![Alibaba's Qwen 3.5 397B-A17: How Smaller Models Beat Trillion-Parameter Giants [2025]](https://tryrunable.com/blog/alibaba-s-qwen-3-5-397b-a17-how-smaller-models-beat-trillion/image-1-1771441715262.png)
How Alibaba's Qwen 3.5 397B-A17 Crushes Larger Models at a Fraction of the Cost
It's January 2025, and the narrative around large language models just shifted. For the last eighteen months, bigger was supposed to be better. More parameters meant more knowledge, more reasoning capability, more "alignment" with what humans want. Scale up, everyone said, and you'll get better results.
Then Alibaba released Qwen 3.5—and promptly demolished that assumption.
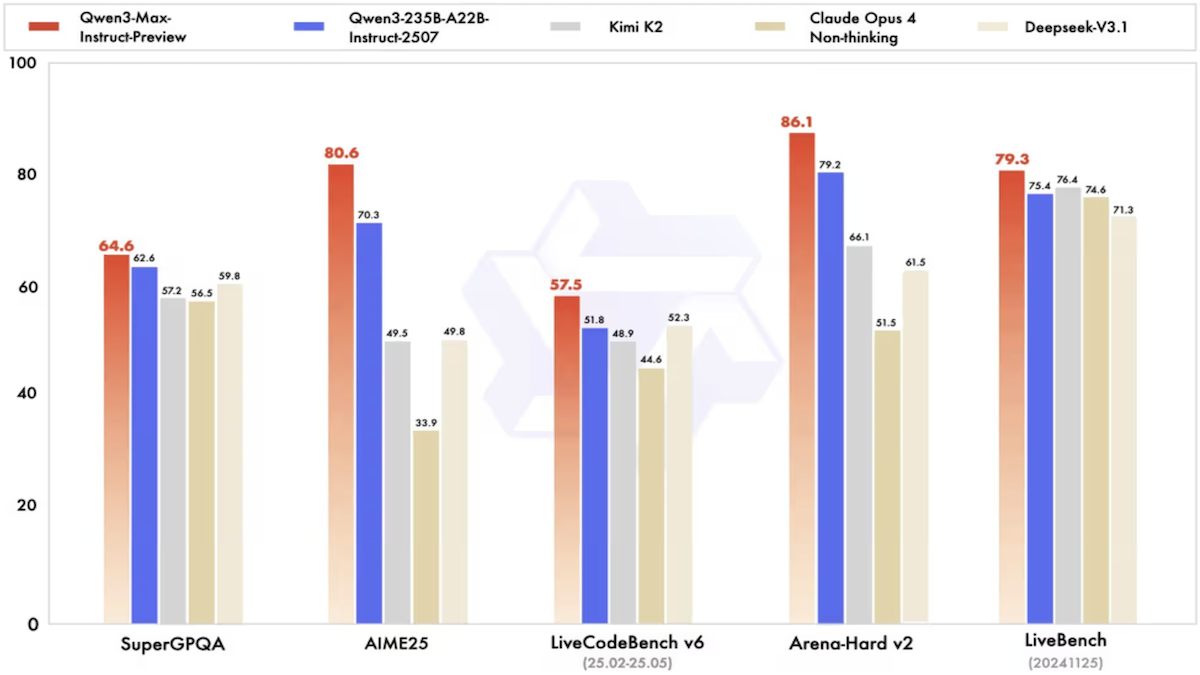
The new flagship model, called Qwen 3.5-397B-A17B, has 397 billion total parameters but activates only 17 billion per token. It's beating Alibaba's own previous flagship, Qwen 3-Max, a model the company explicitly stated exceeded one trillion parameters. Not by a tiny margin. By meaningful numbers across reasoning, coding, and multimodal benchmarks. And it costs roughly 60% less to run.
This isn't a parlor trick. It's not a clever benchmark-gaming setup. This is a legitimate rethinking of how to build production AI systems—and it has enormous implications for anyone responsible for enterprise AI infrastructure decisions in 2025.
Here's what just happened, why it matters, and what it means for the next generation of AI deployments.
TL; DR
- Qwen 3.5 activates only 17B of 397B parameters per token, dramatically reducing compute overhead while maintaining competitive performance
- 19x faster decoding than Qwen 3-Max at 256K context lengths, with 60% lower operational costs
- Sparse Mixture of Experts (Mo E) architecture with 512 experts enables specialized reasoning without full model activation
- Native multimodal training (text, images, video simultaneously) outperforms adapter-based approaches on technical reasoning tasks
- 250K token vocabulary reduces encoding costs by 15-40% for non-Latin scripts, directly lowering inference expenses at scale
- Open-weight model availability gives enterprises genuine ownership and control, unlike proprietary API rentals
- Bottom line: Efficiency beats raw scale; open-weight models can now compete with proprietary flagships on performance while undercutting them dramatically on cost

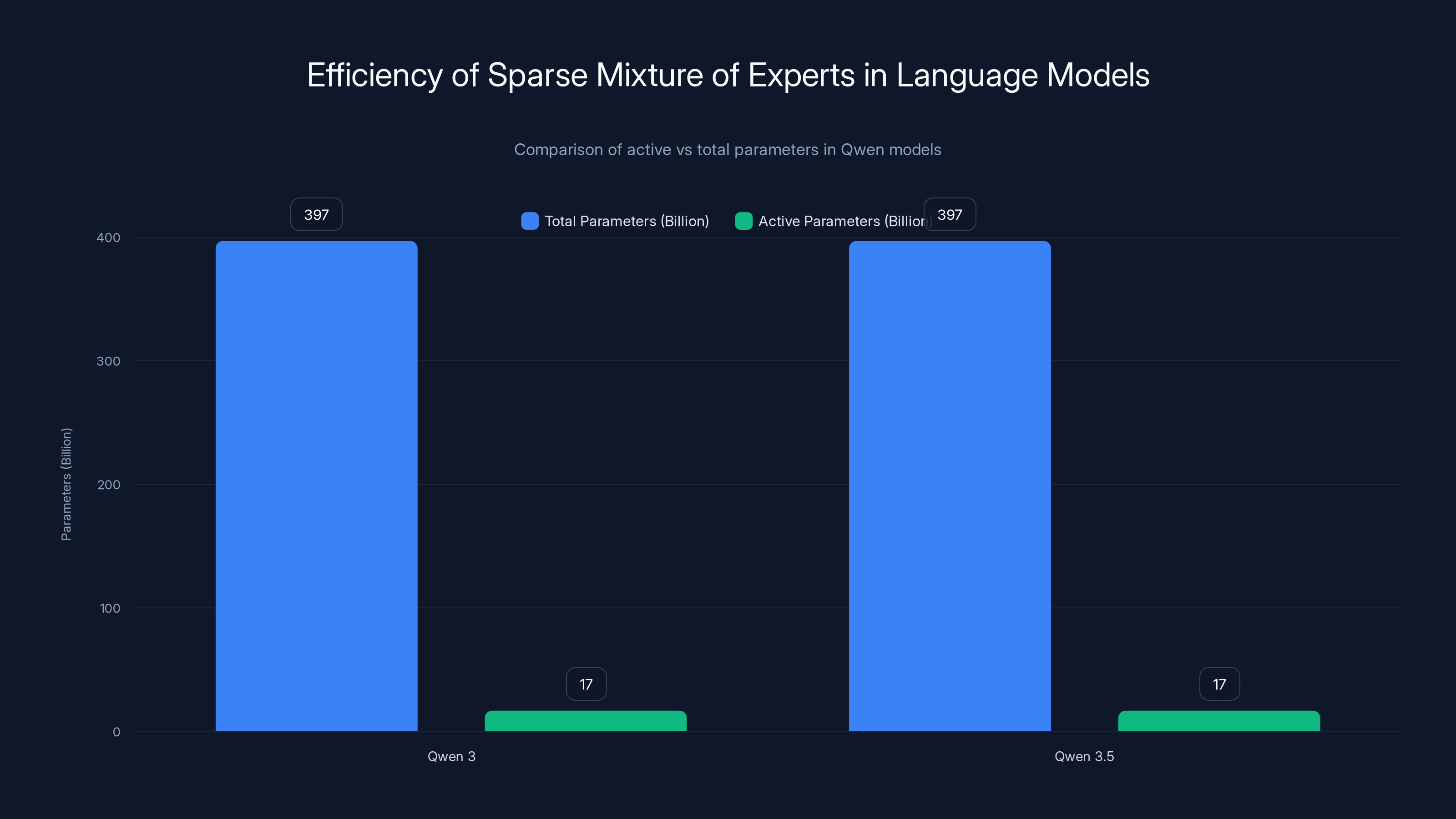
Qwen 3.5, with 512 experts, activates only 4.3% of its parameters per token, optimizing computational efficiency. Estimated data.
