AI Inference Costs: The 23% Revenue Challenge B2B Companies Face in 2025
Introduction: Understanding the Inference Cost Crisis
The artificial intelligence revolution has fundamentally transformed how B2B companies build products, acquire customers, and deliver value. But behind every intelligent feature, predictive algorithm, and automated workflow lies a hidden cost that's becoming increasingly difficult to ignore: inference costs.
Recent data from industry leaders paints a sobering picture. At scaling-stage AI B2B companies, inference costs now consume approximately 23% of total revenue—a figure that's nearly as expensive as maintaining an entire AI engineering team. This represents one of the most significant cost drivers in modern software companies, yet many founders and executives are still grappling with how to manage it.
What makes this challenge particularly acute is that inference costs don't follow the traditional SaaS economic model. Unlike many other operational expenses that naturally decrease as you scale through operational efficiency and better unit economics, inference costs remain stubbornly persistent. As your user base grows and your product usage increases, you need proportionally more inference capacity. You cannot cut corners here without directly degrading product quality and customer experience.
The stakes are equally high from a competitive standpoint. Your well-funded competitors are aggressively investing in inference to make their products demonstrably better. They're using larger, more capable models. They're running inference more frequently. They're pursuing increasingly ambitious feature sets powered by AI. If you pull back on inference spend while they don't, you risk falling behind in a market where product quality increasingly drives acquisition and retention.
This comprehensive guide explores the inference cost challenge in depth. We'll analyze where costs come from, examine the ICONIQ research that established the 23% baseline, explore how successful companies are funding these costs, discuss emerging cost optimization strategies, and provide frameworks for making strategic decisions about inference spending. Whether you're a founder trying to understand your path to profitability or a board member concerned about unit economics, this exploration will help you navigate one of the most consequential cost dynamics in AI-powered B2B software.
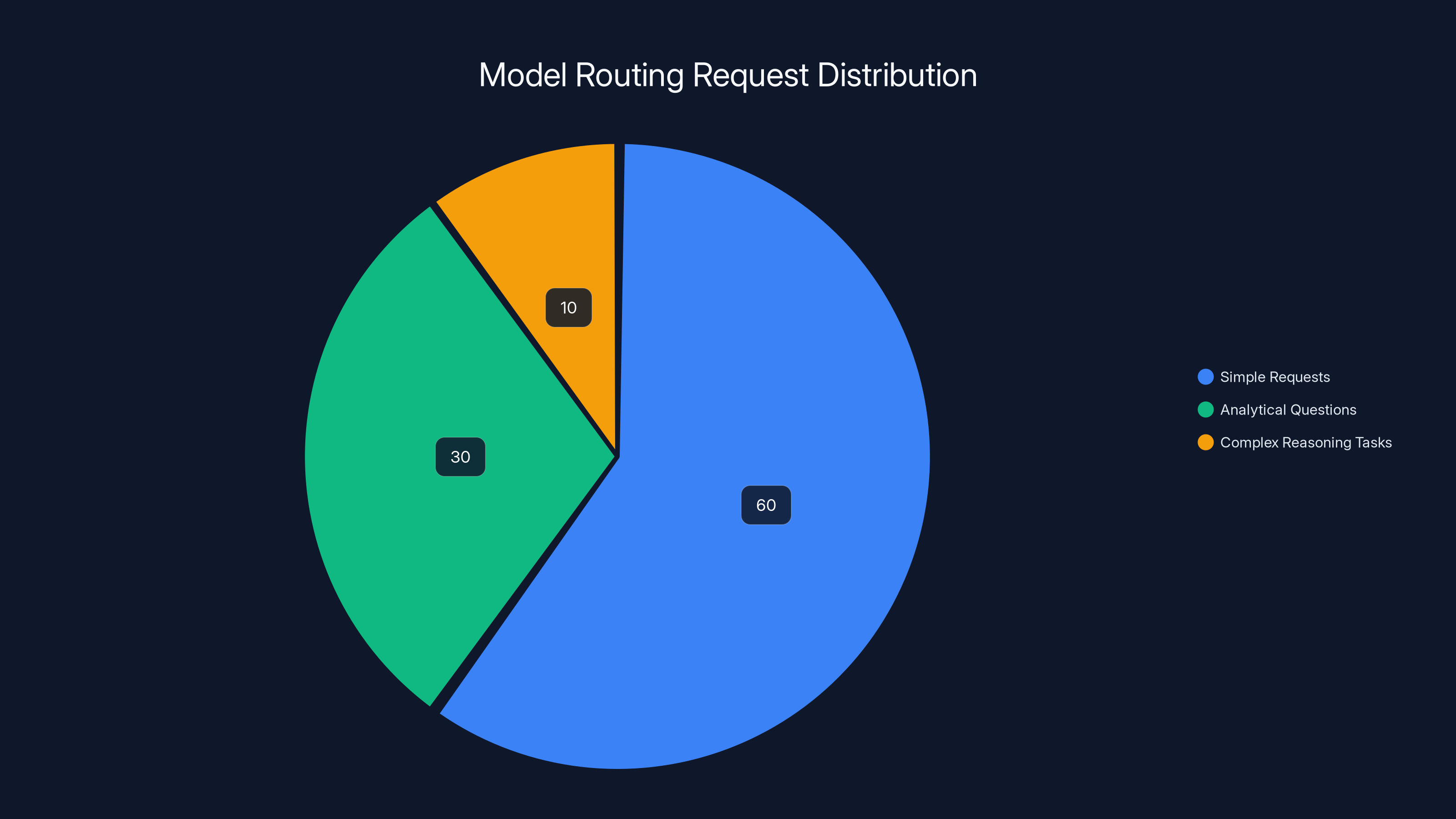
Model routing efficiently allocates requests, with 60% directed to simple models, 30% to mid-tier, and 10% to complex models like GPT-4, optimizing cost without sacrificing quality. Estimated data.
The 23% Benchmark: What the Data Actually Shows
Understanding the Cost Breakdown
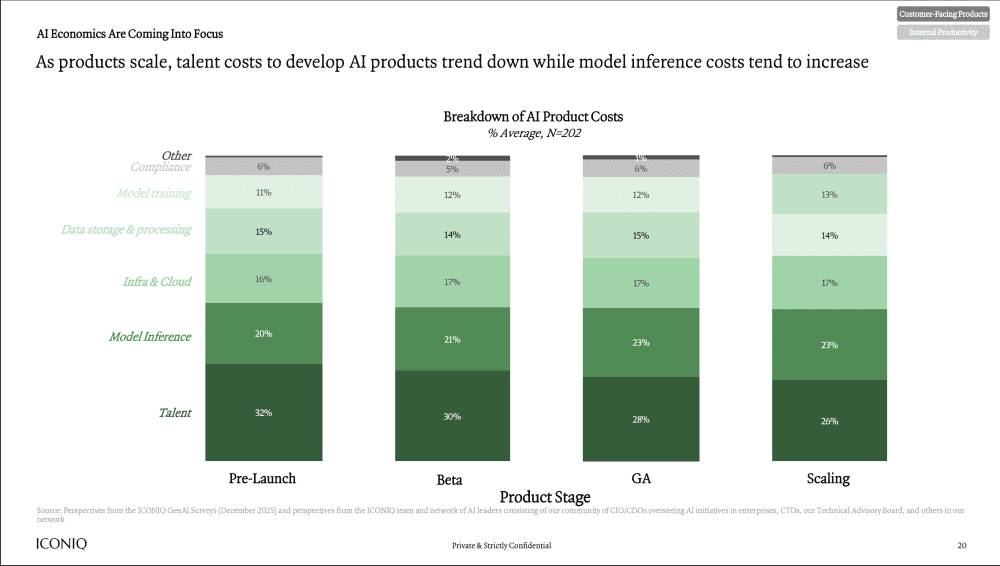
The ICONIQ State of AI report revealed a crucial cost structure that separates thriving AI companies from struggling ones. At scaling-stage operations, companies allocate resources across multiple categories: talent at 26%, inference at 23%, infrastructure at 17%, and other operational costs at the remaining 34%.
