![ChatGPT Safety vs. Usability: The Altman-Musk Debate Explained [2025]](https://tryrunable.com/blog/chatgpt-safety-vs-usability-the-altman-musk-debate-explained/image-1-1768970235835.jpg)
The Safety Paradox Nobody Wants to Talk About
Let's be real: Open AI's got a problem that doesn't have a clean solution. And in a rare public moment, Sam Altman just admitted it out loud.
The core issue? You can't build walls tall enough to keep bad stuff out without accidentally locking good people in. It's the classic security-versus-accessibility trade-off, except the stakes involve millions of users and the most powerful AI tool on the planet.
When Elon Musk challenged Altman on how Chat GPT's safety measures work, Altman didn't dodge. He said it plainly: "It is genuinely hard." Those four words capture the entire tension between protecting vulnerable users and preventing the tool from becoming so restricted that it's basically useless.
This isn't abstract philosophy. It's a real operational nightmare that tech companies face every single day. Build guardrails too strict, and researchers can't test theories. Authors struggle with plot ideas. Teachers can't create lesson plans. But loosen them up, and you're suddenly liable when someone misuses the tool in ways you should've anticipated.
The debate matters because Chat GPT isn't just some niche product anymore. It's being used in hospitals, law firms, classrooms, and startups. Millions of people depend on it working. And millions of others are worried it's dangerous.
Here's what's really happening under the hood, why the problem is harder than most people realize, and what it means for the future of AI safety.
TL; DR
- Safety guardrails exist but are inherently imperfect, blocking some legitimate uses while occasional harmful content still slips through
- The core tension is mathematical: stricter filters protect vulnerable users but reduce accessibility for everyone else
- Vulnerable populations face unique risks—minors, people with mental health challenges, and less tech-literate users need different protection levels
- Enforcement is asymmetrical: it's easier to block bad outputs than to understand user context and intent
- Open AI's approach involves multiple layers (training, fine-tuning, monitoring, reporting mechanisms) but no single layer is foolproof

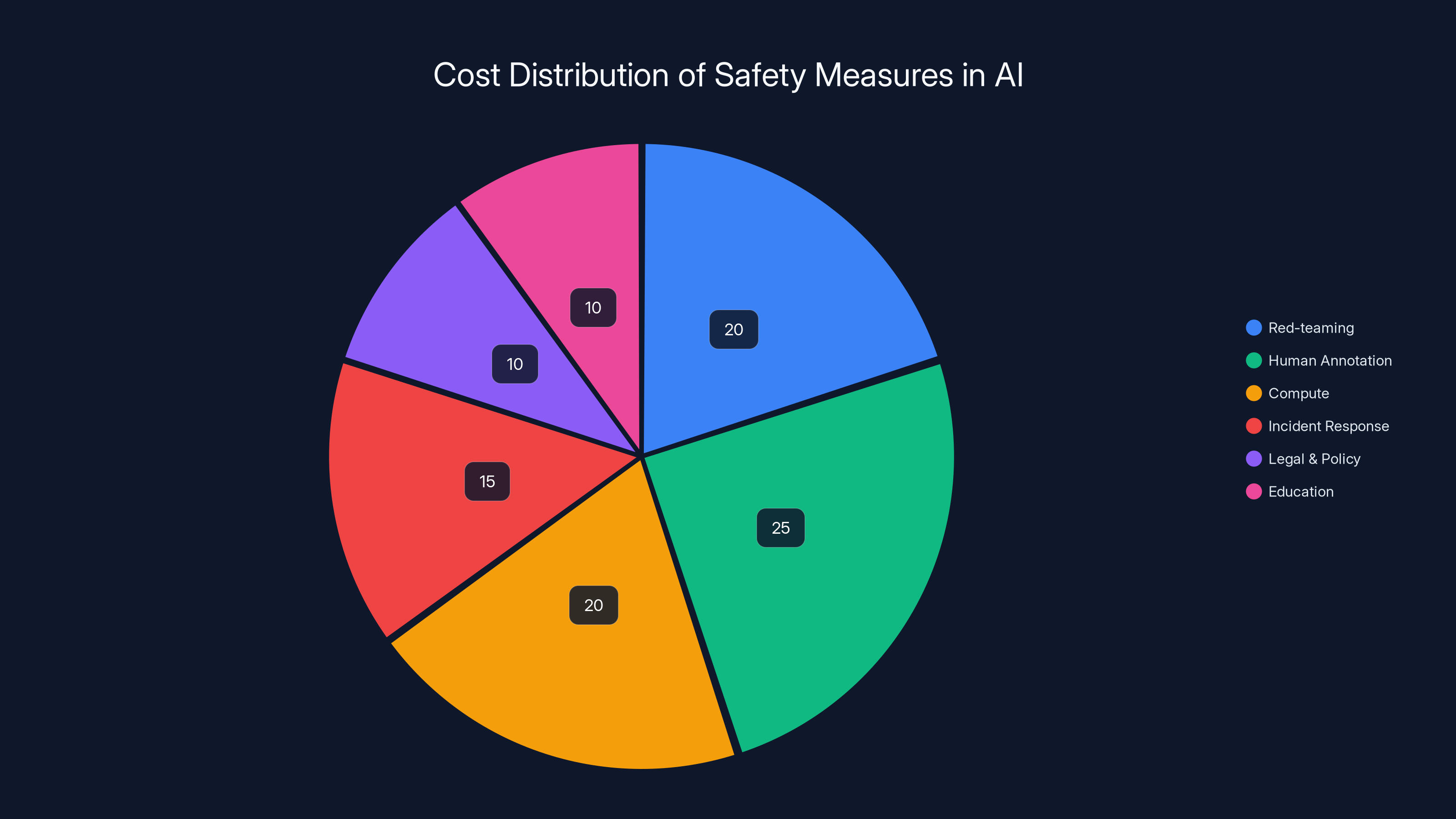
Estimated data shows human annotation and compute costs are the largest portions of safety-related expenses in AI services, each comprising about 20-25% of the total cost.
What Chat GPT's Safety Guardrails Actually Do
People talk about Chat GPT's "guardrails" like it's one thing. It's not. It's more like a building with multiple security checkpoints.
First, there's the training data itself. Open AI's models are trained on massive internet datasets, then fine-tuned with reinforcement learning from human feedback (RLHF). That means actual humans labeled thousands of responses as "good" or "bad," teaching the model which outputs to prioritize.
But here's the catch: training data reflects human judgment, and human judgment varies wildly depending on culture, context, and who's making the decision. What looks like a reasonable safety boundary to one person looks like censorship to another.
Next come the real-time filters. When you type into Chat GPT, your input goes through content moderation systems. These check for obvious red flags—instructions for violence, explicit illegal activity, child safety issues. If something matches a known harmful pattern, the system flags it or refuses to process it.
Then there's the output layer. After Chat GPT generates a response, it gets checked again before you see it. The model is literally trained to avoid certain topics entirely, refuse certain types of requests, and hedge on controversial subjects.