The Efficiency Revolution: Why Smaller Activations Beat Larger Models
To understand what Alibaba built, you need to first understand what it abandoned. Traditional dense language models activate every single parameter for every single computation. You have a 70B parameter model? All 70 billion get multiplied, added, and processed for each token you generate. This is mathematically clean and easy to reason about. It's also computationally wasteful.
Most of those parameters don't need to fire for most tasks. When you're translating Japanese poetry, your chemistry domain expertise isn't helping. When you're debugging Python code, your knowledge of medieval philosophy is dead weight.
Sparse Mixture of Experts (Mo E) architecture solves this by creating specialized "expert" modules within the model. Instead of activating all parameters, the model learns to route incoming requests to the most relevant experts. Think of it like a hospital with specialists—when a patient comes in with a broken leg, you don't call the cardiologist. You route them to orthopedics.
Qwen 3 used Mo E with 128 experts. Qwen 3.5 jumps to 512 experts. This explosion in expert count creates finer specialization. More experts means more granular routing decisions. More routing options means the model can be more selective about which parameters actually activate.
The math is straightforward. If you have 397 billion parameters spread across 512 experts, and only 17 billion activate per token, that means roughly 4.3% of the model's parameters are actually computing for any given forward pass. The rest stay idle. Your GPU doesn't have to load them into memory. Your data center doesn't have to power them. Your inference bill doesn't scale with the total parameter count—it scales with the active parameter count.
This is the efficiency revolution. And the benchmark improvements prove it works.
Inference Speed Gains That Change Economics
At 256K context length, Qwen 3.5 decodes 19 times faster than Qwen 3-Max. Let that sink in. A model with fewer active parameters, on the same hardware, generates tokens roughly two orders of magnitude quicker. For end-users, this means responses arrive faster. For operators, this means you can serve more concurrent requests on the same infrastructure.
Alibaba claims the model can handle eight times more concurrent workloads than its predecessor. This isn't just an isolated speed metric. This is operational capacity doubling, tripling, sometimes octupling, all without buying new hardware. For a large enterprise running AI at scale, this is the difference between needing three data centers and needing one.
The 7.2x speedup compared to Qwen 3's 235B-A22B model is similarly staggering. You're taking a smaller model—only 397B total parameters versus potentially twice that in older variants—and generating responses in one-seventh the time. This isn't coming from faster hardware or better compilers. It's coming from activating fewer parameters while maintaining reasoning quality.
Why Cost Matters More Than You Think
Alibaba quotes 60% lower operational costs. This number tends to get glossed over because it sounds like marketing. Let me make it concrete.
If your company runs large language models for customer support, content generation, or internal automation, your largest expense after salaries is likely inference compute. A 60% reduction in inference costs is transformative. Over a year, across thousands of daily inferences, this compounds. Suddenly you're not asking the CFO for budget increases to handle AI workloads. You're handing them an explanation for why your bills went down.
Alibaba also claims the model costs roughly 1/18th the price of Google's Gemini 3 Pro. This comparison is worth scrutinizing. Gemini 3 Pro is a proprietary, closed API. You can't run it yourself. You can't fine-tune it. You can't inspect it. You pay per token, forever. Qwen 3.5 is open-weight. You can download it, run it on your own infrastructure, and own the deployment. The price difference isn't just about raw inference cost—it's about ownership, control, and long-term economics.
For enterprises evaluating AI infrastructure in 2025, this distinction matters enormously. You're not just comparing per-token pricing. You're comparing rental models versus ownership models. API fees versus infrastructure amortization. Vendor lock-in versus control.
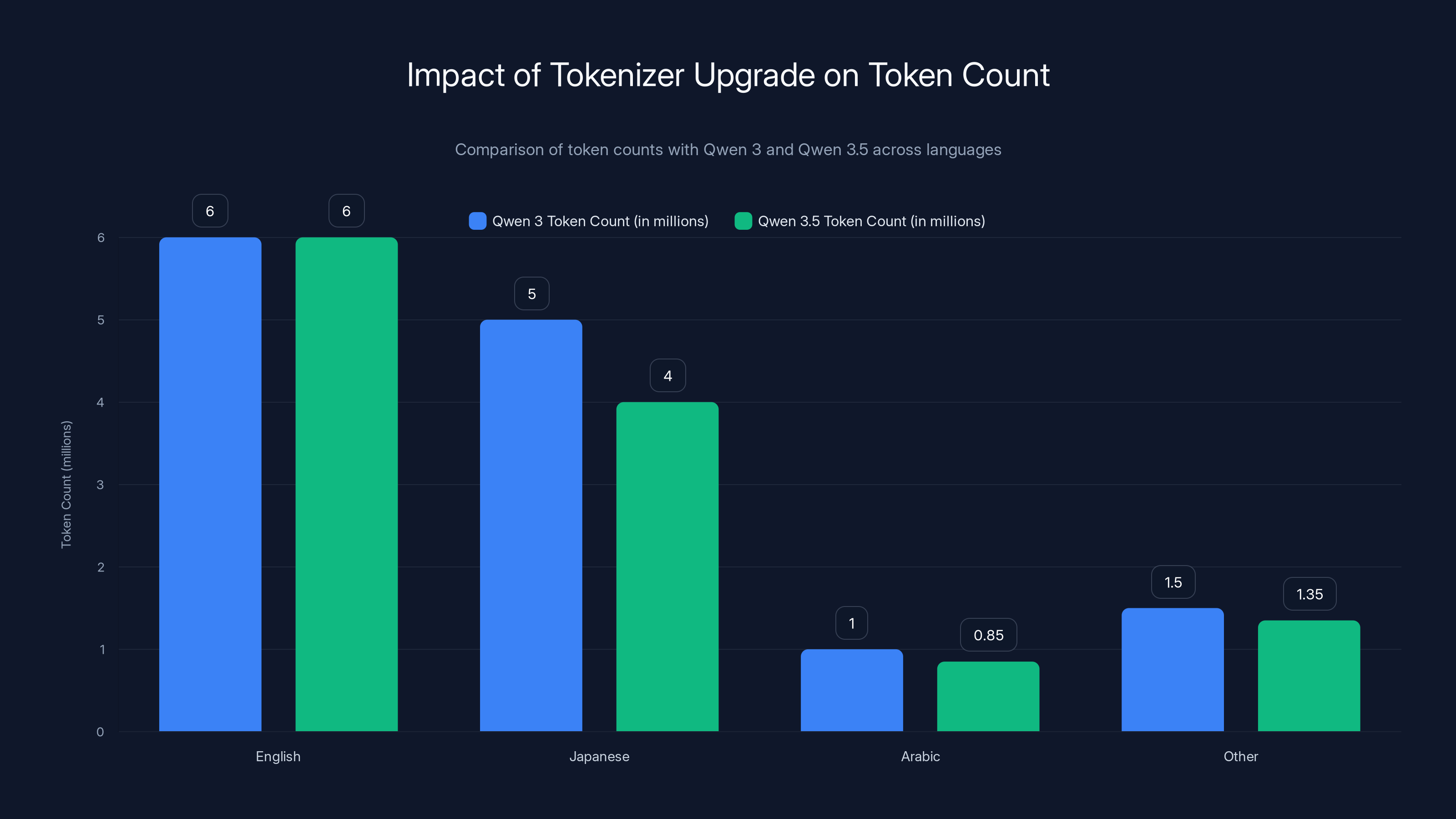
Qwen 3.5's expanded vocabulary reduces token count by 15-40% depending on the language, leading to significant cost savings in global deployments. Estimated data based on typical language tokenization.
The Architecture: Multi-Token Prediction and Memory-Efficient Attention
Speed and cost don't come from magic. They come from deliberate architectural choices. Qwen 3.5 includes three specific innovations that compound the efficiency gains.
The first is multi-token prediction. This isn't Alibaba's invention—Anthropic's Claude and Open AI's recent models have pioneered this—but the implementation matters. Standard language models predict one token at a time. You feed in a prompt, the model generates token one. You feed token one back in, the model generates token two. Repeat. This sequential process is inherently slow for long outputs.
Multi-token prediction lets the model predict two, three, or sometimes four tokens simultaneously. This dramatically accelerates pre-training convergence. During training, the model learns to generate multiple tokens in parallel, which teaches it to reason about downstream consequences earlier. Once trained, during inference, you get the same throughput gains—generating multiple tokens per forward pass instead of one.
The second innovation is the attention mechanism inherited from Qwen 3-Next. Standard attention in large language models has a critical bottleneck: memory requirements scale with context length squared. If you're handling 256K tokens of context, the memory footprint can exceed available VRAM. Qwen 3.5's attention system reduces this memory pressure, allowing the model to operate comfortably at 256K context (and up to 1 million tokens in the hosted Qwen 3.5-Plus variant) without running out of memory.
