![AI Hallucinated Citations at NeurIPS: The Crisis Facing Top Conferences [2025]](https://tryrunable.com/blog/ai-hallucinated-citations-at-neurips-the-crisis-facing-top-c/image-1-1769029927730.jpg)
AI Hallucinated Citations at Neur IPS: The Crisis Facing Top Conferences [2025]
Imagine spending months researching cutting-edge AI. You finally get your paper accepted at Neur IPS, one of the most prestigious conferences in the field. Your career gets a boost. Your citations become part of the scientific record. Except some of those citations don't exist.
That's not hypothetical anymore. Last month, GPTZero, an AI detection startup, scanned all 4,841 papers accepted to the Conference on Neural Information Processing Systems (Neur IPS) and found 100 hallucinated citations across 51 papers. These weren't typos or formatting errors. These were completely fabricated references to papers that don't exist, generated by large language models to fill gaps in research citations.
Here's the thing: most of these papers came from the world's leading AI researchers. People who literally invented the technology that creates these hallucinations. Yet they still couldn't catch the problem. That's not just ironic. It reveals a fundamental crisis in how academic conferences operate when AI tools enter the research pipeline.
TL; DR
- GPTZero found 100 fake citations across 51 Neur IPS papers: Out of 4,841 accepted papers, 1.1% contained at least one hallucinated citation—proof that even elite researchers are using AI tools without proper verification.
- Peer review systems are overwhelmed: Conferences receive thousands of submissions annually, making it impossible for human reviewers to catch every AI-generated hallucination buried in citation sections.
- Citations are currency in academia: Fake citations devalue the entire peer-review system by inflating citation counts and making it harder to track actual influence and novelty in research.
- The real problem isn't the papers, it's the workflow: Researchers likely used AI to draft or complete citation sections, then trusted the output without fact-checking against the actual papers they cited.
- This will only get worse: As AI tools become faster and more convincing, the gap between what conferences can detect and what researchers submit will widen significantly.
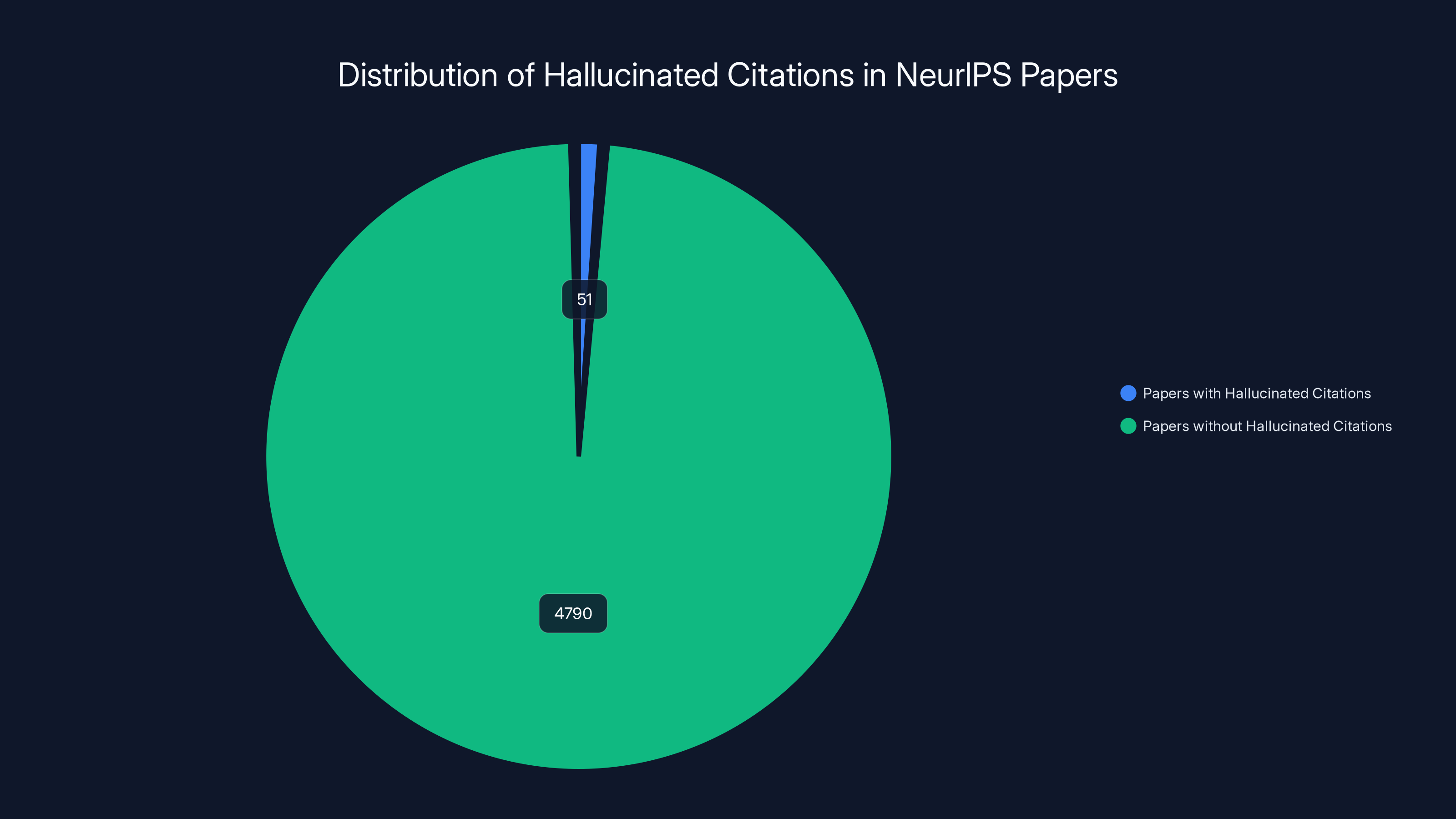
Out of 4,841 NeurIPS papers analyzed, 51 contained hallucinated citations, highlighting the challenge of detecting such errors in academic research.
The Neur IPS Citation Crisis: What Actually Happened
Let's start with the facts. Neur IPS is legitimately a big deal. Getting a paper accepted here is career-changing for researchers. It's the kind of credential that leads to funding, promotions, and collaborations with top labs.
In December 2024, the conference accepted 4,841 papers from thousands of submissions. That's a massive volume. GPTZero's team scanned all of them using detection algorithms designed to spot AI-generated content. What they found was small in percentage terms but significant in what it signals: 100 confirmed hallucinated citations in 51 different papers.
Now, before you panic, understand the scale. With roughly 50 citations per paper on average, that's around 240,000 total citations across all accepted papers. So the 100 fake ones represent roughly 0.04% of all citations. Statistically, it's noise.
But here's why it matters anyway. Each of those papers went through peer review. Multiple experts read them. Their job included checking for exactly this kind of problem. The reviewers didn't catch it. Not because they were lazy or incompetent, but because catching fake citations manually is nearly impossible at this scale.
One of the most telling details: Neur IPS itself told Fortune that invalid citations don't automatically invalidate the research itself. The core science might still be solid. But that's a generous interpretation. The existence of fake citations suggests the authors were cutting corners somewhere in their process. And if they were willing to let AI generate citations without verification, what else might they have skipped?
The researchers involved presumably used large language models somewhere in their workflow. Maybe they asked Chat GPT or Claude to help draft the citations section. Maybe they used AI to organize references. Maybe they even explicitly asked it to generate missing citations when they couldn't remember which papers they'd actually read.
The moment you ask an AI model to generate citations, you're gambling. Large language models don't retrieve from a knowledge base of real papers. They generate plausible-sounding text based on patterns they learned during training. When it comes to specific citations, they occasionally hallucinate entirely fictional references that sound completely real. A paper title that fits the context. An author name that seems authentic. A conference or journal name that exists but didn't publish that specific paper.