Finally, there are policy-based restrictions. Open AI doesn't allow certain uses in their terms of service—the tool can't be used to impersonate people, create bulk surveillance tools, or develop weapons.
The problem is these layers don't stack perfectly. A piece of content might pass through the input filter but fail the output filter. Or it might pass both filters but violate the terms of service. Or it might be completely legitimate but the safety system refuses it anyway because the pattern looks risky.
This is where Altman's comment makes sense. It's "genuinely hard" because there's no universal agreement on what "safe" even means.

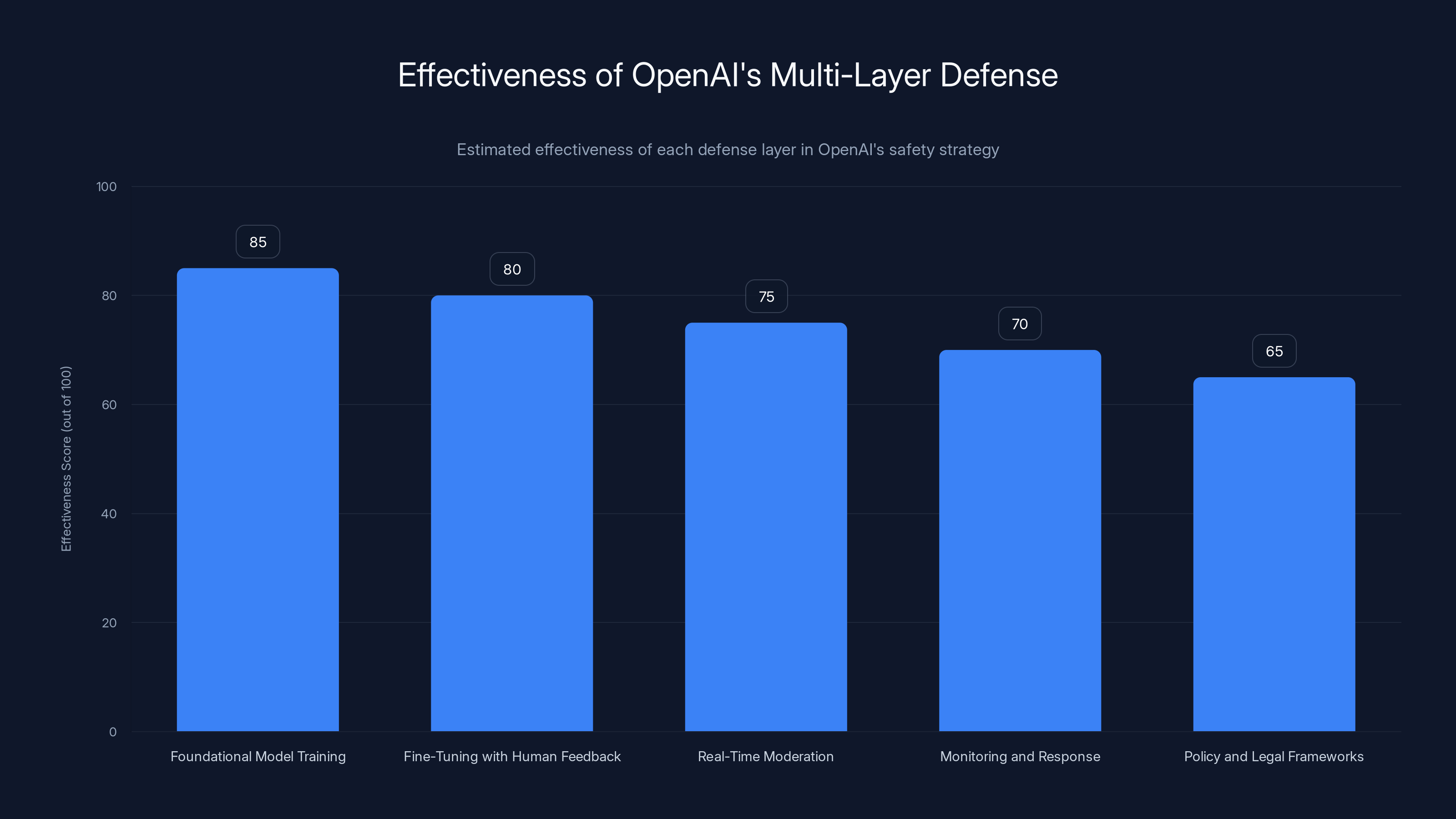
Estimated data suggests foundational model training is the most effective layer in OpenAI's multi-layer defense strategy, with a score of 85 out of 100.
Why Protecting Vulnerable Users Isn't Straightforward
Alright, so who exactly are the "vulnerable users" that Altman's worried about? It's more nuanced than you might think.
Minors are the obvious category. A 12-year-old shouldn't get detailed instructions for self-harm or instructions on manufacturing drugs. That's non-negotiable. But enforcing this creates problems—how do you verify age? How do you know if someone asking about depression is a researcher or a vulnerable teenager?
People with mental health challenges represent another group. Someone experiencing suicidal ideation shouldn't get access to Chat GPT if it's going to amplify those thoughts. But someone managing anxiety who wants to discuss coping strategies? That same person might desperately need to talk to something non-judgmental at 3 AM when their therapist isn't available.
There's also a digital literacy gap. Less tech-savvy users might not realize they're talking to an AI and not a human expert. They might trust Chat GPT's medical advice more than they should. They might not understand how to fact-check outputs. Protection here looks like better disclaimers, clearer labeling, and refusing to roleplay as specific professionals (doctors, lawyers, therapists).
Language barriers add another layer. Someone translating Chat GPT's outputs through multiple languages might lose context around safety warnings. Cultural differences mean what counts as "harmful" in one country is totally acceptable in another.
The global dimension makes this even harder. Open AI serves users in 195+ countries with wildly different legal frameworks, cultural norms, and safety priorities. What needs protecting in the US might be irrelevant in Japan. What counts as dangerous misinformation in Germany might be protected speech in the US.
The vulnerabilities also intersect. A 14-year-old in a non-English speaking country with limited digital literacy and potential mental health challenges faces a completely different risk profile than a 35-year-old researcher in San Francisco.
Altman's real concern is that you can't build a single set of guardrails that protect everyone equally. Protect too aggressively, and you're limiting access for people who need it most. Protect too loosely, and you're exposing vulnerable populations to genuine harm.

The Accessibility Problem: When Safety Blocks Legitimate Use
Now flip the perspective. What happens when safety guardrails get in the way of people just trying to do their jobs?
Authors are hitting walls when writing fiction. They want Chat GPT to help them develop morally complex villains, explore dark themes, or write realistic conflict scenarios. But the safety system sometimes sees "dark theme" and shuts down.
Educators trying to create age-appropriate lessons about tough subjects—drug awareness, sexual health, financial fraud prevention—run into refusals that feel arbitrary. The guardrails can't distinguish between "teacher creating educational content" and "person seeking harmful information."
Researchers studying harmful content (for legitimate safety research!) get blocked from analyzing exactly the kind of data they need to understand how misinformation spreads or how AI systems fail.
