![AI Slop Crisis: Why 800+ Creatives Are Demanding Change [2025]](https://tryrunable.com/blog/ai-slop-crisis-why-800-creatives-are-demanding-change-2025/image-1-1769060258021.jpg)
The Reckoning Has Arrived for AI Training Data
Imagine waking up to discover that your life's work—every song you've written, every novel you've crafted, every performance you've delivered—has been fed into machines without your permission, without compensation, and without your ability to opt out. This isn't science fiction. This is happening right now, and about 800 of the world's most recognizable creatives have had enough.
In early 2025, a coalition representing some of the entertainment industry's biggest names launched the "Stealing Isn't Innovation" campaign. The signatories read like a who's who of contemporary culture: Cate Blanchett, Scarlett Johansson, Cyndi Lauper, George Saunders, Jodi Picoult, the members of R.E.M., Billy Corgan, and The Roots. But this isn't just celebrity grandstanding. It's a wake-up call about the fundamental economics of artificial intelligence, and it's forcing an uncomfortable question: who owns creativity in an age of machines?
The core complaint is straightforward but devastating. Tech companies have scraped billions of copyrighted works—songs, books, scripts, paintings, articles—off the internet to train their AI models. They did this without asking permission. They did it without paying artists a dime. And they're betting that the law won't catch up fast enough to stop them.
What's particularly striking is that this campaign isn't coming from the fringe. It's backed by organizations like the Recording Industry Association of America, professional sports unions, and SAG-AFTRA. This represents real economic power, real legal resources, and real leverage. But here's the thing: these creatives aren't just fighting corporate theft. They're fighting a fundamental reimagining of what "innovation" means in the AI age.
The stakes here are enormous. If AI companies can continue training on copyrighted material without permission, they effectively have a free moat around their competition. They don't have to hire artists. They don't have to negotiate. They don't have to pay for content. They just take it. And the companies that do negotiate—paying millions for exclusive licensing deals—suddenly look foolish for playing by the rules.
This is the "AI slop" future everyone's warning about. Not just lower quality output. Not just fewer opportunities for human creatives. But a complete devaluation of human artistry as a commodity.
What Exactly Is AI Slop and Why Should You Care?
Let's be honest: most AI-generated content is mediocre. It's competent. It's functional. But it lacks soul. It lacks the messy, unexpected brilliance that comes from actual human experience and struggle.
AI slop refers to the avalanche of low-quality, algorithmically generated content flooding the internet. We're talking about AI-written articles optimized purely for search rankings with no real value. AI-generated music that sounds technically correct but emotionally hollow. AI-designed graphics that hit all the right buttons but feel soulless. Images of celebrities that don't quite look right. Videos with synthetic voices that almost fool you until they don't.
The problem isn't that AI can create things. The problem is the economics of slop. Creating a thousand mediocre YouTube videos with AI costs essentially nothing. Creating one genuinely good video with human creators costs real money—equipment, time, expertise, iteration, failure. When you remove the economic friction from creation, you remove the incentive to create anything truly exceptional.
Here's what happens next: the internet drowns in low-quality content. Search engines get worse because they're optimized to surface recent content, and 80% of recent content is AI garbage. News outlets collapse because their content is being trained on for free, but they're competing against AI summaries. Stock photography sites tank because AI image generators are free. Voice actors lose gigs to synthetic voices. Composers lose commissions to algorithmically generated background music.
This isn't hypothetical. It's already happening. On YouTube, the upload rate is accelerating exponentially, and the ratio of human-generated to AI-generated content is shifting noticeably. On social media platforms, low-quality AI-generated posts are cluttering feeds. On content farms, thousands of AI articles are being published daily.
The "Stealing Isn't Innovation" campaign argues that this slop cascade isn't an accidental byproduct of AI progress. It's a direct result of companies training on stolen creative work without compensating creators. Because the input data is free, the economics of slop production become irresistible.
What makes this particularly insidious is the feedback loop. As more slop fills the internet, the training data for future AI models gets worse. AI trained on AI slop compounds the problem. Models collapse. Quality degrades further. The information ecosystem becomes increasingly polluted, and there's no way to recover the original source material.

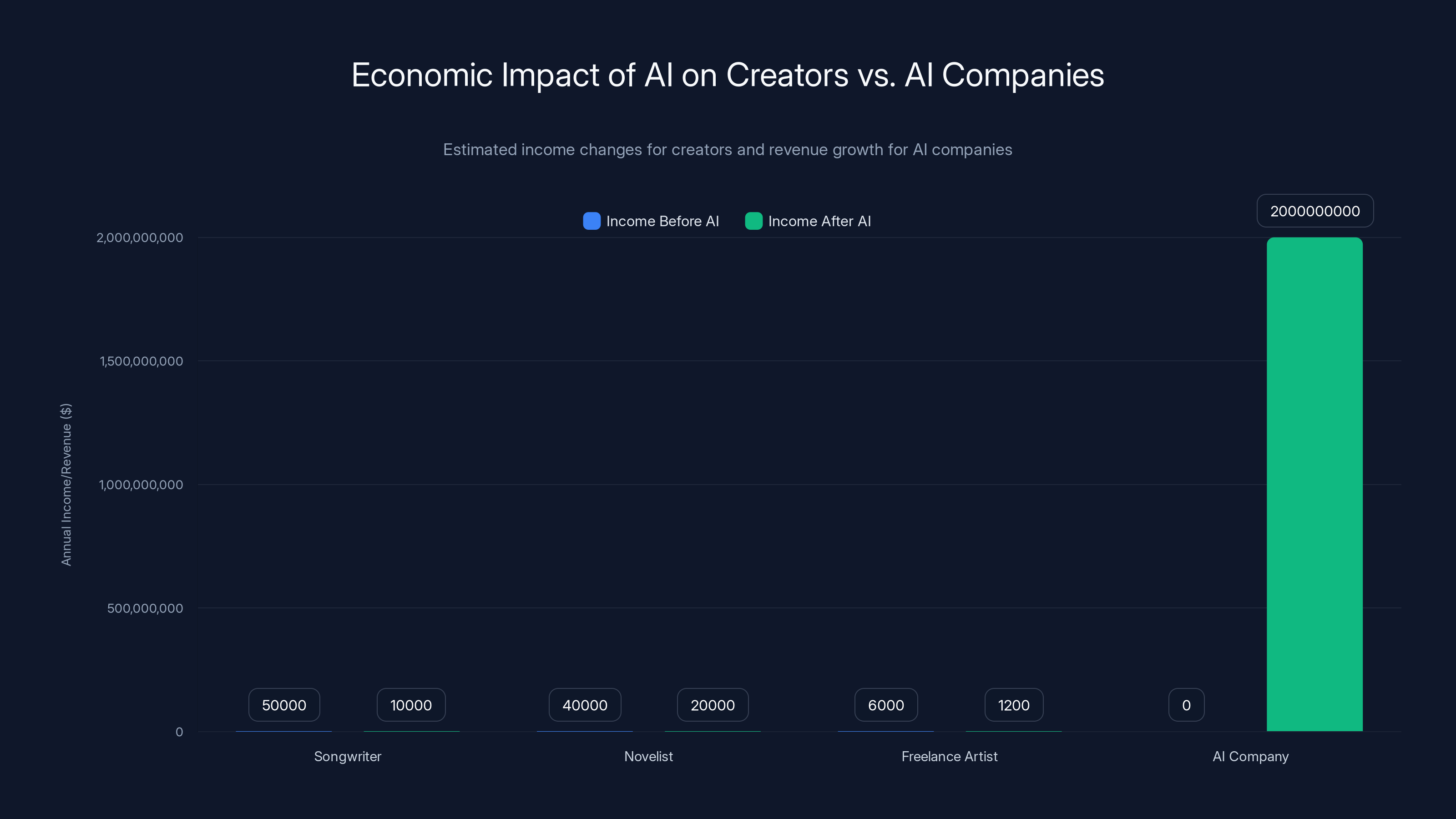
The chart highlights the stark contrast between the declining income of individual creators and the booming revenue of AI companies. Estimated data illustrates the economic shift from creators to AI firms.