To a human reader skimming a citation list, it all looks legitimate.
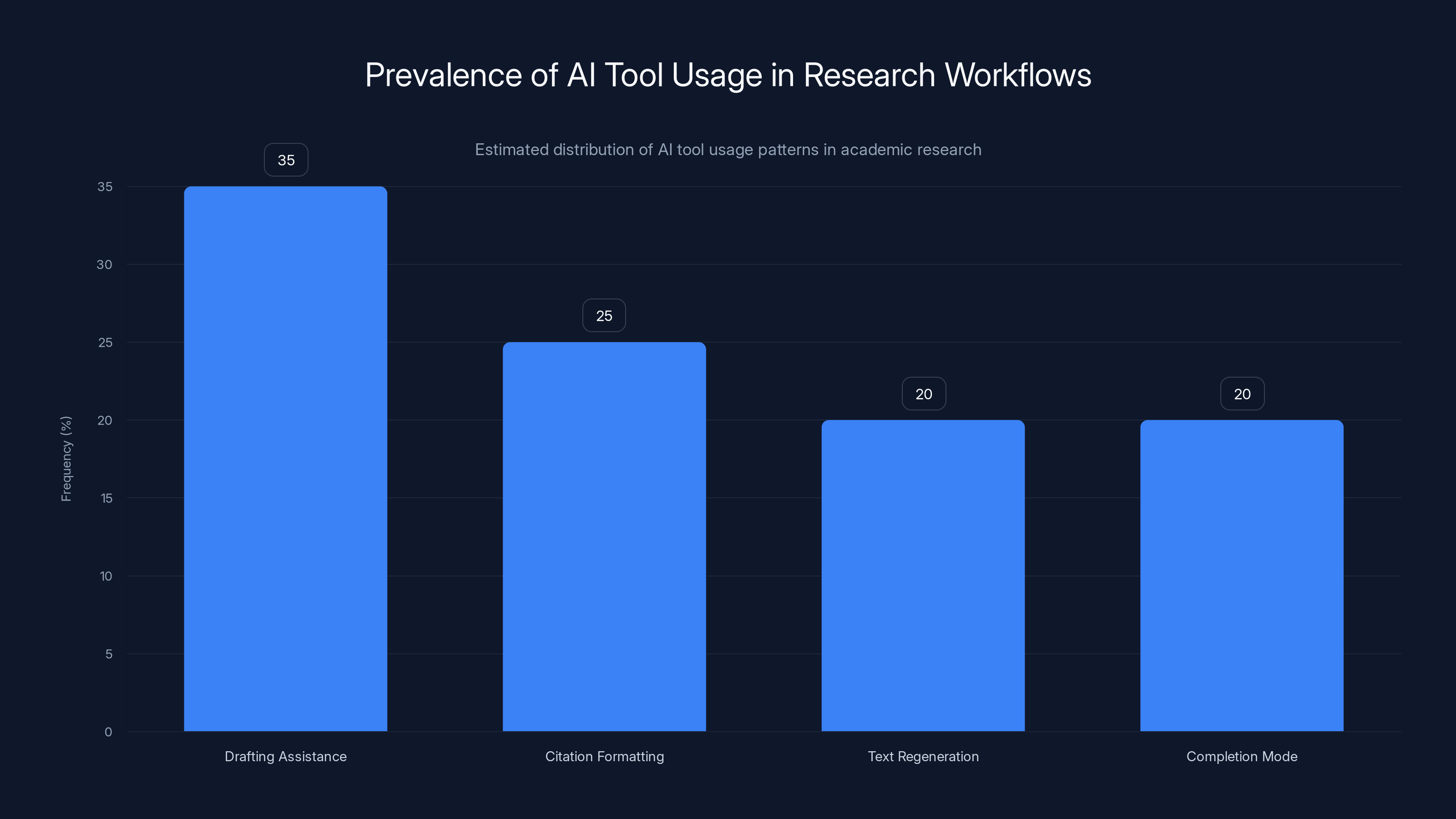
Estimated data shows that drafting assistance is the most common AI tool usage pattern in research workflows, accounting for 35% of cases. Estimated data.
Why Even Elite Researchers Can't Catch AI Hallucinations
This is the part that keeps security professionals and researchers up at night. The scientists publishing at Neur IPS aren't dummies. Many of them literally invented the AI techniques that created the hallucinations they missed.
So why couldn't they catch the fake citations?
Because verification takes effort, and effort requires time that researchers don't have.
Here's the reality: modern academic publishing has become a volume game. Researchers are under constant pressure to publish more, faster. Funding agencies judge productivity by publication count. Career advancement depends on it. Peer review itself has become a bottleneck. Top-tier conferences like Neur IPS receive over 15,000 submissions annually. They accept roughly 30%, meaning thousands of papers get rejected just because there aren't enough reviewers available.
This creates what researchers have called the "peer review crisis". Reviewers are already overwhelmed. They get weeks to evaluate a complex technical paper, check mathematical proofs, verify experimental claims, and spot methodological flaws. Now add the requirement that they also verify every citation? It's not realistic.
And here's the trap: if you're the one who wrote the paper, you should definitely verify the citations yourself. But you know what you probably didn't do? Actually read all 50-100 papers you cited. You skimmed some. You glanced at others based on abstracts. You trusted colleagues' descriptions of certain papers. You used a tool like Zotero or Mendeley to organize them, and the tool gave you the citation format.
Then you got to the writing phase, realized some citations were missing or weak in certain sections, and thought, "Let me have Claude fill this in while I work on the methodology section."
That's probably how it happened. Not malice. Not intentional fraud. Just workflow efficiency that backfired.
The researchers likely didn't even realize they were submitting false citations. They might've been running their draft through an AI tool for grammar checking or restructuring, and the model subtly altered or added citations without explicitly flagging it as doing so.
This is the insidious part of modern AI tools. They don't break your workflow. They integrate into it. They don't announce when they're generating new content versus preserving original content. They're just better, faster, smoother than doing everything manually.
Until something goes wrong.

The Peer Review System Breaks Under Scale
Neur IPS isn't special in this problem. It's just the first to be systematically audited for AI hallucinations. Every major academic conference faces the same pressures.
Consider the math. Neur IPS received roughly 15,500 submissions in 2024. It accepted 4,841. That means roughly 10,659 papers got rejected. The conference uses a double-blind review system where each paper gets evaluated by at least two experts, often more. For a paper to get accepted, reviewers need to verify claims, check math, read through related work, and ensure novelty.
Each review takes 3-6 hours for a thorough job. That's conservatively 45,000+ hours of reviewer work annually for one conference. And Neur IPS isn't even the biggest. Conferences like ICML, ICLR, and AAAI operate at similar or larger scales.
Where do they find all these reviewers? From the research community itself. The same researchers publishing papers also volunteer to review others' work. It's unpaid labor expected of academics as part of the profession. Nobody gets extra recognition for a solid review. If you turn down review invitations, you get a reputation as uncooperative.
So you accept more reviews than you reasonably have time for. You get swamped. You make tradeoffs. You might spend 6 hours on one paper, 2 hours on another. You can't possibly fact-check every citation, especially in a specialized domain where false citations are harder to spot.
Now add AI tools to the author side. Researchers start using LLMs to draft sections, optimize language, suggest citations, format references. Some tools explicitly generate content. Others subtly modify it. The confidence in the output varies wildly, but the pressure to use tools (because competitors are using them) keeps growing.
The peer review system wasn't designed for this. It evolved assuming humans wrote papers deliberately and carefully. Citation fabrication was rare enough that spot-checking could catch most cases. Bad faith actors existed, but they were exceptional.
Now? Bad faith is optional. You don't even need to try to cheat. You just run something through an AI and move on.
Neur IPS itself acknowledged this. According to statements they gave to Fortune, they're aware of the review crisis and understand that catching every AI hallucination is unrealistic. But they also emphasized that having some AI-generated content in papers doesn't invalidate the research itself. The core contributions can still be sound.
