![AI Inference Costs Dropped 10x on Blackwell—What Really Matters [2025]](https://tryrunable.com/blog/ai-inference-costs-dropped-10x-on-blackwell-what-really-matt/image-1-1770912497677.jpg)
AI Inference Costs Dropped 10x on Blackwell—What Really Matters [2025]
Here's something that surprised me when I first dug into this: nobody actually cares about the hardware.
Okay, that's not entirely fair. But it's close to true. When Nvidia announced that their Blackwell platform could deliver 4x to 10x cost reductions in AI inference, every startup and enterprise suddenly wanted to upgrade. Hardware gets the headlines. It's tangible. You can point to a GPU and say, "This one is faster."
But the real story? The actual cost savings that are hitting production workloads right now? That comes from somewhere else entirely. And understanding where those savings really come from is critical before your team spends months migrating to new infrastructure.
This matters because inference costs are becoming the dominant factor in AI economics. Training a model? That's expensive, but you do it once. Inference is the ongoing operational cost. If you're running an AI chatbot, medical coding system, or voice assistant at scale, inference costs directly determine whether your product is profitable or a money-losing venture. A 10x reduction isn't just impressive on a slide—it's the difference between viability and shutdown.
But here's the trap most teams fall into: they see the 10x number and assume it applies to their workload. It doesn't. The cost reductions reported by inference providers like Baseten, Deep Infra, Fireworks AI, and Together AI came from a very specific combination of factors. If you're missing even one of those pieces, your actual savings might look more like 2x or 3x. And that changes the entire business case.
I've spent the last few weeks analyzing the actual deployment data, talking to infrastructure teams, and breaking down exactly where each component of the cost reduction comes from. What I found is both encouraging and complicated. The good news: yes, dramatic cost improvements are absolutely real and achievable. The complicated part: you need to understand what you're actually optimizing for, because each optimization path comes with trade-offs.
Let's start with what everyone gets wrong.
The Hardware-Only Myth: Why Blackwell Alone Isn't Enough
When Nvidia released Blackwell, the narrative was simple: faster chips mean lower costs. That's not wrong, exactly. It's just incomplete.
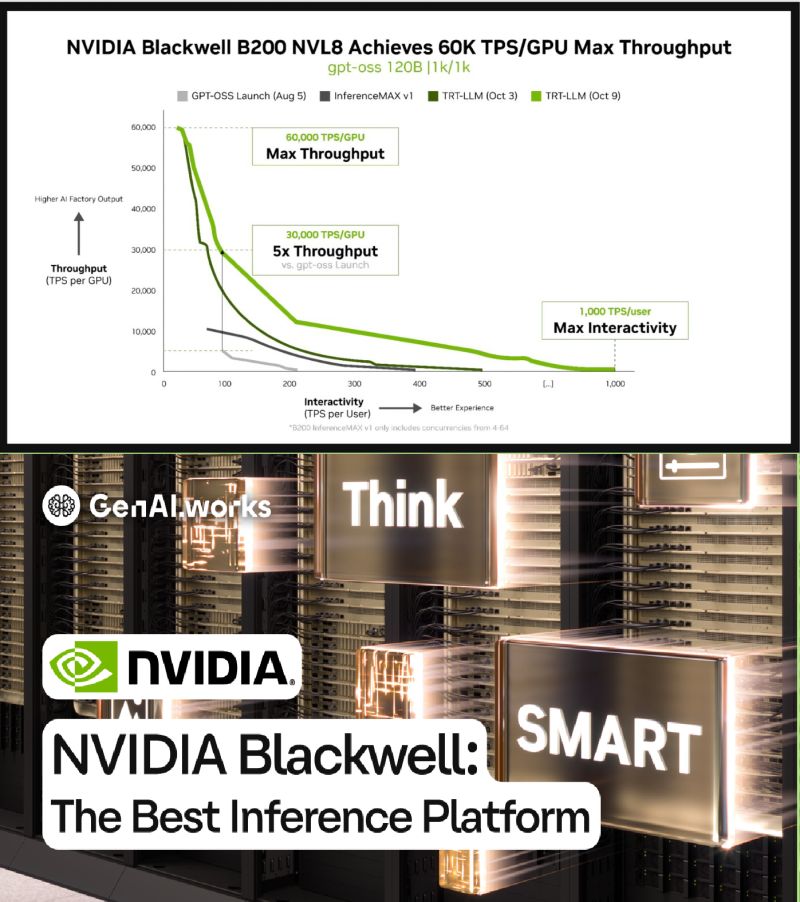
Hardware improvements absolutely do reduce inference costs. According to the deployment data, moving from Nvidia's previous Hopper architecture to Blackwell delivered roughly a 2x cost improvement on its own. That's nothing to dismiss. Doubling your performance is substantial. But here's the problem: the companies claiming 4x to 10x improvements didn't stop at hardware.
Think about how inference economics actually work. You have a model. Requests come in. The GPU processes those requests and generates tokens (the model's output). You charge per token or per request. Your cost structure looks something like this:
Notice what's in the numerator and denominator. Faster hardware (Blackwell) reduces the numerator slightly through better utilization. But the denominator—the number of tokens you can squeeze out per hour—that's where the real leverage is. And that's controlled by software, not chips.
One company in the deployment data, Latitude, showed exactly this dynamic. They ran their mixture-of-experts model on Blackwell infrastructure. Hardware alone: 2x cost reduction. Then they switched to NVFP4, a low-precision format that Blackwell supports natively. Suddenly they hit 4x total improvement. The precision format change alone was worth as much as the hardware upgrade.
Why? Because NVFP4 requires fewer bits to represent each weight and activation in the model. Fewer bits means faster computation. More tokens per second. The same GPU costs the same amount to run, but it now generates twice as many tokens per hour. Your per-token cost drops accordingly.
This is why Nvidia's Dion Harris, their senior director of HPC and AI hyperscaler solutions, kept emphasizing one point in interviews: "Performance is what drives down the cost of inference. Throughput literally translates into real dollar value." He's right. But he's also describing something that's only partially about hardware.
The teams that achieved 10x improvements (like Sully.ai in the healthcare deployment) combined three things: Blackwell hardware, optimized software stacks, and switching from proprietary models (like GPT-4) to open-source alternatives (like Llama or Mixtral). Each component mattered. Miss one, and your savings drop significantly.
The takeaway: if you're planning a migration to Blackwell thinking hardware upgrades alone will cut your costs in half, you're in for a surprise. You need to simultaneously optimize your software stack and probably rethink your model choice.

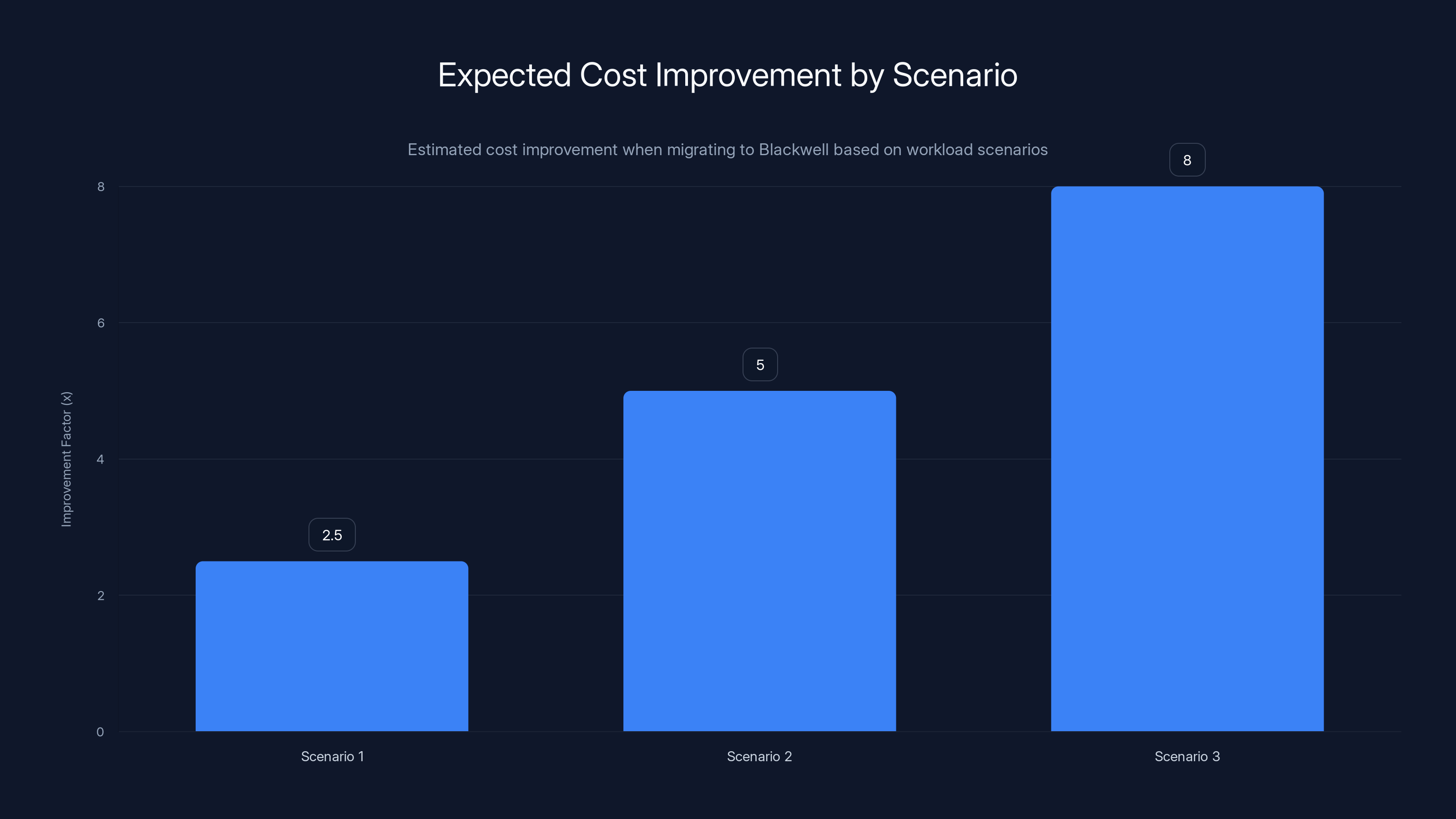
Estimated data shows Scenario 3 offers the highest cost improvement potential, up to 8x, due to batch-friendly, high-volume workloads.