This breakdown deserves deeper examination because it challenges many conventional assumptions about AI economics. First, inference costs rival talent costs—the largest controllable expense in any technology company. Most B2B software companies spend heavily on engineering talent, but typically view it as a productive investment that compounds over time. Inference costs, by contrast, feel like a recurring operational tax on every interaction with your product.
Second, the consistency of the inference percentage is remarkable and troubling. From pre-launch (20% of costs) to scaling stage (23% of costs), inference spending remains relatively flat. This stability reveals a fundamental truth: inference costs are inelastic. As your business grows, you cannot achieve operational leverage on inference through efficiency improvements alone. You need to either reduce inference consumption per user (by using smaller models, limiting inference frequency, or optimizing prompts), or you need to pass costs through to customers via pricing.
Third, observe the trajectory of talent costs. They drop from 32% at pre-launch to 26% at scale—a 6 percentage point decrease. This isn't because companies are paying their AI engineers less. Rather, it reflects the reality that AI is replacing human labor. Work that previously required multiple engineers or domain specialists now runs through inference. This cost reallocation is profound: companies are replacing human budget with inference budget.
The Cost Curve Problem
Here's the critical insight that many founders overlook: inference costs don't improve with scale in the way that most other costs do. Cloud infrastructure costs per customer typically decline as you scale because of better utilization and bulk pricing. Sales and marketing efficiency improves as brand builds and word-of-mouth accelerates. Engineering productivity increases as you hire senior talent who accomplish more per person.
Inference costs move in the opposite direction. As your user base grows, each user generates more inference requests. As your product evolves, you add AI features that were previously impossible. As your competitors improve their products, you need to match their inference-powered capabilities. The result is a cost curve that becomes steeper, not flatter, as you scale.
Consider a concrete example: A company launches with a basic AI-powered writing assistant that generates short summaries. This costs
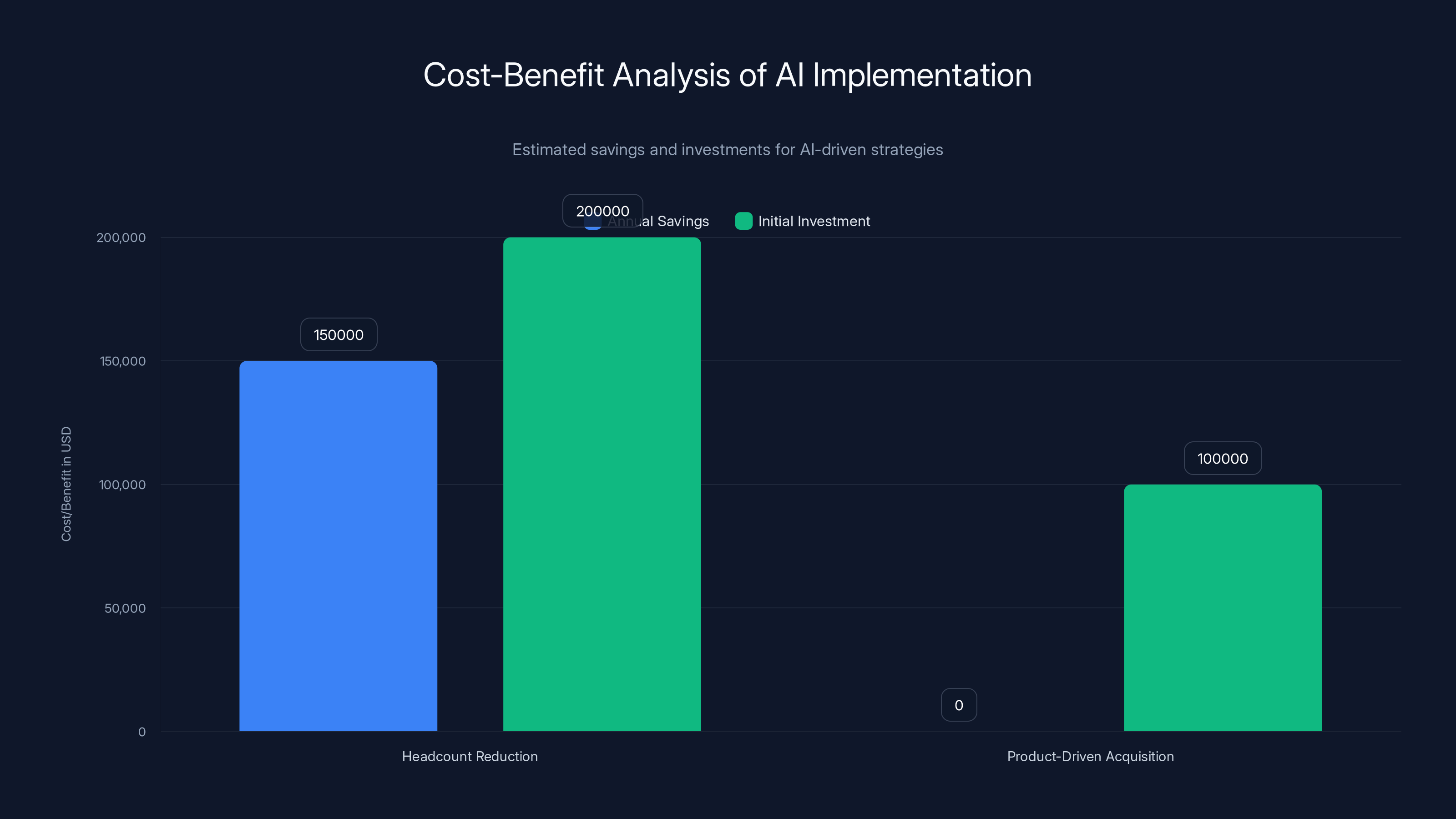
Estimated data shows that while headcount reduction can save
Where Inference Costs Come From: The Technical Reality
Model Selection and Capability
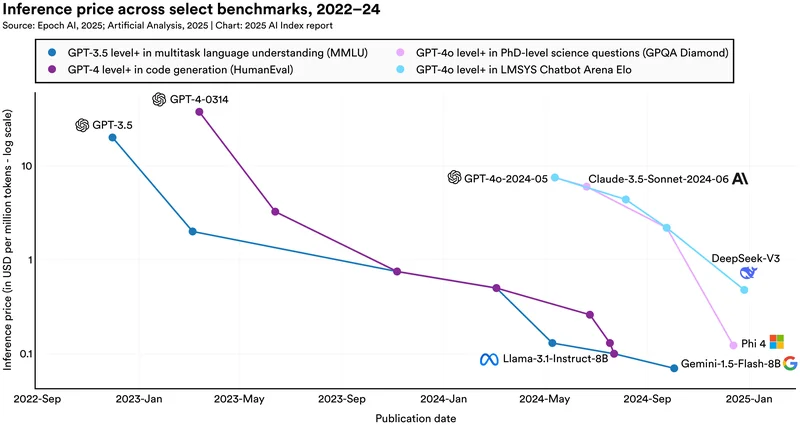
Inference costs primarily reflect the cost of running machine learning models on input data to generate predictions or outputs. The largest models—OpenAI's GPT-4, Anthropic's Claude 3.5, Google's Gemini—cost significantly more per inference because they consume more computational resources and memory.
Here's the economic model: Large language models are typically priced per million tokens processed. GPT-4 Turbo costs roughly
The mathematical implication is straightforward. If your product uses GPT-4 for every inference, costs are 40-100x higher than using Haiku. But the capability trade-off is equally significant. Haiku struggles with nuanced tasks, complex reasoning, and domain-specific knowledge. GPT-4 excels at these, but at a computational premium.
Usage Patterns and Feature Design
Inference costs also depend entirely on how frequently users interact with AI features and how much processing each interaction requires. A user who runs one AI-powered report monthly generates minimal inference costs. A user who collaborates with an AI writing assistant throughout their workday, requesting rewrites, alternatives, and refinements, generates substantial costs.
There's also the question of input size. An AI feature that analyzes a 500-word document costs significantly less than one analyzing a 50,000-word dataset. A chatbot that responds to brief questions costs less than one that needs to reason through complex scenarios. Every architectural decision about what gets processed by AI and how thoroughly it gets processed has direct cost implications.