That's technically true. But it misses the point. The issue isn't whether the papers are good. It's whether the system can maintain integrity when both authors and reviewers are racing against time and resource constraints.
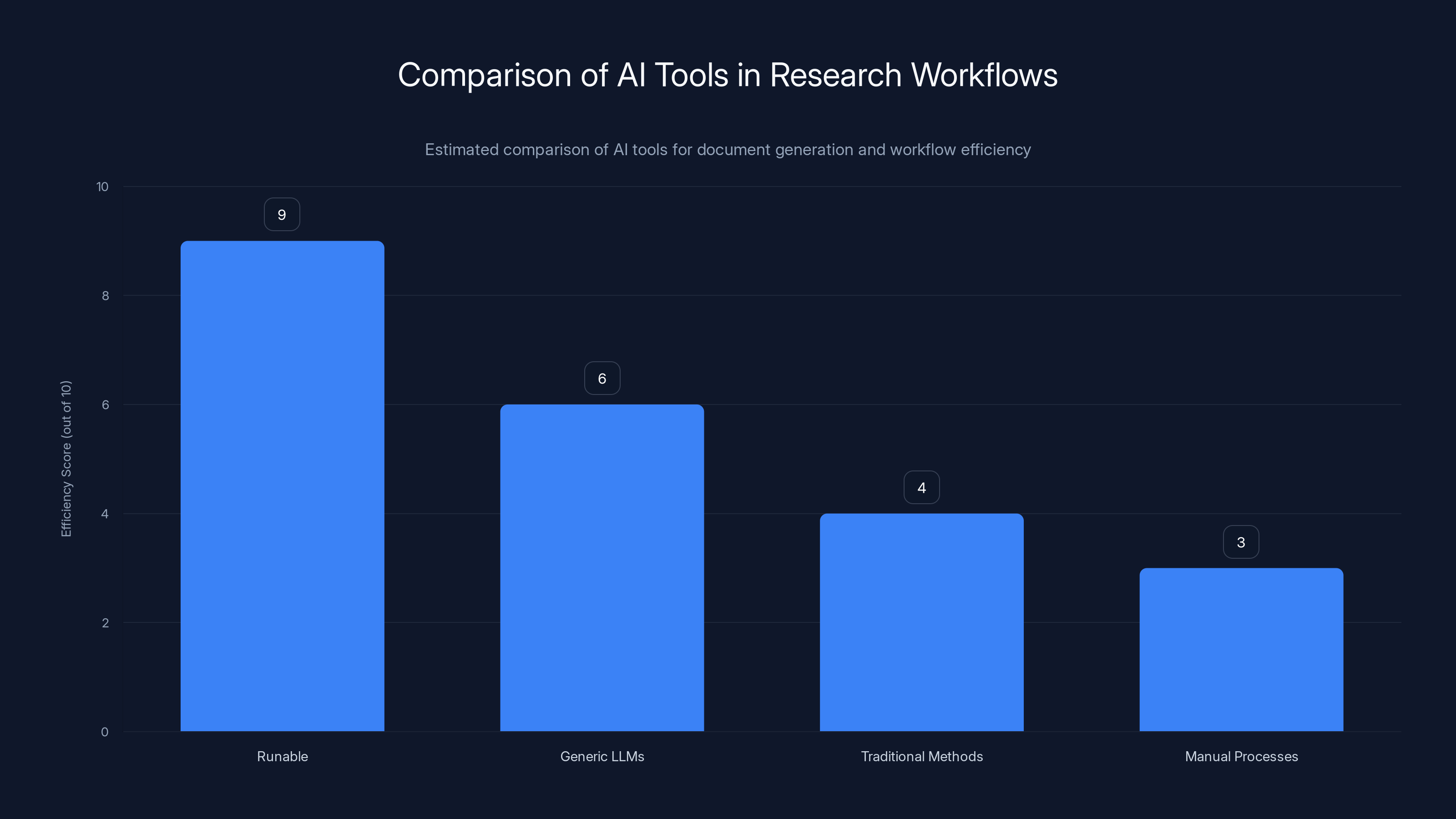
Runable scores highest in efficiency for research workflows due to its structured, verifiable process approach. Estimated data.
Why Citations Matter More Than You Might Think
You might be thinking, "Okay, so some fake citations got through. Who cares? The research is what matters."
That's only half right. Citations matter more than people realize, especially to how science actually functions.
Citations serve multiple purposes in academia. On the surface, they acknowledge prior work and show you understand your field's context. But underneath, they're a currency. Your h-index (the number of papers that have been cited at least h times) determines your reputation, your ability to get funding, your chances at promotions and collaborations.
Universities track citation impact. Funding agencies use it as a metric for evaluating researcher productivity. Hiring committees weigh it heavily. A researcher with high citations is seen as influential. Someone whose work shapes the field.
When AI generates fake citations, it corrupts this entire system. If a paper claims to be citing work that doesn't exist, you can't trust the citation count as a signal of influence. The network of citations that researchers use to discover relevant work becomes polluted.
Imagine you're a junior researcher in a subfield. You find a highly-cited paper that seems foundational. You read it, understand it, cite it in your own work. Then later you discover the paper contained fake citations. Now you're uncertain about what's real and what's hallucinated. Did the paper's claims rest on those citations? If they're fake, is the whole paper suspect?
This creates friction. It slows discovery. Researchers need to spend more time fact-checking sources instead of building on them.
There's also a subtle bad-faith incentive. If you can slip fake citations past peer review, you can make your paper seem more connected to important prior work. You can strengthen your narrative without doing the actual work of engaging with related research. The bar for excellence drops if there's no consequence for cheating.
Neur IPS prides itself on rigorous peer review. The conference explicitly states that it's committed to "rigorous scholarly publishing in machine learning and artificial intelligence." Hallucinated citations violate that mission directly.
Here's what's especially frustrating: the peer reviewers are told to flag hallucinations. That's literally in their instructions. They just couldn't realistically do it at scale. You can't verify 50 citations by hand in 3 hours. You'd need to actually pull up each paper, skim it, confirm it matches the claims in the citing paper. That's not reviewing anymore. That's citation fact-checking. Different job entirely.
The Irony: Elite Researchers, AI-Generated Slop
Let's talk about the elephant in the room: the pure, uncut irony of this situation.
Neur IPS papers are written by some of the world's top AI researchers. These are the people who invented transformer architectures, who created the models that generate hallucinations, who understand LLM behavior at a deep technical level. They literally know how these systems fail.
Yet they still got caught using them for citations without proper verification.
That's not incompetence. That's workflow pressure overriding expertise. It's the same thing that causes experienced pilots to make rookie mistakes when fatigued. The knowledge exists. The ability exists. The motivation to do it right exists. But the time doesn't.
Researchers submitted papers with AI-generated hallucinations not because they wanted to cheat, but because they were on deadline. Because they had to publish something. Because the conference has thousands of submissions and only so many acceptance slots. Because their career depends on having papers accepted at top venues.
This suggests the problem isn't really about researchers being careless or conference reviewers being incompetent. The problem is structural. The academic publishing system has become incompatible with AI integration. You can't use AI tools at your current pace and still maintain the integrity standards you've had for the past 50 years. Something has to give.
GPTZero pointed to a May 2025 paper specifically titled "The AI Conference Peer Review Crisis." The title says it all. Conferences are in crisis mode. They're drowning in submissions, understaffed on review capacity, and now dealing with AI-generated content that's harder to verify than human-written work.
The system worked when academia moved slower. When researchers had more time to prepare papers carefully. When peer review was more thorough. When there were fewer papers competing for space. But that world is gone.
Now you have two choices: either dramatically reduce how many papers you accept (which would massively slow scientific progress), or you accept that the current review process is overwhelmed and some problems will slip through. Neur IPS has implicitly chosen the latter. They've said that having some invalid citations doesn't mean the papers are invalid.
