![AI-Generated Fake Quotes and Journalism: How Standards Broke Down [2025]](https://tryrunable.com/blog/ai-generated-fake-quotes-and-journalism-how-standards-broke-/image-1-1771180538014.jpg)
Introduction: The Day A Tech Publication Broke Its Own Rules
It happened on a Friday afternoon in early 2026. A respected technology publication, one that had spent years warning the industry about the dangers of unchecked AI deployment, published an article containing something it explicitly forbade: AI-generated quotations attributed to a real person who never said them. This incident was highlighted in Ars Technica's editor's note.
This wasn't a case of misquotation or paraphrasing gone wrong. These weren't secondhand accounts or reconstructed dialogue. An AI tool generated fabricated words, and they were presented as direct quotations from an actual source. The publication later apologized to Scott Shambaugh, the person falsely attributed with statements he never made.
On the surface, this looks like a single editorial failure at one outlet. But it's actually a window into something much larger: the collision between journalistic standards that evolved over a century and new AI capabilities that can generate convincing text in milliseconds. It's a moment when the written rules stopped matching the reality of how content is being produced.
For anyone working in media, technology, or trust-critical industries, this incident carries a painful lesson. The tools that make our work faster and easier are the same tools that can silently undermine the foundations of credibility. And the scariest part? Most organizations don't have systems in place to catch when it happens.
This article explores what actually occurred, why it happened despite explicit policies, how the publication responded, and most importantly, what this means for editorial standards in an AI-saturated world. We'll also look at the broader pattern: this wasn't an isolated technical glitch. It was a process failure. Policies existed. They just weren't followed.
What Happened: The Incident In Detail
The publication's editor took the unusual step of publishing a full acknowledgment of what went wrong. This transparency is rare in media, which is partly why this incident became a significant moment in the industry. Most outlets quietly issue corrections; this one published an explanation of the failure itself.
Here's the factual breakdown: an article was published that contained quotations attributed to a source. Those quotations were generated by an AI tool, not actually spoken or written by the person they were attributed to. The article was published on the main website. It was read by thousands of people before the error was caught.
The publication's own written policy explicitly prohibited this exact scenario. AI-generated material cannot be published unless it's clearly labeled and presented for demonstration purposes. That's not vague guidance or a suggestion. It's a rule. In this case, the quotations appeared as normal direct quotes with quotation marks and attribution. There was no labeling. There was no disclaimer.
What makes this particularly significant is the context of the publication itself. For over 25 years, this outlet has covered technology critically and extensively. It has written hundreds of articles about the risks of over-relying on AI tools. Its staff has explored the problems with AI hallucinations, false confidence in generated content, and the breakdown of truth when AI systems are used carelessly.
The irony cuts deep. The publication violated its own standards while the industry was still grappling with what those standards should even be. In other words, if a tech-savvy organization with explicit policies couldn't prevent this, what does that tell us about the rest of the media landscape?
The publication's investigation afterward revealed something important: this appeared to be an isolated incident. They reviewed other recent work and didn't find additional cases of fabricated quotes. That's either reassuring or concerning, depending on how you look at it. Reassuring because it suggests this wasn't systemic. Concerning because it means they might have gotten lucky.
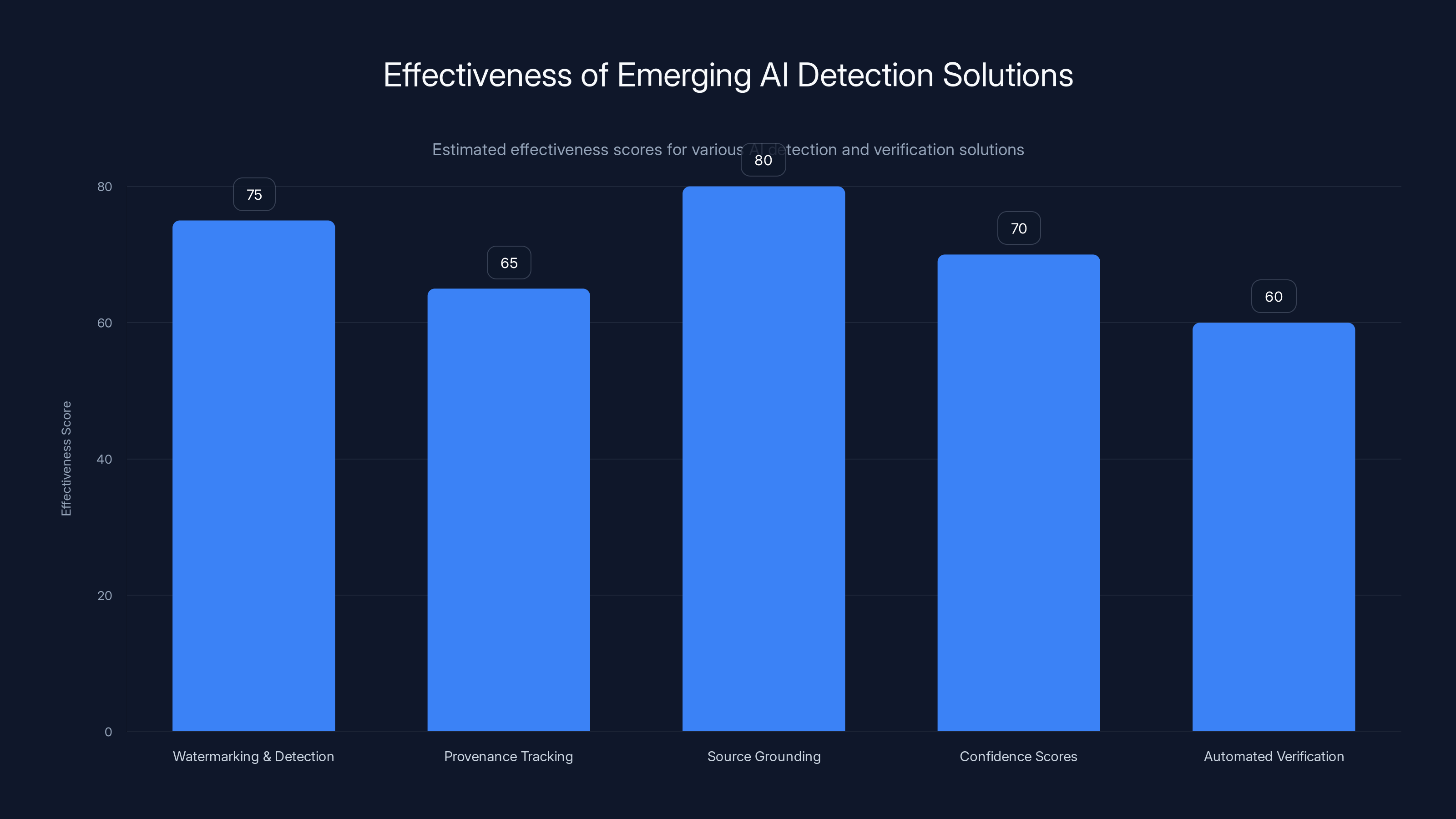
Estimated effectiveness scores show Source Grounding as the most promising with an 80% score, while Automated Verification trails at 60%. These scores reflect the current state of development and potential impact.