Frequency and Real-Time Requirements
Some AI features require inference at every interaction (real-time product recommendations, instant content moderation), while others can batch process during off-peak hours. Real-time inference is more expensive because it requires dedicated compute resources that must be immediately available. Batch inference, processed overnight or during scheduled windows, can leverage cheaper, less time-sensitive compute infrastructure.
Products that offer real-time AI assistance—like GitHub Copilot completing code as developers type, or AI-powered autocomplete in email systems—are inherently more expensive than products that analyze data once per day and deliver results in a scheduled report.

How Scaling Changes the Cost Structure
The User Growth Multiplier
Inference costs scale directly with user growth and usage. A company that grows from 10,000 to 100,000 users doesn't just multiply inference costs by 10. The multiplier is typically higher because:
- Larger user bases enable more sophisticated features - With scale, you can invest in premium AI capabilities that wouldn't be economically viable for smaller user bases. More features → more inference
- Usage increases with product maturity - Early users engage cautiously. Mature users have found workflows deeply integrated with AI features. Usage intensity increases
- Competitive pressure escalates - Competitors with better funding are adding premium AI features. You match them to stay competitive
- Product leverage improves - Your product becomes more valuable with additional AI capabilities. You naturally expand inference-powered features
Empirical data supports this. Companies report that inference costs per user often increase 30-50% year-over-year at scale, driven by both user growth and expansion within existing users.
The Talent-to-Inference Trade
One of the most significant shifts visible in the cost data is the reallocation from talent to inference. The drop from 32% talent costs at pre-launch to 26% at scale reveals this transition clearly.
At pre-launch, companies build products through human engineering. At scale, they increasingly leverage AI to accomplish tasks that would otherwise require additional headcount. A company might:
- Replace three support engineers with AI-powered customer service that handles 60% of requests
- Replace two data analysts with automated AI-powered dashboards and insights
- Replace junior content creators with AI writing assistance tools
- Reduce QA headcount through AI-powered testing and bug detection
Each of these replacements reduces talent costs but increases inference costs. The math works out because well-utilized AI is typically more cost-effective than human labor for routine, high-volume tasks. However, this creates a structurally different cost profile. Talent costs are relatively predictable and controllable—you can adjust headcount based on budget. Inference costs are more variable and harder to cap without degrading product quality.
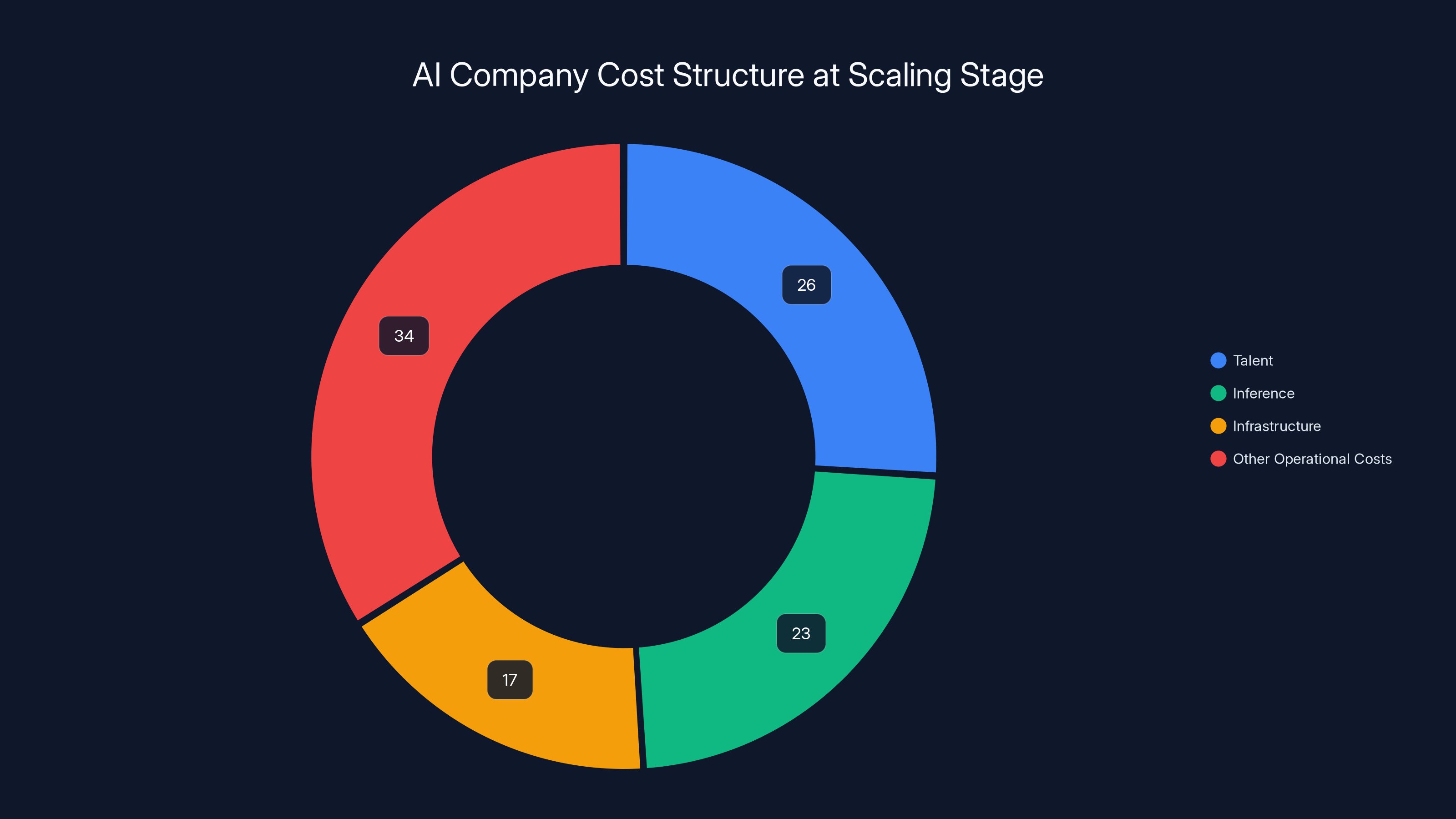
AI companies allocate 23% of their costs to inference, rivaling talent costs at 26%, highlighting the inelastic nature of inference expenses.
The Competitive Arms Race in Inference Spending
Why Cutting Inference is Risky
Founders face an uncomfortable asymmetry: You cannot unilaterally decide to cut inference costs without accepting competitive disadvantage. Here's why:
Your competitors with strong venture backing or healthy cash flow are continuously investing in inference-powered features. They're using larger models for better quality. They're running inference more frequently. They're building increasingly sophisticated AI capabilities into core workflows. This isn't speculation—it's observable in the products themselves.
If you cut inference spending to manage profitability, you're making a strategic choice to have demonstrably worse AI quality and fewer AI-powered capabilities than competitors. In markets where AI quality directly drives acquisition and retention, this is a serious problem.
Consider the market for AI-powered writing tools. Companies competing here must:
- Support sophisticated writing styles and tones
- Provide real-time suggestions as users type
- Maintain knowledge of latest information and examples
- Handle specialized domains (legal writing, technical documentation, creative fiction)
All of this requires powerful, capable models running frequently. A competitor who cuts inference spending to save 20% will produce noticeably worse suggestions, slower response times, and more limited capabilities. This is immediately obvious to customers comparing products.
The Venture-Backed Moat
This creates a structural advantage for well-funded companies. A venture-backed competitor can afford to spend aggressively on inference, achieve superior product quality, build market share, and worry about profitability later. A bootstrapped or moderately-funded competitor faces a choice: match their inference spending and sacrifice profitability, or accept inferior product quality and struggle to acquire customers.
Over a 3-5 year period, this asymmetry becomes decisive. The well-funded player gains feature parity or superiority in AI capabilities, larger customer base, more data to improve models, and more resources to optimize costs. The less-funded player is stuck in a difficult position.
