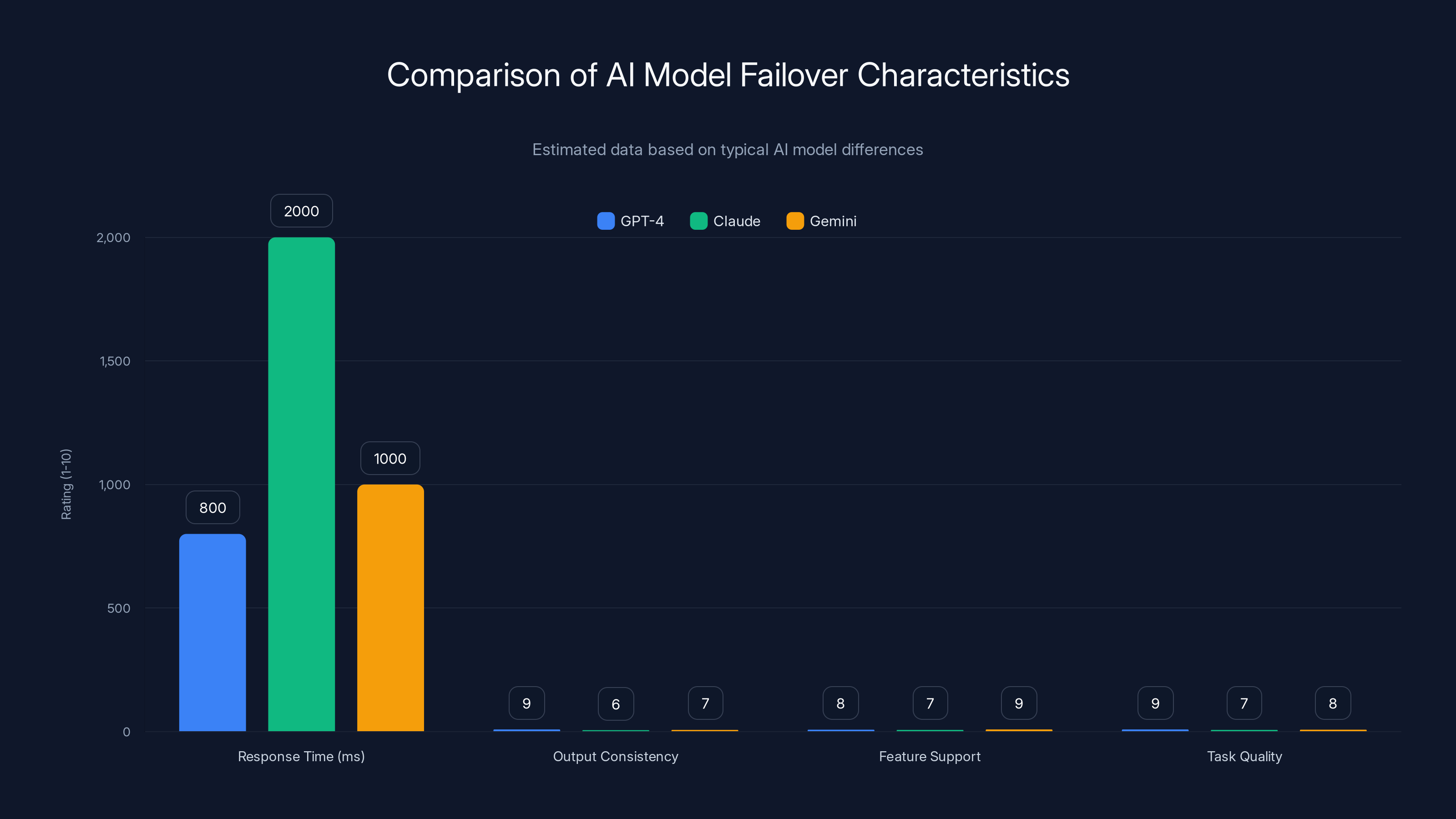
Estimated data shows GPT-4 generally has faster response times and higher output consistency, while Gemini offers better feature support. Claude may excel in creative tasks but has slower response times.