The Legal Battle Over Intellectual Property Theft
Here's where it gets complicated. The legal definition of "theft" when it comes to training data is still being written in real time.
Traditionally, copyright law protected the expression of creative works, not the underlying ideas. If you read a novel, you can't republish it word-for-word. But you could analyze it. You could discuss it. You could write a response to it. This is called fair use, and it's the backbone of creative culture.
AI training exists in this murky space. AI companies argue that analyzing millions of images or texts to extract patterns is "fair use"—essentially, they're reading material to understand it, just like a student reads a book. The fact that they're doing it at scale with machines doesn't change the fundamental nature of the activity, they contend.
Creators and their legal representatives argue this is nonsense. They say using copyrighted material to train commercial systems without permission or compensation is straightforwardly illegal. The scale actually makes it worse, not better. You're not having an isolated encounter with the work. You're systematically extracting value from millions of works to build a competing product.
The problem is that copyright law was written before internet-scale copying was possible. When legislators drafted the Digital Millennium Copyright Act in 1998, they couldn't really imagine a scenario where trillions of copyrighted works would be duplicated simultaneously across data centers for machine learning. So there are genuine gaps.
Multiple lawsuits are already working through the courts. Major publishers like Penguin, Simon & Schuster, and Hachette sued OpenAI for using their books to train Chat GPT without permission. The New York Times filed suit against OpenAI and Microsoft. News organizations are fighting back. Photographers and visual artists are organizing collective action.
But here's the thing: by the time these cases resolve—probably years from now—billions of dollars in AI value will have been created on the back of stolen material. Even if courts rule in favor of creators, the damages calculations will be complicated. Do you value the infringed material at what it would have cost to license? At the value of the resulting AI model? At the lost opportunities for the original creator?
The campaign is calling for three specific legal changes:
-
Mandatory licensing agreements - AI companies must negotiate with creators and rights holders before using their work
-
Opt-out rights - Creators should have the legal right to exclude their work from AI training datasets
-
Enforcement mechanisms - There need to be actual consequences for violating these rights, not just civil lawsuits years later
These are radical from the perspective of current AI industry practice, where training-first-ask-questions-later is the norm. They're obvious common sense from the perspective of anyone who's ever created anything valuable.

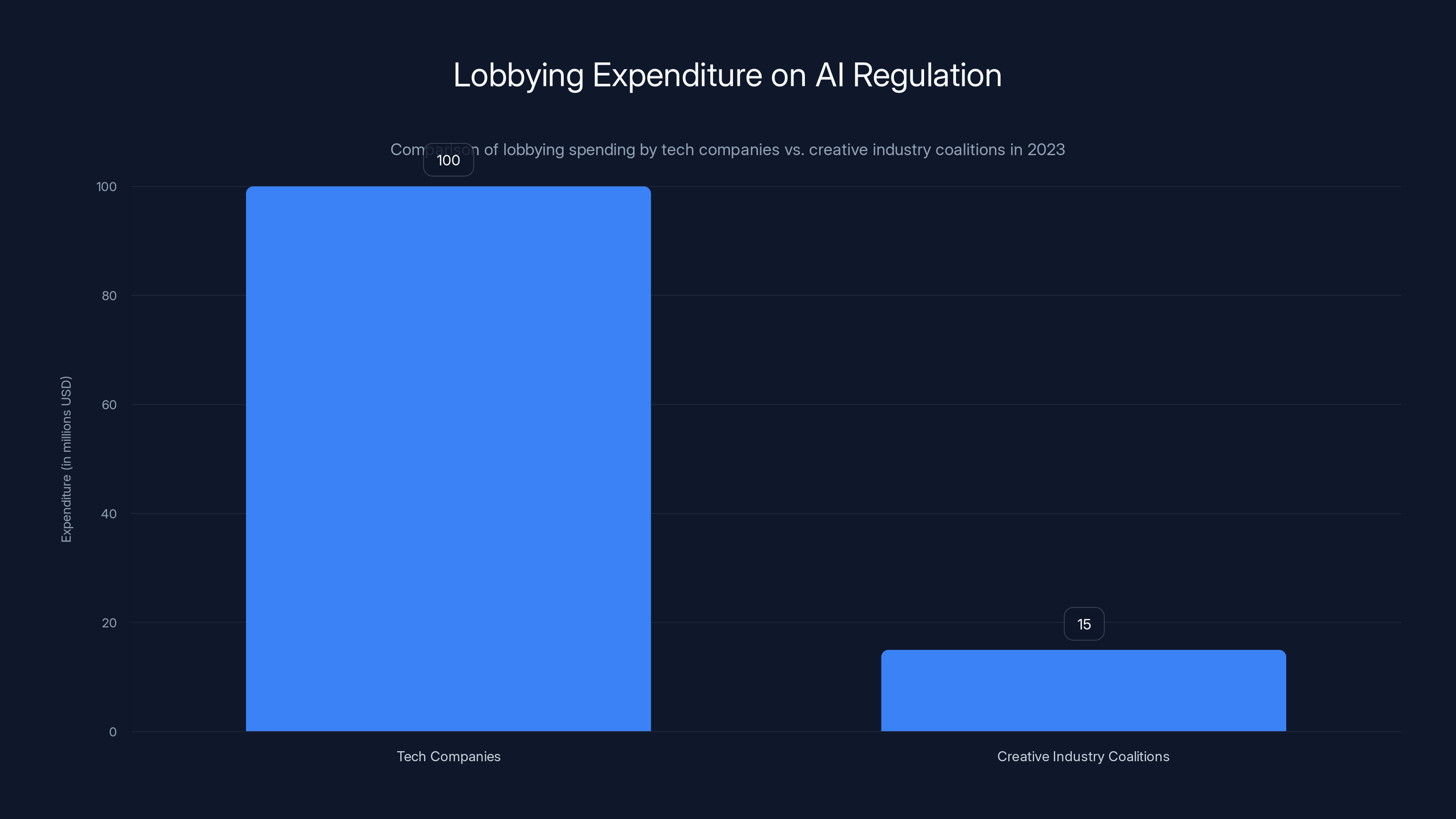
Tech companies have significantly outspent creative industry coalitions on AI lobbying in 2023, with expenditures of
The Hypocrisy of "Innovation" Without Attribution
Tech companies love to talk about innovation. Innovation as disruption. Innovation as breaking the old rules. Innovation as moving fast and breaking things.