This dynamic has important implications for company strategy. Some conclusions:
- Efficiency in inference becomes a competitive advantage - If you can achieve 80% of the quality of competitors with 60% of the inference cost, you've found a genuine moat
- Model selection becomes strategic - Choosing smaller models for certain tasks, larger models for critical tasks, requires thoughtful architecture
- Feature prioritization is critical - You cannot support every possible AI capability. You must focus on features where AI provides the most value and where customers are willing to pay for quality
Five Strategies for Funding Inference Costs
Strategy 1: Headcount Reduction and Reallocation
The most direct approach is the one already happening at scale: replace human labor with AI labor. Companies like Shopify have held headcount flat for three consecutive years while growing revenue at scale. The gap between potential headcount needs and actual headcount is being filled by inference.
This strategy works when:
- The work is routine and high-volume - Customer support, data entry, first-pass content creation, documentation generation
- Quality requirements are moderate - AI can be "good enough" for the task, even if not perfect
- You have time to train and optimize - Building AI systems that successfully replace humans requires investment upfront
The hidden cost here isn't the inference itself—it's the engineering effort to build systems that successfully handle tasks previously managed by humans. You might save
However, once built, the system scales. You can handle 50% more customer support inquiries without additional headcount, and the per-inquiry cost remains relatively constant.
Strategy 2: Product-Driven Acquisition (Inference as Marketing Budget)
The second strategy is conceptually elegant: make your product so good through aggressive AI investment that it acquires customers without traditional marketing or sales efforts. Your inference budget becomes your marketing budget.
This works when:
- Your product has genuine network effects or usage moats - Users benefit more from your product because of their own usage history, integrations with other tools, or network effects
- Product quality is the primary buying decision - In markets where customers choose primarily on how well the product works (not price, integrations, or brand), superior AI quality directly drives adoption
- The market is relatively transparent - Potential customers can easily try your product and experience the quality difference (freemium model, free trial, open-source community)
The best examples are in developer tools and creative software. GitHub Copilot doesn't run significant advertising campaigns. Its market dominance comes from developers trying it, experiencing its value, and becoming dependent on it. Every developer who adopts Copilot generates inference costs, but those costs directly create customer acquisition.
The challenge with this strategy is that the bar is very high. Your product genuinely must be remarkably better than alternatives—not just marginally better. It must solve problems that users care deeply about. And the product category must be one where word-of-mouth and demonstration effects drive adoption.
Strategy 3: Pricing Model Evolution
The data shows a dramatic shift in pricing models among AI B2B companies. Usage-based pricing has jumped from 19% to 35% among surveyed companies. Outcome-based pricing has surged from 2% to 18%. These shifts reflect an intentional strategy: pass inference costs through to the customers who benefit most from them.
Usage-based pricing works like this: Instead of a flat
The advantages are clear:
- Customers self-select into appropriate pricing tiers - Heavy users who get the most value pay more
- You can afford inference for high-value use cases - If a customer is willing to pay $5,000/month, you can run expensive, powerful models for them
- Margins improve naturally as you optimize - When you optimize inference costs, margins improve directly
The disadvantages are equally significant:
- Revenue becomes more unpredictable - If a customer's inference needs double, revenue scales but your budget forecasting becomes harder
- You risk pricing yourself out of the market - If customers see their inference costs escalating rapidly, they may reduce usage or switch competitors
- Requires transparency and trust - Customers need to understand why they're paying more, and need to feel the pricing is fair
Outcome-based pricing takes a different approach: charge based on results delivered, not resources consumed. A company selling AI-powered marketing optimization might charge 5% of revenue improvements delivered, rather than charging by the number of inferences run. This is elegant because it aligns your revenue with customer success.
The challenge is that outcome-based pricing requires:
- Clear, measurable outcomes - You need to prove that your product delivered specific results
- Trust and long-term relationships - Customers must be confident in your measurement and integrity
- Stable business environments - Outcome-based pricing works poorly when customer results fluctuate due to external market factors
Strategy 4: Model Routing and Inference Optimization
This strategy acknowledges that frontier models (GPT-4, Claude 3.5 Opus) are not required for every task. A sophisticated inference architecture routes requests intelligently:
- Simple requests (factual queries, straightforward analysis) route to efficient, smaller models
- Moderate complexity requests (nuanced writing, multi-step reasoning) route to mid-tier models
- High-complexity requests (novel problem-solving, exceptional quality requirements) route to frontier models
This can reduce average inference costs by 50-70% without materially degrading quality for most requests. A company might:
- Route 60% of requests to a local model or fine-tuned smaller model ($0.0001 per inference)
- Route 30% to Claude 3 Haiku ($0.00037 per inference)
- Route 10% to GPT-4 Turbo ($0.04 per inference)
Average cost:
Implementing this strategy requires:
- Request classification system - Accurately determining request complexity in real-time
- Multiple model management - Operating, monitoring, and updating multiple models
- Quality monitoring - Ensuring that routing decisions don't degrade quality below acceptable thresholds
- Fallback strategies - Handling cases where a routed model produces insufficient quality
The practical reality is that model routing is increasingly table stakes. Every serious AI company is doing some form of this. The challenge is that as products become more sophisticated and customers expect increasingly good quality, the percentage of requests that require frontier models increases. You save 50% through routing in year one, but by year three, you might only save 20% as quality expectations rise.
Strategy 5: Venture Funding as Bridge Strategy
For select companies—those in the top decile of growth—venture funding is a viable approach to funding inference costs. The logic is straightforward: if you're growing revenue 3x year-over-year and building a dominant market position, investors will fund inference costs as an investment in growth.
This works when:
- Growth trajectory is exceptional - 3x+ annual growth, with clear path to even higher growth
- Market opportunity is large - $10B+ total addressable market
- Competitive position is strong - You're clearly winning in your market
- Unit economics are acceptable - Even with inference costs, your CAC payback and lifetime value metrics are reasonable
The critical constraint is that this only works for select companies. If your growth is strong but not exceptional (2x instead of 3x), or if your market is smaller (
For bootstrapped companies or those with moderate venture funding, this strategy isn't available. You must pursue one of the other four strategies.
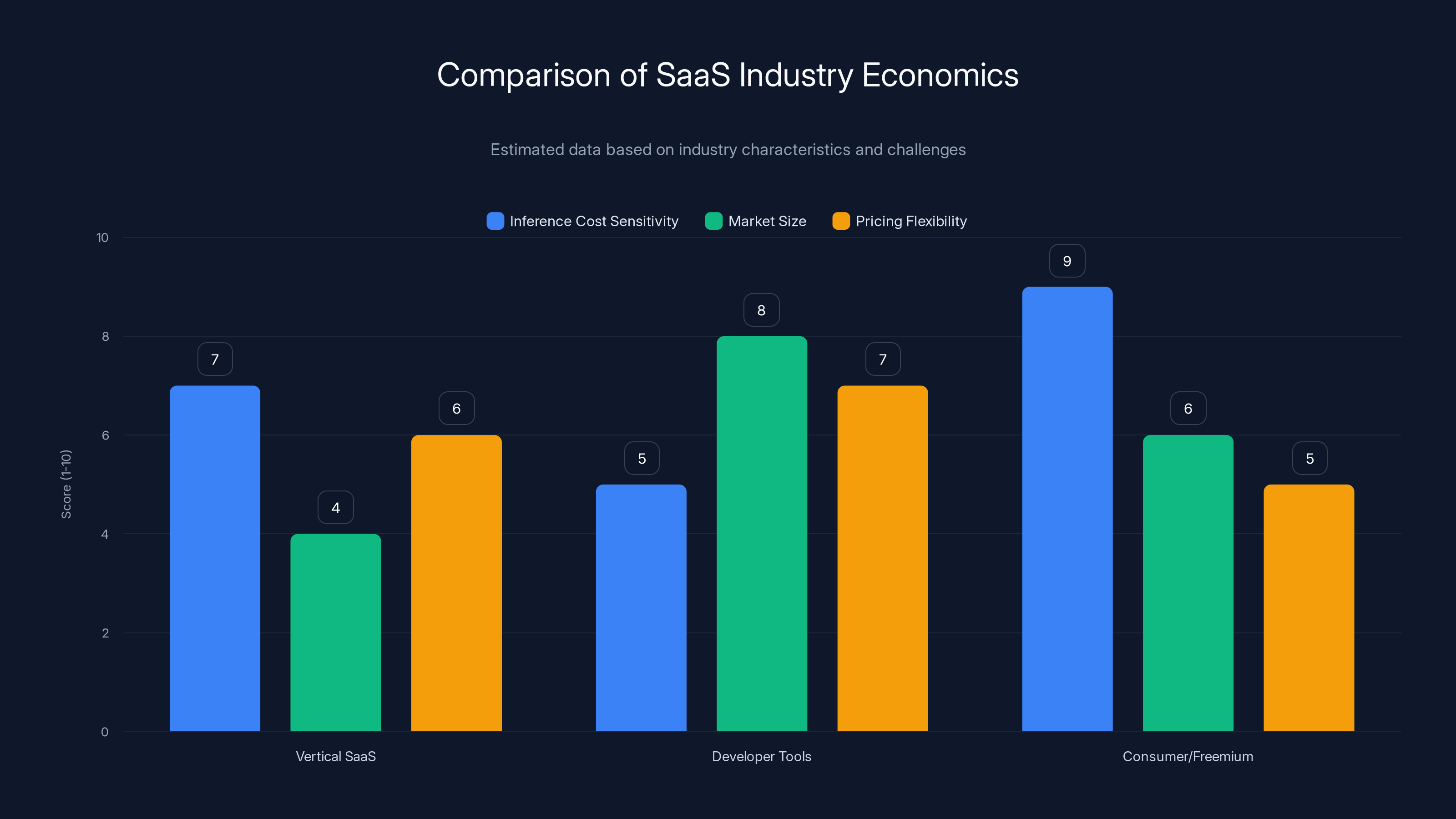
Vertical SaaS companies face high inference cost sensitivity due to smaller market sizes, while developer tools benefit from larger market sizes but face high pricing sensitivity. Estimated data based on industry characteristics.