Mental health professionals can't use Chat GPT as a supplement to patient education because the safety system refuses conversations about psychological conditions, creating this weird situation where a tool that could genuinely help is off-limits.
Journalists investigating criminal networks, weapons trafficking, or hate group recruitment need to have conversations that the guardrails automatically refuse.
The mathematical problem here is real. Let's think about it: suppose Chat GPT's safety system correctly identifies 95% of genuinely harmful requests. Sounds great, right? But if the system is equally aggressive on legitimate uses, it might refuse 30% of those too. That's not a 5% false negative rate—that's a significant accessibility problem.
Open AI tries to balance this by offering a "Usage Policies" document and allowing certain research applications. But the fact that users need to know workarounds proves the underlying tension exists.

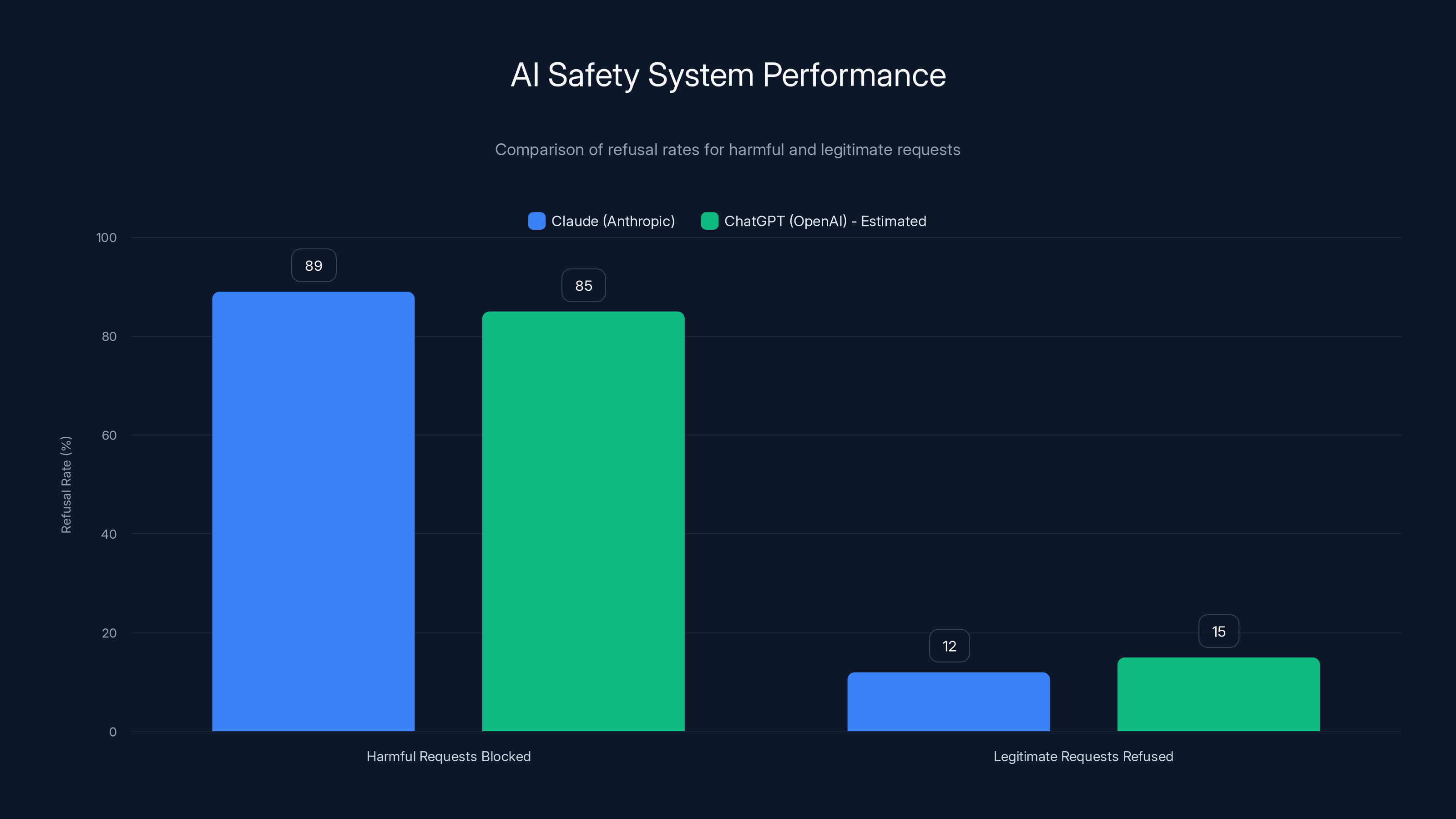
Claude successfully blocked 89% of harmful prompts but also refused 12% of legitimate requests, highlighting the challenge of perfectly calibrating AI safety systems. Estimated data for ChatGPT shows similar trends.
How the Altman-Musk Debate Exposed the Real Problem
Musk has been publicly critical of Open AI's direction for a while now. But this specific debate crystallized something important about how safety gets implemented in practice.
Musk's critique, roughly: the guardrails are too opinionated. They don't just prevent harm—they encode specific political and social positions. When Chat GPT refuses to help with something, is it protecting vulnerable users or is it making value judgments?
Altman's response highlighted that you can't separate safety from values. Deciding what's "harmful" IS a value judgment. Choosing to protect minors but not restrict researchers is a value judgment. Deciding that financial fraud prevention education is good but discussing cryptocurrency security is risky—that's a value judgment.
The deeper disagreement is philosophical. Musk seems to believe the guardrails should be minimal—let users decide what's acceptable. Altman seems to believe Open AI has a responsibility to actively prevent harms, even if that means some legitimate users get inconvenienced.
Neither position is wrong. They're just different risk tolerances. A completely unfiltered AI tool would be cheaper to build and more flexible to use. But it would also be catastrophically dangerous in some scenarios. A perfectly safe AI tool would require restrictions so severe that it becomes basically useless.
The real insight from their debate is that there's no technical solution to this problem. You can't engineer your way out of the safety-versus-accessibility trade-off. You can only make conscious choices about where on the spectrum you want to operate.

The Multi-Layer Defense: How Open AI Actually Tries to Solve This
Open AI isn't sitting around doing nothing. They've built a legitimately sophisticated approach to balancing safety and usability. Here's how it actually works:
Layer 1: Foundational Model Training
The base GPT-4 model undergoes extensive red-teaming during development. Open AI hires security researchers and adversarial thinkers to probe the model, find weaknesses, and report them. The model then gets retrained to handle these edge cases better.
This is expensive and time-consuming, but it catches problems before they reach users. The foundational training also includes constitutional AI principles—guidelines the model learns about being helpful, honest, and harmless.
Layer 2: Fine-Tuning with Human Feedback
After the base model, Open AI uses RLHF to fine-tune the system. Human annotators rate model outputs, and these ratings guide a secondary training pass. This teaches the model to prefer certain types of responses over others.
The quality of this layer depends entirely on the quality of human judgment. If your annotators have blind spots, those become the model's blind spots.