Where the 4x Really Comes From: Precision Formats and Model Architecture
Let me break down the Latitude case in detail, because it's the clearest illustration of how costs actually drop.
Latitude runs AI Dungeon, a generative game platform. They use mixture-of-experts models—think of these as neural networks with many specialized sub-networks inside. For each request, only some of the sub-networks activate. That architecture is incredibly efficient if you've got the right hardware to run it on.
Their cost progression tells the story:
- Hopper baseline: 20 cents per million tokens
- Blackwell hardware: 10 cents per million tokens (2x improvement)
- Add NVFP4 precision format: 5 cents per million tokens (4x total improvement)
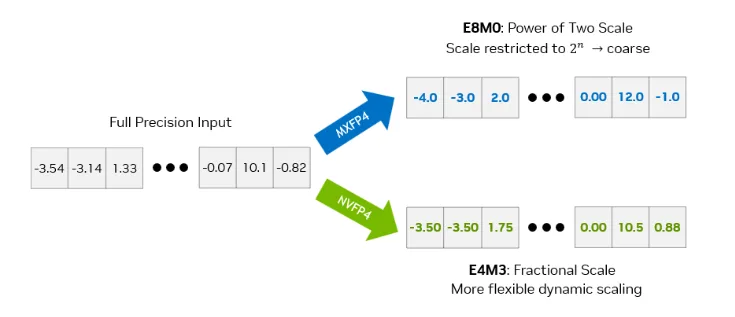
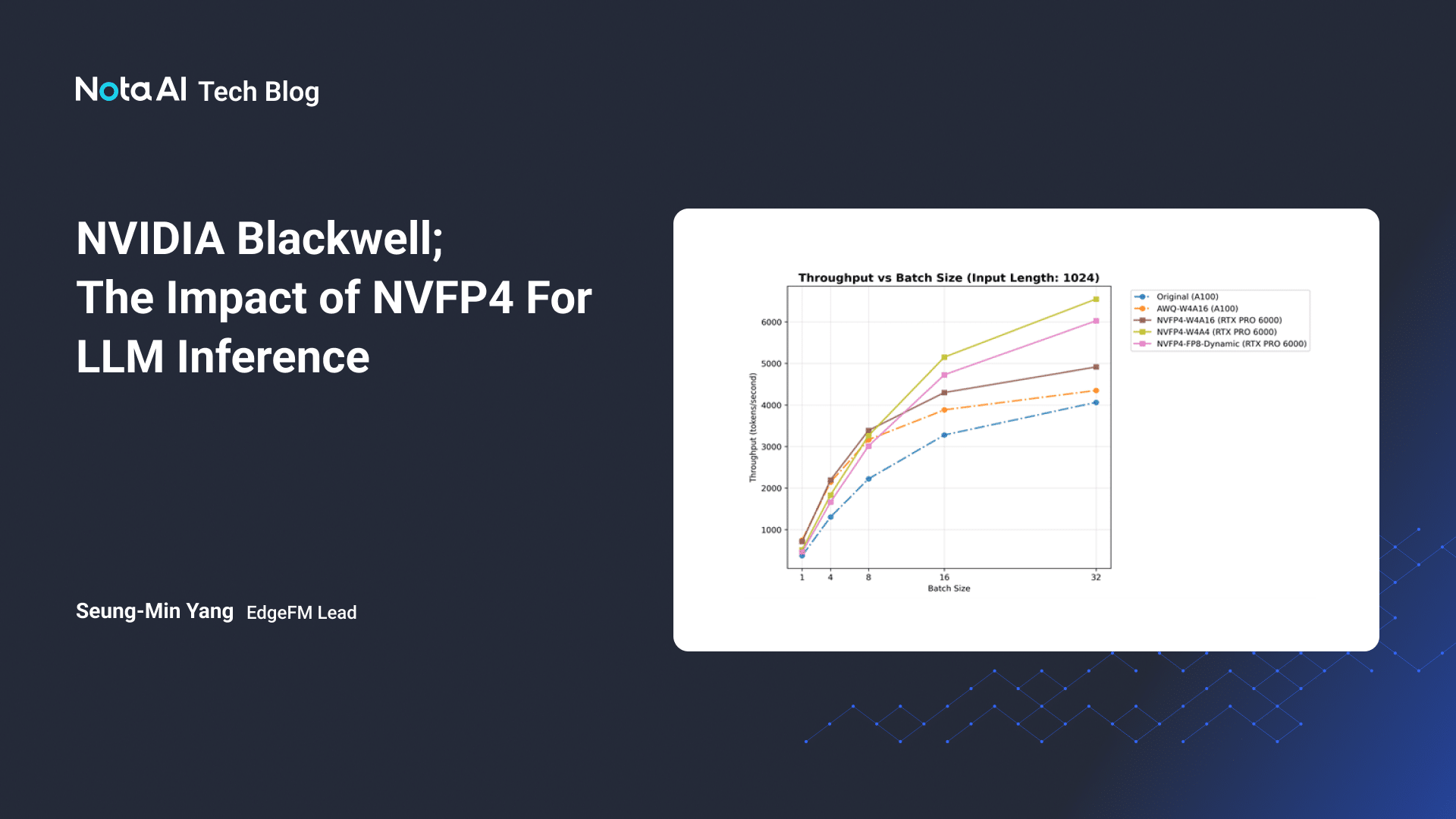
That NVFP4 number is critical. It's a low-precision floating-point format. Standard models typically use FP32 (32-bit floats). FP8 (8-bit floats) has become popular for inference because you can fit more of the model into GPU memory while maintaining accuracy. NVFP4 goes even lower—4-bit precision—while preserving accuracy through careful quantization.
Here's where the architecture piece comes in. With mixture-of-experts, only some of the model's parameters activate per request. That means you don't need to load the entire model into high precision. You can use NVFP4 for most of it, since only the active experts matter for any given request. This is why Mo E models see such dramatic speedups on Blackwell—the hardware has high-bandwidth memory interconnects (NVLink fabric) that let experts communicate rapidly while staying in low precision.
Dense models—the traditional architecture where every parameter activates for every request—don't see the same benefit. If you're running a single large dense model, NVFP4 might buy you 1.3x or 1.5x improvement, not 2x. That's the difference between 6x total savings and 3x.
Software stack integration matters equally. The deployment data showed that teams using Nvidia's full software ecosystem (Tensor RT-LLM for optimization, Dynamo for dynamic compilation, NVL72 architecture) got better results than those using alternatives like v LLM. This isn't because v LLM is bad—it's actually quite good. But when hardware and software are co-designed and optimized together, you get synergies that standalone components can't achieve.
Sully.ai, the healthcare company that hit the 10x mark, used the full integrated stack. They also made another critical choice: they switched from GPT-4 (proprietary, optimized for general intelligence) to an open-source model fine-tuned for their specific medical domain. Open-source models have a huge advantage here—you can quantize them, prune them, and optimize them however you want without hitting API rate limits or paying per-token fees.
The cost structure changes completely. With GPT-4 via API, you pay maybe
That's where 10x comes from. It's not just better hardware. It's the combination of hardware that can actually run these models efficiently, software that extracts full throughput from that hardware, and a shift from proprietary APIs to self-hosted alternatives.