What they usually don't talk about is that their innovation is built on the stolen intellectual property of others.
Let's be specific. When OpenAI trained GPT-3 and GPT-4, they used books, articles, and creative works scraped from the internet without authorization. When Anthropic trained Claude, same story. When Google built Gemini, they vacuumed up massive amounts of copyrighted material. When Midjourney created their image generation model, they trained on millions of copyrighted photographs and artwork.
These companies are worth hundreds of billions of dollars. OpenAI's valuation has hit
Compare this to the traditional entertainment industry. When a movie studio wants to include a song in a film, they negotiate with the songwriter. They pay them. When a publisher wants to republish excerpts of another author's work, they get permission and often pay licensing fees. These systems aren't perfect—artists in traditional industries often get screwed too—but at least there's a mechanism for compensation.
AI companies have essentially decided that the old rules don't apply to them. They're claiming that because they're doing something new and technological, the normal rules of intellectual property don't matter. They frame it as "academic research" or "computational analysis" when it's actually commercial product development.
The hypocrisy becomes even more apparent when you look at what happens inside these companies. They have lawyers. They have contracts. They respect intellectual property when it belongs to them. OpenAI vigorously defends its own models against copying. Google fights piracy of Google content. But somehow, this respect for property rights evaporates when they're the ones doing the taking.
The campaign's framing as "theft" is deliberately provocative. Tech companies prefer euphemisms like "training on publicly available data" or "analyzing text for patterns." But if I walked into a store and said I was "analyzing the store's merchandise for patterns," that wouldn't change the fact that I'm stealing things. The mechanism doesn't matter. The intent does.
This hypocrisy is particularly galling because these are often the same companies that advocate for strict intellectual property enforcement in other contexts. They lobby for stronger copyright protections. They sue over patent infringement. They demand that smaller companies respect their rights. But when they're on the taking end of the equation, suddenly property rights are antiquated obstacles to innovation.
Who's Actually Winning: The Licensing Deal Revolution
Here's where the story gets interesting. Rather than waiting for courts to resolve the theft question, major players are making deals.
Record labels are partnering with AI music companies. Universal Music Group has cut deals with multiple AI platforms. Sony Music is negotiating access to their massive catalog. Rather than fight AI, the music industry is monetizing it. Artists get a cut (usually small), rights holders get compensation, and AI companies get legal cover to use the material.
News organizations are doing the same thing. OpenAI has signed licensing deals with major publishers including Financial Times, Wall Street Journal, and others. The BBC is in talks. These deals allow AI systems to cite and reference news content, and the publishers get paid.
But here's the catch: these licensing deals are only available to massive players with bargaining power. Universal Music negotiated because they represent thousands of artists with significant revenue. Major newspapers negotiated because they have legal resources and market power. A solo artist? An indie writer? A freelance photographer? They have no seat at the table.
This creates a two-tier system. Companies with leverage get compensated. Everyone else gets scraped for free.
The campaign argues this partial solution isn't enough. Yes, deals are great for people who can negotiate them. But the majority of creators can't. There need to be baseline legal protections that apply to everyone, not just those with lawyers and leverage.
Specifically, they're pushing for:
-
Unilateral opt-out rights - Any creator should be able to request their work be removed from training datasets, regardless of whether they have a licensing deal
-
Standardized compensation - If companies are using your work to train models, you get a baseline payment, not negotiated individually
-
Attribution transparency - When AI generates content in a particular style, there should be transparency about which artists influenced it
-
Prevention of deepfakes - Specific legal protections against using creative work to generate deepfakes without consent
These would represent a seismic shift in how AI companies operate. They'd have to identify what training data is copyrighted. They'd have to respect opt-out requests. They'd have to pay baseline fees. They'd have to track which creators influenced which outputs. This would be expensive and complicated.
But that's exactly why these protections are necessary. Right now, the cheap option is to steal. If the law makes stealing legally risky and expensive, licensing becomes the preferred path.

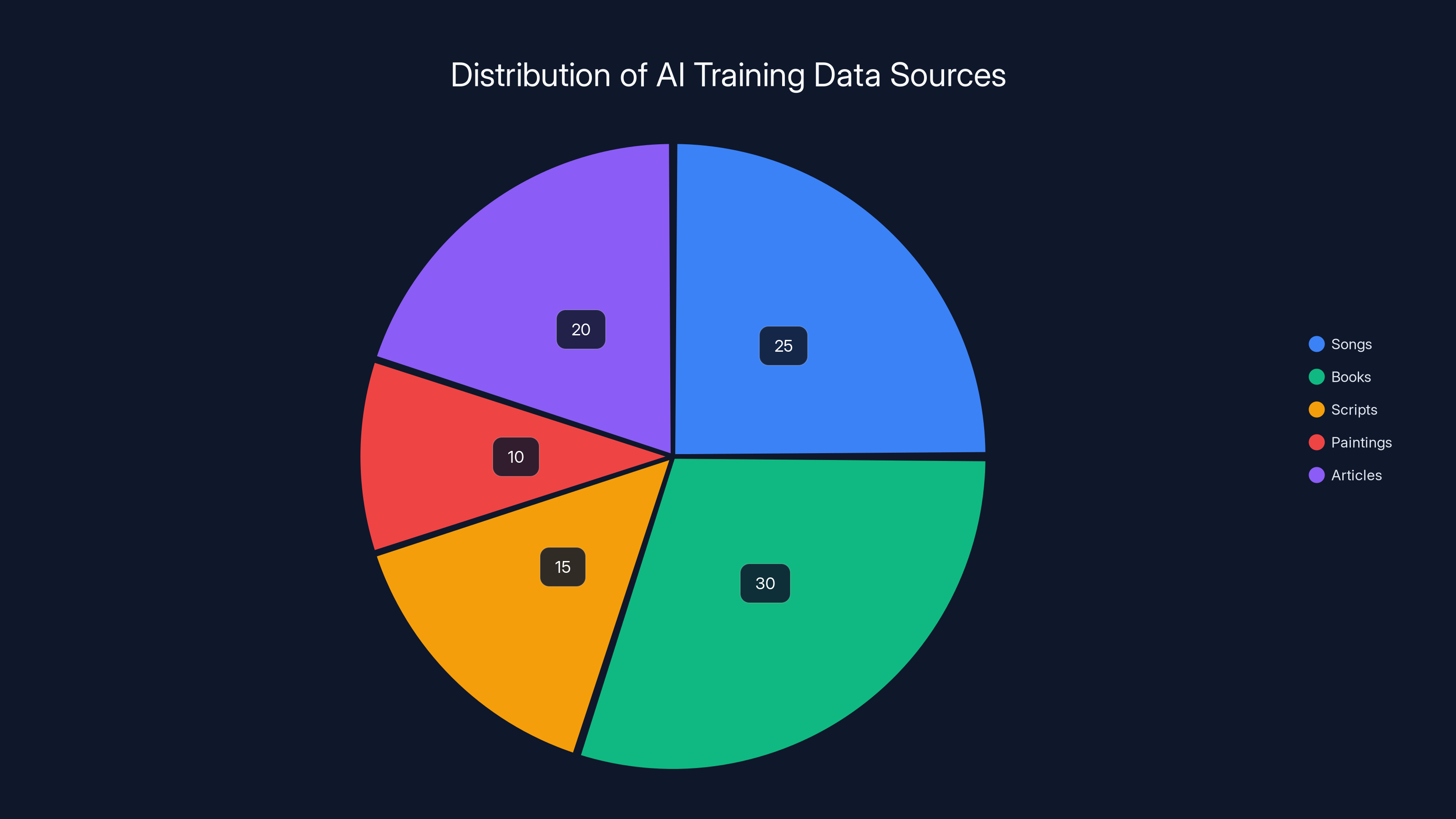
Estimated distribution of creative works used for AI training highlights the diverse sources, with books and songs being the most utilized. Estimated data.
