![AI-Powered Phishing: How LLMs Enable Next-Gen Attacks [2025]](https://tryrunable.com/blog/ai-powered-phishing-how-llms-enable-next-gen-attacks-2025/image-1-1769443727482.jpg)
AI-Powered Phishing: How LLMs Enable Next-Gen Attacks
You click a link in your email. The page loads instantly. Everything looks right—it's your bank, your email provider, your password manager. You enter your credentials. The page accepts them gracefully. Then your actual account gets compromised five minutes later.
But here's the thing: that phishing page wasn't pre-built. It wasn't stored on some attacker's server. It was generated on the fly, specifically for you, using artificial intelligence.
This isn't science fiction anymore. Security researchers from Palo Alto Networks' Unit 42 have documented exactly how this works. And they're warning that this attack vector represents a fundamental shift in how phishing will operate going forward. Unlike traditional phishing campaigns that rely on static pages designed weeks or months in advance, these new attacks leverage large language models to create unique, customized phishing experiences in real-time, adapting to each victim's location, device, browser, and behavioral signals.
The implication is staggering. If attackers can generate completely unique phishing pages for every single target, detection becomes exponentially harder. Security tools that rely on pattern matching against known malicious URLs? They'll find nothing. Browser-based warnings about suspicious sites? The page looks different for each visitor. Sandboxing and analysis? You're analyzing one variant while the attacker's already on to the next hundred.
Let me walk you through what's happening, why it matters, and most importantly, what you can do about it.
TL; DR
- LLMs enable dynamic phishing pages that are generated in real-time, unique for each victim, making traditional detection nearly impossible
- Java Script payloads are generated on-the-fly, meaning no static malicious code ever touches the network where security tools can intercept it
- Attackers need minimal technical skill, as AI handles the complexity of crafting convincing phishing interfaces and evasion techniques
- Current detection methods still work, but require advanced browser-based crawlers and behavioral analysis rather than signature matching
- Workplace restrictions on LLM access can reduce risk, but robust guardrails in LLM platforms themselves are the real long-term solution

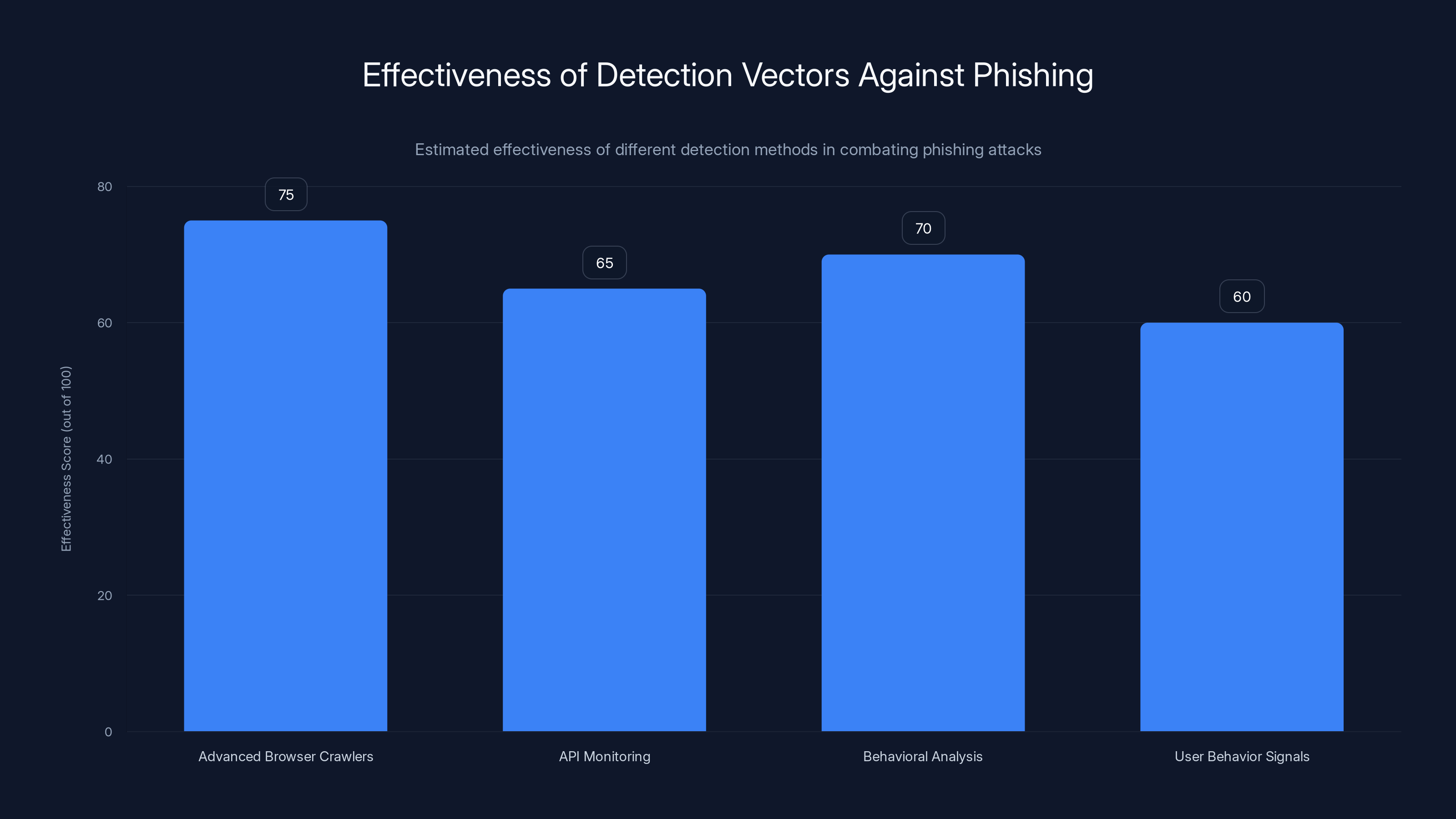
Estimated data suggests that advanced browser crawlers are the most effective detection method, with a score of 75 out of 100. API monitoring, behavioral analysis, and user behavior signals follow closely, indicating a multi-faceted approach is necessary for effective phishing detection.
How Traditional Phishing Works (And Why It's Getting Outdated)
Before we talk about the new stuff, let's establish why traditional phishing works at all. And spoiler: it works really well.
A typical phishing campaign follows a predictable pattern. An attacker registers a domain that looks vaguely legitimate—something like "secure-paypal-verify.com" or "office 365-login-confirm.net." They build a webpage that copies the visual design of the real login page. They send thousands of emails pointing to this page. A percentage of recipients click the link. A smaller percentage actually enters their credentials. And those credentials get harvested.
The entire attack relies on a simple equation: volume times conversion rate equals profit.
But here's the vulnerability that makes this work: the phishing page is static. It was built once, and that same page served to everyone. This creates multiple detection opportunities. A security analyst can visit the page and see it's fake. An email security gateway can scan the page and flag it. A user can hover over links and see they don't match the domain. Once the campaign is discovered, it can be shut down and reported across the internet.
The attacker has to create a new page, register a new domain, and start over.
This is labor-intensive. It requires some technical skill. It's noisy. Every iteration gives defenders a window to react.
Large language models change this entire equation.
The LLM-Powered Phishing Breakthrough
Imagine a phishing attack that works like this:
- Attacker hosts a seemingly innocent webpage—just static HTML with a single element: a Java Script snippet that communicates with an LLM API.
- When you visit the page, that Java Script fires immediately.
- The Java Script sends a carefully engineered prompt to the LLM. This prompt includes context about you: your IP location, your browser type, your device, your referring URL, whatever signals the attacker can grab.
- The LLM, receiving this prompt, generates custom Java Script code designed to create a phishing page tailored specifically for you.
- That generated Java Script executes in your browser, rendering a fully functional phishing interface—but an interface that's unique to you.
- You see what looks exactly like your bank's login page. You enter your credentials. The page accepts them.
- Meanwhile, the entire attack payload—the Java Script code that created the phishing interface—was never stored on the attacker's server. It was generated dynamically. By the time security researchers analyze what happened, the malicious code is gone. The LLM won't generate it again in exactly the same way.