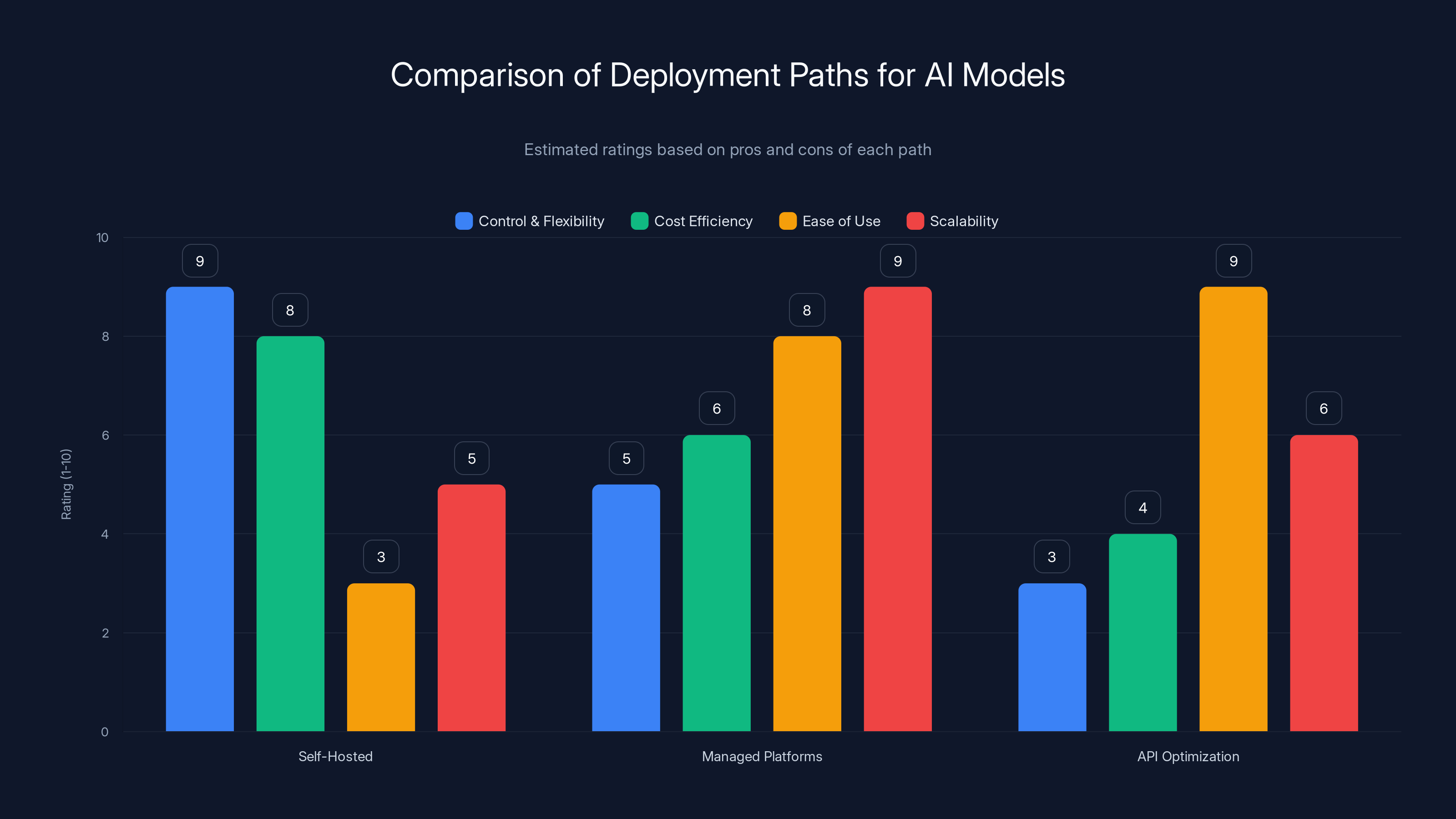
Self-hosted solutions offer the most control but require expertise, while managed platforms provide ease of use and scalability. API optimization is easiest but offers less cost efficiency. Estimated data based on qualitative analysis.
Model Choice: The Overlooked Leverage Point
Here's what surprised me most in the data: model choice created more variance in cost outcomes than any hardware difference.
Think about what happened with Sully.ai. They reduced inference costs by 90% (a 10x improvement). How much of that came from switching to Blackwell hardware? Probably 20-30%. How much came from switching from GPT-4 to an open-source model? Probably 50-60%. The rest came from optimization and precision formats.
But nobody talks about model choice as a cost optimization strategy. The narrative in tech is usually: "We need the most capable model." For many workloads, that's actually true. If you're building a general-purpose chatbot, GPT-4 or Claude is probably the right choice. You need the broad knowledge and reasoning ability.
But healthcare institutions, financial services companies, gaming platforms—these have specialized domains. In those domains, the accuracy sweet spot isn't the frontier model. It's a smaller, fine-tuned model that knows your domain deeply but doesn't waste capacity on everything else.
Llama 3.1, Mixtral, Phi—these models are 5-10x smaller than GPT-4. They're also radically cheaper to run. But here's the key insight: for specific domains, they're equally or more accurate. Sully.ai found that a domain-specific fine-tuned model actually improved medical coding accuracy while cutting costs by 10x. That's not a trade-off. That's just better engineering.
The economics are brutal once you do the math. Say you're running an AI system that makes 100,000 inference calls per day, and each call generates 500 tokens on average. That's 50 million tokens daily.
With GPT-4 API at
With a self-hosted open-source model on reasonable hardware, run efficiently:
That's 30x cheaper. And if that open-source model is domain-optimized, you're also getting better accuracy.
The catch? It requires infrastructure. You need GPUs. You need Dev Ops expertise to manage that infrastructure. You need someone who understands model optimization. For early-stage startups, that's prohibitive. For companies with serious AI workloads, it's a no-brainer.
What's changing is the accessibility of that approach. Inference platforms like Baseten and Together AI are commoditizing the infrastructure piece. You can now deploy fine-tuned open-source models without building your entire MLOps organization. That's shifting the model-choice economics for a lot of companies.
The Workload Profile Gamble: Why 4x Doesn't Equal 6x Doesn't Equal 10x
Here's something that's bothering me about how this data gets reported: everyone talks about the 10x figure like it's a universal improvement.
It isn't. The range from 4x to 10x across different deployments reflects fundamentally different workload characteristics. Understanding what drives each company to a different point on that spectrum is essential if you want to predict what you'll actually achieve.
Let's map the actual cases:
Sully.ai: 10x improvement Healthcare AI for medical coding and note-taking. High-volume, repetitive tasks. The domain is extremely narrow (medical coding has specific rules and vocabularies). Long inference sequences. The company switched from GPT-4 to a fine-tuned open-source model on Baseten's Blackwell infrastructure.
Latitude: 4x improvement AI Dungeon gaming platform. Lower volume, but highly interactive. Uses mixture-of-experts models (inherently more efficient). Deployed on Deep Infra's Blackwell platform with NVFP4 precision.
Sentient Foundation: 25-50% improvement Agentic chat platform with complex multi-agent orchestration. Higher latency tolerance but throughput-sensitive. Deployed on Fireworks AI's Blackwell optimization.
Decagon: 6x improvement Voice customer support. Latency-critical (sub-400ms response times required). Multimodal stack. Deployed on Together AI's Blackwell infrastructure.
Notice the pattern? The biggest improvements (10x) came from the most specialized workload (medical domain). The moderate improvements (4-6x) came from general-purpose or latency-sensitive use cases. The smallest improvement (25-50%) came from the most complex orchestration scenario.
Why? Because each of those improvements came from a different mix of optimizations.
Sully.ai could achieve 10x because they could:
- Switch from a general-purpose proprietary model to a domain-specific open-source one
- Accept longer response latencies (medical coding isn't real-time)
- Run full software optimization because they owned the entire stack
- Achieve near-perfect GPU utilization
Latitude got 4x instead of 10x because they:
- Stayed with a general-purpose model architecture (though fine-tuned for gaming)
- Required lower latencies (gaming players expect quick AI responses)
- Benefited from Mo E architecture but less from model switching
Sentient Foundation saw modest improvements because they:
- Had complex multi-agent orchestration overhead
- Couldn't fully optimize for throughput due to agent coordination requirements
- Couldn't easily switch to simpler models due to reasoning requirements
Decagon landed in the middle because:
- Latency requirements (sub-400ms for voice) limit batching opportunities
- Multimodal processing has inherent overhead
- But they could still optimize throughput through careful batching
The lesson: your actual cost improvement will depend on three things:
- Workload characteristics (how latency-sensitive? how domain-specific? how long are inference sequences?)
- Model flexibility (how much can you switch to domain-optimized or smaller models?)
- Optimization depth (how deeply can you optimize your stack for your specific workload?)
If you're running a low-latency, general-purpose AI application where you can't switch models easily, expect 2-3x improvement from Blackwell. If you're running high-volume, domain-specific inference where latency is flexible, you might hit 6-8x. If you're willing to fully rearchitect your approach (switching models, optimizing for throughput, using the full software stack), you might hit 10x.
But that last scenario is rare. It requires the perfect combination of circumstances.