The Role of Government Policy and Political Power
Here's where political economy enters the picture. Because AI regulation doesn't happen in a vacuum.
The Biden administration released an executive order on AI that acknowledged intellectual property concerns. The U.S. Copyright Office opened an inquiry into AI copyright issues. The European Union has been more aggressive, considering mandatory licensing requirements as part of their broader AI regulatory framework.
But there's enormous countervailing pressure from tech companies. OpenAI, Anthropic, Google, and other AI leaders are lobbying hard against these protections. They argue that mandatory licensing would "stifle innovation." They argue that fair use already covers their training practices. They argue that retroactive fees would be unfair.
There's an asymmetry of power here. Tech companies have massive resources. They can hire the best lawyers. They can make campaign contributions. They can threaten to relocate or reduce investment. What do artists have? They have moral authority and political leverage through coalitions like this campaign.
The political battle is also happening at the state level. Some states are considering AI-specific privacy and rights protections. California, in particular, is a battleground. Tech companies are pushing for loose, innovation-friendly rules. Artist coalitions are pushing for strict protection of IP rights.
International coordination matters too. The EU's AI Act is more restrictive than current U.S. approaches. If the EU mandates licensing for AI training on copyrighted material, tech companies operating in Europe will have to comply with those standards. That creates pressure to adopt similar standards globally, rather than maintain separate systems for different regions.
The campaign's strategy is partly about generating political pressure. By getting celebrity endorsements, by running full-page ads in major publications, by framing the issue in moral terms ("theft"), they're trying to make AI regulation a political liability for politicians who oppose them. They're trying to make "AI companies steal from artists" a talking point that reaches mainstream voters, not just policy experts.
This matters because politicians respond to constituent interest. Right now, AI regulation is mostly driven by tech companies and a small group of policy experts. If creative industries can mobilize voters around this issue, the political calculus changes.

Economic Impact: Who Profits, Who Loses
Let's talk money. Because this campaign isn't really about ideology. It's about who captures the value from AI-generated creativity.
Imagine you're a songwriter. Last year, you made
Or you're a novelist. Your books sell reasonably well. Then AI companies train on your work. An author's AI assistant can now write book summaries, outline plots, generate character backgrounds—all based on analysis of your style and techniques. Your publisher sees declining sales because some readers just use AI instead of reading the book. Your income drops. The AI company's revenue grows.
Or you're a freelance artist on platforms like Fiverr. You used to get
This isn't theoretical. This is happening. Freelance platforms report drops in gig availability as AI becomes more accessible. Voice actors report fewer auditions. Stock photographers report declining sales. Copywriters report fewer leads.
Meanwhile, AI companies are capturing enormous value. OpenAI's enterprise customers pay $30+ per month for Chat GPT Plus, and thousands of companies are paying for API access. That's billions in annual revenue. Where does that money come from? It comes from productivity gains that were partly created by having trained on artists' creative work without compensating them.
This is a transfer of wealth from creators to tech companies. It's not a transfer of the same size of pie. It's value creation that would have accrued to creators under the old system, but now accrues to AI companies because they were able to appropriate creative material for free.
The math gets worse when you think about the macroeconomic impact. Creativity has been a major component of the U.S. economy. Hollywood, music, publishing, visual art, design—these industries collectively employ hundreds of thousands of people and generate billions in GDP.
If AI can replace significant portions of creative work, and if the value goes entirely to tech companies while creators lose income, you have:
-
Hollowing out of creative industries - Fewer opportunities, lower incomes, brain drain
-
Concentration of wealth - Tech companies capture value that would have been distributed among millions of creators
-
Degradation of cultural output - Less investment in quality creative work means more mediocre output
-
Reduced innovation - Creators have less money to experiment and take risks on new work
The campaign is essentially arguing that the current model is unsustainable. It's not just unfair to current creators. It's bad for the long-term health of culture and the creative economy.
Some economists argue that this is just creative destruction. That technology has always displaced workers, and creative jobs are no exception. That if AI can do creative work better and cheaper, that's progress, even if it's painful.
But the campaign's supporters argue there's a difference between displacement and theft. If a better technology comes along and people use it, that's displacement. If a company steals your work to build a competing technology, and then claims they invented the whole thing, that's theft. Displacement is painful but potentially justified. Theft is unjustified under any framework.
The argument for compensation isn't about preventing AI development. It's about ensuring that the people whose work enabled AI development share in the value creation. That's not radical. That's how every other industry works.

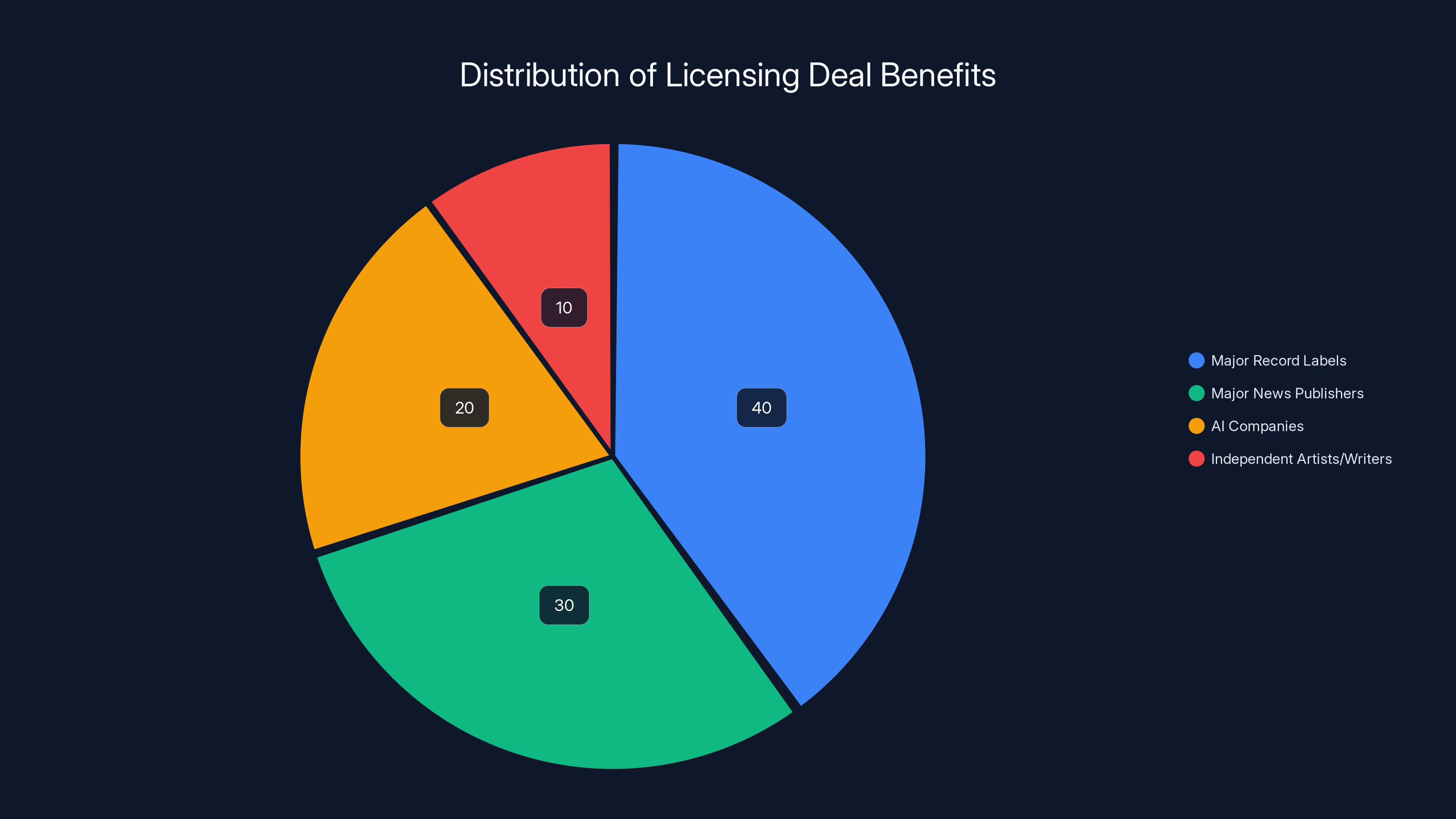
Major record labels and news publishers capture the majority of benefits from AI licensing deals, while independent artists and writers receive minimal compensation. Estimated data.