This is critical for real-world applications. Many enterprise use cases involve processing document collections, code repositories, or conversation histories that exceed 128K tokens. A model that chokes at 32K context is useless for these scenarios. Qwen 3.5 handles them natively.
The third architectural choice involves the sheer number of experts in the Mo E system. With 512 experts, the model can afford to be more selective. When you have 128 experts, each expert handles a broad range of tasks. Routing decisions become coarser. When you have 512 experts, each expert can specialize more finely. The routing decisions become more precise. More precise routing means fewer irrelevant parameters activate. Fewer active parameters mean faster inference and lower power consumption.
Scaling the Expert Pool: From 128 to 512
The jump from 128 to 512 experts is a 4x expansion. This isn't simply scaling the same architecture. It's a fundamental rethinking of how many specializations a model needs to capture.
In traditional deep learning, you rarely see this level of granularity. A standard convolutional neural network might have five to ten layers. A dense transformer typically has 40 to 128 layers. But Qwen 3.5's expert count exceeds this by an order of magnitude. The model is saying: "I need hundreds of specialized modules to capture the diversity of knowledge and reasoning patterns required to be a genuinely capable language model."
This creates an interesting side effect. With 512 experts, the model's routing decisions become interpretable in new ways. You can ask: which experts are activating for physics problems? Which for coding? Which for creative writing? This opens new research directions and fine-tuning strategies. You could, theoretically, disable certain experts for deployment, effectively creating custom model variants for specific domains without retraining.
Multimodal AI Done Right: Text, Images, and Video as Native Equals
For years, the approach to multimodal models was mechanical. Build a language model. Train it thoroughly. Then attach a vision encoder—usually something pre-trained like CLIP or a custom vision transformer. Connect them with a projection layer. Call it "multimodal."
This adapter-based approach works, but it's fundamentally asymmetric. The language model is deeply trained. The vision capability is grafted on. When you ask the model to reason about text and images together, the language and vision streams go through separate processing paths before eventually merging. It's like having a translator sit between two people speaking different languages—useful, but not as natural as true bilingualism.
Qwen 3.5 abandons this entirely. The entire model is trained from scratch on text, images, and video simultaneously. There's no "vision encoder module" bolted onto a language model. There's a single unified architecture that treats tokens, image patches, and video frames as elements of the same representational space. This is native multimodality.
The practical implications are substantial. When models are trained to reason about modalities together from the start, they develop tighter integration between textual and visual understanding. Analyzing a technical diagram alongside its documentation. Processing UI screenshots for automation tasks. Extracting structured data from complex visual layouts. These tasks require genuine text-image reasoning, not sequential processing of separate modalities.
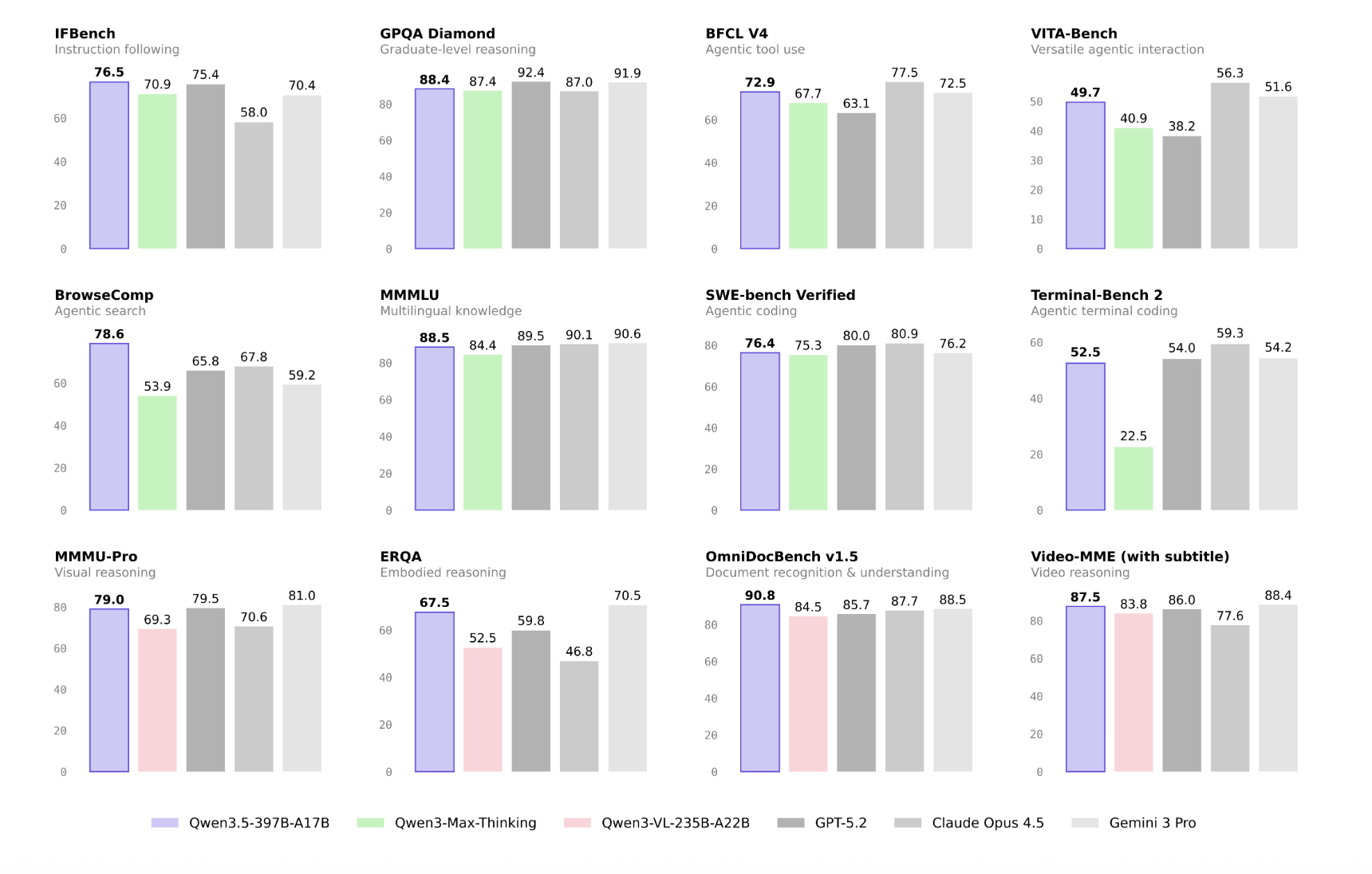
On the Math Vista benchmark, which tests visual mathematical reasoning, Qwen 3.5 scores 90.3. That's competitive with much larger models. On MMMU, a multimodal reasoning benchmark requiring specialized domain knowledge, the model scores 85.0. These numbers aren't record-breaking, but they're impressive given the model's parameter efficiency.
Most importantly, Qwen 3.5 surpasses Anthropic's Claude Opus 4.5 on many multimodal tasks while carrying a fraction of the parameter count. It posts competitive numbers against Open AI's GPT-5.2 and Google's Gemini 3 on general reasoning and coding benchmarks. For an open-weight model released in January 2025, these are significant achievements.
Vision Capabilities That Actually Handle Complex Layouts
Many vision-capable models fail at a simple task: reading and understanding dense visual information. Show them a screenshot of a spreadsheet with dozens of cells, headers, and data points. They often hallucinate numbers or misread relationships. Show them a technical diagram with labels, arrows, and annotations. They frequently miss details or invert relationships.
Qwen 3.5's native multimodal training appears to have solved this more robustly than many competitors. The model can handle dense visual layouts—screenshots, scanned documents, UI elements—with higher accuracy than you'd expect from a model optimized for language first and vision second. This matters for real applications. Insurance claim processing, medical record analysis, financial report review, legal document analysis—these are high-value use cases that require understanding dense visual information.
The video understanding capability is equally interesting. Qwen 3.5 can process video frames natively. This isn't just image understanding applied sequentially to video frames. It's temporal reasoning—understanding how scenes, objects, and actions change across frames. For security monitoring, instructional video analysis, or video-based customer support interactions, this matters significantly.