This is what Unit 42 researchers discovered and documented. And yes, they proved it actually works.
The technical elegance is genuinely impressive, in a deeply concerning way. The attack breaks several fundamental assumptions that security tools rely on:
No static payload to intercept. Traditional malware analysis assumes you can capture the malicious code flowing over the network. Here? The malicious code is generated locally in your browser, after the initial network request completes. By the time your security tools see anything, the harmful content has already executed.
No fingerprinting by URL. You can't block this attack by identifying a known phishing domain because the attack is hosted on a legitimate domain running legitimate LLM APIs. The abuse happens in the interaction, not in the infrastructure.
Uniqueness per victim. Even if one researcher analyzes what they saw, the next person to visit the same initial URL will see a completely different phishing page, generated from scratch. Pattern matching breaks down when there are no patterns.
Minimal infrastructure footprint. The attacker doesn't need a hosting provider, doesn't need to register a suspicious domain, doesn't need to upload files to a server. They just need access to an LLM API. That's it.
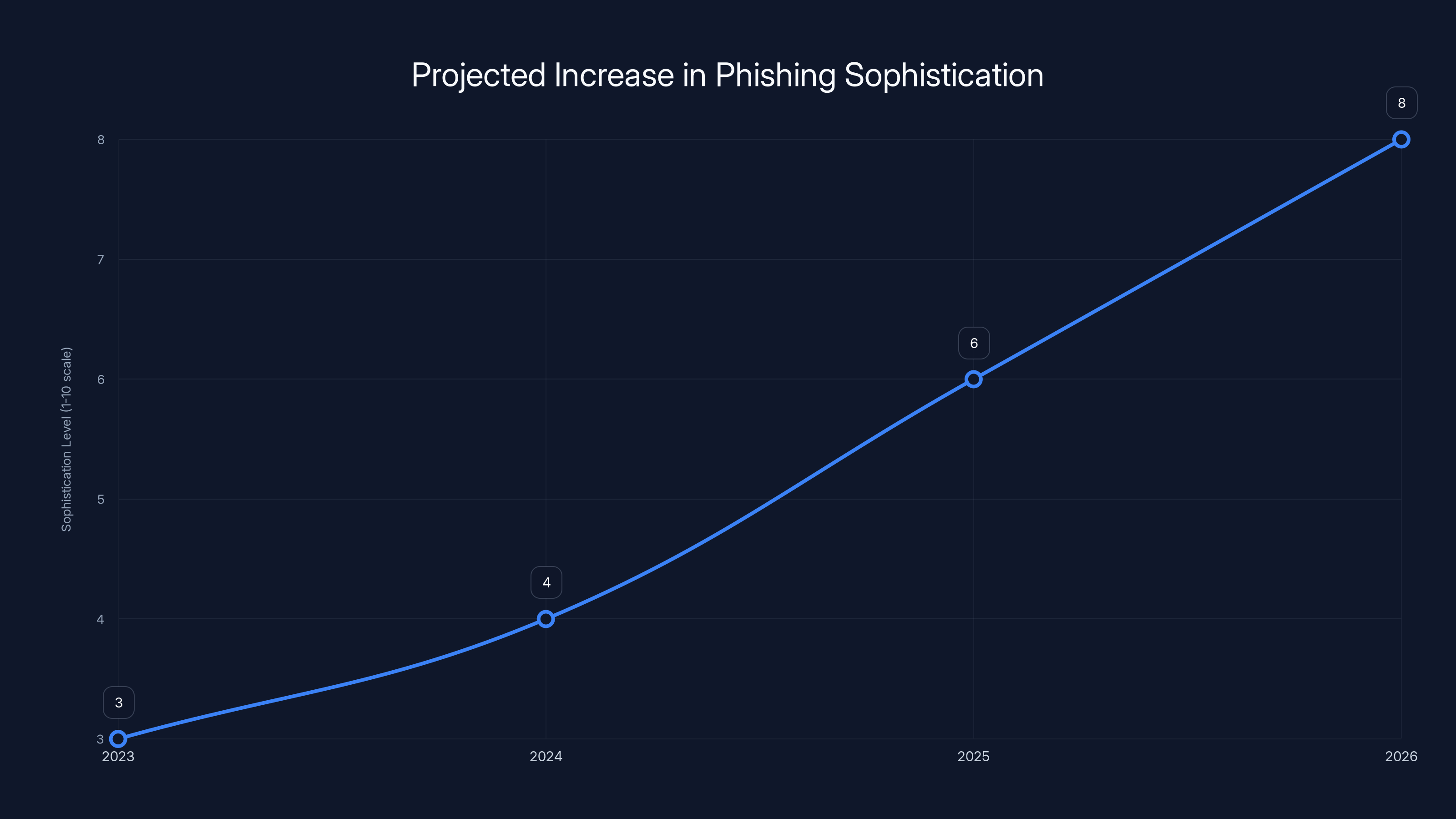
Estimated data shows a projected increase in phishing sophistication, with LLM-powered techniques becoming more prevalent by 2026.
Why Attackers Love This Method
Let's talk about attacker motivation, because understanding that is key to understanding why this threat is credible.
Phishing at scale is a numbers game. Send 10,000 emails, maybe 5% click the link, maybe 2% of those enter credentials. That's 10 victims per 10,000 emails. If you're targeting enterprise email addresses at target companies, maybe one of those 10 victims is in accounting, has access to the wire transfer system, and can be socially engineered into sending money. One win pays for thousands of failed attempts.
But there's a cost to this approach: you have to keep generating new phishing pages and new domains. Law enforcement and security vendors keep taking them down. Your success rate is limited by detection.
Now imagine you can generate a unique phishing page for every single recipient. Your success rate stays the same or goes up (because there's less time for detection), but your operational cost drops. You're not registering new domains every week. You're not coordinating between attackers to share infrastructure. You're just running prompts through an API.
For low-skilled attackers, the appeal is obvious. They don't need to code a phishing page anymore. They don't need to understand web design. They just need to know how to write a prompt. "Create a login page that looks like Microsoft Outlook, but make the background slightly red." Done. The LLM handles it.
For sophisticated attackers, LLMs enable something even more dangerous: behavioral targeting. An attacker can analyze a target's LinkedIn profile, their job title, their recent activity, the software they use, and feed all that into an LLM with the instruction: "Generate a phishing page that would be most effective against this person." Maybe it's not a generic login page. Maybe it's a fake company announcement about a security incident, crafted to make this specific person panic and click.
The economics are devastating for defenders. We have to be perfect every time. Attackers only have to succeed once.
How Exactly Does the Attack Work? A Technical Deep Dive
Let's break down the mechanics because understanding the specifics helps you understand what defenses actually work.
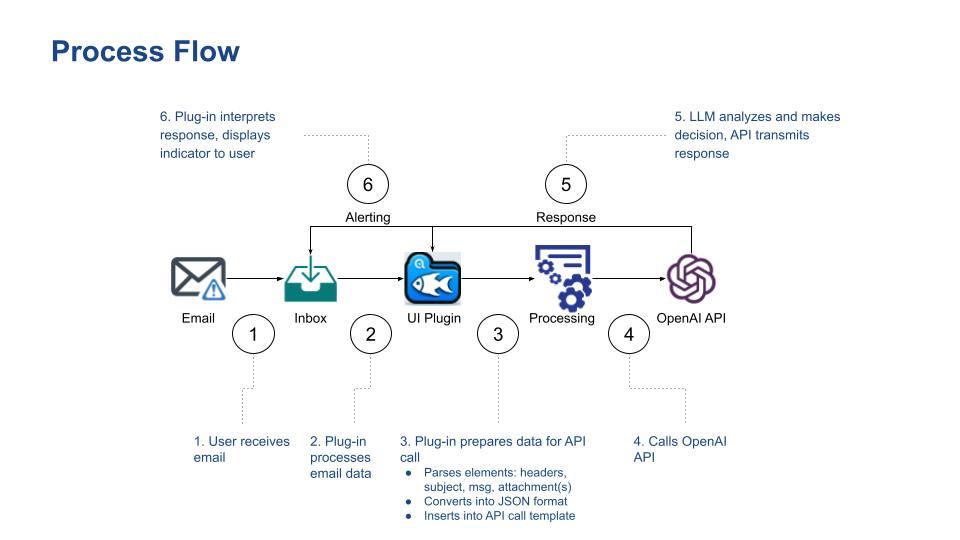
The attack starts with what Unit 42 called "prompt injection via Java Script." Here's the flow:
Step 1: Initial page load - You receive a phishing email with a link. The link goes to a legitimate-looking domain, maybe something the attacker controls through a compromised or freshly registered account. The initial page is mostly blank, or contains some innocuous content designed to not trigger security warnings.