The Technology Behind the Campaign: Who's Building What
Understanding this campaign requires understanding the actual technology at stake.
Large language models like GPT-4, Claude, and Gemini are trained on trillions of tokens of text. That's data extracted from websites, books, news articles, academic papers, and more. The training process involves showing the model a prompt and the correct completion thousands of times. The model learns patterns. It learns that certain words follow other words with certain probabilities. It learns writing styles, factual information, reasoning patterns.
Image generation models like Midjourney, DALL-E, and Stable Diffusion are trained on billions of images paired with captions. Again, these images are scraped from the internet. The model learns that certain visual patterns correlate with certain descriptions. When you prompt it, it generates something in that learned pattern space.
Music generation is newer but works similarly. Models are trained on MIDI files, audio spectrograms, and transcriptions. They learn to generate sequences that sound like music.
All of these require massive datasets. And most of that data was obtained without permission. Midjourney trained on imagery from Deviant Art without permission from the artists. OpenAI trained on books from Project Gutenberg and other sources without negotiating with publishers or authors.
Now, here's where it gets interesting from a technical perspective. The legal question hinges on whether the training process counts as "fair use." Fair use is an exception to copyright that allows certain types of copying for certain purposes. Criticism, parody, education, research—these are traditionally fair use.
AI companies argue their training is fair use because it's computational analysis. The model isn't reproducing copyrighted works. It's learning patterns. When it generates text, the output is original, not a copy of the training data.
But the training process itself clearly involves copying. Billions of copyrighted works had to be copied to the training server. The companies can argue the fair use defense, but courts haven't definitively ruled on this yet.
From a technical perspective, there are already solutions being developed to address these issues:
-
Data provenance tracking - Documenting exactly where training data comes from and getting permission
-
Federated learning - Training models on data without copying it to a central server
-
Differential privacy - Techniques to train on sensitive data while preventing the model from memorizing it
-
Opt-out systems - Allowing creators to request their work not be used in certain models
-
Style obfuscation - Training techniques that prevent the model from replicating particular artists' work
These aren't perfect, and some would slow down AI development or reduce model quality. But they exist. The question isn't whether it's possible to train AI systems responsibly. It's whether companies will choose to do so, or whether regulations will force them to.

The Role of AI Tools in Content Creation: A Paradox
Here's the paradox nobody wants to talk about: some of the people criticizing AI theft are also using AI tools to enhance their own work.
Many creators use Adobe's AI tools to enhance images, Grammarly to check their writing, Eleven Labs for voice generation, and other AI-powered services. These tools make their work better, faster, and easier to produce. They might not be using these tools to replace humans, but they're definitely using AI as creative assistance.
The campaign isn't arguing against using AI. It's arguing for compensating the creators whose work enabled those AI systems.
This gets at a fundamental tension. AI technology is powerful and beneficial. It can make creative work more efficient. It can democratize tools that were previously only available to professionals with expensive software. A solo musician can now produce a song that would have required a team of producers. A small designer can create graphics that would have required a design firm.
But all of this power comes from models trained on collective creative human work. The question is whether that collective contribution should be compensated.
There's an argument that it shouldn't be. That once you put something on the internet, you're accepting that others will use it and build on it. That creative culture has always involved standing on the shoulders of giants. That requiring permission for everything would stifle innovation.
But there's a stronger argument that this logic breaks down at scale. Standing on the shoulders of giants means engaging with their work, building something new based on it, giving them credit. It doesn't mean wholesale copying of their work into a system designed to replace them, without credit or compensation.
The campaign is trying to find a middle path. Not banning AI. Not preventing tools from being built. But ensuring that the people who enabled those tools through their creative work have a say in how they're used and share in the value they create.