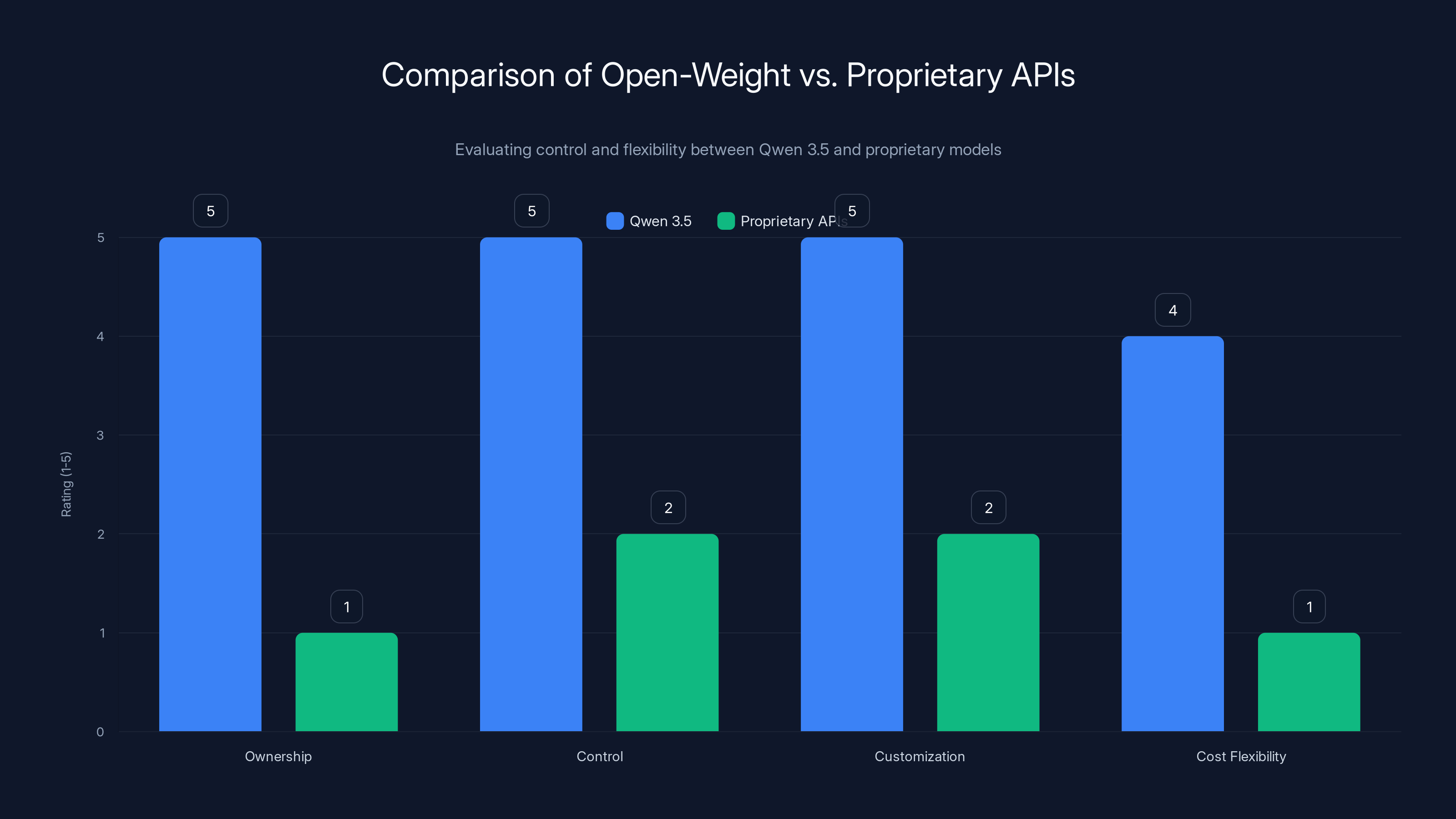
Qwen 3.5 offers superior ownership, control, and customization compared to proprietary APIs, providing long-term cost flexibility despite initial infrastructure requirements. Estimated data based on qualitative analysis.
The Tokenizer Upgrade: How 250K Vocabulary Reduces Global Costs
Tokenizers are often overlooked in model discussions. Everyone focuses on parameters, benchmarks, and reasoning capabilities. But tokenizers determine something fundamental: how efficiently the model encodes information from different languages and domains.
Qwen 3's tokenizer had 150,000 tokens in its vocabulary. Qwen 3.5 jumps to 250,000. That's a 67% expansion. This increase might sound redundant—don't we already have enough tokens?—but it has massive practical implications, especially for global deployments.
Latin scripts (English, Spanish, French, German) are fairly efficient to tokenize. A single token often represents an entire word or concept. But non-Latin scripts—Arabic, Thai, Korean, Japanese, Hindi, Chinese—are structurally different. They require more tokens to represent the same information. A Japanese sentence might tokenize to 2.5x the token count of an equivalent English sentence using a tokenizer optimized for English.
With 250K vocabulary, Qwen 3.5 can include far more language-specific tokens. More language-specific tokens means more efficient encoding. Alibaba claims 15-40% token reduction depending on the language. This isn't theoretical. In production, this translates directly to cost.
Consider a hypothetical deployment. Your AI system processes 10 million tokens per day across multiple languages: 60% English, 20% Japanese, 10% Arabic, 10% other. With a smaller tokenizer, that 10 million becomes 11.5 million after encoding inefficiency. With Qwen 3.5's expanded vocabulary, you might stay at 10.2 million. Over a year, at typical inference pricing, this difference is tens of thousands of dollars.
Language support has expanded from 119 languages in Qwen 3 to 201 languages and dialects in Qwen 3.5. This isn't just marketing. Each new language adds specific tokens to the vocabulary, ensuring tokens are allocated efficiently. You're not forcing Arabic into English-optimized tokens. You're not forcing Korean into a Romanized approximation. You have native representation.
For enterprises operating globally, this is transformative. Your AI systems become cheaper to run in every market. Response times improve. Token billing decreases. The model becomes genuinely multilingual instead of "English-first with some language support bolted on."

Agentic Capabilities: Autonomous Reasoning and Action
The final piece of Qwen 3.5's positioning is its agentic design. This is jargon that deserves explanation: an agentic model is one designed not just to respond to queries, but to take multi-step autonomous action on behalf of users and systems.
Take code generation. A traditional language model generates code snippets. You review them, test them, modify them, deploy them. An agentic model does more. It writes code, tests the code, identifies bugs, fixes bugs, and submits the final result. It's autonomous. It takes action. It iterates without waiting for human feedback between each step.
Alibaba has open-sourced Qwen Code, a command-line interface that lets developers delegate complex coding tasks to Qwen 3.5. You describe what you want: "Build a REST API endpoint that validates email addresses and stores them in a Postgre SQL database with error handling." The model writes the code, identifies potential issues, refines the implementation, and delivers a production-ready result. This is agentic capability in practice.
The release also highlights integration with Open Claw, an open-source agentic framework that's surged in developer adoption. Open Claw provides the scaffolding: planning, task decomposition, resource management, error handling. Qwen 3.5 provides the reasoning. Together, they create autonomous AI systems that can accomplish multi-step objectives without constant human intervention.
This capability matters because it fundamentally changes how enterprises can deploy AI. Instead of AI being a tool you use—"generate a report," "translate this document," "summarize this email"—AI becomes an agent that accomplishes objectives. Instead of "summarize this email," it becomes "categorize this email, extract action items, and schedule follow-up tasks." Instead of "generate a report," it becomes "collect data from three databases, merge them, analyze trends, visualize findings, and deliver a formatted report."
Reinforcement Learning from Human Feedback
The base Qwen 3.5 model is foundation-level—capable but not yet refined. Alibaba has applied reinforcement learning from human feedback (RLHF) to improve the model's responses. More importantly, the company has also applied RL specifically to agentic behavior. This is rare. Most models apply RL to response quality (is the answer correct, helpful, safe?). Qwen 3.5 applies RL to agent behavior: does the agent accomplish objectives efficiently? Does it use available tools effectively? Does it recognize when to ask for human input versus proceeding autonomously?
This compound effect—foundation model capability plus RL for agentic behavior plus integration with frameworks like Open Claw—creates a model genuinely designed for autonomous systems. Not bolted-on afterward. Not retrofitted to agent frameworks. Native agentic design.