Cost Implications: The Economics of Multi-Model Failover
Here's an uncomfortable truth: having backups costs money. You're paying for API access to multiple models. When you failover, you might switch to a more expensive model. Running distributed infrastructure across regions adds costs. Caching and monitoring infrastructure costs something too.
Understanding the economics of failover helps you make intelligent trade-offs. Some scenarios justify the cost. Others don't.
Consider the math:
Scenario A: You run a high-volume customer support chatbot
- Volume: 1 million requests per month
- Primary model: GPT-4 (cheaper tier), $0.0005 per token, average 500 tokens per request
- Cost: $250/month
- Failover model: Claude, $0.003 per input token, average 500 tokens
- Failover cost: $1,500/month
- Failover frequency: 4 hours per month (0.5% of time)
- Monthly failover cost: 7.50
- Total cost with failover infrastructure: ~$300/month
- Revenue protected: If 1-hour outage loses 40,000/month
- ROI: Massive. Failover costs 40,000 loss.
Scenario B: You run a low-volume internal tool
- Volume: 1,000 requests per month
- Primary model: GPT-4, cost per request = $0.15
- Total cost: $150/month
- Revenue protected per outage: $500
- Expected outages: 1 per year
- Revenue protected: $500
- Failover infrastructure cost: $100/month
- Annual ROI: 100 × 12) = -$700
- Verdict: Failover isn't justified economically
These calculations show that failover's economics depend entirely on your revenue at stake during outages. High-revenue operations always justify failover. Low-revenue operations rarely do.
Other cost considerations:
Model choice matters: Failing over to a much more expensive model tanks your economics. Good failover strategy includes cheaper backups for non-critical requests. Process high-value requests with expensive premium models. Process low-value requests with cheaper alternatives even without failover.
Volume discounts: Spreading requests across multiple models usually disqualifies you from volume discounts. Keeping most traffic on one model preserves discounts. This is another reason to make failover selective, not total.
Infrastructure costs: Running monitoring, caching, and failover logic requires servers. This cost is fixed regardless of whether you actually failover. At low volumes, this fixed cost becomes significant. At high volumes, it's negligible.
Incident response costs: If your team has to spend hours responding to outages, that's expensive. Automated failover reduces incident response costs even if the model cost stays the same.
Intelligent cost optimization means:
- Design failover selectively, not for all requests
- Use cheaper models for less critical requests
- Implement aggressive caching to reduce overall model usage
- Monitor costs continuously and adjust thresholds
- Negotiate volume discounts based on total usage across models
Implementing Failover: Practical Architecture Patterns
Implementing failover in your application requires architectural changes, but good systems make these changes minimal. Your application code shouldn't need to change.
The most elegant approach is a proxy pattern. Instead of your code calling Open AI directly, it calls a local failover gateway. The gateway handles all the complexity.
Before failover:
Your Code → Open AI API
After failover:
Your Code → Failover Gateway → Open AI API (when healthy)
→ Claude API (when Open AI fails)
→ Gemini API (when Claude fails)
From your code's perspective, nothing changed. You make the same API call. The gateway handles all the routing, prompt adaptation, monitoring, and failover logic internally.
Implementing a gateway requires:
API compatibility: The gateway must expose the same API interface as the primary model. If your code is calling Open AI's API, the gateway must accept Open AI API calls and return Open AI API responses.
Transparent routing: When the gateway forwards requests to backup models, it must adapt them to match the backup's API. This includes converting Open AI API calls to Claude API calls, for example.
State management: Some conversations require state. If you're doing multi-turn conversations, the gateway must maintain conversation history and route subsequent turns to the same model.
Authentication: The gateway needs credentials for all models it might failover to. Managing these credentials securely is important.