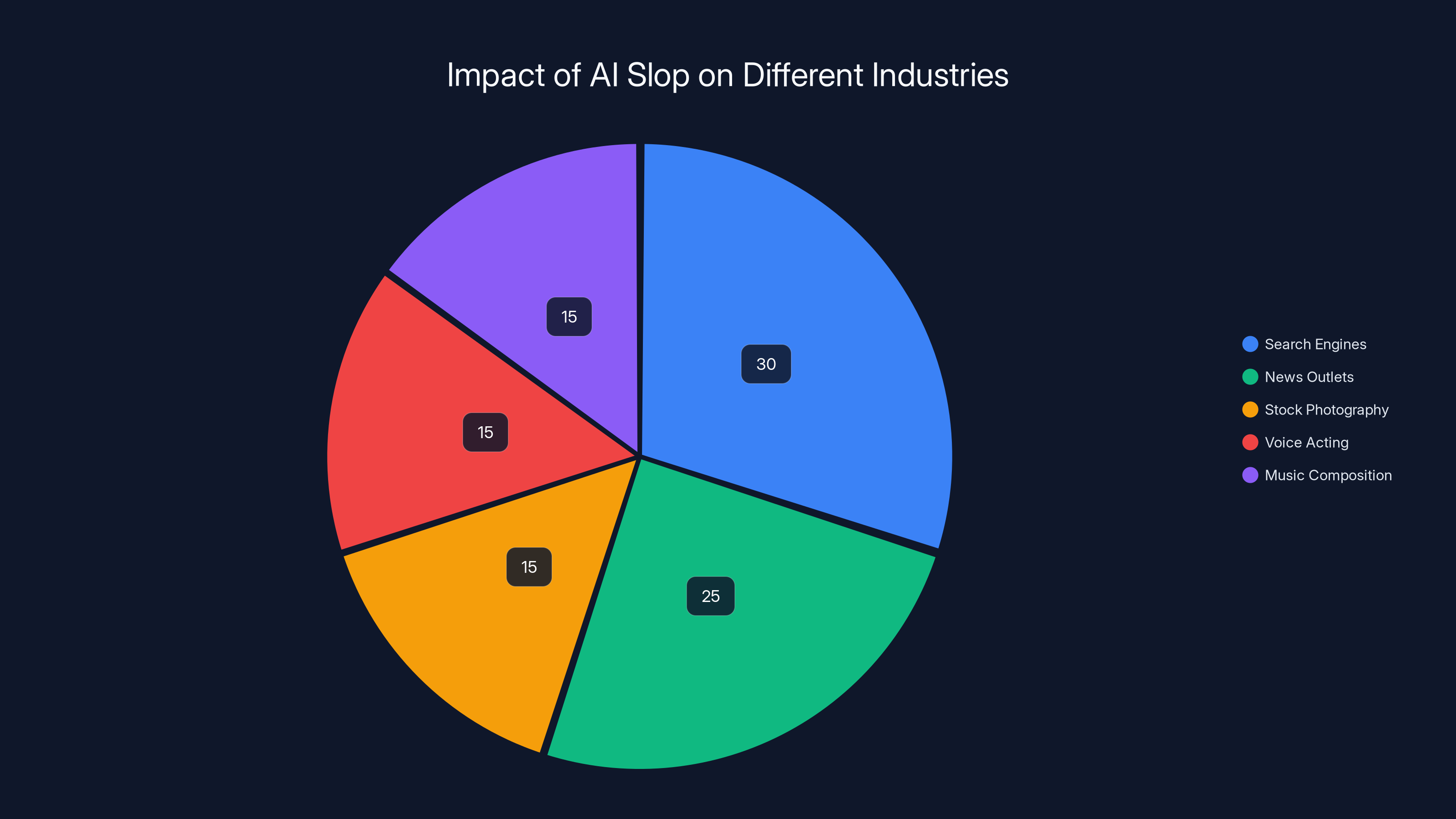
AI-generated content significantly impacts search engines and news outlets, with estimated data showing a 30% and 25% impact respectively. Estimated data.
What Success Would Actually Look Like
If the campaign achieves its goals, what changes?
Regulatory outcomes:
-
Congress passes legislation requiring AI companies to have licensing agreements with rights holders before training on copyrighted material
-
The U.S. Copyright Office establishes guidelines for AI training that make clear what requires permission
-
The EU's AI Act or a similar framework is adopted, mandating transparency about training data sources
-
Artists get unilateral opt-out rights—they can request their work be removed from future training runs
Economic outcomes:
-
AI companies have to negotiate with music labels, book publishers, photography agencies, and individual creators
-
Licensing deals become the norm rather than the exception
-
Creators see some compensation for their contribution to AI model training
-
The cost of training AI increases, but the cost is distributed more fairly
Cultural outcomes:
-
There's a shift toward AI transparency—systems disclose what they trained on
-
Human-created content starts being marked and valued differently
-
Premium creative work (made by humans, licensed) becomes clearly distinguished from commodity AI output
-
AI becomes one tool among many, not the default assumption
None of this would stop AI development. Companies would still build models. Artists would still use AI tools. But the relationship would shift from "steal freely and face legal consequences later" to "negotiate upfront and pay for what you use."
Is this likely to happen? Partially. The momentum is clearly toward more regulation. The political pressure is building. European regulators are moving aggressively. But tech companies will fight hard to maintain their current model.
What's most likely is a hybrid outcome. Mandatory licensing for transparent, large-scale training. Continued litigation around fair use. Some jurisdictions being more protective of creators than others. Companies negotiating selectively with major players while continuing to use freely available data they can defend under fair use arguments.
But the campaign has already succeeded in one crucial way: it's forced the conversation. Two years ago, AI training on copyrighted material was barely discussed. Now it's a central policy question. That's not nothing.

The International Dimension: How Different Countries Are Responding
This isn't just happening in the United States. The AI copyright issue is global, and different countries are taking different approaches.
European Union: The EU has been most aggressive. Their AI Act includes provisions that AI companies must disclose what they trained on if that training includes copyrighted material. They're considering mandatory licensing requirements. The EU's philosophy is that strong rights protection is necessary for a healthy ecosystem.
United Kingdom: Post-Brexit, the UK is taking a more permissive approach, arguing that broad fair use exceptions for text and data mining could benefit their AI industry. But they're also responding to creative industry pressure.
Canada: Canadian regulators have been relatively quiet, but Canadian creators are organizing. The Canadian music industry association has been vocal about licensing demands.
Australia: The Australian government commissioned a report on AI copyright that recommended balance between innovation and creator rights.
Japan: Japan has been explicitly permissive on AI training, with their fair use laws explicitly allowing it. This has made Japan a popular place for AI companies to establish operations.
China: China requires AI companies operating domestically to have government approval of training data, which indirectly creates some regulatory oversight.
The divergence matters because if one jurisdiction (like the EU) imposes strict requirements, companies have to decide: do we comply globally to simplify operations, or do we maintain different systems for different regions?
Historically, companies often comply with the strictest jurisdiction globally. GDPR compliance pushed companies to be more privacy-protective worldwide, not just in Europe. The same dynamic could play out with AI copyright.