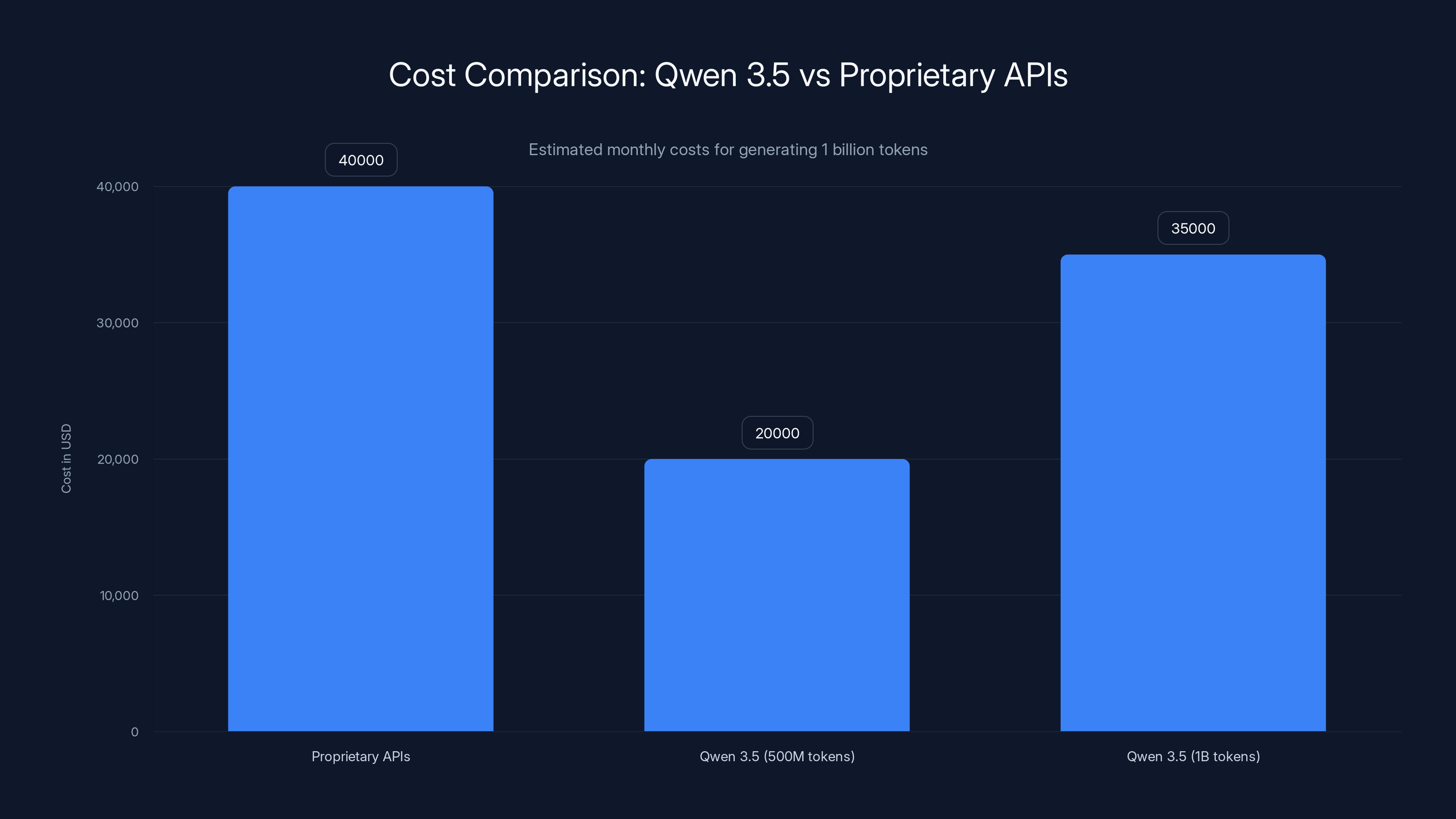
Proprietary APIs cost approximately $40,000/month for 1 billion tokens. Qwen 3.5 becomes more cost-effective for deployments exceeding 500 million tokens monthly. Estimated data based on typical pricing and infrastructure costs.
Benchmark Performance: Not Just Speed, But Reasoning Quality
Benchmarks are imperfect measures of model capability. They're useful for comparing models at scale, but they don't capture nuance, real-world applicability, or edge cases. That said, Qwen 3.5's benchmark performance is worth examining because it's surprisingly strong.
On reasoning benchmarks, the 397B-A17B model outperforms Qwen 3-Max—a model with over one trillion parameters. This is the headline. More parameters should mean more reasoning capability, so a smaller model winning suggests either the benchmark is gaming or the architecture is genuinely superior. Analysis suggests the latter. Qwen 3.5's sparse Mo E architecture, combined with multi-token prediction and improved attention, appears to create more efficient reasoning pathways. The model can allocate parameters to specialized reasoning tasks without the overhead of maintaining parameters for tasks it's not currently solving.
On coding tasks, Qwen 3.5 is competitive with GPT-5.2. This matters because coding is where sparse models can shine. Code generation is often specialized—writing Python versus Java Script versus Rust engages different expertise. With 512 experts, the model can route coding tasks to specialized code-generation experts. The language model's full parameter count never activates for basic syntax tasks. Expert selection handles it.
On general reasoning, Qwen 3.5 is competitive with Claude Opus 4.5 and Gemini 3 Pro. These are serious models. Claude Opus and Gemini 3 are proprietary, expensive, and trained by teams with enormous compute budgets. Qwen 3.5, as an open-weight model released with sparse architecture, matching their performance is significant.
The benchmark results don't prove Qwen 3.5 is universally better. Benchmarks are snapshots. They measure specific capabilities on specific tasks. But they do prove the architectural direction is sound. Smaller active parameters, with better expert selection, can compete with much larger dense models. This validates the efficiency thesis underlying the entire release.

Open-Weight vs. Proprietary APIs: The Control Question
Here's something that gets lost in technical discussions: Qwen 3.5 is open-weight. You can download it. You can run it yourself. You can fine-tune it. You can modify it. You can inspect it.
Gemini 3 Pro, GPT-5.2, and Claude Opus are proprietary. You access them through APIs. You never own the model. You never control the model. You pay per token, forever. If Open AI decides to discontinue the API, you're stuck. If pricing increases, you have no alternative. If you need to make the model understand your proprietary data or domain, you're limited to prompt engineering and few-shot learning. You can't fine-tune on proprietary data without uploading it to Open AI's servers—a non-starter for many enterprises handling sensitive information.
Qwen 3.5 changes this. You download the model, quantize it to fit your hardware, and deploy it. Your inference stays on your infrastructure. Your data never leaves your network. You own the model perpetually. You can fine-tune it on proprietary datasets. You can audit its behavior. You can make deployment decisions based on your needs, not vendor constraints.
This is why the cost comparison is misleading if you only look at per-token pricing. Yes, Qwen 3.5 costs less per token. But it also enables ownership. It enables control. It enables long-term independence from vendor pricing. For enterprises, this is often worth more than the raw per-token savings.
Infrastructure Implications
Running Qwen 3.5 requires significant GPU infrastructure, but it's far less than running proprietary models with equivalent capability. With sparse activation, the model can run on four to eight high-end GPUs depending on throughput requirements. This is achievable for most mid-sized enterprises. Small companies might choose to quantize the model to run on fewer, cheaper GPUs, accepting some quality loss for affordability.
Quantization—reducing the precision of model weights from 32-bit floating point to 8-bit or 4-bit integer—is a mature technique. It typically reduces model size by 75-90% with minimal quality loss. A 397B parameter model quantized to 4-bit occupies roughly 50-60GB of VRAM. This fits on four NVIDIA A100 GPUs or equivalent. Many enterprises already have this infrastructure. Deploying Qwen 3.5 requires buying GPUs, but it's a capital expense, not an indefinite rental model.
The break-even point varies by deployment size. For a company generating 100 million tokens per month, proprietary APIs might be cheaper. For a company generating 10 billion tokens per month, owning the model is almost certainly cheaper. Most mid-market and enterprise deployments fall into the second category. This is why Qwen 3.5's release has generated such interest among enterprise architects.

Hardware requirements and Sparse MoE complexity are the most significant challenges, both rated at an impact level of 8. Estimated data based on typical organizational concerns.
The Competitive Landscape: Where Qwen 3.5 Fits
Qwen 3.5 doesn't exist in isolation. It's part of a broader trend. Meta's Llama 3.3 (70B and 405B models) released in late 2024, also emphasizes efficiency and open availability. Mistral's Codestral and large Mixture of Experts models similarly focus on sparse efficiency. The market is clearly shifting.
But Qwen 3.5 has specific advantages. The 17B active parameters from 397B total is more aggressive sparsity than most competitors. The multimodal capabilities are natively integrated, not adapter-based. The tokenizer efficiency gains are language-specific in ways most competitors don't target. The agentic framework integration is purpose-built rather than retrofitted.
Alibaba's positioning is clear: they're building models for enterprises that need ownership, control, and cost efficiency more than they need cutting-edge proprietary capabilities. For many organizations, this positioning is exactly right. The model is good enough that proprietary alternatives don't justify the vendor lock-in and perpetual rental model.