Layer 3: Real-Time Input/Output Moderation
When you submit a query, it gets checked by content moderation systems. These use a mix of rule-based filters (block exact matches for known harmful content) and machine learning classifiers (detect harmful intent even in novel phrasings).
Output similarly goes through a second pass. If the model generates something that violates policy, it gets blocked before you see it.
Layer 4: Monitoring and Incident Response
Open AI logs conversations (for safety purposes, with privacy protections) and monitors for patterns. If a new exploit emerges—a novel way to bypass safety systems—they can detect it and patch it quickly.
Layer 5: Policy and Legal Frameworks
The terms of service explicitly forbid certain uses. If Open AI detects systematic abuse of the tool, they can suspend accounts. This creates a legal and commercial deterrent beyond just technical controls.
The sophistication here is real. But it's also expensive, slow to update, and imperfect. A determined person can still find ways to manipulate the system. And the stricter you make one layer, the more you need to relax another layer to maintain usability.
Here's the operational math: each additional layer of defense adds latency (users have to wait for processing), increases false positives (legitimate requests get blocked), and creates more surface area for workarounds.

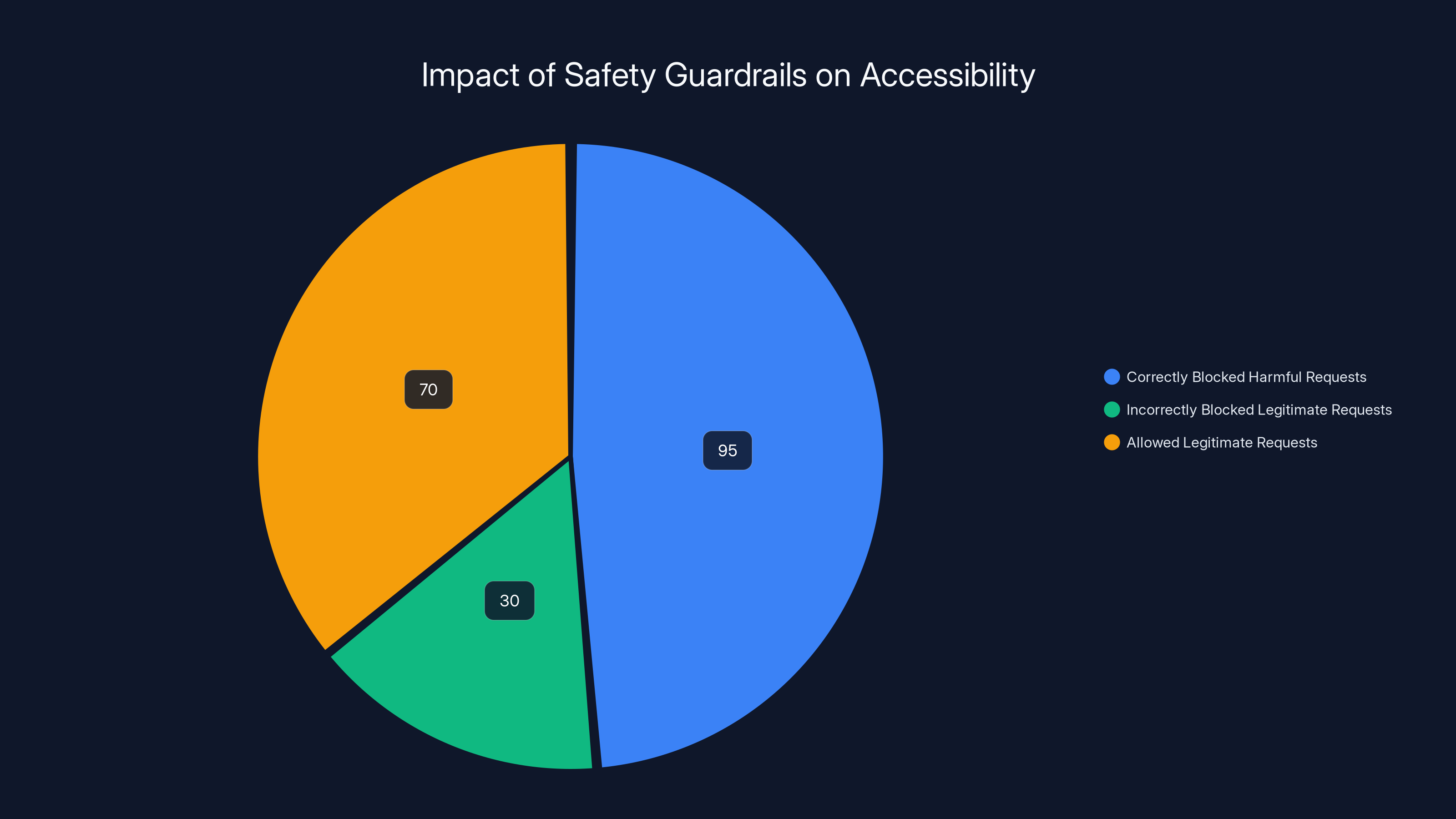
While ChatGPT's safety system effectively blocks 95% of harmful requests, it also incorrectly blocks 30% of legitimate requests, highlighting a significant accessibility issue. Estimated data.
The Vulnerable User Dilemma: Can You Protect Without Paternalizing?
Here's where it gets philosophically interesting. Protecting vulnerable users implies making decisions on their behalf. That's paternalism. And paternalism, even well-intentioned, has costs.
Suppose you implement a rule: Chat GPT won't provide detailed information about depression because minors might use that information harmfully. But a 16-year-old dealing with actual depression who needs to understand their condition just got cut off from a resource that could help them.
You've technically protected them. You've also patronized them and potentially withheld something beneficial.
This is why Altman's comment about "genuinely hard" is understated. The real problem is that vulnerability isn't binary. The same information that's dangerous for one person is therapeutic for another.
Open AI's approach here involves some nuance:
- They allow factual medical information but refuse to roleplay as a therapist
- They explain conditions but won't provide detailed instructions for self-harm
- They discuss controversial topics but add context and multiple perspectives
- They acknowledge limitations of AI conversation and encourage seeking professional help
But none of these distinctions are perfect. And enforcing them at scale, across millions of conversations in hundreds of languages, with varying cultural norms—that's where the "genuinely hard" part comes in.
There's also a temporal dimension. Protecting minors from risk seems noble. But are you protecting them or delaying their maturation? Should a 15-year-old who wants to understand how markets work be prevented from asking about trading? Should a 17-year-old interested in biology be blocked from discussing reproduction?
The guardrails struggle with these age-appropriate boundaries because they work on pattern matching, not contextual understanding. They see "minor + sexual content" and refuse, even when the context is educational and appropriate.
Vulnerable users themselves often want less protection, not more. People with disabilities who can use AI as an accessibility tool get frustrated when safety systems block them. People learning English who could improve with unrestricted conversation get frustrated with overly cautious responses.
So the paternalism question isn't just philosophical—it's practical and often counterproductive.