That's pragmatism. It's also capitulation.

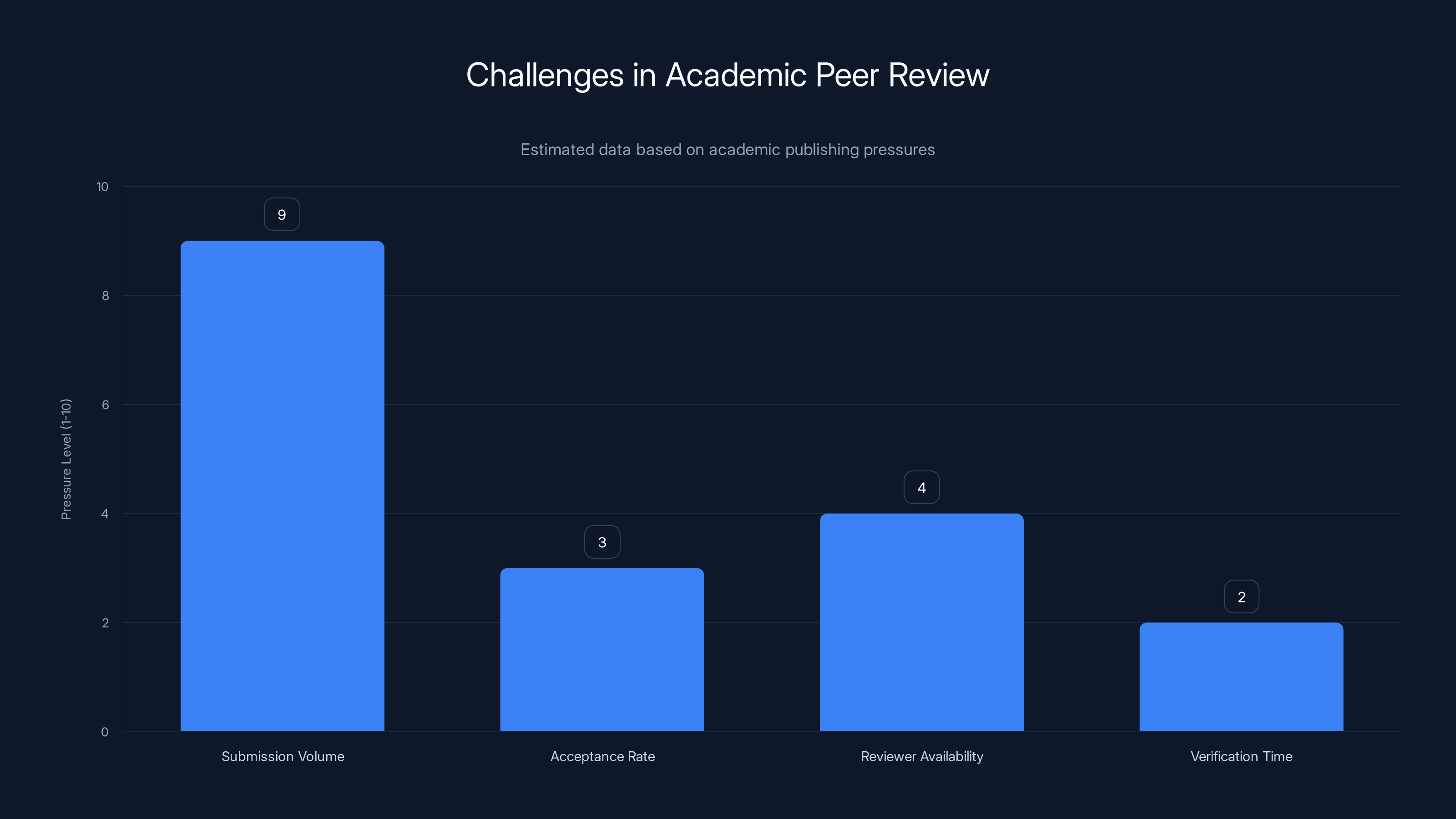
The academic peer review process faces high submission volumes and low acceptance rates, with limited reviewer availability and time for verification. (Estimated data)
How AI Tools Are Sneaking Into Research Workflows
This isn't a mystery. We can trace exactly how fake citations end up in papers. It usually comes down to a few patterns.
Pattern 1: Drafting assistance. A researcher uses a tool like Chat GPT, Claude, or Gemini to help draft the citations or related work section. They give it a topic and ask for references. The model generates plausible-sounding citations. The researcher uses some and adapts others. Doesn't verify everything because they're trusting the AI and they're on deadline.
Pattern 2: Citation formatting. Researchers use AI tools specifically designed to manage references. A tool organizes and formats citations, but the underlying data is sometimes incorrect or the tool invents citations to fill gaps. The researcher sees properly formatted references and assumes they're correct.
Pattern 3: Text regeneration. A researcher runs an entire section of their paper through a paraphrasing or optimization tool (like Grammarly with AI features or similar). The tool subtly alters citations, sometimes inventing new ones to improve flow or increase apparent scholarly depth.
Pattern 4: Completion mode. The researcher has a mostly-written paper but some citations are missing or weak. Instead of doing the research to find real papers, they ask an AI to "complete this section" or "suggest references." The AI generates some real references and some fake ones. The researcher doesn't spot the fakes because they're skimming rather than reading carefully.
All of these are tempting because they save time. The time pressure in academia is real. You have finite hours before a deadline. You have multiple projects ongoing. You're reviewing other papers (unpaid). You're teaching. You might be on the job market or working toward tenure.
Using AI to accelerate the tedious parts (like citation formatting or section refinement) seems obviously smart. The problem is that AI doesn't distinguish between accelerating tedious-but-routine work and introducing errors into critical work.
Researchers who would never consciously submit a paper with fake citations are still ending up with them because the workflow abstracted away the responsibility. You asked a tool to help. The tool made a mistake. You didn't catch it. Now it's in a peer-reviewed venue.
This pattern will get worse as AI tools get better. They'll become more integrated into workflow. More invisible. More trusted. The probability of hallucinations will decrease (because models get better), but the scale of their use will increase so much that absolute numbers of hallucinations might stay the same or grow.

What Conferences Can Actually Do About This
Let's be realistic: Neur IPS can't solve this by being more strict. You can't add more requirements to peer review when reviewers are already drowning. You can't ask them to fact-check every citation when they can barely read the papers in time.
So what actually works?
Automated detection. Conferences could require authors to submit papers through tools like GPTZero before review, or they could scan all submissions themselves. The detection accuracy isn't perfect, but it's good enough to flag suspicious sections for manual review. This shifts work from reviewers to authors (who have more time and motivation to fix errors).
Submission requirements. Conferences could require authors to declare which sections were AI-assisted and which weren't. They could require citations to include DOI links that automatically verify the paper exists. They could require authors to certify that they've verified at least 30% of their citations.
These aren't foolproof, but they're better than the current system where anything goes.
Acceptance rate adjustments. Neur IPS accepts roughly 30% of submissions (4,841 out of 15,500). If they reduced that to 20%, they'd have fewer papers to review, giving reviewers more time per paper. They could dedicate that extra time to verification. This obviously has downsides (slower publication), but it would improve quality.
Incentive changes. Funding agencies and universities could stop using citation count as a metric for research quality. If you measure researchers based on citations, they'll optimize for citations, including by cutting corners. If you measure based on reproducibility, rigor, or actual impact on problems, the incentives shift.
But none of these are being implemented at scale. Conferences keep accepting roughly the same percentage of submissions. Reviewers keep being overloaded. AI tools keep getting integrated into workflows without corresponding safeguards.
Neur IPS's response to GPTZero's findings was basically: "Yeah, it's a problem we're aware of. But the papers are probably still good." That's not really solving the problem. That's acknowledging it and moving on.