Why AI-Generated Quotes Are Different From Other Editorial Mistakes
Journalism has always dealt with errors. Reporters misquote sources. Facts get confused. Context gets dropped. These are occupational hazards that publications have systems to catch: fact-checkers, editors, sources reviewing drafts, corrections policies.
But AI-generated quotes are categorically different in a way that matters for how we should handle them. When a human misquotes someone, they're usually drawing from memory or notes. The error is traceable. You can look at what the source actually said and compare it to what was published. There's a clear deviation from reality.
With AI-generated quotes, there's often no original statement to compare against. The AI created text that sounds plausible, follows the style of the publication, and matches the apparent context of the story. A human editor reading it might think: that sounds like something this person would say. The quotation integrates seamlessly into the narrative.
This is what makes AI fabrication particularly insidious. It doesn't feel fake when you read it. It reads like reporting. It has attribution. It has quotation marks. All the visual markers of legitimate journalism are present. The fraud is entirely content-based: the words were never actually said.
Compare this to other types of editorial failures. A factual error is usually caught through fact-checking or source review. A plagiarism issue is caught through plagiarism detection or recognition by readers. But detecting AI-generated false quotes requires a specific step that traditional editorial workflows don't have: verifying that a quote actually appeared somewhere before it was published.
In traditional reporting, the assumption is that quotes come from interviews, documents, or other sources. The quote is secondary to the source material. With AI generation, there is no source material. The quote is primary. It exists only in the article.
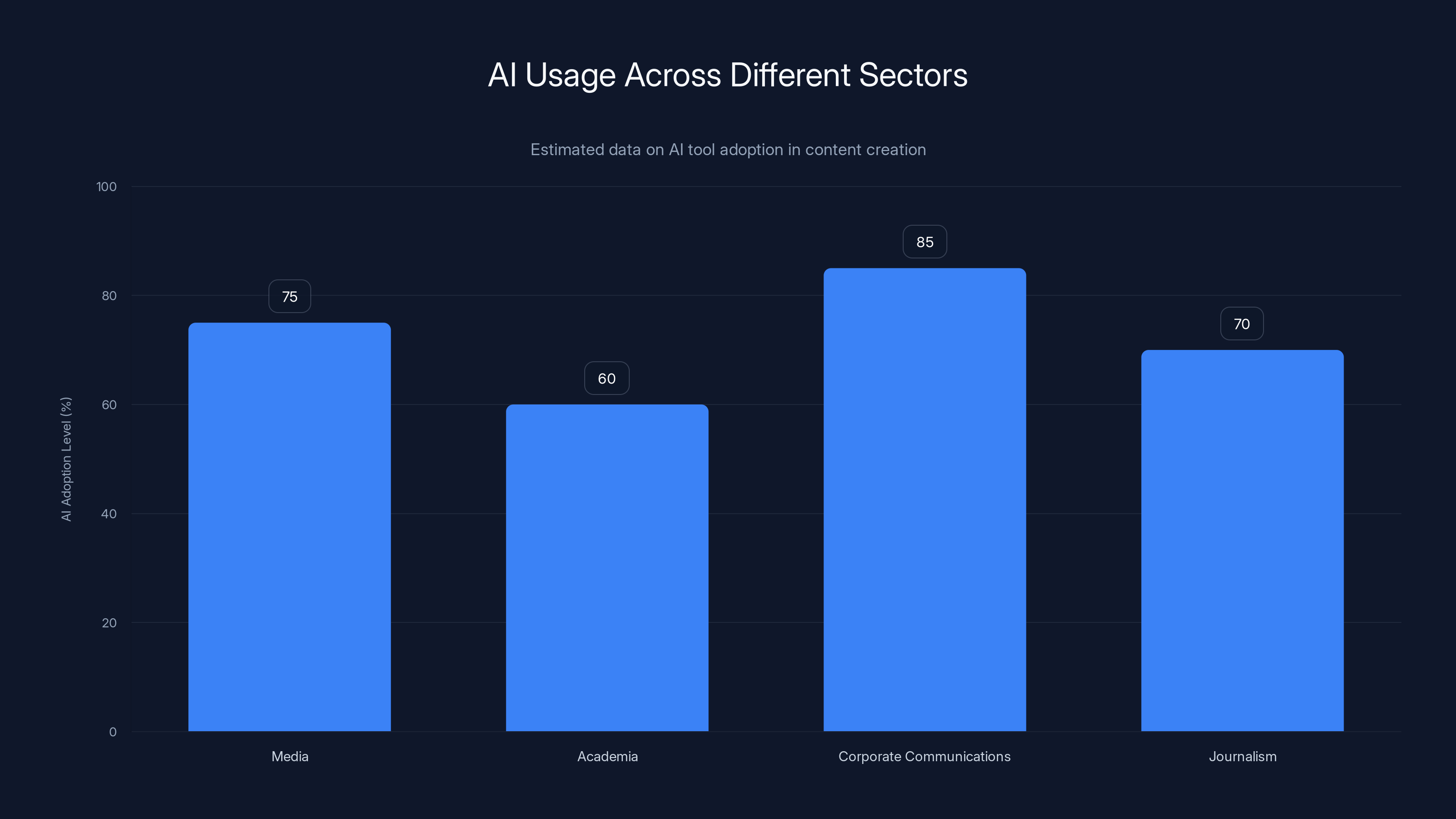
AI tools are widely adopted across sectors, with corporate communications leading at an estimated 85%. Estimated data.