What Happens When Safety Systems Get It Wrong
Even with sophisticated defenses, failures happen. Let's look at the categories of failure:
Type 1: False Negatives (Harmful Content Slips Through)
Despite all the guardrails, occasionally Chat GPT generates something it shouldn't. It might provide information that's technically accurate but dangerous. It might fail to identify a user in genuine crisis. It might make assumptions based on stereotypes.
These failures matter because they affect real people. And they're often discovered not by Open AI but by users who encounter them and report them—or users who encounter them and don't report them, creating undetected harms.
Type 2: False Positives (Legitimate Use Gets Blocked)
The flip side: users trying to do legitimate work get refused. A teacher can't write test questions. A researcher can't analyze harmful narratives. A writer can't develop complex characters. The system errs on the side of caution, and usability suffers.
Type 3: Context Misunderstanding
The system sees a pattern but misses context. Someone asking "how do I talk to my kid about drugs?" gets refused because it contains drug-related keywords, even though the context is obviously educational.
Type 4: Adversarial Jailbreaks
Users figure out phrasing or roleplay scenarios that bypass the safety systems. They ask the AI to "pretend you're a character that doesn't have safety restrictions" or ask questions in roundabout ways that technically don't violate policies.
Each failure has downstream effects. A false negative might go undetected and cause real harm. A false positive frustrates users and undermines trust. Context misunderstandings make the tool feel dumb and unreliable. Jailbreaks create an arms race where Open AI updates defenses and users find new workarounds.
The challenge is that fixing one type of failure often makes another worse. Make the system stricter to prevent false negatives, and you increase false positives. Loosen it to allow more legitimate uses, and you increase the chance that harmful content slips through.
This is the actual operational dilemma that Altman's talking about.
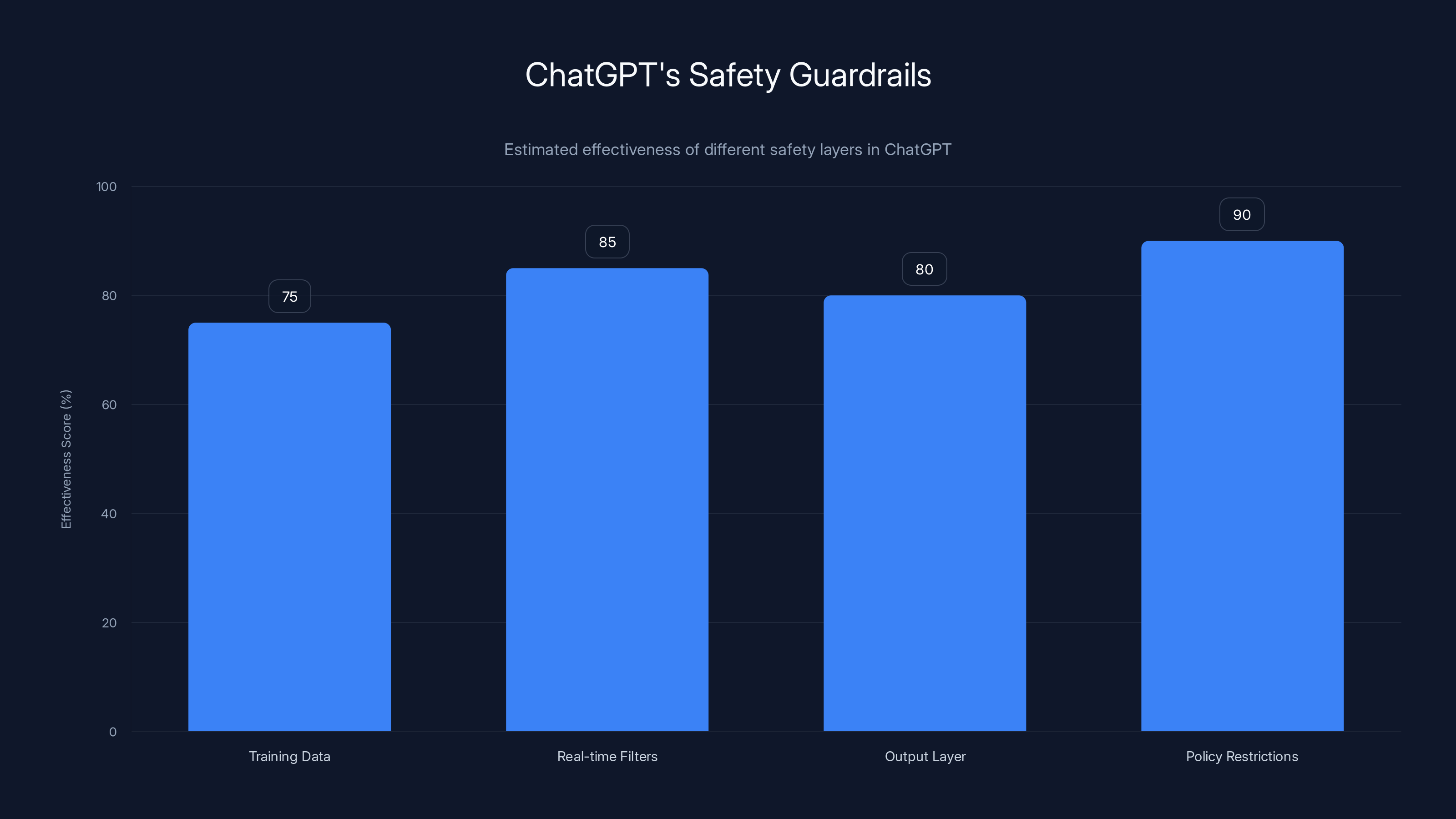
This bar chart estimates the effectiveness of different safety layers in ChatGPT. Policy restrictions are considered the most effective, while training data has the lowest score. Estimated data.
The Economics of Safety: Why It Costs What It Costs
Building safety infrastructure is expensive. It's one of the least talked-about reasons why Chat GPT Plus costs $20/month and why enterprise versions are much more expensive.
Every safety layer has a cost:
Red-teaming costs money. You're paying security researchers to attack your system for months before launch. You're running internal tests. You're compensating bug bounty hunters.
Human annotation costs money. Open AI needs thousands of annotators labeling responses as good or bad. These are often contracted workers, and at scale, this isn't cheap.
Compute costs money. Running content moderation systems alongside the main model adds latency and requires additional servers. The safety systems themselves are neural networks that need to run in real-time.
Incident response costs money. When a new exploit emerges, you need to respond quickly. That means having teams on call, ready to patch systems and communicate with users.
Legal and policy teams cost money. Figuring out what's allowed in which jurisdictions, writing terms of service that hold up in court, handling complaints—these aren't free.
Education costs money. Open AI publishes guides about responsible use, creates documentation, responds to questions about what the system will and won't do. This is effectively customer service for safety.
The economic logic is that as you scale (millions of users), the marginal cost of each of these decreases. But the absolute cost increases because you're protecting a larger surface area.
This creates a weird incentive structure. Smaller competitors with fewer users can afford to be more permissive because they have fewer vulnerable users to protect and fewer regulators paying attention. Open AI, as the market leader, faces the most regulatory scrutiny and therefore has the strongest incentive to over-invest in safety.