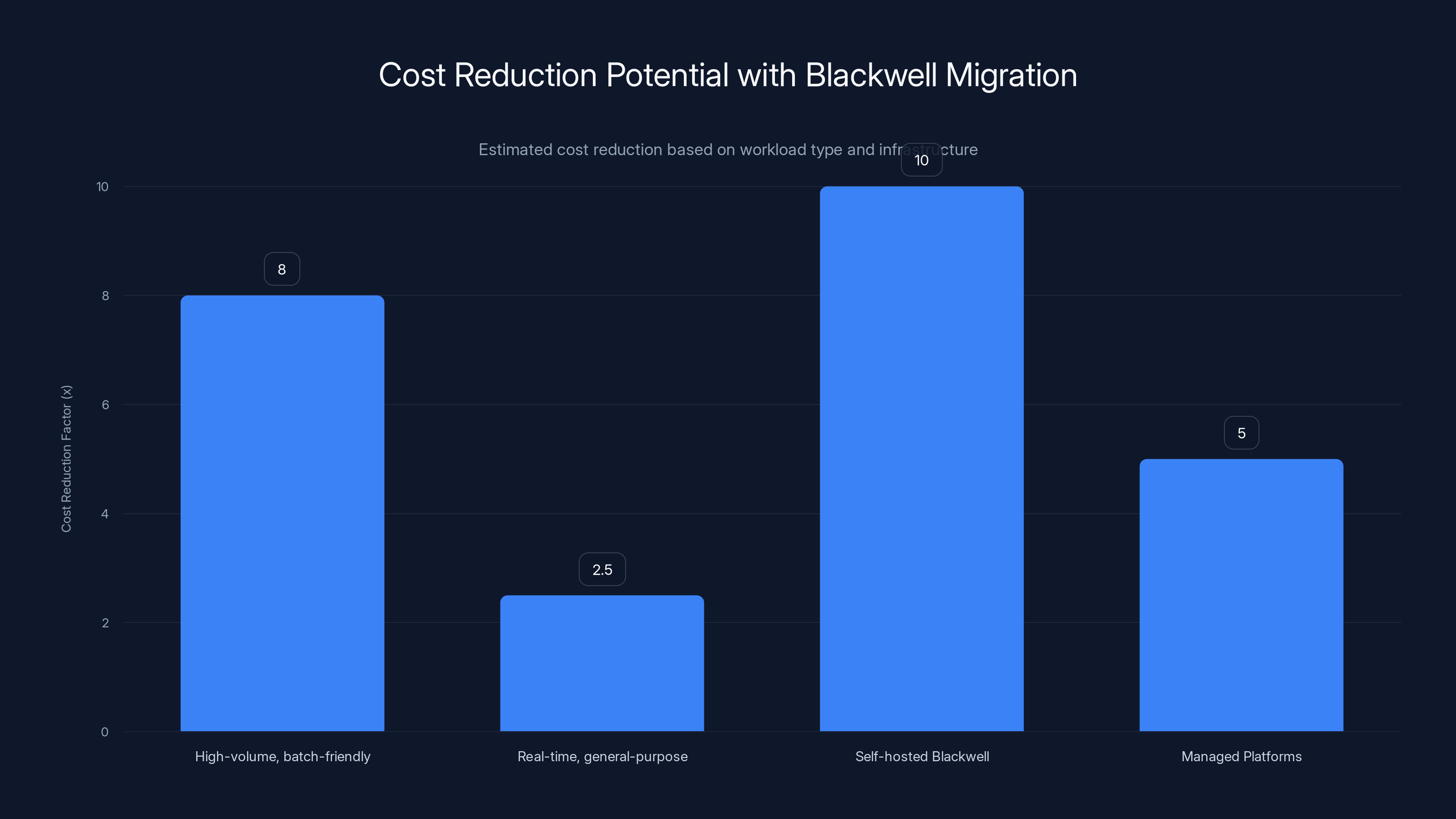
Estimated data shows that high-volume, batch-friendly workloads can achieve up to 8x cost reduction, while self-hosted Blackwell setups can potentially reach 10x, albeit with significant engineering investment.
Token Generation as a Cost Driver: Why Reasoning Models Win on Blackwell
I keep coming back to that formula because it explains something counterintuitive: longer inference sequences can actually be cheaper per token on modern hardware.
Traditional inference optimization assumes shorter outputs are cheaper. You ask a model a question, it gives a 50-token answer, done. Reasoning models don't work that way. They might generate 500 tokens or 5,000 tokens internally while reasoning, then distill that into a final answer.
With older hardware (or standard software stacks), those long inference sequences were expensive—you paid for every token. On Blackwell with optimized software, the dynamics change.
Here's why: Blackwell's architecture excels at sustained, high-throughput workloads. The GPU has enormous bandwidth for moving data between memory and compute. When you're generating thousands of tokens in a single inference request, you're maximizing hardware utilization. The fixed costs (GPU rental, infrastructure overhead) are spread across more tokens, reducing per-token cost dramatically.
Think about the math:
- Short inference (50 tokens): Your GPU sits partially idle while processing a short sequence. That's wasteful. Per-token cost is high because you're not using the hardware's full capacity.
- Long inference (5,000 tokens from a reasoning model): Your GPU is completely utilized throughout the inference process. Per-token cost is low because you're extracting full value from the hardware.
This is why Open AI's o 1 and similar reasoning models are starting to make economic sense in certain scenarios. Yes, they generate more tokens. But on modern infrastructure, those extra tokens might actually be cheaper than the shorter outputs from faster models.
For specialized domains (medical research, legal analysis, engineering), those extra reasoning tokens often produce substantially better outputs. Better output + cheaper per-token cost = obvious win.
This is a shift from the entire history of language model deployment. Historically, you wanted the model that produced correct outputs as quickly as possible. Now the equation is: you want the model that produces correct outputs as efficiently as possible in terms of GPU compute. Those aren't the same thing.
Blackwell's architecture is specifically designed for this. The NVLink fabric enables rapid communication between specialized compute units. The memory bandwidth is enormous. The hardware is optimized for scenarios where you're generating lots of tokens from each inference request.
If your workload is short, quick inference (like traditional API responses), the benefits are modest. If your workload involves longer reasoning sequences, extended context windows, or token generation heavy lifting, Blackwell shows its real advantage.
Software Stack Integration: The Hidden Multiplier
This is where I think the analysis gets interesting, because it's also where most teams get stuck.
Hardware and model choice get the attention, but software stack integration is where 30-40% of the cost improvement actually comes from. And it's largely invisible.
The companies that hit bigger cost reductions used integrated software stacks where hardware, compiler, runtime, and serving layer were all optimized together. Specifically, many used Tensor RT-LLM, Nvidia's inference optimization library.
What does Tensor RT-LLM do? It takes a trained language model and converts it into an optimized computation graph specifically for your inference hardware. It handles quantization, prunning, kernel fusion, memory optimization, and batching strategies. Instead of running generic matrix multiplications (which are slow), it runs specialized kernels that are tuned to your hardware.
The impact is significant. Teams using Tensor RT-LLM reported 1.5-2x improvements versus teams using more generic frameworks like v LLM or Hugging Face inference.
But here's the catch: Tensor RT-LLM requires expertise to deploy properly. You can't just point it at a model and get optimal results. You need someone who understands:
- Quantization strategies - which precision formats work for your model and task?
- Batch size optimization - how do you find the sweet spot between utilization and latency?
- Memory management - how do you fit your model and batch size into GPU VRAM?
- Kernel optimization - which operations are slow and need custom kernels?
For teams without ML infrastructure expertise, this is a barrier. For teams with deep expertise (like Sully.ai, apparently), it's a force multiplier.
This is where platforms like Baseten, Together AI, and Fireworks AI add value. They've already done the Tensor RT-LLM optimization work. They've profiled thousands of model/hardware/workload combinations. When you deploy to their platforms, you get Tensor RT-LLM optimization for free (baked into their pricing).
That's a significant part of why deployment on these platforms—versus self-hosted Blackwell—shows better cost improvements. The platforms have already solved the software optimization problem.
Dynamo (Nvidia's dynamic compiler) adds another layer. It takes your inference code and compiles it specifically for your hardware at runtime. It can fuse operations, optimize memory layout, and parallelize computation in ways that generic compilers can't.
Sully.ai's 10x improvement specifically came from using the full stack: Blackwell hardware + Tensor RT-LLM optimization + Dynamo compilation + NVFP4 precision + optimized serving on Baseten's platform.
If you removed any one of those components, the improvement would drop. Remove Dynamo? Maybe you lose 10-15%. Remove Tensor RT-LLM and use generic inference code? Maybe you lose 30-40%. Now you're looking at 5-6x instead of 10x.
The implication: if you're self-hosting Blackwell hardware without the full software stack optimization, don't expect the 10x improvements you're reading about. You'll probably get 2-3x from hardware alone, maybe 4x if you put in serious software engineering effort. Getting to 6-8x requires either deep expertise or outsourcing to a platform that specializes in this.