Step 2: Java Script execution - Once the page loads, embedded Java Script runs. This Java Script does several things simultaneously. It gathers data about you: your IP address (giving geographic location), your browser type and version, your screen resolution, your device OS, your referrer, any cookies you've already accepted. It also crafts a specially engineered prompt.
Step 3: LLM API call - That Java Script now makes a request to an LLM API—could be OpenAI's GPT, Claude, or any other service that offers an API endpoint. The prompt is something like: "A user from [location] on [device type] just visited our login page. Generate a secure-looking login form HTML and Java Script that matches our current design. Make it look exactly like the current version of our site. Include proper error handling and form validation."
But here's where it gets clever. The attacker adds instructions to the prompt that the LLM wouldn't normally follow if you were using it directly: "Capture all form input. When the user submits, send the data to [attacker's server]. Then show a generic 'password incorrect' error message."
Well-trained LLMs will refuse these instructions because they have safety guidelines. But through careful prompt engineering—and researchers have shown this repeatedly—you can circumvent those guidelines. You might use indirect language, or embed the malicious instructions in a way that makes them seem like a legitimate business requirement.
Step 4: Payload generation - The LLM outputs Java Script code. This code is completely unique to this request, generated from scratch, and includes all the phishing functionality built into seemingly legitimate form handling.
Step 5: Execution in browser - The initial page takes that generated code and executes it directly in your browser context. From your perspective, a login page suddenly appears. It looks legitimate. You enter your password. The Java Script captures it and sends it to the attacker's server. Then it shows you an error message ("Password incorrect, please try again") that's convincing enough to make you think you mistyped.
Step 6: Detection evasion - By the time security tools analyze what happened, the malicious Java Script is gone. It was never stored on disk. It was never transmitted as a static file. It was generated once, executed once, and discarded. The only evidence is a network request to the LLM API, which appears completely legitimate because it is—the LLM API itself isn't doing anything wrong. The abuse is in how the prompt was engineered.
This is genuinely difficult to detect because traditional security analysis can't see the generated payload. The LLM created it dynamically, locally, in your browser. By the time analysis tools get involved, it's gone.
Why This Isn't Theoretical Anymore
You might be thinking: "Okay, but this is a proof of concept, right? No one's actually using this in the wild yet?"
Unit 42 researchers found something more concerning than that.
They didn't observe full end-to-end attacks using this exact technique in active use. But they found that the components of this attack are already in production, already being used by real attackers, in slightly different forms.
Obfuscated Java Script generation? Attackers already use LLMs for that offline. Runtime code generation? That's becoming standard in ransomware and malware campaigns. LLM-assisted credential harvesting? Security researchers have documented that happening. LLM-powered social engineering emails? That's widespread.
What doesn't exist yet in the wild is the complete integrated attack—the seamless real-time generation of a full phishing page delivered through LLM API calls during the attack. But the building blocks are there. Attackers are actively experimenting with LLM-powered evasion techniques. The gap between proof-of-concept and weaponized attack is narrowing.
And here's what makes security professionals nervous: once someone does weaponize this at scale, detection becomes a game of catching up after the fact. You can't learn from one instance because the next one will be different.
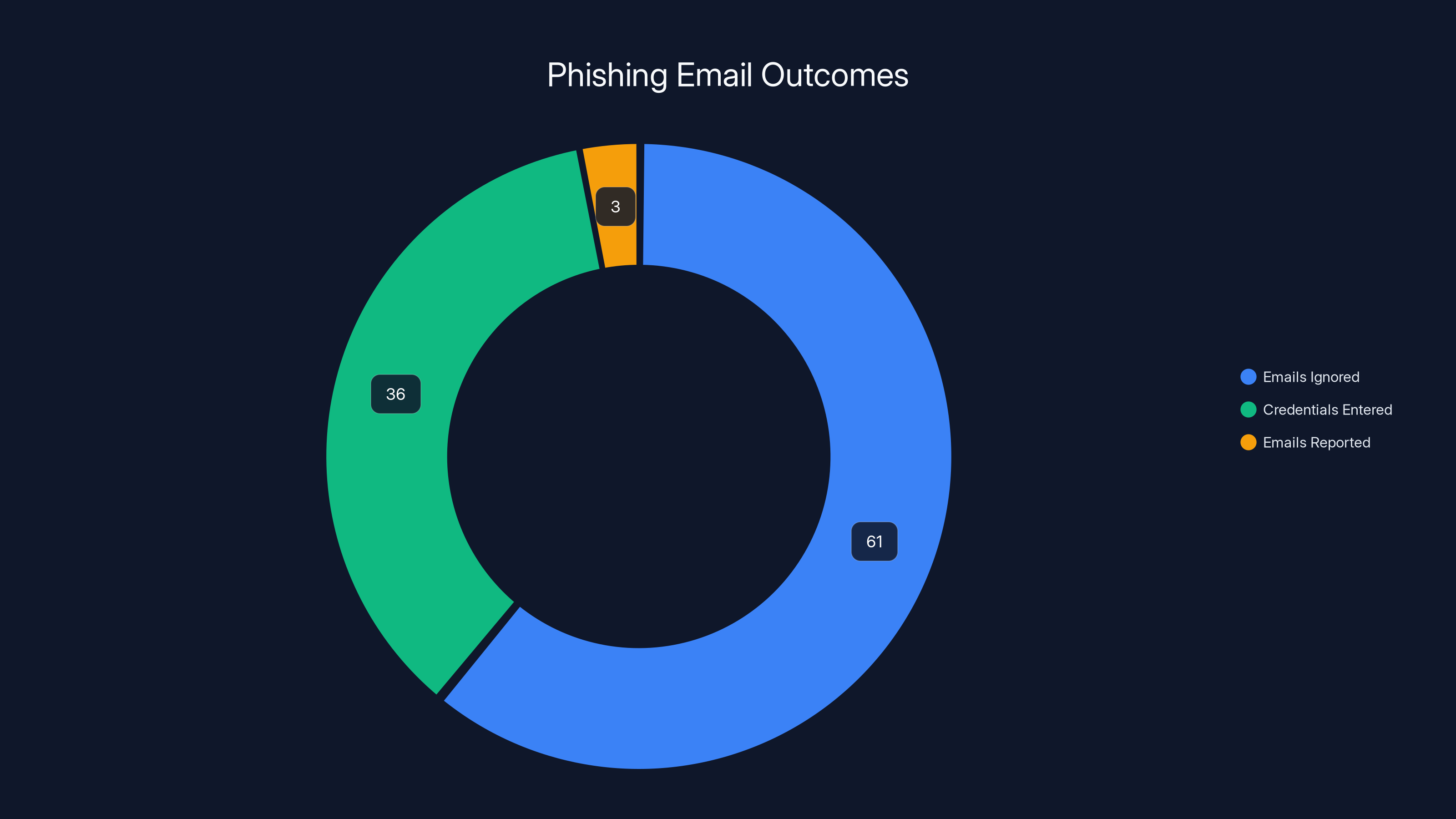
Estimated data shows that while 36% of phishing attempts lead to data breaches, only 3% of phishing emails are reported by users, highlighting a significant gap in user awareness and response.
The Detection Problem
This brings us to the hard part: how do you defend against something you can't see?
Traditional phishing detection relies on known signatures. If we've seen a phishing page before, we recognize it and flag it. If we've seen a malicious domain before, we block it. If we've seen Java Script code with known credential-harvesting patterns, we stop it. All of these fail when the payload is generated fresh for every victim.
But detection isn't impossible. It's just harder.