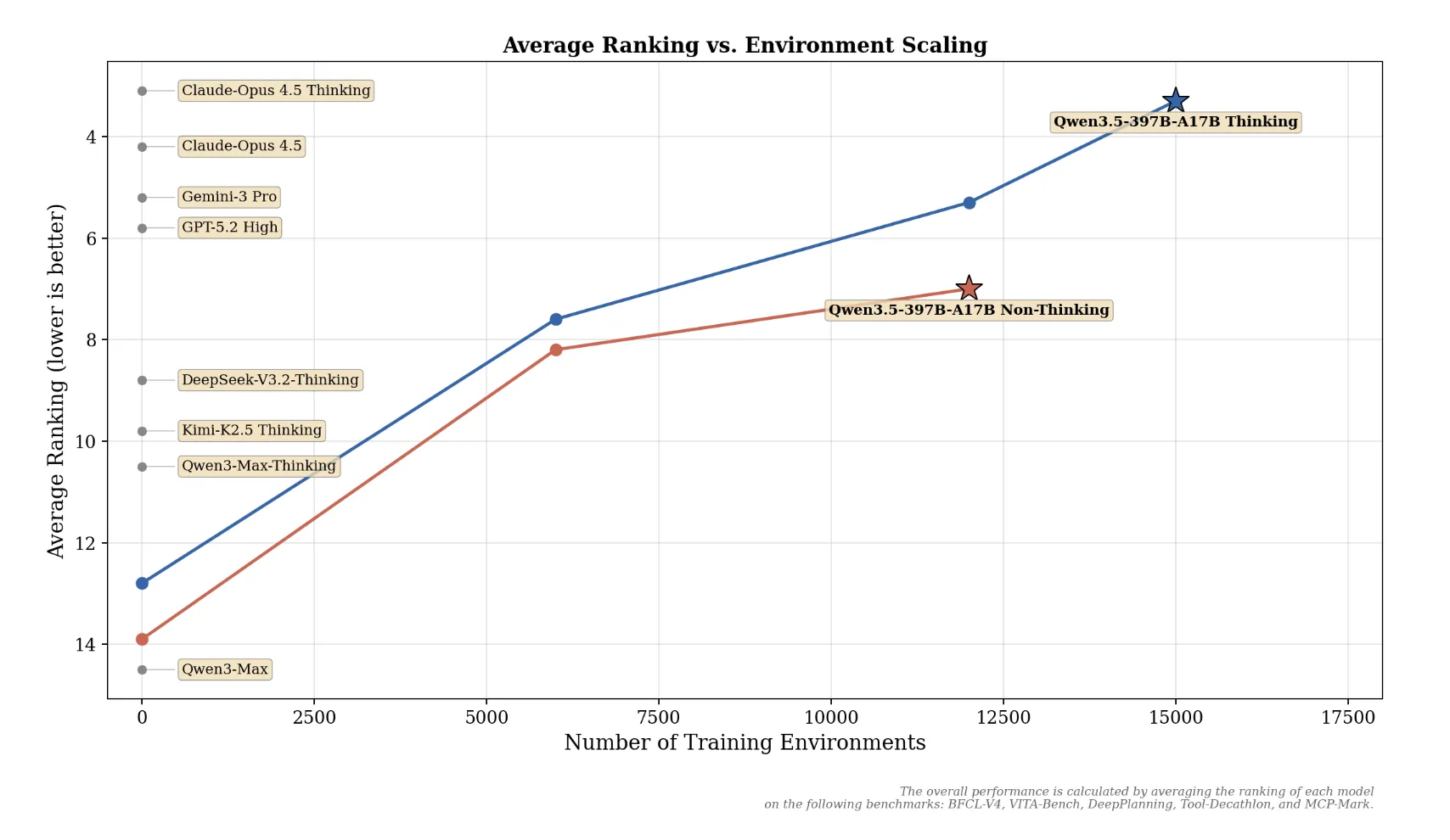
Practical Deployment Considerations
Deploying Qwen 3.5 in production isn't trivial, but it's increasingly straightforward. Several considerations matter.
Hardware Requirements: The model needs approximately 50-60GB of VRAM for 4-bit quantization, or 100-120GB for 8-bit quantization. This maps to four to eight high-end GPUs. Enterprises can also use specialized inference engines like v LLM or llama.cpp for more efficient inference, reducing hardware needs by 20-30%.
Fine-tuning Strategy: Qwen 3.5 is open-weight, meaning you can fine-tune it. The typical approach uses Lo RA (Low-Rank Adaptation) to reduce memory requirements during fine-tuning. You only update a small subset of parameters, keeping the base model frozen. This makes fine-tuning feasible even with limited hardware.
Monitoring and Observability: Running large language models in production requires monitoring inference latency, token throughput, error rates, and cost per request. Tools like Prometheus and Elasticsearch are standard for this.
Safety and Content Filtering: Qwen 3.5, like all large language models, can generate harmful content if prompted. Enterprises typically add safety layers—classifiers that flag potentially harmful outputs, or techniques like constrained decoding that steer the model toward safe responses.
Integration with Applications: Most deployments wrap Qwen 3.5 with an API layer (using frameworks like Fast API or Flask) and integrate with existing application infrastructure. This abstraction layer lets you swap models, change hardware, or modify deployment topology without changing application code.

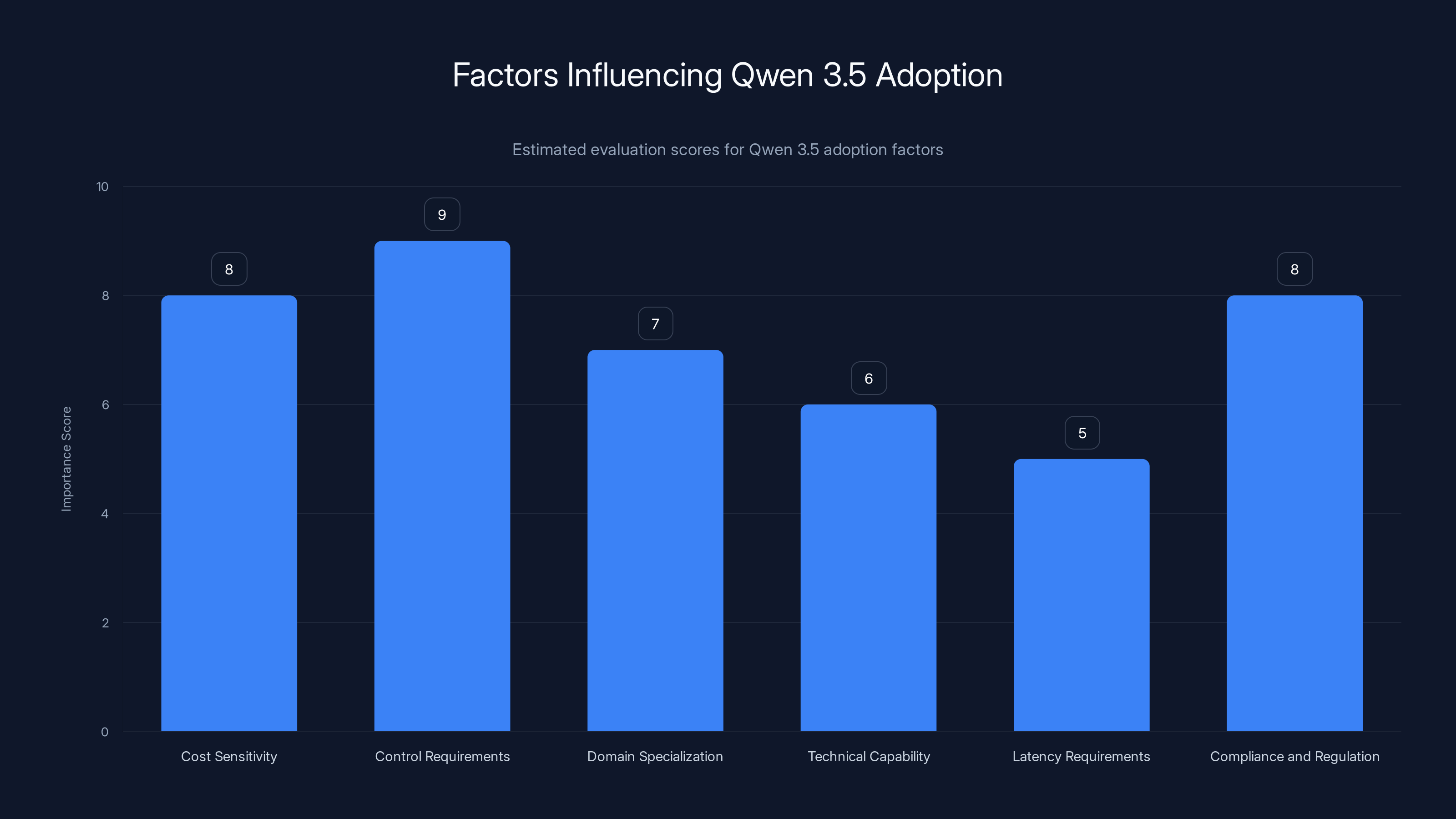
Estimated importance scores for factors influencing the decision to adopt Qwen 3.5. Control requirements and cost sensitivity are highly critical.
Fine-Tuning and Customization: Adapting to Specific Domains
Open-weight models unlock customization that proprietary APIs simply don't allow. Qwen 3.5's fine-tuning capabilities matter significantly for enterprises with specialized needs.
Legal firms want the model to understand contract language with precision. Medical providers want the model to reason about clinical scenarios accurately. Financial institutions want the model to understand regulatory requirements and product structures. Each domain has specific terminology, reasoning patterns, and safety requirements.