Latency tracking: The gateway should measure latency and be as fast as possible. Every millisecond adds up at scale.
Good gateway implementations add minimal latency. We're talking 10-50 milliseconds of overhead for routing and monitoring. At scale, this matters, but it's acceptable.
Alternative architectures exist. You could implement failover client-side in your application code, but this means changing application code and replicating logic everywhere. You could use a service mesh like Istio to handle failover, but this adds infrastructure complexity. A dedicated gateway is usually the cleanest approach.
Configuration matters too. You'll probably want:
- YAML or JSON configuration specifying fallback chains
- Per-endpoint configuration for different use cases
- Dynamic configuration that can change without redeploying
- A/B testing configuration to gradually shift traffic
Version management is important. When you update failover logic, you need to be able to rollback quickly if something breaks. Canary deployments help here. Deploy new versions to 10% of traffic first, measure for issues, then scale up.
Testing Failover: Making Sure It Works When You Need It
Failover systems are only useful if they actually work. You need to test them thoroughly before you need them in production.
Good testing strategies include:
Unit tests: Test individual components like degradation detection, prompt adaptation, and model selection logic in isolation.
Integration tests: Test the entire failover chain end-to-end. Ensure requests actually failover correctly and produce acceptable output.
Load tests: Generate realistic load and see how failover behaves under pressure. Does it stay responsive? Do backups handle overflow?
Chaos engineering: Intentionally break things in staging environments. Stop the primary model's API responses. Introduce latency. Increase error rates. See if failover responds correctly.
Staged production testing: In low-traffic environments or during off-peak hours, force failover and observe. Route 1% of production traffic through failover logic before relying on it completely.
Regular drills: Periodically failover to each backup model deliberately to ensure the system works. Monthly drills are typical. Some teams do weekly drills.
Instrumentation: Before pushing failover to production, ensure comprehensive logging. You need to understand exactly what happened if something goes wrong.
The most common mistake is insufficient testing. Teams build failover systems, never actually trigger them in production, then when a real outage occurs, the failover system has bugs nobody discovered.
Test scenarios should include:
- Primary model completely down
- Primary model slow but not failing
- Primary model producing errors for some requests
- Multiple models failing simultaneously
- Geographic region failures
- Long outages lasting hours
- Intermittent failures that come and go
Each scenario should be tested and the response verified as acceptable.
Emerging Platforms and Solutions for AI Failover
Built-in failover capability isn't yet standard across AI infrastructure platforms. Most teams building failover systems are doing custom work. However, specialized platforms are emerging that handle this complexity.
These platforms abstract away the technical complexity and let you focus on business logic. Some offer built-in failover as a core feature. Others integrate with existing gateway solutions.
Runable is an example of an AI-powered automation platform that supports failover capabilities for presentations, documents, reports, images, and videos. Starting at just $9/month, it provides developers with built-in reliability features that prevent the single-provider dependency problem entirely.
When evaluating failover solutions, look for:
- Ease of integration: Can you integrate without rewriting application code?
- Supported models: Does the platform support all the models you want to failover to?
- Quality preservation: Does it handle prompt adaptation automatically?
- Monitoring: What observability does it provide?
- Cost: What's the total cost including infrastructure?
- Support: What happens when something breaks?
Most emerging platforms follow the gateway pattern described earlier. They sit between your application and model providers, handling routing and failover transparently.
The platform landscape is still evolving. No dominant player has emerged yet. Choose based on your specific needs and integration requirements.
Best Practices for Enterprise AI Failover
Don't wait for a crisis to think about failover. Building resilient systems requires planning from the start.
1. Multi-model from day one: Even in early development, design your prompts to work with multiple models. Test them with backup models regularly. This prevents being locked into a single model.
2. Monitor everything: Implement comprehensive monitoring before failover becomes critical. You need baseline data to detect degradation.
3. Cost-aware failover: Choose backup models strategically based on economics. Don't failover to expensive models for low-value requests.