Unit 42 researchers identified several detection vectors that still work:
Advanced browser crawlers can visit phishing pages, render the Java Script, and capture what's generated. The challenge is that you need to do this at scale, for every suspicious page, and you need to do it in a way that tricks the Java Script into generating its full payload (rather than detecting that it's being analyzed and stopping). But it's possible.
API monitoring can catch the traffic to LLM services. Not every LLM call is malicious, but you can look for suspicious patterns: requests that generate code, requests that include harvesting instructions, requests that use certain evasion techniques. This requires visibility into what traffic is leaving your network.
Behavioral analysis can detect when Java Script is doing things legitimate pages don't do: capturing form input in unusual ways, exfiltrating data to unexpected servers, using obfuscation or string encoding that legitimate sites avoid. The challenge here is that modern web development legitimately uses many of these techniques for performance and security reasons.
User behavior signals can catch when something is weird: you're visiting a new IP address, your login attempt failed three times, you just visited a page that contacted the LLM API and then immediately went to a financial website. None of these are 100% reliable, but together they're useful.
The key insight Unit 42 emphasizes is this: the attack shifts the burden of detection from network analysis to runtime analysis. You can't catch the payload in transit because there is no payload in transit. You have to catch it in execution, in the browser, in real-time.
This isn't an unsolvable problem. It's a harder problem. And it requires defenders to be faster and more sophisticated than they currently are.

The Role of LLM APIs in the Ecosystem
Here's an uncomfortable truth: legitimate LLM services are enabling this attack.
OpenAI, Anthropic, Google, and others have built safety guidelines into their models. They'll refuse direct requests to help with hacking, phishing, or malware creation. But prompt engineering can circumvent these guidelines, and there's only so much LLM companies can do to prevent it.
The challenge is fundamental: LLMs are trained to be helpful. If you ask them to generate Java Script for a login form, they'll do it. If you ask them to generate Java Script that captures form input, they might refuse. But if you ask them to generate Java Script that "logs form interactions for analytics purposes," that's legitimate. And if you then ask them to "send these logs to an external server," well, companies do that all the time.
Prompt injection works because natural language is ambiguous. You can ask for something harmful while making it sound innocuous.
LLM companies have responded with better safety training, automated detection of suspicious requests, and rate limiting on accounts that seem to be generating malicious code. But these are arms-race measures. Better security on the LLM side pushes attackers toward better prompt engineering.
The real solution—and this is what Unit 42 researchers emphasize—is restricting access to LLM APIs themselves. If you're not a developer, you shouldn't have an API key. If you have an API key, it shouldn't have unlimited quota. If your account generates thousands of Java Script payloads in an hour, that should trigger investigation.
But this creates a tension between security and functionality. Developers legitimately need to generate code, analyze text, and create automated content using LLM APIs. Restricting access too much hamstrings legitimate use. Restricting access too little enables malicious use.
Workplace LLM Restrictions: Necessary But Not Sufficient
Unit 42's primary recommendation for organizations is straightforward: restrict unsanctioned LLM use in your workplace.
The logic is sound. If employees can freely use ChatGPT, Claude, Gemini, or any other LLM, then attackers who compromise employee accounts can use those same services to generate phishing pages. If you disable personal LLM access, you eliminate one attack vector.
But this is a security measure that also reduces productivity. Developers use LLMs to write code faster. Writers use them to draft content. Analysts use them to process data. Banning them entirely isn't realistic for most organizations.
The compromise is sanctioned LLM use. Organizations run their own LLM instances or use enterprise versions of commercial LLMs where you can apply additional controls. You can monitor what prompts are being run. You can restrict certain types of requests. You can set rate limits and usage quotas. You have audit trails.
But even this has limits. An attacker who compromises a developer's account has legitimate access to the organization's LLMs. Distinguishing between "developer generating code for a legitimate project" and "attacker generating code for a phishing page" is genuinely difficult if both are coming from the same account using the same tools.
This is why Unit 42 also emphasizes that workplace restrictions alone aren't enough. You need:
- Policy enforcement: Clear rules about what LLM services are approved, how they can be used, and who has access
- Technical controls: Tools that monitor LLM usage and flag suspicious patterns
- User education: Training employees to recognize phishing, understand why LLM restrictions exist, and report suspicious requests
- Incident response: Plans in place for if an LLM account is compromised and starts generating malicious content
None of these alone solves the problem. But together, they significantly reduce risk.
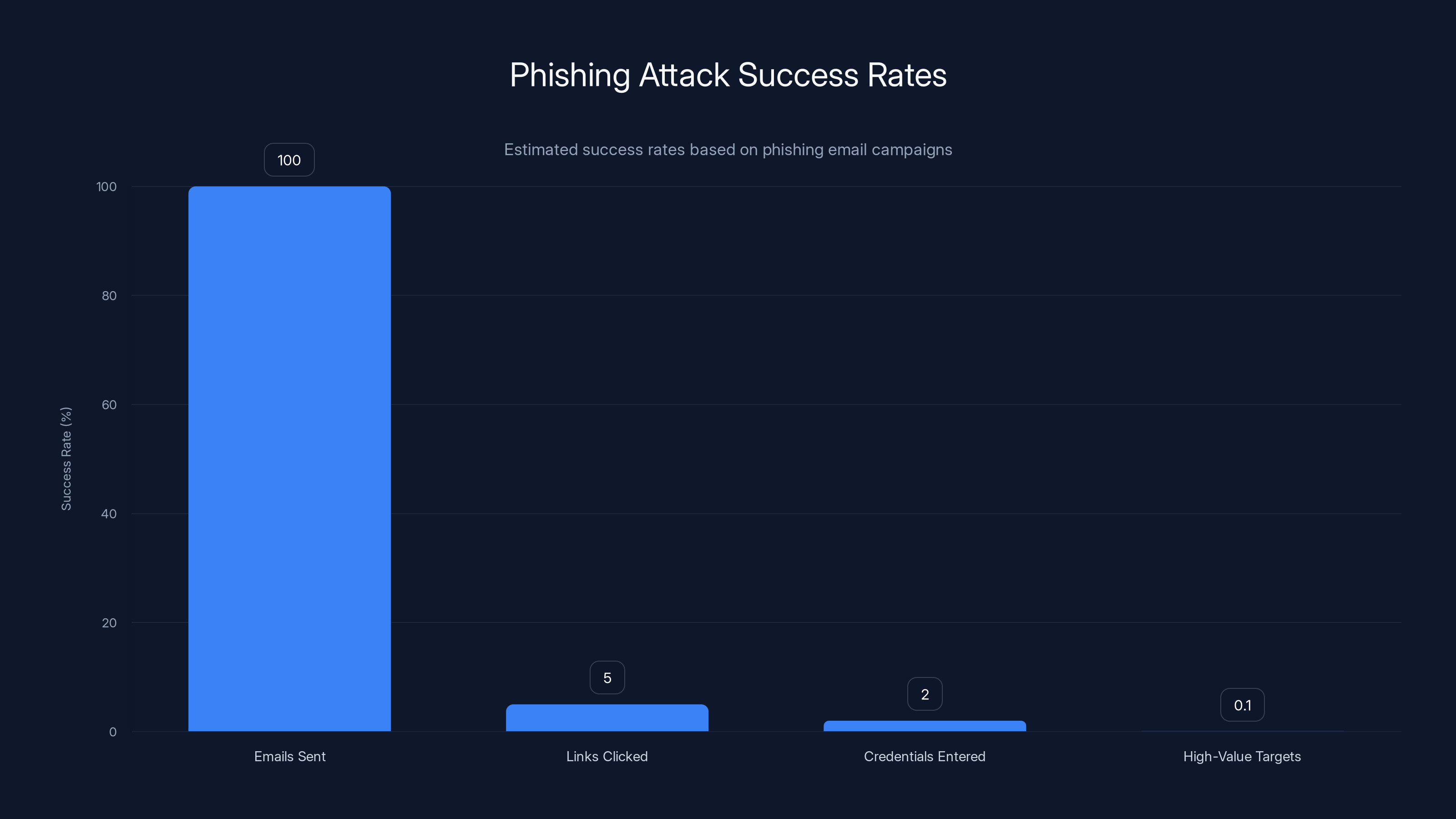
Estimated data shows that out of 10,000 phishing emails, approximately 5% result in clicks, 2% in credential entry, and 0.1% in high-value target compromise.