Cost Optimization Techniques That Actually Work
Prompt Optimization and Output Compression
A surprising amount of inference cost can be reduced through better prompt engineering. Poorly constructed prompts often:
- Request unnecessary information in responses (increasing output tokens)
- Require multiple inference calls to get right answer (multiplying costs)
- Use inefficient language that doesn't map well to model training (requiring longer responses)
Optimized prompts reduce output tokens and improve first-call accuracy. A company might reduce prompt length by 40%, which directly reduces inference costs.
Output compression is similar: instead of returning full prose, return structured data. Instead of an LLM generating a 500-word summary, generate a 50-word structured extraction. This reduces output tokens by 90%, directly reducing costs.
Caching and Deduplication
Many inference calls are repetitive or similar. If you're answering the same question for different users, you're running the same inference multiple times. Implementing caching strategies:
- Cache identical inputs - Store results for identical queries and reuse them
- Cache semantic duplicates - Recognize that slightly different inputs might produce the same or very similar outputs
- Batch similar requests - Process similar requests together, leveraging batch inference pricing (typically 50% cheaper than real-time)
Large companies report that caching can reduce inference costs by 20-35% without any loss of functionality.
Fine-Tuning and Domain-Specific Models
Base models like GPT-4 are trained on broad internet data. They're excellent for general tasks but inefficient for domain-specific work. A model that's been fine-tuned on legal documents can generate legal language more efficiently. A model fine-tuned on customer support conversations can generate better support responses with fewer tokens.
Fine-tuning involves:
- Collecting domain-specific examples (legal documents, support conversations, etc.)
- Training a base model on these examples to specialize its behavior
- Deploying the fine-tuned model instead of the base model
Fine-tuned models often achieve 2-3x better efficiency (fewer tokens needed for same quality) in their domain.
Asynchronous Processing and Batching
Not every inference needs to happen in real-time. Batch processing several inferences together, or processing them during off-peak hours, enables significant cost reductions. Real-time API pricing might be
Companies can redesign workflows to leverage batching:
- Instead of generating insights as users request them, generate overnight and serve cached results
- Instead of processing documents in real-time, queue them for batch processing when compute is cheaper
- Instead of running inference on every user action, run it on a schedule or in response to specific triggers
This requires careful balance—you don't want to degrade user experience by making everything asynchronous. But selective use of batching can reduce inference costs by 30-50%.
Pricing Models: The New AI Economics
Traditional Flat-Rate Pricing Doesn't Work
Historically, B2B SaaS used primarily flat-rate pricing: pay $99/month, get access to all features. This worked when usage patterns were relatively predictable and infrastructure costs were low.
With AI inference, flat-rate pricing creates a structurally broken business model. Here's why: if you charge
Moreover, flat-rate pricing creates perverse incentives. Heavy users—the ones who use your product most intensively and get the most value—pay the same as light users. This is economically inefficient.
Usage-Based Pricing and Implementation
Usage-based pricing aligns costs with customer value. Implementation varies:
Token-based pricing (most direct): Charge per token processed. A customer using 1 million tokens per month pays proportionally more than a customer using 100,000 tokens.
Advantages:
- Perfectly aligned with your actual costs
- Transparent to customers
- Scales naturally with customer success
Disadvantages:
- Unpredictable revenue (if customers cut usage, revenue drops)
- Customers may optimize away usage to reduce costs
- Requires sophisticated metering and reporting
Tiered usage-based pricing: Define tiers (1M tokens =
This smooths out pricing unpredictability while maintaining alignment with usage.
Per-action pricing: Charge per specific action rather than per token. A "generate report" action costs $2, regardless of whether it uses 500K or 2M tokens internally.
This is simpler for customers to understand but requires you to absorb the cost variability.
Outcome-Based and Hybrid Pricing
Outcome-based pricing ties fees to business results: "Pay us 10% of the time you save, measured in productive hours" or "Pay 5% of revenue increases we deliver."
This is most viable for B2B products where outcomes are measurable and attributable. A marketing automation platform might charge based on revenue influenced. An HR analytics platform might charge based on hiring efficiency improvements.
Hybrid pricing combines multiple models:
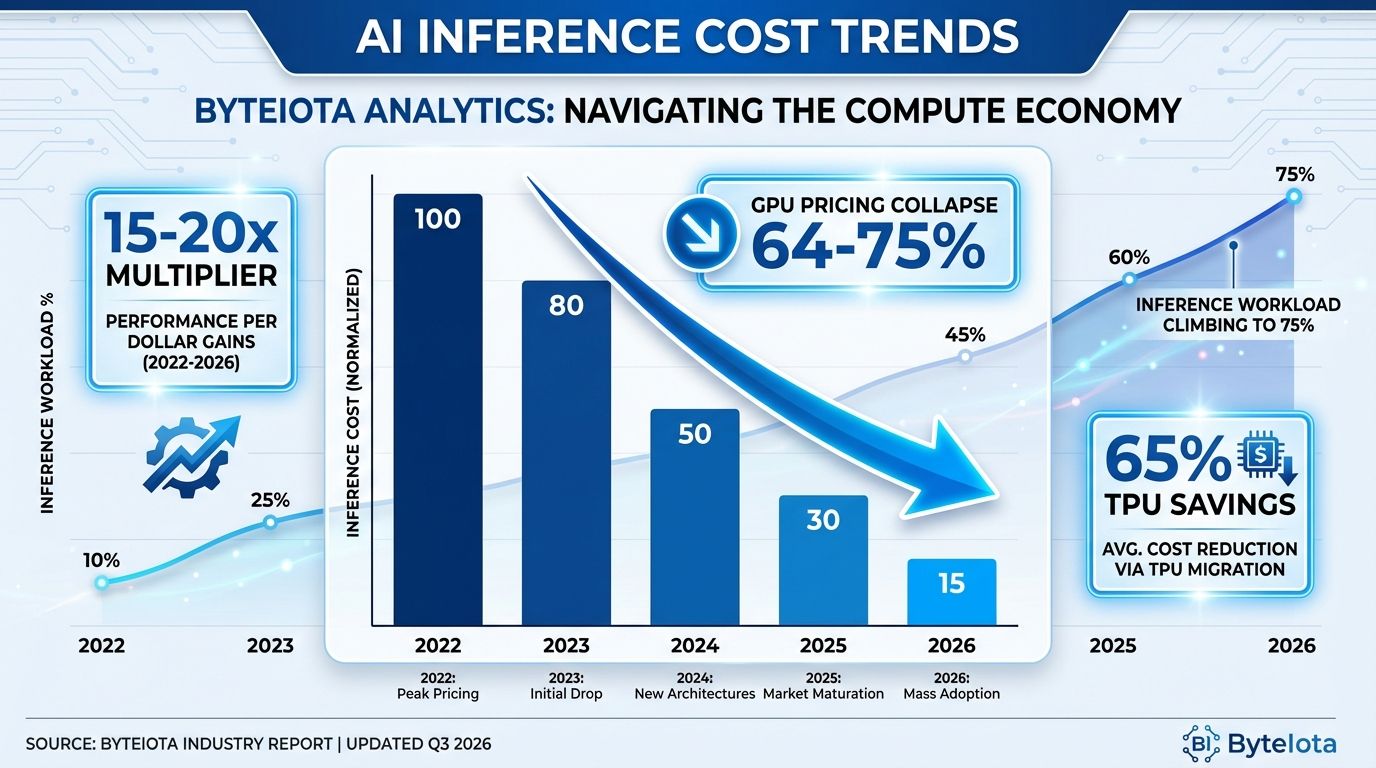
Prompt optimization and output compression can significantly reduce inference costs by up to 90%. Caching and fine-tuning also contribute to cost reductions, making these techniques effective for cost optimization. Estimated data.