How The Policy Existed But Wasn't Followed
This is perhaps the most revealing aspect of the incident. The publication had a clear written policy. Ars Technica does not permit the publication of AI-generated material unless it's clearly labeled and presented for demonstration purposes. That rule is not optional. It's explicit.
So why was it violated? This is where we enter the murky territory of actual newsroom operations versus stated policies. Several factors probably contributed:
First, the person using the AI tool likely didn't perceive what they were doing as violating policy. When you're working under deadline, when you have an AI tool that's convenient and fast, when the generated text reads smoothly and fits the story, the mental category can shift. This starts feeling like a productivity aid, not like fabrication. The policy is for something else, something more obviously wrong.
Second, the workflow didn't include a checkpoint where someone would ask: did this quote come from an actual source? This isn't a question that gets asked in traditional reporting because the answer is obvious. You interviewed someone or you reviewed a document. But when AI tooling enters the workflow, that implicit check becomes necessary. And if it's not explicit in the editorial process, it gets skipped.
Third, there's a confidence problem. AI-generated text is confident. It doesn't hedge or qualify. It presents itself as legitimate. A reporter reading generated quotes might not immediately recognize them as generated if they didn't watch the generation process happen. They might assume they came from a source that was quoted elsewhere.
This is a systems problem, not an individual blame problem. The policy existed, but the process didn't have adequate safeguards to enforce it. There was no mandatory step where someone independently verified each quote came from a source. There was no tool in the workflow that would flag: this quote appears in this article but nowhere else on the internet. There was no requirement to document where the quote came from.
When policies exist in a document but not in actual workflows, the workflow wins. Every time.

The Broader Pattern: Why This Keeps Happening
This incident at one publication is just the visible part of a much larger pattern. We're seeing versions of this across media, academia, and other institutions that depend on credibility.
In research, there have been cases where AI-generated text made its way into academic papers. Sometimes researchers don't even realize they've used AI when they feed text through a tool and then incorporate the output into their writing. The question of "is this my original analysis" becomes harder to answer when your writing process involves multiple AI tools and human editing steps.
In journalism more broadly, there's pressure to produce more content faster. AI tools offer a genuine solution to real problems: they can help draft articles, suggest structures, generate initial versions of routine reporting. The temptation is to let them do more and more of the work, moving further into territory that should remain human-authored.
In corporate communications, there's even more pressure and less scrutiny. When a company generates press releases or marketing copy with AI, who's checking if the claims are accurate? When an executive's quote is AI-generated to match their typical style, who notices?
The common thread is this: the technology makes it easy, policies haven't caught up to what's possible, and enforcement mechanisms don't exist in actual workflows. So the gaps get exploited, usually not maliciously, usually by people trying to work more efficiently within systems that don't properly constrain them.
The scariest version of this pattern is when organizations don't even have explicit policies. At least the publication in this incident had a rule. Many organizations are still operating without clear guidance on how and when AI tools can be used for content creation.