With proprietary models, you're limited to prompt engineering. You write detailed instructions, provide examples, hope the model generalizes. With Qwen 3.5, you can fine-tune the model on domain-specific data. You take 10,000 examples of contracts the firm has analyzed, 5,000 clinical cases with expert annotations, 5,000 regulatory documents. You fine-tune the model on this data. The model learns the domain. Its performance on domain-specific tasks improves 20-40% compared to the base model.
Fine-tuning Qwen 3.5 is feasible with standard techniques. Lo RA (Low-Rank Adaptation) reduces memory requirements by 90%. You can fine-tune on a single A100 GPU instead of needing an entire cluster. Training time is typically days, not weeks. The process is well-documented with multiple reference implementations available.
After fine-tuning, you deploy the customized model. It understands your domain. It performs better on your tasks. It's yours—you own the weights, you control the deployment, you're not dependent on any vendor.
This customization capability is transformative for enterprise AI. It's the difference between AI being a generic tool everyone uses the same way, and AI being a strategic capability tailored to your specific business.
The Broader Implications: Efficiency as the New Scaling Frontier
Qwen 3.5's success signals a fundamental shift in how the AI industry thinks about progress.
For three years, the narrative was clear: scale up. More parameters. More data. More compute. This worked. It drove improvements. But it also created a dynamic where only companies with massive data centers and enormous budgets could build competitive models.
Qwen 3.5 says something different: efficiency might matter more than raw scale. Better architecture beats brute-force parameter count. Smart sparse activation beats dense computation. Native multimodal integration beats bolted-on vision adapters. Optimized tokenizers beat language-agnostic designs.
This shift democratizes AI. If efficiency beats scale, then smaller teams can build competitive models. If open-weight models can match proprietary APIs, then enterprises can own their AI rather than renting from cloud providers. If sparse architectures reduce inference costs by 60%, then AI deployment becomes economically viable for companies that previously found it prohibitively expensive.
This doesn't mean scale is irrelevant. Larger models will still improve. But the industry is learning that bigger isn't always better. Smarter is often better. And smarter, efficient, open-weight models are better for everyone except the vendors charging per-token.

Real-World Applications: Where Qwen 3.5 Shines
Understanding where Qwen 3.5 is best deployed matters for enterprises evaluating adoption.
Customer Support Automation: Qwen 3.5's multimodal capabilities and efficiency make it ideal for automating customer support. Process text inquiries, handle image-based questions (screenshots showing issues), generate responses, and log interactions. At 60% lower cost than predecessors, this becomes economical for high-volume deployments.
Content Generation and Summarization: The model's 256K context window means it can read entire documents or code repositories and generate summaries, refactorings, or analyses. Marketing teams can generate campaign content. Technical teams can auto-generate documentation. Finance teams can summarize reports. The agentic capabilities enable multi-step workflows: draft content, review for accuracy, edit for tone, format for distribution.
Code Generation and Review: Qwen 3.5 is competitive with specialized code models. Developers can use it for code generation, test generation, documentation generation, and code review. The agentic framework enables autonomous code improvement: generate, test, debug, and refinement without human intervention between steps.
Multilingual Processing: With 201 languages natively supported and efficient tokenization for non-Latin scripts, Qwen 3.5 is excellent for multilingual enterprises. Process customer data from global markets. Support customers in their native languages. Reduce token overhead and costs compared to language-agnostic competitors.
Knowledge Work Automation: The combination of reasoning capability, agentic behavior, and multimodal understanding makes Qwen 3.5 suitable for automating knowledge work. Research analysis, report generation, data extraction from complex documents, and structured information synthesis become feasible.
Enterprise Fine-tuning: For organizations with domain-specific data and requirements, Qwen 3.5's open weights enable custom fine-tuning. Legal document analysis, medical diagnosis support, financial analysis, or industry-specific applications all benefit from domain-adapted models.

Challenges and Limitations Worth Understanding
Qwen 3.5 is impressive, but it's not magic. Realistic understanding of limitations matters.
Hallucination Risk: Like all large language models, Qwen 3.5 can generate plausible-sounding but false information. This risk is reduced compared to many models through RLHF, but it persists. Applications requiring strict accuracy need output verification.
Hardware Requirements: Running Qwen 3.5 requires significant GPU infrastructure. For companies without existing AI infrastructure, this represents a capital investment. The total cost of ownership includes not just GPUs but power consumption, cooling, monitoring, and personnel.
Fine-tuning Complexity: While fine-tuning is more accessible than it was five years ago, it still requires data science expertise. Preparing training data, managing compute resources, and evaluating fine-tuned models are non-trivial tasks.
Benchmark Gaming Risk: Benchmarks are valuable but imperfect. A model that scores well on benchmarks might still underperform on your specific use case. Real-world evaluation on actual workloads is essential.
Safety and Bias: Open-weight models make safety more challenging. Without the ability to monitor and update the model, vulnerabilities persist. Enterprises deploying open-weight models need strong safety frameworks.
Sparse Mo E Complexity: Mixture of Experts models are mathematically sophisticated. Debugging, optimizing, and fine-tuning them requires deeper expertise than dense models.
Looking Forward: The 2025-2026 Trajectory
Qwen 3.5's release in January 2025 suggests several near-term trends.
First, we'll see increased focus on efficiency. Other organizations will release sparse models. Meta, Microsoft, and open-source projects will prioritize efficiency over raw parameter count. The era of "bigger is always better" is ending.
Second, enterprises will increasingly adopt open-weight models. The combination of better efficiency, lower cost, and genuine control will outweigh proprietary APIs for many organizations. This will shift how the industry thinks about AI infrastructure. Instead of "which API do we use," the question becomes "which open-weight model do we deploy, and on what infrastructure."
Third, fine-tuning and customization will become standard practice. As enterprises own their models, they'll invest in domain adaptation. The competitive advantage will increasingly come from customization, not from which base model you choose.
Fourth, the infrastructure business will evolve. Instead of cloud vendors renting API access, they'll optimize for efficient deployment of open-weight models. This benefits enterprises (lower costs, better ownership) and infrastructure providers (higher utilization, stronger customer lock-in through infrastructure rather than model lock-in).
Finally, we'll see continued architectural innovation. 512 experts is more than most previous models. I'd expect 2025-2026 to see even more aggressive sparsity—1024, 2048, or even higher expert counts—as the field optimizes the efficiency-capability frontier.
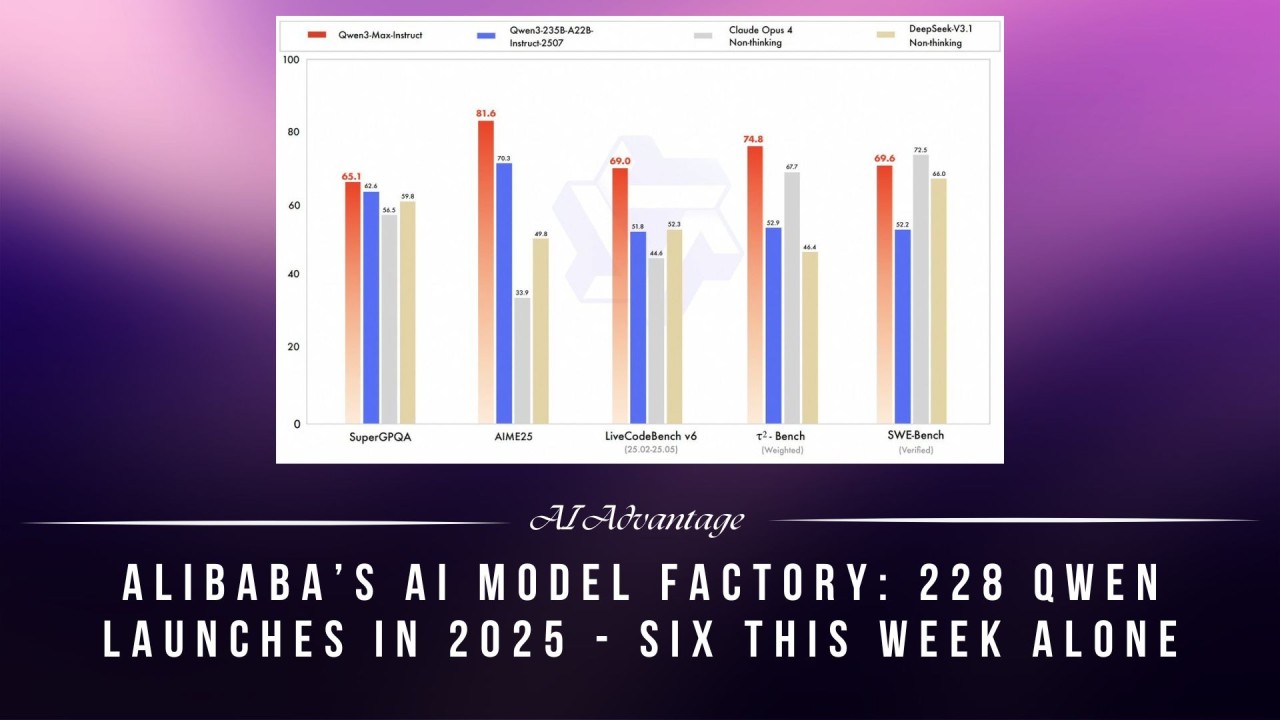
Making the Decision: Is Qwen 3.5 Right for Your Organization?