This isn't necessarily bad—more safety is probably better than less. But it means the safety-versus-accessibility trade-off isn't just technical or philosophical. It's also economic.
For context, platforms like Runable that offer AI-powered automation tools face similar trade-offs. They balance safety (preventing misuse of automation workflows) with accessibility (making the platform easy enough for non-technical users). As these platforms scale, the safety infrastructure costs compound, which eventually gets passed to users through pricing or reduced functionality.

Global Regulation: The Safety Guardrails Are Getting Harder to Balance
Here's a complication nobody planned for: international regulation is making the safety-versus-accessibility problem worse.
The EU's AI Act imposes strict rules on large AI systems, especially those used in "high-risk" contexts. This means Chat GPT needs to be more heavily monitored and restricted in Europe than in the US.
China has different restrictions entirely—content about politics, religion, and sensitive historical events gets tightly controlled.
India, Brazil, and other jurisdictions are developing their own frameworks, each with different priorities.
The problem is you can't easily have one version of Chat GPT for the US, another for Europe, another for Asia. The economics don't work. So Open AI has to build guardrails that satisfy the strictest jurisdiction it operates in, then apply those globally.
This means users everywhere get the European/Chinese/Indian level of restriction, even if they don't live in those places.
Musk's broader critique here makes sense: to the extent that Chat GPT's guardrails reflect political choices in specific countries, applying them globally means imposing one country's values on everyone else.
Altman's counter-point: Open AI's genuinely trying to protect vulnerable populations, not make political statements. But the two get tangled up quickly.
The regulatory environment is also moving faster than the technology. By the time Open AI figures out how to satisfy EU AI Act requirements, there will be new requirements. This creates a ratchet effect: regulations typically only get stricter over time, and they rarely get rolled back.
So expect Chat GPT's guardrails to become more restrictive over the next few years, not less.

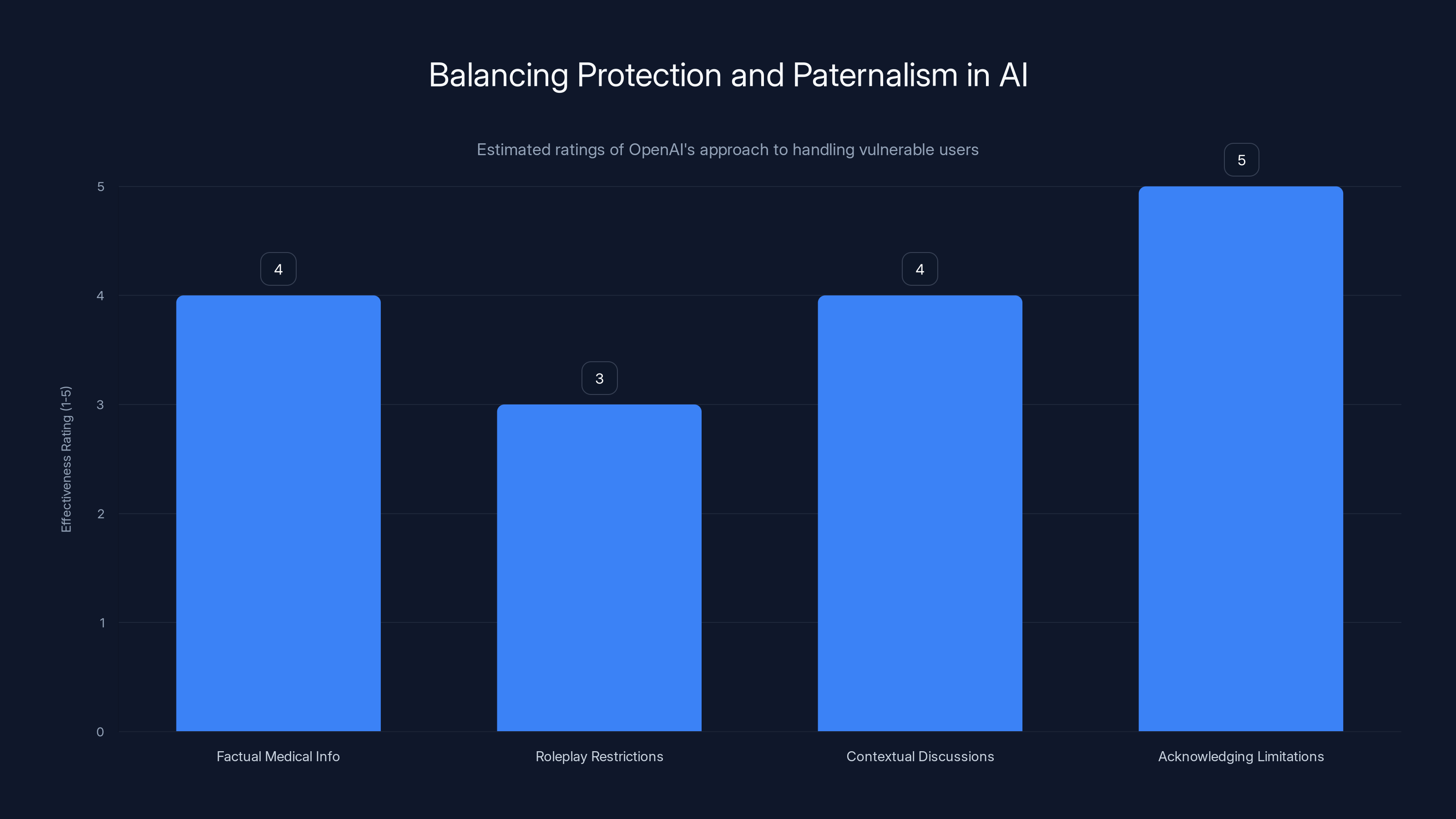
OpenAI's nuanced approach to protecting vulnerable users is rated for effectiveness, with acknowledging limitations scoring highest. Estimated data.
The Technical Reality: Why AI Systems Struggle with Context
Here's something that doesn't get discussed enough: the fundamental technical limitation of current AI systems when it comes to safety.
Large language models like Chat GPT operate on pattern matching. They're incredibly good at it, but pattern matching isn't context understanding. When the system sees certain keywords or structures, it responds based on patterns in training data. It doesn't "understand" your actual intent the way a human would.
This creates inherent ambiguity. The phrase "how to make someone trust me" could be:
- A question about building healthy relationships
- Advice for manipulating people
- A question from someone in therapy trying to rebuild trust after trauma
- A corporate communication strategy question
A human listener would pick up on context cues. They'd ask follow-up questions. They'd understand nuance.
Chat GPT has to choose: allow the pattern (since it's sometimes legitimate) or refuse it (since it's sometimes harmful). There's no in-between where it correctly evaluates your specific context.
This is why safety guardrails inherently reduce usability. They're a blunt instrument. They have to be, because the system can't distinguish context the way humans can.
Future AI systems might be better at this. If models develop deeper contextual understanding, the safety-versus-accessibility trade-off becomes less stark. You could theoretically have a system that understands the difference between legitimate and harmful uses of the same question.