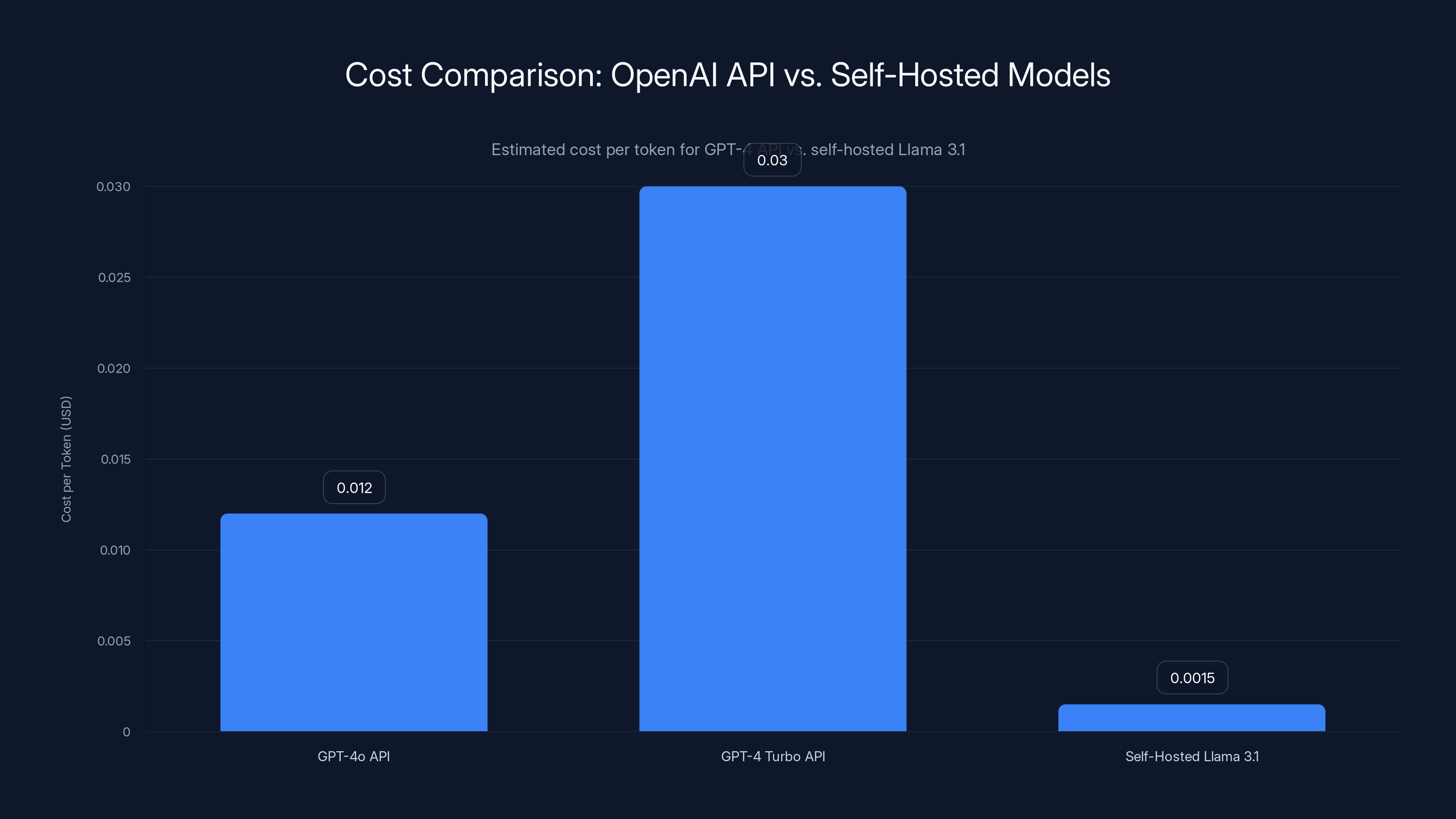
Self-hosted Llama 3.1 models are significantly cheaper per token compared to GPT-4 APIs, offering 10-20x cost savings. Estimated data based on typical usage.
The Latency-Cost Trade-off: Why Faster Doesn't Always Mean Better
Here's a dynamic that doesn't get discussed enough: lower latency requirements can actually increase inference costs per token.
Think about how serving works at scale. You have requests coming in. You want to batch them together to maximize GPU utilization. Larger batches = higher utilization = lower per-token costs. But batching increases latency. If you're waiting for 32 requests to arrive before processing them, each request sits in a queue getting slower.
For voice customer support (like Decagon's use case), you can't afford that. Latency over 400-500 milliseconds and users hang up. You lose the call. So you process requests immediately, even if it means your batch size is just 2-4 requests. Lower batch size = lower utilization = higher per-token cost.
Decagon achieved 6x cost improvement, not 10x, partly because of these latency constraints. They can't wait for perfect batch sizes.
Sully.ai, processing medical coding in batch overnight? Zero latency constraints. They can fill batches to 64, 128, even 256 requests. Perfect GPU utilization. Costs plummet.
This is why the breakdown matters so much:
- Latency-critical workloads (real-time chat, voice, interactive games): Expect 3-4x improvements with Blackwell, maybe 5x with extensive optimization
- Batch-friendly workloads (overnight processing, document analysis, medical coding): Expect 6-10x improvements
You can try to have it both ways—supporting both latency-critical and batch workloads—but it complicates your serving infrastructure. Most platforms (like Together AI and Baseten) solve this with disaggregated serving: they separate the prefill phase (processing input context, which is batch-friendly) from the generation phase (producing output tokens, which is more latency-sensitive). This allows better optimization of each phase independently.
But it's complex. And complexity costs engineering effort.
Before migrating to Blackwell, understand where your workload falls on this spectrum. If you're entirely real-time, don't expect 10x. If you're entirely batch, you might hit 10x. If you're somewhere in the middle (like most companies), you'll probably land in the 4-6x range.
Open-Source Models vs. Proprietary APIs: The Economics Flip
Sometimes the most important optimization is the one nobody wants to talk about because it feels like a "compromise."
Every company in the deployment data achieved their biggest cost improvements by switching from proprietary APIs (Open AI, Anthropic, Google) to self-hosted open-source models.
Let's be clear about what this means: you're trading API convenience for operational control. With Open AI's API, you make a request, you get a response, you pay per token. Done. Someone else manages the infrastructure, scaling, reliability.
With self-hosted models, you own the infrastructure. You manage scaling. You handle failures. You pay for GPUs (whether they're busy or idle). You need Dev Ops people.
But the unit economics are drastically different.
Open AI's pricing:
- GPT-4o: 12 per million output tokens
- GPT-4 Turbo: 0.03 per 1K output
These are premium prices for a service where the company handles infrastructure, reliability, and continuous improvement. Fair pricing? Sure. But it's not optimized for high-volume, cost-sensitive workloads.
Self-hosted Llama 3.1 70B on a single H100 GPU:
- GPU hourly cost: ~$2.50/hour (used GPU or self-owned amortized)
- Throughput: ~1,000-2,000 tokens/second (depending on batch size)
- Cost per token: $0.001-0.002
That's 10-20x cheaper than GPT-4 API.
The catch: you're assuming good GPU utilization. If your GPU is idle 50% of the time, your costs go up 2x. If you don't properly batch requests, your throughput plummets, and your per-token cost rises.
This is the infrastructure cost that most companies underestimate. They think about the GPU cost, but they don't think about:
- Dev Ops engineering to manage auto-scaling, load balancing, failover
- Monitoring and observability to catch issues before they become problems
- Model management to test new versions, handle updates
- Compliance and security (Open AI's API handles this; you need to build it yourself)
For a high-volume company (like Sully.ai with millions of inference requests per day), those costs are worth it. For a low-volume startup, they're not.
This is why platforms exist. They abstract away the infrastructure complexity. You deploy a model to Baseten or Together AI, and they handle scaling, optimization, monitoring. You pay more per token than pure self-hosted, but less than API pricing, and without the infrastructure headache.
Sully.ai's 10x improvement came partly from:
- Switching to self-hosted infrastructure (5-6x from that alone)
- Using the right model for the domain (2x from accuracy and efficiency)
- Optimizing the software stack (1.5x from that)
But that required building significant infrastructure. Most companies wouldn't do this independently. They'd use a platform and accept 5-6x improvements instead of 10x.