Enterprise Considerations and Contracts
Inference Cost Negotiations
Large enterprises are increasingly aware of inference costs and sophisticated about negotiating them. Key strategies:
- Volume discounts - "If we do 100M inferences per month, what's your price?"
- Infrastructure partnerships - "Can we run inference on our infrastructure to reduce your costs?"
- Model selection - "Can we use smaller models for some use cases to reduce costs?"
- Commitment-based pricing - "If we commit to 1000 hours of inference per month, what's the rate?"
Enterprises are also willing to:
- Host inference infrastructure themselves
- Use fine-tuned smaller models
- Implement sophisticated caching
- Optimize inference through architectural changes
As an AI company, you need to be prepared to discuss inference costs openly with enterprise customers and offer flexible arrangements that work for both parties.
Avoiding the Cost Spiral
There's a risk that as enterprises negotiate harder on inference costs, you end up in a downward spiral: lower prices → reduced margins → less investment in product → worse product → customer churn.
Defending against this requires:
- Building efficiency moats - If you can deliver better results with less inference than competitors, this becomes a defensible advantage
- Clear value articulation - Help customers understand what they're paying for and the ROI
- Architectural innovation - Find ways to deliver the same value with fundamentally less computation
Measuring and Monitoring Inference Efficiency
Key Metrics
Successful AI companies track these metrics rigorously:
Cost Per User: Total monthly inference costs divided by monthly active users. A target might be $5-15 per user per month depending on your business model.
Cost Per Revenue: Monthly inference costs divided by monthly revenue. The benchmark is 23%, but efficient companies achieve 15-18%.
Cost Per Outcome: If you're outcome-focused, measure inference cost per successful customer outcome (customer generated, forecast produced, code written, etc.).
Model Distribution: What percentage of inferences use which models? Tracking the shift toward more expensive models identifies where costs are accelerating.
Inference Per User: How many inferences is each user generating? Increasing inference per user might indicate:
- Users are getting more value (good)
- You're over-processing or running unnecessary inference (bad)
- Product adoption is increasing (good)
- You've added AI features that increased inference load (cost)
Dashboards and Alerts
The most sophisticated AI companies build detailed dashboards that track:
- Daily inference volume and costs
- Costs by model, feature, and customer segment
- Variance from budget
- Inference cost per revenue
- Efficiency trends over time
Alerts fire when:
- Daily costs exceed threshold
- Cost per revenue rises above 25%
- Specific features show cost spikes
- Model distribution shifts unexpectedly

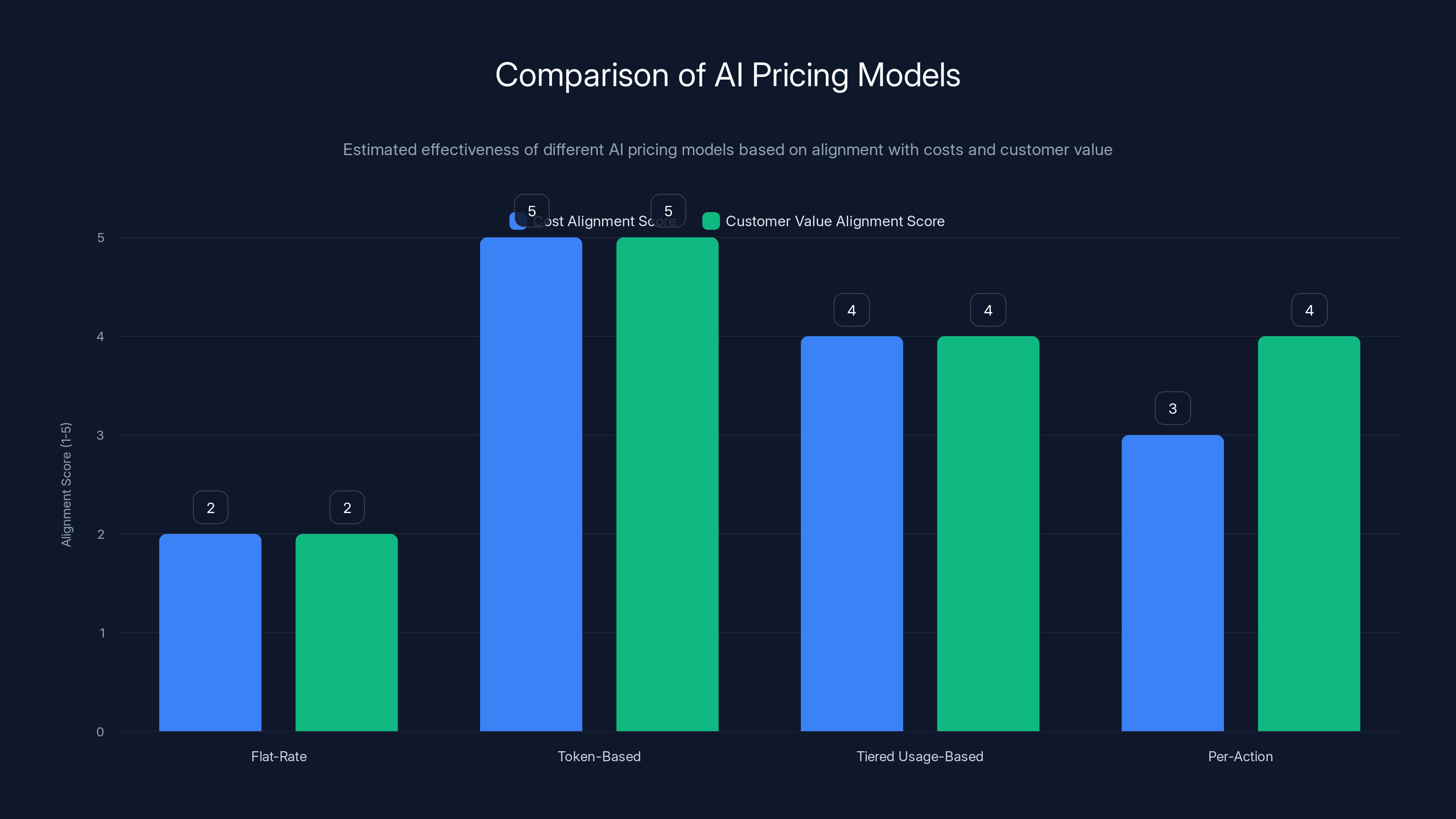
Estimated data suggests that token-based pricing aligns best with both costs and customer value, while flat-rate pricing scores lowest in alignment.
Building a Sustainable Inference Cost Model
The Balanced Approach
There's no single optimal strategy for funding inference costs. Instead, the most sustainable approach typically combines multiple strategies:
-
Baseline efficiency (35-40% of approach): Implement the optimization techniques outlined earlier—prompt optimization, caching, batching, model routing. Target 50% reduction in inference costs through efficiency.