But we're not there yet. Current systems operate with significant uncertainty about intent, and safety systems have to account for that uncertainty.
This is also why jailbreaks are so common. People discover that if they ask the same question in a slightly different way, or add more context, the system's pattern matching works differently. The underlying model is trying to be helpful, so it responds to certain framings it would refuse in other framings.
This technical limitation means the safety-versus-accessibility problem isn't just a policy choice—it's built into how the technology works.

What Real Solutions Might Look Like
So if the current approach is fundamentally limited, what would actually help?
Better User Segmentation
One option is allowing users to declare their use case and adjusting restrictions accordingly. Researchers could get a "research mode" with fewer guardrails. Educators could get "education mode." This already exists partially (Chat GPT offers different tiers and different access levels for businesses), but it could go further.
The downside: this requires significant identity verification and trust. People will lie about their use case to get fewer restrictions.
Contextual Safety Systems
Instead of one-size-fits-all restrictions, imagine a system that understood context better. If the system could assess the user's age, expertise, and stated purpose, it could calibrate responses accordingly.
The downside: this requires collecting significantly more user data, raising privacy concerns. It's also technically difficult—age estimation from usage patterns isn't reliable.
Stronger User Education
Make it much clearer to users what Chat GPT can and can't reliably do. Not just disclaimers, but active education. The system could refuse harmful requests but explain why, teaching users about risks in real-time.
The downside: users need to care about education, and many don't. You can't force people to read disclaimers.
Differential Access
Allow certain groups (minors, people with certain health conditions) to opt into stronger protections. Don't impose paternalism—let people request it for themselves.
The downside: this requires users to self-identify as vulnerable, and many won't. It also creates different "tiers" of access that might feel discriminatory.
Transparent Safety Policies
Publish exactly what the guardrails are, when they activate, and why. Let independent researchers examine the system. This increases accountability.
The downside: this also makes it easier for people to find and exploit workarounds. Transparency helps adversaries too.
Decentralized Alternatives
Instead of one centralized Chat GPT, allow organizations to run their own moderated versions. Schools could set stricter rules for minors. Research institutions could enable more permissive settings. Everyone gets the base model but can configure safety to their needs.
The downside: this fragments the ecosystem. It's more complex. And smaller organizations might cut corners on safety entirely.
None of these are silver bullets. Each creates new trade-offs. But they point toward solutions more nuanced than "one-size-fits-all guardrails."

The Industry-Wide Problem: This Isn't Unique to Open AI
Here's the thing: the Altman-Musk debate about Chat GPT safety is really a proxy for a broader industry problem. Every major AI platform faces this exact tension.
Claude from Anthropic has equally strict guardrails, perhaps stricter in some areas. Google's Gemini has its own complex safety approach. Meta's Llama models (open-source) have generated significant debate about whether to include safety restrictions at all.
Each company is making different choices about where on the safety-accessibility spectrum they want to operate. Claude is more protective. Llama is more permissive. Chat GPT is somewhere in between.
The market pressure actually pushes toward more safety, not less. Why? Because the public incidents get noticed. If an AI system generates something horrific, it becomes a news story. If the same system refuses a legitimate request, that's an individual user frustration, not a scandal.
Publically, companies get punished for failures but not rewarded for accessibility. So the incentive is to err on the side of caution.
Over time, this means the entire industry converges toward stricter guardrails, which narrows the "design space" for what AI can do.
Smaller startups sometimes try to differentiate by being more permissive, but they face regulatory and reputational risk. A startup's AI chatbot generating harmful content becomes a PR disaster. So even they gravitate toward caution.
The Altman-Musk debate is symptom of this deeper industry-wide pressure. Nobody wants to be the CEO of the AI platform that caused harm. Everyone wants to be the CEO of the AI platform that was responsible.
But you can't be both simultaneously.

What This Means for Users: Expect Continued Restrictions
Based on regulatory trends and industry dynamics, here's what's likely to happen:
Chat GPT will become more restricted, not less. Each regulatory jurisdiction adds constraints. Each incident (real or perceived) prompts new safety measures. The ratchet only moves in one direction.
Specialized versions will emerge. Instead of one Chat GPT for everyone, expect more segmented access: education versions, research versions, enterprise versions, with different safety profiles.
Competing products will differentiate on safety. Some will push toward "maximum openness," accepting the reputational risk. Others will position as "safest possible AI." Users will pick based on their needs.
Transparency will increase, then plateau. There's pressure to explain safety decisions. Open AI is responding with more documentation. But complete transparency about guardrails would enable jailbreaks, so transparency will stop at some point.
International fragmentation will accelerate. Chat GPT in Europe will be different from Chat GPT in the US. Users in different regions will experience different capabilities.
Workarounds will persist. As long as there are guardrails, people will probe them. Jailbreaks will become more sophisticated. Open AI will respond with stronger defenses. The arms race continues.
Vulnerable populations will remain a concern. No matter how good the safety systems get, there will be edge cases. A determined person will find ways to misuse the tool. A vulnerable person in the wrong context will encounter unexpected harms.
The realistic scenario isn't that we "solve" the safety problem. It's that we manage it iteratively, making constant trade-offs, with different stakeholders perpetually unsatisfied.
Altman's admission that it's "genuinely hard" is probably the most honest thing a tech executive has said about this in years.

Looking Forward: The Future of AI Safety
Here's where this heads in the next 3-5 years:
First, more AI systems entering high-stakes domains (medicine, law, education) will create new safety requirements. Doctors won't tolerate guardrails that prevent relevant medical education. Lawyers won't tolerate restrictions that prevent legal research. This creates conflicting demands—strict guardrails for consumer safety, loose guardrails for professional use.
Second, the regulatory environment will shift from individual company policies to government mandates. The EU AI Act is the beginning. Expect national-level requirements in other countries. These will likely be stricter and less flexible than what Open AI would choose independently.
Third, better context-aware AI systems will eventually emerge. Not this year or next, but as models improve, distinguishing legitimate from harmful use cases becomes easier. This doesn't eliminate the problem, but it reduces false positives.
Fourth, the market will demand more specialization. One-size-fits-all AI is fine when nobody understands it. But as AI becomes foundational infrastructure, users will demand versions optimized for their specific use cases, with safety/capability trade-offs that match their needs.
Fifth, the safety-versus-accessibility debate will evolve from "how strict should guardrails be?" to "who decides what's safe?" The first question has technical answers (though imperfect ones). The second question is fundamentally political, and no technical solution exists.
This last point is crucial. Altman and Musk's disagreement isn't really about whether Chat GPT's guardrails work. It's about who gets to decide what counts as safe, who bears responsibility for harms, and what trade-offs are acceptable.
These are political questions, not technical ones. They won't be "solved." They'll be negotiated, fought over, and periodically renegotiated as society's priorities shift.

The Honest Assessment
Where does all this leave us?
Chat GPT has safety guardrails. They work, mostly, but imperfectly. They protect some vulnerable users while limiting legitimate uses for others. They're expensive to maintain. They'll get stricter over time as regulation increases.
Is this the right balance? There's no right answer. It's a choice that different people will evaluate differently based on their values, their experience, and their willingness to accept risk.