There are tools being built to help. GPTZero is one. Originality.ai is another. Turnitin has AI detection features. These aren't perfect, but they're better than nothing.
For individual researchers, the solution is simpler: don't use AI for critical content without verification. Use it for drafting, for brainstorming, for organizing. But when it comes to citations, results, or core claims, do it manually or at least verify the AI's output carefully.

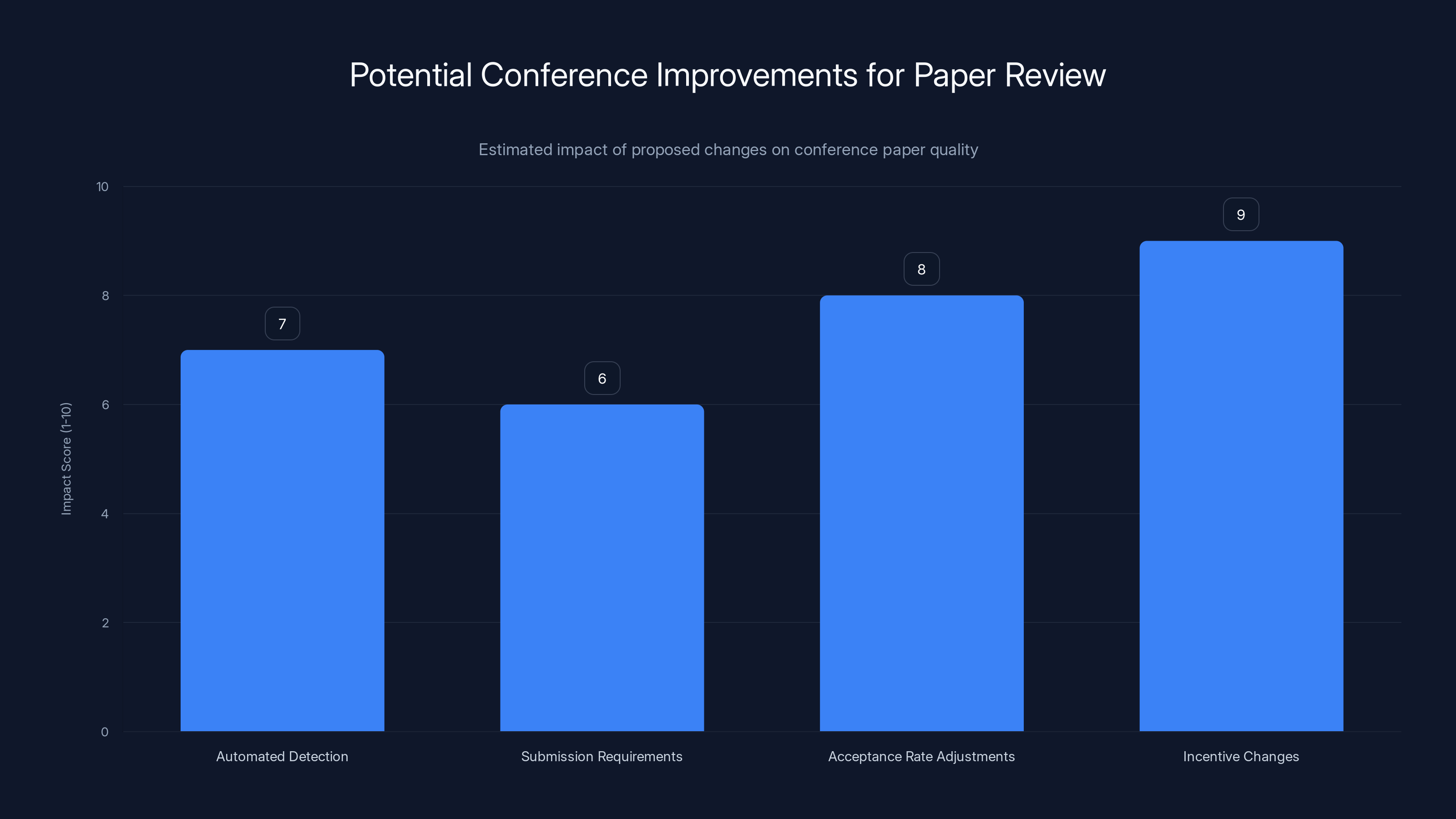
Implementing incentive changes and adjusting acceptance rates could have the highest impact on improving paper quality at conferences. (Estimated data)
The Broader Crisis in Academic Publishing
The hallucinated citations at Neur IPS are a symptom of a much larger problem. Academic publishing is broken, and AI didn't break it. AI just made it worse.
The system has been stressed for years. Researchers publish too much and read too little. Peer review is unpaid labor exploited by for-profit publishers. Journals and conferences prioritize volume over quality. Career incentives reward publication count, not impact. The entire structure was built for a slower, smaller research community.
Then AI arrives. It makes publishing faster. It makes writing easier. It makes it possible for a researcher to submit more papers, faster. But it also makes it easier to cut corners. To not actually engage with prior work. To generate citations instead of reading them. To automate away the human judgment that actually maintains integrity.
Academic publishing became a tragedy of the commons. Individual researchers are incentivized to publish as much as possible. Publishers are incentivized to accept as much as possible (volume = revenue). Conferences are incentivized to accept as many papers as they can review (bigger conference = more prestige). Nobody is incentivized to slow down and verify everything carefully.
AI accelerated this race to the bottom. Now hallucinations are getting through. Now citations can't be trusted. Now reviewers can't possibly keep up.
The irony is that Neur IPS itself exists because AI research was growing faster than traditional academic venues could handle. The field needed a place to publish cutting-edge work quickly. Now that cutting-edge work is being published so fast that the editing process can barely keep up.
Something has to give. Either the system slows down dramatically (fewer conferences, smaller acceptance rates, longer review periods), or it accepts that integrity is a luxury it can no longer afford.
Right now, it's trending toward the latter.