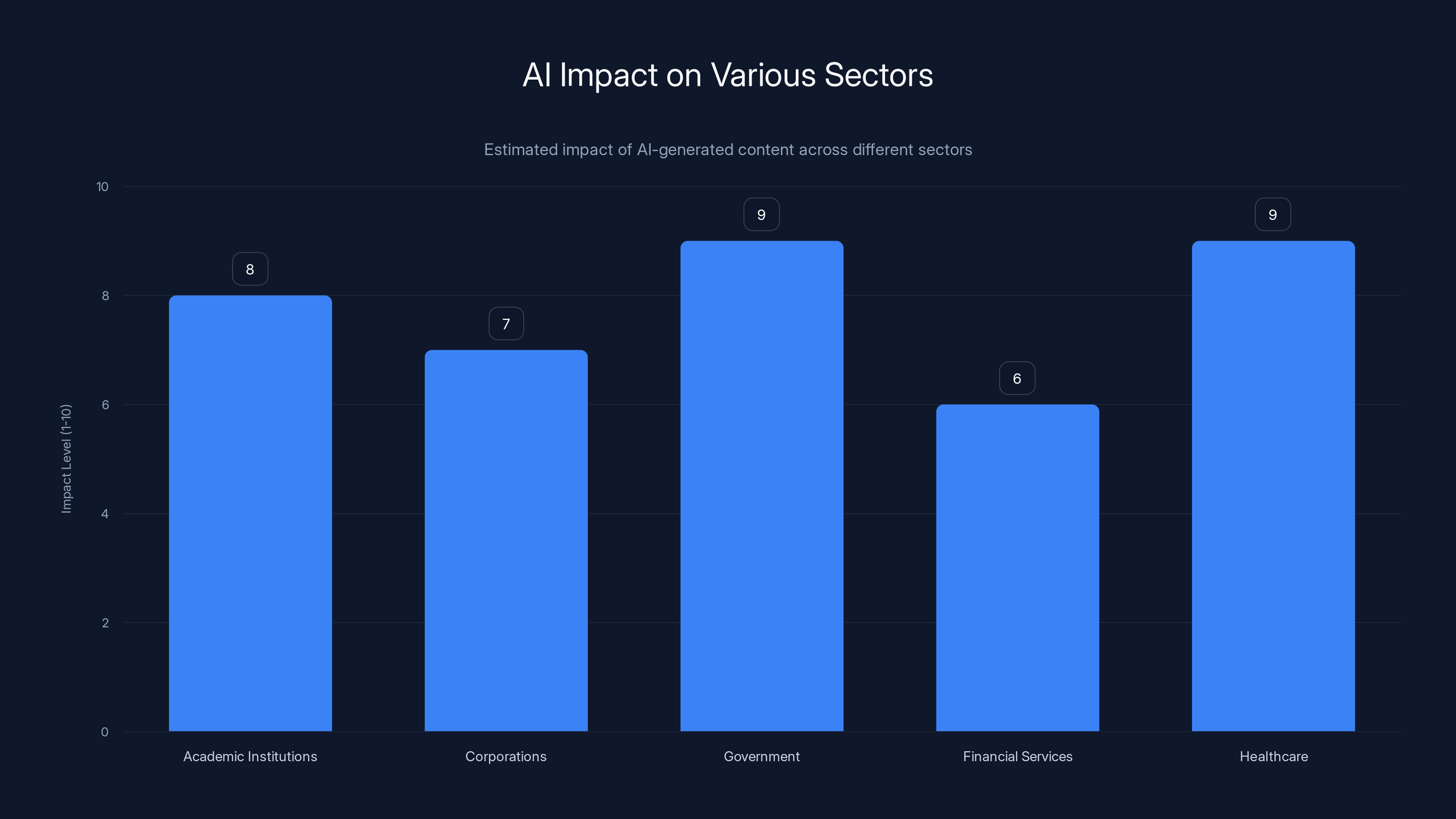
Estimated data shows that government and healthcare sectors face the highest impact from AI-generated content, highlighting the need for stringent verification systems.
Why Quotations Matter Most
Quotations are a specific concern in this ecosystem, and it's worth understanding why they're treated differently from other types of AI-assisted content.
A quotation is a claim about what someone actually said or wrote. It's a representation of reality. When you put something in quotation marks, you're asserting: this is a direct representation of the source's own words. It's not paraphrasing. It's not interpretation. It's what they said.
This matters because quotations carry weight in journalism. They're evidence. They're the source's own voice. A well-chosen quote can be more credible than three paragraphs of explanation because it's unmediated by the journalist's interpretation.
When a quotation is fabricated, the entire evidentiary foundation of the article is compromised. Readers are being shown false evidence. They're being misled about what someone said, and they can't easily verify it because the quote appears nowhere else. They'd have to contact the source directly, which most readers won't do.
This is different from fabricating a statistic or a detail. If you claim that company X's revenue grew 40% last year, someone can check that against the company's earnings report. But if you claim that a CEO said something, and that CEO didn't actually say it, and you're the only source for the quote, the deception is harder to catch.
That's why quotations are the red line. That's why policies specifically address them. And that's why violating that rule, even unintentionally, is a serious breach.
How Editorial Standards Are Being Rebuilt
The publication's response to this incident is instructive. They didn't hide it. They published a full editor's note explaining what happened, that it violated their standards, that it was a failure, and that they apologized both to readers and to the falsely quoted person.
Then they took concrete steps: they reviewed recent work to ensure this wasn't part of a larger pattern. They reinforced their editorial standards. They made clear that the policy isn't optional.
But the real work, the harder work, is building enforcement into the process itself. Some publications are now implementing specific workflows for AI-assisted content:
Separate tracks for AI-generated material. Some outlets are creating distinct workflows where AI-generated content is routed differently, reviewed more carefully, and must be clearly labeled.
Source documentation. Requiring that every quotation include documentation of where it came from: a link to an interview transcript, an audio file, a published statement, a document. If the quote came from an AI tool, that gets documented too, with a label.
Verification steps. Adding checkpoints where an editor asks: where did this come from? Is this a quotation from an actual source or is this generated? Can we verify it?
Tool restrictions. Some newsrooms are creating approved lists of AI tools and approved use cases. You can use Tool A for drafting, but not for quote generation. You can use Tool B for research assistance, but not for content that will be published as-is.
Training. Teaching reporters and editors specifically about how AI tools work, what they can and can't reliably do, and what the risks are. This isn't generic AI training. It's specific to the editorial context.
These measures add friction to the workflow. They slow things down. That's partly the point. In high-stakes domains like journalism, adding friction at the right places can prevent catastrophic errors.

AI models excel in pattern recognition and text generation but struggle with truth verification and confidence indication. Estimated data.
The Technical Perspective: Why AI Tools Make This Easy
From a technical standpoint, understanding why this happened requires understanding how AI language models work and why they generate text so convincingly.