4. Regular testing: Test failover monthly minimum. Treat it like any other critical system.
5. Transparent documentation: Document your failover strategy, which models are backups, and what quality expectations change during failover. Teams need to understand this.
6. Gradual rollout: Don't enable failover for all traffic immediately. Start with 5-10%, measure, then scale.
7. Incident procedures: Document what to do when failover triggers. Create runbooks for your team.
8. Budget for resilience: Failover costs money. Budget for it as you would any other infrastructure cost.
9. Stay informed: Model providers sometimes communicate issues in advance. Join their status pages and communication channels.
10. Hybrid approaches: Combine caching, load shedding, and failover. No single approach solves everything.
The Future of AI Reliability
Eventually, AI model providers will mature and offer the reliability guarantees we expect from cloud infrastructure. They'll build redundancy, implement SLAs, and invest in operations like AWS did decades ago.
When that happens, failover systems might become less critical. But we're not there yet. Model providers are still learning how to operate at scale. Downtime and degradation will continue for years.
In the meantime, enterprises building mission-critical AI applications need failover. It's not optional. It's table stakes for production systems where reliability matters.
The good news is that failover technology keeps improving. Automated degradation detection gets smarter. Model adapters get better. Infrastructure becomes more standardized. What takes weeks to implement today will take days in a year. And days in a month the year after.
The pattern mirrors what happened with cloud databases. Early on, if your database went down, you manually failed over to a replica. Now that's automatic. Eventually, AI failover will be automatic too. Right now, you have to build it yourself or use specialized platforms that do.
Choosing the right approach—custom gateway, managed platform, or combination—depends on your scale, budget, and technical capabilities. What matters is recognizing that single-model dependency is a business risk and addressing it systematically.
FAQ
What is AI failover and why does my application need it?
AI failover is an automated system that detects when your primary AI model provider experiences outages or performance degradation, then seamlessly reroutes traffic to backup models without user interruption. You need it because major LLM providers like Open AI, Anthropic, and Google experience outages and slowdowns every few weeks or months. When these happen, your revenue and customer experience suffer. Failover prevents that by ensuring your application stays online even when primary providers fail.
How does AI failover differ from traditional database failover?
Traditional database failover is straightforward because the data and interface are identical across replicas. AI failover is more complex because different models have different behaviors, quality levels, prompt requirements, and feature support. Switching from GPT-4 to Claude means adjusting prompts in real-time, handling different output formats, managing latency differences, and potentially accepting lower quality. Modern AI failover systems handle this complexity automatically, but it requires more sophisticated logic than traditional failover.
What signals should I monitor to detect AI model degradation?
Monitor response latency (how long requests take), error rates (percentage of failed requests), token efficiency (length of responses), user satisfaction signals (ratings and feedback), and quality heuristics (repetitiveness, topic relevance, helpfulness). No single signal reliably indicates problems, but when multiple signals degrade simultaneously, that's clear evidence the model needs failover. Most systems require baseline data from several weeks of normal operation before they can accurately detect abnormal degradation.
How much does implementing AI failover cost?
Costs include API access to backup models, failover infrastructure (gateway or platform), monitoring systems, and operational overhead. For high-volume operations protecting significant revenue, the cost is negligible compared to preventing outages. For low-volume operations, failover might cost more to implement than the outages would cost. Calculate expected annual outage costs against failover costs to determine if it's economically justified for your situation.
Can I implement AI failover without changing my application code?
Yes, if you use the gateway pattern. Instead of your code calling model APIs directly, it calls a local failover gateway that exposes the same API interface. The gateway handles all routing, prompt adaptation, and failover logic internally. Your application code remains unchanged. This is the cleanest implementation approach and the reason most teams choose it.
What should I include in my failover fallback chain?