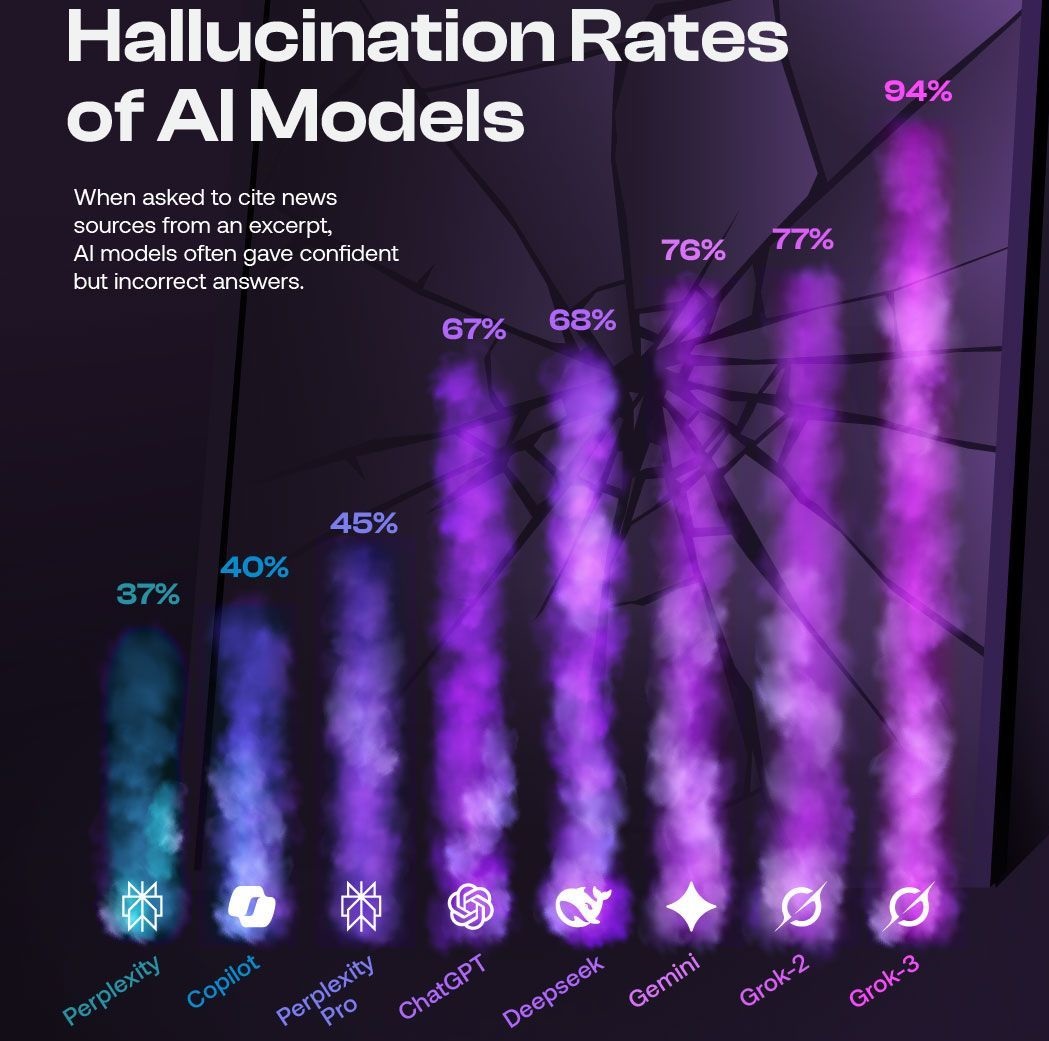
Detecting Hallucinations: The Technical Challenge
GPTZero's detection method isn't magic. They're using machine learning models trained to recognize patterns in AI-generated text. Modern LLMs produce text that's statistically different from human writing in measurable ways. AI text tends to be slightly more uniform, with less variation in sentence structure, fewer rare word choices, and different patterns of word transitions.
But modern models (especially GPT-4 and newer versions) are getting really good at mimicking human writing. They're less detectable than older models. As AI gets better, detection gets harder.
There's also a fundamental problem: the better the AI model, the less likely its output is to contain obvious errors. So hallucinated citations created by cutting-edge language models might be completely undetectable as AI-generated because they read naturally and are well-integrated into the text.
The only way to actually verify a citation is to check if the paper exists. That requires looking it up in databases like Google Scholar, ar Xiv, Pub Med, or journal repositories. For a paper with 50 citations, that's 50 manual lookups. Takes about 30 minutes if you're efficient.
Now multiply that across all 4,841 papers at Neur IPS. That's 2,420,500 citations to verify. At 30 minutes per paper, that's over 40,000 hours of work. No conference has resources for that.
So we're stuck. You can detect that something was probably AI-written using statistical methods, but you can't actually verify it's false without manual work at scale. And you can detect hallucinations by checking if cited papers exist, but that requires time nobody has.
The system is in a bind.
One potential solution is to change how papers are published. Instead of citing papers by name and publishing year, you cite by DOI (digital object identifier). A DOI is a unique identifier assigned to published work. If a citation includes a DOI, verification is automatic: systems can check whether that DOI resolves to a real paper.
Some journals already require DOIs. But not all venues do. And for older papers, DOIs weren't used. So this would be a gradual transition at best.
Another idea: require papers to include a "citations verified" statement. Authors would certify that they've spot-checked or fully verified their citations. This creates accountability. If an author later admits citations were AI-generated and unverified, it damages their reputation. Not foolproof, but it adds friction to the convenient approach of just using AI without checking.
Neither of these solutions is being widely adopted.
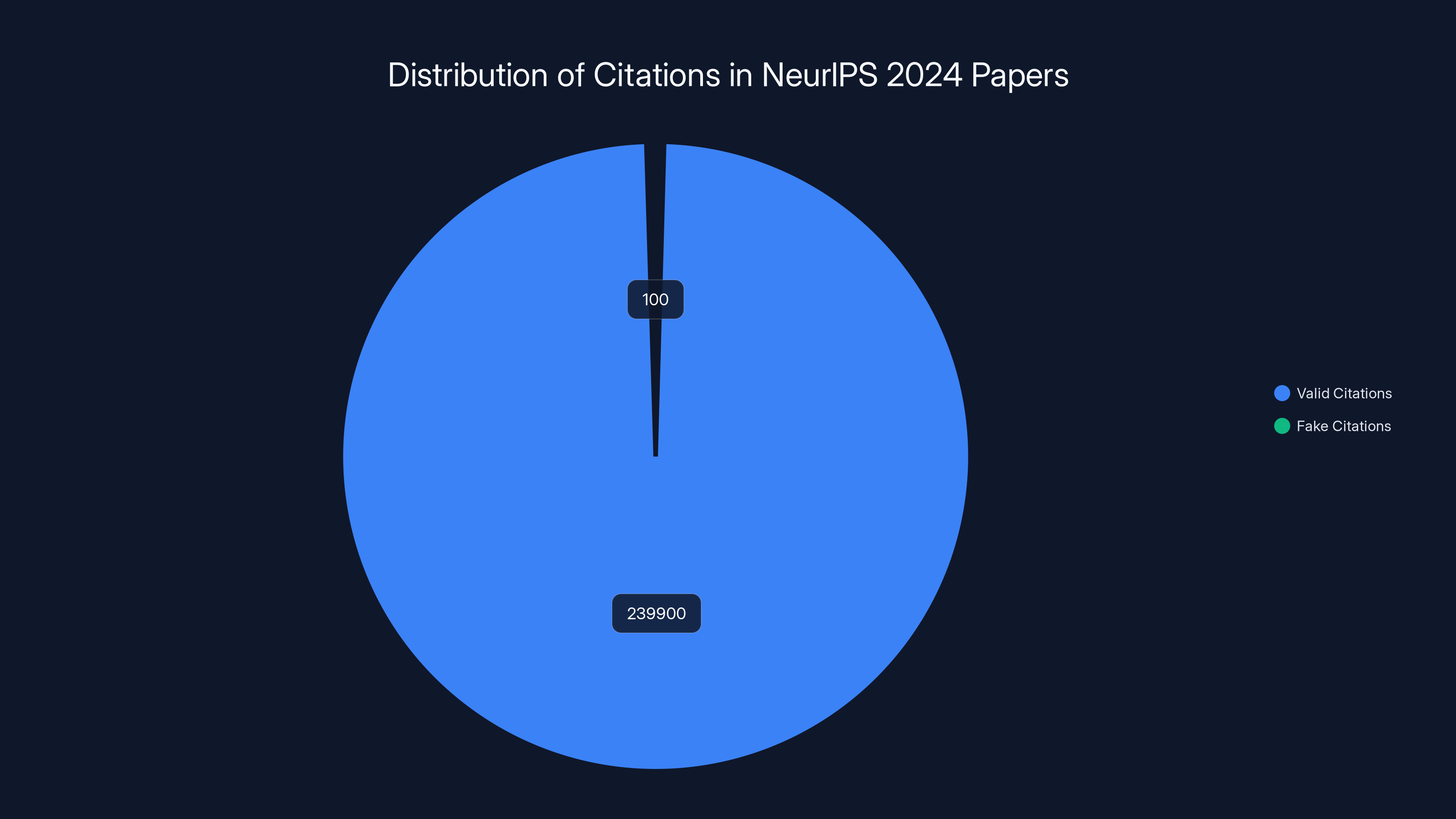
Out of approximately 240,000 citations in NeurIPS 2024 papers, only 100 were identified as fake, representing just 0.04% of the total. Estimated data.
What This Means for AI Safety and Trustworthiness
Here's the meta-irony: Neur IPS exists to advance the field of AI. The conference publishes research on how to make AI systems safer, more trustworthy, more aligned with human values.