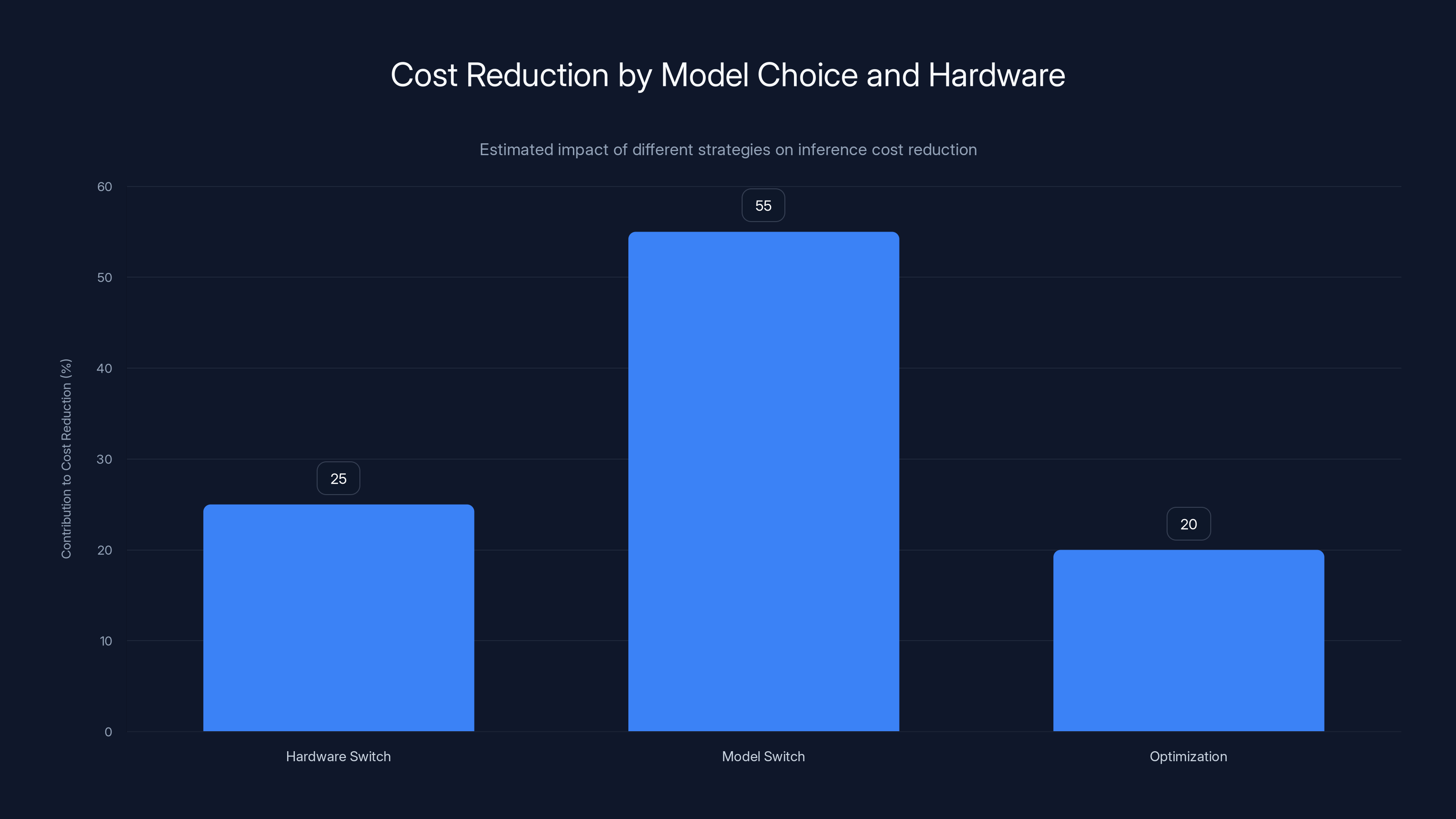
Switching to an open-source model contributed 55% to cost reduction, more than hardware changes or optimizations. Estimated data.
Quantization and Precision Formats: The Technical Deep Dive
Here's where this gets technical, but it's important to understand because it's where significant cost savings actually live.
Modern language models typically use FP32 (32-bit floating-point) or BF16 (16-bit brain float) for inference. These formats have a lot of precision because the models were originally trained that way.
But inference doesn't need that much precision. The model's weights are already optimized for lower precision during training. You can use FP8 or even INT8 (8-bit integer) without significantly degrading output quality. Nvidia's NVFP4 goes further—4-bit precision—with careful quantization to preserve accuracy.
Why does this matter for cost?
Lower precision formats:
- Use less memory - you can fit larger models in GPU VRAM, or fit more batch samples into memory
- Compute faster - fewer bits to move around means faster computation
- Reduce memory bandwidth - bandwidth is often the bottleneck in inference; using less precision means you hit bandwidth limits less often
Combine these, and you're running the same model 1.5-2x faster on the same hardware.
Latitude's case:
- Blackwell hardware: 2x speedup
- Switch from FP8 to NVFP4: 2x speedup
- Total: 4x
But not all models are created equal for quantization. Mixture-of-experts models (where only some parameters activate) quantize better than dense models. Larger models can handle more aggressive quantization than smaller models. Models that were trained with quantization in mind handle it better than models that weren't.
Sully.ai's 10x number partially came from quantization, but also from switching to a smaller, domain-fine-tuned model. Smaller models tolerate quantization better because they have less redundancy in their weights.
The implication: if you're running a large dense model (like a 405B dense model), NVFP4 might buy you 1.3x improvement. If you're running a 70B mixture-of-experts model, it might buy you 2x. If you're running a 7B domain-specific model, it might buy you 1.5x (because there's less room for improvement).
Understanding your model's quantization ceiling is critical before planning migrations.
The Missing Piece: Serving Infrastructure and Disaggregation
Almost nobody talks about this, but it's becoming critical: how you serve the model matters as much as the model itself.
Traditional serving: requests come in, you process them end-to-end (prefill, generation), you output results. Simple. But inefficient for large batch sizes or diverse request patterns.
Disaggregated serving (which together AI, Baseten, and others now use): you split prefill and generation into separate stages.
Why? Because they have different characteristics:
Prefill (processing input context):
- Compute-bound (lots of matrix multiplications relative to memory access)
- Benefits from large batch sizes
- Latency tolerant (users don't care about latency here)
Generation (producing output tokens):
- Memory-bound (each token requires memory bandwidth)
- Batching helps but doesn't scale linearly
- Latency critical (users perceive this directly)
Traditional serving forces you to optimize for both simultaneously, which is impossible. Disaggregated serving lets you optimize each independently.
Sully.ai, running medical coding in batch, could:
- Do prefill with massive batch sizes (256, 512, even larger)
- Then do generation with the output contexts
- Achieve near-perfect GPU utilization
Decagon, running voice support with latency requirements, could:
- Do prefill immediately for each request (required anyway)
- Do generation with smaller batches, knowing latency is the constraint
Disaggregation is also why cloud inference platforms are starting to edge out self-hosted infrastructure for many use cases. They've already built disaggregated serving infrastructure. You don't have to.
But it's invisible. You don't see disaggregation in marketing materials. You see it in cost improvements that nobody can quite explain.
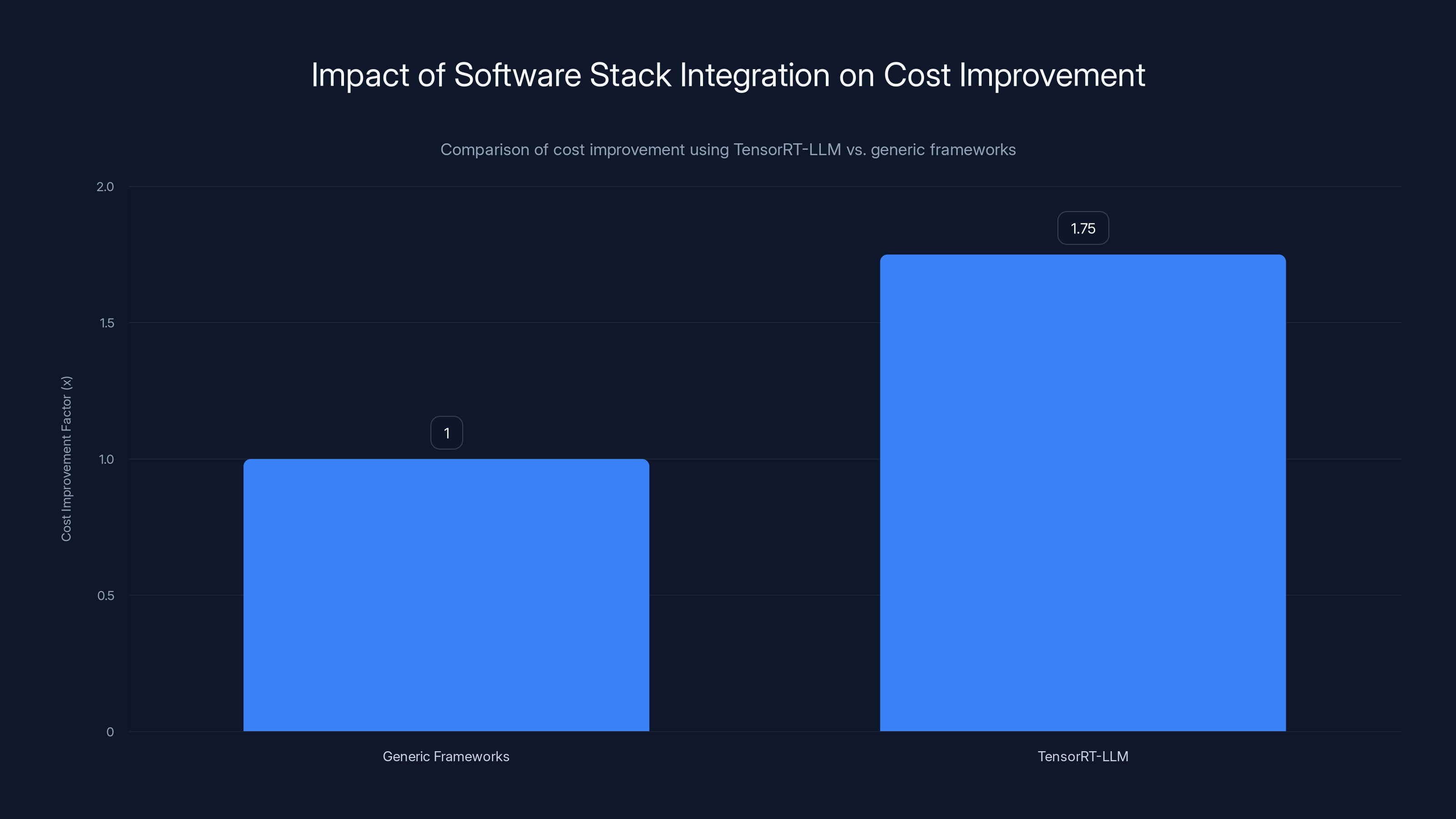
Teams using TensorRT-LLM reported 1.5-2x improvements in cost efficiency compared to those using generic frameworks, highlighting the significant impact of optimized software stack integration. Estimated data.