Large language models are pattern-matching systems trained on vast amounts of text. They learn statistical patterns about how language typically flows, how concepts relate to each other, and how different types of writing are structured. A quotation in a news article follows specific patterns: attribution, quotation marks, stylistically appropriate language that matches the source, and content that fits the story context.
An AI model trained on millions of news articles has learned all these patterns intimately. It can generate text that follows all of them. The generated quote might not have been said by the real person, but it follows all the statistical patterns of a real quote from a real source.
What the model doesn't have is access to the truth. It doesn't know whether the generated words actually match what the person said. It has no mechanism for checking that. It just generates plausible text that follows the patterns it learned.
This is what researchers call the "hallucination problem" or the "confidence problem." The model generates false information with the same confidence and stylistic quality as true information. A human reader can't tell the difference by looking at the output. The falsehood is built into the tokens themselves.
Making this worse, the person using the tool often sees what they expect to see. If they generate a quote supposedly from a CEO about company strategy, and the generated quote talks about company strategy in a way that seems consistent with what they know about the CEO, they might accept it as plausible without thinking about whether the CEO actually said it.
The tool doesn't say: this quote is generated. It doesn't have a confidence score. It doesn't say: I'm not sure about this. It just produces text that looks like a quote.
Technically, it's possible to design systems that resist this. You could require that quotations be generated only with reference to a specific text (like an interview transcript). You could flag any generated text that wasn't grounded in an actual source. You could make AI tools explicitly distinguish between generated content and sourced content.
But those features make the tools less convenient and slower to use. And in the real world, the convenient tool wins.

What This Means For Reader Trust
From a reader's perspective, this incident raises an uncomfortable question: how many other articles contain AI-generated material you don't know about?
This publication was transparent about the error. They published a correction and an explanation. They admitted the failure. Most publications do the same when errors are caught. But trust erosion is asymmetric. One major breach of trust is harder to recover from than ten smaller corrections are to benefit from.
When readers find out that a publication used AI tools to generate false quotations, they have to recalibrate how much they trust everything from that publication. They have to wonder: what else might be AI-generated? How many other quotes are fabricated? How do I know what's real?
This is particularly damaging because quotations are a trust mechanism. Quotations are how readers feel connected to real people's actual views. When that's breached, the entire article becomes suspect.
The irony here is that many AI-assisted articles could be published with full transparency and full trust. An editor could say: we used AI tools to help draft this article, to research this topic, to suggest structures and angles. Here's exactly how we used the tools. Here are the human checkpoints we used. Here are the quotations from real sources. And readers would be fine with that.
But hiding AI involvement, or using AI to fabricate quotes that appear as real sourcing, destroys the foundation of that trust. Readers can't make an informed decision about credibility if they don't know what's real and what's generated.

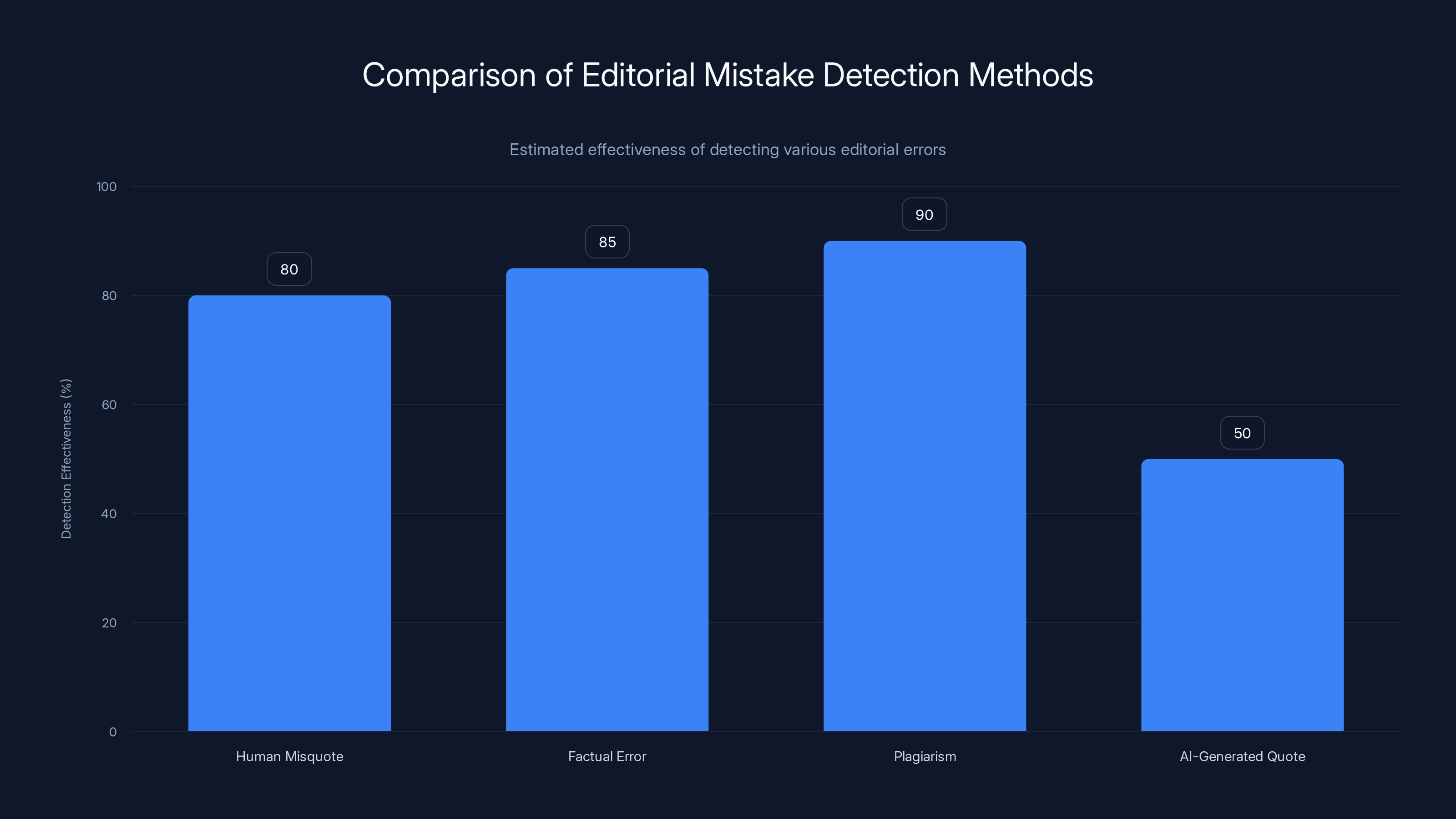
AI-generated quotes are more challenging to detect compared to other editorial mistakes, with an estimated detection effectiveness of only 50%. Estimated data.