Yet researchers at this very conference are using current-generation AI tools in ways that undermine trust and safety. They're using tools they know are prone to hallucination without proper verification. They're submitting work with fabricated citations to a peer review system that's already straining.
It suggests a mismatch between knowledge and behavior. Researchers understand that LLMs hallucinate. They know why citations matter. They understand the importance of peer review integrity. But in the day-to-day workflow, when deadlines loom and tools offer to save time, the knowledge doesn't translate to behavior.
This is actually relevant to broader AI safety concerns. There's a lot of research on how to make AI systems more trustworthy, more transparent, more aligned with human oversight. But what good is any of that if humans just... skip the verification step? If we integrate AI into workflows without the safeguards we built theoretically?
The hallucinated citations at Neur IPS are a small-scale version of the central problem in AI deployment: at what point does convenience override caution? When does the promise of efficiency override the need for verification?
For now, it's happening in academic citations. If the same patterns extend to other domains (medical research, legal documents, financial reports), the stakes get much higher.
That's probably the real story here. Not that some papers have fake citations. But that even among the people who study AI safety, we're making choices that violate our own safety principles.
It's a canary in the coal mine.
The Role of Tools Like Runable in Research Workflows
Given these challenges, some research teams are turning to automation platforms designed specifically for document generation and workflow efficiency. Runable, an AI-powered automation platform, offers a different approach to content creation by emphasizing transparency and structured output.
Rather than asking an AI model to hallucinate citations or generate sections autonomously, Runable enables researchers to build documented workflows where each step is explicit and verifiable. You can create AI agents that pull data from databases, organize information systematically, and generate reports or documents with clear sourcing.
For research teams, this matters because it shifts from "ask AI to write something" to "use AI to automate structured, verifiable processes." When you're generating a presentation from your actual research data, or creating a report from databases you've queried, the AI isn't hallucinating. It's transforming structured inputs into formatted outputs.
At $9/month, Runable's approach to AI automation is fundamentally different from using generic LLMs for citation generation. It's built around the idea that AI works best when it's constrained to documented workflows rather than creative generation of critical content.
For academic workflows specifically, you could imagine using Runable to automate the creation of literature review documents where citations come from actual database queries, not from the model's training data. Or to generate research summaries from structured data about experiments you've actually run.
Use Case: Automate the generation of research summaries and citation lists from your actual database of papers, not from AI hallucinations.
Try Runable For FreeThat's not a complete solution to the Neur IPS problem. But it represents a shift toward AI workflows that maintain verification instead of replacing it.
How Other Conferences Are Responding
Neur IPS isn't the only conference dealing with this. The International Conference on Machine Learning (ICML), the International Conference on Learning Representations (ICLR), and others have started implementing policies around AI usage in submissions.
ICML has guidelines asking authors to disclose AI usage. ICLR similarly requests transparency about computational tools used. But "guidelines" and "requests" aren't requirements. Compliance is voluntary.
Some smaller conferences have been more aggressive. They're requiring AI detection scanning, or they're asking for manual verification of critical citations. But these policies haven't been widely adopted by the major venues because it adds friction to an already strained submission process.
There's also been discussion in the research community about certification systems. Imagine a badge or mark that indicates "this paper's citations have been verified by the authors and independently checked by a reviewer." That would be a signal of quality. But implementing it would require time and resources that don't currently exist.
The broader trend is slow acknowledgment that the current system is broken, with no clear agreement on how to fix it. Conferences are trying to balance integrity with practicality. But practicality keeps winning because integrity is expensive.

The Future of Academic Publishing in the Age of AI
If we're honest, hallucinated citations are just the beginning. As AI tools get better and more integrated into research workflows, we'll see more sophisticated integrity issues.
Imagine AI that generates plausible experimental results. That's technically possible with modern generative models if you give them parameters from similar experiments. A researcher could generate synthetic data that follows expected statistical distributions, making it nearly impossible to spot as fabricated without extremely detailed investigation.
Or imagine AI that generates novel mathematical proofs that are convincing but subtly flawed. The errors would be hard to spot because they'd be novel errors, not patterns the AI was explicitly trained on.
Or AI that generates novel methods that sound rigorous but don't actually work as described. These aren't hallucinations in the sense of making up whole concepts. They're more like adaptive confabulation, where the AI generates plausible-sounding details for methods it doesn't fully understand.
The detection problem gets harder for all of these. For citations, you can at least check if the paper exists. For fabricated data or subtle flaws in proofs, detection requires deep domain expertise and time nobody has.
So the trajectory is likely toward one of a few futures:
Future 1: Radical slowing of publishing. Conferences reduce acceptance rates significantly. Review processes become much more thorough. Verification becomes built into the review criteria. Science slows down but maintains higher integrity.
Future 2: Acceptance of lower integrity. Conferences acknowledge that perfect verification is impossible and accept that some fraction of published work contains errors or fabrications. The peer review system becomes more about filtering for obvious problems than ensuring correctness.
Future 3: Structural changes. Academic publishing moves away from the conference model entirely. Research is published continuously online with rolling review. Reputation systems become more sophisticated at identifying quality. The model shifts from binary accept/reject to nuanced quality signals.
We're currently drifting toward Future 2. That's probably the worst outcome long-term, but it's the path of least resistance for everyone involved.

Lessons for AI Tool Users Across Industries
The Neur IPS hallucinations offer lessons beyond academia. Any industry that relies on generated content should take note.
In legal work, hallucinated citations in contracts could have real consequences. In journalism, fake sources undermine credibility permanently. In software development, fabricated test results mask bugs. In healthcare, false citations in medical literature could influence treatment decisions.
The pattern is the same everywhere: as AI integration increases, the pressure to verify decreases (because who has time?), but the consequences of errors increase (because integration is deeper).
The solution isn't to stop using AI. The solution is to use it thoughtfully. Use it for tasks where hallucinations are low-risk and easy to verify. Don't use it for critical content without additional safeguards.
For citations specifically: never let an AI generate them. Let it help organize them. Let it suggest papers to read. But the actual citation work should be human-driven. The five minutes you save by using AI to generate citations isn't worth the risk of submitting fabricated references.
For code: use AI to generate boilerplate and common patterns. Don't use it to generate security-critical sections without careful review.
For medical content: use AI to draft and organize. Don't use it to make clinical claims without expert verification.
The principle is: AI should augment human judgment, not replace it. Especially for content where judgment is critical and errors are costly.

Why This Story Matters Right Now
The hallucinated citations at Neur IPS matter not because they're shocking, but because they're predictable. We knew this was coming. Research on AI hallucinations has been clear for years. The concern about LLM reliability in high-stakes applications is well-documented.
What's remarkable is that it happened at a venue specifically focused on AI. The researchers publishing papers about AI safety and trustworthiness are the same ones submitting papers with AI-generated hallucinations.
That's not criticism. It's a reality check. It means the problem isn't knowledge. Researchers know this stuff. The problem is systemic. The publishing system incentivizes rapid production over careful verification. AI tools make rapid production faster. So they get used without the accompanying safeguards that careful verification requires.
Fix the incentives and the behavior changes. Keep the incentives the same and more hallucinations will slip through, just in subtler ways.
Neur IPS will probably update its policies slightly. Maybe require more explicit AI disclosure. Maybe implement automated detection scanning. Maybe reduce acceptance rates marginally. But without fundamental changes to how academic research is valued and rewarded, the underlying problem persists.
So the hallucinated citations are a harbinger. They're showing us what happens when integrity requirements meet workflow efficiency. And we're currently betting that efficiency wins.
Time will tell if that was the right bet.

FAQ
What are hallucinated citations and why do they matter in academic research?