Realistic Cost Improvement Expectations: What Your Company Can Actually Achieve
Let's ground this in reality.
You work for a company. You use AI in some capacity (chatbot, recommendation system, content generation, analysis, whatever). Your current inference bill is X. You're considering migrating to Blackwell. What should you expect?
Honestly? It depends on all the factors we've discussed:
Scenario 1: You're Using Open AI/Anthropic APIs Heavily, Not Optimized Your workload:
- General-purpose models (GPT-4, Claude)
- Real-time or near-real-time latency requirements
- No domain-specific optimization
- Running on someone else's infrastructure anyway
What you should expect: 2-3x improvement
- Reason: You can't switch models (you need the capability). You can't dramatically improve latency (it's already a constraint). Self-hosting open-source might save money, but not dramatically because your workload needs general intelligence. Maybe you deploy locally and save 50% versus API pricing. That's good, but not 10x.
Scenario 2: You Have Moderate Volume, Domain-Specific Work Your workload:
- Specialized domain (healthcare, legal, finance)
- Batch processing or flexible latency (not strictly real-time)
- Currently using general-purpose models
- Running on self-hosted infrastructure already
What you should expect: 4-6x improvement
- Reason: You can switch to domain-specific models (2-3x). You can optimize infrastructure (1.5-2x). You can't hit 10x because you probably have some latency constraints or haven't fully co-optimized everything.
Scenario 3: You Have High Volume, Batch-Friendly Work Your workload:
- High volume (millions of inferences per day)
- Batch-friendly (medical coding, document processing)
- Flexible or offline latency
- Currently using APIs or suboptimized self-hosted infrastructure
What you should expect: 6-10x improvement
- Reason: You can switch models (3-4x). You can optimize infrastructure with batching and disaggregation (2-3x). You can use low-precision formats (1.5x). These multiply together. You might hit 10x.
Scenario 4: You're Already Heavily Optimized Your workload:
- Already using domain-specific models
- Already using self-hosted infrastructure
- Already optimized for throughput
- Already using quantization
What you should expect: 1.5-2x improvement
- Reason: You've already captured most of the gains. Blackwell hardware and NVFP4 might give you 1.5-2x, but there's nowhere else to go.
Most companies fall into Scenario 2 or 3. If that's you, plan for 4-6x improvements, hope for 6-8x if you're willing to invest in optimization.
And please, before you start the migration, actually calculate your current per-token costs. Many companies are shocked to discover they're already spending
Implementation Path: How to Actually Do This Without Disaster
Okay, so you've read all this, and you think: "We should migrate to Blackwell and capture some of these improvements." Good instinct. Here's how to do it without wasting six months and blowing your budget.
Phase 1: Audit Your Current State (2-4 weeks)
Don't touch infrastructure yet. Understand what you have:
- What models are you actually using?
- What are your inference volumes by model and use case?
- What are your current costs (in both dollars and per-token terms)?
- What are your latency requirements for each workload?
- What is your GPU utilization for each model right now?
If you don't know the answers to these questions, you can't plan a migration intelligently.
Phase 2: Identify Low-Hanging Fruit (2-4 weeks)
Don't start with Blackwell. Start with cheaper optimizations:
- Are you using proprietary APIs where you could use open-source? (2-5x savings potential)
- Are you using general-purpose models where domain-specific would work? (2-4x savings)
- Are you batching requests effectively? (1.5-2x improvement potential)
- Are you using quantization on your current hardware? (1.3-2x improvement)
Do these first. They're cheap (software engineering time, mostly) and the improvements are predictable.
Phase 3: Benchmark Blackwell (2-3 weeks)
Rent a small amount of Blackwell capacity (via Together AI, Baseten, or other platforms). Run your actual workloads. Measure:
- Actual per-token costs
- Latency characteristics
- Throughput under load
- Cost of NVFP4 quantization versus baseline precision
Don't rely on theoretical numbers. Test your specific workloads.
Phase 4: Make the Decision (1 week)
Can you model out the ROI?
- Current monthly inference cost: $X
- Estimated post-migration cost: $Y
- Migration effort (engineering time): Z hours
- Monthly savings: X - Y
- Payback period: (Z hours * your hourly engineering cost) / (X - Y)
If the payback period is less than 3 months, do it. If it's 6+ months, think twice.
Phase 5: Gradual Migration (4-8 weeks)
Don't flip a switch. Migrate 10% of workload first. Monitor closely. Then 50%. Then 100%.
Why? Because real-world deployments always have surprises. Maybe your model quantizes worse than expected. Maybe your latency characteristics are different at scale. Maybe your serving infrastructure has issues. Better to find out with 10% of traffic.
Phase 6: Optimize (ongoing)
After migration, you're not done. Software optimization is iterative:
- Profile your workloads
- Identify bottlenecks
- Optimize systematically
- Measure improvement
- Repeat
The first optimization usually gives you 20-30%. Getting from there to 40-50% improvement requires ongoing effort.
This entire process (phases 1-5) should take 2-4 months for a reasonably sophisticated team. If it's taking you longer, you're probably over-engineering something.

The Vendors and Platforms: Which Path Makes Sense
So far, I've been theoretical. Let's get practical about the actual vehicles for these improvements.
You've got three basic paths:
Path 1: Self-Hosted Blackwell Hardware
You buy or rent Blackwell GPUs (H200, B200, B100 systems). You manage infrastructure, scaling, optimization, monitoring.
Pros:
- Potential for maximum cost reduction (if you're willing to invest in engineering)
- Full control
- No per-token markup from a platform
Cons:
- Requires deep infrastructure expertise
- Dev Ops is your responsibility
- Upfront capital or rental costs
- Scaling is your problem
- Reliability is your problem
When it makes sense: You have high-volume workloads (millions of daily inferences) and infrastructure expertise. The cost savings justify the engineering investment.
Path 2: Managed Inference Platforms
You deploy models to platforms like Baseten, Together AI, or Fireworks AI. They manage infrastructure, optimization, scaling.
Pros:
- Infrastructure complexity handled for you
- Tensor RT-LLM optimization included
- Disaggregated serving built-in
- Auto-scaling is automatic
- You focus on your application
Cons:
- Higher per-token costs than self-hosted (but still cheaper than APIs)
- Less control over optimization
- Dependent on platform roadmap for features
- Vendor lock-in risk
When it makes sense: You have moderate-to-high inference volumes, want cost savings but don't have deep infrastructure expertise.
Path 3: API Optimization Without Infrastructure Changes
You stay on Open AI/Anthropic APIs but optimize what you can (batching, model selection, prompt engineering).
Pros:
- No infrastructure changes
- Keep your existing setup
- Reliable, proven service
Cons:
- No major cost reductions (maybe 20-30% with optimization)
- Don't benefit from Blackwell improvements
- API pricing stays high
When it makes sense: Your workload is small-to-medium volume, or the cost savings don't justify any operational changes. Actually, at this point, probably don't bother with any of this.
For most companies reading this: Path 2 (managed platforms) is the sweet spot. You get 4-6x improvements without requiring infrastructure expertise. Your engineering effort goes into your product, not Dev Ops.
The platforms that achieved the best results in the deployment data (Baseten, Together AI) offer free trials. Test your specific workloads on their Blackwell infrastructure. Measure the actual cost and latency. Make a decision based on data, not hype.
What Doesn't Change: Where Blackwell Doesn't Help
I want to be clear about what this analysis doesn't cover, because there are scenarios where Blackwell provides minimal benefit.
Small inference volumes: If you're running under 100K inferences per month, the cost savings are maybe $10-50 per month. Not worth the migration effort.
Real-time, latency-critical workloads with diverse requests: If you need sub-100ms response times and batch size of 1, hardware improvements help but not dramatically. You're memory-bound, not compute-bound.
Models you can't optimize for your domain: If you're using GPT-4 because you need its specific reasoning capabilities, switching to smaller models isn't an option. Blackwell helps (maybe 1.5-2x), but you won't hit 4-10x.