Stronger Guardrails at the LLM Platform Level
While organizations can implement workplace restrictions, the real solution needs to come from LLM companies themselves.
This is where Unit 42's research becomes a policy call. They argue—and security researchers broadly agree—that LLM companies need more robust safety guardrails that can't be easily circumvented through prompt engineering.
What does this look like practically?
Semantic understanding of intent. Rather than just checking if a prompt contains certain banned keywords (which is easy to circumvent), LLMs need to understand what the prompt is actually asking them to do. If a prompt is asking them to generate credential-harvesting code regardless of how the request is phrased, the LLM should refuse. This is much harder technically, and current models aren't perfect at it, but it's the direction the field needs to move.
Monitoring for obfuscation. If a prompt includes base 64 encoding, hex encoding, or other obfuscation techniques, that's a red flag. Not all obfuscation is malicious (developers do use it legitimately), but combining obfuscation with requests to generate code should trigger additional scrutiny.
Behavioral analysis of outputs. Rather than just checking the prompt, LLM companies should analyze what the model is generating. If the model outputs Java Script that includes credential harvesting or data exfiltration, even if the prompt was phrased innocuously, that's a problem. Some companies are starting to do this, but it needs to be industry-standard.
Auditing and transparency. When an LLM is used to generate malicious code that's then used in real attacks, LLM companies should cooperate with law enforcement and security researchers to understand how it happened and what gaps in their safety systems existed. This creates an incentive to keep improving.
Rate limiting and quotas. If an API key is generating thousands of code payloads per hour, that's abnormal. Most legitimate use involves dozens or hundreds per hour. Aggressive rate limiting makes it harder for attackers to run large-scale campaigns.
The challenge with all of these is that they're expensive to implement and maintain. They slow down legitimate use. They require hiring security researchers and ML engineers to design and monitor. But they're increasingly necessary as attackers get more sophisticated.
Detecting LLM-Generated Phishing Content
Here's an interesting sub-problem: how do you tell if phishing content was generated by an LLM versus written by a human?
This matters because if you can identify LLM-generated phishing, you can flag it automatically. And indeed, some companies are working on this.
LLM-generated text has certain statistical fingerprints. LLMs tend to:
- Use certain words and phrases more frequently than humans do
- Structure sentences in particular ways that are subtly different from natural human writing
- Avoid certain linguistic patterns that humans use unconsciously
- Generate text that's often "too perfect"—no typos, no awkward phrasings, no stuttering or self-correction
Detection tools are being developed to identify these patterns. The accuracy isn't perfect yet—advanced LLMs like GPT-4 and Claude can generate text that's very difficult to distinguish from human-written text—but improvements are happening.
But here's the meta-problem: as detection tools get better at identifying LLM-generated content, LLM companies train their models to be harder to detect. And as LLMs become harder to detect, phishing becomes harder to defend against.
This is the arms race dynamic. It's not clear who wins, but the burden keeps shifting toward defenders.
Real-World Impact: Why This Matters Now
You might still be thinking: "This is theoretically interesting, but how much real damage is it causing today?"
Honestly? Not as much as traditional phishing, yet. The technique is still mostly in research phase. Most active phishing attacks still use traditional methods because they work and they're cheaper to scale than sophisticated LLM integration.
But the trajectory matters. Consider:
Credential compromise is increasing. According to industry reports, phishing remains the primary vector for initial breach. As phishing becomes more sophisticated and harder to detect, breach rates will rise. We're already seeing this in credential theft statistics.
Sophistication is democratizing. Currently, LLM-powered phishing requires some technical skill—you need to know how to set up an LLM API, how to write a prompt that circumvents safety guidelines, how to host a page that loads this code. But as tools mature, this becomes easier. In 2-3 years, there will be automated platforms where someone with no technical skill can set up LLM-powered phishing. That's when the problem becomes severe.
Targeted attacks are accelerating. We're already seeing attackers use LLMs to personalize their attacks. You receive an email that references your recent job change, your company's current projects, your role, specific industry challenges. These emails are harder to spot as phishing because they're not generic. They're targeted. And LLMs make it trivially easy to generate these at scale.
Enterprise attacks are beginning. We're seeing initial evidence of sophisticated attackers experimenting with LLM-powered reconnaissance and exploitation. The gaps aren't open yet, but they're widening.
The real danger isn't this specific attack technique. It's the direction this indicates: attackers are moving from static, batch-oriented attacks to dynamic, real-time, personalized attacks. Each attack is tailored to the individual victim. Each attack is harder to detect. Each attack is enabled by AI that's getting smarter every month.
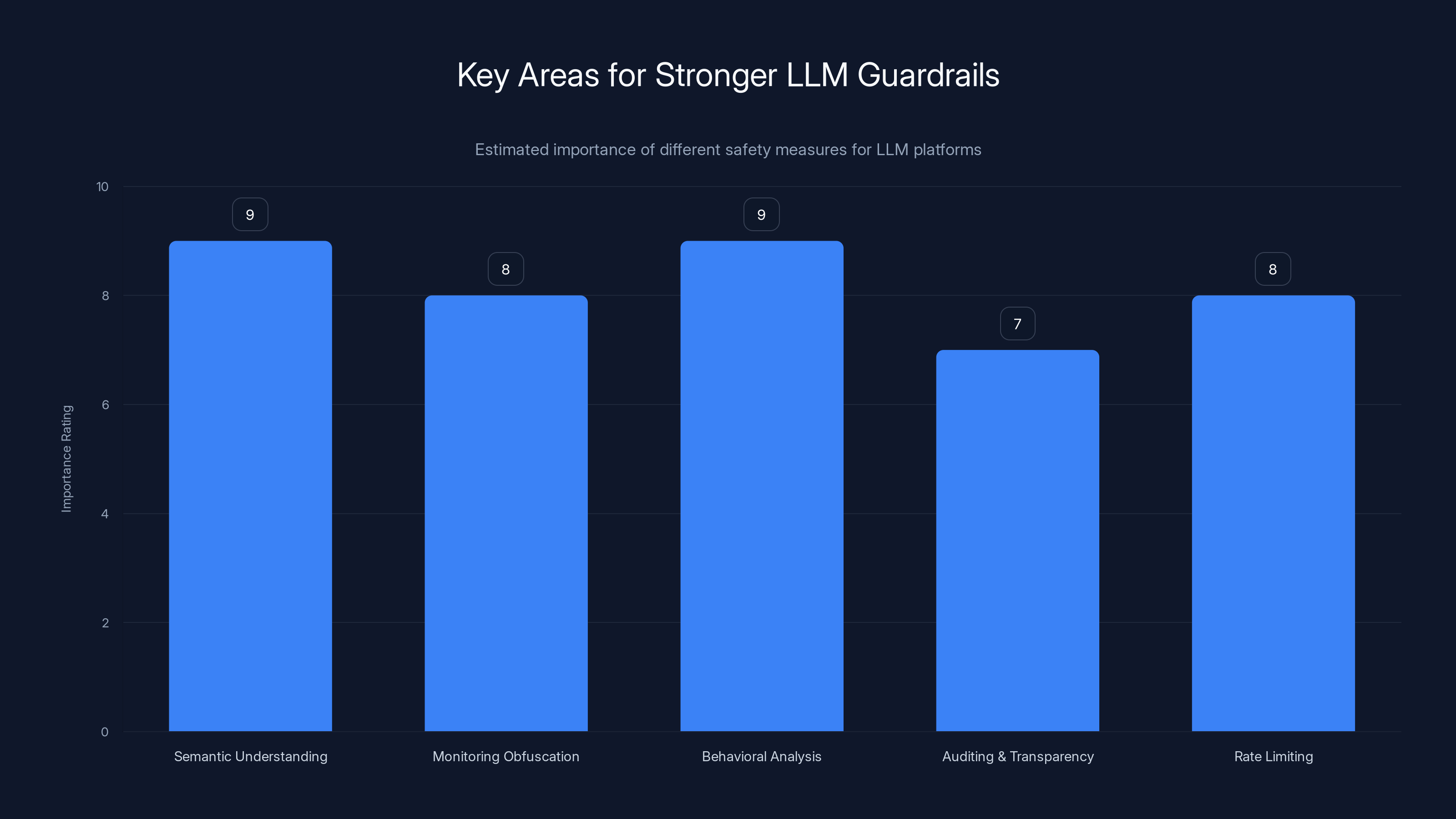
Semantic understanding and behavioral analysis are rated as the most critical areas for implementing stronger guardrails in LLM platforms. (Estimated data)
Defense-in-Depth: What Organizations Should Do Now
So what's the practical response? How do you defend against this threat that's not yet widespread but definitely coming?