Evaluating Qwen 3.5 for your specific needs requires honest assessment of several factors.
Cost Sensitivity: If inference costs are a significant budget line—your organization generates billions of tokens monthly—Qwen 3.5's efficiency advantage justifies infrastructure investment. Calculate break-even: at what usage volume does owning infrastructure become cheaper than API rentals?
Control Requirements: If you need to audit model behavior, ensure data stays on your infrastructure, or deploy models offline, open-weight models are essential. If you're comfortable with proprietary APIs, control becomes less critical.
Domain Specialization: If your use cases are generic (general chat, simple summarization), proprietary models are adequate. If you need domain-specific performance, fine-tuning capability justifies adoption.
Technical Capability: Deploying and maintaining large language models requires specific expertise. Do you have data scientists, ML engineers, and Dev Ops personnel capable of managing this? Or do you need external support?
Latency Requirements: If your application demands sub-100ms response times, dense models might still be necessary. Qwen 3.5's latency is excellent but slightly higher than specialized small models optimized for speed. Profile your workload.
Compliance and Regulation: Some regulated industries (finance, healthcare, legal) have specific requirements around model provenance, auditability, and data handling. Qwen 3.5's open-weight, auditable nature often aligns better with these requirements than proprietary black boxes.
For most mid-market and large enterprises, Qwen 3.5 presents a compelling option. The efficiency, control, and performance characteristics align with typical enterprise requirements. The infrastructure investment is achievable. The cost model is favorable. The technical complexity is manageable with proper support.
For startups and small companies, Qwen 3.5 requires more consideration. The upfront infrastructure investment might be high relative to company size. Proprietary APIs might be more cost-effective at small scale.
Conclusion: Efficiency Beats Scale
Alibaba's Qwen 3.5 represents a meaningful inflection point. For three years, the AI industry operated under a single assumption: bigger models are better models. Scale solves everything.
Qwen 3.5 disproves this. A smaller model with only 17 billion active parameters, deployed on open-weight architecture, can outperform much larger proprietary models. It does so while costing 60% less to operate. It achieves this through architectural sophistication, not brute-force parameter count.
This matters because it democratizes AI. If efficiency beats scale, then smaller organizations can compete. If open-weight models can match proprietary APIs, then enterprises can control their infrastructure. If sparse architectures reduce costs dramatically, then AI deployment becomes economical at scale previously considered prohibitive.
The implications extend beyond Qwen 3.5. This release signals that the era of "scale at all costs" is ending. The next phase of AI progress will be dominated by efficiency, architectural sophistication, and ownership models that respect enterprise requirements for control and data security.
For IT leaders evaluating AI infrastructure in 2025, Qwen 3.5 deserves serious consideration. Not as a replacement for all use cases—proprietary models still have advantages in specific scenarios—but as a practical, cost-effective, controllable option for enterprises willing to invest in owning their AI infrastructure.
The question is no longer just "which model performs better?" It's "which model fits our requirements for cost, control, and capability?" For many organizations, the answer is increasingly clear: an open-weight model like Qwen 3.5, deployed on owned infrastructure, offering genuine control and long-term economic sustainability.

FAQ
What does "397B-A17B" actually mean?
The notation breaks down into two numbers. 397B refers to the total parameter count in billions. A17B refers to the active parameter count per token, also in billions. So Qwen 3.5 has 397 billion total parameters, but only 17 billion are active for any given forward pass. The "A" stands for "active," distinguishing it from the total count.
How does sparse mixture-of-experts actually work in practice?
The model uses a routing network that analyzes incoming tokens and decides which experts should handle the computation. Think of it like a hospital triage system: a patient arrives, triage nurses assess them, and route them to the appropriate specialist. Similarly, tokens are routed to the most relevant experts from the 512 available. This selective activation means the model uses far fewer compute resources while maintaining reasoning quality through access to specialized expert modules.
What's the actual cost difference between Qwen 3.5 and proprietary APIs?
This depends on usage patterns, but the difference is significant. If you're generating 1 billion tokens monthly through proprietary APIs at typical pricing (
How does Qwen 3.5 compare to Meta's Llama models for open-source deployments?
Meta's Llama 3.3 (70B and 405B variants) emphasizes different strengths. Llama offers a dense 70B model that's lightweight and efficient, or a dense 405B model that's larger but less sparse than Qwen 3.5. Qwen 3.5's 17B active parameters are more aggressive sparsity than Llama's approach. Qwen 3.5 has native multimodal support; Llama is text-only. Qwen 3.5 has 201 language support with optimized tokenization; Llama focuses on English-dominant use cases. For efficiency and multilingual reach, Qwen 3.5 has advantages. For straightforward dense models with strong community support, Llama is solid.
Can I run Qwen 3.5 on consumer hardware like gaming GPUs?
Technically yes, but practically it's challenging. Qwen 3.5 with 4-bit quantization requires approximately 50-60GB of VRAM. Consumer GPUs like RTX 4090 max out at 24GB. You could use distributed inference techniques (running the model across multiple GPUs) or use quantization methods that reduce quality more aggressively (2-bit quantization). However, inference would be slow. For actual deployment, datacenter GPUs (A100, H100, L40S) or cloud services designed for this are necessary. Consumer hardware might work for experimentation but not production.
How does the 256K context window compare to competitors?
Chat GPT supports 128K context with GPT-4 Turbo, or 200K with GPT-4o. Claude 3 supports 200K context. Gemini 1.5 supports 1 million tokens. Qwen 3.5's 256K is competitive with most, though Gemini exceeds it significantly. However, Gemini at 1 million tokens requires API access and per-token charges that compound costs. Qwen 3.5's 256K on owned infrastructure is often more practical than Gemini's 1M on APIs, when you calculate total cost including infrastructure.
What's the realistic timeline for fine-tuning Qwen 3.5 on custom domain data?
With moderate-sized domain-specific datasets (5,000-10,000 examples) and Lo RA fine-tuning, expect 2-5 days on a single A100 GPU. Training time scales with dataset size and desired quality. Larger datasets (50,000+ examples) might need 1-2 weeks. You also need time for data preparation (cleaning, labeling, formatting), training infrastructure setup, evaluation on test sets, and inference optimization. From start to production deployment, plan 2-4 weeks for straightforward domains, longer for complex ones requiring careful evaluation.
How does Qwen 3.5 handle real-time applications requiring sub-100ms response times?
At sub-100ms requirements, even Qwen 3.5's efficiency has limits. Generating tokens itself takes time. With aggressive quantization and inference optimization, you might achieve 50-100ms latency for short outputs (10-50 tokens) on high-end hardware. Longer outputs or 256K context processing will exceed 100ms. For true real-time applications (chat interfaces requiring sub-500ms latency), Qwen 3.5 is viable. For applications requiring <100ms, you likely need smaller specialized models or edge deployments. The tradeoff is capability versus latency.

Try Runable For AI Automation
If you're interested in leveraging AI-powered automation without managing infrastructure complexity, consider exploring Runable. It offers AI-powered automation for creating presentations, documents, reports, images, videos, and slides starting at just $9/month. Rather than managing large language models yourself, Runable abstracts the complexity, letting you focus on results.
Use Case: Generate technical documentation from code comments and API specifications automatically
Try Runable For Free
Key Takeaways
- Sparse MoE architecture with only 17B active parameters from 397B total enables efficient inference while maintaining capability
- Qwen 3.5 outperforms Alibaba's own trillion-parameter Qwen3-Max across reasoning and coding benchmarks while costing 60% less
- Native multimodal training (text, images, video) produces better technical reasoning than adapter-based approaches used by competitors
- 250K token vocabulary supporting 201 languages reduces encoding overhead by 15-40% for non-Latin scripts, directly lowering global inference costs
- Open-weight model ownership provides control, customization, and long-term economics superior to proprietary API rental models for mid-market+ organizations
Related Articles
- Sarvam AI's Open-Source Models Challenge US Dominance [2025]
- AI Memory Crisis: Why DRAM is the New GPU Bottleneck [2025]
- Agentic AI & Supply Chain Foresight: Turning Volatility Into Strategy [2025]
- Edge AI Models on Feature Phones, Cars & Smart Glasses [2025]
- Google I/O 2026: 5 Game-Changing Announcements to Expect [2025]
- OpenClaw AI Ban: Why Tech Giants Fear This Agentic Tool [2025]