Start with your primary model (GPT-4 if you want the best quality), then add backups in order of preference: equivalent capability models first (Claude for GPT-4), then slightly weaker but still capable models (Gemini), then cheaper alternatives (Mistral), then self-hosted or final fallback options. Each backup should be tested to ensure it handles your specific prompts and use cases acceptably. Geographic distribution matters too—include the same model in different regions before switching model providers entirely.
How often should I test my failover system?
Test monthly minimum, and consider weekly testing for mission-critical applications. Monthly drills should systematically trigger failover to each backup model and verify the system works as expected. Additionally, run chaos engineering tests in staging environments regularly where you intentionally break components and verify failover responds correctly. Never rely on failover in production without extensive testing first.
What's the relationship between caching and failover?
Caching reduces failover demand by serving responses from historical data instead of hitting models. Strategic caching can handle 30-50% of requests without any model being involved, reducing load and often preventing failures from occurring in the first place. Failover handles the remaining failures that caching misses. Together, they form a complete resilience strategy: caching prevents most failures, failover handles the ones that slip through.
How do I preserve output quality when failover switches models?
Develop model-specific prompt variants that are optimized for each model's training and behavior. Test your prompt with each backup model, observe output quality, and refine until all variants produce acceptable results. Some systems use language models to transform prompts in real-time, while others use output post-processing to normalize backup model responses. The best approach combines multiple techniques: prompt adaptation, transformation fallbacks, and output normalization.
Conclusion
AI failover has transformed from a nice-to-have optimization into a business necessity for enterprises. As AI powers increasingly critical operations, the cost of downtime has exploded. A two-hour outage affects not just revenue but customer trust, employee productivity, and service reliability metrics.
The technology for solving this exists. Failover systems—whether custom-built or from specialized platforms—can keep your applications online even when primary providers fail. The complexity is manageable if you choose the right architecture and invest in proper testing.
What's changed in 2025 is recognition that this is everyone's problem, not just huge enterprises. Midsize companies now have applications whose revenue depends on AI reliability. Small companies building AI-powered products discover outages affect their reputation and customer retention. The stakes are too high to ignore.
The journey to reliable AI infrastructure starts with understanding your risk. What revenue is at stake during outages? What's the cost of customer frustration? Then work backwards to design failover matching that risk. For some applications, multi-model failover on the same provider is sufficient. For others, you need geographic distribution across cloud providers. Design based on actual business impact, not just technical sophistication.
Test before you deploy. Monitor relentlessly. Keep detailed incident records. Learn from each failover event about whether your backup strategy is working. Adjust based on what you learn.
AI reliability will improve over time. Eventually, model providers will match the reliability guarantees of traditional cloud infrastructure. Until then, you're responsible for ensuring your users can always get AI-powered responses. Failover systems make that possible.
The companies building reliable AI systems right now—before it's expected, before it's easy, before there's a standard solution—are building competitive advantages. When they experience outages, their users don't notice. When competitors go down, those users stay loyal. That's worth the investment.

Key Takeaways
- AI model providers experience outages and degradation every few weeks or months, affecting thousands of enterprises
- Single-provider AI infrastructure is risky because unlike traditional cloud services, AI models aren't yet mature in their reliability engineering
- Modern AI failover requires degradation-aware routing that monitors latency, error rates, quality metrics, and token efficiency simultaneously
- Failover ROI is positive for high-revenue operations but must be calculated carefully for low-volume applications
- Gateway architecture enables failover without changing application code, making implementation cleaner and safer
Related Articles
- From AI Hype to Real ROI: Enterprise Implementation Guide [2025]
- Google Gemini vs OpenAI: Who's Winning the AI Race in 2025?
- Tesla's Dojo Supercomputer Restart: What Musk's AI Vision Really Means [2025]
- Parloa's $3B Valuation: AI Customer Service Revolution 2025
- Verizon's 10-Hour Outage 2026: What Happened & How to Prevent Service Disruptions
- Apple & Google AI Partnership: Why This Changes Everything [2025]