-
Pricing strategy (30-35% of approach): Align your pricing model with actual inference costs. Whether through usage-based pricing, outcome-based pricing, or hybrid approaches, tie customer value to your actual cost structure.
-
Headcount reallocation (20-25% of approach): Where appropriate, replace human labor with AI labor. This should be done thoughtfully—not every function should be automated—but identifying 3-5 key areas where AI can efficiently replace human work creates sustainable cost benefits.
-
Product differentiation (10-15% of approach): Build inference-powered features that competitors don't have, creating defensibility. This supports premium pricing and reduces pressure to cut inference costs.
Sustainability Milestones
As your company scales, target these efficiency milestones:
At $1M ARR: Inference costs at 25-30% of revenue (above benchmark, expected at scale-up stage). Focus on foundational optimization.
At $5M ARR: Achieve 20-23% of revenue (at benchmark). You should have implemented most optimization strategies. Pricing model should be working effectively.
At $20M+ ARR: Target 15-18% of revenue (below benchmark). At this scale, efficiency compounds and pricing power increases. Well-optimized companies should achieve single-digit percentages.

Industry Variations and Special Cases
Vertical SaaS Considerations
Vertical SaaS companies (selling to specific industries) have different inference economics than horizontal platforms:
Advantages: Vertical focus enables fine-tuning, domain-specific models, and specialized knowledge that reduces inference needs. A real estate-focused platform understands real estate context deeply, requiring less inference.
Challenges: Smaller market size means less volume to amortize fixed inference costs. You might have 5,000 customers generating $50M ARR, where each customer is price-sensitive to inference-driven costs.
Vertical SaaS companies should:
- Invest heavily in domain-specific fine-tuned models (larger upfront cost, lower ongoing inference costs)
- Build pricing aligned with customer industry benchmarks (real estate customers will pay differently than healthcare customers)
- Focus on inference-light features that provide high value (better to have one really good AI feature than three mediocre ones)
Developer Tools and API Platforms
Developer tools have unique economics:
- Inference is closer to commodity - Developers care about developer experience and features more than inference
- Volume can be extreme - Popular developer tools might run billions of inferences monthly
- Pricing sensitivity is high - Developers closely track costs
Successful developer tool companies often:
- Build their own models rather than relying on APIs (lower cost at scale, more control)
- Offer on-premises or self-hosted options for cost-conscious customers
- Use very aggressive caching and deduplication (developers run similar code millions of times)
- Focus on efficiency to an extreme degree
Consumer/Freemium Models
Consumer-focused AI apps using freemium models face extreme inference cost pressure:
- Free tier users generate no direct revenue but incur inference costs
- Inference costs are massive driver of unit economics
- Competitive pressure from well-funded competitors limits pricing power
Successful consumer AI apps typically:
- Dramatically limit free tier (5-10 requests per month rather than unlimited)
- Use very small, efficient models for free tier
- Reserve powerful models for paid tiers
- Aggressively monetize through premium features ($10-100/month)
- Require volume to achieve profitability (10M+ users, 5%+ paid conversion)
Future Trends: Where Will Inference Costs Go?
Hardware Efficiency and Specialization
The future of inference costs depends significantly on hardware evolution. AI-specific chips (like Nvidia's H100, TPUs, and emerging alternatives) are more efficient than general-purpose CPUs for inference. As more specialized hardware emerges and competes, inference costs should decrease.
Projection: 2-3x improvement in cost efficiency per compute dollar over next 3-5 years as specialized hardware matures and competition increases.
Open Models and Self-Hosting
The growth of open-source large language models (Llama, Mistral, etc.) creates an alternative to expensive API-based models. Companies can:
- Download open models
- Fine-tune them on private data
- Deploy them on own infrastructure
- Achieve better privacy and much lower inference costs
Projection: 20-30% of inference will shift from API-based to self-hosted over next 3-5 years as open models improve and deployment tooling matures.
Model Efficiency
Research into more efficient models (distillation, pruning, quantization) continues. Future models might achieve 70-80% of GPT-4's capability at 20-30% of the inference cost.
Projection: Frontier models will improve in efficiency by 30-40% over next 2-3 years, reducing the cost curve for equivalent capability.
Price Competition
As more companies compete in the LLM API space (OpenAI, Anthropic, Google, and emerging competitors), pricing should become more competitive. Volume discounts will increase.
Projection: LLM API prices will decrease 20-30% in nominal terms over next 2-3 years as competition intensifies.
Architectural Innovation
The biggest gains might come from fundamental architectural changes:
- AI features that require less real-time inference (preprocessing, batching, caching)
- Hybrid approaches combining small and large models
- Architectures that avoid inference in many cases (deterministic logic, rules-based systems, pre-computed results)
- Edge inference and federated learning reducing inference load
Projection: Well-optimized companies might achieve 8-12% inference costs through architectural innovation, while less-optimized companies remain at 25-30%.

Building Your Inference Cost Strategy
Framework for Decision-Making
When evaluating inference cost strategy, ask:
-
What's our current cost percentage? Benchmark against the 23% baseline. Are you above or below?
-
What's sustainable for profitability? Work backward from your target gross margin. If you target 70% gross margin and inference is your primary variable cost, what percentage can you afford?
-
Which optimization strategies are available? Evaluate feasibility:
- Model routing: Requires classification system (2-4 week dev effort)
- Fine-tuning: Requires training data collection (4-8 weeks)
- Batching: Requires architectural changes (variable effort)
- Caching: Requires infrastructure changes (1-3 week dev effort)
-
What pricing model aligns with customer value? Can you implement usage-based pricing without losing customers? Do customers understand and accept the pricing?
-
What's the competitive inference spend? Research competitors' perceived AI quality, feature completeness, and real-time requirements. This gives you a sense of their inference investment.
-
What's our funding situation? Venture-funded companies can afford to invest in inference. Bootstrap companies need to hit profitability faster. This affects strategy.
90-Day Action Plan
Weeks 1-4: Measurement
- Implement detailed inference cost tracking
- Calculate cost per user, cost per revenue, cost per outcome
- Benchmark against competitors (qualitatively)
- Document baseline metrics
Weeks 5-8: Quick Wins
- Implement prompt optimization (reduce output tokens by 20-30%)
- Implement basic caching for identical queries
- Audit features for unnecessary inference
- Target 15-20% cost reduction
Weeks 9-12: Strategic Improvements
- Implement model routing if not already done
- Evaluate pricing model changes
- Plan feature prioritization to manage inference load
- Design 12-month efficiency roadmap
Real-World Challenges and Solutions
Challenge: Customer Expectations of Consistent Quality
If you implement model routing, some customer requests get smaller models. What if quality is worse?
Solution: Implement graceful degradation. If a smaller model produces low-confidence output, automatically escalate to a larger model. Use rubrics and A/B testing to ensure quality thresholds are maintained.
Challenge: Competitor Spending More on Inference
Your competitor with
Solution: You don't need to match. You need to compete on efficiency. Can you achieve 80% of their quality with 50% of the cost? That's a defensible position. Focus on specific features where quality matters most.
Challenge: Unpredictable Usage and Costs
Usage-based pricing means revenue fluctuates with usage. One month you make
Solution: Implement minimum commitments or base fees for larger customers. A $10K/month base fee plus usage overage creates more predictable revenue. Smaller customers pay pure usage-based.
Challenge: Customers Complaining About High Inference Costs
A customer sees their bill increasing because inference costs rose, and they're upset.
Solution: This is a feature, not a bug. Reframe it: "Your inference costs increased because you've doubled usage of our advanced AI features. This generated 2x more value for you." Show customers the correlation between their usage and their value.
Key Considerations for Product Teams
Feature Planning with Inference in Mind
When product teams plan new AI features, they should consider inference costs in the prioritization framework:
High Value/Low Inference Cost: Highest priority. AI features that deliver significant value while consuming modest inference.
High Value/High Inference Cost: Medium priority. Only if inference can be optimized or passed through pricing.
Low Value/Low Inference Cost: Low priority. Not worth building.
Low Value/High Inference Cost: Don't build. Destroys unit economics.