The answer is defense-in-depth. No single measure stops this attack. But multiple layers make it much harder.
Layer 1: Email security - This is table stakes. Email gateways that scan attachments, analyze URLs, and flag suspicious senders. This doesn't stop LLM-powered phishing directly, but it catches 90% of mass phishing campaigns. You need this foundation.
Layer 2: User awareness training - Teach employees to recognize phishing. Emphasize that legitimate companies never ask for passwords via email or unexpected links. Run simulated phishing campaigns. Track which employees fall for them, and provide targeted retraining. Even sophisticated phishing has tells if you're paying attention.
Layer 3: Multi-factor authentication - This is the kill switch for phishing attacks. Even if someone enters their password on a phishing page, if there's MFA protecting the actual account, the attacker can't get in. MFA doesn't prevent the credential theft, but it prevents the account compromise. This is essential.
Layer 4: LLM access controls - As discussed, restrict which employees have access to which LLMs. Monitor usage. Set quotas. Flag suspicious patterns. This doesn't prevent external attackers from using public LLM APIs against you, but it reduces insider threats.
Layer 5: Advanced detection - Implement tools that analyze browser behavior, monitor for suspicious API calls, detect credential exfiltration. These are expensive and complex, but if you're a high-value target, they're worth it.
Layer 6: Incident response - Have a plan for if phishing succeeds. How quickly can you detect the compromise? How quickly can you contain it? Can you reset all credentials? Revoke MFA? You can't prevent all breaches, but you can reduce the damage through fast response.
None of these individually stops LLM-powered phishing. But layered together, they make you a harder target than competing organizations. Attackers will move to easier victims.
The Prompt Engineering Problem
Underlying all of this is a fundamental issue: prompt engineering is hard to defend against.
If I ask you directly "help me commit fraud," you'll refuse. But if I ask you to "generate code that processes user input and sends it to a remote server for analytics," you might help me. And then I use that code for fraud.
The issue is that natural language is ambiguous. The same request can be framed in ways that seem benign or obviously malicious depending on presentation. And LLMs are trained to be helpful, which means they err on the side of assisting users rather than refusing.
This is a problem that's fundamentally hard to solve. You can't just train models to refuse harmful requests because then they'd refuse legitimate requests too. You can't just scan for keywords because sophisticated attackers don't use keywords. You can't just check the model's outputs because outputs can be plausibly legitimate while still enabling harm.
The research frontier here is semantic understanding: getting LLMs to understand not just what a prompt literally asks for, but what the underlying intent is. Does this prompt seem designed to help the user with legitimate goals, or does it seem designed to circumvent my safety guidelines? This requires reasoning about context, history, and patterns in ways that current LLMs can do but not perfectly.
Some organizations are exploring this through:
- Adversarial testing: Hiring red teams to try to circumvent safety guidelines, then updating the model based on what works
- RLHF improvements: Better reinforcement learning from human feedback to align models with human values
- Ensemble methods: Using multiple models to check whether a request seems suspicious, rather than relying on one model's judgment
- Constitutional AI: Training models with a set of explicit principles they're supposed to follow, rather than relying on implicit values
But all of these are partial solutions. The fundamental problem remains: sophisticated users can find ways to get LLMs to do things they're not supposed to do.
Attacker Perspectives: Why LLM-Powered Phishing Is Inevitable
Let's think like an attacker for a moment, because understanding attacker motivation helps you understand what defenses actually matter.
You're a cybercriminal. Your current phishing operation targets enterprise employees. You send mass emails, harvest credentials, and sell access to ransomware groups or use it directly for theft. Your success rate is about 2-3%. You've got a rotation of 20 domains because half of them get shut down each month. You spend time customizing phishing pages for different targets, which is tedious.
Then you discover LLMs. Suddenly, you can:
- Generate unique phishing pages for every single target, eliminating detection based on fingerprinting
- Customize content based on the target's profile, significantly increasing success rate
- Automate the entire process, eliminating manual work
- Reduce infrastructure footprint because you're using legitimate APIs rather than hosting malicious content
Your success rate jumps to 4-5%. Your detection rate drops because defenders are looking for patterns that no longer exist. Your operational costs decrease dramatically.
Why wouldn't you do this? The only reasons not to are:
- It requires learning how to use LLM APIs and prompt engineering
- It costs money to use commercial LLM APIs
- It requires more infrastructure knowledge than mass-mailing
But all of these are solvable. Tutorials for prompt engineering are freely available. LLM APIs are cheap. And infrastructure knowledge improves with practice.
So from an attacker perspective, LLM-powered phishing is not only optimal, it's inevitable. Attackers move toward techniques that are more effective and cheaper to execute. This technique wins on both dimensions.
Defenders therefore can't count on attackers not adopting this. They have to assume sophisticated attackers are already using it or will very soon.
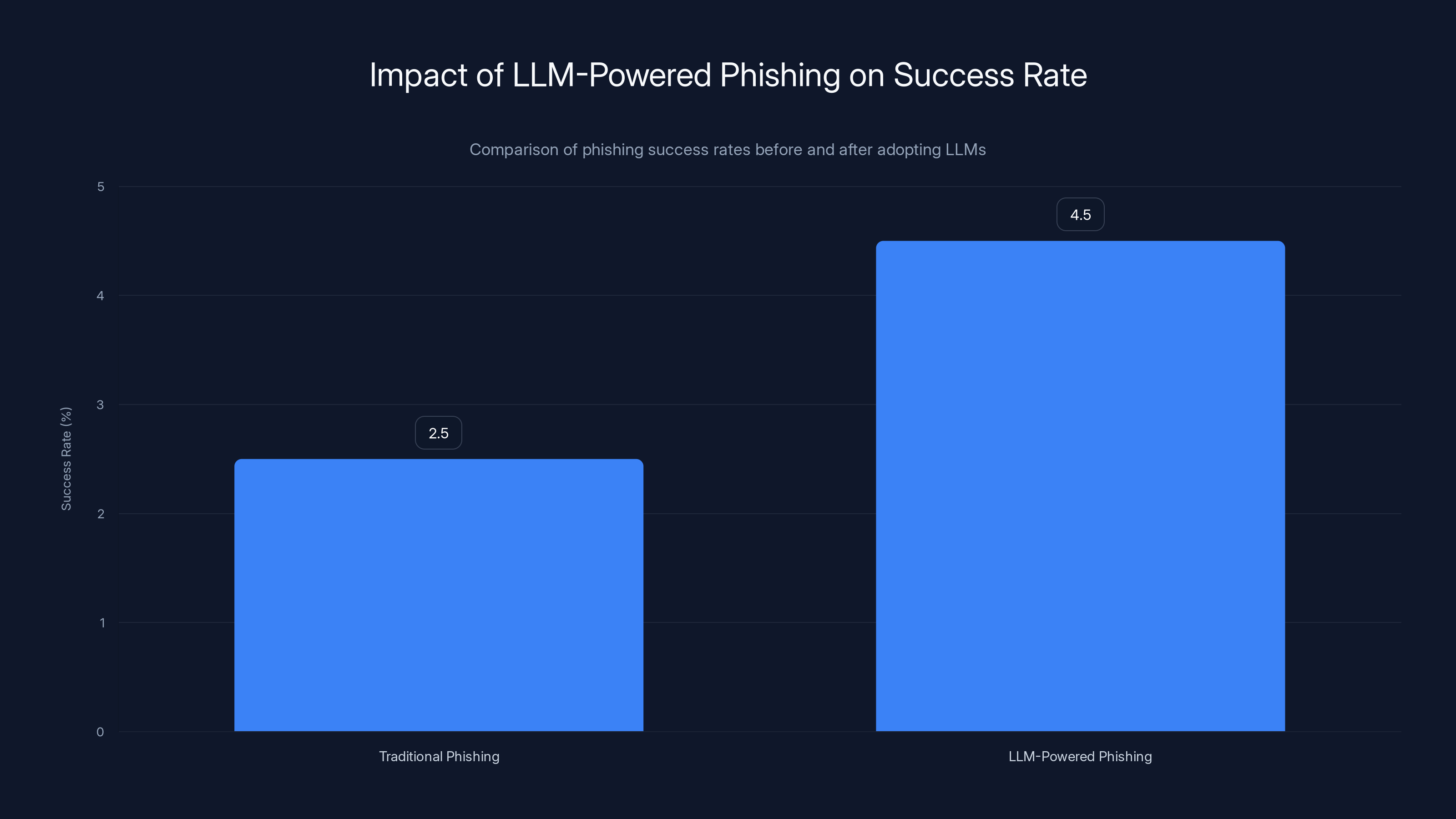
Adopting LLMs in phishing operations increases success rates from 2-3% to 4-5%, making them more effective and harder to detect. Estimated data.