Already-optimized infrastructure: If you've spent the last two years optimizing your inference stack, you've probably already captured 70-80% of the potential gains. Blackwell might give you another 20-30%, but it's not transformational.
Multi-tenant Saa S serving diverse models: If you're serving 100 different customer models on shared infrastructure, optimization complexity explodes. You might see 2-3x improvements instead of 4-10x.
These scenarios are legitimate. If your situation matches any of them, Blackwell migration might not be the right priority. There are other ways to reduce costs (model compression, distillation, better caching, different architectures) that might be more effective.
The 4-10x improvements are real, but they're not universal. They're real for high-volume, batch-friendly, domain-specific workloads where you're willing to optimize deeply.

Looking Forward: What's Beyond Blackwell
Nvidia's already talking about Rubin (the next generation after Blackwell). The cadence suggests we'll see iterative improvements every 18-24 months.
But here's the interesting thing: the biggest improvements in the deployment data came from software and model choices, not hardware. That trend is likely to continue.
The next 2-3x improvements in inference costs will probably come from:
- Better quantization and precision formats - NVFP4 was a step forward, but there's room for even more aggressive quantization that preserves accuracy
- Smarter batching and scheduling - disaggregated serving is the frontier; further disaggregation is possible
- Model architecture improvements - mixture-of-experts is better than dense for efficiency, but new architectures might be even better
- Reasoning efficiency - longer chain-of-thought might become efficient enough that we question whether external reasoning is even necessary
- Domain-specific models - as open-source model quality improves, the economics increasingly favor specialized models over frontier models
Hardware will continue improving (Rubin, beyond), but the gains are getting more incremental. The real game now is software and model optimization.
This means companies that develop strong in-house expertise in inference optimization will have sustainable advantages. You can't out-hardware your competitors forever, but you can out-optimize them in software.
For your company's perspective, this means:
- Invest in optimization expertise (MLOps, inference optimization)
- Don't bet everything on a single hardware generation
- Build flexibility into your inference stack so you can switch technologies as the landscape evolves
- Focus on model choice and optimization as much as hardware
That's a longer conversation, and it's beyond the scope of hardware migrations. But it's important context for understanding why Blackwell matters less than the narrative suggests.

FAQ
How much will my inference costs actually drop after migrating to Blackwell?
It depends on your specific workload. If you're running high-volume, batch-friendly, domain-specific inference where you can switch to open-source models, you might hit 6-10x improvements. If you're running real-time, general-purpose workloads, expect 2-3x. Most companies fall somewhere in the 4-6x range. Before migrating, audit your current costs, model choices, and latency requirements to set realistic expectations.
Can I achieve 10x cost reductions with self-hosted Blackwell hardware?
Potentially, but it requires significant engineering investment. You need deep expertise in inference optimization, software stack integration (Tensor RT-LLM, Dynamo), model quantization, and serving infrastructure. You also need high enough volume to justify the infrastructure complexity. Most companies are better served by managed inference platforms where the optimization is already done.
What's the difference between NVFP4 and other quantization formats?
NVFP4 is Nvidia's 4-bit floating-point format designed specifically for inference on Blackwell. It requires fewer bits than FP8 or INT8 while preserving accuracy through careful quantization. For mixture-of-experts models, NVFP4 can double throughput compared to FP8. For dense models, the improvement is more modest (1.3-1.5x). You need to test your specific model to see if NVFP4 is worth using.
Should I switch from Open AI's API to self-hosted open-source models?
If your workload is high-volume (millions of monthly inferences), domain-specific, and you have infrastructure expertise, yes. You could cut costs 5-10x. If your workload is lower volume or you lack infrastructure expertise, using a managed platform like Baseten or Together AI is a better middle ground—you get 4-6x cost reduction without building your own infrastructure. If your volume is small, the API is probably still your best option despite higher per-token costs.
How does disaggregated serving work, and why does it matter for costs?
Disaggregated serving splits inference into two phases: prefill (processing input context) and generation (producing output tokens). These phases have different performance characteristics. Prefill is compute-heavy and batches efficiently; generation is memory-bound and benefits less from batching. By optimizing each phase independently, you can achieve higher throughput and lower per-token costs. Managed platforms handle this for you; self-hosted infrastructure requires custom serving implementations.
What should I benchmark before migrating to Blackwell?
Test your actual workloads on Blackwell infrastructure using a managed platform. Measure per-token costs (not just hardware costs), latency characteristics under load, model accuracy in NVFP4 precision, and throughput at your expected batch sizes. Compare against your current costs and latency requirements. Use this data to model ROI and payback period before committing to a full migration.
Why do mixture-of-experts models perform better on Blackwell than dense models?
Mixture-of-experts models only activate a subset of parameters for each inference request, reducing compute requirements. Blackwell's NVLink fabric provides high-bandwidth communication between specialized compute units, allowing experts to exchange information rapidly. This architecture aligns well with how Mo E models work. Dense models, which activate all parameters, don't benefit from the same optimizations and see more modest improvements.
Is migrating to Blackwell worth it for real-time applications with strict latency requirements?
Typically, no. Real-time applications require small batch sizes to meet latency constraints, which limits GPU utilization and reduces the impact of throughput improvements. You might see 2-3x cost reductions from hardware improvements alone, but you won't capture the bigger gains that come from batching and optimization. If latency is flexible (batch processing), the ROI improves significantly.
How does model choice affect inference cost improvements?
Significantly. Switching from a large general-purpose model (like GPT-4) to a smaller, domain-specific open-source model can provide 2-4x cost improvement on its own. This compounds with hardware improvements. Sully.ai achieved 10x total cost reduction partly because they switched models (5-6x of improvement) and then optimized infrastructure (the remaining 4-5x). If you can't change models, your cost improvements will be more limited.
What's the hidden cost of self-hosting inference infrastructure?
Beyond GPU costs, you need to budget for Dev Ops engineering, monitoring and observability, model management and updates, compliance and security infrastructure, and ongoing optimization work. These costs often exceed pure GPU costs for teams without existing infrastructure expertise. This is why managed platforms have emerged—they internalize these costs and spread them across many customers, making them economical even with per-token markups.
When should I use an inference platform versus self-hosting?
Use a platform if you have moderate-to-high volume but lack infrastructure expertise, want to focus engineering effort on your product rather than Dev Ops, or need auto-scaling and high reliability. Self-host if you have very high volume where the cost savings justify infrastructure investment, you already have strong Dev Ops expertise, or you need custom optimization for very specific workloads. Many companies benefit from starting with a platform and self-hosting only after reaching sufficient scale.
What We've Learned About Real Inference Economics
The narrative around Blackwell—"10x cost reductions"—isn't wrong. It's just incomplete.
Yes, some companies are achieving 4-10x improvements. But those improvements come from a careful combination of hardware, software optimization, and model choices. Miss any piece, and your improvements drop significantly.
The uncomfortable truth: most companies won't achieve 10x. They'll probably hit 3-5x if they're diligent. That's still great—it's a meaningful improvement to their bottom line. But it's not the transformational savings that headlines suggest.
What matters is understanding where the gains actually come from in your specific situation:
- What model switching opportunities exist in your domain?
- How flexible are your latency requirements?
- What's your current GPU utilization?
- Do you have infrastructure expertise to handle self-optimization?
- What's the ROI for your specific workload?
Those are the questions that determine your actual cost improvements.
If you're going to invest in a migration, invest in the planning and measurement phase first. Run benchmarks on your actual workload. Calculate ROI based on realistic assumptions. Then decide whether Blackwell makes sense, or whether you're better served by cheaper optimizations (model switching, batching, quantization) on your current infrastructure.
The best time to optimize inference was two years ago. The second-best time is today. But do it with your eyes open to what's actually driving costs in your system.
Blackwell is impressive hardware. But it's one piece of a much larger optimization puzzle. Treat it that way, and you'll be in good shape.
Key Takeaways
- Blackwell hardware alone delivers roughly 2x cost improvements; reaching 4-10x requires combining hardware with software optimization and model changes
- NVFP4 precision format can double inference throughput by reducing memory requirements, but quantization impact varies by model architecture
- Switching from proprietary APIs to self-hosted open-source models provides 5-10x cost reduction but requires infrastructure expertise or managed platforms
- Disaggregated serving (separating prefill and generation phases) enables better GPU utilization and lower per-token costs, especially for batch workloads
- Most companies should expect 4-6x improvements in practice; 10x improvements require optimal conditions (high volume, domain-specific models, flexible latency)
Related Articles
- EU Data Centers & AI Readiness: The Infrastructure Crisis [2025]
- Steam Deck OLED Out of Stock: The RAM Crisis Explained [2025]
- GLM-5: The Open-Source AI Model Eliminating Hallucinations [2025]
- xAI's Interplanetary Vision: Musk's Bold AI Strategy Revealed [2025]
- Anthropic's Data Center Power Pledge: AI's Energy Crisis [2025]
- Who Owns Your Company's AI Layer? Enterprise Architecture Strategy [2025]