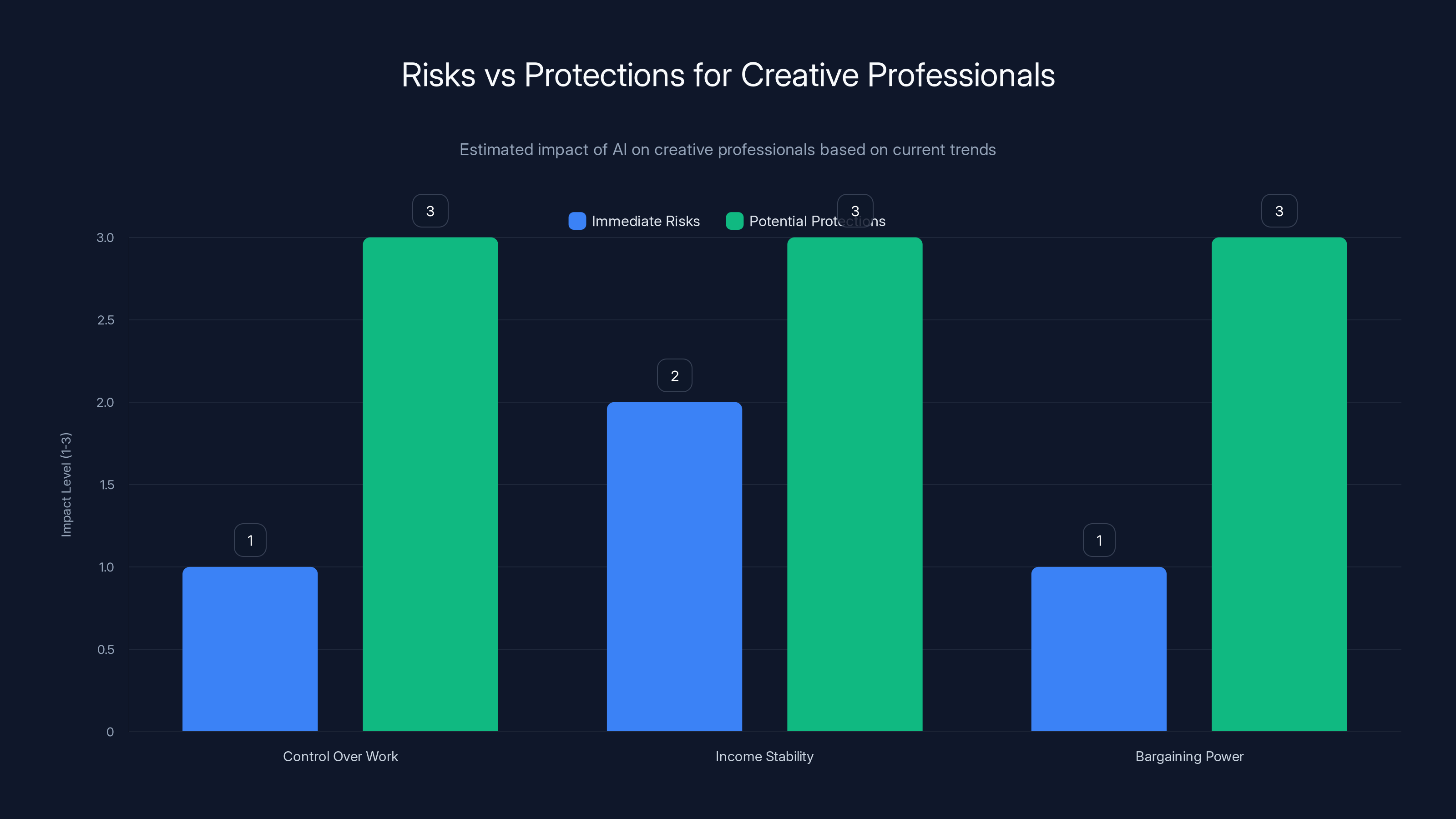
Creative professionals face significant risks from AI, but potential protections could enhance their control, income, and bargaining power. Estimated data.
Why This Matters for Individual Creators Right Now
You might be thinking: "This is interesting policy discussion, but how does it affect me?"
If you're a creative professional:
Your immediate risks:
- Your work might already be in training datasets. You have no control over this and aren't being compensated.
- Your income might decline as AI-generated alternatives become available
- Your bargaining power is weakening if clients can use AI instead of hiring you
Your potential protections (if the campaign succeeds):
- Legal right to know if your work is in a training dataset
- Legal right to exclude your work from future training
- Potential compensation if your work was used without permission
- Better bargaining power when negotiating with companies
What you should do now:
-
Document your work. Keep records of what you've created, when you created it, where you published it.
-
Monitor usage. Search for your work being used in unexpected contexts. If you find AI-generated content in your style, that's evidence of style transfer training.
-
Register copyrights. In the U.S., registering your copyright is necessary for statutory damages if infringement occurs.
-
Join organizations. If you're a musician, join your performing rights organization. If you're a writer, consider joining creator coalitions. Collective action is more powerful.
-
Opt out where possible. Some platforms and tools now allow creators to opt out of AI training. Use these options.
-
Negotiate strategically. If companies want to use your work for AI training, get it in writing with compensation.
If you're not a creative professional, this still matters because:
- The information you consume is affected by how creators are compensated
- If creative professionals can't make a living, we get less quality creative work
- The ecosystem of culture depends on this working

The Future of AI and Creativity: Possible Scenarios
Let's think forward. What does the creative economy look like in 2030 or 2035?
Scenario 1: Aggressive regulation wins
In this scenario, the campaign's pressure leads to strict legal requirements. AI companies must have licenses before training on copyrighted material. Opt-out rights are established. Creators get baseline compensation. This leads to:
- Higher costs for training AI models
- Fewer models, but more responsible ones
- Creators maintaining income but having less access to AI tools themselves
- AI development slowing but becoming more legitimate
- More of the value going to large media companies that can negotiate, less to individual creators
Scenario 2: Tech companies win, mostly maintaining status quo
AI companies successfully defend fair use, argue that training is not infringement, and maintain the ability to scrape freely. This leads to:
- Rapid AI development with minimal licensing requirements
- Massive disruption to creative industries
- Significant income loss for many creators
- Explosive growth of AI slop as the baseline economics make it irresistible
- Potential talent drain from creative industries as people seek more stable income
- Eventual regulatory backlash when the cultural impact becomes undeniable
Scenario 3: Messy compromise
This is most likely. Some licensing required for obvious commercial use. Fair use defended in some contexts. Different rules in different jurisdictions. Gradual shift toward licensing becoming standard but not universal. This leads to:
- Some creators getting compensated, most not
- Slow but continued income decline for many creators
- AI development continuing but with friction and uncertainty
- A bifurcated creative economy where those with bargaining power do well, others struggle
- Ongoing litigation and regulatory battles
Scenario 4: Technological solution bypasses the problem
This is speculative but possible. Technology develops that allows creators to watermark their work in ways AI systems can't use. Models can be trained on public domain materials only. Synthetic data generation reduces reliance on scraped training data. This leads to:
- Cleaner separation between licensed and unlicensed content
- Creator control over their work increasing
- AI development maybe slower but more legitimately founded
- Potential resolution without needing perfect legislation
Most experts think we're headed toward Scenario 3, with elements of Scenario 4 gradually emerging. Complete regulatory victory (Scenario 1) is unlikely because tech companies have too much political power. Complete tech company victory (Scenario 2) is politically unsustainable—voters will eventually demand something be done.
The most likely outcome is an ongoing tension between regulation and innovation, with gradual shifts toward more protection for creators but not complete compensation or control.

Why The Verge and Other Media Cover This Story
You might wonder why a tech publication like The Verge—which usually covers gadgets and consumer tech—is dedicating resources to this campaign.
Partially, it's because The Verge's parent company, Vox Media, has a commercial interest. Vox Media creates content. That content is being used to train AI models without compensation. So there's a direct financial incentive to cover this story.
But there's also a broader reason: this story is important for understanding the future of tech. How AI copyright issues get resolved will shape the business models of AI companies for the next decade. It affects whether startups can compete with giants. It affects whether creative tools become democratized or locked behind corporate gates. It affects whether the internet remains a diverse ecosystem of creators or becomes increasingly dominated by corporate content and AI slop.
The media has a particular stake in this because news organizations are being both affected and enlisted. They're affected because their content is being used to train AI models, and they've lost revenue to web traffic to aggregators and search engines for years. They're being enlisted as allies by the campaign because they have platforms and audiences.
Some media companies have negotiated licensing deals (like The New York Times, Financial Times). Others are holding out, hoping to either get better deals or have the law protect them. The strategy differs depending on the company's size and leverage.
The coverage also matters because it helps inform public opinion. If this stays a dry policy debate between lawyers and lobbyists, tech companies maintain their advantage. If it becomes a public story—"Big Tech steals from artists and destroys culture"—that changes the political calculus. That's why the campaign runs ads and pursues media coverage. They're trying to change the conversation.