The Industry Reckoning: How Other Publications Are Responding
This incident triggered a broader conversation in media about standards. Publications started reviewing their own AI policies and workflows. Professional journalism organizations started issuing guidance.
Some newsrooms implemented immediate changes: no AI tool can generate quotes without explicit human review. All AI-assisted content requires an editor sign-off. Sources must be documented. AI-generated material must be labeled.
Other newsrooms took a step back and started asking more fundamental questions: what is journalism in an age of AI? What parts of our work should remain human-authored? What parts can AI meaningfully assist with? How do we maintain credibility when our tools can fabricate so convincingly?
These are harder questions to answer because they don't have obvious technical solutions. You can build a workflow that prevents fabricated quotes. But you can't easily build a culture that resists the temptation to use AI in ways that are convenient but risky.
Some publications established AI boards or advisory groups specifically to review contentious uses of the technology. Others created separate standards for different content types: news versus analysis versus features versus reviews each might have different rules for AI involvement.
The underlying tension remains: AI tools are genuinely useful for many things, and organizations are under real pressure to produce more content faster. The temptation to push the tools past their safe boundaries is constant. Without strong enforcement mechanisms and without making the safe approach obviously easier than the risky approach, violations will keep happening.

Lessons For Organizations Beyond Media
This incident carries lessons that extend far beyond journalism. Any organization that cares about credibility, accuracy, or legal liability should pay attention.
For academic institutions: if research papers or published findings include AI-generated material or are written partially by AI tools, that needs to be disclosed. Reviewers and readers need to know. Some universities are still grappling with whether to permit AI use in thesis work, and how to detect it if it's used secretly.
For corporations: marketing claims, customer testimonials, expert endorsements, all of these can be fabricated by AI. If you're publishing content that makes factual claims, you need to ensure those claims are actually true, not generated. If you're attributing statements to people or organizations, you need to ensure those statements were actually made.
For government and legal contexts: AI-generated evidence is a growing concern. If an AI system generates a document that looks official, or generates text that appears to be from a real source, that's potentially very serious. Legal discovery processes are going to have to adapt to detect AI-generated material.
For financial services: if you're making investment decisions or financial reports based on AI analysis or AI-generated recommendations, you need to understand that the AI doesn't know what it doesn't know. It can be very wrong with high confidence.
For healthcare: if medical information is generated by AI and presented as authoritative, that has real consequences. Patients could act on false information. Doctors could make decisions based on fabricated guidelines or statistics.
The common thread is this: anywhere that credibility, accuracy, or consequences matter, you need systems that prevent AI-generated material from being passed off as real. You need policies, but more importantly, you need workflows that enforce those policies automatically.

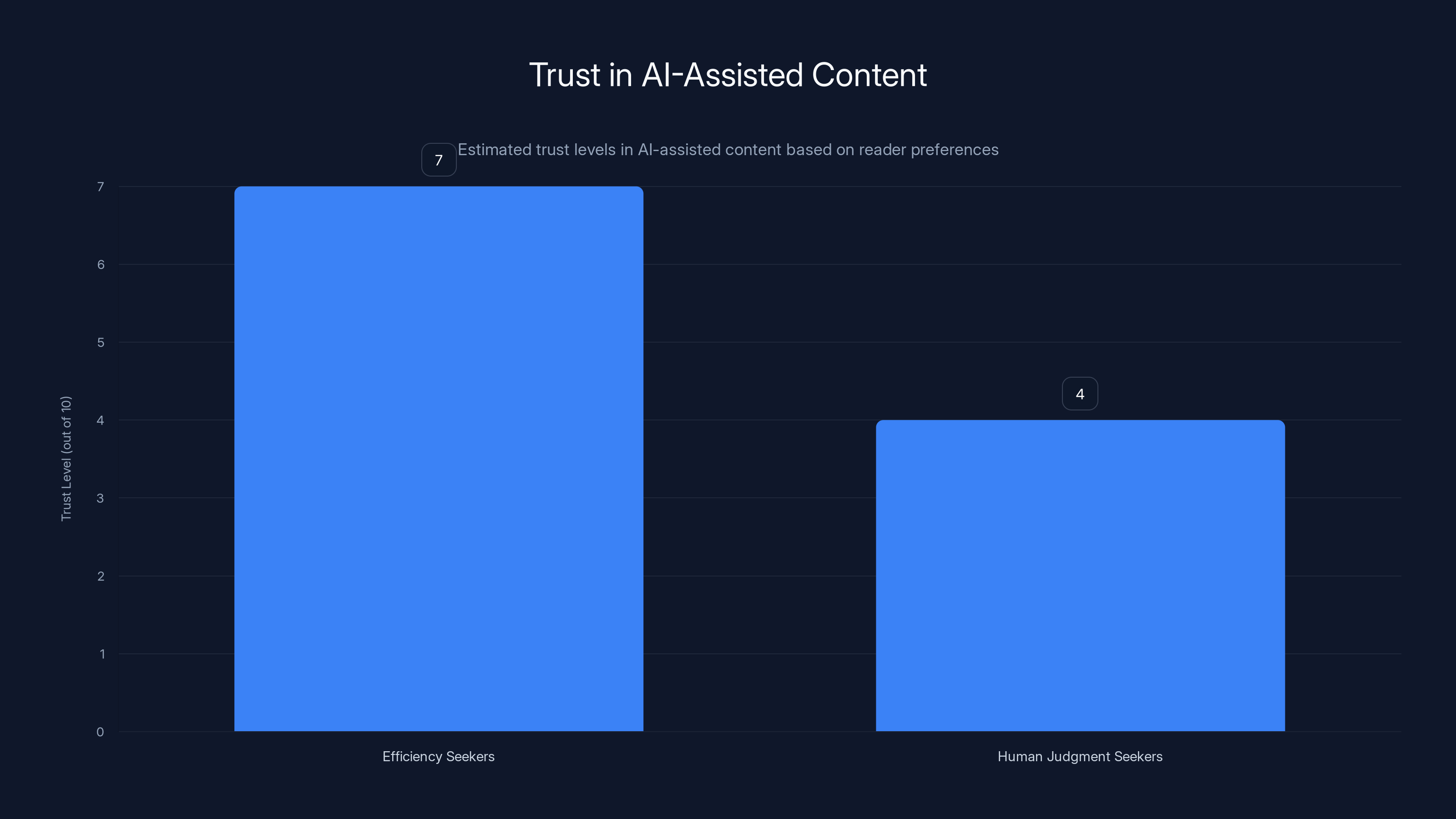
Estimated data suggests that readers who value efficiency may have higher trust in AI-assisted content compared to those who prioritize human judgment.
Technical Solutions Being Developed
As organizations grapple with this problem, technologists are working on solutions. These aren't perfect, but they're moving in the right direction.
Watermarking and detection: Some researchers are developing methods to detect AI-generated text with reasonable accuracy. Tools can now identify whether text was likely generated by GPT-4, Claude, Gemini, or other models with meaningful accuracy levels. These detection systems are improving rapidly.