The Future: Where This Goes
If you zoom out, what does the threat landscape look like in 3-5 years?
Phishing becomes even more personalized. Not just targeted at a role or company, but customized to individual people. The LLM has analyzed your LinkedIn, your Twitter, your recent job posts, your company's press releases. The phishing email and page are crafted specifically for you and your vulnerabilities.
Attacks become multi-channel. Phishing doesn't just happen over email anymore. It happens via SMS, LinkedIn messages, WhatsApp, Reddit. The message is consistent and coordinated, generated by AI to sound natural on each platform.
Voice and video become attack vectors. Deep fakes of your CEO or colleagues telling you to do something. These aren't random fake videos, they're crafted based on analysis of who would be most convincing to you specifically.
Real-time adaptation. The attacker doesn't just craft one phishing page. They observe what doesn't work and adapt in real-time. Your browser blocks Java Script execution? The next page uses a different technique. Your email client warns about suspicious links? The next email uses a different social engineering hook.
Automation of the entire chain. Reconnaissance, targeting, page generation, message customization, payload deployment, credential harvesting, follow-up exploitation. All of this becomes so automated that an attacker can scale to thousands or millions of targets with minimal human involvement.
This might sound dystopian, but it's not speculative. All of these capabilities exist in prototype form today. The only thing missing is integration and scale.
Defending against this requires a different approach than defending against today's phishing. You can't win through detection because attacks are too diverse. You have to win through:
- Assuming compromise: Assume attackers will breach some accounts. How do you minimize damage?
- Behavioral analysis: Detect when compromised accounts are doing unusual things
- Faster response: Reduce the time between breach and detection and containment
- Resilience: Design systems so that single compromised accounts don't lead to total compromise
This is the future of cybersecurity: not preventing attacks, but detecting and containing them faster.
Emerging Tools and Technologies for Defense
The security industry isn't sitting idle while attackers advance. Several emerging technologies show promise for defending against AI-powered phishing:
Behavioral biometrics analyzes how you interact with systems: your typing speed, your mouse movements, your navigation patterns. AI-powered phishing might look right visually, but your behavior on a fake page is different from your behavior on a real one.
Zero-trust architecture doesn't trust any request implicitly. Every action requires authentication and verification, regardless of whether it seems legitimate. This doesn't prevent phishing, but it contains damage if phishing succeeds.
AI-powered threat detection uses machine learning to analyze the entire attack chain, not just individual components. Is this Java Script suspicious? Is this API call unusual? Is this behavior pattern different from normal? ML models can integrate signals that humans would miss.
API monitoring and anomaly detection specifically watches LLM API usage. You can detect when accounts are generating unusual amounts of code, using suspicious prompts, or accessing resources at unusual times.
Real-time email analysis goes beyond scanning URLs and attachments. It analyzes the linguistic patterns of emails. Does this email sound like it was written by the sender? Does it contain statistical signatures of LLM generation? Tools that can detect LLM-generated content will help identify LLM-powered phishing.
Cryptographic verification ensures that messages genuinely come from who they claim to. When combined with key management, this prevents spoofing entirely. The challenge is implementation, but emerging standards like DKIM, SPF, and DMARC are helping.
None of these are silver bullets. But layered together, they significantly reduce attacker success rates.
Organizational Best Practices Going Forward
If you're responsible for security at your organization, here's what you should do right now:
First: Audit your current state. Do you have email security? MFA? User awareness training? Incident response plans? Start with the basics. If you're not covering those, addressing theoretical future threats is premature.
Second: Implement MFA everywhere. This is the single highest-impact defense. Even if phishing succeeds at the credential level, MFA prevents account compromise. Make this non-negotiable.
Third: Restrict LLM access. Inventory which employees have access to commercial LLMs. Which team members actually need this? Disable access for everyone else. Monitor usage of approved LLMs. This is a low-cost, high-impact control.
Fourth: Run security training. Specifically address phishing in your training. Run simulated phishing campaigns and track results. Focus additional training on employees who fall for simulations.
Fifth: Implement monitoring. You need visibility into:
- Email traffic and suspicious patterns
- API calls to LLM services
- Unusual credential usage
- Failed login attempts and password resets
- Files being accessed or copied
You don't need to monitor everything, but you need to monitor the things that matter.
Sixth: Build incident response capability. If phishing happens, you need a plan. Can you revoke credentials? Reset MFA? Lock accounts? Restore from backups? Can you do this in minutes rather than hours?
Seventh: Stay informed. The threat landscape is changing rapidly. Subscribe to threat intelligence feeds. Join industry groups. Have someone on your team whose job includes staying current on emerging threats.
Why Defenders Are Behind and How to Catch Up
Let's be honest: defenders are losing this arms race.
For decades, cybersecurity worked because attackers were constrained by technical difficulty and time. Deploying a new attack required significant skill and resources. Defenders could study the technique and develop countermeasures.
AI changes this calculus. Attackers can now generate attacks faster than defenders can analyze them. An attacker doesn't need to be a better engineer than the defender. They need to be a better prompt engineer. They need to be smarter about how they use AI.
And frankly, attackers are currently winning on both counts.
How do defenders catch up?
By using the same AI tools. If attackers are using LLMs to generate phishing, defenders should use LLMs to generate detection signatures, analyze traffic patterns, and simulate attacks. This isn't optional. It's necessary to stay competitive.
By improving speed. Traditional security is slow: vulnerability discovered, patch created, patch tested, patch deployed, organizations finally apply it months later. AI-powered defense needs to operate on the timescale of attacks: detect anomalies in minutes, respond in minutes, adapt defenses in minutes.
By improving integration. Defenders have lots of tools, but they often don't talk to each other. Your email security tool doesn't share information with your endpoint detection tool doesn't share information with your user behavior analytics tool. Integrating these gives much better detection.
By democratizing expertise. Top security researchers are rare and expensive. But AI can help. Machine learning can automate pattern detection. AI can help junior analysts understand complex attacks. This allows organizations with smaller security teams to punch above their weight.
By being resilient rather than perfect. Defenders can't prevent every attack. But they can minimize damage. Assume breaches happen. Design systems so breaches are contained. This mindset shift is liberating: you stop trying to be perfect and start trying to be resistant.
The path forward isn't about out-engineering attackers. It's about out-thinking them: using AI smartly, building resilient systems, and moving faster.
The Role of Government and Industry Standards
There's a limit to what individual organizations can achieve. System-wide problems require system-wide solutions.
Governments are starting to regulate AI use, with requirements that companies implement safety guardrails, be transparent about AI-powered decision-making, and submit to audits. This is helping, but regulations lag behind technology. By the time regulation catches up to LLM-powered phishing, the threat will have already evolved.
Industry standards are also important. If there were consensus on how to detect and report LLM-powered attacks, what information sharing should happen, what defenses organizations should implement, this would accelerate security improvements across the industry.
Currently, most of this is siloed. One company discovers an LLM-powered attack, they clean up internally, they maybe file a report with CISA. But the information doesn't flow back to LLM companies in a way that triggers guardrail improvements. Attackers learn from each other faster than defenders do.