The Bottom Line: What Needs to Happen
Let's cut through the complexity. Here's what the current situation actually is:
AI companies have built extraordinarily valuable systems by using creative work they didn't license or pay for. They're making enormous profits. Creators are seeing declining income and loss of control over their work. The legal situation is unclear. Regulatory pressure is building but tech companies are fighting hard to prevent strict requirements.
What needs to happen:
-
Legal clarity: Courts and legislatures need to clearly establish what counts as fair use and what counts as infringement. The ambiguity currently favors tech companies because it creates litigation risk for those trying to enforce rights.
-
Licensing becoming standard: Rather than the exception, licensing should be the default. Companies should have to affirmatively negotiate rights, not assume they have them.
-
Creator compensation: The people whose work was used to create value should share in that value. This doesn't require equal sharing. But some sharing is clearly just.
-
Opt-out rights: Creators should have the legal right to exclude their work from AI training, period. No exceptions.
-
Transparency: When AI systems are influenced by particular creators' work, that should be disclosed. Users should know if an image was generated in someone's style or if text was influenced by a particular author.
-
Enforcement: Rights need to be enforceable with meaningful consequences. Right now, companies can infringe, make billions, and face lawsuits years later with uncertain outcomes. That's not a real deterrent.
This is the campaign's core ask. Not ending AI. Not preventing innovation. But establishing that creative work has value, and that people who create it deserve compensation and control.
It seems obvious when stated this simply. But against the political and economic power of tech companies, it remains uncertain whether it will happen.

FAQ
What exactly does the "Stealing Isn't Innovation" campaign want?
The campaign calls for three main changes: (1) mandatory licensing agreements so AI companies must negotiate with creators before using their work in training, (2) unilateral opt-out rights allowing creators to exclude their work from AI training datasets, and (3) a "healthy enforcement environment" with meaningful penalties for unauthorized use. The campaign also emphasizes the right for artists to understand when and how their work is being used by AI systems and to receive compensation when it is.
How does AI training on copyrighted work differ from traditional fair use?
Traditional fair use (like criticism or parody) typically involves small excerpts used for a transformative purpose. AI training involves copying entire works—often billions of works—into proprietary systems not primarily for the public benefit but for commercial product development. When a court case tests whether this qualifies as fair use, the outcomes will likely hinge on whether copying billions of works for commercial AI development constitutes a "transformative use" that benefits the public, or if it's simply appropriation of creative labor for profit.
What's the difference between licensing deals and regulation?
Licensing deals are voluntary agreements between specific companies and rights holders (like record labels or publishers). Regulation would create legally binding requirements for all companies. The campaign wants both—licensing should happen, but if it doesn't, regulation should force it. Currently, only companies with bargaining power can negotiate favorable deals, while individual creators have no leverage. Regulation would establish a baseline for everyone.
Could AI still develop successfully with mandatory licensing?
Yes. Many AI companies already license content—OpenAI has deals with news organizations, music companies have partnerships with AI startups. It would make AI development more expensive and slower, but it wouldn't stop it. The question is whether tech companies want to pay for content, not whether they can. Mandatory licensing would level the playing field by making the choice to license a legal requirement rather than optional.
How does this affect AI tools I might use, like Chat GPT or Midjourney?
If stricter licensing becomes law, these tools might become more expensive as companies pay licensing fees to creators. The training data might be better quality if it's curated rather than indiscriminately scraped. The models might be smaller and more specialized if companies can't access unlimited free data. But the tools themselves would likely still exist—they'd just be more legitimate and expensive to operate.
What can individual creators do right now to protect themselves?
Creators should register their copyrights (which is necessary for statutory damages in lawsuits), document what they've created and when, monitor for unauthorized use of their work or style, join relevant professional organizations that can advocate collectively, and opt out of AI training wherever possible. Some platforms like Hugging Face have processes for removing copyrighted content from datasets. When companies want to use your work for AI training, negotiate it in writing with clear terms and compensation.
Is this campaign just about stopping AI innovation?
No. The campaign explicitly doesn't oppose AI or AI development. It opposes unpaid use of creative work without permission. Many campaign signatories actively use AI tools in their creative practice. The ask is for fairness in how AI is developed—that creators should be compensated if their work is used to build valuable systems. This is a standard business principle in other industries.
What would happen to the internet if mandatory licensing for AI training became law?
Users would likely see slower changes initially as AI companies renegotiate access. But the long-term effects would probably be positive—more responsible AI development, clearer legal standards, and a healthier creative ecosystem. The internet would still function normally. Websites would still be indexed and analyzed. The difference would be that companies would need permission or fair use arguments before scraping content at scale for AI training, rather than assuming it's fair game.
The "Stealing Isn't Innovation" campaign represents a pivotal moment in the AI era. For the first time, a coalition of truly massive creative figures—not fringe voices or individual lawsuits, but hundreds of respected artists, writers, actors, and musicians—is forcing the conversation about whose work builds AI systems and who should benefit financially from that.
The outcome will shape whether AI becomes a tool that strengthens creative industries or one that extracts value from them while providing minimal compensation. It'll determine whether individual creators have any leverage or whether only massive media companies with legal resources can negotiate favorable terms. It'll affect whether the cultural output of the next decade comes from diverse creators or from increasingly consolidated AI systems optimized for engagement rather than quality.
These aren't small questions. They're foundational questions about what kind of creative economy we want to have. The campaign isn't guaranteed to win—tech companies have enormous resources and political power. But the very fact that this conversation is happening, that it's being taken seriously by policymakers and media, represents a fundamental shift in how we think about AI and ownership.
For creatives, this is the time to be vocal, to be organized, and to refuse to accept the premise that their work should be free raw material for someone else's multibillion-dollar business. The outcome will be written over the next 2-3 years. The campaign is just the opening chapter.

Key Takeaways
- 800+ major creatives signed the 'Stealing Isn't Innovation' campaign opposing unauthorized AI training on copyrighted work
- AI companies trained models on billions of copyrighted works without permission or compensation, creating an asymmetric value capture
- The campaign demands three changes: mandatory licensing, opt-out rights for creators, and enforcement mechanisms for copyright protection
- AI slop—low-quality generated content—is an economic byproduct of free training data; licensing requirements would change the incentive structure
- Regulatory pressure is building globally, with EU leading on strict requirements and US still debating fair use applicability to AI training
- Creator income has declined 40-50% over two decades; unauthorized AI training could accelerate this collapse without licensing requirements
- Licensing deals are emerging but only available to major players with bargaining power; individual creators lack leverage in current system
- The legal outcome will determine whether AI development remains predicated on creative theft or shifts to legitimate licensing-based model
Related Articles
- ChatGPT Safety vs. Usability: The Altman-Musk Debate Explained [2025]
- Meta's Global Threads Ads Expansion: What Advertisers Need to Know [2025]
- Meta Expands Ads to All Threads Users Globally [2025]
- Threads Ads Global Rollout: What It Means for Users and Creators [2025]
- Why We're Nostalgic for 2016: The Internet Before AI Slop [2025]
- Instagram's AI Problem Isn't AI at All—It's the Algorithm [2025]