Provenance tracking: Some platforms are implementing systems that track where content came from, what tools were used, and what human review happened at each step. This creates a chain of custody for content.
Source grounding: Tools are being built that generate text only in reference to specific source documents. The AI can't make claims beyond what's in the source material. This prevents hallucination by design.
Confidence scores: Emerging AI systems are starting to include confidence metrics. Instead of just generating text, they say: I'm 92% confident in this claim and 34% confident in that claim. This at least gives humans a signal.
Automated verification: Some newsrooms are testing systems that automatically check generated quotes against databases of things that were actually said. If a quote appears in the generated text but not in any real source, the system flags it.
None of these solutions is perfect. Detection systems have false positives and false negatives. Watermarking can be stripped. Confidence scores can be misleading. But they're tools that, combined with proper workflow design and editorial discipline, can significantly reduce the risk.
The Future of Editorial Standards In An AI World
The publication at the center of this incident has been covering technology for 25 years. It has built credibility through consistent standards and quality reporting. One incident dents that, but doesn't destroy it, largely because of how they handled the response.
But the question remains: what do editorial standards look like when AI tools are part of the newsroom?
I think we're heading toward a model where transparency becomes the standard. Publications will disclose when AI tools were used, for what purposes, and how the output was reviewed. Readers will develop literacy about what that means. Some people will trust AI-assisted content more (because they value efficiency), and others will trust it less (because they value human judgment). Both perspectives will be legitimate.
We'll probably also see different standards for different content types. Breaking news might have a different standard than feature writing. Analysis might require more human judgment than factual reporting. Reviews might require more human voice than news items.
The quotation barrier, though, I think remains firm. Direct quotations represent what someone actually said. That's not going to change. AI-generated false quotes will remain a red line because the cost of crossing it is too high.
What will change is how aggressively organizations police that line. I expect we'll see more sophisticated detection systems, more training, more automated checkpoints in workflows, and stronger enforcement because we've seen what happens when you have policies on paper but not in practice.
The incident at Ars Technica is not the future of journalism. It's a warning about what can happen when convenience outpaces caution. The fact that they caught it, owned it, and fixed it is exactly how the system should work when it functions well.

How Organizations Can Rebuild Trust After AI-Related Failures
If you're in an organization that's experienced an AI-related error, the recovery playbook matters. Ars Technica's response provides a model:
Transparency first. Publish a clear explanation of what happened. Don't hide it. Don't minimize it. Readers can handle mistakes if you're honest about them. They struggle with deceit.
Specific accountability. Explain exactly what the policy was and how it was violated. This shows that you had standards and that the breach was against those standards, not that the standards don't exist.
Direct apology to harmed parties. In this case, the person who was falsely quoted deserved an apology. That matters more than any public statement.
System changes, not just warnings. Say what you're going to change about how you work. New workflows. New checkpoints. New training. Changes that make future violations harder.
Public commitment. Make a clear statement about what you're committing to going forward. This gives readers a metric to hold you to.
Trust is harder to build than it is to break, but the repair process is clear. It requires honesty, specific change, and demonstrated follow-through.