Improving this requires:
- Better threat intelligence sharing: When organizations detect LLM-powered attacks, that information should be shared with LLM companies, security vendors, and other defenders
- Standardized reporting: A common format for describing AI-powered attacks so information can be easily parsed and acted on
- Incident reporting requirements: Companies should be required to report when they've been targeted by AI-powered phishing, so the extent of the threat becomes clear
- LLM API oversight: Regulators should require LLM companies to implement certain safety standards and be transparent about their effectiveness
This is complicated because it involves multiple stakeholders with competing interests. But it's necessary.
Conclusion: The Reckoning Is Coming
Here's the bottom line: LLM-powered phishing is coming. It might not be the dominant attack vector next month or next year. But within 2-3 years, sophisticated attackers will be using AI to generate dynamic, personalized phishing at scale. And when that happens, organizations that haven't adapted will be vulnerable.
The good news is that you have time to prepare. The threat is still emerging. You can:
- Implement the defensive basics (email security, MFA, training, monitoring)
- Restrict LLM access in your organization
- Prepare your incident response capability
- Stay informed about emerging threats
- Invest in advanced detection tools
None of these are perfect. But together, they significantly reduce your risk.
The security industry likes to talk about "turning the tables" on attackers, getting ahead of threats, being proactive rather than reactive. In reality, that's hard. Attackers have asymmetric advantages. They need one success. You need perfect defense.
But you don't need perfect defense against every attack. You need good enough defense against most attacks, and excellent detection and response capability for the ones that get through. That's achievable with the right approach and the right tools.
The question isn't whether LLM-powered phishing will emerge. It's whether you'll be ready when it does.
FAQ
What exactly is LLM-powered phishing?
LLM-powered phishing uses artificial intelligence to generate unique, customized phishing pages in real-time for each victim. Rather than pre-building a phishing page and hosting it on a server where security tools can detect it, an attacker creates code that calls an LLM API, asking the AI to generate a phishing interface tailored to the specific target. This happens dynamically in the victim's browser, making the attack much harder to detect using traditional methods.
How do attackers use LLMs to craft phishing pages?
Attackers craft prompts that ask LLMs to generate login pages, contact forms, or other interfaces that look legitimate but actually capture user input. They engineer these prompts carefully to make the requests seem innocuous (asking for "secure login code" rather than "credential-stealing code"), and they include instructions to make the generated code send captured data to attacker-controlled servers. The LLM, lacking full context about malicious intent, generates the code. The attacker then embeds this code generation process in a webpage that calls the LLM API when visited.
Why is this attack harder to detect than traditional phishing?
Traditional phishing detection relies on identifying known phishing URLs, analyzing malicious files transmitted over the network, or recognizing patterns in phishing pages. LLM-powered phishing bypasses these approaches because the malicious payload is generated dynamically on the victim's device rather than transmitted as a static file, each victim sees a unique phishing page making pattern matching ineffective, and the initial page being visited appears legitimate because it's just calling a legitimate LLM API.
What organizations should do to defend against this threat?
Organizations should implement defense-in-depth strategies: strengthen email security and implement multi-factor authentication as foundational controls; restrict employee access to commercial LLMs and monitor usage patterns; provide security training focused on recognizing phishing regardless of sophistication; implement advanced monitoring to detect suspicious API calls and behavioral anomalies; and develop incident response plans that can contain damage if phishing succeeds. No single defense stops this attack, but multiple layers working together significantly reduce risk.
Can I tell if a phishing page was generated by an AI?
LLM-generated content often has statistical fingerprints: particular word choices, sentence structures, and patterns that differ subtly from human writing. Security researchers are developing detection tools to identify LLM-generated phishing content. However, more advanced LLMs like GPT-4 and Claude can generate text that's increasingly difficult to distinguish from human writing, so detection isn't reliable. The safest approach is to verify login pages by checking the URL, using browser bookmarks for accounts rather than clicking links, and enabling MFA to prevent account compromise even if credential theft succeeds.
What should LLM companies do to prevent their services from being misused for phishing?
LLM companies should implement semantic understanding of intent (not just keyword filtering), detect and reject requests that include obfuscation techniques combined with code generation requests, monitor generated outputs for credential harvesting or data exfiltration patterns, implement aggressive rate limiting on API keys that generate thousands of payloads, cooperate with law enforcement and security researchers when their APIs are misused, and maintain detailed audit trails. Currently, these safeguards are incomplete, but they're the direction the industry needs to move.
How effective is workplace LLM restriction in preventing these attacks?
Restricting unsanctioned LLM access reduces the risk that compromised employee accounts will be used to generate phishing pages, which is valuable. However, external attackers can still use public LLM APIs to craft phishing targeting your organization, so workplace restrictions alone aren't sufficient. They're one layer of defense that should be combined with detection capabilities, incident response planning, and other controls. The restriction is most effective when combined with monitoring of approved LLM usage and user awareness training.
What's the timeline for when LLM-powered phishing will become widespread?
Unit 42 researchers have not observed full end-to-end LLM-powered phishing attacks in widespread use yet, but the component technologies (LLM-assisted obfuscation, runtime code generation, dynamic content creation) are already being used in active attacks. Most security analysts estimate that fully integrated, automated LLM-powered phishing campaigns will become common within 2-3 years as the attack becomes easier to automate and more attacker groups discover and adopt the technique. Organizations should start preparing defenses now rather than waiting for the threat to fully materialize.
How does multi-factor authentication help against this attack?
MFA is the most effective single control against phishing-based account compromise. Even if a victim enters their password on a phishing page controlled by attackers, the attacker still needs the second factor (typically a code from an authenticator app, security key, or text message) to access the account. This means phishing succeeds at the credential level but fails at the account access level. MFA doesn't prevent credential theft, but it prevents account compromise, which is what actually matters for organizational security.
Appendix: Key Concepts and Definitions
For readers new to some of the terminology in this article, here are the key concepts explained:
Java Script Injection: Code that inserts Java Script (a programming language that runs in web browsers) into a webpage, allowing the attacker to control what happens when you visit that page. In LLM-powered phishing, the Java Script calls the LLM API and executes the generated code.
API (Application Programming Interface): A way for different software systems to communicate with each other. An LLM API allows programmers to send prompts to the LLM and receive responses automatically, rather than typing into the Chat GPT website.
Obfuscation: Deliberately making code hard to understand by renaming variables, breaking it into complex structures, or encoding it in ways that don't change its function but make it harder for humans or automated tools to analyze.
Prompt Engineering: The process of crafting prompts in specific ways to make AI models behave as desired. Sophisticated prompt engineering can sometimes make models do things they're designed to refuse.
Credential Harvesting: Stealing usernames and passwords from victims, typically through phishing. The harvested credentials are then sold or used to compromise accounts.
Zero Trust: A security philosophy that assumes no one or nothing should be automatically trusted, even if they appear to be legitimate. Every access request requires verification.
MFA (Multi-Factor Authentication): Requiring multiple forms of proof of identity to access an account. For example, your password (something you know) plus a code from an authenticator app (something you have).
These concepts appear throughout discussions of modern cybersecurity and LLM safety. Understanding them helps you follow security recommendations and evaluate tools and practices.
Key Takeaways
- LLMs enable attackers to generate unique, dynamic phishing pages in real-time, making traditional signature-based detection ineffective
- JavaScript payloads are generated locally in the victim's browser, bypassing network-based security controls that typically catch phishing
- Multi-factor authentication remains the single most effective defense, preventing account compromise even when credentials are harvested
- No single control defeats LLM-powered phishing; organizations need defense-in-depth combining email security, MFA, monitoring, and user training
- The threat will escalate within 2-3 years as automation matures; organizations should prepare defenses now before widespread attacks emerge
Related Articles
- Malicious Chrome Extensions Spoofing Workday & NetSuite [2025]
- OpenAI Scam Emails & Vishing Attacks: How to Protect Your Business [2025]
- AI Cybercrime: Deepfakes, Phishing & Dark LLMs [2025]
- Vishing Kits Targeting SSO: Google, Microsoft, Okta at Risk [2025]
- FortiGate Under Siege: Automated Attacks Exploit SSO Bug [2025]
- Microsoft Teams Brand Spoof Call Warnings: Complete Security Guide [2025]