Altman's honesty about the difficulty is refreshing. So is Musk's willingness to publicly challenge the approach. The truth is probably that both are right about something:
Yes, protecting vulnerable populations matters. Yes, guardrails that over-restrict legitimate use are genuinely problematic. Yes, it's hard to balance these. Yes, the current approach has significant limitations.
And yes, this will remain hard for the foreseeable future.
The best outcome isn't a perfect solution (impossible) but a more thoughtful, transparent, and iterative approach to managing the trade-offs.
Open AI seems to be moving in that direction. More documentation. More user feedback mechanisms. More willingness to discuss the trade-offs openly instead of pretending they don't exist.
That's not the same as solving the problem. But it's probably better than the alternative.

FAQ
What does "safety guardrails" mean in the context of Chat GPT?
Safety guardrails are technical and policy-based restrictions built into Chat GPT to prevent harmful outputs. These include training methods that discourage harmful responses, real-time content moderation on inputs and outputs, explicit refusals of certain request types, and monitoring systems that flag suspicious patterns. They operate across multiple layers—from foundational model training to deployment-time filtering.
Why is balancing safety with accessibility genuinely difficult?
The balance is hard because the same feature that protects one user can restrict another. Guardrails that block a minor from accessing harmful content might also block an educator from creating health curricula. Content moderation systems can't reliably distinguish context—they work on pattern matching. Additionally, making safety decisions means implicitly making value judgments about acceptable use, which varies across cultures and regulatory jurisdictions.
How does Open AI currently implement safety in Chat GPT?
Open AI uses a multi-layered approach including: foundational model training with red-teaming, reinforcement learning from human feedback (RLHF), real-time input and output moderation, continuous monitoring for exploits, and policy-based account restrictions. No single layer is foolproof, which is why the system remains imperfect even with significant investment.
What are the main types of users that safety guardrails protect?
Vulnerable populations include minors (who may lack judgment about harmful information), people with mental health conditions (who might be harmed by certain content), less tech-literate users (who may over-trust AI outputs), and users from different cultures (where safety concepts vary). The challenge is that vulnerability isn't binary—the same information is protective for one person and restrictive for another.
What happens when Chat GPT refuses a request—is it always for safety reasons?
Not always. Refusals come from multiple sources: safety guardrails (preventing harmful content), capability limits (the model doesn't actually know how to do something), clarification requests (the model asks for more context), and policy violations (terms of service restrictions). When the system refuses something, it's not always clear which category it falls into, which creates user frustration.
How do international regulations affect Chat GPT's safety approach?
Regulations like the EU AI Act impose strict requirements on large AI systems, especially in high-risk contexts. Since Open AI operates globally but can't easily maintain different versions of Chat GPT for each jurisdiction, they typically implement guardrails that satisfy the strictest jurisdiction, effectively applying those restrictions worldwide. This means users everywhere get the European-level protections whether they live in Europe or not.
Can the safety-versus-accessibility problem be completely solved?
Technically? No, not at current capability levels. AI systems work through pattern matching, not true contextual understanding, so they can't reliably distinguish between legitimate and harmful uses of identical requests. Philosophically? No, because safety involves value judgments that different people and cultures disagree on. The problem can be managed better through improved transparency, user segmentation, and iterative refinement, but a perfect solution doesn't exist.
What's likely to happen to Chat GPT's guardrails in the next few years?
Expect them to become stricter, not more permissive. Regulatory pressure, market incentives, and public incidents all push toward tighter restrictions. The ratchet of regulation typically only moves in one direction. Additionally, as AI enters more critical domains (medicine, law, education), safety requirements will intensify, though this creates tension with the need for more capable tools in specialized contexts.
How do I report if Chat GPT's safety guardrails seem too restrictive?
Chat GPT includes a feedback mechanism directly in the interface. When the system refuses a request, you can select "This refusal seems too strict" to report it. These reports are collected and analyzed to identify patterns where the safety system might be over-correcting. Alternatively, if you find a genuine safety bypass that could enable harm, Open AI's security team operates a bug bounty program for responsible disclosure.
Are other AI systems facing the same safety-versus-accessibility trade-off?
Yes, every major AI platform faces identical tensions. Claude has similar (arguably stricter) guardrails. Google's Gemini has its own safety approach. Smaller startups and open-source models like Meta's Llama make different choices about where on the safety-accessibility spectrum to operate, but the underlying tension remains universal in AI systems.
The Bottom Line
Sam Altman's public admission that maintaining Chat GPT's safety guardrails is "genuinely hard" isn't a weakness—it's the most honest thing he could say.
The safety-versus-accessibility trade-off is fundamental. You can build guardrails that protect vulnerable users, but not without limiting legitimate uses. You can build systems that are maximally useful, but not without accepting unacceptable risks.
Currently, Chat GPT leans toward protective restrictions. That choice reflects Open AI's risk tolerance, regulatory environment, and values. Different companies make different choices. Different users would prefer different balances.
The real progress isn't finding the "perfect" balance—it's being transparent about the trade-offs, empowering users to understand them, and iteratively adjusting based on evidence.
The Altman-Musk debate captures this perfectly: two intelligent people looking at the same problem and honestly disagreeing about the right approach. That's not a bug in the system. That's how complex, values-laden problems get managed in practice.
Expect this debate to continue. Expect regulations to push toward stricter guardrails. Expect user frustration with false positives. Expect occasional harms despite all the safety measures. And expect Open AI to keep doing what Altman said: genuinely struggling to balance protecting vulnerable users while keeping the tool usable for everyone else.
That struggle is the feature, not a bug.
Key Takeaways
- ChatGPT's safety guardrails operate across five layers: training, fine-tuning, input/output moderation, monitoring, and policy enforcement—no single layer is foolproof
- The core tension is mathematical: stricter filters reduce false negatives (harmful content slipping through) but increase false positives (legitimate requests being blocked)
- Vulnerable populations include minors, people with mental health conditions, less tech-literate users, and those from different cultural contexts—each facing different types of risks
- Safety infrastructure costs 20-30% of OpenAI's operational budget, making safety a significant competitive and economic factor, not just a technical one
- Regulatory pressure globally is pushing guardrails stricter over time; expect fragmentation where ChatGPT in Europe is more restricted than ChatGPT elsewhere
- Current AI systems can't distinguish context reliably, forcing safety systems to use pattern matching that inevitably blocks some legitimate uses
- The safety-versus-accessibility problem is fundamentally political and ethical, not technical—different stakeholders will always want different trade-offs
Related Articles
- How Grok's Deepfake Crisis Exposed AI Safety's Critical Failure [2025]
- xAI's Grok Deepfake Crisis: What You Need to Know [2025]
- ChatGPT's Age Prediction Feature: How AI Now Protects Young Users [2025]
- X's Algorithm Open Source Move: What Really Changed [2025]
- ICE Verification on Bluesky Sparks Mass Blocking Crisis [2025]
- Jimmy Wales on Wikipedia Neutrality: The Last Tech Baron's Fight for Facts [2025]