The Bigger Picture: AI Credibility In Information Ecosystems
This incident is important because it's not just about one article or one publication. It's about what happens to credibility and trust in an information system where AI can generate convincing false content faster than humans can verify it.
We're in a transitional period where AI tools are becoming more capable and more integrated into content creation, but our institutions and processes haven't fully adapted. This creates a vulnerability window. In that window, mistakes like this happen.
The long-term question is whether institutions can adapt faster than AI tools advance. Can we build policies, workflows, and detection systems faster than new AI models can generate more convincing false content? Can we educate people faster than tools make misuse easier?
I think the answer is yes, but it requires taking the problem seriously. It requires not just policies but systems. It requires treating this as a central institutional challenge, not a side issue.
Publications that figure this out first will gain a competitive advantage because they'll be known as trustworthy in an era of AI-generated content. Readers will actively choose them because they know the standards are being enforced.
Publications that ignore the problem or handle it badly will find their credibility eroding. Once readers stop trusting your sourcing, they stop trusting everything you publish.
This is why Ars Technica's response matters. They understood the stakes. They understood that a single incident could damage decades of credibility. So they handled it by being transparent, being specific, and committing to change.
That's the model other organizations should follow.

FAQ
What exactly were the fabricated quotations in the Ars Technica incident?
The specific quotes weren't detailed publicly in the correction. What matters is that an AI tool generated quotations that were attributed to Scott Shambaugh, a real person who never made those statements. The quotes appeared in the article with standard quotation marks and attribution, making them appear like legitimate sourced material when they were entirely fabricated.
How did an AI-generated quote make it past editors if the policy was clear?
The policy existed in the written editorial standards, but the actual workflow didn't include checkpoints to enforce it. Nobody in the publication process asked: "Did this person actually say this?" or "Can we verify this quote came from a real source?" When systems don't have specific enforcement mechanisms, policies become suggestions rather than requirements, especially when working under deadline pressure or when using convenient tools.
How can organizations detect AI-generated quotations before publishing?
The most reliable method is having a step in the editorial process that verifies every quotation comes from an actual source: an interview transcript, audio file, published statement, or document. Automated detection systems are improving but aren't yet reliable enough to be the sole safeguard. Human verification of sourcing remains the gold standard, particularly for direct quotes.
What makes AI-generated false quotes different from traditional misquotation errors?
Traditional misquotes usually involve distorting something someone actually said. With AI-generated quotes, there's nothing authentic to begin with. This makes the deception harder to detect because readers can't compare the quote to what was actually said. They'd have to contact the source directly to discover the fraud, which most readers won't do.
Are there legitimate uses for AI in journalism?
Absolutely. AI can help with research, drafting, structure suggestions, fact-checking, and dozens of other tasks that improve reporting. The line is specifically about AI-generated material being presented as something a real person said or wrote. Using AI to assist the reporting process is fine. Using AI to replace actual sourcing is where problems start.
Should publications continue using AI tools after incidents like this?
Yes, but with appropriate safeguards. Abandoning AI tools entirely isn't realistic or necessary. What's necessary is building workflows where AI-generated content is clearly separated from sourced content, where automation doesn't replace verification, and where quotations always trace back to actual sources. The tool isn't the problem. Using the tool without proper constraints is the problem.
How can readers tell if an article contains AI-generated content?
Transparent publications will disclose AI involvement. Look for labels indicating AI assistance or AI generation. Beyond that, you can check quotations: try searching the exact quote on Google. If it appears nowhere else and only in this one article, that's a signal to be cautious. Reach out to the source and ask if they actually made the statement. Publication corrections sections also reveal patterns of errors.
What are organizations doing to prevent this from happening again?
Leading organizations are implementing separate workflows for AI-assisted content, requiring source documentation for every quote, adding editor checkpoints specifically for AI-generated material, using detection tools to flag potential problems, and training staff about how AI tools work and their limitations. Some are creating approved-use lists for AI tools and banning them entirely for certain content types like quotes.
Could this happen in other industries besides journalism?
Yes. Any field where credibility matters—research, academia, finance, healthcare, law—faces similar risks. A researcher could use AI to generate fabricated citations. A doctor could use AI to generate patient notes. A lawyer could use AI to generate case citations. The problem is universal wherever false information generated to look real could cause harm.
What should I look for if my organization uses AI tools for content creation?
First, audit where AI tools are being used and for what. Second, check if you have explicit policies about AI use. Third, examine your actual workflows to see if those policies are being enforced. Fourth, identify high-risk areas where AI generation could do the most damage if wrong. Fifth, add checkpoints there. Finally, train your team specifically about how the tools work and what they can and can't reliably do.

Key Takeaways
- Editorial policies don't enforce themselves; actual workflows must have checkpoints where AI-generated content is caught and verified
- Direct quotations are fundamentally different from other content because they represent claims about what someone actually said, making AI fabrication particularly dangerous
- Even organizations with strong AI literacy and explicit policies can violate them if daily workflows don't include verification steps for sourcing
- Transparent disclosure of AI involvement in content actually builds reader trust, while hiding AI use destroys credibility when discovered
- Fixing this requires systems-level changes to editorial processes, not just stronger policy language
Related Articles
- SAG-AFTRA vs Seedance 2.0: AI-Generated Deepfakes Spark Industry Crisis [2025]
- India's New Deepfake Rules: What Platforms Must Know [2026]
- OpenAI's Super Bowl Hardware Hoax: What Really Happened [2025]
- New York's AI Regulation Bills: What They Mean for Tech [2025]
- The Jeffrey Epstein Fortnite Account Conspiracy, Debunked [2025]
- Google AI Overviews Scams: How to Protect Yourself [2025]