Hallucinated citations are references to research papers or sources that don't actually exist, typically generated by AI language models when instructed to produce citations. They matter because citations are the foundation of academic credibility—they show that your work builds on established knowledge and give credit to prior research. When citations are fabricated, it undermines the entire peer review system, corrupts citation metrics that researchers use for career advancement, and makes it harder for other scientists to distinguish real from fictional prior work. A fake citation in a peer-reviewed paper at a top venue like Neur IPS signals that the verification systems everyone relies on are inadequate.
How does GPTZero detect hallucinated citations in research papers?
GPTZero uses machine learning models trained to identify patterns distinctive to AI-generated text. Modern large language models produce text with slightly different statistical properties than human writing: more uniform sentence structure, fewer rare word choices, and different patterns of word transitions. Additionally, GPTZero can flag suspicious citations for manual verification by comparing them against academic databases like Google Scholar and ar Xiv. The system scanned all 4,841 Neur IPS papers and identified 100 confirmed hallucinated citations across 51 papers by finding references that don't resolve to actual published work.
Why couldn't peer reviewers catch these hallucinated citations during the review process?
Peer reviewers face an impossible volume problem. Major conferences like Neur IPS receive 15,000+ submissions and accept only 30%, which means reviewers must evaluate papers under severe time constraints (typically 3-6 hours per paper). Manually verifying every citation by checking databases would require an additional 30+ minutes per paper. With roughly 240,000 citations across all Neur IPS papers, thorough verification would require over 10,000 hours of additional work. Reviewers are already unpaid volunteers working at capacity, so asking them to fact-check every citation is unrealistic. Additionally, when AI-generated citations are well-written and contextually appropriate, they're difficult to distinguish from real ones without actually checking if the paper exists.
What percentage of citations at Neur IPS turned out to be hallucinated?
The hallucinations represent approximately 0.04% of all citations across Neur IPS (100 fake citations out of roughly 240,000 total). However, 1.1% of papers (51 out of 4,841) contained at least one hallucinated citation. While the percentage is small statistically, it reveals a significant process failure: these papers passed peer review despite containing fabricated references. The issue isn't the raw percentage, but what it signals about the viability of the current verification system when AI-assisted research becomes mainstream.
How are researchers accidentally creating papers with hallucinated citations?
Most researchers aren't intentionally committing fraud. Instead, they're using AI tools to accelerate workflows without proper verification. Common scenarios include asking Chat GPT or Claude to help draft the citations section, using AI to complete missing references when the researcher is on deadline, running entire sections through paraphrasing tools that subtly alter citations, or using citation management tools that integrate with AI and sometimes generate citations to fill gaps. The pressure to publish quickly, combined with the convenience of AI assistance, creates a workflow where verification gets skipped. Researchers know the risks theoretically but face practical time constraints that make the risks feel acceptable until citations get audited.
What can individual researchers do to prevent hallucinated citations in their work?
The most reliable approach is to never let AI generate citations independently. Instead, use AI for drafting and organizing, then manually verify the final list by searching each citation in Google Scholar or your field's primary databases. Create a verification checklist: (1) Does the paper appear in Google Scholar or ar Xiv? (2) Are the author names spelled correctly? (3) Is the publication year accurate? (4) Have you read at least the abstract of every cited paper? Set aside 30-45 minutes before submission to spot-check at least 30% of citations manually. For papers using AI assistance extensively, run them through tools like GPTZero or Originality.ai before submission to flag suspicious sections for manual review.
What structural changes could conferences implement to reduce hallucinated citations?
Conferences could require authors to submit papers through AI detection tools before formal review, shifting verification responsibility to authors rather than overburdened reviewers. They could mandate that citations include DOI (Digital Object Identifier) links that automatically verify a paper exists in official repositories. They could reduce acceptance rates from the current 30% to 20-25%, giving reviewers more time per paper for verification. Funding agencies could stop using citation count as a metric for researcher productivity, removing the incentive to maximize citations at any cost. Universities could implement institutional verification standards for papers before they count toward tenure or promotion. While no single change solves the problem, combinations of these approaches would create meaningful friction against casual AI usage in critical sections.
Will this problem get worse as AI models improve?
Probably yes, for a subtle reason. As AI models become more sophisticated, hallucinated text becomes less obviously AI-generated and harder to detect statistically. Simultaneously, models become more helpful and integrated into workflows, increasing adoption without corresponding safeguards. The percentage of hallucinations per model might decrease, but absolute numbers could stay constant or grow because far more people will use AI tools. Additionally, more subtle forms of AI errors (plausible-sounding errors in methods or results, rather than obviously fake citations) will become harder to detect without expert review. The system's integrity depends on verification capacity, which isn't growing as fast as AI adoption.
What does this mean for other industries beyond academic research?
The pattern applies anywhere critical content is generated with AI: legal documents with fake citations of precedent, medical literature with fabricated sources, financial reports with made-up data points, journalism with false sources. The common thread is that convenience (using AI) conflicts with safety (verification). In fields where errors have higher stakes (healthcare, law, finance), the consequences are more severe. The lesson is universal: use AI to augment human capabilities in low-risk areas, but don't use AI to generate critical content without verification from someone who has domain expertise and time to check the work carefully.

Conclusion: The System's Breaking Point
The discovery of hallucinated citations at Neur IPS isn't an indictment of the researchers involved. It's evidence that the academic publishing system has reached a breaking point where traditional integrity safeguards can no longer function.
Researchers are under pressure to publish more, faster. Conferences are overwhelmed with submissions that exceed their review capacity. Peer reviewers are unpaid and overcommitted. And now AI tools make it possible to do the work faster without the time-consuming verification steps that maintain quality.
It's a perfect storm of incentives misaligned with integrity.
The researchers at Neur IPS didn't set out to submit papers with fake citations. They were trying to meet deadlines and leverage tools that promised to save time. Most of them probably didn't even realize the citations were hallucinated. That's the insidious part of modern AI—it doesn't announce when it's fabricating. It just provides confident-sounding output that looks like everything else.
Neur IPS's response—acknowledging the problem while emphasizing that the core research is probably still sound—is pragmatic but concerning. It suggests we're accepting a new equilibrium where some fraction of published work contains undetected errors. That's fine for a system where errors are cheap to fix. For academic research, where errors can mislead future work and corrupt the historical record, it's problematic.
The real question isn't what happened at Neur IPS. The question is what comes next. Do conferences implement stronger verification? Do researchers adopt better practices? Do AI tool vendors build in safeguards?
Or do we just accept that this is how research works now, and adjust our expectations accordingly?
Right now, the trajectory suggests the latter. Which means we should probably start being skeptical of citations we encounter in papers. Not of the papers themselves, but of any references the authors may have leaned on AI to generate.
Trust, but verify. Especially when AI was involved in the writing.
That's not cynicism. That's just good science.

Key Takeaways
- GPTZero found 100 hallucinated citations across 51 NeurIPS papers, exposing that even elite AI researchers can't catch AI-generated fabrications in peer review
- Peer review systems are structurally broken: reviewers have only 3-6 hours per paper but would need 30+ minutes per paper just to verify citations alone
- Hallucinated citations don't invalidate papers' core research, but they corrupt the citation system that researchers depend on for credibility and career advancement
- Most researchers aren't intentionally committing fraud—they're using AI to meet deadlines without the time-consuming verification steps that integrity requires
- The problem will worsen as AI models become more convincing and more integrated into workflows, widening the gap between detection capacity and adoption rate
Related Articles
- AI's Hype Problem and What CES 2026 Must Deliver [2025]
- The Post-Truth Era: How AI Is Destroying Digital Authenticity [2025]
- AI Bubble Myth: Understanding 3 Distinct Layers & Timelines
- Anna's Archive Court Order: Why Judges Can't Stop Shadow Libraries [2025]
- UK Police AI Hallucination: How Copilot Fabricated Evidence [2025]
- Gemini's Personal Intelligence: How AI Now Understands Your Digital Life [2025]