Monitoring and Optimization Culture
The best companies build a culture of inference consciousness:
- Engineering teams track inference costs of features they build
- Product teams evaluate feature value vs. inference cost
- Data science teams optimize models and prompts continuously
- Finance/ops teams work with product on pricing and unit economics
This requires:
- Good dashboards and visibility
- Shared metrics and goals
- Regular reviews of inference efficiency
- Rewarding optimization
Conclusion: Making Strategic Choices in the Age of Inference Costs
The 23% benchmark represents a fundamental shift in AI B2B economics. For the first time in SaaS history, the cost of the core product functionality—the inference that powers AI features—rivals talent costs as the largest controllable expense. This has profound implications for how companies are structured, how they price, and how they compete.
There's no universal right answer to the "inference cost problem." Instead, there are five primary strategies—headcount reallocation, product-driven growth, pricing innovation, efficiency optimization, and venture funding—and successful companies typically combine multiple approaches tailored to their specific circumstances.
The most important insight is that inference costs are not an unusual problem to be solved. They're a structural reality of AI-powered products. Rather than treating them as a challenge to be hidden or minimized through accounting, successful companies treat them as a central driver of product strategy, pricing strategy, and operational focus.
Companies that do this will have significant advantages:
- Superior unit economics - They'll be profitable faster
- Competitive flexibility - They can respond to competition by optimizing costs rather than cutting features
- Sustainable growth - They won't hit margin walls that force difficult choices between growth and profitability
- Strategic optionality - They can choose to invest aggressively in inference for competitive advantage, because they understand the economics
Companies that don't address inference economics head-on will face increasing pressure:
- Margin compression - As inference costs grow faster than revenue, margins decline
- Competitive vulnerability - Competitors with better cost structures can undercut pricing or invest in better features
- Difficult choices - They'll be forced to choose between profitability and product quality
The math is clear, and the time to build inference economics into your strategy is now. Whether you're a founder building an AI company from scratch, a board member overseeing an AI startup, or an executive at an enterprise software company adding AI features, understanding and planning for the 23% inference cost baseline is essential.
The companies that master inference economics will be the ones that thrive in the AI era. The ones that don't will struggle with profitability, competitiveness, and ultimately, sustainability.

FAQ
What exactly counts as inference costs?
Inference costs are the expenses incurred when running machine learning models on input data to generate predictions or outputs. This includes API costs for using hosted models like GPT-4 or Claude, compute costs for running models on your own infrastructure, and related infrastructure costs for supporting inference workloads. It includes every token processed by every model, whether that's language models, vision models, embedding models, or specialized models.
Why does inference cost stay relatively constant as you scale, unlike other SaaS costs?
Inference costs remain around 23% of revenue from pre-launch to scale because they scale directly with usage. As your user base grows and each user engages more with AI features, you need proportionally more inference capacity. Unlike infrastructure that becomes more efficient at scale or talent that becomes more productive, inference is essentially a variable cost that doesn't improve with scale. You cannot achieve operational leverage on inference through efficiency improvements alone.
How does model routing actually reduce costs while maintaining quality?
Model routing directs simple requests to cheaper, smaller models and complex requests to expensive, powerful models. For example, a routing system might send straightforward factual queries (60% of requests) to an efficient model costing
Can companies really pass inference costs to customers through usage-based pricing without losing them?
Yes, but it requires transparency and value alignment. Companies that clearly communicate why costs are usage-based and show customers that their costs correlate with their value gain can successfully implement usage-based pricing. The key is making sure that heavier users genuinely get more value—if you're charging by inference tokens but the customer isn't seeing proportional benefit, they'll rightfully object. When implemented well, usage-based pricing aligns incentives and makes sense to customers.
What's the difference between outcome-based and usage-based pricing for AI products?
Usage-based pricing charges customers based on consumption (number of inferences, tokens processed, API calls made). Outcome-based pricing charges based on results delivered (revenue improved, time saved, customers generated). Usage-based is simpler to implement and understand. Outcome-based is more aligned with customer value but requires measuring outcomes, which can be complex. Usage-based works for any AI product; outcome-based works best when outcomes are clearly measurable and attributable.
Are open-source models like Llama a realistic replacement for GPT-4 and Claude for B2B applications?
It depends on the specific use case. Open-source models are excellent for applications where 80-85% of GPT-4's capability is sufficient, costs are highly sensitive, and you can invest in fine-tuning and optimization. They struggle with nuanced language understanding, novel reasoning, and specialized knowledge. Many B2B applications (simple extraction, categorization, basic generation) work fine with open models. Applications requiring top-tier quality still need frontier models. A hybrid approach—open models for 70% of use cases, frontier models for 30%—is increasingly common.
How should I think about inference costs in my company's financial model and projections?
Treat inference as a variable cost that scales with usage and revenue. At minimum, model inference at 23% of revenue (the industry benchmark). For early stage (pre-launch and early scale), use 25-30%. For companies at scale ($20M+ ARR) with good optimization, use 15-20%. Stress-test under scenarios where inference costs are higher than expected—if you add a new feature that doubles inference per user, what happens to margins? Build in detailed month-by-month projections of inference costs, not just annual approximations, because usage can fluctuate significantly.
What's the most common mistake companies make in managing inference costs?
Ignoring the problem until it becomes critical. Companies launch products with aggressive AI features without carefully understanding the inference cost implications. By the time they're at scale and have significant customers, inference costs have become a major drag on unit economics. The best time to start optimizing is before you have millions of customers dependent on current architecture. Second most common mistake: optimizing costs by degrading quality. You can't cut inference corners without customers noticing and switching. Optimization should come through efficiency, pricing, architecture, and smart feature prioritization—not through lower-quality AI.
How do I benchmark my inference costs against competitors?
Direct comparison is hard because companies don't publish inference costs. Instead, benchmark qualitatively: use competitor products extensively and evaluate AI quality, real-time requirements, response times, and feature richness. Products with immediate real-time responses, extremely nuanced output, and advanced features likely have high inference costs. Products with 5-second latency, more basic features, and obvious compromises likely optimize for lower costs. You can also talk to customers about their usage patterns and estimate competitor volumes based on market share. The goal isn't exact comparison but understanding whether competitors are optimizing for quality, efficiency, or balance.
Will inference costs decrease significantly over the next few years?
Yes, gradually. Expect 2-3x improvement in cost-efficiency per compute dollar over 3-5 years from hardware improvements, model efficiency gains, and price competition. Open-source models will improve, reducing reliance on expensive APIs. But this isn't a silver bullet—increased usage will offset some cost improvements. A company with naive inference spending might save 50% through optimization and pricing innovations, but only save 30% from external improvements. Plan your strategy assuming inference costs stay materially similar, and treat cost improvements as upside.
Key Takeaways
- Inference costs average 23% of revenue at scaling-stage AI B2B companies, rivaling talent costs as the largest controllable expense
- Inference costs don't improve with scale—unlike other SaaS costs, they remain relatively constant as a percentage of revenue, requiring strategic management
- Five primary strategies exist for funding inference costs: headcount reallocation, product-driven growth, pricing innovation, efficiency optimization, and venture capital
- Model routing can reduce inference costs by 50-70% by directing simple requests to cheaper models and complex requests to powerful models
- Usage-based and outcome-based pricing models are increasingly adopted (35% and 18% respectively) to align customer costs with actual inference spending
- Companies can optimize inference through prompt engineering, caching, fine-tuning, asynchronous processing, and architectural innovation
- Sustainable inference economics require balancing product quality with cost efficiency—cutting costs at the expense of quality creates competitive vulnerability
- Open-source models will reduce costs over time, but won't eliminate the need for frontier models in many use cases
- Measurement and monitoring are critical—companies should track cost per user, cost per revenue, and inference efficiency metrics continuously
Related Articles
- AMI Labs: Inside Yann LeCun's World Model Startup [2025]
- Own's $2B Salesforce Acquisition: Strategy, Focus & Lessons
- Nvidia's $100B OpenAI Investment: Reality vs. Reports [2025]
- Optical Transistor GPU: How Tulkas T100 Breaks Moore's Law | 2025
- Nvidia's $2B CoreWeave Investment: AI Infrastructure Strategy Explained
- Hubristic Fundraising: Brex's $5.15B Acquisition & Lessons [2025]

